一、资料
- OpenType® specification
- OpenType Wikipedia
- ISO/IEC 14496-22
- Adobe OpenType
- c066391_ISO_IEC_14496-22_2015.pdf
- c069450_ISO_IEC_14496-22_2015_Amd_1_2017.pdf
- c070994_ISO_IEC_14496-22_2015_Amd_2_2017.pdf
二、正文
- 1.概述
- 2.布局概述
- 3.OpenType字体变体概述
- 4.OpenType字体文件
- 5.OpenType™布局公用表格式
- 5.1.概要
- 5.2.OpenType布局和字体变体
- 5.3.表组织
- 5.4.脚本和语言
- 5.5.脚本列表表和脚本记录
- 5.6.脚本表和语言系统记录
- 5.7.语言系统表
- 5.8.功能和查找
- 5.9.功能列表表
- 5.10.功能表
- 5.11.查找列表表
- 5.12.查找表
- 5.13.覆盖表
- 5.14.类定义表
- 5.15.Device和VariationIndex表
- 5.16.功能变化表
- 5.17.条件集表
- 5.18.条件表
- 5.19.FeatureTableSubstitution表
- 5.20.常用表示例
- 5.21.示例1:ScriptList表和ScriptRecords
- 5.22.示例2:脚本表,LangSysRecord和LangSys表
- 5.23.示例3:FeatureList表和特征表
- 5.24.示例4:LookupList表和查找表
- 5.25.示例5:CoverageFormat1表(字形ID列表)
- 5.26.示例6:CoverageFormat2表(字形ID范围)
- 5.27.示例7:ClassDefFormat1表(类数组)
- 5.28.示例8:ClassDefFormat2表(类范围)
- 5.29.示例9:设备表
- 6.OpenType字体变体常用表格式
- 7.表
- 7.1.avar 轴变化表
- 7.2.BASE 基线表
- 7.3.CBDT 彩色位图数据表
- 7.4.CBLC 颜色位图位置表
- 7.5.CFF 紧凑字体格式表
- 7.6.CFF2 压缩字体格式版本2
- 7.7.cmap 字形到字形索引映射表
- 7.8.COLR 颜色表
- 7.9.CPAL 调色板表
- 7.10.cvar CVT变化表
- 7.11.cvt 控制值表
- 7.12.DSIG 数字签名表
- 7.13.EBDT 嵌入式位图数据表
- 7.14.EBLC 嵌入式位图位置表
- 7.15.EBSC 嵌入式位图缩放表
- 7.16.fpgm 字体程序
- 7.17.fvar 字体变体表
- 7.18.gasp 网格拟合和扫描转换程序表
- 7.19.GDEF 字形定义表
- 7.20.glyf 字形数据
- 7.21.GPOS 字形定位表
- 7.22.GSUB 雕文替换表
- 7.23.gvar 字形变体表
- 7.24.hdmx 水平设备指标
- 7.25.head 字体标题表
- 7.26.hhea 水平标题表
- 7.27.hmtx 水平度量表
- 7.28.HVAR 水平度量变化表
- 7.29.JSTF 理由表
- 7.30.kern 字距
- 7.31.loca 位置索引
- 7.32.LTSH 线性阈值
- 7.33.MATH 数学排版表
- 7.34.maxp 最大轮廓
- 7.35.MERG 合并表
- 7.36.meta 元数据表
- 7.37.MVAR 指标变体表
- 7.38.name 命名表
- 7.39.OS/2 OS/2和Windows度量表
- 7.40.pclt PCL 5表
- 7.41.post PostScript表
- 7.42.prep 控制价值计划
- 7.43.sbix 标准位图图形表
- 7.44.STAT 样式属性表
- 7.45.SVG SVG(可缩放矢量图形)表
- 7.46.VDMX 垂直设备指标
- 7.47.vhea 垂直标题表
- 7.48.vmtx 垂直度量表
- 7.49.VORG 垂直原点表
- 7.50.VVAR 垂直度量变化表
- 8.OpenType布局标记注册表
- 9.设计变体轴标记注册表
- 10.勘误表
- 11.附录
- 12.存档版本
- 13.脚本开发规范
- 14.ClearType字体清晰度
- 15.传统的字体技术
- 16.工具
1.概述
微软和Adobe于1996年推出结合Apple的TrueType和Adobe的Type 1(PostScript)格式的新扩展格式。
最多可容纳65,536个字形
- 字形最大64KB,支持PostScript Type 1 或 TrueType轮廓,支持高级印刷功能
- OpenType和TrueType一样,基于Unicode,包括排版细化,连字,替代字符串,完整的重音字符和变音符号
- 允许64000个字形
2.布局概述
本概述介绍了OpenType Layout字体模型的强大功能和灵活性。
2.1.OpenType布局一瞥
扩展了具有TrueType或CFF轮廓的字体功能,支持高质量的国际排版。
OpenType解决了复杂的印刷问题,尤其会影响在多语言和非拉丁语环境中使用文本处理应用程序的人。
可能包含替代形式的字符和访问它们的机制。
如阿拉伯语中的”ha”在单词的开头、中间或结尾,其形状是不一样的:
同样,文本垂直或水平放置时的字符形式,如垂直的汉字和括号:
支持连字的组合和分解,如拉丁文”fi”:
字形替换只是扩展字体功能的一种方式。使用精确的X和Y坐标来定位字形,OpenType布局字体还可以识别将一个字形附加到另一个字形的点,以创建需要变音或其他特殊标记的草书文本和字形。
OpenType布局字体还可能包含指定如何水平或垂直定位字形的基线信息。由于基线可能因一个脚本(字符集)而异,因此此信息对于对齐混合来自不同语言的脚本的字形的文本特别有用:
2.2.TrueType与OpenType布局
TrueType字体是包含不同类型数据的多个表的集合:glyph outlines, metrics, bitmaps, mapping 信息(字形轮廓,度量,位图,映射)等等。OpenType布局字体还包含高级排版信息的其他表。
文本处理应用程序,称为OpenType布局的客户端,可以检索和解析OpenType布局表中的信息,文本处理客户端可以选择正确的字符形状并正确分隔它们。
OpenType布局表尽可能只定义特定于字体布局的信息。这些表不会尝试编码在特定语言的约定或特定脚本的排版中保持不变的信息。将在给定语言的所有字体中复制的此类信息属于该语言的文本处理应用程序,而不是字体。
2.3.OpenType布局术语
OpenType布局模型围绕字形,脚本,语言系统和功能进行组织。
字符(Characters)与字形(glyphs)
用户不查看或打印字符:用户查看或打印字形。字符是一个抽象的实体,在数据中用数字表示;字形是角色的可视化。例如,字符CAPITAL LETTER A由诸如Times New Roman Bold之类的字体用字形”A”可视地描绘。字体是字形的集合。要检索字形,客户端使用字体 cmap 表中的信息,该表将客户端的字符代码映射到表中的字形索引。
字形也可以表示字符组合和字符的替代形式:字形和字符并不严格一一对应。例如,用户可能会键入两个字符,这可能更好地用单个连字字形表示。相反,相同的字符可能在单词的开头,中间或结尾处采用不同的形式,因此字体需要几个不同的字形来表示单个字符。OpenType布局字体包含一个表,该表为客户端提供有关可能的字形替换的信息。

脚本(Scripts)
脚本由一组相关字符组成,可以由一种或多种语言使用。拉丁文,阿拉伯文和泰文是使用脚本的例子。字体可以使用单个脚本,也可以使用多个脚本。在OpenType布局字体中,脚本由唯一的4字节标记标识。

语言系统(Language systems)

反过来,脚本可以分为语言系统。例如,拉丁文脚本用于编写英语,法语或德语,但每种语言对文本处理都有自己的特殊要求。字体开发人员可以选择提供针对脚本,语言系统或两者定制的信息。
与文本不同,语言系统在文本处理客户端检查正在使用的字符时不一定明显。为避免歧义,用户或操作系统需要识别语言系统。否则,客户端将使用每个脚本提供的默认语言系统信息。特征(Features)

特征定义字体的基本功能。包含处理变音标记的表的字体将具有“标记”功能。支持替换垂直字形的字体将具有 vert 功能。
OpenType布局功能模型为字体开发人员提供了极大的灵活性,因为功能不必由Microsoft Corporation预定义。相反,字体开发人员可以与应用程序开发人员一起确定字体的有用功能,将这些功能添加到OpenType布局字体,并使客户端应用程序能够支持这些功能。
OpenType布局表
OpenType布局包含五个新表:GSUB, GPOS, BASE, JSTF和GDEF。
GSUB:包含有关字形替换的信息,以处理单字形替换,一对多替换(连字分解),美学替代,多个字形替换(连字)和上下文字形替换。 GPOS:包含有关字形的X和Y定位的信息,以处理单个字形调整,成对字形的调整,草书附件,标记附件和上下文字形定位。 BASE:基于逐个脚本包含有关基线偏移的信息。 JSTF:包含理由信息,包括空格和Kashida调整。 GDEF:包含有关字体中所有单个字形的信息:类型(简单字形,连字或组合标记),附着点(如果有)和连字插入符号(如果是连字字形)。
2.4.使用OpenType布局字体进行文本处理
文本处理客户端遵循标准过程,将用户输入的字符串转换为定位的字形。要使用OpenType布局字体生成文本:
- 使用字体中的 cmap 表,客户端将字符代码转换为字形索引字符串。使用 GSUB 表中的信息,客户端修改结果字符串,替换位置或垂直字形,连字或其他适当的替代方案。
- 使用 GPOS 表中的定位信息和 BASE 表中的基线偏移信息,客户端然后定位字形。
- 使用设计坐标,客户端确定与设备无关的换行符。设计坐标是高分辨率和设备无关的。
- 如果用户指定了这样的对齐,则客户端使用 JSTF 表中的信息来证明这些行的合理性。
- 操作系统对字形行进行栅格化,并在设备坐标中呈现与输出设备的分辨率对应的字形。
在整个过程中,文本处理客户端跟踪原始文本的字符代码与最终渲染文本的字形索引之间的关联。此外,客户端可以在文本流中保存语言和脚本信息,以清楚地将字符代码与印刷行为相关联。
2.5.OpenType布局和字体变体
OpenType字体变体允许单个字体沿着一个或多个设计变体轴支持许多设计变体。例如,具有重量和宽度变化的字体可能支持从细到黑的重量,以及从超浓缩到超扩展的宽度。
用于支持字体变体的机制已集成到用于OpenType布局的表中。字体变体空间中字形轮廓和度量的变化会影响在OpenType布局表中使用的设计网格距离,例如 GPOS 附件查找中使用的锚点位置。OpenType布局格式的增强功能允许将现有格式中的默认值与变体数据相关联,这些变体数据描述了如何针对不同的变体实例调整给定值。
在一些可变字体中,可能需要对字体的变化空间内的不同区域使用不同的字形替换或字形定位动作。例如,对于计数器变小的狭窄或重型实例,可能需要进行某些字形替换以使用移除了某些笔划的替代字形或简化的轮廓以允许更大的计数器。使用 GSUB 或 GPOS 表中的特征变化表可以实现这样的效果。
可变字体的不同变体实例具有相同的字形ID。出于这个原因,似乎可以在字形序列中应用查找,其中使用可变字体的不同变体实例来格式化字形。但是,这样做可能会导致不可预测的行为,因为字体开发人员可能无法充分控制如何生成查找表,并且测试大量可能的跨实例交互是不可行的。由于这些原因,布局处理实现必须将可变字体的不同变体实例视为不同的样式运行,以用于OpenType布局处理。
2.6.从左到右和从右到左的文本
当OpenType文本布局引擎应用Unicode bidi算法并且到达需要在具有偶数(即从左到右(LTR),已解析的级别的运行上执行镜像的点时,它执行以下操作:
对于具有奇数(即从右到左(RTL),已解析级别的运行,引擎执行以下操作:
- 字符级镜像:
1 | For each character i in the RTL run: |
这里,OMPL引用OpenType镜像对列表,cmap(j)引用Unicode cmap 子表中代码点j处的字形。
例如,假设U+0028,是左括号,在解析级别1的运行中发生。运行中该代码点的字形将被cmap(U+0029)替换,因为{U+0028, U+0029} 是OMPL中的一对。字形镜像:
引擎将 rtlm 功能应用于整个RTL运行。该特征(如果存在)将镜像形式替换为OMPL对的第一个元素所覆盖的字符以外的字符(否则,它可以取消字符级镜像的效果)。
OMPL的数据内容与Unicode 5.1的Bidi镜像字形属性文件相同,永远不会被修改。因此,如果需要,它将由 rtlm 功能提供(a)具有“镜像”属性的Unicode 5.1代码点但没有适当的Unicode 5.1字符镜像的镜像形式,以及(b)所有 未来“镜像”属性添加到Unicode,无论是否存在字符镜像。
通过布局引擎和字体之间的这种分工,大多数字体不需要包含 rtlm 功能,因为Unicode cmap 子表中的镜像表单就足够了。
RTL字形交替:
引擎将 rtla 功能应用于整个RTL运行。该特征(如果存在)替代适用于从右到左文本的变体(镜像形式除外)。
在实践中,引擎可以同时应用特征,因此,字体供应商需要确保对特征的查找进行排序以实现上述算法的期望效果。引擎可以以各种方式优化其实现,例如, 通过利用字符和字形级镜像不会同时应用于运行中的同一元素这一事实。
3.OpenType字体变体概述
这一章提供了OpenType字体变体的概述,包括基本概念的介绍,术语表和关键算法的规范:坐标规范化和实例值的插值。
3.1.介绍
OpenType Font Variations允许字体设计者将字体系列中的多个字体面合并到单个字体资源中。可变字体 - 使用OpenType字体变体机制的字体 - 为内容作者和设计者提供了极大的灵活性,同时还允许以高效格式表示字体数据。
可变字体允许沿某些给定设计轴的连续变化,例如重量:

从概念上讲,可变字体定义了一个或多个轴,设计特征可以在这些轴上变化。重量是一种可能的变体轴,但是许多不同类型的变化是可能的。可变字体可以组合两个或更多个不同的变体轴。例如,以下说明了重量和宽度变化的组合:

可变字体包括表格,字体变体 fvar 表,用于描述该字体使用的变体轴。此表确定如何将变体字体及其变体参数呈现给用户和应用程序。每个轴由数值范围定义,使用固定(16.16)数据类型表示的小数值。从概念上讲,这提供了连续的变化梯度,允许选择大量的设计变化实例。每个实例将由设计变化空间内的坐标数组指定 - 沿每个设计轴的特定值。因此,例如,如果用户或应用程序需要对宽度进行小的调整或稍微更明显的衬线,则可以对这种变体轴进行精细控制。
字体设计者还可以预先定义某些具有特定名称的实例。例如,字体可以在权重轴上具有连续变化,但是设计者可以将特定变体实例识别为”Light”或”Semibold”。命名实例可用于受支持的设计变体空间中的任何实例。例如,在具有权重和宽度轴的字体中,命名实例可能包括”Light”, “Extended”或”Semibold Condensed”。有关命名实例的详细信息也包含在字体变体表中。
重量和宽度是设计变化的常用轴,但是可变字体可以使用各种其他可能的变体轴。
除了特征变化表之外,变体字体还包括样式属性 STAT 表,该表描述了关于每个变体轴的附加细节以及沿着每个轴的特定值(由设计者选择)。这些细节包括这些值的描述符字符串,例如”Bold”,”Extended”或”Semi-sans”。例如,weight/width可变字体可能支持”Bold Extended”变化,并且 STAT 表将提供分别对应于沿重量轴和宽度轴的特定值的”Bold”和”Extended”的字符串。这些字符串可用于创建字体选择器用户界面。它们还可以用于将多轴字体系列的成员投影到用于假定子系列变化的轴数量有限的字体系列的不同模型中,例如weight/width/slant模型。例如,一个命名实例”Semi-sans Light Condensed”可能被投射到一个单独的”Semi-sans”系列的”Light Condensed”成员中。因为 STAT 表标识每个轴上的值,所以软件永远不需要解析子系列字符串并猜测字符串标记(例如”Halbfett”)是指某个轴上的特定值。
注意:样式属性表使具有许多设计轴的字体可以定义为单个多轴族,但仍然可以在旧应用程序中支持所有这些轴的实例,这些应用程序可能只识别一组有限的轴变化,或轴上的有限数量的值。主机平台必须支持样式属性表,可以将多轴系列中的实例转换为较旧应用程序将识别的多个系列中的较少实例。由于选择了字体的不同变体实例,因此必须相应地调整字体内的各种数据项。例如,glyf 表可以提供给定字形的默认轮廓,但是需要以某种方式调整轮廓以反映不同的设计变化。除了字形轮廓之外的其他几个数据项也可能需要类似的调整,包括字形范围的度量,CVT值或字形定位查找表中的锚位置。可变字体包括必需表和可选表,这些表描述了字体中的这些项如何根据不同设计变化实例的需要从默认值更改为不同值。例如,虽然 glyf 表可以为字形提供默认轮廓,但是字形变体 gvar 表将提供相应的数据,描述每个字形轮廓如何针对不同的变体实例进行更改。
变体字体具有默认实例,轴参数值设置为 fvar 表中为每个轴定义的默认值。字体中的多个表为许多不同的数据项提供默认值 - 例如 glyf 表中字形轮廓点的位置,或 OS/2 表中的字体范围上升距离。字体的默认实例使用此类项目的默认值而不进行任何调整,并且不需要特定于变体的表格。如果特定于变体的表 - fvar,gvar,MVAR 等 - 将从字体中删除或被忽略,则剩余数据将包含默认实例的完整字体。
使用TrueType轮廓的字体的字体变体机制最初由Apple在”TrueType GX”中引入。用于OpenType字体变体的一些表格已经从Apple的早期规范改编而来,并进行了一些增强和修订。(特别是,fvar 表规范中使用的格式和数据值都有重大变化,并且未使用 fmtx 表。)还创建了其他扩展,以便将变体机制集成到OpenType中。实施者可能希望参考Apple的历史见解规范,但应将OpenType规范作为OpenType字体变体实现的参考。
3.2.术语
有几个术语在讨论OpenType字体变体时很有用,并将在本规范中使用。
OpenType Font Variations(OpenType字体变体):本章中描述的技术名称。
Font face(字体):共享特定设计参数的字形数据的逻辑集合,以及相关的度量数据,名称或其他元数据。
Font resource(字体资源):OpenType数据,包括(至少)构成功能字体表所需的最小表集。
注意:在OpenType字体文件中,每个偏移表及其引用的表都包含字体资源。格式良好的.OTF或.TTF文件包含单个字体资源,格式良好的.OTC或.TTC文件包括一个或多个字体资源。没有与变体相关的表的字体资源提供单个字体的数据。包含与变体相关的表的单个字体资源可以为多个字体面提供数据。Font family(字体系列):一组具有共同系列名称的字体资源 - 名称ID 16(印刷系列名称)或名称ID 1的相同字符串值。
注意:假设一个系列中的所有字体都将共享某些设计特征,但在其他字体中则不同。使用OpenType字体变体机制可能支持可能不同的设计特征。Axis of variation(变体轴):设计师确定的字体设计变体,可用于在一个族中推导出多个变体设计。
Variable font(可变字体):一种字体资源,它使用OpenType字体变体机制沿着设计者定义的变体轴支持族中的多个字体 - 也就是说,通过表中的变体表和其他变体数据。
Glyph design grid(字形设计网格):可视化的二维空间,其中设计了字体的字形轮廓。
Design-variation space(设计变化空间):由字体设计者在设计字体系列时使用的变体轴定义的抽象多维空间。在变体字体的上下文中,变化空间指的是由字体 fvar 表中指定的变体轴定义的n维空间。
注意:变体空间可以有一个或多个轴。在可变字体中,变体空间受 fvar 表中指定的最小值和最大值限制。零点原点在设计变化空间内没有特殊意义。但是,在可变字体内,零原点(使用标准化坐标刻度 - 在下面定义)是标记位置,因为它对应于由字体资源的名称,字形和度量表直接表示的字体面,而不参考任何变化表或其他变体数据。Variation data(变体数据):用于变体字体的数据,用于描述字体中数据项的值从默认值调整到变体空间内不同实例所需的备用值的方式。
Variation tables(变体表):与Font Variations特别相关的OpenType表,包括以下内容:
Axis variations avar table
CVT (control value table) variations cvar table
Font variations fvar table
Glyph variations gvar table
Horizontal metrics variations HVAR table
Metrics variations MVAR table
Vertical metrics variations VVAR table
注意:fvar 表描述了字体的变体空间,其他变体表提供了变体数据,用于描述不同数据项在字体变体空间中的变化情况。请注意,并非所有这些表都是可变字体所必需的。另请注意,某些字体数据项的变体数据可能包含在与字体变体没有特别关联的其他表中。此外,可变字体中需要某些与字体变体没有特别关系的表格。有关详细信息,请参阅下面的变体数据表和其他要求部分。
Point(点):为了避免歧义,point将仅用于引用字形设计网格中的(X,Y)位置。在讨论设计变化空间时,位置将用于指代该空间内的位置。
Variation instance(变体实例):对应于可变字体的变体空间内的特定位置的字体。
Named instance(命名实例):在 fvar 表中专门定义并分配名称的变体实例。
User coordinate scale(用户坐标比例):用于表征给定变体轴的数字刻度,以及应用程序在选择变体字体实例时使用的比例。
注意:某些变体轴具有规定的有限范围,以用户比例表示。当使用特定的可变字体时,给定轴的用户比例受 fvar 表中指定的最小值和最大值的限制,并且通常可以是该轴的有效范围的子范围。Normalized coordinate scale(标准化坐标比例):当处理变体字体中的变体数据以导出特定实例的值时,将应用标准化过程将每个轴上的用户比例值映射到适用于该字体范围从-1到1的标准化比例。
注意:fvar 表指定每个轴的用户比例最小值,默认值和最大值。在归一化过程中,它们分别映射到-1,0和1,沿每个轴的其他值映射到中间点。其他值的映射由 avar 表调制(如果存在)。字体中的所有变体数据都根据标准化比例值参考字体变化空间内的轴值或位置。Tuple / N-tuple(元组/N元组):一组有序的坐标值,用于指定字体变体空间内的位置。
注意:这里使用的“元组”的含义与计算机科学和数学中的常规用法一致。在Apple TrueType规范中,“元组”已被用于具有不同含义,以指代与字体的设计变化空间的特定区域相关联的变体数据集。在OpenType规范中,“元组变体数据”用于该含义,并且在许多情况下使用“n元组”以避免与Apple规范中的使用混淆。Region(区域):设计变化空间的子空间(即,一些部分或子集),在该子空间上描述变化调整。
注意:区域涉及字体变化空间的所有轴,在仅涉及轴的子集的意义上,它不是“子空间”。在标准化坐标中,区域总是直线的:它们具有直边和直角。可以在字体的变体空间中为多达65535个区域定义变体数据。Master(母版):一组源字体数据,包括特定字体的完整大纲数据,用于字体开发工作流程。
注意:某些字体开发工作流使用多个母版作为源数据,用于为族中的不同面创建字体资源。多个源母版也可用于创建可变字体。每个源主设备将对应于变体空间中的单个实例,并且可能对应于可变字体中的特定区域的变体数据。然而,每个主数据包括完整的轮廓数据,而变体字体仅包括一组完整的轮廓数据(在 glyf 或 CFF2 表中),其中补充了不同区域的变体数据,以表示支持的全部实例 按字体。Deltas / Adjustment deltas(增量/调整增量):变体数据中的数值,用于指定变体空间内特定区域或特定轴内子范围的数据项默认值的调整。
Delta set(增量集):与变化空间的特定区域相关联的一组调整增量。
Scalars(标量):应用于增量的系数值,以获得特定变体实例所需的调整值。
Interpolation(插值):为特定变体实例导出某些字体数据项的调整值的过程,例如字形轮廓点的X和Y坐标。
3.3.变体空间,默认实例和调整增量
可变字体支持一个或多个变体轴。应该注册常用的变体轴,但也可以使用定制的,设计者定义的轴。每个轴都有一个不同的标记,用于在 fvar 表中标识它。
用于变体字体的轴的规格在 fvar 表中给出,以及每个轴的最小值,默认值和最大值。这定义了字体的变体空间。完全由设计人员决定每个轴支持的设计变化范围,以及设计如何与每个轴的刻度对齐。
例如,可变字体可以支持从细到黑的全范围权重:

但设计师也可能选择仅支持有限的重量范围:

变体字体有一个默认实例,它对应于变体空间中的位置,坐标设置为 fvar 表中指定的每个轴的默认值。默认实例使用直接在非变体特定字体表中提供的各种数据项的默认值,例如 glyf 表中字形的轮廓点的网格坐标。

所有其他实例都具有一个或多个轴的非默认坐标值。变体数据支持这些其他实例,这些变体数据为从其默认值产生调整的各种字体数据项提供调整增量。


通常,为每个变体轴上的极值提供增量,但也可以为变化空间中的其他位置提供增量。(有关详细信息,请参见下文)对于默认值与最小值或最小值之间的轴位置,插补其他值。
字体设计者可以确定哪个设计被认为是默认设置,以及提供了哪些增量。例如,具有从稀薄到黑色的权重变化的字体可以使用Regular(400)作为默认值,并且Thin(100)和Black(900)作为最小值/最大值。在这种情况下,变体数据将包括Thin extreme的增量以及Black extreme的增量。

但是,可以使用Thin作为默认值和最小值以及Black作为最大值来实现具有从细到黑的权重变化的不同字体。在这种情况下,变体数据可能包括仅针对Black extreme的增量。

请注意,默认选择中的考虑因素是遗留应用程序或不支持字体变体的平台中的所需行为:在此类软件中,仅支持变体字体的默认实例。
开发可变字体的常用过程涉及使用多个主源字体。每个主数据为变体空间内的不同位置的设计提供完整的字形轮廓数据。例如,字体设计器可能会沿着权重轴为极端和极端极端创建字体。

从这两个源母版中,字体工具可以派生出一个可变字体,该字体具有完整的字形轮廓,用于默认权重加上一个或多个非默认权重的增量,包括最小或最大权重。

请注意,每种源,主字体都具有特定设计变体的完整轮廓数据。相反,变体字体只有一个变体实例的完整轮廓,所有其他实例使用默认轮廓加上增量。每个源主设备可以对应于具有可变字体中的相关变体数据的区域,尽管源主设备与字体内的变体数据集之间的关系将取决于设计的性质和用于产生可变字体的工具。
还要注意,使用多个主,字体源来派生可变字体的要求是相应的字形轮廓必须是点兼容的:它们必须具有相同数量的轮廓和每个轮廓中相同数量的点。
3.4.坐标尺度和标准化
变体空间内的位置可以表示为n元组 - 坐标值的有序列表。示例将在下面看到。n元组的坐标值可以使用用户轴标度,或者可以使用标准化标度。将描述这些尺度之间的精确关系。
用户坐标是指使用用户轴刻度表示的n元组坐标值。用户比例是指用于描述 fvar 表中变体轴的数字刻度。每个变体轴使用其自己的数字刻度,以适应该变体轴的性质。注册轴标签的刻度被定义为轴标签注册的一部分,尽管不同的字体可以支持轴刻度的不同子范围。以这种方式,给定字体的 fvar 表定义了该字体的变化空间的特定坐标系,其可以与其他字体不同。
fvar 表中的定义以用户坐标表示,而变体字体中使用的变体数据格式使用标准化坐标系 - 标准化坐标 - 其中为 fvar 中的每个轴指定的最小值,默认值和最大值表分别映射到-1, 0和1。
例如,下图说明了具有重量和宽度变体轴的可能字体的变体空间的用户坐标系:
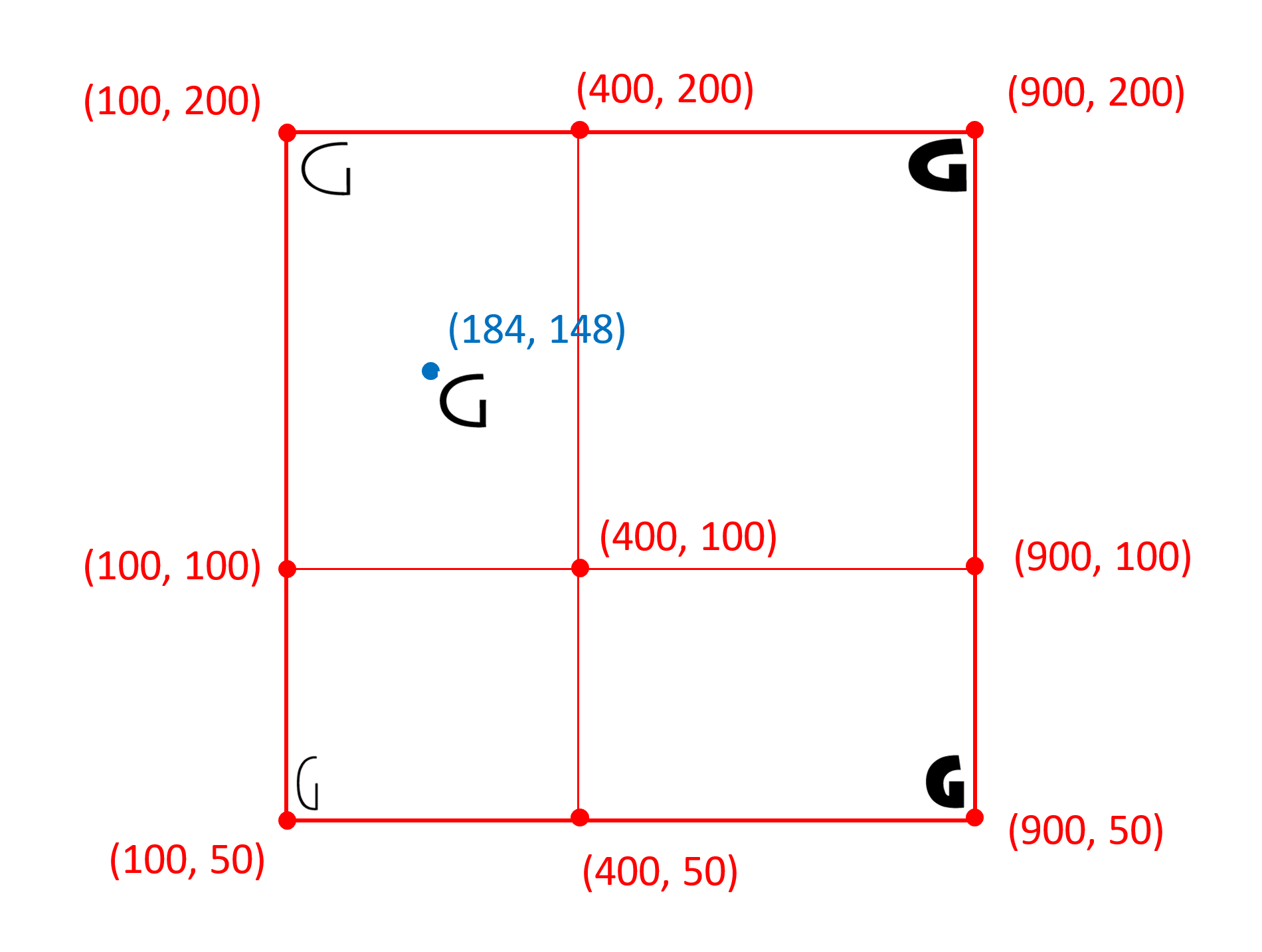
下图说明了相同字体的标准化坐标系:
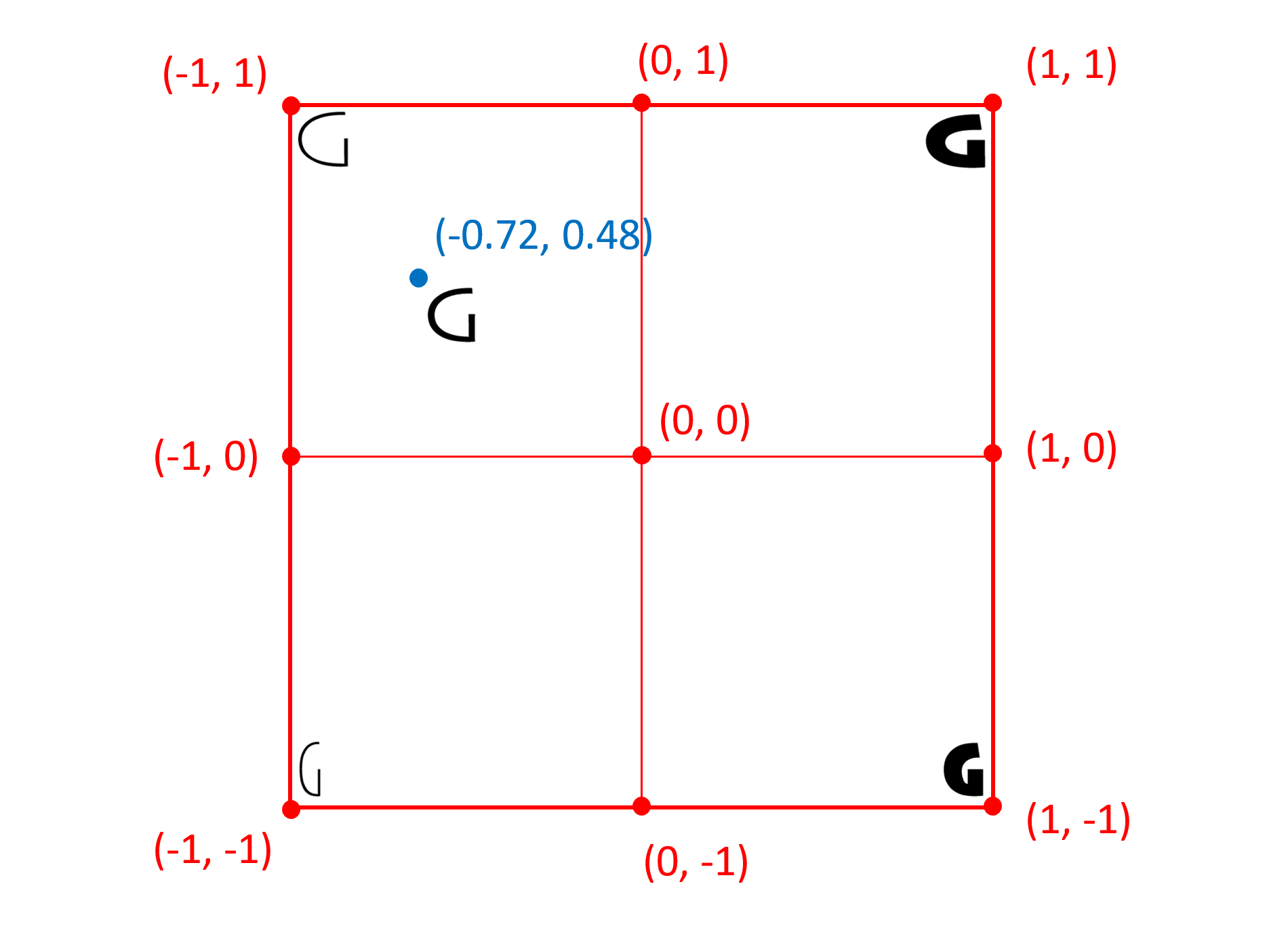
规范化转换使用默认转换,然后对 avar 表中定义的转换进行二次修改(如果存在)。avar 表不会影响最小值,默认值和最大值到-1,0和1的映射;它只能影响干预值的映射。
默认规范化映射将每个轴的变化范围分为两个部分:最小值到默认值,默认值到最大值。最小值,默认值和最大值分别映射为-1,0和1。在每个段内,所有其他值均线性插值,如下所示:
令userValue为给定轴的用户选择实例值的用户比例坐标值,将normalizedValue设为规范化实例值,让axisMin为 fvar 表中指定轴的最小值,等等。
通过钳制到最小值和最大值来强制用户比例坐标值在范围内:1 | if userValue < axisMin |
在不同的段内线性插值:1 | if (userValue < axisDefault) { |
处理变体实例坐标和变体数据时,使用的精度和圆角处理可能会对视觉结果产生明显影响。为了确保跨实现的给定字体的一致行为,实现必须遵守与精度和舍入相关的以下要求:
- 规范化的输入必须是16.16格式。如果应用程序提供表示为 float 或 double 数据类型的输入值,则必须使用下面描述的方法将其转换为16.16。
- 上面指定的归一化的数学计算在16.16中完成。
- 执行默认标准化计算后,某些结果可能略微超出范围[-1,+ 1]。必须将值限制在此范围内:
1 | if result < -1 |
- 如果存在 avar 表,则在16.16中进行数学计算,并将结果钳制到如上所述的范围[-1,+ 1]。
- 通过此方法将最终的标准化16.16坐标值转换为2.14:添加0x00000002,并将符号扩展向右移动2。
- 必须在某些操作中存储和返回2.14结果,如下所述。
- 对于后续计算 - 插值标量的计算或标度增量值的累积 - 可以将2.14表示转换为浮点数,16.16或其他特定于实现的表示。建议保持至少16个小数位的精度,并且在使用值之前的最后一点进行任何舍入。
从float或double数据类型转换为16.16时,必须使用以下方法:
1. 将小数分量乘以65536,并将结果舍入为最接近的整数(对于小数值0.5和更高,取下一个更高的整数;对于其他小数值,截断)。将结果存储在低位字中。
2. 将整数分量的二进制补码表示移动到高位字。必须完全按照上述步骤1-5中的规定获得2.14表示中的标准化值。在具有TrueType指令的字体中,必须通过GET VARIATION指令返回此精确值。如果字体具有使用 FeatureVariation 表的OpenType布局表,则在与条件表中指定的轴范围值进行比较时,必须使用此精确值。
3.5.变体数据
变体数据提供描述变化空间上特定字体值的变化的数据。例如,gvar 表中的变体数据描述了如何通过指定字形轮廓中的各个点如何针对不同的变体实例移动来转换 glyf 表中的字形轮廓。
给定字体值的变化表示为应用于变化空间的不同区域的增量的组合,并且以加权的方式组合以导出对变化空间中的不同位置处的实例的调整。变体数据中的每个增量与变化空间的特定区域相关联,在该区域中它具有效果。增量及其相关区域的总和组合包括变体数据。字体中不同项目的变体数据存储在不同的位置。例如,glyf 表中条目的变体数据存储在 gvar 表中,OS/2 表中某些条目的变体数据存储在 MVAR 表中。对于 CFF2 表中的轮廓数据,变体数据存储在 CFF2 表本身中。
如上所述,每个delta值与其应用的变化空间的特定区域相关联。delta的有效区域始终是直线的(在标准化坐标中)。因此,该区域总是可以由一对n元组指定,这对n元组指定该区域的对角线对角处的位置。在指定区域内,变化效应将在零区域内的特定位置从零变化到某些峰值变化变化。因此,在一般情况下,存在三个重要的位置:限定区域范围的对角线相对角,以及发生峰值变化的位置。
注意:下图所示的数字将使用两个变体轴。然而,所做的概念和陈述适用于具有任意数量的变体轴的字体:区域总是直线的,对角线相对的角加上峰值是描述区域的位置。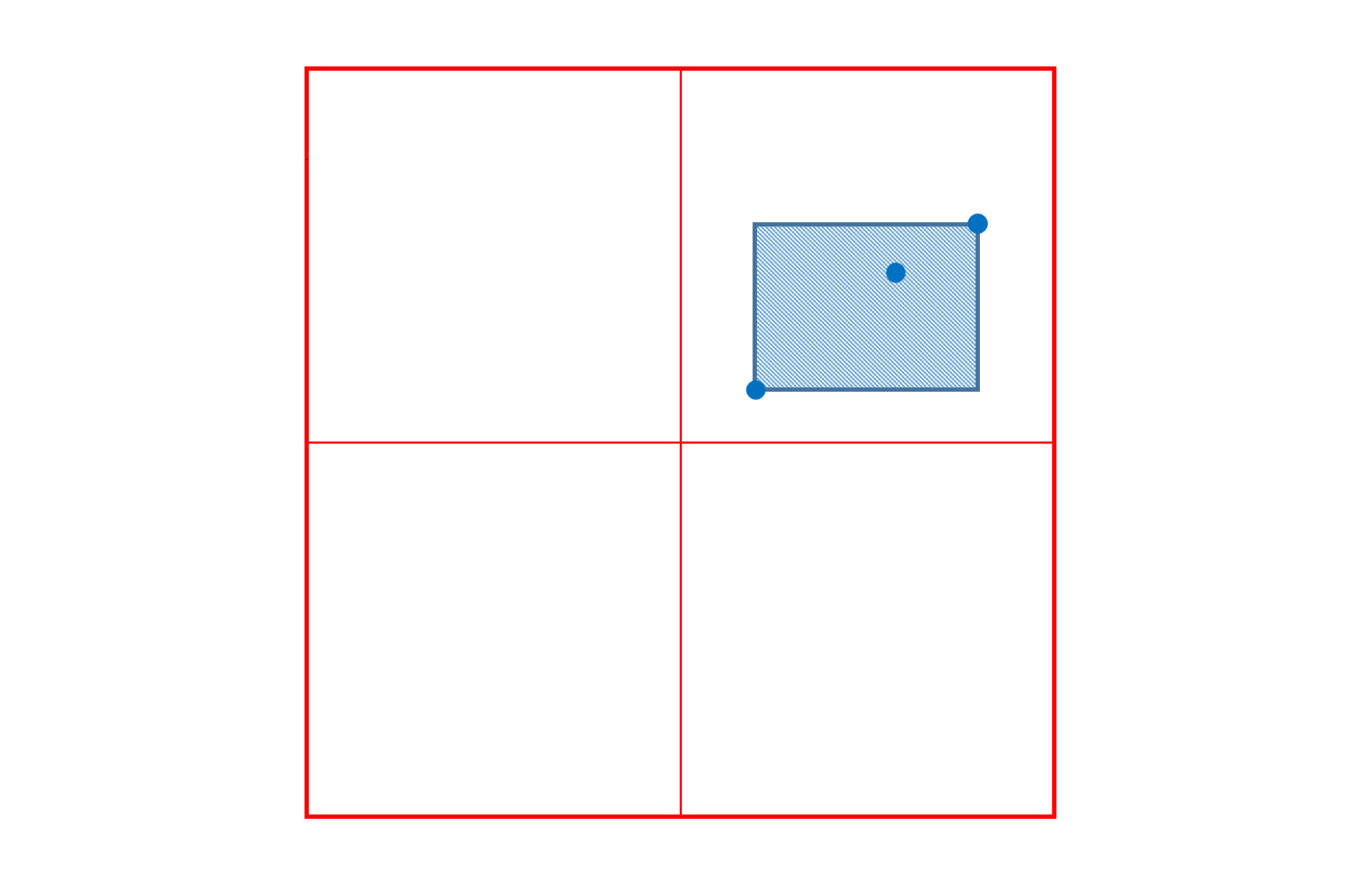
这种一般情况在实践中并不常见。在大多数情况下,需要描述变化空间的外部位置处的最大变化,其在零原点处减小到零变化 - 默认实例。在这种情况下,零原点是适用区域的角位置之一,并且峰值变化发生在对角线相对位置。对于这种常见情况,则可以使用单个n元组来描述有效区域和峰值位置。

更普遍但不太常见的案例涉及任意区域,如前所述,这些被称为中间区域。在这些情况下,变体数据需要三个n元组:一个用于峰值变化位置,两个用于对角线对角处的起点和终点位置。
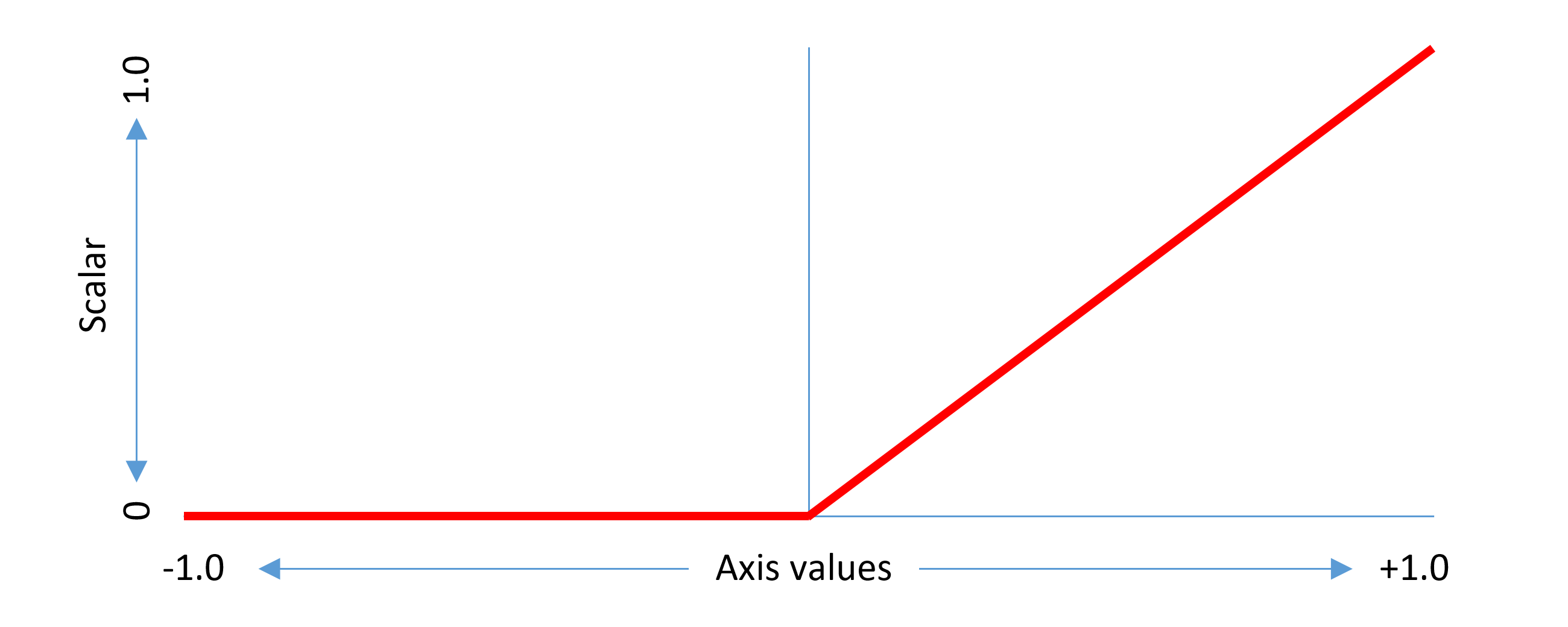
变体数据中的增量值指定峰值位置处的实例的最大调整。对于其他情况,效果逐渐减少,对于适用范围之外的实例,效果降至零。当选择给定变体实例时,计算标量值并将其应用于给定增量,以导出与该实例的该增量相关联的净调整。这些标量将始终在0(零调整)到1(最大调整)范围内。下面提供了有关此标量计算的具体细节。
一个例子将有助于解释这些概念。考虑具有权重变化的单轴字体。在 glyf 表中定义的特定字形轮廓可能具有一对点(以及其他点),这些点是杆的相对侧上的曲线上点。glyf 表中的条目将为字体的默认实例指定这些点的字形设计网格坐标,可能对应于常规权重:
将为重量轴上的最大值定义变体数据,对应于标准化体重标度中的1.0。这些数据将为两个轮廓点提供X和Y增量,以根据最重要支持的权重实例的需要移动它们的位置:
在这个例子中,第一个点的X和Y增量分别为+40和+10,第二点的增量为+140和+10。这些提供了轮廓点的最大调整,在用户选择的实例处于最大权重时应用。对于默认值和最大值之间的权重,例如标准化权重值0.5,将缩小效果。

在这种情况下,将标量系数0.5应用于增量值。
标量计算可以被认为是将每个归一化轴值从-1到1映射到0到1的标量范围的函数。每个具有关联变体数据的区域都有自己的标量函数,并且标量函数被精确定义 按地区描述。
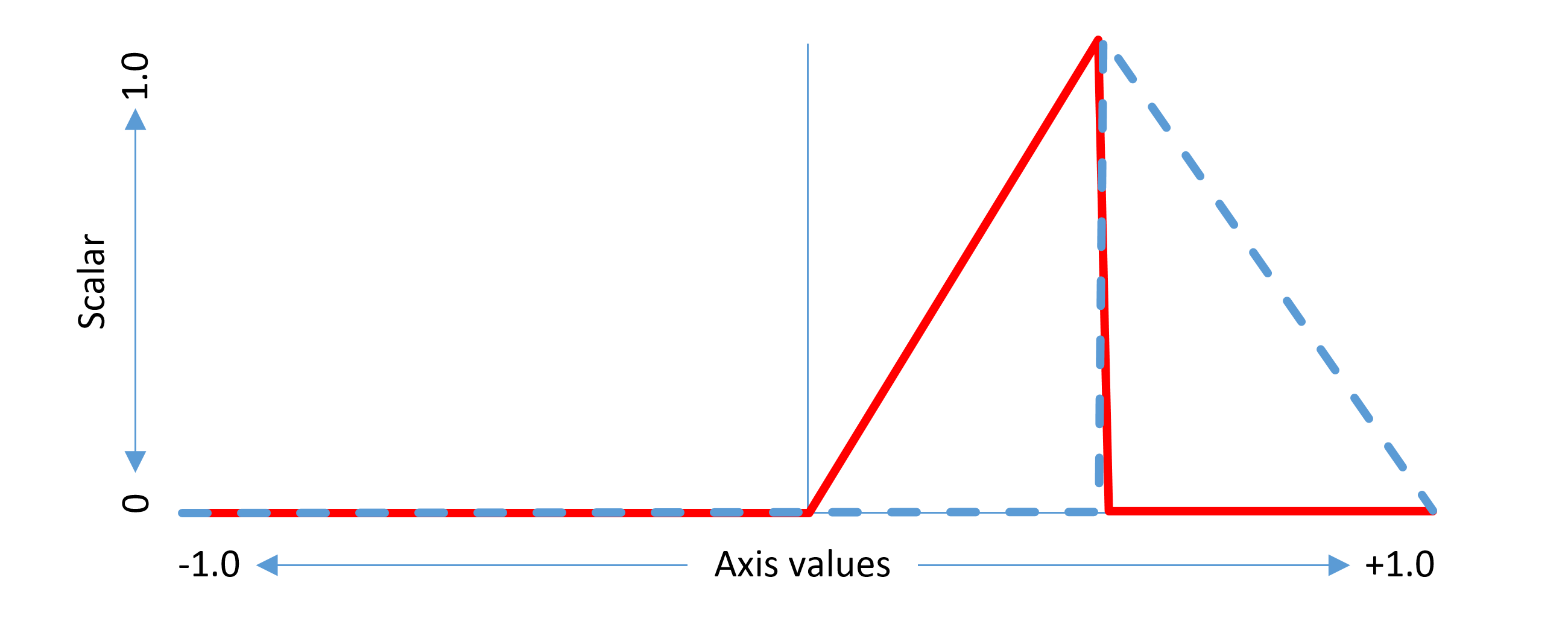
例如,在单轴字体中,如果为0到1的区域提供增量,峰值效果为1,则标量函数如下:
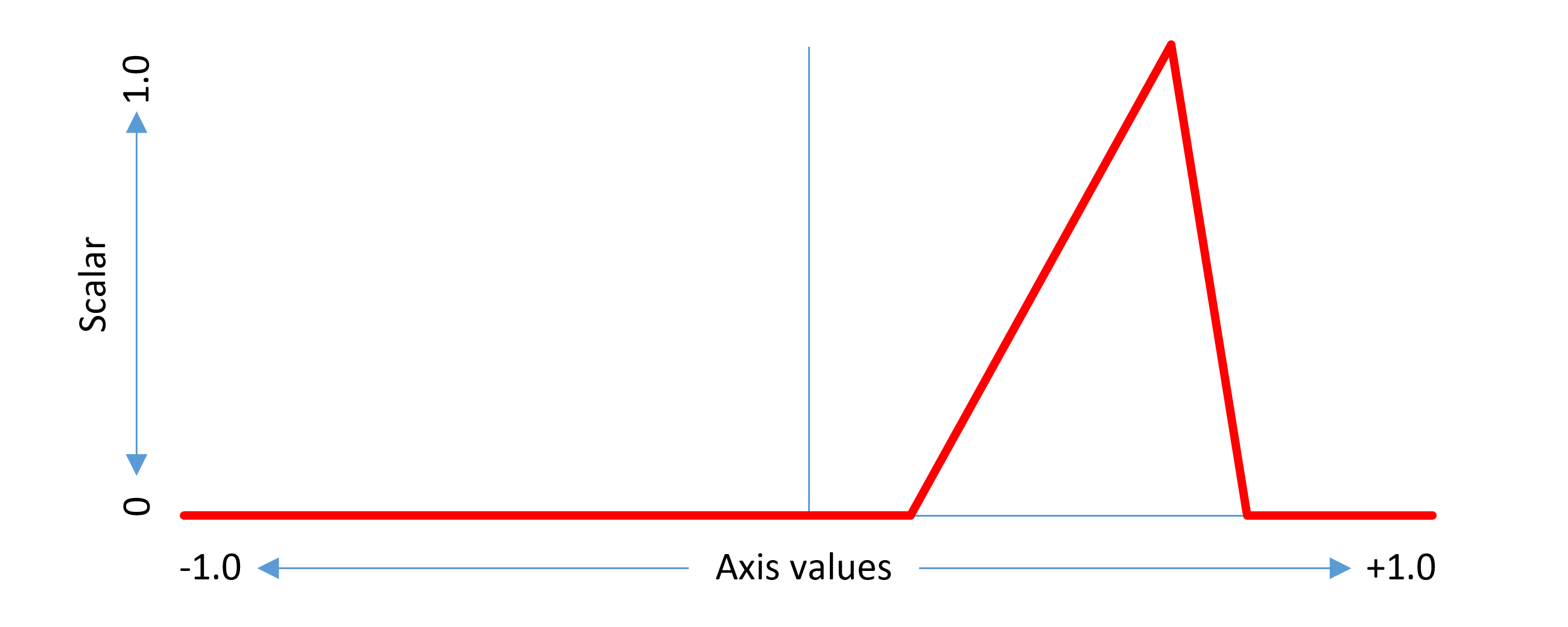
此示例考虑非中间区域。相同的概念可以推广到中间区域。中间区域具有开始和结束轴值,在它们之间存在一些调整效果,以及应用完全调整效果的峰值轴值。标量函数在适用范围内具有三角形形状,在峰值轴值处为1.0,在起始轴值处或以下为0,在终点轴值之上为0。
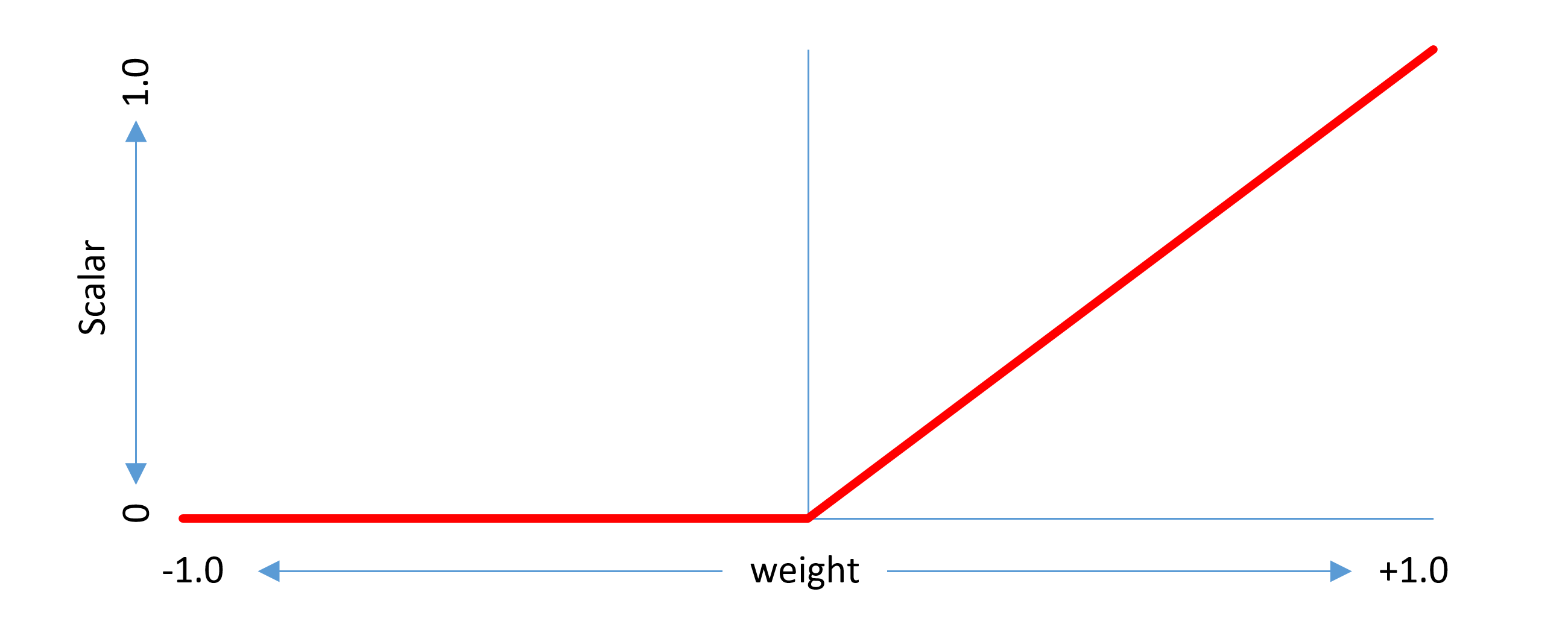
当推广到两个或更多个轴时,类似的概念适用,但每个轴的贡献被组合成整体效果。计算每个轴的标量,并将每轴标量相乘,以产生给定增量和给定实例的总标量。例如,下图说明了峰值为(1, 1)的双轴字体区域的标量函数的近似值:

由于为每个轴计算的标量值介于0和1之间,因此每个轴的标量乘以时的乘积也在0和1之间。给定增量的最大调整效果仅在所有轴的实例轴值时获得与该增量相关的区域的峰值坐标值对齐。
在 fvar 表中为轴指定的最小值和最大值确定了用户可以选择的实例的限制。如果用户请求轴值低于最小值的实例,则使用最小值,或者如果要求高于最大值的轴值,则使用最大值。因此,当处理所选实例的变体数据时,标准化轴值将始终在-1和1之间。
假设该约束,让我们在实例轴值超出适用性区域时考虑给定增量的标量值。如果所选实例在任何轴上超出范围,则与该轴有关的标量值将为0。如上所述,每轴标量乘以一起以产生整体标量。因此,如果所选实例在任何轴上超出范围,则该增量的整体标量将为0,并且不会应用该增量的调整。
当为由某些轴的峰值为0的n元组定义的区域提供增量时,该轴不会影响标量计算。这意味着如果其他轴值保持不变,则该轴的任何值的调整效果都相同。实际上,适用范围跨越零轴的整个范围。例如,假设字体具有两个轴,权重和宽度,并且为从(0, 0)到(1, 0)的区域提供增量。在这种情况下,只要第一个轴(权重)中的实例值在范围内,增量就适用于第二个轴(宽度)上的任何实例值:

在这种情况下,第二轴(宽度)的标量函数实际上是常数值1,对净标量计算没有影响。下图说明了此示例中两个轴(重量和宽度)中每个轴的标量函数:

对于给定的字体值,可以为变化空间中的若干不同区域提供增量。当选择特定变体实例时,根据实例的位置是否落入每个增量的适用性区域内,这些增量中的零个,一个或多个可能具有效果。针对每个适用的增量计算不同的标量,并且将适用的增量的标度值组合以得出净调整。
创建单轴字体时,该轴的最小和最大极限都需要增量。(两个极端,即除非一个也是默认值)也可以提供附加的中间区域增量。创建多轴字体时,通常会为每个轴上的最小和最大极值提供增量。下图说明了两轴字体:

如上所述,当为某个轴值为零的区域指定增量时,则增量将应用于该轴上的所有值。因此,对于位置(1, 1)的实例,(1, 0)和(0, 1)的增量都将适用。这意味着对(1, 0)增量的调整和(0,1)增量的调整都将应用于产生组合效果。如果对每个轴进行的调整完全独立于另一个轴的调整,则两组增量可能足以为(1, 1)实例提供预期值。
然而,通常,仅仅这两组增量不足以为所有实例提供期望的结果,并且另外需要额外的增量(1, 1)位置。概括地说,在多轴字体中,通常情况是角极端以及轴端点需要至少一些增量。

如上面的“变体空间,默认实例和调整增量”部分所述,默认实例可以对应于一个或多个轴上的最小值或最大值。这可以允许使用更少的区域和相关联的增量数据来实现变体空间上的变化。下图说明了双轴字体的一些其他可能性。


如上所述,中间区域提供具有三角形或“齿”形状的轴标量函数。一对中间区域几乎不重叠并且在重叠处具有急剧倾斜,可以用于沿着轴提供关于一些变化行为的拐点。
注意,每个中间区域具有其自己的相关联的增量值,并且增量可以用于在重叠点处给出一些急剧的过渡。例如,轮廓点可能会突然移动,使字形结构的某些元素出现或消失,如下图所示。

注意:使用此类技术时,应同时考虑沿轴放置此类转换点和放置命名实例,以便在命名实例附近不会发生明显的转换。这将避免在使用由于处理数值时的小差异而可能出现的命名实例时在不同应用程序中出现不一致行为的任何可能性。
注意:使用此类技术时,请务必记住,某些应用程序将支持选择任意实例,包括轴值在重叠范围内的实例,以及在重叠范围内,两个中间区域的缩放增量 将适用累积效应。可能需要一些设计迭代,对delta值进行小的调整或区域重叠的方式,以避免在过渡范围内出现意外或不期望的结果。
注意:上图说明了使用中间区域来实现“减少中风”的效果。可用于改变特定变体轴值范围的字形结构的另一种实现技术是字形替换。当在一个或多个轴的某个范围内选择变体实例时,可以使用与 GSUB 表中的 FeatureVariations 表组合的OpenType Layout Required Variation Alternates特征来执行字形替换。这可能是更容易和更容易维护的技术,并且通常被推荐用于实现这样的效果。以上概述了变体数据中涉及的基本概念:适用性区域,每轴和整体标量,以及多种适用增量的综合效应。下面提供插值过程的详细说明。
3.6.变体数据表和杂项要求
上一节将字形轮廓点的X和Y坐标识别为需要针对不同变体实例进行调整的数据项。字体中的许多其他数据项也可能需要进行类似的调整,包括以下内容:
- OS/2 中的字体范围度量值,hhea ,vhea 或 post 表
- hmtx ,vmtx 或 VORG 表中的字形度量值
- PPEM 范围在 gasp 表中
- 锚点位置,以及对 GPOS 或 JSTF 表中字形位置或前进的调整
- GDEF 表中连字插入位置的X或Y坐标
- BASE 表中基线指标的X或Y坐标
- CVT 值
可变字体可以包含任何或所有这些的变体数据。不同项目的变体数据在字体内的各种表格中提供。
注意:虽然字体中的多个数据项可能需要针对不同实例进行调整,但是其他项目不会在实例之间进行更改。例如,字体系列和unitsPerEm不受变化的影响。然而,应特别注意,变体数据不支持可能受变化影响的某些值。特别是,变体数据不支持字体标题 [head](#table-head) 表中的xMin,yMin,xMax,yMax,macStyle和lowestRecPPEM字段,并且只应与字体的默认实例相关使用。此外,不支持字距调整 kern 表中值的变化;变体字体应使用 GPOS 表处理字距调整。所有可变字体都需要两个表:
- 需要字体变体 fvar 表来描述字体支持的变体。
- 样式属性 STAT 表是必需的,用于建立属于一个族的不同字体之间的关系,并通过允许平台将涉及多个轴的变体实例投影到较旧的字体族模型中来提供与遗留应用程序的某种程度的兼容性。一组有限的轴。
如果变体字体在 glyf 表中具有TrueType轮廓,则轮廓变体数据将在字形变体 gvar 表中提供,这是必需的。可以在可选的CVT变体 cvar 表中提供CVT值的变体数据。
如果变体字体在Compact Font Format 2.0( CFF2 )表中具有PostScript样式的轮廓,则 CFF2 表本身也包含相关的变体数据。
注意:CFF2 表可以用于非变体字体以及可变字体。另请注意,不支持使用(压缩字体格式版本1.0 CFF 表格的轮廓变体。度量变化 MVAR 表用于为 gasp,hhea, OS/2,post 和 vhea 表中的各种字体范围度量或其他数值提供变体数据。如果需要调整任何这些值,则应添加 MVAR 表。请注意,不需要为 MVAR 表所涵盖的所有数据项提供变体数据:变体数据对于所有项都是可选的。如果给定项目没有变体数据,则默认值适用于所有实例。
注意:Apple平台允许使用字体度量 fmtx 表通过引用指定字形的轮廓点的X或Y坐标来指定各种字体范围的度量值。OpenType字体变体不使用字体度量表。hmtx 和 vmtx 表提供水平和垂直字形指标。可以使用水平度量变化 HVAR 和 VVAR 垂直度量变化表来提供水平和垂直字形度量的变体数据。
在具有TrueType轮廓的字体中,光栅化器将 hmtx 和 vmtx 值与 glyf 表中的字形xMin,xMax,yMin和yMax值组合,以生成对应于字形水平和垂直度量的四个“幻像”点值。在变体字体中,gvar 表中字形的变体数据将包括字形幻像点的调整增量。结果,可以通过内插实例的虚线点位置来获得给定实例的内插字形度量。然而,对于某些文本布局操作而言,这可能是昂贵的。为了在所有平台上提供最佳性能,建议所有具有TrueType轮廓的可变字体都包含 HVAR 表。如果字体支持垂直布局并包含 vhea 和 vmtx 表,则建议字体包含 VVAR 表。
CFF 2光栅化器不生成幻像点,CFF 2变体数据不包括幻像点的调整增量。因此,在具有CFF 2轮廓的可变字体中,需要 hmtx 和 HVAR 表。同样,如果字体支持垂直布局,则需要 vmtx 和 VVAR 表。
注意:hdmx 和 VDMX 表不用于可变字体。如果字体具有OpenType布局表,则 GDEF,GPOS 或 JSTF 表中的值的变体数据将根据需要包含在 GDEF 表中。BASE 表的变体数据将根据需要包含在 BASE 表本身中。
在一些可变字体中,可能需要对字体的变化空间内的不同区域使用不同的字形替换或字形定位动作。例如,对于计数器变小的窄宽度或重量级实例,可能需要进行某些字形替换以使用删除了某些笔划的替代字形或简化的轮廓以允许更大的计数器。使用 GSUB 或 GPOS 表中的子功能变体可以实现这种效果。
在具有TrueType轮廓的可变字体中,每个字形的左侧方位必须等于xMin,并且必须设置 head 表的flags字段中的位1。
在所有可变字体中,必须清除 head 表的flags字段中的第5位。(在某些平台上,第5位会影响垂直布局中的指标。必须清除第5位以确保所有平台上的兼容行为。)
3.7.实例值插值算法
内插不同变体实例的调整值的过程用于需要变化的所有字体数据项 - 轮廓字形点的位置,上升或其他字体范围的度量等。插值过程涉及以下内容:
- 确定适用于该实例的增量。
- 对于每个适用的delta,计算该实例的每轴标量,然后将每轴标量相乘,以生成该delta的整体标量。
- 通过计算的该增量的标量来缩放每个适用的增量。
- 结合所有缩放的增量来产生整体调整。
处理 gvar 表时,计算中还有一个步骤,即在未明确给出增量时推断点的delta调整。这仅适用于 gvar 表,并在 gvar 表中描述。
如前所述,在给定增量的适用范围之外的实例轴值等于具有每轴标量值为零。此外,具有相对于给定delta没有影响的轴(n元组对于该轴具有零的峰值)等效于具有每轴标量值1。因此,适用性和轴相互作用的确定都可以组合成导出整体标量的步骤。
下面的插值过程的描述将涉及开始,峰值和结束坐标值。如前所述,使用三个n元组描述中间区域,两个用于指定区域范围的对角线相对角(开始和结束)和峰值。非中间区域具有峰值处的一个角和零原点处的另一个角。在一些变体数据结构中,使用单个n元组(峰值的n元组)指定非中间区域。在这种情况下,开始和结束坐标是隐式的:一个与峰值相同,另一个是零原点。
为了使变体数据中的区域的定义有效,必须对起始值,峰值和结束值进行良好排序。也就是说,对于每个轴,起始轴坐标必须小于或等于峰值坐标,并且峰值坐标必须小于或等于末端。此外,开始和结束坐标必须都是非负的或非正的 - 它们不能交叉为零。
在这方面的讨论中,已经将各个增量描述为具有相关的适用性区域。可以以不同方式组织变体数据。在某些情况下,如在 gvar 表中,对应于许多目标项的几个增量(字形的所有轮廓点)和变化空间的单个区域被组织在一起。在一些其他情况下,如在 MVAR 或 CFF2 表中,覆盖多个区域的增量由各个目标项组织在一起。在任一种情况下,每个单独的增量都与变化空间的特定区域相关联。插值过程的以下描述将涉及内插单个项目的值,但是当应用于诸如 gvar 表的特定上下文时,应该理解,相同的计算并行地应用于许多不同的项目。
如上所述,给定Δ的效果由范围从0到1的标量函数调制,对于与该delta相关联的区域的峰值位置处的实例,值为1。整体标量是每轴标量的乘积,并且每个每轴标量计算为实例坐标值与峰值坐标值的接近度相对于峰值距区域边缘的距离的比例。
例如,考虑一个双轴变化空间中的中间区域(下图中的绿色),角点位于(0.3, 0.15)和(1, 1),峰值(下图中的蓝色)位于(0.7, 0.5):
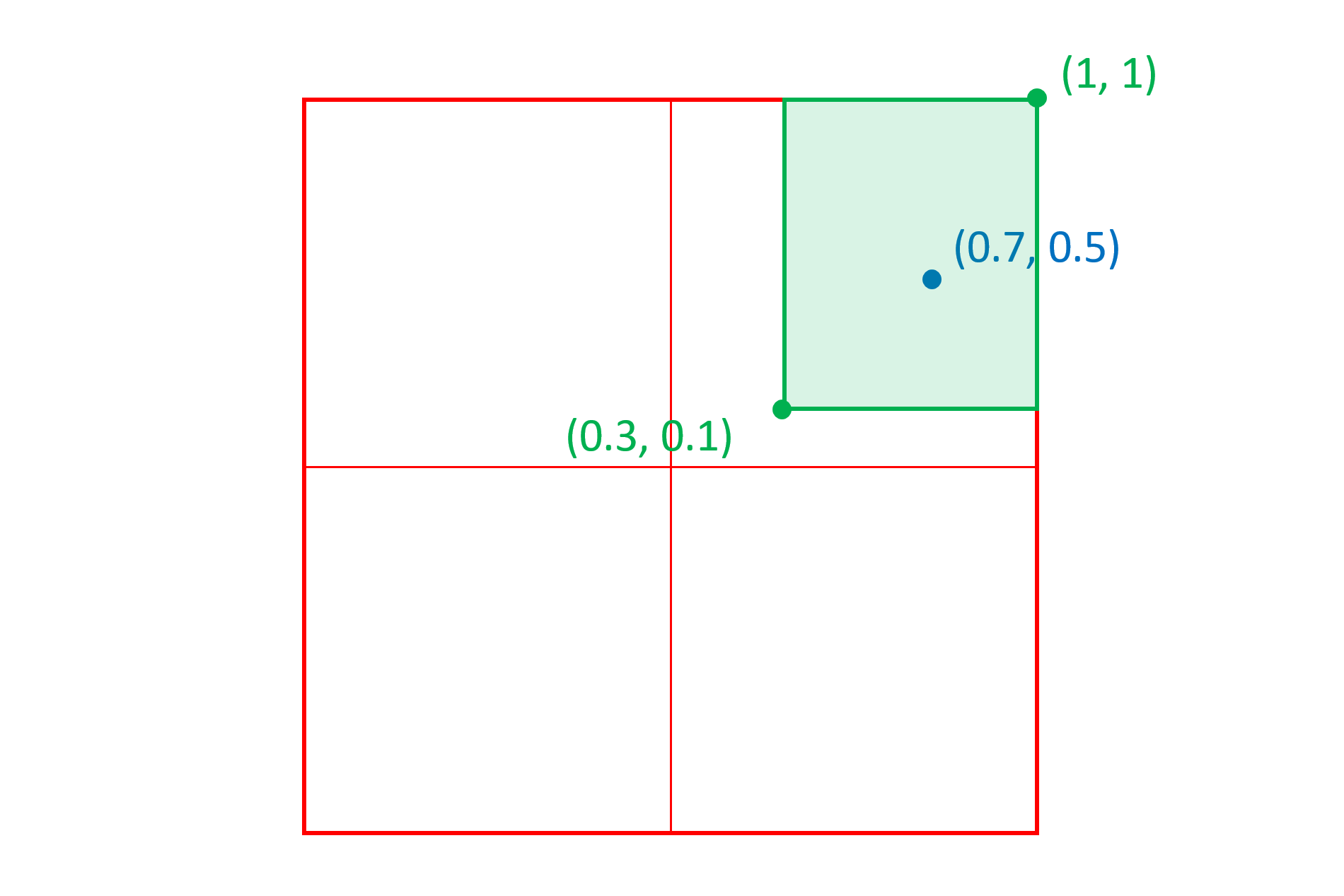
然后在(0.5, 0.35)处考虑实例(下图中的红色)。每轴标量将是实例坐标值距离区域最近边缘的距离除以峰值距该边缘的距离:
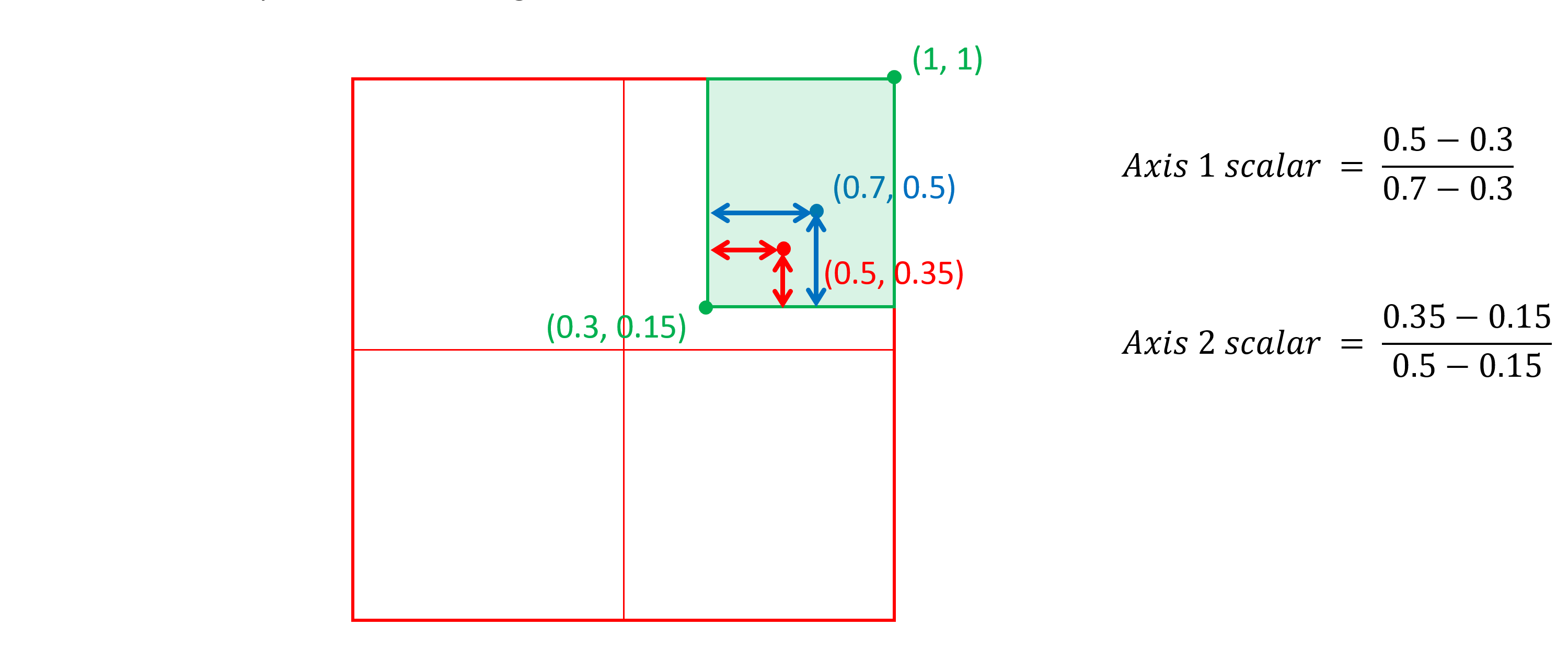
与该区域相关的实例的整体标量将是两个轴标量的乘积:0.5×0.571429 = 0.285714。
用于计算给定目标项和给定实例的内插值的详细算法如下:
- 假设instanceCoords是实例的规范化实例坐标n-tuple,其中轴元素为instanceCoords [i]。
- 设区域是为给定项目提供相关增量的区域集合,并且令R是该集合内的区域。
- 让startCoords,peakCoords和endCoords为某个指定区域的起始,峰值和结束n元组。让startCoords [i]等为给定轴的坐标值。
- 让AS成为每轴标量,让S成为给定区域的整体标量。
- 设delta是与给定区域相关联的变体数据中的delta值,并且scaledDelta是给定区域和实例的缩放delta。
- 让netAdjustment成为给定项目的累计调整。
- 设defaultvalValue是字体中指定的项的默认值,let interpolatedValue是给定实例的项的插值。
以下伪代码提供了插值算法的规范:
netAdjustment = 0; /* initialize the accumulated adjustment to zero */
(for each R in Regions) { /* For each region, calculate a scalar S */
S = 1; /* initialize the overall scalar for the region to one */
/* for each axis, calculate a per-axis scalar AS */
(for i = 0; i < axisCount; i++) {
/* If a region definition is not valid in relation to some axis,
then ignore the axis. For a region to be valid in relation to a
given axis, it must have a peak that is between the start and
end values, and the start and end values cannot have different
signs if the peak is non-zero. (Start and end can have different
signs if the peak is zero, however: this can be used if an axis is
to be ignored in the scalar calculation.) */
if (startCoords[i] > peakCoords[i] || peakCoords[i] > endCoords[i])
AS = 1;
else if (startCoords[i] < 0 && endCoords[i] > 0 && peakCoords[i] != 0)
AS = 1;
/* Note: for remaining cases, start, peak and end will all be <= 0 or
will all be >= 0, or else peak will be == 0. */
/* If the peak is zero for some axis, then ignore the axis. */
else if (peakCoords[i] == 0)
AS = 1;
/* If the instance coordinate is out of range for some axis, then the
region and its associated deltas are not applicable. */
else if (instanceCoords[i] < startCoords[i]
|| instanceCoords[i] > endCoords[i])
AS = 0;
/* The region is applicable: calculate a per-axis scalar as a proportion
of the proximity of the instance to the peak within the region. */
else {
if (instanceCoords[i] == peakCoords[i])
AS = 1;
else if (instanceCoords[i] < peakCoords[i]) {
AS = (instanceCoords[i] – startCoords[i])
/ (peakCoords[i] – startCoords[i]);
} else { /* instanceCoords[i] > peakCoords[i] */
AS = (endCoords[i] – instanceCoords[i])
/ (endCoords[i] – peakCoords[i]);
}
}
/* The overall scalar is the product of all per-axis scalars.
Note: the axis scalar and the overall scalar will always be
>= 0 and <= 1. */
S = S * AS;
} /* per-axis loop */
/* get the scaled delta for this region */
scaledDelta = S * delta;
/* accumulate the adjustments from each region */
netAdjustment = netAdjustment + scaledDelta;
} /* per-region loop */
/* apply the accumulated adjustment to the default to derive the interpolated value */
interpolatedValue = defaultValue + netAdjustment;3.8.插值示例
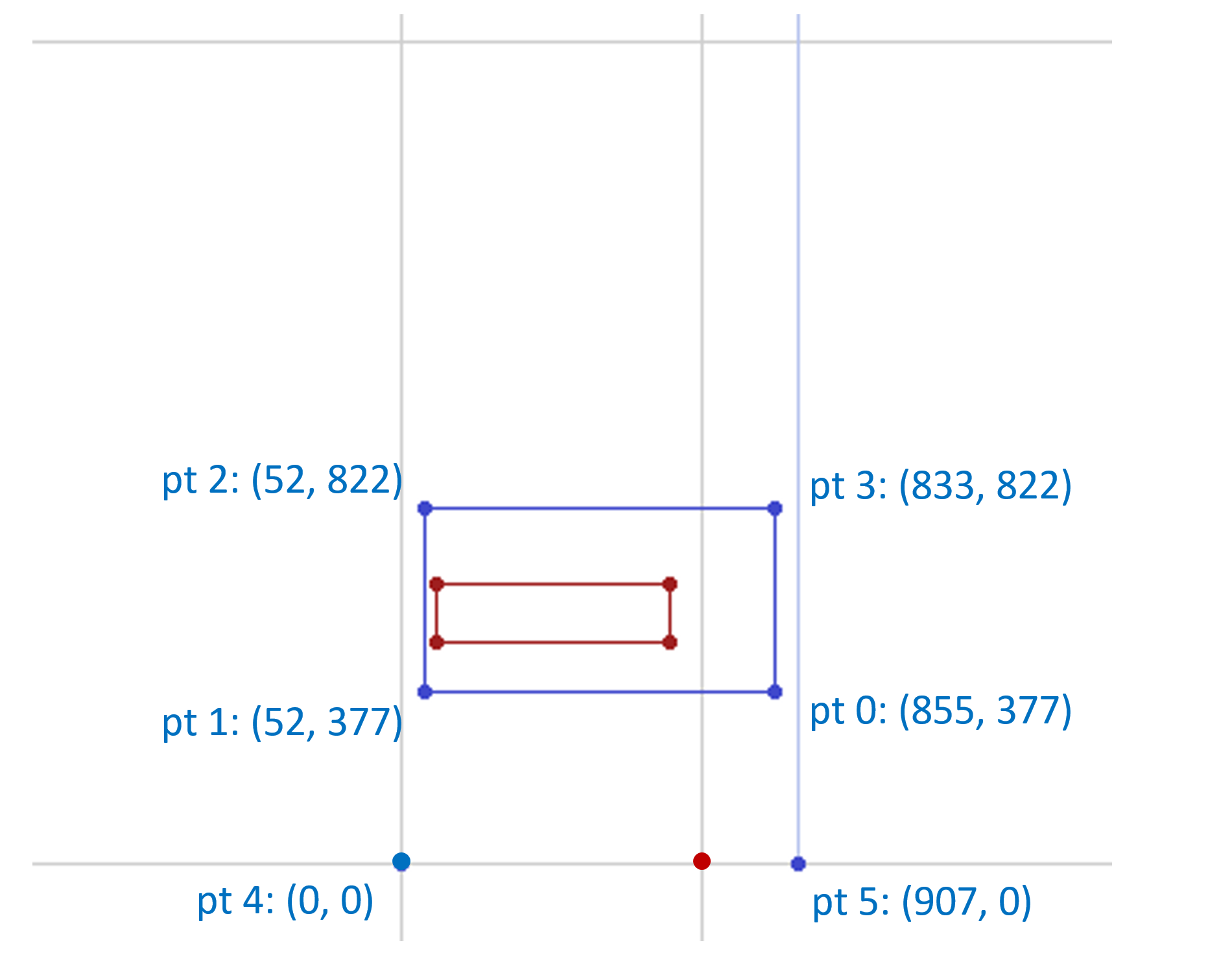
以下示例说明了特定实例的插值过程。此示例基于Skia字体的字形45(字形名称”hyphen.oldstyle”),它是字符U + 002D HYPHEN-MINUS的字形。
注意:Skia字体包含在Apple的OSX平台中。在发布OpenType 1.8规范时,Skia字体的现有版本整体上不符合OpenType 1.8规范,但是 [gvar](#table-gvar) 表中的变体数据的实现,这是这里所示的, 符合。glyf 表中的字形条目有一个带有四个点的轮廓。基于 hmtx 表中的字形45的值,在光栅化器中推断出“幻影”点以表示左侧和右侧轴承。(对于此示例,假设水平布局,因此忽略顶部和底部幻像点。)这些幻像点位于(0, 0)和(698, 0)。因此,有六个点需要插值。
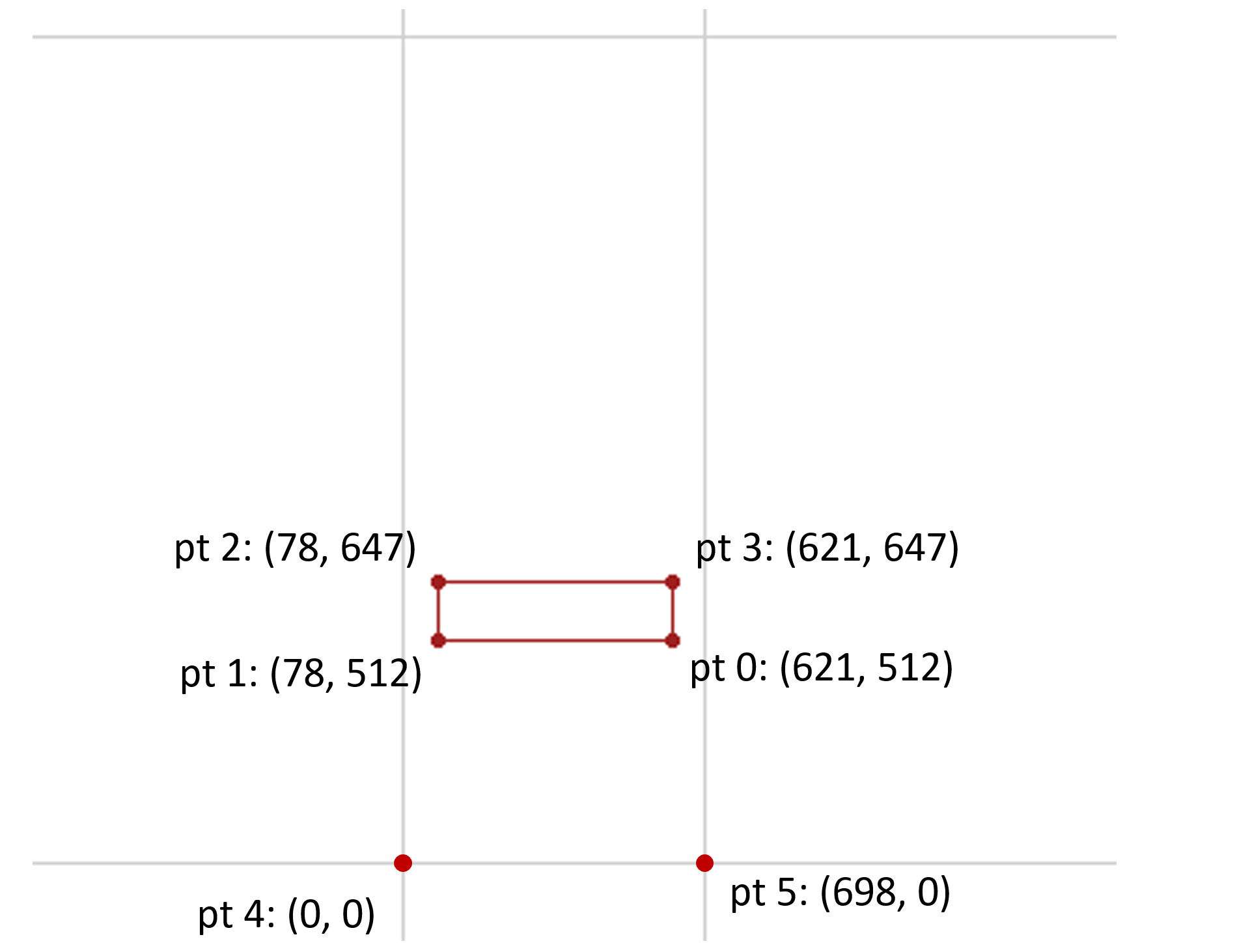
Skia字体有重量和宽度轴。gvar 表中的字形45的变体数据具有与权重 - 宽度变化空间内的8个区域相关联的增量。其中三个将被考虑,并将被称为R1,R2和R3。这些中的每一个都是非中间区域,因此使用单个n元组来定义。每个元组的n元组如下:
| Region | (weight, width) |
|---|---|
| R1 | (1, 0) |
| R2 | (0, 1) |
| R3 | (1, 1) |
下图说明了每个区域的变化空间的适用范围:
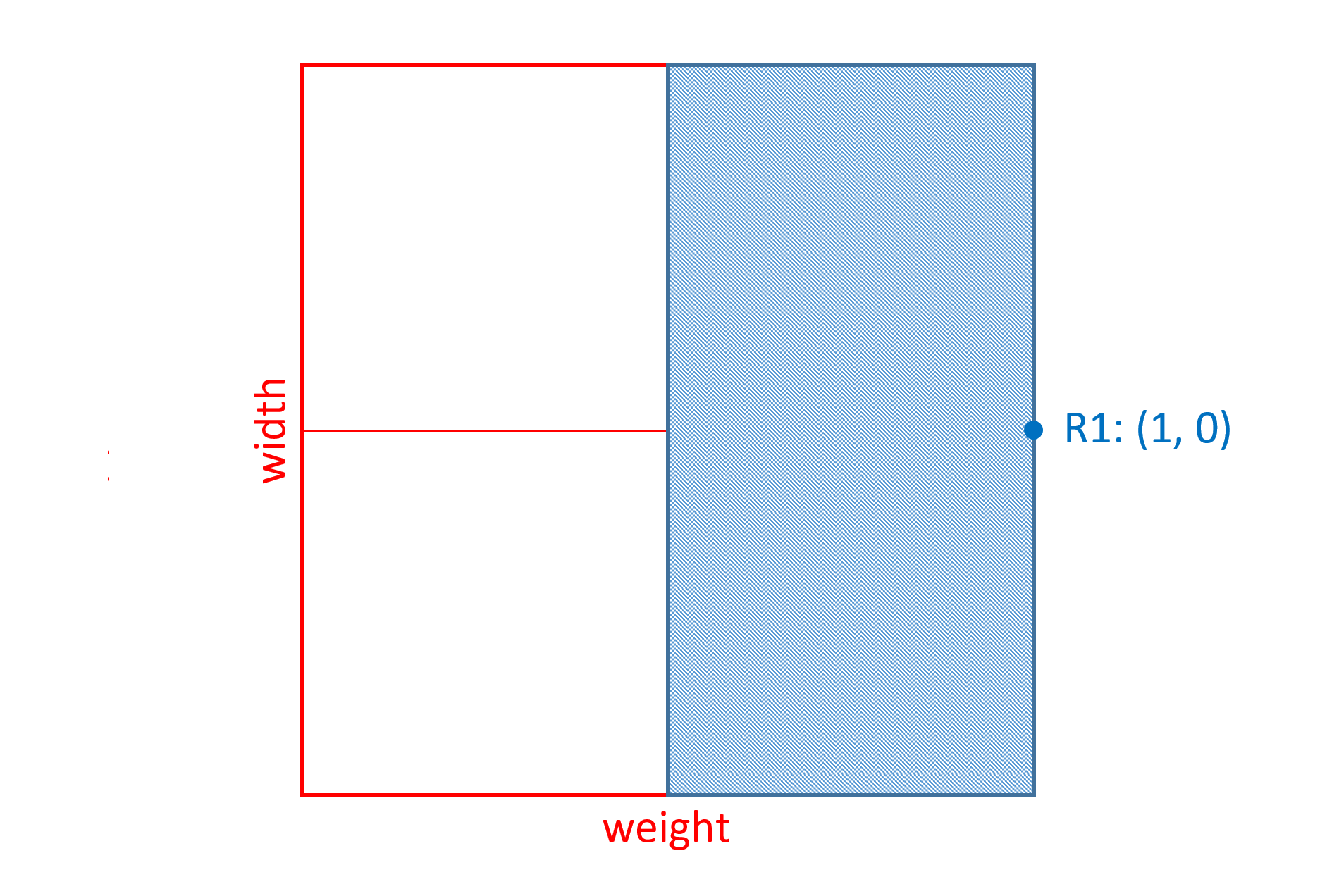
R1具有宽度轴的零坐标值,这意味着变体实例的宽度变化对此区域的标量计算没有影响。
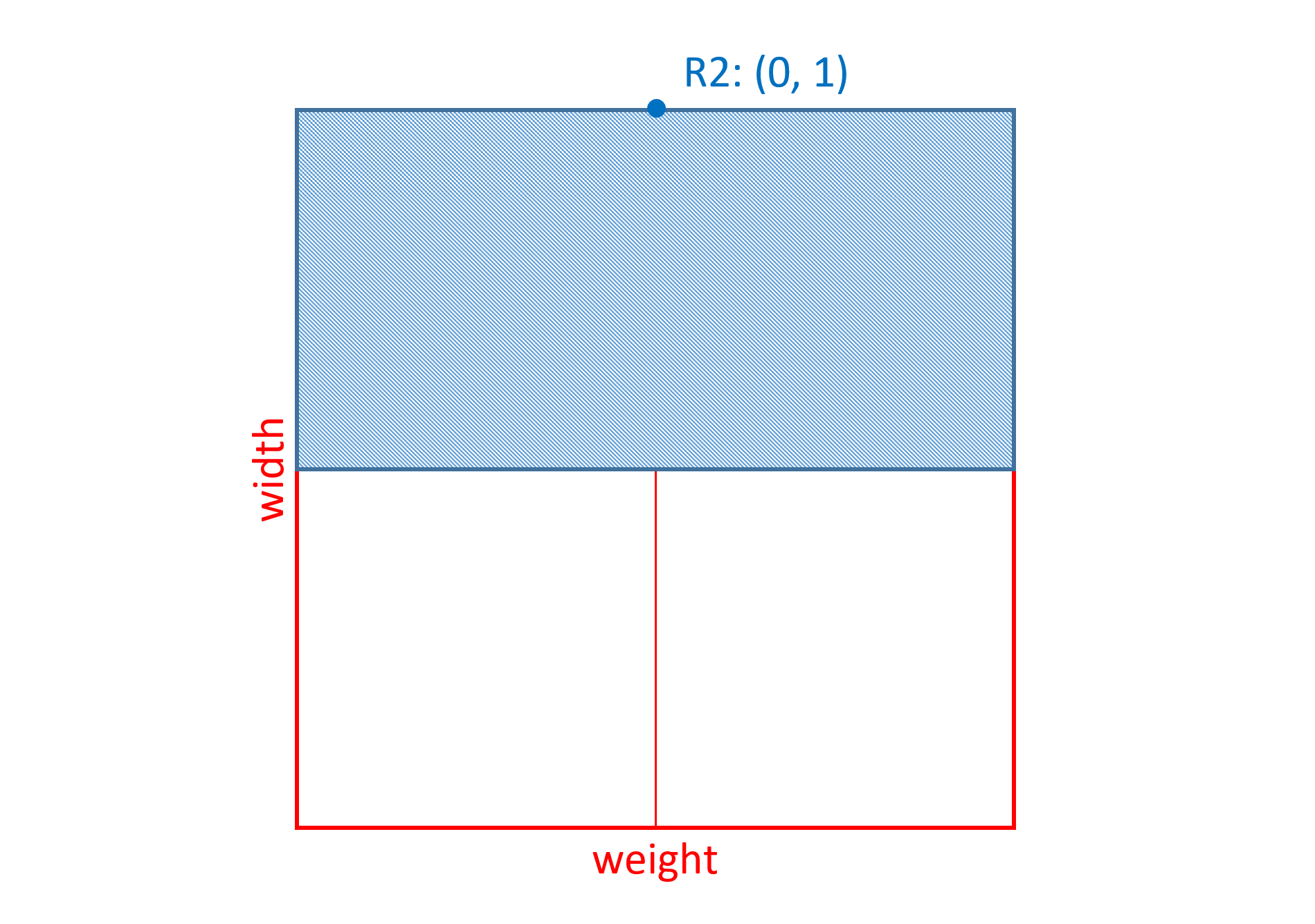
R2对于权重轴具有零坐标值,这意味着变体实例的权重变化对该区域的标量计算没有影响。
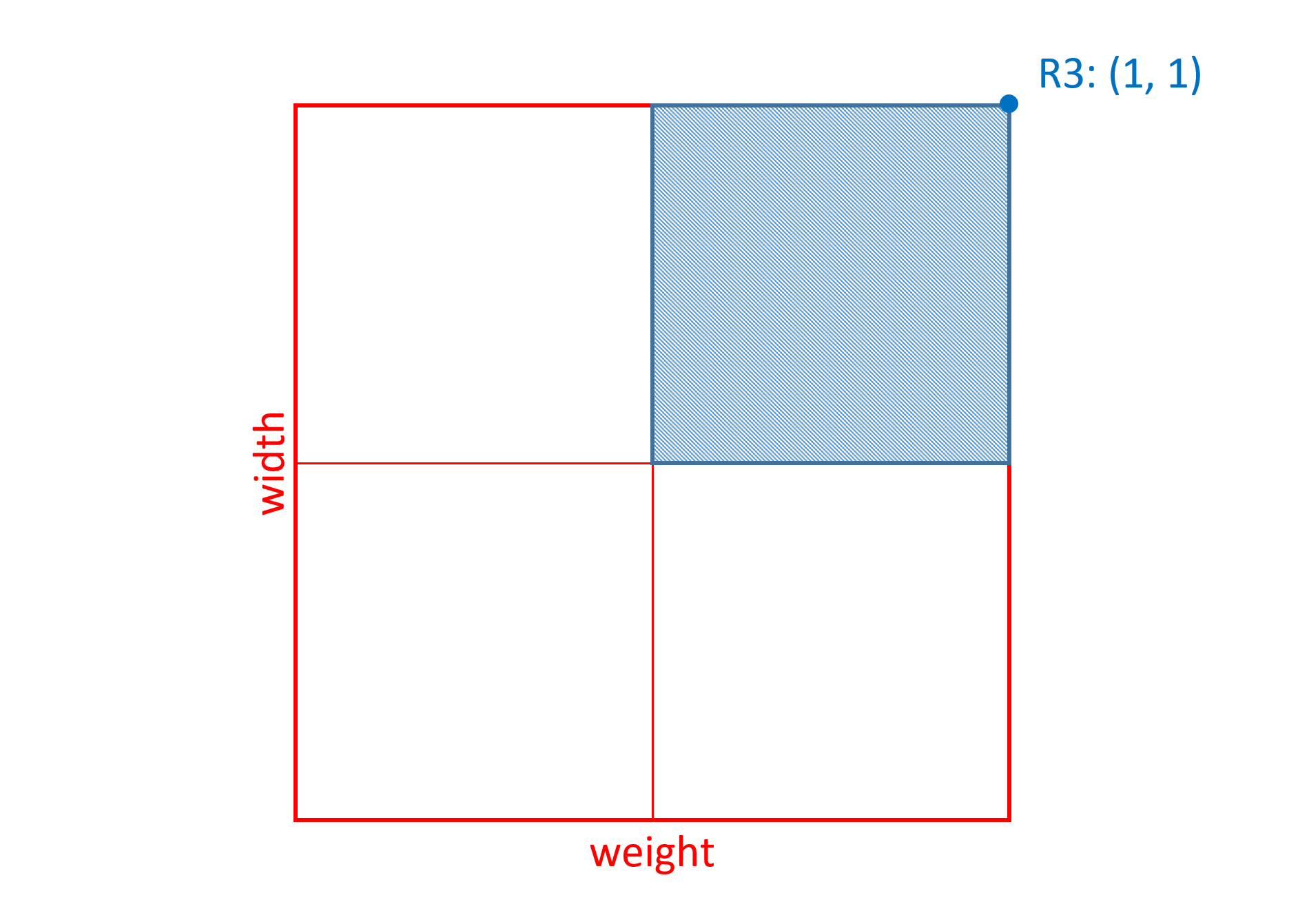
R3对于重量轴和宽度轴都具有非零坐标值,这意味着变体实例在重量或宽度上的更改将影响该区域的标量计算。
现在考虑与这三个区域相关联的每个点的字体中指定的增量值。为每个点指定X和Y增量。
R1具有以下相关的增量:
| pt0 | pt1 | pt2 | pt3 | pt4 | pt5 | |
|---|---|---|---|---|---|---|
| X | 234 | -26 | -26 | 234 | 0 | 209 |
| Y | -135 | -135 | 175 | 175 | 0 | 0 |
将这些增量应用于原始点位置,与R1关联的增量的最大影响是修改轮廓,如下所示:
对于(1, 0)的变化实例(最重的权重,默认宽度),其他区域的标量将为零,因此这将是该实例的结果字形轮廓。减小实例的权重值会减弱变化的程度,在原始轮廓和轮廓的最大修改之间插入轮廓。
现在考虑R2:它具有以下与之关联的增量:
| pt0 | pt1 | pt2 | pt3 | pt4 | pt5 | |
|---|---|---|---|---|---|---|
| X | 165 | 20 | 20 | 165 | 0 | 187 |
| Y | -2 | -2 | 2 | 2 | 0 | 0 |
将这些增量应用于原始点位置,与R2关联的增量的最大影响是修改轮廓,如下所示:
对于(0, 1)的变化实例(常规权重,最宽的宽度),其他区域的标量将为零,因此这将是该实例的结果插值字形轮廓。
现在考虑R3:它具有以下相关的增量:
| pt0 | pt1 | pt2 | pt3 | pt4 | pt5 | |
|---|---|---|---|---|---|---|
| X | 0 | 0 | 0 | 0 | 0 | 0 |
| Y | 0 | 0 | 0 | 0 | 0 | 0 |
由于所有delta值均为零,因此与此区域关联的数据对字形轮廓完全没有影响。(事实上,这些数据是多余的。)
现在,考虑(1, 1)的变化实例(最重的,最宽的宽度)。所有三个区域R1,R2和R3适用于此实例。如上所述,与R3相关的变体数据对字形没有影响。但是区域R1和R2的数据也适用于这种情况,并且它们的最大效果将被组合。也就是说,来自与R1和R2相关联的数据的每个点的X和Y增量将应用于点X和Y坐标。这将导致字形轮廓被修改如下:
对于权重> 0且<1且宽度> 0且<1的其他变体实例,将应用区域R1和R2的数据,但两个区域的标量会发生变化,从而导致对轮廓的不同比例影响 每个地区的数据。例如,考虑一个坐标为(0.2, 0.7)的变化实例 - 轻微的重量增加和大的宽度增加。R1和R2的区域标量为0.2和0.7。其中每个都将应用于每个区域的增量,并且给定点的缩放增量值组合:
| pt0 | pt1 | pt2 | pt3 | pt4 | pt5 | |
|---|---|---|---|---|---|---|
| X | 0.2 × 234 + 0.7 × 165 = 162.3 | 0.2 × -26 + 0.7 × 20 = 8.8 | 0.2 × -26 + 0.7 × 20 = 8.8 | 0.2 × 234 + 0.7 × 165 = 162.3 | 0.2 × 0 + 0.7 × 0 = 0 | 0.2 × 209 + 0.7 × 187 = 172.7 |
| Y | 0.2 × -135 + 0.7 × -2 = -134.8 | 0.2 × -135 + 0.7 × -2 = -134.8 | 0.2 × 175 + 0.7 × 2 = 36.4 | 0.2 × 175 + 0.7 × 2 = 36.4 | 0.2 × 0 + 0.7 × 0 = 0 | 0.2 × 0 + 0.7 × 0 = 0 |
这将导致字形轮廓被修改如下:

3.9.动态生成静态实例字体
在某些应用程序工作流程中,可能需要为特定实例动态生成静态字体资源 - 即,使用特定实例的插值的传统非变体字体表。这可能是需要的,以便将字体数据提供给遗留软件或不理解或支持可变字体的数据格式,例如传统打印机驱动程序,或具有嵌入字体数据的PDF或XPS文件。
例如,可能需要以可变字体处理 glyf 和 gvar 表以生成新的 glyf 表,该表具有针对特定实例的插值轮廓数据,或者处理 hhea 和 MVAR 表以生成一个新的 hhea 表,其中包含特定实例的数据。
不同的应用场景可能需要更多或更少完整的字体数据,需要生成需要生成的不同组的非变体特定字体表。此处未指定最低要求。但应注意以下几点:
- 某些方案可能需要在实例字体数据中使用PostScript名称(名称ID 6),并为每个使用的实例指定不同的名称。Adobe技术说明提供了Postscript名称生成的规范,可用于从可变字体派生的实例字体。请参阅Adobe技术说明#5902:“变体字体的PostScript名称生成”。
- 对于具有CFF 2轮廓的可变字体,某些工作流程(例如,打印)可能需要使用”CFF”表生成实例字体。在这种情况下,如果变体字体在FDArray中有多个Font DICT,则应生成CID加密的CFF字体,其ROS为”Adobe-Identity-0”。如果变体字体在FDArray中有一个字体DICT,那么如果在 post 表中提供字形名称,则可以生成名称键控的CFF字体(一些遗留工作流看起来用于语义的字形名称);否则,可以如上生成CID加密的CFF。将CFF 2 CharStrings转换为Type2 CharStrings将涉及重新优化CharString参数和运算符,以避免超出允许的最大堆栈深度。从CFF 2规范中删除的大多数CFF字段可以省略,因此它们将继承CFF默认值。填写其余字段的源信息记录在附录D,CFF2 表格章节的CFF 1.0变更中。
- 具有TrueType轮廓的可变字体可以利用GET VARIATION指令来为字形程序提供当前变体轴坐标。在需要动态生成实例字体数据的场景中,应该假定不支持该指令。在生成插值 glyf 表的过程中,需要对GET VARIATION指令进行特殊处理,以确保程序获得给定实例的适当轴坐标值。有关详细信息,请参阅TrueType指令集的第2部分。
4.OpenType字体文件
OpenType字体文件包含表格格式的数据,包括TrueType或压缩字体格式(CFF)轮廓字体。光栅化器使用字体中包含的表中的数据组合来呈现TrueType或PostScript字形轮廓。无论使用哪种大纲格式,都会使用其中一些支持数据,一些支持数据特定于TrueType或PostScript。
4.1.文件名
OpenType字体可能具有.OTF,.TTF,.OTC或.TTC扩展名。扩展名.OTC和.TTC应仅用于字体集合文件。
4.2.数据类型
OpenType字体文件中使用以下数据类型。所有OpenType字体都使用摩托罗拉式字节排序(Big Endian):
| Data | Type | Description |
|---|---|---|
| uint8 | 8-bit unsigned integer | |
| int8 | 8-bit signed integer | |
| uint16 | 16-bit unsigned integer | |
| int16 | 16-bit signed integer | |
| uint24 | 24-bit unsigned integer | |
| uint32 | 32-bit unsigned integer | |
| int32 | 32-bit signed integer | |
| Fixed | 32-bit signed fixed-point number (16.16) | |
| FWORD | int16 | that describes a quantity in font design units. |
| UFWORD | uint16 | that describes a quantity in font design units. |
| F2DOT14 | 16-bit signed fixed number with the low 14 bits of fraction (2.14). | |
| LONGDATETIME | Date | represented in number of seconds since 12:00 midnight, January 1, 1904. The value is represented as a signed 64-bit integer. |
| Tag | Array of four uint8s | (length = 32 bits) used to identify a table, design-variation axis, script, language system, feature, or baseline |
| Offset16 | Short | offset to a table, same as uint16, NULL offset = 0x0000 |
| Offset32 | Long | offset to a table, same as uint32, NULL offset = 0x00000000 |
F2DOT14格式由带符号的2的补码整数和无符号分数组成。要计算实际值,请取整数并添加分数。2.14值的示例是:
| Decimal Value | Hex Value | Integer | Fraction |
|---|---|---|---|
| 1.999939 | 0x7fff | 1 | 16383/16384 |
| 1.75 | 0x7000 | 1 | 12288/16384 |
| 0.000061 | 0x0001 | 0 | 1/16384 |
| 0.0 | 0x0000 | 0 | 0/16384 |
| -0.000061 | 0xffff | -1 | 16383/16384 |
| -2.0 | 0x8000 | -2 | 0/16384 |
Tag值是uint8数组。数组中的每个字节必须具有0x20到0x7E范围内的值。这对应于UTF-8编码中Unicode Basic Latin字符的值范围,与可打印的ASCII字符相同。结果,Tag值可以被重新解释为四字符序列,这通常是它们的引用方式。但是,形式上,值是字节数组。重新解释为字符时,Tag值区分大小写。它必须有一到四个非空格字符,用尾随空格填充(字节值0x20)。空格字符后面不能跟一个空格字符。
4.3.表版本号
大多数表都有版本号,整个字体的版本号包含在表目录中。请注意,有五种不同的版本号类型,每种类型都有自己的编号方案。
- 单个uint16字段。这用在许多表中,通常版本从零(0)开始。
- 单独的uint16主要和次要版本字段。这用在许多表中,通常版本从1.0开始。
- 主要/次要版本号的固定字段。这用于 maxp,post 和 vhea 表。
- 带有枚举值的uint32字段。
- 带有数值的uint32字段。这仅在DSIG和 meta 表中使用。
只有某些表使用固定值作为版本,并且仅出于向后兼容的原因。当固定数用作版本时,高16位包含主版本号,低16位包括次版本。然而,非零次要版本的表示与固定值的正常处理不一致,其中低16位表示小数值N * 2 ^ -16。相反,具有非零次版本号的表始终指定版本号的文字值。例如,maxp 表版本0.5的版本号是0x00005000,vhea 表版本1.1的版本号是0x00011000。当Fixed被指示为版本字段的类型时,可能的值应被视为特定值的枚举,而不是能够表示许多潜在主要和次要版本的数值。
表目录使用uint32字段,其中包含表示四字符标记的已定义值的枚举;有关详细信息,请参阅下面的“OpenType字体的组织”部分。
读取表的实现必须包含用于检查版本号的代码,以便在格式和版本号发生更改时,旧版实现将优雅地处理更新版本。
次要版本号更改始终意味着格式更改是兼容的扩展。如果实现了解主要版本号,则可以安全地继续阅读该表。如果次要版本大于实现识别的最新版本,则扩展字段将无法检测到实现。
出于兼容性的目的,使用单个uint16或uint32值表示的版本号被视为次要版本号,并且任何格式更改都是兼容的扩展。
请注意,在较早版本中未定义或保留的某些字段值可能会在次要版本更改中分配含义。实现不应该对位字段中的保留值或未分配值或位进行假设,并且如果遇到则可以忽略它们。在编写字体数据时,工具应始终为保留字段或位写入零。验证器应警告对于未针对要验证数据的给定版本定义的字段或位的任何非零值。
如果未识别主要版本,则实现不得读取该表,因为它不能对二进制数据的解释做出任何假设。实现应该将表视为缺失。
4.4.组织OpenType字体
OpenType格式的一个关键特性是TrueType sfnt”wrapper”,它以一般和可扩展的方式为表集合提供组织。
OpenType字体以Offset Table开头。如果字体文件只包含一种字体,则偏移表将从文件的字节0开始。如果字体文件是OpenType字体集合文件(见下文),则每个字体的偏移表的起始点在TTCHeader中指示。
Offset Table:
| Type | Name | Description |
|---|---|---|
| uint32 | sfntVersion | 0x00010000 or 0x4F54544F (‘OTTO’) — see below. |
| uint16 | numTables | Number of tables. |
| uint16 | searchRange | (Maximum power of 2 <= numTables) x 16. |
| uint16 | entrySelector | Log2(maximum power of 2 <= numTables). |
| uint16 | rangeShift | NumTables x 16-searchRange. |
包含TrueType轮廓的OpenType字体应使用值0x00010000作为sfntVersion。包含CFF数据(版本1或2)的OpenType字体应使用0x4F54544F(‘OTTO’,当重新解释为标记时)用于sfntVersion。
注意:TrueType字体的Apple规范允许 sfnt 版本为"true"和"typ1"。这些版本标记不应用于包含OpenType表的字体。Offset Table紧跟表记录条目。表记录中的条目必须按标签按升序排序。表记录中的偏移值是从字体文件的开头开始测量的。
Table Record:
| Type | Name | Description |
|---|---|---|
| Tag | tableTag | Table identifier. |
| uint32 | checkSum | CheckSum for this table. |
| Offset32 | offset | Offset from beginning of TrueType font file. |
| uint32 | length | Length of this table. |
表记录使得给定字体只能包含它实际需要的那些表。因此,numTables没有标准值。
表标签是OpenType字体文件中为表提供的名称。有关标记值的要求,请参阅上面的数据类型。
一些表具有内部结构,子表位于指定的偏移处,因此,可以构造具有交错的不同表的数据的字体。通常,表应该连续排列而不重叠不同表的范围。但是,在任何情况下,表长度都会测量包含表的所有数据的连续字节范围。这适用于任何子表以及顶级表。
4.5.字体集合
表校验和是给定表的uint32单元的无符号和。在C中,以下函数可用于确定校验和:
1 | uint32 CalcTableChecksum(uint32 *Table, uint32 Length) |
注意:此函数意味着表的长度必须是四个字节的倍数。事实上,如果没有正确的填充,字体就不会被认为是结构良好的。所有表必须以四字节边界开始,表之间的任何剩余空间都用零填充。所有表格的长度应记录在表格记录中,并记录其实际长度(不是填充长度)。要计算 head 表的checkSum,该表本身包含整个字体的checkSumAdjustment条目,请执行以下操作:
- 将checkSumAdjustment设置为0。
- 计算包括 head 表在内的所有表的校验和,并将该值输入表目录。
- 计算整个字体的校验和。
- 从0xB1B0AFBA中减去该值。
- 将结果存储在checkSumAdjustment中。
包含整个字体的checkSumAdjustment条目的 head 表的checkSum现在不正确。那不是问题。不要改变它。尝试验证 head 表未更改的应用程序应通过不包括checkSumAdjustment值来计算该表的checkSum,并将结果与表目录中的条目进行比较。
OpenType字体集合(以前称为TrueType集合)是一种在单个文件结构中提供多个OpenType字体资源的方法。字体集合的格式允许共享两个或多个字体之间相同的字体表。当要一起传递的字体共享许多共同的字形时,包含轮廓字形数据(TrueType,CFF,CFF2 或SVG)的字体集合最有用。通过允许多个字体共享字形集和其他常见字体表,字体集可以显着节省文件空间。
例如,一组日文字体可能各自都有自己的假名字形设计,但共享相同的汉字设计。对于普通的OpenType字体文件,包含常见汉字字形的唯一方法是将其字形数据复制到每种字体中。由于汉字表示比假名更多的数据,因此导致大量浪费的字形数据重复。定义字体集合以解决此问题。
注意:尽管字体集合的原始定义(作为TrueType规范的一部分)旨在与包含TrueType轮廓的字体一起使用,并且此约束在早期的OpenType版本中得到维护,但这不再是OpenType中的约束。无论字体是否存在布局表,字体集合文件都可以包含各种类型的轮廓(或它们的混合)。
注意:使用OpenType字体变体机制的变体字体在功能上等同于多个非变体字体。变体字体不需要包含在集合文件中。然而,集合文件可以包括一个甚至多个可变字体,甚至可以组合变体和非变体字体。字体集合文件结构
字体集合文件由单个TTC标头表,一个或多个具有表目录的偏移表(每个对应于不同的字体资源)和许多OpenType表组成。TTC标头必须位于TTC文件的开头。
TTC文件必须包含每个字体资源的完整偏移表和表目录。TTC文件表目录与TTF文件表目录具有完全相同的格式。TTC文件中所有表目录中的表偏移量是从TTC文件的开头开始测量的。
TTC文件中的每个OpenType表都通过使用该表的每种字体的偏移表和表目录引用。某些OpenType表必须出现多次,对于TTC中包含的每种字体一次;而其他表可能由TTC中的多种字体共享。
例如,考虑一个结合了两种日文字体(Font1和Font2)的TTC文件。字体有不同的假名设计(Kana1和Kana2),但使用相同的设计汉字。TTC文件包含一个 glyf 表,其中包括kana和汉字的两种设计;两种字体的表目录都指向这个 glyf 表。但是每个字体的表目录指向不同的 cmap 表,该表标识要使用的字形集。Font1的 cmap 表指向假名字形的 loca 和 glyf 表的Kana1区域,以及汉字的汉字区域。Font2的 cmap 表指向假名字形的 loca 和 glyf 表的Kana2区域,以及汉字的相同汉字区域。
每个字体应具有唯一副本的表是系统用于识别字体及其字符映射的表,包括 cmap,name 和 OS/2。应该由TTC中的字体共享的表是定义字形和指令数据或使用字形索引来访问数据的表:glyf,loca,hmtx,hdmx,LTSH,cvt,fpgm,prep,EBLC,EBDT,EBSC,maxp 等。实际上,可以共享具有两种或更多种字体的相同数据的任何表。
Microsoft提供了一个工具来帮助构建.TTC文件。该过程包括密切关注字体中的字形重新编号问题以及可能导致的 cmap 表和其他地方的副作用。要合并的字体还必须具有兼容的TrueType指令 - 也就是说,它们的预编程,函数定义和控制值不得冲突。
包含TrueType字形outlnes的集合文件应使用文件名后缀.TTC。包含CFF或 CFF2 轮廓的集合文件应使用文件扩展名.OTC。
TTC标题
TTC标题有两个版本:版本1.0已用于没有数字签名的TTC文件。版本2.0可用于带或不带数字签名的TTC文件 - 如果没有签名,则版本2.0标头的最后三个字段保留为空。
如果使用数字签名,则文件的DSIG表必须是TTC文件中的最后一个表。TTC文件中的签名应为格式1签名。
TTC标头表的目的是在TTC文件中找到不同的偏移表。TTC标头位于TTC文件的开头(偏移= 0)。它由识别标签,版本号,文件中OpenType字体数量以及每个偏移表的偏移数组组成。
TTC Header Version 1.0:
| Type | Name | Description |
|---|---|---|
| TAG | ttcTag | Font Collection ID string: ‘ttcf’ (used for fonts with CFF or CFF2 outlines as well as TrueType outlines) |
| uint16 | majorVersion | Major version of the TTC Header, = 1. |
| uint16 | minorVersion | Minor version of the TTC Header, = 0. |
| uint32 | numFonts | Number of fonts in TTC |
| Offset32 | offsetTable[numFonts] | Array of offsets to the OffsetTable for each font from the beginning of the file |
TTC Header Version 2.0:
| Type | Name | Description |
|---|---|---|
| TAG | ttcTag | Font Collection ID string: ‘ttcf’ |
| uint16 | majorVersion | Major version of the TTC Header, = 2. |
| uint16 | minorVersion | Minor version of the TTC Header, = 0. |
| uint32 | numFonts | Number of fonts in TTC |
| Offset32 | offsetTable[numFonts] | Array of offsets to the OffsetTable for each font from the beginning of the file |
| uint32 | dsigTag | Tag indicating that a DSIG table exists, 0x44534947 (‘DSIG’) (null if no signature) |
| uint32 | dsigLength | The length (in bytes) of the DSIG table (null if no signature) |
| uint32 | dsigOffset | The offset (in bytes) of the DSIG table from the beginning of the TTC file (null if no signature) |
4.6.字体表
如果填充表格,则TrueType光栅化器可以更轻松地遍历表格,以便每个表格从4字节边界开始。此外,用于计算表校验和的算法假定表是32位对齐的。因此,所有表必须是32位对齐并用零填充。
必填表格
无论是在OpenType字体中使用TrueType还是CFF轮廓,都需要以下表格才能使字体正常运行:
| Tag | Name |
|---|---|
| cmap | Character to glyph mapping |
| head | Font header |
| hhea | Horizontal header |
| hmtx | Horizontal metrics |
| maxp | Maximum profile |
| name | Naming table |
| OS/2 | OS/2 and Windows specific metrics |
| post | PostScript information |
与TrueType轮廓相关的表
对于基于TrueType轮廓的OpenType字体,使用以下表格:
| Tag | Name |
|---|---|
| cvt | Control Value Table (optional table) |
| fpgm | Font program (optional table) |
| glyf | Glyph data |
| loca | Index to location |
| prep | CVT Program (optional table) |
| gasp | Grid-fitting/Scan-conversion (optional table) |
与CFF大纲相关的表格
对于基于CFF轮廓的OpenType字体,使用以下表格:
| Tag | Name |
|---|---|
| CFF | Compact Font Format 1.0 |
| CFF2 | Compact Font Format 2.0 |
| VORG | Vertical Origin (optional table) |
强烈建议用于垂直书写的CFF OpenType字体包括垂直原点 VORG 表。
OpenType中的多个Master支持已从规范的1.3版本中停止。不再支持在1.3版之前的版本中定义的 MMSD 和 MMFX 表。
与SVG轮廓相关的表
| Tag | Name |
|---|---|
| SVG | The SVG (Scalable Vector Graphics) table |
与位图字形相关的表
| Tag | Name |
|---|---|
| EBDT | Embedded bitmap data |
| EBLC | Embedded bitmap location data |
| EBSC | Embedded bitmap scaling data |
| CBDT | Color bitmap data |
| CBLC | Color bitmap location data |
| sbix | Standard bitmap graphics |
除了轮廓之外,OpenType字体还可以包含字形的位图。手动调整的位图在OpenType字体中特别有用,用于表示非常小的复杂字形。如果以字体提供特定大小的位图,则在渲染字形时系统将使用它而不是轮廓。
高级印刷表
几个可选表支持高级印刷功能:
| Tag | Name |
|---|---|
| BASE | Baseline data |
| GDEF | Glyph definition data |
| GPOS | Glyph positioning data |
| GSUB | Glyph substitution data |
| JSTF | Justification data |
| MATH | Math layout data |
用于OpenType字体变体的表
| Tag | Name |
|---|---|
| avar | Axis variations |
| cvar | CVT variations (TrueType outlines only) |
| fvar | Font variations |
| gvar | Glyph variations (TrueType outlines only) |
| HVAR | Horizontal metrics variations |
| MVAR | Metrics variations |
| STAT | Style attributes (required for variable fonts, optional for non-variable fonts) |
| VVAR | Vertical metrics variations |
请注意,除了上面列出的特定于变体的表之外,某些与变体相关的格式可能会用在表中。特别是,可变字体中的 GDEF 或 BASE 表可以包括使用公共表格式的变体数据。可变字体的 CFF2 表也可以包括变体数据,但使用特定于 CFF2 表的格式。
与颜色字体相关的表
| Tag | Name |
|---|---|
| COLR | Color table |
| CPAL | Color palette table |
| CBDT | Color bitmap data |
| CBLC | Color bitmap location data |
| sbix | Standard bitmap graphics |
| SVG | The SVG (Scalable Vector Graphics) table |
请注意,对于与SVG轮廓相关的表以及与位图字形相关的表,其他部分中也列出了其中一些表。
其他OpenType表
| Tag | Name |
|---|---|
| DSIG | Digital signature |
| hdmx | Horizontal device metrics |
| kern | Kerning |
| LTSH | Linear threshold data |
| MERG | Merge |
| meta | Metadata |
| STAT | Style attributes |
| PCLT | PCL 5 data |
| VDMX | Vertical device metrics |
| vhea | Vertical Metrics header |
| vmtx | Vertical Metrics |
请注意,变体字体中需要 STAT 表。此外,hdmx 和 VDMX 表不用于可变字体。
5.OpenType™布局公用表格式
OpenType布局由五个表组成:字形替换表(GSUB),字形定位表(GPOS),基线表 BASE,对齐表(JSTF)和字形定义表 GDEF 。这些表使用一些相同的数据格式。
本章介绍了所有OpenType布局表中使用的约定,并介绍了常用的表格格式。单独的章节提供了有关GSUB,GPOS,BASE,JSTF 和 GDEF 表的完整详细信息。
5.1.概要
OpenType布局表提供印刷信息,用于正确定位和替换字形,在许多语言环境中准确排版所需的操作。OpenType布局数据按脚本,语言系统,印刷功能和查找进行组织。
脚本在顶层定义。脚本是用于以书面形式表示一种或多种语言的字形集合(参见图2a)。例如,单个脚本 - 拉丁语 - 用于编写英语,法语,德语和许多其他语言。相比之下,三个剧本 - 平假名,片假名和汉字 - 用于写日语。使用OpenType布局,单个字体可能支持多个脚本。

语言系统可以修改脚本中的字形的功能或外观以表示特定语言。例如,eszet连字在德语系统中使用,但不是法语或英语(见图2b)。阿拉伯语脚本包含用于编写波斯语和乌尔都语语言的不同字形。在OpenType布局中,语言系统在脚本中定义。

语言系统定义功能,这些功能是使用字形表示语言的排版规则。样本要素是替换日语中的垂直字形的”vert”特征,使用连字代替单独字形的”liga”特征,以及相对于阿拉伯语中的基本字形定位变音标记的“标记”特征(参见图2c))。在没有特定于语言的规则的情况下,默认语言系统功能适用于整个脚本。例如,阿拉伯语脚本的默认语言系统功能基于字形在单词中的位置替换初始,中间和最终字形表单。

功能使用查找数据实现,文本处理客户端使用该数据替换和定位字形。查找描述受操作影响的字形,要应用于这些字形的操作类型以及生成的字形输出。
字体还可以包括 GPOS 或 GSUB 表中的FeatureVariations数据,其允许在特定条件适用时由替代查找数据替换与特征相关联的默认查找数据。目前,此机制仅用于使用OpenType字体变体的可变字体。
5.2.OpenType布局和字体变体
OpenType字体变体允许单个字体沿着一个或多个设计变体轴支持许多设计变体。例如,具有重量和宽度变化的字体可能支持从细到黑的重量,以及从超浓缩到超扩展的宽度。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
选择不同的变体实例时,各个字形的设计和指标会发生变化。这会影响 GPOS,BASE,JSTF 或 GDEF 表中给出的字体单位值,例如附件锚位置的X和Y坐标。这些表中给出的字体单位值适用于变体字体的默认实例。如果需要对不同变体实例进行调整,则使用变体数据完成此操作,其中过程类似于用于字形轮廓和其他字体数据的过程,如章节OpenType字体变体概述中所述。GPOS,JSTF 或 GDEF 值的变体数据包含在ItemVariationStore表中,而ItemVariationStore表又包含在 GDEF 表中,BASE 值的变体数据包含在 BASE 表本身的ItemVariationStore表中。ItemVariationStore的格式在OpenType Font Variations Common Table Formats一章中有详细描述。对于需要变化的 GPOS,BASE,JSTF 或 GDEF 表中的字体单位值,ItemVariationStore中特定变体数据的引用在VariationIndex表中提供,如下所述。
在一些可变字体中,可能需要对字体的变化空间内的不同区域使用不同的字形替换或字形定位动作。例如,对于计数器变小的狭窄或重型实例,可能需要进行某些字形替换以使用移除了某些笔划的替代字形或简化的轮廓以允许更大的计数器。使用 GSUB 或 GPOS 表中的FeatureVariations表可以实现这样的效果。FeatureVariations表如下所述。
5.3.表组织
两个OpenType布局表 GSUB 和 GPOS 使用相同的数据格式来描述字形的排版功能以及它们支持的语言和脚本:ScriptList表,FeatureList表,LookupList表和FeatureVariations表。在 GSUB 中,表定义了字形替换数据。在 GPOS 中,它们定义字形定位数据。本章介绍这些常见的表格格式。
ScriptList以字体标识脚本,每个脚本由包含脚本和语言系统数据的脚本表表示。语言系统表引用要素,这些要素在FeatureList中定义。每个要素表都引用LookupList中定义的查找数据,该数据描述了实现该功能的方式,时间和位置。

注意:BASE 和 JSTF 表中的数据也是由脚本和语言系统组织的。但是,数据格式与 GSUB 和GPOS中的数据格式不同,并且它们不包括FeatureList或LookupList。BASE 和 JSTF 数据格式在 BASE 和 JSTF 章节中描述。用于替换和定位字形的信息在Lookup子表中定义。每个子表提供一种类型的信息,具体取决于查找是否是 GSUB 或 GPOS 表的一部分。例如,GSUB 查找可以指定要替换的字形和发生替换的上下文,GPOS 查找可以指定字距调整以进行字距调整。OpenType Layout有八种类型的 GSUB 查找(在GSUB 章节中描述)和九种类型的 GPOS 查找。
每个子表(Extension LookupType子表除外)包括Coverage表,该表列出将导致字形替换或定位操作的“覆盖”字形。本章描述了Coverage表格式。
某些替换或定位操作可能适用于字形的组或类。GSUB 和 GPOS 查找子表使用“类定义”表将字形分配给类。本章包括类定义表格式的说明。
在非变体字体中,GPOS 查找子表还可以包含设备表,以调整特定输出大小和分辨率的缩放轮廓字形坐标。设备表还可用于对 BASE 和 GDEF 表中的基线度量或插入符偏移值进行类似调整。类似地,在可变字体中,GPOS 查找子表,BaseCoord表和CaretValue表可以包含VariationIndex表,其引用变体数据以调整字体设计变化空间内的不同变体实例可能需要的字体单位值。本章描述了Device和VariationIndex表。
如上所述,要素表引用查找列表中的一组查找。FeatureVariations表允许在特定条件下使用给定特征的默认查找集替换为不同的查找集。这可以在变体字体中使用,以便为不同的变体实例提供不同的替换或定位操作。例如,对于计数器变小的狭窄或重型实例,可能需要进行某些字形替换以使用移除了某些笔划的替代字形或简化的轮廓以允许更大的计数器。
本章介绍OpenType布局中使用的常见数据类型。本章末尾提供了说明常见数据格式的示例表和列表。
5.4.脚本和语言
三个表及其相关记录适用于脚本和语言:脚本列表表(ScriptList)及其脚本记录(ScriptRecord),脚本表及其语言系统记录(LangSysRecord)和语言系统表(LangSys)。
5.5.脚本列表表和脚本记录
OpenType布局字体可能包含一组或多组用于呈现各种脚本的字形,这些脚本在ScriptList表中枚举。GSUB 和 GPOS 表都定义了脚本列表表(ScriptList):
- GSUB 表使用ScriptList表来访问适用于脚本的字形替换功能。
- GPOS 表使用ScriptList表来访问适用于脚本的字形定位功能。
ScriptList表由字体中的字形(ScriptCount)表示的脚本计数和记录数组(ScriptRecord)组成,每个脚本对应一个字体,其中字体定义特定于脚本的功能(没有脚本特定功能的脚本)不需要ScriptRecord)。每个ScriptRecord都包含一个标识脚本的ScriptTag和一个脚本表的偏移量。ScriptRecord数组按脚本标记的字母顺序存储。
可以在字体中使用带有脚本标记DFLT(默认)的脚本表来定义非特定于脚本的功能。如果没有与正在格式化的文本的特定脚本相关联的脚本表,或者文本没有特定脚本(例如,它仅包含符号或标点符号),则应用程序应使用DFLT脚本表。
注意:如果符号或标点符号具有Unicode脚本属性"Common"但与特定脚本的字符一起使用,则应用于这些符号或标点字符的功能不一定按DFLT脚本进行组织,但可以在具体脚本。应用程序可以处理与脚本无关的字符以及前面或后面的脚本特定字符,以提高处理效率。在这种情况下,应用程序将通过使用特定脚本的脚本表来查找对中性字符进行操作的功能。但是,如果文本仅包含中性字符,则仍将使用DFLT脚本。如果存在DFLT脚本表,则它必须具有非NULL DefaultLangSys值,该值为默认语言系统表提供偏移量(如下所述)。
由于语言是使用特定脚本编写的,因此通常希望语言特定的排版效果与特定脚本相关联,而不是与通用DFLT脚本相关联。因此,DFLT脚本表的LangSysCount值通常应为0(没有非默认语言系统表)。但是,允许字体具有带有非默认语言系统表的DFLT脚本表,如果DFLT脚本表适用,则应用程序可以使用与其中一个相关联的功能 - 特定脚本不存在脚本表,或者文本上下文中没有特定的脚本 - 如果指定了某个特定的语言系统。在这种情况下,如果字体包含具有此配置的表,则应用程序应支持使用与DFLT脚本关联的非默认语言系统表。
本章末尾的示例1显示了使用三个脚本的日语字体的ScriptList表和ScriptRecords。
ScriptList table
| Type | Name | Description |
|---|---|---|
| uint16 | scriptCount | Number of ScriptRecords |
| ScriptRecord | scriptRecords[scriptCount] | Array of ScriptRecords, listed alphabetically by script tag |
ScriptRecord
| Type | Name | Description |
|---|---|---|
| Tag | scriptTag | 4-byte script tag identifier |
| Offset16 | scriptOffset | Offset to Script table, from beginning of ScriptList |
5.6.脚本表和语言系统记录
脚本表标识每个语言系统,该系统定义如何在脚本中使用特定语言的字形。它还引用了一个默认语言系统,该系统定义了在没有语言特定知识的情况下如何使用脚本的字形。
脚本表以默认语言系统表(defaultLangSys)的偏移量开始,该表定义了一组用于控制脚本默认行为的功能。接下来,语言系统计数(LangSysCount)定义使用该脚本的语言系统(不包括DefaultLangSys)的数量。此外,语言系统记录数组(LangSysRecord)使用标识标记(LangSysTag)和语言系统表(LangSys)的偏移量定义每个语言系统(不包括默认值)。LangSysRecord数组按LangSysTag的字母顺序存储记录。
如果未定义特定于语言的脚本行为,则将LangSysCount设置为零(0),并且不分配任何LangSysRecords。
Script table
| Type | Name | Description |
|---|---|---|
| Offset16 | defaultLangSys | Offset to default LangSys table, from beginning of Script table — may be NULL |
| uint16 | langSysCount | Number of LangSysRecords for this script — excluding the default LangSys |
| LangSysRecord | langSysRecords[langSysCount] | Array of LangSysRecords, listed alphabetically by LangSys tag |
LangSysRecord
| Type | Name | Description |
|---|---|---|
| Tag | langSysTag | 4-byte LangSysTag identifier |
| Offset16 | langSysOffset | Offset to LangSys table, from beginning of Script table |
5.7.语言系统表
所有其他功能都是可选的。对于每个可选功能,从零开始的索引值引用FeatureRecord数组中的记录(FeatureRecord),该记录存储在功能列表表(FeatureList)中。特征索引本身(不包括ReqFeatureIndex)以任意顺序存储在FeatureIndex数组中。FeatureCount指定FeatureIndex数组中列出的要素总数。
功能在FeatureList表,FeatureRecord和Feature表中完整指定,本章稍后将对其进行介绍。本章末尾的示例2显示了用于阿拉伯语脚本中的上下文定位的脚本表,LangSysRecord和LangSys表。
LangSys table
| Type | Name | Description |
|---|---|---|
| Offset16 | lookupOrder | = NULL (reserved for an offset to a reordering table) |
| uint16 | requiredFeatureIndex | Index of a feature required for this language system; if no required features = 0xFFFF |
| uint16 | featureIndexCount | Number of feature index values for this language system — excludes the required feature |
| uint16 | featureIndices[featureIndexCount] | Array of indices into the FeatureList, in arbitrary order |
5.8.功能和查找
功能定义OpenType布局字体的功能,并命名它们以向文本处理客户端传达含义。考虑一个名为”liga”的功能来创建连字。由于其名称,客户端知道该功能的作用,并可以决定是否应用它。字体开发人员可以使用这些功能,也可以创建自己的功能。
选择要使用的功能后,客户端会根据所选功能组装所有查找。可能需要多次查找来定义不同替换和定位操作所需的数据,以及控制这些操作的顺序和效果。
为了实现功能,客户端按查找定义在LookupList中发生的顺序应用查找。因此,在 GSUB 或 GPOS 表中,可以在文本处理期间交错来自若干不同特征的查找。当客户端找到目标字形或字形上下文并执行替换(如果指定)或定位(如果指定)时,查找完成。
注意:替换(GSUB)查找始终在定位(GPOS)查找之前发生。TrueType中的查找排序机制依赖于字体来确定文本处理操作的正确顺序。查找数据在一个或多个子表中定义,这些子表包含有关特定字形和要对其执行的操作的信息。每种类型的查找都有一个或多个相应的子表定义。子表格式的选择取决于两个因素:应用于操作的信息的精确内容以及所需的存储效率。
OpenType布局功能定义特定于字体中字形布局的信息。它们不编码在特定语言的约定或特定脚本的排版中不变的信息。将在给定语言的所有字体中复制的信息属于该语言的文本处理应用程序,而不是字体。
5.9.功能列表表
GSUB 和 GPOS 表的标题包含功能列表表(FeatureList)的偏移量,用于枚举字体中的所有功能。特定FeatureList中的功能不限于任何单个脚本。FeatureList包含 GSUB 或 GPOS 功能的完整列表,这些功能用于呈现字体中所有脚本中的字形。
FeatureList表枚举记录数组(FeatureRecord)中的要素,并指定要素总数(FeatureCount)。每个要素都必须有一个FeatureRecord,它包含一个标识要素的FeatureTag和一个Feature表的偏移量(如下所述)。FeatureRecord数组按FeatureTag名称的字母顺序排列。
注意:存储在LangSys表的FeatureIndex数组中的值用于定位FeatureList表的FeatureRecord数组中的记录。FeatureList table
| Type | Name | Description |
|---|---|---|
| uint16 | featureCount | Number of FeatureRecords in this table |
| FeatureRecord | featureRecords[featureCount] | Array of FeatureRecords — zero-based (first feature has FeatureIndex = 0), listed alphabetically by feature tag |
FeatureRecord
| Type | Name | Description |
|---|---|---|
| Tag | featureTag | 4-byte feature identification tag |
| Offset16 | featureOffset | Offset to Feature table, from beginning of FeatureList |
5.10.功能表
功能表定义具有一个或多个查找的功能。客户端使用查找来替换或定位字形。
GSUB 表中定义的要素表包含对字形替换查找的引用,GPOS 表中定义的要素表包含对字形定位查找的引用。如果文本处理操作同时需要字形替换和定位,则 GSUB 和 GPOS 表都必须定义Feature表,并且表必须使用相同的FeatureTag。
Feature表包含Feature Parameters(FeatureParams)表的偏移量(如果已为此功能定义了一个 - 请参阅下一段中的注释),为该功能列出的查找计数(LookupCount)以及任意排序LookupList(LookupListIndex)中的索引数组。LookupList索引是对Lookup表的偏移数组的引用。
“功能参数”表的格式特定于特定功能,必须在OpenType布局标记注册表的“功能标记”部分的功能条目中指定。必须在“功能参数”表本身中隐式或显式指定“功能参数”表的长度。Feature Table中的FeatureParams字段记录相对于Feature Table开头的偏移量。如果不需要“特征参数”表,则必须将FeatureParams字段设置为NULL。
为了识别 GSUB 或 GPOS 表中的功能,文本处理客户端读取给定LangSys表中引用的每个FeatureRecord的FeatureTag。然后客户端选择它想要实现的功能,并使用LookupList检索所选功能的Lookup索引。接下来,客户端按LookupList顺序排列索引。最后,客户端应用查找数据来替换或定位字形。
本章末尾的示例3显示了用于替换两种语言的连字的FeatureList和Feature表。
Feature table
| Type | Name | Description |
|---|---|---|
| Offset16 | featureParams | = NULL (reserved for offset to FeatureParams) |
| uint16 | lookupIndexCount | Number of LookupList indices for this feature |
| uint16 | lookupListIndices[lookupIndexCount] | Array of indices into the LookupList — zero-based (first lookup is LookupListIndex = 0) |
5.11.查找列表表
GSUB 和 GPOS 表的标题包含用于字形替换(GSUB表)和字形定位(GPOS表)的查找列表表(LookupList)的偏移量。LookupList表包含Lookup表(Lookup)的偏移数组。字体开发人员在Lookup数组中定义Lookup序列,以控制文本处理客户端将查找数据应用于字形替换和定位操作的顺序。LookupCount指定数组中Lookup表偏移的总数。
本章末尾的示例4显示了LookupList表中的三个连字查找。
LookupList table
| Type | Name | Description |
|---|---|---|
| uint16 | lookupCount | Number of lookups in this table |
| Offset16 | lookups[lookupCount] | Array of offsets to Lookup tables, from beginning of LookupList — zero based (first lookup is Lookup index = 0) |
5.12.查找表
查找表(查找)定义用于实现功能的替换或定位操作的特定条件,类型和结果。例如,替换操作需要要替换的目标字形索引列表,替换字形索引列表以及替换操作类型的描述。
每个查找表可能只包含一种类型的信息(LookupType),由查找是否是 GSUB 或 GPOS 表的一部分决定。GSUB 支持八种LookupTypes,GPOS 支持九种LookupTypes。
每个LookupType都使用一个或多个子表定义,每个子表定义提供不同的表示格式。格式由操作所需信息的内容和所需的存储效率决定。当字形信息最好以多种格式呈现时,只要所有子表都是相同的LookupType,单个查找可能包含多个子表。例如,在给定查找内,字形索引数组格式可以最好地表示一组目标字形,而字形索引范围格式对于另一组目标字形可能更好。
在文本处理期间,客户端在移动到下一个查找之前对字符串中的每个字形应用查找。在客户端进行替换/定位操作后,字形的查找完成。要移动到“下一个”字形,客户端通常会跳过参与查找操作的所有字形:替换/定位的字形以及形成操作上下文的任何其他字形。然而,在对定位操作(即,字距调整)的情况下,序列中的“下一个”字形可以是所定位对的第二字形(有关细节,请参见对定位查找)。
Lookup表包含指定为整数的LookupType,用于定义查找中存储的信息类型。LookupFlag指定查找限定符,以帮助文本处理客户端替换或定位字形。subTableCount字段指定SubTable的总数。SubTable数组指定从Lookup表的开头测量的偏移量到SubTable数组中枚举的每个SubTable。
Lookup table
| Type | Name | Description |
|---|---|---|
| uint16 | lookupType | Different enumerations for GSUB and GPOS |
| uint16 | lookupFlag | Lookup qualifiers |
| uint16 | subTableCount | Number of subtables for this lookup |
| Offset16 | subtableOffsets[subTableCount] | Array of offsets to lookup subtables, from beginning of Lookup table |
| uint16 | markFilteringSet | Index (base 0) into GDEF mark glyph sets structure. This field is only present if bit useMarkFilteringSet of lookup flags is set. |
LookupFlag使用两个字节的数据:
- 可以设置前四位中的每一位,以便指定用于将查找应用于字形串的附加指令。LookUpFlag位枚举表提供了有关这些位的使用的详细信息。
- 第五位表示Lookup表中存在MarkFilteringSet字段。
- 接下来的三位保留供将来使用。
- 设置高字节以指定标记附件的类型。
LookupFlag bit enumeration
| Type | Name | Description |
|---|---|---|
| 0x0001 | rightToLeft | This bit relates only to the correct processing of the cursive attachment lookup type (GPOS lookup type 3). When this bit is set, the last glyph in a given sequence to which the cursive attachment lookup is applied, will be positioned on the baseline. Note: Setting of this bit is not intended to be used by operating systems or applications to determine text direction. |
| 0x0002 | ignoreBaseGlyphs | If set, skips over base glyphs |
| 0x0004 | ignoreLigatures | If set, skips over ligatures |
| 0x0008 | ignoreMarks | If set, skips over all combining marks |
| 0x0010 | useMarkFilteringSet | If set, indicates that the lookup table structure is followed by a MarkFilteringSet field. The layout engine skips over all mark glyphs not in the mark filtering set indicated. |
| 0x00E0 | reserved | For future use (Set to zero) |
| 0xFF00 | markAttachmentType | If not zero, skips over all marks of attachment type different from specified. |
IgnoreBaseGlyphs,IgnoreLigatures或IgnoreMarks引用 GDEF 表格中Glyph类定义表中定义的基本字形,连字和标记。如果设置了这些标志中的任何一个,则必须存在字形类定义表。如果设置了这些位中的任何一个,则查找必须忽略相应类型的字形;也就是说,必须处理其他字形,就好像这些字形不存在一样。
如果MarkAttachmentType不为零,则必须在 GDEF 表的Mark Attachment Class Definition Table中定义标记附件类。处理字形序列时,查找必须忽略不在指定标记附件类中的任何标记字形;仅处理指定类型的标记。
如果任何查找设置了UseMarkFilteringSet标志,则Lookup标头必须包含MarkFilteringSet字段,并且 GDEF 表中必须存在MarkGlyphSetsTable。查找必须忽略任何不在指定标记字形集中的标记字形;仅处理指定标记字形集中的字形。
如果指定了标记过滤集,则它将取代查找标志中的任何标记附件类型指示。如果设置了IgnoreMarks位,则取代任何标记过滤集或标记附件类型指示。
例如,在阿拉伯语文本中,字符串可能具有模式基准标记库。该字符串可以转换为由两个组件组成的连字,每个基本字符一个,第一个组件上有组合标记字形。要生成此连字,字体开发人员将设置连字替换查找的IgnoreMarks位以告知客户端忽略该标记,首先替换连字字形,然后将标记字形置于后续 GPOS 查找中。或者,可以使用未设置IgnoreMarks位的查找来描述由第一基本字形,标记字形和第二基本字形组成的三分量连字字形。
再例如,通过将标记附件类型指定为仅包括顶部标记的类,创建具有顶部标记的基本字形的连字的查找可以跳过所有底部标记。
5.13.覆盖表
查找中的每个子表(Extension LookupType子表除外)都引用Coverage表(Coverage),该表指定受子表中描述的替换或定位操作影响的所有字形。GSUB,GPOS 和 GDEF 表依赖于这种覆盖概念。如果字形未出现在Coverage表中,则客户端可以跳过该子表并立即移动到下一个子表。
Coverage表通过两种方式通过字形索引(字形ID)标识字形:
- 作为字形集中的各个字形索引的列表。
- 作为连续指数的范围。范围格式提供了许多起始字形和结束字形索引对,以表示表所覆盖的连续字形。
在Coverage表中,格式代码(CoverageFormat)将格式指定为整数:1 =列表,2 =范围。
Coverage表为每个覆盖的字形定义唯一索引值(Coverage Index)。覆盖率索引是连续的,从0到覆盖的字形数减1.这个唯一值指定覆盖字形在Coverage表中的位置。客户端使用Coverage Index在每个字形的子表中查找值。
覆盖格式1
覆盖格式1由格式代码(coverageFormat)和覆盖字形(glyphCount)计数组成,后跟一个字形索引数组(glyphArray)。字形索引必须按数字顺序进行二进制搜索列表。当在Coverage表中找到字形时,它在glyphArray中的位置确定返回的Coverage Index - 第一个字形的Coverage Index = 0,最后一个字形的Coverage Index = GlyphCount -1。
本章末尾的示例5显示了Coverage表,该表使用Format 1列出字体中所有小写下延字形的字形ID。
CoverageFormat1表:单个字形索引
| Type | Name | Description |
|---|---|---|
| uint16 | coverageFormat | Format identifier — format = 1 |
| uint16 | glyphCount | Number of glyphs in the glyph array |
| uint16 | glyphArray[glyphCount] | Array of glyph IDs — in numerical order |
覆盖格式2
格式2由格式代码(coverageFormat)和字形索引范围计数(rangeCount)组成,后跟记录数组(rangeRecords)。每个RangeRecord包含一个起始字形索引(startGlyphID),一个结束字形索引(endGlyphID)和与该范围的Start字形相关联的Coverage Index。范围必须是字形ID顺序,并且它们必须是不同的,没有重叠。
第一个范围的覆盖率索引从零(0)开始,并按顺序增加到(endGlyphId - startGlyphId)。对于每个连续范围,起始覆盖指数比前一范围的结束覆盖指数大1。因此,每个非初始范围的startCoverageIndex必须等于前一范围(startGlyphID - startGlyphID + 1)的长度,该范围被添加到前一范围的startGlyphIndex中。这允许使用以下公式快速计算任何范围内任何字形的覆盖率索引:覆盖率索引(glyphID)= startCoverageIndex + glyphID - startGlyphID。
本章末尾的示例6显示了Coverage表,该表使用格式2来标识字体中的一系列数字字形。
CoverageFormat2表:Range of glyphs
| Type | Name | Description |
|---|---|---|
| uint16 | coverageFormat | Format identifier — format = 2 |
| uint16 | rangeCount | Number of RangeRecords |
| RangeRecord | rangeRecords[rangeCount] | Array of glyph ranges — ordered by startGlyphID. |
RangeRecord
| Type | Name | Description |
|---|---|---|
| uint16 | startGlyphID | First glyph ID in the range |
| uint16 | endGlyphID | Last glyph ID in the range |
| uint16 | startCoverageIndex | Coverage Index of first glyph ID in range |
5.14.类定义表
在OpenType布局中,索引值标识字形。为了提高效率和易于表示,字体开发人员可以将字形索引分组以形成字形类。从一个查找子表到另一个查找子表,类赋值的含义各不相同。例如,在 GSUB 和 GPOS 表中,类用于描述字形上下文。GDEF 表也使用了字形类的概念。
考虑替换操作,该替换操作仅替换字形字符串中的小写上升字形。为了更容易地描述替换的适当上下文,字体开发人员可能将字体的小写字形分成两个类,一个包含上升符,另一个包含没有上升符的符号。
字体开发人员可以将任何字形分配给任何类,每个字都用一个称为类值的整数标识。类定义表(ClassDef)按类对字形索引进行分组,从类1开始,然后是类2,依此类推。未分配给类的所有字形都属于类0.在给定的类定义表中,字体中的每个字形恰好属于一个类。
ClassDef表可以有两种格式:一种是将一系列连续的字形索引分配给不同的类,另一种是将一组连续的字形索引放入同一个类中。
类定义表格式1
第一类定义格式(ClassDefFormat1)指定一系列连续的字形索引和相应的字形类值列表。此表对于将每个字形分配给不同的类非常有用,因为每个类中的字形索引不会组合在一起。
ClassDef Format 1表以格式标识符(ClassFormat)开头。表所覆盖的字形ID范围由两个值标识:第一个字形的字形ID(StartGlyphID)和将分配类值(GlyphCount)的连续字形ID(包括第一个字形ID)。ClassValueArray列出了分配给每个字形ID的类值,从StartGlyphID的类值开始,并遵循与字形ID相同的顺序。任何不包括在覆盖字形ID范围内的字形都自动属于Class 0。
本章末尾的示例7使用格式1将类值分配给字体中的小写,x高度,上升和下降字形。
ClassDefFormat1表:Class array
| Type | Name | Description |
|---|---|---|
| uint16 | classFormat | Format identifier — format = 1 |
| uint16 | startGlyphID | First glyph ID of the classValueArray |
| uint16 | glyphCount | Size of the classValueArray |
| uint16 | classValueArray[glyphCount] | Array of Class Values — one per glyph ID |
类定义表格式2
第二类定义格式(ClassDefFormat2)定义属于同一类的多组字形索引。每个组由连续顺序的离散范围的字形索引组成(范围不能重叠)。
ClassDef Format 2表包含格式标识符(ClassFormat),定义组和分配类值的ClassRangeRecords计数(ClassRangeCount),以及按每个记录(ClassRangeRecord)中第一个字形的字形ID排序的ClassRangeRecords数组。
每个ClassRangeRecord都包含一个Start字形索引,一个End字形索引和一个Class值。范围内的所有字形ID(从“开始”到“包含”)构成由“类”值标识的类。假定ClassRangeRecord未涵盖的任何字形属于Class 0。
本章末尾的示例8使用格式2将类值分配给阿拉伯语脚本中的四种类型的字形。
ClassDefFormat2表:Class ranges
| Type | Name | Description |
|---|---|---|
| uint16 | classFormat | Format identifier — format = 2 |
| uint16 | classRangeCount | Number of ClassRangeRecords |
| ClassRangeRecord | classRangeRecords[classRangeCount] | Array of ClassRangeRecords — ordered by startGlyphID |
ClassRangeRecord
| Type | Name | Description |
|---|---|---|
| uint16 | startGlyphID | First glyph ID in the range |
| uint16 | endGlyphID | Last glyph ID in the range |
| uint16 | class | Applied to all glyphs in the range |
5.15.Device和VariationIndex表
设备表和VariationIndex表用于调整 GPOS,JSTF,GDEF 或 BASE 表中的字体单位值,例如附件锚位置的X和Y坐标。设备表仅用于非可变字体。VariationIndex表仅用于可变字体,是Device表的变体格式。当值需要调整数据时,包含该值的表还将包含Device表或VariationIndex表的偏移量。
注意:因为相同的字段用于向Device表提供偏移量或者为VariationIndex表提供偏移量,因此Device表和VariationIndex表不能同时用于给定的定位值。设备表只能用于非变体字体,VariationIndex表只能用于可变字体。字体中的字形以字体开发人员指定的设计单位定义。字体缩放增加或减少字形的大小,并将其四舍五入到最接近的整个像素。然而,精确的字形定位通常需要调整这些缩放和舍入值,特别是在小PPEM尺寸时。提示,应用于字形轮廓中的点,是解决此问题的有效方法,但可能需要字体开发人员重新设计或重新提示字形。
GPOS,BASE,JSTF 和 GDEF 表在非可变字体中使用的另一种解决方案是使用Device表来指定校正值以调整缩放的设计单位。Device表将校正值应用于StartSize和EndSize标识的大小范围,这些大小指定需要调整的最小和最大像素(ppem)大小。
由于设备表调整通常非常小(一个像素或两个像素),因此可以将校正压缩为每个大小的2位,4位或8位表示。两位可以表示范围{-2,-1,0或1}中的数字,四位可以表示范围{-8到7}中的数字,八位可以表示范围中的数字{ - 128到127}。
在可变字体中,GPOS,JSTF 或 GDEF 数据中的X或Y字体单位值可能需要调整字体变体空间内的不同变体实例。其变体数据包含在 GDEF 表中包含的ItemVariationStore表中。类似地,BASE 表中的值可能需要调整,并且其变体数据包含在 BASE 表中的ItemVariationStore表中。ItemVariationStore的格式在OpenType Font Variations Common Table Formats一章中有详细描述。它包含许多组合成为使用delta-set索引引用的集合的delta值。存储在ItemVariationStore外部的数据为需要变化的每个目标项提供增量集索引。在 GPOS,JSTF, GDEF 和 BASE 表中,delta-set索引存储在VariationIndex表中。
Device和VariationIndex表包含一个DeltaFormat字段,用于标识包含的数据格式。格式值0x0001至0x0003用于设备表,并指示直接包含在设备表中的增量调整值的格式:带符号的2位,4位,8位或8位值。格式值0x8000用于VariationIndex表,并指示delta-set索引用于引用ItemVariationStore表中的delta数据。
DeltaFormat values:
| Mask | Name | Description |
|---|---|---|
| 0x0001 | LOCAL_2_BIT_DELTAS | Signed 2-bit value, 8 values per uint16 |
| 0x0002 | LOCAL_4_BIT_DELTAS | Signed 4-bit value, 4 values per uint16 |
| 0x0003 | LOCAL_8_BIT_DELTAS | Signed 8-bit value, 2 values per uint16 |
| 0x8000 | VARIATION_INDEX | VariationIndex table, contains a delta-set index pair. |
| 0x7FFC | Reserved | For future use — set to 0 |
Device表包含一个uint16值数组(deltaValue []),用于将调整delta值存储在压缩表示中。2位,4位或8位有符号值打包到uint16值中,首先从最高有效位开始。例如,使用2的DeltaFormat(4位值),值等于{1,2,3,-1}的数组将由DeltaValue 0x123F表示。单个设备表为一系列大小的一个目标值提供增量信息。deltaValue数组列出了在目标范围内每个ppem大小调整指定X或Y值的像素数。在数组中,第一个索引位置指定在需要校正的最小ppem大小处从坐标添加或减去的像素数,第二个索引位置指定在下一个ppem大小的坐标处添加或减去的像素数 ,等等范围内的每个ppem大小。
Device table
| Type | Name | Description |
|---|---|---|
| uint16 | startSize | Smallest size to correct, in ppem |
| uint16 | endSize | Largest size to correct, in ppem |
| uint16 | deltaFormat | Format of deltaValue array data: 0x0001, 0x0002, or 0x0003 |
| uint16 | deltaValue[ ] | Array of compressed data |
本章末尾的示例9使用Device表来定义数学脚本的最小范围值。
在变体字体中,ItemVariationStore表对变体数据使用两级组织:储存可以有多个项目变体数据子表,每个子表具有多个增量集行。增量集索引是一个由两部分组成的索引:选择特定项目变体数据子表的外部索引,以及选择该子表中特定增量集行的内部索引。VariationIndex表指定增量集索引的外部和内部部分。
VariationIndex table
| Type | Name | Description |
|---|---|---|
| uint16 | deltaSetOuterIndex | A delta-set outer index — used to select an item variation data subtable within the item variation store. |
| uint16 | deltaSetInnerIndex | A delta-set inner index — used to select a delta-set row within an item variation data subtable. |
| uint16 | deltaFormat | Format, = 0x8000 |
请注意,VariationIndex表比Device表短,因为它不直接包含delta数据数组。其格式类似于具有空delta数组的Device表。当应用程序获得Device或VariationIndex表的偏移量时,它们应首先读取前三个字段,然后测试DeltaFormat字段以确定前两个字段的解释以及是否有其他数据要读取。
5.16.功能变化表
特征变化表描述了基于各种条件的特征效果的变化。也就是说,它允许在特定条件下用给定的替换查找替换给定特征的默认查找集。
功能列表提供了一系列功能表和相关的功能标记,LangSys表标识了给定脚本和语言系统将支持的特定功能表/标记对的特定集合。当前条件与特征变体表中定义的变化条件不匹配时,默认情况下使用LangSys表中指定的要素表。这些默认值也将在不支持功能变体表的实现中的所有条件下使用。
特征变化表具有条件记录数组,每个条件记录引用一组条件(条件集表),以及当运行时上下文与条件集匹配时要使用的一组备用要素表。
给出的替换是另一个特征表的替换。备用要素表附加在要素变体表的末尾,并且不包含在要素列表表中。因此,功能列表表中没有与备用功能表对应的功能记录。备用要素表维护与默认要素表相同的要素标记关联。此外,虽然使用16位偏移引用要素列表表中的默认要素表,但使用要素变体表中的32位偏移来引用备用要素表。
处理文本时,从LangSys表中获取一组默认的要素表,每个要素表都有一个关联的要素标记,用于给定的脚本和语言系统。按顺序评估条件集,测试与当前运行时上下文匹配的条件集。找到第一个匹配项时,相应的要素表替换表用于修改默认情况下通过LangSys表获取的要素表集,如下所述(请参阅FeatureTableSubstitution表)。
特征变化表的格式如下。
FeatureVariations Table
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the FeatureVariations table — set to 1. |
| uint16 | minorVersion | Minor version of the FeatureVariations table — set to 0. |
| uint32 | featureVariationRecordCount | Number of feature variation records. |
| FeatureVariationRecord | featureVariationRecords[featureVariationRecordCount] | Array of feature variation records. |
特征变化记录具有条件集表和特征表替换表的偏移量。
如果ConditionSet偏移量为0,则没有条件设置表。这被视为通用条件:所有上下文都匹配。
如果FeatureTableSubstitution偏移量为0,则没有要素表替换表,并且不进行替换。
必须按条件集的优先顺序对要素变体记录进行排序。在处理过程中,将读取特征变化记录,并按照它们出现的顺序测试相应的条件集。如果为给定记录设置的条件与运行时上下文不匹配,则检查下一条记录。条件集与运行时上下文匹配的第一个特征变体记录将被视为候选:如果支持FeatureTableSubstitution表的版本,则将使用此特征变体记录,并且不会考虑其他特征变体记录。如果不支持FeatureTableSubtitution表的版本,则拒绝此功能变体记录,处理将移至下一个功能变体记录。
FeatureVariationRecord
| Type | Name | Description |
|---|---|---|
| Offset32 | conditionSetOffset | Offset to a condition set table, from beginning of FeatureVariations table. |
| Offset32 | featureTableSubstitutionOffset | Offset to a feature table substitution table, from beginning of the FeatureVariations table. |
5.17.条件集表
条件集表指定要应用要素表替换的一组条件。条件集可以指定与各种因素相关的条件;目前,支持一种因子:变体字体的变体实例。各个条件在子表中表示,根据定义条件的因素的性质,可以使用不同的格式。
对于给定的条件集,条件是连接相关的(布尔AND):必须满足所有指定的条件才能应用关联的特征表替换。条件集不需要为所有可能的因子指定条件值。如果没有为某个因子指定值,则条件集将匹配该因子的所有运行时值。
如果给定条件集不包含任何条件,则它将匹配所有上下文,并始终应用关联的要素表替换,除非在数组中先前有一个FeatureVariation记录,其条件设置与当前上下文匹配。
ConditionSet Table
| Type | Name | Description |
|---|---|---|
| uint16 | conditionCount | Number of conditions for this condition set. |
| Offset32 | conditions[conditionCount] | Array of offsets to condition tables, from beginning of the ConditionSet table. |
5.18.条件表
条件表描述了特定条件。可以定义条件表的不同格式,每种格式用于特定种类的条件限定符。目前,定义了一种格式:ConditionTableFormat1,用于指定变体字体中变体轴值的值范围。
将来可能会添加其他条件限定符的新条件表格式。如果布局引擎遇到具有无法识别格式的条件表,则它应该无法匹配条件集,但继续测试其他条件集。通过这种方式,可以在可以在现有实现中以向后兼容的方式工作的字体中定义和使用新的条件格式。
条件表格式1:字体变体轴范围
字体变体轴范围条件是指可变字体中的设计变体轴的值的范围。变体轴在字体的字体变体 fvar 表中指定。如果使用格式1条件表,则字体中必须有 fvar 表,并且AxisIndex值(从零开始)必须小于 fvar 表中的axisCount值。如果AxisIndex无效,则忽略包含此条件表的功能变体记录。
格式1条件表指定沿单个轴的变化实例值的匹配范围。对于给定变体轴,缺少格式1条件意味着该轴不是确定条件集的适用性的因素。
fvar 表为每个变体轴定义了一系列有效值。在处理特定变体实例的过程中,应用标准化过程,将 fvar 表中定义的范围内的用户值映射到范围为-1到1的标准化标度。格式1条件表中指定的值为以标准化比例表示,因此可以是从-1到1的任何值。
如果当前选择的变体实例具有给定轴的值大于或等于FilterRangeMinValue且小于或等于FilterRangeMaxValue,则满足字体变体轴范围条件。
ConditionTableFormat1
| Type | Name | Description |
|---|---|---|
| uint16 | Format | Format, = 1 |
| uint16 | AxisIndex | Index (zero-based) for the variation axis within the fvar table. |
| F2DOT14 | FilterRangeMinValue | Minimum value of the font variation instances that satisfy this condition. |
| F2DOT14 | FilterRangeMaxValue | Maximum value of the font variation instances that satisfy this condition. |
5.19.FeatureTableSubstitution表
特征表替换表描述了当对应条件集与当前运行时上下文匹配时要应用的一组特征表替换。使用特征表替换记录数组表示这些替换。每条记录都可以简单地将一个要素表替换为另一个要素表。当检查特定特征索引时,匹配具有该索引的第一记录,并且如果遇到具有更高索引值的记录则搜索结束。
请注意,记录必须按FeatureIndex值的递增顺序排序,并且没有两个记录可能具有相同的FeatureIndex值。
FeatureTableSubstitution table:
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the feature table substitution table — set to 1 |
| uint16 | minorVersion | Minor version of the feature table substitution table — set to 0. |
| uint16 | substitutionCount | Number of feature table substitution records. |
| FeatureTableSubstitutionRecord | substitutions[substitutionCount] | Array of feature table substitution records. |
FeatureTableSubstitutionRecord:
| Type | Name | Description |
|---|---|---|
| uint16 | featureIndex | The feature table index to match. |
| Offset32 | alternateFeatureTable | Offset to an alternate feature table, from start of the FeatureTableSubstitution table. |
如上所述,评估条件集,并且可以选择条件集以处理相关联的特征表替换表,以用从备用特征表替换从LangSys表获得的默认特征表。给定从LangSys表中获取的所选要素的默认要素表数组,可以按如下方式替换备用要素表:
- 对于每个要素索引,请按顺序评估FeatureTableSubstitutionRecords。
- 如果遇到匹配记录(FeatureIndex =当前要素索引),则使用记录中给出的偏移处的备用要素表替换该要素索引的要素表。停止处理该功能索引。
- 如果遇到具有更高要素索引值的记录,请停止搜索该要素索引,没有替代。
5.20.常用表示例
本章的其余部分描述并说明了所有常见表格格式的示例。所有示例都反映了唯一的参数,但样本为构建特定于其他情况的表提供了有用的参考。
这些示例有三列显示十六进制数据,源和注释。
5.21.示例1:ScriptList表和ScriptRecords
示例1说明了具有多个脚本的日语字体的ScriptList表和ScriptRecord定义:Han Ideographic,Kana和Latin。每个脚本都有特定于脚本的行为。
Example 1
| Hex Data | Source | Comment |
|---|---|---|
| ScriptList TheScriptList | ScriptList table definintion | |
| 0003 | 3 | scriptCount |
| scriptRecords[0] | In alphabetical order by script tag. | |
| 68616E69 | ‘hani’ | scriptTag, Han Ideographic script |
| 0014 | HanIScriptTable | offset to Script table |
| scriptRecords[1] | In alphabetical order by script tag. | |
| 6B616E61 | ‘kana’ | scriptTag, Hiragana and Katakana scripts |
| 0018 | KanaScriptTable | offset to Script table |
| scriptRecords[2] | In alphabetical order by script tag. | |
| 6C61746E | ‘latn’ | scriptTag, Latin script |
| 001C | LatinScriptTable | offset to Script table |
5.22.示例2:脚本表,LangSysRecord和LangSys表
示例2说明了阿拉伯语脚本和Urdu语言系统的Script表,LangSysRecord和LangSys表定义。默认的LangSys表定义了三个默认的阿拉伯语脚本功能,用于替换单词中的某些字形及其正确的初始,中间和最终字形。这些上下文替换是不变的,并且发生在使用阿拉伯语脚本的所有语言系统中。
阿拉伯语脚本中的许多替代字形具有特定于语言的用途。例如,阿拉伯语,波斯语和乌尔都语语言系统使用不同的字形作为数字。为了保持字符集兼容性,Unicode标准包括阿拉伯语和波斯语数字字形的单独字符代码。但是,该标准对波斯语和乌尔都语数字使用相同的字符代码,即使三个乌尔都语字形(4, 6和7)与波斯语字形不同。要访问和显示乌尔都语数字的正确字形,文本处理客户端的用户必须输入波斯语数字的字符代码。然后,文本处理客户端使用在Urdu LangSys表中定义的必需的OpenType布局字形替换功能来访问4,6和7数字的正确Urdu字形。
请注意,Urdu LangSys表重复默认的脚本功能。这种重复是必要的,因为乌尔都语语言系统还在单词的初始,中间和最终字形位置使用替代字形。
Example 2
| Hex Data | Source | Comment |
|---|---|---|
| Script ArabicScriptTable | Script table definition | |
| 000A | DefLangSys | offset to default LangSys table |
| 0001 | 1 | langSysCount |
| langSysRecords[0] | In alphabetical order by LangSys tag. | |
| 55524420 | “URD “ | langSysTag, Urdu language |
| 0016 | UrduLangSys | offset to LangSys table for Urdu |
| LangSys DefLangSys | default LangSys table definition | |
| 0000 | NULL | lookupOrder, reserved, null |
| FFFF | 0xFFFF | requiredFeatureIndex, no required features |
| 0003 | 3 | featureIndexCount |
| 0000 | 0 | featureIndices[0], in arbitrary order |
| ‘init’ | feature (initial glyph) | |
| 0001 | 1 | featureIndices[1], ‘fina’ feature (final glyph) |
| 0002 | 2 | featureIndices[2], for ‘medi’ feature (medial glyph) |
| LangSys UrduLangSys | LangSys table definition | |
| 0000 | NULL | lookupOrder, reserved, null |
| 0003 | 3 | requiredFeatureIndex, numeral subsitution in Urdu |
| 0003 | 3 | featureIndexCount |
| 0000 | 0 | featureIndices[0], in arbitrary order |
| ‘init’ | feature (initial glyph) | |
| 0001 | 1 | featureIndices[1], ‘fina’ feature (final glyph) |
| 0002 | 2 | featureIndices[2], ‘medi’ feature (medial glyph) |
5.23.示例3:FeatureList表和特征表
示例3显示了Latin脚本中连字的FeatureList和Feature表定义。FeatureList有三个功能,全部是可选的,名为”liga”。如果没有特定于语言的功能指定其他连字,则一个功能(也是默认功能)将实现拉丁语中的连字。另外两个功能分别使用土耳其语和德语进行连字。
三个查找定义用于以此字体呈现连字的字形替换。第一次查找产生”ffi”和”fi”连字;第二个产生”ffl”,”fl”和”ff”连字;第三个产生eszet结扎。
以”f”开头的连字被分成两组,因为土耳其语有一个无点的”i”字形,因此不使用”ffi”和”fi”连字。但是,土耳其语确实使用”ffl”,”fl”和”ff”连字,而TurkishLigatures要素表列出了这一个查找。
只有德语系统使用eszet连字,因此GermanLigatures要素表包括用于渲染连字的查找。
由于Latin脚本可以使用两组连字,因此DefaultLigatures要素表定义了两个LookupList索引:一个用于”ffi”和”fi”连字,一个用于”ffl”,”fl”和”ff”连字。如果文本处理客户端选择此功能,则该字体应用两个查找。
请注意,TurkishLigatures和DefaultLigatures要素表都列出了一个(1)的LookupListIndex,用于”ffl”,”fl”和”ff”连字查找。这是因为特定于语言的查找会覆盖所有默认的语言系统查找,并且语言系统功能表必须明确列出适用于该语言的所有查找。
Example 3
| Hex Data | Source | Comment |
|---|---|---|
| FeatureList | ||
| TheFeatureList | FeatureList table definition | |
| 0003 | 3 | featureCount |
| featureRecords[0] | ||
| 6C696761 | ‘liga’ | featureTag |
| 0014 | TurkishLigatures | offset to Feature table, FflFfFlLiga |
| featureRecords[1] | ||
| 6C696761 | ‘liga’ | featureTag |
| 001A | DefaultLigatures | offset to Feature table, FfiFiLiga, FflFfFlLiga |
| featureRecords[2] | ||
| 6C696761 | ‘liga’ | featureTag |
| 0022 | GermanLigatures | offset to Feature table, EszetLiga |
| Feature | ||
| TurkishLigatures | Feature table definition | |
| 0000 | NULL | featureParams, reserved, null |
| 0001 | 1 | lookupIndexCount |
| 0000 | 1 | lookupListIndices[1], ffl, fl, ff ligature substitution Lookup |
| Feature | ||
| DefaultLigatures | Feature table definition | |
| 0000 | NULL | featureParams - reserved, null |
| 0002 | 2 | lookupIndexCount |
| 0000 | 0 | lookupListIndices[0], in arbitrary order, ffi, fi ligatures |
| 0001 | 1 | lookupListIndices[1], ffl, fl, ff ligature substitution Lookup |
| Feature | ||
| GermanLigatures | Feature table definition | |
| 0000 | NULL | featureParams - reserved, null |
| 0001 | 3 | lookupIndexCount |
| 0000 | 0 | lookupListIndices[0], in arbitrary order, ffi, fi ligatures |
| 0001 | 1 | lookupListIndices[1], ffl, fl, ff ligature substitution Lookup |
| 0002 | 2 | lookupListIndices[2], eszet ligature substitution Lookup |
5.24.示例4:LookupList表和查找表
示例3的示例继续,示例4在LookupList表中显示了三个连字查找。第一个生成”ffi”和”fi”连字,第二个产生”ffl”,”fl”和”ff”连字,第三个产生eszet结扎。每个查找表定义子表的偏移量,该子表包含用于连字替换的数据。
Example 4
| Hex Data | Source | Comment |
|---|---|---|
| LookupList | ||
| TheLookupList | LookupList table definition | |
| 0003 | 3 | lookupCount |
| 0008 | FfiFiLookup | offset to lookups[0] table, in design order |
| 0010 | FflFlFfLookup | offset to lookups[1] table |
| 0018 | EszetLookup | offset to lookups[2] table |
| Lookup | ||
| FfiFiLookup | lookups[0] table definition | |
| 0004 | 4 | lookupType: ligature subst |
| 000C | 0x000C | lookupFlag: IgnoreLigatures, IgnoreMarks |
| 0001 | 1 | subTableCount |
| 0018 | FfiFiSubtable | offset to FfiFi ligature substitution subtable |
| Lookup | ||
| FflFlFfLookup | lookups[1] table definition | |
| 0004 | 4 | lookupType: ligature subst |
| 000C | 0x000C | lookupFlag: IgnoreLigatures, IgnoreMarks |
| 0001 | 1 | subTableCount |
| 0028 | FflFlFfSubtable | offset to FflFlFf ligature substitution subtable |
| Lookup | ||
| EszetLookup | lookups[2] table definition | |
| 0004 | 4 | lookupType: ligature subst |
| 000C | 0x000C | lookupFlag: IgnoreLigatures, IgnoreMarks |
| 0001 | 1 | subTableCount |
| 0038 | EszetSubtable | offset to Eszet ligature substitution subtable |
5.25.示例5:CoverageFormat1表(字形ID列表)
示例5说明了Coverage表,其中列出了字体中所有小写下延字形的字形ID。该表使用列表格式而不是范围格式,因为下降字形的字形ID不是连续排序的。
Example 5
| Hex Data | Source | Comment |
|---|---|---|
| CoverageFormat1 | ||
| DescenderCoverage | Coverage table definition | |
| 0001 | 1 | coverageFormat: glyph ID list |
| 0005 | 5 | glyphCount |
| 0038 | gGlyphID | glyphArray[0], in glyph ID order |
| 003B | jGlyphID | glyphArray[1] |
| 0041 | pGlyphID | glyphArray[2] |
| 0042 | qGlyphID | glyphArray[3] |
| 004A | yGlyphID | glyphArray[4] |
5.26.示例6:CoverageFormat2表(字形ID范围)
示例6显示了Coverage表,它定义了十个数字字形(0到9)。该表使用范围格式而不是列表格式,因为字形ID在字体中连续排序。StartCoverageIndex为零(0)表示零字形的第一个字形ID返回Coverage Index为0.第二个字形ID,对于数字一(1)字形,返回Coverage Index为1,依此类推。
Example 6
| Hex Data | Source | Comment |
|---|---|---|
| CoverageFormat2 | ||
| NumeralCoverage | Coverage table definition | |
| 0002 | 2 | coverageFormat: glyph ID ranges |
| 0001 | 1 | rangeCount |
| rangeRecords[0] | ||
| 004E | 0glyphID | startGlyphID |
| 0057 | 9glyphID | endGlyphID |
| 0000 | 0 | StartCoverageIndex, first CoverageIndex = 0 |
5.27.示例7:ClassDefFormat1表(类数组)
示例7中的ClassDef表将类值分配给字体中的小写字形。x高度字形在Class 0中,上升字形在Class 1中,下降字形在Class 2中。数组以小写”a”字形的索引开头。
Example 7
| Hex Data | Source | Comment |
|---|---|---|
| ClassDefFormat1 | ||
| LowercaseClassDef | ClassDef table definition | |
| 0001 | 1 | classFormat: class array |
| 0032 | aGlyphID | startGlyph |
| 001A | 26 | glyphCount |
| classValueArray | ||
| 0000 | 0 | aGlyph, Xheight Class 0 |
| 0001 | 1 | bGlyph, Ascender Class 1 |
| 0000 | 0 | cGlyph, Xheight Class 0 |
| 0001 | 1 | dGlyph, Ascender Class 1 |
| 0000 | 0 | eGlyph, Xheight Class 0 |
| 0001 | 1 | fGlyph, Ascender Class 1 |
| 0002 | 2 | gGlyph, Descender Class 2 |
| 0001 | 1 | hGlyph, Ascender Class 1 |
| 0000 | 0 | iGlyph, Ascender Class 1 |
| 0002 | 2 | jGlyph, Descender Class 2 |
| 0001 | 1 | kGlyph, Ascender Class 1 |
| 0001 | 1 | lGlyph, Ascender Class 1 |
| 0000 | 0 | mGlyph, Xheight Class 0 |
| 0000 | 0 | nGlyph, Xheight Class 0 |
| 0000 | 0 | oGlyph, Xheight Class 0 |
| 0002 | 2 | pGlyph, Descender Class 2 |
| 0002 | 2 | qGlyph, Descender Class 2 |
| 0000 | 0 | rGlyph, Xheight Class 0 |
| 0000 | 0 | sGlyph, Xheight Class 0 |
| 0001 | 1 | tGlyph, Ascender Class 1 |
| 0000 | 0 | uGlyph, Xheight Class 0 |
| 0000 | 0 | vGlyph, Xheight Class 0 |
| 0000 | 0 | wGlyph, Xheight Class 0 |
| 0000 | 0 | xGlyph, Xheight Class 0 |
| 0002 | 2 | yGlyph, Descender Class 2 |
| 0000 | 0 | zGlyph, Xheight Class 0 |
5.28.示例8:ClassDefFormat2表(类范围)
在示例8中,ClassDef表将类值分配给阿拉伯语脚本中的四种类型的字形:中等高度基本字形,高基字形,非常高的基本字形和默认标记字形。该表仅列出了Class 1,Class 2和Class 3,未明确分配类的所有字形都属于Class 0。
该表使用范围格式,因为每个类中的字形ID在字体中连续排序。在ClassRange数组中,ClassRange定义按每个范围中的Start glyph索引排序。ClassRange [0]中定义的高基字形的索引首先在字体中,并且类值为2. ClassRange [1]定义所有非常高的基本字形并指定类值3. ClassRange [2 ]包含所有默认标记字形,类值为1.类0由所有中等高度的基本字形组成,未明确指定类值。
Example 8
| Hex Data | Source | Comment |
|---|---|---|
| ClassDefFormat2 | ||
| GlyphHeightClassDef | Class table definition | |
| 0002 | 2 | classFormat: ranges |
| 0003 | 3 | classRangeCount |
| classRangeRecords[0] | ordered by startGlyphID | |
| 0030 | tahGlyphID | startGlyphID — first glyph ID in the range |
| 0031 | dhahGlyphID | endGlyphID — last glyph ID in the range |
| 0002 | 2 | class: high base glyphs |
| classRangeRecords[1] | ||
| 0040 | cafGlyphID | startGlyphID |
| 0041 | gafGlyphID | endGlyphID |
| 0003 | 3 | class: very high base glyphs |
| classRangeRecords[2] | ||
| 00D2 | fathatanDefaultGlyphID | startGlyphID |
| 00D3 | dammatanDefaultGlyphID | endGlyphID |
| 0001 | 1 | class: default marks |
5.29.示例9:设备表
示例9定义了数学脚本的最小范围值,使用Device表根据输出字体的大小调整值。这里,Device表定义了从11 ppem到15 ppem的字体大小的单像素调整。DeltaFormat为1,表示带符号的2位值的打包数组,每个uint16个值为16。
Example 9
| Hex Data | Source | Comment |
|---|---|---|
| DeviceTableFormat1 | ||
| MinCoordDeviceTable | Device Table definition | |
| 000B | 11 | startSize: 11 ppem |
| 000F | 15 | endSize: 15 ppem |
| 0001 | 1 | deltaFormat: signed 2 bit value (8 values per uint16) |
| 1 | increase 11ppem by 1 pixel | |
| 1 | increase 12ppem by 1 pixel | |
| 1 | increase 13ppem by 1 pixel | |
| 1 | increase 14ppem by 1 pixel | |
| 5540 | 1 | increase 15ppem by 1 pixel |
6.OpenType字体变体常用表格式
OpenType字体变体允许字体设计者将字体系列中的多个面合并到单个字体资源中。可变字体允许沿一个或多个设计轴的连续变化,例如重量或宽度。应用程序可以在字体的设计变体空间中选择任意变体实例来格式化文本。字体具有各种数据项的默认值,例如字形轮廓点的X和Y坐标。布局和渲染过程将这些默认值与变体数据组合在一起,以插入适合实例的新值。
OpenType字体变体概述中提供了OpenType字体变体的概述和用于插入变体实例值的算法的规范。应首先阅读该章。本章介绍了各种字体表中使用的变体数据的格式,例如 gvar 或 MVAR 表。使用本章中描述的格式存储的数据将按照概述章节中的详细说明进行处理;此处提供了有关处理的更高级别信息。
6.1.概要
字体具有许多不同的数据项,这些数据项位于几个不同的字体表中,这些字体表提供特定于特定字体表的值。示例包括字形特定值,例如字形轮廓点和字形前进宽度的位置,以及面宽值,例如子族名称,权重类别,上升和下降值。在可变字体中,大多数或所有这些值可能需要针对不同的变体实例而变化。当应用程序在字体的变体空间中选择特定的变体实例时,需要导出适合于该实例的此类项的新值。这是使用为给定字体数据项和变体空间内的特定区域指定的增量调整值来完成的。
例如,字体的 OS/2 表可以提供默认的sxHeight值970.MVAR 表可以提供+50的delta值,其用于从默认值到最重支持的权重的权重轴值。对于特定实例,插值过程可以使用标量系数0.4来缩放该delta,从而导出实例sxHeight值990。
这些概念和用于导出实例值的插值算法在OpenType字体变体概述一章中有详细描述。
字体的变体数据由许多增量调整值组成。每个单独的增量应用于特定的目标数据项 - 特定字形的特定点的X坐标,或字体的sTypoAscender - 并且还与字体设计变体空间中适用的特定区域相关联。因此,给定的delta在逻辑上由目标数据项和适用的区域键控。
可变字体包括大量增量。在最高级别,增量被组织成不同目标项集的集合:
- glyf 表的点位置的增量存储在 gvar 表中。
- CFF2 表的点位置的增量存储在 CFF2 表中。
- cvt 表中CVT值的增量存储在 cvar 表中。
- hmtx 表中的字形度量的增量存储在HVAR表中,vmtx 或 VORG 表中的字形度量的增量和增量存储在 VVAR 表中。
- GPOS 查找中的锚位置和 GDEF ,GPOS 或 JSTF 表中使用的其他项目的增量存储在 GDEF 表中包含的变体数据中。
- BASE 表中基线度量的增量存储在 BASE 表中。
- 来自 OS/2,hhea,gasp,post 或 vhea 表的字体范围度量和其他项目的Deltas存储在 MVAR 表中。
在可变字体中,最大的增量组用于字形轮廓点的位置。对于 glyf 表中的TrueType轮廓,增量存储在 gvar 表中,第二级组织按字形ID分组增量。有关详细信息,请参阅 gvar 表规范。
在这些较高级别的组织之下,大多数变体数据以两种方式之一组织。(CFF 2轮廓的变化数据是部分例外 - 见下文。)
- 通过应用它们的变体空间区域将多个目标项目的增量组合组织成分组。由于区域是使用n元组(或“元组”)定义的,因此这种数据集将被称为元组变体存储。
- 将与不同区域相关联的增量组按其应用的目标项组织为分组。这些数据集将被称为项目变体存储。
这两种格式具有表示定义适用区域的n元组的不同方式,以及将增量与目标字体数据项相关联的不同方式。元组变体存储格式针对字形轮廓变化数据的紧凑表示进行了优化,该数据全部针对给定变体实例进行处理。另一方面,项目变体存储格式被设计为允许直接访问任意目标项目的变化数据,允许在不需要计算所有项目的内插值的上下文中进行更有效的处理。(下面提供了其他详细信息。) gvar 和 cvar 表使用元组变体存储格式,而大多数其他表中的变体数据(包括 MVAR,HVAR 和 GDEF 表)使用项目变体存储格式。
CFF 2轮廓的变化数据的处理方式与其他情况略有不同。字形轮廓描述的增量直接在压缩字体格式2(CFF2)表中的轮廓描述中交错。但是与增量集相关联的区域集在项变体存储中定义,包含在CFF2表中作为子表。
6.2.元组变体储存
元组变体存储在 gvar 和 cvar 表中使用,并将变化数据集组织成分组,每个分组与变化空间内的特定适用区域相关联。在 gvar 表中,每个字形都有一个单独的变体存储。在 cvar 表中,有一个变体储存为所有CVT值提供变体。
在这两种情况下,储存的顶级结构存在细微差别。在 cvar 表中,整个 cvar 表包含特定的变体存储格式,标题以主要/次要版本字段开头。gvar 表中字形特定数据的特定变体存储格式是GlyphVariationData表(每个字形ID一个),不包含任何版本字段。在其他方面,cvar 表和GlyphVariationData表格式是相同的。在GlyphVariationData表和 cvar 表中可能出现的某些数据也存在细微差别。gvar 和 cvar 表之间的差异将在本节后面进行总结。
就逻辑信息内容而言,GlyphVariationData和 cvar 表由一组逻辑元组变化数据表组成,每个数据表用于变化空间的特定区域。然而,在物理布局中,逻辑元组变化表被分成单独存储的单独部分:标题部分和序列化数据部分。
就整体结构而言,GlyphVariationData表和 cvar 表都以标题开头,后跟序列化数据。标头包含一个包含所有元组变体头的数组。序列化数据包括将在下面解释的增量和其他数据。

元组记录
元组变体存储格式使用元组记录引用字体变体空间内的区域。这些参考文献根据标准化坐标识别位置,使用F2DOT14值。
Tuple record (F2DOT14):
| Type | Name | Description |
|---|---|---|
| F2DOT14 | coordinates[axisCount] | Coordinate array specifying a position within the font’s variation space. The number of elements must match the axisCount specified in the fvar table. |
元组变体存储标题
元组变体存储头的两个变体,GlyphVariationData表头和 cvar 头,只是略有不同。每种格式如下:
GlyphVariationData header:
| Type | Name | Description |
|---|---|---|
| uint16 | tupleVariationCount | A packed field. The high 4 bits are flags (see below), and the low 12 bits are the number of tuple variation tables for this glyph. The count can be any number between 1 and 4095. |
| Offset16 | dataOffset | Offset from the start of the GlyphVariationData table to the serialized data. |
| TupleVariationHeader | tupleVariationHeaders[tupleVariationCount] | Array of tuple variation headers. |
‘cvar’ table header:
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version number of the cvar table — set to 1. |
| uint16 | minorVersion | Minor version number of the cvar table — set to 0. |
| uint16 | tupleVariationCount | A packed field. The high 4 bits are flags (see below), and the low 12 bits are the number of tuple variation tables. The count can be any number between 1 and 4095. |
| Offset16 | dataOffset | Offset from the start of the cvar table to the serialized data. |
| TupleVariationHeader | tupleVariationHeaders[tupleVariationCount] | Array of tuple variation headers. |
tupleVariationCount字段包含一个打包值,该值包含标志和逻辑元组变体表的数量 - 这也是物理元组变体头的数量。tupleVariationCount值的格式如下:
| Mask | Name | Description |
|---|---|---|
| 0x8000 | SHARED_POINT_NUMBERS | Flag indicating that some or all tuple variation tables reference a shared set of “point” numbers. These shared numbers are represented as packed point number data at the start of the serialized data. |
| 0x7000 | Reserved | Reserved for future use — set to 0. |
| 0x0FFF | COUNT_MASK | Mask for the low bits to give the number of tuple variation tables. |
If the sharedPointNumbers flag is set, then the serialized data following the header begins with packed “point” number data. In the context of a GlyphVariationData table within the gvar table, these identify outline point numbers for which deltas are explicitly provided. In the context of the cvar table, these are interpreted as CVT indices rather than point indices. The format of packed point number data is described below.
TupleVariationHeader
GlyphVariationData和 cvar 标头格式包括元组变体标头的数组。TupleVariationHeader格式如下。
TupleVariationHeader:
| Type | Name | Description |
|---|---|---|
| uint16 | variationDataSize | The size in bytes of the serialized data for this tuple variation table. |
| uint16 | tupleIndex | A packed field. The high 4 bits are flags (see below). The low 12 bits are an index into a shared tuple records array. |
| Tuple | peakTuple | Peak tuple record for this tuple variation table — optional, determined by flags in the tupleIndex value. Note that this must always be included in the cvar table. |
| Tuple | intermediateStartTuple | Intermediate start tuple record for this tuple variation table — optional, determined by flags in the tupleIndex value. |
| Tuple | intermediateEndTuple | Intermediate end tuple record for this tuple variation table — optional, determined by flags in the tupleIndex value. |
请注意,TupleVariationHeader的大小是可变的,具体取决于是否包含峰值或中间元组记录。(请参阅下面的详细信息。)
variationDataSize值指示序列化数据中包含的给定元组变体表的序列化数据的大小。它不包括TupleVariationHeader的大小。
每个元组变体表都有一个相关的峰值元组记录。大多数元组变体表使用非中间区域,因此只需要峰值元组记录来定义区域。在 cvar 表中,只有一个变体存储,因此任何给定的区域只需要引用一次。但是,在 gvar 表中,每个字形ID都有一个GlyphVariationData表,因此任何区域都可以被多次引用;实际上,对于大多数字形,大多数区域都将在GlyphVariationData表中引用。为了提供更有效的表示,元组变体存储格式允许存储在元组变体存储结构外部的元组记录数组,这些元组可以在许多元组变体存储库之间共享。这仅在 gvar 表中使用, cvar 表中不需要或不支持它。这些格式交替允许特定于给定元组变体表的非共享峰值元组记录直接嵌入TupleVariationHeader中。这在 gvar 表中是可选的,但在 cvar 表中是必需的,它不使用共享峰值元组记录。
有关该表中共享元组记录表示的详细信息,请参阅 gvar 一章。
tupleIndex字段包含一个打包值,该值包含标志和共享元组记录数组的索引(未在 cvar 表中使用)。tupleIndex字段的格式如下。
tupleIndex format:
| Mask | Name | Description |
|---|---|---|
| 0x8000 | EMBEDDED_PEAK_TUPLE | Flag indicating that this tuple variation header includes an embedded peak tuple record, immediately after the tupleIndex field. If set, the low 12 bits of the tupleIndex value are ignored. Note that this must always be set within the cvar table. |
| 0x4000 | INTERMEDIATE_REGION | Flag indicating that this tuple variation table applies to an intermediate region within the variation space. If set, the header includes the two intermediate-region, start and end tuple records, immediately after the peak tuple record (if present). |
| 0x2000 | PRIVATE_POINT_NUMBERS | Flag indicating that the serialized data for this tuple variation table includes packed “point” number data. If set, this tuple variation table uses that number data; if clear, this tuple variation table uses shared number data found at the start of the serialized data for this glyph variation data or cvar table. |
| 0x1000 | Reserved | Reserved for future use — set to 0. |
| 0x0FFF | TUPLE_INDEX_MASK | Mask for the low 12 bits to give the shared tuple records index. |
请注意,intermediateRegion 标志独立于 embeddedPeakTuple 标志或共享元组记录索引。每个元组变体表都有一个峰值n元组,由嵌入的元组记录(在 cvar 表中始终为true)或通过索引到共享元组记录数组(仅在 gvar 表中)指示。中间区域元组变化表还具有开始和结束n元组,它们也用于插值过程;这些总是使用嵌入式元组记录来表示。
另请注意,privatePointNumbers标志独立于 GlyphVariationData 或 cvar 标头的 tupleVariationCount 字段中的 sharedPointNumbers 标志。GlyphVariationData或 cvar 表可以具有由多个元组变体表使用的共享点数数据,但是任何给定的元组变体表可以具有它使用的私有点数数据。
如上所述,元组变体头的大小是可变的。下一个TupleVariationHeader可以按如下方式计算:
1 | const TupleVariationHeader* NextHeader( const TupleVariationHeader* currentHeader, int axisCount ) |
序列化数据
在 GlyphVariationData 或 cvar 标头(包括TupleVariationHeader数组)之后是一个序列化数据块。标题中提供了此数据块的偏移量。
序列化数据块以共享“点”数字数据开始,然后是元组变体表的变化数据。共享点号数据是可选的:如果在标题的tupleVariationCount字段中设置了相应的标志,则它是存在的。如果存在,则共享数字数据表示为打包点数,如下所述。

其余数据按元组变体标题的顺序包含特定于单个元组变体表的数据运行。每个TupleVariationHeader指示该元组变体表的相应数据运行的数据大小。
如果在TupleVariationHeader的tupleIndex字段中设置privatePointNumbers标志,则每元组变化表数据可选地以私有“点”数开始。专用点编号表示为打包点编号,如下所述。
在私有点数数据(如果存在)之后,元组变体数据将包括打包的增量数据。打包增量的格式如下。在 gvar 表中,有X坐标的打包增量,后跟Y坐标的打包增量。

在 cvar 表中,有一组打包的增量。

TupleVariationHeader中指示的数据大小包括私有点号数据的大小(如果存在)加上打包的增量的大小。
打包”Point”数字
元组变体数据指定要应用于特定项目的增量:gvar 表中字形轮廓点的X和Y坐标,以及 cvar 表中的CVT值。对于给定的字形,可以为字形的任何一个或全部点提供增量,包括在光栅化器内生成的表示字形侧支承点的“幻像”点。同样,在 cvar 表中,可以为任何或所有CVT提供增量。提供增量的字形点或CVT的集合由压缩点数指定。
注意:如果字形是复合字形,则“点”数是组成复合字形的组件的组件索引。同样,在 cvar 表的上下文中,“point”数字是CVT条目的索引。
注意:在 gvar 表中,如果没有为某些点明确提供增量,则可能需要计算推断的delta值。但是,这不适用于 cvar 表:如果没有为某些CVT值提供增量,则不会对与特定元组变体表相关的那些CVT进行调整。打包的点数存储为计数,然后存储一个或多个点数数据。
计数可以存储在一个或两个字节中。在读取第一个字节后,可以确定是否需要第二个字节。计数字节按如下方式处理:
- 如果第一个字节为0,则不使用第二个计数字节。此值具有特殊含义:元组变体数据为所有字形点(包括“幻像”点)或所有CVT提供增量。
- 如果第一个字节非零且高位清零(值为1到127),则不使用第二个计数字节。点数等于第一个字节的值。
- 如果设置了第一个字节的高位,则使用第二个字节。读取计数是将两个字节解释为big-endian uint16值,其中高位被屏蔽掉。
因此,如果计数适合7位,则将其存储在单个字节中,值0具有特殊解释。如果计数不适合7位,则计数存储在前两个字节中,第一个字节的高位设置为不属于计数的标志 - 计数使用15位。
例如,计数0x00表示为所有点编号/所有CVT提供增量,不需要额外的点编号数据;计数为0x32表示总共指定了50个点数;计数0x81 0x22表示总共指定了290(= 0x0122)个点数。
点数数据在计数后运行。每个数据运行都以一个控制字节开始,该控制字节指定运行中定义的点编号的数量,以及一个指示运行数据格式的标志位。控制字节的高位指定运行是以8位还是16位值表示。低7位指定运行中的元素数减1.控制字节的格式如下:
| Mask | Name | Description |
|---|---|---|
| 0x80 | POINTS_ARE_WORDS | Flag indicating the data type used for point numbers in this run. If set, the point numbers are stored as unsigned 16-bit values (uint16); if clear, the point numbers are stored as unsigned bytes (uint8). |
| 0x7F | POINT_RUN_COUNT_MASK | Mask for the low 7 bits of the control byte to give the number of point number elements, minus 1. |
例如,控制字节0x02表示运行有三个元素表示为uint8值,控制字节0xD4表示运行具有0x54 + 1 = 85个元素,表示为uint16值。
在第一个点运行中,第一个点编号直接表示(即,与零的差值)。该运行中的每个后续点编号都存储为它与前一个点编号之间的差值。在后续运行中,所有元素(包括第一个元素)表示与最后一个点数的差异。
由于打包数据中的值都是无符号的,因此将按递增顺序给出点编号。由于打包表示可以包括零值,因此可以在导出的点编号列表中重复给定的点编号。在这种情况下,与该点号相关联的增量数据中将存在多个增量值。所有这些增量必须累积应用于给定点。
打包Deltas
元组变体数据指定要应用于字形点坐标或CVT值的增量。与点数数据的情况一样,增量以打包格式存储。
压缩增量数据不包括数据中的增量值总数。逻辑上,在点数数据中指定的每个点编号或CVT索引都有增量。因此,逻辑增量的计数等于为该元组变体表指定的点数的计数。但由于增量以打包格式表示,因此存储值的实际计数通常小于逻辑计数。读取数据直到获得预期的增量逻辑计数。
注意:在 gvar 表中,每个点编号将有两个逻辑增量:一个适用于X坐标,另一个适用于Y坐标。因此,总逻辑增量计数是点数计数的两倍。打包的增量首先排列X坐标的所有增量,然后是Y坐标的增量。打包的增量存储为一系列运行。每个增量运行包含一个控制字节,后跟该运行的实际增量值。控制字节是打包值,标志位为高2位,计数位于低6位。标志指定运行中增量值的数据大小。控制字节的格式如下:
| Mask | Name | Description |
|---|---|---|
| 0x80 | DELTAS_ARE_ZERO | Flag indicating that this run contains no data (no explicit delta values are stored), and that all of the deltas for this run are zero. |
| 0x40 | DELTAS_ARE_WORDS | Flag indicating the data type for delta values in the run. If set, the run contains 16-bit signed deltas (int16); if clear, the run contains 8-bit signed deltas (int8). |
| 0x3F | DELTA_RUN_COUNT_MASK | Mask for the low 6 bits to provide the number of delta values in the run, minus one. |
例如,控制字节0x03表示控制字节后面有四个8位有符号delta值,控制字节0x40表示控制字节后面有一个16位有符号delta值,控制字节0x94表示此次运行没有附加数据,并且运行表示0x14 + 1 = 21个增量等于零的序列。
03 0A 97 00 C6 87 41 10 22 FB 34此数据有三个运行:四个8位值的运行,一个解释为八个零的运行,以及两个16位值的运行:
Run 1: 03 0A 97 00 C6
Run 2: 87
Run 3: 41 10 22 FB 34此打包数据将表示以下delta值的逻辑顺序:
10, -105, 0, -58, 0, 0, 0, 0, 0, 0, 0, 0, 4130, -1228处理元组变体存储数据
当选择了特定的变体实例时,应用程序需要处理变体存储数据以导出该实例的插值 - 轮廓点的插值网格坐标或插值的CVT值。在 gvar 表的情况下,这将根据需要以字形为标志。应用程序可以处理TupleVariationHeaders以过滤适用于当前实例的元组变体表,或直接计算每个元组变体表的标量。然后可以将标量应用于每个元组变体表中的增量,并将净调整应用于目标项。
注意:在 cvar 表中,打包点数数据中给出的每个CVT索引都有一个逻辑增量。在 gvar 表中,每个点编号有两个逻辑增量:一个用于点的X坐标,一个用于Y坐标。delta数据首先组织X坐标的所有增量,然后是Y坐标的增量。
注意:在 gvar 表中,如果给定字形的数据列出了轮廓中某些点的点数而不是其他点,则必须推断出省略的点数的delta值。有关详细信息,请参阅 gvar 表章节。有关确定给定元组变体表的适用性以及标量计算和目标项目净调整的详细信息,请参阅OpenType字体变体概述一章。
由于点数和增量数据存储在打包表示中,因此必须从头开始处理数据,以确定是否存在任何特定点编号,或检索特定项的增量。因此,格式最适合一次处理给定元组变体表中的所有数据,而不是处理各个目标项的数据。在字形轮廓的情况下,这是合理的,因为没有用于内插单个轮廓点的调整位置的常见应用场景。
然而,提供侧支承和提前宽度信息的“幻影”点是该概括的可能例外。特别是,某些文本布局操作需要字形度量(提前宽度或侧面方位),而不一定需要字形轮廓数据。然而,gvar 表中使用的元组变体存储格式要求计算插值轮廓以便获得插值的字形度量。HVAR 表和 VVAR 表提供表示水平和垂直字形度量变化数据的替代方式,并且这些使用项目变体存储格式,其专门设计为适合于处理特定目标项目的数据。
gvar 和 cvar 表之间的差异
以下是 gvar 和 cvar 表中元组变体存储之间关键差异的摘要。
- gvar 表是元组变体存储的父表,并且包含每个字形ID的一个元组变体存储(字形变体数据表)。相比之下,整个 cvar 表由一个略微扩展(带有版本字段)元组变体存储组成。
- 由于 gvar 表包含多个元组变体存储,因此可以在元组变体存储之间共享数据,并用于共享元组记录。因为 cvar 表具有单个元组变体存储,所以不会出现共享数据的可能性。
- 元组变体存储内的TupleVariationHeader结构的tupleIndex字段包括指示结构实例是否包括嵌入的峰值元组记录的标志。在 gvar 表中,这是可选的。在 cvar 表中,必须使用峰值元组记录。
- 序列化数据包括打包的“点”数字。在 gvar 表中,这些是指字形轮廓点编号,或者在复合字形的情况下,是指组件索引。在 cvar 表的上下文中,这些是CVT条目的索引。
- 在 gvar 表中,点数覆盖了 glyf 条目中定义的点或组件以及表示字形的水平和垂直前进和侧面方位的四个额外“幻像”点。(有关幻像点的更多背景信息,请参阅“指示TrueType字形”一章。)任何字形的最后四个点数(包括复合字形)都用于幻像点。
- 在 gvar 表中,如果没有为某些点提供增量并且点索引没有在点数数据中表示,则在某些情况下将推断这些点的插值增量。但是,这不是在 cvar 表中完成的。
- 在 gvar 表中,给定区域的序列化数据对于每个点编号具有两个逻辑增量:一个用于X坐标,一个用于Y坐标。因此,增量总数是控制点数的两倍。但是,在 cvar 表中,每个点编号只有一个delta。
项目变体存储
项目变体存储用于除用于TrueType字形轮廓的大多数变体数据,包括 MVAR,HVAR,VVAR,BASE 和 GDEF 表中的变体数据。
注意:对于 CFF2 字形轮廓,delta值直接在 CFF2 表中的字形轮廓描述中交错。与增量集相关联的区域集在项变体存储中定义,包含在 CFF2 表内的子表中。项目变体存储格式将目标项目的变体数据集合组织成分组。这使得格式非常适合于计算特定字体数据项的内插实例值。这对于某些文本布局操作很有用,其中只需要某些数据项,例如特定字形的预先宽度或特定 GPOS 查找表中使用的锚位置。
使用项目变体储存的不同表格具有自己的顶级格式。每个都包含对itemVariationStore表的偏移量,其中包含变体数据。本章介绍共享格式:itemVariationStore及其组件结构。
变体数据由增量调整值组成,这些增量调整值适用于特定目标项,并且对字体变化空间的特定区域内的实例有效。需要一些机制来将delta值与目标项相关联。在元组变体存储格式(本章前面所述)中,包含一组增量的数据还包括一组点数索引,用于标识增量适用的目标项。然而,在项目变体存储中,增量值块具有隐式增量集索引,并且提供项目变体存储之外的单独数据,其指示与特定目标项目相关联的增量集合索引。例如,MVAR 表头包括一组记录,用于标识目标字体数据项和每个项的增量集索引。
itemVariationStore表包含一个变体区域列表,该列表定义了为其定义变体数据的字体变体空间的所有不同区域。它还包括一组itemVariationData子表,每个子表提供总变体数据的一部分。每个子表与定义的区域的某个子集相关联,并且将包括用于一个或多个目标项的增量。从概念上讲,增量形成一个二维数组,其中delta-set行包含该子表引用的每个区域的delta。从这个角度来看,表格列对应于区域。
项目变体存储包括变化区域列表和项目变体数据子表的数组。下图说明了整体结构。

请注意,仅当不同增量集数据的数量超过65,536时,才需要多个子表。然而,也可以使用多个子表来提供更紧凑的数据表示。有三种方法可以使增量数据更紧凑。
首先,值为零的增量对其目标项没有影响。如果有多个delta-set行对于同一个区域具有零增量,那么这些行可以移动到不引用该区域的子表中。因此,每行中的delta值将减少,从而使这些行的数据大小更小。
此外,一些增量值需要16位表示,但有些仅需要8位。对于给定的子表,每行中的增量对应于引用的区域,但区域的顺序无效。因此,可以重新排序每行内的区域和相应的增量。因此,可以一起订购需要16位增量表示的区域。itemVariationData格式指定使用16位增量表示的区域(列)计数,每行使用8位的剩余增量。通过重新排序列,可以减少给定增量集行所需的大小。如果一组行对哪些列具有需要16位与8位表示的增量有相似的要求,则可以将这些行移动到具有列顺序的子表中,该子表允许使用8位而非最大数量的增量比16位表示。
请注意,每个子表的开销最小:10个字节(子表头中为6个字节,父表中为偏移量为4个字节),每个引用的区域加上2个字节。
完整的delta-set索引涉及itemVariationData子表数组的外层索引,以及该子表中delta-set行的内层索引。如上所述,增量集索引存储在变体存储之外。使用项目变体存储的不同父表将以不同方式存储索引,并且可以利用不同方案来以有效方式表示索引。例如,HVAR 和 VVAR 表允许外部和内部索引组合成一个字节,两个字节,三个字节或四个字节的表示形式,具体取决于变体存储的索引要求。对于较大的变化数据集,例如 HVAR 或 VVAR 表可能需要的变体数据,索引数据以及增量数据的优化可能对总体大小具有显着影响。优化编译器可能需要同时考虑对索引表示的影响,因为它优化了项目变体存储以实现最佳的整体结果。
变体区域
如上所述,变化数据由增量调整值组成,这些增量调整值对字体变化空间内的特定区域有影响。在元组变体存储(本章前面描述)中,增量按适用性区域组织成分组,每个分组与特定区域相关联。相反,项目变体存储格式通过它们应用的目标项目将增量组织成分组,每个分组具有多个区域的增量。因此,项目变体储存使用不同的格式来描述其中应用一组增量的区域。
对于给定的项目变体存储,使用VariationRegionList指定一组区域。
VariationRegionList:
| Type | Name | Description |
|---|---|---|
| uint16 | axisCount | The number of variation axes for this font. This must be the same number as axisCount in the fvar table. |
| uint16 | regionCount | The number of variation region tables in the variation region list. |
| VariationRegion | variationRegions[regionCount] | Array of variation regions. |
区域可以是任何顺序。区域使用RegionAxisCoordinates记录数组定义,每个记录对应于 fvar 表中定义的每个轴:
VariationRegion record:
| Type | Name | Description |
|---|---|---|
| RegionAxisCoordinates | regionAxes[axisCount] | Array of region axis coordinates records, in the order of axes given in the fvar table. |
每个RegionAxisCoordinates记录提供沿单个轴的区域的坐标值:
RegionAxisCoordinates记录:
| Type | Name | Description |
|---|---|---|
| F2DOT14 | startCoord | The region start coordinate value for the current axis. |
| F2DOT14 | peakCoord | The region peak coordinate value for the current axis. |
| F2DOT14 | endCoord | The region end coordinate value for the current axis. |
这三个值必须都在-1.0到+1.0的范围内。startCoord必须小于或等于peakCoord,而peakCoord必须小于或等于endCoord。这三个值必须全部为非正数或全部为非负数,但有一个可能的例外:如果peakCoord为零,则startCoord可以为负或0,而endCoord可以为正或零。
注意:以下准则用于在不同方案中设置三个值:- In the case of a non-intermediate region for which the given axis should factor into the scalar calculation for the region, either startCoord and peakCoord are set to a negative value (typically, -1.0) and endCoord is set to zero, or startCoord is set to zero and peakCoord and endCoord are set to a positive value (typically +1.0).
- In the case of an intermediate region for which the given axis should factor into the scalar calculation for the region, startCoord, peakCoord and endCoord are all set to non-positive values or are all set to non-negative values.
- If the given axis should not factor into the scalar calculation for a region, then this is achieved by setting peakCoord to zero. In this case, startCoord can be any non-positive value, and endCoord can be any non-negative value. It is recommended either that all three be set to zero, or that startCoord be set to -1.0 and endCoord be set to +1.0.
实例值插值的完整算法在OpenType字体变体概述一章中给出。逻辑算法涉及计算给定区域和给定实例的每轴标量值。然后组合区域的每轴标量以产生该区域的整体标量,然后将其应用于增量调整值。给定选定的变体实例,可以为每个RegionAxisCoordinates记录计算每轴标量。可以通过组合该区域的每轴标量来计算区域的整体标量。
项目变体存储标题和项目变体数据子表
项目变体存储表具有具有以下结构的标题。
ItemVariationStore table:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Format — set to 1 |
| Offset32 | variationRegionListOffset | Offset in bytes from the start of the item variation store to the variation region list. |
| uint16 | itemVariationDataCount | The number of item variation data subtables. |
| Offset32 | itemVariationDataOffsets[itemVariationDataCount] | Offsets in bytes from the start of the item variation store to each item variation data subtable. |
项目变体存储包括项目变体数据子表的偏移数组。每个项目变体数据子表包括一些项目的增量和一些区域的子集。区域由变化区域列表中的索引数组指示。
ItemVariationData subtable:
| Type | Name | Description |
|---|---|---|
| uint16 | itemCount | The number of delta sets for distinct items. |
| uint16 | shortDeltaCount | The number of deltas in each delta set that use a 16-bit representation. Must be less than or equal to regionIndexCount. |
| uint16 | regionIndexCount | The number of variation regions referenced. |
| uint16 | regionIndexes[regionIndexCount] | Array of indices into the variation region list for the regions referenced by this item variation data table. |
| DeltaSet | deltaSets[itemCount] | Delta-set rows. |
deltaSets数组表示具有itemCount行和regionIndexCount列的delta值的逻辑二维表。表中的行为特定目标项提供增量集,而列对应于变体空间的区域。数组中的每个DeltaSet记录表示一行delta值表 - 一个delta集。
DeltaSet record:
| Type | Name | Description |
|---|---|---|
| int16, int8 | DeltaData[shortDeltaCount + regionIndexCount] | Variation delta values. |
逻辑上,每个DeltaSet记录都有regionIndexCount元素数。第一个shortDeltaCount元素表示为带符号的16位值(int16),剩余的regionIndexCount - shortDeltaCount元素表示为带符号的8位值(int8)。每行的数据长度为shortDeltaCount + regionIndexCount。
注意:Delta值均直接表示。它们没有像元组变体储存那样打包。处理项目变体存储数据
当选择了特定变体实例时,应用程序需要处理与特定目标项相关联的变体存储数据,以导出那些项和该实例的内插值。
对于给定的目标项目,项目变体存储之外的数据为该项目提供增量集外部/内部索引对。目标项和增量集索引之间的关联在不同的父表中以不同的方式表示;对于使用的格式,应参考每个字体表的规范。
要计算给定目标项的插值实例值,应用程序使用父表中的数据来获取该项的增量集索引。它使用外层索引部分选择项目变体存储中的项目变体数据子表格,并使用内层索引部分选择该子表格中的delta集合行。delta集包含子表引用的每个区域的一个delta,按regionIndices数组中给出的区域索引的顺序排列。读取增量集中的增量值,将第一个shortDeltaCount元素读取为16位值(int16),将剩余的regionIndexCount - shortDeltaCount值读取为8位(int8)值。应用程序使用该子表的regionIndices数组来标识适用的区域,并根据所选实例为每个区域计算标量。然后将每个标量应用于增量集内的相应增量,以导出缩放调整。然后组合该行的缩放调整以获得该项目的整体调整。
有关插值算法逻辑的完整详细信息,请参见OpenType字体变体概述一章。
当选择了特定的变体实例时,应用程序通常需要为可能在不同的项目变体数据子表中使用增量的多个项目插值。所有子表都将引用共享变体区域列表中的区域定义。选择实例后,应用程序可以为区域列表中的每个区域预先计算和缓存该实例的标量。然后,当处理不同的目标项时,可以使用缓存的标量数组,而无需为每个目标项重新计算区域标量。
应用程序可以为区域列表中的每个区域预先计算和缓存该实例的标量。然后,当处理不同的目标项时,可以使用缓存的标量数组,而无需为每个目标项重新计算区域标量。
6.3.项变体储存
项目变体存储用于除用于TrueType字形轮廓的大多数变体数据,包括 MVAR,HVAR,VVAR,BASE 和 GDEF 表中的变体数据。
注意:对于 CFF2 字形轮廓,delta值直接在 CFF2 表中的字形轮廓描述中交错。与增量集相关联的区域集在项变体存储中定义,包含在 CFF2 表内的子表中。项目变体存储格式将目标项目的变体数据集合组织成分组。这使得格式非常适合于计算特定字体数据项的内插实例值。这对于某些文本布局操作很有用,其中只需要某些数据项,例如特定字形的预先宽度或特定 GPOS 查找表中使用的锚位置。
使用项目变体储存的不同表格具有自己的顶级格式。每个都包含对itemVariationStore表的偏移量,其中包含变体数据。本章介绍共享格式:itemVariationStore及其组件结构。
变体数据由增量调整值组成,这些增量调整值适用于特定目标项,并且对字体变化空间的特定区域内的实例有效。需要一些机制来将delta值与目标项相关联。在元组变体存储格式(本章前面所述)中,包含一组增量的数据还包括一组点数索引,用于标识增量适用的目标项。然而,在项目变体存储中,增量值块具有隐式增量集索引,并且提供项目变体存储之外的单独数据,其指示与特定目标项目相关联的增量集合索引。例如,MVAR 表头包括一组记录,用于标识目标字体数据项和每个项的增量集索引。
itemVariationStore表包含一个变体区域列表,该列表定义了为其定义变体数据的字体变体空间的所有不同区域。它还包括一组itemVariationData子表,每个子表提供总变体数据的一部分。每个子表与定义的区域的某个子集相关联,并且将包括用于一个或多个目标项的增量。从概念上讲,增量形成一个二维数组,其中delta-set行包含该子表引用的每个区域的delta。从这个角度来看,表格列对应于区域。
项目变体存储包括变化区域列表和项目变体数据子表的数组。下图说明了整体结构。
请注意,仅当不同增量集数据的数量超过65,536时,才需要多个子表。然而,也可以使用多个子表来提供更紧凑的数据表示。有三种方法可以使增量数据更紧凑。
首先,值为零的增量对其目标项没有影响。如果有多个delta-set行对于同一个区域具有零增量,那么这些行可以移动到不引用该区域的子表中。因此,每行中的delta值将减少,从而使这些行的数据大小更小。
此外,一些增量值需要16位表示,但有些仅需要8位。对于给定的子表,每行中的增量对应于引用的区域,但区域的顺序无效。因此,可以重新排序每行内的区域和相应的增量。因此,可以一起订购需要16位增量表示的区域。itemVariationData格式指定使用16位增量表示的区域(列)计数,每行使用8位的剩余增量。通过重新排序列,可以减少给定增量集行所需的大小。如果一组行对哪些列具有需要16位与8位表示的增量有相似的要求,则可以将这些行移动到具有列顺序的子表中,该子表允许使用8位而非最大数量的增量比16位表示。
请注意,每个子表的开销最小:10个字节(子表头中为6个字节,父表中为偏移量为4个字节),每个引用的区域加上2个字节。
完整的delta-set索引涉及itemVariationData子表数组的外层索引,以及该子表中delta-set行的内层索引。如上所述,增量集索引存储在变体存储之外。使用项目变体存储的不同父表将以不同方式存储索引,并且可以利用不同方案来以有效方式表示索引。例如,HVAR 和 VVAR 表允许外部和内部索引组合成一个字节,两个字节,三个字节或四个字节的表示形式,具体取决于变体存储的索引要求。对于较大的变化数据集,例如 HVAR 或 VVAR 表可能需要的变体数据,索引数据以及增量数据的优化可能对总体大小具有显着影响。优化编译器可能需要同时考虑对索引表示的影响,因为它优化了项目变体存储以实现最佳的整体结果。
变体区域
如上所述,变化数据由增量调整值组成,这些增量调整值对字体变化空间内的特定区域有影响。在元组变体存储(本章前面描述)中,增量按适用性区域组织成分组,每个分组与特定区域相关联。相反,项目变体存储格式通过它们应用的目标项目将增量组织成分组,每个分组具有多个区域的增量。因此,项目变体储存使用不同的格式来描述其中应用一组增量的区域。
对于给定的项目变体存储,使用VariationRegionList指定一组区域。
VariationRegionList:
| Type | Name | Description |
|---|---|---|
| uint16 | axisCount | The number of variation axes for this font. This must be the same number as axisCount in the fvar table. |
| uint16 | regionCount | The number of variation region tables in the variation region list. |
| VariationRegion | variationRegions[regionCount] | Array of variation regions. |
区域可以是任何顺序。区域使用RegionAxisCoordinates记录数组定义,每个记录对应于 fvar 表中定义的每个轴:
VariationRegion record:
| Type | Name | Description |
|---|---|---|
| RegionAxisCoordinates | regionAxes[axisCount] | Array of region axis coordinates records, in the order of axes given in the fvar table. |
每个RegionAxisCoordinates记录提供沿单个轴的区域的坐标值:
RegionAxisCoordinates record:
| Type | Name | Description |
|---|---|---|
| F2DOT14 | startCoord | The region start coordinate value for the current axis. |
| F2DOT14 | peakCoord | The region peak coordinate value for the current axis. |
| F2DOT14 | endCoord | The region end coordinate value for the current axis. |
这三个值必须都在-1.0到+1.0的范围内。startCoord必须小于或等于peakCoord,而peakCoord必须小于或等于endCoord。这三个值必须全部为非正数或全部为非负数,但有一个可能的例外:如果peakCoord为零,则startCoord可以为负或0,而endCoord可以为正或零。
注意:以下准则用于在不同方案中设置三个值:- 在非中间区域的情况下,给定轴应该考虑该区域的标量计算,startCoord和peakCoord都设置为负值(通常为-1.0),endCoord设置为零,或者startCoord为设置为零,peakCoord和endCoord设置为正值(通常为+1.0)。
- 在给定轴应该考虑该区域的标量计算的中间区域的情况下,startCoord,peakCoord和endCoord都被设置为非正值或者都被设置为非负值。
- 如果给定的轴不应该考虑区域的标量计算,那么可以通过将peakCoord设置为零来实现。在这种情况下,startCoord可以是任何非正值,endCoord可以是任何非负值。建议将所有三个设置为零,或者将startCoord设置为-1.0并将endCoord设置为+1.0。
实例值插值的完整算法在OpenType字体变体概述一章中给出。逻辑算法涉及计算给定区域和给定实例的每轴标量值。然后组合区域的每轴标量以产生该区域的整体标量,然后将其应用于增量调整值。给定选定的变体实例,可以为每个RegionAxisCoordinates记录计算每轴标量。可以通过组合该区域的每轴标量来计算区域的整体标量。
项目变体存储标题和项目变体数据子表
项目变体存储表具有具有以下结构的标题。
ItemVariationStore table:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Format — set to 1 |
| Offset32 | variationRegionListOffset | Offset in bytes from the start of the item variation store to the variation region list. |
| uint16 | itemVariationDataCount | The number of item variation data subtables. |
| Offset32 | itemVariationDataOffsets[itemVariationDataCount] | Offsets in bytes from the start of the item variation store to each item variation data subtable. |
项目变体存储包括项目变体数据子表的偏移数组。每个项目变体数据子表包括一些项目的增量和一些区域的子集。区域由变化区域列表中的索引数组指示。
ItemVariationData subtable:
| Type | Name | Description |
|---|---|---|
| uint16 | itemCount | The number of delta sets for distinct items. |
| uint16 | shortDeltaCount | The number of deltas in each delta set that use a 16-bit representation. Must be less than or equal to regionIndexCount. |
| uint16 | regionIndexCount | The number of variation regions referenced. |
| uint16 | regionIndexes[regionIndexCount] | Array of indices into the variation region list for the regions referenced by this item variation data table. |
| DeltaSet | deltaSets[itemCount] | Delta-set rows. |
deltaSets数组表示具有itemCount行和regionIndexCount列的delta值的逻辑二维表。表中的行为特定目标项提供增量集,而列对应于变体空间的区域。数组中的每个DeltaSet记录表示一行delta值表 - 一个delta集。
DeltaSet record:
| Type | Name | Description |
|---|---|---|
| int16, int8 | DeltaData[shortDeltaCount + regionIndexCount] | Variation delta values. |
逻辑上,每个DeltaSet记录都有regionIndexCount元素数。第一个shortDeltaCount元素表示为带符号的16位值(int16),剩余的regionIndexCount - shortDeltaCount元素表示为带符号的8位值(int8)。每行的数据长度为shortDeltaCount + regionIndexCount。
注意:Delta值均直接表示。它们没有像元组变体储存那样打包。处理项目变体存储数据
当选择了特定变体实例时,应用程序需要处理与特定目标项相关联的变体存储数据,以导出那些项和该实例的内插值。
对于给定的目标项目,项目变体存储之外的数据为该项目提供增量集外部/内部索引对。目标项和增量集索引之间的关联在不同的父表中以不同的方式表示;对于使用的格式,应参考每个字体表的规范。
要计算给定目标项的插值实例值,应用程序使用父表中的数据来获取该项的增量集索引。它使用外层索引部分选择项目变体存储中的项目变体数据子表格,并使用内层索引部分选择该子表格中的delta集合行。delta集包含子表引用的每个区域的一个delta,按regionIndices数组中给出的区域索引的顺序排列。读取增量集中的增量值,将第一个shortDeltaCount元素读取为16位值(int16),将剩余的regionIndexCount - shortDeltaCount值读取为8位(int8)值。应用程序使用该子表的regionIndices数组来标识适用的区域,并根据所选实例为每个区域计算标量。然后将每个标量应用于增量集内的相应增量,以导出缩放调整。然后组合该行的缩放调整以获得该项目的整体调整。
有关插值算法逻辑的完整详细信息,请参见OpenType字体变体概述一章。
当选择了特定的变体实例时,应用程序通常需要为可能在不同的项目变体数据子表中使用增量的多个项目插值。所有子表都将引用共享变体区域列表中的区域定义。选择实例后,应用程序可以为区域列表中的每个区域预先计算和缓存该实例的标量。然后,当处理不同的目标项时,可以使用缓存的标量数组,而无需为每个目标项重新计算区域标量。
应用程序可以为区域列表中的每个区域预先计算和缓存该实例的标量。然后,当处理不同的目标项时,可以使用缓存的标量数组,而无需为每个目标项重新计算区域标量。
7.表
7.1.avar 轴变化表(Axis Variations Table)
轴变化表 avar 是一个可选表,用于使用OpenType字体变体机制的可变字体。它可用于修改设计如何随特定设计变体轴的不同实例而变化的方面。具体地,它允许修改在处理特定变体实例的变化数据时使用的坐标归一化。
有关OpenType字体变体以及坐标和规范化的一般概述,请参阅OpenType字体变体概述一章。
avar 表必须与字体变体 fvar 表以及可变字体中使用的其他必需或可选表结合使用。有关其他详细信息,请参阅“概述”一章中的“变体数据表和其他要求”。
7.1.1.概要
fvar 表定义了字体支持的一系列设计变体 - 字体的变化空间。它使用适合每个轴性质的比例指定使用的某些变体轴,以及每个轴的支持值范围。处理字体的变体数据以导出特定变体实例的字形轮廓或其他值时,用户选择的坐标必须从用于将 fvar 表中的轴定义的标度映射到标准化的标度,即 每个轴都一样。
定义了一个默认的标准化映射,它将分别为 fvar 表中为每个轴指定的最小值,默认值和最大值映射到-1,0和1,并通过这些值之间的线性插值映射其中的其他值。默认映射可以由以下伪代码表示。
1 | if (userValue < axisDefaultValue) |
请注意,如果用户选择的轴值超出字体中指定的最小/最大范围,则必须将使用的值钳制到最小值或最大值。
默认标准化使用沿每个轴的三个位置的预定义映射到特定值,将每个轴的整个范围划分为两个段。如果存在 avar 表,则可以通过允许为沿每个比例的附加位置定义映射来进一步修改默认归一化的输出,从而创建多个分段,其中每个分段内的其他值被内插。下图说明了此类修改的示例。

这些附加比例映射的概念效果是使沿轴的变化不那么线性。值在每个段内线性变化,但是其他段使得整个轴范围内的值变化的方式总体上更不线性。该效果还可以描述为压缩比例的某些部分,同时使其他部分压缩较少。
avar 表中附加轴值映射的视觉效果可以看作字形轮廓如何随着轴的用户比例值的变化而变化。用户比例值的相同变化量可以对应于轴范围的一部分中的字形轮廓的细微变化,但是轴范围的另一部分中的字形轮廓的更显着变化。
注意,通过为变化空间的附加区域添加字形变化数据,可以实现相同或类似的效果。然而,该方法需要更多的工作和更多的字体数据,并且可能需要繁琐的设计迭代来获得期望的结果。avar 表可以提供简单且轻量的方式来实现特定效果。
另请注意,字体设计器创建的变体数据也会对用户比例值和字形轮廓是否均匀变化产生重大影响。当使用 avar 表时,avar 表和字形变体数据(对于TrueType或CFF 2)都是用户将看到的变化行为的因素。
7.1.2.表格式
avar 表由每个轴的小标题和段映射组成。
Axis variation table:
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version number of the axis variations table — set to 1. |
| uint16 | minorVersion | Minor version number of the axis variations table — set to 0. |
| uint16 | <reserved> | Permanently reserved; set to zero. |
| uint16 | axisCount | The number of variation axes for this font. This must be the same number as axisCount in the fvar table. |
| SegmentMaps | axisSegmentMaps[axisCount] | The segment maps array — one segment map for each axis, in the order of axes specified in the fvar table. |
fvar 表中定义的每个轴必须有一个段映射,并且必须按照 fvar 表中指定的轴的顺序给出不同轴的段映射。每个轴的段映射由轴值映射记录列表组成。
SegmentMaps record:
| Type | Name | Description |
|---|---|---|
| uint16 | positionMapCount | The number of correspondence pairs for this axis. |
| AxisValueMap | axisValueMaps[positionMapCount] | The array of axis value map records for this axis. |
每个轴值映射记录提供单轴 - 值映射对应关系。
AxisValueMap record:
| Type | Name | Description |
|---|---|---|
| F2DOT14 | fromCoordinate | A normalized coordinate value obtained using default normalization. |
| F2DOT14 | toCoordinate | The modified, normalized coordinate value. |
可以为任何轴提供轴值映射,但仅在修改轴的规范化映射时才需要。如果给定轴的段映射具有任何值映射,则它必须包括至少三个值映射:-1到-1,0到0和1到1.这些值映射对于变体机制的设计是必不可少的即使没有为给定轴指定其他映射,也是必需的。如果缺少任何这些,则不会对该轴进行轴坐标值的修改。
给定轴的所有轴值映射记录必须具有不同的坐标值,并且轴值映射记录必须按fromCoordinate值的递增顺序排列。如果记录的fromCoordinate值小于或等于数组中先前记录的fromCoordinate值,则可忽略给定记录。
此外,对于除第一个以外的任何给定记录,toCoordinate值必须大于或等于前一记录的toCoordinate值。此要求确保在遍历用户比例值范围时不存在逆行行为。如果记录的toCoordinate值小于前一记录的值,则可以忽略给定记录。
7.1.3.处理
给定轴的每对轴值映射记录定义该轴范围内的段。在段内,中间值线性插值。对于给定的用户比例坐标,应用了 avar 修改的完全标准化过程如下。
- 如上所述,计算默认的标准化坐标值defaultNormalizedValue。
- 使用给定轴的SegmentMaps记录,扫描AxisValueMap记录以查找fromCoordinate值大于或等于defaultNormalizedValue的第一条记录。将此记录指定为endSeg。
- 如果endSeg.fromCoordinate等于defaultNormalizedValue,则最终的修改后的标准化值为endSeg.toCoordinate。返回此结果并结束。
- else case(endSeg.fromCoordinate严格大于defaultNormalizedValue - endSeg不能是第一个映射记录,也就是-1):将前一条记录指定为startSeg。
- 最终的修改后的标准化值finalNormalizedValue计算如下:

请注意,实施时必须遵守有关所用精度水平和如何处理舍入的某些要求。有关详细规范,请参阅OpenType字体变体概述一章中的坐标比例和规范化。
7.1.4.轴段示例
以下示例说明了 avar 映射的工作原理。本章前面的图示说明了这个例子。
假设字体的 avar 表具有特定轴的以下映射:
| Record index | fromCoordinate | toCoordinate |
|---|---|---|
| 0 | -1.0 | -1.0 |
| 1 | -0.75 | -0.5 |
| 2 | 0 | 0 |
| 3 | 0.4 | 0.4 |
| 4 | 0.6 | 0.9 |
| 5 | 1.0 | 1.0 |
假设用户选择了一个实例,该实例的默认规范化值为-0.5。该值的相关段由记录1和记录2定义。最终的标准化值计算如下:

下表显示了这个 avar 数据如何修改几个标准化坐标值:
| Default normalized value | Final normalized value |
|---|---|
| -1.0 | -1.0 |
| -0.75 | -0.5 |
| -0.5 | -0.3333 |
| -0.25 | -0.1667 |
| 0 | 0 |
| 0.25 | 0.25 |
| 0.5 | 0.65 |
| 0.75 | 0.9375 |
| 1.0 | 1.0 |
7.2.BASE 基线表(Baseline table)
Baseline表(BASE)提供用于在一行文本中对齐不同脚本和大小的字形的信息,无论字形是相同的字体还是不同的字体。为了改进文本布局,Baseline表还为字体中的每个脚本,语言系统或功能提供最小(最小)和最大(最大)字形范围值。
7.2.1.概要
由不同脚本和点大小的字形组成的文本行需要调整以校正行间距和对齐。例如,设计为相同磅值的字形通常在高度和深度上从一种字体到另一种字体不同(见图5a)。此变化可能会产生看起来太大或太小的行间距,并且可能会剪切变音标记,数学符号,下标和上标。
的字形对齐不正确")
此外,不同的基线可以使文本行在视觉上动摇,因为来自不同脚本的字形彼此相邻放置。例如,表意文字脚本将所有字形定位在低基线上。但是,对于拉丁文脚本,基线较高,而某些字形则低于它。最后,几个印度语脚本使用高“悬挂基线”来对齐字形的顶部。
为了解决这些组合问题,BASE表推荐了每个脚本的基线位置和最小/最大范围(见图5b)。可以针对特定语言系统或功能修改脚本最小/最大范围。
的字形")
7.2.2.基线值
BASE 表使用一种模型,假设在一个大小的一个脚本是文本处理期间的“主导运行” - 也就是说,所有其他基线都是相对于主导运行定义的。
例如,拉丁字形和表意汉字字形具有不同的基线。如果将特定大小的拉丁字母指定为主要运行,则所有大小的所有拉丁字形将在罗马基线上对齐,并且所有汉字字形将在为拉丁文本使用而定义的较低表意基线上对齐。因此,所有字形在每行文本中看起来都是对齐的。
BASE 表提供了建议的基线位置,客户可以指定其他人。例如,客户端可能希望分配与字体中的基线位置不同的基线位置。

BASE 表中,使用在OpenType布局标记注册表中找到的基线标记来标识不同的基线类型。每个基线类型的定位是在逐个脚本的基础上指定的,要使用的基线坐标值是主要运行的脚本的坐标值。
7.2.3.最小/最大范围值
BASE 表为客户提供了使用脚本,语言系统或特定于功能的范围值来改进组合的选项(参见图5c)。例如,假设字体包含拉丁语和阿拉伯语脚本中的字形,并且为阿拉伯语脚本定义的最小/最大范围大于拉丁范围。该字体还支持Urdu,一种包含阿拉伯字形的特定变体的语言系统,并且一些Urdu变体需要比默认的阿拉伯语范围更大的最小/最大范围。为了容纳Urdu字形,BASE 表可以定义特定于语言的最小/最大范围值,这些值将覆盖默认的阿拉伯语范围 - 但仅在呈现Urdu字形时。
BASE 表还可以定义特定于功能的最小/最大值,仅在启用特定功能时才应用。假设前面描述的字体也支持Farsi语言系统,该系统有一个功能,需要对阿拉伯语脚本范围进行微小改动才能正确显示。BASE 表可以指定这些范围值,并仅在使用Farsi语言启用该功能时应用它们。
7.2.4.BASE表和OpenType字体变体
OpenType字体变体允许单个字体沿着一个或多个设计变体轴支持许多设计变体。例如,具有重量和宽度变化的字体可能支持从细到黑的重量,以及从超浓缩到超扩展的宽度。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
当选择不同的变体实例时,各个字形的设计会发生变化,整个字体的度量特征也会发生变化。因此,BASE表中的度量值也可能需要相应的更改。
BASE 表中的度量标准使用显式X或Y字体单位值直接在BaseCoord表中表示。在可变字体中,这些X和Y值适用于默认实例,可能需要针对当前变体实例进行调整。这是使用变体数据完成的,其过程类似于用于字形轮廓和其他字体数据的过程,如OpenType字体变体概述一章中所述。
注意:某些 BASE 指标可以通过参考特定的字形轮廓点间接表示。在可变字体中,使用字形点来指定度量值将需要调用光栅化器来处理字形轮廓变化数据,以便在可以使用 BASE 度量值之前获得该点的调整位置。这可能对文本布局处理的性能产生显着的负面影响。因此,建议在变体字体中,任何需要针对不同变体实例进行调整的 BASE 度量标准值应始终直接表示为X和Y值。用于调整 BASE 值的变化数据存储在 BASE 表内的项目变体存储表中。项目变体存储和组成格式在章节OpenType字体变体公用表格格中描述。项目变体存储也用于 GDEF 表,以及 MVAR 和其他表格,但不同于 cvar 或 gvar 表中使用的变体数据的格式。
项目变体存储内的变化数据包括多个调整增量,这些调整增量应用于字体变化空间的特定区域内的变体实例的目标项目的默认值。项目变体存储格式使用增量集索引来引用应用它们的特定目标,字体数据项的变体增量数据。项目变体储存外部的数据标识要用于每个给定目标项目的增量集索引。在 BASE 表中,这些索引在VariationIndex表中指定,每个项目引用一个VariationIndex表,需要进行变体调整。
请注意,VariationIndex表是Device表的变体,具有不同的格式值。(有关Device和VariationIndex表格格式的完整详细信息,请参阅OpenType布局公用表格式章节。)这样做是为了使变体字体的默认实例可以与不支持字体变体的应用程序兼容。因此,可变字体无法使用设备表。在不支持字体变体的应用程序中,或者如果字体不是可变字体,将忽略VariationIndex表。
项目变体储存格式对变体数据使用两级组织:储存可以有多个项目变体数据子表,每个子表格具有多个delta集合行。增量集索引是一个由两部分组成的索引:选择特定项目变体数据子表的外部索引,以及选择该子表中特定增量集行的内部索引。VariationIndex表指定增量集索引的外部和内部部分。
7.2.5.表组织
BASE 表以Axis表的偏移开始,这些表描述了文本的水平和垂直布局方向的布局数据。字体可以为文本方向或仅为一个文本方向提供布局数据:
水平轴表(HorizAxis)定义用于水平布局文本的信息。所有基线和最小/最大值均指Y方向。
垂直轴表(VertAxis)定义用于垂直布局文本的信息。所有基线和最小/最大值均指X方向。
注意:相同的基线标签可用于水平轴和垂直轴。例如,用于垂直轴的’romn’标签描述将指示旋转的拉丁文本的基线。
在可变字体中,轴表的偏移之后可以是对项变化存储表的偏移,其用于提供变化数据,用于调整字体变化空间内的不同变体实例的BASE度量值。
图5d显示了 BASE 表的组织方式。

7.2.6.文字方向
HorizAxis和VertAxis表按BaseScriptList表中的脚本组织布局信息。BaseScriptList枚举以特定方向(水平或垂直)写入的字体中的所有脚本。
例如,考虑包含Kanji,Kana和Latin脚本的日语字体。由于所有三个脚本都是水平呈现的,因此所有三个脚本都在HorizAxis表的BaseScriptList中定义。Kanji和Kana也是垂直渲染的,因此这两个脚本也在VertAxis表的BaseScriptList中定义。
7.2.7.基线数据
每个Axis表还引用一个BaseTagList,它标识以相同方向(水平或垂直)写入的所有脚本的所有基线。BaseTagList还可以包括其他字体支持的脚本的基线标签。
BaseScriptList中的每个脚本都由BaseScriptRecord表示。此记录引用BaseScript表,该表包含脚本的布局数据。反过来,BaseScript表引用BaseValues表,该表包含基线信息和几个定义最小/最大范围值的MinMax表。
BaseValues表指定BaseTagList中所有基线的坐标值。此外,它还将其中一个基线标识为脚本的默认基线。随着脚本中的字形缩放,它们会从脚本的默认基线位置增长或缩小。每个基线都可以有唯一的坐标。这与TrueType 1.0形成对比,后者暗示了字体中所有脚本的单个固定基线。使用OpenType™布局表,每个脚本可以独立对齐,但多个脚本可以使用相同的基线值。
必须相互指定相同字体的脚本的基线坐标才能正确对齐字形。考虑前面讨论过的包含拉丁字母和汉字字形的字体。如果HorizAxis表的BaseTagList指定了两个基线,即罗马和表意文字,那么拉丁文和汉字脚本的布局数据将指定两个基线的坐标位置:
- 拉丁文脚本的BaseValues表将为两个基线提供坐标,并将罗马基线指定为默认值。
- Kanji脚本的BaseValues表将为两个基线提供坐标,并将表意基线指定为默认基线。
7.2.8.最小/最大范围
BaseScript表可以为每个脚本,语言系统或功能定义最小和最大范围值。(这些值与 head,hhea,vhea 和 OS/2 表中整体字体记录的最小/最大范围值不同。)这些范围值出现在三个表中:
DefaultMinMax表定义脚本的默认最小/最大范围。
通过BaseLangSysRecord引用的MinMax表指定最小/最大范围以容纳特定语言系统中的字形。
从MinMax表引用的FeatMinMaxRecord提供最小/最大范围值以支持特定于功能的字形操作。
注意:语言系统或特定于功能的范围值可能对定义某些字体至关重要。但是,为每个脚本指定的默认最小/最大范围值通常应足以支持高质量的文本布局。
BASE 表使用的实际基线和最小/最大范围值驻留在BaseCoord表中。为BaseCoord表数据定义了三种格式。所有格式都以设计单位定义单个X或Y坐标值,但两种格式支持基于轮廓点或设备表对这些值进行精细调整。
本章的其余部分描述了 BASE 表中定义的所有表。本章末尾提供了说明字体典型数据的示例表和列表。
7.2.9.BASE标题
BASE 表以标题开头,标题以版本号开头。定义了两个版本。版本1.0包含水平和垂直轴表(HorizAxis和VertAxis)的偏移量。1.1版还包括Item Variation Store表的偏移量。
每个Axis表存储一个布局方向的所有基线信息和最小/最大范围。HorizAxis表包含水平文本布局的Y值,VertAxis表包含垂直文本布局的X值。
字体可以提供两个布局方向的信息。如果字体仅具有一个文本方向的值,则另一个方向的Axis表偏移值将设置为NULL。
可选的项目变体存储表用于可变字体,以便为Axis表中的BASE度量值提供变体数据。
本章末尾的示例1显示了一个示例BASE标头。
BASE Header, Version 1.0
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the BASE table, = 1 |
| uint16 | minorVersion | Minor version of the BASE table, = 0 |
| Offset16 | horizAxisOffset | Offset to horizontal Axis table, from beginning of BASE table (may be NULL) |
| Offset16 | vertAxisOffset | Offset to vertical Axis table, from beginning of BASE table (may be NULL) |
BASE Header, Version 1.1
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the BASE table, = 1 |
| uint16 | minorVersion | Minor version of the BASE table, = 1 |
| Offset16 | horizAxisOffset | Offset to horizontal Axis table, from beginning of BASE table (may be NULL) |
| Offset16 | vertAxisOffset | Offset to vertical Axis table, from beginning of BASE table (may be NULL) |
| Offset32 | itemVarStoreOffset | Offset to Item Variation Store table, from beginning of BASE table (may be null) |
7.2.10.轴表:HorizAxis和VertAxis
Axis表用于水平或垂直渲染脚本。它包括从Axis表的开头到BaseTagList和BaseScriptList的偏移量:
- BaseScriptList枚举在文本布局方向上呈现的所有脚本。
- BaseTagList枚举用于在文本布局方向上呈现脚本的所有基线。如果没有可用于文本方向的基线数据,则可以将对应的BaseTagList的偏移设置为NULL。
本章末尾的示例1显示了Axis表的示例。
Axis Table
| Type | Name | Description |
|---|---|---|
| Offset16 | baseTagListOffset | Offset to BaseTagList table, from beginning of Axis table (may be NULL) |
| Offset16 | baseScriptListOffset | Offset to BaseScriptList table, from beginning of Axis table |
7.2.11.BaseTagList表
BaseTagList表标识以相同文本方向呈现的字体中所有脚本的基线。每个基线用4字节基线标签识别。OpenType布局标记注册表的“基准标记”部分列出了当前注册的基准标记。BaseTagList可以定义任意数量的基线,并且它可以包括其他字体支持的脚本的基线标签。
BaseScriptList表中的每个脚本都必须指定其中一个BaseTagList基线作为其默认值,OpenType布局服务使用该基线来对齐脚本中的所有字形。尽管BaseScriptList和BaseTagList是彼此独立定义的,但BaseTagList通常包含在布局方向上呈现脚本所需的每个不同默认基线的标记。如果某些脚本使用相同的默认基线,则BaseTagList只需列出一次公共基线标记。
BaseTagList表由一系列基线标识标记(baselineTags)组成,按字母顺序列出,以及数组中基线标记总数的计数(baseTagCount)。
本章末尾的示例1显示了一个示例BaseTagList表。
BaseTagList table
| Type | Name | Description |
|---|---|---|
| uint16 | baseTagCount | Number of baseline identification tags in this text direction — may be zero (0) |
| Tag | baselineTags[baseTagCount] | Array of 4-byte baseline identification tags — must be in alphabetical order |
7.2.12.BaseScriptList表
BaseScriptList表标识以相同布局方向呈现的字体中的所有脚本。如果此处未列出脚本,则文本处理客户端将使用为整个字体指定的布局信息呈现脚本。
对于BaseScriptList表中列出的每个脚本,必须定义一个BaseScriptRecord,用于标识脚本并引用其布局数据。BaseScriptRecords存储在baseScriptRecords数组中,由每个记录中的baseScriptTag按字母顺序排序。baseScriptCount指定数组中BaseScriptRecords的总数。
本章末尾的示例1显示了一个示例BaseScriptList表。
BaseScriptList table
| Type | Name | Description |
|---|---|---|
| uint16 | baseScriptCount | Number of BaseScriptRecords defined |
| BaseScriptRecord | baseScriptRecords[baseScriptCount] | Array of BaseScriptRecords, in alphabetical order by baseScriptTag |
7.2.13.BaseScriptRecord
BaseScriptRecord包含一个脚本标识标记(baseScriptTag),它必须与用于在 GSUB 或 GPOS 表的ScriptList中定义脚本的ScriptTag相同。每条记录还必须包含一个BaseScript表的偏移量,该表定义脚本的基线和最小/最大范围数据。
本章末尾的示例1显示了一个示例BaseScriptRecord。
BaseScriptRecord
| Type | Name | Description |
|---|---|---|
| Tag | baseScriptTag | 4-byte script identification tag |
| Offset16 | baseScriptOffset | Offset to BaseScript table, from beginning of BaseScriptList |
7.2.14.BaseScript表
BaseScript表组织并指定一个脚本的基线数据和最小/最大范围数据。在BaseScript表中,BaseValues表包含基线信息,一个或多个MinMax表包含最小/最大范围数据。
BaseValues表标识脚本的默认基线,并列出相应BaseTagList中指定的每个基线的坐标位置。每个脚本可以为每个基线分配不同的位置,因此每个脚本可以相对于任何其他脚本独立对齐。(有关更多详细信息,请参阅本章后面的BaseValues表说明。)
默认的MinMax表定义脚本的默认最小/最大范围值。(有关详细信息,请参阅下面的MinMax表说明。)如果字体中定义的语言系统或功能对脚本的默认最小/最大范围没有影响,则OpenType布局服务将使用默认脚本值。
有时,需要特定于语言的覆盖最小/最大范围才能正确呈现特定语言系统中的字形。例如,语言系统中所需的字形替换可能会导致字形的范围超出脚本的默认最小/最大范围。指定最小/最大范围值的每个语言系统必须定义BaseLangSysRecord。该记录应标识语言系统(baseLangSysTag)并包含特定于语言的范围坐标的MinMax表的偏移量。
还可能需要针对最小/最大范围的特定于特征的覆盖以适应用于实现特定特征的字形动作的效果。例如,上标或下标功能可能需要更改默认脚本或语言系统范围。可以在默认的MinMax表中指定不限于特定语言系统的特定于功能的范围值。但是,用于特定语言系统的范围值需要BaseLangSysRecord和MinMax表。除了指定坐标数据外,MinMax表还必须包含定义特定于特征的最小/最大数据的FeatMinMaxRecords的偏移量。
BaseScript表有四个组件:
- BaseValues表的偏移量(baseValuesOffset)。如果没有为脚本定义基线数据或相应的BaseTagList设置为NULL,则BaseValues表的偏移量可以设置为NULL。
- 默认MinMax表的偏移量。如果没有为脚本定义默认的最小/最大范围数据,则可以将此偏移设置为NULL。
- 一组BaseLangSysRecords(baseLangSysRecords)。存储在BaseLangSysRecord数组中的各个记录由baseLangSysTag按字母顺序列出。
- 包含BaseLangSysRecords的计数(baseLangSysCount)。如果未定义语言系统或特定于语言的功能最小/最大值,则baseLangSysCount可以设置为零(0)。
本章末尾的示例2显示了一个示例BaseScript表。
BaseScript Table
| Type | Name | Description |
|---|---|---|
| Offset16 | baseValuesOffset | Offset to BaseValues table, from beginning of BaseScript table (may be NULL) |
| Offset16 | defaultMinMaxOffset | Offset to MinMax table, from beginning of BaseScript table (may be NULL) |
| uint16 | baseLangSysCount | Number of BaseLangSysRecords defined — may be zero (0) |
| BaseLangSysRecord | baseLangSysRecords[baseLangSysCount] | Array of BaseLangSysRecords, in alphabetical order by BaseLangSysTag |
7.2.15.BaseLangSysRecord
BaseLangSysRecord定义语言系统或特定于语言的功能的最小/最大范围。每条记录包含语言系统的标识标记(baseLangSysTag)和MinMax表(MinMax)的偏移量,该表定义语言系统的范围坐标值并引用特定于要素的范围数据。
本章末尾的示例2显示了BaseLangSysRecord。
BaseLangSysRecord
| Type | Name | Description |
|---|---|---|
| Tag | baseLangSysTag | 4-byte language system identification tag |
| Offset16 | minMaxOffset | Offset to MinMax table, from beginning of BaseScript table |
7.2.16.BaseValues表
BaseValues表列出了相应BaseTagList的baselineTags数组中指定的所有基线的坐标位置,并标识了脚本的默认基线。
注意:当对应的BaseTagList的偏移量为NULL时,不需要BaseValues表。但是,如果偏移量不为NULL,则每个脚本必须为BaseTagList中指定的所有基线指定坐标位置。默认基线(每个脚本一个)是用于布局和对齐脚本中的字形的基线。BaseValues表中的defaultBaselineIndex标识默认基线,其值等于baselineTags数组中相应标记的数组索引位置。
例如,Han和Latin脚本使用不同的基线来对齐文本。如果字体支持这些脚本中,baselineTags阵列中的HorizAxis表的BaseTagList将包含两个标签,按字母顺序列出:在baselineTags在baselineTags [0]为汉表意基线“IDEO”和“romn” [1]对于拉丁语基线。拉丁文脚本的BaseValues表将罗马基线指定为默认值,因此拉丁语BaseValues表中的defaultBaselineIndex将为“1”以指示罗马基线标记。在Han脚本的BaseValues表中,defaultBaselineIndex将为“0”以指示表意基线标记。
两个或多个脚本可以共享默认基线。例如,如果上述字体也支持西里尔语脚本,则baselineTags数组不需要西里尔语的基线标记,因为西里尔语和拉丁语共享相同的基线。在Cyrillic脚本的BaseValues表中定义的defaultBaselineIndex将指定“1”以指示罗马基线标记,该标记列在baselineTags数组的第二个位置。
在除了识别defaultBaselineIndex,所述BaseValues表包含一个偏移到该列表中的所有基线,包括默认基线,相关联的baselineTags阵列中命名的坐标位置BaseCoord表(baseCoords)的阵列。为每个基线定义一个BaseCoord表。baseCoordCount字段定义BaseCoord表的总数,它必须等于BaseTagList中baseTagCount中列出的基线标记的数量。
每个基线坐标定义为从相关X或Y轴上的零位置测量的设计单位中的单个X或Y值。例如,HorizAxis表中定义的BaseCoord表将包含Y值,因为水平基线垂直放置。BaseCoord值可能为负值。每个脚本可以为每个基线分配不同的坐标。
每个BaseCoord表的偏移量存储在BaseValues表中的baseCoords数组中。存储的偏移的顺序对应于BaseTagList的baselineTags数组中列出的标记的顺序。换句话说,该baseCoords阵列中的第一个条目将定义的偏移量BaseCoord表中为baselineTags阵列中命名的第一基线,第二位置将确定的偏移量BaseCoord表中为baselineTags阵列中指定的第二基线,等等。
本章末尾的示例3包含两部分,一部分显示BaseValues表,另一部分显示为多个脚本定义的具有不同基线位置的图表。
BaseValues table
| Type | Name | Description |
|---|---|---|
| uint16 | defaultBaselineIndex | Index number of default baseline for this script — equals index position of baseline tag in baselineTags array of the BaseTagList |
| uint16 | baseCoordCount | Number of BaseCoord tables defined — should equal baseTagCount in the BaseTagList |
| Offset16 | baseCoords[baseCoordCount] | Array of offsets to BaseCoord tables, from beginning of BaseValues table — order matches baselineTags array in the BaseTagList |
7.2.17.MinMax表和FeatMinMaxRecord
MinMax表指定脚本和语言系统的范围。它还包含一组FeatMinMaxRecords,用于定义特定于功能的扩展区。
MinMax表和FeatMinMaxRecord都定义了两个BaseCoord表的偏移量:一个定义了最小范围值(minCoord),另一个定义了最大范围值(maxCoord)。每个范围值都是单个X或Y值,具体取决于文本方向,并以设计单位指定。坐标值可能是负数。
不同的表定义脚本,语言系统和功能的最小/最大范围值:
- 脚本的最小/最大范围值在默认的MinMax表中定义,在BaseScript表中引用。
- 在默认的MinMax表中,FeatMinMaxRecords可以为适用于整个脚本的要素指定范围值。
- 语言系统的最小/最大范围值在MinMax表中定义,在BaseLangSysRecord中引用。
- 可以在MinMax表中定义FeatMinMaxRecords,以指定语言系统中应用的功能的范围值。
在FeatMinMaxRecord中,minCoord和maxCoord表指定要素的最小和最大坐标值,featureTableTag定义4字节要素识别标记。featureTableTag必须与用于标识 GSUB 或 GPOS 表的FeatureList中的功能的标记匹配。
超出默认最小/最大值的每个功能都需要一个FeatMinMaxRecord。所有FeatMinMaxRecords都按MinMax表中的数组(featMinMaxRecords)中的featureTableTag按字母顺序列出。featMinMaxCount字段定义FeatMinMaxRecords的总数。
文本处理客户端应使用以下过程来访问脚本,语言系统和特定于功能的范围数据:
- 确定与文本内容相关的脚本范围。
- 根据使用的语言系统选择特定于语言的范围值。
- 让应用程序或用户选择特定于功能的范围值。
- 如果没有为语言系统或特定于语言的功能定义范围值,请使用脚本的默认最小/最大范围值。
本章末尾的示例4包含两部分。一个显示MinMax表和一个FeatMinMaxRecord用于不同的脚本,语言系统和功能范围。第二部分显示了当语言系统需要特定于功能的特定范围值来表示隐藏功能时如何定义这些表,否则语言系统和脚本范围值匹配。
MinMax table
| Type | Name | Description |
|---|---|---|
| Offset16 | minCoord | Offset to BaseCoord table that defines the minimum extent value, from the beginning of MinMax table (may be NULL) |
| Offset16 | maxCoord | Offset to BaseCoord table that defines maximum extent value, from the beginning of MinMax table (may be NULL) |
| uint16 | featMinMaxCount | Number of FeatMinMaxRecords — may be zero (0) |
| FeatMinMaxRecord | featMinMaxRecords[featMinMaxCount] | Array of FeatMinMaxRecords, in alphabetical order by featureTableTag |
FeatMinMaxRecord
| Type | Name | Description |
|---|---|---|
| Tag | featureTableTag | 4-byte feature identification tag — must match feature tag in FeatureList |
| Offset16 | minCoord | Offset to BaseCoord table that defines the minimum extent value, from beginning of MinMax table (may be NULL) |
| Offset16 | maxCoord | Offset to BaseCoord table that defines the maximum extent value, from beginning of MinMax table (may be NULL) |
7.2.18.BaseCoord表
在 BASE 表中,BaseCoord表定义了基线和最小/最大范围值。每个BaseCoord表定义一个X或Y值:
- 如果在HorizAxis表中定义,则BaseCoord表包含Y值。
- 如果在VertAxis表中定义,则BaseCoord表包含X值。
所有值都以设计单位定义,通常在缩放字形时进行缩放并舍入为最接近的整数。价值观可能是负面的。
BaseCoord表数据可用的三种格式以设计单位定义单个X或Y坐标值。其中两种格式还支持基于轮廓点或设备表对X或Y值进行微调。在可变字体中,第三种格式根据需要使用VariationIndex表(Device表的变体)来引用变体数据,以调整当前变体实例的X或Y值。
BaseCoord格式1
第一个BaseCoord格式(BaseCoordFormat1)由格式标识符组成,后跟一个指定BaseCoord值的设计单元坐标。这种格式具有体积小和简单的优点,但不能暗示BaseCoord值可以在不同尺寸或设备分辨率下进行微调。
本章末尾的示例5显示了BaseCoordFormat1表的示例。
BaseCoordFormat1 table: Design units only
| Type | Name | Description |
|---|---|---|
| uint16 | baseCoordFormat | Format identifier — format = 1 |
| int16 | coordinate | X or Y value, in design units |
BaseCoord格式2
第二种BaseCoord格式(BaseCoordFormat2)以设计单位指定BaseCoord值,但也提供字形索引和轮廓点以供参考。在字体提示期间,字形轮廓上的轮廓点可能会移动。提示后点的最终位置提供了呈现给定字体大小的最终值。
注意:[GPOS](#table-GPOS) 表中定义的字形定位操作不会影响点的最终位置。示例6显示了BaseCoordFormat2表的示例。
BaseCoordFormat2 table: Design units plus contour point
| Type | Name | Description |
|---|---|---|
| uint16 | baseCoordFormat | Format identifier — format = 2 |
| int16 | coordinate | X or Y value, in design units |
| uint16 | referenceGlyph | Glyph ID of control glyph |
| uint16 | baseCoordPoint | Index of contour point on the reference glyph |
BaseCoord格式3
第三种BaseCoord格式(BaseCoordFormat3)也以设计单位指定BaseCoord值,但是,在非变体字体中,它使用Device表而不是轮廓点来调整值。此格式提供了对任何字体大小和设备分辨率微调BaseCoord值的优势。(有关设备表的更多信息,请参阅“通用表格格式”一章。)
在可变字体中,必须使用BaseCoordFormat3来引用变体数据,以根据需要调整不同变体实例的X或Y值。在这种情况下,BaseCoordFormat3指定VariationIndex表的偏移量,VariationIndex表是用于引用变体数据的Device表的变体。
注意:虽然需要变体的每个Coordinate值都需要单独的VariationIndex表引用,但是需要相同变体数据值的两个或多个值可以具有指向相同VariationIndex表的偏移量,并且两个或更多VariationIndex表可以引用相同的VariationIndex表变体数据条目。
注意:如果没有VariationIndex表用于特定的X或Y值(偏移量为零,或者使用不同的BaseCoord格式),则该值将用于所有变体实例。本章末尾的示例7显示了BaseCoordFormat3表的示例。
BaseCoordFormat3 table: Design units plus Device or VariationIndex table
| Type | Name | Description |
|---|---|---|
| uint16 | baseCoordFormat | Format identifier — format = 3 |
| int16 | coordinate | X or Y value, in design units |
| Offset16 | deviceTable | Offset to Device table (non-variable font) / Variation Index table (variable font) for X or Y value, from beginning of BaseCoord table (may be NULL). |
7.2.19.项目变体存储表
-ItemVariationStore表及其组成格式的格式和处理在OpenType Font Variations Common Table Formats一章中描述。在OpenType字体变体概述一章中给出了用于导出特定变体实例的值的插值算法的规范。
ItemVariationStore包含排列在一组或多组增量中的调整 - 增量值,这些增量使用增量集索引进行引用。对于需要变化调整的值,使用增量集索引来引用该目标值所需的特定变体数据。在 BASE 表中,delta-set索引在BaseCoordFormat3表中包含的VariationIndex表中提供。有关VariationIndex表的说明,请参阅OpenType布局公用表格式一章。有关在BaseCoord表中使用VariationIndex表的详细信息,请参阅本章前面的讨论。
7.2.20.基础表示例
本章的其余部分描述并说明了所有 BASE 表的示例。所有示例都反映了下面描述的唯一参数,但这些示例为构建特定于其他情况的表提供了有用的参考。
大多数示例都有三列显示十六进制数据,源和注释。
示例1:BASE标头表,轴表,BaseTagList表,BaseScriptList表和BaseScriptRecord
示例1描述了一个包含四个脚本的示例字体:Cyrillic,Devanagari,Han和Latin。所有四个脚本都是水平渲染的;只有一个脚本Han是垂直渲染的。因此,BASE标题为两个Axis表提供了偏移量:HorizAxis和VertAxis。示例1仅显示HorizAxis表中定义的数据。
在HorizAxis表中,BaseScriptList枚举所有四个脚本。BaseTagList表为渲染这些脚本命名了三个水平基线:悬挂,表意和罗马。悬挂基线是Devanagari的默认值,表意基线是Han的默认值,罗马基线是拉丁语和西里尔语的默认值。
VertAxis表(未显示)将以类似方式定义:其BaseScriptList将枚举一个脚本Han,其BaseTagList将指定用于呈现Han脚本的垂直居中基线。
Example 1
| Hex Data | Source | Comments |
|---|---|---|
| BASEHeader TheBASEHeader | BASE table header definition | |
| 00010000 | 0x00010000 | Version |
| 0008 | HorizontalAxisTable | Offset to HorizAxis table |
| 010C | VerticalAxisTable | Offset to VertAxis table |
| Axis HorizontalAxisTable | Axis table definition | |
| 0004 | HorizBaseTagList | Offset to BaseTagList table |
| 0012 | HorizBaseScriptList | Offset to BaseScriptList table |
| BaseTagList HorizBaseTagList | BaseTagList table definition | |
| 0003 | 3 | baseTagCount |
| 68616E67 | ‘hang’ | baselineTags[0], in alphabetical order |
| 6964656F | ‘ideo’ | baselineTags[1] |
| 726F6D6E | ‘romn’ | baselineTags[2] |
| BaseScriptList HorizBaseScriptList | BaseScriptList table definition | |
| 0004 | 4 | baseScriptCount |
| baseScriptRecords[0] | records in alphabetical order by baseScriptTag | |
| 6379726C | ‘cyrl’ | baseScriptTag: Cyrillic script |
| 001A | HorizCyrillicBaseScriptTable | Offset to BaseScript table for Cyrillic script |
| baseScriptRecords[1] | ||
| 6465766E | ‘devn’ | baseScriptTag: Devanagari script |
| 0060 | HorizDevanagariBaseScriptTable | Offset to BaseScript table for Devanagari script |
| baseScriptRecords[2] | ||
| 68616E69 | ‘hani’ | baseScriptTag: Han script |
| 008A | HorizHanBaseScriptTable | Offset to BaseScript table for Han script |
| baseScriptRecords[3] | ||
| 6C61746E | ‘latn’ | baseScriptTag: Latin script |
| 00B4 | HorizLatinBaseScriptTable | Offset to BaseScript table for Latin script |
7.2.21.示例2:BaseScript表和BaseLangSysRecord
示例2显示了Cyrillic脚本的BaseScript表和BaseLangSysRecord,它是示例1中描述的示例字体中包含的四个脚本之一.BaseScript表指定包含Cyrillic的基线和最小/最大范围数据的表的偏移量。(字体中其他三个脚本的BaseScript表将以类似方式定义。)同样,该表仅指定水平文本布局信息。
HorizCyrillicBaseValues表包含脚本的基线信息,HorizCyrillicDefaultMinMax表包含默认的脚本范围。此外,BaseLangSysRecord定义俄语系统的最小/最大范围数据。
Example 2
| Hex Data | Source | Comments |
|---|---|---|
| BaseScript HorizCyrillicBaseScriptTable | BaseScript table definition for Cyrillic script | |
| 000C | HorizCyrillicBaseValuesTable | Offset to BaseValues table |
| 0022 | HorizCyrillicDefault | |
| MinMaxTable | Offset to default MinMax table — default script extents | |
| 0001 | 1 | baseLangSysCount — BaseLangSysRecords for language-specific extents |
| baseLangSysRecords[0] | Records in alphabetical order by baseLangSysTag. | |
| 52555320 | “RUS ” | BaseLangSysTag, Russian language system |
| 0030 | HorizRussianMinMaxTable | Offset to MinMax table — language-specific extents |
7.2.22.示例3:BaseValues表
示例3扩展了示例1和2中描述的Cyrillic脚本的 BASE 表定义。它包含两部分:
- 示例3A示出了用于西里尔语的完全定义的BaseValues表。该表包括相应的BaseCoord表定义。
- 示例3B示出了可以为样本字体中的四个脚本中的每一个定义的两组不同的基线值。
示例仅显示水平文本布局数据,字体使用2,048个设计单位/ em。
7.2.23.示例3A:西里尔的基值表
示例3A的BaseValues表标识了Cyrillic的默认基线,并指定了示例1中所示的BaseTagList中列出的每个基线的坐标位置:
- 悬挂基线是梵文脚本的默认值,它具有最高的基线位置。
- 表意基线是汉字脚本的默认值,它具有最低的基线位置。
- 罗马基线是拉丁语和西里尔语脚本的默认基础,其位置介于悬挂和表意基线之间。
Example 3A
| Hex Data | Source | Comments |
|---|---|---|
| BaseValues HorizCyrillicBaseValuesTable | BaseValues table definition for Cyrillic script | |
| 0002 | 2 | defaultBaselineIndex: roman baseline baselineTags index |
| 0003 | 3 | baseCoordCount, equals baseTagCount |
| 000A | HorizHangingBaseCoordForCyrl | Offset to baseCoords[0] table: hanging baseline coordinate — order matches order of baselineTags array in BaseTagList |
| 000E | HorizIdeographicBaseCoordForCyrl | Offset to baseCoords[1] table: ideographic baseline coordinate |
| 0012 | HorizRomanBaseCoordForCyrl | Offset to baseCoords[2] table: roman baseline coordinate |
| BaseCoordFormat1 HorizHangingBaseCoordForCyrl | BaseCoord table definition | |
| 0001 | 1 | BaseCoordFormat design units only |
| 05DC | 1500 | coordinate — Y value, in design units |
| BaseCoordFormat1 HorizIdeographicBaseCoordForCyrl | BaseCoord table definition | |
| 0001 | 1 | baseCoordFormat: design units only |
| FEE0 | -288 | coordinate — Y value, in design units |
| BaseCoordFormat1 HorizRomanBaseCoordinateForCyrl | BaseCoord table definition | |
| 0001 | 1 | baseCoordFormat: design units only |
| 0000 | 0 | coordinate — Y value, in design units |
7.2.24.示例3B:四个脚本的基线值
示例3B显示了两个表,其中包含示例1中描述的示例字体中的四个脚本中的每个脚本的基线值:
- 第一个表显示了如果一致地设计所有四个脚本中的基线值可能会发生什么。它们各自的BaseValues表列出了相同的基线值,罗马基线位于Y值为零(0),表意基线位于-288,悬挂基线位于1500。
- 第二个表显示了如果脚本中的基线值与零(0)坐标处的每个脚本的默认基线设计不同,可能会发生什么。
可以在 BASE 表中使用分配基线值的任一方法。
实施例3B:相同的基线值
| Baseline type | Han | Latin | Cyrillic | Devanagari |
|---|---|---|---|---|
| hanging | 1500 | 1500 | 1500 | 1500 |
| roman | 0 | 0 | 0 | 0 |
| ideographic | -288 | -288 | -288 | -288 |
示例3B:分配的基线值,默认基线为0
| Baseline type | Han | Latin | Cyrillic | Devanagari |
|---|---|---|---|---|
| hanging | 1788 | 1500 | 1500 | 0 |
| roman | 288 | 0 | 0 | -1500 |
| ideographic | 0 | -288 | -288 | -1788 |
7.2.25.示例4:MinMax表和FeatMinMaxRecord
示例4显示了前一个示例中描述的相同Cyrillic脚本的MinMax表和FeatMinMaxRecord定义。它包含两部分:
- 示例4A定义了具有不同脚本,语言系统和特征范围的表。
- 示例4B显示了当语言系统扩展区与脚本扩展区匹配时编写的这些相同的表定义,但是如果实现该功能,则语言系统的模糊特征需要特定于功能的扩展区。
示例仅显示水平文本布局数据,字体使用2,048个设计单位/ em。
示例4A:西里尔文脚本,俄语和俄语特征的最小/最大范围
示例4A显示了Cyrillic脚本的两个MinMax表和一个FeatMinMaxRecord,以及示例BaseCoord表。仅包含MinCoord范围数据。
Example 4A
| Hex Data | Source | Comments |
|---|---|---|
| MinMax HorizCyrillicDefault MinMaxTable | Default MinMax table definition, Cyrillic script | |
| 0006 | HorizCyrillic MinCoordTable | minCoord — offset to BaseCoord table |
| 000A | HorizCyrillic MaxCoordTable | maxCoord — offset to BaseCoord table |
| 0000 | 0 | featMinMaxCount: no default feature extents featMinMaxRecords[] — no FeatMinMaxRecords |
| BaseCoordFormat1 HorizCyrillic MinCoordTable | BaseCoord table definition, default Cyrillic min extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| FF38 | -200 | coordinate — Y value, in design units |
| BaseCoordFormat1 HorizCyrillic MaxCoordTable | BaseCoord table definition default Cyrillic max extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| 0674 | 1652 | coordinate — Y value, in design units |
| MinMax HorizRussianMinMaxTable | MinMax table definition, Russian language extents | |
| 000E | HorizRussianLangSys MinCoordTable | minCoord — offset to BaseCoord table |
| 0012 | HorizRussianLangSys MaxCoordTable | maxCoord — offset to BaseCoord table |
| 0001 | 1 | featMinMaxCount |
| featMinMaxRecords[0] | Records in alphabetical order by featureTableTab. | |
| 7469746C | ‘titl’ | featureTableTag: Titling Feature must be same as Tag in FeatureList |
| 0016 | HorizRussianFeature MinCoordTable | minCoord — offset to BaseCoord table |
| 001A | HorizRussianFeature MaxCoordTable | maxCoord — offset to BaseCoord table |
| BaseCoordFormat1 HorizRussianLangSys MinCoordTable | BaseCoord table definition: Russian language min extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| FF08 | -248 | coordinate — Y value, in design units Increased min extent beyond default Cyrillic min extent |
| BaseCoordFormat1 HorizRussianLangSys MaxCoordTable | BaseCoord table definition: Russian language feature max extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| 06A4 | 1700 | coordinate — Y value, in design units Increased max extent beyond default Cyrillic max extent |
| BaseCoordFormat1 HorizRussianFeature MinCoordTable | BaseCoord table definition: Russian language min extent coordinate | |
| 0001 | 1 | baseCoordFormat: design Units Only |
| FED8 | -296 | coordinate — Y value, in design units Increased min extent beyond default Cyrillic script and Russian language min extents |
| BaseCoordFormat1 HorizRussianFeature MaxCoordTable | BaseCoord table definition: Russian language feature Max extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| 06D8 | 1752 | coordinate — Y value, in design units Increased max extent beyond default Cyrillic script and Russian language max extents |
例4B:西里尔文脚本和俄罗斯特征的最小/最大范围
如果特定语言系统的范围与为脚本定义的默认范围匹配,则不需要定义最小/最大范围坐标。但是,语言系统中的一个模糊或不经常使用的功能可能需要特定于功能的范围值才能正确呈现。
示例4B显示了针对此情况的MinMax和FeatMinMaxRecord表定义。该示例还包括BaseScript表,但不包括BaseValues表,因为它与此示例无关。该示例显示了西里尔语脚本的水平文本布局范围和俄语系统中一个功能的特定于功能的范围。从实施例4A重复大部分数据并在此修改以进行比较。
BaseScript表包括用于西里尔文脚本的DefaultMinMax表和用于定义BaseLangSysTag的BaseLangSysRecord以及用于俄语的MinMax表的偏移量。MinMax表包含一个FeatMinMaxRecord并指定一个FeatMinMaxCount,但MinMax表中的MinCoord和MaxCoord偏移都设置为NULL,因为没有为俄语定义特定于语言的范围值。FeatMinMaxRecord定义俄语特征的最小/最大坐标,并指定正确的FeatureTableTag。
Example 4B
| Hex Data | Source | Comments |
|---|---|---|
| BaseScript HorizCyrillicBaseScriptTable | BaseScript table definition: Cyrillic script | |
| 0000 | NULL | offset to BaseValues table |
| 000C | HorizCyrillicDefault MinMaxTable | offset to default MinMax table for default script extents |
| 0001 | 1 | baseLangSysCount |
| baseLangSysRecords[0] | For Russian language-specific extents. | |
| 52555320 | “RUS ” | baseLangSysTag: Russian |
| 001A | HorizRussian MinMaxTable | offset to MinMax table for language-specific extents |
| MinMax HorizCyrillicDefault MinMaxTable | Default MinMax table definition: Cyrillic script | |
| 0006 | HorizCyrillic MinCoordTable | minCoord — offset to BaseCoord table |
| 000A | HorizCyrillic MaxCoordTable | maxCoord — offset to BaseCoord table |
| 0000 | 0 | featMinMaxCount, no default feature extents featMinMaxRecords[], no FeatMinMaxRecords |
| BaseCoordFormat1 HorizCyrillic MinCoordTable | BaseCoord table definition: default Cyrillic min extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| FF38 | -200 | coordinate — Y value, in design units |
| BaseCoordFormat1 HorizCyrillic MaxCoordTable | BaseCoord table definition: default Cyrillic max extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| 0674 | 1652 | coordinate — Y value, in design units |
| MinMax HorizRussian MinMaxTable | MinMax table definition for Russian language — no extent differences for Russian language itself | |
| 0000 | NULL | minCoord — offset to min BaseCoord table not defined, matches script default |
| 0000 | NULL | maxCoord — offset to max BaseCoord table not defined, matches script default |
| 0001 | 1 | featMinMaxCount featMinMaxRecords[0] |
| 7469746C | ‘titl’ | featureTableTag: Titling Feature must be same as Tag in FeatureList |
| 000E | HorizRussianFeature MinCoordTable | minCoord — offset to BaseCoord table |
| 0012 | HorizRussianFeature MaxCoordTable | maxCoord — offset to BaseCoord table |
| BaseCoordFormat1 HorizRussianFeature MinCoordTable | BaseCoord table definition: Russian ‘titl’ feature min extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| FED8 | -296 | coordinate — Y value, in design units Increased min extent beyond default Cyrillic min extent |
| BaseCoordFormat1 HorizRussianFeature MaxCoordTable | BaseCoord table definition: Russian ‘titl’ feature max extent coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| 06D8 | 1752 | coordinate — Y value, in design units Increased max extent beyond default Cyrillic max extent |
7.2.26.示例5:BaseCoordFormat1表
示例5说明了BaseCoordFormat1,它仅以设计单位指定单个坐标值。该字体使用2,048个设计单位/ em。该示例定义数学脚本的默认最小范围坐标。
Example 5
| Hex Data | Source | Comments |
|---|---|---|
| BaseCoordFormat1 HorizMathMinCoordTable | Definition of BaseCoord table for Math min coordinate | |
| 0001 | 1 | baseCoordFormat: design units only |
| FEE8 | -280 | coordinate — Y value, in design units |
7.2.27.示例6:BaseCoordFormat2表
示例6说明了BaseCoord格式2.与示例5类似,它指定了数学脚本的最小范围坐标。使用此格式时,坐标值取决于一个字形上特定轮廓点的最终位置,即提示后的整数数学符号。同样,该值以设计单位(2,048单位/ em)表示。
Example 6
| Hex Data | Source | Comments |
|---|---|---|
| BaseCoordFormat2 HorizMathMinCoordTable | BaseCoord table definition for Math min coordinate | |
| 0002 | 2 | baseCoordFormat: design units plus contour point |
| FEE8 | -280 | coordinate — Y value, in design units |
| 0128 | IntegralSignGlyphID | referenceGlyph: math integral sign |
| 0043 | 67 | baseCoordPoint: glyph contour point index |
7.2.28.示例7:BaseCoordFormat3表
示例7说明了BaseCoord格式3.与示例5和6类似,它以设计单位(2,048个单位/ em)指定数学脚本的最小范围坐标。但是,此格式使用Device表来修改输出字体的磅值和分辨率的坐标值。这里,Device表定义了从11 ppem到15 ppem的字体大小的像素调整。调整在每个尺寸上添加一个像素。
Example 7
| Hex Data | Source | Comments |
|---|---|---|
| BaseCoordFormat3 HorizMathMinCoordTable | BaseCoord table definition for Math min coordinate | |
| 0003 | 3 | baseCoordFormat: design units plus device table |
| -280 | coordinate — Y value, in design units | |
| 000C | HorizMathMin CoordDeviceTable | Offset to Device table |
| DeviceTableFormat1 HorizMathMin CoordDeviceTable | Device table definition for MinCoord | |
| 000B | 11 | startSize: 11 ppem |
| 000F | 15 | endSize: 15 ppem |
| 0001 | 1 | deltaFormat: signed 2 bit value (8 values per uint16) |
| 1 | Increase 11ppem by 1 pixel | |
| 1 | Increase 12ppem by 1 pixel | |
| 1 | Increase 13ppem by 1 pixel | |
| 1 | Increase 14ppem by 1 pixel | |
| 5540 | 1 | Increase 15ppem by 1 pixel |
7.3.CBDT 彩色位图数据表(Color Bitmap Data Table)
表结构
CBDT表用于嵌入彩色位图字形数据。它与CBLC表一起使用,后者提供嵌入式位图定位器。这两个表的格式向后兼容用于嵌入式单色和灰度位图的 EBDT 和 EBLC 表。
CBDT表以包含表格版本号的标题开头。
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the CBDT table, = 3. |
| uint16 | minorVersion | Minor version of the CBDT table, = 0. |
请注意,CBDT表的第一个版本是3.0。
CBDT表的其余部分是位图数据的集合。数据可以三种可能的格式呈现,由CBLC表中的信息指示。一些格式包含度量信息和图像数据,而其他格式仅包含图像数据。这些子表不需要长字对齐,字节对齐就足够了。
未压缩的颜色位图
CBLC表中的BitmapSize表的bitDepth字段中的值32用于识别每像素具有8位蓝/绿/红/α(“BGRA”)通道的彩色位图,按照每个像素的顺序编码。颜色通道表示预乘的颜色,并且是sRGB颜色空间中的编码颜色。例如,颜色“半绿色半全半”被编码为\ x00 \ x80 \ x00 \ x80,而不是\ x00 \ xFF \ x00 \ x80。
EBDT / EBLC 表中定义的所有位图图像数据格式都适用于CBDT / CBLC表。
压缩颜色位图
每个字形的图像存储为直接PNG数据。此类PNG数据中仅允许以下块:IHDR,PLTE,tRNS,sRGB,IDAT和IEND。如果存在其他块,则行为未定义。无论PNG数据中其他块中可能存在的颜色信息如何,图像数据都应在sRGB颜色空间中。单个图像必须与位图指标中的表具有相同的大小。
字形度量标准
字形度量标准还有两种不同的格式:大字形度量标准和小字形度量标准。大字形度量标准定义水平和垂直布局的度量信息。这在可以使用两种类型的布局的字体(例如汉字)中很重要。小字形指标仅定义一个布局方向的指标信息。哪个方向适用,水平或垂直,由CBLC表中的BitmapSize表中的flags字段确定。
BigGlyphMetrics
| Type | Name |
|---|---|
| uint8 | height |
| uint8 | width |
| int8 | horiBearingX |
| int8 | horiBearingY |
| uint8 | horiAdvance |
| int8 | vertBearingX |
| int8 | vertBearingY |
| uint8 | vertAdvance |
SmallGlyphMetrics
| Type | Name |
|---|---|
| uint8 | height |
| uint8 | width |
| int8 | bearingX |
| int8 | bearingY |
| uint8 | advance |
字形位图数据格式
除了已经为 EBDT 表中的字形位图数据定义的九种不同格式之外,还有三种新格式如下所述
格式17:小指标,PNG图像数据
| Type | Name | Description |
|---|---|---|
| smallGlyphMetrics | glyphMetrics | Metrics information for the glyph |
| uint32 | dataLen | Length of data in bytes |
| uint8 | data[dataLen] | Raw PNG data |
格式18:大指标,PNG图像数据
| Type | Name | Description |
|---|---|---|
| bigGlyphMetrics | glyphMetrics | Metrics information for the glyph |
| uint32 | dataLen | Length of data in bytes |
| uint8 | data[dataLen] | Raw PNG data |
格式19:CBLC表中的度量,PNG图像数据
| Type | Name | Description |
|---|---|---|
| uint32 | dataLen | Length of data in bytes |
| uint8 | data[dataLen] | Raw PNG data |
缩放行为
使用这些字形的应用程序可能需要缩放它们以适合可用于显示的光栅大小。如何进行这种缩放取决于应用程序。建议尽可能使用大于所需结束光栅大小的最接近大小的位图来缩减应用程序。
7.4.CBLC 颜色位图位置表(Color Bitmap Location Table)
表结构
CBLC表提供嵌入式位图定位器。它与CBDT表一起使用,后者提供嵌入的彩色位图字形数据。这两个表的格式向后兼容用于嵌入式单色和灰度位图的 EBDT 和 EBLC 表。
CBLC表以包含表格版本和罢工次数的标题开头。
CblcHeader
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the CBLC table, = 3. |
| uint16 | minorVersion | Minor version of the CBLC table, = 0. |
| uint32 | numSizes | Number of BitmapSize tables |
请注意,CBLC表的第一个版本是3.0。
CblcHeader后面紧跟BitmapSize表数组。CblcHeader中的numSizes表示数组中BitmapSize表的数量。每个警示都由一个BitmapSize表定义。
BitmapSize表
| Type | Name | Description |
|---|---|---|
| Offset32 | indexSubTableArrayOffset | Offset to index subtable from beginning of CBLC. |
| uint32 | indexTablesSize | Number of bytes in corresponding index subtables and array. |
| uint32 | numberofIndexSubTables | There is an index subtable for each range or format change. |
| uint32 | colorRef | Not used; set to 0. |
| SbitLineMetrics | hori | Line metrics for text rendered horizontally. |
| SbitLineMetrics | vert | Line metrics for text rendered vertically. |
| uint16 | startGlyphIndex | Lowest glyph index for this size. |
| uint16 | endGlyphIndex | Highest glyph index for this size. |
| uint8 | ppemX | Horizontal pixels per em. |
| uint8 | ppemY | Vertical pixels per em. |
| uint8 | bitDepth | In addtition to already defined bitDepth values 1, 2, 4, and 8 supported by existing implementations, the value of 32 is used to identify color bitmaps with 8 bit per pixel RGBA channels. |
| int8 | flags | Vertical or horizontal (see the Bitmap Flags section of the EBLC table chapter). |
indexSubTableArrayOffset是从CBLC表的开头到indexSubTableArray的偏移量。每次攻击都有其中一个阵列,以支持各种格式和不连续的位图范围。indexTablesSize是indexSubTableArray和相关indexSubTables中的总字节数。numberOfIndexSubTables是此警示的indexSubTables的计数。
CBLC表结构的其余部分与已为 EBLC 定义的结构相同。
7.5.CFF 紧凑字体格式表(Compact Font Format table)
此表包含压缩字体格式字体表示(也称为PostScript Type 1或CIDFont),其结构符合Adobe技术说明#5176:“压缩字体格式规范”和Adobe技术说明#5177:“Type 2字符串格式。“
具有TrueType轮廓的OpenType字体使用字形索引来指定和访问字体内的字形;例如,在 loca 表中索引,从而访问 glyf 表中的字形数据。这个概念保留在OpenType CFF字体中,除了通过’CFF’表的CharStrings INDEX访问字形数据。
CFF数据中的名称INDEX必须只包含一个条目;也就是说,CFF FontSet中只能有一种字体。并不要求此名称与“名称”表中的名称ID 6条目相同。请注意,在OpenType字体集合文件中,可以跨多种字体共享单个“CFF”表;应用程序使用的名称必须是“名称”表中提供的名称,而不是名称INDEX条目。CFF Top DICT必须指定CharstringType值为2,maxp 表中的numGlyphs字段必须与CFF的CharStrings INDEX中的条目数相同。OpenType字体字形索引与字体中所有字形的CFF字形索引相同。
7.6.CFF2 压缩字体格式版本2(Compact Font Format (CFF) Version 2)
1.简介
本文档描述了 CFF2 格式。与CFF 1.CFF2 允许有效存储字形轮廓和元数据。CFF2 格式与CFF版本1.0的不同之处在于它不能用作独立的字体程序:它仅用于OpenType字体的上下文中,作为带有标记 CFF2 的 sfnt 表,并且取决于数据在其他OpenType表中。将删除1.0格式的所有数据,这些数据由其他表中的数据复制,或者未在OpenType字体的上下文中使用。
另一个重要的区别是 CFF2 格式添加了新的运算符,允许 CFF2 表示可变字体的数据:包含每个字形的几个不同变体的表示的字体,可以将其混合以产生中间实例。有关可变字体的一般概述以及支持可变字体所需的表的完整列表,请参阅OpenType字体变体概述一章。
最后,CFF2 格式需要使用 CFF2 CharStrings而不是Type 2 CharStrings。这种CharString格式与 CFF2 格式本身一样,已经删除了运算符以减小文件大小,并添加了新的运算符来支持可变字体。有关 CFF2 CharStrings的更多信息,请参见第8节,CharStrings INDEX。
有关CFF格式版本1.0和 CFF2 之间差异的完整描述,请参阅附录D,来自CFF 1.0的更改。
2.数据布局
从概念上讲,二进制数据被组织为许多单独的数据结构。二进制数据中的总体布局如表1所示。前三个结构占据固定位置。其余部分通过偏移达到,并且可以更改它们的顺序。
Table 1 CFF2 Data Layout
| Entry | Comments |
|---|---|
| Header | Fixed location |
| Top DICT | Fixed location |
| Global Subr INDEX | Fixed location |
| VariationStore | |
| FDSelect | Present only if there is more than one Font DICT in the Font DICT INDEX. |
| Font DICT INDEX | |
| Array of Font DICT | Included in Font DICT INDEX. |
| Private DICT | One per Font DICT. |
附录A,示例 CFF2 字体,显示了 CFF2 表的带注释的示例。
3.数据类型
本节介绍 CFF2 格式使用的数据表示和类型。
所有多字节数字数据和偏移字段都以big-endian字节顺序(高字节低偏移)存储,并且不遵守任何对齐限制。这导致了一种没有填充字节的格式。
数据对象通常由相对于 CFF2 数据中某个参考点的字节偏移量指定。这些偏移的长度为1到4个字节。在每种情况下指示偏移的参考位置。
CFF2 表中使用的数据类型如表2所示。
Table 2 CFF2 Data Types
| Name | Range | Description |
|---|---|---|
| uint8 | 0 to 255 | 8-bit unsigned number |
| uint16 | 0 to 65535 | 16-bit unsigned number |
| uint32 | 0 to 4294967295 | 32-bit unsigned number |
| Offset | varies | 1, 2, 3, or 4 byte offsets (specified by OffSize field in an Index table) |
| OffSize | 1 to 4 | 1-byte unsigned number specifies the size of an Offset field or fields |
本文档通过列出字段类型,名称和描述来描述数据结构。可以给数据结构赋予类型名称并随后进行描述。对象数组由包含数组长度的通常方括号约定表示。
大多数 CFF2 数据由称为DICT和INDEX的两种数据结构中的任何一种包含,后面的章节对此进行了描述。
4. DICT数据
包括键值对的字体字典数据以紧凑的标记化格式表示,该格式类似于用于表示CharStrings的格式。字典键被编码为1或2字节运算符,字典值被编码为可变大小的数字操作数。运算符前面是指定其值的操作数。DICT只是连接在一起的操作数/运算符字节序列。有三种结构使用DICT数据格式:Top DICT,Font DICT和Private DICT。每个DICT运营商的列表可以在第7节,Top DICT,第10节,字体DICT和第11节,私人DICT中找到。附录C CFF2 DICT编码中提供了所有DICT运营商的摘要。
定义了许多不同大小的整数操作数类型,并按表3所示进行编码(操作数的第一个字节是b0,第二个是b1,依此类推)。
表3操作数编码
| Size | b0 range | Value range | Value calculation |
|---|---|---|---|
| 1 | 32 to 246 | -107 to +107 | b0 – 139 |
| 2 | 247 to 250 | +108 to +1131 | (b0 – 247) * 256 + b1 + 108 |
| 2 | 251 to 254 | -1131 to -108 | -(b0 – 251) * 256 – b1 – 108 |
| 3 | 28 | -32768 to +32767 | b1 << 8 | b2 |
| 5 | 29 | -(2^31) to +(2^31 – 1) | b1 << 24 | b2 << 16 | b3 << 8 | b4 |
注意:1字节,2字节和3字节整数格式与 CFF2 CharStrings使用的格式相同。表4中显示了整数格式的示例。
表4整数格式示例
| Value | Encoding |
|---|---|
| 0 | 8b |
| 100 | ef |
| -100 | 27 |
| 1000 | fa 7c |
| 10000 | 1c 27 10 |
| -10000 | 1c d8 f0 |
| 100000 | 1d 00 01 86 a0 |
| -100000 | 1d ff fe 79 60 |
除整数操作数外,还提供实数操作数。该操作数以字节值30开头,后跟可变长度的字节序列。每个字节由表5中定义的两个4位半字节组成。一对中的第一个半字节存储在一个字节的最高有效4位中,而一对中的第二个半字节存储在一个字节的最低有效4位中。字节。
表5半字节定义
| Nibble value | Represents |
|---|---|
| 0 to 9 | 0 to 9 |
| a | . (decimal point) |
| b | E |
| c | E– |
| d | <reserved> |
| e | – (minus) |
| f | end of number |
实数由一个(或两个)0xf半字节终止,因此它总是填充到一个完整的字节。因此,值-2.25由字节序列(1e e2 a2 5f)编码,值0.140541E-3由序列(1e 0a 14 05 41 c3 ff)编码。
可以通过检查它们的第一个字节来区分运算符和操作数。值28,29,30和32至254指定操作数(数字)。所有其他值指定运算符或保留。可以在操作符之前的操作数的最大数量由当前堆栈限制设置。
运算符可以具有表6中所示类型的一个或多个操作数。
表6操作数类型
| Type | Description |
|---|---|
| number | Integer or real number |
| array | One or more numbers |
| delta | A number or a delta-encoded array of numbers (see below) |
通过计算运算符之前的操作数来确定数组或delta类型的长度。delta中的第二个和后续数字被编码为连续值之间的差异。例如,数组a0,a1,a2,…,an将被编码为:a0(a1-a0)(a2-a1)…,(an-an-1)。
双字节运算符的初始转义字节为12。
通过为各种DICT键建立默认值来实现字典数据的进一步压缩。对于那些具有默认值的键,DICT中缺少相应的运算符意味着键应采用其默认值。
5. INDEX数据
INDEX是一个可变大小的对象数组。它包括标题,偏移数组和对象数据。偏移数组指定对象数据中的偏移量。通过索引偏移数组并在指定的偏移量处获取对象来检索对象。可以通过从偏移数组中的下一个偏移减去其偏移量来确定对象的长度。在偏移数组的末尾添加附加偏移,以便可以确定最后一个对象的长度。INDEX格式如表7所示。
表7 INDEX格式
| Type | Name | Description |
|---|---|---|
| uint32 | count | Number of objects stored in INDEX |
| OffSize | offSize | Offset array element size |
| Offset | offset [count+1] | Offset array — offsets are from byte preceding object data. |
| uint8 | data [<varies>] | Object data |
偏移数组中的偏移量相对于对象数据之前的字节。因此,偏移数组的第一个元素始终为1.(这可确保每个对象都具有相应的偏移量,该偏移量始终为非零值,并允许有效实现动态对象加载。)
空INDEX由计数字段表示,其值为0且没有其他字段。因此,空INDEX的总大小是4个字节。
注意:跳转到偏移数组的最后一个元素指定的偏移量可以跳过INDEX。6.标题
二进制数据以具有表8中所示格式的标题开始。
表8标题格式
| Type | Name | Description |
|---|---|---|
| uint8 | majorVersion | Format major version. Set to 2. |
| uint8 | minorVersion | Format minor version. Set to zero. |
| uint8 | headerSize | Header size (bytes). |
| uint16 | topDictLength | Length of Top DICT structure in bytes. |
在查找Top DICT数据的开头时,必须使用headerSize字段。提供该格式的未来版本可以以与旧实现兼容的方式在topDictLength字段和Top DICT数据之间引入附加数据。
7.热门DICT数据
这是 CFF2 表的顶级DICT。
顶级DICT运营商的名称和默认值(如果适用)如表9所示。
表9顶级DICT运营商条目
| Name | Value | Operand(s) | Default | Notes |
|---|---|---|---|---|
| FontMatrix | 12 7 | array | 0.001 0 0 0.001 0 0 | |
| CharStrings | 17 | number | — | CharStrings INDEX offset, from start of the CFF2 table. |
| FDArray | 12 36 | number | — | Font DICT (FD) INDEX offset, from start of the CFF2 table. |
| FDSelect | 12 37 | number | — | FDSelect structure offset, from start of the CFF2 table. |
| vstore | 24 | number | — | VariationStore structure offset, from start of the CFF2 table. |
如果 head 表中的unitsPerEm值不是1000,则需要Top DICT FontMatrix运算符。如果unitsPerEm为1000,则可以省略FontMatrix运算符。包含时,FontMatrix操作数数组必须为1 / unitsPerEm 0 0 1 / unitsPerEm 0 0.上面显示的默认值假定unitsPerEm为1000。
如果Font DICT INDEX包含多个Font DICT,则需要FDSelect运算符及其指向的结构,否则必须省略它。
如果存在变体数据,则需要vstore运算符及其指向的数据,如果没有变体数据,则必须省略。
Top DICT,Font DICT,Private DICT和CharStrings中的运算符最多可以包含513个操作数。
8. CharStrings INDEX
CharStrings INDEX是一个INDEX结构,包含字体中的所有 CFF2 字形。每个CharString提供字形的定义,并由字形索引(“GID”)访问。第一个CharString(GID 0)必须是.notdef标志符号。可以从CharString INDEX计数字段确定 CFF2 表中定义的字形数。该字段的值必须与 maxp 表中numGlyphs字段的值匹配。
CFF2 数据的CharString数据的格式,以及解释方法,是 CFF2 CharString格式。这基于Type 2 CharString格式,区别仅在于添加了一些运算符,并且删除了许多运算符。有关详细信息,请参阅 CFF2 CharString格式一章。主要变化如下:
- CFF2 CharStrings不包含提前宽度的值。
- 对于 CFF2 表,CharStrings的填充规则必须始终是非零绕组数规则,而不是偶数奇数规则。这是为了支持可变字体数据所必需的,其中强制删除路径之间的重叠是不切实际的。
- 堆栈深度从48增加到513。
- CharString运算符集在 CFF2 中扩展,包括blend(16)和vsindex(15)运算符。在第12节“OpenType字体变体的扩展”中,这些运算符的工作方式如下所述,与等效的 CFF2 私有DICT运算符有关。但是,请注意,在CharStrings中使用时,运算符对这些运算符的编码与等效 CFF2 专用DICT运算符的运算符代码不同。
- 将删除Type 2运算符endchar和return。
- 将删除Type 2逻辑,存储和数学运算符。
CFF2 格式不包含字形标记的字形名称或CID值。但是,提供某些语义内容的字形标签可用于调试,也可用作导出编码信息的最后手段。CFF2 表的字形标记可以由版本2.0 post 表中的PostScript字形名称表示。字形名称添加到字体大小并且是可选的。或者,字体可以使用3.0版 post 表,它省略了字形名称。
9.本地和全球Subr指数
子程序(“subr”)通常是CharString字节序列,表示在字体的CharString数据中的多个位置使用的子程序。subr可以存储一次,但是通过使用call-subroutine运算符从一个或多个CharStrings中多次引用,该运算符将要调用的subr的数量作为操作数。
有些分子是本地的;也就是说,它们包含在私人DICT中,并且可以通过与私人字典相关联的一组CharStrings访问。本地子目录包含在INDEX结构中;使用Subrs运算符指定私有DICT中INDEX的偏移量。CharString通过callsubr运算符引用其Private DICT中的本地subr。
Subrs也可以是全局的,可以访问字体中的任何CharString。全局子数据存储在Global Subrs INDEX中,后者跟随Top DICT数据。字体可能没有任何全局子字符,在这种情况下,Global Subrs INDEX为空。CharString通过callgsubr运算符引用全局子参数。
子编号由称为“子编号偏差”的数字偏斜,该编号是根据本地或全局子索引中的子程序的计数计算的。偏差计算如下:
1 | uint16 bias; |
对于正确的子选择,必须在访问适当的子INDEX之前将计算的偏差添加到子编号操作数。该技术允许使用负数和正数指定子编号,从而充分利用可用的数字范围,从而节省空间。
表10字体DICT运算符条目
| Name | Value | Operand(s) | Default | Notes |
|---|---|---|---|---|
| Private | 18 | number number | — | Private DICT size and offset, from start of the CFF2 table. |
本规范的早期版本记录了使用双字节操作符代码12的Font DICT FontMatrix操作符。在 CFF2 字体中不需要使用Font DICT FontMatrix操作符,现在不推荐使用。
如果有多个Font DICT,则使用FDSelect表来提供有关哪些字体DICT(“FD”)用于哪些字形的信息。仅当存在多个字体DICTS时才使用FDSelect。
FDSelect表的位置作为Top DICT中FDSelect运算符的操作数给出。FDSelect表通过指定该字形的FD索引将Font DICT与字形相关联。FD索引用于访问存储在Font DICT INDEX中的Font DICT之一。目前定义了FDSelect表的三种格式,如下表所示。
表11 FDSelect格式0
| Type | Name | Description |
|---|---|---|
| uint8 | format | Set to 0 |
| uint8 | fds [nGlyphs] | FD selector array |
fds数组的每个元素代表FDArray中Font DICT的FD索引。当FD索引处于相当随机的顺序时,应该使用这种格式。字形数(nGlyphs)是CharStrings INDEX中count字段的值。
表12 FDSelect格式3
| Type | Name | Description |
|---|---|---|
| uint8 | format | Set to 3 |
| uint16 | nRanges | Number of ranges |
| Range3 | range3 [nRanges] | Array of Range3 records (see below) |
| uint16 | sentinel | Sentinel GID |
表13 Range3记录格式
| Type | Name | Description |
|---|---|---|
| uint16 | first | First glyph index in range |
| uint8 | fd | FD index for all glyphs in range |
每个Range3描述一组具有相同FD索引的顺序GID。每个范围包括范围记录中第一个GID的GID,但不包括下一个范围记录的第一个GID。Range3数组中的记录必须按第一个GID的递增顺序排列。第一个范围必须具有0的第一个GID。最后一个范围元素之后的Sentinel GID用于分隔数组中的最后一个范围。将标记GID设置为等于字体中的字形数。也就是说,它的值比字体中的最后一个GID大1。这种格式特别适用于排序良好的FD索引(通常情况下)。
表14 FDSelect格式4
| Type | Name | Description |
|---|---|---|
| uint8 | format | Set to 4 |
| uint32 | nRanges | Number of ranges |
| Range4 | range4 [nRanges] | Array of Range4 records (see below) |
| uint32 | sentinel | Sentinel GID |
格式4与格式3的不同之处仅在于它通过对nRanges和sentinel字段使用uint32类型以及Range4记录数组来容纳超过65536个字形。
表15 Range4记录格式
| Type | Name | Description |
|---|---|---|
| uint32 | first | First glyph index in range |
| uint16 | fd | FD index for all glyphs in range |
Range4格式与Range3的不同之处仅在于它通过对第一个GID字段使用uint32而对FD索引使用uint16字段来容纳超过65536个字形。
注意:虽然FDSelect格式4允许超过65536个字形,但OpenType格式的其他部分(例如“maxp”表的numGlyphs字段)仍然限制为65536个字形。11.私人DICT数据
表16中所示的私有DICT运营商的名称在可能的情况下与相应的类型1字典密钥相同。没有相应的Type 1 dict键的运算符在表16中用注释表示。
表16私人DICT运营商
| Name | Value | Operand(s) | Default | Notes |
|---|---|---|---|---|
| BlueValues | 6 | delta | — | |
| OtherBlues | 7 | delta | — | |
| FamilyBlues | 8 | delta | — | |
| FamilyOtherBlues | 9 | delta | — | |
| BlueScale | 12 | 9 | number | 0.039625 |
| BlueShift | 12 | 10 | number | 7 |
| BlueFuzz | 12 | 11 | number | 1 |
| StdHW | 10 | number | — | |
| StdVW | 11 | number | — | |
| StemSnapH | 12 | 12 | delta | — |
| StemSnapV | 12 | 13 | delta | — |
| LanguageGroup | 12 | 17 | number | 0 |
| ExpansionFactor | 12 | 18 | number | 0.06 |
| vsindex | 22 | number | 0 | itemVariationData index in the VariationStore structure table. |
| blend | 23 | delta, numberOfBlends | — | Leaves numberOfBlends values on the operand stack. |
| Subrs | 19 | number | — | Offset to local subrs INDEX, from start of the Private DICT. |
本地子字节偏移量相对于私有DICT数据的开头。
OtherBlues和FamilyOtherBlues运算符必须分别在BlueValues和FamilyBlues运算符之后出现。
私有DICT是必需的,但如果没有要存储的非默认值,则可以指定为大小为0。
12. OpenType字体变体的扩展
为了支持 CFF2 表中的字形变体数据,以 CFF2 格式添加了三个新运算符:vsindex,blend和vstore。
变体字体保存表示几个不同设计变体的等效数据,并使用算法在这些设计之间进行插值或混合,以获得连续的设计实例。这允许整个字体系列由单个可变字体表示。例如,变体字体可以包含等同于来自族的Light和Heavy设计的数据,然后可以对其进行插值以导出Light和Heavy之间的连续范围内的任何权重的实例。
有关OpenType字体变体的一般背景,用于支持变体字体的表格的详细信息,术语以及用于混合值以导出特定设计实例的插值算法的规范,请参阅OpenType字体变体概述一章。
CFF2 格式的可变字体的轮廓数据的构建非常类似于将构建的非变体 CFF2 表,其结构和运算符与用于默认设计表示的结构和运算符完全相同。但是,在默认设计中出现值的任何地方,一个设计的单个值都会补充一组delta值,然后是混合运算符。(为了提高效率,单个混合运算符可以遵循一系列此类增量集,而不是在每个单独集之后。)与其他DICT运算符不同,混合在处理时不会清除堆栈。混合运算符的结果保留在堆栈中,由以下运算符处理。
在可变字体内,不同的字形可以使用不同的区域集合和相关的增量值来进行混合操作。处理给定的字形时,解释器必须确定要使用的集合。这些集存储在ItemVariationStore结构的 CFF2 表中。ItemVariationStore包含一个或多个ItemVariationData子表,每个子表包含一个变体区域列表。如果未指定其他子表,则默认使用第一个ItemVariationData子表(索引0)。当一组delta值需要除默认值以外的ItemVariationData子表时,将使用vsindex运算符。当在Private DICT中使用此运算符来设置非默认itemVariationData索引时,这将成为私有DICT的默认项变体数据索引,但也成为引用该私有DICT的所有CharStrings的默认项变体数据索引。当在CharString中使用vsindex运算符时,它将取代私有DICT中的任何vsindex。CFF2 表中的所有私有DICT和CharStrings共享相同的ItemVariationStore。
Font Variations的语法支持运算符。
vsindex
|- ivs vsindex (22) |-
选择要用于混合的ItemVariationData子表,ivs参数是ItemVariationData索引。使用时,vsindex必须位于混合运算符之前。
请注意,运算符代码22与等效的CharStrings运算符不同。此运算符仅可用于私有DICT。blend
num(0)…num(n-1), delta(0,0)…delta(k-1,0),
delta(0,1)…delta(k-1,1) … delta(0,n-1)…delta(k-1,n-1)
n blend (23) val(0)…val(n-1)
对于k个区域,从n *(k + 1)个操作数产生n个内插结果值。
请注意,运算符代码23与等效的CharStrings运算符不同。此运算符仅可用于私有DICT。vstore
|- offset vstore (24) |-
为 CFF2 表中的VariationStore数据提供偏移量。此运算符仅可用于Top DICT。VariationStore数据内容
VariationStore数据由两部分组成:指定长度的uint16字段,后跟指定长度的Item Variation Store结构。Item Variation Store格式在OpenType Font Variations Common Table Formats一章中指定。下面是 CFF2 表中使用的格式的简要说明。
为了支持字形或其他字体数据的变化,所使用的信息包括特定数据项的默认值,用于修改默认值的一组增量调整值,以及字体变体空间内的一组区域,不同的delta值适用。项目变体存储格式旨在容纳区域集和增量值。在 CFF2 表中,项目变体存储用于表示不同的区域,但增量值在使用它们的CharStrings内交错。
项目变体存储包含两个重要的列表。第一个列表是描述变体字体中使用的每个设计的变体空间中的影响区域的数据。其中每一个都称为变化区域。变体区域的整个列表称为变化区域列表。
第二个列表是ItemVariationData结构的数组,每个结构都指定一组变体区域,作为变体区域列表中的索引列表。这允许不同的字形具有适用于不同区域集的增量值。通常只有一个itemVariationData结构,因此只有一组区域被所有字形使用。如果需要多个区域集,则添加itemVariationData结构以定义每个集合。vsindex运算符可以在Private DICT中用于为引用Private DICT的所有字形设置itemVariationData索引,或者当CharString需要使用与Private DICT中指定的不同的ItemVariationData结构时,可以在特定的 CFF2 CharStrings中使用它。
CFF2 表中的变体存储结构的示例可以在附录A中看到。示例 CFF2 字体。
附录A示例CFF2字体
二进制转储(226字节):
0000: 02 00 05 00 07 CF 0C 24 C3 11 9B 18 00 00 00 00
0010: 00 26 00 01 00 00 00 0C 00 01 00 00 00 1C 00 01
0020: 00 02 C0 00 E0 00 00 00 C0 00 C0 00 E0 00 00 00
0030: 00 00 00 02 00 00 00 01 00 00 00 02 01 01 03 05
0040: 20 0A 20 0A 00 00 00 01 01 01 05 F7 06 DA 12 77
0050: 9F F8 6C 9D AE 9A F4 9A 95 9F B3 9F 8B 8B 8B 8B
0060: 85 9A 8B 8B 97 73 8B 8B 8C 80 8B 8B 8B 8D 8B 8B
0070: 8C 8A 8B 8B 97 17 06 FB 8E 95 86 9D 8B 8B 8D 17
0080: 07 77 9F F8 6D 9D AD 9A F3 9A 95 9F B3 9F 08 FB
0090: 8D 95 09 1E A0 37 5F 0C 09 8B 0C 0B C2 6E 9E 8C
00A0: 17 0A DB 57 F7 02 8C 17 0B B3 9A 77 9F 82 8A 8D
00B0: 17 0C 0C DB 95 57 F7 02 85 8B 8D 17 0C 0D F7 06
00C0: 13 00 00 00 01 01 01 1B BD BD EF 8C 10 8B 15 F8
00D0: 88 27 FB 5C 8C 10 06 F8 88 07 FC 88 EF F7 5C 8C
00E0: 10 06分析:
| Hex data | Source | Comments |
|---|---|---|
| Header | CFF2 offsets: 0000 to 0004 | |
| 02 | majorVersion | = 2 |
| 00 | minorVersion | = 0 |
| 05 | headerSize | = 5 |
| 00 07 | topDictSize | = 7 |
| Top DICT Data | CFF2 offsets: 0005 to 000B | |
| CF 0C 24 | |- offset FDArray |- | = 68 FDArray The bytes 0C 24 represent the FDArray operator. The operand byte is hex CF = decimal 207, which is decoded using the rule for byte values from 32 to 246 (see Table 3, Operand Encoding): b0 - 139. This gives the offset of the Font DICT INDEX: decimal 68 = hex 44. |
| C3 11 | |- offset CharStrings |- | = 56 CharStrings The byte 11 represents the CharStrings operator. The operand byte is hex C3, which is the encoded representation of the value 56. This gives the offset of the CharStrings INDEX: decimal 56 = hex 38. |
| 9B 18 | |- offset vstore |- | = 16 vstore The byte 18 represents the vstore operator. The operand byte is hex 9B, which is the encoded representation of the value 16. This gives the offset of the VariationStore Data: decimal 16 = hex 10. |
| Global Subr INDEX | CFF2 offsets: 000C to 000F | |
| 00 00 00 00 | count | = empty INDEX; no additional fields represented. |
| VariationStore Data | CFF2 offsets: 0010 to 0037 | |
| 00 26 | length | = 38 — length in bytes of the Item Variation Store structure that follows. |
| ItemVariationStore | CFF2 offsets: 0012 to 0037 | |
| 00 01 | format | = 1 |
| 00 00 00 0C | variationRegionListOffset | = 12 — offset in bytes from the start of the ItemVariationStore. |
| 00 01 | itemVariationDataCount | = 1 — number of ItemVariationData subtables. |
| 00 00 00 1C | itemVariationDataOffsets[0] | = 28 — offset in bytes from start of the ItemVariationStore to ItemVariationData subtable 0. |
| VariationRegionList | CFF2 offsets: 001E to 002D | |
| 00 01 | axisCount | = 1 |
| 00 02 | regionCount | = 2 |
| variationRegions[0] | CFF2 offsets: 0022 to 0027 | |
| regionAxes[0] | CFF2 offsets: 0022 to 0027 | |
| C0 00 | startCoord | = -1.0 (F2DOT14 value) |
| E0 00 | peakCoord | = -0.5 (F2DOT14 value) |
| 00 00 | endCoord | = 0.0 (F2DOT14 value) |
| variationRegions[1] | CFF2 offsets: 0028 to 002D | |
| regionAxes[0] | CFF2 offsets: 0028 to 002D | |
| C0 00 | startCoord | = -1.0 (F2DOT14 value) |
| C0 00 | peakCoord | = -1.0 (F2DOT14 value) |
| E0 00 | endCoord | = -0.5 (F2DOT14 value) |
| ItemVariationData subtable 0 | CFF2 offsets: 002E to 0037 | |
| 00 00 | itemCount | = 0 |
| 00 00 | shortDeltaCount | = 0 |
| 00 02 | regionIndexCount | = 2 |
| 00 00 00 01 | regionIndexes[] | = {0, 1} |
| CharStrings INDEX | CFF2 offsets: 0038 to 0043 | |
| 00 00 00 02 | count | = 2 |
| 01 | offSize | = 1 |
| 01 03 05 | offset[] | = {1, 3, 5} (number of elements is count + 1) |
| CharString 0 | CFF2 offsets: 0040 to 0041 | |
| 20 0A | |- subr# callsubr |- | = -107 callsubr The byte 0A represents the callsubr operator. The operand byte is 20, which is the encoded representation of the value -107. |
| CharString 1 | CFF2 offsets: 0042 to 0043 | |
| 20 0A | |- subr# callsubr |- | = -107 callsubr The byte 0A represents the callsubr operator. The operand byte is 20, which is the encoded representation of the value -107. |
| Font DICT INDEX | CFF2 offsets: 0044 to 004E | |
| 00 00 00 01 | count | = 1 |
| 01 | offSize | = 1 |
| 01 05 | offset[] | = {1, 5} (number of elements is count + 1) |
| Font DICT 0 | CFF2 offsets: 004B to 004E | |
| F7 06 DA 12 | |- size offset Private |- | = 114 79 Private The byte 12 represents the Private operator. The operand bytes F7 06 are the encoded representation of the value 114. The operand byte DA is the encoded representation of the value 79. This gives the size and offset of a Private DICT: size is 114 bytes, offset (from start of CFF2 table) is 79 bytes (hex 4F). |
| Private DICT | CFF2 offset: 004F to 00C0 | |
| 77 9F F8 6C 9D AE 9A F4 9A 95 9F B3 9F 8B 8B 8B 8B 85 9A 8B 8B 97 73 8B 8B 8C 80 8B 8B 8B 8D 8B 8B 8C 8A 8B 8B 97 17 06 | |- num* blend BlueValues |- | = -20 20 472 18 35 15 105 15 10 20 40 20 0 0 0 0 -6 15 0 0 12 -24 0 0 1 -11 0 0 0 2 0 0 1 -1 0 0 12 blend BlueValues The byte 06 represents the BlueValues operator. The byte 17 represents the blend operator. The operand bytes 77.. 97 are the encoded representation of the values -20… 12. |
| FB 8E 95 86 9D 8B 8B 8D 17 07 | |- num* blend OtherBlues |- | = -250 10 -5 18 0 0 2 blend OtherBlues The byte 07 represents the OtherBlues operator. The byte 17 represents the blend operator. The operand bytes FB.. 8D are the encoded representation of the values -250… 2. |
| 77 9F F8 6D 9D AD 9A F3 9A 95 9F B3 9F 08 | |- num* FamilyBlues |- | = -20 20 473 18 34 15 104 15 10 20 40 20 FamilyBlues The byte 08 represents the operator FamilyBlues. The operand bytes 77… 9F are the encoded representation of the values -20… 20. |
| FB 8D 95 09 | |- num* FamilyOtherBlues |- | = -249 10 FamilyOtherBlues The byte 09 represents the FamilyOtherBlues operator. The operand bytes FB 8D are the encoded representation of the value -249. The operand byte 95 is the encoded representation of the value 10. |
| 1E A0 37 5F 0C 09 | |- num BlueScale |- | = 0.0375 BlueScale The bytes 0C 09 represent the BlueScale operator. The operand bytes 1E A0 37 5F are the encoded representation of the value 0.0375. |
| 8B 0C 0B | |- num BlueFuzz |- | = 0 BlueFuzz. The bytes 0C 0B represents the BlueFuzz operator. The operand byte 8B is the encoded representation of the value 0. |
| C2 6E 9E 8C 17 0A | |- num* blend StdHW |- | = 55 -29 19 1 blend StdHW The byte 0A represents the StdHW operator. The byte 17 represents the blend operator. The operand bytes C2 6E 9E 8C are the encoded representation of the values 55 -29 |
| DB 57 F7 02 8C 17 0B | |- num* blend StdVW |- | = 80 -52 110 1 blend StdVW The byte 0B represents the StdVW operator. The byte 17 represents the blend operator. The operand bytes DB 57 F7 02 8C are the encoded representation of the values 80 -52 110 1. |
| B3 9A 77 9F 82 8A 8D 17 0C 0C | |- num* blend StemSnapH |- | = 40 15 -20 20 -9 -1 2 blend StemSnapH The bytes 0C 0C represent the StemSnapH operator. The byte 17 represents the blend operator. The operand bytes B3 9A 77 9F 82 8A 8D are the encoded representation of the values 40 15 -20 20 -9 -1 2. |
| DB 95 57 F7 02 85 8B 8D 17 0C 0D | |- num* blend StemSnapV |- | = 80 10 -52 110 -6 0 2 blend StemSnapV The bytes 0C 0D represent the StemSnapV operator. The byte 17 represents the blend operator. The operand bytes DB 95 57 F7 02 85 8B 8D are the encoded representation of the values 80 10 -52 110 -6 0 2. |
| F7 06 13 | |- num Subrs |- | = 114 Subrs The byte 13 represents the Subrs operator. The operand bytes F7 06 are the encoded representation of the value 114. This gives the offset (from the start of the Private DICT) to the local Subr INDEX: 114 bytes (hex 72). |
| Local Subr INDEX | CFF2 offsets: 00C1 to 00E1 | |
| 00 00 00 01 | count | = 1 |
| 01 | offSize | = 1 |
| 01 1B | offset[] | = {1, 27} (number of elements is count + 1) |
| subr 0 | CFF2 offsets: 00C8 to 00E1 | |
| BD BD EF 8C 10 8B 15 | |- num* blend num rmoveto |- | = 50 50 100 1 blend 0 rmoveto The byte 15 represents the rmoveto CharString operator. The byte 10 represents the blend CharString operator. The operand bytes BD BD EF 8C are the encoded representation of the values 50 50 100 1. The operand byte 8B is the encoded representation of the value 0. |
| F8 88 27 FB 5C 8C 10 06 | |- num* blend hlineto |- | = 500 -100 -200 1 blend hlineto The byte 06 represents the hlineto CharString operator. The byte 10 represents the blend CharString operator. The operand bytes F8 88 27 FB 5C 8C are the encoded representation of the values 500 -100 -200 1. |
| F8 88 07 | |- num vlineto |- | = 500 vlineto The byte 07 represents the vlineto CharString operator. The operand bytes F8 88 are the encoded representation of the value 500. |
| FC 88 EF F7 5C 8C 10 06 | |- num* blend hlineto |- | = -500 100 200 1 blend hlineto The byte 06 represents the hlineto CharString operator. The byte 10 represents the blend CharString operator. The operand bytes FC 88 EF F7 5C 8C are the encoded representation of the values -500 100 200 1. |
附录B相关文档
有关Adobe字体技术的更多信息,可以参考以下文档。所有这些都可以在Adobe Font Technical Notes中找到。
- 紧凑字体格式规范#5176
- Type 2 CharString格式#5177
- 使用OpenType字体变体生成字体的PostScript名称#5902
附录C CFF2 DICT编码
表17单字节 CFF2 DICT运算符
| Dec | Hex | Operator | Note |
|---|---|---|---|
| 0 to 5 | 00 to 05 | <reserved> | |
| 6 | 06 | BlueValues | |
| 7 | 07 | OtherBlues | |
| 8 | 08 | FamilyBlues | |
| 9 | 09 | FamilyOtherBlues | |
| 10 | 0a | StdHW | |
| 11 | 0b | StdVW | |
| 12 | 0c | escape | First byte of a 2-byte operator. |
| 13 to 16 | 0d to 10 | <reserved> | |
| 17 | 11 | CharStrings | |
| 18 | 12 | Private | |
| 19 | 13 | Subrs | |
| 20 to 21 | 14 to 15 | <reserved> | |
| 22 | 16 | vsindex | |
| 23 | 17 | blend | |
| 24 | 18 | vstore | |
| 25 to 27 | 19 to 1b | <reserved> | |
| 28 | 1c | <numbers> | First byte of a 3-byte sequence specifying a signed integer value (following two bytes are an int16). |
| 29 | 1d | <numbers> | First byte of a 5-byte sequence specifying a signed integer value (following four bytes are an int32). |
| 30 | 1e | BCD | |
| 31 | 1f | <reserved> | |
| 32 to 246 | 20 to f6 | <numbers> | |
| 247 to 254 | f7 to fe | <numbers> | First byte of a 2-byte sequence specifying a number. |
| 255 | ff | <reserved> |
注意:操作员代码25(0x19)先前已被指定为maxstack运算符。这在 [CFF2](#table-CFF2) 字体中从不需要,不再受支持。表18双字节 CFF2 DICT运算符
| Dec | Hex | Operator |
|---|---|---|
| 12 0 to 12 6 | 0c 00 to 0c 06 | <reserved> |
| 12 7 | 0c 07 | FontMatrix |
| 12 8 | 0c 08 | <reserved> |
| 12 9 | 0c 09 | BlueScale |
| 12 10 | 0c 0a | BlueShift |
| 12 11 | 0c 0b | BlueFuzz |
| 12 12 | 0c 0c | StemSnapH |
| 12 13 | 0c 0d | StemSnapV |
| 12 14 to 12 16 | 0c 0e to 0c 10 | <reserved> |
| 12 17 | 0c 11 | LanguageGroup |
| 12 18 | 0c 12 | ExpansionFactor |
| 12 19 to 12 35 | 0c 13 to 0c 23 | <reserved> |
| 12 36 | 0c 24 | FDArray |
| 12 37 | 0c 25 | FDSelect |
| 12 38 to 12 255 | 0c 26 to 0c ff | <reserved> |
注意:FontMatrix运算符在Top DICT中有效,但不推荐在Font DICT中使用。附录D来自CFF 1.0的变化
D1.表名和版本
具有 CFF2 字体数据的字体必须使用表标记 CFF2,并且表主要版本必须设置为2。
D2.DICT布局
从 CFF2 表中删除以下CFF 1.0表:
- 名称索引。CFF2 表不包含PostScript名称。此外,CFF2 格式不支持FontSet。从 CFF2 表创建CFF 1.0实例快照时,可以从“名称”表中的名称ID 6值复制PostScript字体名称。对于可变字体,必须通过为变体字体指定的启发式和 fvar 和 STAT 表中的信息来导出。请参阅Adobe技术说明5902,使用OpenType字体变体进行字体的PostScript名称生成#5902。
- 热门DICT指数。由于 CFF2 格式不支持FontSets,因此只能有一个Top DICT。
- 字符串表。如果需要,可以在 post 表中提供字形名称。
- 编码表。CFF2 表仅从 cmap 表中获取编码信息。
- Charset表。不再使用了。字形标识符来自 post 表。
INDEX的count字段是uint32而不是uint16。
CFF2 报头与CFF 1.0报头的不同之处在于第4个字段现在表示Top DICT数据结构的长度。有关详细信息,请参见第6节“标题”。
顶部DICT数据在标题数据之后立即开始。CFF2 格式的固定数据布局顺序为:
- 头
- 热门DICT数据
- Global Subr INDEX
以下INDEX表由TopDICT或Private DICT中指定的偏移量访问:
- FDSelect
- CharStrings INDEX
- VariationStore Data
- Font DICT INDEX
- Private DICT
- Local Subrs INDEX
D3.热门DICT数据
Top DICT不直接引用私人DICT。相反,它使用FDArray运算符来引用始终存在的Font DICT INDEX。Font DICT INDEX将始终包含至少一个Font DICT。如果Font DICT INDEX包含多个Font DICT,则Top DICT还必须引用FDSelect结构。
添加了一个新的Top DICT运营商:vstore。有关详细信息,请参见第12节“OpenType字体变体的扩展”。
可以从其他OpenType表派生或不再使用的顶级DICT运算符都已从 CFF2 格式规范中删除。在 CFF2 表中使用这些运算符无效,如果遇到,必须忽略它们。
CFF2 表中允许的唯一CFF 1 Top DICT运算符如下:
- FontMatrix (12 7) array
- CharStrings (17) offset
- FDArray (12 36) offset
- FDSelect (12 37) offset
下表列出了 CFF2 中不支持的CFF 1 Top DICT运算符,以及 CFF2 字体中替代机制的详细信息:
表19 CFF 1中未使用的CFF 1顶部DICT运算符
| Name | Code (decimal) | CFF2 equivalent |
|---|---|---|
| version | 0 | Equivalent to the fontRevision field in the head table. A CFF 1 version operand can be derived from the fontRevision field, which is a 16.16 Fixed value, and formatting it as a decimal number with three decimal places of precision. |
| Notice | 1 | Equivalent to the concatenation of strings from the ‘name’ table: the Copyright string (name ID 0), a space, followed by the Trademark string (name ID 7). |
| FullName | 2 | Equivalent to the Full Name string (name ID 4) in the ‘name’ table. |
| FamilyName | 3 | Equivalent to the Typographic Family Name string (name ID 16) in the ‘name’ table, if present, else the Famly Name string (name ID 1). |
| Weight | 4 | Equivalent to the usWeightClass field in the OS/2 table. |
| FontBBox | 5 | Approximately equivalent to the combination of the xMin, xMax, yMin and yMax fields in the head table. These will be only approximate, as they will be for the default value only, but are accurate enough if deriving values for CFF 1 interpreters. Some interpreters use these values to influence the hints for global coloring, and some use this to set flattening parameters. |
| Copyright | 12 0 | Equivalent to the Copyright string (name ID 0) in the ‘name’ table. |
| IsFixedPitch | 12 1 | Equivalent to the isFixedPitch field in the post table. |
| ItalicAngle | 12 2 | Equivalent to the italicAngle field in the post table. |
| UnderlinePosition | 12 3 | Equivalent to the underlinePosition field in the post table. |
| UnderlineThickness | 12 4 | Equivalent to the underlineThickness field in the post table. |
| PaintType | 12 5 | There is no equivalent in a CFF2 font. If deriving CFF 1-compatible data, use the CFF 1 default value of zero. |
| StrokeWidth | 12 8 | There is no equivalent in a CFF2 font. In a CFF 1 font, it is used only for PaintType 2. If deriving CFF 1-compatible data, PaintType 0 should be used. |
| SyntheticBase | 12 20 | There is no equivalent in a CFF2 font. |
| PostScript | 12 21 | There is no equivalent in a CFF2 font. CFF 1 allowed for embedded PostScript code, but this was only ever used in CFF 1 OpenType fonts to provide an FSType key in the Top DICT, to carry the font embedding permissions from the fsType field of the OS/2 table. If deriving CFF 1-compatible data, the value can be copied from the OS/2 table. |
| BaseFontName | 12 22 | There is no equivalent in a CFF2 font. |
| BaseFontBlend | 12 23 | There is no equivalent in a CFF2 font. |
| ROS | 12 30 | There is no equivalent in a CFF2 font. If generating CFF 1-compatible font instance from a CFF2 variable font that has more than one Font DICT in the Font DICT INDEX, the CFF 1 font must be written as a CID-keyed font. The ROS used should be Adobe-Identity-0. This maps all glyph IDs to a CID of the same value and carries no semantic content. |
| CIDFontVersion | 12 31 | There is no equivalent in a CFF2 font. If deriving CFF 1-compatible data, use the CFF 1 default value of zero. |
| CIFFontRevision | 12 32 | There is no equivalent in a CFF2 font. If deriving CFF 1-compatible data, use the CFF 1 default value of zero. |
| CIDFontType | 12 33 | There is no equivalent in a CFF2 font. If deriving CFF 1-compatible data, use the CFF 1 default value of zero. |
| CIDCount | 12 34 | Equivalent to the numGlyphs field in the ‘maxp’ table. |
| UIDBase | 12 35 | No longer required — see comments on UniqueID. |
| UniqueID | 13 | No longer required: This was originally used for caching fonts in printers. However, many third-party fonts with conflicting UnicodeID values have made it unreliable. More importantly, performance tests have shown that font caching no longer provides significant performance improvements when printing. |
| XUID | 14 | No longer required — see comments on UniqueID. |
| charset | 15 | If required, glyph names can be represented in a version 2.0 post table. |
| Encoding | 16 | Equivalent to the ‘cmap’ table. |
| Private | 18 | No longer required: In a CFF2 font, a Private DICT is always referenced from a Font DICT in the Font DICT INDEX. |
D4.私人DICT数据
添加了两个可以在私人DICT中使用的新运营商:vsindex和blend。
在 CFF2 中不使用不再使用的私有DICT运算符或在其他OpenType表中具有现有等价物的私有DICT运算符。在 CFF2 表中使用这些运算符无效,如果遇到,必须忽略它们。下表列出了 CFF2 中不支持的CFF 1 Private DICT运算符,以及 CFF2 字体中替代机制的详细信息:
表20 CFF 1未在 CFF2 中使用的私有DICT运算符
| Name | Code (decimal) | CFF2 equivalent |
|---|---|---|
| defaultWidthX | (20) | Horizontal glyph metrics for CharStrings in a CFF2 table are obtained from the ‘hmtx’ and HVAR tables |
| nominalWidthX | (21) | Horizontal glyph metrics for CharStrings in a CFF2 table are obtained from the ‘hmtx’ and HVAR tables |
附录E早期版本以来的变化
自OpenType 1.8首次发布以来,已进行了以下更改和修订。
首次发布:OpenType 1.8(2016年9月)。请参阅附录D,来自CFF 1.0的更改。
OpenType 1.8.1(2017年1月):
数据类型Card8,Card16和Card32被uint8,uint16和uint32替换,以匹配OpenType规范其余部分的用法。
对FontSets的所有引用都被删除或重写(CFF2 中不支持FontSet)。
在表2中,CFF2 数据类型,为uint32添加了一个条目。
在第4节DICT数据中,修改了操作数和运算符的描述,并更正了表引用。
在第4节“操作数类型”的表6中,删除了布尔类型(未在 CFF2 中使用)。
在第5节“INDEX数据”中,空INDEX的大小被更正为4个字节。
在第7节“Top DICT数据”中,添加了最大堆栈深度的允许范围,以及它仅影响Private DICT和 CFF2 CharString运算符的堆栈深度的说明。
第8节“雕文组织”合并到以下部分。
在第8节(之前的第9节)中,CharStrings INDEX文本被重新编写以便更清晰,并添加了关于字形名称和字形ID的段落。
在第9节(之前的第10节),本地和全球子索引,文本进行了重新措辞,以便更清晰,并删除了从次级数偏差节省空间的详细讨论。
在第10节(以前的第11节)中,字体DICT INDEX,字体DICT和FDSelect,文字被重新编写以便更清晰;添加了一个注释,字体DICT INDEX可以包含超过256个字体DICT;哨兵雕文ID的描述已经恢复;并且删除了对FontName的引用(此CFF 1运算符未在 CFF2 中使用)。
在第11节(先前的第12节),私人DICT数据中,删除了关于提前宽度的段落。
在第12节(之前的第13节)中,混合运算符示例被替换为对“CFF2 CharString格式”一章4.5节中提供的示例的引用。
在附录A,示例 CFF2 字体中,添加了 CFF2 字体数据的示例。
在附录C,CFF2 DICT编码中,进行了格式化更改。
在附录D中,对CFF 1.0的更改,文本在各个地方进行了重写。
在附录D,DICT布局的D2部分中,添加了关于INDEX计数字段类型的注释,并更正了表引用。
在附录D的D3部分中,Top DICT Data,CharStringType已从支持的运算符列表中删除,并添加了有关支持的运算符的详细信息。此外,在CFF 1 ROS运算符的描述中,“Adobe-Identity-1”被改变为“Adobe-Identity-0”。还进行了其他格式更改。
在附录D的D4部分中,从 CFF2 中未使用的CFF 1运算符列表中删除了ForceBold和initialRandomSeed,并进行了其他格式更改。
删除了附录D的D5部分,CharString数据以及D6部分外部表格。
对术语的一致性进行了许多改变,例如一致的大写和“CharString”,“VariationStore”,CFF2 的拼写,以及使用“Font DICT INDEX”,其中它比“FDArray”更合适。OpenType 1.8.2(2017年7月):
有限使用Top DICT FontMatrix运算符(第7节),并且不推荐使用Font DICT FontMatrix运算符(第10节,附录C)。
修正了保留的双字节DICT运算符的数值范围内的错误(附录C)。
删除了maxstack运算符。(无意中引入了第一个 CFF2 规范,但从未被要求过。)
编辑修订。
7.7.cmap 字形到字形索引映射表
7.7.1.概览
此表定义了字符代码到默认字形索引的映射。可以定义不同的子表,每个子表包含用于不同字符编码方案的映射。表头表示子表存在的字符编码。
无论编码方案如何,与字体中任何字形不对应的字符代码都应映射到字形索引0.此位置的字形必须是表示缺少字符的特殊字形,通常称为.notdef。
每个子表格都采用七种可能的格式之一,并以指示所用格式的格式字段开头。前两种格式 - 格式0,2,4和6 - 最初是在Unicode 2.0之前定义的。这些格式允许8位单字节,8位多字节和16位编码。随着Unicode 2.0中补充平面的引入,Unicode可寻址代码空间扩展到16位以上。为了适应这种情况,增加了三种额外的格式 - 格式8,10和12 - 允许32位编码方案。
Unicode中的其他增强功能导致添加其他子表格格式。子表格式13允许将许多字符有效地映射到单个字形;这对于“最后的”字体非常有用,它为所有可能的Unicode字符提供后备渲染,并为不同的Unicode范围提供不同的后备字形。子表格式14提供了支持Unicode变体序列的统一机制。
注意:对于使用较新子表格式的字体,cmap 表版本号保持为0x0000。7.7.2.cmap 头
字符到字形索引映射表的组织如下:
| Type | Name | Description |
|---|---|---|
| uint16 | version | Table version number (0). |
| uint16 | numTables | Number of encoding tables that follow. |
| EncodingRecord | encodingRecords[numTables] |
7.7.3.编码记录和编码
编码记录数组指定特定编码以及每个编码的子表的偏移量。
EncodingRecord:
| Type | Name | Description |
|---|---|---|
| uint16 | platformID | Platform ID. |
| uint16 | encodingID | Platform-specific encoding ID. |
| Offset32 | offset | Byte offset from beginning of table to the subtable for this encoding. |
编码记录中的 Platform ID 和特定于平台的 Encoding ID 用于指定特定的字符编码。 对于Macintosh平台,映射子表中的语言字段也用于此目的。
cmap 标头中的编码记录条目必须首先按 Platform ID 排序,然后按平台特定的 Encoding ID 排序,然后按相应子表中的语言字段排序。 每个 Platform ID,特定于平台的 Encoding ID 和子表格语言组合可能只在 cmap 表中出现一次。
Unicode平台(Platform ID = 0)
字体支持的Unicode变体序列应使用格式14子表在 cmap 表中指定。 格式14子表必须仅在 Platform ID 0和 Encoding ID 5下使用。
Macintosh平台(Platform ID = 1)
构建将在Macintosh上使用的字体时,Platform ID 应为1,Encoding ID 应为0。
Windows平台(Platform ID = 3)
为Windows构建Unicode字体时,Platform ID 应为3,Encoding ID 应为1.为Windows构建符号字体时,Platform ID 应为3,Encoding ID 应为0。
Microsoft强烈建议对所有字体使用 Unicode cmap 子表。 但是,其他非Unicode编码也会在Windows平台的现有字体中使用。 以下是为Windows平台定义的 Encoding ID:
Windows编码
| Platform ID | Encoding ID | Description |
|---|---|---|
| 3 | 0 | Symbol |
| 3 | 1 | Unicode BMP |
| 3 | 2 | ShiftJIS |
| 3 | 3 | PRC |
| 3 | 4 | Big5 |
| 3 | 5 | Wansung |
| 3 | 6 | Johab |
| 3 | 7 | Reserved |
| 3 | 8 | Reserved |
| 3 | 9 | Reserved |
| 3 | 10 | Unicode full repertoire |
为Windows构建符号字体时,Platform ID 应为3,Encoding ID 应为0。
在Windows平台上支持Unicode BMP字符(U + 0000到U + FFFF)的字体必须具有格式4 cmap 子表,用于 Platform ID 3,平台特定编码1。
在Windows平台上支持Unicode辅助平面字符(U + 10000到U + 10FFFF)的字体必须具有12个子格式,用于 Platform ID 3,Encoding ID 10.为了确保与旧软件和设备的向后兼容,格式4子表格 对于 Platform ID 3,还需要 Encoding ID 1。 格式4子表格中支持的字符必须是12子表格格式中字符的子集,并且应包括字体支持的所有Unicode BMP字符。
自定义 Platform(Platform ID = 4)和OTF Windows NT兼容性映射
如果具有CFF轮廓的OpenType字体中存在 Platform ID 4(自定义),Encoding ID 0-255(OTF Windows NT兼容性映射) cmap 编码,则Windows NT中的OTF字体驱动程序将:(a)叠加在相应的Windows ANSI(代码页1252)的编码中以字符代码0-255编码的字形,以Unicode编码的Unicode值报告给系统; (b)将Windows ANSI(CharSet 0)添加到字体支持的CharSets列表中; (c)将编码ID的值视为Windows CharSet值,并将其添加到字体支持的CharSet列表中。注意:cmap 子表必须使用格式0或6作为其子表,并且编码必须与CFF的编码相同。
这种 cmap 编码不是必需的。它为使用该字体的非Unicode应用程序提供兼容机制,就像它是Windows ANSI编码一样。 Adobe发布的非Windows ANSI Type 1字体(如西里尔字体和中欧字体)在.PFM文件的CharSet字段中记录的“0”(Windows ANSI);用于Windows 9x的ATM完全忽略了CharSet。 Adobe在从Type1字体转换的每个OTF中提供此兼容性 cmap 编码,其中Encoding不是StandardEncoding。
7.7.4.使用 cmap 子表中的语言字段
对于 Platform ID 不是Macintosh(Platform ID 1)的所有 cmap 子表,语言字段必须设置为零。 对于 Platform ID 为Macintosh的 cmap 子表,将此字段设置为 cmap 子表的Macintosh语言ID加1,如果 cmap 子表不是特定于语言,则设置为零。 例如,Mac OS土耳其语 cmap 子表必须将此字段设置为18,因为土耳其语的Macintosh语言ID为17.Mac OS Roman cmap 子表必须将此字段设置为0,因为Mac OS Roman不是 语言特定的编码。
7.7.5.格式0:字节编码表
这是标准符号映射表的Apple标准字符。
cmap Subtable Format 0:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Format number is set to 0. |
| uint16 | length | This is the length in bytes of the subtable. |
| uint16 | language | For requirements on use of the language field, see “Use of the language field in cmap subtables” in this document. |
| uint8 | glyphIdArray[256] | An array that maps character codes to glyph index values. |
这是字符代码到字形索引的简单1对1映射。 字形集限制为256.请注意,如果使用此格式索引更大的字形集,则只能访问前256个字形。
7.7.6.格式2:通过表格的高字节映射
此子表对于用于日语,中文和韩语字符的国家字符代码标准非常有用。 这些代码标准使用混合的8/16位编码,其中某些字节值表示2字节字符的第一个字节(但这些值也是合法的2字节字符的第二个字节)。
此外,即使对于2字节字符,字符代码到字形索引值的映射在很大程度上取决于第一个字节。 因此,该表以一个数组开始,该数组将第一个字节映射到SubHeader记录。 对于2字节字符代码,SubHeader用于通过subArray映射第二个字节的值,如下所述。 处理混合的8/16位文本时,SubHeader 0是特殊的:它用于单字节字符代码。 当使用SubHeader 0时,不需要第二个字节; 单字节值通过subArray映射。
cmap Subtable Format 2:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Format number is set to 2. |
| uint16 | length | This is the length in bytes of the subtable. |
| uint16 | language | For requirements on use of the language field, see “Use of the language field in cmap subtables” in this document. |
| uint16 | subHeaderKeys[256] | Array that maps high bytes to subHeaders: value is subHeader index × 8. |
| SubHeader | subHeaders[] | Variable-length array of SubHeader records. |
| uint16 | glyphIndexArray[] | Variable-length array containing subarrays used for mapping the low byte of 2-byte characters. |
SubHeader的结构如下:
| Type | Name | Description |
|---|---|---|
| uint16 | firstCode | First valid low byte for this SubHeader. |
| uint16 | entryCount | Number of valid low bytes for this SubHeader. |
| int16 | idDelta | See text below. |
| uint16 | idRangeOffset | See text below. |
895/5000
firstCode和entryCount值指定从firstCode开始并且长度等于entryCount值的子范围。 该子范围保持在被映射字节的0-255范围内。 此子范围之外的字节映射到字形索引0(缺少字形)。然后,此子范围内字节的偏移量将用作glyphIndexArray的相应子数组的索引。 此子阵列的长度也为entryCount。 idRangeOffset的值是idRangeOffset字的实际位置之后的字节数,其中出现与firstCode对应的glyphIndexArray元素。
最后,如果从子数组获得的值不是0(表示缺少的字形),则应该向其添加idDelta以获取glyphIndex。 值idDelta允许将相同的子数组用于多个不同的子头。 idDelta算术的模数为65536。
7.7.7.格式4:段映射到增量值
这是Windows平台的标准字符到字形索引映射表,用于支持Unicode BMP字符的字体。
当字体表示的字符的字符代码落入几个连续的范围时,使用此格式,可能在某些或所有范围中有孔(即,某个范围中的某些代码可能没有字体中的表示形式)。 格式相关的数据分为三个部分,必须按以下顺序进行:
- 四字标题为分段列表的优化搜索提供参数;
- 四个并行阵列描述了段(每个连续代码范围的一个段);
- 可变长度的字形ID数组(无符号字)。
cmap Subtable Format 4:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Format number is set to 4. |
| uint16 | length | This is the length in bytes of the subtable. |
| uint16 | language | For requirements on use of the language field, see “Use of the language field in cmap subtables” in this document. |
| uint16 | segCountX2 | 2 × segCount. |
| uint16 | searchRange | 2 × (2**floor(log2(segCount))) |
| uint16 | entrySelector | log2(searchRange/2) |
| uint16 | rangeShift | 2 × segCount - searchRange |
| uint16 | endCode[segCount] | End characterCode for each segment, last=0xFFFF. |
| uint16 | reservedPad | Set to 0. |
| uint16 | startCode[segCount] | Start character code for each segment. |
| int16 | idDelta[segCount] | Delta for all character codes in segment. |
| uint16 | idRangeOffset[segCount] | Offsets into glyphIdArray or 0 |
| uint16 | glyphIdArray[] | Glyph index array (arbitrary length) |
段数由segCount指定,该段未明确显示在标题中,但是,所有的头参数都是从它派生的。 searchRange值是2的最大幂的两倍,小于或等于segCount。 例如,如果segCount = 39,我们有以下内容:
| segCountX2 | 78 |
| searchRange | 64 (= 2 × largest power of 2 <=39) |
| entrySelector | 5 (= log232) |
| rangeShift | 14 (= 2 × 39 - 64) |
每个段由startCode和endCode以及idDelta和idRangeOffset描述,这些idDelta和idRangeOffset用于映射段中的字符代码。段按照endCode值增加的顺序排序,段值在四个并行数组中指定。您搜索第一个大于或等于要映射的字符代码的endCode。如果相应的startCode小于或等于字符代码,则使用相应的idDelta和idRangeOffset将字符代码映射到字形索引(否则,返回missingGlyph)。对于要终止的搜索,最终的起始码和endCode值必须为0xFFFF。该段不需要包含任何有效映射。 (它只能将单个字符代码0xFFFF映射到missingGlyph)。但是,该段必须存在。
如果段的idRangeOffset值不为0,则字符代码的映射依赖于glyphIdArray。从startCode偏移的字符代码将添加到idRangeOffset值。此总和用作idRangeOffset本身内当前位置的偏移量,以索引正确的glyphIdArray值。这种模糊的索引技巧有效,因为glyphIdArray紧跟在字体文件中的idRangeOffset之后。产生字形索引的C表达式是:
1 | glyphId = *(idRangeOffset[i]/2 + (c - startCount[i]) + &idRangeOffset[i]) |
值c是有问题的字符代码,i是出现c的段索引。 如果从索引操作获得的值不是0(表示missingGlyph),则将idDelta [i]添加到其中以获取字形索引。 idDelta算术的模数为65536。
如果idRangeOffset为0,则将idDelta值直接添加到字符代码偏移量(即idDelta [i] + c)以获得相应的字形索引。 同样,idDelta算术模数为65536。
例如,将字符10-20,30-90和153-480映射到连续范围的字形索引上的表的变体部分可能如下所示:
| segCountX2: | 8 |
| searchRange: | 8 |
| entrySelector: | 4 |
| rangeShift: | 0 |
| endCode: | 20 90 480 0xffff |
| reservedPad: | 0 |
| startCode: | 10 30 153 0xffff |
| idDelta: | -9 -18 -27 1 |
| idRangeOffset: | 0 0 0 0 |
此表执行以下映射:
10 ⇒ 10 - 9 = 1
20 ⇒ 20 - 9 = 11
30 ⇒ 30 - 18 = 12
90 ⇒ 90 - 18 = 72
...请注意,可以重新设计增量值,以便重新排序段。
7.7.8.格式6:修剪表格映射
‘cmap’ Subtable Format 6:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Format number is set to 6. |
| uint16 | length | This is the length in bytes of the subtable. |
| uint16 | language | For requirements on use of the language field, see “Use of the language field in ‘cmap’ subtables” in this document. |
| uint16 | firstCode | First character code of subrange. |
| uint16 | entryCount | Number of character codes in subrange. |
| uint16 | glyphIdArray[entryCount] | Array of glyph index values for character codes in the range. |
firstCode和entryCount值指定可能的字符代码范围内的子范围(从firstCode开始,length = entryCount)。 该子范围之外的代码被映射到字形索引0.该子范围内的代码(来自第一代码)的偏移量被用作glyphIdArray的索引,其提供字形索引值。
7.7.9.格式8:混合16位和32位覆盖
格式8类似于格式2,因为它提供了混合长度的字符代码。但是,它不允许使用8位和16位字符代码,而是允许使用16位和32位字符代码。
如果字体包含Unicode辅助平面字符(U + 10000到U + 10FFFF),那么它也可能包含Unicode BMP字符(U + 0000到U + FFFF)。因此,需要映射16位和32位字符代码的混合。进行了简化的假设:即,没有32位字符代码与任何16位字符代码共享相同的前16位。 (由于Unicode代码空间仅扩展到U + 1FFFFF,因此仅对字符U + 0000到U + 001F存在潜在冲突,这些字符是非打印控制字符。)这意味着确定是否为特定的16位value是一个独立的字符代码,或者可以通过直接查看16位值来创建32位字符代码的开头,而无需进一步的信息。
‘cmap’ Subtable Format 8:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Subtable format; set to 8. |
| uint16 | reserved | Reserved; set to 0 |
| uint32 | length | Byte length of this subtable (including the header) |
| uint32 | language | For requirements on use of the language field, see “Use of the language field in ‘cmap’ subtables” in this document. |
| uint8 is32[8192] | Tightly packed array of bits (8K bytes total) indicating whether the particular 16-bit (index) value is the start of a 32-bit | character code |
| uint32 | numGroups | Number of groupings which follow |
| SequentialMapGroup | groups[numGroups] | Array of SequentialMapGroup records. |
每个连续映射组记录指定字符范围和从第一个字符映射的起始字形ID。 后续字符的字形ID按顺序进行。
SequentialMapGroup Record:
| Type | Name | Description |
|---|---|---|
| uint32 | startCharCode | First character code in this group; note that if this group is for one or more 16-bit character codes (which is determined from the is32 array), this 32-bit value will have the high 16-bits set to zero |
| uint32 | endCharCode | Last character code in this group; same condition as listed above for the startCharCode |
| uint32 | startGlyphID | Glyph index corresponding to the starting character code |
这里有几点说明。使用endCharCode而不是计数,因为组匹配的比较通常在现有字符代码上完成,并且endCharCode明确地保存了每组添加的必要性。必须通过增加startCharCode对组进行排序。组的endCharCode必须小于以下组的startCharCode(如果有)。
要确定特定字(cp)是否是32位代码点的前半部分,可以使用诸如(is32 [cp / 8]&(1 <<(7 - (cp%8)))之类的表达式。如果这不是零,则该字是32位代码点的前半部分。
0不是32位代码点的高位字的特殊值。字体可能不具有代码点0x0000的字形和具有高字0x0000的代码点的字形。
即使字体不包含特定16位起始值的字形,指示特定16位值是否是32位字符代码的开头的打包数组的存在也是有用的。这是因为系统软件通常需要知道下一个字符开始前面有多少字节,即使当前字符映射到缺少的字形。通过在此表中明确地包含此信息,不需要将“秘密”知识编码到OS中。
尽管创建此格式是为了支持Unicode补充平面字符,但它并未得到广泛支持或使用。此外,除Unicode之外的任何字符编码都不使用混合的16/32位字符。不鼓励使用这种格式。
7.7.10.格式10:修剪数组
格式10类似于格式6,因为它为紧密范围的字符代码定义了一个修剪过的数组。 然而,它的不同之处在于使用32位字符代码:
‘cmap’ Subtable Format 10:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Subtable format; set to 10. |
| uint16 | reserved | Reserved; set to 0 |
| uint32 | length | Byte length of this subtable (including the header) |
| uint32 | language | For requirements on use of the language field, see “Use of the language field in ‘cmap’ subtables” in this document. |
| uint32 | startCharCode | First character code covered |
| uint32 | numChars | Number of character codes covered |
| uint16 | glyphs[] | Array of glyph indices for the character codes covered |
此格式未得到广泛使用,并且不受Microsoft支持。 它最适合仅支持连续范围的Unicode辅助平面字符的字体,但这种字体很少见。
7.7.11.格式12:分段覆盖
这是Windows平台的标准字符到字形索引映射表,用于支持Unicode辅助平面字符(U + 10000到U + 10FFFF)的字体。 有关Windows平台上Unicode编码的子表格式的更多详细信息,请参阅上面的Windows平台(平台ID = 3)。
格式12类似于格式4,因为它定义了稀疏表示的段。 然而,它的不同之处在于它使用32位字符代码。
‘cmap’ Subtable Format 12:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Subtable format; set to 12. |
| uint16 | reserved | Reserved; set to 0 |
| uint32 | length | Byte length of this subtable (including the header) |
| uint32 | language | For requirements on use of the language field, see “Use of the language field in ‘cmap’ subtables” in this document. |
| uint32 | numGroups | Number of groupings which follow |
| SequentialMapGroup | groups[numGroups] Array of SequentialMapGroup records. |
顺序映射组记录的格式与格式8子表的格式相同。 但是,关于16位字符代码的资格不适用,因为字符代码统一为32位。
SequentialMapGroup Record:
| Type | Name | Description |
|---|---|---|
| uint32 | startCharCode | First character code in this group |
| uint32 | endCharCode | Last character code in this group |
| uint32 | startGlyphID | Glyph index corresponding to the starting character code |
必须通过增加startCharCode对组进行排序。 组的endCharCode必须小于以下组的startCharCode(如果有)。 使用endCharCode而不是计数,因为组匹配的比较通常在现有字符代码上完成,并且endCharCode明确地保存了每组添加的必要性。
7.7.12.格式13:多对一范围映射
该子表提供了相同的字形用于跨越代码空间的多个范围的数百甚至数千个连续字符的情况。 该子表格格式对于“最后的”字体可能是有用的,尽管这些字体也可以使用其他合适的子表格格式。 (对于“最后的”字体,另请参阅’head’表格标志,位14。)
注意:子表格式13与格式12具有相同的结构; 它仅在startGlyphID / glyphID字段的解释上有所不同。‘cmap’ Subtable Format 13:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Subtable format; set to 13. |
| uint16 | reserved | Reserved; set to 0 |
| uint32 | length | Byte length of this subtable (including the header) |
| uint32 | language | For requirements on use of the language field, see “Use of the language field in ‘cmap’ subtables” in this document. |
| uint32 | numGroups | Number of groupings which follow |
| ConstantMapGroup | groups[numGroups] Array of ConstantMapGroup records. |
常量映射组记录具有与顺序映射组记录相同的结构,具有开始和结束字符代码以及映射的字形ID。 但是,相同的字形ID适用于指定范围内的所有字符,而不是顺序字形ID。
ConstantMapGroup Record:
| Type | Name | Description |
|---|---|---|
| uint32 | startCharCode | First character code in this group |
| uint32 | endCharCode | Last character code in this group |
| uint32 | glyphID | Glyph index to be used for all the characters in the group’s range. |
7.7.13.格式14:Unicode变体序列
子表格式14指定字体支持的Unicode变体序列(UVSes)。 根据Unicode标准,变体序列包括基本字符,后跟变体选择器。 例如,<U + 82A6,U + E0101>。
子表将字体支持的UVSes分为两类:“默认”和“非默认”UVSes。 给定UVS,如果通过在Unicode’cmap’子表中查找该序列的基本字符(即BMP子表或BMP +补充平面子表)获得的字形是用于该序列的字形,那么序列 是默认的UVS; 否则它是非默认的UVS,并且用于该序列的字形以14子格式本身的格式指定。
页面底部的示例显示了字体供应商如何使用格式14作为JIS-2004感知字体。
‘cmap’ Subtable Format 14:
| Type | Name | Description |
|---|---|---|
| uint16 | format | Subtable format. Set to 14. |
| uint32 | length | Byte length of this subtable (including this header) |
| uint32 | numVarSelectorRecords | Number of variation Selector Records |
| VariationSelector | varSelector[numVarSelectorRecords] | Array of VariationSelector records. |
每个变体选择器记录指定变体选择器字符,并偏移到用于使用该变体选择器映射变体序列的默认和非默认表。
VariationSelector Record:
| Type | Name | Description |
|---|---|---|
| uint24 | varSelector | Variation selector |
| Offset32 | defaultUVSOffset | Offset from the start of the format 14 subtable to Default UVS Table. May be 0. |
| Offset32 | nonDefaultUVSOffset | Offset from the start of the format 14 subtable to Non-Default UVS Table. May be 0. |
变体选择器记录按varSelector的递增顺序排序。 没有两个记录可能具有相同的varSelector。
变量选择器记录及其偏移量指向的数据指定变量选择器为记录的varSelector值的字体支持的UVS。 UVSes的基本字符存储在偏移指向的表中。 UVSes按默认或非默认UVSes进行分区。
用于非默认UVSes的字形ID在非默认UVS表中指定。
默认的UVS表
默认UVS表只是Unicode标量值的范围压缩列表,表示使用关联变体选择器记录的varSelector的默认UVSes的基本字符。
DefaultUVS Table:
| Type | Name | Description |
|---|---|---|
| uint32 | numUnicodeValueRanges | Number of Unicode character ranges. |
| UnicodeRange | ranges[numUnicodeValueRanges] | Array of UnicodeRange records. |
每个Unicode范围记录指定一系列连续的Unicode值。
UnicodeRange Record:
| Type | Name | Description |
|---|---|---|
| uint24 | startUnicodeValue | First value in this range |
| uint8 | additionalCount | Number of additional values in this range |
例如,范围U + 4E4D - U + 4E4F(3个值)将startUnicodeValue设置为0x004E4D,additionalCount设置为2.单个范围将additionalCount设置为0。
总和(startUnicodeValue + additionalCount)不得超过0xFFFFFF。
Unicode值范围按startUnicodeValue的递增顺序排序。 范围不得重叠; 即,(startUnicodeValue + additionalCount)必须小于以下范围的startUnicodeValue(如果有)。
非默认UVS表
非默认UVS表是Unicode标量值和字形ID对的列表。 Unicode值表示使用关联变体选择器记录的varSelector的所有非默认UVS的基本字符,字形ID指定用于UVSes的字形ID。
NonDefaultUVS Table:
| Type | Name | Description |
|---|---|---|
| uint32 | numUVSMappings | Number of UVS Mappings that follow |
| UVSMapping | uvsMappings[numUVSMappings] | Array of UVSMapping records. |
每个UVSMapping记录为一个基本Unicode字符提供字形ID映射,当在具有当前变体选择器的变体序列中使用该基本字符时。
UVSMapping Record:
| Type | Name | Description |
|---|---|---|
| uint24 | unicodeValue | Base Unicode value of the UVS |
| uint16 | glyphID | Glyph ID of the UVS |
UVS映射按unicodeValue的递增顺序排序。 此表中没有两个映射可能具有相同的’unicodeValue’值。
例
以下是如何在知道JIS-2004变体字形的字体中使用格式14’cmap’子表的示例。此示例中的CID(字符ID)是指Adobe字符集“Adobe-Japan1”中的那些,并且可以假设它们与我们示例中的字体中的字形ID相同。
JIS-2004更改了某些代码点的默认字形变体。例如:
JIS-90:U +82A6⇒CID1142
JIS-2004:U +82A6⇒CIID7961
通过使用UVSes支持这两种字形变体,因为Unicode的UVS注册表中的以下示例显示:
U + 82A6 U +E0100⇒CIID1142
U + 82A6 U +E0101⇒CIID7961
如果字体默认支持JIS-2004变体,它将:
编码Unicode'cmap'子表格中U + 82A6处的字形ID 7961,
在UVS'cmap'子表的默认UVS表中指定<U + 82A6,U + E0101>(varSelector将为0x0E0101,defaultUVSOffset将指向包含0x0082A6 Unicode值的数据)
在UVS'cmap'子表的非默认UVS表中指定<U + 82A6,U + E0100>⇒字形ID 1142(varSelector将为0x0E0100,nonDefaultBaseUVOffset将指向包含unicodeValue 0x0082A6和glyphID 1142的数据)。但是,如果字体默认支持JIS-90变体,它将:
编码Unicode'cmap'子表格中U + 82A6处的字形ID 1142,
在UVS'cmap'子表的默认UVS表中指定<U + 82A6,U + E0100>
在UVS'cmap'子表格的非默认UVS表中指定<U + 82A6,U + E0101>⇒字形ID 79617.8.COLR 颜色表
COLR表以与现有文本引擎兼容的方式添加对多色字形的支持,并且易于使用当前的OpenType字体文件。
COLR表定义了基本字形列表 - 这些字形是常规字形,通常与“cmap”条目相关联。每个基本字形由COLR表与一个字形列表相关联,每个字形对应于可以组合的层,从而创建基本字形的彩色表示。分层字形以自下而上的z顺序显式定义,并且它们的每个前进宽度必须与基本字形的宽度相匹配。如果字体具有垂直度量标准,则关联的图层字形也必须具有与基本字形相同的提前高度和垂直Y原点。
COLR表与CPAL表一起使用,CPAL表保存颜色层使用的调色板。
使用COLR和CPAL表的字体必须将字形ID 1实现为.null字形。如果COLR表存在于字体中但不存在CPAL表,则此字体将不支持COLR表。
7.8.1.Header
该表以固定部分开始,描述了颜色字体记录的整体设置。 除非另有说明,否则所有偏移都将从表格的开头开始
| Type | Name | Description |
|---|---|---|
| uint16 | version | Table version number (starts at 0). |
| uint16 | numBaseGlyphRecords | Number of Base Glyph Records. |
| Offset32 | baseGlyphRecordsOffset | Offset (from beginning of COLR table) to Base Glyph records. |
| Offset32 | layerRecordsOffset | Offset (from beginning of COLR table) to Layer Records. |
| uint16 | numLayerRecords | Number of Layer Records. |
7.8.2.Base Glyph Record
COLR表的标题指向基本字形记录。此记录用于将基本字形与分层字形匹配。每个基本字形记录都包含基本字形索引。这通常是’cmap’表中引用的字形索引。层数用于指示将为此基本字形使用多少个颜色层。然后每个记录都有一个字形层记录的索引。每个基本字形都有numLayers层记录。 firstLayerIndex指的是彩色字形的最低z顺序或底部字形id。下一层记录将代表z顺序中的下一个最高字形,并且这将继续自下而上,直到它到达z顺序顶部的numLayers字形。索引相对于图层记录的开头。索引对于每个基本字形ID不必是唯一的。如果两个基本字形需要共享颜色字形和调色板索引,这是可以接受的。同样,基础字形记录可以指向另一个基本字形的z顺序。
基本字形记录按字形id排序。假设二进制搜索可用于有效地访问具有颜色值的字形ID。尝试将字形映射到字符代码的任何使用场景都必须知道COLR表完成的映射。
| Type | Name | Description |
|---|---|---|
| uint16 | gID | Glyph ID of reference glyph. This glyph is for reference only and is not rendered for color. |
| uint16 | firstLayerIndex | Index (from beginning of the Layer Records) to the layer record. There will be numLayers consecutive entries for this base glyph. |
| uint16 | numLayers | Number of color layers associated with this glyph. |
7.8.3.Layer Record
| Type | Name | Description |
|---|---|---|
| uint16 | gID | Glyph ID of layer glyph (must be in z-order from bottom to top). |
| uint16 | paletteIndex | ndex value to use with a selected color palette. This value must be less than numPaletteEntries in the CPAL table. A palette entry index value of 0xFFFF is a special case indicating that the text foreground color (defined by a higher-level client) should be used and shall not be treated as actual index into CPAL ColorRecord array. |
选择用于给定层记录的调色板是更高级别客户的责任。 使用CPAL版本0 - 需要根据随字体分发的信息进行调色板选择。 CPAL版本1根据调色板条目和调色板标签的文本描述提供用户可选择的调色板。
7.9.CPAL 调色板表
调色板表是一组一个或多个调色板,每个调色板包含预定数量的具有BGRA值的颜色记录。它还可能包含描述调色板及其条目的“名称”表ID。
选项板由一组颜色记录定义。所有调色板都具有相同数量的颜色记录,由numColorRecords指定。所有调色板的所有颜色记录都排列在一个数组中,任何给定调色板的颜色记录都是该数组中连续的颜色记录序列。每个调色板的第一个颜色记录在colorRecordIndices数组中提供。
多个colorRecordIndices可以引用相同的颜色记录,在这种情况下,多个调色板将使用相同的颜色记录;因此,功能不同的调色板的数量可能少于numPalettes条目。此外,不同调色板的颜色记录序列可能重叠,在多个调色板之间共享某些颜色记录。因此,CPAL表中的颜色记录的总数可以小于调色板条目的数量乘以调色板的数量。
第一个调色板,调色板索引0,是默认调色板。如果表存在,则必须在CPAL表中提供至少一个调色板。选项板必须至少有一个颜色记录。不允许使用没有调色板且没有颜色记录的空CPAL表。
调色板中的颜色由基零指数引用。每个调色板中的颜色数由numPaletteEntries给出。颜色记录数组(numColorRecords)中的颜色记录数必须大于或等于max(colorRecordIndices)+ numPaletteEntries。
7.9.1.Palette Table Header
CPAL表以标题开头,标题以版本号开头。 目前,仅定义版本0和1。
CPAL version 0
CPAL标头版本0的组织结构如下:
| Type | Name | Description |
|---|---|---|
| uint16 | version | Table version number (=0). |
| uint16 | numPaletteEntries | Number of palette entries in each palette. |
| uint16 | numPalettes | Number of palettes in the table. |
| uint16 | numColorRecords | Total number of color records, combined for all palettes. |
| Offset32 | offsetFirstColorRecord | Offset from the beginning of CPAL table to the first ColorRecord. |
| uint16 | colorRecordIndices[numPalettes] | Index of each palette’s first color record in the combined color record array. |
CPAL version 1
CPAL标头版本1在表头的末尾添加了三个附加字段,其组织方式如下:
| Type | Name | Description |
|---|---|---|
| uint16 | version | Table version number (=1). |
| uint16 | numPaletteEntries | Number of palette entries in each palette. |
| uint16 | numPalettes | Number of palettes in the table. |
| uint16 | numColorRecords | Total number of color records, combined for all palettes. |
| Offset32 | offsetFirstColorRecord | Offset from the beginning of CPAL table to the first ColorRecord. |
| uint16 | colorRecordIndices[numPalettes] | Index of each palette’s first color record in the combined color record array. |
| Offset32 | offsetPaletteTypeArray | Offset from the beginning of CPAL table to the Palette Type Array. Set to 0 if no array is provided. |
| Offset32 | offsetPaletteLabelArray | Offset from the beginning of CPAL table to the Palette Labels Array. Set to 0 if no array is provided. |
| Offset32 | offsetPaletteEntryLabelArray | Offset from the beginning of CPAL table to the Palette Entry Label Array. Set to 0 if no array is provided. |
7.9.2.Palette Entries and Color Records
CPAL表中定义的颜色由调色板索引和调色板条目索引引用。 指数基数为零。 对于给定的调色板索引和调色板条目索引,导出颜色记录数组中的条目:colorRecordIndex = colorRecordIndices [paletteIndex] + paletteEntryIndex。
颜色记录数组由颜色记录组成:
| Type | Name | Description |
|---|---|---|
| ColorRecord | colorRecords[numColorRecords] | Color records for all palettes |
每个颜色记录都有BGRA值。 这些值的颜色空间是sRGB。
| Type | Name | Description |
|---|---|---|
| uint8 | blue | Blue value (B0). |
| uint8 | green | Green value (B1). |
| uint8 | red | Red value (B2). |
| uint8 | alpha | Alpha value (B3). |
颜色记录中的颜色不应预先相乘,并且应为每个调色板条目显式设置alpha值。
当放置和登记重叠元素时,存在“缝合”的可能性,其中一个元素的边缘渲染干扰另一个元素。 基于所使用的颜色的对比度,这可以或多或少地可见。
7.9.3.Palette Type Array
| Type | Name | Description |
|---|---|---|
| uint32 | paletteTypes[numPalettes] | Array of 32-bit flag fields that describe properties of each palette. See below for details. |
The following flags are defined:
| Mask | Name | Description |
|---|---|---|
| 0x0001 | USABLE_WITH_LIGHT_BACKGROUND | Bit 0: palette is appropriate to use when displaying the font on a light background such as white. |
| 0x0002 | USABLE_WITH_DARK_BACKGROUND | Bit 1: palette is appropriate to use when displaying the font on a dark background such as black. |
| 0xFFFC | Reserved | Reserved for future use — set to 0. |
请注意,USABLE_WITH_LIGHT_BACKGROUND和USABLE_WITH_DARK_BACKGROUND标志不是互斥的:它们都可以设置。
7.9.4.Palette Labels Array
| Type | Name | Description |
|---|---|---|
| uint16 | paletteLabels[numPalettes] | Array of ‘name’ table IDs (typically in the font-specific name ID range) that specify user interface strings associated with each palette. Use 0xFFFF if no name ID is provided for a particular palette. |
7.9.5.Palette Entry Label Array
| Type | Name | Description |
|---|---|---|
| uint16 | paletteEntryLabels[numPaletteEntries] | Array of ‘name’ table IDs (typically in the font-specific name ID range) that specify user interface strings associated with each palette entry, e.g. “Outline”, “Fill”. This set of palette entry labels applies to all palettes in the font. Use 0xFFFF if no name ID is provided for a particular palette entry. |
7.9.6.Relationship to COLR and SVG Tables
COLOR和SVG表都可以使用COAL来定义其调色板。
COLR和CPAL
在具有COLR表的字体中,CPAL表是必需的,并包含多色字形使用的所有字体指定颜色。
如COLR表描述中所述,如果在COLR表中指定,则调色板条目索引0xFFFF表示系统中使用的前景色。此特殊值不会在多个调色板中发生变化。最大调色板条目索引是65535 - 1,因为在COLR表中使用65536位置来指示前景字体颜色。
SVG和CPAL
在具有SVG表的字体中,CPAL表可用于包含SVG表中SVG字形描述使用的任何颜色变量的值。但是,SVG字形描述也可以直接包含颜色规范。因此,对于具有SVG表的字体,CPAL表是可选的。
前景颜色和前景颜色不透明度由SVG字形描述中的上下文填充和上下文填充不透明度属性表示。
与SVG表一起使用时,默认调色板的颜色必须设置为与SVG字形描述中颜色变量的默认值相同的值;这适用于支持SVG表但不支持调色板的文本引擎。 SVG字形描述也能够表达它们自己的显式或“硬编码”颜色。这些与颜色变量无关,因此不会因调色板选择而异。有关更多详细信息,请参阅SVG表规范。
7.10.cvar CVT变化表
控制值表(CVT)变量表用于可变字体,以提供CVT值的变化数据。有关OpenType字体变体的一般概述,请参阅OpenType字体变体概述一章。
对字形使用Truetype轮廓格式并具有提示指令的字体通常也会有一个’cvt’表。 CVT表提供了可由指令引用的控制值的索引列表。示例值是衬线的高度,x高度或上壳体的宽度。当通过指令调整字形轮廓点以改善特定PPEM大小的光栅化时,指令可以使用控制值来为这些调整提供设计距离值 - 通常,需要在所有字形中保持不变的值。给定PPEM大小的字体。
在可变字体内,可能需要针对不同的变体实例调整特定控制值的数值,以使更改与不同实例的轮廓相匹配。 CVT变量表为此目的提供变化数据。通过使用插值来导出特定实例的调整后的CVT值,指令可以获得适合实例的值,并且相同的指令可以用于所有变体。
CVT变量表必须与TrueType轮廓和’cvt’表结合使用,还可以与字体变体(’fvar’)表以及变量字体中使用的其他必需或可选表结合使用。请参阅OpenType字体变体概述一章中的变体数据表和其他要求。
7.10.1.Table Format
‘cvar’表使用元组变体存储格式的变体,在章节OpenType Font Variations Common Table Formats中描述。 ‘gvar’表对每个字形使用这种格式的略有不同的变体。
就整体结构而言,’cvar’表以标题开头,后跟序列化的变异数据。

变化数据包括适用于变化空间的不同区域的数据的逻辑分组 - 元组变化数据表。 这些逻辑分组存储在两个部分中:标题和序列化数据。 ‘cvar’头包括一组元组变量数据头,每个数据头与序列化数据的特定部分相关联。
序列化数据包括调整增量值以及打包“点数”数据,这些数据标识增量适用的CVT条目。 给定区域的序列化数据可以包括适用于该特定元组变化数据的点数数据,但也可以存在一组共享的点数数据,存储在序列化数据的开头,可以用于关系 到多个元组变量数据表。
‘cvar’标题的格式如下。
‘cvar’ table header:
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version number of the CVT variations table — set to 1. |
| uint16 | minorVersion | Minor version number of the CVT variations table — set to 0. |
| uint16 | tupleVariationCount | A packed field. The high 4 bits are flags, and the low 12 bits are the number of tuple-variation data tables. The count can be any number between 1 and 4095. |
| Offset16 | dataOffset | Offset from the start of the ‘cvar’ table to the serialized data. |
| TupleVariationHeader | tupleVariationHeaders[tupleVariationCount] Array of tuple variation headers. |
有关tupleVariationCount字段的完整详细信息,tupleVariationCount中使用的标志,TupleVariationHeader格式以及序列化数据的格式在OpenType字体变体公用表格式章节中提供。有关如何处理数据以获取特定实例的插值CVT值的详细信息,请参见该章和OpenType字体变体概述一章。
如上所述,’cvar’表的格式与’gvar’表中使用的格式密切相关。以下是需要注意的主要差异:
TupleVariationHeader结构包括特定字段tupleIndex。这是一个包含标志位的打包字段,其中一个标志位指示结构是否包含嵌入的峰值元组记录。在'gvar'表中,这是可选的,并且不总是需要设置标志。但是,在'cvar'表中,嵌入的峰值元组记录是必需的,并且必须始终设置此标志。
序列化数据包括打包的“点”数字。在'gvar'表的上下文中,这些是特定字形的轮廓点的索引。在'cvar'表中,这些是'cvt'表中CVT值的索引。
在'gvar'表中,每个枚举的轮廓点有两个逻辑增量:一个用于X坐标,一个用于Y坐标。因此,逻辑增量的总数是点数的两倍。在'cvar'表中,每个点编号只有一个逻辑增量。请注意,CVT值都是FWORD,CVT值的总数由’cvt’表的长度决定。因此,CVT索引值的范围从0到楼层(cvtLength / sizeof(FWORD)) - 1。
7.11.cvt 控制值表
此表包含可由指令引用的值列表。 除其他外,它们可用于控制不同字形的特征。 表的长度必须是FWORD单位的整数。
| Type | Description |
|---|---|
| FWORD[ n ] | List of n values referenceable by instructions. n is the number of FWORD items that fit in the size of the table. |
7.12.DSIG 数字签名表
DSIG表包含OpenType™字体的数字签名。签名格式被广泛记录并依赖于密钥对架构。软件开发人员或在Internet上发布材料的发布者使用私钥创建签名。操作系统或应用程序使用公钥对签名进行身份验证。
W3C和主要软件和操作系统开发人员已经指定了描述签名格式的安全标准,指定了Web对象的安全集合,并推荐了身份验证体系结构。带签名的OpenType字体将支持这些标准。
OpenType字体提供许多安全功能:
操作系统和浏览应用程序可以在使用之前识别字体文件的来源和完整性,
字体开发人员可以在OpenType字体中指定嵌入限制,并且这些限制不能在开发人员签名的字体中更改。
签名的实施是一种管理策略,可以由使用字体的主机环境支持。系统可能会限制使用无符号字体,或者可能允许系统管理员控制策略。
任何人都可以免费或以非常低的成本从Verisign或GTE的Cybertrust等认证机构获得身份证明和加密密钥。
DSIG表的组织如下。表格的第一部分是标题:
DSIG header
| Type | Name | Description |
|---|---|---|
| uint32 | version | Version number of the DSIG table (0x00000001) |
| uint16 | numSignatures | Number of signatures in the table |
| uint16 | flags | permission flags Bit 0: cannot be resigned Bits 1-7: Reserved (Set to 0) |
| SignatureRecord | signatureRecords[numSignatures] Array of signature records |
DSIG表的版本表示为uint32,从0开始。当前使用的DSIG表的版本是版本1(0x00000001)。
权限位0允许签署字体的一方阻止任何其他方也签署字体(反签名)。 如果该位设置为零(0),则字体可以在现有数字签名上应用签名。 想要确保其签名是最后签名的一方可以设置此位。
DSIG标头有一组签名记录,用于指定签名块的格式和偏移量。
SignatureRecord
| Type | Name | Description |
|---|---|---|
| uint32 | format | Format of the signature |
| uint32 | length | Length of signature in bytes |
| Offset32 | offset | Offset to the signature block from the beginning of the table |
签名包含在一个或多个签名块中。 签名块可以具有各种格式; 目前定义了一种格式。 格式标识符指定签名块的格式,以及用于创建和验证签名的散列算法。
Signature Block Format 1
| Type | Name | Description |
|---|---|---|
| uint16 | reserved1 | Reserved for future use; set to zero. |
| uint16 | reserved2 | Reserved for future use; set to zero. |
| uint32 | signatureLength | Length (in bytes) of the PKCS#7 packet in the signature field. |
| uint8 | signature[signatureLength] | PKCS#7 packet |
有关PKCS#7签名的更多信息,请参阅ftp://ftp.rsa.com/pub/pkcs/ascii/pkcs-7.asc
有关反签名的详细信息,请参阅ftp://ftp.rsa.com/pub/pkcs/ascii/pkcs-9.asc
格式1:对于整个字体,具有TrueType轮廓和/或CFF数据
PKCS#7或PKCS#9。已签名的内容摘要创建如下:
- 如果字体中存在现有DSIG表,
从字体中删除DSIG表。
从sfnt表目录中删除DSIG表条目。
根据需要调整表偏移量。
将“head”表中的文件校验和清零。
添加usFlag(保留,现在设置为1)到字节流 - 使用安全的单向散列(例如MD5)散列完整的字节流来创建内容摘要。
- 使用内容摘要创建PKCS#7签名块。
- 创建一个包含签名块的新DSIG表。
- 将DSIG表添加到字体中,根据需要调整表偏移量。
- 将DSIG表条目添加到sfnt表目录。
- 重新计算“head”表中的校验和。
在签署字体文件之前,请确保满足以下所有属性。
'head'表中的幻数是正确的。
给定offset表中的表数值,offset表中的其他值是一致的。
表的标签按字母顺序排序,没有重复的标签。
每个表的偏移量是4的倍数。(也就是说,表是长字对齐的。)
文件中的第一个实际表紧跟在表的目录之后。
如果表按偏移量排序,那么对于所有表i(其中索引0表示具有最小偏移量的表),Offset [i] + Length [i] <= Offset [i + 1]和Offset [i] + Length [i]> = Offset [i + 1] - 3.换句话说,表不重叠,表之间最多有3个字节的填充。
表之间的填充字节全为零。
文件中最后一个表的偏移量加上其长度不大于文件的大小。
所有表的校验和都是正确的。
'head'表的checkSumAdjustment字段是正确的。7.12.1.Signatures for TrueType Collections
TrueType集合(TTC)的DSIG表必须是TTC文件中的最后一个表。 表的偏移量和校验和放在TTCHeader(版本2)中。 TTC文件的签名应为格式1签名。
TTC文件的签名适用于整个文件,而不适用于TTC中包含的各个字体。 对TTC文件进行签名可确保其他内容不会添加到TTC。
TrueType集合中包含的单个字体不应单独签名,因为使TTC可能使字体上的签名无效。
7.13.EBDT 嵌入式位图数据表
EBDT表用于嵌入单色或灰度位图字形数据。 它与提供嵌入式位图定位器的EBLC表和提供嵌入式位图缩放信息的EBSC表一起使用。
OpenType嵌入式位图也称为“sbits”(用于“缩放器位图”)。 给定大小的面部的一组位图称为打击。
EBLC表标识了sbits的大小和字形范围,并保留了indexSubTables中字形位图数据的偏移量。 然后,EBDT表以多种不同的可能格式存储字形位图数据。 字形度量信息可以存储在EBLC或EBDT表中,这取决于indexSubTable和字形位图数据格式。 EBSC表标识将通过按比例放大或缩小其他sbit大小来处理的大小。
EBDT表是Apple的Apple高级版式(AAT)’bdat’表的超级集合。
7.13.1.EDBT Header
EBDT表以一个仅包含表版本号的标头开头。
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the EBDT table, = 2. |
| uint16 | minorVersion | Minor version of the EBDT table, = 0. |
请注意,EBDT表的第一个版本是2.0。
EBDT表的其余部分是位图数据的集合。 数据可以是多种可能的格式,由EBLC表中的信息表示。 一些格式包含度量信息和图像数据,而其他格式仅包含图像数据。 这些子表不需要长字对齐; 字节对齐就足够了。
字形度量标准还有两种不同的格式:大字形度量标准和小字形度量标准。 大字形度量标准定义水平和垂直布局的度量信息。 这在可以使用两种类型的布局的字体(例如汉字)中很重要。 小字形指标仅定义一个布局方向的指标信息。 哪个方向适用,水平或垂直,由EBLC表中的BitmapSize表中的flags字段确定。
7.13.2.BigGlyphMetrics
| Type | Name |
|---|---|
| uint8 | Nheight |
| uint8 | Nwidth |
| int8 | NhoriBearingX |
| int8 | NhoriBearingY |
| uint8 | NhoriAdvance |
| int8 | NvertBearingX |
| int8 | NvertBearingY |
| uint8 | NvertAdvance |
7.13.3.SmallGlyphMetrics
| Type | Name |
|---|---|
| uint8 | height |
| uint8 | width |
| int8 | bearingX |
| int8 | bearingY |
| uint8 | advance |
7.13.4.Glyph Bitmap Data
下面列出并描述了当前为字形位图数据定义的九种不同格式。 不同的格式更适合不同的目的。 Apple’bdat’表仅支持格式1到7。
在所有格式中,如果bitDepth大于1,则所有像素的位都连续存储在存储器中,并且所有行的像素都连续存储。
注意:这些格式中的每一种都可以包含黑/白或灰度位图,具体取决于EBLC表中bitDepth字段的设置。 出于性能原因,我们建议对bitDepth为8的嵌入式位图使用字节对齐格式。
格式1:小指标,字节对齐数据
| Type | Name | Description |
|---|---|---|
| SmallGlyphMetrics | smallMetrics | Metrics information for the glyph |
| uint8 | imageData[variable] | Byte-aligned bitmap data |
| 字形位图格式1由小的度量记录(水平或垂直,取决于EBLC表中的BitmapSize表的flags字段)和字节对齐的位图数据组成。 位图数据以对应于边界框的左上角像素的第一个字节的最高有效位开始,继续从左向右移动的后续位。 每行的数据填充到字节边界,因此下一行以新字节的最高有效位开始。 1位对应黑色,0位对应白色。 |
格式2:小指标,位对齐数据
| Type | Name | Description |
|---|---|---|
| SmallGlyphMetrics | smallMetrics | Metrics information for the glyph |
| uint8 | imageData[variable] | Bit-aligned bitmap data |
除了位图数据是位对齐之外,字形位图格式2与格式1相同。 这意味着新行的数据将从紧跟在前一行的最后一位之后的位开始。 每个字形的开头必须是字节对齐的,因此字形的最后一行可能需要填充。 这种格式需要花费更多时间来解析,但与格式1相比节省了文件空间。
格式3 :(已过时)
格式4:EBLC中的(不支持)度量标准,压缩数据
字形位图格式4是Apple在某些东亚字体中使用的压缩格式。 OpenType不支持此格式。
格式5:EBLC中的度量,仅比特对齐的图像数据
| Type | Name | Description |
|---|---|---|
| uint8 | imageData[variable] Bit-aligned bitmap data |
字形位图格式5类似于格式2,除了不包括度量信息,仅包括位对齐数据。 此格式用于EBLC indexSubTable格式2或格式5,它将包含所有字形的度量信息。 它适用于汉字字体。
光栅化器重新计算格式5位图数据的sbit指标,允许Windows报告正确的ABC宽度,即使位图在位图图像的任一侧有空白区域也是如此。 这允许字体以高效的格式5存储等宽的位图字形,而不会破坏Windows GetABCWidths调用。
格式6:大指标,字节对齐数据
| Type | Name | Description |
|---|---|---|
| BigGlyphMetrics | bigMetrics | Metrics information for the glyph |
| uint8 | imageData[variable] | Byte-aligned bitmap data |
字形位图格式6与格式1相同,除了使用大字形度量而不是小字形。
格式7:大指标,位对齐数据
| Type | Name | Description |
|---|---|---|
| BigGlyphMetrics | bigMetrics | Metrics information for the glyph |
| uint8 | imageData[variable] | Bit-aligned bitmap data |
字形位图格式7与格式2相同,除了使用大字形度量而不是小字形。
EbdtComponent记录
EbdtComponent记录用于字形位图数据格式8和9。
| Type | Name | Description |
|---|---|---|
| uint16 | glyphID | Component glyph ID |
| int8 | xOffset | Position of component left |
| int8 | yOffset | Position of component top |
EbdtComponent记录包含组件的字形ID,可用于查找EBLC表中组件字形数据的位置,以及xOffset和yOffset值,这些值指定组件左上角的位置 在复合材料中。 允许嵌套合成(复合材料的复合),嵌套级别的数量由实现堆栈空间决定。
格式8:小指标,组件数据
| Type | Name | Description |
|---|---|---|
| SmallGlyphMetrics | smallMetrics | Metrics information for the glyph |
| uint8 | pad | Pad to 16-bit boundary |
| uint16 | numComponents | Number of components |
| EbdtComponent | components[numComponents] | Array of EbdtComponent records |
格式9:大指标,组件数据
| Type | Name | Description |
|---|---|---|
| BigGlyphMetrics | bigMetrics | Metrics information for the glyph |
| uint16 | numComponents | Number of components |
| EbdtComponent | components[numComponents] | Array of EbdtComponent records |
字形位图格式8和9用于复合位图。 对于重音字符和其他复合字形,分别存储每个组件的副本可能更有效,然后使用复合描述来构造完成的字形。 复合格式允许任意数量的组件,并允许组件定位在完成的字形中的任何位置。 格式8使用小指标,格式9使用大指标。
7.14.EBLC 嵌入式位图位置表
EBLC提供嵌入式位图定位器。它与EDBT表一起使用,EDBT表提供嵌入式,单色或灰度位图字形数据,以及EBSC表,它提供嵌入式位图缩放信息。
OpenType嵌入式位图称为“sbits”(用于“缩放器位图”)。给定大小的面部的一组位图称为打击。
EBLC表标识了sbits的大小和字形范围,并保留了IndexSubTables中字形位图数据的偏移量。然后,EBDT表还以多种不同的可能格式存储字形位图数据。字形度量信息可以存储在EBLC或EBDT表中,具体取决于IndexSubTable和字形位图格式。 EBSC表标识将通过按比例放大或缩小其他sbit大小来处理的大小。
EBLC表使用与Apple Apple Advanced Typography(AAT)’bloc’表格相同的格式。
EBLC表以包含表格版本和罢工次数的标题开头。 OpenType字体可能在EBDT表中嵌入了一个或多个打击。
7.14.1.EBLC Header
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the EBLC table, = 2. |
| uint16 | minorVersion | Minor version of the EBLC table, = 0. |
| uint32 | numSizes | Number of BitmapSize tables. |
请注意,EBLC表的第一个版本是2.0。
EblcHeader后面紧跟BitmapSize表数组。 EblcHeader中的numSizes字段表示数组中BitmapSize表的数量。 每个警示都由一个BitmapSize表定义。
7.14.2.BitmapSize Table
| Type | Name | Description |
|---|---|---|
| Offset32 | indexSubTableArrayOffset | Offset to IndexSubtableArray, from beginning of EBLC. |
| uint32 | indexTablesSize | Number of bytes in corresponding index subtables and array. |
| uint32 | numberOfIndexSubTables | There is an IndexSubtable for each range or format change. |
| uint32 | colorRef | Not used; set to 0. |
| SbitLineMetrics | hori | Line metrics for text rendered horizontally. |
| SbitLineMetrics | vert | Line metrics for text rendered vertically. |
| uint16 | startGlyphIndex | Lowest glyph index for this size. |
| uint16 | endGlyphIndex | Highest glyph index for this size. |
| uint8 | ppemX | Horizontal pixels per em. |
| uint8 | ppemY | Vertical pixels per em. |
| uint8 | bitDepth | The Microsoft rasterizer v.1.7 or greater supports the following bitDepth values, as described below: 1, 2, 4, and 8. |
| int8 | flags | Vertical or horizontal (see Bitmap Flags, below). |
indexSubTableArrayOffset是从EBLC表的开头到IndexSubTableArray的偏移量。 每次攻击都有其中一个阵列,以支持各种格式和不连续的位图范围。 indexTablesSize是IndexSubTableArray和关联的IndexSubTables中的总字节数。 numberOfIndexSubTables是此警示的IndexSubTables的计数。
水平和垂直线指标包含警示的上升,下行,线间隙和预先信息。 行度量标准格式如下表所述:
7.14.3.SbitLineMetrics
| Type | Name |
|---|---|
| int8 | ascender |
| int8 | descender |
| uint8 | widthMax |
| int8 | caretSlopeNumerator |
| int8 | caretSlopeDenominator |
| int8 | caretOffset |
| int8 | minOriginSB |
| int8 | minAdvanceSB |
| int8 | maxBeforeBL |
| int8 | minAfterBL |
| int8 | pad1 |
| int8 | pad2 |
插入符号斜率确定绘制插入符号的角度,偏移量是移动插入符号的像素数(+或 - )。这是一个有符号整数,因为我们正在处理整数度量。 minOriginSB,minAdvanceSB,maxBeforeBL和minAfterBL在下图中描述。这些数字的主要需求是可能需要预先分配内存和/或需要更多度量信息来定位字形的缩放器。所有行度量都是一个字节长度。线性度量标准不是由光栅化器直接使用,但可供要解析EBLC表的客户端使用。
startGlyphIndex和endGlyphIndex描述了警示中的最小和最大字形ID,但是警示不一定包含此范围内所有字形ID的位图。 IndexSubTables确定EBDT表中实际存在哪些字形。
ppemX和ppemY字段描述每个Em的打击大小(以像素为单位)。 ppem测量相当于每英寸72点设备的点大小。通常,对于具有“方形”像素的设备,ppemX将等于ppemY。为了适应具有矩形像素的设备,并允许具有其他宽高比的位图,ppemX和ppemY可能不同。
7.14.4.Bit Depth
位图大小表的位深度字段用于指定嵌入位图中使用的灰度级数。 Microsoft rasterizer v.1.7或更高版本支持以下值。
| Value | Description |
|---|---|
| 1 | black/white |
| 2 | 4 levels of gray |
| 4 | 16 levels of gray |
| 8 | 256 levels of gray |
flags字节包含两个位,用于指示小字形度量的方向:水平或垂直。 其余位保留。
7.14.5.Bitmap Flags
| Mask | Name | Description |
|---|---|---|
| 0x01 | HORIZONTAL_METRICS | Horizontal |
| 0x02 | VERTICAL_METRICS | Vertical |
| 0xFC | Reserved | For future use — set to 0. |
colorRef和bitDepth字段保留用于将来的增强功能。 对于单色位图,它们应具有值colorRef = 0和bitDepth = 1。


与警示中每个字形的图像数据相关联的是一组字形度量。这些字形度量描述了边界框的高度和宽度,以及侧边承载和前进宽度信息。字形度量可以在两个地方之一找到。对于每个字形的度量可能不同的字形范围(不一定是整个打击),字形度量与字形图像数据一起存储在EBDT表中。有关如何完成此操作的详细信息,请参阅本文档的EBDT部分。对于每个字形的度量标准相同的字形范围,我们通过在EBLC中的IndexSubTable中存储字形度量的单个副本来节省大量空间。
字形度量标准还有两种不同的格式:大字形度量标准和小字形度量标准。大字形度量标准定义水平和垂直布局的度量信息。这在可以使用两种类型的布局的字体(例如汉字)中很重要。小字形指标仅定义一个布局方向的指标信息。哪个方向适用,水平或垂直,由BitmapSize表中的flags字段确定。
7.14.6.BigGlyphMetrics
| Type | Name |
|---|---|
| uint8 | height |
| uint8 | width |
| int8 | horiBearingX |
| int8 | horiBearingY |
| uint8 | horiAdvance |
| int8 | vertBearingX |
| int8 | vertBearingY |
| uint8 | vertAdvance |
7.14.7.SmallGlyphMetrics
| Type | Name |
|---|---|
| uint8 | height |
| uint8 | width |
| int8 | bearingX |
| int8 | bearingY |
| uint8 | advance |
下图说明了字形度量的含义。

每个警示的BitmapSize表包含IndexSubTableArray元素数组的偏移量。 每个元素描述一个字形ID范围和该范围的IndexSubTable的偏移量。 这允许打击包含多个字形ID范围,并且如果需要,可以用多种索引格式表示。
7.14.8.IndexSubTableArray
| Type | Name | Description |
|---|---|---|
| uint16 | firstGlyphIndex | First glyph ID of this range. |
| uint16 | lastGlyphIndex | Last glyph ID of this range (inclusive). |
| Offset32 | additionalOffsetToIndexSubtable | Add to indexSubTableArrayOffset to get offset from beginning of EBLC. |
确定打击后,rasterizer将在此数组中搜索包含给定字形ID的范围。 找到范围后,将additionalOffsetToIndexSubtable添加到indexSubTableArrayOffset以获取EBLC中IndexSubTable的偏移量。
第一个indexSubTableArray位于最后一个bitmapSizeSubTable条目之后。 然后是罢工的IndexSubTables。 另一个IndexSubTableArray(如果有多个警示)及其IndexSubTableArray是下一个。 对于每次攻击,EBLC继续使用数组和IndexSubTables。
我们现在有了IndexSubTable的偏移量。 所有IndexSubTable格式都以IndexSubHeader开头,它标识IndexSubTable格式,EBDT图像数据的格式,以及从EBDT表开头到此范围的图像数据开头的偏移量。
7.14.9.IndexSubHeader
| Type | Name | Description |
|---|---|---|
| uint16 | indexFormat Format of this IndexSubTable. | |
| uint16 | imageFormat Format of EBDT image data. | |
| Offset32 | imageDataOffset Offset to image data in EBDT table. |
7.14.10.IndexSubtables
目前有五种不同的格式用于IndexSubTable,具体取决于字形ID范围中位图数据的大小和类型。 Apple’flaoc’表仅支持格式1到3。
选择使用哪种IndexSubTable格式取决于字体制造商,但应尽量减小字体文件的大小。 具有可变度量的字形范围 - 即,在边界框高度,宽度,侧面方位或前进中字形可能彼此不同的地方 - 必须使用格式1,3或4.具有常量度量的字形范围可以通过使用格式来节省空间 2或5,它们在IndexSubTable中保留度量信息的单个副本,而不是EBDT表中每个字形的副本。 在一些等宽字体中,有意义的是在一些字形周围存储额外的空白以保持所有度量相同,从而允许使用格式2或5。
下面列出了每种IndexSubTable格式的结构。
IndexSubTable1: variable-metrics glyphs with 4-byte offsets
| Type | Name | Description |
|---|---|---|
| IndexSubHeader | header | Header info. |
| Offset32 | offsetArray[] | offsetArray[glyphIndex] + imageDataOffset = glyphData sizeOfArray = (lastGlyph - firstGlyph + 1) + 1 + 1 pad if needed |
IndexSubTable2: all glyphs have identical metrics
| Type | Name | Description |
|---|---|---|
| IndexSubHeader | header | Header info. |
| uint32 | imageSize | All the glyphs are of the same size. |
| BigGlyphMetrics | bigMetrics All glyphs have the same metrics; glyph data may be compressed, byte-aligned, or bit-aligned. |
IndexSubTable3: variable-metrics glyphs with 2-byte offsets
| Type | Name | Description |
|---|---|---|
| IndexSubHeader | header | Header info. |
| Offset16 | offsetArray[] | offsetArray[glyphIndex] + imageDataOffset = glyphData sizeOfArray = (lastGlyph - firstGlyph + 1) + 1 + 1 pad if needed |
IndexSubTable4: variable-metrics glyphs with sparse glyph codes
| Type | Name | Description |
|---|---|---|
| IndexSubHeader | header | Header info. |
| uint32 | numGlyphs | Array length. |
| GlyphIdOffsetPair | glyphArray[numGlyphs + 1] | One per glyph. |
GlyphIdOffsetPair record:
| Type | Name | Description |
|---|---|---|
| uint16 | glyphID | Glyph ID of glyph present. |
| Offset16 | offset | Location in EBDT. |
IndexSubTable5: constant-metrics glyphs with sparse glyph codes
| Type | Name | Description |
|---|---|---|
| IndexSubHeader | header | Header info. |
| uint32 | imageSize | All glyphs have the same data size. |
| BigGlyphMetrics | bigMetrics All glyphs have the same metrics. | |
| uint32 | numGlyphs | Array length. |
| uint16 | glyphIdArray[numGlyphs] | One per glyph, sorted by glyph ID. |
可以从IndexSubTable信息计算EBDT图像数据的大小。对于常量度量格式(2和5),图像数据大小是恒定的,并在imageSize字段中给出。对于可变度量格式(1,3和4),图像数据必须连续存储并以字形ID顺序存储,因此可以通过从下一个字形的偏移量中减去当前字形的偏移量来计算图像数据大小。因此,有必要在offsetArray中存储一个额外元素,指向刚好超出范围图像数据的末尾。这将允许正确计算范围中最后一个字形的图像数据大小。
连续或几乎连续的字形ID范围最好由格式1,2和3处理,格式1,2和3存储范围中每个字形ID的偏移量。非常稀疏的字形ID范围应该使用格式4或5,它明确地调出范围中表示的字形ID。通过使丢失的字形的偏移量跟随下一个字形的相同偏移量,从而指示数据大小为零,可以在格式1或3中有效地表示少量丢失的字形。
格式1和3之间的唯一区别是offsetArray元素的大小:格式1使用uint32s而格式3使用uint16s。因此,格式1可以覆盖更大的范围(> 64k字节),而格式3可以在EBLC表中节省更多空间。由于offsetArray元素被添加到IndexSubHeader中的imageDataOffset基地址,因此可以通过将其分成多个范围(每个范围小于64k字节)来处理非常大的字形位图数据集,从而允许使用更高效的格式3 。
EBLC表规范要求所有子表的16位对齐。这种情况自然发生在IndexSubTable格式1,2和4中,但可能不适用于格式3和5,因为它们包含uint16类型的数组。当这些数组中存在奇数个元素时,必须添加额外的填充元素以保持正确的对齐。
7.15.EBSC 嵌入式位图缩放表
EBSC表提供了一种机制,用于描述通过缩放其他嵌入式位图创建的嵌入式位图。 虽然这是大纲字体技术被发明以避免的类型,但有些情况(例如小尺寸的汉字),其中缩放位图产生比扫描转换轮廓更清晰的字体。 因此,EBSC表允许字体将位图打击定义为另一个打击的缩放版本。
EBSC表与EBDT表一起使用,EBDT表提供嵌入式单色或灰度位图数据,EBLC表提供嵌入式位图定位器。
7.15.1.EBSC Header
EBSC表以包含表格版本和罢工次数的标题开头。
| Type | Name | Description |
|---|---|---|
| uint16 | majorVersion | Major version of the EBSC table, = 2. |
| uint16 | minorVersion | Minor version of the EBSC table, = 0. |
| uint32 | numSizes |
请注意,EBLC表的第一个版本是2.0。
标题后面紧跟BitmapScale表数组。 numSizes字段指示数组中BitmapScale表的数量。 每个警示都由一个BitmapScale表定义。
7.15.2.BitmapScale Table
| Type | Name | Description |
|---|---|---|
| SbitLineMetrics | hori | line metrics |
| SbitLineMetrics | vert | line metrics |
| uint8 | ppemX | target horizontal pixels per Em |
| uint8 | ppemY | target vertical pixels per Em |
| uint8 | substitutePpemX | use bitmaps of this size |
| uint8 | substitutePpemY | use bitmaps of this size |
行度量与BitmapSize表中的含义相同,并在缩放后引用字体范围度量。 ppemX和ppemY值描述缩放后字体的大小。 substitutePpemX和substitutePpemY值描述在EBLC和EBDT中作为sbit存在的打击的大小,并且将按比例放大或缩小以生成新的打击。
请注意,x方向上的缩放与y方向上的缩放无关,并且它们的缩放值可能不同。 方形长宽比可以按比例缩放到非方形长宽比。 字形度量按与每个Em的像素(在适当的方向上)相同的因子缩放,并舍入到最接近的整数像素。
7.16.fpgm 字体程序
此表类似于CVT程序,只是在首次使用字体时它只运行一次。它仅用于FDEF和IDEF。因此,CVT程序不需要包含函数定义。但是,CVT计划可能会重新定义现有的FDEF或IDEF。
该表是可选的。
| 类型 | 描述 |
|---|---|
| uint8 [ n ] | 说明。n是适合表大小的uint8项的数量。 |
7.17.fvar 字体变体表
OpenType Font Variations允许字体设计者将字体系列中的多个面合并到单个字体资源中。可变字体可以为内容作者和设计者提供极大的灵活性,同时还允许以有效格式表示字体数据。
可变字体允许沿某些给定设计轴的连续变化,例如重量:

从概念上讲,可变字体定义了一个或多个轴,设计特征可以在这些轴上变化。重量是一种可能的变化轴,但是许多不同类型的变化是可能的。可变字体不限于单个变化轴,而是可以组合两个或更多个不同的变化轴。例如,以下说明了重量和宽度变化的组合:

由字体支持的轴集定义了该字体的变体空间,在该空间的位置支持可能大量的设计变体实例。
字体变体表(’fvar’)提供字体内支持的变体的全局定义。它指定了使用的变化轴和每个轴的变化范围。它还允许字体设计者将字体变体空间中的某些坐标位置指定为命名实例。命名实例具有设计者提供的名称,有效地等同于子系列名称,应用程序可以将其用作可以提供给用户的“预先选择”设计变体的简短列表。
有关OpenType字体变体的一般介绍,请参阅OpenType字体变体概述。
所有可变字体必须包含字体变体表,以及可变字体中使用的其他必需或可选表。有关可变字体中使用的其他表的更多信息,请参阅“概述”一章中的“ 变体数据表”和“其他要求 ”。
请注意,字体变体表中的某些信息也需要反映在样式属性(STAT)表中,这在所有可变字体中也是必需的。特别是,在字体变体表中指定的每个轴和每个命名实例必须在样式属性表中具有匹配的轴记录和轴值表。
7.17.1.Table Formats
字体变体表包含一个表头,后跟一个变异轴记录数组,后跟一个命名实例记录数组:

‘fvar’标题
字体变体表头的格式如下。
字体变体标题:
| 类型 | 名称 | 描述 |
|---|---|---|
| UINT16 | majorVersion | 字体变体表的主要版本号 - 设置为1。 |
| UINT16 | minorVersion | 字体变体表的次要版本号 - 设置为0。 |
| Offset16 | axesArrayOffset | 从表的开头到VariationAxisRecord数组的开头以字节为单位的偏移量。 |
| UINT16 | (保留) | 该字段是永久保留的。设为2。 |
| UINT16 | axisCount | 字体中变化轴的数量(轴数组中的记录数)。 |
| UINT16 | axisSize | 每个VariationAxisRecord的大小(以字节为单位) - 此版本设置为20(0x0014)。 |
| UINT16 | instanceCount | 字体中定义的命名实例数(实例数组中的记录数)。 |
| UINT16 | instanceSize | 每个InstanceRecord的大小(以字节为单位) - 设置为axisCount * sizeof(Fixed)+ 4,或者设置为axisCount * sizeof(Fixed)+ 6。 |
标题后跟轴和实例数组。轴数组的位置在axesArrayOffset字段中指定; instances数组直接跟在轴数组之后。
| 类型 | 名称 | 描述 |
|---|---|---|
| VariationAxisRecord | 轴[axisCount] | 变异轴阵列。 |
| InstanceRecord | 实例[instanceCount] | 命名实例数组。 |
注意: axisSize和instanceSize字段指示VariationAxisRecord和InstanceRecord结构的大小。在此版本的'fvar'表中,InstanceRecord结构具有可选字段,因此可以使用两种不同的大小。'fvar'表的未来次要版本更新可以定义任一格式的兼容扩展。实现必须使用axisSize和instanceSize字段来确定每条记录的开头。组成字体变化空间的轴组由变化轴记录数组定义。记录数和轴数由axisCount字段确定。功能变量字体必须具有大于零的axisCount值。如果axisCount为零,则该字体不能用作可变字体,必须将其视为非可变字体; 任何特定于变体的表或数据都将被忽略。
VariationAxisRecord
变异轴记录的格式如下:
| 类型 | 名称 | 描述 |
|---|---|---|
| 标签 | axisTag | 用于标识轴的设计变化的标签。 |
| 固定 | minValue(最小值) | 轴的最小坐标值。 |
| 固定 | 默认值 | 轴的默认坐标值。 |
| 固定 | 包括maxValue | 轴的最大坐标值。 |
| UINT16 | 旗 | Axis限定符 - 请参阅下面的详细信息。 |
| UINT16 | axisNameID | “名称”表中为条目提供显示名称的条目的名称ID。 |
每个轴都有一个标记,用于标识轴的设计变化。例如,标签’wght’表示重量变化。标签被注册用于常用的设计轴,但也可以使用代工厂定义的标签。已注册的标签为所有字体的轴定义有效的坐标值范围。变异轴记录定义了字体支持的最小值和最大值,这可能比为已注册标签定义的有效范围更有限。
注意:变异轴记录中给出的轴值使用特定于每个轴标记的用户比例坐标。每个注册标签的用户比例用每个标签的定义来描述。在包含变体相关数据的大多数其他字体表中,轴坐标值使用标准化坐标标度表示。有关用户比例和标准化比例的更多信息以及规范化过程的规范,请参阅OpenType字体变体概述一章中的“ 坐标比例和标准化”部分。轴标签必须符合某些要求才有效。此外,注册标签和代工厂定义标签的有效模式是互斥的。这是确保现有字体中的代工厂定义的标签与新注册的标签之间永远不会发生冲突所必需的。
有关轴标签和已注册设计变化轴定义的更多详细信息,请参阅OpenType Design-Variation Axis Tag Registry。
默认值以特定方式与字形和字形变体表交互:具有每个轴的默认坐标值的变体实例将使用字形表中定义的字形轮廓,而不应用应用的字形变体表的任何变化。此实例称为默认实例。
可以指定标志以指示给定轴的某些用途或行为,与特定轴标签及其定义无关。如果没有设置标志,则不会超出已注册轴的定义进行任何假设。定义了以下标志。
| 面具 | 名称 | 描述 |
|---|---|---|
| 0×0001 | HIDDEN_AXIS | 轴不应直接暴露在用户界面中。 |
| 0xFFFE | 保留的 | 保留供将来使用 - 设置为0。 |
提供HIDDEN_AXIS标志以指示字体开发者建议轴不直接暴露给应用程序用户界面中的最终用户。设置此标志的原因可能包括轴仅用于编程交互,或者用于字体开发人员的字体内部使用。如果设置了此标志,则不应在应用程序用户界面中向用户公开该轴,除非在特殊情况下(例如字体检查实用程序)。该标志不应影响对命名实例的处理,该实例应始终在文本格式化用户界面中公开。如果未设置此标志,则应用程序可以在默认用户界面中公开给定轴,或者,基于轴的性质,可以选择在高级用户界面中公开它。
axisNameID字段提供了一个名称ID,可用于从“名称”表中获取可用于在应用程序用户界面中引用轴的字符串。名称ID必须大于255且小于32768.对于已注册的轴标签,提供传统的美国英语轴名称; 建议在应用程序用户界面中使用该名称或本地化衍生名称,以便在不同字体之间提供更高的用户体验一致性。
InstanceRecord
实例记录格式包括一个n元组坐标数组,用于定义字体变体空间内的位置。n元组数组具有以下格式:
元组记录(固定):
| 类型 | 名称 | 描述 |
|---|---|---|
| 固定 | 坐标[axisCount] | 坐标数组,指定字体变体空间内的位置。 |
实例记录的格式如下。
InstanceRecord:
| 类型 | 名称 | 描述 |
|---|---|---|
| UINT16 | subfamilyNameID | “名称”表中用于为此实例提供子系列名称的条目的名称ID。 |
| UINT16 | 旗 | 保留供将来使用 - 设置为0。 |
| 元组 | 坐标 | 此实例的坐标数组。 |
| UINT16 | postScriptNameID | 可选的。“名称”表中为此实例提供PostScript名称的条目的名称ID。 |
postScriptNameID字段是可选的,但应包含在所有可变字体中,并且在某些平台中可能需要。请注意,给定字体中的所有实例记录必须大小相同,并且所有实例都包含或省略postScriptNameID字段。
subfamilyNameID字段提供了一个名称ID,可用于从“名称”表中获取字符串,该字符串可视为与给定实例的名称ID 17(印刷子系列)字符串等效。可以使用2或17的值; 否则,值必须大于255且小于32768.仅当命名实例对应于字体的默认实例时,才应使用值2或17。
postScriptNameID字段提供了一个名称ID,可用于从“名称”表中获取字符串,该字符串可视为与给定实例的名称ID 6(PostScript名称)字符串等效。可以使用6和0xFFFF的值; 否则,值必须大于255且小于32768.如果值为0xFFFF,则忽略该值,并且不为该实例提供等效的PostScript名称。仅当命名实例对应于字体的默认实例时,才应使用值6。
字体中的所有实例记录都应具有不同的坐标和不同的subfamilyNameID和postScriptName ID值。如果两个或多个记录共享相同的坐标,相同的nameID值或相同的postScriptNameID值,则可以忽略除第一个以外的所有记录。
字体的默认实例是每个轴的坐标值是相应变体轴记录中指定的defaultValue的实例。虽然可以提供实例记录,但默认实例不需要实例记录。枚举命名实例时,即使没有相应的实例记录,也应枚举默认实例。如果默认实例包含实例记录(即实例记录的坐标设置为默认值),则nameID值应设置为2或17,postScriptNameID值应设置为6。
注意:由于不需要默认实例的实例记录,因此在'fvar'表中没有定义实例记录的变量字体(instanceCount为零)仍然有一个命名实例。7.17.2.Variation Instance Selection
使用可变字体格式化文本时,应用程序必须选择特定的变体实例; 也就是说,必须为字体变体表中定义的每个轴指定特定的范围内值。可以通过引用在实例记录中定义的命名实例来选择实例,或者通过对各个轴使用一组任意轴值来选择实例。如果未为任何特定轴指定值,则使用字体中定义的该轴的默认值。如果应用程序指定轴的值小于字体中定义的minValue,则必须使用minValue。同样,如果应用程序指定的值大于字体中定义的maxValue,则必须使用maxValue。
7.17.3.Example
此示例适用于具有系列名称“SelawikV”的假设字体,其具有两个变化轴,用于重量和宽度。此表总结了字体轴的说明:
| 轴标签 | 最低价值 | 默认值 | 最大价值 | 轴名称ID |
|---|---|---|---|---|
| ‘wght’ | 300 | 400 | 700 | 256 |
| ‘WDTH’ | 62.5 | 100 | 150 | 257 |
此字体还具有以下命名实例:
| 实例子系列名称 | 子系列名称ID | PostScript名称 | PostScript名称ID | ‘wght’的值 | ‘wdth’的值 |
|---|---|---|---|---|---|
| 定期 | 258 | SelawikV正规 | 262 | 400 | 100 |
| 胆大 | 259 | SelawikV粗体 | 263 | 700 | 100 |
| 简明 | 260 | SelawikV冷凝 | 264 | 400 | 75 |
| 浓缩大胆 | 261 | SelawikV-CondensedBold | 265 | 700 | 75 |
‘fvar’表的构造如下:
| 十六进制数据 | 领域 | 评论 |
|---|---|---|
| 头 | ||
| 0001 | majorVersion | |
| 0000 | minorVersion | |
| 0010 | axesArrayOffset | 16个字节 - 轴数组之前的字段组合大小。 |
| 技术 | countSizePairs | 2个计数/大小对:轴,实例 |
| 技术 | axisCount | 2轴(’wght’,’wdth’) |
| 0014 | axisCount | 每个变异轴记录的大小为20个字节。 |
| 0004 | instanceCount | 4个命名实例 |
| 000E | instanceSize | 实例记录的大小为14个字节。 |
| 第一个变异轴记录 | ||
| 77676874 | axisTag | 轴标记’wght’。 |
| 012C0000 | minValue(最小值) | 最小’wght’值为300(固定格式)。 |
| 01900000 | 默认值 | 默认’wght’值为400。 |
| 02BC0000 | 包括maxValue | 最大’wght’值为700。 |
| 0000 | 旗 | |
| 0100 | axisNameID | 显示名称“Weight”使用名称ID 256。 |
| 第二个变异轴记录 | ||
| 77647468 | axisTag | 轴标记’wdth’。 |
| 003E8000 | minValue(最小值) | 最小’wdth’值为62.5(固定格式)。 |
| 00640000 | 默认值 | 默认’wdth’值为100。 |
| 00960000 | 包括maxValue | 最大’wdth’值为150。 |
| 0000 | 旗 | |
| 0101 | axisNameID | 显示名称“宽度”使用名称ID 257。 |
| 一审记录 | ||
| 0102 | subfamilyNameID | 实例子系列名称“Regular”使用名称ID 258。 |
| 0000 | 旗 | |
| 01900000 | 坐标[0] | ‘wght’坐标为400。 |
| 00640000 | 坐标[1] | ‘wdth’坐标为100。 |
| 0106 | postScriptNameID | Instance PostScript名称“SelawikV-Regular”使用名称ID 262。 |
| 二审记录 | ||
| 0103 | subfamilyNameID | 实例子系列名称“Bold”使用名称ID 259。 |
| 0000 | 旗 | |
| 02BC0000 | 坐标[0] | ‘wght’坐标是700。 |
| 00640000 | 坐标[1] | ‘wdth’坐标为100。 |
| 0107 | postScriptNameID | Instance PostScript名称“SelawikV-Bold”使用名称ID 263。 |
| 三审记录 | ||
| 0104 | subfamilyNameID | 实例子系列名称“Condensed”使用名称ID 260。 |
| 0000 | 旗 | |
| 01900000 | 坐标[0] | ‘wght’坐标为400。 |
| 004B0000 | 坐标[1] | ‘wdth’坐标为75。 |
| 0108 | postScriptNameID | Instance PostScript名称“SelawikV-Condensed”使用名称ID 264。 |
| 四审记录 | ||
| 0105 | subfamilyNameID | 实例子系列名称“Condensed Bold”使用名称ID 261。 |
| 0000 | 旗 | |
| 02BC0000 | 坐标[0] | ‘wght’坐标是700。 |
| 004B0000 | 坐标[1] | ‘wdth’坐标为75。 |
| 0109 | postScriptNameID | Instance PostScript名称“SelawikV-CondensedBold”使用名称ID 265。 |
表的总大小为112个字节。
7.18.gasp 网格拟合和扫描转换程序表
此表包含的信息描述了在具有灰度功能的设备上呈现时字体的首选光栅化技术。此表还可用于单色设备,可以使用该表关闭非常大或小的提示,以提高性能。
在非常小的尺寸下,灰度设备上的最佳外观通常可以通过在不使用提示的情况下渲染灰度字形来实现。在中等大小,提示和单色渲染通常会产生最佳外观。在大尺寸下,提示和灰度渲染的组合通常会产生最佳外观。
如果字体中不存在’gasp’表,则光栅化器可以应用默认规则来决定如何在灰度设备上渲染字形。
7.18.1.’gasp’ Table Formats
‘gasp’表包含一个标题,后跟’gasp’记录分组。
‘喘气’标题
类型 名称 描述
UINT16 版 版本号(设置为1)
UINT16 numRanges 要遵循的记录数
GaspRange gaspRanges [numRanges] 按ppem排序
GaspRange记录数组提供了各种ppem大小的推荐行为。
GaspRange记录
类型 名称 描述
UINT16 rangeMaxPPEM PPEM中范围的上限
UINT16 rangeGaspBehavior 描述所需光栅化器行为的标志。
定义了四个RangeGaspBehavior标志。
RangeGaspBehavior标志
面具 名称 描述
0×0001 GASP_GRIDFIT 使用gridfitting
0×0002 GASP_DOGRAY 使用灰度渲染
0x0004 GASP_SYMMETRIC_GRIDFIT 使用带有ClearType对称平滑的网格配件
仅在版本1“gasp”中受支持
×0008 GASP_SYMMETRIC_SMOOTHING 使用ClearType®沿多个轴平滑
仅在版本1’gasp’中受支持
0xFFF0 保留的 保留标志 - 设置为0
可以在将来扩展该组位标志。前两个位标志独立于以下两个位标志运行。如果启用了字体平滑,则使用前两个位标志。如果启用了ClearType,则使用以下两位标志。rangeGaspBehavior的七个当前定义的值将具有以下用途:
旗 值 含义
GASP_DOGRAY 0×0002 小尺寸,通常ppem <9
GASP_GRIDFIT 0×0001 中等大小,通常为9 <= ppem <= 16
GASP_DOGRAY | GASP_GRIDFIT 为0x0003 大尺寸,通常ppem> 16
(均未) 为0x0000 非常大的可选项,通常ppem> 2048
GASP_SYMMETRIC_GRIDFIT 0x0004 通常始终启用
GASP_SYMMETRIC_SMOOTHING ×0008 更大的屏幕尺寸,通常ppem> 15,最常用于gridfit标志。
GASP_SYMMETRIC_SMOOTHING | GASP_SYMMETRIC_GRIDFIT 0x000C 更大的屏幕尺寸,通常ppem> 15
也不 为0x0000 非常大的可选项,通常ppem> 2048
gaspRange []数组中的记录必须按rangeMaxPPEM值的增加顺序排序。最后一条记录应该使用0xFFFF作为rangeMaxPPEM的标记值,并且应该描述所有大小超过前一条记录上限的行为。如果’gasp’中的唯一条目是0xFFFF标记值,则所描述的行为将用于所有大小。
7.18.2.’gasp’ Table and OpenType Font Variations
在可变字体中,可能需要针对不同的变体实例调整光栅化器行为改变的阈值大小。可以在度量变化(MVAR)表中提供用于调整最多十个GaspRange记录的rangeMaxPPEM值的变化数据,使用值标签’gsp0’到’gsp9’来引用。请注意,对于不同的变体实例,不能更改给定GaspRange记录的光栅化器行为。只能调整rangeMaxPPEM值。
假设’gasp’表中的最后一个GaspRange记录的rangeMaxPPEM值为0xFFFF(实际上是无穷大)。从不为不同的实例调整最后一条记录的rangeMaxPPEM值; MVAR表中与’gasp’条目关联的值记录数必须不超过numRanges减去1。
有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章
7.18.3.Sample ‘gasp’ table
旗 值 字体平滑的意思 具有对称平滑含义的ClearType
版 0×0001
numRanges 0x0004
范围[0],标志 0x0008
0x000A ppem <= 8,仅灰度 ppem <= 8,仅对称ClearType
范围[1],旗帜 0x0010
0x0005 9 <= ppem <= 16,仅限gridfit 9 <= ppem <= 16,仅对称网格
范围[2],旗帜 0x0013
0x0007 17 <= ppem <= 19,gridfit和灰度 17 <= ppem <= 19,对称网格
范围[3],旗帜 0xFFFF
0x000F 20 <= ppem,gridfit和灰度 20 <= ppem,对称网格和对称平滑
7.19.GDEF 字形定义表
字形定义(GDEF)表提供OpenType布局处理中使用的各种字形属性。
7.19.1.Overview
GDEF表包含六个独立子表中的六种类型的信息:
- 该GlyphClassDef表的分类,不同类型的字体字形。
- 所述AttachmentList表标识上的字形,从而简化数据访问和位图缓存所有连接点。
- 所述LigatureCaretList表包含结扎插入记号,其文本处理客户端使用在屏幕上选择和高亮显示一个连字字形的各个部件定位数据。
- 该MarkAttachClassDef表分类标志字形,帮组一起被类似定位标记。
- 所述MarkGlyphSetsTable允许可被用作标记附着类定义的扩展,以允许查找由任意组标记的筛选标记字形字形集的任意数的枚举。
- 所述ItemVariationStore表在可变的字体用于包含用于在GDEF,GPOS或JSTF表中的值的调整的变化数据。
- GSUB,GPOS或JSTF表可以引用用于处理查找表的某些GDEF表信息。例如,请参阅OpenType布局公用表格式中的LookupFlag位枚举。在可变字体中,GDEF,GPOS和JSTF表都可以引用GDEF表中包含的ItemVariationStore表中的变体数据。有关可变字体和ItemVariationStore表的进一步讨论,请参见下文。
客户可以在文本处理期间使用六个GDEF表中的任何一个或多个。本概述解释了如何组织和使用六个表中的每一个(参见图7a)。本章的其余部分描述了各个GDEF表及其引用的表。

字形类定义表概述
Glyph类定义(GlyphClassDef)表标识了字体中的四种字形:基本字形,连字字形,组合标记字形和字形组件(参见图7b)。GSUB和GPOS查找定义并使用这些字形类来区分字符串中的字形类型。例如,GPOS使用字形类来区分简单的基本字形和跟随它的标记字形。

此外,客户端使用类定义来正确应用GSUB和GPOS LookupFlag数据。例如,LookupFlag可以指定在字形操作期间忽略连字和标记。如果字体不包含GlyphClassDef表,则客户端必须在使用GSUB和GPOS表时定义和维护此信息。
附件点列表表概述
附件点列表表(AttachmentList)标识GPOS表中定义的所有附着点及其关联的字形,以便客户端可以快速访问每个字形的附加点的坐标。因此,客户端可以缓存附着点的坐标以及字形位图,并避免每次显示字形时重新计算附着点。如果没有此表,处理速度会变慢,因为客户端必须解码定义附着点的GPOS查找并编译列表中的点。
Ligature Caret列表表概述
Ligature Caret List表(LigatureCaretList)在阿拉伯语和其他具有许多连字的脚本中特别有用,它指定了在字体中所有连字上定位插入符的坐标。客户端使用此数据选择并突出显示文本中的连字组件(参见图7c)。

每个连线可以有多个插入位置,每个位置根据脚本或语言系统的书写方向在基线上定义为X或Y值。字体开发人员可以使用三种格式中的任何一种来表示插入符号坐标值。一种格式仅代表设计单位的值,另一种格式根据指定的轮廓点微调值,第三种格式使用Device表(仅限非可变字体)调整特定字体大小的值。
在可变字体中,可能需要针对不同的变化实例调整插入位置。这是使用ItemVariationStore表中的数据完成的。有关可变字体和ItemVariationStore表的更多信息,请参见下文。
如果没有Ligature Caret List表,客户端必须在不知道连字组件位置的情况下定义插入位置。由此产生的突出显示或命中测试可能不明确。例如,假设客户端沿着假设的“wi”结扎线的宽度将插入符号放置在中点位置。因为“w”比“i”宽,所以该位置不能清楚地表明选择了哪个组件。相反,为了准确选择,应将插入符号向右移动,以便可以清楚地突出显示“w”或“i”。
标记附件类定义表概述
标记类定义表用于将标记字形分配到可以在GSUB或GPOS表中的查找表中使用的不同类中,以控制字形序列中的标记字形如何被查找处理。有关使用标记附件类的详细信息,请参阅OpenType布局公用表格式一章的“查找表”部分中的查找标志说明。
标记字形设置表概述
Mark Glyph Sets表用于定义可在GSUB或GPOS表中的查找表中使用的标记字形集,以控制字形序列中的标记字形如何被查找处理。有关使用标记字形集的更多信息,请参阅OpenType布局公用表格式一章的“查找表”部分中的查找标志说明。
项目变体商店概述
Item Variation Store表用于可变字体。OpenType字体变体允许单个字体沿着一个或多个设计变体轴支持许多设计变体。例如,具有重量和宽度变化的字体可能支持从细到黑的重量,以及从超浓缩到超扩展的宽度。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
选择不同的变体实例时,各个字形的设计会发生变化。使用相同的轮廓和点,但每个点的设计网格中的位置可以改变,整体字形度量也可以改变。结果,对于插入符号X或Y位置也可能需要相应的改变。
插入符号位置的变化数据存储在“项目变体存储”表中。GDEF表中的同一个表也可以保存GPOS或JSTF表中用于X或Y值的变量数据。项目变体存储和组成格式在章节OpenType字体变体公用表格格中描述。项目变体存储也用于MVAR,HVAR和其他表格,但不同于“cvar”或“gvar”表中使用的变体数据的格式。
项目变体商店中的变体数据由多个调整增量组成,这些调整增量应用于字体变体空间的特定区域内的变体实例的目标项目的默认值。项目变体存储格式使用增量集索引来引用应用它们的特定目标,字体数据项的变体增量数据。Item Variation Store外部的数据标识要用于每个给定目标项的delta-set索引。在GDEF,GPOS或JSTF表中,这些索引在VariationIndex表中指定,每个项目引用一个VariationIndex表,需要进行变量调整。
请注意,VariationIndex表是Device表的变体,具有不同的格式值。(有关Device和VariationIndex表格格式的完整详细信息,请参阅OpenType布局公用表格式章节。)这样做是为了使变量字体的默认实例可以与不支持字体变体的应用程序兼容。因此,可变字体无法使用设备表。在不支持字体变体的应用程序中,或者如果字体不是可变字体,将忽略VariationIndex表。
项目变体存储格式使用变量数据的两级组织:存储可以具有多个项目变体数据子表,每个子表具有多个增量集行。增量集索引是一个由两部分组成的索引:选择特定项目变体数据子表的外部索引,以及选择该子表中特定增量集行的内部索引。VariationIndex表指定增量集索引的外部和内部部分。
7.19.2.GDEF Header
GDEF表以标题开头,标题以版本号开头。定义了三个版本。版本1.0包含Glyph类定义表(GlyphClassDef)的偏移量,附件列表表的偏移量(AttachList),Ligature Caret List表(LigCaretList)的偏移量以及Mark Attachment Class Definition表的偏移量(MarkAttachClassDef) )。版本1.2还包括Mark Markph Sets Definition表(MarkGlyphSetsDef)的偏移量。版本1.3还包括项目变体存储表的偏移量。
本章末尾的示例1显示了GDEF标头表。
GDEF标题,版本1.0
类型 名称 描述
UINT16 majorVersion GDEF表的主要版本,= 1
UINT16 minorVersion GDEF表的次要版本,= 0
Offset16 glyphClassDefOffset 从GDEF标头的开头偏移到字形类型的类定义表(可能为NULL)
Offset16 attachListOffset 偏移到附件点列表表,从GDEF头开始(可能为NULL)
Offset16 ligCaretListOffset 绑定到插入符号列表表,从GDEF头开始(可能为NULL)
Offset16 markAttachClassDefOffset 从GDEF标头的开头偏移到标记附件类型的类定义表(可能为NULL)
GDEF标题,版本1.2
类型 名称 描述
UINT16 majorVersion GDEF表的主要版本,= 1
UINT16 minorVersion GDEF表的次要版本,= 2
Offset16 glyphClassDefOffset 从GDEF标头的开头偏移到字形类型的类定义表(可能为NULL)
Offset16 attachListOffset 偏移到附件点列表表,从GDEF头开始(可能为NULL)
Offset16 ligCaretListOffset 绑定到插入符号列表表,从GDEF头开始(可能为NULL)
Offset16 markAttachClassDefOffset 从GDEF标头的开头偏移到标记附件类型的类定义表(可能为NULL)
Offset16 markGlyphSetsDefOffset 从GDEF头的开头偏移到标记字形集定义表(可能为NULL)
GDEF标题,版本1.3
类型 名称 描述
UINT16 majorVersion GDEF表的主要版本,= 1
UINT16 minorVersion GDEF表的次要版本,= 3
Offset16 glyphClassDefOffset 从GDEF标头的开头偏移到字形类型的类定义表(可能为NULL)
Offset16 attachListOffset 偏移到附件点列表表,从GDEF头开始(可能为NULL)
Offset16 ligCaretListOffset 绑定到插入符号列表表,从GDEF头开始(可能为NULL)
Offset16 markAttachClassDefOffset 从GDEF标头的开头偏移到标记附件类型的类定义表(可能为NULL)
Offset16 markGlyphSetsDefOffset 从GDEF头的开头偏移到标记字形集定义表(可能为NULL)
OFFSET32 itemVarStoreOffset 从GDEF标头的开头偏移到Item Variation Store表(可能为NULL)
7.19.3.Glyph Class Definition Table
GSUB和GPOS表使用Glyph类定义表(GlyphClassDef)来标识要使用查找调整的字形类。
该表使用与“ 类定义”表相同的格式(在“ OpenType布局公用表格式”一章中定义)。但是,GlyphClassDef表使用已在GlyphClassDef Enumeration列表中定义的类值:
GlyphClassDef枚举列表
类 描述
1 基本字形(单个字符,间距字形)
2 Ligature字形(多个字符,间距字形)
3 标记字形(非间距组合字形)
4 组件字形(单个字符的一部分,间距字形)
字体开发人员不必对字体中的每个字形进行分类,但任何未分配类值的字形都属于Class 0(0)。例如,类值可能对字体中的阿拉伯字形有用,但对拉丁字形不适用。然后GlyphClassDef表将仅列出阿拉伯字形,并且 - 默认情况下 - 拉丁字形将被分配给类0.组件字形可以放在一起以生成连字。可以通过在引用组件字形的字体中创建字形,或以所需顺序输出组件字形来生成连字。组件字形不用于定义任何GSUB或GPOS格式。
本章末尾的示例2定义了一个GlyphClassDef表,其中包含每个已分配类的示例字形。
7.19.4.Attachment Point List Table
附件点列表表(AttachList)可用于缓存附着点坐标以及字形位图。
该表由Coverage表(Coverage)的偏移量组成,列出了在GPOS表中定义附着点的所有字形,带有附着点的字形数(GlyphCount),以及AttachPoint表(AttachPoint)的偏移数组。该数组列出了AttachPoint表,Coverage表中每个字形一个,与Coverage Index的顺序相同。
AttachList表
类型 名称 描述
Offset16 coverageOffset 偏移到Coverage表 - 从AttachList表的开头
UINT16 glyphCount 带附着点的字形数
Offset16 attachPointOffsets [glyphCount] AttachPoint表的偏移数组 - 从AttachList table-in Coverage Index顺序开始
AttachPoint表包含单个字形(PointCount)上的附着点计数和这些点(PointIndex)的轮廓索引数组,按递增的数字顺序列出。
本章末尾的示例3演示了AttachList表,该表定义了两个字形的附着点。
AttachPoint表
类型 名称 描述
UINT16 pointCount 此字形上的附着点数
UINT16 pointIndices [pointCount] 轮廓点指数数组 - 按数字顺序递增
7.19.5.Ligature Caret List Table
Ligature Caret List表(LigCaretList)定义了字体中所有连字的插入位置。该表由Coverage表的偏移量组成,该表列出了所有连字字形(Coverage),已定义连字的计数(LigGlyphCount)以及LigGlyph表(LigGlyph)的偏移数组。该数组列出了LigGlyph表,Coverage表中每个连字一个,与Coverage Index的顺序相同。
本章末尾的示例4显示了LigCaretList表。
LigCaretList表
类型 名称 描述
Offset16 coverageOffset 偏移到Coverage表 - 从LigCaretList表的开头
UINT16 ligGlyphCount 连字字形数量
Offset16 ligGlyphOffsets [ligGlyphCount] LigGlyph表的偏移数组,从LigCaretList表开始-in Coverage Index order
Ligature雕文表
Ligature Glyph表(LigGlyph)包含单个连字字形的插入符号坐标。在单独的CaretValue表中定义的坐标值的数量等于结扎中的组件数减去一(1)。
LigGlyph表包含为连字(CaretCount)定义的CaretValue表的数量和CaretValue表(CaretValue)的偏移数组。
本章末尾的示例4显示了LigGlyph表。
LigGlyph表
类型 名称 描述
UINT16 caretCount 此结扎的CaretValue表的数量(组件 - 1)
Offset16 caretValueOffsets [caretCount] CaretValue表的偏移数组,从LigGlyph表的开头 - 增加坐标顺序
插入物价值表
用于定义结扎线的插入位置的插入值表(CaretValue)可以是三种可能的格式中的任何一种。一种格式使用设计单位来定义插入位置。其他两种格式使用轮廓点或(在非可变字体中)Device表来微调插入符在特定字体大小和设备分辨率下的位置。在可变字体中,第三种格式使用VariationIndex表(Device表的变体)来引用变体数据,以根据需要调整当前变体实例的插入位置。插入符号坐标是X或Y值,具体取决于文本方向。
CaretValue格式1
第一种格式(CaretValueFormat1)由格式标识符(CaretValueFormat)组成,后跟插入符号位置的单个坐标(坐标)。坐标是设计单位。
这种格式具有体积小和简单的优点,但无法在不同的设备分辨率下对协调值进行微调。
本章末尾的示例4显示了CaretValueFormat1表。
CaretValueFormat1表:仅限设计单位
类型 名称 描述
UINT16 caretValueFormat 格式标识符:format = 1
INT16 坐标 X或Y值,以设计单位表示
CaretValue格式2
第二种格式(CaretValueFormat2)根据特定字形上的轮廓点索引指定插入符号坐标。在字体提示期间,字形轮廓上的轮廓点可能会移动。提示后点的最终位置提供了呈现给定字体大小的最终值。
该表包含格式标识符(CaretValueFormat)和轮廓点索引(CaretValuePoint)。
本章末尾的示例5演示了CaretValueFormat2表。
CaretValueFormat2表:轮廓点
类型 名称 描述
UINT16 caretValueFormat 格式标识符:format = 2
UINT16 caretValuePointIndex 字形上的轮廓点索引
CaretValue格式3
第三种格式(CaretValueFormat3)也以设计单位指定值,但是,在非变量字体中,它使用Device表而不是轮廓点来调整值。此格式提供了对任何设备分辨率微调Coordinate值的优势。(有关设备表的更多信息,请参阅“通用表格格式”一章。)
在可变字体中,必须使用CaretValueFormat3来引用变体数据,以根据需要调整不同变体实例的插入位置。在这种情况下,CaretValueFormat3指定VariationIndex表的偏移量,该表是用于变体的Device表的变体。
注意:虽然需要变量的每个值都需要单独的VariationIndex表引用,但是需要相同变体数据值的两个或多个值可以具有指向相同VariationIndex表的偏移量,并且两个或更多VariationIndex表可以引用相同的变体数据条目。
注意:如果没有VariationIndex表用于特定插入位置值,则该值将用于所有变体实例。
格式由格式标识符(CaretValueFormat),X或Y值(坐标)以及Device或VariationIndex表的偏移量组成。
本章末尾的示例6显示了CaretValueFormat3表。
CaretValueFormat3表:设计单位加上Device或VariationIndex表
类型 名称 描述
UINT16 caretValueFormat 格式标识符格式= 3
INT16 坐标 X或Y值,以设计单位表示
Offset16 deviceOffset 从CaretValue表的开头偏移到设备表(非可变字体)/变异索引表(可变字体)的X或Y值
7.19.6.Mark Attachment Class Definition Table
标记附件类定义表定义标记符号可能属于的类。此表使用与“ 类定义”表(在“ OpenType布局公用表格式”一章中定义)相同的格式。
本文档中的示例7显示了MarkAttachClassDef表。
7.19.7.Mark Glyph Sets Table
在GSUB和GPOS查找中使用标记字形集来过滤考虑或忽略字符串中的哪些标记。标记字形集在MarkGlyphSets表中定义,该表包含各个集合的偏移量,每个集合由标准Coverage表表示:
MarkGlyphSetsTable
类型 名称 描述
UINT16 markGlyphSetTableFormat 格式标识符== 1
UINT16 markGlyphSetCount 定义的标记字形集数
OFFSET32 coverageOffsets [markGlyphSetCount] 用于标记字形集覆盖表的偏移数组。
标记字形集用于与标记附件类相同的目的,作为GSUB和GPOS查找的过滤器。标记字形集与标记附件类不同,但是,标记字形集可以根据字体开发人员的需要进行交叉。对于标记附件类,在任何给定的查找中只能引用一个标记字形集。
请注意,Coverage表的偏移数组使用Offset32,而不是Offset16。
7.19.8.Item Variation Store Table
Item Variation Store表及其组成格式的格式和处理在OpenType Font Variations Common Table Formats一章中描述。用于导出特定变体实例的值的插值算法的规范在OpenType字体变体概述一章中给出。
项目变体存储包含以一组或多组增量排列的调整 - 增量值,这些增量使用增量集索引进行引用。对于需要变化调整的值,使用增量集索引来引用该目标值所需的特定变体数据。在GDEF,GPOS或JSTF表中,在与特定目标项相关联的VariationIndex表中提供增量集索引,例如GDEF表中的插入符位置。(VariationIndex表在OpenType布局公用表格式中描述有关在GDEF表中使用VariationIndex表的详细信息,请参阅本章前面的讨论。有关在GPOS或JSTF表中使用VariationIndex表的详细信息,请参阅每个表的章节中对OpenType字体变体的讨论。
7.19.9.GDEF Table Examples
本章的其余部分描述了所有GDEF表格格式的示例。所有示例都反映了下面描述的唯一参数,但这些示例为构建特定于其他情况的表提供了有用的参考。
这些示例有三列显示十六进制数据,源和注释。
示例1:GDEF标头
示例1显示了GDEF标头定义,其中包含GDEF中每个主表的偏移量。
Hex数据 资源 评论
GDEFHeader
TheGDEFHeader GDEFHeader表定义
00010000 0x00010000在 主要/次要版本
000C GlyphClassDefTable 偏移到GlyphClassDef表
0026 AttachListTable 偏移到AttachList表
0040 LigCaretListTable 偏移到LigCaretList表
005A MarkAttachClassDefTable 偏移到标记附件类定义表
示例2:GlyphClassDef表
示例2中的GlyphClassDef表为GlyphClassDef枚举列表中预定义的每个字形类指定了一个字形。
Hex数据 资源 评论
ClassDefFormat2
GlyphClassDefTable ClassDef表定义
技术 2 classFormat
0004 4 classRangeCount
classRangeRecords [0]
0024 iGlyphID startGlyphID
0024 iGlyphID endGlyphID
0001 1 class:基本字形
classRangeRecords [1]
009F ffiLigGlyphID startGlyphID
009F ffiLigGlyphID endGlyphID
技术 2 class:连字符字形
classRangeRecords [2]
0058 umlautAccentGlyphID startGlyphID
0058 umlautAccentGlyphID endGlyphID
0003 3 class:标记字形
classRangeRecords [3]
018F CurvedTailComponentGlyphID startGlyphID
018F CurvedTailComponentGlyphID endGlyphID
0004 4 class:组件字形
示例3:AttachList表
在示例3中,AttachList表枚举为两个字形定义的附着点。GlyphCoverage表标识字形:“a”和“e。”对于每个覆盖的字形,AttachPoint表指定附着点计数和点索引:“a”字形的一个点和“e”字形的两个点。
Hex数据 资源 评论
AttachList
AttachListTable AttachList表定义
0012 GlyphCoverage 偏移到Coverage表
技术 2 glyphCount
0008 aAttachPoint attachPointOffsets [0]
000C eAttachPoint attachPointOffsets [1]
AttachPoint
aAttachPoint AttachPoint表定义
0001 1 pointCount
0012 18 pointIndices [0]
AttachPoint
eAttachPoint AttachPoint表定义
技术 2 pointCount
000E 14 pointIndices [0]
0017 23 pointIndices [1]
CoverageFormat1
GlyphCoverage 覆盖表定义
0001 1 coverageFormat
技术 2 glyphCount
001C aGlyphID glyphArray [0]
0020 eGlyphID glyphArray [1]
示例4:LigCaretList表,LigGlyph表和CaretValueFormat1表
示例4定义了连字插入符的列表。LigCoverage表列出了定义插入位置的所有连字字形。在此示例中,覆盖了两个连字,“ffi”和“fi”。对于每个覆盖的字形,LigGlyph表指定连字的插入符号数及其坐标值。“fi”结扎线定义了一个插入符号,位于“f”和“i”组件之间; “ffi”连字定义了两个,一个位于两个“f”组件之间,另一个位于“f”和“i”之间。此处显示的CaretValue表使用Format1,其中值仅以设计单位指定。
Hex数据 资源 评论
LigCaretList
LigCaretListTable LigCaretList表定义
0008 LigCoverage 偏移到Coverage表
技术 2 ligGlyphCount
0010 fiLigGlyph ligGlyphOffsets [0]
0014 ffiLigGlyph ligGlyphOffsets [1]
CoverageFormat1
LigCoverage 覆盖表定义
0001 1 coverageFormat
技术 2 glyphCount
009F ffiLigGlyphID glyphArray [0]
00A5 fiLigGlyphID glyphArray [1]
LigGlyph
fiLigGlyph LigGlyph表定义
0001 1 caretCount,等于组件数量 - 1
000E CaretFI caretValueOffsets [0]
LigGlyph
ffiLigGlyph LigGlyph表定义
技术 2 caretCount,等于组件数量 - 1
0006 CaretFFI1 caretValueOffsets [0]
000E CaretFFI2 caretValueOffsets [1]
CaretValueFormat1
CaretFI CaretValue表定义
0001 1 caretValueFormat:仅限设计单位
025B 603 坐标(X或Y值)
CaretValueFormat1
CaretFFI1 CaretValue表定义
0001 1 caretValueFormat:仅限设计单位
025B 603 坐标(X或Y值)
CaretValueFormat1
CaretFFI2 CaretValue表定义
0001 1 caretValueFormat:仅限设计单位
04B6 1206 坐标(X或Y值)
例5:CaretValueFormat2表
示例5显示了CaretValueFormat2表,该表根据特定字形上的轮廓点索引指定连字插入符号坐标。插入符号的最终位置取决于提示后字形上轮廓点的位置。
Hex数据 资源 评论
CaretValueFormat2
Caret1 CaretValue表定义
技术 2 caretValueFormat:轮廓点
000D 13 caretValuePointIndex
例6:CaretValueFormat3表
在示例6中,CaretValueFormat3表以设计单位定义插入位置,但包括一个Device表,用于调整输出字体的磅值和分辨率的X或Y坐标。这里,Device表指定从12 ppem到17 ppem的字体大小的像素调整。
Hex数据 资源 评论
CaretValueFormat3
Caret3 CaretValue表定义
0003 3 caretValueFormat:设计单位加设备表
04B6 1206 坐标(X或Y值,设计单位)
0006 CaretDevice 偏移到设备表
DeviceTableFormat2
CaretDevice 设备表定义
000C 12 startSize
0011 17 endSize
技术 2 deltaFormat
1 增加12ppm 1个像素
1 增加13ppm 1个像素
1 增加14ppm 1个像素
1111 1 增加15ppm 1个像素
2 增加16ppm 2像素
2200 2 增加17ppm 2像素
例7:MarkAttachClassDef表
在示例7中,MarkAttachClassDef表将GlyphClassDef枚举列表中预定义的每个字形范围的附件类指定为标记。
Hex数据 资源 评论
ClassDefFormat2
theMarkAttachClassDefTable ClassDef表定义
技术 2 classFormat:字形范围
0004 4 classRangeCount
classRangeRecords [0]
0268 graveAccentGlyphID startGlyphID
026A circumflexAccentGlyphID endGlyphID
0001 1 class:top marks
ClassRangeRecord [1]
classRangeRecords [1]
0270 diaeresisAccentGlyphID startGlyphID
0272 acuteAccentGlyphID endGlyphID
0001 1 class:最高分
classRangeRecords [2]
028C diaeresisBelowGlyphID startGlyphID
028F cedillaGlyphID endGlyphID
技术 2 class:bottom标记
ClassRangeRecord [3]
classRangeRecords [3]
0295 circumflexBelowGlyphID startGlyphID
0295 circumflexBelowGlyphID endGlyphID
技术 2 class:底痕
7.20.glyf 字形数据
此表包含以TrueType大纲格式描述字体中的字形的信息。有关光栅化器(缩放器)的信息是指TrueType光栅化器。
7.20.1.Table Organization
‘glyf’表由一个字形数据块列表组成,每个字形数据块提供单个字形的描述。标志符号(字形ID)引用字形,它们是从零开始的连续整数。字形总数由’ maxp ‘表中的numGlyphs字段指定。’glyf’表不包括任何整体表头或提供字形数据块偏移的记录。相反,’loca’表提供一个由字形ID索引的偏移数组,它提供’glyf’表中每个字形数据块的位置。请注意,’glyf’表必须始终与’loca’和’maxp’表一起使用。每个字形数据块的大小是根据’loca’表中两个连续偏移之间的差异推断的(提供一个额外的偏移以给出最后一个字形数据块的大小)。作为’loca’格式的结果,’glyf’表中的字形数据块必须是字形ID顺序。
7.20.2.Glyph Headers
每个字形描述都以标题开头:
雕文标题
类型 名称 描述
INT16 numberOfContours 如果轮廓的数量大于或等于零,则这是一个简单的字形。如果是负数,则这是一个复合字形 - 值-1应该用于复合字形。
INT16 XMIN 坐标数据的最小x。
INT16 YMIN 坐标数据的最小y。
INT16 XMAX 坐标数据的最大x。
INT16 YMAX 坐标数据的最大y。
请注意,每个字符的边界矩形定义为左下角(xMin,yMin)和右上角(xMax,yMax)的矩形。
注意:如果已创建字形坐标使得xMin等于lsb,则缩放器将表现更好。例如,如果lsb为123,则字形的xMin应为123.如果lsb为-12,则xMin应为-12。如果lsb为0,则xMin为0.如果所有字形都是这样完成的,则在’head’表中设置flags字段的第1位。
注意:字形描述不包括侧面轴承信息。左侧轴承在’hmtx’表中提供,右侧轴承从提前宽度(也在’hmtx’表中提供)和’glyf’表中提供的边界框坐标推断。对于垂直布局,“vmtx”表中提供了顶侧轴承,并推断出了底侧轴承。光栅化器将以“幻像”点的形式生成侧支承的表示,其在字形描述的末尾添加为四个附加点,并且可以通过字形指令来引用和操纵。有关幻像点的更多背景信息,请参阅“ 指示TrueType字形 ”一章。
7.20.3.Simple Glyph Description
这是numberOfContours大于或等于零时所需的表信息,也就是说,字形不是复合词。请注意,点编号是基数为零的索引,在字形的所有轮廓上按顺序编号; 也就是说,每个轮廓的第一个点数(第一个除外)比前一个轮廓的最后一个点数大一个。
简单的字形表
类型 名称 描述
UINT16 endPtsOfContours [numberOfContours] 每个轮廓最后一个点的点索引数组,以递增的数字顺序排列。
UINT16 instructionLength 指令的总字节数。如果instructionLength为零,则此字形不存在任何指令,并且该字段直接跟随flags字段。
UINT8 指令[instructionLength] 字形的指令字节代码数组。
UINT8 flags [ 变量 ] 数组的标志元素。有关标志数组元素数量的详细信息,请参见下文。
uint8或int16 xCoordinates [ 变量 ] 轮廓点x坐标。有关坐标数组元素数量的详细信息,请参见下文。第一点的坐标是相对于(0,0); 其他人相对于前一点。
uint8或int16 yCoordinates [ 变量 ] 轮廓点y坐标。有关坐标数组元素数量的详细信息,请参见下文。第一点的坐标是相对于(0,0); 其他人相对于前一点。
注意:在’glyf’表中,点的位置不是以绝对值存储,而是以相对于前一点的向量存储。delta-x和delta-y向量表示这些(通常很小的)位置变化。坐标值以字体设计单位表示,由“head”表中的unitsPerEm字段定义。请注意,较小的unitsPerEm值将使delta-x和delta-y值更有可能适合较小的表示(8位而不是16位),尽管可以在级别或精度上进行权衡。用于描述大纲。
flags数组中的每个元素都是一个字节,每个元素都有多个具有不同含义的标志位,如下所示。
在逻辑上,每个点有一个标志字节元素,一个x坐标和一个y坐标。但请注意,标志字节元素和坐标数组使用压缩表示。特别是,如果重复标志元素的逻辑序列或x或y坐标的序列,则可以在单个条目中给出实际的标志字节元素或坐标值,并使用特殊标志来指示该值重复用于后续逻辑条目。必须通过解析flags数组条目来确定标志或坐标数组的实际存储大小。有关详细信息,请参阅下面的标志说
简单的标志符号标志
面具 名称 描述
0×01 ON_CURVE_POINT 位0:如果设置,该点在曲线上; 否则,它不在曲线上。
0×02 X_SHORT_VECTOR 位1:如果置位,相应的x坐标长度为1个字节。如果未设置,则为两个字节长。有关此值的符号,请参阅X_IS_SAME_OR_POSITIVE_X_SHORT_VECTOR标志的说明。
0×04 Y_SHORT_VECTOR 位2:如果置位,相应的y坐标长度为1个字节。如果未设置,则为两个字节长。有关此值的符号,请参阅Y_IS_SAME_OR_POSITIVE_Y_SHORT_VECTOR标志的说明。
0x08的 REPEAT_FLAG 位3:如果置位,则下一个字节(读为无符号)指定该标志字节在逻辑标志数组中重复的次数 - 即,在该条目之后插入的附加逻辑标志条目的数量。(在扩展的逻辑数组中,忽略该位。)这样,列出的标志数可能小于字形描述中的点数。
为0x10 X_IS_SAME_OR_POSITIVE_X_SHORT_VECTOR 位4:该标志有两个含义,具体取决于X_SHORT_VECTOR标志的设置方式。如果设置了X_SHORT_VECTOR,则该位描述值的符号,其中1表示正数,0表示负数。如果未设置X_SHORT_VECTOR且设置此位,则当前x坐标与前一个x坐标相同。如果未设置X_SHORT_VECTOR且未设置此位,则当前x坐标是带符号的16位增量矢量。
为0x20 Y_IS_SAME_OR_POSITIVE_Y_SHORT_VECTOR 位5:该标志有两个含义,具体取决于Y_SHORT_VECTOR标志的设置方式。如果设置了Y_SHORT_VECTOR,则该位描述值的符号,其中1表示正数,0表示负数。如果未设置Y_SHORT_VECTOR且设置此位,则当前y坐标与前一个y坐标相同。如果未设置Y_SHORT_VECTOR且该位也未设置,则当前y坐标是带符号的16位增量矢量。
0x40的 OVERLAP_SIMPLE 位6:如果设置,字形描述中的轮廓可能会重叠。在OpenType中不需要使用此标志 - 也就是说,在没有设置此标志的情况下使轮廓重叠是有效的。但是,它可能会影响某些平台的行为。(有关Apple平台行为的详细信息,请参阅Apple规范中“重叠轮廓”的讨论。)使用时,必须在字形的第一个标志字节上设置。请参阅下面的其他详细
0x80的 保留的 位7保留:设置为零。
当轮廓重叠时,需要非零填充算法以避免丢失。某些光栅化器实现使用OVERLAP_SIMPLE标志来确保使用非零填充算法而不是偶数奇数填充算法。始终使用非零填充算法的实现将忽略此标志。请注意,某些实现可能会在非变量字体中特别检查此标志,但始终对可变字体使用非零填充算法。当字形具有重叠轮廓时,可以使用此标志以提供字体的广泛互操作性 - 特别是非可变字体。
请注意,可变字体通常使用重叠轮廓。如果需要对派生字体进行广泛的互操作性,这会对为特定变量字体实例生成静态字体数据的工具产生影响:如果字形在给定实例中具有重叠轮廓,则工具应设置此标志派生的字形数据,否则应合并轮廓以消除不同轮廓的重叠。
注意:下面描述的OVERLAP_COMPOUND标志与复合字形有类似的用途。为OVERLAP_SIMPLE标志描述的相同注意事项也适用于OVERLAP_COMPOUND标志。
7.20.4.Composite Glyph Description
如果numberOfContours为负数,则使用复合字形描述。
注意:建议使用numberOfContours值-1来表示复合字形。
复合字形以两个uint16值开始(“flags”和“glyphIndex”,即此复合字形中第一个轮廓的索引); 然后数据根据“标志”而变化。
复合字形表
类型 名称 描述
UINT16 旗 组件标志
UINT16 glyphIndex 组件的字形索引
uint8,int8,uint16或int16 自变量1 组件或点号的x偏移量; type取决于组件标志中的位0和1
uint8,int8,uint16或int16 参数2 组件或点号的y偏移量; type取决于组件标志中的位0和1
转型期权
下面的C伪代码片段显示了如何存储和解析复合字形信息; “flags”位的定义遵循以下片段:
复制
do {
uint16 flags;
uint16 glyphIndex;
if ( flags & ARG_1_AND_2_ARE_WORDS) {
(int16 or FWord) argument1;
(int16 or FWord) argument2;
} else {
uint16 arg1and2; /* (arg1 << 8) | arg2 /
}
if ( flags & WE_HAVE_A_SCALE ) {
F2Dot14 scale; / Format 2.14 /
} else if ( flags & WE_HAVE_AN_X_AND_Y_SCALE ) {
F2Dot14 xscale; / Format 2.14 /
F2Dot14 yscale; / Format 2.14 /
} else if ( flags & WE_HAVE_A_TWO_BY_TWO ) {
F2Dot14 xscale; / Format 2.14 /
F2Dot14 scale01; / Format 2.14 /
F2Dot14 scale10; / Format 2.14 /
F2Dot14 yscale; / Format 2.14 */
}
} while ( flags & MORE_COMPONENTS )
if (flags & WE_HAVE_INSTR){
uint16 numInstr
uint8 instr[numInstr]
Argument1和argument2可以是要添加到字形的x和y偏移(设置ARGS_ARE_XY_VALUES标志),或两个点数(未设置ARGS_ARE_XY_VALUES标志)。在后一种情况下,第一个点数表示要与新字形匹配的点。第二个数字表示新字形的“匹配”点。一旦添加了一个字形,其点数就会在最后一个字形后直接开始(第一个字形的端点+ 1)。
当参数1和2是x和ay偏移而不是点并且ROUND_XY_TO_GRID位设置为1时,在将它们添加到字形之前将值四舍五入为最接近的网格线的值。在FUnits中描述了X和Y偏移。
如果设置了WE_HAVE_A_SCALE位,则以2.14格式读取标度值 - 该值可以介于-2到+2之间。在网格拟合之前,将通过此值缩放字形。
位WE_HAVE_A_TWO_BY_TWO允许通过指定2×2矩阵来线性变换X和Y坐标。例如,这可以用于缩放和字形分量的90度旋转。
定义了以下复合字形标志:
复合字形标志
面具 名称 描述
0×0001 ARG_1_AND_2_ARE_WORDS 位0:如果设置此参数,则参数为16位(uint16或int16); 否则,它们是字节(uint8或int8)。
0×0002 ARGS_ARE_XY_VALUES 位1:如果设置了此参数,则参数为xy值; 否则,它们是无符号的点数。
0x0004 ROUND_XY_TO_GRID 位2:如果前面的条件为真,则为xy值。
×0008 WE_HAVE_A_SCALE 位3:这表示组件有一个简单的比例。否则,scale = 1.0。
0×0020 MORE_COMPONENTS 位5:在此之后至少再指示一个字形。
即0x0040 WE_HAVE_AN_X_AND_Y_SCALE 位6:x方向将使用与y方向不同的比例。
0x0080 WE_HAVE_A_TWO_BY_TWO 第7位:有一个2乘2变换将用于缩放组件。
0100 WE_HAVE_INSTRUCTIONS 位8:最后一个组件之后是复合字符的指令。
0200 USE_MY_METRICS 位9:如果设置,则强制复合的aw和lsb(和rsb)等于来自此原始字形的aw和lsb(和rsb)。这适用于暗色和非暗色字符。
的0x0400 OVERLAP_COMPOUND 位10:如果设置,复合字形的组件重叠。OpenType中不需要使用此标志 - 也就是说,在没有设置此标志的情况下使组件重叠是有效的。但是,它可能会影响某些平台的行为。(有关Apple平台行为的详细信息,请参阅Apple的规范。)使用时,必须在第一个组件的标志字上设置。有关简单字形描述中使用的类似OVERLAP_SIMPLE标志,请参阅上面的其他备注。
为0x0800 SCALED_COMPONENT_OFFSET 位11:复合材料设计为具有缩放的元件偏移。
为0x1000 UNSCALED_COMPONENT_OFFSET 位12:复合材料的设计不会使元件偏移缩放。
0xE010 保留的 第4,13,14和15位保留:设置为0。
USE_MY_METRICS的目的是强制lsb和rsb采用所需的值。例如,i-circumflex(U + 00EF)通常由回旋和无点i组成。为了强制复合具有与dotless-i相同的度量,请为复合的无点-i组件设置USE_MY_METRICS。如果没有这个位,rsb和lsb将从复合的’hmtx’条目计算(或者需要使用TrueType指令显式设置)。
请注意,对于旋转的复合组件,未定义USE_MY_METRICS操作的行为。
SCALED_COMPONENT_OFFSET和UNSCALED_COMPONENT_OFFSET标志用于确定在缩放组件字形时如何解释x和y偏移值。如果设置了SCALED_COMPONENT_OFFSET标志,则认为x和y偏移值位于组件字形的坐标系中,并且缩放变换应用于这两个值。如果设置了UNSCALED_COMPONENT_OFFSET标志,则认为x和y偏移值在当前字形的坐标系中,并且比例变换不应用于任一值。如果两个标志都未设置,则光栅化器将应用默认行为。在Microsoft和Apple平台上,默认行为与设置UNSCALED_COMPONENT_OFFSET标志时的行为相同; 建议所有光栅化器实现都使用此行为。如果字体设置了两个标志,这是无效的; 对于这种情况,rasterizer应该使用其默认行为。
7.21.GPOS 字形定位表
字形定位表(GPOS)提供对字形位置的精确控制,以便在字体支持的每个脚本和语言系统中进行复杂的文本布局和渲染。
7.21.1.Overview
复杂的字形定位成为编写系统的一个问题,例如越南语,它使用变音和其他标记来修改字符的声音或含义。这些书写系统需要相对于彼此控制所有标记的放置,以提高易读性和语言准确性。

其他书写系统需要复杂的字形定位才能获得正确的印刷构图。例如,乌尔都语字形是书法的,并且沿着从右到左进行的下降的对角线文本线彼此连接。要正确呈现Urdu,文本处理客户端必须修改每个字形的水平(X)和垂直(Y)位置。

使用GPOS表,字体开发人员可以使用OpenType字体定义一组完整的定位调整功能。通过脚本和语言系统组织的GPOS数据易于文本处理客户端用于定位字形。
使用TrueType 1.0定位字形
TrueType中的字形定位仅使用两个值(placement和advance)来指定文本布局的字形位置。如果字形相对于沿着文本行移动的虚拟“笔尖”定位,则放置描述字形相对于当前笔尖的位置,而advance描述移动笔尖的位置以定位下一个字形(请参阅图4c)。对于水平文本,放置对应于左侧轴承,而advance对应于前进宽度。

TrueType指定仅在水平布局的X方向上放置和前进,而在垂直布局中仅在Y方向上前进。对于简单的拉丁文本布局,这两个值可能足以正确定位字形。但是,对于需要更复杂布局的文本,这些值必须涵盖更丰富的范围。放置和前进可能需要垂直调整,也可以水平调整。
TrueType中定义的唯一定位调整是对字距调整,它修改两个字形之间的水平间距。典型的字距调整表列出了字形对,并指定文本处理客户端应在字形之间添加或删除多少空间以正确显示每对字符。它没有提供有关如何调整每对字形的具体信息,也无法调整两个以上字形的上下文。
使用OpenType定位字形
OpenType字体允许出色的控制和灵活性,可以定位单个字形并将多个字形相对于彼此定位。通过使用GPOS表定义的放置和前进的X和Y值以及使用字形附加点,客户端可以更精确地调整字形的位置。
此外,GPOS表可以引用Device表来定义对任何字体大小和设备分辨率的任何放置或高级值的细微的,依赖于设备的调整。例如,Device表可以指定每个51像素(ppem)的调整,这些调整不会发生在50 ppem。
无论书写方向如何,在OpenType字体中为放置操作指定的X和Y值始终位于典型的笛卡尔坐标系(左侧基线的原点)内。此外,指定的所有值都是在字体单位测量中完成的。这对于字体设计者来说特别方便,因为字形是在相同的坐标系中绘制的。但是,重要的是要注意“提前宽度”的含义会根据书写方向而改变。
例如,在从左到右的脚本中,如果第一个字形的前进宽度为100,则第二个字形从100,0开始。在从右到左的脚本中,如果第一个字形的前进宽度为100,则第二个字形从-100,0开始。对于从上到下的特征,要将字形的前进高度增加100,YAdvance = 100.对于任何特征,无论书写方向如何,要将“o”降低10个单位,设置YPlacement = -10。
其他GPOS功能可以定义附加点以组合字形并将它们相对于彼此定位。字形可能有多个附着点。使用的点将取决于要附加的字形。例如,基本字形可以具有用于不同变音符号的附着点。

为了减小字体文件的大小,基本字形可以对分配给特定类的所有标记字形使用相同的附着点。例如,基本字形可以有两个附着点,一个位于字形上方,另一个位于字形下方。然后,附加在字形上方的所有标记将附加在高点处,并且附加在字形下方的所有标记将附加在低点处。附加点在诸如阿拉伯语之类的脚本中非常有用,这些脚本将多个字形与元音标记组合在一起。
附件点也可用于连接草书式字形。草书字体中的字形可以设计为在渲染时附加或重叠。或者,字体开发人员可以使用OpenType创建草书附件功能,并为每个字形定义显式的出口和入口附着点(参见图4d)。

GPOS表支持八种用于定位和附加字形的操作:
甲单一的调节位置中的一个字形,诸如标或下标。
阿一对调整位置的两个字形相对于彼此。字距调整是对调整的一个例子。
甲草书附件描述草书和被呈现时与连接点连接的其他字形。
甲马克-基极附着位置相对于基座字形,组合标记如阿拉伯定位元音,变音符号,或音调标记时,希伯来语,和越南语。
甲盯结扎附着位置组合标记相对于结扎字形。由于连字可能有多个点用于附加标记,因此字体开发人员需要将每个标记与一个连字字形的组件相关联。
甲标记到标记attachment 1马克相对位置到另一个,当相对于元音越南区别标记定位音调标记。
上下文定位描述了如何在特定字形,字形类或各种字形集的可识别序列内在上下文中定位一个或多个字形。可以对“输入”上下文序列执行一个或多个定位操作。图4e示出了用于定位调整的上下文。
链接上下文定位描述了如何在特定字形,字形类或各种字形集的可识别序列内的链接上下文中定位一个或多个字形。可以对“输入”上下文序列执行一个或多个定位操作。

7.21.2.GPOS Table and OpenType Font Variations
OpenType字体变体允许单个字体沿着一个或多个设计变体轴支持许多设计变体。例如,具有重量和宽度变化的字体可能支持从细到黑的重量,以及从超浓缩到超扩展的宽度。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
选择不同的变体实例时,各个字形的设计会发生变化。使用相同的轮廓和点,但每个点的设计网格中的位置可以改变,默认的水平或垂直前进和侧面轴承也可以改变。因此,GPOS表中的定位和提前调整也可能需要相应的更改。
GPOS表中的定位操作直接使用显式X或Y字体单位值表示。在可变字体中,这些X和Y值适用于默认实例,可能需要针对当前变体实例进行调整。这是使用变体数据完成的,其过程类似于用于字形轮廓和其他字体数据的过程,如OpenType字体变体概述一章中所述。
注意:对于某些GPOS操作,可以通过参考特定字形轮廓点间接表示位置。在可变字体中,使用字形点来指定定位动作将需要调用光栅化器来处理字形轮廓变化数据,以便在完成字形定位操作之前获得点的调整位置。这可能对文本布局处理的性能产生显着的负面影响。因此,建议在可变字体中,需要针对不同变体实例进行调整的位置应始终直接表示为X和Y值。
用于调整GPOS X或Y值的变化数据存储在GDEF表中的Item Variation Store表中。相同的项目变体存储也用于调整GDEF和JSTF表中的值。的项目变化商店和组成格式的章节,在被描述的OpenType字体变化公用表的格式。这些格式也用于BASE表,以及MVAR和其他表中,但不同于’cvar’或’gvar’表中使用的变体数据的格式。
项目变体商店中的变体数据由多个调整增量组成,这些调整增量应用于字体变体空间的特定区域内的变体实例的目标项目的默认值。项目变体存储格式使用增量集索引来引用应用它们的特定目标,字体数据项的变体增量数据。Item Variation Store外部的数据标识要用于每个给定目标项的delta-set索引。在GPOS表中,这些索引在VariationIndex表中指定,每个项目引用一个VariationIndex表,需要进行变量调整。
请注意,VariationIndex表是Device表的变体,具有不同的格式值。(有关Device和VariationIndex表格格式的完整详细信息,请参阅OpenType布局公用表格格式一章。)这样做是为了使可变字体的默认实例与不支持字体变体的应用程序兼容。因此,可变字体无法使用设备表。在不支持字体变体的应用程序中,或者如果字体不是可变字体,将忽略VariationIndex表。
项目变体存储格式使用变量数据的两级组织:存储可以具有多个项目变体数据子表,每个子表具有多个增量集行。增量集索引是一个由两部分组成的索引:选择特定项目变体数据子表的外部索引,以及选择该子表中特定增量集行的内部索引。VariationIndex表指定增量集索引的外部和内部部分。
7.21.3.Table Organization
GPOS表以一个标头开头,该标头定义了ScriptList,FeatureList,LookupList和一个可选的FeatureVariations表的偏移量(见图4f):
该ScriptList标识使用字形定位的字体的所有脚本和语言系统。
该FeatureList定义了所有渲染这些脚本和语言系统所需的字形定位功能。
该LookupList包含了所有实现每个字形定位功能需要查找数据。
所述FeatureVariations表可以用来替换一个备用组查找表以用于在特定条件下任何给定功能。目前仅在变量字体中使用。
有关ScriptLists,FeatureLists,LookupLists和FeatureVariation表的详细讨论,请参阅OpenType Layout Common Table Formats一章。

GPOS表是有条理的,因此文本处理客户端可以轻松找到适用于特定脚本或语言系统的功能和查找。要访问GPOS信息,客户端应使用以下过程:
在GPOS ScriptList表中找到当前脚本。
如果语言系统已知,请在脚本中搜索正确的LangSys表; 否则,请使用脚本的默认LangSys表。
LangSys表在GPOS FeatureList表中提供索引号,以访问所需的功能和许多其他功能。
检查每个要素的featureTag,并选择要应用于输入字形字符串的要素表。
如果存在“特征变体”表,请评估“特征变体”表中的条件,以确定是否应将任何最初选择的特征表替换为备用特征表。
每个功能都在GPOS LookupList表中提供一组索引号。从所选要素表集中汇编所有查找,并按LookupList表中给出的顺序应用查找。
有关“功能变体”表及其处理方式的详细说明,请参阅“ OpenType布局公用表格式 ”一章。
查找数据在查找表中定义,查找表在OpenType布局公用表格式章节中定义。LookupTable包含一个或多个子表,用于定义用于实现功能的定位操作的特定条件,类型和结果。特定查找子表单类型用于字形定位操作,并在本章中定义。Lookup表中的所有子表必须具有相同的查找类型,如下表中列出的GPOS LookupType枚举:
GPOS LookupType枚举
值 类型 描述
1 单一调整 调整单个字形的位置
2 配对调整 调整一对字形的位置
3 草书附件 附上草书字形
4 MarkToBase附件 将组合标记附加到基本字形
五 MarkToLigature附件 将组合标记附加到结扎线上
6 MarkToMark附件 将组合标记附加到另一个标记
7 上下文定位 在上下文中定位一个或多个字形
8 链式上下文定位 在链接上下文中定位一个或多个字形
9 扩展定位 其他定位的扩展机制
10+ 保留的 供将来使用(设为零)
每个LookupType都有一个或多个子表格式。“最佳”格式取决于定位操作的类型和最终的存储效率。当字形信息最好以多种格式呈现时,只要所有子表具有相同的LookupType,单个查找可以定义多个子表。例如,在给定查找内,字形索引数组格式可以最好地表示一组目标字形,而字形索引范围格式对于另一组可以更好。
某些结构用于多个GPOS Lookup子表格类型和格式。所有Lookup子表都使用Coverage表,该表在OpenType Layout Common Table Formats一章中定义。单个和对调整(LookupTypes 1和2)使用ValueRecord结构和关联的ValueFormat枚举,这些枚举将在本章后面定义。附件子表(LookupTypes 3,4,5和6)使用Anchor和MarkArray表,这些表也在本章后面定义。
对同一个字形或字符串的一系列定位操作需要多次查找,每个单独的操作一次。在这些情况下累积定位调整值。每个查找在LookupList表中具有不同的数组索引,并以LookupList顺序应用。
在文本处理期间,客户端在移动到下一个查找之前对字符串中的每个字形应用查找。在客户端找到目标字形或字形上下文并执行定位操作(如果已指定)后,将对字形完成查找。要移动到“下一个”字形,客户端通常会跳过参与查找操作的所有字形:定位的字形以及形成操作上下文的任何其他字形。
只有一个例外:序列中的“下一个”字形可能是形成刚刚执行的操作的上下文的字形之一。例如,在对定位操作(即,字距调整)的情况下,如果第二个字形的ValueRecord为空,则该字形被视为序列中的“下一个”字形。
本章的其余部分描述了GPOS标头和为每个LookupType定义的子表。实施例在此章的最后示出了GPOS头和9个LookupTypes七个,以及所述ValueRecord和锚和MarkArray表。
7.21.4.GPOS Header
GPOS表以包含表的版本号的标头开头。定义了两个版本。版本1.0包含三个表的偏移:ScriptList,FeatureList和LookupList。1.1版还包括FeatureVariations表的偏移量。有关这些表的说明,请参阅OpenType布局公用表格式一章。本章末尾的示例1显示了GPOS Header 1.0版表定义。
GPOS标题,版本1.0
类型 名称 描述
UINT16 majorVersion GPOS表的主要版本,= 1
UINT16 minorVersion GPOS表的次要版本,= 0
Offset16 scriptListOffset 从GPOS表的开头偏移到ScriptList表
Offset16 featureListOffset 从GPOS表的开头偏移到FeatureList表
Offset16 lookupListOffset 从GPOS表的开头偏移到LookupList表
GPOS标题,1.1版
类型 名称 描述
UINT16 majorVersion GPOS表的主要版本,= 1
UINT16 minorVersion GPOS表的次要版本,= 1
Offset16 scriptListOffset 从GPOS表的开头偏移到ScriptList表
Offset16 featureListOffset 从GPOS表的开头偏移到FeatureList表
Offset16 lookupListOffset 从GPOS表的开头偏移到LookupList表
OFFSET32 featureVariationsOffset 从GPOS表的开头偏移到FeatureVariations表(可能为NULL)
7.21.5.Lookup Type 1: Single Adjustment Positioning Subtable
单个调整定位子表(SinglePos)用于调整单个字形的放置或前进,例如下标或上标。此外,SinglePos子表通常用于实现上下文定位的查找数据。
SinglePos子表将具有以下两种格式之一:一种对一系列字形应用相同的调整(格式1),另一种对每种唯一字形应用不同的调整(格式2)。
单一调整定位格式1:单一定位值
SinglePosFormat1子表将相同的定位值应用于其Coverage表中列出的每个字形。例如,当字体使用旧式数字时,可以应用此格式来均匀地降低所有数学运算符字形的位置。
Format 1子表包含格式标识符(posFormat),Coverage表的偏移量,用于定义要通过定位值(coverageOffset)调整的字形,以及格式标识符(valueFormat),用于描述数据的数量和种类。 ValueRecord。
ValueRecord指定要应用于所有覆盖的字形的一个或多个定位值(valueRecord)。例如,如果Coverage表中的所有字形都需要水平和垂直调整,则ValueRecord将指定xPlacement和yPlacement的值。
本章末尾的示例2显示了用于调整下标字形位置的SinglePosFormat1子表。
SinglePosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 coverageOffset 从SinglePos子表的开头偏移到Coverage表。
UINT16 valueFormat 定义ValueRecord中的数据类型。
ValueRecord valueRecord 定义定位值 - 应用于Coverage表中的所有字形。
单调整定位格式2:定位值数组
SinglePosFormat2子表提供ValueRecords数组,其中包含Coverage表中每个字形的一个定位值。此格式比格式1更灵活,但它在字体文件中需要更多空间。
例如,假设Cyrillic脚本将用于左对齐文本。对于所有字形,格式2可以定义左侧轴承的位置调整以对齐段落的左边缘。为实现此目的,Coverage表将列出脚本中的每个字形,SinglePosFormat2子表将为每个覆盖的字形定义ValueRecord。相应地,每个ValueRecord将指定左侧轴承的xPlacement调整值。
注意:单个ValueFormat适用于SinglePos子表中定义的所有ValueRecords。在此示例中,如果xPlacement是ValueRecord光学对齐字形所需的唯一值,则X_PLACEMENT标志将是子表的valueFormat字段中设置的唯一标志。
与格式1一样,格式2子表包含格式标识符(posFormat),Coverage表的偏移量,用于定义要通过定位值(coverageOffset)调整的字形,以及ValueFormat标志字段(valueFormat),用于描述ValueRecords中的数据量和种类。此外,格式2子表包括:
ValueRecords(valueCount)的计数。为Coverage表中的每个字形定义一个ValueRecord。
一组ValueRecords,用于指定定位值(valueRecords)。由于数组遵循Coverage Index顺序,因此第一个ValueRecord应用于Coverage表中列出的第一个字形,依此类推。
本章末尾的示例3显示了如何使用SinglePosFormat2子表调整三个短划线字形的间距。
SinglePosFormat2子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 2
Offset16 coverageOffset 从SinglePos子表的开头偏移到Coverage表。
UINT16 valueFormat 定义ValueRecords中的数据类型。
UINT16 valueCount ValueRecords的数量 - 必须等于Coverage表中的glyphCount。
ValueRecord valueRecords [valueCount] ValueRecords数组 - 应用于字形的定位值。
7.21.6.Lookup Type 2: Pair Adjustment Positioning Subtable
对调整定位子表(PairPos)用于调整两个字形相对于彼此的放置或前进 - 例如,指定字形对的字距调整数据。然而,与典型的字距调整表相比,PairPos子表提供了更多的灵活性和对字形定位的精确控制。PairPos子表可以在X和Y方向上独立调整一对中的每个字形,并且它可以明确地描述应用于每个字形的特定调整类型。
PairPos子表可以是两种格式之一:一种是通过索引(格式1)单独标识字形,另一种是按类标识字形(格式2)。
配对调整定位格式1:字形对的调整
格式1使用字形索引来访问一个或多个特定字形对的定位数据。所有对都按照文本布局方向确定的顺序指定。
注意:对于从右到左书写的文本,最右边的字形将是一对中的第一个字形; 相反,对于从左到右书写的文本,最左边的字形将是第一个。
PairPosFormat1子表包含格式标识符(posFormat)和两个ValueFormat字段:
valueFormat1适用于每对中第一个字形的ValueRecords。单个ValueFormat字段适用于所有第一个字形的ValueRecords。如果valueFormat1设置为零(0),则相应的字形没有ValueRecord,因此不应重新定位。
valueFormat2适用于每对中第二个字形的ValueRecords。单个ValueFormat字段适用于所有第二个字形的ValueRecords。如果valueFormat2设置为0,则该对的第二个字形是应该执行查找的“下一个”字形。
PairPos子表还定义了Coverage表(coverageOffset)的偏移量,该表列出了每对中第一个字形的索引。多个对可以具有相同的第一个字形,但Coverage表将仅列出该字形一次。
子表还包含PairSet表的偏移数组(pairSetOffsets)和已定义表的计数(pairSetCount)。PairSet数组包含Coverage表中列出的每个字形的一个偏移量,并使用与覆盖率索引相同的顺序。
PairPosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 coverageOffset 从PairPos子表的开头偏移到Coverage表。
UINT16 valueFormat1 定义valueRecord1中的数据类型 - 对于该对中的第一个字形(可能为零)。
UINT16 valueFormat2 定义valueRecord2中的数据类型 - 对于该对中的第二个字形(可以为零)。
UINT16 pairSetCount PairSet表的数量
Offset16 pairSetOffsets [pairSetCount] PairSet表的偏移数组。偏差来自PairPos子表的开头,按Coverage Index排序。
PairSet表枚举以覆盖的字形开头的所有字形对。PairValueRecords(pairValueRecords)数组包含每对的一条记录,并列出按每对中第二个字形的字形ID排序的记录。pairValueCount字段指定集合中的PairValueRecords数。
配对表
类型 名称 描述
UINT16 pairValueCount PairValueRecords的数量
PairValueRecord pairValueRecords [pairValueCount] PairValueRecords数组,按第二个字形的字形ID排序。
PairValueRecord指定对中的第二个字形(secondGlyph)并为每个字形定义ValueRecord(valueRecord1和valueRecord2)。如果PairPos子表中的valueFormat1设置为零(0),则valueRecord1将为空; 同样,如果valueFormat2为0,则valueRecord2将为空。
本章末尾的示例4显示了一个PairPosFormat1子表,它定义了两种对称字距调整的情况。
PairValueRecord
类型 名称 描述
UINT16 secondGlyph 对中第二个字形的字形ID(第一个字形在Coverage表中列出)。
ValueRecord valueRecord1 定位对中第一个字形的数据。
ValueRecord valueRecord2 定位对中第二个字形的数据。
配对调整定位格式2:类对调整
格式2将一对定义为一组两个字形类,并修改一个类中所有字形的位置。例如,此格式在日语脚本中很有用,这些脚本将特定的字距调整操作应用于包含标点符号的所有字形对。一个类将被定义为可以与标点符号结合的所有字形,而其他类将是类似标点符号的组。
在PairPosFormat2子表中,使用“类型定义”表定义字形类,该表在“OpenType布局公用表格式”一章中定义。
PairPos Format2子表以格式标识符(posFormat)和Coverage表(coverageOffset)的偏移量开始,从PairPos子表的开头开始测量。Coverage表列出了每个字形对中可能出现的第一个字形的索引。多个对可以以相同的字形开头,但Coverage表仅列出一次字形索引。
PairPosFormat2子表还包括两个ValueFormat字段:
valueFormat1适用于每对中第一个字形的ValueRecords。单个ValueFormat字段适用于所有第一个字形的ValueRecords。如果valueFormat1设置为零(0),则第一个字形的ValueRecords将为空,因此不会重新定位第一个字形。
valueFormat2适用于每对中第二个字形的ValueRecords。单个ValueFormat字段适用于所有第二个字形的ValueRecords。如果valueFormat2设置为0,则该对的第二个字形的ValueRecords将为空,第二个字形不会重新定位,并且它将成为执行查找的“下一个”字形。
PairPosFormat2要求将所有对中的每个字形分配给一个类,该类由称为类值的整数标识。然后,对在二维数组中表示为两个类值的序列。可以在一个Format 2子表中表示多对。
PairPosFormat2子表包含两个类定义表的偏移量(classDef1Offset,classDef2Offset):一个将类值分配给所有对中的所有第一个字形(classDef1),另一个将类值分配给所有对中的所有第二个字形(classDef2) 。如果一对中的两个字形使用相同的类定义,则classDef1的偏移值可以与classDef2的偏移值相同,但它们不需要相同。子表还指定了classDef1(class1Count)和classDef2(class2Count)中定义的字形类的数量,包括Class 0。
对于ClassDef1表中标识的每个类,Class1Record枚举包含特定类作为第一个组件的所有对。Class1Record数组根据类值存储所有Class1Records。
注意: Class1Records未标记类值标识符。相反,数组中Class1Record的索引值定义了记录所代表的类值。例如,第一个Class1Record枚举以Class 0字形开头的对,第二个Class1Record枚举以Class 1字形开头的对,依此类推。
PairPosFormat2子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 2
Offset16 coverageOffset 从PairPos子表的开头偏移到Coverage表。
UINT16 valueFormat1 ValueRecord定义 - 对于该对的第一个字形(可能为零)。
UINT16 valueFormat2 ValueRecord定义 - 对于该对的第二个字形(可以为零)。
Offset16 classDef1Offset 从PairPos子表的开头偏移到ClassDef表 - 对于该对的第一个字形。
Offset16 classDef2Offset 从PairPos子表的开头偏移到ClassDef表 - 对于该对的第二个字形。
UINT16 class1Count classDef1表中的类数 - 包括类0。
UINT16 class2Count classDef2表中的类数 - 包括Class 0。
Class1Record class1Records [class1Count] Class1记录的数组,按classDef1中的类排序。
每个Class1Record包含一个Class2Records(class2Records)数组,它们也按类值排序。必须为classDef2表中的每个类声明一个Class2Record,包括Class 0。
Class1Record
类型 名称 描述
Class2Record class2Records [class2Count] Class2记录的数组,按classDef2中的类排序。
Class2Record由两个ValueRecords组成,一个用于类对中的第一个字形(valueRecord1),另一个用于第二个字形(valueRecord2)。请注意,Class2Record的两个字段都是可选的:如果PairPos子表的valueFormat1或valueFormat2的值为零(0),则相应的记录(valueRecord1或valueRecord2)将为空 - 即不存在。例如,如果valueFormat1为零,则Class2Record将以valueRecord2开头并仅由valueRecord2组成。文本处理客户端必须知道Class2Record的变量性质,并使用valueFormat1和valueFormat2字段来确定Class2Record的大小和内容。
本章末尾的示例5演示了在PairPosFormat2子表中使用字形类进行对字距调整。
Class2Record
类型 名称 描述
ValueRecord valueRecord1 定位第一个字形 - 如果valueFormat1 = 0则为空。
ValueRecord valueRecord2 定位第二个字形 - 如果valueFormat2 = 0则为空。
7.21.7.Lookup Type 3: Cursive Attachment Positioning Subtable
设计了一些草书字体,以便在使用默认定位进行渲染时,相邻的字形会加入。但是,如果需要进行定位调整以连接字形,则草书附件定位(CursivePos)子表可以通过对齐两个锚点来描述如何连接字形:字形的指定出口点和以下字形的指定入口点。
锚定对准的定位调整可以是水平的也可以是垂直的。请注意,文本布局方向(水平,水平布局)中的定位效果与交叉流方向(垂直,水平布局)的工作方式不同:
为了调整行布局方向,布局引擎调整第一个字形的前进(按逻辑顺序)。这有效地使第二字形相对于第一字形移动,使得锚在该方向上对齐。
对于交叉流方向,调整一个字形的放置以使锚定线对齐。调整哪个字形由父查找表中的rightToLeft标志确定:如果rightToLeft标志是清除的,则调整第二个字形以使锚与第一个字形对齐; 如果设置了rightToLeft标志,则调整第一个字形以使锚与第二个字形对齐。
请注意,如果设置了rightToLeft查找标志,则连接序列中的最后一个字形将保持其相对于基线的交叉流方向的初始位置,并调整前面连接的字形的交叉流位置。
子表有一种格式:CursivePosFormat1。
草书附件定位格式1:草书附件
CursivePosFormat1子表以格式标识符(posFormat)和Coverage表(coverageOffset)的偏移量开头,该表列出了定义草书附件数据的所有字形。此外,子表包含Coverage表中列出的每个字形的一个EntryExitRecord,这些记录的计数(entryExitCount),以及与Coverage Index(entryExitRecords)的顺序相同的记录数组。
CursivePosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 coverageOffset 从CursivePos子表开始偏移到Coverage表。
UINT16 entryExitCount EntryExit记录的数量
EntryExitRecord entryExitRecord [entryExitCount] EntryExit记录数组,以Coverage索引顺序排列。
每个EntryExitRecord包含两个偏移:一个到Anchor表,用于标识字形上的入口点(entryAnchorOffset),以及一个到Anchor表的偏移量,用于标识字形上的出口点(exitAnchorOffset)。(有关Anchor表的完整说明,请参阅本章末尾。)
要使用CursivePosFormat1子表定位字形,文本处理客户端会将字形的ExitAnchor点与以下字形的EntryAnchor点对齐。如果不存在相应的锚点,则EntryAnchor或ExitAnchor偏移量可能为NULL。
在本章的最后,示例6描述了乌尔都语中的草书字形附件。
EntryExitRecord
类型 名称 描述
Offset16 entryAnchorOffset 从CursivePos子表开始偏移到entryAnchor表(可能为NULL)。
Offset16 exitAnchorOffset 从CursivePos子表开始偏移到exitAnchor表(可能为NULL)。
7.21.8.Lookup Type 4: Mark-to-Base Attachment Positioning Subtable
MarkToBase附件(MarkBasePos)子表用于相对于基本字形定位组合标记字形。例如,阿拉伯语,希伯来语和泰语脚本将元音,变音符号和音调标记与基本字形组合在一起。
在MarkBasePos子表中,每个标记字形都有一个锚点,并且还分配给标记类。然后,每个基本字形为其使用的每个标记类定义一个锚点。当标记与给定基础组合时,将调整标记放置,以使标记锚与适用标记类的基础锚对齐。基本字形的放置和两个字形的前进不受影响。
例如,假设有两个标记类:位于基本字形(Class 0)上方的所有标记,以及位于基本字形(Class 1)下方的所有标记。在这种情况下,使用这些标记的每个基本字形将定义两个锚点,一个用于附加类0中列出的标记字形,另一个用于附加类1中列出的标记字形。
要识别与标记组合的基本字形,文本处理客户端必须在从标记到前一个基本字形的字形字符串中向后看。为了组合标记和基本字形,客户端对齐它们的附着点,将标记相对于基本字形的最终笔尖(前进)位置定位。
标记类由特定整数标识。在MarkBasePos子表中,使用MarkArray表和标记Coverage表提供每个标记的锚定义以及每个标记到标记类的分配。首先,标记Coverage表指定子表所涵盖的所有标记字形。然后,对于Coverage表中的每个标记,MarkArray表都有一个相应的MarkRecord,用于定义标记的锚点和类别赋值。该MarkArray表和MarkRecord在本章后面定义。
MarkToBase附件子表有一种格式:MarkBasePosFormat1。
标记到基础附件定位格式1:标记到基础的附着点
MarkBasePosFormat1子表以格式标识符(posFormat)和偏移量(markCoverageOffset,baseCoverageOffset)开头到两个Coverage表:一个列出子表中引用的所有标记字形(markCoverage),另一个列出子表中引用的所有基本字形(baseCoverage)。
MarkBasePosFormat1子表还包含MarkArray表的偏移量(markArrayOffset)。对于标记Coverage表中的每个标记字形,MarkArray表中的MarkRecord指定其类以及描述标记附着点的Anchor表的偏移量。classCount字段指定在所有MarkRecords中定义的不同标记类的总数。
MarkBasePosFormat1子表还包含BaseArray表(baseArrayOffset)的偏移量,该表为每个基本字形定义一个锚点数组,每个标记类对应一个锚点数组。
MarkBasePosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 markCoverageOffset 从MarkBasePos子表的开头偏移到markCoverage表。
Offset16 baseCoverageOffset 偏移到baseCoverage表,从MarkBasePos子表开始。
UINT16 markClassCount 为标记定义的类数
Offset16 markArrayOffset 从MarkBasePos子表的开头偏移到MarkArray表。
Offset16 baseArrayOffset 从MarkBasePos子表的开头偏移到BaseArray表。
BaseArray表由BaseRecords的数组(baseRecords)和count(baseCount)组成。该数组以与baseCoverage索引相同的顺序存储BaseRecords。baseCoverage表中的每个基本字形都有一个BaseRecord。
BaseArray表
类型 名称 描述
UINT16 baseCount BaseRecords的数量
BaseRecord baseRecords [baseCount] BaseRecords数组,按baseCoverage索引的顺序排列。
BaseRecord为MarkArray表的MarkRecords中标识的每个标记类(包括Class 0)声明一个Anchor表。每个Anchor表指定一个附加点,用于将特定类中的所有标记附加到基本字形。BaseRecord包含一个Anchor表的偏移数组(baseAnchorOffsets)。从零开始的偏移数组定义了每个基本字形用于附加标记的整个连接点集。Anchor表的偏移量按标记类排序。
注意:锚表未标记类值标识符。相反,数组中Anchor表的索引值定义了Anchor表所表示的类值。
本章末尾的示例7使用MarkBasePosFormat1子表定义基本字形上方和下方的标记定位。
BaseRecord
类型 名称 描述
Offset16 baseAnchorOffset [markClassCount] Anchor表的偏移量数组(每个标记类别一个)。偏移量来自BaseArray表的开头,按类排序。
7.21.9.Lookup Type 5: Mark-to-Ligature Attachment Positioning Subtable
MarkToLigature附件(MarkLigPos)子表用于定位组合标记字形与连字基础字形的关系。使用前面描述的MarkToBase附件,每个基本字形都有为每类标记定义的附着点。MarkToLigature附件类似,除了每个连字字形被定义为具有多个组件(在虚拟意义上 - 不是实际字形),并且每个组件具有为不同标记类定义的单独的连接点集。
因此,连字字形可能具有一类标记的多个基础连接点。对于分配给特定类的给定标记,适当的基础附着点由与标记相关联的连字分量确定。这取决于原始字符串和后续的字符或字形序列处理,而不仅仅是字体数据。当文本布局客户端使用GSUB表执行任何基于字符的预处理或任何字形替换操作时,文本布局客户端必须跟踪标记与特定连字字形组件的关联。
MarkLigPos子表可用于定义多个标记到结扎的附件。在子表中,每个标记字形都有一个锚点,并与一类标记相关联。与MarkToBase附件一样,使用MarkArray表和标记Coverage表定义标记锚点和类别赋值。每个连字字形都指定一个二维数据数组:对于连字中的每个组件,定义一个锚点数组,每个标记类别一个。
例如,假设有两个标记类:位于基本字形(Class 0)上方的所有标记,以及位于基本字形(Class 1)下方的所有标记。在这种情况下,基本连字字形的每个组件可以定义两个锚点,一个用于附加类0中列出的标记字形,另一个用于附加类1中列出的标记字形。或者,如果语言系统不允许标记在第二组件上,第一连字组件可以定义两个锚点,每个标记对应一个标记,第二连字组件可以不定义锚点。
要使用MarkToLigature附件子表定位组合标记,文本处理客户端必须从标记向后工作到前面的连字字形。要正确访问子表,客户端必须跟踪与标记关联的组件。对齐附着点结合了标记和结扎。
与标记到基础附件一样,当标记与给定的结扎基部组合时,标记放置被调整,使得标记锚与适用的基础锚对齐。基本字形的放置和两个字形的前进不受影响。
MarkToLigature附件子表有一种格式:MarkLigPosFormat1。
Mark-To-Ligature附件定位格式1:Mark-to-Ligature附件
MarkLigPosFormat1子表以格式标识符(posFormat)和两个偏移量(markCoverageOffset,baseCoverageOffset)开头,Coverage表列出了子表中引用的所有标记字形(markCoverage)和Ligature字形(ligatureCoverage)。
MarkLigPosFormat1子表还包含MarkArray表(markArrayOffset)的偏移量。对于标记Coverage表中的每个标记字形,MarkArray表中的MarkRecord指定其类以及描述标记附着点的Anchor表的偏移量。markClassCount字段指定在所有MarkRecords中定义的不同标记类的总数。
MarkLigPosFormat1子表还包含LigatureArray表(ligatureArrayOffset)的偏移量,该表为每个连字字形定义了锚数据的二维数组:每个标记类每个连字组件一个锚。
MarkLigPosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 markCoverageOffset 从MarkLigPos子表的开头偏移到markCoverage表。
Offset16 ligatureCoverageOffset 从MarkLigPos子表的开头偏移到ligatureCoverage表。
UINT16 markClassCount 已定义标记类的数量
Offset16 markArrayOffset 从MarkLigPos子表的开头偏移到MarkArray表。
Offset16 ligatureArrayOffset 从MarkLigPos子表的开头偏移到LigatureArray表。
LigatureArray表包含一个计数(ligatureCount)和一个偏移数组(ligatureAttachOffsets)到LigatureAttach表。ligatureAttachOffsets数组列出了偏移量
LigatureAttach表,一个用于ligatureCoverage表中列出的每个连字字形,与ligatureCoverage索引的顺序相同。
LigatureArray表
类型 名称 描述
UINT16 ligatureCount LigatureAttach表偏移的数量
Offset16 ligatureAttachOffsets [ligatureCount] LigatureAttach表的偏移数组。偏移量来自LigatureArray表的开头,由ligatureCoverage索引排序。
每个LigatureAttach表都包含一个连字中组件字形的数组(componentRecords)和count(componentCount)。该数组以与连字中的组件相同的顺序存储ComponentRecords。记录的顺序也对应于文本的书写方向 - 即逻辑方向。对于从左到右书写的文本,第一个组件位于左侧; 对于从右到左书写的文本,第一个组件在右侧。
LigatureAttach表
类型 名称 描述
UINT16 componentCount 此连字中的ComponentRecords数
ComponentRecord componentRecords [componentCount] 组件记录数组,按书写方向排序。
ComponentRecord,一个用于连字中的每个组件,包含一个到Anchor表的偏移量数组(ligatureAnchorOffsets),用于定义用于将标记附加到组件的所有附着点。对于MarkArray记录中标识的每个标记类(包括类0),Anchor表指定用于将特定类中的所有标记相对于组件附加到连字基本字形的点。
在ComponentRecord中,从零开始的ligatureAnchorOffsets数组按标记类列出了Anchor表的偏移量。如果组件没有为特定类别的标记定义附着点,则对应的Anchor表的偏移量将为NULL。
本章末尾的示例8显示了MarkLisPosFormat1子表,用于将标记重音附加到阿拉伯语脚本中的连字字形。
ComponentRecord
类型 名称 描述
Offset16 ligatureAnchorOffsets [markClassCount] Anchor表的偏移量数组(每个类一个)。偏移量来自LigatureAttach表的开头,按类排序(可能为NULL)。
7.21.10.Lookup Type 6: Mark-to-Mark Attachment Positioning Subtable
MarkToMark附件(MarkMarkPos)子表格与MarkToBase附件子表格的形式相同,但其功能不同。MarkToMark附件定义了一个标记相对于另一个标记的位置,例如,相对于越南语中的元音变音符号定位色调标记。
附着标记为mark1,附加的基准标记为mark2。在MarkMarkPos子表中,每个mark1字形都有一个锚点附加点,并被分配给一类标记。对于MarkToBase附件中的标记字形,mark1字形的定位点和类分配是使用MarkArray表结合mark1 Coverage表定义的。每个mark2字形为每类标记定义一个锚点。
例如,假设有两个mark1类:所有标记位于mark2字形(Class 0)的左侧,所有标记位于mark2字形(Class 1)的右侧。使用这些标记的每个mark2字形定义了两个锚点:一个用于附加类0中列出的mark1字形,另一个用于附加类1中列出的mark1字形。
与mark1字形组合的mark2字形是以字形字符串顺序在mark1字形之前的字形(根据LookupFlags跳过字形)。当mark2Coverage覆盖mark2字形时,子表格恰好适用。为了组合标记字形,调整mark1字形的位置,使得相关的附着点重合。提前宽度不受影响。MarkToBase,MarkToLigature和MarkToMark定位表的输入上下文是正在定位的标记。如果序列包含多个标记,则查找可能会多次对其进行操作以定位它们。
MarkToMark附件子表有一种格式:MarkMarkPosFormat1。
标记 - 标记附件定位格式1:标记 - 标记附件
MarkMarkPosFormat1子表以格式标识符(posFormat)和两个偏移量(mark1CoverageOffset,mark2CoverageOffset)开头到Coverage表:一个列出子表中引用的所有mark1字形(mark1Coverage),另一个列出子表中引用的所有mark2字形(mark2Coverage)。
子表还具有Mark1字形(mark1ArrayOffset)的MarkArray表的偏移量。对于mark1Coverage表中的每个标记字形,MarkArray表中的MarkRecord指定其类以及描述标记附着点的Anchor表的偏移量。markClassCount字段指定在所有MarkRecords中定义的不同标记类的总数。
MarkMarkPosFormat1子表还有Mark2字形(mark2ArrayOffset)的MarkArray表的偏移量,它为每个mark2字形定义一个锚点数组,每个mark1标记类一个。
MarkMarkPosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 mark1CoverageOffset 从MarkMarkPos子表开始,组合Mark Coverage表的偏移量。
Offset16 mark2CoverageOffset 从MarkMarkPos子表的开头偏移到Base Mark Coverage表。
UINT16 markClassCount 已定义的组合标记类的数量
Offset16 mark1ArrayOffset 从MarkMarkPos子表的开头偏移到mark1的MarkArray表。
Offset16 mark2ArrayOffset 从MarkMarkPos子表的开头偏移到mark2的Mark2Array表。
Mark2Array表包含mark2Coverage表中列出的每个mark2字形的一个Mark2Record。它以与mark2Coverage索引相同的顺序存储记录。
Mark2Array表
类型 名称 描述
UINT16 mark2Count Mark2记录数
Mark2Record mark2Records [mark2Count] 覆盖顺序中的Mark2Records数组。
每个Mark2Record包含一个到Anchor表的偏移数组(mark2AnchorOffsets)。从Mark2Array表开始测量的从零开始的偏移数组定义了用于将mark1字形附加到特定mark2字形的整个mark2附着点集。mark2AnchorOffsets数组中引用的Anchor表按mark1类值排序。
Mark2Record为MarkArray的MarkRecords中标识的每个标记类(包括Class 0)声明一个Anchor表。每个Anchor表指定一个mark2附着点,用于将特定类中的所有mark1字形附加到mark2字形。
本章末尾的示例9显示了一个MarkMarkPosFormat1子表,用于在阿拉伯语脚本中将一个标记附加到另一个标记。
Mark2Record
类型 名称 描述
Offset16 mark2AnchorOffsets [markClassCount] Anchor表的偏移量数组(每个类一个)。偏移量来自Mark2Array表的开头,按类顺序排列。
7.21.11.Lookup Type 7: Contextual Positioning Subtables
上下文定位(ContextPos)子表定义了最强大的字形定位查找类型。它描述了上下文中的字形定位,因此文本处理客户端可以调整某个字形模式中的一个或多个字形的位置。每个子表描述了一个或多个“输入”字形序列以及要对该序列执行的一个或多个定位操作。
ContextPos子表可以具有三种格式之一,它们与用于上下文字形替换的格式非常相似。一种格式适用于特定的字形序列(格式1),一种格式根据字形类(格式2)定义上下文,第三种格式根据字形集(格式3)定义上下文。
ContextPos子表的所有三种格式都在PosLookupRecord中指定定位数据。该记录的描述如下。
位置查找记录
所有上下文定位子表都指定PosLookupRecord中的定位数据。每条记录都包含一个sequenceIndex字段,该字段指示定位操作在字形序列中的位置。此外,lookupListIndex字段标识要在sequenceIndex指定的字形位置应用的查找。
查找应用于整个字形序列的顺序(称为“设计顺序”)可能很重要,因此应相应地定义PosLookupRecord数据。
示例10,11和12中定义的上下文替换子表显示了PosLookupRecords。
PosLookupRecord
类型 名称 描述
UINT16 sequenceIndex 索引(从零开始)输入字形序列
UINT16 lookupListIndex 将Lookup表中的索引(从零开始)应用于字形序列中的该位置。
上下文定位子表格式1:简单字形上下文
格式1将字形定位操作的上下文定义为特定的字形序列。例如,上下文可以是
在上下文中,格式1标识特定字形序列位置(不是字形索引)作为特定调整的目标。当文本处理客户端在文本字符串中查找上下文时,它通过应用为该位置的目标位置定义的查找数据来进行调整。
例如,假设当一个悬垂的大写字母字形位于元音之前时,必须降低小写x高度元音字形上方的重音符号字形。当客户端在文本中找到此上下文时,子表标识重音符号的位置和查找索引。查找指定了一个定位动作,它可以降低元音上的重音符号,使其不会与悬垂的资本发生碰撞。
ContextPosFormat1在两个地方定义上下文。Coverage表指定输入序列中的第一个字形,PosRule表指定剩余的字形。为了描述前一个例子中使用的上下文,Coverage表列出了序列的第一个分量的字形索引(悬垂的大写),PosRule表定义了小写x高度元音字形和重音标记的索引。
单个ContextPosFormat1子表可以定义多个上下文字形序列。如果不同的上下文序列以相同的字形开头,则Coverage表应仅列出一次字形,因为表中的所有第一个字形必须是唯一的。例如,如果三个上下文各自以“s”开头而两个以“t”开头,那么Coverage表将列出一个“s”和一个“t”。
对于每个上下文,PosRule表列出了第一个字形后面的所有字形,以字形顺序排列。该表还包含一个PosLookupRecords数组,用于指定上下文中每个字形位置(包括第一个字形位置)的定位查找数据。
定义以相同第一个字形开头的上下文的所有PosRule表被组合在一起并在PosRuleSet表中定义。例如,定义以“s”开头的三个上下文的PosRule表分组在一个PosRuleSet表中,定义以“t”开头的两个上下文的PosRule表在第二个PosRuleSet表中分组。Coverage表中列出的每个唯一字形必须具有PosRuleSet表,该表定义覆盖字形的所有PosRule表。
为了定位上下文字形序列,文本处理客户端每次开始处理新的字形序列上下文时都会搜索Coverage表。如果覆盖了第一个字形,则客户端将读取相应的PosRuleSet表并检查集合中的每个PosRule表,以确定其中定义的其余上下文是否与字形序列中的后续字形匹配。如果上下文和字形序列匹配,则客户端找到目标字形位置,应用该位置的查找,并完成定位操作。
ContextPosFormat1子表包含格式标识符(posFormat),Coverage表的偏移量(coverageOffset),定义的PosRuleSet数量的计数(posRuleSetCount),以及PosRuleSet表的偏移数组(posRuleSetOffsets)。如上所述,必须为Coverage表中列出的每个字形定义一个PosRuleSet表。
在posRuleSetOffsets数组中,PosRuleSet表的偏移量按Coverage索引顺序排序。数组中的第一个PosRuleSet应用于Coverage表中列出的第一个字形ID,数组中的第二个PosRuleSet应用于Coverage表中列出的第二个字形ID,依此类推。
ContextPosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 coverageOffset 从ContextPos子表的开头偏移到Coverage表。
UINT16 posRuleSetCount PosRuleSet表的数量
Offset16 posRuleSetOffsets [posRuleSetCount] PosRuleSet表的偏移数组。偏移量来自ContextPos子表的开头,按Coverage Index排序。
Coverage表中的每个字形都有一个PosRuleSet表。每个PosRuleSet表对应于Coverage表中的给定字形,并描述以该字形开头的所有上下文。
PosRuleSet表由PosRule表(posRuleOffsets)的偏移数组组成,按优先级排序,以及集合(posRuleCount)中定义的PosRule表的计数。
PosRuleSet表
类型 名称 描述
UINT16 posRuleCount PosRule表的数量
Offset16 posRuleOffsets [posRuleCount] PosRule表的偏移数组。偏移量来自PosRuleSet的开头,按优先顺序排序。
PosRule表包含要在输入上下文序列(glyphCount)中匹配的字形的计数,包括序列中的第一个字形,以及描述上下文的字形索引数组(inputSequence)。Coverage表指定上下文中第一个字形的索引,inputSequence数组以上下文序列中的第二个字形开头。结果,inputSequence数组中的第一个元素对应于字形序列位置索引一(1),而不是零(0)。inputSequence数组按照写入方向(逻辑)顺序,按照对应字形在文本中出现的顺序列出索引。对于从右到左书写的文字,最右边的字形将是第一个; 相反,对于从左到右书写的文本,最左边的字形将是第一个。
PosRule表还包含要对输入字形序列(posCount)执行的定位操作的计数以及PosLookupRecords(posLookupRecords)数组。每个记录指定输入字形序列中的位置和要在其中应用的定位查找的LookupList索引。数组应按设计顺序列出记录,或者应将查找应用于整个字形序列的顺序。
本章末尾的示例10演示了ContextPosFormat1子表在上下文中的字形字距调整。
PosRule表
类型 名称 描述
UINT16 glyphCount 输入字形序列中的字形数
UINT16 posCount PosLookupRecords的数量
UINT16 inputSequence [glyphCount - 1] 输入字形ID数组 - 从第二个字形开始。
PosLookupRecord posLookupRecords [posCount] 按设计顺序排列的定位查找数组。
上下文定位子表格式2:基于类的字形上下文
格式2比格式1更灵活,描述了基于类的上下文定位。对于此格式,必须为所有上下文字形序列中的每个字形分配一个称为类值的特定整数。然后将上下文定义为类值的序列。该子表可以定义多个上下文。
在ContextPosFormat2子表中,使用“类型定义”表定义字形类,该表在“OpenType布局公用表格式”一章中定义。
为了阐明基于类的上下文规则的概念,假设三个字形的某些序列需要特殊的字距调整。字形序列由一个在右侧悬垂的大写字形,一个标点符号字形,然后是一个引号字形组成。在这种情况下,一组大写字形将构成一个字形类(Class1),标点符号字形集将构成第二个字形类(Class 2),并且引号标记字形集将构成第三个字形类(Class 3)。可以使用上下文规则(PosClassRule)指定输入上下文,该规则描述“形成三个字形类序列的字形字符串集合,一个字体来自类1,后面跟着一个来自类2的字形,后面跟着一个来自类的字形3.”
每个ContextPosFormat2子表都包含一个类定义表(classDefOffset)的偏移量,该表定义子表描述的输入上下文中所有字形的类值。通常,将在包含在字体中的ContextPosFormat2子表的每个实例中声明唯一的classDef,即使多个Format 2子表可以共享classDef表。课程是独家集合; 一个字形一次不能超过一个类。替换上下文序列中的字形的输出字形不需要类值,因为它们在字形ID的其他地方指定。
ContextPosFormat2子表还包含格式标识符(posFormat),并定义Coverage表(coverageOffset)的偏移量。对于此格式,Coverage表列出了完整字形集(非字形类)的索引,这些字形可能显示为任何基于类的上下文的第一个字形。换句话说,Coverage表包含所有类中可能首先在任何上下文类序列中的所有字形的字形索引列表。例如,如果上下文以Class 1或Class 2标志符号开头,则Coverage表将列出所有Class 1和Class 2标志符号的索引。
ContextPosFormat2子表还定义了PosClassSet表(posClassSetOffsets)的偏移数组,以及PosClassSet表(posClassSetCount)的计数(包括Class 0)。在数组中,PosClassSet表按升序类值排序(从0到posClassSetCount - 1)。
posClassSetOffsets数组包含每个glyph类的一个偏移量,包括Class 0.PosClassSets没有用类值显式标记; 相反,PosClassSet数组中PosClassSet的索引值定义了PosClassSet表示的类。PosClassSet枚举以特定字形类开头的所有PosClassRules。
例如,数组中列出的第一个PosClassSet包含定义以Class 0字形开头的上下文的所有PosClassRules,第二个PosClassSet包含定义以Class 1字形开头的上下文的所有PosClassRules,依此类推。如果没有PosClassRules以特定类开头(即,如果PosClassSet不包含PosClassRules),那么PosClassSet数组中该特定PosClassSet的偏移量将设置为NULL。
ContextPosFormat2子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 2
Offset16 coverageOffset 从ContextPos子表的开头偏移到Coverage表。
Offset16 classDefOffset 从ContextPos子表的开头偏移到ClassDef表。
UINT16 posClassSetCount PosClassSet表的数量
Offset16 posClassSetOffsets [posClassSetCount] PosClassSet表的偏移数组。偏移量来自ContextPos子表的开头,按类排序(可能为NULL)。
定义以相同类开头的上下文的所有PosClassRules被组合在一起并在PosClassSet表中定义。因此,PosClassSet表标识了上下文的第一个组件的类。
每个PosClassSet表包含PosClassSet(posClassRuleCount)中定义的PosClassRules的计数和PosClassRule表(posClassRuleOffsets)的偏移数组。PosClassRule表在PosClassSet的posClassRuleOffsets数组中按优先顺序排序。
PosClassSet表
类型 名称 描述
UINT16 posClassRuleCount PosClassRule表的数量
Offset16 posClassRuleOffsets [posClassRuleCount] PosClassRule表的偏移数组。偏移量来自PosClassSet的开头,按优先顺序排序。
对于每个上下文,PosClassRule表包含给定上下文(glyphCount)中的字形类的计数,包括上下文序列中的第一个类。类数组列出了从第二个类开始的类,它们跟在上下文中的第一个类之后。列出的第一个类表示上下文序列中的第二个位置。
注意:文本顺序取决于文本的书写方向。对于从右到左书写的文本,最右边的字形将是第一个。相反,对于从左到右书写的文本,最左边的字形将是第一个。
classes数组中指定的值是classDef表中定义的值。例如,考虑一个由序列组成的上下文:Class 2,Class 7,Class 5,Class 0. classes数组将读取:classes [0] = 7,classes [1] = 5,classes [2] = 0序列中的第一个类,Class 2,由posClassSetOffsets数组的索引定义。classes数组中列出的字形类的总数和顺序必须与输入上下文中包含的字形类的总数和顺序相匹配。
PosClassRule还包含要在上下文(PosCount)上执行的定位操作的计数以及提供定位数据的PosLookupRecords(PosLookupRecord)数组。对于需要定位操作的上下文中的每个位置,PosLookupRecord指定LookupList索引以及应用查找的输入字形类序列中的位置。PosLookupRecord数组按设计顺序列出PosLookupRecords,或查找应用于整个字形序列的顺序。
本章末尾的示例11演示了一个ContextPosFormat2子表,该子表使用字形类来修改字形字符串中的重音位置。
PosClassRule表
类型 名称 描述
UINT16 glyphCount 要匹配的字形数
UINT16 posCount PosLookupRecords的数量
UINT16 类[glyphCount - 1] 要与输入字形序列匹配的类数组,从第二个字形位置开始。
PosLookupRecord posLookupRecords [posCount] PosLookupRecords数组,按设计顺序排列。
上下文定位子表格式3:基于覆盖的字形上下文
格式3,基于覆盖的上下文定位,将上下文规则定义为一系列覆盖。序列中的每个位置可以为与上下文模式匹配的字形集指定不同的Coverage表。使用格式3,不同Coverage表中定义的字形集可能会相交,不像格式2指定查找的固定类分配(它们不能在上下文序列中的每个位置更改)和独占类(字形不能更多)而不是一次一堂课)。
例如,考虑一个包含大写字形(位置0)的输入上下文,后跟任何窄的大写字形(位置1),然后是另一个大写字形(位置2)。此上下文需要三个Coverage表,每个位置一个:
在位置0,即第一个位置,Coverage表列出了所有大写字形的集合。
在位置1,即第二个位置,Coverage表列出了所有窄大写字母的集合,这是在位置0的Coverage表中列出的字形的子集。
在位置2中,Coverage表再次列出所有大写字形的集合。
注意:位置0和位置2都可以使用相同的Coverage表。
与格式1和格式2不同,此格式一次只定义一个上下文规则。它由格式标识符(posFormat),要匹配的序列中的字形数量(glyphCount)以及描述输入上下文序列(coverageOffsets)的Coverage偏移数组组成。
注意: coverageOffsets数组中引用的Coverage表必须根据写入方向按文本顺序列出。对于从右到左书写的文本,最右边的字形将是第一个。相反,对于从左到右书写的文本,最左边的字形将是第一个。
子表还包含要按设计顺序对输入Coverage序列(posCount)和PosLookupRecords(posLookupRecords)数组执行的定位操作的计数,或者查找应用于整个字形序列的顺序。
本章末尾的示例12使用ContextPosFormat3子表更改数学方程中数学符号字形的位置。
ContextPosFormat3子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 3
UINT16 glyphCount 输入序列中的字形数
UINT16 posCount PosLookupRecords的数量
Offset16 coverageOffsets [glyphCount] 从ContextPos子表的开头到Coverage表的偏移量数组。
PosLookupRecord posLookupRecords [posCount] PosLookupRecords数组,按设计顺序排列。
7.21.12.LookupType 8: Chaining Contextual Positioning Subtable
链接上下文定位子表(ChainContextPos)描述了在上下文中的字形定位,具有在字形序列中回顾和/或向前看的能力。链接上下文定位子表的设计与上下文定位子表的设计平行,包括三种格式的可用性。
要指定上下文,coverage表列出输入序列中的第一个字形,ChainPosRule子表定义其余字形。一旦在位置i找到覆盖的字形,客户端就会读取相应的ChainPosRuleSet表并检查每个表以确定它是否与文本中的周围字形匹配。如果字符串
如果匹配,则客户端找到用于定位的目标字形并执行操作。请注意(就像在ContextPosFormat1子表中一样)这些查找需要在从覆盖字形到输入序列末尾的文本范围内操作。不能为回溯序列或先行序列定义定位操作。
为了阐明输入,回溯和先行序列的字形数组的排序,提供了下图。输入序列匹配从输入序列匹配开始的i开始。回溯序列从i -1 开始排序,并且随着离开i而增加偏移值。先行序列在输入序列之后开始并且以逻辑顺序增加。
逻辑顺序 - 一个 b C d Ë F G H 一世 Ĵ
一世
输入顺序 - 0 1
回溯序列 - 3 2 1 0
前瞻序列 - 0 1 2 3
链接上下文定位格式1:简单字形上下文
此格式与上下文定位查找的格式1相同,只是PosRule表替换为ChainPosRule表。(相应地,ChainPosRuleSet表与PosRuleSet表的不同之处仅在于它列出了对ChainPosRule表而不是PosRule表的偏移量;而ChainContextPosFormat1子表列出了对ChainPosRuleSet表而不是PosRuleSet表的偏移量。)
ChainContextPosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
Offset16 coverageOffset 从ChainContextPos子表的开头偏移到Coverage表。
UINT16 chainPosRuleSetCount ChainPosRuleSet表的数量
Offset16 chainPosRuleSetOffsets [chainPosRuleSetCount] ChainPosRuleSet表的偏移数组。偏移量来自ChainContextPos子表的开头,按Coverage Index排序。
Coverage表中的每个字形都有一个ChainPosRuleSet表。每个ChainPosRuleSet表对应于Coverage表中的给定字形,并描述以该字形开头的所有上下文。
ChainPosRuleSet表由ChainPosRule表(chainPosRuleOffsets)的偏移数组组成,按优先级排序,以及set(chainPosRuleCount)中定义的ChainPosRule表的计数。
ChainPosRuleSet表
类型 名称 描述
UINT16 chainPosRuleCount ChainPosRule表的数量
Offset16 chainPosRuleOffsets [chainPosRuleCount] ChainPosRule表的偏移数组。偏移量来自ChainPosRuleSet的开头,按优先顺序排序。
ChainPosRule表
类型 名称 描述
UINT16 backtrackGlyphCount 回溯序列中的字形总数。
UINT16 backtrackSequence [backtrackGlyphCount] 回溯字形ID数组。
UINT16 inputGlyphCount 输入序列中的字形总数 - 包括第一个字形。
UINT16 inputSequence [inputGlyphCount - 1] 输入字形ID数组 - 以第二个字形开头。
UINT16 lookaheadGlyphCount 前瞻序列中的字形总数。
UINT16 lookAheadSequence [lookAheadGlyphCount] 前瞻字形ID的数组。
UINT16 posCount PosLookupRecords的数量
PosLookupRecord posLookupRecords
[posCount] PosLookupRecords数组,按设计顺序排列。
链接上下文定位格式2:基于类的字形上下文
此查找格式与Context Positioning格式2并行,PosClassSet子表更改为ChainPosClassSet子表,而PosClassRule子表更改为ChainPosClassRule子表。
在ChainContextPosFormat2子表中,使用“类型定义”表定义字形类,该表在“OpenType布局公用表格式”一章中定义。
为了链上下文,在字形ClassDef表中使用了三个类:backtrackClassDef,inputClassDef和lookaheadClassDef。
ChainContextPosFormat2子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 2
Offset16 coverageOffset 从ChainContextPos子表的开头偏移到Coverage表。
Offset16 backtrackClassDefOffset 从ChainContextPos子表的开头偏移到包含回溯序列上下文的ClassDef表。
Offset16 inputClassDefOffset 从ChainContextPos子表的开头偏移到包含输入序列上下文的ClassDef表。
Offset16 lookaheadClassDefOffset 从ChainContextPos子表的开头偏移到包含超前序列上下文的ClassDef表。
UINT16 chainPosClassSetCount ChainPosClassSet表的数量
Offset16 chainPosClassSetOffsets [chainPosClassSetCount] ChainPosClassSet表的偏移数组。偏移量来自ChainContextPos子表的开头,按输入类排序(可能为NULL)。
定义以相同类开头的上下文的所有ChainPosClassRules被组合在一起并在ChainPosClassSet表中定义。因此,ChainPosClassSet表标识了上下文的第一个组件的类。
ChainPosClassSet表
类型 名称 描述
UINT16 chainPosClassRuleCount ChainPosClassRule表的数量
Offset16 chainPosClassRuleOffsets [chainPosClassRuleCount] ChainPosClassRule表的偏移数组。偏移量来自ChainPosClassSet的开头,按优先顺序排序。
ChainPosClassRule表
类型 名称 描述
UINT16 backtrackGlyphCount 回溯序列中的字形总数。
UINT16 backtrackSequence [backtrackGlyphCount] 回溯序列类的数组。
UINT16 inputGlyphCount 输入序列中的类总数 - 包括第一个类。
UINT16 inputSequence [inputGlyphCount - 1] 要与输入字形序列匹配的输入类数组,从第二个字形位置开始。
UINT16 lookaheadGlyphCount 前瞻序列中的类总数。
UINT16 lookAheadSequence [lookAheadGlyphCount] 前瞻序列类的数组。
UINT16 posCount PosLookupRecords的数量
PosLookupRecord posLookupRecords [posCount] PosLookupRecords数组,按设计顺序排列。
链接上下文定位格式3:基于覆盖的字形上下文
格式3将链接上下文规则定义为Coverage表序列。序列中的每个位置可以为与上下文模式匹配的字形集定义不同的Coverage表。对于格式3,不同Coverage表中定义的字形集可能会相交,不像格式2指定固定类赋值(对于回溯,输入或先行序列中的每个位置都相同)和独占类(字形不能超过一次一堂课)。
注意: Coverage数组中列出的Coverage表的顺序必须遵循书写方向。对于从右到左书写的文本,最右边的字形将是第一个。相反,对于从左到右书写的文本,最左边的字形将是第一个。
子表还包含要按设计顺序对输入Coverage序列(posCount)和PosLookupRecords(posLookupRecords)数组执行的定位操作的计数:即,应将查找应用于整个字形序列的顺序。
ChainContextPosFormat3子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 3
UINT16 backtrackGlyphCount 回溯序列中的字形数
Offset16 backtrackCoverageOffsets [backtrackGlyphCount] 返回序列的覆盖表的偏移量数组,以字形顺序排列。
UINT16 inputGlyphCount 输入序列中的字形数
Offset16 inputCoverageOffsets [inputGlyphCount] 输入序列的覆盖表的偏移数组,以字形顺序排列。
UINT16 lookaheadGlyphCount 先行序列中的字形数
Offset16 lookaheadCoverageOffsets [lookaheadGlyphCount] 前瞻序列的覆盖表的偏移数组,以字形顺序排列。
UINT16 posCount PosLookupRecords的数量
PosLookupRecord posLookupRecords [posCount] PosLookupRecords数组,按设计顺序排列。
7.21.13.LookupType 9: Extension Positioning
此查找提供了一种机制,其中任何其他查找类型的子表存储在GPOS表中的32位偏移位置。如果子表的总大小超过GPOS表中各种其他偏移的16位限制,则需要这样做。在本说明书中,存储在32位偏移位置的子表被称为“扩展”子表。
此子表类型使用一种格式:ExtensionPosFormat1。
扩展定位子表格式1
ExtensionPosFormat1子表
类型 名称 描述
UINT16 posFormat 格式标识符:format = 1
UINT16 extensionLookupType 由extensionOffset引用的子表的查找类型(即扩展子表)。
OFFSET32 extensionOffset 相对于ExtensionPosFormat1子表的开头,查找类型extensionLookupType的扩展子表的偏移量。
ExtensionLookupType必须设置为除9之外的任何查找类型.LookupType 9查找中的所有子表必须具有相同的extensionLookupType。扩展子表中的所有偏移都以通常的方式设置,即相对于扩展子表本身。
当OpenType布局引擎遇到LookupType 9 Lookup表时,它应该:
继续进行,就像Lookup表的LookupType字段设置为子表的extensionLookupType一样。
继续执行,就好像extensionOffset引用的每个扩展子表替换了引用它的LookupType 9子表。
7.21.14.Shared Tables: Value Record, Anchor Table, and Mark Array Table
本章前面介绍的几个查找子表引用了一个或多个用于定位数据的表:ValueRecord,Anchor表和MarkArray表。这里描述了这些共享表。
本章末尾的示例14使用ValueFormat表和ValueRecord在GPOS中指定定位值。
价值记录
GPOS子表使用ValueRecords来描述用于调整字形或字形集位置的所有变量和值。ValueRecord可以定义X和Y值的任意组合(以设计单位表示)以添加到(正值)或从(负值)中减去字体中提供的放置和提前值。在非变量字体中,ValueRecord还可以包含每个指定值的Device表的偏移量。在可变字体中,它还可以包含每个指定值的VariationIndex表的偏移量。
请注意,ValueRecord的所有字段都是可选的:为了节省空间,只需要在给定实例中包含所需的字段。由于GPOS表将ValueRecords用于多种用途,因此ValueRecords的大小和内容可能因子表而异。ValueRecord始终伴有ValueFormat标志字段,该字段指定存在哪些ValueRecord字段。如果ValueRecord指定了多个值,则必须按ValueRecord定义中显示的顺序列出值。如果关联的ValueFormat标志指示字段不存在,则下一个当前字段紧跟在最后一个前一个当前字段之后。文本处理客户端必须了解GPOS表中ValueRecords的灵活性和可变性。
ValueRecord
类型 名称 描述
INT16 xPlacement 以设计单位进行水平调整。
INT16 yPlacement 以设计单位垂直调整放置位置。
INT16 xAdvance 以设计单位进行水平调整 - 仅用于水平布局。
INT16 yAdvance 以设计单位进行垂直调整 - 仅用于垂直布局。
Offset16 xPlaDeviceOffset 水平放置的偏移到设备表(非可变字体)/ VariationIndex表(可变字体),从直接父表的开头(SinglePos或PairPosFormat2查找子表,PairPosFormat1查找子表中的PairSet表) - 可以是NULL。
Offset16 yPlaDeviceOffset 垂直放置的偏移到设备表(非可变字体)/ VariationIndex表(可变字体),从直接父表的开头(SinglePos或PairPosFormat2查找子表,PairPosFormat1查找子表中的PairSet表) - 可以是NULL。
Offset16 xAdvDeviceOffset 水平前进的偏移到设备表(非可变字体)/ VariationIndex表(可变字体),从直接父表的开头(SinglePos或PairPosFormat2查找子表,PairPosFormat1查找子表中的PairSet表) - 可以是NULL。
Offset16 yAdvDeviceOffset 垂直前进的偏移到设备表(非可变字体)/ VariationIndex表(可变字体),从直接父表的开头(SinglePos或PairPosFormat2查找子表,PairPosFormat1查找子表中的PairSet表) - 可以是NULL。
注意:设备表仅用于非变量字体,而VariationIndex表仅用于可变字体。
在可变字体中,必须使用VariationIndex表来引用需要针对不同变体实例进行调整的任何放置或高级值的变体数据。
注意:虽然需要变量的每个值都需要对VariationIndex表单独引用,但是需要相同变体数据的两个或多个值可以具有指向相同VariationIndex表的偏移量,并且两个或更多VariationIndex表可以引用相同的变量数据变异数据条目。
注意:如果没有VariationIndex表用于特定的展示位置或高级值,则该值将用于所有变体实例。
ValueFormat标志字段定义ValueRecords指定的定位调整数据的类型。SinglePos子表将在字形序列中具有单个字形位置的ValueRecords; PairPos子表将为两个字形位置分别设置ValueRecords。在给定的子表中,相同的ValueFormat适用于给定字形位置的每个ValueRecord。
ValueFormat确定ValueRecords是否:
适用于展示位置,预付款或两者兼而有之
应用于水平位置(X坐标),垂直位置(Y坐标)或两者。
对于任何指定的值,可以引用一个或多个Device表(在非变量字体中)或VariationIndex表(在可变字体中)。
ValueFormat标志中的每个定义位对应于ValueRecord中的字段,并将ValueRecord的大小增加2个字节。ValueFormat为0x0000对应于空的ValueRecord,表示没有定位更改。
要识别每个ValueRecord中的字段,请使用下面显示的ValueFormat标志。要使用ValueFormat指定多个字段,请使用逻辑OR运算添加相关字段的位设置。
例如,要调整字形的左侧方位,ValueFormat将为0x0001,ValueRecord将定义xPlacement值。要调整不同字形的前进宽度,ValueFormat将为0x0004,ValueRecord将描述xAdvance值。要调整一组字形的xPlacement和xAdvance,ValueFormat将为0x0005,ValueRecord将按照它们在ValueRecord定义中列出的顺序指定这两个值。
ValueFormat标志
面具 名称 描述
0×0001 X_PLACEMENT 包括水平调整放置
0×0002 Y_PLACEMENT 包括垂直调整放置
0x0004 X_ADVANCE 包括提前的水平调整
×0008 Y_ADVANCE 包括提前垂直调整
0×0010 X_PLACEMENT_DEVICE 包括用于水平放置的设备表(非可变字体)/ VariationIndex表(可变字体)
0×0020 Y_PLACEMENT_DEVICE 包括垂直放置的设备表(非可变字体)/ VariationIndex表(可变字体)
即0x0040 X_ADVANCE_DEVICE 包括用于水平前进的设备表(非可变字体)/ VariationIndex表(可变字体)
0x0080 Y_ADVANCE_DEVICE 包括垂直前进的设备表(非可变字体)/ VariationIndex表(可变字体)
为0xFF00 保留的 供将来使用(设为零)
锚表
GPOS表使用锚点将一个字形相对于另一个字符定位。每个字形定义一个锚点,文本处理客户端通过对齐其对应的锚点来附加字形。
为了描述锚点,Anchor表可以使用三种格式之一。第一种格式使用设计单位中的X和Y坐标来指定锚点相对于给定字形的轮廓位置的位置。其他两种格式使用轮廓点(格式2)或设备表(格式3)细化锚点的位置。在可变字体中,第三种格式使用VariationIndex表(Device表的变体)来引用变体数据,以根据需要调整当前变体实例的锚位置。
锚表格式1:设计单位
AnchorFormat1由格式标识符(anchorFormat)和一对设计单元坐标(xCoordinate和yCoordinate)组成,用于指定锚点的位置。这种格式具有体积小和简单的优点,但不能暗示锚点调整其位置以适应不同的设备分辨率。
本章末尾的示例15使用AnchorFormat1。
AnchorFormat1表
类型 名称 描述
UINT16 anchorFormat 格式标识符,= 1
INT16 x坐标 水平值,以设计单位表示
INT16 y坐标 垂直值,以设计单位表示
锚表格式2:设计单位加轮廓点
与AnchorFormat1类似,AnchorFormat2指定格式标识符(anchorFormat)和锚点(xCoordinate和yCoordinate)的一对设计单元坐标。
为了微调锚点的位置,AnchorFormat2还为字形轮廓上的字形轮廓点(anchorPoint)提供索引。提示可用于移动轮廓锚点。在渲染文本中,锚点将提供给定ppem大小的最终定位数据。
本章末尾的示例16使用AnchorFormat2。
AnchorFormat2表
类型 名称 描述
UINT16 anchorFormat 格式标识符,= 2
INT16 x坐标 水平值,以设计单位表示
INT16 y坐标 垂直值,以设计单位表示
UINT16 anchorPoint 字形轮廓点的索引
锚表格式3:Design Units Plus Device或VariationIndex表
与AnchorFormat1类似,AnchorFormat3指定格式标识符(anchorFormat)并定位锚点(xCoordinate和yCoordinate)。并且,与AnchorFormat 2一样,它允许将可变字体精细调整为坐标值。但是,AnchorFormat3使用Device表而不是轮廓点进行此调整。
使用Device表,客户端可以调整任何字体大小和设备分辨率的锚点位置。AnchorFormat3可以为X坐标(xDeviceTableOffset)和Y坐标(yDeviceTableOffset)指定设备表的偏移量。如果只需要调整一个坐标,则可以将另一个坐标的Device表偏移量设置为NULL。
在可变字体中,必须使用AnchorFormat3来引用变体数据,以便根据需要调整不同变体实例的锚点。在这种情况下,AnchorFormat3指定VariationIndex表的偏移量,该表是用于变体的Device表的变体。如果没有VariationIndex表用于特定锚点X或Y坐标,则该值将用于所有变体实例。虽然需要变量的每个值都需要单独的VariationIndex表引用,但是需要相同变体数据值的两个或多个值可以具有指向相同VariationIndex表的偏移量,并且两个或更多VariationIndex表可以引用相同的变体数据条目。
本章末尾的示例17显示了一个AnchorFormat3表。
AnchorFormat3表
类型 名称 描述
UINT16 anchorFormat 格式标识符,= 3
INT16 x坐标 水平值,以设计单位表示
INT16 y坐标 垂直值,以设计单位表示
Offset16 xDeviceOffset 从Anchor表的开头(可能为NULL)偏移到X坐标的设备表(非可变字体)/ VariationIndex表(可变字体)
Offset16 yDeviceOffset 偏移到设备表(非可变字体)/ VariationIndex表(可变字体)为Y坐标,从Anchor表的开头(可能为NULL)
标记数组表
MarkArray表定义标记字形的类和锚点。三种GPOS子表格类型 - MarkToBase附件,MarkToLigature附件和MarkToMark附件 - 使用MarkArray表指定附加标记的数据。
MarkArray表包含MarkRecords(markCount)的数量和这些记录的数组(markRecords)。每个标记记录定义标记的类和Anchor表的包含标记数据的偏移量。
类值可以为零(0),但MarkRecord必须显式指定该类值。(这与类定义表不同,其中所有未分配类值的字形自动属于类0.)引用MarkArray表的GPOS子表使用类分配来索引包含每个标记类数据的从零开始的数组。
在本章末尾的示例18中,MarkArray表和两个MarkRecords定义了两个标记类。
MarkArray表
类型 名称 描述
UINT16 markCount MarkRecords的数量
MarkRecord markRecords [markCount] MarkRecords数组,由相关标记Coverage表中的相应字形排序。
MarkRecord
类型 名称 描述
UINT16 markClass 为关联标记定义的类。
Offset16 markAnchorOffset 从MarkArray表的开头偏移到Anchor表。
7.21.15.GPOS Subtable Examples
本章的其余部分描述了所有GPOS子表格格式的示例,包括可用于上下文定位的三种格式中的每一种。所有示例都反映了下面描述的唯一参数,但这些示例为构建特定于其他情况的子表提供了有用的参考。
所有示例都有三列显示十六进制数据,源和注释。
示例1:GPOS标头表
示例1显示了典型的GPOS Header表定义,其中包含对ScriptList,FeatureList和LookupList的偏移。
例1
Hex数据 资源 评论
GPOSHeader
TheGPOSHeader GPOSHeader表定义
00010000 0x00010000在 主要/次要版本
000A TheScriptList 偏移到ScriptList表
001E TheFeatureList 偏移到FeatureList表
002C TheLookupList 偏移到LookupList表
示例2:SinglePosFormat1子表
示例2使用SinglePosFormat1子表来降低字体中下标字形的Y位置。LowerSubscriptsSubTable定义了一个Coverage表,名为LowerSubscriptsCoverage,它列出了数字/数字下标字形的一个字形索引范围。子表的ValueFormat设置指示ValueRecord仅指定YPlacement值,将每个下标字形降低80个设计单位。
例2
Hex数据 资源 评论
SinglePosFormat1
LowerSubscriptsSubTable SinglePos子表定义
0001 1 posFormat
0008 LowerSubscriptsCoverage 偏移到Coverage表
技术 0×0002 valueFormat:Y_PLACEMENT
ValueRecord
FFB0 -80 向下移动Y位置
CoverageFormat2
LowerSubscriptsCoverage 覆盖表定义
技术 2 coverageFormat:范围
0001 1 rangeCount
rangeRecords [0]
01B3 ZeroSubscriptGlyphID 开始,第一个字形ID
01BC NineSubscriptGlyphID 结束,最后一个字形ID
0000 0 startCoverageIndex
示例3:SinglePosFormat2子表
此示例使用SinglePosFormat2子表来按不同的量调整三个短划线字形的间距。em破折号间距变化10个单位,仪表间距变化25个单位,标准破折号的间距变化50个单位。
DashSpacingSubTable包含一个Coverage表,其中包含三个短划线字形索引,以及一个ValueRecords数组,每个覆盖字形一个。ValueRecords使用相同的ValueFormat来修改每个字形的XPlacement和XAdvance值。ValueFormat位设置为0x0005是通过添加XPlacement和XAdvance位设置生成的。
例3
Hex数据 资源 评论
SinglePosFormat2
DashSpacingSubTable SinglePos子表定义
技术 2 posFormat
0014 DashSpacingCoverage 偏移到Coverage表
0005 0×0005 ValueFormat:X_PLACEMENT || X_ADVANCE
0003 3 valueCount
valueRecords [0] 用于破折号字形
0032 50 xPlacement
0032 50 xAdvance
valueRecords [1] 为短划线字形
0019 25 xPlacement
0019 25 xAdvance
valueRecords [2] 为em破折号字形
000A 10 xPlacement
000A 10 xAdvance
CoverageFormat1
DashSpacingCoverage 覆盖表定义
0001 1 coverageFormat:列表
0003 3 glyphCount
004F DashGlyphID glyphArray [0]
0125 EnDashGlyphID glyphArray [1]
0129 EmDashGlyphID glyphArray [2]
示例4:PairPosFormat1子表
示例4使用PairPosFormat1子表来克服两个字形对 - “Po”和“To” - 通过调整第一个字形的XAdvance和第二个字形的XPlacement。定义了两个ValueFormats,每个字形一个。子表包含Coverage表,该表列出了每对中第一个字形的索引。它还包含每个覆盖字形的PairSet表的偏移量。
PairSet表定义了一个PairValueRecords数组,用于指定包含覆盖字形作为其第一个组件的所有字形对。在此示例中,PairSet表有一个PairValueRecord,用于标识“Po”对中的第二个字形和两个ValueRecords,一个用于第一个字形,另一个用于第二个字形。PairSet表还有一个PairValueRecord,列出“To”对中的第二个字形和两个ValueRecords,每个字形一个。
例4
Hex数据 资源 评论
PairPosFormat1
PairKerningSubTable PairPos子表定义
0001 1 posFormat
001E PairKerningCoverage 偏移到Coverage表
0004 0x0004 valueFormat1:仅限X_ADVANCE
0001 0×0001 ValueFormat2:仅限X_PLACEMENT
技术 2 PairSetCount
000E PairSetTable pairSetOffsets [0]
0016 PairSetTable pairSetOffsets [1]
PairSetTable
PairSetTable PairSet表定义
0001 1 pairValueCount
pairValueRecords [0]
0059 LowercaseOGlyphID secondGlyph
valueRecord1 第一个字形的ValueRecord
FFE2 -30 xAdvance
valueRecord2 ValueRecord为第二个字形
FFEC -20 xPlacement
PairSetTable
PairSetTable PairSet表定义
0001 1 pairValueCount
pairValueRecords [0]
0059 LowercaseOGlyphID secondGlyph
valueRecord1 第一个字形的ValueRecord
FFD8 -40 xAdvance
valueRecord2 ValueRecord为第二个字形
FFE7 -25 xPlacement
CoverageFormat1
PairKerningCoverage 覆盖表定义
0001 1 coverageFormat:列表
技术 2 glyphCount
002D UppercasePGlyphID glyphArray [0]
0031 UppercaseTGlyphID glyphArray [1]
例5:PairPosFormat2子表
本例中的PairPosFormat2子表定义了由两个字形类组成的对。定义了两个ClassDef表,每个表用于一个glyph类。每对中的第一个字形是一类具有对角线形状(v,w,y)的小写字形,在LowercaseClassDef表中定义了Class1。每对中的第二个字形都在一个标点符号字形(逗号和句点)中,在PunctuationClassDef表的Class1中定义。Coverage表仅列出LowercaseClassDef表中字形的索引,因为它们占据了对中的第一个位置。
子表为LowecaseClassDef中定义的类定义了两个Class1Records,包括Class0。反过来,每个记录为PunctuationClassDef中定义的每个类定义Class2Record,包括Class0。Class2Records指定字形的定位调整。
通过将第一个字形的XAdvance减少50个设计单位来对这些对进行剪切。由于第二个字形没有定位更改,因此将其ValueFormat2设置为0,以指示每对的Value2为空。
由于没有对以Class0或Class2字形开头,因此Class1Record [0]中引用的所有ValueRecords都包含0或为空。但是,Class1Record [1]确实在其Class2Record [1]中定义了一个XAdvance值,用于对包含Class1字形后跟Class2字形的所有对进行字距调整。
例5
Hex数据 资源 评论
PairPosFormat2
PunctKerningSubTable PairPos子表定义
技术 2 posFormat
0018 PunctKerningCoverage 偏移到Coverage表
0004 0x0004 valueFormat1:仅限X_ADVANCE
0000 0 ValueFormat2:第二个字形没有ValueRecord
0022 LowercaseClassDef 偏移到ClassDef1表,对于第一类对
0032 PunctuationClassDef 偏移到ClassDef2表,对于第二类对
技术 2 Class1Count
技术 2 Class2Count
class1Records [0] First Class1Record,用于从0级开始的上下文
class2Records [0] class1Records [0]的First Class2Record; valueFormat2为零,因此没有valueRecord2。
valueRecord1
0000 0 xAdvance:第一个字形无变化
class2Records [1] 没有valueRecord2
valueRecord1
0000 0 xAdvance:第一个字形无变化
class1Records [1] 对于从1级开始的上下文
class2Records [0] 没有与0级作为第二个字形的上下文; 没有valueRecord2
valueRecord1
0000 0 xAdvance:第一个字形无变化
class2Records [1] 将第1类作为第二个字形的上下文; 没有valueRecord2
valueRecord1
FFCE -50 xAdvance:移动标点符号
CoverageFormat1
PunctKerningCoverage 覆盖表定义
0001 1 coverageFormat:列表
0003 3 glyphCount
0046 LowercaseVGlyphID glyphArray [0]
0047 LowercaseWGlyphID glyphArray [1]
0049 LowercaseYGlyphID glyphArray [2]
ClassDefFormat2
LowercaseClassDef ClassDef表定义
技术 2 classFormat:范围
技术 2 classRangeCount
classRangeRecords [0]
0046 LowercaseVGlyphID startGlyphID
0047 LowercaseWGlyphID endGlyphID
0001 1 类
classRangeRecords [1]
0049 LowercaseYGlyphID startGlyphID
0049 LowercaseYGlyphID endGlyphID
0001 1 类
ClassDefFormat2
PunctuationClassDef ClassDef表定义
技术 2 classFormat:范围
0001 1 classRangeCount
classRangeRecords [0]
006A PeriodPunctGlyphID startGlyphID
006B CommaPunctGlyphID endGlyphID
0001 1 类
示例6:CursivePosFormat1子表
在示例6中,Urdu语言系统使用CursivePosFormat1子表来沿着从右到左下降的对角线基线附加字形。两个字形使用附件数据定义,并在Coverage表中列出 - Kaf和Ha字形。对于每个字形,子表包含一个EntryExitRecord,它定义两个Anchor表的偏移量,一个条目附着点和一个出口附着点。每个Anchor表定义X和Y坐标值。要向下和对角渲染Urdu,入口点的Y坐标高于基线,出口点的Y坐标位于基线下方。
例6
Hex数据 资源 评论
CursivePosFormat1
DiagonalWritingSubTable CursivePos子表定义
0001 1 posFormat
000E DiagonalWritingCoverage 偏移到Coverage表
技术 2 entryExitCount
entryExitRecords [0] 用于Kaf字形的EntryExitRecord
0016 KafEntryAnchor 到EntryAnchor表的偏移量
001C KafExitAnchor 偏移到ExitAnchor表
entryExitRecords [1] Ha字形的EntryExitRecord
0022 HaEntryAnchor 到EntryAnchor表的偏移量
0028 HaExitAnchor 偏移到ExitAnchor表
CoverageFormat1
DiagonalWritingCoverage 覆盖表定义
0001 1 coverageFormat:列表
技术 2 glyphCount
0203 KafGlyphID glyphArray [0]
027E HaGlyphID glyphArray [1]
AnchorFormat1
KafEntryAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
05DC 1500 x坐标
002C 44 y坐标
AnchorFormat1
KafExitAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
0000 0 x坐标
FFEC -20 y坐标
AnchorFormat1
HaEntryAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
05DC 1500 x坐标
002C 44 y坐标
AnchorFormat1
HaExitAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
0000 0 x坐标
FFEC -20 y坐标
例7:MarkBasePosFormat1子表
示例7中的MarkBasePosFormat1子表定义了一个阿拉伯语基本字形,Tah和两个阿拉伯标记字形:基本字形上方的fathatan标记和基本字形下方的kasra标记。BaseGlyphsCoverage表列出了基本字形,MarkGlyphsCoverage表列出了标记字形。
MarkArray中还列出了每个标记及其附着点数据和标记Class值。MarkArray定义了两个标记类:Class0由位于基本字形上方的标记组成,Class1由位于基本字形下方的标记组成。
BaseArray定义基本字形的附件数据。在此数组中,为Tah字形定义了一个BaseRecord,其中包含两个BaseAnchor表的偏移量,每个表标记一个。AboveBaseAnchor为放置在Tah基本字形上方的标记定义附着点,而BelowBaseAnchor为放置在其下方的标记定义附着点。
例7
Hex数据 资源 评论
MarkBasePosFormat1
MarkBaseAttachSubTable MarkBasePos子表定义
0001 1 posFormat
000C MarkGlyphsCoverage offset到markCoverage表
0014 BaseGlyphsCoverage 偏移到baseCoverage表
技术 2 markClassCount
001A MarkGlyphsArray 偏移到MarkArray表
0030 BaseGlyphsArray 偏移到BaseArray表
CoverageFormat1
MarkGlyphsCoverage 覆盖表定义
0001 1 coverageFormat:列表
技术 2 glyphCount
0333 fathatanMarkGlyphID glyphArray [0]
033F kasraMarkGlyphID glyphArray [1]
CoverageFormat1
BaseGlyphsCoverage 覆盖表定义
0001 1 coverageFormat:列表
0001 1 glyphCount
0190 tahBaseGlyphID glyphArray [0]
MarkArray
MarkGlyphsArray MarkArray表定义
技术 2 markCount
markRecords [0] 标记索引顺序中的MarkRecords
0000 0 markClass,用于基础上的标记
000A fathatanMarkAnchor markAnchorOffset
markRecords [1]
0001 1 markClass,用于标记下
0010 kasraMarkAnchor markAnchorOffset
AnchorFormat1
fathatanMarkAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
015A 346 x坐标
FF9E -98 y坐标
AnchorFormat1
kasraMarkAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
0105 261 x坐标
0058 88 y坐标
BaseArray
BaseGlyphsArray BaseArray表定义
0001 1 baseCount
baseRecords [0]
0006 AboveBaseAnchor baseAnchorOffset [0]
000C BelowBaseAnchor baseAnchorOffsets [1]
AnchorFormat1
AboveBaseAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
033E 830 x坐标
0640 1600 y坐标
AnchorFormat1
BelowBaseAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
033E 830 x坐标
FFAD -83 y坐标
例8:MarkLigPosFormat1子表
示例8使用MarkLigPosFormat1子表将标记附加到阿拉伯语脚本中的连字字形。假设的结扎由三个字形组成:一个Lam(初始形式),一个meem(内侧形式)和一个jeem(内侧形式)。前两个部分定义了重音符号:sukun重音位于lam上方,kasratan重音位于meem下方。
LigGlyphsCoverage表列出了连字字形,MarkGlyphsCoverage表列出了两个重音符号。MarkArray中还列出了每个标记及其附着点数据和标记Class值。MarkArray定义了两个标记类:Class0由位于基本字形上方的标记组成,Class1由位于基本字形下方的标记组成。
对于覆盖的连字字形,LigGlyphsArray对一个LigatureAttach表有一个偏移量。此表称为LamWithMeemWithJeemLigAttach,它定义了连字中组件字形的计数和数组。每个ComponentRecord定义两个Anchor表的偏移量,每个标记类对应一个。
在该示例中,第一个字形组件lam指定用于定位上方重音的高附着点,但未指定用于在下方放置重音的低附着点。第二个字形组件meem定义了一个低附着点,用于在下方放置重音符号,但不在上方。第三个组件jeem没有附加点,因为该示例没有定义任何重音符号。
例8
Hex数据 资源 评论
MarkLigPosFormat1
MarkLigAttachSubTable MarkLigPos子表定义
0001 1 posFormat
000C MarkGlyphsCoverage offset到markCoverage表
0014 LigGlyphsCoverage offset到ligatureCoverage表
技术 2 markClassCount
001A MarkGlyphsArray 偏移到MarkArray表
0030 LigGlyphsArray 偏移到LigatureArray表
CoverageFormat1
MarkGlyphsCoverage 覆盖表定义
0001 1 coverageFormat:列表
技术 2 glyphCount
033C sukunMarkGlyphID glyphArray [0]
033F kasratanMarkGlyphID glyphArray [1]
CoverageFormat1
LigGlyphsCoverage 覆盖表定义
0001 1 coverageFormat:列表
0001 1 glyphCount
0234 LamWithMeemWithJeem
LigatureGlyphID glyphArray [0]
MarkArray
MarkGlyphsArray MarkArray表定义
技术 2 markCount
markRecords [0] 标记索引顺序中的MarkRecords
0000 0 markClass,用于组件上方的标记
000A sukunMarkAnchor markAnchorOffset
markRecords [1]
0001 1 markClass,用于组件下方的标记
0010 kasratanMarkAnchor markAnchorOffset
AnchorFormat1
sukunMarkAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
015A 346 x坐标
FF9E -98 y坐标
AnchorFormat1
kasratanMarkAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
0105 261 x坐标
01E8 488 y坐标
LigatureArray
LigGlyphsArray LigatureArray表定义
0001 1 ligatureCount
0004 LamWithMeemWithJeemLigAttach ligatureAttachOffsets [0]
LigatureAttach
LamWithMeemWithJeemLigAttach LigatureAttach表定义
0003 3 componentCount
componentRecords [0] 从右到左的文字; 写入方向(逻辑)顺序的ComponentRecords:最右边的字形
000E AboveLamAnchor ligatureAnchorOffsets [0] - 按标记类排序的偏移量
0000 空值 ligatureAnchorOffsets [1] - 没有Class1标记的附着点
componentRecords [1]
0000 空值 ligatureAnchorOffsets [0] - 没有类0标记的附着点
0014 BelowMeemAnchor ligatureAnchorOffsets - 用于1级标记(下)
componentRecords [2]
0000 空值 ligatureAnchorOffsets - 类0标记没有附加点
0000 空值 ligatureAnchorOffsets [1] - 没有第1类标记的附着点
AnchorFormat1
AboveLamAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
0271 625 x坐标
0708 1800 y坐标
AnchorFormat1
BelowMeemAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
0178 376 x坐标
FE90 -368 y坐标
例9:MarkMarkPosFormat1子表
例9中的MarkMarkPosFormat1子表定义了两个阿拉伯标记字形。hanza标记(基准标记(Mark2))在Mark2GlyphsCoverage表中标识。damma标记(附加标记(Mark1))在Mark1GlyphsCoverage表中定义。
Mark1Array中还列出了每个Mark1字形及其附着点数据和标记Class值。Mark1GlyphsArray定义了一个标记类Class0,它由位于Mark2基本字形上方的标记组成。Mark1GlyphsArray包含dammaMarkAnchor表的偏移量,用于指定damma标记的附着点的坐标。
Mark2GlyphsArray表定义了Mark2Records的计数和数组,每个Mark2Records用于每个覆盖的Mark2基本字形。每个记录包含每个Mark1类的Mark2Anchor表的偏移量。一个Anchor表AboveMark2Anchor指定用于将damma标记附加到hanza基本标记上方的坐标值。
例9
Hex数据 资源 评论
MarkMarkPosFormat1
MarkMarkAttachSubTable MarkBasePos子表定义
0001 1 posFormat
000C Mark1GlyphsCoverage 偏移到mark1Coverage表
0012 Mark2GlyphsCoverage 偏移到mark2Coverage表
0001 1 markClassCount
0018 Mark1GlyphsArray 偏移到mark1Array表
0024 Mark2GlyphsArray 偏移到mark2Array表
CoverageFormat1
Mark1GlyphsCoverage 覆盖表定义
0001 1 coverageFormat:列表
0001 1 glyphCount
0296 dammaMarkGlyphID glyphArray [0]
CoverageFormat1
Mark2GlyphsCoverage 覆盖表定义
0001 1 coverageFormat:列表
0001 1 glyphCount
0289 hanzaMarkGlyphID glyphArray [1]
MarkArray
Mark1GlyphsArray MarkArray表定义
0001 1 markCount
markRecords [0] 标记索引顺序中的MarkRecords
0000 0 markClass - 用于基准标记以上的标记
0006 dammaMarkAnchor markAnchorOffset
AnchorFormat1
dammaMarkAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
00BD 189 x坐标
FF99 -103 y坐标
Mark2Array
Mark2GlyphsArray Mark2Array表定义
0001 1 mark2Count
mark2Records [0]
0004 AboveMark2Anchor mark2AnchorOffsets [0]
AnchorFormat1
AboveMark2Anchor 锚表定义
0001 1 anchorFormat:仅限设计单位
00DD 221 x坐标
012D 301 y坐标
示例10:ContextPosFormat1 Subtable和PosLookupRecord
示例10使用ContextPosFormat1子表来调整单词中三个阿拉伯字形之间的间距。上下文是字形序列(从右到左):heh(初始形式),thal(最终形式)和heh(隔离形式)。在渲染的单词中,前两个字形是连接的,但最后一个字形(heh的孤立形式)是分开的。此子表减少了最后一个字形与单词其余部分之间的空间量。
子表包含一个WordCoverage表,列出单词中的第一个字形,heh(初始)和一个名为WordPosRuleSet的PosRuleSet表,它定义了以此覆盖字形开头的所有上下文。
WordPosRuleSet包含一个PosRule,用于描述三个字形的单词上下文,并标识第二个和第三个字形(第一个字形由WordPosRuleSet标识)。当文本处理客户端在文本中找到此上下文时,它会在位置2处应用SinglePos查找(在示例中未显示)以减少字形之间的间距。
例10
Hex数据 资源 评论
ContextPosFormat1
MoveHehInSubtable ContextPos子表定义
0001 1 posFormat
0008 WordCoverage 偏移到Coverage表
0001 1 posRuleSetCount
000E WordPosRuleSet posRuleSetOffsets [0]
CoverageFormat1
WordCoverage 覆盖表偏移量
0001 1 coverageFormat:列表
0001 1 glyphCount
02A6 hehInitialGlyphID glyphArray [0]
PosRuleSet
WordPosRuleSet PosRuleSet表定义
0001 1 posRuleCount
0004 WordPosRule posRuleOffsets [0]
PosRule
WordPosRule PosRule表定义
0003 3 glyphCount
0001 1 posCount
02DD thalFinalGlyphID inputSequence [0]
02C6 hehIsolatedGlyphID inputSequence [1]
posLookupRecords [0]
技术 2 sequenceIndex
0001 1 lookupListIndex
例11:ContextPosFormat2子表
例11中的ContextPosFormat2子表定义了五个字形类的上下文字符串:Class1由大写字母组成,它们在其右侧悬垂并创建一个宽敞的空间; Class2由大写字母组成,悬垂并在其右侧创建一个狭窄的空间; Class3包含小写x高度元音; 和Class4包含放在小写元音上的重音字形。字体中的其余字形属于Class0。
MoveAccentsSubtable定义了两个类似的上下文字符串。第一个包含一个Class1大写字形,后跟一个Class3小写元音字形,元音上有一个Class4重音字形。当在文本中找到此上下文时,客户端会降低元音上的重音符号,以使其不会与悬垂的字形形状发生碰撞。第二个上下文包含一个Class2大写字形,后跟一个Class3小写元音字形,在元音上有一个Class4重音字形。当在文本中找到此上下文时,客户端会增加大写字形的前进宽度,以扩展它与重音元音之间的空间。
MoveAccents子表定义了一个MoveAccentsCoverage表,该表标识了两个上下文中的第一个字形以及五个PosClassSet表的偏移量,每个类对应于ClassDef表中定义的每个类。由于没有上下文以Class0,Class3或Class4字形开头,因此这些类的PosClassSet表的偏移量为NULL。PosClassSet [1]定义以Class1字形开头的所有上下文; 它被称为UCWideOverhangPosClass1Set。PosClassSet [2]定义了以Class2字形开头的所有上下文,它被称为UCNarrowOverhangPosClass1Set。
每个PosClassSet定义一个PosClassRule。UCWideOverhangPosClass1Set使用UCWideOverhangPosClassRule指定第一个上下文。此上下文字符串中的第一个类由PosClassSet标识,该PosClassSet包含PosClassRule,在本例中为Class1。PosClassRule表将上下文中的第二个和第三个类列为Class3和Class4。SinglePos Lookup(未显示)降低上下文字符串中位置3的重音字形。
UCNarrowOverhangPosClass1Set为第二个上下文定义UCNarrowOverhangPosClassRule。此PosClassRule与UCWideOverhangPosClassRule相同,只是上下文字符串中的第一个类是Class2小写字形。SinglePos Lookup(未显示)增加了上下文字符串中位置0中悬垂的大写字形的前进宽度。
例11
Hex数据 资源 评论
ContextPosFormat2
MoveAccentsSubtable ContextPos子表定义
技术 2 posFormat
0012 MoveAccentsCoverage 偏移到覆盖范围表
0020 MoveAccentsClassDef 抵消ClassDef
0005 五 posClassSetCount
0000 空值 posClassSetOffsets [0] - 没有上下文以Class 0字形开头
0060 UCWideOverhangPosClass1Set posClassSetOffsets [1] - 以Class 1字形开头的上下文
0070 UCNarrowOverhangPosClass2Set PosClassSetOffsets [2] - 以Class 2字形开头的上下文
0000 空值 posClassSetOffsets [3] - 没有上下文以Class 3字形开头
0000 空值 posClassSetOffsets [4] - 没有上下文以Class4字形开头
CoverageFormat1
MoveAccentsCoverage 覆盖表定义
0001 1 coverageFormat:列表
0005 五 glyphCount
0029 UppercaseFGlyphID glyphArray [0]
0033 UppercasePGlyphID glyphArray [1]
0037 UppercaseTGlyphID glyphArray [2]
0039 UppercaseVGlyphID glyphArray [3]
003A UppercaseWGlyphID glyphArray [4]
ClassDefFormat2
MoveAccentsClassDef ClassDef表定义定义了五个类:0(所有其他),1(T,V,W:UCUnderhang),2(F,P:UCOverhang),3(a,e,I,o,u:LCVowels),4(波尔德,变音符号)
技术 2 classFormat:范围
000A 10 classRangeCount
classRangeRecords [0]
0029 UppercaseFGlyphID startGlyphID
0029 UppercaseFGlyphID endGlyphID
技术 2 类
classRangeRecords [1]
0033 UppercasePGlyphID startGlyphID
0033 UppercasePGlyphID endGlyphID
技术 2 类
classRangeRecords [2]
0037 UppercaseTGlyphID startGlyphID
0037 UppercaseTGlyphID endGlyphID
0001 1 类
classRangeRecords [3]
0039 UppercaseVGlyphID startGlyphID
003A UppercaseWGlyphID endGlyphID
0001 1 类
classRangeRecords [4]
0042 LowercaseAGlyphID startGlyphID
0042 LowercaseAGlyphID endGlyphID
0003 3 类
classRangeRecords [5]
0046 LowercaseEGlyphID startGlyphID
0046 LowercaseEGlyphID endGlyphID
0003 3 类
classRangeRecords [6]
004A LowercaseIGlyphID startGlyphID
004A LowercaseIGlyphID endGlyphID
0003 3 类
classRangeRecords [7]
0051 LowercaseOGlyphID startGlyphID
0051 LowercaseOGlyphID endGlyphID
0003 3 类
classRangeRecords [8]
0056 LowercaseUGlyphID startGlyphID
0056 LowercaseUGlyphID endGlyphID
0003 3 类
classRangeRecords [9]
00F5 TildeAccentGlyphID startGlyphID
00F6 UmlautAccentGlyphID endGlyphID
0004 4 类
PosClassSet
UCWideOverhangPosClass1Set PosClassSet表定义
0001 1 posClassRuleCount
0004 UCWideOverhangPosClassRule posClassRuleOffsets [0]
PosClassRule
UCWideOverhangPosClassRule PosClassRule表定义
0003 3 glyphCount
0001 1 posCount
0003 3 classes [0] - 小写元音
0004 4 课程[1] - 口音
posLookupRecords [0]
技术 2 sequenceIndex
0001 1 lookupListIndex - 降低重音
PosClassSet
UCNarrowOverhangPosClass2Set PosClassSet表定义
0001 1 posClassRuleCount
0004 UCNarrowOverhangPosClassRule posClassRuleOffsets [0]
PosClassRule
UCNarrowOverhangPosClassRule PosClassRule表定义
0003 3 glyphCount
0001 1 posCount
0003 3 classes [0] - 小写元音
0004 4 课程[1] - 口音
posLookupRecords [0]
0000 0 sequenceIndex
技术 2 lookupListIndex - 增加悬伸提前宽度
例12:ContextPosFormat3子表
示例12使用ContextPosFormat3子表来降低数学方程中数学符号的位置,该数学方程由小写下降或x高度字形,数学符号字形和任何小写字形组成。Format3最好用于此上下文而不是基于类的Format2,因为位置0和2的覆盖字形集重叠。
LowerMathSignsSubtable包含三个Coverage表(XhtDescLCCoverage,MathSignCoverage和LCCoverage)的偏移量,一个用于上下文字形字符串中的每个位置。当客户端在文本流中找到上下文时,它会在位置1应用PosLookupRecord数据并重新定位数学符号。
例12
Hex数据 资源 评论
ContextPosFormat3
LowerMathSignsSubtable ContextPos子表定义
0003 3 posFormat
0003 3 glyphCount
0001 1 posCount
0010 XhtDescLCCoverage coverageOffsets [0]
003C MathSignCoverage coverageOffsets [1]
0044 LCCoverage coverageOffsets [2]表
posLookupRecords [0]
0001 1 sequenceIndex
0001 1 lookupListIndex
CoverageFormat1
XhtDescLCCoverage 覆盖表定义
0001 1 coverageFormat:列表
0014 20 glyphCount
0033 LCaGlyphID glyphArray [0]
0035 LCcGlyphID glyphArray [1]
0037 LCeGlyphID glyphArray [2]
0039 LCgGlyphID glyphArray [3]
003B LCiGlyphID glyphArray [4]
003C LCjGlyphID glyphArray [5]
003F LCmGlyphID glyphArray [6]
0040 LCnGlyphID glyphArray [7]
0041 LCoGlyphID glyphArray [8]
0042 LCpGlyphID glyphArray [9]
0043 LCqGlyphID glyphArray [10]
0044 LCrGlyphID glyphArray [11]
0045 LCsGlyphID glyphArray [12]
0046 LCtGlyphID glyphArray [13]
0047 LCuGlyphID glyphArray [14]
0048 LCvGlyphID glyphArray [15]
0049 LCwGlyphID glyphArray [16]
004A LCxGlyphID glyphArray [17]
004B LCyGlyphID glyphArray [18]
004C LCzGlyphID glyphArray [19]
CoverageFormat1
MathSignCoverage 覆盖表定义
0001 1 coverageFormat:列表
技术 2 glyphCount
011E EqualsSignGlyphID glyphArray [0]
012D PlusSignGlyphID glyphArray [1]
CoverageFormat2
LCCoverage 覆盖表定义
技术 2 coverageFormat:范围
0001 1 rangeCount
rangeRecords [0]
0033 LCaGlyphID startGlyphID
004C LCzGlyphID endGlyphID
0000 0 startCoverageIndex
例13:PosLookupRecord
示例13中的PosLookupRecord标识要在上下文字形字符串中的第二个字形位置应用的查找。
例13
Hex数据 资源 评论
PosLookupRecord
posLookupRecords [0] PosLookupRecord定义
0001 1 sequenceIndex - 用于第二个字形位置
0001 1 lookupListIndex - 将此查找应用于第二个字形位置
示例14:ValueFormat表和ValueRecord
示例14演示了如何在GPOS表中指定定位值。这里,SinglePosFormat1子表定义了ValueFormat和ValueRecord。ValueFormat位设置为0x0099表示相应的ValueRecord包含字形的XPlacement和YAdvance的值。设备表指定这些值的像素调整,字体大小从11 ppem到15 ppem。
例14
Hex数据 资源 评论
SinglePosFormat1
OnesSubtable SinglePos子表定义
0001 1 posFormat
000E 冠状病毒 偏移到覆盖范围表
0099 0x0099 valueFormat:X_PLACEMENT + Y_ADVANCE + X_PLACEMENT_DEVICE,Y_ADVANCE_DEVICE
valueRecord
0050 80 xPlacement
00D2 210 yAdvance
0018 XPlaDeviceTable xPlaDeviceOffset
0020 YAdvDeviceTable yAdvDeviceOffset
CoverageFormat2
Cov 覆盖表定义
技术 2 coverageFormat:范围
0001 1 rangeCount
rangeRecords [0]
00C8 200 startGlyphID
00D1 209 endGlyphID
0000 0 startCoverageIndex
DeviceTableFormat1
XPlaDeviceTable 设备表定义
000B 11 startSize
000F 15 endSize - 五个delta值(大小11到15)
0001 1 deltaFormat:LOCAL_2_BIT_DELTAS
1 deltaValue [0]:将11ppem增加1个像素
1 deltaValue [1]:将12ppem增加1个像素
1 deltaValue [2]:增加13ppem 1个像素
1 deltaValue [3]:增加14ppem 1个像素
5540 1 deltaValue [4]:增加15ppem 1个像素
DeviceTableFormat1
YAdvDeviceTable 设备表定义
000B 11 startSize
000F 15 endSize - 五个delta值(大小11到15)
0001 1 deltaFormat:LOCAL_2_BIT_DELTAS
1 deltaValue [0]:将11ppem增加1个像素
1 deltaValue [1]:将12ppem增加1个像素
1 deltaValue [2]:增加13ppem 1个像素
1 deltaValue [3]:增加14ppem 1个像素
5540 1 deltaValue [4]:增加15ppem 1个像素
例15:AnchorFormat1表
例15说明了阿拉伯文脚本中damma标记字形的Anchor表。Format1用于以设计单位指定X和Y坐标值。
例15
Hex数据 资源 评论
AnchorFormat1
dammaMarkAnchor 锚表定义
0001 1 anchorFormat:仅限设计单位
00BD 189 x坐标
FF99 -103 y坐标
例16:AnchorFormat2表
示例16显示了放置在基本字形上方的附着点的AnchorFormat2表。使用此格式,Anchor的坐标值取决于提示后基本字形上特定轮廓点的最终位置。坐标以设计单位指定。
例16
Hex数据 资源 评论
AnchorFormat2
AboveBaseAnchor 锚表定义
技术 2 anchorFormat:设计单位加上轮廓点
0142 322 x坐标
0384 900 y坐标
000D 13 anchorPoint - 字形轮廓点索引
例17:AnchorFormat3表
示例17显示了一个AnchorFormat3表,它指定了基本字形上方的附着点。设备表修改Anchor的X和Y坐标,以获得输出字体的磅值和分辨率。这里,Device表定义了从12 ppem到17 ppem的字体大小的像素调整。
例17
Hex数据 资源 评论
AnchorFormat3
AboveBaseAnchor 锚表定义
0003 3 anchorFormat:设计单位加设备表
0117 279 x坐标
0515 1301 y坐标
000A XDevice xDeviceOffset(可能为NULL)
0014 YDevice yDeviceOffset(可能为NULL)
DeviceTableFormat2
XDevice 设备表定义
000C 12 startSize
0011 17 endSize - 六个delta值(大小12到17)
技术 2 deltaFormat:LOCAL_4_BIT_DELTAS
1 deltaValue [0]:将12ppem增加1个像素
1 deltaValue [1]:将13ppem增加1个像素
1 deltaValue [2]:增加14ppem 1个像素
1111 1 deltaValue [3]:增加15ppem 1个像素
2 deltaValue [4]:将16ppem增加1个像素
2200 2 deltaValue [5]:增加17ppem 1个像素
DeviceTableFormat2
YDevice 设备表定义
000C 12 startSize
0011 17 endSize - 六个delta值(大小12到17)
技术 2 deltaFormat:LOCAL_4_BIT_DELTAS
1 deltaValue [0]:将12ppem增加1个像素
1 deltaValue [1]:将13ppem增加1个像素
1 deltaValue [2]:增加14ppem 1个像素
1111 1 deltaValue [3]:增加15ppem 1个像素
2 deltaValue [4]:将16ppem增加1个像素
2200 2 deltaValue [5]:增加17ppem 1个像素
例18:MarkArray表和MarkRecord
示例18显示了MarkArray表,其中包含两个重音符号,一个坟墓和一个cedilla的类和附着点数据。定义了两个MarkRecords,每个覆盖的标记字形一个。第一个MarkRecord将标记类值0指定给放置在基本字形上方的重音符号(例如坟墓),并且具有到graveMarkAnchor表的偏移量。第二个MarkRecord为位于基本字形下方的所有重音分配标记类值1,例如cedilla,并且具有到cedillaMarkAnchor表的偏移量。
例18
Hex数据 资源 评论
MarkArray
MarkGlyphsArray MarkArray表定义
技术 2 markCount
markRecords [0] 对于markCoverage表中的第一个标记:严重
0000 0 markClass - 用于放置在基本字形上方的标记
000A graveMarkAnchor markAnchorOffset
markRecords [1] 对于markCoverage表中的第二个标记:cedilla
0001 1 markClass - 用于放置在基本字形下方的标记
0010 cedillaMarkAnchor markAnchorOffset
7.22.GSUB 雕文替换表
字形替换(GSUB)表为字形的替换提供数据,以便适当地呈现脚本,例如在阿拉伯语脚本中粗略地连接表单,或者用于高级印刷效果,例如连字。
7.22.1.Overview
字形替换表(GSUB)包含用于替换字形以呈现字体支持的脚本和语言系统的信息。许多语言系统都需要字形替代品。例如,在阿拉伯语脚本中,描绘特定字符的字形形状根据其在单词或文本字符串中的位置而变化(参见图1)。在其他语言系统中,字形替代品是用户的美学选择,例如在英语中使用连字字形(参见图2)。


OpenType字体使用字符编码标准,例如Unicode标准,它假设字符和字形之间有区别:文本被编码为字符序列,’cmap’表提供从该字符到单个默认字形的映射。根据连字的需要,多个字符不会直接映射到单个字形; 并且单个字符不会直接映射到多个字形,这可能是某些复杂脚本方案所需要的。GSUB表提供了一种描述此类替代的方法,使应用程序能够在文本布局和渲染期间应用此类子类以实现所需的结果。
为了访问替换字形,GSUB将字形索引或’cmap’子表中定义的索引映射到字形索引或替换字形的索引。例如,如果字体有三种替代形式的&符号字形,则’cmap’表将&符号的字符代码与这些字形中的一个相关联。在GSUB中,然后从这一个默认索引引用其他&符号的索引。
文本处理客户端使用GSUB数据来管理字形替换操作。GSUB识别输入到每个字形替换操作和从每个字形替换操作输出的字形,指定客户端使用字形替换的方式和位置,并调整字形替换操作的顺序。可以为以字体表示的每个脚本或语言系统定义任意数量的替换。
GSUB表支持七种类型的字形替换,广泛用于国际排版:
阿单替换替换另一个单个字形一个字形。这用于渲染远东阿拉伯语和垂直文本中的位置字形变体(参见图3)。

阿多取代替换单个字形与多于一个字形。这用于指定绑定分解等操作(参见图4)。

一个替代的替代标识字形的功能上等同的,但不同的找形式。这些字形通常被称为美学替代品。例如,字体可能有五个不同的符号用于符号符号,但是一个字体在’cmap’表中有一个默认的字形索引。客户端可以使用默认字形或替换四种替代方案中的任何一种(参见图5)。

甲结扎取代替代多个字形索引与单个标志符号索引,因为当一个阿拉伯连字字形代替单独的字形的一个字符串(见图6)。当一串字形可以用单个连字字形替换时,第一个字形将被连字替换。字符串中剩余的字形将被删除,这不包括因查找标志而跳过的字形。

上下文替换是上述查找类型的强大扩展,描述了上下文中的字形替换 - 即,在某个字形模式中替换一个或多个字形。每个替换描述了一个或多个输入字形序列以及要对该序列执行的一个或多个替换。上下文替换可以应用于特定的字形序列,字形类或字形集。
链接上下文替换,扩展了上下文替换的功能。这样,通过将输入序列链接到“回溯”和/或“超前”序列,可以对字形图案(输入序列)内的一个或多个字形执行一个或多个替换。每个这样的替换可以以三种格式应用以处理输入序列中的字形,字形类或字形集。这些格式中的每一种都可以描述一个或多个回溯,输入和先行序列。
反向链接上下文单个替换,允许通过将输入字形链接到“回溯”和/或“超前”序列来将一个字形替换为另一个字形。此查找类型与其他查找类型之间的区别在于输入字形序列的处理从头到尾。
7.22.2.GSUB Table and OpenType Font Variations
OpenType字体变体允许单个字体沿着一个或多个设计变体轴支持许多设计变体。例如,具有重量和宽度变化的字体可能支持从细到黑的重量,以及从超浓缩到超扩展的宽度。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
在可变字体中,可能希望对字体的变化空间内的不同区域使用不同的字形替换动作。例如,对于计数器变小的窄或重的实例,可能需要进行某些字形替换以使用替换的字形,其中移除了某些笔划或简化了轮廓以允许更大的计数器。使用GSUB表中的FeatureVariations表可以实现这样的效果。FeatureVariations表在OpenType布局公用表格式章节中描述。另请参阅OpenType布局标记注册表中的必需变体替换(’rvrn’)功能。
7.22.3.Table Organization
GSUB表以标题开头,该标题定义了ScriptList,FeatureList,LookupList和可选的FeatureVariations表的偏移量(参见图3g):
该ScriptList标识在使用替代品字形字体中所有的脚本和语言系统。
该FeatureList定义了所有渲染这些脚本和语言系统所需的字形替换功能。
该LookupList包含了所有实现每个字形替换功能所需的查找数据。
所述FeatureVariations表可以用来代替查找表的替代设置用于指定条件下任何给定功能。目前仅用于可变字体。
有关ScriptLists,FeatureLists,LookupLists和FeatureVariation表的详细讨论,请参阅OpenType Layout Common Table Formats一章。

该组织帮助文本处理客户端轻松找到适用于特定脚本或语言系统的功能和查找。要访问GSUB信息,客户端应使用以下过程:
在GSUB ScriptList表中找到当前脚本。
如果语言系统已知,请在脚本中搜索正确的LangSys表; 否则,请使用脚本的默认LangSys表。
LangSys表在GSUB FeatureList表中提供索引号,以访问所需的功能和许多其他功能。
检查每个Feature表的featureTag,并选择要应用于输入字形字符串的要素表。
如果存在“特征变体”表,请评估“特征变体”表中的条件,以确定是否应将任何最初选择的特征表替换为备用特征表。
每个Feature表都在GSUB LookupList表中提供了一个索引号数组。从所选特征集合中汇编所有查找,并按LookupList表中给出的顺序应用查找。
有关“功能变体”表及其处理方式的详细说明,请参阅“OpenType布局公用表格式”一章中的“功能变量表”部分。
查找数据在查找表中定义,查找表在OpenType布局公用表格式章节中定义。查找表包含一个或多个查找子表,用于定义用于实现功能的替换操作的特定条件,类型和结果。特定查找子表单类型用于字形替换操作,并在本章中定义。Lookup表中的所有子表必须具有相同的查找类型,如下表中列出的GSUB LookupType枚举:
GSUB LookupType枚举
值 类型 描述
1 单(格式1.1 1.2) 用一个字形替换一个字形
2 多个(格式2.1) 用一个以上的字形替换一个字形
3 替代(格式3.1) 将一个字形替换为多个字形中的一个
4 Ligature(格式4.1) 用一个字形替换多个字形
五 上下文(格式5.1 5.2 5.3) 在上下文中替换一个或多个字形
6 链接上下文(格式6.1 6.2 6.3) 在链接上下文中替换一个或多个字形
7 扩展替换(格式7.1) 其他替换的扩展机制(即这不包括扩展类型替换本身)
8 反向链接上下文单一(格式8.1) 以相反的顺序应用,在链接上下文中替换单个字形
9+ 保留的 供将来使用(设为零)
每个LookupType都有一个或多个子表格式。“最佳”格式取决于替换类型和最终存储效率。当字形信息最好以多种格式呈现时,只要所有子表都使用相同的LookupType,单个查找可以定义多个子表。例如,在给定查找内,字形索引数组格式可以最好地表示一组目标字形,而字形索引范围格式对于另一组可以更好。
对同一个字形或字符串的一系列替换操作需要多次查找,每次单独操作一次。每个查找在LookupList表中具有不同的数组索引,并以LookupList顺序应用。
在文本处理期间,客户端在移动到下一个查找之前对字符串中的每个字形应用查找。在客户端找到目标字形或字形上下文并执行替换(如果已指定)后,将对字形完成查找。要移动到“下一个”字形,客户端通常会跳过参与查找操作的所有字形:替换的字形以及形成操作上下文的任何其他字形。
在链接上下文查找(LookupType 6)的情况下,包括回溯和超前序列的字形可以参与多个上下文。
本章的其余部分描述了GSUB标头和为每个GSUB LookupType定义的子表。实施例在此章的最后示出了GSUB头和八个LookupTypes,包括可用于上下文取代(LookupType 5)的三种格式中的六个。
7.22.4.GSUB Header
GSUB表以一个标题开头,该标题包含表的版本号和三个表的偏移量:ScriptList,FeatureList和LookupList。有关每个表的说明,请参阅OpenType布局公用表格式一章。本章末尾的示例1显示了GSUB标头表定义。
GSUB标题,版本1.0
类型 名称 描述
UINT16 majorVersion GSUB表的主要版本,= 1
UINT16 minorVersion GSUB表的次要版本,= 0
Offset16 scriptListOffset 从GSUB表的开头偏移到ScriptList表
Offset16 featureListOffset 从GSUB表的开头偏移到FeatureList表
Offset16 lookupListOffset 从GSUB表的开头偏移到LookupList表
GSUB Header,1.1版
类型 名称 描述
UINT16 majorVersion GSUB表的主要版本,= 1
UINT16 minorVersion GSUB表的次要版本,= 1
Offset16 scriptListOffset 从GSUB表的开头偏移到ScriptList表
Offset16 featureListOffset 从GSUB表的开头偏移到FeatureList表
Offset16 lookupListOffset 从GSUB表的开头偏移到LookupList表
OFFSET32 featureVariationsOffset 从GSUB表的开头偏移到FeatureVariations表(可能为NULL)
7.22.5.LookupType 1: Single Substitution Subtable
单替换(SingleSubst)子表告诉客户端用另一个字形替换单个字形。子表可以是两种格式。两种格式都需要两组不同的字形索引:一组定义输入字形(在Coverage表中指定),另一组定义输出字形。格式1比格式2需要更少的空间,但灵活性较差。
1.1单一替换格式1
格式1计算输出字形的索引,这些字形未在子表中明确定义。要计算输出字形索引,格式1会为输入字形索引添加一个常量delta值。为了使替换正确发生,输入和输出范围中的字形索引必须具有相同的顺序。此格式不使用Coverage表返回的Coverage索引。
SingleSubstFormat1子表以格式标识符(substFormat)为1开始。偏移量引用Coverage表,该表指定输入字形的索引。deltaGlyphID是添加到每个输入字形索引的常量值,用于计算相应输出字形的索引。deltaGlyphID的加法模数为65536。
本章末尾的示例2使用格式1将衬里数字替换为标准数字。
SingleSubstFormat1子表:计算的输出字形索引
类型 名称 描述
UINT16 substFormat 格式标识符:format = 1
Offset16 coverageOffset 从替换子表开始偏移到Coverage表
INT16 deltaGlyphID 添加到原始字形ID以获取替换字形ID
1.2单一替换格式2
格式2比格式1更灵活,但需要更多空间。它提供了一个输出字形索引数组(substituteGlyphIDs),它们与Coverage表中指定的输入字形索引明确匹配。
SingleSubstFormat2子表指定格式标识符(substFormat),定义输入字形索引的Coverage表的偏移量,substituteGlyphIDs数组中的输出字形索引计数(glyphCount),以及输出字形索引的列表。替换数组(substituteGlyphIDs)。
substituteGlyphIDs数组必须包含与Coverage表相同数量的字形索引。要在substituteGlyphIDs数组中找到相应的输出字形索引,此格式使用从Coverage表返回的Coverage索引。
本章末尾的示例3使用格式2将垂直方向的字形替换为水平方向的字形。
SingleSubstFormat2子表:指定的输出字形索引
类型 名称 描述
UINT16 substFormat 格式标识符:format = 2
Offset16 coverageOffset 从替换子表开始偏移到Coverage表
UINT16 glyphCount substituteGlyphIDs数组中的字形ID数
UINT16 substituteGlyphIDs [GlyphCount] 替换字形ID的数组 - 按Coverage索引排序
7.22.6.LookupType 2: Multiple Substitution Subtable
多重替换(MultipleSubst)子表替换具有多个字形的单个字形,就像多个字形替换单个连字一样。子表具有单一格式:MultipleSubstFormat1。
2.1多次替换格式1
多重替换格式1子表指定格式标识符(substFormat),定义输入字形索引的Coverage表的偏移量,sequenceOffsets数组(sequenceCount)中的偏移计数,以及定义序列表的序列表的偏移数组输出字形索引(sequenceOffsets)。Sequence表偏移量按输入字形的Coverage索引排序。
对于Coverage表中列出的每个输入字形,Sequence表定义输出字形。每个Sequence表包含输出字形序列(glyphCount)中的字形计数和输出字形索引数组(substituteGlyphIDs)。
注意:输出字形索引的顺序取决于文本的书写方向。对于从左到右书写的文本,最左边的字形将是序列中的第一个字形。相反,对于从右到左书写的文本,最右边的字形将是第一个。
禁止使用多个替换来删除输入字形。glyphCount值必须始终大于0。
本章末尾的示例4显示了如何用三个字形替换单个连字。
MultipleSubstFormat1子表:多个输出字形
类型 名称 描述
UINT16 substFormat 格式标识符:format = 1
Offset16 coverageOffset 从替换子表开始偏移到Coverage表
UINT16 sequenceCount sequenceOffsets数组中的序列表偏移数
Offset16 sequenceOffsets [sequenceCount] 序列表的偏移数组。偏移是从替换子表开始,按Coverage索引排序
序列表
类型 名称 描述
UINT16 glyphCount substituteGlyphIDs数组中的字形ID数。这必须始终大于0。
UINT16 substituteGlyphIDs [glyphCount] 要替换的字形ID字符串
7.22.7.LookupType 3: Alternate Substitution Subtable
替代替换(AlternateSubst)子表标识任意数量的美学替代,用户可以从中选择字形变体来替换输入字形。例如,如果一个字体包含&符号的四个变体,’cmap’表将指定四个字形之一的索引作为默认字形索引,AlternateSubst子表将列出其他三个字形的索引作为替代。然后,文本处理客户端可以选择使用三个备选方案中的任何一个替换默认字形。
子表有一种格式:AlternateSubstFormat1。
3.1替代替代格式1
替代替换格式1子表包含格式标识符(substFormat),Coverage表的偏移量,包含具有替代形式的字形索引(coverageOffset),AlternateSet表的偏移计数(alternateSetCount)以及AlternateSet的偏移数组表(alternateSetOffsets)。
对于每个字形,AlternateSet子表包含替代字形(glyphCount)的计数和其字形索引的数组(alternateGlyphIDs)。因为所有字形在功能上都是等效的,所以它们可以在数组中以任何顺序排列。
本章末尾的示例5显示了如何使用替代字形替换默认的&符号字形。
AlternateSubstFormat1子表:替代输出字形
类型 名称 描述
UINT16 substFormat 格式标识符:format = 1
Offset16 coverageOffset 从替换子表开始偏移到Coverage表
UINT16 alternateSetCount AlternateSet表的数量
Offset16 alternateSetOffsets [alternateSetCount] AlternateSet表的偏移数组。偏移是从替换子表开始,按Coverage索引排序
AlternateSet表
类型 名称 描述
UINT16 glyphCount alternateGlyphIDs数组中的字形ID数
UINT16 alternateGlyphIDs [glyphCount] 替换字形ID的数组,按任意顺序排列
7.22.8.LookupType 4: Ligature Substitution Subtable
Ligature Substitution(LigatureSubst)子表标识连字替换,其中单个字形替换多个字形。一个LigatureSubst子表可以指定任意数量的连字替换。子表有一种格式:LigatureSubstFormat1。
4.1连字替换格式1
它包含格式标识符(substFormat),Coverage表偏移量(coverageOffset),此表中定义的连字集的计数(ligatureSetCount),以及LigatureSet表(ligatureSetOffsets)的偏移数组。Coverage表仅指定每个连字集的第一个字形组件的索引。
本章末尾的示例6显示了如何使用单个连字替换字符串。
LigatureSubstFormat1子表:脚本中的所有连字替换
类型 名称 描述
UINT16 substFormat 格式标识符:format = 1
Offset16 coverageOffset 从替换子表开始偏移到Coverage表
UINT16 ligatureSetCount LigatureSet表的数量
Offset16 ligatureSetOffsets [ligatureSetCount] LigatureSet表的偏移量数组。偏移是从替换子表开始,按Coverage索引排序
LigatureSet表(每个覆盖的字形一个)指定以覆盖的字形开头的所有连字字符串。例如,如果Coverage表列出了小写“f”的字形索引,则LigatureSet表将定义“ffl”,“fl”,“ffi”,“fi”和“ff”连字。如果Coverage表还列出了小写“e”的字形索引,则不同的LigatureSet表将定义“etc”连字。
LigatureSet表包含以覆盖字形(ligatureCount)开头的连字计数和Ligature表的偏移数组(ligatureSetOffsets),它们定义每个连字中的字形。Ligature偏移数组中的顺序定义了使用连字的首选项。例如,如果“ffl”连字优于“ff”连字,则Ligature数组会在偏移到“ff”Ligature表之前列出“ffl”Ligature表的偏移量。
LigatureSet表:以相同字形开头的所有连字
类型 名称 描述
UINT16 ligatureCount Ligature表的数量
Offset16 ligatureOffsets [LigatureCount] Ligature表的偏移数组。偏移量来自LigatureSet表的开头,按优先顺序排序。
对于集合中的每个连字,Ligature表指定输出连字字形(ligatureGlyph)的字形ID; 连字中组件字形总数的计数,包括第一个组件(componentCount); 以及组件的字形ID数组(componentGlyphIDs)。数组以连字中的第二个分量字形开始(字形序列索引= 1,componentGlyphIDs数组索引= 0),因为第一个分量字形在Coverage表中指定。
注意: componentGlyphIDs数组根据文本的写入方向(即逻辑顺序)列出字形ID。对于从右到左书写的文本,最右边的字形将是第一个。相反,对于从左到右书写的文本,最左边的字形将是第一个。
Ligature表:一个结扎的字形组件
类型 名称 描述
UINT16 ligatureGlyph 要替换的结扎的字形ID
UINT16 componentCount 结扎中的组件数量
UINT16 componentGlyphIDs [componentCount - 1] 组件字形ID的数组 - 从第二个组件开始,按写入方向排序
7.22.9.Substitution Lookup Record
替换子类型1到4允许描述字形替换操作,而不提供描述字形序列上下文的方式 - 即,为了应用替换而必须出现字形的上下文。另一方面,子表类型5,6和8允许描述在特定上下文中出现的字形替换。类型5和6的上下文替换子表指定替换查找记录(SubstLookupRecord)中的替换数据,该记录标识上下文序列中的哪些字形将被作用,以及哪个替换操作(在单独的查找表中给出)是应用。
每条记录都包含一个glyphSequenceIndex,它指示将发生替换的上下文字形序列中的位置。此外,lookupListIndex标识要在glyphSequenceIndex指定的字形位置应用的查找。
本章末尾的示例7,8和9中定义的上下文替换子表显示了SubstLookupRecords。
SubstLookupRecord
类型 名称 描述
UINT16 glyphSequenceIndex 索引到当前字形序列 - 第一个字形= 0。
UINT16 lookupListIndex 查找适用于该位置 - 从零开始的索引。
SubstLookupRecord中的glyphSequenceIndex必须考虑查找应用于整个字形序列的顺序。因为在给定上下文中可能发生多个替换,所以glyphSequenceIndex在文本处理客户端应用任何先前的查找之后引用字形序列。换句话说,glyphSequenceIndex标识在应用查找时替换的位置。
例如,考虑四个字形的输入字形序列。第一个字形没有替代,但中间的两个字形将被替换为连字,单个字形将替换第四个字形。在这个例子中,连字替换和单个替换都表示为上下文替换,其中上下文从第一个字形开始。
第一个字形位于位置0.在位置0不会应用任何查找,因此不会定义任何SubstLookupRecord。
为绑定替换定义的SubstLookupRecord将glyphSequenceIndex指定为位置1,它是连字字符串中第一个字形组件的位置。然而,在连字替换位置1和2中的字形之后,输入字形序列仅由三个字形组成,而不是原始四个字形。
要替换序列中的最后一个字形,查找子表指定一个由三个字形组成的上下文,而不是四个; 并且SubstLookupRecord将glyphSequenceIndex定义为位置2,而不是位置3.此位置和该上下文反映在此单个替换之前应用的绑定替换的效果。
注意:此示例假定LookupList指定单替换查找之前的连字替换查找。
7.22.10.LookupType 5: Contextual Substitution Subtable
Contextual Substitution(ContextSubst)子表定义了一种强大的字形替换查找类型:它描述了上下文中的字形替换,它替换了某种字形模式中的一个或多个字形。
ContextSubst子表可以是三种格式中的任何一种,它们根据字形,字形类或字形集的特定序列定义上下文。每种格式可以描述一个或多个输入字形序列以及每个序列的一个或多个替换。所有三种格式都在SubstLookupRecord中指定替换数据,如上所述。
5.1上下文替换格式1:简单字形上下文
格式1将字形替换的上下文定义为特定的字形序列。例如,上下文可以是
在上下文序列中,格式1将特定字形位置(不是字形索引)标识为特定替换的目标。当文本处理客户端在文本字符串中查找上下文时,它会查找目标位置的查找数据,并通过在该位置应用查找数据进行替换。
例如,如果客户端要用其反向字形字符串
要指定上下文,Coverage表列出序列中的第一个字形,SubRule表标识剩余的字形。为了描述前一个示例中使用的
单个ContextSubstFormat1子表可以定义多个上下文字形序列。如果不同的上下文序列以相同的字形开头,则Coverage表应仅列出一次字形,因为表中的所有字形必须是唯一的。例如,如果三个上下文各自以“s”开头而两个以“t”开头,那么Coverage表将列出一个“s”和一个“t”。
对于每个上下文,SubRule表列出了第一个字形后面的所有字形。该表还包含一个SubstLookupRecords数组,用于指定上下文中每个字形位置(包括第一个字形位置)的替换查找数据。
定义以相同第一个字形开头的上下文的所有SubRule表都组合在一起并在SubRuleSet表中定义。例如,定义以“s”开头的三个上下文的SubRule表分组在一个SubRuleSet表中,定义以“t”开头的两个上下文的SubRule表分组在第二个SubRuleSet表中。Coverage表中列出的每个字形必须具有SubRuleSet表,该表定义适用于覆盖字形的所有SubRule表。
要定位上下文字形序列,文本处理客户端每次遇到新文本字形时都会搜索Coverage表。如果覆盖了字形,则客户端将读取相应的SubRuleSet表并检查集合中的每个SubRule表,以确定上下文的其余部分是否与文本中的后续字形匹配。如果上下文和文本字符串匹配,则客户端找到目标字形位置,应用这些位置的查找,并完成替换。
ContextSubstFormat1子表包含格式标识符(substFormat),Coverage表的偏移量(coverageOffset),已定义的SubRuleSets(subRuleSetCount)的计数,以及SubRuleSet表(subRuleSetOffsets)的偏移数组。如上所述,必须为Coverage表中列出的每个字形定义一个SubRuleSet表。
在SubRuleSet数组中,SubRuleSet表偏移按Coverage索引顺序排序。数组中的第一个SubRuleSet应用于Coverage表中列出的第一个字形ID,数组中的第二个SubRuleSet应用于Coverage表中列出的第二个字形ID,依此类推。
本章末尾的示例7显示了如何使用ContextSubstFormat1子表将一个三个字形的序列替换为法语系统首选的序列。
ContextSubstFormat1子表
类型 名称 描述
UINT16 substFormat 格式标识符:format = 1
Offset16 coverageOffset 从替换子表开始偏移到Coverage表
UINT16 subRuleSetCount SubRuleSet表的数量 - 必须等于Coverage表中的glyphCount
Offset16 subRuleSetOffsets [subRuleSetCount] SubRuleSet表的偏移数组。偏移是从替换子表开始,按Coverage索引排序
SubRuleSet表由SubRule表(subRuleOffsets)的偏移数组组成,按优先级排序,以及set(subRuleCount)中定义的SubRule表的计数。SubRule数组中的顺序可能很关键。考虑两个上下文,
SubRuleSet表:以相同字形开头的所有上下文
类型 名称 描述
UINT16 subRuleCount SubRule表的数量
Offset16 subRuleOffsets [subRuleCount] SubRule表的偏移数组。偏移量来自SubRuleSet表的开头,按优先顺序排序
SubRule表包含要在输入上下文序列(glyphCount)中匹配的字形的计数,包括序列中的第一个字形,以及描述上下文的字形索引数组(inputSequence)。Coverage表指定上下文中第一个字形的索引,Input数组以上下文序列中的第二个字形开头(字形序列索引= 1,inputSequence数组索引= 0)。
注意: Input数组按照相应字形在文本中出现的顺序列出索引。对于从右到左书写的文字,最右边的字形将是第一个; 相反,对于从左到右书写的文本,最左边的字形将是第一个。
SubRule表还包含要对输入字形序列(substitutionCount)执行的替换计数以及SubstLookupRecords(substLookupRecords)数组。每个记录指定输入字形序列中的位置和指定在该位置应用的替换查找的LookupList索引。数组应按设计顺序列出记录,或者应将查找应用于整个字形序列的顺序。
SubRule表:一个简单的上下文定义
类型 名称 描述
UINT16 glyphCount 输入字形序列中的字形总数 - 包括第一个字形。
UINT16 substitutionCount SubstLookupRecords的数量
UINT16 inputSequence [glyphCount - 1] 输入字形ID数组 - 以第二个字形开头
SubstLookupRecord substLookupRecords [substitutionCount] 按设计顺序排列的SubstLookupRecords数组
5.2上下文替换格式2:基于类的字形上下文
格式2是比格式1更灵活的格式,它描述了基于类的上下文替换。对于此格式,必须为所有上下文字形序列中的每个字形组件分配一个称为类值的特定整数。然后将上下文定义为字形类值的序列。可以一次定义多个上下文。
例如,假设一个swash大写字母应该替换每个大写字母字形,前面跟一个空格字形,后面跟一个小写字母字形(空格的字形序列 - 大写 - 小写)。大写字形集将构成一个字形类(类1),小写字形集将构成第二类(类2),空格字形构成第三类(类3)。可以使用上下文规则(称为SubClassRule)指定输入上下文,该上下文规则描述“形成三个字形类序列的字形字符串集合,来自类别3的一个字形,后面是来自类1的一个字形,后跟一个字形从第2课开始。“
每个ContextSubstFormat2子表都包含一个类定义表(classDefOffset)的偏移量,该表定义了所有输入上下文的字形类值。通常,将在包含在字体中的ContextSubstFormat2表的每个实例中声明唯一的ClassDef表,即使多个Format 2表可以共享ClassDef表。类分配是固定的(对于上下文中的每个位置都是相同的),并且类是独占的(一个字形一次不能在多个类中)。替换上下文序列中的字形的输出字形不需要类值,因为它们在字形ID的其他地方指定。
ContextSubstFormat2子表还包含格式标识符(substFormat)并定义Coverage表(coverageOffset)的偏移量。对于此格式,Coverage表列出了可能显示为任何基于类的上下文的第一个字形的完整唯一字形集(非字形类)的索引。换句话说,Coverage表包含所有类中可能首先在任何上下文类序列中的所有字形的字形索引列表。例如,如果上下文以Class 1或Class 2标志符号开头,则Coverage表将列出所有Class 1和Class 2标志符号的索引。
ContextSubstFormat2子表还定义了SubClassSet表(subClassSetOffsets)的偏移量数组和SubClassSet表(subClassSetCount)的计数。该数组在ClassDef表中为每个类(包括Class 0)包含一个偏移量。在数组中,类值定义偏移量的索引位置,而SubClassSet偏移量按升序类值排序(从0到subClassSetCount - 1)。
例如,数组中列出的第一个SubClassSet包含以Class 0字形开头的所有上下文,第二个SubClassSet包含以Class 1字形开头的所有上下文,依此类推。如果没有上下文以特定类开头(即,如果SubClassSet不包含SubClassRule表),则SubClassSet数组中该特定SubClassSet的偏移量将设置为NULL。
本章末尾的示例8使用格式2将阿拉伯标记字形替换为不同高度的基本字形。
ContextSubstFormat2子表
类型 名称 描述
UINT16 substFormat 格式标识符:format = 2
Offset16 coverageOffset 从替换子表开始偏移到Coverage表
Offset16 classDefOffset 从替换子表开始,偏移到字形ClassDef表
UINT16 subClassSetCount SubClassSet表的数量
Offset16 subClassSetOffsets [subClassSetCount] SubClassSet表的偏移量数组。偏移是从替换子表的开始,按类排序(可以是NULL)。
每个上下文都在SubClassRule表中定义,并且指定以相同类值开头的上下文的所有SubClassRule都在SubClassSet表中进行分组。因此,包含上下文的SubClassSet标识了上下文的第一个类组件。
每个SubClassSet表包含SubClassSet(subClassRuleCount)中定义的SubClassRule表的计数和SubClassRule表(subClassRuleOffsets)的偏移数组。SubClassRule表在SubClassSet的SubClassRule数组中按优先顺序排序。
SubClassSet子表
类型 名称 描述
UINT16 subClassRuleCount SubClassRule表的数量
Offset16 subClassRuleOffsets [subClassRuleCount] SubClassRule表的偏移数组。偏移量来自SubClassSet的开头,按优先顺序排序。
对于每个上下文,SubClassRule表包含上下文序列(glyphCount)中的字形类的计数,包括第一个类。Class数组列出了类,从第二个上下文位置的类开始(字形序列索引= 1,inputSequence数组索引= 0)。
注意:文本顺序取决于文本的书写方向。对于从右到左书写的文字,最右边的课程将是第一个。相反,对于从左到右书写的文本,最左边的类将是第一个。
Class数组中指定的值是ClassDef表中定义的值。例如,由序列“Class 2,Class 7,Class 5,Class 0”组成的上下文将生成一个7,5,0的Class数组。序列中的第一个类,Class 2,在ContextSubstFormat2表中由相应SubClassSet的SubClassSet数组索引标识。
SubClassRule还包含要在上下文(substitutionCount)上执行的替换计数以及提供替换数据的SubstLookupRecords(substLookupRecords)数组。对于需要替换的上下文中的每个位置,SubstLookupRecord指定LookupList索引以及应用查找的输入字形序列中的位置。substLookupRecords数组按设计顺序列出了SubstLookupRecords - 也就是说,应该将查找应用于整个字形序列的顺序。
SubClassRule表:一个类的上下文定义
类型 名称 描述
UINT16 glyphCount 为规则中的上下文指定的类的总数 - 包括第一个类
UINT16 substitutionCount SubstLookupRecords的数量
UINT16 inputSequence [glyphCount - 1] 要与输入字形序列匹配的类数组,从第二个字形位置开始。
SubstLookupRecord substLookupRecords [substitutionCount] 按设计顺序排列的替换查找数组。
5.3上下文替换格式3:基于覆盖的字形上下文
格式3,基于覆盖的上下文替换,将上下文规则定义为一系列覆盖表。序列中的每个位置可以为与上下文模式匹配的字形集定义不同的Coverage表。对于格式3,不同Coverage表中定义的字形集可以相交,不像格式2指定固定类赋值(对于上下文序列中的每个位置相同)和独占类(字形一次不能在多个类中) )。
例如,考虑一个输入上下文,其中包含一个小写字形(位置0),后跟一个大写字形(位置1),小写或数字字形(位置2),然后是小写或大写元音(位置3) 。此上下文需要四个Coverage表,每个位置一个:
在位置0,Coverage表列出了一组小写字形。
在位置1中,Coverage表列出了一组大写字形。
在位置2中,Coverage表列出了一组小写和数字字形,即位置0的Coverage表中定义的字形的超集。
在位置3中,Coverage表列出了小写和大写元音的集合,这是位置0和1中Coverage表中定义的字形的子集。
与格式1和格式2不同,此格式一次只定义一个上下文规则。它由格式标识符(substFormat),要匹配的序列中的字形计数(glyphCount)以及描述输入上下文序列(coverageOffsets)的Coverage偏移数组组成。
注意: Coverage数组中列出的Coverage表的顺序必须遵循书写方向。对于从右到左书写的文本,最右边的字形将是第一个。相反,对于从左到右书写的文本,最左边的字形将是第一个。
子表还包含要对输入Coverage序列(substitutionCount)执行的替换计数以及按设计顺序执行的SubstLookupRecords(substLookupRecords)数组 - 即,应将查找应用于整个字形序列的顺序。
本章末尾的示例9使用ContextSubstFormat3将swash字形替换为序列中三个字形中的两个。
ContextSubstFormat3子表
类型 名称 描述
UINT16 substFormat 格式标识符:format = 3
UINT16 glyphCount 输入字形序列中的字形数
UINT16 substitutionCount SubstLookupRecords的数量
Offset16 coverageOffsets [glyphCount] Coverage表的偏移数组。偏移是从替换子表的开始,以字形顺序排列。
SubstLookupRecord substLookupRecords [substitutionCount] 按设计顺序排列的SubstLookupRecords数组。
7.22.11.LookupType 6: Chaining Contextual Substitution Subtable
链接上下文替换子表(ChainContextSubst)描述了在上下文中的字形替换,其具有在字形序列中回顾和/或向前看的能力。链接上下文替换子表的设计与上下文替换子表的设计平行,包括处理字形,字形类或字形集序列的三种格式的可用性。每种格式可以描述一个或多个回溯,输入和先行序列以及每个序列的一个或多个替换。
6.1链接上下文替换格式1:简单字形上下文
格式1将字形替换的上下文定义为特定的字形序列。例如,上下文可以是
在上下文序列中,格式1将特定字形位置(不是字形索引)标识为特定替换的目标。当文本处理客户端在文本字符串中查找上下文时,它会查找目标位置的查找数据,并通过在该位置应用查找数据进行替换。
要指定上下文,coverage表列出输入序列中的第一个字形,ChainSubRule子表定义其余字形。一旦在位置i找到覆盖的字形,客户端就会读取相应的ChainSubRuleSet表并检查每个表以确定它是否与文本中的周围字形匹配。在最简单的情况下,如果字符串
为了阐明输入,回溯和先行序列的字形数组的排序,提供了下图。输入序列匹配从输入序列匹配开始的i开始。回溯序列从i -1 开始排序,并且随着离开i而增加偏移值。先行序列在输入序列之后开始并且以逻辑顺序增加。
逻辑顺序 - 一个 b C d Ë F G H 一世 Ĵ
一世
输入顺序 - 0 1
回溯序列 - 3 2 1 0
前瞻序列 - 0 1 2 3
如果存在匹配,则客户端找到替换的目标字形位置并完成替换。请注意(就像在ContextSubstFormat1子表中一样)这些查找需要在从覆盖字形到输入序列末尾的文本范围内操作。不能为回溯序列或先行序列定义替换。
一旦替换完成,客户端应该在匹配的输入序列之后立即移动到字形位置并从那里继续查找过程。
单个ChainContextSubstFormat1子表可以定义多个上下文字形序列。如果不同的上下文序列以相同的字形开头,则Coverage表应仅列出一次字形,因为表中的所有字形必须是唯一的。例如,如果三个上下文各自以“s”开头而两个以“t”开头,那么Coverage表将列出一个“s”和一个“t”。
定义以相同第一个字形开头的上下文的所有ChainSubRule表都组合在一起并在ChainSubRuleSet表中定义。例如,定义以“s”开头的三个上下文的ChainSubRule表分组在一个ChainSubRuleSet表中,定义以“t”开头的两个上下文的ChainSubRule表在第二个ChainSubRuleSet表中分组。Coverage表中列出的每个字形必须具有ChainSubRuleSet表,该表定义适用于覆盖字形的所有ChainSubRule表。
ChainContextSubstFormat1子表包含格式标识符(substFormat),Coverage表的偏移量(coverageOffset),定义的ChainSubRuleSets(chainSubRuleSetCount)的计数,以及ChainSubRuleSet表(chainSubRuleSetOffsets)的偏移数组。如上所述,必须为Coverage表中列出的每个字形定义一个ChainSubRuleSet表。
在ChainSubRuleSet数组中,ChainSubRuleSet表偏移量按Coverage索引顺序排序。数组中的第一个ChainSubRuleSet应用于Coverage表中列出的第一个字形ID,数组中的第二个ChainSubRuleSet应用于Coverage表中列出的第二个字形ID,依此类推。
ChainContextSubstFormat1子表
类型 名称 描述
UINT16 substFormat 格式标识符:format = 1
Offset16 coverageOffset 从替换子表开始偏移到Coverage表。
UINT16 chainSubRuleSetCount ChainSubRuleSet表的数量 - 必须等于Coverage表中的GlyphCount。
Offset16 chainSubRuleSetOffsets [chainSubRuleSetCount] ChainSubRuleSet表的偏移数组。偏移是从替换子表开始,按Coverage索引排序。
ChainSubRuleSet表由ChainSubRule表(chainSubRuleOffsets)的偏移数组组成,按优先级排序,以及集合中定义的ChainSubRule表的计数(chainSubRuleCount)。
ChainSubRule数组中的顺序可能很关键。考虑两个上下文,
ChainSubRuleSet表:以相同字形开头的所有上下文
类型 名称 描述
UINT16 chainSubRuleCount ChainSubRule表的数量
Offset16 chainSubRuleOffsets [chainSubRuleCount] ChainSubRule表的偏移数组。偏移量来自ChainSubRuleSet表的开头,按优先顺序排序。
ChainSubRule表包含要在回溯,输入和先行上下文序列中匹配的字形计数,包括每个序列中的第一个字形,以及描述上下文的每个部分的字形索引数组。Coverage表指定每个上下文中第一个字形的索引,每个数组以上下文序列中的第二个字形开头(字形序列索引= 1,inputSequence数组索引= 0)。
注意:所有数组都按照相应字形在文本中出现的顺序列出索引。对于从右到左书写的文字,最右边的字形将是第一个; 相反,对于从左到右书写的文本,最左边的字形将是第一个。
ChainSubRule表还包含要对输入字形序列(substitutionCount)执行的替换计数以及SubstitutionLookupRecords(substLookupRecords)数组。每个记录指定输入字形序列中的位置和指定在该位置应用的替换查找的LookupList索引。数组应按设计顺序列出记录,或者应将查找应用于整个字形序列的顺序。
ChainSubRule子表
类型 名称 描述
UINT16 backtrackGlyphCount 回溯序列中的字形总数(在输入序列的第一个字形之前要匹配的字形数)。
UINT16 backtrackSequence [backtrackGlyphCount] 回溯字形ID的数组 - 在输入序列之前匹配。
UINT16 inputGlyphCount 输入序列中的字形总数 - 包括第一个字形。
UINT16 inputSequence [inputGlyphCount - 1] 输入字形ID数组 - 以第二个字形开头。
UINT16 lookaheadGlyphCount 前瞻序列中的字形总数(输入序列后要匹配的字形数)。
UINT16 lookAheadSequence [lookAheadGlyphCount] 前瞻字形ID的数组 - 在输入序列之后匹配。
UINT16 substitutionCount SubstLookupRecords的数量
SubstLookupRecord substLookupRecords [SubstCount] 按设计顺序排列的SubstLookupRecords数组。
6.2链接上下文替换格式2:基于类的字形上下文
格式2描述了基于类的链接上下文替换。对于此格式,必须为所有上下文字形序列中的每个字形组件分配一个称为类值的特定整数。然后将上下文定义为字形类值的序列。可以一次定义多个上下文。
为了链上下文,在字形ClassDef表中使用了三个类:backtrack ClassDef,输入ClassDef和lookahead ClassDef。
ChainContextSubstFormat2子表还包含格式标识符(substFormat),并定义Coverage表(coverageOffset)的偏移量。对于此格式,Coverage表列出了可能显示为任何基于类的上下文的第一个字形的完整唯一字形集(非字形类)的索引。换句话说,Coverage表包含所有类中可能首先在任何上下文类序列中的所有字形的字形索引列表。例如,如果上下文以Class 1或Class 2标志符号开头,则Coverage表将列出所有Class 1和Class 2标志符号的索引。
ChainContextSubstFormat2子表还定义了ChainSubClassSet表(chainSubClassSetOffsets)的偏移量数组和ChainSubClassSet表(chainSubClassSetCount)的计数。该数组在ClassDef表中为每个类(包括Class 0)包含一个偏移量。在数组中,类值定义偏移量的索引位置,ChainSubClassSet偏移量按升序类值排序(从0到ChainSubClassSetCnt - 1)。
如果没有上下文以特定类开头(即,如果ChainSubClassSet不包含ChainSubClassRule表),则ChainSubClassSet数组中该特定ChainSubClassSet的偏移量将设置为NULL。
ChainContextSubstFormat2子表
类型 名称 描述
UINT16 substFormat 格式标识符:format = 2
Offset16 coverageOffset 从替换子表开始偏移到Coverage表。
Offset16 backtrackClassDefOffset 从替换子表开始,包含回溯序列数据的字形ClassDef表的偏移量。
Offset16 inputClassDefOffset 从替换子表开始,包含输入序列数据的字形ClassDef表的偏移量。
Offset16 lookaheadClassDefOffset 从替换子表开始,包含前瞻序列数据的字形ClassDef表的偏移量。
UINT16 chainSubClassSetCount ChainSubClassSet表的数量
Offset16 chainSubClassSetOffsets [chainSubClassSetCount] ChainSubClassSet表的偏移数组。偏移量来自替换子表格的开头,按输入类排序(可能为NULL)
每个上下文都在ChainSubClassRule表中定义,并且指定以相同类值开头的上下文的所有ChainSubClassRules都被分组在ChainSubClassSet表中。因此,包含上下文的ChainSubClassSet标识了上下文的第一个类组件。
每个ChainSubClassSet表包含ChainSubClassSet(chainSubClassRuleCount)中定义的ChainSubClassRule表的计数和ChainSubClassRule表(chainSubClassRuleOffsets)的偏移数组。ChainSubClassRule表在ChainSubClassSet的ChainSubClassRule数组中按优先顺序排序。
ChainSubClassSet子表
类型 名称 描述
UINT16 chainSubClassRuleCount ChainSubClassRule表的数量
Offset16 chainSubClassRuleOffsets [chainSubClassRuleCount] ChainSubClassRule表的偏移数组。偏移量来自ChainSubClassSet的开头,按优先顺序排序。
对于每个上下文(回溯,输入,前瞻),ChainSubClassRule表包含上下文序列的每个部分(backtrackGlyphCount,inputGlyphCount,lookaheadGlyphCount)的字形类计数,包括第一个类。Class数组列出了类,从第二个上下文位置的类开始(输入字形序列索引= 1,inputSequence数组索引= 0),它跟在上下文中的第一个类之后。
注意:文本顺序取决于文本的书写方向。对于从右到左书写的文字,最右边的课程将是第一个。相反,对于从左到右书写的文本,最左边的类将是第一个。
Class数组中指定的值是ClassDef表中定义的值。序列中的第一个类Class 2在ChainContextSubstFormat2表中由相应ChainSubClassSet的ChainSubClassSet数组索引标识。
ChainSubClassRule还包含要在上下文(substitutionCount)上执行的替换计数以及提供替换数据的SubstLookupRecords(substLookupRecords)数组。对于需要替换的上下文中的每个位置,SubstLookupRecord指定LookupList索引以及应用查找的输入字形序列中的位置。SubstLookupRecord数组按设计顺序列出了SubstLookupRecords - 也就是说,查找应该应用于整个字形序列的顺序。
ChainSubClassRule表:链接一个类的上下文定义
类型 名称 描述
UINT16 backtrackGlyphCount 回溯序列中的字形总数(在输入序列的第一个字形之前要匹配的字形数)。
UINT16 backtrackSequence [backtrackGlyphCount] 回溯类数组 - 在输入序列之前与字形序列匹配。
UINT16 inputGlyphCount 输入序列中的类总数 - 包括第一个类。
UINT16 inputSequence [inputGlyphCount - 1] 要与输入字形序列匹配的类数组,从第二个字形位置开始。
UINT16 lookaheadGlyphCount 前瞻序列中的字形总数(输入序列后要匹配的字形数)。
UINT16 lookAheadSequence [lookAheadGlyphCount] 前瞻类的数组 - 在输入序列之后与字形序列匹配。
UINT16 substitutionCount SubstLookupRecords的数量
SubstLookupRecord substLookupRecords [substitutionCount] 按设计顺序排列的SubstLookupRecords数组。
6.3链接上下文替换格式3:基于覆盖的字形上下文
格式3将链接上下文规则定义为Coverage表序列。序列中的每个位置可以为与上下文模式匹配的字形集定义不同的Coverage表。对于格式3,不同Coverage表中定义的字形集可能会相交,不像格式2指定固定类赋值(对于回溯,输入或先行序列中的每个位置都相同)和独占类(字形不能超过一次一堂课)。
注意: Coverage数组中列出的Coverage表的顺序必须遵循书写方向。对于从右到左书写的文本,最右边的字形将是第一个。相反,对于从左到右书写的文本,最左边的字形将是第一个。
子表还包含要对输入Coverage序列(substitutionCount)执行的替换计数以及按设计顺序执行的SubstLookupRecords(substLookupRecords)数组 - 即,应将查找应用于整个字形序列的顺序。
ChainContextSubstFormat3子表
类型 名称 描述
UINT16 substFormat 格式标识符:format = 3
UINT16 backtrackGlyphCount 回溯序列中的字形数。
Offset16 backtrackCoverageOffsets [backtrackGlyphCount] 回溯序列中覆盖表的偏移量数组。偏移是从字符序列顺序开始的子类子表。
UINT16 inputGlyphCount 输入序列中的字形数
Offset16 inputCoverageOffsets [inputGlyphCount] 输入序列中覆盖表的偏移量数组。偏移是从字符序列顺序开始的子类子表。
UINT16 lookaheadGlyphCount 先行序列中的字形数
Offset16 lookaheadCoverageOffsets [lookaheadGlyphCount] 前瞻序列中覆盖表的偏移量数组。偏移是从替换子表的开始,以字形顺序排列。
UINT16 substitutionCount SubstLookupRecords的数量
SubstLookupRecord substLookupRecords [substitutionCount] 按设计顺序排列的SubstLookupRecords数组
7.22.12.LookupType 7: Extension Substitution
此查找提供了一种机制,其中任何其他查找类型的子表存储在GSUB表中的32位偏移位置。如果子表的总大小超过GSUB表中各种其他偏移的16位限制,则需要这样做。在本说明书中,存储在32位偏移位置的子表被称为“扩展”子表。
此子表类型使用一种格式:ExtensionSubstFormat1。
7.1扩展替换子表格式1
ExtensionSubstFormat1子表
类型 名称 描述
UINT16 substFormat 格式标识符。设为1。
UINT16 extensionLookupType extensionOffset引用的子表的查找类型(即扩展子表)。
OFFSET32 extensionOffset 相对于ExtensionSubstFormat1子表的开头,查找类型extensionLookupType的扩展子表的偏移量。
必须将extensionLookupType字段设置为7以外的任何查找类型.LookupType 7查找中的所有子表必须具有相同的extensionLookupType。扩展子表中的所有偏移都以通常的方式设置,即相对于扩展子表本身。
当OpenType布局引擎遇到LookupType 7 Lookup表时,它应该:
继续进行,就像Lookup表的lookupType字段设置为子表的extensionLookupType一样。
继续执行,就好像extensionOffset引用的每个扩展子表替换了引用它的LookupType 7子表。
7.22.13.LookupType 8: Reverse Chaining Contextual Single Substitution Subtable
反向链接上下文单个替换子表(ReverseChainSingleSubst)描述了上下文中的单字形替换,具有在字形序列中回顾和/或向前看的能力。此查找类型与其他查找类型之间的主要区别在于输入字形序列的处理从头到尾。
与Chaining Contextual Sustitution(查找子表类型6)相比,此格式仅限于基于coverage的子表格式,输入序列只能包含单个字形,并且此字形上只允许单个替换。此约束已集成到子表格式中。
此查找类型专门用于阿拉伯语脚本编写样式,如nastaliq,其中字形的形状由以下字形确定,从“joor”的最后一个字形开始,或连接字形集。
8.1反向链接上下文单个替换格式1:基于覆盖的字形上下文
格式1将链接上下文规则定义为Coverage表序列。序列中的每个位置可以为与上下文模式匹配的字形集定义不同的Coverage表。使用格式1,在不同Coverage表中定义的字形集可能会相交。
注意: 尽管逆序处理,Coverage数组中列出的Coverage表的顺序必须符合逻辑顺序(遵循书写方向)。回溯序列如LookupType 6:Chaining Contextual Substitution子表中所示。输入序列是位于逻辑字符串中的i处的一个字形。回溯从i -1 开始,并且随着向字符串的逻辑开始移动而增加偏移值。超前序列从i + 1 开始,并随着向字符串的逻辑末端移动而增加偏移值。在处理反向链接替换时,我从字符串的逻辑结尾开始并移到开头。
子表包含用于输入字形的Coverage表和用于回溯和超前序列的Coverage表数组。它还包含一组替换字形索引(substituteGlyphIDs),它们是Coverage表中字形的替代,以及substituteGlyphIDs数组中的字形计数。substituteGlyphIDs数组必须包含与Coverage表相同数量的字形索引。要在substituteGlyphIDs数组中找到相应的输出字形索引,此格式使用从Coverage表返回的Coverage索引。
本章末尾的示例10使用ReverseChainSingleSubstFormat1替换左侧(出口)具有正确笔划粗细的阿拉伯字形,以匹配以下字形右侧(条目)的笔划粗细(按逻辑顺序)。
ReverseChainSingleSubstFormat1子表
类型 名称 描述
UINT16 substFormat 格式标识符:format = 1
Offset16 coverageOffset 从替换子表开始偏移到Coverage表。
UINT16 backtrackGlyphCount 回溯序列中的字形数。
Offset16 backtrackCoverageOffsets [backtrackGlyphCount] 回溯序列中覆盖表的偏移数组,以字形顺序排列。
UINT16 lookaheadGlyphCount 先行序列中的字形数。
Offset16 lookaheadCoverageOffsets [lookaheadGlyphCount] 前瞻序列中覆盖表的偏移量数组,以字形顺序排列。
UINT16 glyphCount substituteGlyphIDs数组中的字形ID数。
UINT16 substituteGlyphIDs [glyphCount] 替换字形ID的数组 - 按Coverage索引排序。
7.22.14.GSUB Subtable Examples
本章的其余部分描述并说明了所有GSUB子表的示例,包括可用于上下文替换的三种格式中的每一种。所有示例都反映了下面描述的唯一参数,但这些示例为构建特定于其他情况的子表提供了有用的参考。
所有示例都有三列显示十六进制数据,源和注释。
示例1:GSUB标头表
示例1显示了典型的GSUB标头表定义。
例1
Hex数据 资源 评论
GSUBHeader
TheGSUBHeader GSUBHeader表定义
00010000 0x00010000在 主要/次要版本
000A TheScriptList 偏移到ScriptList表
001E TheFeatureList 偏移到FeatureList表
002C TheLookupList 偏移到LookupList表
示例2:SingleSubstFormat1子表
示例2说明了SingleSubstFormat1子表,它使用范围将单个输入字形替换为其对应的输出字形。输出字形的索引是通过将恒定的delta值添加到输入字形的索引来计算的。在此示例中,Coverage表的格式标识符为1以指示范围格式,因为输入字形索引在字体中是连续的顺序,所以使用该范围格式。Coverage表指定一个范围,其中包含“0”(零)字形的startGlyphID和“9”字形的endGlyphID。
例2
Hex数据 资源 评论
SingleSubstFormat1
LiningNumeralSubtable SingleSubst子表定义
0001 1 substFormat:计算输出字形索引
0006 LiningNumeralCoverage 偏移到输入字形的Coverage表
00C0 192 deltaGlyphID = 192:添加到每个输入字形索引以生成输出字形索引
CoverageFormat2
LiningNumeralCoverage 覆盖表定义
技术 2 coverageFormat:范围
1 rangeCount
rangeRecords [0]
004E 78 数字零字形的起始字形ID
0058 87 数字九字形的结束字形ID
0000 0 startCoverageIndex:first CoverageIndex = 0
示例3:SingleSubstFormat2子表
示例3使用列表的SingleSubstFormat2子表来替换垂直写入的日文文本中的标点符号。水平方向的括号和方括号(输入字形)被垂直方向的括号和方括号(输出字形)替换。
Coverage表格式1标识每个输入字形索引。Coverage表中列出的输入字形索引数与子表中列出的输出字形索引数相匹配。为了正确替换,Coverage表中的字形索引的顺序(输入字形)必须与Substitute数组中的顺序(输出字形)匹配。
例3
Hex数据 资源 评论
SingleSubstFormat2
VerticalPunctuationSubtable SingleSubst子表定义
技术 2 substFormat:列表
000E VerticalPunctuationCoverage 偏移到Coverage表
0004 4 glyphCount - 等于Coverage表中的glyphCount
0131 VerticalOpenBracketGlyph substituteGlyphIDs [0],按Coverage索引排序
0135 VerticalClosedBracketGlyph substituteGlyphIDs [1]
013E VerticalOpenParenthesisGlyph substituteGlyphIDs [2]
0143 VerticalClosedParenthesisGlyph substituteGlyphIDs [3]
CoverageFormat1
VerticalPunctuationCoverage 覆盖表定义
0001 1 coverageFormat:列表
0004 4 glyphCount
003C HorizontalOpenBracketGlyph glyphArray [0],按字形ID排序
0040 HorizontalClosedBracketGlyph glyphArray [1]
004B HorizontalOpenParenthesisGlyph glyphArray [2]
004F HorizontalClosedParenthesisGlyph glyphArray [3]
示例4:MultipleSubstFormat1子表
示例4使用MultipleSubstFormat1子表将单个“ffi”连字替换为形成字符串
例4
Hex数据 资源 评论
MultipleSubstFormat1
FfiDecompSubtable MultipleSubst子表定义
0001 1 substFormat
0008 FfiDecompCoverage 偏移到Coverage表
0001 1 sequenceCount - 在Coverage表中等于glyphCount
000E FfiDecompSequence sequenceOffsets [0](偏移到Sequence表0)
CoverageFormat1
FfiDecompCoverage 覆盖表定义
0001 1 coverageFormat:列表
0001 1 glyphCount
00F1 ffiGlyphID 结扎字形
序列
FfiDecompSequence 序列表定义
0003 3 glyphCount
001A fGlyphID 第一个字形按顺序排列
001A fGlyphID 第二个字形
001D iGlyphID 第三个字形
示例5:AlternateSubstFormat 1子表
示例5使用AlternateSubstFormat1子表将默认的&符号字形(输入字形)替换为两个替代的符号和字形(输出字形)之一。
在这种情况下,Coverage表指定单个字形的索引,即默认的&符号,因为它是此查找所覆盖的唯一字形。此覆盖字形的AlternateSet表标识备用字形:AltAmpersand1GlyphID和AltAmpersand2GlyphID。
在示例5中,AlternateSet数组中AlternateSet表偏移量的索引位置为零(0),这与Coverage表中默认&符号字形的索引位置(也为零)相关。
例5
Hex数据 资源 评论
AlternateSubstFormat1
AltAmpersandSubtable AlternateSubstFormat1子表定义
0001 1 substFormat
0008 AltAmpersandCoverage 偏移到Coverage表
0001 1 alternateSetCount - 在Coverage表中等于glyphCount
000E AltAmpersandSet alternateSetOffsets [0](偏移到AlternateSet表0)
CoverageFormat1
AltAmpersandCoverage 覆盖表定义
0001 1 coverageFormat:列表
0001 1 glyphCount
003A DefaultAmpersandGlyphID glyphArray [0]
AlternateSet
AltAmpersandSet AlternateSet表定义
技术 2 glyphCount
00C9 AltAmpersand1GlyphID alternateGlyphIDs [0] - 任意顺序的字形
00CA AltAmpersand2GlyphID alternateGlyphIDs [1]
例6:LigatureSubstFormat1子表
示例6显示了LigatureSubstFormat1子表,该子表定义了用单个连字字形替换字符串的数据。因为LigatureSubstFormat1子表可以为多个连字指定字形替换,所以此子表定义了三个连字:“etc”,“ffi”和“fi”。
样本子表包含格式标识符(4)和Coverage表的偏移量。Coverage表列出了连字中每个第一个字形的索引,列出了“e”和“f”字形的索引。此处使用Coverage表范围格式,因为“e”和“f”字形索引是连续编号的。
在LigatureSubst子表中,ligatureSetCount指定两个LigatureSet表,每个表用于每个覆盖的字形,ligatureSetOffsets数组存储偏移量。在此数组中,“e”LigatureSet位于“f”LigatureSet之前,与Coverage表中相应的第一个字形组件的顺序相匹配。
每个LigatureSet表都标识以覆盖的字形开头的所有连字。为“e”字形定义的样本LigatureSet表仅包含一个连字,“等”为“f”字形定义的LigatureSet表包含两个连字,“ffi”和“fi”。
示例FLigaturesSet表具有两个Ligature表的偏移量,一个用于“ffi”,一个用于“fi”.ligatureOffsets数组首先列出“ffi”Ligature表,以指示“ffi”连字优先于“fi”连接。
例6
Hex数据 资源 评论
LigatureSubstFormat1
LigaturesSubtable LigatureSubstFormat1子表定义
0001 1 substFormat
000A LigaturesCoverage 偏移到Coverage表
技术 2 ligatureSetCount
0014 ELigaturesSet ligatureSetOffsets [0](偏移到LigatureSet表0) - Coverage索引顺序中的LigatureSet表
0020 FLigaturesSet ligatureSetOffsets [1]
CoverageFormat2
LigaturesCoverage 覆盖表定义
技术 2 coverageFormat:范围
0001 1 rangeCount
rangeRecords [0]
0019 eGlyphID 开始,第一个字形ID
001A fGlyphID 结束,范围内的最后一个字形ID
0000 0 startCoverageIndex:起始字形ID = 0的覆盖索引
LigatureSet
ELigaturesSet LigatureSet表定义 - 以e开头的所有连字
0001 1 ligatureCount
0004 etcLigature ligatureOffsets [0](偏移到Ligature表0)
Ligature
etcLigature Ligature表定义
015B etcGlyphID ligatureGlyph - 输出字形ID
0003 3 componentCount
0028 tGlyphID componentGlyphIDs [0] - 连字中的第二个组件
0017 cGlyphID componentGlyphIDs [1] - 连字中的第三个组件
LigatureSet
FLigaturesSet LigatureSet表定义所有连字以f开头
技术 2 ligatureCount
0006 ffiLigature ligatureOffsets [0] - 首先列出因为ffi连字比fi连字更受欢迎
000E fiLigature ligatureOffsets [1]
Ligature
ffiLigature Ligature表定义
00F1 ffiGlyphID ligatureGlyph - 输出字形ID
0003 3 componentCount
001A fGlyphID componentGlyphIDs [0] - 连字中的第二个组件
001D iGlyphID componentGlyphIDs [1] - 连字中的第三个组件
Ligature
fiLigature Ligature表定义
00F0 fiGlyphID ligatureGlyph - 输出字形ID
技术 2 componentCount
001D iGlyphID componentGlyphIDs [0] - 连字中的第二个组件
示例7:ContextSubstFormat1 Subtable和SubstLookupRecord
示例7使用ContextSubstFormat1子表格为字形序列将三个字形的字符串替换为另一个字符串。对于法语系统,子表定义了一个上下文替换,用输出序列替换输入序列,空间 - 破折号空间,稀疏空间 - 破折号 - 空间。
在此示例中称为Dash Lookup的上下文替换包含一个名为DashSubtable的ContextSubstFormat1子表。子表指定两个上下文:SpaceGlyph后跟DashGlyph,DashGlyph后跟SpaceGlyph。在每个序列中,单个替换用ThinSpaceGlyph替换SpaceGlyph。
标记为DashCoverage的Coverage表列出了SpaceGlyph和DashGlyph序列中第一个字形的两个字形ID。为每个覆盖的字形定义一个SubRuleSet表。
SpaceAndDashSubRuleSet列出了以SpaceGlyph开头的所有上下文。它包含一个SubRule表的偏移量(SpaceAndDashSubRule),它在上下文序列中指定了两个字形,第二个是DashGlyph。SubRule表包含一个到SubstLookupRecord的偏移量,它列出了应该发生字形替换的序列中的位置(位置0)以及应用SpaceToThinSpaceLookup的索引以用ThinSpaceGlyph替换SpaceGlyph。DashAndSpaceSubRuleSet列出了以DashGlyph开头的所有上下文。SubRule表的偏移量(DashAndSpaceSubRule)指定上下文序列中的两个字形,第二个是SpaceGlyph。SubRule表包含一个SubstLookupRecord的偏移量,它列出了应该进行字形替换的序列中的位置,和SpaceAndDashSubRule中使用的相同查找的索引。查找用ThinSpaceGlyph替换SpaceGlyph。
例7
Hex数据 资源 评论
ContextSubstFormat1
DashSubtable Lookup [0],DashLookup的ContextSubstFormat1子表定义
0001 1 substFormat
000A DashCoverage 偏移到Coverage表
技术 2 subRuleSetCount
0012 SpaceAndDashSubRuleSet subRuleSetOffsets [0](偏移到SubRuleSet表0) - 按覆盖率索引排序的SubRuleSet
0020 DashAndSpaceSubRuleSet subRuleSetOffsets [1]
CoverageFormat1
DashCoverage 覆盖表定义
0001 1 coverageFormat:列表
技术 2 glyphCount
0028 SpaceGlyph glyphArray [0] - 按字母顺序排列的字形
005D DashGlyph glyphArray [1],破折号字形ID
SubRuleSet
SpaceAndDashSubRuleSet SubRuleSet [0]表定义
0001 1 subRuleCount
0004 SpaceAndDashSubRule subRuleOffsets [0](偏移到SubRule表0) - 按优先级排序的SubRule表
SubRule
SpaceAndDashSubRule SubRule [0]表定义
技术 2 glyphCount - 输入序列中的数字
0001 1 substitutionCount
005D DashGlyph inputSequence [0],从第二个字形开始 - 在Coverage表中的SpaceGlyph,是第一个字形
substLookupRecords [0]
0000 0 sequenceIndex - 第一个字形位置的替换(0)
0001 1 lookupListIndex - LookupList中SpaceToThinSpaceLookup的索引
SubRuleSet
DashAndSpaceSubRuleSet SubRuleSet [1]表定义
0001 1 subRuleCount
0004 DashAndSpaceSubRule subRuleOffsets [0](偏移到SubRule表0) - 按优先级排序的SubRule表
SubRule
DashAndSpaceSubRule SubRule [0]表定义
技术 2 glyphCount - 输入字形序列中的数字
0001 1 substitutionCount
0028 SpaceGlyph inputSequence [0] - 从第二个字形开始
substLookupRecords [0]
0001 1 sequenceIndex - 第二个字形位置的替换(字形序列索引= 1)
0001 1 lookupListIndex - SpaceToThinSpaceLookup的索引
例8:ContextSubstFormat2子表
示例8使用带有字形类的ContextSubstFormat2子表来将默认标记字形替换为其替代形式。根据它们组合的基本字形的高度选择字形替代方案 - 即,高基础字形上方使用的标记字形与非常高的基础字形上方的标记字形不同。
在示例中,SetMarksHighSubtable包含一个Class表,它定义了四个字形类:中等高度字形(Class 0),所有默认标记字形(Class 1),高字形(Class 2)和非常高的字形(Class 3)。子表还包含一个Coverage表,该表列出了每个基本字形,它作为上下文中的第一个组件,按字形索引排序。
定义了两个SubClassSets,一个用于替换高分,另一个用于非常高的分数。没有为Class 0和Class 1字形指定SubClassSets,因为没有上下文以这些类中的字形开头。SubClassSet数组按数字顺序列出SubClassSets,因此SubClassSet 2在SubClassSet 3之前。
在每个SubClassSet中,定义了一个SubClassRule。在SetMarksHighSubClassSet2中,SubClassRule表指定上下文中的两个字形,第2类中的第一个字形(高字形)和第1类中的第二个字形(标记字形)。SubstLookupRecord指定在序列中的第二个位置应用SubstituteHighMarkLookup - 也就是说,高标记字形将替换默认标记字形。
在SetMarksVeryHighSubClassSet3中,SubClassRule在上下文中指定两个字形,第一个在Class 3中(一个非常高的字形),第二个在Class 1中(标记字形)。SubstLookupRecord指定在序列中的第二个位置应用SubstituteVeryHighMarkLookup - 也就是说,一个非常高的标记字形将替换默认标记字形。
例8
Hex数据 资源 评论
ContextSubstFormat2
SetMarksHighSubtable ContextSubstFormat2子表定义
技术 2 substFormat
0010 SetMarksHighCoverage 偏移到Coverage表
001C SetMarksHighClassDef 偏移到Class Def表
0004 4 subClassSetCount
0000 空值 subClassSetOffsets [0] - NULL:不定义以Class 0字形开头的上下文
0000 空值 subClassSetOffsets [1] - 没有定义以Class 1字形开头的上下文
0032 SetMarksHighSubClassSet2 subClassSetOffsets [2] - 偏向SubClassSet表,用于以Class 2字形(高基字形)开头的上下文
0040 SetMarksVeryHighSubClassSet3 subClassSetOffsets [3] - 偏向SubClassSet表,用于以Class 3字形开头的上下文(非常高的基本字形)
CoverageFormat1
SetMarksHighCoverage 覆盖表定义
0001 1 coverageFormat:列表
0004 4 glyphCount
0030 tahGlyphID glyphArray [0],高基字形
0031 dhahGlyphID glyphArray [1],高基字形
0040 cafGlyphID glyphArray [2],非常高的基础字形
0041 gafGlyphID glyphArray [3],非常高的基础字形
ClassDefFormat2
SetMarksHighClassDef 类表定义
技术 2 classFormat:范围
0003 3 classRangeCount
classRangeRecords [0] 由startGlyphID排序的ClassRangeRecords; 记录2级,高基字形
0030 tahGlyphID 开始,第一个范围内的字形ID
0031 dhahGlyphID 结束,最后一个字形ID在范围内
技术 2 课程:2
classRangeRecords [1] ClassRangeRecord用于Class 3,非常高的基本字形
0040 cafGlyphID 开始,范围内的第一个字形ID
0041 gafGlyphID 结束,范围内的最后一个字形ID
0003 3 class:3
ClassRange [2]用于Class 1,标记gyphs
classRangeRecords [2] 类1的ClassRangeRecord,标记字形
00D2 fathatanDefaultGlyphID 开始,第一个范围默认fathatan标记的字形ID
00D3 dammatanDefaultGlyphID 结束,最后一个字形ID在默认的dammatan标记范围内
0001 1 上课:1
SubClassSet
SetMarksHighSubClassSet2 SubClassSet [2]表定义
以Class 2字形开头的所有上下文
0001 1 subClassRuleCount
0004 SetMarksHighSubClassRule2 subClassRuleOffsets [0](偏移到SubClassRule表0) - 按优先级排序的SubClassRule表
SubClassRule
SetMarksHighSubClassRule2 SubClassRule [0]表定义,Class 2字形(高基)字形后跟1类字形(标记)
技术 2 glyphCount
0001 1 substitutionCount
0001 1 inputSequence [0] - 以输入上下文序列中的第二个Class开头的输入序列; 第1类,标记字形
substLookupRecords [0] substLookupRecords数组按设计顺序排列
0001 1 sequenceIndex - 将替换应用于位置2,即标记
0001 1 lookupListIndex
SubClassSet
SetMarksVeryHighSubClassSet3 SubClassSet [3]表定义 - 以Class 3字形开头的所有上下文
0001 1 subClassRuleCount
0004 SetMarksVeryHighSubClassRule3 subClassRuleOffsets [0]
SubClassRule
SetMarksVeryHighSubClassRule3 SubClassRule [0]表定义 - 第3类字形(非常高的基本字形),后跟第1类字形(标记)
技术 2 glyphCount
0001 1 substitutionCount
0001 1 inputSequence [0] - 以输入上下文序列中的第二个Class开头的输入序列; 第1类,标记字形
substLookupRecords [0] substLookupRecords数组按设计顺序排列
0001 1 sequenceIndex - 将替换应用于位置2,第二个字形类(标记)
技术 2 lookupListIndex
例9:ContextualSubstFormat3子表
示例9使用带有Coverage表的ContextSubstFormat3子表来描述模式中三个小写字形的上下文序列:位置0(零)中的任何上升或下降字形,位置1中的任何x高度字形以及位置2中的任何下降字形位置0和2的覆盖字形的重叠集合使得格式3对于该上下文比基于类的格式2更好。
在位置0和2中,字形的swash版本替换默认字形。上下文替换查找是SwashLookup(LookupList index = 0),其子表是SwashSubtable。SwashSubtable分别为上下文序列中的每个字形位置定义了三个Coverage表:AscenderDescenderCoverage,XheightCoverage和DescenderCoverage。
SwashSubtable还定义了两个SubstLookupRecords:一个适用于位置0,一个适用于位置2.(没有替换应用于位置1.)位置0的记录使用名为AscDescSwashLookup的单个替换查找来替换当前上升或下降字形用斜线上升或下降字形。位置2的记录使用名为DescSwashLookup的单个替换查找来用swash下行字形替换当前下降字形。
例9
Hex数据 资源 评论
ContextSubstFormat3
SwashSubtable ContextSubstFormat3子表定义
0003 3 substFormat
0003 3 glyphCount - 输入字形序列中的数字
技术 2 substitutionCount
0030 AscenderDescenderCoverage coverageOffsets [0] - 按上下文顺序排列到Coverage表的偏移量
004C XheightCoverage coverageOffsets [1]
006E DescenderCoverage coverageOffsets [2]
substLookupRecords [0] 在字形位置顺序中的SubstLookupRecords
0000 0 sequenceIndex
0001 1 lookupListIndex - 单个替换输出ascender或descender swash
substLookupRecords [1]
技术 2 sequenceIndex
技术 2 lookupListIndex - 单个替换以输出下行器swash
CoverageFormat1
AscenderDescenderCoverage 覆盖表定义
0001 1 coverageFormat:列表
000C 12 glyphCount
0033 bGlyphID glyphArray [0] - 字形ID顺序中的字形
0035 dGlyphID glyphArray [1]
0037 fGlyphID glyphArray [2]
0038 gGlyphID glyphArray [3]
0039 hGlyphID glyphArray [4]
003B jGlyphID glyphArray [5]
003C kGlyphID glyphArray [6]
003D lGlyphID glyphArray [7]
0041 pGlyphID glyphArray [8]
0042 qGlyphID glyphArray [9]
0045 tGlyphID glyphArray [10]
004A yGlyphID glyphArray [11]
CoverageFormat1
XheightCoverage 覆盖表定义
0001 1 coverageFormat:列表
000F 15 glyphCount
0032 aGlyphID glyphArray [0]
0034 cGlyphID glyphArray [1]
0036 eGlyphID glyphArray [2]
003A iGlyphID glyphArray [3]
003E mGlyphID glyphArray [4]
003F nGlyphID glyphArray [5]
0040 oGlyphID glyphArray [6]
0043 rGlyphID glyphArray [7]
0044 sGlyphID glyphArray [8]
0045 tGlyphID glyphArray [9]
0046 uGlyphID glyphArray [10]
0047 vGlyphID glyphArray [11]
0048 wGlyphID glyphArray [12]
0049 xGlyphID glyphArray [13]
004B zGlyphID GlyphArray [14]
CoverageFormat1
DescenderCoverage 覆盖表定义
0001 1 coverageFormat:列表
0005 五 glyphCount
0038 gGlyphID glyphArray [0]
003B jGlyphID glyphArray [1]
0041 pGlyphID glyphArray [2]
0042 qGlyphID glyphArray [3]
004A yGlyphID glyphArray [4]
示例10:ReverseChainSingleSubstFormat1 Subtable和SubstLookupRecord
示例10将字形序列的ReverseChainSingleSubstFormat1子表用于具有与左侧(粗出口)的粗连接的正确形式的字形。这允许字形正确连接到它左侧的字母形式。
ThickExitCoverage表是要替换匹配的字形列表。
标记为ThickEntryCoverage的LookaheadCoverage表列出了替换覆盖率字形后面的字形的四个字形ID。此前瞻性覆盖尝试匹配将导致替换发生的上下文。
Substitute表映射字形以替换ThickConnectCoverage表中的字形。
例10
Hex数据 资源 评论
ReverseChainSingleSubstFormat1
ThickConnect ReverseChainSingleSubstFormat1子表定义
0001 1 substFormat
0068 ThickExitCoverage 偏移到Coverage表
0000 0 backtrackGlyphCount
0000 null - 未使用 backtrackCoverageOffsets [0]
0001 1 lookaheadGlyphCount
0026 ThickEntryCoverage lookaheadCoverageOffsets [0]
000C 12 glyphCount
00A7 BEm2 substituteGlyphIDs [0] - 替换由Coverage索引排序的字形
00B9 BEi3 substituteGlyphIDs [1]
00C5 JIMm3 substituteGlyphIDs [2]
00D4 JIMi2 substituteGlyphIDs [3]
00EA SINm2 substituteGlyphIDs [4]
00F2 SINi2 substituteGlyphIDs [5]
00FD SADm2 substituteGlyphIDs [6]
010D SADi2 substituteGlyphIDs [7]
011B TOEm3 substituteGlyphIDs [8]
012B TOEi3 substituteGlyphIDs [9]
013B AINm2 substituteGlyphIDs [10]
0141 AINi2 substituteGlyphIDs [11]
CoverageFormat1
ThickEntryCoverage 覆盖表定义
0001 1 coverageFormat:列表
001F 31 glyphCount
00A5 ALEFf1 glyphArray [0] - 字形ID顺序中的字形
00A9 BEm4 glyphArray [1]
00AA BEm5 glyphArray [2]
00E2 DALf1 glyphArray [3]
0167 KAFf1 glyphArray [4]
0168 KAFfs1 glyphArray [5]
0169 KAFm1 glyphArray [6]
016D KAFm5 glyphArray [7]
016E KAFm6 glyphArray [8]
0170 KAFm8 glyphArray [9]
0183 GAFf1 glyphArray [10]
0184 GAFfs1 glyphArray [11]
0185 GAFm1 glyphArray [12]
0189 GAFm5 glyphArray [13]
018A GAFm6 glyphArray [14]
018C GAFm8 glyphArray [15]
019F LAMf1 glyphArray [16]
01A0 LAMm1 glyphArray [17]
01A1 LAMm2 glyphArray [18]
01A2 LAMm3 glyphArray [19]
01A3 LAMm4 glyphArray [20]
01A4 LAMm5 glyphArray [21]
01A5 LAMm6 glyphArray [22]
01A6 LAMm7 glyphArray [23]
01A7 LAMm8 glyphArray [24]
01A8 LAMm9 glyphArray [25]
01A9 LAMm10 glyphArray [26]
01AA LAMm11 glyphArray [27]
01AB LAMm12 glyphArray [28]
01AC LAMm13 glyphArray [29]
01EC HAYf2 glyphArray [30]
CoverageFormat1
ThickExitCoverage 覆盖表定义
0001 1 coverageFormat:列表
000C 12 glyphCount
00A6 BEm1 glyphArray [0]
00B7 BEi1 glyphArray [1]
00C3 JIMm1 glyphArray [2]
00D2 JIMi1 glyphArray [3]
00E9 SINm1 glyphArray [4]
00F1 SINi1 glyphArray [5]
00FC SADm1 glyphArray [6]
010C SADi1 glyphArray [7]
0119 TOEm1 glyphArray [8]
0129 TOEi1 glyphArray [9]
013A AINm1 glyphArray [10]
0140 AINi1 glyphArray [11]
7.23.gvar 字形变体表
OpenType Font Variations允许字体设计者将字体系列中的多个面合并到单个字体资源中。在可变字体中,字体变体(’fvar’)表定义了字体支持的一组设计变体,然后各种表提供指定不同字体值的数据,例如字形的X高度或X和Y坐标轮廓点,针对不同的变化实例进行调整。字形变体(’gvar’)表提供了描述’glyf’表格中TrueType字形轮廓如何在字体变体空间中变化的所有变体数据。
有关OpenType字体变体的一般概述,请参阅OpenType字体变体概述一章。
7.23.1.Introduction
字形变体表必须与TrueType轮廓结合使用 - 字形(’glyf’)表 - 还可以与字体变体(’fvar’)表以及变量字体中使用的其他必需或可选表结合使用。请参阅OpenType字体变体概述一章中的变体数据表和其他要求。
‘gvar’表包含字形变体数据子表,其中包含’glyf’表中每个字形的变体数据。字形变体数据是元组变体存储格式的特定变体,其在OpenType字体变体公用表格式一章中详细描述。元组变体存储的另一个变体也用在’cvar’表中。“公共表格格式”一章中描述了这些与“gvar”表特有的细节之间的差异。
变化数据由许多调整 - 增量值组成。这些增量适用于特定目标项,例如某些字形轮廓点的X或Y坐标,适用于字体变体空间的特定区域内的实例。元组变体存储格式根据适用性区域将增量组织成分组,每个区域具有不同的数据组。由于字形轮廓通常包含字体中最大的数据量,元组变体存储格式使用行程编码和其他优化机制来提供变体数据的有效表示。
每个区域特定的数据分组包括覆盖给定字形的所有轮廓点的数据。这意味着元组变体存储格式适合于一次解包和处理所有轮廓点的delta值,而不是随机轮廓点。在大多数应用场景中,字形轮廓处理一次涉及整个字形轮廓,因此格式中的这种偏差通常不是特别的限制。
但是,一个值得注意的例外是在渲染之前的文本布局操作中使用水平或垂直字形度量。TrueType光栅化器为每个字形动态生成“幻像”点,表示水平和垂直前进宽度和侧面方位,“gvar”表中的变化数据包括这些幻像点的数据。(有关幻像点的更多背景,请参阅“ 指示TrueType字形 ”一章。)因此,文本布局实现可以利用“gvar”表来获取给定变体实例的插值字形度量。但是,这样做需要调用光栅化器并处理每个字形的所有轮廓点的数据,而不仅仅是字形度量模型点。作为替代方案,水平度量变化(HVAR)和垂直度量变化(VVAR)表可以提供字形度量的变化数据,可以在不调用光栅化器的情况下处理,并且使用更适合处理特定项目数据的不同格式 - 前进或侧面轴承对于特定的字形。因此,建议变量字体包含HVAR表,如果字体具有“vhea”和“vmtx”表以支持垂直布局,则建议使用VVAR表。
7.23.2.Glyph variations table format
字形变体表由每个字形的标题后跟GlyphVariationData子表组成,描述每个字形在字体变体空间中的变换方式。
每个字形变体数据表包括引用字体变体空间内的各个区域的数据集。每个区域使用一个或三个元组记录定义,需要“峰值”元组记录。在许多情况下,一个字形引用的区域也将被许多其他字形引用。作为优化,’gvar’表允许一组共享的元组记录,可以由任何字形的元组变体存储数据引用。
‘gvar’表的高级结构如下:

标题包括共享元组数据开始的偏移量,以及字形变体数据表的开始。
每个字形变体数据表提供特定字形的变体数据。它们的大小各不相同。由于这个原因,标题还包括从字形变化数据表数组的开始每个字形变化数据表的偏移数组。每个字形ID对应一个偏移量加一个额外偏移量。(注意,相同的方案也用于索引到位置(’loca’)表。)数组中两个连续偏移之间的差异表示给定表的大小,在数组中有一个额外的偏移量来表示大小最后一张桌子。以这种方式导出的一些大小可以是零,在这种情况下,对于该特定字形没有字形变化数据,并且在整个变化空间中使用相同的轮廓用于该字形ID。
7.23.3.’gvar’ header
字形变体表头格式如下:
‘gvar’标题:
类型 名称 描述
UINT16 majorVersion 字形变体表的主要版本号 - 设置为1。
UINT16 minorVersion 字形变体表的次要版本号 - 设置为0。
UINT16 axisCount 此字体的变化轴数。这必须与’fvar’表中的axisCount相同。
UINT16 sharedTupleCount 共享元组记录的数量。共享元组记录可以在字形变体数据表中为多个字形引用,而不是直接存储在字形变体数据表中的其他元组记录。
OFFSET32 sharedTuplesOffset 从此表的开头到共享元组记录的偏移量。
UINT16 glyphCount 此字体中的字形数。这必须与字体中其他位置存储的字形数相匹配。
UINT16 旗 比特字段,给出后面的偏移数组的格式。如果位0清零,则偏移量为uint16; 如果设置了位0,则偏移量为uint32。
OFFSET32 glyphVariationDataArrayOffset 从此表的开头到GlyphVariationData数组的数组偏移。
Offset16或Offset32 glyphVariationDataOffsets [glyphCount + 1] 从GlyphVariationData数组的开头到每个GlyphVariationData表的偏移量。
如果短格式(Offset16)用于偏移,则存储的值是偏移量除以2.因此,字体内GlyphVariationData表的位置的实际偏移量将是存储在偏移量数组中的值乘以2。
7.23.4.Shared tuples array
共享元组数组提供一组变体空间位置,可由任何字形的变体数据引用。共享元组数组遵循’gvar’标头末尾的GlyphVariationData偏移数组。这个数据只是一个元组记录数组,每个都代表字体变化空间中的位置。
共享元组数组:
类型 名称 描述
TupleRecord sharedTuples [sharedTupleCount] 在所有字形变体数据表中共享的元组记录数组。
共享数组中的元组记录或直接包含在给定字形变体数据表中的元组记录使用2.14值来表示标准化坐标值。有关详细信息,请参见“通用表格格式”一章。
7.23.5.The glyphVariationData table array
glyphVariationData表数组遵循’gvar’标头和共享元组数组。每个glyphVariationData表描述字体中单个字形的变体数据。
字形变体数据表是元组变体存储格式的特定形式,在OpenType字体变体公用表格式一章中描述。它由标题组成,后跟序列化数据。

变异数据包括适用于变异空间的不同区域的数据的逻辑分组 - 元组变异数据表。这些逻辑分组存储在两个部分中:标题和序列化数据。字形变体数据头包括元组变体 - 数据头的阵列,每个元组与序列化数据的特定部分相关联。
序列化数据包括调整增量值以及打包的“点”数字,这些数字标识增量适用的字形轮廓中的点。在复合字形的情况下,这些数字是组件索引而不是点数索引。给定区域的序列化数据可以包括应用于该特定元组变化数据的点数数据,但是也可以存储在序列化数据的开始处存储的共享点数数据集。共享点数数据可以与给定字形的多个元组变化数据表相关联地使用。
glyphVariationData标头的结构如下。
GlyphVariationData标头:
类型 名称 描述
UINT16 tupleVariationCount 一个包装的领域。高4位是标志,低12位是该字形的元组变化表的数量。元组变体表的数量可以是1到4095之间的任何数字。
Offset16 dataOffset 从GlyphVariationData表的开头到序列化数据的偏移量
TupleVariationHeader tupleVariationHeaders [tupleCount] 元组变体标头的数组。
有关tupleVariationCount字段和该字段中使用的标志,tupleVariationHeader格式以及序列化数据格式的完整详细信息,请参阅OpenType字体变体常用表格格式一章。
7.23.6.Processing the ‘gvar’ table
当为特定变体实例处理可变字体的字形数据时,将从’glyf’表获得默认字形轮廓数据,该表与’gvar’表中的相应字形变体数据子表组合。
所选字形变体数据表中的元组变体标题将分别指定字体变体空间内的特定适用区域。这些将与所选变体实例的坐标进行比较,以确定哪些元组变体数据表适用,并计算每个变量数据表的标量值。这些比较和标量计算使用标准化尺度坐标值完成。
对于适用的每个元组变体数据表,将解压缩和处理点数和增量数据。适用区域的数据可以按任何顺序处理。导出的增量值将对应于从打包点数数据导出的特定点编号。对于给定的点编号,将计算的标量应用于X坐标,将Y坐标增量应用为系数,然后将结果增量调整应用于该点的X和Y坐标。
在OpenType字体变体概述一章中描述了坐标归一化,标量计算和目标项目(例如点坐标)的调整值的推导算法。“gvar”表特有的附加处理有两个方面。
首先,在复合字形的情况下,点数指的是组件或虚拟点。对于常规点处理幻像点的调整,但是对组件的调整的处理方式不同。下面提供关于处理复合字形的变化数据的附加信息。
其次,在给定的元组变化数据表中,可以为所有字形的点(和幻像点)提供增量,或仅为某些点提供增量。如果仅为字形轮廓中的某些点编号提供增量,则可能需要使用插值推断未参考点的增量值。这是特定于’gvar’表的附加处理,如下所述。
7.23.7.Point numbers and processing for composite glyphs
上面的一般性讨论和概述章节中的插值描述假定了简单的字形。某些特殊注意事项适用于复合字形。
复合字形的变化数据也使用表示一系列数字的打包点数数据,但在这种情况下,除了最后四个“幻像”点数之外,数字指的是构成字形的组件而不是轮廓点。复合字形的字形组件根据字形条目中给出的组件的顺序分配这些伪点编号,从0开始。表示侧支承的四个幻像点数仍然添加在最后,就像简单的字形一样。
例如,考虑“é”的复合字形,由两个组成部分组成:基本字形“e”和重音字形,位于指定的偏移处。伪点和幻像点数如下:
点数 元件
0 基本字形
1 口音雕文
2 左侧轴承点
3 右侧支承点
4 顶侧支承点
五 底侧支承点
此字形的压缩点数数据可包括引用任何或所有这些元素的数字。
组件字形的调整增量调整组件的位置。如果打包点编号中未引用字形组件,则不会调整其位置。复合中的每个组件字形都有自己的字形条目,它本身具有自己的变体数据。组件字形的处理必须以最深嵌套的非复合字形开始。
组件的位置可以用两种方式之一表示:直接使用X和Y偏移值,或间接使用对齐的父级和组件字形中的点编号。使用哪种方法由复合字形描述的标志字段中的位确定:如果设置了ARGS_ARE_XY_VALUES(位1),则使用X和Y偏移; 如果该位清零,则使用点编号。如果使用X和Y偏移表示组件的位置 - 设置ARGS_ARE_XY_VALUES标志 - 则可以将调整增量应用于这些偏移。但是,如果使用点编号表示组件的位置 - 未设置ARGS_ARE_XY_VALUES标志 - 则调整增量对该组件没有影响,因此不应指定。
除了组件的放置,复合字形描述还可以指定要应用于组件的缩放值或2×2矩阵变换。调整增量对应用于组件的缩放或2×2转换没有任何影响。增量仅影响组件的定位。
如果复合字形中的任何组件条目设置了USE_MY_METRICS标志,那么整个组合的提示字形度量标准将从该组件中获取,而不是使用为复合字形本身提供的值。也就是说,复合字形的幻像点的位置被设置为组件的幻像点的暗示位置。如果设置了多个组件标志符号,则复合标志符号的度量标准取自设置了此标志的最后一个组件。在可变字体中,如果组件条目设置了此标志,则复合字形的幻像点位置将设置为组件幻像点的插值和提示位置,并且不使用复合字形幻像点的delta值。
注意:当复合字形具有设置了USE_MY_METRICS标记的组件时,复合字形的’hmtx’和HVAR数据的使用方式与’hmtx’数据用于非变量字体的方式相同。’hmtx’和HVAR数据应设置为合成字形的适当值,尽管暗示的幻像点位置可能与从’hmtx’和HVAR数据获得的线性缩放度量不完全匹配。
转换复合字形的过程如下。
设componentCount为复合字形中的组件数。令components []为复合字形(基本0索引)的组件描述,并让C为复合字形描述中的组件条目。
使用标准变化插值算法,处理字形的变化数据,以获得每个分量和幻像点的净X和Y delta调整。
将净X和Y delta调整应用于幻像点(p = componentCount到componentCount + 3;请注意,幻像点位置可能稍后被组件覆盖):
对于AW和LSB点,应用净X增量调整,并忽略Y增量。
对于AH和TSB点,应用净Y delta调整,并忽略X delta。
对于p = 0到componentCount - 1:
C =成分[p]
对于C.glyphIndex中的字形,应用变异插值过程并运行提示程序。
如果在C.flags中设置了ARGS_ARE_XY_VALUES:
将索引p的净X和Y delta调整应用于C的X和Y定位偏移:
X position offset = C.argument1 + netAdjustmentX
Y位置偏移= C.argument2 + netAdjustmentY
否则(未设置ARGS_ARE_XY_VALUES):
忽略为此组件提供的任何增量调整。
根据情况应用缩放到C - 如果缩放定位偏移,则是缩放的Δ调整偏移。
如果在C.flags中设置了USE_MY_METRICS:
将复合体的幻像点的位置设置为等于幻像点的暗示位置C。
循环(下一个p)
例如,考虑Skia字体的字形128,它是“Ä”的字形。字形条目有两个组件条目,都设置了ARGS_ARE_XY_VALUES。’hmtx’表中的前进宽度为1358,左侧轴承为16; 这将左侧轴承和右侧轴承幻像点(点指数2和3)置于(0,0)和(1358,0)。复合字形描述的相关细节如下:
零件 glyphIndex argument1(X偏移) argument2(Y偏移)
0 65 0 0
1 315 286 0
字形128具有变化空间内各个区域的元组变化数据; 本例中将考虑三个,标准化坐标位置如下:
区域 (重量,宽度)
R1 (1,0)
R2 (0,1)
R3 (1,1)
R1的数据如下:
pt 0 第1页 第2页 第3页
X 0 69 58 145
ÿ 0 0 0 0
R2的数据如下:
pt 0 第1页 第2页 第3页
X 0 53 38 351
ÿ 0 0 0 0
R3的数据如下:
pt 0 第1页 第2页 第3页
X 0 21 -6 25
ÿ 0 0 0 0
由于所有Y delta值均为零,因此不会调整Y坐标值。
现在考虑一个坐标为(0.2,0.7)的变化实例。上述所有三个区域的变化数据都会产生影响,标量值如下:
区域 定标器
R1 0.2
R2 0.7
R3 0.14
组件偏移和幻像点的X坐标值的净调整如下:
项目 派生X坐标调整
组件1 X偏移 0.2×69 + 0.7×53 + 0.14×21
= 53.84
左侧承载点X坐标 0.2×58 + 0.7×38 + 0.14×-6
= 37.36
右侧承载点X坐标 0.2×145 + 0.7×351 + 0.14×25
= 278.2
将这些调整与’glyf’条目中的默认值组合会产生以下结果:
分量0(X,Y)偏移 (0,0)
组件1(X,Y)偏移 (286 +
53.84,0 )=(339.84,0)
左侧承载幻像点 (0 + 37.36,0)
=(37.36,0)
右侧轴承幻像点 (1358 +
278.2,0 )=(1636.2,0)
7.23.8.Inferred deltas for un-referenced point numbers
给定字形和区域(给定元组变化数据集)的元组变化数据可以包括所有轮廓点的增量,或仅包括一些。打包点数数据标识提供增量的点。如果点数列表中省略了某些点,则数据不会明确包含它们的增量值,并且可能需要推断增量。基于每组元组变化数据指定的点数,在逐个区域的基础上对给定的字形进行此操作。
注意:推断未引用点的增量仅适用于简单字形,而不适用于复合字形。
单组点数数据用于X方向和Y方向的增量。如果一个点有明确的增量,那么它对X和Y方向都有明确的增量。如果该点需要推断的增量,则推断出X和Y三角洲。推断的X和Y增量的值分别计算。
针对给定区域和变体实例计算的标量应用于推断的增量,以获得应用于点坐标的缩放增量调整,就像显式增量一样。
计算推断的变化增量的过程在某种程度上与TrueType Interpolate Untouched Points(IUP)指令相当。(有关IUP指令的更多信息,请参阅“ 指示TrueType字形 ”一章。)两者都根据对相邻受影响点的调整计算未受影响点的调整。然而,在IUP指令的情况下,计算的调整基于在应用其他指令之后相邻点的位置。相反,推断的变化增量的计算基于默认位置点和给定区域的未缩放delta值。它不受处理不同区域的元组变化数据的顺序的影响,并且可以在完成对特定实例的任何处理之前预先计算推断的增量。此外,用于导出推断增量值的计算与用于IUP指令的计算略有不同。
在逐个轮廓的基础上对给定的字形和给定区域进行推断的增量的计算。
对于给定的轮廓,如果点编号列表不包括该轮廓中的任何点,则轮廓中的所有点都不受影响,并且不需要计算推断的增量。
如果点编号列表包括给定轮廓中的一些但不是所有点,则必须针对未包括在点编号列表中的点导出推断的增量,如下所述。
首先,对任何未参照点,前后确定最近点,点号的顺序,这是引用。请注意,相同的参考点将用于计算X和Y推断的增量。如果引用的轮廓中没有较低的点编号,则使用该轮廓中最高的参考点编号。类似地,如果没有引用该轮廓的较高点数,则使用最低的参考点数。
一旦识别出相邻的参考点,则对X和Y方向分别进行推断 - 增量计算。
接下来,比较相邻的参考点的(X或Y)网格坐标值。如果这些坐标相同,则比较相邻点的增量值:如果增量值相同,则将该值用作目标未参考点的推断增量。如果增量值不同,则目标点的推断增量为零。
注意:如果在点编号列表中仅引用了轮廓中的一个点,则该轮廓中的每个点都使用与该点相同的X和Y delta值。这作为上述的具体情况如下:对于未参考的所有其他点,一个参考点同时是前一个相邻点和后一个相邻点。因此,相邻点具有相同的坐标值和相同的增量,因此未参考的点获得相同值的推断的增量。
如果相邻参考点的坐标不同,则将目标点的相同(X或Y)方向的坐标与那些坐标进行比较。如果目标点的坐标在相邻点的坐标之间,则插值delta,如下所述。但是如果目标点的坐标不在相邻点的坐标之间,则推断的delta是相邻点中的任何一个在给定方向上更接近的Δ。
以下伪代码总结了上述细节。
复制
if precedingPoint.coord = followingPoint.coord
{
if precedingPoint.delta = followingPoint.delta
targetPoint.delta = precedingPoint.delta
else
targetPoint.delta = 0
}
else /* precedingPoint.coord <> followingPoint.coord /
{
if targetPoint.coord <= min(precedingPoint.coord, followingPoint.coord)
{
if precedingPoint.coord < followingPoint.coord
targetPoint.delta = precedingPoint.delta
else / followingPoint.coord < precedingPoint.coord /
targetPoint.delta = followingPoint.delta
}
else if targetPoint.coord >= max(precedingPoint.coord, followingPoint.coord)
{
if precedingPoint.coord > followingPoint.coord, then
targetPoint.delta = precedingPoint.delta
else / followingPoint.coord > precedingPoint.coord /
targetPoint.delta = followingPoint.delta
}
else / target point coordinate is between adjacent point coordinates /
{
/ target point delta is derived from the adjacent point deltas
using linear interpolation */
}
}
当两个相邻点的坐标不同并且目标点的坐标在这些坐标之间时,则通过两个相邻点的增量的线性插值来计算目标点的Δ。以下描述了X或Y方向的计算。
注意:此时算法的逻辑流程意味着两个相邻点的坐标不同。这避免了在以下计算中除以零,否则会发生。
选择两个相邻点中的一个作为参考点,让另一个作为比较点。哪个是哪个都没关系。设refCoord是前者当前方向的坐标值,让compCoord为后者的坐标值。让targetCoord成为目标未参考点的坐标值。计算比例,比例如下:
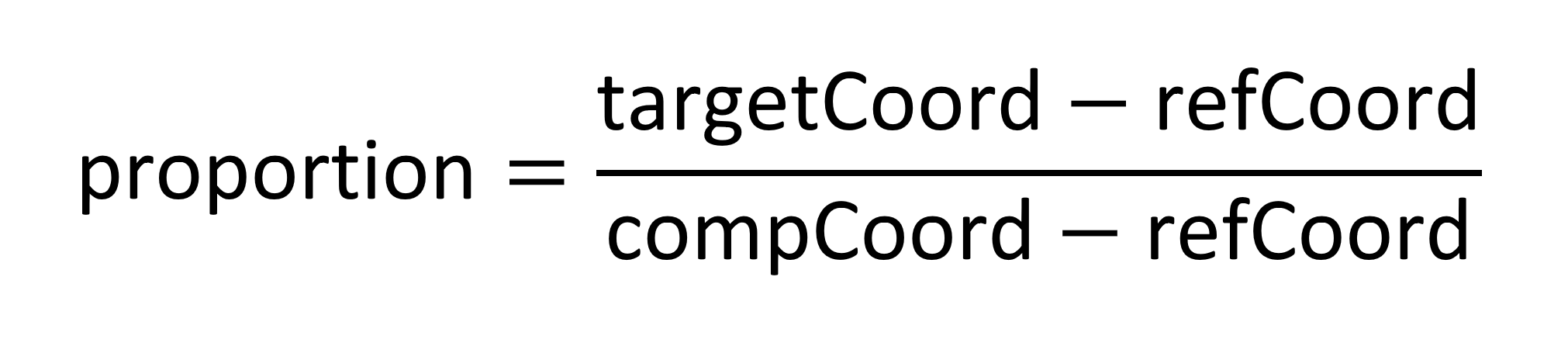
现在让deltaRef和deltaComp为参考点和比较点的变量数据中的未缩放调整 - 增量值。目标点的推断delta deltaTarget计算如下:
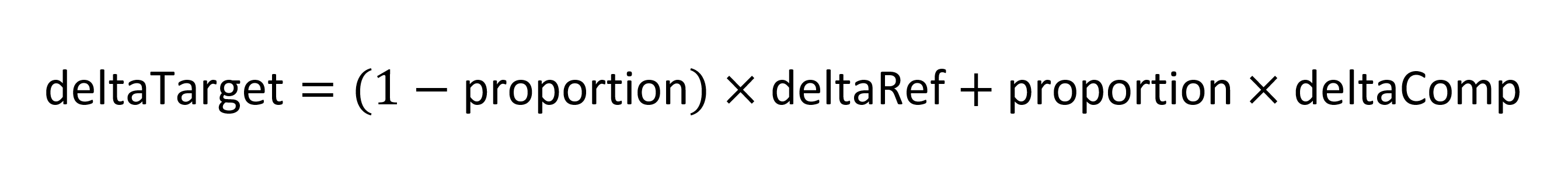
以下示例说明了获取推断增量的过程。假设P1,P2和P3是相同轮廓中的点,坐标位置如下所示,P1和P3在点编号数据中引用,而P2不在。

请注意,P1和P3具有不同的X和Y坐标。还要注意,在X方向上,P2在两个相邻点之间,而在Y方向上则不是。对于Y方向,推断的delta将是更近点P3的增量。
对于X方向,让P1为参考点; P3是比较点。计算一个比例:
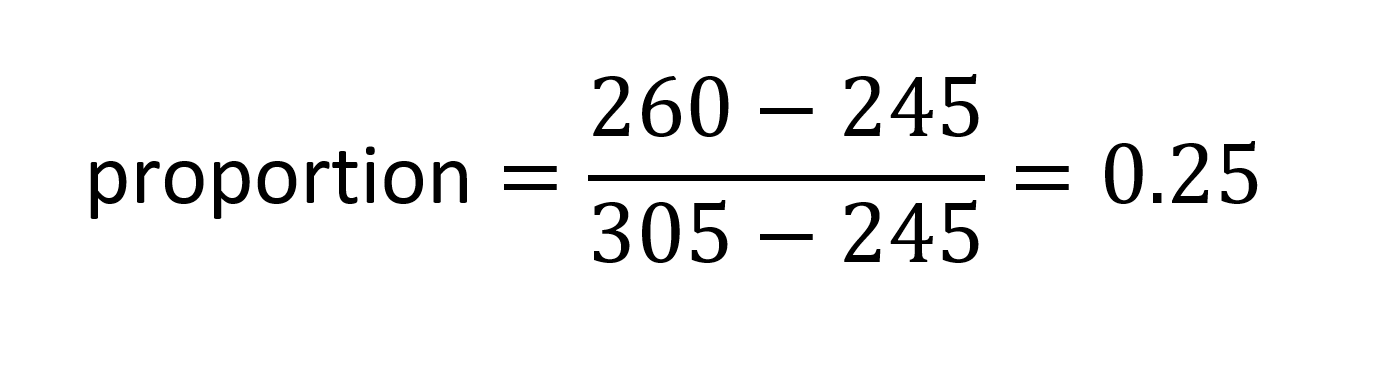
现在假设P1和P3在变体数据中有X和Y增量,如下所示:
点 X delta Y delta
P1 +28 -62
P3 -42 -57
P2的推断X delta,deltaX_P2,计算如下:
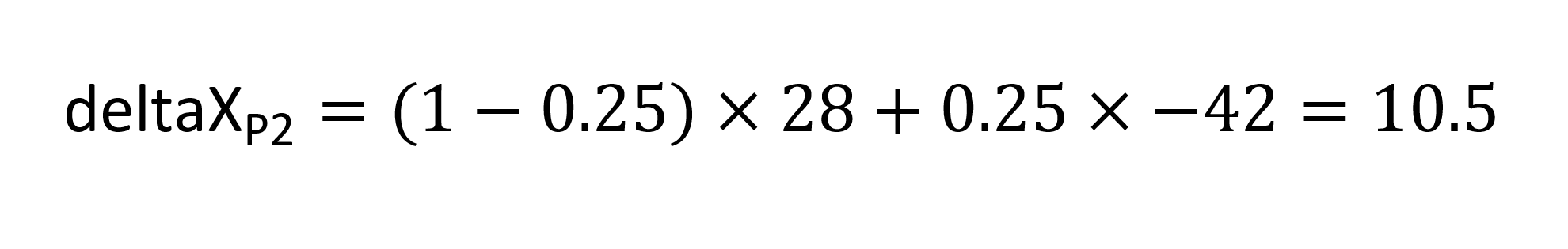
P2的推断Y delta是P3的Y delta值。因此,获得所有三个点的增量:
点 X delta Y delta
P1 +28 -62
P2 +10.5 -57
P3 -42 -57
现在可以在插值算法中使用这些增量值,其中基于区域坐标和当前变化实例的坐标将标量应用于每个。
7.24.hdmx 水平设备指标
‘hdmx’表与具有TrueType轮廓的OpenType™字体相关。水平设备度量标准表存储按特定像素大小缩放的整数提前宽度。这允许字体管理器构建整数宽度表,而无需为每个字形调用缩放器。通常,此表仅包含选定的屏幕尺寸。此表按像素大小排序。此表的校验和适用于列出的两个子表。
请注意,对于非方形像素网格,字符宽度(以像素为单位)将用于确定要使用的设备记录。例如,分辨率为72x96的设备上的12点字符将是12像素高和16像素宽。将使用16个像素字符的’hdmx’设备记录。
如果未设置’head’表中标志字段的第4位,则假定字体线性缩放; 在这种情况下,’hdmx’表不是必需的,不应该构建。如果设置了标志字段的第4位,则假定字体中的一个或多个字形非线性地缩放。在这种情况下,可以通过将’hdmx’表与重要大小的一个或多个重要设备记录包括在一起来提高性能。有关更多详细信息,请参阅“OpenType字体的建议”一章。
表格如下:
‘hdmx’标题
类型 名称 描述
UINT16 版 表版本号(0)
INT16 numRecords 设备记录数。
INT32 sizeDeviceRecord 设备记录的大小,32位对齐。
DeviceRecord 记录[numRecords] 设备记录数组。
格式0的每个DeviceRecord都是这样的。
设备记录
类型 名称 描述
UINT8 pixelSize 以下宽度的像素大小(以ppem为单位)。
UINT8 maxWidth 最大宽度。
UINT8 宽度[numGlyphs] 宽度数组(numGlyphs来自’maxp’表)。
每个DeviceRecord用0填充以使其32位对齐。
每个Width值是特定字形的宽度(以像素为单位),以DeviceRecord开头列出的每个em(ppem)大小的像素为单位。
沿y轴测量ppem尺寸。
7.25.head 字体标题表
此表提供有关字体的全局信息。应仅使用具有轮廓的字形计算边界框值。出于这些计算的目的,应忽略没有轮廓的字形。
类型 名称 描述
UINT16 majorVersion 字体标题表的主要版本号 - 设置为1。
UINT16 minorVersion 字体标题表的次要版本号 - 设置为0。
固定 fontRevision 由字体制造商设置。
UINT32 checkSumAdjustment 要计算:将其设置为0,将整个字体求和为uint32,然后存储0xB1B0AFBA - sum。如果字体用作字体集合文件中的组件,则通过更改文件结构和字体表目录将使该字段的值无效,并且必须忽略该字段。
UINT32 magicNumber 设置为0x5F0F3CF5。
UINT16 旗 位0: y = 0时字体的基线;
位1: x = 0时的左侧支点(仅适用于TrueType光栅化器) - 请参阅下面有关可变字体的注释;
位2:指令可能取决于点大小;
位3:强制ppem为所有内部定标器数学的整数值; 如果该位清零,则可以使用分数ppem大小;
位4:指令可能会改变前进宽度(前进宽度可能不会线性缩放);
位5:此位未在OpenType中使用,不应设置为确保所有平台上的兼容行为。如果设置,则可能导致某些平台中垂直布局的行为不同。(参见Apple的规范有关Apple平台行为的详细信息。)
位6-10:这些位不在Opentype中使用,应始终清除。(有关Apple平台中使用的遗留问题的详细信息,请参阅Apple的规范。)
位11:由于经过优化转换和/或压缩(例如ISO / IEC 14496定义的压缩机制),字体数据“无损” 18,MicroType Express,WOFF 2.0或类似的)其中保留了原始字体功能和特征,但不保证输入和输出字体文件之间的二进制兼容性。作为应用变换的结果,DSIG表也可能无效。
位12:字体转换(产生兼容的指标)
位13:针对ClearType™优化的字体。请注意,依赖于嵌入式位图(EBDT)进行渲染的字体不应被视为针对ClearType进行了优化,因此应保持此位清零。
第14位: Last Resort字体。如果设置,则表示’cmap’子表中编码的字形只是代码点范围的通用符号表示,并不真正表示对这些代码点的支持。如果未设置,则表示’cmap’子表中编码的字形表示对这些代码点的适当支持。
位15:保留,设置为0
UINT16 unitsPerEm 设置为16到16384之间的值。此范围内的任何值均有效。在具有TrueType轮廓的字体中,建议使用2的幂,因为这允许在某些光栅化器中进行性能优化。
LONGDATETIME 创建 自格林威治标准时间/ UTC时区1904年1月1日午夜12:00起的秒数。64位整数
LONGDATETIME 改性 自格林威治标准时间/ UTC时区1904年1月1日午夜12:00起的秒数。64位整数
INT16 XMIN 对于所有字形边界框。
INT16 YMIN 对于所有字形边界框。
INT16 XMAX 对于所有字形边界框。
INT16 YMAX 对于所有字形边界框。
UINT16 macStyle 位0:粗体(如果设置为1);
位1:斜体(如果设置为1)
位2:下划线(如果设置为1)
位3:大纲(如果设置为1)
位4:阴影(如果设置为1)
位5:压缩(如果设置为1)
位6:扩展(如果设置为1)
位7-15:保留(设置为0)。
UINT16 lowestRecPPEM 最小的可读大小(以像素为单位)。
INT16 fontDirectionHint 不推荐使用(设为2)。
0:完全混合的方向字形;
1:只有强烈从左到右;
2:像1一样但也包含中性;
-1:只有从右到左;
-2:与-1相似但也包含中性。
(中性字符没有固有的方向性;它不是宽度为零(0)的字符。空格和标点符号是中性字符的例子。非中性字符是具有固有方向性的字符。例如,罗马字母(左对齐)右侧)和阿拉伯字母(从右到左)具有方向性。在存在空格和标点符号的“普通”罗马字体中,字体方向提示应设置为两(2)。)
INT16 indexToLocFormat 0表示短偏移(Offset16),1表示长偏移(Offset32)。
INT16 glyphDataFormat 0表示当前格式。
注意,macStyle位必须与OS / 2表fsSelection位一致。fsSelection位用于Microsoft Windows中的macStyle位。PANOSE值和’post’表值将被忽略,以确定粗体或斜体字体。
由于历史原因,Windows不使用此表中包含的fontRevision值来确定字体的版本。相反,Windows会评估“名称”表中的版本字符串(ID 5)。
请注意,在具有TrueType轮廓的可变字体中,每个字形的左侧方位必须等于xMin,并且必须设置flags字段中的位1。此外,必须以所有可变字体清除第5位。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
7.26.hhea 水平标题表
该表包含水平布局的信息。minRightSidebearing,minLeftSideBearing和xMaxExtent中的值应仅使用具有轮廓的字形进行计算。出于这些计算的目的,应忽略没有轮廓的字形。所有保留区域必须设置为0。
类型 名称 描述
UINT16 majorVersion 水平标题表的主要版本号 - 设置为1。
UINT16 minorVersion 水平标题表的次要版本号 - 设置为0。
F字 伸 印刷上升(距离最高上升的基线的距离)。
F字 伸 印刷下降(距离最低下降基线的距离)。
F字 lineGap 印刷线间隙。
在一些传统平台实现中,负LineGap值被视为零。
UFWORD advanceWidthMax ‘hmtx’表中的最大提前宽度值。
F字 minLeftSideBearing ‘hmtx’表中的最小左侧承载值。
F字 minRightSideBearing 最小右侧承载值; 计算为Min(aw - lsb - (xMax - xMin))。
F字 xMaxExtent 最大值(lsb +(xMax - xMin))。
INT16 caretSlopeRise 用于计算光标的斜率(上升/下降); 1表示垂直。
INT16 caretSlopeRun 0表示垂直。
INT16 caretOffset 需要移动字形上的倾斜高光以产生最佳外观的量。对于非倾斜字体,设置为0
INT16 (保留) 设为0
INT16 (保留) 设为0
INT16 (保留) 设为0
INT16 (保留) 设为0
INT16 metricDataFormat 0表示当前格式。
UINT16 numberOfHMetrics ‘hmtx’表中的hMetric条目数
注意:此表中的ascender,descender和linegap值是Apple特定的。另请参阅OS / 2表中的信息。
7.26.1.’hhea’ Table and OpenType Font Variations
在可变字体中,可能需要针对不同的变体实例调整水平标头表内的各种字体度量值。可以在度量变化(MVAR)表中提供“hhea”条目的变体数据。使用值标记将不同的’hhea’条目与MVAR表中的特定变体数据相关联,如下所示:
‘hhea’进入 标签
caretOffset ‘hcof’
caretSlopeRise ‘HCRS’
caretSlopeRun ‘hcrn’
有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
7.27.hmtx 水平度量表
用于水平文本布局的字形度量包括字形前进宽度,侧向方位和X方向最小值和最大值(xMin,xMax)。这些是使用字形轮廓数据(’glyf’,’CFF’或CFF2)和水平度量表的组合得出的。水平度量(’hmtx’)表提供字形前进宽度和左侧轴承。
在具有TrueType轮廓数据的字体中,’glyf’表提供xMin和xMax值,但不提供高度宽度或侧向轴承。提前宽度始终从’hmtx’表中获得。在某些字体中,根据“head”表中标志的状态,左侧轴承可能与“glyf”表中的xMin值相同,但并非所有字体都适用。(参见’head’表中flags字段的bit 1的描述。)因此,左侧轴承在’hmtx’表中提供。右侧轴承始终使用’hmtx’表中的前进宽度和左侧轴承值以及字形描述中的边界框信息得出 - 有关详细信息,请参见下文。
在具有TrueType轮廓数据的可变字体中,’hmtx’表中的左侧方位值必须始终等于xMin(必须设置’head’标志字段的第1位)。因此,这些值也可以直接从’glyf’表中导出。请注意,这些值仅适用于变量字体的默认实例:非默认实例可能具有不同的侧面轴承值。这些可以使用’gvar’表(参见下面的其他详细信息)从插值的“幻像点”坐标导出,或者通过将HVAR表中的变体数据应用于’glyf’或’hmtx’表中的默认实例值。
在具有CFF版本1轮廓数据的字体中,“CFF”表确实包括提前宽度。这些值由PostScript处理器使用,但不在OpenType布局中使用。在OpenType上下文中,’hmtx’表是必需的,必须用于提前宽度。请注意,共享“CFF”表的字体集合文件中的字体可以在特定字形索引的字体特定“hmtx”表中指定不同的预先宽度。另请注意,CFF2表不包括提前宽度。另外,对于CFF或CFF2数据,没有明确的xMin和xMax值; 侧轴承隐含在CharString数据中,可以从CFF / CFF2光栅化器获得。但是,某些布局引擎可能会在’hmtx’表中使用左侧轴承值; 因此,字体生成工具应确保’hmtx’表中的lsb值与CharString数据中反映的隐式xMin值匹配。在具有CFF2轮廓数据的可变字体中,应通过组合来自’hmtx’和HVAR表的信息来获得非默认实例的左侧方位和前进宽度值。
该表使用longHorMetric记录来给出字形的前进宽度和左侧方位。记录由字形ID索引。作为优化,记录的数量可以小于字形的数量,在这种情况下,最后一个记录的提前宽度值适用于所有剩余的字形ID。这在等宽字体或具有大量具有相同前进宽度的字形的字体中非常有用(前提是字形是相应排序的)。longHorMetric记录的数量由’hhea’表中的numberOfHMetrics字段确定。
如果longHorMetric数组小于字形总数,则该数组后面跟着一个数组,表示剩余字形的左侧方位值。左侧方位中的元素数量将从numberOfHMetrics加上’ maxp ‘表中的numGlyphs字段得出。
水平度量表:
类型 名称 描述
longHorMetric hMetrics [numberOfHMetrics] 每个字形的成对前进宽度和左侧方位值。记录由字形ID索引。
INT16 leftSideBearings [numGlyphs - numberOfHMetrics] 符号ID大于或等于numberOfHMetrics的左侧方位。
longHorMetric记录:
类型 名称 描述
UINT16 advanceWidth 以字体设计单位提前宽度。
INT16 LSB 字形左侧轴承,字体设计单位。
在具有TrueType轮廓的字体中,每个字形的xMin和xMax值在’glyf’表中给出。前进宽度(“aw”)和左侧方位(“lsb”)可以从字形“幻像点”导出,它们由TrueType光栅化器计算; 或者它们可以从’hmtx’表中获得。在具有CFF或CFF2轮廓的字体中,可以从CFF / CFF2光栅化器获得xMin(=左侧轴承)和xMax值。根据这些值,右侧轴承(“rsb”)计算如下:
复制
rsb = aw - (lsb + xMax - xMin)
如果pp1和pp2是用于控制lsb和rsb的TrueType幻像点,则它们在X方向上的初始位置计算如下:
复制
pp1 = xMin - lsb
pp2 = pp1 + aw
7.28.HVAR 水平度量变化表
HVAR表用于可变字体,以提供水平字形度量值的变体。这可用于为’hmtx’表中的提前宽度提供变化数据。在具有TrueType轮廓的字体中,它还可用于为从“hmtx”表和字形边界框获得的左侧和右侧轴承提供变化数据。
有关OpenType字体变体和与变体相关的术语的一般概述,请参阅OpenType字体变体概述一章。
在具有TrueType轮廓的字体中,光栅化器将生成表示左,右,顶部和底部轴承的“幻像”点。(有关幻像点的更多背景,请参阅“ 指示TrueType字形 ”一章。)在TrueType变量字体中,字形变体(’gvar’)表格将包括每个字形的幻像点的变体数据,允许为不同的变体实例插入字形度量,作为导出插值字形轮廓的一部分。因此,在具有TrueType轮廓的可变字体中不需要HVAR表。但是,对于需要字形度量但不是实际字形轮廓的文本布局操作,能够获得实例的调整后的字形度量而不需要插入字形轮廓,可以获得显着的性能优势。因此,建议将HVAR表包含在具有TrueType轮廓的可变字体中。
CFF 2光栅化器不会像TrueType光栅化器那样生成幻像点。出于这个原因,需要HVAR表来处理具有CFF 2轮廓的可变字体中的水平字形度量的任何变化。
请注意,在具有TrueType轮廓的可变字体中,每个字形的左侧方位必须等于xMin,并且必须设置“head”表的flags字段中的位1。
HVAR表包含用于表示变体数据的项目变体存储表。项目变体存储和组成格式在章节OpenType字体变体公用表格格式中描述。项目变体存储也用于VVAR,GDEF和某些其他表格,但不同于“cvar”或“gvar”表中使用的变体数据的格式。
项目变体存储格式使用增量集索引来引用应用它们的特定目标,字体数据项的变体增量数据,例如特定字形的前进宽度。项目变体商店外部的数据标识要用于每个给定目标项目的增量集索引。在HVAR表内,字形ID可以用作提前宽度变化的隐式索引,或者可以使用可选的增量集索引映射表,其明确地提供与每个字形ID相关联的提前宽度的增量集索引。
高级宽度映射表在HVAR表中添加了附加数据,但它也可以在项目变体存储中使用更紧凑的数据表示。例如,如果多个字形具有相同的预先宽度,则映射表允许它们全部引用存储中的单个增量集。项目变体商店中的其他优化是可能的。有关大小优化的更多讨论,请参见“通用表格格式”一章。通常,建议包含预先宽度映射。
可选的映射表也可用于为字形侧轴承提供增量集索引。在具有TrueType轮廓的可变字体中,建议使用侧面轴承的变化数据。如果提供侧面轴承的变化数据,则应包括左侧和右侧轴承的数据。还必须包括左侧和右侧轴承的映射表。
7.28.1.Related and Co-Requisite Tables
HVAR表仅用于可变字体。它必须与水平度量(’hmtx’)表结合使用,还可以与字体变体(’fvar’)表以及变量字体中使用的其他必需或可选表结合使用。有关一般信息,请参阅OpenType字体变体概述一章中的变体数据表和其他要求。
对于具有TrueType轮廓的可变字体,HVAR表是可选的,但建议使用。对于具有CFF 2轮廓的可变字体,如果变体空间中的字形前进宽度存在任何变化,则需要HVAR表。
注意: ‘hdmx’表不用于可变字体。
7.28.2.Table Formats
水平度量变化表具有以下格式。
水平指标变化表:
类型 名称 描述
UINT16 majorVersion 水平度量变量表的主要版本号 - 设置为1。
UINT16 minorVersion 水平度量变量表的次要版本号 - 设置为0。
OFFSET32 itemVariationStoreOffset 从此表的开头到项目变体存储表的偏移量(以字节为单位)。
OFFSET32 advanceWidthMappingOffset 从该表的开头到提前宽度的增量集索引映射的偏移量(可以是NULL)。
OFFSET32 lsbMappingOffset 从该表的开头到左侧轴承的增量集索引映射的偏移量(可以是NULL)。
OFFSET32 rsbMappingOffset 从该表的开头到右侧轴承的delta集合索引映射的偏移量(可以是NULL)。
项目变体存储表记录在OpenType字体变体常用表格格式一章中。
映射表是可选的。如果未提供给定的映射表,则将偏移量设置为NULL。
需要提前宽度的变化数据。可以提供用于提前宽度的增量集索引映射表,但是是可选的。如果未提供映射表,则将字形索引用作隐式增量集索引。要访问给定字形前进的增量集,增量集外层索引为零,字形ID用作内层索引。
侧轴承的变化数据是可选的。如果包含,则需要映射表来为每个字形提供增量集索引。
增量集索引映射表具有以下格式。
DeltaSetIndexMap表:
类型 名称 描述
UINT16 entryFormat 一个压缩字段,描述了delta集索引的压缩表示。详情见下文。
UINT16 mapCount 映射条目的数量。
UINT8 属于MapData [变量] 增量集索引映射数据。详情见下文。
mapCount字段指示增量集索引映射条目的数量。字形ID用作映射数组的索引。如果给定的字形ID大于mapCount - 1,则使用最后一个条目。
每个映射条目表示增量集外层索引和内层索引组合。逻辑上,这些索引中的每一个都是16位无符号值。它们以包装格式表示,使用一个,两个,三个或四个字节。entryFormat字段是一个压缩位域,用于描述给定deltaSetIndexMap表的mapData字段中使用的压缩表示。entryFormat字段的格式如下:
EntryFormat字段掩码
面具 名称 描述
0x000F INNER_INDEX_BIT_COUNT_MASK 低4位的掩码,它给出了内部索引的每个条目中使用的位数减1。
0x0030 MAP_ENTRY_SIZE_MASK 用于指示以字节为单位的大小减去每个条目之一的位的掩码。
0xFFC0 保留的 保留供将来使用 - 设置为0。
innerBitCountMask和mapEntrySizeMask使内部索引的大小范围为1到16位,外部索引的大小范围为0到31位,组合大小由mapEntrySizeMask确定。每个映射条目的大小是((entryFormat&mapEntrySizeMask)>> 4 + 1)。地图数据数组的总大小为entrySize * mapCount。
对于给定条目,可以按如下方式获得外层和内层索引:
outerIndex = entry >> ((entryFormat & innerIndexBitCountMask) + 1)
innerIndex = entry & ((1 << ((entryFormat & innerIndexBitCountMask) + 1)) – 1)
7.28.3.Processing
使用可变字体的特定变体实例执行文本布局时,应用程序将需要获取该实例的调整后的字形度量标准。应用程序从’hmtx’和’glyf’表中获取默认值,并使用HVAR表获取应用于默认值的插值调整值。
基于字形ID获得增量集索引。如果没有用于提前宽度的delta-set索引映射表,则字形ID隐式地提供索引:对于给定的字形ID,delta-set外层索引为零,并且字形ID为delta-set inner-水平指数。
如果提供了delta-set索引映射,则外层索引和内层索引以打包格式组合,每个映射条目使用一到四个字节。每个映射表提供描述打包格式的信息; 这用于提取单独的外部和内部级别索引。
索引用于引用项目变化存储内的目标前进宽度或侧向承载的增量集。项目变体存储中的两级数据组织在OpenType字体变体公用表格式一章中描述。每个增量集包括不同的增量,这些增量适用于落在变化空间的不同区域内的变体实例。在OpenType字体变体概述一章中描述了处理增量以导出给定目标项的内插值的过程。
7.29.JSTF 理由表
对齐表(JSTF)为字体开发人员提供了对对齐文本中字形替换和定位的额外控制。文本处理客户端现在有更多选项来扩展或缩小字和字形间距,因此文本填充指定的行长度。
7.29.1.Overview
在对文本进行验证时,文本处理客户端会分配每行中的字符以完全填充指定的行长度。无论是删除空间以适应行中的更多字符还是添加更多空间来扩展字符,对齐都会在单词之间产生较大的间隙,狭窄或扩展的字形间距,不均匀的断线图案以及其他刺耳的视觉效果。例如:

为了抵消这些影响,文本处理客户端使用了对齐算法,该算法通过一系列字形间距调整来重新分配空间,从最小到最明显。通常,客户端将首先扩展或压缩单词之间的空格。如果这些更改不够或看起来分散注意力,客户端可能会在行的末尾连字,或者调整一行或多行中的字形之间的空格。
为了掩盖间距不一致性,以便它们不会破坏读者的文本流,字体开发人员可以使用JSTF表来启用或禁用单个字形替换和定位操作,这些操作适用于字体中的特定脚本,语言系统和字形。
例如,连字字形可以替换多个字形,通过不显眼的局部调整缩短文本行(参见图6b)。特定于字体的定位更改可应用于组合两种或更多字体的文本行中的特定字形。其他选项包括重新定位行中的各个字形,扩展特定字形对之间的空间,以及减少特定字形序列中的间距。

字体设计者或开发人员将JSTF数据定义为优先级建议。每个建议都列出了客户端可用于调整文本行的特定操作。对齐行为可能适用于垂直和水平文本。
7.29.2.Table Organization
JSTF表通过脚本和语言系统组织数据,GSUB和GPOS表也是如此。JSTF表以一个标题开头,该标题列出了JstfScriptRecords数组中的脚本(参见图6c)。每条记录都包含一个ScriptTag和一个包含脚本和特定于语言的数据的JstfScript表的偏移量:
默认对齐语言系统表(JstfLangSys)定义在没有任何特定于语言的信息的情况下应用于整个脚本的特定于脚本的数据。
对齐语言系统表存储每个语言系统的对齐数据。

JstfLangSys表包含一个理由建议列表。每个建议都包含一个GSUB或GPOS LookupList索引列表,可以启用或禁用查找,以添加或删除文本行中的空格。此外,每个建议可以包括一组具有最大调整值的专用对齐查找,以扩展或缩小空间量。
字体开发者根据它们如何影响文本行的外观和功能来确定建议的优先级,并且客户端按该顺序应用建议。低编号(高优先级)建议对应于“最差”选项。
每个脚本还可以提供扩展器字形列表,例如阿拉伯语中的kashidas。除了理由建议之外,客户端可以使用扩展器字形。
只有在为字符串实现所有选定的GSUB和GPOS功能后,客户端才开始证明一行文本。从编号最小的建议开始,客户端启用或禁用JSTF表中指定的查找,重新组装LookupList顺序中的查找,并将它们一个接一个地应用于字符串中的每个字形。如果该行仍然不是正确的长度,则客户端按优先级的升序处理下一个建议。这一直持续到线长度满足理由要求。
注意: 如果任何优先级的任何JSTF建议修改先前应用于字形字符串的GSUB或GPOS查找,则文本处理客户端必须将JSTF建议应用于未修改的字形字符串版本。
注意: 可以在GSUB或GPOS表中使用FeatureVariations表,以使用基于特定条件的备用查找集替换由给定特征触发的查找。(目前,这些条件仅适用于可变字体的使用,这将在下面进一步讨论。)针对给定特征应用的实际查找可能与该特征的默认查找集不同。在处理对齐建议时,检查先前应用程序的查找列表应该是应用的实际查找,其中有效的任何特征变化,而不是默认查找。此外,在JSTF表中添加数据以禁用GSUB或GPOS查找时,字体开发人员应考虑与功能变体表的可能交互,例如需要在要禁用的查找集中包含此类备用查找。请注意,这仅适用于GSUB和GPOS表中的功能和查找:对于直接包含在JSTF表中的查找,没有类似的功能变化机制。
在本章后面,将描述JSTF表用于脚本和语言系统的以下表和记录:
脚本信息,包括JstfScript表(及其关联的JstfLangSysRecords)和ExtenderGlyph表。
语言系统信息,包括JstfLangSys表,JstfPriority表(及其关联的JstfDataRecord),JstfModList表和JstfMax表。
7.29.3.JSTF Table and OpenType Font Variations
OpenType字体变体允许单个字体沿着一个或多个设计变体轴支持许多设计变体。例如,具有重量和宽度变化的字体可能支持从细到黑的重量,以及从超浓缩到超扩展的宽度。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
当选择不同的变体实例时,各个字形的设计和度量会发生变化,整个字体的度量特征也可能会发生变化。由于指标与理由相关,因此需要考虑理由数据与变体之间的相互作用。
如上所述,假设理由是一个迭代过程,其中应用程序按优先级顺序测试字体中定义的不同建议,以找到导致满足应用程序确定的理由要求的行长度的建议。选择可变字体的实例时,行布局将使用为该实例调整的字形轮廓和度量。因此,一个变化实例的度量可以与另一个不同,并且如果用不同的变化实例格式化,则在理由之后给定行的文本内容可以是不同的,但是理由处理以相同的方式进行。
如上所述,在处理选定的GSUB和GPOS特征之后,将对齐建议应用于结果。如果GSUB或GPOS表包含FeatureVariations表,则FeatureVariations表的效果与对齐建议之间可能存在交互。请参阅上面的其他讨论。
如上所述,理由建议可以使用GPOS表中包含的GPOS查找或直接在JSTF表中使用。GPOS查找子表包含X或Y字体单位值,用于指定对单个字形位置或度量的修改。在可变字体中,这些X和Y值适用于默认实例,可能需要调整不同的变体实例。这是使用变体数据完成的,其过程类似于用于字形轮廓和其他字体数据的过程,如章节OpenType字体变体概述中所述。用于调整GPOS查找中的X或Y值的变化数据存储在位于GDEF内的项目变体存储表中表。这适用于GPOS或JSTF表中的查找。相同的项目变体存储也用于调整GDEF表中的值。有关可变字体中GPOS查找值变化的其他详细信息,请参阅GPOS章节。
7.29.4.JSTF Header
JSTF表以包含表的版本号,字体中使用的脚本数(jstfScriptCount)和记录数组(jstfScriptRecords)的标头开头。每条记录都包含一个脚本标记(jstfScriptTag)和一个JstfScript表的偏移量(jstfScriptOffset)。
请注意,jstfScriptTag值必须与GSUB和GPOS表中列出的脚本标记相对应。
本章末尾的示例1显示了JSTF Header表和JstfScriptRecord。
JSTF标题
类型 名称 描述
UINT16 majorVersion JSTF表的主要版本,= 1
UINT16 minorVersion JSTF表的次要版本,= 0
UINT16 jstfScriptCount 此表中的JstfScriptRecords数
JstfScriptRecord jstfScriptRecords [jstfScriptCount] JstfScriptRecords数组,由jstfScriptTag按字母顺序排列
JstfScriptRecord
类型 名称 描述
标签 jstfScriptTag 4字节JstfScript标识
Offset16 jstfScriptOffset 从JSTF标头开始偏移到JstfScript表
7.29.5.Justification Script Table
对齐脚本(JstfScript)表描述了单个脚本的对齐信息。它由一个表的偏移量组成,该表定义了扩展符字形(extenderGlyphOffset),脚本默认对齐表的偏移量(defJstfLangSysOffset),以及定义对齐数据(jstfLangSysCount)的语言系统的计数。
如果脚本对所有语言系统使用相同的对齐信息,则字体开发人员仅定义默认的JstfLangSys表,并将jstfLangSysCount值设置为零(0)。但是,如果任何语言系统具有唯一的理由建议,则jstfLangSysCount将为正值,并且JstfScript表必须包含一个记录数组(jstfLangSysRecords),每个语言系统一个。每个JstfLangSysRecord都包含一个语言系统标记(jstfLangSysTag)和一个对齐语言系统表(jstfLangSysOffset)的偏移量。在jstfLangSysRecords数组中,记录按字母顺序由jstfLangSysTag排序。
注意: 没有为默认脚本数据定义JstfLangSysRecord; 数据存储在默认的JstfLangSys表中。
本章末尾的示例2显示了阿拉伯语脚本的JstfScript表和Farsi语言系统的JstfLangSysRecord。
JstfScript表
类型 名称 描述
Offset16 extenderGlyphOffset 从JstfScript表的开头偏移到ExtenderGlyph表(可能为NULL)
Offset16 defJstfLangSysOffset 从JstfScript表的开头偏移到默认的JstfLangSys表(可能为NULL)
UINT16 jstfLangSysCount 此表中的JstfLangSysRecords数量可能为零(0)
JstfLangSysRecord jstfLangSysRecords [jstfLangSysCount] JstfLangSysRecords数组,由JstfLangSysTag按字母顺序排列
JstfLangSysRecord
类型 名称 描述
标签 jstfLangSysTag 4字节JstfLangSys标识符
Offset16 jstfLangSysOffset 从JstfScript表的开头偏移到JstfLangSys表
7.29.6.Extender Glyph Table
Extender Glyph表(ExtenderGlyph)列出了字形索引,例如阿拉伯语kashidas,客户端可以插入这些字符以扩展行的长度以进行调整。该表包含脚本的扩展符号的字数(glyphCount)和扩展符号字符索引(extenderGlyphs)的数组,按递增的数字顺序排列。
本章末尾的示例2显示了阿拉伯语kashida字形的ExtenderGlyph表。
ExtenderGlyph表
类型 名称 描述
UINT16 glyphCount 此脚本中的扩展器字形数
UINT16 extenderGlyphs [glyphCount] 扩展器字形ID - 以递增的数字顺序
7.29.7.Justification Language System Table
对齐语言系统(JstfLangSys)表包含一系列对齐建议,按优先级排序。进行理由的文本处理客户端应该从具有零(0)优先级的建议开始,然后在必要时应用增加优先级的建议,直到文本合理为止。
字体开发人员定义优先级的数量和含义。每个优先级都是独立的; 它的建议没有添加到以前的级别。JstfLangSys表包含优先级数量(jstfPriorityCount)和优先级顺序存储的对齐优先级表(jstfPriorityOffsets)的偏移数组。本章末尾的示例2显示了如何定义JstfLangSys表。
JstfLangSys表
类型 名称 描述
UINT16 jstfPriorityCount JstfPriority表的数量
Offset16 jstfPriorityOffsets [jstfPriorityCount] 从JstfLangSys表的开头按优先级顺序排列的JstfPriority表的偏移量数组
7.29.8.Justification Priority Table
对齐优先级(JstfPriority)表定义单个优先级的对齐建议。每个优先级指定是启用还是禁用GSUB和GPOS查找,还是应用文本对齐查找来缩小和扩展文本行。
JstfPriority具有四个具有行收缩数据的表的偏移:两个是用于启用和禁用字形替换查找的JstfGSUBModList表,两个是用于启用和禁用字形定位查找的JstfGPOSModList表。JstfGSUBModList和JstfGPOSModList表的偏移也是为行扩展定义的。
本章末尾的示例3演示了两个JstfPriority表,用于两个对齐建议。
JstfPriority表
类型 名称 描述
Offset16 shrinkageEnableGSUB 偏移到收缩 - 启用JstfGSUBModList表,从JstfPriority表的开头(可能为NULL)
Offset16 shrinkageDisableGSUB 从JstfPriority表的开头偏移到收缩 - 禁用JstfGSUBModList表(可能为NULL)
Offset16 shrinkageEnableGPOS 偏移到收缩 - 启用JstfGPOSModList表,从JstfPriority表的开头(可能为NULL)
Offset16 shrinkageDisableGPOS 偏移到收缩 - 禁用JstfGPOSModList表,从JstfPriority表的开头(可能为NULL)
Offset16 shrinkageJstfMax 从JstfPriority表的开头偏移收缩JstfMax表(可能为NULL)
Offset16 extensionEnableGSUB 从JstfPriority表的beginnning偏移到扩展启用JstfGSUBModList表(可能为NULL)
Offset16 extensionDisableGSUB 从JstfPriority表的开头偏移到扩展禁用JstfGSUBModList表(可能为NULL)
Offset16 extensionEnableGPOS 从JstfPriority表的开头偏移到扩展启用JstfGPOSModList表(可能为NULL)
Offset16 extensionDisableGPOS 从JstfPriority表的开头偏移到扩展禁用JstfGPOSModList表(可能为NULL)
Offset16 extensionJstfMax 从JstfPriority表的开头偏移到扩展JstfMax表(可能为NULL)
7.29.9.Justification Modification List Tables
“对齐修改列表”表(JstfGSUBModList和JstfGPOSModList)包含GSUB或GPOS表的查找列表中的索引列表。客户端可以启用或禁用查找以证明文本的合理性。例如,要增加行长度,客户端可能会禁用GSUB绑定替换。
每个JstfModList表都包含一个Lookups(LookupCount)和一个查找索引数组(LookupIndex)。
为了证明一行文本,文本处理客户端启用或禁用JstfModList表中的指定查找,重新组合LookupList顺序中的查找,并将它们一个接一个地应用于字符串中的每个字形。
注意: 如果任何优先级的任何JSTF建议修改先前应用于字形字符串的GSUB或GPOS查找,则文本处理客户端必须将JSTF建议应用于未修改版本的字形字符串。
本章末尾的示例3显示了JstfGSUBModList和JstfGPOSModList表,其中包含用于收缩和扩展文本行长度的数据。
JstfGSUBModList表
类型 名称 描述
UINT16 lookupCount 此修改的查找次数
UINT16 gsubLookupIndices [lookupCount] GSUB LookupList中的Lookup索引数组,按数字顺序递增
JstfGPOSModList表
类型 名称 描述
UINT16 lookupCount 此修改的查找次数
UINT16 gposLookupIndices [lookupCount] GPOS LookupList中的查找索引数组,按递增的数字顺序排列
7.29.10.Justification Maximum Table
对齐最大表(JstfMax)由对齐查找的偏移数组(查找)和已定义查找的计数(查找)组成。JstfMax查找通常位于字体定义中的JstfMax表之后。
JstfMax表具有与GPOS表中的查找表和子表相同的格式,但JstfMax查找驻留在JSTF表中并仅包含对齐数据。查找数据可以指定用于在脚本中定位所有字形的单个调整值,或者它可以指定更精细的调整,例如不同字形的不同值或特定字形对的特殊值。
注意: 除了上下文定位查找之外的所有GPOS查找类型都可以在JstfMax表中定义。
JstfMax查找值在GPOS ValueRecords中定义,可以指定任何高级或放置位置,无论是水平还是垂直。这些值定义每个字形允许的最大收缩或扩展。为了证明文本的合理性,文本处理客户端可以选择将字形的定位调整为从零(0)到指定的最大值的任何量。
本章末尾的示例4显示了JstfMax表。它定义了一个调整查找,以更改字空间字形的大小以扩展行长度。
JstfMax表
类型 名称 描述
UINT16 lookupCount 此修改的查找索引数
Offset16 lookupOffsets [lookupCount] 从设计顺序开始,从JstfMax表的开头到GPOS类型查找表的偏移量数组
7.29.11.JSTF Table Examples
本章的其余部分描述了所有JSTF表格式的示例。所有示例都反映了下面描述的唯一参数,但这些示例为构建特定于其他情况的表提供了有用的参考。
这些示例有三列显示十六进制数据,源和注释。
示例1:JSTF标头表和JstfScriptRecord
示例1演示了如何在JSTF Header中使用JstfScriptRecord定义脚本,该脚本标识脚本并引用其JstfScript表。
例1
Hex数据 资源 评论
JSTFHeader
TheJSTFHeader JSTFHeader表定义
00010000 0x00010000在 主要/次要版本
0001 1 jstfScriptCount
jstfScriptRecords [0]
74686169 ‘泰国’ jstfScriptTag
000C ThaiScript 偏移到JstfScript表
示例2:JstfScript表,ExtenderGlyph表,JstfLangSysRecord和JstfLangSys表
示例2显示了阿拉伯语脚本及其引用的表的JstfScript表。默认的JstfLangSys表定义了在没有特定于语言的信息的情况下应用于脚本的对齐数据。在该示例中,该表按优先级顺序列出了两个理由建议。
JstfScript还为Farsi语言提供特定于语言的理由数据。JstfLangSysRecord标识语言并引用其JstfLangSys表。FarsiJstfLangSys列出了一个证明波斯语文本合理性的建议。
JstfScript中的ExtenderGlyph表列出了脚本中使用的所有扩展器字形的索引。
例2
Hex数据 资源 评论
JstfScript
ArabicScript JstfScript表定义
000C ArabicExtenders extenderGlyphOffset
0012 ArabicDefJstfLangSys 偏移到默认的JstfLangSys表
0001 1 jstfLangSysCount
jstfLangSysRecords [0]
50455220 “FAR” jstfLangSysTag
0018 FarsiJstfLangSys jstfLangSys
ExtenderGlyph
ArabicExtenders ExtenderGlyph表定义
技术 2 glyphCount
01D3 TatweelGlyphID extenderGlyphs [0]
01D4 LongTatweelGlyphID extenderGlyphs [1]
JstfLangSys
ArabicDefJstfLangSys JstfLangSys表定义
技术 2 jstfPriorityCount
000A ArabicScriptJstfPriority1 jstfPriorityOffsets [0]
001E ArabicScriptJstfPriority2 jstfPriorityOffsets [1]
JstfLangSys
FarsiJstfLangSys JstfLangSys表定义
0001 1 jstfPriorityCount
002C FarsiLangJstfPriority1 jstfPriorityOffsets [0]
示例3:JstfPriority表,JstfGSUBModList表和JstfGPOSModList表
示例3显示了按优先级顺序定义的两个对齐建议的JstfPriority和JstfModList表定义。第一个建议使用连字替换来缩小文本行的长度,并通过将连字替换为其各自的字形组件来扩展行长度。在此优先级别不建议使用其他查找操作,并将其设置为NULL。关联的JstfModList表启用和禁用三个替换查找。
第二个建议使字形字距能够减少线条长度并禁用字形字距以延长线条长度。每个操作使用三次查找。该建议还包括一个扩展行长度的JstfMax表,称为WordSpaceExpandMax,如例4所述。
例3
Hex数据 资源 评论
JstfPriority
USEnglishFirstJstfPriority JstfPriority表定义
0028 EnableGSUBLookupsToShrink shrinkageEnableGSUB(偏移到收缩 - 启用JstfGSUBModList表)
0000 空值 shrinkageDisableGSUB
0000 空值 shrinkageEnableGPOS
0000 空值 hrinkageDisableGPOS
0000 空值 shrinkageJstfMax
0000 空值 extensionEnableGSUB
0038 DisableGSUBLookupsToExtend extensionDisableGSUB
0000 空值 extensionEnableGPOS
0000 空值 extensionDisableGPOS
0000 空值 extensionJstfMax
JstfPriority
USEnglishSecondJstfPriority JstfPriority表定义
0000 空值 shrinkageEnableGSUB
0000 空值 shrinkageDisableGSUB
0000 空值 shrinkageEnableGPOS
001C DisableGPOSLookupsToShrink shrinkageDisableGPOS
0000 空值 shrinkageJstfMax
0000 空值 extensionEnableGSUB
0000 空值 extensionDisableGSUB
002C EnableGPOSLookupsToExtend extensionEnableGPOS
0000 空值 extensionDisableGPOS
0000 空值 extensionJstfMax
JstfGSUBModList
EnableGSUBLookupsToShrink JstfGSUBModList表定义,启用三个连字替换查找
0003 3 lookupCount
002E 46 gsubLookupIndices [0]
0035 53 gsubLookupIndices [1]
0063 99 gsubLookupIndices [2]
JstfGPOSModList
DisableGPOSLookupsToShrink JstfGPOSModList表定义,禁用三个紧密的字距调整查找
0003 3 lookupCount
006C 108 gposLookupIndices [0]
006E 110 gposLookupIndices [1]
0070 112 gposLookupIndices [2]
JstfGSUBModList
DisableGSUBLookupsToExtend JstfGSUBModList表定义,禁用三个连字替换查找
0003 3 lookupCount
002E 46 gsubLookupIndices [0]
0035 53 gsubookupIndices [1]
0063 99 gsubLookupIndices [2]
JstfGPOSModList
EnableGPOSLookupsToExtend JstfGPOSModList表定义启用三个紧密字距调查查找
0003 3 lookupCount
006C 108 gposLookupIndices [0]
006E 110 gposLookupIndices [1]
0070 112 gposLookupIndices [2]
例4:JstfMax表
示例4中的JstfMax表定义了一个查找,以扩展字空间字形的前进宽度并扩展行长度。查找定义与GPOS表中的SinglePos查找类型相同,但仅在对齐文本时才启用它。WordSpaceExpand查找子表中的ValueRecord指定360个单位的XAdvance调整,这是字体开发人员为可接受的文本呈现推荐的最大值。文本处理客户端可以使用零和最大值之间的任何值来实现查找。
例4
Hex数据 资源 评论
JstfMax
WordSpaceExpandMax JstfMax表定义
0001 1 lookupCount
0004 WordSpaceExpandLookup lookupOffsets [0](偏移到JSTF查找表)
查找
WordSpaceExpandLookup Jstf查找表定义
0001 1 lookupType:SinglePos查找
0000 为0x0000 lookupFlag
0001 1 subTableCount
0008 WordSpaceExpandSubtable subtableOffsets [0],SinglePos子表
SinglePosFormat1
WordSpaceExpandSubtable SinglePos子表定义
0001 1 posFormat
0008 WordSpaceCoverage 偏移到Coverage表
0004 0x0004 valueFormat:仅限XAdvance
0168 360 value - Jstf中的XAdvance值:这是最大值,将字空间从零扩展到此数量
CoverageFormat1
WordSpaceCoverage 覆盖表定义
0001 1 coverageFormat
0001 1 glyphCount
0022 WordSpaceGlyphID glyphArray [0]
7.30.kern 字距
注意: Apple扩展了“kern”表的定义以提供其他功能。Windows不支持Apple扩展。用于跨平台使用或Windows平台的字体通常应符合此处指定的“kern”表格格式。
字距调整表包含控制字体中字形的字符间间距的值。目前没有系统级别的字距调整支持(除了返回kern对和kern值)。’kern’表不支持包含CFF轮廓的OpenType™字体,并且必须使用GPOS OpenType布局表。
每个子表格的格式各不相同,可以包含垂直或水平文本的信息,并且可以包含字距调整值或最小值。字距调整值用于调整字符间间距,最小值用于限制缩放器通过字距调整和跟踪的组合应用的调整量。由于调整是附加的,因此包含字距调整值的子表的顺序并不重要。但是,包含最小值的表通常应放在最后,以便它们可用于限制其他子表的总效果。
OpenType字体文件中的字距调整表有一个标题,其中包含格式编号和存在的子表的数量,以及子表本身。
类型 领域 描述
UINT16 版 表版本号(0)
UINT16 nTables 字距调整表中的子表数量。
Kerning子表将共享相同的标头格式。此标头用于标识子表的格式及其包含的信息类型:
类型 领域 描述
UINT16 版 Kern子表版本号
UINT16 长度 子表的长度,以字节为单位(包括此标头)。
UINT16 覆盖 此表中包含哪些类型的信息。
coverage字段分为以下子字段,大小以位给出:
子场 位 大小(位) 描述
横 0 1 如果表有水平数据,则为1;如果垂直,则为0。
最低限度 1 1 如果此位设置为1,则表具有最小值。如果设置为0,则表格具有字距调整值。
横流 2 1 如果设置为1,则字距调整垂直于文本流。
如果文本通常是水平书写,则将在上下方向进行字距调整。如果字距调整值为正,则文本将向上调整; 如果它们是否定的,那么文本将被向下调整。
如果文本通常垂直书写,则将在左右方向上进行字距调整。如果字距调整值为正,则文本将向右调整; 如果它们是否定的,则文本将被左侧变为kerned。
字距调整数据中的值0x8000将交叉流字距调整重置为0。
覆盖 3 1 如果此位设置为1,则此表中的值应替换当前正在累积的值。
保留1 4-7 4 保留。这应该设置为零。
格式 8-15 8 子表的格式。仅定义了格式0和2。格式1和3到255保留供将来使用。
7.30.1.Format 0
格式0是Windows支持的唯一子表格式。
该子表是字距调整对和值的排序列表。该列表前面有信息,可以对列表进行有效的二进制搜索:
类型 领域 描述
UINT16 nPairs 这给出了表中的字距调整对数。
UINT16 searchRange 小于或等于nPairs值的2的最大幂乘以表中条目的字节大小。
UINT16 entrySelector 这被计算为2的最大幂的log2小于或等于nPairs的值。该值表示必须进行多少次搜索循环迭代。(例如,在八个项目的列表中,必须有三次循环迭代)。
UINT16 rangeShift nPairs的值减去小于或等于nPairs的2的最大幂,然后乘以表中条目的字节大小。
接下来是字距调整对和值列表。每种都有以下格式:
类型 领域 描述
UINT16 剩下 字距调整对中左手字形的字形索引。
UINT16 对 字距调整对中右手字形的字形索引。
F字 值 FUnits中上述对的字距调整值。如果此值大于零,则字符将移开。如果此值小于零,则角色将靠近在一起。
字距调整对的左半部分和右半部分形成无符号的32位数字,然后用于以数字方式对字距调整对进行排序。
如果搜索范围是2的幂,则二进制搜索被最有效地编码。通过移动而不是分割,搜索范围可以减半。通常,字距调整对的数量nPairs不是2的幂。搜索范围searchRange的值应该是小于或等于nPairs的2的最大幂。searchRange未涵盖的对数(即nPairs - searchRange)是值rangeShift。
Windows v3.1不使用’kern’数据,而是通过GetFontData()API将其公开给应用程序.Format 2
7.30.2.Format 2
该子表是一个二维的字距调整值数组。使用左手和右手字形的不同映射将字形映射到类。这允许具有相似的右侧或左侧形状的字形一起处理。每个相似的右手或左手形状都被认为是单一的。
字距调整数组中的每一行代表一个左手字形类,每列代表一个右手字形类,每个单元格包含一个字距调整值。行0和列0始终表示不包含全部零的字形。
右类表中的值预先与单个字距调整值中的字节数相乘,并且左类表中的值预先乘以一行中的字节数。这消除了将行和列值相乘以确定字距调整值的位置的需要。可以通过执行右侧和左侧类映射,将类值添加到数组的地址,以及获取新地址指向的字距调整值来索引数组。
简单数组的标头具有以下格式:
类型 领域 描述
UINT16 rowWidth 表中行的宽度(以字节为单位)。
Offset16 leftClassTable 从此子表的开头到左侧类表的偏移量。
Offset16 rightClassTable 从此子表开始到右侧类表的偏移量。
Offset16 排列 从此子表的开头到字距调整数组的开头偏移。
每个类表都有以下标题:
类型 领域 描述
UINT16 firstGlyph 类范围内的第一个字形。
UINT16 nGlyphs 类范围内的字形数。
此标头后面是nGlyphs数量的类值,它们采用uint16格式。不参与字距调整的字形的条目应指向位置零处的行或列。
数组本身是左对右的字距调整值数组,它们是FWords,其中left是左手类的数量,R是右手类的数量。该数组按行存储。
请注意,此格式是最快的处理,因为每次查找只需要几个索引操作。该表可以非常大,因为它将包含等于右手类数量和左手类数量的乘积的单元格数,即使这些类中的许多不相互克服。
7.31.loca 位置索引
indexToLoc表将偏移量存储到字体中字形的位置,相对于glyphData表的开头。为了计算最后一个字形元素的长度,在最后一个有效索引之后有一个额外的条目。
根据定义,索引零指向“缺失字符”,这是在字体中找不到字符时出现的字符。缺失的字符通常由空白框或空格表示。如果字体不包含缺失字符的轮廓,则第一个和第二个偏移应具有相同的值。这也适用于没有轮廓的任何其他字符,例如空格字符。如果一个字形没有轮廓,则loca [n] = loca [n + 1]。在最后一个字形的特定情况下,loca [n]将等于字形数据(’glyf’)表的长度。偏移量必须按升序排列,loca [n] <= loca [n + 1]。
大多数例程将查看’maxp’表以确定字体中的字形数,但’loca’表中的值必须一致。
该表有两个版本:短版本和长版本。该版本在“head”表的indexToLocFormat条目中指定。
7.31.1.Short version
类型 名称 描述
Offset16 抵消[ n ] 存储实际的局部偏移量除以2。n的值是numGlyphs + 1.numGlyphs的值可以在’maxp’表中找到。
7.31.2.Long version
类型 名称 描述
OFFSET32 抵消[ n ] 存储实际的本地偏移量。n的值是numGlyphs + 1.numGlyphs的值可以在’maxp’表中找到。
请注意,本地偏移应为32位对齐。非32位对齐的偏移可能会严重降低某些处理器的性能。
7.32.LTSH 线性阈值
LTSH表涉及包含TrueType轮廓的OpenType™字体。当小心地将指令应用于侧面时,屏幕上的字体会有明显的改进。为了找到字形的实际前进宽度(因为指令可能正在移动侧支点),操作系统必须使网格适合字形,从而抵消了可读性的提高。TrueType大纲格式已经有两种机制可以解决速度问题:’hdmx’表,其中可以为选定的ppem大小保存预先计算的高级宽度;以及VDMX表,其中可以为选定的ppem大小保存预先计算的垂直前进宽度。LTSH表(Linear ThreSHold)是第二种补充方法。
LTSH表定义了在逐个字形的基础上假设线性缩放的前进宽度是合理的点。此表不被包括在内,除非在“头部”表中的“标志”字段的第4位被设置。线性缩放的标准是:
一个。(ppem尺寸≥50)AND(圆角线宽和圆角指示宽度之差≤圆角线宽的2%)
或b。线性宽度==指示宽度
LTSH表记录每个字形的ppem,在该字形处,缩放再次变为线性,尽管指令影响了前进宽度。需要的是,在记录的阈值大小及其以上,字形在其缩放中保持线性(即,如果字形在90 ppem处再次变为非线性,则将阈值设置为55 ppem是不合法的)。该表的格式为:
类型 名称 描述
UINT16 版 版本号(从0开始)。
UINT16 numGlyphs 字形数量(来自“maxp”表中的“numGlyphs”)。
UINT8 yPels [numGlyphs] 垂直像素高度,可以假设字形线性缩放。基于每个字形。
请注意,没有关于其sidebearings的说明的字形应该具有yPels = 1; 即,始终线性扩展。
7.33.MATH 数学排版表
数学公式是复杂的文本对象,其中组合了具有各种度量,样式或定位属性的多个元素。为了使数学布局引擎支持数学公式的布局,需要特定于公式布局的几种类型的特定于字体的信息。MATH表提供数学公式布局所需的特定于字体的信息。
请注意,这不是数学布局的完整规范。MATH表提供了数学布局所需的字体数据,但未指定使用数据的详细算法。不同的数学布局引擎实现可以使用该数据根据不同的目的或目标产生不同的布局结果。
7.33.1.Overview
数学公式的布局与使用GSUB和GPOS等表格的常规文本布局完全不同。常规文本布局主要处理一行文本,通常使用单一字体格式化。在这种情况下,可以通过访问文本行的完整上下文来完成诸如上下文替换或字距调整的动作,并且可以根据已知的字形序列来表达规则。数学布局与此截然不同。
数学公式的一般结构是分层的,公式由较小的子公式表达式组成,其中每个表达式可以由更简单的表达式组成,依此类推到单个字符串 - 运算符符号,变量名称和数字。

同样,数学公式布局的过程也是递归的。子组件首先被格式化,然后被安排以形成其父级布局,该过程在从最简单的块到整个公式的每个级别上重复。每个子公式都有自己的组件结构和如何执行布局的规则。例如,分数表达式由分子和分母子表达式组成,这些子表达式将放在彼此之上,并使用分数规则将它们分开。积分表达式包含整数符号,可选的上限和下限表达式以及后续子表达式。
公式中最简单的块通常包含字符串。孤立地,每个都可以通过使用其他表(例如GSUB和GPOS)的常规文本布局处理来布局。数学布局超出了这个范围。它主要涉及将这些简单块组合成一个复杂的分层公式所涉及的布局处理。MATH表中提供的数据允许数字布局处理具有印刷意识,因此可以实现具有高印刷质量的表示。
数学布局引擎使用表示单个公式组件作为布局单位的框。在布局过程中,各个盒子可以相对于彼此布置; 他们可以拉伸,取决于他们互动的其他盒子的大小; 或者他们可以根据公式中的框大小或位置使用不同的字形变体。MATH表提供了通知如何完成这些操作的数据。每个框都有一个相关的字体,提供包含该框的印刷要求的信息。根据盒子内部的布局操作结果,这些可能是对该盒子的要求; 或者它们可能是关于其他盒子如何与布局中的盒子交互的要求。
通过提供有关字体或字体中特定字形的信息,MATH表可以使数学布局引擎生成适合字体设计的布局,并通过使用样式和拉伸字形变体实现字体的完整排版潜力由字体提供。
7.33.2.Shared Formats: MathValueRecord, Coverage
MathValueRecord
MATH子表使用数学值记录来描述放置或调整数学公式元素的值。这些值以字体设计单位表示。
MathValueRecord还可以指定设备表的偏移量,该设备表在特定显示分辨率下提供对给定值的校正。设备表格式在OpenType布局公用表格式章节中描述。设备表可以提供多个校正值,用于几种不同的PPEM尺寸。根据校正值的大小要求,提供用于表示校正值的不同格式以允许有效表示。在MathValueRecords中使用时,建议使用格式1。
在设计MATH表时,可以为用于定位公式的元素的许多值指定设备表。这产生了许多设备校正可能在给定布局中累积的可能性。然而,这种积累将导致公式元素的度量与在高分辨率设备上呈现的相同元素的比例调整维度显着不同。它会在屏幕和打印再现之间产生不一致,并且还可能导致剪切。由于这些原因,许多校正的累积是不希望的。
虽然字体可以指定设备校正,但是这些校正的使用受给定布局引擎实现的控制。为了保持具有不同分辨率的设备之间的一致性,引擎可以限制累积的设备校正的数量,或者可以完全忽略它们。布局引擎也可以提供自己的更正,其中没有在字体中指示。由于累积的校正大小应保持最小,因此建议MathValueRecord引用的设备表使用格式1来表示校正值。此格式允许最多-2到+1像素的校正。MathValueRecords中使用的建议值为-1,0或1。
MathValueRecord
类型 名称 描述
INT16 值 设计单位中的X或Y值
Offset16 deviceTableOffset 偏离设备表 - 从父表的开头。可能是NULL。设备表的建议格式为1。
覆盖表
MATH子表使用在OpenType布局公用表格式章节中定义的Coverage表来指定字形集。可以在MATH表中使用所有Coverage表格式。
7.33.3.MATH Header
MATH表以一个标题开头,该标题由表的版本号(majorVersion / minorVersion)组成,当前设置为1.0,并指定下表的偏移量,这些表存储有关数学公式元素定位的信息:
MathConstants表存储用于排版每个支持的数学函数的字体参数,例如分数或基数。
MathGlyphInfo表提供基于每个字形定义的定位信息。
MathVariants表包含用于构造不同高度或宽度的字形变体的信息,可以通过在字体中查找具有所需测量值的预定义字形,或者通过从字形集中找到的片段组装所需的形状。
MATH标题
类型 名称 描述
UINT16 majorVersion MATH表的主要版本,= 1。
UINT16 minorVersion MATH表的次要版本,= 0。
Offset16 mathConstantsOffset 偏移到MathConstants表 - 从MATH表的开头。
Offset16 mathGlyphInfoOffset 偏移到MathGlyphInfo表 - 从MATH表的开头。
Offset16 mathVariantsOffset 偏移到MathVariants表 - 从MATH表的开头。
7.33.4.MathConstants Table
MathConstants表定义了正确定位数学公式元素所需的一些常量。这些常量属于几组与语义相关的值,例如重音的定位值,上标和下标的定位以及分数元素的定位。该表还包含可能影响公式所有部分的常用常量,例如轴高和数学前导。请注意,大多数常量都涉及垂直定位的各个方面。
在大多数情况下,MathConstants表中的值假定为正值。例如,对于下行和下移值,正常数表示向下方向的移动。MathConstants表中的大多数值由MathValueRecord表示,它允许字体设计者在必要时为这些值提供设备更正。
对于与基本元素和从属元素之间的布局交互有关的值(例如,上标或限制),使用的特定值取自与基础相关联的字体,并且值的大小相对于基本的大小。
以下命名约定用于MathConstants表中的字段:
高度 - 指定距主基线的距离。
Kern - 表示要引入的固定空闲空间量。
间隙 - 表示可能需要增加以满足特定条件的空白空间量。
下降和上升 - 指定必须满足特定条件的两个要相对于彼此定位的元素的测量之间的关系(但不一定以类似堆栈的方式)。对于Drop,必须向下移动一个定位元素以满足这些标准; 对于一个崛起,运动是向上的。
Shift - 定义应用于坐在基线上的元素的垂直移位。
Dist - 定义两个元素的基线之间的距离。
MathConstants表
类型 名称 描述
INT16 scriptPercentScaleDown 降级1级上标和下标的百分比。建议值:80%。
INT16 scriptScriptPercentScaleDown 缩放级别2(scriptScript)上标和下标的百分比。建议值:60%。
UINT16 delimitedSubFormulaMinHeight 分隔表达式(包含在括号内等)所需的最小高度将被视为子公式。建议值:法线高度×1.5。
UINT16 displayOperatorMinHeight 显示模式中公式的n-ary运算符的最小高度(例如积分和求和)(即,显示为独立页面元素,不嵌入文本内嵌)。
MathValueRecord mathLeading 数学公式之间留有空白以确保正确的行间距。例如,对于将线间隙视为线上升线的一部分的应用程序,墨水高于(os2.sTypoAscender + os2.sTypoLineGap - MathLeading)或墨水低于os2.sTypoDescender的公式将导致线高度增加。
MathValueRecord axisHeight 轴的高度字体。
在数学排版中,术语轴指的是用于定位公式中元素的水平参考线。数学轴与常规文本布局的基线类似但不同。例如,在一个简单的等式中,负号或分数规则将在轴上,但变量名的字符串将设置在偏离轴的基线上。axisHeight值确定该偏移量。
MathValueRecord accentBaseHeight 重点基础的最大(墨水)高度,不需要提高重音。建议:字体的x高度(os2.sxHeight)加上任何可能的打捞。
MathValueRecord flattenedAccentBaseHeight 重点基础的最大(墨水)高度,不需要压平重音。建议:字体的上限(os2.sCapHeight)。
MathValueRecord subscriptShiftDown 标准降档应用于下标元素。向下移动是正面的。建议:os2.ySubscriptYOffset。
MathValueRecord subscriptTopMax 下标(墨水)顶部的最大允许高度,不需要进一步向下移动下标。建议:4/5 x-高度。
MathValueRecord subscriptBaselineDropMin 下标基线相对于基础(墨水)底部的最小允许下降。检查被视为盒子或延长形状的基部。下标基线的正数降至基线底部以下。
MathValueRecord superscriptShiftUp 标准升档应用于上标元素。建议:os2.ySuperscriptYOffset。
MathValueRecord superscriptShiftUpCramped 上标相对于基础的标准移位,以狭窄的方式。
MathValueRecord superscriptBottomMin 上标(墨水)底部的最小允许高度,不需要进一步向上移动下标。建议:¼x高度。
MathValueRecord superscriptBaselineDropMax 上标基线相对于基座(墨水)顶部的最大允许下降。检查被视为盒子或延长形状的基部。基线顶部以下的上标基线为正。
MathValueRecord subSuperscriptGapMin 上标和下标墨水之间的最小间隙。建议:4×默认规则厚度。
MathValueRecord superscriptBottomMaxWithSubscript 在下标开始向下移动之前,可以推动(墨水)上标的最大水平以增加上标和下标之间的间隙。建议:4/5 x高度。
MathValueRecord spaceAfterScript 每个下标和上标后添加额外的空格。建议:12磅字体为0.5磅。
MathValueRecord upperLimitGapMin 上限(墨水)底部与基本操作员(墨水)顶部之间的最小间隙。
MathValueRecord upperLimitBaselineRiseMin 基准操作员上限基线和(墨水)顶部之间的最小距离。
MathValueRecord lowerLimitGapMin 下限的(墨水)顶部和基本操作员的(墨水)底部之间的最小间隙。
MathValueRecord lowerLimitBaselineDropMin 基准操作员下限基线与(墨水)底部之间的最小距离。
MathValueRecord stackTopShiftUp 标准升档应用于堆栈的顶部元素。
MathValueRecord stackTopDisplayStyleShiftUp 标准升档应用于显示样式的堆栈顶部元素。
MathValueRecord stackBottomShiftDown 标准降档应用于堆栈的底部元素。向下移动是正面的。
MathValueRecord stackBottomDisplayStyleShiftDown 标准降档应用于显示样式的堆栈底部元素。向下移动是正面的。
MathValueRecord stackGapMin 堆叠顶部元件的(墨水)底部与底部元件的(墨水)顶部之间的最小间隙。建议:3×默认规则厚度。
MathValueRecord stackDisplayStyleGapMin 堆叠顶部元素(墨水)底部与显示样式底部元素(墨水)顶部之间的最小间隙。建议:7×默认规则厚度。
MathValueRecord stretchStackTopShiftUp 标准升档应用于拉伸堆叠的顶部元素。
MathValueRecord stretchStackBottomShiftDown 标准向下移动应用于拉伸堆叠的底部元素。向下移动是正面的。
MathValueRecord stretchStackGapAboveMin 拉伸元件的墨水与上述元件的(墨水)底部之间的最小间隙。建议:与upperLimitGapMin相同的值。
MathValueRecord stretchStackGapBelowMin 拉伸元件的墨水与下面元素的(墨水)顶部之间的最小间隙。建议:与lowerLimitGapMin相同的值。
MathValueRecord fractionNumeratorShiftUp 标准升档应用于分子。
MathValueRecord fractionNumeratorDisplayStyleShiftUp 标准升档应用于显示样式的分子。建议:与stackTopDisplayStyleShiftUp相同的值。
MathValueRecord fractionDenominatorShiftDown 标准降档应用于分母。向下移动是正面的。
MathValueRecord fractionDenominatorDisplayStyleShiftDown 标准降档应用于显示样式的分母。向下移动是正面的。建议:与stackBottomDisplayStyleShiftDown相同的值。
MathValueRecord fractionNumeratorGapMin 分子(墨水)底部与分数条墨水之间的最小容差。建议:默认规则厚度。
MathValueRecord fractionNumDisplayStyleGapMin 分子的(墨水)底部与显示样式中分数条的墨水之间的最小容差。建议:3×默认规则厚度。
MathValueRecord fractionRuleThickness 分数条的厚度。建议:默认规则厚度。
MathValueRecord fractionDenominatorGapMin 分母(墨水)顶部与分数条墨水之间的最小容差。建议:默认规则厚度。
MathValueRecord fractionDenomDisplayStyleGapMin 分母的(墨水)顶部与显示样式的分数条的墨水之间的最小容差。建议:3×默认规则厚度。
MathValueRecord skewedFractionHorizontalGap 倾斜分数的顶部和底部元素之间的水平距离。
MathValueRecord skewedFractionVerticalGap 倾斜部分的顶部和底部元素的墨水之间的垂直距离。
MathValueRecord overbarVerticalGap 上杆和底座(墨水)顶部之间的距离。建议:3×默认规则厚度。
MathValueRecord overbarRuleThickness 上限的厚度。建议:默认规则厚度。
MathValueRecord overbarExtraAscender 在纵横上方保留额外的空白区域。建议:默认规则厚度。
MathValueRecord underbarVerticalGap 底座与底座(墨水)底部之间的距离。建议:3×默认规则厚度。
MathValueRecord underbarRuleThickness 下杆的厚度。建议:默认规则厚度。
MathValueRecord underbarExtraDescender 底栏下方预留了额外的空白区域。总是积极的。建议:默认规则厚度。
MathValueRecord radicalVerticalGap 表达式的(墨水)顶部与其上方的条形之间的空间。建议:1¼默认规则厚度。
MathValueRecord radicalDisplayStyleVerticalGap 表达式的(墨水)顶部与其上方的条形之间的空间。建议:默认规则厚度+¼x高度。
MathValueRecord radicalRuleThickness 激进统治的厚度。这是设计或构造的激进标志中规则的厚度。建议:默认规则厚度。
MathValueRecord radicalExtraAscender 激进之上保留了额外的空白区域。建议:与radicalRuleThickness相同的值。
MathValueRecord radicalKernBeforeDegree 在激进程度之前的额外水平kern,如果存在的话。
MathValueRecord radicalKernAfterDegree 在激进程度之后的负kern,如果存在的话。建议:-10/18的em。
INT16 radicalDegreeBottomRaisePercent 如果存在激进度的底部的高度,则与激进符号的上升部分成比例。建议:60%。
7.33.5.MathGlyphInfo Table
MathGlyphInfo表包含基于每个字形定义的定位信息。该表包含以下部分:
MathItalicsCorrectionInfo表,包含有关斜体校正值的信息。
MathTopAccentAttachment表,包含用于附加数学重音的水平位置。
扩展形状覆盖表。此表所涵盖的字形应视为扩展形状。
MathKernInfo表,提供用于数学字距调整的每字形信息。
MathGlyphInfo表
类型 名称 描述
Offset16 mathItalicsCorrectionInfoOffset 从MathGlyphInfo表的开头偏移到MathItalicsCorrectionInfo表。
Offset16 mathTopAccentAttachmentOffset 从MathGlyphInfo表的开头偏移到MathTopAccentAttachment表。
Offset16 extendedShapeCoverageOffset 从MathGlyphInfo表的开头偏移到ExtendedShapes coverage表。当框的左侧或右侧的字形是扩展形状变体时,(墨水)框应该用于垂直定位目的,而不是MathConstants表中的值定义的默认位置。可能是NULL。
Offset16 mathKernInfoOffset 从MathGlyphInfo表的开头偏移到MathKernInfo表。
7.33.6.MathItalicsCorrectionInfo Table
MathItalicsCorrectionInfo表包含数学布局中使用的倾斜字形的斜体校正值。倾斜字形的顶部可能突出超过字形的前进宽度。这可能导致与其他相互作用元件的碰撞,或者在放置其他相互作用元件时出现令人不愉快的情况,除非为这种相互作用做出一些调节。MathItalicsCorrectionInfo表提供校正值以适应此类突出。
该表包含以下部分:
提供斜体校正值的字形的覆盖范围。对于所有其他字形,斜体校正被假定为零。
覆盖的字形数。
每个覆盖字形的斜体校正值的数组,按覆盖顺序排列。斜体校正值可以用作对相互作用元素的定位的调整,以允许突出到字形顶部的右侧。例如,较高的字母倾向于具有较大的斜体校正,并且V可能具有比L更大的斜体校正。
斜体校正可用于以下情况:
当一系列倾斜字符后跟一个直字符(例如运算符或分隔符)时,最后一个字形的斜体校正将被添加到其前进宽度。
当在N元运算符上定位限制(例如,积分符号)时,上限的水平位置向右移动斜体校正的1/2,而下限的位置向左移动。距离。
定位上标和下标时,它们的默认水平位置也会因前一个字形的斜体校正量而不同。
MathItalicsCorrectionInfo表
类型 名称 描述
Offset16 italicsCorrectionCoverageOffset 偏移到Coverage表 - 从MathItalicsCorrectionInfo表的开头。
UINT16 italicsCorrectionCount 斜体校正值的数量。应与覆盖字形的数量一致。
MathValueRecord italicsCorrection [italicsCorrectionCount] MathValueRecords数组,用于为每个覆盖的字形定义斜体校正值。
7.33.7.MathTopAccentAttachment Table
MathTopAccentAttachment表包含有关顶部数学重音的水平定位的信息。该表包含以下部分:
提供有关数学重音水平定位信息的字形覆盖。要将重音定位在任何其他字形上,可以使用其几何中心(相对于前进宽度)。
覆盖的字形数。
每个覆盖字形的顶部重音附着点数组,按覆盖顺序排列。这些附着点用于在字符上查找重音的水平位置。它是通过将基本字形的连接点与重音的连接点对齐来完成的。请注意,这与标记到基础附件非常相似,但此处对齐仅在水平方向上发生,并且重音的垂直位置由不同的方式确定。
MathTopAccentAttachment表
类型 名称 描述
Offset16 topAccentCoverageOffset 从MathTopAccentAttachment表的开头偏移到Coverage表。
UINT16 topAccentAttachmentCount 顶部重音符号附加值的数量。必须与Coverage表中引用的字形ID数相同。
MathValueRecord topAccentAttachment [topAccentAttachmentCount] MathValueRecords数组,用于定义每个覆盖字形的顶部重音附着点。
7.33.8.ExtendedShapeCoverage Table
此表所涵盖的字形应视为扩展形状。这些字形是在垂直方向上延伸的变体,例如,以匹配公式的另一部分的高度。因为与字形集中的正常字形相比,它们的尺寸可能非常大,所以标准定位算法在应用于它们时将不会产生最佳结果。在垂直方向上,其他公式元素将不是相对于那些字形定位,而是定位到包含它们的子表达的墨盒。
例如,考虑用括号括起来的一个分数和一个上标。请注意’ z ‘和’ Z ‘ 上的上标如何垂直对齐,尽管它们具有不同的高度。如果右括号不被视为扩展形状,则上标将与该行上的任何其他上标对齐,如下所示:
因为这是不合需要的,所以在这种情况下右括号应该被认为是扩展形状,导致上标相对于整个子表达式定位:
7.33.9.MathKernInfo Table
MathKernInfo表提供了用于相对于基本字形的下标和上标字形的字距调整的数学字距调整值。其目的是改善诸如或等情况下的间距
数学字距是高度依赖的; 也就是说,可以为字形垂直范围内的不同高度指定不同的字距调整量。对于任何给定的字形,可以为四个角位置指定不同的值 - 右上角,左上角等 - 根据字形是否作为下标,上标,基础被修改而允许不同的字距调整辅助。下标,或用上标字母修改的基数。
下标和上标的字距调整算法如下:
使用MathConstants表计算下标和上标的垂直位置。
在基本字形后面立即设置下标的默认水平位置。
在基数之后设置上标的默认水平位置,如果为MathItalicsCorrectionInfo表中的基本字形指示,则应用斜体校正的移位。
计算上标字距值如下:
评估两个校正高度(如下图所示):
在上标 - 字形边界框的底部。(基本字形的相应高度是从基本字形基线到上标边界框底部的距离。)
在基本字形边界框的顶部。(上标字形的相应高度是从上标基线到基本字形边界框顶部的距离。)
对于每个校正高度,将基本字形的右上角字距值添加到上标字形的左下角字距值。
取这两个总和中的最小值:kern基数和上标数量。
计算下标字距值如下:
评估两个校正高度:
在下标 - 字形边界框的顶部。(基本字形的相应高度是从基本字形基线到下标边界框顶部的距离。)
在基本字形边界框的底部。(下标字形的相应高度是从下标基线到基本字形边界框底部的距离。)
对于每个校正高度,将基本字形的右下角字距值添加到下标字形的左上角字距值。
取这两个总和中的最小值:kern基数和下标数量。
注意:如果基本表达式,下标表达式或上标表达式是一个框,则数学布局引擎可以对框的每个角使用零字距值,或者可以通过某种方式计算与高度相关的字距调整量。
下图说明了基数和上标的修正高度:
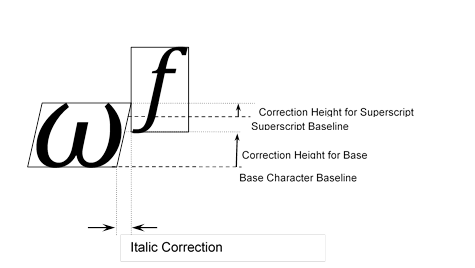
上标定位的水平和垂直字距调整示例。
MathKernInfo表包含以下字段:
提供数学字距调整信息的字形的覆盖率表。对于所有其他字形,假设数学字距调整量为零。
MathKernInfoRecords计数。
每个覆盖的字形的MathKernInfoRecords数组,遵循Coverage表中的字形顺序。
MathKernInfo表
类型 名称 描述
Offset16 mathKernCoverageOffset 从MathKernInfo表的开头偏移到Coverage表。
UINT16 mathKernCount MathKernInfoRecords的数量。必须与Coverage表中引用的字形ID数相同。
MathKernInfoRecord mathKernInfoRecords [mathKernCount] MathKernInfoRecords数组,每个覆盖的字形一个。
MathKernInfoRecord
每个MathKernInfoRecord指向字形周围每个角的最多四个kern表。如果没有为角提供kern表,则假定字距调整量为零。
MathKernInfoRecord
类型 名称 描述
Offset16 topRightMathKernOffset 从MathKernInfo表的开头偏移到MathKern表的右上角。可能是NULL。
Offset16 topLeftMathKernOffset 从MathKernInfo表的开头向左上角的MathKern表偏移。可能是NULL。
Offset16 bottomRightMathKernOffset 从MathKernInfo表的开头向右下角的MathKern表偏移。可能是NULL。
Offset16 bottomLeftMathKernOffset 从MathKernInfo表的开头到左下角的MathKern表的偏移量。可能是NULL。
MathKern表
MathKern表提供字形垂直范围中不同高度的字距调整量。提供一组字距调整值,每个字符串值适用于高度范围。相应的高度阵列表示连续范围之间的转变点。
每个字形的校正高度相对于字形基线,正高度值高于基线,负高度值低于基线。correctionHeights数组按升序排序,从最低到最高。
通过在correctionHeight阵列中找到两个连续条目使得给定高度大于或等于第一条目并且小于第二条目来确定对应于特定高度的字距调整值。第二个条目的索引用于在kernValues数组中查找字距调整值。如果给定高度小于correctionHeights数组中的第一个条目,则使用第一个字距调整值(索引0)。对于大于或等于correctionHeights数组中最后一个条目的高度,使用最后一个条目。
MathKern表
类型 名称 描述
UINT16 heightCount kern值变化的高度数。
MathValueRecord correctionHeight [heightCount] 校正高度数组,以设计单位排序,从最低到最高排序。
MathValueRecord kernValues [heightCount + 1] 不同高度范围的字距调整值数组。负值用于将字形移动到彼此更近的位置。
7.33.10.MathVariants Table
MathVariants表解决了以下问题:给定特定的默认字形形状和特定的宽度或高度,找到具有所需测量值的变体形状字形(或通过将几个字形放在一起而创建的构造)。需要此功能来增加括号以匹配表达式的高度,增加基本符号以匹配激进下表达式的高度,拉伸重音符号,如将它们放在几个字符上,用于拉伸箭头,水平卷曲大括号,等等。
MathVariants表包含以下字段:
计算和覆盖可以在垂直方向上生长的字形。
计算和覆盖可以在水平方向上生长的字形。
MinConnectorOverlap定义了两个字形在用于构造更大形状时需要相互重叠的程度。在构造扩展形状时用作构建块的每个字形在任一端或两端都具有直线部分。此连接器部件用于将该字形连接到程序集中的其他字形。这些连接器需要重叠以补偿较低分辨率的舍入误差和提示校正。MinConnectorOverlap值表示此特定字体需要多少重叠。
MathGlyphConstruction表的两个偏移数组:一个用于在垂直方向上增长的字形数组,另一个用于在水平方向上增长的字形数组。数组必须按覆盖顺序排列并具有指定的大小。
MathVariants表
类型 名称 描述
UINT16 minConnectorOverlap 设计单位中字形构造期间连接字形的最小重叠。
Offset16 vertGlyphCoverageOffset 从MathVariants表的开头偏移到Coverage表。
Offset16 horizGlyphCoverageOffset 从MathVariants表的开头偏移到Coverage表。
UINT16 vertGlyphCount 为垂直增长变体提供信息的字形数。必须与垂直Coverage表中引用的字形ID数相同。
UINT16 horizGlyphCount 为水平增长变体提供信息的字形数。必须与水平Coverage表中引用的字形ID数相同。
Offset16 vertGlyphConstructionOffsets [vertGlyphCount] MathVlyphConstruction表的偏移数组,从MathVariants表的开头,用于在垂直方向上增长的形状。
Offset16 horizGlyphConstructionOffsets [horizGlyphCount] MathVlyphConstruction表的偏移数组,从MathVariants表的开头,用于在水平方向上增长的形状。
MathGlyphConstruction表
MathGlyphConstruction表提供有关查找或组装一个特定字形的扩展变体的信息。它可用于在水平或垂直方向上生长的形状。
第一个条目是GlyphAssembly表的偏移量,它指定如何从字体的字形集中找到的部件组合此字形的形状。如果不存在此类程序集,则此偏移量将设置为NULL。
MathGlyphConstruction表还包含指定字形的现成字形变体的计数和数组。每个变体都包含字形索引和此字形在扩展方向上的测量(垂直或水平)。
请注意,很可能GlyphAssembly表和某些变体都是针对特定字形定义的。例如,字体可以提供具有不同尺寸的花括号的几种变体,并且还通过堆叠在字形集中找到的部分来构造更大版本的花括号的一般机制。首先,尝试在提供的变体中找到字形。但是,如果所需的大小大于所提供的任何字形变体,则可以使用一般机制将花括号排版为字形组件。
MathGlyphConstruction表
类型 名称 描述
Offset16 glyphAssemblyOffset 从MathGlyphConstruction表的开头偏移到此形状的GlyphAssembly表。可能是NULL。
UINT16 variantCount 此字形的字形增长变体计数。
MathGlyphVariantRecord mathGlyphVariantRecord [variantCount] MathGlyphVariantRecords用于字形的替代变体。
MathGlyphVariantRecord
类型 名称 描述
UINT16 variantGlyph 变体的字形ID。
UINT16 advanceMeasurement 以请求的字形扩展方向,以设计单位提升变体的宽度/高度。
GlyphAssembly表
GlyphAssembly表指定如何根据字形集中找到的部分构造特定字形的形状。该表定义了所得到的组件的斜体校正,以及必须放在一起形成所需形状的许多部件。一些字形部分可以被指定为扩展器,可以根据需要重复以获得目标大小。
GlyphAssembly
类型 名称 描述
MathValueRecord italicsCorrection 斜体校正此GlyphAssembly。不应该取决于装配尺寸。
UINT16 partCount 此装配中的零件数量。
GlyphPartRecord partRecords [partCount] 零件记录数组,从左到右(对于水平延伸的组件)或从下到上(对于垂直延伸的组件)。
组装过程的结果是一个字形数组,其中为每个字形指定了偏移量。当在这些偏移处连续绘制时,字形应该正确组合并产生所需的形状。
生长方向上的偏移(提前偏移)以及扩展器部件的数量是根据所得组件的尺寸要求确定的。
注意,构成组件的字形应设计成使它们在与生长方向垂直的方向上正确对齐。
因此,GlyphPartRecord包含以下字段:
部件的字形ID。
字形每端的连接器长度。连接器是字形的直线部分,可用于将其与下一个或上一个部分链接。相邻部件的连接器可以通过不同的量重叠,从而提供如何将这些字形组合在一起的灵活性。但是,重叠不应小于MathVariants表中定义的minConnectorOverlap值,并且不应超过该字形末端的指定连接器长度。如果零件的一端没有连接器,则相应的连接器长度应设置为零。
部分全面推进。它还用于通过使用以下公式确定结果的度量:
装配尺寸=最后一部分的偏移+最后一部分的完全前进
PartFlags是最后一个字段。它将某些部分标识为扩展程序:可以重复的部分(即,可以使用它们的多个实例代替一个)或完全跳过。通常,延伸器是具有适当厚度的垂直或水平杆,与组件的其余部分对齐。
为了确保宽度/高度均匀分布并保持形状的对称性,数学布局引擎可以使用以下步骤。
在移除所有扩展器的情况下组装所有部件,并按最大量重叠连接。这给出了尽可能小的结果。
通过使用最小重叠确定可以从相邻部件之间的所有现有连接获得多少额外宽度/高度。如果这足以实现大小目标,则通过更改连接器的重叠来平等地扩展每个连接以完成作业。
如果所有连接都已扩展到最小重叠并且需要进一步增长,请添加每个扩展器中的一个,并从第一步开始重复该过程。
请注意,对于在垂直方向上生长的组件,未定义上升和下降之间的高度分布。数学布局引擎负责相对于基线定位生成的程序集。
GlyphPartRecord
类型 名称 描述
UINT16 glyphID 部件的字形ID。
UINT16 startConnectorLength 在设计单元中,在延伸方向上字形开始处的直条连接器材料的前进宽度/高度(左端为水平延伸,下端为垂直延伸)。
UINT16 endConnectorLength 在设计单元中,在延伸方向上字形末端的直条连接器材料的前进宽度/高度(水平延伸的右端,垂直延伸的顶端)。
UINT16 fullAdvance 该部件在延伸方向上的全部前进宽度/高度,以设计单位表示。
UINT16 partFlags 部分限定符。PartFlags枚举当前只使用一位:
0x0001 fExtender如果设置,则可以跳过或重复该部分。
0xFFFE保留。
7.33.11.OpenType Layout tags used with the MATH Table
数学布局引擎可以使用以下OpenType布局标记来访问特定的字形变体集。有关功能标记的详细说明,请参阅OpenType布局标记注册表的功能标记部分。
用于数学处理的OpenType布局标签
标签 描述
‘数学’ 脚本标记用于数学布局中的要素。此标记支持的唯一语言系统是默认语言系统。
‘SSTY’ 脚本样式
此功能提供的字形变体调整为更适合在下标和上标中使用。
不应在字体中缩放或移动这些脚本样式表单; 缩放和移动它们是由数学布局引擎完成的。相反,’ssty’功能应该提供字形表单,这些形式在数学引擎缩放和定位时会产生看起来很好的形状作为上标和下标。在设计脚本表单时,字体开发人员可能会假设MathConstants表中的scriptPercentScaleDown和scriptScriptPercentScaleDown值将是由数学引擎应用于备用字形大小的缩放因子。
此功能可以有一个指示脚本级别的参数:1表示简单下标和上标,2表示二级下标和上标(即脚本上的脚本),依此类推。(目前,仅使用前两个替代项)。
对于此功能未涵盖的字形,原始字形用于下标和上标。
推荐格式:替代替换表(如果没有二级表单,则单替换)。应该没有背景。
“后手” 超过首都的扁平口音
此功能提供扁平形式的口音,可用于高层基础(如大写字母)。
此功能应仅更改重音的形状,不应在垂直或水平方向上移动。重音的移动由数学布局引擎完成。
如果数学引擎的基数高于MathConstants表中的flattenedAccentBaseHeight值,则数字引擎会对其进行展平。
推荐格式:单个替换表。应该没有背景。
‘DTLS’ 无点形式
此功能为数学字母数字字符提供无点形式 ,例如U + 1D422 MATHEMATICAL BOLD SMALL I,U + 1D423 MATHEMATICAL BOLD SMALL J,U + 1D456 U + MATHEMATICAL ITALIC SMALL I,U + 1D457 MATHEMATICAL ITALIC SMALL J等等上。
无点形式将用作基础形式,用于在它们上面放置数学重音。
推荐格式:单个替换表。应该没有背景。
7.34.maxp 最大轮廓
此表确定此字体的内存要求。具有CFF数据的字体必须使用此表的0.5版,仅指定numGlyphs字段。具有TrueType轮廓的字体必须使用此表的1.0版,其中需要所有数据。
版本0.5
类型 名称 描述
固定 版 版本0.5的0x00005000
(注意非零小数部分的表示形式的差异,固定数字。)
UINT16 numGlyphs 字体中的字形数。
版本1.0
类型 名称 描述
固定 版 版本1.0的0x00010000。
UINT16 numGlyphs 字体中的字形数。
UINT16 maxPoints 非复合字形中的最大点数。
UINT16 maxContours 非复合字形中的最大轮廓。
UINT16 maxCompositePoints 复合字形中的最大点数。
UINT16 maxCompositeContours 复合字形中的最大轮廓。
UINT16 maxZones 如果指令不使用黄昏区域(Z0),则为1;如果指令使用Z0,则为2; 在大多数情况下应该设置为2。
UINT16 maxTwilightPoints Z0中使用的最大点数。
UINT16 maxStorage 存储区位置数。
UINT16 maxFunctionDefs FDEF的数量,等于最高功能数+ 1。
UINT16 maxInstructionDefs IDEF的数量。
UINT16 maxStackElements 整个字体方案(最大堆栈深度“FPGM”表),CVT计划(“准备”表)和所有的字形指令(在“glyf”表)。
UINT16 maxSizeOfInstructions 字形指令的最大字节数。
UINT16 maxComponentElements 对于任何复合字形,在“顶级”引用的最大组件数。
UINT16 maxComponentDepth 最大递归水平; 1表示简单组件。
7.35.MERG 合并表
MERG表使字体能够指定是否可以为每个字形单独执行字形运行中的字形的抗锯齿过滤,或者在执行抗锯齿之前是否应将某些字形对或序列组合在一起 - 或合并。
当在执行抗锯齿之后将字形组合在一起时,这可能导致在某些情况下渲染伪像,其中字形接触或重叠。(对于任何每个基元的抗锯齿都是如此。)在抗锯齿之前将字形合并在一起消除了这些伪像,但它也增加了显着的性能成本。一种字体可以使用MERG表以指示特定的字形对或为其以避免呈现伪影的风险需要抗锯齿预合并序列,而隐式地声明其他字形对或序列不要求预抗锯齿合并。
关于术语的注释:此后,“合并”将用于指在抗锯齿过滤之前将字形组合在一起。
注意: 某些实现可能会使用字形呈现结果的缓存作为性能优化的方法。如果不需要合并字形序列,则可以组合高速缓存的渲染而无需再次渲染字形或字形序列。
使用的方法是对应该进行合并的案例给出积极的声明。如果提供了MERG表但没有对任何对进行声明,那么预期的解释是不需要合并。(但是,某些实现仍然可以在抗锯齿之前合并字形。)如果没有提供MERG表,则实现应始终在过滤之前合并字形以避免伪像。
为成对的字形类提供数据。一对中的第一个和第二个字形元素对应于运行中字形的逻辑排序。由于字形按逻辑顺序处理,但可以按从左到右或从右到左的顺序显示,因此可以为从左到右或从右到左的顺序提供单独的建议。
在某些情况下,可能有必要考虑两个以上字形的序列的交互,而不仅仅是一对。数据格式允许字体开发者指定需要在合并中一起处理的序列; 这将在下面进一步解释。
确定是否应该合并是字体开发人员的设计考虑因素。字形可能会触碰或重叠,但视觉效果可能没有任何可察觉的伪影。如果设计者确定不需要合并特定的对或序列来提供足够的视觉效果,那么不将该对或序列声明为需要合并将会带来性能优势。
请注意,不同的平台可能支持不同的渲染技术,可能支持也可能不支持MERG表。在某些平台上,无论是否在字体中提供MERG数据,在执行抗锯齿之前,可能始终合并字形序列。类似地,在某些其他平台中,无论是否在字体中提供MERG数据,都可以在执行抗锯齿之后始终组合字形。字体开发人员应查阅不同平台的开发人员文档,其中将使用哪些字体来确定MERG表可能提供的好处,并应评估相关平台上的呈现结果,以确定哪些字形对或序列应声明为需要合并。
为了构造MERG表,第一步是基于期望的合并行为对字形进行分类,使得每个字形具有关联的合并类(由基于零的索引表示)。分类系统和类的数量将取决于字体和字体开发人员的自由裁量权,但可以考虑字形的一般形状以及它是否连接到其他字形等属性。在将字形分配给类之后,然后为每对合并类选择推荐的合并行为。
注意: 提供数据的对数是合并类数的平方。因此,合并类的数量应尽可能少。
7.35.1.Grouping of Glyphs
在某些情况下,为了合并,可能需要将一系列字形视为一个单元。例如,组合重音的字形可能根本不会与下面的字形进行排版交互,但它可能在进行交互并可能需要合并的字形之间按逻辑顺序排列。这在下图中说明(假设从左到右的视觉顺序)。

在两个印刷相互作用的字形之间逻辑上的重音字形
在这种情况下,重音和基本“e”字形可以作为一个单元来处理,以便用以下“f”字形评估所需的合并行为。请注意,如果需要合并“e”和“f”字形,则重音也需要包含在一起进行抗锯齿处理的序列中。
指定应如何处理字形对的合并数据条目包括指示应将字形对组合在一起作为一个单元的值,而不指定是否需要合并。是否需要合并将仅在将该组与其他字形进行比较时确定。在上图中,重音与“e”字形组合在一起,但是是否需要任何合并将通过将该组合与下面的“f”字形进行比较来确定。
每当一对字形被分组或合并时,当相对于以下字形评估组合时,一个或另一个将是最相关的。在上面的示例中,“e”-plus-accent组合在与下一个字形交互时所需的行为可以由“e”确定。在不同的示例中,它可以是与后续字形交互最相关的一对字形中的第二个。因此,每当对一对字形进行分组或合并时,数据指示序列的合并类是否采用该对的第一或第二元素的类。这通过使用标志来指示:在未标记的情况下(标志未设置),序列采用第二个字形的合并类。但如果第二个是从属的 如果设置了标志,那么序列将采用该对的第一个元素的合并类。
有关合并条目值及其处理方式的完整详细信息,请参阅以下部分。
7.35.2.Table Formats
MERG表由标题,一组类定义表和一组合并条目数据组成。标题的格式如下。
合并标题:
类型 名称 描述
UINT16 版 合并表的版本号 - 设置为0。
UINT16 mergeClassCount 合并类的数量。
Offset16 mergeDataOffset 偏移到合并条目数据的数组。
UINT16 classDefCount 类定义表的数量。
Offset16 offsetToClassDefOffsets 偏移到类定义表的偏移数组 - 以MERG表开头的字节为单位。
offsetToClassDefOffsets字段为偏移数组的开头提供偏移量。数组中的每个元素都是从MERG表的起点到类定义表的偏移(无符号16位)。classDefCount字段给出偏移数组中的元素数和类定义表的数量。
注意: 给定的类定义表可用于将不同的字形分配给多个类。类定义表的数量不确定合并类的数量。而是,mergeClassCount字段确定合并条目数据可以引用的类的数量。具体来说,为合并类0提供合并条目到mergeClassCount - 1.如果任何字形被分配给大于或等于mergeClassCount的类ID,则对于涉及该类的对将没有合并条目,这实际上意味着合并该类永远不需要带有其他字形的字形。
类定义表使用与OpenType布局表中使用的格式相同的格式。可以使用ClassDefFormat1和ClassDefFormat2。有关类定义表格式的详细信息,请参阅OpenType布局公用表格式章节的“ 类定义表”部分。
注意: 类定义表给出了特定类ID的字形显式赋值。未分配给类的任何字形都隐式分配给类零。
任何给定的字形必须分配给最多一个类。此外,由于按顺序读取类定义表,因此字形ID引用必须严格按顺序递增。如果不按顺序给出字形ID,则MERG表无效并被忽略。
合并条目数据数组是字形类对的条目的2D表。每个条目都是uint8值,数据的总大小是mergeClassCount ^ 2。数据被组织为mergeClassCount行数,每行具有mergeClassCount列条目数。
MergeEntry表:
类型 名称 描述
MergeEntryRow mergeEntryRows [mergeClassCount] 合并条目行的数组。
MergeEntryRow记录:
类型 名称 描述
UINT8 mergeEntries [mergeClassCount] 合并条目数组。
每个合并条目指定一对合并类的行为:行索引表示第一个元素的类,按逻辑顺序,列索引表示第二个元素的类。
每个合并条目都是一个位字段,定义了六个标志。这些描述了从左到右和从右到左视觉顺序的三种不同处理行为。标志分配如下。
合并入口标志
面具 名称 描述
0×01 MERGE_LTR 合并字形,用于LTR视觉顺序。
0×02 GROUP_LTR 组字形,用于LTR视觉顺序。
0×04 SECOND_IS_SUBORDINATE_LTR 对于LTR视觉顺序,第二个字形从属于第一个字形。
0x08的 保留的 保留供将来使用的标志 - 设置为0
为0x10 MERGE_RTL 合并字形,用于RTL视觉顺序。
为0x20 GROUP_RTL 组字形,用于RTL视觉顺序。
0x40的 SECOND_IS_SUBORDINATE_RTL 对于RTL视觉顺序,第二个字形从属于第一个字形。
0x80的 保留的 保留供将来使用的标志 - 设置为0
合并标志(MergeLTR,MergeRTL)表示应在抗锯齿之前合并这对项目。
上一节中描述的组标志表示该对应被视为一个单元,而不指示是否需要合并 - 这将决定是否评估与其他字形相关的组合。
仅当设置了相同视觉顺序的Merge或Group标志时,才会使用上一节中描述的SecondIsSubordinate标志。这些指示合并或分组序列的类应该是该对的第一项还是第二项的类。如果设置了SecondIsSubordinate标志但是没有设置相同视觉顺序的Merge或Group标志,则忽略它。
以下部分提供了处理Merge,Group和SecondIsSubordinate标志的详细说明。
7.35.3.Processing
在处理字形运行中的字形时使用合并条目,以确定在执行抗锯齿过滤之前哪些字形序列需要合并。以对视觉顺序通用的方式给出以下描述。因此,例如,“合并标志”如果可视顺序是LTR则引用MergeLTR标志,或者如果可视顺序是RTL则引用MergeRTL标志。
在以下描述中,合并组是作为一个单元处理的一个或多个字形的序列。除了字形序列之外,合并组还有一个布尔mergeRequired属性,默认情况下设置为false。该组还具有mergeClass属性,其设置如下所述。
合并处理过程如下:
开始:处理算法的开始状态是当前字形不需要与前面的字形或字形序列合并的状态。(这包括字形运行的开始。)当前字形是group.mergeRequired = false的新合并组的开头。
确定当前字形的合并类。将group.mergeClass设置为此类ID。
处理下一个字形:确定下一个字形的合并类。
使用group.mergeClass作为行索引并将下一个字形的合并类作为列索引,检索给定行和列的合并条目。
如果合并条目为零,或者当前或下一个字形的合并类大于或等于mergeClassCount,则下一个字形不需要合并到当前合并序列中。不要将下一个字形添加到合并组中,而是继续执行步骤10。
否则,如果合并条目设置了合并标志,则下一个字形将添加到当前合并组,并且group.mergeRequired设置为true。继续执行第8步。
否则,如果合并条目设置了组标志,则下一个字形将添加到当前合并组。group.mergeRequired属性未更改。继续执行第8步。
确定组的新合并类:
如果合并条目设置了SecondIsSubordinate标志,则不更改group.mergeClass属性。
否则(SecondIsSubordinate标志清除),然后将group.mergeClass属性设置为下一个字形的合并类。
合并组已经扩展; 继续下一个字形:next变为current,并且组属性保持在步骤6-8中设置。返回第3步。
合并组已终止:
如果group.mergeRequired为true,则在进行抗锯齿过滤之前合并此合并组中的所有字形。
否则(group.mergeRequired为false),则合并组中的任何字形都不需要合并。
继续下一个字形(下一个变为当前字符)并返回到开始状态,即步骤1。
7.36.meta 元数据表
元数据表包含字体的各种元数据值。不同类别的元数据由四个字符的标签标识。不同类别的值可以是二进制或文本。
7.36.1.Table Formats
元数据表以标题开头,结构如下。
元数据标题:
类型 名称 描述
UINT32 版 元数据表的版本号 - 设置为1。
UINT32 旗 旗帜 - 目前尚未使用; 设为0。
UINT32 (保留) 不曾用过; 应设为0。
UINT32 dataMapsCount 表中的数据映射数。
数据图 数据地图[dataMapsCount] 数据映射记录数组。
注意: 保留字段最初在Apple规范中记录为数据偏移量。这是多余的,因为DataMap记录包含从’meta’表开始的偏移,因此不使用。
数据映射记录具有以下格式。
DataMap记录:
类型 名称 描述
标签 标签 指示元数据类型的标记。
OFFSET32 dataOffset 从元数据表的开头到此标记的数据的偏移量(以字节为单位)。
UINT32 DATALENGTH 数据长度,以字节为单位。数据不需要填充到任何字节边界。
给定记录的数据可以是文本的也可以是二进制的。为每个标记指定表示格式。根据标记,可以允许或不允许给定标记的多个记录或多个记录中的分隔值,如为每个标记指定的那样。如果标记只允许一个记录或值,则可以忽略第一个之后的任何实例。
7.36.2.Metadata Tags
元数据标签标识所提供的信息的类别和用于给定元数据值的表示格式。维护常用标签的注册表,但也可以使用由供应商确定的私有标签。
与其他OpenType标记一样,元数据标记是四个无符号字节,可以等效地解释为由四个ASCII字符组成的字符串。元数据标签必须以字母(0x41至0x5A,0x61至0x7A)开头,并且必须仅使用字母,数字(0x30至0x39)或空格(0x20)。空格字符只能作为少于四个字母或数字的标记中的尾随字符出现。
私有定义的轴标签必须以大写字母(0x41至0x5A)开头,并且必须仅使用大写字母或数字。已注册的轴标签不得使用该模式,但可以是任何其他有效模式。
每个注册的标签都定义了相关元数据值的语义,以及这些值的表示格式。注册标签的值可以是文本或二进制。如果是文本的,除非另有明确说明,否则它将采用UTF-8编码。
此时定义或保留以下注册标记:
标签 名称 格式 描述
申请 (保留) 保留 - Apple使用。
图片报 (保留) 保留 - Apple使用。
DLNG 设计语言 文本,仅使用基本拉丁语(ASCII)字符。 指示字体主要为其设计的用户受众的语言和/或脚本。只使用一个实例。请参阅下面的其他详细信息
SLNG 支持的语言 文本,仅使用基本拉丁语(ASCII)字符。 指示声明字体能够支持的语言和/或脚本。只使用一个实例。请参阅下面的其他详细信息
‘dlng’和’slng’的值由一系列以逗号分隔的ScriptLangTag组成,下面将详细介绍。空格可以跟随逗号分隔符并被忽略。每个ScriptLangTag都标识一种语言或脚本。标记列表被解释为暗示包含所有语言或脚本。
‘dlng’值用于指示为其设计字体的主要用户受众的语言或脚本。该值可用于基于内容语言选择默认字体格式,用于基于用户语言偏好呈现过滤的字体选项,或涉及内容的语言或脚本或用户设置的类似应用。
‘slng’值用于声明字体能够支持的语言或脚本。此值可能对字体回退机制或涉及内容的语言或脚本或用户设置的其他应用程序有用。
注意: 在字体中使用“slng”值的实现可以选择忽略OS / 2表中设置的Unicode范围位。
一些示例将有助于理解设计和支持语言之间的区别:
考虑重音拉丁字母的情况:虽然口音被许多语言共同使用,但口音的精确形状可能取决于特定语言的印刷传统。例如,波兰语比法语更喜欢韵律。使用专门用于波兰语的重音设计的字体会将波兰语声明为设计语言,但可能会声明支持使用拉丁语脚本的任何语言。
为东亚市场设计的字体通常包括拉丁语,希腊语和西里尔语的字形,因为这些字符包含在重要的东亚字符集标准中,但使用东亚字体用于使用这些脚本编写的语言通常不能令人满意。因此,这些字体会在’slng’值中包含这些脚本,但不包含在’dlng’值中。
简体中文和繁体中文共有的字符在字形设计上存在一些系统差异,例如使用它的所有字符中绘制“骨”字根的方式。专门设计用于简体中文的字体通常可用于显示繁体中文,但任何具有“骨”字根的字符对于繁体中文的读者来说都是错误的。这样的字体将包括简化的中文’dlng’值,但简化和繁体中文的“slng”值。
7.36.3.ScriptLangTag Values
‘dlng’和’slng’元数据使用此处定义的ScriptLangTag值。
ScriptLangTag表示与字体相关联的特定语言或脚本。这些改编自IETF BCP 47规范,“用于识别语言的标签”(参见http://tools.ietf.org/html/bcp47)。
BCP 47语言标签可以包括提供不同类型限定符的各种子标签,例如语言,脚本或区域。在BCP 47语言标记中,语言子标记元素是必需的,其他子标记是可选的。用于’dlng’和’slng’元数据值的ScriptLangTag值使用BCP 47语法的修改:脚本子标签是必需的,其他子标签是可选的。使用以下增强的BNF语法,改编自BCP 47:
复制
ScriptLangTag = [language “-“]
script
[“-“ region]
*(“-“ variant)
*(“-“ extension)
[“-“ privateuse]
元素的扩展和与每个元素相关的预期语义如BCP 47中所定义。脚本子标签取自ISO 15924.目前,没有为ScriptLangTags定义任何扩展,任何扩展都将被忽略。以“-x”为前缀的私有元素由源和接收者之间的私有协议定义,可以忽略。
子标签必须在BCP 47中有效并包含在IANA维护的语言子标签注册表中。有关详细信息,请参阅http://www.iana.org/assignments/language-subtag-registry/language-subtag-registry和BCP 47的第3部分。
注意: OpenType布局脚本和语言系统标记与BCP 47中使用的不同,在创建或处理ScriptLangTags时不应引用。
任何不符合这些规范的ScriptLangTag值都将被忽略。
ScriptLangTag可以表示相当具体的信息; 例如,“en-Latn-IN”代表“用于印度英语的拉丁文字”。但是,在大多数情况下,应使用通用标记,并且预计“dlng”和“slng”元数据声明中使用的大多数标记将仅包含脚本子标记。但是,可以包括语言或其他子标签,并且在某些情况下可能是适当的。实现必须允许包含其他子标签的ScriptLangTag,但是它们也可以选择仅解释脚本子标签并忽略其他子标签。
例子:
“Latn”表示拉丁文脚本(以及使用拉丁文字的任何语言或书写系统)。
“Cyrl”表示西里尔字母。
“sr-Cyrl”表示用于编写塞尔维亚语的西里尔字母; 具有此属性值的字体可能不适合显示俄语或使用西里尔文脚本编写的其他语言的文本。
“en-Dsrt”表示用Deseret脚本书写的英语。
“Hant”表示繁体中文。
“Hant-HK”表示在中国使用的繁体中文。
“Jpan”表示日文写作 - ISO 15924将“Jpan”定义为Han + Hiragana + Katakana的别名。
“Kore”表示韩文写作 - ISO 15924将“Kore”定义为Hangul + Han的别名。
“Hang”表示Hangul脚本(专门 - Hanja并不暗示“Hang”)。
Unicode标准使用ISO 15924标识符“Zinh”(“继承”)和“Zyyy”(“未确定”)。这些不应该在ScriptLangTags中使用。同样,不应使用“Zxxx”(“未写入文档”)和“Zzzz”(“未编码脚本”)。
另一方面,Unicode标准中没有使用“Zmth”(“数学符号”)和“Zsym”(“符号”),但它们在字体文件中作为声明非常有用。(事实上,它们被添加到ISO 15924中,用于与字体相关。)
关于东亚文字,“Jpan”的声明可用于涵盖平假名,片假名和汉字。同样,“Kore”可用于覆盖韩文和韩语,但只有韩文支持的韩语字体应使用“Hang”。对于中文字体,通常应使用“汉斯”和“汉特”来区分简体字和繁体字,而不是更通用的声明“哈尼”。还可以声明区域特定的变体,例如“Hant-HK”。在某些情况下,使用通用声明“Hani”(表示’Han / Hanzi / Kanji / Hanja’)来描述字体功能(但可能不是设计目标)可能是合适的。
区域子标签的BCP 47规范允许大陆和次大陆区域。例如,“039”可用于表示南欧。建议不要在ScriptLangTag值中使用此类扩展区域子标签,因为软件实现可能没有逻辑来与更具体的区域或与这些区域相关联的语言进行适当的关联。
7.37.MVAR 指标变体表
度量变量表用于可变字体,以提供OS / 2表和其他字体表中找到的字体范围度量值的变体。有关OpenType字体变体和与变体相关的术语的一般概述,请参阅OpenType字体变体概述一章。
度量变化表包含用于表示变体数据的项变体存储结构。项目变体存储和组成格式在章节OpenType字体变体公用表格格式中描述。项目变体存储也用于HVAR和GDEF表,但不同于’cvar’或’gvar’表中使用的变体数据的格式。
项目变体存储格式使用增量集索引来引用应用它们的特定目标字体数据项的变体增量数据。项目变体商店外部的数据标识要用于每个给定目标项目的增量集索引。在MVAR表中,值标记记录数组标识一组目标项,并提供用于每个目标项的增量集索引。目标项由四字节标记标识,给定标记表示在另一个表中找到的某些字体范围值。例如,标签’hasc’代表OS / 2.sTypoAscender值。下面提供了有关标签的更多细节。
项目变体存储格式使用变量数据的两级组织:商店可以具有多个项目变体数据子表,并且每个子表具有多个增量集行。增量集索引是一个由两部分组成的索引:选择特定项目变体数据子表的外部索引,以及选择该子表中特定增量集行的内部索引。值记录指定增量集索引的外部和内部部分。
注意: Apple平台允许使用字体度量(’fmtx’)表,通过引用指定“魔术”字形的轮廓点的X或Y坐标来指定各种字体范围的度量值。OpenType字体变体不使用字体度量表。
度量变量表必须与字体变体(’fvar’)表以及变量字体中使用的其他必需或可选表结合使用。有关其他详细信息,请参阅OpenType字体变体概述一章中的变体数据表和其他要求。
7.37.1.Table Formats
指标变化表格式如下。
指标变化表:
类型 名称 描述
UINT16 majorVersion 度量变量表的主要版本号 - 设置为1。
UINT16 minorVersion 度量变量表的次要版本号 - 设置为0。
UINT16 (保留) 不曾用过; 设为0。
UINT16 valueRecordSize 每个值记录的大小(以字节为单位) - 必须大于零。
UINT16 valueRecordCount 值记录的数量 - 可以为零。
Offset16 itemVariationStoreOffset 从此表的开头到项目变体存储表的偏移量(以字节为单位)。如果valueRecordCount为零,则设置为零; 如果valueRecordCount大于零,则必须大于零。
ValueRecord valueRecords [valueRecordCount] 标识目标项的值记录数组以及每个值的相关增量集索引。valueTag记录必须是其valueTag字段的二进制顺序。
valueRecordSize字段指示每个值记录的大小。MVAR表的未来,次要版本更新可以定义具有附加字段的值记录格式的兼容扩展。实现必须使用valueRecordSize字段来确定每条记录的开头。
valueRecords数组是一个值记录数组,用于标识目标,为其提供变体调整数据的字体范围度量(目标项),以及每个项目的外部和内部增量集索引到项目变体存储数据中。
ValueRecord:
类型 名称 描述
标签 valueTag 标识字体范围度量的四字节标记。
UINT16 deltaSetOuterIndex 增量集外部索引 - 用于选择项目变体商店中的项目变体数据子表格。
UINT16 deltaSetInnerIndex 增量集内部索引 - 用于选择项目变体数据子表中的增量集行。
值记录必须以valueTag值的二进制顺序给出。每个标记都标识在其他字体表中找到的字体范围度量。例如,如果值记录的值标记为“hasc”,则这对应于OS / 2.sTypoAscender字段。下面提供了MVAR表中使用的标签的详细信息。
7.37.2.Processing
读取变量字体中的值(例如OS / 2.sCapHeight值(目标项))时,将扫描度量变量表中的值标记数组,以查找与该目标项对应的标记。数组中的记录以valueTag字段中的值的二进制顺序存储。如果标记数组中没有出现标记,则该项目在字体的变体空间中保持不变。但是,如果标签确实发生,则delta-set索引用于引用项目变体存储中的一组增量。项目变体存储中的两级数据组织在OpenType字体变体公用表格式一章中描述。每个增量集包括不同的增量,这些增量适用于落在变化空间的不同区域内的变体实例。在OpenType字体变体概述一章中描述了处理增量以导出给定目标项的内插值的过程。
7.37.3.Value Tags
四字节标记用于表示特定度量或其他值。例如,标签’hasc’(水平上升)用于表示OS / 2.sTypoAscender值。标签是针对OS / 2和Windows度量标准(OS / 2)表中的各种值定义的,水平标题(’hhea’)表,网格拟合和扫描转换(’gasp’)表,PostScript( ‘post’)表,以及垂直指标标题(’vhea’)表。
注意: MVAR表中的变体数据不支持OS / 2.usWeightClass,OS / 2.usWidthClass和post.italicAngle值。这是因为这三个字段的值直接对应于’wght’,’wdth’和’slnt’变化轴的输入轴值。有关这些字段与相应设计轴之间关系的详细信息,请参阅OpenType设计 - 变量轴标记注册表中有关这些轴的讨论。
指标变体表中的标签区分大小写。此表中定义的标签仅使用小写字母或数字。
字体度量变量表中使用的标记应该是此表规范中记录的标记。字体也可以使用私有定义的标签,其具有仅由私有协议知道的语义。专用标记必须使用大写字母开头,并且只使用大写字母或数字。如果在给定字体中使用私有用途标记,则任何无法识别该标记的应用程序都应忽略它。
定义了以下标记:
按逻辑分组排序的值标记:
标签 助记符 价值代表
“众议院武装部队委员会” 水平上升 OS / 2.sTypoAscender
‘HDSC’ 水平下降 OS / 2.sTypoDescender
‘HLGP’ 水平线间隙 OS / 2.sTypoLineGap
‘hcla’ 水平剪裁上升 OS / 2.usWinAscent
‘HCLD’ 水平剪裁下降 OS / 2.usWinDescent
‘VASC’ 垂直上升 vhea.ascent
‘VDSC’ 垂直下降器 vhea.descent
‘vlgp’ 垂直线间隙 vhea.lineGap
‘HCRS’ 水平插入上升 hhea.caretSlopeRise
‘hcrn’ 水平插入运行 hhea.caretSlopeRun
‘hcof’ 水平插入符号 hhea.caretOffset
“录像机” 垂直插入 vhea.caretSlopeRise
‘VCRN’ 垂直插入运行 vhea.caretSlopeRun
‘vcof’ 垂直插入符号 vhea.caretOffset
‘xhgt’ x高度 OS / 2.sxHeight
‘cpht’ 帽高 OS / 2.sCapHeight
‘sbxs’ 下标em x大小 OS / 2.ySubscriptXSize
‘sbys’ 下标大小 OS / 2.ySubscriptYSize
‘sbxo’ 下标em x offset OS / 2.ySubscriptXOffset
‘sbyo’ 下标em y offset OS / 2.ySubscriptYOffset
‘spxs’ 上标em x大小 OS / 2.ySuperscriptXSize
‘spys’ 上标大小 OS / 2.ySuperscriptYSize
‘SPXO’ 上标em x offset OS / 2.ySuperscriptXOffset
‘spyo’ 上标和偏移 OS / 2.ySuperscriptYOffset
“可疑交易” 删除线大小 OS / 2.yStrikeoutSize
‘STRO’ 删除线偏移 OS / 2.yStrikeoutPosition
‘unds’ 下划线大小 post.underlineThickness
“撤消” 下划线偏移 post.underlinePosition
‘gsp0’ gaspRange [0] gasp.gaspRange [0] .rangeMaxPPEM
‘GSP1’ gaspRange [1] gasp.gaspRange [1] .rangeMaxPPEM
‘GSP2’ gaspRange [2] gasp.gaspRange [2] .rangeMaxPPEM
‘GSP3’ gaspRange [3] gasp.gaspRange [3] .rangeMaxPPEM
‘gsp4’ gaspRange [4] gasp.gaspRange [4] .rangeMaxPPEM
‘GSP5’ gaspRange [5] gasp.gaspRange [5] .rangeMaxPPEM
‘GSP6’ gaspRange [6] gasp.gaspRange [6] .rangeMaxPPEM
‘gsp7’ gaspRange [7] gasp.gaspRange [7] .rangeMaxPPEM
‘gsp8’ gaspRange [8] gasp.gaspRange [8] .rangeMaxPPEM
‘gsp9’ gaspRange [9] gasp.gaspRange [9] .rangeMaxPPEM
值标签,按标签的字母顺序排列:
标签 助记符 价值代表
‘cpht’ 帽高 OS / 2.sCapHeight
‘gsp0’ gaspRange [0] gasp.gaspRange [0] .rangeMaxPPEM
‘GSP1’ gaspRange [1] gasp.gaspRange [1] .rangeMaxPPEM
‘GSP2’ gaspRange [2] gasp.gaspRange [2] .rangeMaxPPEM
‘GSP3’ gaspRange [3] gasp.gaspRange [3] .rangeMaxPPEM
‘gsp4’ gaspRange [4] gasp.gaspRange [4] .rangeMaxPPEM
‘GSP5’ gaspRange [5] gasp.gaspRange [5] .rangeMaxPPEM
‘GSP6’ gaspRange [6] gasp.gaspRange [6] .rangeMaxPPEM
‘gsp7’ gaspRange [7] gasp.gaspRange [7] .rangeMaxPPEM
‘gsp8’ gaspRange [8] gasp.gaspRange [8] .rangeMaxPPEM
‘gsp9’ gaspRange [9] gasp.gaspRange [9] .rangeMaxPPEM
“众议院武装部队委员会” 水平上升 OS / 2.sTypoAscender
‘hcla’ 水平剪裁上升 OS / 2.usWinAscent
‘HCLD’ 水平剪裁下降 OS / 2.usWinDescent
‘hcof’ 水平插入符号 hhea.caretOffset
‘hcrn’ 水平插入运行 hhea.caretSlopeRun
‘HCRS’ 水平插入上升 hhea.caretSlopeRise
‘HDSC’ 水平下降 OS / 2.sTypoDescender
‘HLGP’ 水平线间隙 OS / 2.sTypoLineGap
‘sbxo’ 下标em x offset OS / 2.ySubscriptXOffset
‘sbxs’ 下标em x大小 OS / 2.ySubscriptXSize
‘sbyo’ 下标em y offset OS / 2.ySubscriptYOffset
‘sbys’ 下标大小 OS / 2.ySubscriptYSize
‘SPXO’ 上标em x offset OS / 2.ySuperscriptXOffset
‘spxs’ 上标em x大小 OS / 2.ySuperscriptXSize
‘spyo’ 上标和偏移 OS / 2.ySuperscriptYOffset
‘spys’ 上标大小 OS / 2.ySuperscriptYSize
‘STRO’ 删除线偏移 OS / 2.yStrikeoutPosition
“可疑交易” 删除线大小 OS / 2.yStrikeoutSize
“撤消” 下划线偏移 post.underlinePosition
‘unds’ 下划线大小 post.underlineThickness
‘VASC’ 垂直上升 vhea.ascent
‘vcof’ 垂直插入符号 vhea.caretOffset
‘VCRN’ 垂直插入运行 vhea.caretSlopeRun
“录像机” 垂直插入 vhea.caretSlopeRise
‘VDSC’ 垂直下降器 vhea.descent
‘vlgp’ 垂直线间隙 vhea.lineGap
‘xhgt’ x高度 OS / 2.sxHeight
请注意,标记’gsp0’到’gsp9’用于为网格拟合和扫描转换过程(’gasp’)表中的rangeMaxPPEM记录成员提供变体数据。最后一个’gasp’表项始终使用rangeMaxPPEM值0xFFFF。’gasp’条目的最大值记录数不得超过’gasp’表中条目数的一个以上。
7.38.name 命名表
命名表允许多语言字符串与OpenType™字体相关联。这些字符串可以表示版权声明,字体名称,姓氏,样式名称等。为了简化此表,字体制造商可能希望用一些小的语言制作一组有限的条目; 之后,字体可以“本地化”并翻译或添加字符串。需要这些字符串的OpenType字体的其他部分可以使用与语言无关的名称ID来引用它们。除语言变体外,该表还允许特定于平台的字符编码变体。需要特定字符串的客户端可以通过其平台ID,编码ID,语言ID和名称ID查找。请注意,不同的平台可能对字符串的编码有不同的要求。
如果字体不包含该平台的字符串,则许多较新的平台可以使用针对不同平台的字符串。但是,如果不包含当前平台的字符串,某些应用程序可能会显示不正确的字符串。
7.38.1.Naming table header
命名表有两种格式。格式0使用特定于平台的数字语言标识符。格式1允许使用语言标记字符串来指示字符串的语言。两种格式都包括可变大小的字符串数据存储,以及用于标识字符串类型(名称ID),字符串的平台,编码和语言变体以及存储中的位置的名称记录数组。
命名表格式0
格式0命名表的组织如下:
类型 名称 描述
UINT16 格式 格式选择器(= 0)。
UINT16 计数 名称记录数。
Offset16 stringOffset 偏移到字符串存储的开始(从表的开始)。
NameRecord nameRecord [COUNT] 名称记录count是记录数。
(变量) 存储实际的字符串数据。
格式0与格式1的不同之处在于语言识别的处理:它仅使用数字语言ID,通常是小于0x8000的值,并具有特定于平台的解释。请参阅下面的名称记录以获取更多详
命名表格式1
格式1命名表添加了其他元素,组织如下:
类型 名称 描述
UINT16 格式 格式选择器(= 1)。
UINT16 计数 名称记录数。
Offset16 stringOffset 偏移到字符串存储的开始(从表的开始)。
NameRecord nameRecord [COUNT] 名称记录count是记录数。
UINT16 langTagCount 语言标签记录的数量。
LangTagRecord langTagRecord [langTagCount] language-tag记录了langTagCount是记录数的位置。
(变量) 存储实际的字符串数据。
使用格式1时,名称记录中的语言ID可以小于或大于0x8000。如果语言ID小于0x8000,则它具有特定于平台的解释,与格式0命名表一样。如果语言ID等于或大于0x8000,则它与引用语言标记字符串的语言标记记录(LangTagRecord)相关联。通过这种方式,语言ID与语言标记字符串相关联,该字符串使用该语言ID指定名称记录的语言,而不管平台如何。这些可用于支持此语言标记机制的任何平台。
使用格式1命名表的字体可以使用平台特定语言ID的组合以及给定平台和编码的语言标签记录。
每个LangTagRecord的组织如下:
类型 名称 描述
UINT16 长度 语言标记字符串长度(以字节为单位)
Offset16 抵消 语言标记字符串从存储区域的开始偏移(以字节为单位)。
存储在命名表中的语言标记字符串必须以UTF-16BE编码。语言标签必须符合IETF规范BCP 47。这提供了诸如“en”,“fr-CA”和“zh-Hant”之类的标签来识别语言,包括方言,书面形式和其他语言变体。
语言标记记录按顺序与以0x8000开头的语言ID相关联。每个语言标签记录对应的语言ID大于前一个语言标签记录的语言ID。因此,与语言标记记录关联的语言ID必须在0x8000到0x8000 + langTagCount - 1的范围内。如果名称记录使用大于此的语言ID,则该语言的标识未知; 不应使用此类名称记录。
例如,假设一个字体有两个语言标记记录引用存储中的字符串:第一个引用字符串“en”,第二个引用字符串“zh-Hant-HK”在这种情况下,使用语言ID 0x8000在名称记录中索引英语字符串。语言ID 0x8001在名称记录中用于索引香港使用的繁体中文字符串。
7.38.2.Name Records
字符串存储中的每个字符串都由名称记录引用。名称记录具有多部分键,用于标识字符串的逻辑类型及其语言或特定于平台的实现变体,以及字符串存储中字符串的位置。
每个NameRecord的组织如下:
类型 名称 描述
UINT16 platformID 平台ID。
UINT16 encodingID 特定于平台的编码ID。
UINT16 languageID 语言ID。
UINT16 填充NameID 名称ID。
UINT16 长度 字符串长度(以字节为单位)。
Offset16 抵消 从存储区域开始的字符串偏移量(以字节为单位)。
名称ID标识逻辑字符串类别,例如姓氏或版权。所有平台和语言的名称ID都相同; 这些在下面详细描述。密钥的其他三个元素允许特定于平台的实现:平台ID,特定于平台的编码ID和语言ID。
与’cmap’表中的编码记录一样,名称记录必须首先按平台ID排序,然后按特定于平台的ID排序,然后按语言ID排序,再按名称ID排序。下面是各种ID的描述。
7.38.3.Platform, encoding and language IDs
名称记录的平台,编码和语言ID允许特定于平台的实现。不同的平台可以支持不同的编码和不同的语言。所有编码ID都是特定于平台的。语言ID类似于平台特定,除了与上面描述的命名表格式1的语言标记机制结合使用的ID的情况。
注意: “cmap”表中还使用了平台ID,特定于平台的编码ID以及在某些情况下特定于平台的语言ID。
语言ID是指标识特定字符串的语言的值。小于0x8000的值是在特定于平台的基础上定义的。格式0命名表必须仅使用下面给出的特定于平台的枚举中小于0x8000的语言ID值。(但是,在用户定义的平台 - 平台ID 240到255的情况下,允许例外情况。)大于或等于0x8000的值可以在格式1命名表中与语言标记记录一起使用,如上所述。并非所有平台都具有特定于平台的语言ID,并非所有平台都支持语言标记记录。
7.38.4.Platform IDs
定义了以下平台ID:
平台ID 平台名称 特定于平台的编码ID 语言ID
0 统一 各个 没有
1 苹果 脚本管理器代码 各个
2 ISO [已弃用] ISO编码 [已弃用] 没有
3 视窗 Windows编码 各个
4 习惯 习惯 没有
自OpenType版本v1.3起,不推荐使用Platform ID 2(ISO)。它旨在表示ISO / IEC 10646,而不是Unicode。然而,这是多余的,因为两个标准具有相同的字符代码分配。
平台ID值240到255保留给用户定义的平台。此规范永远不会将这些值分配给已注册的平台。
7.38.5.Platform-specific encoding and language IDs: Unicode platform (platform ID = 0)
定义了以下编码ID以用于Unicode平台:
编码ID 描述
0 Unicode 1.0语义
1 Unicode 1.1语义
2 ISO / IEC 10646语义
3 Unicode 2.0及以上语义,仅限Unicode BMP(’cmap’子表格式0,4,6)。
4 Unicode 2.0及以上语义,Unicode完整曲目(’cmap’子表格式0,4,6,10,12)。
五 Unicode变体序列(’cmap’子表格式14)。
6 Unicode完整曲目(’cmap’子表格格式为0,4,6,10,12,13)。
如果新版本的Unicode移动字符,则将分配Unicode平台的新编码ID,以便正确指定字符代码语义。(由于Unicode稳定性策略,不需要这样的需求。)Unicode平台特定编码ID 1和2之间的区别仅出于历史原因; 事实上,Unicode标准在保留曲目和编码方面与ISO 10646完全相同。对于当前字体的所有实际用途,编码ID 0,1和2提供的区别并不重要,因此不推荐使用这些编码ID。
当新的“cmap”子表格格式添加到规范时,有时会分配Unicode平台的新编码ID,以便与现有解析器兼容。例如,当’cmap’子表格式10和12被添加到规范时,也添加了编码ID 4,并且当’cmap’子表格式13被添加到规范时,添加了编码ID 6。上表中列出的’cmap’子表格格式是唯一可用于相应编码ID的格式。
Unicode平台编码ID 5可用于’cmap’表中的编码,但不能用于’name’表中的字符串。
没有为Unicode平台定义特定于平台的语言ID。语言ID = 0可用于Unicode平台字符串,但这并不表示任何特定语言。如上所述,大于或等于0x8000的语言ID可以与语言标签记录一起使用。
7.38.6.Platform-specific encoding and language IDs: Windows platform (platform ID= 3)
Windows编码ID
定义了以下编码ID以用于Windows平台:
编码ID 描述
0 符号
1 Unicode BMP
2 的ShiftJIS
3 中国
4 中文
五 Wansung
6 裘哈
7 保留的
8 保留的
9 保留的
10 Unicode完整曲目
为Windows构建Unicode字体时,平台ID应为3,编码ID应为1,并且引用的字符串数据必须以UTF-16BE编码。为Windows构建符号字体时,平台ID应为3,编码ID应为0,并且引用的字符串数据必须以UTF-16BE编码。构建将在Macintosh上使用的字体时,平台ID应为1,编码ID应为0。
Windows语言ID
以下是Microsoft分配的特定于平台的语言ID:
主要语言 区域 语言ID(十六进制)
南非荷兰语 南非 0436
阿尔巴尼亚人 阿尔巴尼亚 041C
阿尔萨斯 法国 0484
阿姆哈拉语 埃塞俄比亚 045E
阿拉伯 阿尔及利亚 1401
阿拉伯 巴林 3C01
阿拉伯 埃及 0C01
阿拉伯 伊拉克 0801
阿拉伯 约旦 2C01
阿拉伯 科威特 3401
阿拉伯 黎巴嫩 3001
阿拉伯 利比亚 1001
阿拉伯 摩洛哥 1801
阿拉伯 阿曼 2001年
阿拉伯 卡塔尔 4001
阿拉伯 沙特阿拉伯 0401
阿拉伯 叙利亚 2801
阿拉伯 突尼斯 1C01
阿拉伯 阿联酋 3801
阿拉伯 也门 2401
亚美尼亚 亚美尼亚 042B
阿萨姆 印度 044D
阿塞拜疆(西里尔文) 阿塞拜疆 082C
阿塞拜疆语(拉丁语) 阿塞拜疆 042C
巴什基尔 俄国 046D
巴斯克 巴斯克 042D
白俄罗斯 白俄罗斯 0423
孟加拉 孟加拉国 0845
孟加拉 印度 0445
波斯尼亚语(西里尔语) 波斯尼亚和黑塞哥维那 201A
波斯尼亚语(拉丁语) 波斯尼亚和黑塞哥维那 141A
布列塔尼 法国 047E
保加利亚语 保加利亚 0402
加泰罗尼亚 加泰罗尼亚 0403
中文 香港特区 0C04
中文 澳门特区 1404
中文 中华人民共和国 0804
中文 新加坡 1004
中文 台湾 0404
科西嘉 法国 0483
克罗地亚 克罗地亚 041A
克罗地亚语(拉丁语) 波斯尼亚和黑塞哥维那 101A
捷克 捷克共和国 0405
丹麦 丹麦 0406
达里语 阿富汗 048C
迪维希 马尔代夫 0465
荷兰人 比利时 0813
荷兰人 荷兰 0413
英语 澳大利亚 0C09
英语 伯利兹 2809
英语 加拿大 1009
英语 加勒比 2409
英语 印度 4009
英语 爱尔兰 1809
英语 牙买加 2009年
英语 马来西亚 4409
英语 新西兰 1409
英语 菲律宾共和国 3409
英语 新加坡 4809
英语 南非 1C09
英语 特立尼达和多巴哥 2C09
英语 英国 0809
英语 美国 0409
英语 津巴布韦 3009
爱沙尼亚语 爱沙尼亚 0425
法罗群岛 法罗群岛 0438
菲律宾 菲律宾 0464
芬兰 芬兰 040B
法国 比利时 080C
法国 加拿大 0C0C
法国 法国 040C
法国 卢森堡 140C
法国 摩纳哥公国 180C
法国 瑞士 100C
弗里斯兰 荷兰 0462
加利西亚 加利西亚 0456
格鲁吉亚 格鲁吉亚 0437
德语 奥地利 0C07
德语 德国 0407
德语 列支敦士登 1407
德语 卢森堡 1007
德语 瑞士 0807
希腊语 希腊 0408
格陵兰 格陵兰 046F
古吉拉特语 印度 0447
豪萨(拉丁文) 尼日利亚 0468
希伯来语 以色列 040D
印地语 印度 0439
匈牙利 匈牙利 040E
冰岛的 冰岛 040F
伊博 尼日利亚 0470
印度尼西亚 印度尼西亚 0421
因纽特语 加拿大 045D
Inuktitut(拉丁语) 加拿大 085D
爱尔兰的 爱尔兰 083C
索萨语 南非 0434
祖鲁语 南非 0435
意大利 意大利 0410
意大利 瑞士 0810
日本 日本 0411
卡纳达语 印度 044B
哈萨克人 哈萨克斯坦 043F
高棉 柬埔寨 0453
K’iche 危地马拉 0486
卢旺达语 卢旺达 0487
斯瓦希里 肯尼亚 0441
孔卡尼语 印度 0457
朝鲜的 韩国 0412
吉尔吉斯 吉尔吉斯斯坦 0440
老挝 老挝人民民主共和国 0454
拉脱维亚 拉脱维亚 0426
立陶宛 立陶宛 0427
下索布语 德国 082E
卢森堡 卢森堡 046E
马其顿(前南斯拉夫马其顿共和国) 前南斯拉夫的马其顿共和国 042F
马来语 文莱达鲁萨兰国 083E
马来语 马来西亚 043E
马拉雅拉姆语 印度 044C
马耳他语 马耳他 043A
毛利 新西兰 0481
马普切语 智利 047A
马拉 印度 044E
莫霍克 莫霍克 047C
蒙古语(西里尔语) 蒙古 0450
蒙古语(繁体) 中华人民共和国 0850
尼泊尔 尼泊尔 0461
挪威语(博克马尔) 挪威 0414
挪威人(尼诺斯克) 挪威 0814
奥克 法国 0482
奥迪亚(原奥里亚) 印度 0448
普什图语 阿富汗 0463
抛光 波兰 0415
葡萄牙语 巴西 0416
葡萄牙语 葡萄牙 0816
旁遮普 印度 0446
克丘亚语 玻利维亚 046B
克丘亚语 厄瓜多尔 086B
克丘亚语 秘鲁 0C6B
罗马尼亚 罗马尼亚 0418
罗曼什 瑞士 0417
俄语 俄国 0419
萨米(伊纳里) 芬兰 243B
萨米(吕勒) 挪威 103B
萨米(吕勒) 瑞典 143B
萨米(北部) 芬兰 0C3B
萨米(北部) 挪威 043B
萨米(北部) 瑞典 083B
萨米(斯科尔特) 芬兰 203B
萨米(南部) 挪威 183B
萨米(南部) 瑞典 1C3B
梵文 印度 044F
塞尔维亚语(西里尔语) 波斯尼亚和黑塞哥维那 1C1A
塞尔维亚语(西里尔语) 塞尔维亚 0C1A
塞尔维亚语(拉丁语) 波斯尼亚和黑塞哥维那 181A
塞尔维亚语(拉丁语) 塞尔维亚 081A
Sesotho sa Leboa 南非 046C
茨瓦纳语 南非 0432
僧伽罗语 斯里兰卡 045B
斯洛伐克 斯洛伐克 041B
斯洛文尼亚 斯洛文尼亚 0424
西班牙语 阿根廷 2C0A
西班牙语 玻利维亚 400A
西班牙语 智利 340A
西班牙语 哥伦比亚 240A
西班牙语 哥斯达黎加 140A
西班牙语 多明尼加共和国 1C0A
西班牙语 厄瓜多尔 300A
西班牙语 萨尔瓦多 440A
西班牙语 危地马拉 100A
西班牙语 洪都拉斯 480A
西班牙语 墨西哥 080A
西班牙语 尼加拉瓜 4C0A
西班牙语 巴拿马 180A
西班牙语 巴拉圭 3C0A
西班牙语 秘鲁 280A
西班牙语 波多黎各 500A
西班牙语(现代排序) 西班牙 0C0A
西班牙语(繁体排序) 西班牙 040A
西班牙语 美国 540A
西班牙语 乌拉圭 380A
西班牙语 委内瑞拉 200A
瑞典 芬兰 081D
瑞典 瑞典 041D
叙利亚 叙利亚 045A
塔吉克(西里尔文) 塔吉克斯坦 0428
Tamazight(拉丁文) 阿尔及利亚 085F
泰米尔人 印度 0449
鞑靼 俄国 0444
泰卢固语 印度 044A
泰国 泰国 041E
藏 中国 0451
土耳其 火鸡 041F
土库曼 土库曼斯坦 0442
维吾尔 中国 0480
乌克兰 乌克兰 0422
上索布语 德国 042E
乌尔都语 巴基斯坦伊斯兰共和国 0420
乌兹别克语(西里尔语) 乌兹别克斯坦 0843
乌兹别克语(拉丁语) 乌兹别克斯坦 0443
越南 越南 042A
威尔士语 英国 0452
沃洛夫语 塞内加尔 0488
雅库特 俄国 0485
义 中国 0478
约鲁巴 尼日利亚 046A
7.38.7.Platform-specific encoding and language IDs: Macintosh platform (platform ID = 1)
Macintosh编码ID(脚本管理器代码)
定义了以下编码ID以用于Macintosh平台:
编码ID 脚本 编码ID 脚本
0 罗马 17 马拉雅拉姆语
1 日本 18 僧伽罗语
2 中国传统的) 19 缅甸语
3 朝鲜的 20 高棉
4 阿拉伯 21 泰国
五 希伯来语 22 老挝的
6 希腊语 23 格鲁吉亚
7 俄语 24 亚美尼亚
8 RSymbol 25 简体中文)
9 梵文 26 藏
10 古尔穆基 27 蒙
11 古吉拉特语 28 吉兹
12 奥里亚语 29 斯拉夫
13 孟加拉 三十 越南
14 泰米尔人 31 信德
15 泰卢固语 32 未解释
16 卡纳达语
Macintosh语言ID
以下是Apple分配的特定于平台的语言ID:
语言ID 语言 语言ID 语言
0 英语 59 普什图语
1 法国 60 库尔德
2 德语 61 克什米尔
3 意大利 62 信德
4 荷兰人 63 藏
五 瑞典 64 尼泊尔
6 西班牙语 65 梵文
7 丹麦 66 马拉
8 葡萄牙语 67 孟加拉
9 挪威 68 阿萨姆
10 希伯来语 69 古吉拉特语
11 日本 70 旁遮普
12 阿拉伯 71 奥里亚语
13 芬兰 72 马拉雅拉姆语
14 希腊语 73 卡纳达语
15 冰岛的 74 泰米尔人
16 马耳他语 75 泰卢固语
17 土耳其 76 僧伽罗语
18 克罗地亚 77 缅甸语
19 中国传统的) 78 高棉
20 乌尔都语 79 老挝
21 印地语 80 越南
22 泰国 81 印度尼西亚
23 朝鲜的 82 他加禄语
24 立陶宛 83 马来语(罗马文字)
25 抛光 84 马来语(阿拉伯文字)
26 匈牙利 85 阿姆哈拉语
27 爱沙尼亚语 86 提格雷语
28 拉脱维亚 87 五倍子
29 萨米 88 索马里
三十 法罗群岛 89 斯瓦希里
31 波斯语/波斯语 90 卢旺达语/卢安达
32 俄语 91 隆迪语
33 简体中文) 92 尼扬贾文/ Chewa
34 佛兰芒语 93 马尔加什
35 爱尔兰盖尔语 94 世界语
36 阿尔巴尼亚人 128 威尔士语
37 罗马尼亚 129 巴斯克
38 捷克 130 加泰罗尼亚
39 斯洛伐克 131 拉丁
40 斯洛文尼亚 132 克丘亚语
41 意第绪语 133 瓜拉尼
42 塞尔维亚 134 艾马拉
43 马其顿 135 鞑靼
44 保加利亚语 136 维吾尔
45 乌克兰 137 不丹文
46 白俄罗斯 138 爪哇(罗马文字)
47 乌兹别克 139 Sund他(罗马文字)
48 哈萨克人 140 加利西亚
49 阿塞拜疆(西里尔文字) 141 南非荷兰语
50 阿塞拜疆(阿拉伯文字) 142 布列塔尼
51 亚美尼亚 143 因纽特语
52 格鲁吉亚 144 苏格兰盖尔语
53 摩尔多瓦 145 Manx Gaelic
54 吉尔吉斯人 146 爱尔兰盖尔语(上面有点)
55 塔吉克 147 同安区
56 土库曼 148 希腊语(polytonic)
57 蒙古语(蒙古语) 149 格陵兰
58 蒙古语(西里尔文字) 150 阿塞拜疆(罗马文字)
7.38.8.Platform-specific encoding and language IDs: ISO platform (platform ID=2) [Deprecated]
定义了以下编码ID以用于ISO平台:
码 ISO编码
0 7位ASCII
1 ISO 10646
2 ISO 8859-1
没有特定于ISO的语言ID,并且此平台不支持语言标记记录。这意味着它可能用于’cmap’表中的编码,但不能用于’name’表中的字符串。请注意,不推荐在’cmap’表中使用ISO平台。
7.38.9.Platform-specific encoding and language IDs: Custom platform (platform ID = 4)
ID 自定义编码
0-255 OTF Windows NT兼容性映射
如果存在用于OTF Windows NT兼容性的自定义平台“cmap”,则必须将编码ID设置为原始Type 1字体的.PFM文件中存在的Windows字符集值(范围为0到255,包括0和255) 。有关OTF Windows NT兼容性“cmap”的更多详细信息,请参阅“cmap”表。
没有为Custom平台定义特定于平台的语言ID,并且此平台不支持语言标记记录。这意味着它可以用于’cmap’表中的编码,但不能用于’name’表中的字符串。
7.38.10.Name IDs
以下名称ID是预定义的,除非另有说明,否则它们适用于所有平台。名称ID 26到255(包括两者)保留给将来的标准名称。名称ID 256到32767(包括两者)保留用于特定于字体的名称,例如由字体的布局功能引用的名称。
码 含义
0 版权声明。
1 字体系列名称。字体系列名称与字体子系列名称(名称ID 2)结合使用,并且最多只能在重量或样式不同的四种字体之间共享(如下所述)。
这种四向区别也应该反映在OS / 2.fsSelection字段中,使用位0和5.
虽然某些平台或应用程序没有此约束,但许多使用这对名称的现有应用程序假定字体系列名称由最多四种形成字体样式链接组的字体共享:常规,斜体(或倾斜),粗体和粗体斜体(或粗斜体)。为了与最广泛的平台和应用程序兼容,强烈建议字体以这种方式限制使用字体系列名称。
对于包含四种基本样式(常规,斜体,粗体,粗体斜体)以外的字体的扩展印刷系列,强烈建议在字体中使用名称ID 16和17来创建扩展的印刷分组。(请参阅下面提供的示例。)
强烈建议应用程序使用名称ID 16和17支持扩展的排版族分组。特别注意,变量字体可以包含大量命名实例,每个实例都使用一个共享印刷系列名称(名称ID 16),并具有印刷子系列名称(相当于名称ID 17)。假设基于名称ID 1和2的四种家庭分组的应用程序可能会提供使用可变字体的糟糕用户体验。
对于超出基本四向区别的扩展印刷系列中的字体,区别属性应反映在字体系列名称中,以便这些字体显示为单独的字体系列。例如,Arial Narrow字体的字体系列名称是“Arial Narrow”; Arial Black字体的字体系列名称为“Arial Black”。请注意,在这种情况下,名称ID 16也应包含在反映完整印刷族的共享名称中。
2 字体子系列名称。字体子系列名称与字体系列名称(名称ID 1)结合使用,并使用相同的字体系列名称区分组中的字体。这应仅用于样式和重量变体(如下所述)。
这种四向区别也应该反映在OS / 2.fsSelection字段中,使用位0和5.字体没有明显的重量或样式(例如中等重量,不是斜体,OS / 2.fsSelection第6位)应使用字符串“Regular”作为Font Subfamily名称(英语)。
虽然某些平台或应用程序没有此约束,但许多使用这对名称的现有应用程序假定字体系列名称最多由四种形成字体样式链接组的字体共享,而字体子系列名称将反映一个四种基本风格,常规,斜体(或倾斜),粗体和粗体斜体(或粗斜体)。为了与最广泛的平台和应用程序兼容,强烈建议字体应以这种方式限制字体系列的使用。
对于包含四种基本样式(常规,斜体,粗体,粗体斜体)以外的字体的扩展印刷系列,强烈建议在字体中使用名称ID 16和17来创建扩展的印刷分组。
在包含常规,粗体,斜体或粗体斜体之外的字体的扩展印刷系列中,在字体系列名称中进行区分,以便字体显示在不同的系列中。在某些情况下,这可能会导致为可能不会被视为常规字体的字体指定子系列名称“Regular” 。例如,Arial Black字体的字体系列名称为“Arial Black”,子系列名称为“Regular”。请注意,在这种情况下,还应包括名称ID 16和17,使用反映完整印刷族的名称ID 16的共享值,以及适当反映每种字体的实际设计变体的名称ID 17的值。
3 唯一字体标识符
4 反映所有系列和相关子系列描述符的全字体名称。完整字体名称通常是名称ID 1和2,或名称ID 16和17的组合,或类似的人类可读变体。
对于扩展印刷系列中的字体(即包含常规,斜体,粗体和粗体斜体变体的系列),通常选择名称ID 1和2的值,以提供与某些家庭最多拥有的应用程序的兼容性四种与样式相关的字体。在这种情况下,某些字体最终可能会以“常规”的子系列名称(名称ID 2)结束,即使字体不会被考虑,也可能是常规字体字体。对于名称ID 2指定为“常规”的非常规字体,通常会从名称ID 4中省略“常规”描述符。例如,Arial Black字体具有字体系列名称(名称ID 1) “Arial Black”和“Regular”的子家族名称(名称ID 2),但具有“Arial Black”的完整字体名称(名称ID 4)。请注意,名称ID 16和17也应包含在这些字体中,名称ID 4通常是名称ID 16和17的组合,无需任何有关“常规”的其他限定条件。
五 版本字符串。应以语法“Version
该字符串必须包含以下格式的版本号:一个或多个数字(0-9)的值小于65,535,后跟一个句点,后跟一个或多个值小于65,535的数字。除数字之外的任何字符都将终止次要号码。诸如“;”之类的字符有助于分隔不同的版本信息。
安装软件可以使用字符串中的第一个这样的匹配来比较字体版本。请注意,某些安装程序可能要求字符串以“Version”开头,后跟上面的版本号。
6 字体的PostScript名称; 名称ID 6指定一个字符串,用于调用与此OpenType字体对应的PostScript语言字体。当转换为ASCII时,名称字符串不得超过63个字符并限制为可打印的ASCII子集,代码33到126,除了10个字符’[‘,’]’,’(’,’)’,’ {‘,’}’,’<’,’>’,’/‘,’%’。
在CFF OpenType字体中,不要求此名称与CFF的名称索引中的字体名称相同。因此,可以在字体集合中的多个字体组件之间共享相同的CFF。有关其他信息,请参阅“OpenType字体的建议” 的“名称”表部分。
7 商标; 这用于保存此字体的任何商标声明/信息。此类信息应基于法律建议。这与版权明显不同。
8 生产商名称。
9 设计师; 字体设计者的名字。
10 描述; 字体的描述。可以包含修订信息,使用建议,历史记录,功能等。
11 网址供应商; 字体供应商的URL(带协议,例如http://,ftp://)。如果URL中嵌入了唯一的序列号,则可以使用它来注册字体。
12 网址设计师; 字体设计者的URL(带协议,例如http://,ftp://)。
13 许可证说明; 可以合法使用字体的描述,或许可使用的不同示例方案。这个字段应该用简单的语言编写,而不是法律术语。
14 许可证信息URL; 可以找到其他许可信息的URL。
15 保留。
16 印刷族姓名:印刷家庭分组不对其中的面孔数量施加任何限制,与4式家庭分组(ID 1)形成对比,后者出于历史原因和表达样式链接组而存在。如果名称ID 16不存在,则名称ID 1被认为是印刷姓氏。(在规范的早期版本中,名称ID 16被称为“首选系列”。)
17 排版子系列名称:这允许字体设计者在排版系列分组中指定子系列名称。该字符串在特定印刷系列中必须是唯一的。如果不存在,则名称ID 2被认为是印刷子系列名称。(在规范的早期版本中,名称ID 17被称为“首选子系列”。)
18 兼容Full(仅限Macintosh); 在Macintosh上,使用FOND资源构造菜单名称。这通常与全名匹配。如果希望字体名称与全名不同,则可以在ID 18中插入Compatible Full Name。
19 示范文本; 这可以是字体名称,或设计者认为是显示字体的最佳样本的任何其他文本。
20 PostScript CID findfont名称; 它以字体存在意味着nameID 6包含一个PostScript字体名称,该名称与“composefont”调用一起使用,以便在PostScript解释器中调用字体。请参阅名称ID 6的定义。名称ID
20字符串中保存的值被解释为PostScript字体名称,该名称旨在与“findfont”调用一起使用,以便在PostScript解释器中调用该字体。
当转换为ASCII时,此名称字符串必须限制为可打印的ASCII子集,代码33到126,除了10个字符:’[‘,’]’,’(’,’)’,’{‘,’} ‘,’<’,’>’,’/‘,’%’。
21 WWS姓氏。用于提供符合WWS的系列名称,以防ID 16和17的条目不符合WWS模型。(即,如果ID 17的条目包括除了权重,宽度或斜率之外的某些属性的限定符。)如果设置了fsSelection字段的第8位,则不应该需要WWS系列名称条目,并且不应该包括该条目。相反,如果包含此ID的条目,则不应设置位8。(有关详细信息,请参阅OS / 2.fsSelection字段。)名称ID 21的示例:“Minion Pro Caption”和“Minion Pro Display”。(对于这些示例,名称ID 16将是“Minion Pro”。)
22 WWS亚科名称。与ID 21结合使用时,如果ID 16和17的条目不符合WWS模型,则此ID提供符合WWS的子系列名称(仅反映重量,宽度和坡度属性)。与ID 21的情况一样,该ID的使用应与所设置的fsSelection字段的第8位相反地相关。名称ID 22的示例:“Semibold Italic”,“Bold Condensed”。(例如,名称ID 17可以是“Semibold Italic Caption”或“Bold Condensed Display”。)
23 浅色背景调色板。如果在CPAL表的Palette Labels Array中使用此ID,则指定CPAL表中的相应调色板适合在字体(如白色)上显示时与字体一起使用。此ID的字符串用作与此调色板关联的用户界面字符串。
24 黑暗的背景调色板。如果在CPAL表的Palette Labels Array中使用此ID,则指定CPAL表中的相应调色板适合在黑色背景下显示时使用该字体。此ID的字符串用作与此调色板关联的用户界面字符串
25 变体PostScript名称前缀。如果以可变字体存在,则可以将其用作变体字体的PostScript名称生成算法中的族前缀。字符集限制为ASCII范围的大写拉丁字母,小写拉丁字母和数字。当转换为ASCII时,字体中名称ID 25的所有名称字符串必须相同。有关在字体中包含名称ID 25的原因以及示例,请参阅Adobe技术说明#5902:“变体字体的PostScript名称生成”。有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
请注意,虽然Apple和Microsoft都支持相同的名称字符串集,但解释可能会有所不同。但由于名称字符串是通过平台,编码和语言(为Apple和MS平台放置单独的字符串)存储的,因此这不应该是一个问题。
此平台的Microsoft平台关键信息与名称ID 1,2,4,16和17的使用有关。请注意,某些较新的应用程序将使用名称ID 16和17,而某些旧版应用程序需要名称ID 1和2以及还假设对这些值有某些限制(参见上面名称ID 1和2的描述)。字体应包含所有这些字符串,以实现最广泛的应用程序兼容性。为了更好地理解如何为这些名称ID设置值,已创建名称用法,权重类和样式标志的一些示例。
Windows平台(平台ID 3)的所有命名表字符串必须以UTF-16BE编码。Macintosh平台的字符串(平台ID 1)使用特定于平台的单字节或双字节编码。
请注意,对于包含与除了权重,宽度或坡度之外的属性相比不同于常规的成员面的印刷族,可能还存在一些仅与这三个属性相关的成员面。ID 21和22仅应用于那些与重量,宽度或坡度以外的属性不同的常规面的字体。
7.38.11.Examples
以下是基于Times New Roman Bold如何定义这些字符串的示例:
0.字体供应商的版权字符串。©版权所有Monotype Corporation plc,1990
1.用户看到的名称。Times New Roman
2.风格的名称。粗体
3.应用程序可以存储的唯一标识符,用于标识正在使用的字体。Monotype:Times New Roman Bold:1990
4.完整,独特,人类可读的字体名称。Windows使用此名称。Times New Roman Bold
5.来自字体供应商的版本和版本信息。版本1.00 1990年6月1日,初始版本
6.字体在PostScript打印机上的名称。TimesNewRoman-Bold
7.商标字符串。Times New Roman是Monotype Corporation的注册商标。
8.制造商。Monotype Corporation plc
9.设计师。Stanley Morison
10.描述。1932年为伦敦时报报纸设计。出色的可读性和窄的整体宽度,每行可以比大多数字体更多的单词。
11.供应商的URL。http://www.monotype.com
- Designer的URL。http://www.monotype.com
13.许可证说明。此字体可能安装在您的所有计算机和打印机上,但您不得向其他任何人出售或提供这些字体。
14.许可证信息URL。http://www.monotype.com/license/
15.保留。
16.首选家庭。不存在名称字符串,因为它与名称ID 1(字体系列名称)相同。
17.优选的亚家族。不存在名称字符串,因为它与名称ID 2(字体子系列名称)相同。
18.兼容Full(仅限Macintosh)。不存在名称字符串,因为它与名称ID 4(全名)相同。
19.示例文本。敏捷的棕色狐狸跳过了懒狗。
PostScript CID findfont名称。没有名称字符串。因此,名称ID 6定义的PostScript名称应与“findfont”调用一起使用,以便在PostScript解释器的上下文中定位字体。
WWS系列名称:由于Times New Roman是WWS字体,因此不需要指定此字段。如果字体包含诸如“标题”,“显示”,“手写”等样式,则会在此处注明。
WWS子系列名称:由于Times New Roman是WWS字体,因此不需要指定此字段。
23.浅色背景调色板名称。没有名称字符串,因为这不是一种颜色字体。
24.深色背景调色板名称。没有名称字符串,因为这不是一种颜色字体。
25.变体PostScript名称前缀。没有名称字符串,因为这不是可变字体。
以下是CFF OpenType日语字体Kozuka Mincho Std Regular中仅名称ID 6和20的示例(此字体中还存在其他名称ID):
PostScript名称:KozMinStd-Regular。由于字体中存在名称ID 20(参见下文),因此名称ID 6定义的PostScript名称应与“composefont”调用一起使用,以便在PostScript解释器的上下文中定位字体。
PostScript CID findfont名称:KozMinStd-Regular-83pv-RKSJ-H,在平台1 [Macintosh]的名称记录中,特定于平台的脚本1 [日语],语言:0xFFFF [英语]。此名称字符串是一个PostScript名称,应与“findfont”调用一起使用,以便在PostScript解释器的上下文中定位字体,并与以下“cmap”子表指定的编码相关联,该子表必须存在于font:Platform:1 [Macintosh]; 特定于平台的编码:1 [日语]; 语言:0 [不是语言特定的]。
以下是扩展的仅限WWS的系列的族/子系列命名示例。考虑Adobe Caslon Pro,有六个成员:常规,半粗体和粗体重的直立和斜体版本。(OS / 2表的fsSelection字段的第8位,版本4,应该为所有六种字体设置,并且没有一个应该包括ID 21或22的’name’条目。)
Adobe Caslon Pro Regular:名称ID 1:Adobe Caslon Pro
名称ID 2:常规
Adobe Caslon Pro Italic:名称ID 1:Adobe Caslon Pro
名称ID 2:斜体
Adobe Caslon Pro Semibold:名称ID 1:Adobe Caslon Pro
名称ID 2:粗体
名称ID 16:Adobe Caslon Pro
名称ID 17:Semibold
Adobe Caslon Pro Semibold Italic:名称ID 1:Adobe Caslon Pro
名称ID 2:粗体斜体
名称ID 16:Adobe Caslon Pro
名称ID 17:Semibold斜体
Adobe Caslon Pro Bold:名称ID 1:Adobe Caslon Pro粗体
名称ID 2:常规
名称ID 16:Adobe Caslon Pro
名称ID 17:粗体
Adobe Caslon Pro Bold Italic:名称ID 1:Adobe Caslon Pro粗体
名称ID 2:斜体
名称ID 16:Adobe Caslon Pro
名称ID 17:粗体斜体
以下是扩展的非WWS系列的系列/子系列命名示例。考虑使用32种成员字体的Minion Pro Opticals:四种光学尺寸中的常规,中等,半粗和粗体重的直立和斜体版本:常规,标题,显示和子标题。以下显示了此系列中字体样本的名称。(OS / 2表中版本4的fsSelection字段的第8位应设置为那些不包含ID 21或22的’name’条目的字体,并且只能在那些字体中设置。)
Minion Pro Regular:名称ID 1:Minion Pro
名称ID 2:常规
Minion Pro Italic:名称ID 1:Minion Pro
名称ID 2:斜体
Minion Pro Semibold:名称ID 1:Minion Pro SmBd
名称ID 2:常规
名称ID 16:Minion Pro
名称ID 17:Semibold
Minion Pro Semibold Italic:名称ID 1:Minion Pro SmBd
名称ID 2:斜体
名称ID 16:Minion Pro
名称ID 17:Semibold斜体
Minion Pro标题:名称ID 1:Minion Pro Capt
名称ID 2:常规
名称ID 16:Minion Pro
名称ID 17:标题
名称ID 21:Minion Pro标题
名称ID 22:常规
Minion Pro Semibold Italic标题:名称ID 1:Minion Pro SmBd Capt
名称ID 2:斜体
名称ID 16:Minion Pro
名称ID 17:Semibold斜体标题
名称ID 21:Minion Pro标题
名称ID 22:Semibold斜体
7.38.a.1.Name String Examples
以下是如何为Arial系列创建名称字符串的示例。
字形 名称ID 1 名称ID 2 姓名ID 4 名称ID 16 姓名ID 17
Arial Narrow Arial Narrow 定期 Arial Narrow 宋体 狭窄
Arial Narrow Italic Arial Narrow 斜体 Arial Narrow Italic 宋体 窄斜体
Arial Narrow Bold Arial Narrow 胆大 Arial Narrow Bold 宋体 窄大胆
Arial Narrow Bold Italic Arial Narrow 加粗斜体 Arial Narrow Bold Italic 宋体 窄大胆的斜体
宋体 宋体 定期 宋体 宋体
Arial斜体 宋体 斜体 Arial斜体 宋体 斜体
Arial Bold 宋体 胆大 Arial Bold 宋体 胆大
Arial Bold Italic 宋体 加粗斜体 Arial Bold Italic 宋体 加粗斜体
Arial Black Arial Black 定期 Arial Black 宋体 黑色
Arial Black Italic Arial Black 斜体 Arial Black Italic 宋体 黑色斜体
除了名称字符串之外,还显示了OS / 2.usWeightClass,OS / 2.usWidthClass,OS / 2.fsSelection样式位和head.macStyle位。这些设置允许字体组合成一个不同重量和压缩/扩展的系列。
字形 OS / 2 usWeightClass OS / 2 usWidthClass OS / 2 fsSelection Italic OS / 2 fsSelection Bold OS / 2 fsSelection Regular ‘头’macStyle大胆 ‘head’macStyle Italic ‘head’macStyle凝聚 ‘head’macStyle扩展
Arial Narrow 400 3 X X
Arial Narrow Italic 400 3 X X X
Arial Narrow Bold 700 3 X X X
Arial Narrow Bold Italic 700 3 X X X X X
宋体 400 五 X
Arial斜体 400 五 X X
Arial Bold 700 五 X X
Arial Bold Italic 700 五 X X X X
Arial Black 900 五 X X
Arial Black Italic 900 五 X X
7.39.OS/2 OS/2和Windows度量表
OS / 2表由一组指标和OpenType字体中所需的其他数据组成。
已定义六个版本的OS / 2表:版本0到5.支持所有版本,但强烈建议使用版本4或更高版本。
7.39.1.OS/2 Table Formats
第5版
版本5在OpenType 1.7中定义。版本5除了版本4之外还有两个附加字段。版本5的格式如下:
类型 名称 评论
UINT16 版 0×0005
INT16 xAvgCharWidth
UINT16 usWeightClass
UINT16 usWidthClass
UINT16 文件系统类型
INT16 ySubscriptXSize
INT16 ySubscriptYSize
INT16 ySubscriptXOffset
INT16 ySubscriptYOffset
INT16 ySuperscriptXSize
INT16 ySuperscriptYSize
INT16 ySuperscriptXOffset
INT16 ySuperscriptYOffset
INT16 yStrikeoutSize
INT16 yStrikeoutPosition
INT16 sFamilyClass
UINT8 潘糖[10]
UINT32 ulUnicodeRange1 比特0-31
UINT32 ulUnicodeRange2 第32-63位
UINT32 ulUnicodeRange3 第64-95位
UINT32 ulUnicodeRange4 比特96-127
标签 achVendID
UINT16 fsSelection
UINT16 usFirstCharIndex
UINT16 usLastCharIndex
INT16 sTypoAscender
INT16 sTypoDescender
INT16 sTypoLineGap
UINT16 usWinAscent
UINT16 usWinDescent
UINT32 ulCodePageRange1 比特0-31
UINT32 ulCodePageRange2 第32-63位
INT16 sxHeight
INT16 sCapHeight
UINT16 usDefaultChar
UINT16 usBreakChar
UINT16 usMaxContext
UINT16 usLowerOpticalPointSize
UINT16 usUpperOpticalPointSize
版本4
版本4在OpenType 1.5中定义。版本4比版本5少两个字段,与版本3中的字段相同。虽然新版本的字段未添加到版本3之外,但某些字段的规范已修订。版本4的格式如下:
类型 名称
UINT16 版
INT16 xAvgCharWidth
UINT16 usWeightClass
UINT16 usWidthClass
UINT16 文件系统类型
INT16 ySubscriptXSize
INT16 ySubscriptYSize
INT16 ySubscriptXOffset
INT16 ySubscriptYOffset
INT16 ySuperscriptXSize
INT16 ySuperscriptYSize
INT16 ySuperscriptXOffset
INT16 ySuperscriptYOffset
INT16 yStrikeoutSize
INT16 yStrikeoutPosition
INT16 sFamilyClass
UINT8 潘糖[10]
UINT32 ulUnicodeRange1
UINT32 ulUnicodeRange2
UINT32 ulUnicodeRange3
UINT32 ulUnicodeRange4
标签 achVendID
UINT16 fsSelection
UINT16 usFirstCharIndex
UINT16 usLastCharIndex
INT16 sTypoAscender
INT16 sTypoDescender
INT16 sTypoLineGap
UINT16 usWinAscent
UINT16 usWinDescent
UINT32 ulCodePageRange1
UINT32 ulCodePageRange2
INT16 sxHeight
INT16 sCapHeight
UINT16 usDefaultChar
UINT16 usBreakChar
UINT16 usMaxContext
版本3
版本3在OpenType 1.4中定义。版本3与版本4具有相同的字段,与版本2中的字段相同。虽然新版本的字段未添加到版本2中,但某些字段的规范已经过修改,以反映Uniode 3.2中的更改。版本3的格式与上面给出的版本4的格式相同。
版本2
版本2在OpenType 1.1中定义。版本2具有与版本3中相同的字段,以及除版本1之外的五个附加字段。版本2的格式与上面给出的版本4的格式相同。
版本1
版本1在TrueType版本1.66中定义。版本1比版本2少五个字段,除了版本0之外还有两个附加字段。版本1的格式如下:
类型 名称
UINT16 版
INT16 xAvgCharWidth
UINT16 usWeightClass
UINT16 usWidthClass
UINT16 文件系统类型
INT16 ySubscriptXSize
INT16 ySubscriptYSize
INT16 ySubscriptXOffset
INT16 ySubscriptYOffset
INT16 ySuperscriptXSize
INT16 ySuperscriptYSize
INT16 ySuperscriptXOffset
INT16 ySuperscriptYOffset
INT16 yStrikeoutSize
INT16 yStrikeoutPosition
INT16 sFamilyClass
UINT8 潘糖[10]
UINT32 ulUnicodeRange1
UINT32 ulUnicodeRange2
UINT32 ulUnicodeRange3
UINT32 ulUnicodeRange4
标签 achVendID
UINT16 fsSelection
UINT16 usFirstCharIndex
UINT16 usLastCharIndex
INT16 sTypoAscender
INT16 sTypoDescender
INT16 sTypoLineGap
UINT16 usWinAscent
UINT16 usWinDescent
UINT32 ulCodePageRange1
UINT32 ulCodePageRange2
版本0
版本0在TrueType版本1.5中定义。版本0的格式如下:
类型 名称
UINT16 版
INT16 xAvgCharWidth
UINT16 usWeightClass
UINT16 usWidthClass
UINT16 文件系统类型
INT16 ySubscriptXSize
INT16 ySubscriptYSize
INT16 ySubscriptXOffset
INT16 ySubscriptYOffset
INT16 ySuperscriptXSize
INT16 ySuperscriptYSize
INT16 ySuperscriptXOffset
INT16 ySuperscriptYOffset
INT16 yStrikeoutSize
INT16 yStrikeoutPosition
INT16 sFamilyClass
UINT8 潘糖[10]
UINT32 ulUnicodeRange1
UINT32 ulUnicodeRange2
UINT32 ulUnicodeRange3
UINT32 ulUnicodeRange4
标签 achVendID
UINT16 fsSelection
UINT16 usFirstCharIndex
UINT16 usLastCharIndex
INT16 sTypoAscender
INT16 sTypoDescender
INT16 sTypoLineGap
UINT16 usWinAscent
UINT16 usWinDescent
注意:Apple的TrueType参考手册中的 OS / 2版本0的文档在usLastCharIndex字段处停止,并且不包括Microsoft定义的表的最后五个字段。某些传统的TrueType字体可能是使用缩短版本0 OS / 2表构建的。在读取这些字段之前,应用程序应检查版本0 OS / 2表的表长度。
7.39.2.OS/2 Field Details
本节提供了涵盖OS / 2表的所有版本的详细信息。
版
格式: UINT16
单位: N / A
标题: OS / 2表版本号。
描述: OS / 2表的版本号:0x0000到0x0005。
评论: 版本号允许识别OS / 2表的精确内容和布局。
xAvgCharWidth
格式: INT16
单位: 字体设计单位
标题: 平均加权擒纵机构。
描述: “平均字符宽度”参数指定字体中所有非零宽度字形的擒纵(宽度)的算术平均值。
评论: 通过获取字体中所有非零宽度字形宽度的算术平均值来计算xAvgCharWidth的值。此外,强烈建议实施者不要依赖此值来计算文本行的布局,尤其是在使用复杂脚本的情况下。
版本差异: 版本0到2:首次定义时,规范偏向于基本拉丁字符,并且认为xAvgCharWidth值可用于估计文本行的平均长度。使用小写字母a-z的使用频率加权因子提供了用于计算xAvgCharWidth的公式。这种计算该字段值的方法在OpenType 1.4中被取代,引入了OS / 2表的版本3。
usWeightClass
格式: UINT16
标题: 重量级。
描述: 表示字体中字符的视觉权重(黑度或笔画粗细)。值1到1000有效。
评论: usWeightClass值使用与’wght’轴相同的比例,该轴在变量字体的’fvar’表和STAT表中使用。虽然支持1到1000之间的整数值,但某些传统平台可能对受支持的值有限制。以下是常用值:
值 描述 C定义(来自windows.h)
100 瘦 FW_THIN
200 超轻(超轻) FW_EXTRALIGHT
300 光 FW_LIGHT
400 正常(常规) FW_NORMAL
500 介质 FW_MEDIUM
600 半粗体(黛米粗体) FW_SEMIBOLD
700 胆大 FW_BOLD
800 超粗体(超粗体) FW_EXTRABOLD
900 黑色(重) FW_BLACK
usWidthClass
格式: UINT16
标题: 宽度类。
描述: 表示字体设计者为字体中的字形指定的正常宽高比(宽高比)的相对变化。
评论: 尽管字体中的每个字形可能具有不同的数字宽高比,但是正常宽度字体中的每个字形被认为具有相对宽高比为1。当创建不同宽度类的新类型样式时(通过字体设计器或通过某些自动方式),新字体中字符的相对宽高比大于或小于普通字体中相同字符的百分比 - 这个参数指定的是这个差异。
有效的usWidthClass值显示在下表中。请注意,usWidthClass值与变量字体的’fvar’表和STAT中使用的’wdth’轴的比例相关但不同。表。下表中的“%of normal”列提供了从usWidthClass值1 - 9到’wdth’值的映射。
值 描述 C定义 正常的百分比
1 超浓缩 FWIDTH_ULTRA_CONDENSED 50
2 超浓缩 FWIDTH_EXTRA_CONDENSED 62.5
3 简明 FWIDTH_CONDENSED 75
4 半浓缩 FWIDTH_SEMI_CONDENSED 87.5
五 中(正常) FWIDTH_NORMAL 100
6 半发泡 FWIDTH_SEMI_EXPANDED 112.5
7 扩展 FWIDTH_EXPANDED 125
8 额外的扩展 FWIDTH_EXTRA_EXPANDED 150
9 超扩展 FWIDTH_ULTRA_EXPANDED 200
文件系统类型
格式: UINT16
标题: 输入标志。
描述: 表示字体嵌入字体的许可权限。标志的解释如下:
位(S) 面具 描述
0 - 3 0x000F 使用权限。有效字体必须至少设置位1,2或3中的一个; 位0是永久保留的,必须为零。此子字段的有效值为0,2,4或8.这些值的含义如下:
0:可安装嵌入:可以嵌入字体,可以永久安装以在远程系统上使用,或者用于由其他用户使用。远程系统的用户获得与该字体的原始购买者相同的该字体的权利,义务和许可,并且受到与原始用户相同的最终用户许可协议,版权,外观设计专利和/或商标的约束。购买者。
2:受限制的许可证嵌入:未经合法所有者的明确许可,不得以任何方式修改,嵌入或交换字体。
4:预览和打印嵌入:可以嵌入字体,并且可以临时加载到其他系统上以便查看或打印文档。包含预览和打印字体的文档必须以“只读”方式打开; 不能对文档应用任何编辑。
8:可编辑嵌入:可以嵌入字体,并且可以临时加载到其他系统上。与预览和打印嵌入一样,可以打开包含可编辑字体的文档以供阅读。此外,允许编辑,包括使用嵌入字体格式化新文本的功能,并且可以保存更改。
4 - 7 保留,必须为零。
8 0100 无子集:当设置此位时,在嵌入之前可能不会对字体进行子集化。位0到3和位9中指定的其他嵌入限制也适用。
9 0200 仅位图嵌入:设置此位时,只能嵌入字体中包含的位图。不能嵌入轮廓数据。如果字体中没有可用的位图,则该字体将被视为不可嵌入,并且嵌入服务将失败。位0-3和8中指定的其他嵌入限制也适用。
10 - 15 保留,必须为零。
评论: 可嵌入字体可以存储在文档中。当在没有安装字体的系统(远程系统)上打开具有嵌入字体的文档时,可以通过嵌入感知应用程序加载嵌入字体以临时(在某些情况下,永久)在该系统上使用。嵌入许可权利由字体的供应商授予。
实现字体嵌入支持的应用程序不得嵌入未经许可允许嵌入的字体。此外,在将字体嵌入文档时,应用程序不得修改此字段中指示的嵌入权限和限制。此外,加载嵌入式字体以供临时使用的应用程序(预览和打印或可编辑嵌入)必须关闭包含嵌入字体的文档时删除字体。
位0到3(嵌入权限子字段)是互斥的:字体永远不应该设置多个这些位。请注意,如果设置了两个或更多位,则某些应用程序可能会假定指示的限制最少的权限。(有关更多讨论,请参阅版本差异。)注意:字体供应商负责正确设置这些位以获得所需的应用程序行为。要使限制许可证嵌入生效,嵌入权限子字段必须具有值2(即,仅设置位1)。
注意: Apple的TrueType参考手册指定fsType字段的第1位,并且仅指定第1位,因为具有指定的语义。这源于OS / 2表的预发布草案规范。但是,OS / 2表的版本0的最终规范定义了位0到3.此外,一些早期字体实现错误地使用值1(位0集),导致非互操作性的问题。因此,在版本0的最终规范中将位0指定为保留。位0是永久保留的,不推荐使用它。
版本差异: 版本0到1:仅分配了0到3位。在读取版本0或版本1表时,应用程序必须忽略位4到15。
版本0到2:版本0到2的规范未指定位0到3必须互斥。相反,那些规范声明,如果在给定字体中设置了多于一个的位0到3,则指示的最小限制性许可优先。特别是,使用版本0到版本2 OS / 2表的某些字体同时设置了位2和位3,意图指示预览/打印和编辑权限。允许应用程序对具有版本0到版本2 OS / 2表的字体使用此行为。
版本3及更高版本: 在OpenType 1.4中添加的版本3的规范引入了明确的要求,即位0到3必须是互斥的。
ySubscriptXSize
格式: INT16
单位: 字体设计单位
标题: 下标水平字体大小。
描述: 字体设计单位的推荐水平尺寸,用于此字体的下标。
评论: 如果字体有两个推荐的下标大小,例如数字和其他,则应强调数字大小。此大小字段映射到用于下标的字体的em大小。水平字体大小指定字体设计者建议的与此字体关联的下标字形的水平尺寸。如果字体不包含应用程序的所有必需下标字形,并且应用程序可以通过缩放字体的字形或通过替换另一种字体的字形来替换字形,则此参数指定这些下标字形的建议标称宽度。
例如,如果字体的em为2048个单位且ySubScriptXSize设置为205,则模拟下标字形的水平大小将是正常字形大小的1/10。
ySubscriptYSize
格式: INT16
单位: 字体设计单位
标题: 下标垂直字体大小。
描述: 此字体下标的字体设计单位的建议垂直大小。
评论: 如果字体有两个推荐的下标大小,例如数字和其他,则应强调数字大小。此大小字段映射到用于下标的字体的em大小。垂直字体大小指定字体设计者对与此字体关联的下标字形的垂直大小的建议。如果字体不包含应用程序的所有必需下标字形,并且应用程序可以通过缩放字体中的字形或通过替换另一种字体的字形来替换字形,则此参数指定这些下标字形的建议标称高度。
例如,如果字体的em为2048个单位且ySubScriptYSize设置为205,则模拟下标字形的垂直大小将是正常字形大小的1/10。
ySubscriptXOffset
格式: INT16
单位: 字体设计单位
标题: 下标x偏移量。
描述: 此字体下标的字体设计单位中建议的水平偏移量。
评论: 下标X偏移参数指定字体设计者建议的水平偏移 - 从字形原点到下标字形的字形原点 - 用于与此字体关联的下标字形。如果字体不包含应用程序的所有必需下标字形,并且应用程序可以替换字形,则此参数指定从第一个下标字形之前的最后一个字形的字形转义点开始的建议水平位置。对于直立字形,此值通常为零; 但是,如果字体的字形具有倾斜(斜体或倾斜),则通常会调整下标字形的参考点以补偿倾斜角度。
ySubscriptYOffset
格式: INT16
单位: 字体设计单位
标题: 下标y偏移量。
描述: 字体设计单位中建议的垂直偏移量,该字体的下标基线。
评论: 下标Y偏移量参数指定字体设计者建议的从字形基线到与该字体关联的下标字形的字形基线的垂直偏移。值表示为字形基线以下的正偏移量。如果字体不包含应用程序的所有必需下标字形,则此参数指定这些下标字形的字形基线下方的建议垂直距离。
ySuperscriptXSize
格式: INT16
单位: 字体设计单位
标题: 上标水平字体大小。
描述: 此字体的上标的字体设计单位的建议水平尺寸。
评论: 如果字体有两个推荐的上标大小,例如数字和其他,则应强调数字大小。此大小字段映射到用于上标的字体的em大小。水平字体大小指定字体设计者建议的与此字体关联的上标字形的水平尺寸。如果字体不包含应用程序的所有必需上标字形,并且应用程序可以通过缩放字体的字形或通过替换另一种字体的字形来替换字形,则此参数指定这些上标字形的建议标称宽度。
例如,如果字体的em为2048个单位且ySuperScriptXSize设置为205,则模拟上标字形的水平大小将是正常字形大小的1/10。
ySuperscriptYSize
格式: INT16
单位: 字体设计单位
标题: 上标垂直字体大小。
描述: 此字体的上标的字体设计单位的建议垂直大小。
评论: 如果字体有两个推荐的上标大小,例如数字和其他,则应强调数字大小。此大小字段映射到用于上标的字体的em大小。垂直字体大小指定字体设计者建议的与此字体关联的上标字形的垂直大小。如果字体不包含应用程序的所有必需的上标字形,并且应用程序可以通过缩放字体的字形或通过替换另一种字体的字形来替换字形,则此参数指定这些上标字形的建议标称高度。
例如,如果字体的em为2048个单位且ySuperScriptYSize设置为205,则模拟上标字形的垂直大小将是正常字形大小的1/10。
ySuperscriptXOffset
格式: INT16
单位: 字体设计单位
标题: 上标x偏移量。
描述: 此字体上标的字体设计单位的建议水平偏移量。
评论: Superscript X Offset参数指定字体设计者建议的水平偏移 - 从字形的原点到与该字体关联的上标字符的上标字形的原点。如果字体不包含应用程序的所有必需上标字符,则此参数指定从第一个上标字符前的字符的转义点开始的建议水平位置。对于直立字符,此值通常为零; 但是,如果字体的字符具有倾斜(斜体字符),则通常会调整上标字符的参考点以补偿倾斜角度。
ySuperscriptYOffset
格式: INT16
单位: 字体设计单位
标题: 上标y抵消。
描述: 字体设计单位中建议的垂直偏移量与此字体的上标的基线相对应。
评论: Superscript Y Offset参数指定字体设计者建议的垂直偏移 - 从字形的基线到与该字体关联的上标字形的基线。此参数的值表示为字符基线上方的正偏移量。如果字体不包含应用程序的所有必需上标字符,则此参数指定这些上标字符的字符基线上方的建议垂直距离。
yStrikeoutSize
格式: INT16
单位: 字体设计单位
标题: 罢工大小。
描述: 字体设计单位中三角形笔划的粗细。
评论: 此字段通常应为当前字体的em破折号的厚度,并且还应与“post”表中指定的下划线粗细相匹配。
yStrikeoutPosition
格式: INT16
单位: 字体设计单位
标题: 罢工位置。
描述: 在字体设计单位中,三角形笔划顶部相对于基线的位置。
评论: 正值表示基线以上的距离; 负值表示低于基线的距离。建议将删除位置与em破折号对齐。但请注意,删除线位置不应干扰标准字符的识别,因此不应与字体中的交叉开关对齐。
sFamilyClass
格式: INT16
标题: 字体族和子类。
描述: 此参数是字体系列设计的分类。
评论: 字体类和字体子类是IBM为每个字体系列分配的注册值。此参数用于在请求的字体不可用时选择备用字体。字体类是最通用的,字体子类是最具体的。该字段的高字节包含族类,而低字节包含族子类。有关此字段的更多信息。
潘
格式: UINT8 [10]
标题: PANOSE分类号
国际: PANOSE需要附加规范来对非拉丁字符集进行分类。
描述: 这个10字节的数字系列用于描述给定字体的视觉特征。然后使用这些特征将字体与具有不同名称的类似外观的其他字体相关联。下面列出了每个数字的变量。Panose值在PANOSE分类度量指南中有详细描述,该指南目前由Monotype Imaging拥有,维护于https://monotype.github.io/panose/。
评论: PANOSE定义包含十个字节,每个字节可以有多个可能的值。请注意,第一个字节用于高级别分类“Family Kind”,并且剩余字节的解释取决于第一个字节的值。例如,如果Family Kind值为2(拉丁文本),则下一个字节指定“Serif Style”; 但如果Family Kind值为3(Latin Hand Written),则下一个字节指定“Tool Kind”。某些应用程序可能仅支持某些Family Kind值。下表给出了当Family Kind为Latin Text时panose数组的解释:
类型 名称
UINT8 bFamilyType;
UINT8 bSerifStyle;
UINT8 bWeight;
UINT8 bProportion;
UINT8 bContrast;
UINT8 bStrokeVariation;
UINT8 bArmStyle;
UINT8 bLetterform;
UINT8 bMidline;
UINT8 bXHeight;
某些应用程序可能会使用panose值进行字体选择,以选择与某些参数匹配的字体。例如,比例(对于Family Kind = Latin Text)可用于确定字体是否为等宽字体; 或Serif Style可用于确定字体是否属于通用serif或sans serif类。某些应用程序将使用Family Kind = 5(拉丁符号)来标识符号字体,这可能会影响字体选择或回退行为。应用程序应如何使用panose值没有要求。
在使用OpenType字体变体机制的可变字体中,无法为字体支持的不同实例表示不同的PANOSE值。可以基于默认实例设置PANOSE值。
版本差异: 该规范的早期版本提供了有关PANOSE值的更多详细信息。但是,上面引用的外部规范是规范性来源,应该参考这些细节。
ulUnicodeRange1(位0-31)
ulUnicodeRange2(位32-63)
ulUnicodeRange3(位64-95)
ulUnicodeRange4(位96-127)
格式: uint32 [4] - 总共128位。
标题: Unicode字符范围
描述: 此字段用于指定平台3的’cmap’子表中的字体文件所包含的Unicode块或范围,编码ID 1(Microsoft平台,Unicode BMP)和平台3,编码ID 10(Microsoft平台,Unicode完整指令集) 。如果设置了位(1),则分配给该位的Unicode范围被认为是有效的。如果该位清零(0),则该范围不被认为是有效的。每个比特被视为独立标志,并且可以以任何组合设置比特。“功能”的确定由字体设计者决定,尽管如果可能的话,字符集选择应该尝试按范围起作用。
所有保留字段必须为零。每个uint32都是Big-Endian形式。
位 Unicode范围 阻挡范围 笔记
0 基础拉丁语 0000-007F
1 Latin-1补充 0080-00FF
2 拉丁语扩展-A 0100-017F
3 Latin Extended-B 0180-024F
4 IPA扩展 0250-02AF
语音扩展 1D00-1D7F 在OS / 2版本4的OpenType 1.5中添加。
语音扩展补充 1D80-1DBF 在OS / 2版本4的OpenType 1.5中添加。
五 间距修改字母 02B0-02FF
修饰语音字母 A700-A71F 在OS / 2版本4的OpenType 1.5中添加。
6 结合变音符号 0300-036F
结合变音标记补充 1DC0-1DFF 在OS / 2版本4的OpenType 1.5中添加。
7 希腊语和科普特语 0370-03FF
8 科普特 2C80-2CFF 在OpenType 1.5 for OS / 2版本4中添加。请参阅下面的其他版本差异。
9 西里尔 0400-04FF
西里尔文补充 0500-052F 在OpenType 1.4 for OS / 2版本3中添加。
西里尔文扩展-A 2DE0-2DFF 在OS / 2版本4的OpenType 1.5中添加。
Cyrillic Extended-B A640-A69F 在OS / 2版本4的OpenType 1.5中添加。
10 亚美尼亚 0530-058F
11 希伯来语 0590-05FF
12 奥钢联 A500-A63F 在OpenType 1.5 for OS / 2版本4中添加。请参阅下面的其他版本差异。
13 阿拉伯 0600-06FF
阿拉伯文补编 0750-077F 在OS / 2版本4的OpenType 1.5中添加。
14 NKO 07C0-07FF 在OpenType 1.5 for OS / 2版本4中添加。请参阅下面的其他版本差异。
15 梵文 0900-097F
16 孟加拉 0980-09FF
17 古尔穆基 0A00-0A7F
18 古吉拉特语 0A80-0AFF
19 奥里亚语 0B00-0B7F
20 泰米尔人 0B80-0BFF
21 泰卢固语 0C00-0C7F
22 卡纳达语 0C80-0CFF
23 马拉雅拉姆语 0D00-0D7F
24 泰国 0E00-0E7F
25 老挝 0E80-0EFF
26 格鲁吉亚 10A0-10FF
格鲁吉亚补编 2D00-2D2F 在OS / 2版本4的OpenType 1.5中添加。
27 巴厘 1B00-1B7F 在OpenType 1.5 for OS / 2版本4中添加。请参阅下面的其他版本差异。
28 Hangul Jamo 1100-11FF
29 拉丁语扩展附加 1E00-1EFF
拉丁语扩展-C 2C60-2C7F 在OS / 2版本4的OpenType 1.5中添加。
Latin Extended-D A720-A7FF 在OS / 2版本4的OpenType 1.5中添加。
三十 希腊语扩展 1F00-1FFF
31 一般标点符号 2000-206F
补充标点符号 2E00-2E7F 在OS / 2版本4的OpenType 1.5中添加。
32 上标和下标 2070-209F
33 货币符号 20A0-20CF
34 结合变音符号的符号 20D0-20FF
35 字母符号 2100-214F
36 数字表格 2150-218F
37 箭头 2190-21FF
补充箭头-A 27F0-27FF 在OpenType 1.4 for OS / 2版本3中添加。
补充箭头-B 2900-297F 在OpenType 1.4 for OS / 2版本3中添加。
杂项符号和箭头 2B00-2BFF 在OS / 2版本4的OpenType 1.5中添加。
38 数学运算符 2200-22FF
补充数学运算符 2A00-2AFF 在OpenType 1.4 for OS / 2版本3中添加。
杂项数学符号-A 27C0-27EF 在OpenType 1.4 for OS / 2版本3中添加。
杂项数学符号-B 2980-29FF 在OpenType 1.4 for OS / 2版本3中添加。
39 杂项技术 2300-23FF
40 控制图片 2400-243F
41 光学字符识别 2440-245F
42 封闭的字母数字 2460-24FF
43 框图 2500-257F
44 块元素 2580-259F
45 几何形状 25A0-25FF
46 杂项符号 2600-26FF
47 装饰符号 2700-27BF
48 CJK符号和标点符号 3000-303F
49 平假名 3040-309F
50 片假名 30A0-30FF
片假名语音扩展 31F0-31FF 在OpenType 1.4 for OS / 2版本3中添加。
51 汉语拼音 3100-312F
Bopomofo扩展 31A0-31BF 在OpenType 1.3中添加,扩展OS / 2版本2。
52 韩文兼容性Jamo 3130-318F
53 八思巴 A840-A87F 在OpenType 1.5 for OS / 2版本4中添加。请参阅下面的其他版本差异。
54 随函附上CJK快报和月份 3200-32FF
55 CJK兼容性 3300-33FF
56 韩语音节 AC00-D7AF
57 非飞机0 10000-10FFFF 仅表示基本多语言平面之外的至少一个字符。首先在OpenType 1.3中为OS / 2版本2分配。
58 腓尼基 10900-1091F 首先在OpenType 1.5中为OS / 2版本4分配。
59 CJK统一表意文字 4E00-9FFF
CJK Radicals Supplement 2E80-2EFF 在OpenType 1.3 for OS / 2版本2中添加。
康熙激进派 2F00-2FDF 在OpenType 1.3 for OS / 2版本2中添加。
表意文字描述字符 2FF0-2FFF 在OpenType 1.3 for OS / 2版本2中添加。
中日韩统一表意文字扩展A 3400-4DBF 在OpenType 1.3 for OS / 2版本2中添加。
中日韩统一表意文字扩展B 20000-2A6DF 在OpenType 1.4 for OS / 2版本3中添加。
汉文 3190-319F 在OpenType 1.4 for OS / 2版本3中添加。
60 私人使用区域(0号飞机) E000-F8FF
61 CJK Strokes 31C0-31EF 在OS / 2版本4的OpenType 1.5中添加了范围。
CJK兼容性表意文字 F900-FAFF
CJK兼容性表意文字补充 2F800-2FA1F 在OpenType 1.4 for OS / 2版本3中添加。
62 字母表示形式 FB00-FB4F
63 阿拉伯语演讲表格-A FB50-FDFF
64 结合半标记 FE20-FE2F
65 垂直形式 FE10-FE1F 在OS / 2版本4的OpenType 1.5中添加了范围。
CJK兼容表格 FE30-FE4F
66 小型变体 FE50-FE6F
67 阿拉伯语演讲表格-B FE70-FEFF
68 半宽和全宽表格 FF00-FFEF
69 特价 FFF0-FFFF
70 藏 0F00-0FFF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
71 叙利亚 0700-074F 首先在OpenType 1.3中分配,扩展OS / 2版本2。
72 塔纳文 0780-07BF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
73 僧伽罗语 0D80-0DFF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
74 缅甸 1000-109F 首先在OpenType 1.3中分配,扩展OS / 2版本2。
75 衣索比亚 1200-137F 首先在OpenType 1.3中分配,扩展OS / 2版本2。
Ethiopic补充 1380-139F 在OS / 2版本4的OpenType 1.5中添加。
Ethiopic扩展 2D80-2DDF 在OS / 2版本4的OpenType 1.5中添加。
76 切诺基 13A0-13FF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
77 统一的加拿大原住民音节 1400-167F 首先在OpenType 1.3中分配,扩展OS / 2版本2。
78 欧甘文 1680-169F 首先在OpenType 1.3中分配,扩展OS / 2版本2。
79 符文 16A0-16FF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
80 高棉 1780-17FF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
高棉符号 19E0-19FF 在OS / 2版本4的OpenType 1.5中添加。
81 蒙 1800-18AF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
82 盲文模式 2800-28FF 首先在OpenType 1.3中分配,扩展OS / 2版本2。
83 彝族音节 A000-A48F 首先在OpenType 1.3中分配,扩展OS / 2版本2。
Yi Radicals A490-A4CF 在OpenType 1.3中添加,扩展OS / 2版本2。
84 他加禄语 1700-171F 首先在OpenType 1.4中为OS / 2版本3分配。
哈努诺文 1720-173F 在OpenType 1.4 for OS / 2版本3中添加。
布迪文 1740-175F 在OpenType 1.4 for OS / 2版本3中添加。
塔格巴努亚文 1760-177F 在OpenType 1.4 for OS / 2版本3中添加。
85 旧斜体 10300-1032F 首先在OpenType 1.4中为OS / 2版本3分配。
86 哥特 10330-1034F 首先在OpenType 1.4中为OS / 2版本3分配。
87 犹他州 10400-1044F 首先在OpenType 1.4中为OS / 2版本3分配。
88 拜占庭音乐符号 1D000-1D0FF 首先在OpenType 1.4中为OS / 2版本3分配。
音乐符号 1D100-1D1FF 在OpenType 1.4 for OS / 2版本3中添加。
古希腊音乐符号 1D200-1D24F 在OS / 2版本4的OpenType 1.5中添加。
89 数学字母数字符号 1D400-1D7FF 首先在OpenType 1.4中为OS / 2版本3分配。
90 私人使用(飞机15) F0000-FFFFD 首先在OpenType 1.4中为OS / 2版本3分配。
私人使用(飞机16) 100000-10FFFD 在OpenType 1.4 for OS / 2版本3中添加。
91 变异选择器 FE00-FE0F 首先在OpenType 1.4中为OS / 2版本3分配。
变异选择器补充 E0100-E01EF 在OpenType 1.4 for OS / 2版本3中添加。
92 标签 E0000-E007F 首先在OpenType 1.4中为OS / 2版本3分配。
93 林布 1900-194F 首先在OpenType 1.5中为OS / 2版本4分配。
94 泰乐 1950-197F 首先在OpenType 1.5中为OS / 2版本4分配。
95 新泰略 1980-19DF 首先在OpenType 1.5中为OS / 2版本4分配。
96 布吉文 1A00-1A1F 首先在OpenType 1.5中为OS / 2版本4分配。
97 格拉哥里 2C00-2C5F 首先在OpenType 1.5中为OS / 2版本4分配。
98 提弗纳文 2D30-2D7F 首先在OpenType 1.5中为OS / 2版本4分配。
99 易经卦符号 4DC0-4DFF 首先在OpenType 1.5中为OS / 2版本4分配。
100 Syloti Nagri A800-A82F 首先在OpenType 1.5中为OS / 2版本4分配。
101 线性B音节 10000-1007F 首先在OpenType 1.5中为OS / 2版本4分配。
线性B表意文字 10080-100FF 在OS / 2版本4的OpenType 1.5中添加。
爱琴海数字 10100-1013F 在OS / 2版本4的OpenType 1.5中添加。
102 古希腊数字 10140-1018F 首先在OpenType 1.5中为OS / 2版本4分配。
103 乌加里特 10380-1039F 首先在OpenType 1.5中为OS / 2版本4分配。
104 老波斯语 103A0-103DF 首先在OpenType 1.5中为OS / 2版本4分配。
105 萧伯纳 10450-1047F 首先在OpenType 1.5中为OS / 2版本4分配。
106 奥斯曼亚语 10480-104AF 首先在OpenType 1.5中为OS / 2版本4分配。
107 塞浦路斯音节 10800-1083F 首先在OpenType 1.5中为OS / 2版本4分配。
108 卡罗须提文 10A00-10A5F 首先在OpenType 1.5中为OS / 2版本4分配。
109 大玄经符号 1D300-1D35F 首先在OpenType 1.5中为OS / 2版本4分配。
110 楔形的 12000-123FF 首先在OpenType 1.5中为OS / 2版本4分配。
楔形文字数和标点符号 12400-1247F 在OS / 2版本4的OpenType 1.5中添加。
111 计数棒数字 1D360-1D37F 首先在OpenType 1.5中为OS / 2版本4分配。
112 巽 1B80-1BBF 首先在OpenType 1.5中为OS / 2版本4分配。
113 雷布查 1C00-1C4F 首先在OpenType 1.5中为OS / 2版本4分配。
114 Ol Chiki 1C50-1C7F 首先在OpenType 1.5中为OS / 2版本4分配。
115 索拉什特拉 A880-A8DF 首先在OpenType 1.5中为OS / 2版本4分配。
116 凯莉莉 A900-A92F 首先在OpenType 1.5中为OS / 2版本4分配。
117 拉让 A930-A95F 首先在OpenType 1.5中为OS / 2版本4分配。
118 湛 AA00-AA5F 首先在OpenType 1.5中为OS / 2版本4分配。
119 古代符号 10190-101CF 首先在OpenType 1.5中为OS / 2版本4分配。
120 Phaistos Disc 101D0-101FF 首先在OpenType 1.5中为OS / 2版本4分配。
121 卡里亚 102A0-102DF 首先在OpenType 1.5中为OS / 2版本4分配。
利西亚 10280-1029F 在OS / 2版本4的OpenType 1.5中添加。
吕底亚 10920-1093F 在OS / 2版本4的OpenType 1.5中添加。
122 多米诺瓷砖 1F030-1F09F 首先在OpenType 1.5中为OS / 2版本4分配。
麻将牌 1F000-1F02F 首先在OpenType 1.5中为OS / 2版本4分配。
123-127 保留用于进程内部使用
评论: 从Unicode 5.1开始,所有可用位都已耗尽。在OpenType 1.5中,OS / 2版本4的位分配最后更新。当前版本的Unicode中支持许多其他范围,OS / 2表中的这些字段不支持这些范围。请参阅“meta”表中的“dlng”和“slng”标记,以获取另一种机制,以声明字体可以支持或设计的脚本或语言。
版本差异: 当不同的Unicode版本是最新版本时,创建了OS / 2表的不同版本,并且给定版本的初始规范定义的位分配比后续版本少。某些应用程序可能不支持具有早期OS / 2版本的字体的所有分配。
上面列出的所有位分配对OS / 2表的任何版本都有效,但OS / 2版本1和2指定了一些与明确定义的Unicode范围不对应且与后续分配冲突的分配 - 请参阅详情如下。如果字体具有版本1或版本2 OS / 2表,其中设置了这些位之一,则过时的分配可能是预期的解释。但是,由于这些分配与明确定义的范围不对应,因此隐含的字符覆盖范围不明确。
版本0:首次指定版本0时,未定义任何位分配。某些应用程序可能会忽略版本0 OS / 2表中的这些字段。
版本1:
版本1首先与Unicode 1.1同时指定,并且仅为位0到69定义了位分配。对于具有版本1表的字体,某些应用程序可能只识别0到69位。
此外,版本1指定了一些与明确定义的Unicode范围不对应的位分配:
第8位:“希腊符号和科普特语”(第7位被指定为“基本希腊语”)
第12位:“希伯来语扩展”(第11位被指定为“基本希伯来语”)
位14:“阿拉伯语扩展”(第13位被指定为“基本阿拉伯语”)
第27位:“格鲁吉亚扩展”(第26位被指定为“基本格鲁吉亚语”)
从版本2开始
,这些分配已停止。 此外,版本1和版本2定义为位53指定为“CJK杂项”,它也不对应任何明确定义的Unicode范围。从版本3开始,此分配已停止。
版本2:
版本2在OpenType 1.1中定义,与Unicode 2.1并发。此时,仅为位0到69定义了位分配。版本2的位分配在OpenType 1.3中更新,添加了对应于Unicode 2.0和Unicode 3.0中分配的新块的位70到83的分配。对于具有版本2表的字体,某些应用程序可能只识别在OpenType 1.2或OpenType 1.3中分配的那些位。
此外,版本2的规范继续对第53位使用有问题的分配 - 请参阅版本1的详细信息。从版本3开始,此分配已停止。
版本3:版本3在OpenType 1.4中定义,其中第84至91位的分配对应到Unicode 3.2中的其他范围。此外,一些已经分配的位被扩展为覆盖相关字符的附加Unicode范围; 请参阅上表中的详细信息。
第4版:版本4在OpenType 1.5中定义,其中第58位和第92至122位的分配对应于Unicode 5.1中的其他范围。此外,还重新分配了位8,12,14,27和53(参见先前分配的版本1)。此外,一些已经分配的位被扩展为覆盖相关字符的附加Unicode范围; 请参阅上表中的详细信息。
achVendID
格式: 标签
标题: 字体供应商标识
描述: 给定类型的供应商的四字符标识符。
评论: 这不是原始艺术品的版税所有者。这是负责正在分类的字体的营销和分发的公司。例如,可能有多家ITC Zapf Dingbats供应商,一些供应商在其字体中提供差异化的好处(更多的kern对,非正规数据,手提示等)。此标识符将允许使用正确的供应商类型而不是另一个可能较差的字体文件。
Microsoft维护供应商ID的注册表。注册的ID必须对单个供应商是唯一的。也可以使用未注册的ID,但不鼓励:强烈建议供应商注册ID以确保不同供应商之间在使用给定ID时没有冲突,并且客户能够找到供应商的联系信息。给定字体。此字段也可以留空(设置为null,或者由四个空格字符组成的标记)。
所有供应商ID都使用Tag数据类型,该类型相当于由一组有限的ASCII字符组成的四字符字符串。有关Tag数据类型的详细信息,请参阅数据类型。按照惯例,只有注册的标签应该只包含大写字母(或空格)。
有关已注册供应商ID的列表,或有关注册供应商ID或更新供应商信息的详细信息,请参阅已注册的排版供应商。
fsSelection
格式: UINT16
标题: 字体选择标志。
描述: 包含有关字体模式性质的信息,如下所示:
位# macStyle位 C定义 描述
0 第1位 ITALIC 字体包含斜体或斜体字形,否则它们是直立的。
1 UNDERSCORE 字形被强调。
2 负 字形的前景和背景相反。
3 概述 轮廓(空心)字形,否则它们是实心的。
4 三振出局 字形是过度的。
五 位0 胆大 字形是胆大的。
6 定期 字形是字体的标准重量/样式。
7 USE_TYPO_METRICS 如果设置,强烈建议应用程序使用OS / 2.sTypoAscender - OS / 2.sTypoDescender + OS / 2.sTypoLineGap作为此字体的默认行间距。
8 WWS 该字体具有与重量/宽度/坡度系列一致的“名称”表格字符串,无需使用名称ID 21和22.(请参阅下面的更详细说明。)
9 斜 字体包含倾斜的字形。
10-15 <保留> 保留; 设为0。
评论: 所有未定义的位必须为零。
位0:位0的设置必须与’head’表的macStyle字段中位1的设置相匹配。
位1 - 4:位1 - 4是很少使用的位,表示字体主要是装饰或专用字体。
位5:位5的设置必须与’head’表的macStyle字段中位0的设置相匹配。
位6: 如果第6位置1,则必须清零第0位和第5位,否则行为未定义。注意,如果位0和位5都清零,则不会给出关于位6是否清零的任何指示。例如,Arial Light不是Arial的常规样式,并且会清除所有位。
第7位:
第7版在版本4中定义。对于新字体,鼓励供应商使用版本4或更高版本的OS / 2表并设置第7位。
如果使用早期版本的OS / 2表创建了字体并将其更新为当前版本的OS / 2表,则设置位7可能会创建使用字体的现有文档的重排的可能性。为了最大限度地降低这种风险,只有在使用OS / 2.usWin *线条高度指标时,才会设置该位,这会比使用OS / 2.sTypo *值产生明显更差的结果。
位8:
如果设置了位8,则提供家族和子系列的“名称”表字符串,其与权重/宽度/斜率族系列模型一致,而不需要使用名称ID 21或22。
许多印刷族包含仅在权重,宽度和斜率中的一个或多个属性上不同的面。即使一个家庭可能拥有大量的成员面孔,如果这些变体仅属于这些属性,那么使用ID 1和2或16和17在“名称”表中提供的族和子家族名称将与权重/一致宽度/斜率族模型。在这种情况下,应设置位8,并且不应包括名称ID 21和22的“名称”条目。
一些印刷系列包括除了重量,宽度或坡度之外的属性不同的面。例如,一个系列可能包括“手写”,“标题”,“显示”,“光学尺寸”等的变体。在这种情况下,一些构件面可能仅在重量,宽度或坡度上与常规面不同属性,而其他成员与其他属性的关系不同。这些成员面的字体与仅在重量,宽度或斜率上的常规字体不同,应该设置第8位,并且不应使用名称ID 21或22.但是那些不同于常规的成员面的字体在其他属性方面不应该有8位设置,他们应该使用名称ID 21和22将这些面映射到符合WWS的家庭模型。
因此,如果字体具有版本4或更高版本的OS / 2表,则当且仅当ID 16和17的“名称”条目与WWS模型一致且不包括ID 21和22的条目时,应设置位8 。相反,如果未设置位8,则将解释为表示ID 16和17提供的名称与WWS模型不一致,并且包括ID 21和22的“名称”条目。
在此上下文中,“印刷族”是名称ID 16的Microsoft Unicode字符串(如果存在),否则是名称ID 1的Microsoft Unicode字符串; “weight”是OS / 2.usWeightClass; “width”是OS / 2.usWidthClass; “slope”是OS / 2.fsSelection位0(ITALIC)和位9(OBLIQUE)。
第9位:
如果设置了第9位,则该字体将被视为“倾斜”样式,这些过程区分倾斜和斜体样式,例如层叠样式表字体匹配。例如,通过算法倾斜直立面创建的字体将设置此位。
如果字体具有版本4或更高版本的OS / 2表并且未设置此位,则该字体不应被视为“倾斜”样式。例如,具有经典斜体设计的字体不会设置此位。
与ITALIC位(位0)不同,该位与假定由常规,斜体,粗体和粗体斜体组成的四成员字体系列模型的应用程序中的样式链接无关。它可以独立于ITALIC位设置或取消设置。在大多数情况下,如果设置了OBLIQUE,那么也将设置ITALIC,尽管这不是必需的。
位15:位15永久保留。它已经在一些遗留实现中使用,并且可能在某些实现中导致特殊行为。不推荐使用此位。
版本差异: 版本0到3:仅分配位0(斜体)到位6(常规)。第7位至第15位保留,必须设置为0.应用程序应忽略具有版本0到版本3 OS / 2表的字体中的位7到15。
版本4到5:版本4(OpenType 1.5)中定义了第7到9位。第10至15位保留,必须设置为0.应用程序应忽略具有版本4或版本5 OS / 2表的字体中的位10到15。
usFirstCharIndex
格式: UINT16
描述: 此字体中的最小Unicode索引(字符代码),根据平台ID 3的“cmap”子表和平台特定的编码ID 0或1.对于支持Win-ANSI或其他字符集的大多数字体,此值将为0x0020 。该字段不能表示补充字符值(代码点大于0xFFFF)。如果最小索引值是补充字符,则支持增补字符的字体应将此字段中的值设置为0xFFFF。
usLastCharIndex
格式: UINT16
描述: 此字体中的最大Unicode索引(字符代码),根据平台ID 3的“cmap”子表和编码ID 0或1.此值取决于字体支持的字符集。该字段不能表示补充字符值(代码点大于0xFFFF)。支持增补字符的字体应将此字段中的值设置为0xFFFF。
sTypoAscender
格式: INT16
描述: 这种字体的印刷上升器。此字段应与sTypoDescender和sTypoLineGap值组合以确定默认行间距。
此字段类似于’hhea’表中的ascender字段以及此表中的usWinAscent字段。但是,传统平台实现将这些字段用于特定于平台的行为。因此,这些字段受到向后兼容性要求的限制,并且不能确保跨实现的一致布局。sTypoAscender,sTypoDescender和sTypoLineGap字段旨在允许应用程序以印刷正确和便携的方式布置文档。
fsSelection字段的USE_TYPO_METRICS标志(位7)用于在使用sTypo *值或usWin *值之间进行选择,以用于默认线度量。有关其他详细信息,请参阅fsSelection。
一般要求sTypoAscender - sTypoDescender等于unitsPerEm。应设置这些值以提供适合字体旨在支持的主要语言的默认行间距。
对于旨在用于垂直(以及水平)布局的CJK(中文,日文和韩文)字体,sTypoAscender所需的值是描述表意文字框顶部的值。。例如,如果字体的表意符号框从坐标0,-120延伸到1000,880(即,1000×1000框设置120个设计单位低于拉丁基线),则必须设置sTypoAscender的值到880.如果不遵守这些要求,将导致垂直布局不正确。 有关此字段的更多信息,
另请参阅建议部分。
sTypoDescender
格式: INT16
描述: 这种字体的印刷下降器。此字段应与sTypoAscender和sTypoLineGap值组合以确定默认行间距。
此字段类似于’hhea’表中的下降字段以及此表中的usWinDescent字段。但是,传统平台实现将这些字段用于特定于平台的行为。因此,这些字段受到向后兼容性要求的限制,并且不能确保跨实现的一致布局。sTypoAscender,sTypoDescender和sTypoLineGap字段旨在允许应用程序以印刷正确和便携的方式布置文档。
fsSelection字段的USE_TYPO_METRICS标志(位7)用于在使用sTypo *值或usWin *值之间进行选择,以用于默认线度量。有关其他详细信息,请参阅fsSelection。
一般要求sTypoAscender - sTypoDescender等于unitsPerEm。应设置这些值以提供适合字体旨在支持的主要语言的默认行间距。
对于旨在用于垂直(以及水平)布局的CJK(中文,日文和韩文)字体,sTypoDescender所需的值是描述表意文字框的底部的值。。例如,如果字体的表意符号框从坐标0,-120延伸到1000,880(即1000×1000框设置120个设计单位低于拉丁基线),则必须设置sTypoDescender的值到-120。如果不遵守这些要求,将导致垂直布局不正确。 有关此字段的更多信息,
另请参阅建议部分。
sTypoLineGap
格式: INT16
描述: 此字体的印刷线间隙。此字段应与sTypoAscender和sTypoDescender值组合以确定默认行间距。
该字段类似于’hhea’表中的lineGap字段。但是,传统平台实现会使用特定于平台的行为来处理该字段。因此,该字段受向后兼容性要求的约束,并且无法确保跨实现的一致布局。sTypoAscender,sTypoDescender和sTypoLineGap字段旨在允许应用程序以印刷正确和便携的方式布置文档。
fsSelection字段的USE_TYPO_METRICS标志(位7)用于在使用sTypo *值或usWin *值之间进行选择,以用于默认线度量。见fsSelection 了解更多细节。
usWinAscent
格式: UINT16
描述: “Windows ascender”指标。这应该用于指定剪裁区域的基线上方的高度。
这类似于sTypoAscender字段,也类似于’hhea’表中的ascender字段。然而,这些之间存在重要差异。
在Windows GDI实现中,usWinAscent和usWinDescent值已用于确定TrueType光栅化器中位图表面的大小。Windows GDI将剪切出现在usWinAscent值上方的TrueType字形轮廓的任何部分。如果任何裁剪是不可接受的,则应将该值设置为大于或等于yMax。
注意:这适用于字形的默认位置,而不是它们在应用GPOS或“kern”表的数据后的布局中的最终位置。此外,此剪切行为还与VDMX表交互:如果存在VDMX表并且存在当前设备宽高比和光栅化大小的数据,则VDMX数据将取代usWinAscent和usWinDescent值。
某些遗留应用程序使用usWinAscent和usWinDescent值来确定默认行间距。强烈建议不要这样做。sTypo *字段应该用于此目的。
请注意,某些应用程序使用usWin *值或sTypo *值来确定默认行间距,具体取决于是否设置了fsSelection字段的USE_TYPO_METRICS标志(位7)。这可能有助于提供与使用旧字体的旧文档的兼容性,同时还使用较新的字体提供更好和更便携的布局。有关其他详细信息,请参阅fsSelection。
将sTypo *字段用于默认行间距的应用程序可以使用usWin *值来确定剪切区域的大小。某些应用程序使用剪切区域来编辑场景,以确定在编辑文本时要重绘的显示表面的哪个部分,或者在选择文本时要绘制的选择矩形的大小。这适用于usWin *值。
此规范的早期版本建议将usWinAscent值计算为Windows“ANSI”字符集中所有字符的yMax。对于新字体,应根据字体设计支持的主要语言确定值,并应考虑适应高字形或标记定位所需的额外高度。
usWinDescent
格式: UINT16
描述: “Windows下行”指标。这应该用于指定剪裁区域的基线下方的垂直范围。
这类似于sTypoDescender字段,也类似于’hhea’表中的下降字段。然而,这些之间存在重要差异。下面描述了这些差异中的一些。此外,usWinDescent值将基线以下的距离视为正值; 因此,usWinDescent通常是正值,而sTypoDescender和hhea.descender通常是负值。
在Windows GDI实现中,usWinDescent和usWinAscent值已用于确定TrueType光栅化器中位图表面的大小。Windows GDI将剪切下面显示的TrueType字形轮廓的任何部分(-1×usWinDescent)。如果任何裁剪是不可接受的,则应将该值设置为大于或等于(-yMin)。
注意:这与字形的默认位置有关,而不是在应用GPOS或“kern”表的数据后它们在布局中的最终位置。此外,此剪切行为还与VDMX表交互:如果存在VDMX表并且存在当前设备宽高比和光栅化大小的数据,则VDMX数据将取代usWinAscent和usWinDescent值。
某些遗留应用程序使用usWinAscent和usWinDescent值来确定默认行间距。强烈建议不要这样做。sTypo *字段应该用于此目的。
请注意,某些应用程序使用usWin *值或sTypo *值来确定默认行间距,具体取决于是否设置了fsSelection字段的USE_TYPO_METRICS标志(位7)。这可能有助于提供与使用旧字体的旧文档的兼容性,同时还使用较新的字体提供更好和更便携的布局。有关其他详细信息,请参阅fsSelection。
将sTypo *字段用于默认行间距的应用程序可以使用usWin *值来确定剪切区域的大小。某些应用程序使用剪切区域来编辑场景,以确定在编辑文本时要重绘的显示表面的哪个部分,或者在选择文本时要绘制的选择矩形的大小。这适用于usWin *值。
此规范的早期版本建议将usWinDescent值计算为Windows“ANSI”字符集中所有字符的-yMin。对于新字体,应根据字体设计支持的主要语言确定值,并应考虑适应具有低下划线或标记定位的字形所需的额外垂直范围。
ulCodePageRange1位0-31
ulCodePageRange2位32-63
格式: uint32 [2] - 总共64位。
标题: 代码页字符范围
描述: 此字段用于指定平台3的’cmap’子表中的字体文件所包含的代码页,编码ID 1(Microsoft平台,Unicode BMP)。如果字体文件的编码ID为0,则应设置符号字符集位。
如果设置了给定位(1),则认为代码页是有效的。如果该位清零(0)则代码页不被认为是有效的。每个比特被视为独立标志,并且可以以任何组合设置比特。“功能”的确定由字体设计者决定,尽管如果可能的话,字符集选择应该尝试通过代码页来起作用。
符号字符集具有特殊含义。如果设置符号位(31),并且字体文件包含平台3和编码ID为1的’cmap’子表,则Unicode范围0xF000 - 0xF0FF(包括)中的所有字符将用于枚举符号字符集。如果未设置该位,则该范围内的任何字符都不会被枚举为符号字符集。
所有保留字段必须为零。每个uint32都是Big-Endian形式。
位 代码页 描述
0 1252 拉丁文1
1 1250 拉丁文2:东欧
2 1251 西里尔
3 1253 希腊语
4 1254 土耳其
五 1255 希伯来语
6 1256 阿拉伯
7 1257 Windows波罗的海
8 1258 越南
9-15 保留用于备用ANSI
16 874 泰国
17 932 JIS /日本
18 936 中文:简化字符 - 中国和新加坡
19 949 韩国万松
20 950 中文:传统字符 - 台湾和香港
21 1361 韩国人Johab
22-28 保留用于备用ANSI或OEM
29 Macintosh字符集(美国罗马)
三十 OEM字符集
31 符号字符集
32-47 保留给OEM
48 869 IBM希腊语
49 866 MS-DOS俄语
50 865 MS-DOS北欧
51 864 阿拉伯
52 863 MS-DOS加拿大法语
53 862 希伯来语
54 861 MS-DOS冰岛语
55 860 MS-DOS葡萄牙语
56 857 IBM土耳其语
57 855 IBM西里尔文; 主要是俄语
58 852 拉丁文2
59 775 MS-DOS波罗的海
60 737 希腊语; 前437 G
61 708 阿拉伯; ASMO 708
62 850 WE /拉丁语1
63 437 我们
版本差异: 版本0:这些字段未在版本0中定义。如果版本0 OS / 2表的大小超出usWinDescent字段,则应忽略usWinDescent字段之外的其他数据。
版本1:版本1中未分配位8.所有其他当前分配的位在版本1中定义。
版本2及更高版本:所有当前分配的位在版本2中定义。
sxHeight
格式: INT16
描述: 此度量指定基线与在FUnits中测量的非升序小写字母的近似高度之间的距离。此值通常由类型设计者指定,但在无法实现的情况下,例如在转换旧字体时,可以将值设置为等于编码字形的未缩放和未显示的字形边界框的顶部在U + 0078(LATIN SMALL LETTER X)。如果在此位置没有编码字形,则字段应设置为0.
此指标(如果已指定)可用于字体替换:可以缩放一种字体的xHeight值以接近另一种字体的外观尺寸。
版本差异: 版本0,版本1:此版本未在版本0或版本1中定义。如果版本0 OS / 2表的大小超出usWinDescent字段,或者版本1 OS / 2表的大小超出了代码页范围字段,应忽略此附加数据。
版本2及更高版本:此字段在OS / 2表的版本2中定义。
sCapHeight
格式: INT16
描述: 此度量指定基线与在FUnits中测量的大写字母的近似高度之间的距离。此值通常由类型设计者指定,但在无法实现的情况下,例如在转换旧字体时,可以将值设置为等于编码字形的未缩放和未显示的字形边界框的顶部在U + 0048(LATIN CAPITAL LETTER H)。如果在此位置没有编码字形,则字段应设置为0.
此度量标准(如果已指定)可用于按以毫米为单位的资本高度指定类型大小的系统。它也可以用作对齐度量; 例如,丢弃资本的顶部可以与第一行文本的sCapHeight度量对齐。
版本差异: 版本0,版本1:此版本未在版本0或版本1中定义。如果版本0 OS / 2表的大小超出usWinDescent字段,或者版本1 OS / 2表的大小超出了代码页范围字段,应忽略此附加数据。
版本2及更高版本:此字段在OS / 2表的版本2中定义。
usDefaultChar
格式: UINT16
描述: 这是UTF-16编码中的Unicode代码点,如果字体中不支持请求的字符,则该字符可用于默认字形。如果此字段的值为零,则字形ID 0将用于默认字符。此字段不能表示补充平面字符值(代码点大于0xFFFF),因此强烈建议不要使用此字段。
版本差异: 版本0,版本1:此版本未在版本0或版本1中定义。如果版本0 OS / 2表的大小超出usWinDescent字段,或者版本1 OS / 2表的大小超出了代码页范围字段,应忽略此附加数据。
版本2及更高版本:此字段在OS / 2表的版本2中定义。
usBreakChar
格式: UINT16
描述: 这是UTF-16编码的Unicode代码点,可用作默认中断字符的字符。break字符用于分隔单词和对齐文本。大多数字体将U + 0020 SPACE指定为中断字符。此字段不能表示补充平面字符值(代码点大于0xFFFF),因此强烈建议不要使用此字段。
版本差异: 版本0,版本1:此版本未在版本0或版本1中定义。如果版本0 OS / 2表的大小超出usWinDescent字段,或者版本1 OS / 2表的大小超出了代码页范围字段,应忽略此附加数据。
版本2及更高版本:此字段在OS / 2表的版本2中定义。
usMaxContext
格式: UINT16
描述: 此字体中任何要素的目标字形上下文的最大长度。例如,仅具有成对字距调整功能的字体应将此字段设置为2.如果字体还具有连字特征,其中字形序列“ffi”由连字“ffi”替换,则应设置此字段这个领域可能对复杂的破线引擎有用,可以确定它们应该向前看多远,以测试某些东西是否会改变,从而影响断线。对于链接上下文查找,应考虑字符串的长度(覆盖字形)+(输入序列)+(超前序列)。
版本差异: 版本0,版本1:此版本未在版本0或版本1中定义。如果版本0 OS / 2表的大小超出usWinDescent字段,或者版本1 OS / 2表的大小超出了代码页范围字段,应忽略此附加数据。
版本2及更高版本:此字段在OS / 2表的版本2中定义。
usLowerOpticalPointSize
格式: UINT16
单位: TWIP为单位
描述: 此字段用于具有多种光学样式的字体。
此值是设计此字体的大小范围的较低值。该字段的单位是TWIP(一点二十分之一,或每英寸1440)。该值是包含的 - 意味着该字体被设计为在此点上最佳地工作,但不包括usUpperOpticalPointSize指示的点大小。当与同时指定usLowerOpticalPointSize和usUpperOpticalPointSize值的印刷系列中的其他光学尺寸变体字体一起使用时,可以预期另一种字体将usUpperOpticalPointSize字段设置为与此字段中的值相同的值,除非设计此字体适用于家庭中字体的最小尺寸范围。光学尺寸集中的最小字体应将此值设置为0。
usLowerOpticalPointSize值必须小于usUpperOpticalPointSize。最大有效值为0xFFFE。
对于不是为多个光学尺寸变体设计的字体,此字段应设置为0(零),并且usUpperOpticalPointSize应设置为0xFFFF。
注意: STAT表已取代此字段的使用。有关更多信息,请参阅建议部分。
版本差异: 版本0 - 4:版本0 - 4中未定义此字段。如果OS / 2表的大小超出为给定版本定义的最后一个字段,则应忽略此附加数据。
版本5:此字段在OS / 2表的版本5中定义。
usUpperOpticalPointSize
格式: UINT16
单位: TWIP为单位
描述: 此字段用于具有多种光学样式的字体。
此值是为此字体设计的大小范围的上限值。该字段的单位是TWIP(一点二十分之一,或每英寸1440)。该值是独占的 - 意味着该字体被设计为在此点大小以下工作到usLowerOpticalPointSize阈值。当与印刷族中的其他光学尺寸变体字体一起使用时,也指定usLowerOpticalPointSize和usUpperOpticalPointSize值,可以预期另一种字体将usLowerOpticalPointSize字段设置为与此字段中的值相同的值,除非设计此字体适用于家庭中字体的最大尺寸范围。光学大小集中的最大字体应将此值设置为0xFFFF,这被解释为无穷大。
usUpperOpticalPointSize值必须大于usLowerOpticalPointSize。该字段的最小有效值为2(两)。该字段代表的最大可能包含点大小为3276.65点; 任何更高的值都将表示为无穷大。
对于不是为多个光学尺寸变体设计的字体,此字段应设置为0xFFFF,而usLowerOpticalPointSize应设置为0(零)。
注意: STAT表已取代此字段的使用。有关更多信息,请参阅建议部分。
版本差异: 版本0 - 4:版本0 - 4中未定义此字段。如果OS / 2表的大小超出为给定版本定义的最后一个字段,则应忽略此附加数据。
版本5:此字段在OS / 2表的版本5中定义。
7.39.3.OS/2 Table and OpenType Font Variations
在可变字体中,应始终使用sTypoAscender,sTypoDescender和sTypoLineGap值设置默认线度量,并且应设置fsSelection字段中的USE_TYPO_METRICS标志。’hhea’表中的ascender,descender和lineGap字段应设置为与sTypoAscender,sTypoDescender和sTypoLineGap相同的值。usWinAscent和usWinDescent字段应该用于指定推荐的剪切矩形。
在可变字体中,可能需要针对不同的变体实例调整OS / 2表内的各种字体度量值。可以在度量变化(MVAR)表中提供OS / 2条目的变体数据。使用值标记将不同的OS / 2条目与MVAR表中的特定变体数据相关联,如下所示:
OS / 2条目 标签
sCapHeight ‘cpht’
sTypoAscender “众议院武装部队委员会”
sTypoDescender ‘HDSC’
sTypoLineGap ‘HLGP’
sxHeight ‘xhgt’
usWinAscent ‘hcla’
usWinDescent ‘HCLD’
yStrikeoutPosition ‘STRO’
yStrikeoutSize “可疑交易”
ySubscriptXOffset ‘sbxo’
ySubScriptXSize ‘sbxs’
ySubscriptYOffset ‘sbyo’
ySubscriptYSize ‘sbys’
ySuperscriptXOffset ‘SPXO’
ySuperscriptXSize ‘spxs’
ySuperscriptYOffset ‘spyo’
ySuperscriptYSize ‘spys’
注意: usWeightClass和usWidthClass值不会被变体数据调整,因为它们对应于’wght’和’wdth’变化轴,可用于定义字体的变化空间。变量实例的适当usWeightClass和usWidthClass值可以从用于选择特定变体实例的’wght’和’wdth’用户坐标导出。对于大于200的’wdth’值,usWidthClass值被限制为9.有关这些OS / 2字段之间关系的详细信息,请参阅OpenType Design-Variation Axis Tag Registry中 ‘wght’和’wdth’轴的讨论。和相应的设计轴。
注意:变量数据不会调整usLowerOpticalPointSize和usUpperOpticalPointSize值。这些值(现在由STAT表取代)用于指示已为其设计给定字体的一系列大小。假设使用’opsz’变化轴实现针对不同尺寸的变化。如果变量字体支持’opsz’作为变化轴,则可以将usLowerOpticalPointSize和usUpperOpticalPointSize字段设置为与’fvar’表中’opsz’轴的minValue和maxValue字段相同的值。
要在变量字体中包含可变线度量标准,应在MVAR表中使用’hasc’,’hdsc’和’hlgp’值标记来改变sTypoAscender,sTypoDescender和sTypoDescender中指定的默认值的上升,下降和线间隙值。 sTypoLineGap字段。除了在winAscent和winDescent字段中指定的默认值中改变剪切区域的大小之外,还可以使用’hcla’和’hcld’值标记。其他指标可以使用上面列出的值标签进行更改。
有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
7.39.a.IBM Font Class Parameters
本节定义了字体设计者或供应商在字体设计分类中使用的IBM Font Class和IBM Font Subclass参数值。此信息存储在字体OS / 2表的sFamilyClass字段中。
7.39.a.1.sFamilyClass
格式: int16
标题:字体系列类和子类。
说明:此参数是字体系列设计的分类。
注释:字体类和字体子类是IBM为每个字体系列分配的注册值。此参数用于在请求的字体不可用时选择备用字体。字体类是最通用的,字体子类是最具体的。该字段的高字节包含族类,而低字节包含族子类。
这些值对字体设计的外观进行了分类,但未标识特定字体系列,字体变体,设计器,供应商,大小或度量标准表差异。应该注意的是,某些字体设计可以同样分类为IBM Font Class或Subclass。此类设计应与分类匹配,对于该分类,从同一类或子类替换另一种字体设计通常会导致所呈现文档的类似外观。
7.39.a.2.Class ID = 0 No Classification
该类ID用于指示关联字体没有设计分类,或者设计分类对字体资源的创建者或用户不重要。
7.39.a.3.Class ID = 1 Oldstyle Serifs
这种风格通常基于15至17世纪的拉丁印刷风格,在笔画强调中具有温和的对角线对比度(左上角到右下角较轻,右上角到左下角较重)和括号内衬。此IBM类反映了ISO Serille Class,Oldstyle和Legibility Subclasses,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.4.Subclass ID = 0 : No Classification
该子类ID用于指示关联字体没有设计子分类,或者设计子类别对字体资源的创建者或用户不重要。
7.39.a.5.Subclass ID = 1 : IBM Rounded Legibility
这种风格通常具有较大的x高度,具有短的上升和下降。具体来说,它的特点是中等分辨率,手动调整,更一般的圆形易读性子类的位图再现。此IBM子类未在ISO / IEC 9541-1修订1标准中明确反映。
7.39.a.6.Subclass ID = 2 : Garalde
这种风格通常以中等x高度为特征,具有高的上升。这种字体样式的一个例子是ITC Garamond系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Oldstyle Subclass和Garalde Specific Group。
7.39.a.7.Subclass ID = 3 : Venetian
这种风格通常以中等x高度为特征,具有相对单调的外观和基于早期威尼斯打印机设计的清扫尾巴。此IBM子类未在ISO / IEC 9541-1修订1标准中明确反映。
7.39.a.8.Subclass ID = 4 : Modified Venetian
这种风格的特征通常是具有较大的x高度,具有相对单调的外观和基于早期威尼斯打印机设计的扫尾。这种字体样式的一个例子是Allied Linotype Palatino家族。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Transitional Subclass和Modified Specific Group。
7.39.a.9.Subclass ID = 5 : Dutch Modern
这种风格通常具有较大的x高度,具有楔形衬线和圆形外观,类似于下面的荷兰传统子类,但具有较轻的罢工。此IBM子类未在ISO / IEC 9541-1修订1标准中明确反映。
7.39.a.10.Subclass ID = 6 : Dutch Traditional
这种类型的特征通常是具有大的x高度,具有楔形衬线和碗的圆形外观。这种字体样式的一个例子是IBM Press Roman系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类和可读性子类。
7.39.a.11.Subclass ID = 7 : Contemporary
这种风格的特点是x高度小,有轻微的笔触和衬线。这种字体样式的一个例子是大学家庭。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类和当代子类。
7.39.a.12.Subclass ID = 8 : Calligraphic
这种风格的特点一般是书法的精细手写风格,同时保留了古老的外观风格。此IBM子类未反映在ISO / IEC 9541-1修订1标准中。
7.39.a.13.Subclass ID = 9-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.14.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.15.Class ID = 2 Transitional Serifs
这种风格通常基于18至19世纪的拉丁印刷风格,在笔画强调中具有明显的垂直对比度(垂直笔画比水平笔画重)和括号内衬。此IBM类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Transitional Subclass。
7.39.a.16.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.17.Subclass ID = 1 : Direct Line
这种风格通常以中等x高度为特征,具有精细的衬线,明显的对比度和大致相同宽度的国会大厦字母。这种字体样式的一个例子是Monotype Baskerville系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Transitional Subclass和Direct Line Specific Group。
7.39.a.18.Subclass ID = 2 : Script
这种风格通常以手写脚本外观为特征,同时保留Transitional Direct Line风格。这种字体样式的一个例子是IBM Nasseem(阿拉伯语)系列。虽然ISO Serif类,Transitional Subclass和Direct Line Specific Group将非常接近,但这个IBM Subclass并未在ISO / IEC 9541-1修订1标准中明确反映出来。
7.39.a.19.Subclass ID = 3-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.20.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.21.Class ID = 3 Modern Serifs
这种风格通常基于20世纪的拉丁印花风格,在笔触的粗细部分之间形成极端对比。此IBM类反映了ISO Seril Class,现代子类,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.22.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.23.Subclass ID = 1 : Italian
这种风格通常以中等x高度为特征,具有薄的发丝衬线。这种字体样式的一个例子是Monotype Bodoni系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,现代子类和意大利特定组。
7.39.a.24.Subclass ID = 2 : Script
这种风格的特点是手写的脚本外观,同时保留了现代意大利风格。这种字体样式的一个例子是IBM Narkissim(希伯来语)系列。虽然ISO Serif类,现代子类和意大利特定组将非常接近,但此IBM子类未在ISO / IEC 9541-1修订1标准中明确反映。
7.39.a.25.Subclass ID = 3-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.26.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.27.Class ID = 4 Clarendon Serifs
这种风格是Oldstyle Serifs和Transitional Serifs的变体,具有温和的垂直笔触对比和括号衬线。此IBM类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif Class,Square Serif Subclass。
7.39.a.28.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.29.Subclass ID = 1 : Clarendon
这种风格通常以x高度为特征,具有相同重量的衬线和笔划。这种字体样式的一个例子是Allied Linotype Clarendon系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif Class,Square Serif Subclass和Clarendon Specific Group。
7.39.a.30.Subclass ID = 2 : Modern
这种风格的特点通常是x高度较大,衬垫的重量比笔划轻,重量轻于传统。这种字体样式的一个例子是Monotype Century Schoolbook系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif Class,Square Serif Subclass和Clarendon Specific Group。
7.39.a.31.Subclass ID = 3 : Traditional
这种类型的特征通常是具有较大的x高度,具有比笔划轻的重量的衬线。这种字体样式的一个例子是Monotype Century系列。这个IBM子类反映了ISO / IEC 9541-1修正案1标准中记录的ISO Serif Class,Square Serif Subclass和Clarendon Specific Group。
7.39.a.32.Subclass ID = 4 : Newspaper
这种风格通常具有较大的x高度,具有更简单的设计风格和比笔划更轻的衬线。这种字体样式的一个例子是Allied Linotype Excelsior Family。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif Class,Square Serif Subclass和Clarendon Specific Group。
7.39.a.33.Subclass ID = 5 : Stub Serif
这种类型的特征通常是具有较大的x高度,具有短的短腿衬线和相对粗的茎。这种字体风格的一个例子是切尔滕纳姆家族。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Square Serif子类和短特定组。
7.39.a.34.Subclass ID = 6 : Monotone
这种风格通常具有较大的x高度,具有单调的茎。这种字体样式的一个例子是ITC Korinna系列。此IBM子类未在ISO / IEC 9541-1修订1标准中明确反映。
7.39.a.35.Subclass ID = 7 : Typewriter
这种类型的特征通常在于具有较大的x高度,具有中等行程厚度的打字机特征。Prestige Elite系列就是这种字体样式的一个例子。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif Class,Square Serif Subclass和Typewriter Specific Group。
7.39.a.36.Subclass ID = 8-14: (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.37.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.38.Class ID = 5 Slab Serifs
这种风格的特点是衬线在笔画和衬线之间有一个方形过渡(没有括号)。此IBM类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif Class,Square Serif Subclass(Clarendon Specific Group除外)。
7.39.a.39.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.40.Subclass ID = 1 : Monotone
这种风格通常以x高度为特征,具有相同重量的衬线和笔划。这种字体样式的一个例子是ITC Lubalin Family。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Square Serif子类和单调特定组。
7.39.a.41.Subclass ID = 2 : Humanist
这种风格通常以中等x高度为特征,具有比笔画更轻的衬线。这种字体样式的一个例子是Candida Family。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Square Serif子类和单调特定组。
7.39.a.42.Subclass ID = 3 : Geometric
这种风格通常具有较大的x高度,具有相同重量的衬线和笔划以及几何(圆形和线条)设计。这种字体样式的一个例子是Monotype Rockwell系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Square Serif子类和单调特定组。
7.39.a.43.Subclass ID = 4 : Swiss
这种风格通常以x高度为特征,具有相同重量的衬线和笔划,并强调角色的白色空间。这种字体样式的一个例子是Allied Linotype Serifa Family。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Serif类,Square Serif子类和单调特定组。
7.39.a.44.Subclass ID = 5 : Typewriter
这种类型的特征通常是具有较大的x高度,具有相同但中等厚度的衬线和笔划,以及几何设计。这种字体样式的一个示例是IBM Courier系列。虽然ISO Serif类,Square Serif子类和Monotone Specific Group将非常接近,但这个IBM Subclass并没有明确地反映在ISO / IEC 9541-1修订1标准中。
7.39.a.45.Subclass ID = 6-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.46.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.47.Class ID = 6 (reserved for future use)
此类ID保留供将来分配,未经IBM正式分配不得使用。
7.39.a.48.Class ID = 7 Freeform Serifs
这种风格包括衬线,但表达了一般不适合其他衬线设计分类的设计自由。此IBM类反映了ISO / IEC 9541-1修订1标准中记录的剩余ISO Serif类子类。
7.39.a.49.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.50.Subclass ID = 1 : Modern
这种风格通常以中等x高度为特征,笔触具有明亮的对比度和圆形的完整设计。这种字体样式的一个例子是ITC纪念品系列。此IBM子类未反映在ISO / IEC 9541-1修订1标准中。
7.39.a.51.Subclass ID = 2-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.52.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.53.Class ID = 8 Sans Serif
此样式包括笔划上没有衬线的大多数基本字母形式(不包括脚本和装饰品)。此IBM类反映了ISO / IEC 9541-1修订1标准中记录的ISO Sans Serif类。
7.39.a.54.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.55.Subclass ID = 1 : IBM Neo-grotesque Gothic
这种风格的特点是具有较大的x高度,具有统一的笔画宽度和简单的单层设计,以中等分辨率,手动调整,更通用的新怪诞哥特式子类的位图再现为特色。这种字体样式的一个示例是IBM Sonoran Sans Serif系列。此IBM子类未在ISO / IEC 9541-1修订1标准中明确反映。
7.39.a.56.Subclass ID = 2 : Humanist
这种风格通常以中等x高度为特征,笔触具有鲜明的对比度和经典的罗马字母。这种字体样式的一个例子是Allied Linotype Optima系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Sans Serif类,Humanist Subclass。
7.39.a.57.Subclass ID = 3 : Low-x Round Geometric
这种风格通常以低x高度为特征,具有单调的行程重量和圆形几何设计。这种字体样式的一个例子是Fundicion Tipograficia Neufville Futura系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Sans Serif类,几何子类,Round Specific Group。
7.39.a.58.Subclass ID = 4 : High-x Round Geometric
这种风格通常具有高x高度,具有均匀的行程重量和圆形几何设计。这种字体样式的一个例子是ITC Avant Garde Gothic系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Sans Serif类,几何子类,Round Specific Group。
7.39.a.59.Subclass ID = 5 : Neo-grotesque Gothic
这种风格通常以高x高度为特征,具有均匀的笔划宽度和简单的单层设计。这种字体样式的一个例子是Allied Linotype Helvetica系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Sans Serif Class,Gothic Subclass,Neo-geotesque Specific Group。
7.39.a.60.Subclass ID = 6 : Modified Neo-grotesque Gothic
这种风格类似于新奇怪的哥特式风格,G和Q的设计变化。这种字体风格的一个例子是Allied Linotype Univers家族。此IBM子类未在ISO / IEC 9541-1修订1标准中明确反映,但ISO Sans Serif类,哥特式子类,新怪诞特定组将非常接近。
7.39.a.61.Subclass ID = 7-8 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.62.Subclass ID = 9 : Typewriter Gothic
这种风格类似于新奇怪的哥特式风格,具有中等行程厚度的打字机特征。这种字体样式的一个例子是IBM Letter Gothic系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Sans Serif类,Gothic子类,打字机特定组。
7.39.a.63.Subclass ID = 10 : Matrix
这种风格通常是点阵打印机的简单设计特征。这种字体样式的一个例子是IBM Matrix Gothic系列。此IBM子类未反映在ISO / IEC 9541-1修订1标准中。
7.39.a.64.Subclass ID = 11-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.65.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.66.Class ID = 9 Ornamentals
此样式包括高度装饰或风格化的字符形状,通常用于标题。此IBM类反映了ISO / IEC 9541-1修订1标准中记录的ISO Ornamental Class和ISO Blackletter Class。
7.39.a.67.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.68.Subclass ID = 1 : Engraver
这种风格的特点是茎上刻有细纹或线条。这种字体样式的一个例子是Copperplate系列。此IBM子类反映ISO / IEC 9541-1修订1标准中记录的ISO Ornamental Class和Inline Subclass,或Serif Class和Engraving Subclass。
7.39.a.69.Subclass ID = 2 : Black Letter
这种风格通常基于12至15世纪德国修道院和印刷商的印刷风格。这种字体样式的一个例子是Old English家族。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Blackletters类。
7.39.a.70.Subclass ID = 3 : Decorative
这种风格的特点是装饰设计(通常来自大自然,如树叶,花朵,动物等)并入角色的茎和笔画。这种字体样式的一个例子是Saphire系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO装饰类和装饰子类。
7.39.a.71.Subclass ID = 4 : Three Dimensional
此样式的特征在于由阴影或几何效果创建的字符的三维(凸起)外观。这种字体样式的一个例子是Thorne Shaded系列。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO装饰类和三维子类。
7.39.a.72.Subclass ID = 5-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.73.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.74.Class ID = 10 Scripts
这种风格包括那些旨在模拟手写的字体。此IBM类反映了ISO脚本类和Uncial类,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.75.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.76.Subclass ID = 1 : Uncial
这种风格的特点是未加入(非连接)的角色,这些角色通常基于6至9世纪欧洲的手写风格。Libra系列就是这种字体样式的一个例子。此IBM子类反映了ISO / IEC 9541-1修订1标准中记录的ISO Uncial Class。
7.39.a.77.Subclass ID = 2 : Brush Joined
这种风格的特点是连接(连接)字符,其外观使用画笔绘制,在粗细笔划之间具有中等对比度。这种字体样式的一个例子是Mistral家族。此IBM子类反映了ISO脚本类,连接子类和非正式特定组,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.78.Subclass ID = 3 : Formal Joined
这种风格的特点是连接(连接)字符,这些字符具有印刷(或用硬笔刷绘制)外观,在粗细笔划之间具有极强的对比度。Coronet系列就是这种字体样式的一个例子。此IBM子类反映了ISO脚本类,连接子类和正式特定组,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.79.Subclass ID = 4 : Monotone Joined
这种风格的特征在于连接(连接)字符,这些字符具有均匀的外观,在笔划中具有很少或没有对比度。这种字体样式的一个例子是Kaufmann家族。此IBM子类反映了ISO脚本类,连接子类和单调特定组,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.80.Subclass ID = 5 : Calligraphic
这种风格的特点是精美的手绘,未连接(非连接)字符,其外观用宽边笔绘制。这种字体样式的一个例子是Thompson Quillscript系列。此IBM子类反映了ISO脚本类,未加入子类和书法特定组,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.81.Subclass ID = 6 : Brush Unjoined
这种风格的特点是没有连接(非连接)的字符,其外观用刷子绘制,在粗细笔划之间具有中等对比度。Saltino系列就是这种字体样式的一个例子。此IBM子类反映了ISO脚本类,未加入子类和刷子特定组,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.82.Subclass ID = 7 : Formal Unjoined
这种风格的特点是没有连接(非连接)的字符,这些字符具有印刷(或用硬刷绘制)外观,在粗细笔划之间具有极强的对比度。这种字体样式的一个例子是Virtuosa系列。此IBM子类反映了ISO脚本类,未加入子类和正式特定组,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.83.Subclass ID = 8 : Monotone Unjoined
这种风格的特征在于未连接(非连接)字符,其具有均匀的外观,在笔划中具有很少或没有对比度。Gilles Gothic系列就是这种字体风格的一个例子。此IBM子类反映了ISO脚本类,未加入子类和单调特定组,如ISO / IEC 9541-1修订1标准中所述。
7.39.a.84.Subclass ID = 9-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.85.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.86.Class ID = 11 (reserved for future use)
此类ID保留供将来分配,未经IBM正式分配不得使用。
7.39.a.87.Class ID = 12 Symbolic
这种风格通常与设计无关,适用于Pi和特殊字符(图标,装饰符号,技术符号等),可以与任何字体同样使用。此IBM类反映了各种ISO特定组,如下所述并记录在ISO / IEC 9541-1修订1标准中。
7.39.a.88.Subclass ID = 0 : No Classification
该子类ID用于指示相关联的字体没有设计子分类,或者设计子分类对字体资源的创建者或用户不重要。
7.39.a.89.Subclass ID = 1-2 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用
7.39.a.90.Subclass ID = 3 : Mixed Serif
这种风格的特征在于,对于设计很重要的字体字符(例如,上标和下标字符,数字,版权或商标符号等),要么是衬线和无衬线字体设计的两者或组合。IBM Symbol系列中提供了此字体样式的示例。此IBM子类未反映在ISO / IEC 9541-1修订1标准中。
7.39.a.91.Subclass ID = 4-5 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.92.Subclass ID = 6 : Oldstyle Serif
这种风格的特点是Oldstyle Serif IBM Class设计,用于设计重要的字体字符(例如,上标和下标字符,数字,版权或商标符号等)。IBM Sonoran Pi Serif系列中提供了此字体样式的示例。此IBM子类未直接反映在ISO / IEC 9541-1修订1标准中,但它间接由ISO Serif类和可读性子类(暗示字体的所有字符都表现出设计外观,而只有一部分字符实际上展示了设计)。
7.39.a.93.Subclass ID = 7 : Neo-grotesque Sans Serif
这种风格的特点是Neo-grotesque Sans Serif IBM字体类和子类设计在那些设计很重要的字体上(例如,上标和下标字符,数字,版权或商标符号等)。IBM Sonoran Pi Sans Serif系列中提供了此字体样式的示例。这个IBM子类没有直接反映在ISO / IEC 9541-1修订版1标准中,尽管它间接由ISO Sans Serif类和Gothic子类(暗示字体的所有字符都表现出设计外观,而只是子集的一部分)角色实际上展示了设计)。
7.39.a.94.Subclass ID = 8-14 : (reserved for future use)
这些子类ID保留供将来分配,未经IBM正式指定不得使用。
7.39.a.95.Subclass ID = 15 : Miscellaneous
此子类ID用于相关设计类的其他设计,这些设计类未被另一个子类覆盖。
7.39.a.96.Class ID = 13 Reserved
7.39.a.97.Class ID = 14 Reserved
7.40.pclt PCL 5表
对于具有TrueType轮廓的OpenType™字体,强烈建议不要使用PCLT表。有关其中许多字段的更多信息,请参阅Hewlett-Packard Boise打印机部门提供的“ HP PCL 5打印机语言技术参考手册”。
该表的格式为:
类型 入境名称
UINT16 MajorVersion
UINT16 MinorVersion
UINT32 FontNumber
UINT16 沥青
UINT16 X字高
UINT16 样式
UINT16 TypeFamily
UINT16 大写高度
UINT16 SymbolSet
INT8 字体[16]
INT8 CharacterComplement [8]
INT8 文件名[6]
INT8 strokeWeight,用于
INT8 WidthType
UINT8 SerifStyle
UINT8 保留(垫)
7.40.1.Major and Minor Version
当前的PCLT表版本是1.0。
7.40.2.FontNumber
这个32位数字分为两部分。最重要的位表示本机格式与转换格式。只有字体供应商才能创建这个位为零的字体。Hewlett-Packard Boise打印机部门将7个下一个最重要的位分配给主要的字体供应商。最低有效24位由供应商分配。字体供应商应该尝试确保每个字体都标有唯一值。
码 供应商
一个 Adobe Systems
乙 比特流公司
C 爱克发公司
H Bigelow&Holmes
大号 Linotype公司
中号 Monotype Typography Ltd.
7.40.3.Pitch
FUnits中的空间宽度(FUnits由’head’表的unitsPerEm字段描述)。等宽字体从此字段中获取所有字符的宽度。
7.40.4.xHeight
描述FUnits中小写x高度的光学线的高度。这可能与小写x的测量高度不同。
7.40.5.Style
最重要的6位是保留的。5个下一个最重要的位编码结构。接下来的3个最重要的位编码外观宽度。2个最低有效位编码姿势。
结构(第5-9位)
0 固体(正常,黑色)
1 轮廓(空心)
2 内联(切割,雕刻)
3 轮廓,边缘(古董,苦恼)
4 坚实的影子
五 大纲与阴影
6 内嵌阴影
7 带阴影的轮廓或边缘
8 图案填充
9 模式填充#1(当多个模式时)
10 图案填充#2(当两个以上的图案时)
11 图案填充#3(超过三个图案时)
12 图案充满了阴影
13 图案充满阴影#1(当多个图案或阴影时)
14 图案充满阴影#2(当有两个以上的图案或阴影时)
15 图案充满阴影#3(当超过三个图案或阴影时)
16 逆
17 与边界相反
18-31 保留的
宽度(第2-4位)
0 正常
1 冷凝
2 压缩,额外浓缩
3 额外压缩
4 超压缩
五 保留的
6 扩展,扩展
7 额外扩展,额外扩展
姿势(0-1位)
0 直立
1 斜,斜体
2 交替斜体(后退,草书,斜线)
3 保留的
7.40.6.TypeFamily
4个最重要的位是字体供应商代码。12个最低有效位是字体系列代码。两者均由HP Boise Division分配。
供应商代码(第12-15位)
0 保留的
1 爱克发公司
2 比特流公司
3 Linotype公司
4 Monotype Typography Ltd.
五 Adobe Systems
6 字体重新包装
7 独特字体的供应商
8-15 保留的
7.40.7.CapHeight
描述FUnits中大写字母H顶部的光学线的高度。这可能与大写H的测量高度不同。
7.40.8.SymbolSet
最重要的11位是符号集“数字”字段的值。当加到64时,最低有效5位的值是符号集“ID”字段的ASCII值。符号集值由HP Boise Division分配。未绑定字体或“字体”的符号设置值应为0.有关最新发布的代码列表,请参阅“ PCL 5打印机语言技术参考手册”或“ PCL 5比较指南”。
例子
PCL 十进制
Windows 3.1“ANSI” 19U 629
Windows 3.0“ANSI” 9U 309
Adobe“符号” 19M 621
苹果 12J 394
PostScript ISO Latin 1 11J 362
PostScript标准。编码 10J 330
代码页1004 9J 298
桌面 7J 234
7.40.9.TypeFace
这个16字节的ASCII字符串出现在PCL打印机的“字体打印”中。应注意确保一个系列的所有字体的基本字符串是一致的,并且粗体,斜体等的标识符是标准化的。
例
时代新
时代新 BD
时代新 它
时代新 BdIt
快递新
快递新 BD
快递新 它
快递新 BdIt
7.40.10.CharacterComplement
该8字节字段标识由字体提供的符号集合,每个位标识符号集合并且被独立解释。符号集绑定字体应包含此字段集中的所有位(位0除外)。
例
DOS / PCL补充 0xFFFFFFFF003FFFFE
Windows 3.1“ANSI” 0xFFFFFFFF37FFFFFE
苹果 0xFFFFFFFF36FFFFFE
ISO 8859-1拉丁文1 0xFFFFFFFF3BFFFFFE
ISO 8859-1,2,9拉丁文1,2,5 0xFFFFFFFF0BFFFFFE
每个位标识的字符集如下:
31 ASCII(支持多种标准解释)
三十 拉丁语1扩展
29 拉丁文2扩展
28 拉丁语5扩展
27 桌面发布扩展
26 口音扩展(东欧和西欧)
25 PCL扩展
24 Macintosh扩展程序
23 PostScript扩展
22 代码页扩展
字符补全字段还表示与未绑定字体一起使用的索引机制。当以Unicode顺序提供字体元素时,必须始终清除位0。
7.40.11.FileName
这个6字节的字段由3部分组成。前3个字节是行业标准字体系列字符串。第四个字节是一个处理字符,例如R,B,I。最后两个字符是未绑定字体的零或符号集的两个字符助记符(如果找到符号集)。
例子
TNRR00 新时代(文字重量,直立)
TNRI00 时代新斜体
TNRB00 时代新大胆
TNRJ00 Times New Bold Italic
COUR00 信使
COUI00 Courier Italic
COUB00 快递大胆
COUJ00 Courier Bold Italic
治疗标志
[R 文字,普通,书籍等
一世 斜体,倾斜,倾斜等
乙 胆大
Ĵ 粗斜体,粗斜体
d Demibold
Ë Demibold Italic,Demibold Oblique
ķ 黑色
G 黑色斜体,黑色斜体
大号 光
P 浅斜体,浅斜
C 简明
一个 凝聚斜体,凝聚斜
F 大胆凝聚
H Bold Condensed Italic,Bold Condensed Oblique
小号 Semibold(比demibold轻)
Ť Semibold Italic,Semibold Oblique
随着时间的推移分配其他治疗标志。
7.40.12.StrokeWeight
该int8字段包含PCL笔划权重值。只有-7到7范围内的值才有效:
-7 超薄
-6 超薄
-5 瘦
-4 超轻
-3 光
-2 Demilight
-1 Semilight
0 书,文字,常规等
1 Semibold(中等,比书本深)
2 Demibold
3 胆大
4 额外大胆
五 黑色
6 额外的黑色
7 超黑或超
类型设计师经常使用有趣的名称来表示重量或重量和样式的组合,例如重型,紧凑型,Inserat,粗体2号等.PCL行程重量是根据整个族和面的使用来分配的。通常,显示面没有“文本”权重分配。
7.40.13.WidthType
此int8字段包含PCL外观宽度值。这些值与上面样式字段的外观上的值没有直接关系。只有-5到5范围内的值才有效。
-5 超压缩
-4 额外压缩
-3 压缩或额外压缩
-2 简明
0 正常
2 扩展
3 额外扩展
7.40.14.SerifStyle
此uint8字段包含PCL serif样式值。该字节的最重要的2位指定字体的serif / sans或contrast / monoline特征。
底部6位值:
0 Sans Serif Square
1 Sans Serif Round
2 衬线
3 衬线三角形
4 Serif Swath
五 Serif Block
6 衬线支架
7 圆形支架
8 Flair Serif,改良Sans
9 脚本不连接
10 脚本加入
11 脚本书法
12 脚本碎信
前2位值:
0 保留的
1 Sans Serif / Monoline
2 衬线/对比
3 保留的
7.40.15.Reserved
应该设置为零。
7.41.post PostScript表
此表包含在PostScript打印机上使用TrueType或OpenType™字体所需的其他信息。这包括FontInfo字典条目的数据和所有字形的PostScript名称。有关PostScript名称的详细信息,请参阅Adobe Glyph列表规范。
版本1.0,2.0和2.5指的是带有TrueType数据的TrueType字体和OpenType字体。具有TrueType数据的OpenType字体也可以使用3.0版。带有CFF数据的OpenType字体仅使用3.0版。
7.41.1.Header
表格如下:
类型 名称 描述
固定 版 0x00010000版本1.0
0x00020000版本2.0
0x00025000版本2.5 (不建议使用)
0x00030000版本3.0
固定 italicAngle 斜角从垂直方向逆时针旋转。直立文本为零,右侧(向前)倾斜的文本为负数。
F字 underlinePosition 这是下划线顶部与基线的建议距离(负值表示低于基线)。
由于历史原因,不使用此FontInfo字典键的PostScript定义(笔划中心的y坐标)。可以通过从该字段的值减去underlineThickness的一半来计算PostScript键的值。
F字 underlineThickness 下划线厚度的建议值。通常,下划线粗细应与下划线字符(U + 005F LOW LINE)的厚度匹配,并且还应与OS / 2表中指定的删除线厚度相匹配。
UINT32 isFixedPitch 如果字体按比例间隔设置为0,如果字体不按比例间隔(即等宽),则设置为非零。
UINT32 minMemType42 下载OpenType字体时的最小内存使用量。
UINT32 maxMemType42 下载OpenType字体时的最大内存使用量。
UINT32 minMemType1 将OpenType字体作为Type 1字体下载时的最小内存使用量。
UINT32 maxMemType1 将OpenType字体作为Type 1字体下载时的最大内存使用量。
表中的最后四个条目是存在的,因为如果在下载字体之前已知可下载的OpenType字体的虚拟内存(VM)要求,则PostScript驱动程序可以执行更好的内存管理。如果已知,应提供此信息。如果未知,请将值设置为零。驱动程序仍然可以工作,但效率会降低。
最大内存使用量是最小内存使用量加上最大运行时内存使 最大运行时内存使用量取决于字体缩放器可能栅格化的任何位图的最大波段大小。可以通过渲染不同点大小的字符并比较内存使用来计算运行时内存使用情况。
如果版本是1.0或3.0,则表格在此处结束。版本2.0和2.5的附加条目如下所示。Apple已定义4.0版用于Apple Advanced Typography(AAT),该文档在其文档中有所描述。
7.41.2.Version 1.0
此版本用于在字体文件包含标准Macintosh TrueType字体文件中的258个字形时提供PostScript字形名称(请参阅Apple的规范中的“发布”格式1以获取258个Macintosh字形名称的列表),以及字体不提供字形名称。因此,字形名称取自系统,字体不需要存储。
7.41.3.Version 2.0
这是为不在其他地方提供字体的字体提供PostScript字形名称所需的版本。版本2.0’post’表可用于具有TrueType或CFF版本2轮廓的字体。
类型 名称 描述
UINT16 numGlyphs 字形数量(这应该与’maxp’表中的numGlyphs相同)。
UINT16 glyphNameIndex [numGlyphs]。 这不是偏移量,而是“post”字符串表中字形的序号。
INT8 名称[numberNewGlyphs] 字符名称,长度为bytes [variable](Pascal字符串)。
此字体文件包含不在标准Macintosh集中的字形,或字体文件中字形的顺序与标准Macintosh集不同。字形名称数组将此字体中的字形映射到名称索引。如果名称索引介于0到257之间,请将名称索引视为Macintosh标准顺序中的字形索引。如果名称索引介于258和65535之间,则减去258并使用它索引到表末尾的Pascal字符串列表。因此,给定的字体可以将其一些字形映射到标准字形名称,并将一些字体映射到它自己的名称。
如果您不想将PostScript名称与特定字形关联,请使用索引号0,该索引号指向名称.notdef。
7.41.4.Version 2.5
从OpenType Specification v1.3开始,不推荐使用此版本的’post’表。
此版本为基于TrueType的字体提供了一个节省空间的表,其中包含标准Macintosh字形集的纯子集或简单重新排序。
类型 名称 描述
UINT16 numGlyphs 字形数量
INT8 偏移numGlyphs] 图形索引与标志符号顺序的区别
此版本对于基于TrueType的字体文件非常有用,该字体文件仅包含标准Macintosh字形集中的字形,但这些字形具有以非标准顺序排列或缺少某些字形的字形。该表包含字体文件中每个字形的一个字节。该字节被视为有符号偏移量,将此字体中使用的字形索引映射到标准字形索引中。换句话说,假设字体包含三个字形A,B和C,它们是标准排序中的第37,第38和第39个字形,’post’表将包含字节+ 36,+ 36,+ 36 。截至2000年2月,Apple已弃用此格式。
7.41.5.Version 3.0
此版本可以创建一个没有大型’post’表格字形名称组成的字体。具有TrueType或CFF(版本1或2)数据的OpenType字体可以使用3.0版’post’表。
此版本指定不为此字体文件中的字形提供PostScript名称信息。此版本在PostScript打印机上的打印行为未指定,除非它不会导致致命或不可恢复的错误。有些司机可能没有打印; 其他驱动程序可能尝试使用默认命名方案进行打印。
Windows在’post’表中使用斜体角度值,但实际上并不需要将任何字形名称存储为Pascal字符串。
7.41.6.’post’ Table and OpenType Font Variations
在可变字体中,可能需要针对不同的变体实例调整“post”表内的各种字体度量值。可以在度量变化(MVAR)表中提供“后”条目的变体数据。使用值标记将不同的“post”条目与MVAR表中的特定变体数据相关联,如下所示:
‘post’条目 标签
underlinePosition “撤消”
underlineThickness ‘unds’
注意: italicAngle值不会根据变体数据进行调整,因为这对应于可用于定义字体变体空间的“slnt”变化轴。可以从用于选择特定变体实例的“slnt”用户坐标导出变体实例的适当post.italicAngle值。有关italicAngle和“slnt”轴之间关系的详细信息,请参阅OpenType Design-Variation Axis Tag注册表中对“slnt”轴的讨论。
有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
7.42.prep 控制价值计划
控制值程序由一组TrueType指令组成,这些指令将在字体或点大小或变换矩阵更改时以及每个字形被解释之前执行。任何指令在CV程序中都是合法的,但由于没有与之关联的字形,因此不能在CV程序中使用旨在移动特定字形轮廓内的点的指令。名称’prep’是不合时宜的(该表曾被称为Pre Program表。)
类型 描述
uint8 [ n ] 每当点大小或字体或转换发生变化时执行的指令集。n是适合表大小的uint8项的数量。
7.43.sbix 标准位图图形表
此表提供对标准图形格式(如PNG,JPEG或TIFF)的位图数据的访问。
‘sbix’表的功能有点类似于EBDT表,因为它们都提供了字形表示的位图数据。然而,它们在三个重要方面有所不同。首先,虽然EBDT表仅支持黑/白或灰度位图,但’sbix’表支持彩色位图。其次,虽然EBDT表使用特定于OpenType规范的格式,但’sbix’表使用常用的标准位图图形格式。第三,虽然EBDT表必须与其他表(EBLC和EBSC)一起用于处理位图数据,但’sbix’表包含处理位图所需的完整数据。
包含’sbix’表的字体还可以在’glyf’或’CFF’表中包括轮廓字形数据。’sbix’表可以为所有字形ID提供位图数据,或仅为字形ID的子集提供位图数据。字体还可以包括不同大小的不同位图数据(“打击”),并且一个大小的字形覆盖可以与另一个大小的字形覆盖不同。
7.43.1.Header
‘sbix’表以标题开头:
‘sbix’标题
类型 名称 描述
UINT16 版 表版本号 - 设置为1
UINT16 旗 位0:设置为1.
位1:绘制轮廓。
位2到15:保留(设置为0)。
UINT32 numStrikes 位图罢工次数。
OFFSET32 strikeOffsets [numStrikes] 从’sbix’表的开头到每个单独的位图打击的数据的偏移量。
由于历史原因,flags字段的第0位应始终设置为1。
如果flags字段的第1位是清除的,则指示应用程序仅绘制’sbix’表中支持的每个字形的位图。如果设置了位1,则指示应用程序按顺序绘制位图和轮廓(即,轮廓覆盖在位图的顶部)。如果’sbix’表不包含字形的位图数据,则无论第1位的状态如何,都会始终绘制轮廓。
注意:对flags字段的第1位的应用程序支持是可选的。要确保最佳兼容性,请将此位设置为0。
7.43.2.Strikes
每个警示包括标题和字形位图数据。标头具有以下格式:
类型 名称 描述
UINT16 ppem 设计此次攻击的PPEM大小。
UINT16 PPI 设计此击打的设备像素密度(以PPI为单位)。(例如,96 PPI,192 PPI。)
OFFSET32 glyphDataOffsets [numGlyphs + 1] 从打击数据头的开头到单个字形ID的位图数据的偏移量。
glyphDataOffset数组包括每个字形ID的偏移量加上一个额外值。字形数量由’maxp’表确定。每个字形的位图数据的长度是可变的,并且可以根据两个连续偏移之间的差异来确定。因此,字形N的数据长度是glyphDataOffset [N + 1] - glyphDataOffset [N]。如果为零,则此警示中没有该字形的位图数据。数组中有一个额外的偏移量,以便为最后一个字形提供数据长度。
注意:非打印字形(如空格)的数据长度应始终为零。
攻击不需要包含每个字形的数据,也不需要包含与其他字符相同的字形集的数据。如果应用程序使用位图数据绘制文本,并且在任何打击中都存在字形的位图数据,则必须使用来自某些打击的位图绘制字形。如果确切的大小不可用,则实现可以基于最接近的可用较大大小,或最接近的可用整数 - 大的较大大小,或在某些其他基础上选择位图。唯一不使用位图绘制字形的情况是应用程序是否未请求使用位图数据绘制文本,或者是否在任何警示中没有字形的位图数据。
每次打击都针对特定的PPEM大小和设备像素密度(PPI)。因此,字体可以包含针对相同PPEM但是不同像素密度的两次打击,或者针对相同像素密度但是针对不同PPEM的两次打击。请注意,某些平台可能不支持针对特定像素密度的目标进行定位。
7.43.3.Glyph data
每个字形的数据包括标题和实际的嵌入图形数据,格式如下:
类型 名称 描述
INT16 originOffsetX 从图形左边缘到字形原点的水平(x轴)偏移。也就是说,字形左边缘基线上的点的x坐标。
INT16 originOffsetY 从图形下边缘到字形原点的垂直(y轴)偏移。也就是说,字形左边缘基线上的点的y坐标。
标签 graphicType 指示嵌入图形数据的格式:’jpg’,’png’或’tiff’之一,或特殊格式’dupe’。
UINT8 数据[] 实际嵌入的图形数据。从glyphDataOffsets数组中的连续条目和前面字段的固定大小(8字节)推断总长度。
graphicType字段指示嵌入图形数据的格式。支持三种标准格式:JPEG,PNG和TIFF; 这些分别使用标签值’jpg’,’png’和’tiff’表示。
‘dupe’的特殊graphicType表示数据字段包含uint16,big-endian字形ID。指示字形的位图数据应该用于当前字形。
注意: Apple的TrueType字体规范允许使用’pdf’或’mask’的graphicType标记值。但是,OpenType规范不支持这些值。
7.43.4.Table dependencies
字形计数来自’maxp’表。高级和侧面支持字形度量标准存储在’hmtx’表中以进行水平布局,而’vmtx’表存储在垂直布局中。
7.44.STAT 样式属性表
样式属性表描述了区分字体系列中字体样式变体的设计属性。它还提供了这些属性和名称元素之间的关联,这些属性可用于在应用程序用户界面中显示字体选项。
7.44.1.Introduction
字体系列是一组共享设计关键方面的字体。这些设计方面对于该系列中的所有字体都是通用的,并将该系列与其他字体系列区分开来。但是,一个家族中的字体在特定方面也各不相同:笔划厚度的差异,对比度的差异等等; 或这些差异的组合。通过这种方式,系列中的字体是家庭设计的样式变体。给定系列将具有一组特定的属性类型,成员字体通过这些属性类型不同:变化轴。
系列中的样式变体可以实现为离散字体中的静态变体,例如Arial Light或Arial Bold。它们也可以使用字体变体(’fvar’)表和相关表格实现为可变字体的动态变化; 例如,Skia字体的重量或宽度变化。单个字体还可以使用“fvar”和相关表以及静态样式属性组合动态变体。例如,一个族可能有与权重属性相关的变体以及罗马与斜体的区别,权重使用’fvar’和相关表实现为动态变体,但罗马和斜体作为静态设计属性 - 罗马字体重量变化,以及具有重量变化的相应斜体字体。
样式属性表允许软件实现理解族中各种字体或设计变体实例之间的关系。它提供了一些字符串,可用于创建具有各个样式属性控件的用户界面,或用于组合旧版应用程序中可能需要的字符串。
注意:样式属性表提供了字体相对于它所属的整个族的特征,而不仅仅是单独的一种字体。这种表征可能涉及用户不会与字体本身相关联的属性。例如,常规字体的部分表征将包括斜体轴值(非斜体))如果字体系列包含斜体成员,即使该字体不是斜体字体。(参见下面的示例2.)对于可变字体,相关的轴组可以是’fvar’表中使用的轴的超集,如果这些轴与整个系列相关。例如,一个族可以包括具有权重变化的罗马变量字体,以及配对的斜体字体,也具有权重变化。斜体轴与两种字体的完整表征相关,因为斜体轴与整个系列相关。(见下面的例5)
所有可变字体都需要样式属性表。有关OpenType字体变体的一般概述,请参阅OpenType字体变体概述一章。
对于所有新的非变量字体,也建议使用样式属性表,尤其是如果字体在除重量,宽度或斜率之外的轴中具有样式属性时。
在多轴字体中使用时,样式属性表可以实现名称ID 21和22的预期目的,但使用更通用和灵活的机制。对于仅在较新的应用程序中使用的字体,如果存在样式属性表,则可能不需要名称ID 21和22的字符串。但是,当字体也需要在较旧的应用程序中工作时,应在适用时继续使用名称ID 21和22。
7.44.2.Style Attributes Header
样式属性表1.2版按如下方式组织:
样式属性标题:
类型 名称 描述
UINT16 majorVersion 样式属性表的主要版本号 - 设置为1。
UINT16 minorVersion 样式属性表的次要版本号 - 设置为2。
UINT16 designAxisSize 每个轴记录的大小(以字节为单位)。
UINT16 designAxisCount 设计轴记录的数量。在带有’fvar’表的字体中,此值必须大于或等于’fvar’表中的axisCount值。在所有字体中,如果axisValueCount大于零,则必须大于零。
OFFSET32 designAxesOffset 从STAT表的开头到设计轴数组的起始点的偏移量(以字节为单位)。如果designAxisCount为零,则设置为零; 如果designAxisCount大于零,则必须大于零。
UINT16 axisValueCount 轴值表的数量。
OFFSET32 offsetToAxisValueOffsets 从STAT表的开头到设计轴的起始值的偏移量以字节为单位偏移数组。如果axisValueCount为零,则设置为零; 如果axisValueCount大于零,则必须大于零。
UINT16 elidedFallbackNameID 当名称投影到特定字体模型时,名称ID用作后备,生成仅包含elidable元素的子系列名称。
在样式属性表的1.0版中,未包含elidedFallbackNameId字段。不推荐使用版本1.0。1.1版添加了elidedFallbackNameId字段。版本1.2增加了对格式4轴值表的支持; 否则,版本1.2和版本1.1是相同的。
elidedFallbackNameId字段提供了一个名称,如果所有轴值名称都是elidable,则可以在编写名称时使用该名称。例如,“正常”权重和“罗马”倾斜都可以标记为可删除的轴值名称,因此正常权重和罗马倾斜的组合名称可能会导致空字符串。elidedFallbackNameId用于提供在这种情况下使用的备用名称ID,例如“Regular”。在许多字体中,这可能引用名称ID 17或名称ID 2。
标题后面是设计轴和轴值偏移数组,其位置由偏移字段提供。
类型 名称 描述
AxisRecord designAxes [designAxisCount] 设计轴阵列。
Offset16 axisValueOffsets [axisValueCount] 轴值表的偏移量数组,以字节值开始的字节值偏移数组。
designAxisSize字段指示每个轴记录的大小。STAT表的未来次要版本更新可以定义具有附加字段的轴记录格式的兼容扩展。实现必须使用designAxisSize designAxisSize字段来确定每条记录的开头。
7.44.3.Axis Records
轴记录提供有关单个设计轴的信息。
AxisRecord:
类型 名称 描述
标签 axisTag 标识设计变化轴的标签。
UINT16 axisNameID “名称”表中为条目提供显示字符串的条目的名称ID。
UINT16 axisOrdering 应用程序可用于确定面部名称的主要排序或在编写族名称或面部名称时对描述符进行排序的值。
每个轴记录都有一个标记轴的标签。请注意,标记值必须遵循OpenType Design-Variation Axis Tag Registry中描述的标记规则。
axisNameID字段提供了一个名称ID,可用于从“名称”表中获取可用于在应用程序用户界面中引用轴的字符串。名称ID必须大于255且小于32768。
在可变字体中,字体变体表中定义的每个轴都必须有轴记录,并且必须使用字体变体表中使用的相同名称ID。如果从STAT表中省略了变异轴,或者使用了不同的名称ID,则应用程序在使用STAT表数据时可能会出现意外行为。但是,STAT表中轴记录的顺序是任意的,不需要匹配’fvar’表中记录的顺序。
如果变量字体具有在字体变体表中未实现为动态变化轴的附加轴,但是与其所属的字体或族相关,则还应包括轴记录。
非可变字体应包括与其所属的字体或其族相关的任何轴的轴记录,尤其是在使用除了重量,宽度和斜率之外的轴时。
注意:对于使用轴记录声明的每个轴,轴应该是在’fvar’表中定义的变化轴,否则它应该反映在字体的子族名称(名称ID 17或名称ID 2)中,除了如果该轴上的字体值是从子族名称中抑制的“正常”值的情况。
轴排序字段允许字体开发人员影响用户界面中轴的排序,以及将面名称投影到不同字体系列模型时轴值描述符的排序。假设较低的值具有较早的排序顺序或较高的优先级而不是较高的值。值不必是连续的,并且记录不需要与轴排序字段有关。没有两个记录应该具有相同的值。除此之外,这里没有规定关于如何在应用程序中使用这些值的严格要求。
可以使用axisOrdering值的一种方法是在一个族中呈现一个枚举的面部名称列表:不是按任意顺序列出面,而是可以使用这些值对它们进行排序,以确定主要,次要等顺序。例如,如果宽度的值低于权重,则具有一个特定宽度的所有权重将在具有下一个宽度的不同权重之前列出,依此类推。
可以使用axisOrdering的另一种方法是组合名称。对此的一个特殊情况是生成符合使用四个成员常规,粗体,斜体,粗体斜体(R / B / I / BI)或重量/宽度/斜率(WWS)模型的应用程序的期望的系列和子系列名称字体系列。在非变量字体中,设计者可以包括名称ID对1/2和21/22来支持这些模型,但是在变量字体中没有其他规定。样式属性表提供了各个轴值描述符字符串,可以根据需要以不同方式组合以满足名称ID 1/2或21/22的要求。但是,在这样做时,没有关于如何在系列名称中排序不同元素的独立规范。例如,“Arial Serif Caption”和“Arial Caption Serif”都可以作为名称ID 21等效。应在应用程序中使用axisOrdering值来选择组合此类名称时的顺序。
为了确保面部名称如何呈现给用户的一致性,轴记录中给出的轴排序应该在一个族中的不同字体之间保持一致,并且与排版子系列中使用的轴值描述符的排序(名称ID 17)相一致。在可变字体中,轴排序还应与在’fvar’表中定义的命名实例引用的字符串中使用的轴值描述符的顺序一致。
某些遗留应用程序可能会在文档标记中序列化面部名称以指示文本格式。此类应用程序可以使用轴排序字段生成用于序列化目的的名称,以便提高与读取相同文档格式的其他应用程序成功交换的可能性。但是,不建议在序列化标记中使用面名称。这包括使用STAT表中轴值记录引用的字符串。相反,应用程序应使用印刷系列名称(名称ID 16)加上由轴标记值对组成的设计向量,或者一个完全限定的非本地化名称:唯一字体标识符(名称ID 3),或者Postscript名称(名称ID 6)。
属于同一系列的不同字体应具有匹配的轴记录值。但是,如果一个系列的一组字体被释放,然后稍后使用新的变形轴扩展系列的附加字体,则不需要使用附加的轴记录更新以前发送的字体; 较新的字体将提供轴细节。
7.44.4.Axis Value Tables
轴值表提供有关设计变化的某个特定轴上的特定样式属性值的详细信息,或设计变化轴值的组合,以及这些值与名称元素的关系。此信息可用于在应用程序用户界面中显示字体。
轴值表的特定用途是帮助平台支持印刷系列,这些平台系列涉及旧应用中的各种设计变化,这些应用假设在一个系列中变化的选择更有限。具体而言,轴值表可用于将印刷族和子家族名称转换为适合于不同家庭模型的替代名称。例如,某些应用程序假设WWS系列模型(一个系列只能包括重量,宽度或斜体或斜体变体); 某些应用程序可能会假设R / B / I / BI系列模型(一个系列只能包含Regular,Bold,Italic或Bold Italic变体)。轴值表的这种用法在目的上类似于’name’表中的备用族/子系列名称ID对:
R / B / I / BI系列模型的名称ID 1和2。
WWS系列模型的名称ID 21和22。
名称ID 16和17表示无限制的印刷族模型。
但是,在可变字体中,为名称实例提供的名称仅包括名称ID 16和17当量; 没有名称ID 1/2或名称ID 21/22当量。因此,轴值表在可变字体中尤其重要,以允许在较旧的应用程序中支持命名实例,特别是当使用超出重量,宽度或斜体或倾斜的任何变化时。
在可变字体中,’fvar’表中定义的所有命名实例的印刷子系列名称的每个元素都应反映在轴值表中。对于未出现在任何命名实例中的名称元素,可以包括附加轴值表; 这些可用于某些字体选择用户界面,但不需要将排版系列/子系列名称映射到旧命名模型。某些可变字体可能包含未反映在任何命名实例的子系列名称中的轴 - 也就是说,沿这些轴的变体只能通过数值轴值进行选择。在这种情况下,不需要为这些轴上的值指定名称或创建轴值表。
在许多情况下,name元素将与单个轴上的特定值相关联。例如,“粗体”表示特定的重量轴值; 或“Condensed”表示特定的宽度值。假设这些名称元素可以与与其他轴上的值相关联的名称元素组合,如实例名称“Bold Condensed”。此类型的名称元素称为分析名称。
在其他情况下,名称元素可以与多个轴上的特定值组合相关联,并且不适合分析为更简单的独立元素。例如,用于刻字的可变字体可以使用几个自定义轴来提供不同的笔划或swash-terminal修改,并且可以为这些轴的某些值组合定义命名实例,这些轴具有用于这些组合的不可分解的名称; 例如,“Florid”表示行程轴和终止轴值的特定组合。此类型的名称元素称为非分析。请注意,具有非分析名称的字体也可能使用诸如使用分析名称的权重之类的轴,从而导致某些命名实例组合非分析和分析元素,例如“Florid Bold”和“Florid Semibold”。
注意:如果应用程序将族和子系列名称转换为与R / B / I / BI系列模型兼容,则任何非“常规”,“粗体”,“斜体”或“倾斜”的子系列名称元素将被移入一个姓氏。例如,给定姓氏“Selawik”和子家族名称“Condensed Bold”,这将被转换为R / B / I / BI模型,其姓氏为“Selawik Condensed”,子家族名称为“Bold”。(“Selawik”和“Selawik Condensed”将在R / B / I / BI模型中被视为单独的系列。)同样,当名称转换为WWS族模型时,任何不代表权重值的子系列名称元素,宽度值,或斜体或倾斜将移动到姓氏。出于这个原因,建议宽度,重量和斜体/倾斜描述符始终放在子科名称的最后,
请注意,变量字体可能具有一些区别的子系列属性,这些属性是静态的,不是作为变体实现的,而是与完整的排版系列相关。例如,权重变化字体可以具有成对的斜体权重变化字体。还应为在家庭中相关的任何此类区别提供轴值记录。
轴值表对于可变字体尤为重要,但也可以用于非变量字体。请注意,较新的平台实现可以使用轴值表(如果包含在非变量字体中),而不是名称ID 1/2或名称ID 21/22对,以支持较旧的应用程序。在非变量字体中,可以为任何样式变量区分提供轴值记录,该区别适用于字体并与其所属的字体系列相关。
在非变量字体中使用时,特定值的轴值表应该在族中的字体中一致地实现。特别是,一个族中的两种不同字体可以共享某些样式属性,并且应该一致地实现这些值的轴值表。例如,Bold Condensed和Bold Semi-Condensed字体都具有相同的权重属性Bold,并且应该具有Bold匹配的轴值表。如果它们不一致,某些应用程序可能会在字体相关操作中出现意外行为,例如字体在用户界面中的显示方式,或者如何在后备或其他字体选择操作中选择字体。
定义了四种不同的轴值表格式。格式1,2和3适用于与分析名称元素关联的单轴值。格式4用于与非分析名称元素相关联的多轴值组合。将来可能会支持其他格式,并对STAT表进行次要版本更新。
注意:对于’wght’和’wdth’轴上的值,以及’Italic’(’ital’轴上的值为1.0)或“Oblique”,特别推荐使用格式1,格式2或格式3轴值表“(’slnt’轴上的非零值)变体。
注意:对于非分析子系列名称以及静态字体系列中的相应轴值组合或者也涉及“wght”或“wdth”轴的可变字体,或者“斜体“或”倾斜“变体。
对于任何格式的轴值表,读取第一个字段以确定格式。如果无法识别格式,则可以忽略轴值表。
每种格式都包含valueNameID字段,该字段引用与数值轴值或轴值组合关联的显示字符串。如果名称ID具有轴值的相应字符串,则可以使用定义的名称ID,例如名称ID 2,17或22。否则,名称ID必须大于255且小于32768。
不同的格式都包括具有数值轴值的字段。对于具有已注册轴标记的任何轴,轴值表中的数值将以与在字体变体表中解释的方式相同的方式进行解释。特别是,它们将根据为该轴指定的用户坐标比例和约定进行解释。类似地,如果变量字体具有使用未注册的自定义标记定义的变体轴,则假定轴值表和字体变体表中的值使用相同的自定义比例进行解释,即使它不是常规的定义。
在某些情况下,使用新设计轴的属性可能会在其他字体发布后引入系列,新属性在初始字体中不会以任何方式出现。例如,字体设计者可能最初创建设计的Regular,Bold和Italic变体,然后添加宽度变体,如Condensed。在这种情况下,初始字体可能未标识它们表示宽度比例上的“正常”属性。较新的字体应包括描述早期字体的轴值记录。定义一个标志来指定这样的轴值记录; 这将在下面详细描述。
没有两个表应该提供相同轴值的信息。
轴值表,格式1
轴值表格式1具有以下结构。
AxisValueFormat1:
类型 名称 描述
UINT16 格式 格式标识符 - 设置为1。
UINT16 axisIndex 轴记录数组中的零基索引,用于标识轴值记录应用的设计变化轴。必须小于designAxisCount。
UINT16 旗 标志 - 详情请见下文。
UINT16 valueNameID “名称”表中为条目提供此属性值的显示字符串的条目的名称ID。
固定 值 此属性值的数值。
格式1表仅用于将特定轴值与名称相关联。
轴值表,格式2
轴值表格式2具有以下结构。
AxisValueFormat2
类型 名称 描述
UINT16 格式 格式标识符 - 设置为2。
UINT16 axisIndex 轴记录数组中的零基索引,用于标识轴值记录应用的设计变化轴。必须小于designAxisCount。
UINT16 旗 标志 - 详情请见下文。
UINT16 valueNameID “名称”表中为条目提供此属性值的显示字符串的条目的名称ID。
固定 nominalValue 此属性值的标称数值。
固定 rangeMinValue 与指定名称ID关联的范围的最小值。
固定 rangeMaxValue 与指定名称ID关联的范围的最大值。
如果给定名称与特定轴值相关联,则可以使用格式2表,但也与一系列值相关联。例如,在支持光学尺寸变化的系列中,“子标题”可以用于一系列尺寸。rangeMinValue和rangeMaxValue字段用于定义该范围。在可变字体中,命名实例具有每个轴的特定坐标。nominalValue字段允许某些特定的标称值与名称相关联,以与字体变体表中定义的命名实例对齐,而rangeMinValue和rangeMaxValue字段允许相同的名称也与一系列轴值相关联。
一些设计轴可以是开放式的,具有负无穷大的有效最小值,或正无穷大的有效最大值。要表示负无穷大的有效最小值,请将rangeMinValue设置为0x80000000。要表示正无穷大的有效最大值,请将rangeMaxValue设置为0x7FFFFFFF。
给定轴的两个格式2表不应具有重叠大于零的范围。如果字体对于给定轴T1和T2具有两个格式2表,并且具有重叠范围,则将应用以下规则:
如果T1的范围与T2的范围的较高端重叠,其最大值大于T2(T1.rangeMaxValue> T2.rangeMaxValue和T1.rangeMinValue <= T2.rangeMaxValue),则T1用于其范围内的所有值,包括与T2范围重叠的部分。
如果T2的范围完全包含在T1的范围内(T2.rangeMinValue> = T1.rangeMinValue和T2.rangeMaxValue <= T1.rangeMaValue),则忽略T2。
在两个表具有相同轴的相同范围的情况下,它将取决于所使用的实现并且被忽略。
轴值表,格式3
轴值表格式3具有以下结构:
AxisValueFormat3:
类型 名称 描述
UINT16 格式 格式标识符 - 设置为3。
UINT16 axisIndex 轴记录数组中的零基索引,用于标识轴值记录应用的设计变化轴。必须小于designAxisCount。
UINT16 旗 标志 - 详情请见下文。
UINT16 valueNameID “名称”表中为条目提供此属性值的显示字符串的条目的名称ID。
固定 值 此属性值的数值。
固定 linkedValue 此值的样式链接映射的数值。
格式3表可用于指示同一轴上的另一个值,该值将被视为与当前值相关联的样式。这主要用于在重量轴上进行“粗体”样式链接。当用户选择“粗体”格式化选项时,可以在应用程序中使用这些映射来确定应该选择族中的哪种样式。映射是从“非粗体”值到其“粗体”对应值定义的。没有必要为每个权重值提供“粗体”映射; 应提供较轻重量的映射,但较重的重量(通常为半钢或以上)已经被认为是“粗体”,并且不需要“粗体”映射。
注意:在实现文本格式化用户界面时,不要求应用程序使用这些样式链接的映射。可以以字体提供此数据,以便为选择这样做的应用程序提供帮助。如果给定的应用程序不为给定的轴应用此类样式映射,则忽略linkedValue字段。
轴值表,格式4
轴值表格式4具有以下结构:
AxisValueFormat4:
类型 名称 描述
UINT16 格式 格式标识符 - 设置为4。
UINT16 axisCount 有助于此轴值组合的轴总数。
UINT16 旗 标志 - 详情请见下文。
UINT16 valueNameID “名称”表中条目的名称ID,为此组合轴值提供显示字符串。
AxisValue axisValues [axisCount] AxisValue记录数组,提供轴值的组合,每个贡献轴一个。
axisValues数组使用AxisValue记录,其格式如下。
AxisValue记录:
类型 名称 描述
UINT16 axisIndex 轴记录数组的零基索引,用于标识此值适用的轴。必须小于designAxisCount。
固定 值 此属性值的数值。
每个AxisValue记录必须具有不同的axisIndex值。记录可以按任何顺序排列。
旗
定义了以下轴值表标志:
面具 名称 描述
0×0001 OLDER_SIBLING_FONT_ATTRIBUTE 如果设置,则此轴值表提供适用于同一字体系列中其他字体的轴值信息。如果之前发布的其他字体并且不包含有关某些轴的值的信息,则使用此方法。如果其他字体的较新版本包含信息本身并且存在,则忽略此记录。
0×0002 ELIDABLE_AXIS_VALUE_NAME 如果设置,则表示轴值表示轴的“正常”值,在组成名称字符串时可以省略。
0xFFFC 保留的 保留供将来使用 - 设置为零。
当使用OlderSiblingFontAttribute标志时,实现可以使用提供的信息来确定与同一族中的不同字体相关联的行为。如果先前发布的系列使用新设计变体轴的样式变体字体进行扩展,那么所有这些字体都应该包含一个OlderSiblingFontAttribute表,用于表示早期字体的“正常”值。不同字体中的值应匹配; 如果他们不这样做,应用程序行为可能是不可预测的。
注意:设置OlderSiblingFontAttribute标志时,该轴值表用于提供有关同一系列中其他字体的默认信息,但不包含该轴值表所包含的字体。该字体应包含不同的轴值表,这些表不使用此标志来声明自身。
ElidableAxisValueName标志可用于指定通常不应出现在面名称中的轴的“正常”值。例如,设计者可能更喜欢面部名称不包括“正常”宽度或“常规”重量。如果设置了此标志,则允许应用程序从面部名称中省略这些描述符,但它们也可能在某些情况下包含它们。
注意:字体应为“普通”轴值提供轴值表,即使它们通常不应反映在面名中。
注意:如果选择了所有轴值都设置了ElidableAxisValueName标志的字体或变量字体实例,那么应用程序可以保留权重轴的名称(如果存在),以用作构造的子系列名称,其名称为all其他轴值被省略。
设置OlderSiblingFontAttribute标志时,通常会在某些新引入的轴上提供有关“正常”值的信息。在这种情况下,还可以根据需要设置ElidableAxisValueName标志。当应用于早期字体时,那些可能不会包含新轴的任何描述符,因此隐式假设ElidableAxisValueName标志的效果。
如果多个轴值表具有相同的轴索引,则应满足以下条件之一:
字体是可变字体,轴在字体变体表中定义为变体。
OlderSiblingFontAttribute标志在其中一个记录中设置。
一个系列中的两种不同字体可以共享某些共同的样式属性。例如,Bold Condensed和Bold Semi Condensed字体都具有相同的权重属性Bold。特定值的轴值表应在整个系列中一致地实现。如果它们不一致,应用程序可能会出现不可预测的行为。
7.44.5.Examples
以下示例说明了各种字体方案的样式属性表提供的数据。
示例1:使用非可变字体的不同权重变体的族
假设字体系列具有Regular,Bold和Heavy weight变体。这些字体将具有匹配的轴记录:
轴标签 轴名称 轴排序
‘wght’ 重量 0
这三种字体的轴值数据如下:
字形 轴标签 值 名称字符串 旗 其他数据
字体1 ‘wght’ 400 定期 ElidableAxisValueName linkedValue = 700
字体2 ‘wght’ 700 胆大
字体3 ‘wght’ 900 重
示例2:使用非变量字体的族为不同的权重值加斜体
假设示例1中的字体系列也有斜体变体。字体将具有反映重量和斜体轴的匹配轴记录:
轴标签 轴名称 轴排序
‘wght’ 重量 0
‘ITAL’ 斜体 1
三种非斜体字体中的每一种都包括一个额外的轴值记录,以反映非斜体属性。这六种字体的数据如下:
字形 轴标签 值 名称字符串 旗 其他数据
字体1 ‘wght’ 400 定期 ElidableAxisValueName linkedValue = 700
字体1 ‘ITAL’ 0 定期 ElidableAxisValueName linkedValue = 1
字体2 ‘wght’ 700 胆大
字体2 ‘ITAL’ 0 定期 ElidableAxisValueName linkedValue = 1
字体3 ‘wght’ 900 重
字体3 ‘ITAL’ 0 定期 ElidableAxisValueName linkedValue = 1
字体4 ‘wght’ 400 定期 ElidableAxisValueName linkedValue = 700
字体4 ‘ITAL’ 1 斜体
字体5 ‘wght’ 700 胆大
字体5 ‘ITAL’ 1 斜体
字体6 ‘wght’ 900 重
字体6 ‘ITAL’ 1 斜体
示例3:使用具有权重和斜体变体的非可变字体的族,后来扩展为添加宽度变体
假设示例2中的字体系列稍后使用不同的宽度变体进行扩展。系列中的新字体将包括反映三个轴的匹配轴记录:
轴标签 轴名称 轴排序
‘WDTH’ 宽度 0
‘wght’ 重量 1
‘ITAL’ 斜体 2
最初发布的字体的较新版本还将包括附加轴记录。当较新的字体与早期字体的原始版本共存时,将使用较新字体中更完整的轴记录的排序。
为了允许其中一个较新的字体与较旧的字体(未引用宽度轴)共存的情况,较新的字体应各自包含一个轴记录来描述“正常”宽度,这可以推断到更早的字体。
轴标签 值 名称字符串 旗 其他数据
‘WDTH’ 100 正常 OlderSiblingFontAttribute
示例4:重量/宽度可变字体
考虑一个由单个可变字体组成的系列,其中包含重量和宽度变化。此字体将具有两个变化轴的轴记录:
轴标签 轴名称 轴排序
‘wght’ 重量 0
‘WDTH’ 宽度 1
假设变量字体有6个命名实例,它们对应于两个宽度中的每一个的三个不同权重。样式属性表应包括至少这三个权重和这两个宽度的轴值记录,但也可以包括其他权重或宽度值的记录。字体可能包括以下轴值记录:
轴标签 值 名称字符串 旗 其他数据
‘wght’ 300 光 linkedValue = 600
‘wght’ 400 定期 ElidableAxisValueName linkedValue = 700
‘wght’ 600 Semibold
‘wght’ 700 胆大
‘wght’ 900 黑色
‘WDTH’ 62.5 额外的冷凝
‘WDTH’ 75 简明
‘WDTH’ 100 正常 ElidableAxisValueName
‘WDTH’ 125 扩展
‘WDTH’ 150 特扩展
示例5:由非斜体可变字体加斜体可变字体组成的族
考虑一个由非斜体,重量/宽度可变字体加上相应的斜体,重量/宽度可变字体组成的系列。每种字体都有三个轴的轴记录:
轴标签 轴名称 轴排序
‘wght’ 重量 0
‘WDTH’ 宽度 1
‘ITAL’ 斜体 2
除了各种权重或宽度值的轴值记录外,第一种字体还包括反映非斜体属性的记录:
轴标签 值 名称字符串 旗 其他数据
‘ITAL’ 0 正常 ElidableAxisValueName linkedValue = 1
除了各种权重和宽度值的记录之外,第二种字体还包括反映斜体属性的记录:
轴标签 值 名称字符串 旗 其他数据
‘ITAL’ 1 斜体
此示例中的模式可以应用于涉及具有使用字体变体机制和静态非变体设计的组合实现的样式变体的族的其他情况。每种字体的轴记录将跨越变化轴和非变化轴。给定字体中的轴值记录将包括使用字体变化机制实现的轴的多个值,以及其他轴的相关属性值的单个记录。
示例6:具有与多个轴值关联的非分析子系列名称的可变字体
考虑一个使用多个自定义轴的可变字体,’TRM1’,’TRM2’,’STK1’,’STK2’,以及注册的’wght’轴。假设此字体具有命名实例“Florid”和“Jagged”,其涉及自定义轴的特定值组合; 以及与这两个命名实例相对应但具有其他’wght’值的其他命名实例:“Florid Bold”,“Florid Semibold”等。字体将具有’wght’值的轴值表,其数据如下所示:
轴标签 值 名称字符串 旗 其他数据
‘wght’ 400 定期 ElidableAxisValueName linkedValue = 700
‘wght’ 700 胆大
‘wght’ 900 重
该字体还具有对应于“Florid”和“Jagged”的格式4轴值表,其数据如下:
名称字符串 AxisValue记录
花语 ‘TRM1’=
250’TRM2’=
1000’STK1’=
550’STK2’= 0
盘陀 ‘TRM1’=
900’TRM2’=
450’STK1’=
0’STK2’= 310
7.45.SVG SVG(可缩放矢量图形)表
此表包含字体中部分或全部字形的SVG描述。
7.45.1.Introduction
OpenType为颜色字体提供了各种格式,其中一种是SVG表。SVG表提供了使用可缩放矢量图形标记语言支持可缩放彩色图形的好处,这是一种在Web上广泛使用的矢量图形文件格式,可提供丰富的图形功能,如渐变。
SVG的开发是为了在允许丰富功能的环境中使用,包括利用层叠样式表的全部功能进行样式设置,以及使用SVG文档对象模型对图形对象进行编程操作。采用SVG在OpenType中使用并不需要批量整合所有SVG功能。与通用SVG引擎相比,文本呈现引擎通常具有更严格的安全性,性能和架构要求。因此,当在OpenType字体中使用时,语言的表现力受到限制并简化为适合于发生字体处理和文本布局的环境。
SVG表是可选的,可以在具有TrueType,CFF或CFF2轮廓的OpenType字体中使用。对于每个SVG字形描述,字体中必须有相应的TrueType,CFF或CFF2字形描述。
7.45.2.SVG Table Header
类型 名称 描述
UINT16 版 表格版本(从0开始)。设为0。
OFFSET32 offsetToSVGDocumentList 从SVG表的开头偏移到SVG文档列表。必须非零。
UINT32 保留的 设为0。
7.45.3.SVG Document List
SVG文档列表提供一组SVG文档,每个文档定义一个或多个字形描述。
SVGDocumentList:
类型 名称 描述
UINT16 numEntries SVG文档记录的数量。必须非零。
SVGDocumentRecord documentRecords [numEntries] SVG文档记录数组。
每个SVG文档记录指定一系列字形ID(从startGlyphID到endGlyphID,包括端点),以及SVG表中关联的SVG文档的位置。
SVGDocumentRecord:
类型 名称 描述
UINT16 startGlyphID 此记录所涵盖范围的第一个字形ID。
UINT16 endGlyphID 此记录所涵盖范围的最后一个字形ID。
OFFSET32 svgDocOffset 从SVGDocumentList的开头到SVG文档的偏移量。必须非零。
UINT32 svgDocLength SVG文档数据的长度。必须非零。
必须按照startGlyphID增加的顺序对记录进行排序。对于任何给定记录,startGlyphID必须小于或等于该记录的endGlyphID,并且还必须大于任何先前记录的endGlyphID。
注意:两个或多个记录可以指向同一个SVG文档。通过这种方式,单个SVG文档可以提供不连续字形ID范围的字形描述。见例1。
7.45.4.SVG Documents
SVG规范
SVG表中使用的SVG标记语言在外部可缩放矢量图形(SVG)1.1(第二版)规范中定义,网址为http://www.w3.org/TR/SVG11。除非另有明确说明,否则不支持除SVG 1.1规范之外的任何“SVG”功能。
此规范的先前版本允许使用上下文填充和其他context- *属性值,这些值在草案SVG 2规范中定义。不推荐使用这些属性:符合要求的实现可能支持这些属性,但不要求或建议使用支持,强烈建议不要在字体中使用这些属性。
文档编码和格式
OpenType SVG表中的SVG文档可以是纯文本或gzip编码,支持SVG表的应用程序必须同时支持两者。
gzip格式在RFC 1952“GZIP文件格式规范版本4.3”中定义,可从http://www.ietf.org/rfc/rfc1952.txt获得。在gzip编码的SVG文档中,必须使用deflate压缩方法(在http://www.ietf.org/rfc/rfc1951.txt中定义)。因此,gzip编码的文档头的前三个字节必须是0x1F,0x8B,0x08。
无论使用压缩编码还是纯文本传输编码,SVG文档记录的svgDocLength字段都指定编码数据的长度,而不是解码文档。
(未压缩的)SVG文档的字符编码必须是UTF-8。
虽然SVG 1.1被定义为XML应用程序,但Web的一些SVG实现使用“HTML方言”。“HTML方言”与基于XML的定义有各种不同,包括不区分大小写(XML区分大小写),并且不需要SVG根元素上的xmlns属性。支持OpenType SVG表的应用程序必须支持SVG 1.1的基于XML的定义。应用程序可以使用也支持“HTML方言”的SVG解析库。但是,OpenType字体中的SVG文档必须始终符合基于XML的定义。
虽然SVG 1.1要求符合规范的解释器支持XML命名空间构造,但是支持OpenType SVG表的应用程序不需要完全支持XML命名空间。每个SVG文档的根元素必须将SVG声明为默认命名空间:
<svg version =“1.1”xmlns =“http://www.w3.org/2000/svg”>
如果使用XLink href属性,则root还必须将“xlink”声明为根元素中的命名空间:
<svg version =“1.1”xmlns =“http://www.w3.org/2000/svg”xmlns:xlink =“http://www.w3.org/1999/xlink”>
在文档中的任何位置都不能使用其他XLink属性或其他机制。此外,不应在任何元素中进行其他命名空间声明。
SVG功能要求和限制
OpenType支持大多数SVG 1.1功能,并且应该支持所有支持SVG表的OpenType应用程序。某些SVG 1.1功能不是必需的,可以选择在应用程序中支持。OpenType中不支持某些其他功能,不得在OpenType字体中的SVG文档中使用。
以下功能仅限于在OpenType中使用,不得用于符合要求的字体。如果在字体中遇到关联元素的使用,则符合要求的应用程序必须忽略并不呈现这些元素。
<text>,<font>和相关元素<foreignObject>元素<switch>元素<script>元素<a>元素<view>元素
XSL处理
使用相对单位em,例如
在<image>元素中使用SVG数据
使用颜色配置文件(<icccolor>数据类型,<color-profile>元素,颜色配置文件属性或CSS @颜色配置文件规则)
使用contentStyleType属性
使用CSS2系统颜色关键字
SVG文档可能包含<desc>,<metadata>或<title>元素,但实现会忽略这些元素。
在符合实现中不需要支持以下功能,但某些应用程序可能支持它们。字体开发人员应在使用字体之前评估对其字体使用的目标环境中对这些功能的支持。为确保在最广泛的环境中实现互操作性,应避免使用这些功能。
内部CSS样式表(使用<style>元素表示)
CSS内联样式(使用style属性表示)
CSS变量(自定义属性) - 但请参阅下面的进一步资格
CSS媒体查询,calc()或动画
SVG动画
SVG子元素<filter>元素和相关属性,包括enableBackground<pattern>元素<mask>元素<marker>元素<symbol>元素
使用XML实体
在JPEG或PNG以外的格式中使用
交互功能(事件属性,zoomAndPan属性,游标属性或
注意:在用于广泛分发的字体中,建议使用XML演示文稿来定义样式,而不是CSS样式,因为它将在各种实现中提供最广泛的支持。
注意:建议不要使用媒体查询来响应字形描述中的环境更改,即使在提供CSS媒体查询支持的应用程序中使用字体时也是如此。相反,更高级别的表示框架应该处理环境变化。更高级别的框架可以使用OpenType机制(例如字形替换或颜色调色板的选择)与字体内实现的选项进行交互。
虽然支持使用CSS变量是可选的,但强烈建议所有实现都支持CPAL表中定义的颜色变量的CSS var()函数。字体不应在SVG文档中定义任何变量; var()只应在接受颜色值的属性或属性中使用,并且只应作为值中的第一项出现。有关详细信息,请参阅下面的颜色和调色板。
虽然不需要支持图案和蒙版,但所有符合要求的实现都必须支持渐变(<linearGradient>和<radialGradient>元素),剪切路径和不透明度属性。
符合要求的实现必须支持SVG 1.1的所有其他功能,这些功能未在上面列出限制或可选,并且最好避免广泛的互操作性。
7.45.5.Colors and Color Palettes
在SVG 1.1中,可以通过各种方式指定颜色值。对于其中一些,在SVG表中使用时需要考虑特殊注意事项。此外,OpenType为可在SVG字形描述中使用的备用的,用户可选择的调色板提供了一种机制。
颜色
实现必须支持数字RGB规范; 例如,“#ffbb00”或“rgb(255,187,0)”。实现还必须支持SVG 1.1中支持的所有已识别的颜色关键字。但是,不支持CSS2系统颜色关键字,不得使用。
某些实现可能使用碰巧使用rgba()函数支持RGBA规范的图形引擎。但是,OpenType不支持此功能,并且rgba()规范不得用于符合字体。请注意,SVG 1.1提供了可以实现相同效果的不透明度属性。
实现还必须支持“currentColor”关键字。初始值必须由文本布局引擎或应用程序环境设置。这可以以任何被认为最适合应用程序的方式设置。通常,建议将其设置为应用于给定文本行的文本前景色。
注意:在SVG文档中,任何元素的“currentColor”值都是该元素的当前颜色属性值。如果在元素上显式设置了color属性,它将重置该元素及其子元素的“currentColor”值。这样做将覆盖主机环境设置的值。在SVG表中的SVG文档中,没有必要设置颜色属性值的场景,因为可以通过其他方式实现任何效果。应避免设置颜色属性值。
调色板
实现可以选择支持CPAL表中定义的调色板。CPAL表允许字体设计者定义一个或多个调色板,每个调色板包含许多颜色。字体中定义的所有调色板具有相同数量的颜色,这些颜色由基零索引引用。在SVG表中的SVG文档中,使用var()函数将CPAL调色板中的颜色引用为实现定义的CSS变量(自定义属性)。
强烈建议在实现中支持CPAL表和调色板。支持调色板的实现必须支持CSS var()函数,以便将调色板条目作为自定义属性引用。字体应仅使用自定义属性和var()函数来引用CPAL调色板条目。字体不应在SVG文档中定义任何变量。var()函数只应在接受颜色值的属性或属性中使用,并且应仅作为值中的第一项出现。
注意:即使实现不支持CPAL调色板,强烈建议支持var()函数,并且实现能够应用指定为第二个var()参数的回退值,如果第一个参数(颜色变量)不受支持。这将允许用于广泛分发的字体包括CPAL表的使用,但是在某些应用程序中不支持CPAL调色板的情况下能够指定回退颜色。
文本布局引擎或应用程序为每个调色板条目定义自定义属性,并为每个调色板条目分配颜色值。只应为包含CPAL表的字体定义自定义颜色属性。通常,应使用CPAL表中的调色板条目设置自定义属性的值,尽管应用程序可以分配通过其他方式(例如用户输入)派生的值。从CPAL调色板条目中分配值时,通常应默认使用第一个调色板。但是,如果字体具有使用USABLE_WITH_LIGHT_BACKGROUND或USABLE_WITH_DARK_BACKGROUND标记标记的调色板,则可以使用其中一个调色板作为默认调色板。
但是,如果分配了值,则定义的自定义属性数必须为numPaletteEntries,如CPAL表头中所指定。自定义属性名称必须为“–color
以下说明了如何在SVG字形描述中使用颜色变量:
<path fill =“var( - color0,yellow)”d =“...”/>
在支持颜色变量和调色板的实现中,将应用分配给变量的颜色值。但是,如果实现不支持颜色变量和调色板,则将忽略颜色变量,并应用回退颜色值黄色。
CPAL表中的调色板条目被指定为BGRA值。(CPAL alpha值在0到255范围内,其中0表示完全透明,255表示完全不透明。)请注意,SVG 1.1支持RGB颜色值,但不支持RGBA / BGRA颜色值。如上所述,不支持在SVG表中使用SVG文档中的rgba()颜色值,并且不得在符合字体的情况下使用它们。但是,支持CPAL条目中的Alpha值。当CPAL颜色条目应用于形状元素的填充或描边属性,渐变停止元素的停止颜色或feFlood滤镜元素的泛色属性时,则该调色板条目的alpha值必须转换为[0.0 - 1.0]范围内的值,并乘以相同元素的相应填充不透明度,笔触不透明度,停止不透明度或泛光不透明度属性。如果实现支持feDiffuseLighting或feSpecularLighting过滤器,并且调色板条目应用于lighting-color属性,则忽略alpha值。当以这种方式将alpha值应用于元素的不透明度属性时,它是由子元素继承的原始不透明度属性值,而不是将alpha值应用于不透明度属性的计算结果。但是,alpha值作为颜色相关属性(填充,描边等)的组件继承。不是将alpha值应用于opacity属性的计算结果。但是,alpha值作为颜色相关属性(填充,描边等)的组件继承。不是将alpha值应用于opacity属性的计算结果。但是,alpha值作为颜色相关属性(填充,描边等)的组件继承。
7.45.6.Glyph Identifiers
如上所述,每个SVG文档定义一个或多个字形描述。对于SVG文档列表中文档记录的字形ID范围中的每个字形ID,关联的SVG文档必须包含ID为“glyph <glyphID>”的元素,其中<glyphID>是表示为非零的字形ID -padded十进制值。此元素用作给定字形ID的SVG字形描述。
例如,假设具有100个字形(字形ID 0 - 99)的字体仅具有其最后5个字形的SVG字形定义。还假设最后一个SVG字形定义有自己的SVG文档,但是其他四个字形在单个SVG文档中定义(例如,利用共享的图形元素)。将有两个文档记录:第一个,具有字形ID范围[95,98]; 第二个,字形ID范围[99,99]。第一条记录引用的SVG文档将包含ID为“glyph95”,“glyph96”,“glyph97”和“glyph98”的元素。第二条记录引用的SVG文档将包含ID为“glyph99”的元素。
字形标识符可能出现在SVG元素层次结构的深处,但SVG本身并未定义如何呈现部分SVG文档。因此,字体引擎应根据SVG的
<svg version =“1.1”xmlns =“http://www.w3.org/2000/svg”>
</ SVG>
注意: SVG中的
当字体引擎呈现字形14时,结果应与呈现以下SVG文档相同:
<svg version =“1.1”xmlns =“http://www.w3.org/2000/svg”xmlns:xlink =“http://www.w3.org/1999/xlink”>
</ defs>
<use xlink:href =“#glyph14”/>
</ SVG>
7.45.7.Glyph Semantics and Text-Layout Processing
SVG表中的SVG字形描述是对应字形描述的替代,在’glyf’,’CFF’或CFF2表中具有相同的字形ID。SVG字形描述必须提供与相应的TrueType / CFF字形描述相同的抽象字形的描述。
使用SVG字形描述时,使用’cmap’,’hmtx’,GSUB和其他表以相同的方式完成文本布局。这导致在表面上的特定x,y位置处排列的最终字形ID的阵列(以及适用的缩放/旋转矩阵)。完成此布局处理后,将在渲染中使用可用的SVG描述,而不是TrueType / CFF描述。对于最终字形数组中的每个字形ID,如果SVG字形描述可用于该字形ID,则使用SVG引擎呈现该字形ID; 否则,呈现TrueType或CFF字形描述。SVG字形的字形前进宽度或高度与TrueType / CFF字形相同,但字形墨水边界框可能存在小的差异。因为进步是一样的,
7.45.8.Coordinate Systems and Glyph Metrics
与TrueType / CFF设计网格相比,默认SVG坐标系是垂直镜像的:正y轴指向下方,而不是正向y轴向上指向OpenType的常规约定。在其他方面,SVG文档的默认坐标系对应于TrueType / CFF设计网格:SVG文档的默认单位等同于字体设计单位; SVG原点(0,0)与TrueType / CFF设计网格中的原点对齐; y = 0是用于文本布局的默认水平基线。
SVG文档的初始视口的大小是em square:height和width都等于head.unitsPerEm。如果在
虽然初始视口大小是em方形,但不能剪切视口。假设<svg>元素的剪辑属性值为auto,溢出属性值为visible。字体不应在<svg>元素上指定剪辑或溢出属性。如果在<svg>元素上使用任何其他值指定了剪辑或溢出属性,则必须忽略它们。
注意:由于SVG使用y-down坐标系,因此默认情况下,字形通常会在SVG坐标系的+ x -y象限中绘制。(参见示例2.)然而,在许多其他环境中,图形元素可能需要位于+ x + y象限中才能看到。字体开发工具应该在设计环境和字体SVG表中的表示之间提供适当的转换。在示例3中,viewBox属性用于向上移动视口。在示例4中,对容器元素使用转换变换以移位包括字形描述的图形元素。
字形前进宽度在’hmtx’表中指定; 提前高度在’vmtx’表中指定。请注意,字形前进是静态的,无法设置动画。
与CFF字形一样,不记录明确的字形边界框。注意,左侧轴承在“hmtx”表中的值,上侧的轴承在“vmtx”表中,并且在的标志字段的位1 “头部”表不用于SVG字形的描述。如果需要边界框,则应使用渲染的SVG字形的“墨水”边界框; 对于字形的动画渲染和静态渲染,此框可能不同。
字形前进和位置可以通过GPOS或“kern”表中的数据进行调整。请注意,GPOS和’kern’表中的数据使用y-up坐标系,与TrueType或CFF字形描述一样。应用于SVG字形描述时,应用程序必须处理y-up坐标系和用于SVG字形描述的y-down坐标之间的转换。
7.45.9.Animations
一些实现可以支持使用动画 - SVG动画或CSS动画。请注意,对动画的支持是可选的,不建议用于广泛分发的字体。
在某些情况下,支持动画的应用程序可能需要对包含动画的字形进行静态渲染。例如,在打印时可能需要这样做。请注意,静态渲染是通过忽略SVG文档中的任何动画而不是运行任何动画来获得的,而不是通过允许动画在时间= 0运行和捕获初始帧来获得。
请注意,字形前进宽度和前进高度在“hmtx”和“vmtx”表中定义,并且无法设置动画。字形的边界框可能会在动画期间发生变化,但应保持在字形前进宽度/高度和字体的默认线度量内,以避免与其他文本元素发生冲突。
7.45.10.Examples
这些示例中的SVG代码与使用SVG字形描述的OpenType字体的SVG文档中使用的完全相同。为简洁起见,代码未进行优化。
示例1:SVG表头和文档列表
此示例显示SVG表头和文档列表。
在SVG文档列表中,多个SVG文档记录可以指向相同的SVG文档。通过这种方式,单个SVG文档可以为不连续范围的字形ID提供字形描述。此示例显示文档列表中指向同一SVG文档的多个记录。
例1:
Hex数据 资源 评论
SVGHeader
0000 版 表版本= 0
0000000A offsetToSVGDocumentList 偏移到文档列表
00000000 保留的
SVGDocumentList
0005 numEntries 5 documentRecord条目,索引0到4
documentRecords [0] 字形ID范围的文档记录[1,1]
0001 startGlyphID
0001 endGlyphID
0000003E svgDocOffset 偏移到glyph1的SVG文档
0000019F svgDocLength glyph1的SVG文档长度
documentRecords [1] 字形ID范围的文档记录[2,2]
技术 startGlyphID
技术 endGlyphID
000001DD svgDocOffset 偏移到glyph2的SVG文档。相同的SVG文档也用于glyph13,glyph14。
000002FF svgDocLength 字形2的SVG文档的长度 - 整个SVG文档的长度,包括字形2,13和14。
documentRecords [2] 字形ID范围的文档记录[3,12]
0003 startGlyphID
000C endGlyphID
000004DC svgDocOffset 对于字形3到12的SVG文档的偏移量
000006F4 svgDocLength 字形3到12的SVG文档长度
documentRecords [3] 字形ID范围的文档记录[13,14]
000D startGlyphID
000E endGlyphID
000001DD svgDocOffset 对于字形2,13,14的SVG文档偏移。偏移与documentRecords [1]相同。
000002FF svgDocLength 字形2,13,14的SVG文档长度。长度与documentRecords [1]相同。
documentRecords [4] 字形ID范围的文档记录[15,19]
000F startGlyphID
0013 endGlyphID
00000BD0 svgDocOffset 对于字形15到19的SVG文档的偏移量
00000376 svgDocLength 字形15到19的SVG文档长度
示例4示出了具有不连续范围[2,2],[13,14]的字形描述的SVG文档。
示例2:直接在预期位置指定的字形
在此示例中,字母“i”直接绘制在SVG坐标系的+ x -y象限中,直立,其基线位于x轴上。请注意,
例2:
1 | <svg id="glyph7" version="1.1" xmlns="http://www.w3.org/2000/svg"> |
下图显示了视觉效果:

示例3:使用viewBox向上移动雕文
在SVG插图应用程序中进行设计时,在SVG坐标系的+ x + y象限中绘制对象可能是最自然的。在此示例中,字母“i”的字形描述在+ x + y象限中以竖直方向指定,就像在SVG坐标系中基线处于y = 1000一样。然后使用<svg>元素中的viewBox将视口向下移动1000个单位,以使实际基线与设计的基线对齐。
注意:在<svg>元素上使用viewBox属性时,为宽度和高度值指定unitsPerEm以避免缩放效果非常重要。有关更多信息,请参阅坐标系和字形度量标准。
例3:
1 | <svg id="glyph7" version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="0 1000 1000 1000"> |
视觉结果与实施例2所示的相同。
示例4:在同一SVG doc中跨字形共享的公共元素
在此示例中,字母“i”的基数被指定为<defs>元素中的一个组件,以便可以跨三个字形重复使用它。使用标识符“i-base”引用此共享组件。在glyph2中,该组件单独用于构成“无点i”。在glyph13中,顶部添加了一个点。在glyph14中,顶部添加了强烈的重音。
此示例还说明了使用平移变换来移动在SVG坐标系的+ x + y象限中绘制的元素,使它们出现在基线上方的+ x -y象限中。
例4:
1 | <svg version="1.1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink"> |
下图显示了从左到右的字形ID 2,13和14的可视结果。

示例5:在字形中指定currentColor
此示例使用与示例2中相同的“i”字形描述,并进行一项修改:“i”的点的“darkblue”颜色值替换为“currentColor”关键字。应用程序设置currentColor的颜色值,通常使用文本前景色。
例5:
1 | <svg id="glyph7" version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="0 1000 1000 1000"> |
下图说明了应用程序将currentColor设置为两个不同颜色值的可视结果:黑色(左)和红色(右)。

示例6:在字形中指定调色板变量
此示例对示例2中的“i”使用相同的字形描述,但进行了修改:使用颜色变量–color0和–color1指定线性渐变的停止颜色。
此示例中的字体包括CPAL表。颜色变量的值由应用程序设置,通常使用CPAL条目。此示例中假定的CPAL表有两个调色板,每个调色板有两个条目,BGRA颜色值如下:
调色板0:{8B0000FF,B3AA00FF}
调色板1:{800080FF,D670DAFF}
(调色板0中颜色的SVG等价物为{darkblue,#00aab3}。调色板1中颜色的SVG等价物为{紫色,兰花}。)
在用于引用颜色变量的每个var()调用中,已指定了回退颜色值的第二个参数。这些值与调色板0中使用的值匹配。如果应用程序不支持CPAL表,则将使用这些回退值。
例6:
1 | <svg id="glyph7" version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="0 1000 1000 1000"> |
以下图像显示了从左到右三种情况下的视觉效果:

左边的第一种情况显示了使用CPAL表中的调色板0设置颜色变量值时的结果。第二种情况,在中间,显示使用调色板1设置值时的结果。
第三种情况,在右侧,显示了一个结果,其中应用程序使用具有用户指定颜色的自定义调色板设置颜色变量的值:
–color0:红色
–color1:橙色
请注意,在所有三种情况下,“i”的点仍然是深蓝色,因为它在字形描述中是硬编码的,而不是由颜色变量控制。
如果应用程序没有为–color0和–color1设置值(例如,因为它不支持CPAL表),则使用var()函数(分别为darkblue和#00aab3)中提供的回退值。请注意,这些颜色实际上与第一个(默认)CPAL调色板中的颜色相同,这意味着字形将像上面显示的第一种情况一样呈现。
例7:在SVG字形中嵌入PNG
在此示例中,PNG数据嵌入在<image>元素中。
嵌入PNG数据的典型用例是刻字字体的详细图稿。
例7:
1 | <svg id="glyph2" version="1.1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" viewBox="0 1000 1000 1000"> |
下图显示了视觉效果:

7.46.VDMX 垂直设备指标
VDMX表与具有TrueType轮廓的OpenType™字体相关。在Windows下,OS / 2表中的usWinAscent和usWinDescent值将用于确定任何给定大小的字体的最大黑色高度。Windows将此距离称为字体高度。因为TrueType指令可能导致字体高度与实际缩放和舍入值不同,严格基于yMax和yMin的字体高度会导致“丢失像素”.Windows会剪切任何延伸到yMax之上或yMin之下的像素。为了避免网格拟合整个字体以确定正确的高度,已定义VDMX表。
VDMX表包含一个标头,后跟VDMX记录的分组。
VDMX标题:
类型 名称 描述
UINT16 版 版本号(0或1)。
UINT16 numRecs 存在的VDMX组数
UINT16 numRatios 宽高比分组数
RatioRange ratRange [numRatios] 比率记录数组。
Offset16 偏移numRatios] 从此表的开始到相应RatioRange记录的VDMXGroup表的偏移量。
RatioRange记录:
类型 名称 描述
UINT8 bCharSet 字符集(见下文)。
UINT8 xRatio 用于x-Ratio的值
UINT8 yStartRatio 开始y-Ratio值。
UINT8 yEndRatio 结束y比率值。
比率设定如下:
对于1:1的宽高比 Ratios.xRatio = 1;
Ratios.yStartRatio = 1;
Ratios.yEndRatio = 1;
比例为1:1到2:1 Ratios.xRatio = 2;
Ratios.yStartRatio = 1;
Ratios.yEndRatio = 2;
比例为1.33:1 Ratios.xRatio = 4;
Ratios.yStartRatio = 3;
Ratios.yEndRatio = 3;
适用于所有宽高比 Ratio.xRatio = 0;
Ratio.yStartRatio = 0;
Ratio.yEndRatio = 0;
所有设置为零的值都表示要使用的默认分组; 如果存在,则必须是表中的最后一个比率组。2:2的比率与1:1相同。
通过基于当前X分辨率对整个比率范围记录进行归一化并且在归一化之后对每个记录执行Y分辨率的范围检查,将宽高比与目标设备匹配。找到匹配后,搜索将停止。如果在搜索期间遇到0,0,0组,则使用它(因此,如果该组不在比率分组的末尾,则不会使用其后的组)。如果没有匹配且没有0,0,0记录,则该宽高比没有VDMX数据。
请注意,范围检查在概念上执行如下:
复制
(deviceXRatio == Ratio.xRatio) && (deviceYRatio >= Ratio.yStartRatio) && (deviceYRatio <= Ratio.yEndRatio)
每个比率分组是指特定的VDMX记录组; 表中必须至少有1个VDMX组。
bCharSet值用于表示根据字体文件中存在的字形子集计算VDMX组的情况。bCharSet的语义根据VDMX表的版本而有所不同。建议使用VDMX版本1。当前定义的字符集值为:
字符集值,版本0:
值 描述
0 没有子集; VDMX组适用于字体中的所有字形。这用于符号或dingbat字体。
1 Windows ANSI子集; 仅使用完成Windows ANSI字符集所需的字形计算VDMX组。Windows将忽略任何不属于ANSI子集的VDMX条目(即ANSI_CHARSET)
字符集值,版本1:
值 描述
0 没有子集; VDMX组适用于字体中的所有字形。如果将新字符集添加到现有字体,请添加此标志以及支持它的必要组。这应该只与ANSI_CHARSET一起使用。
1 没有子集; VDMX组适用于字体中的所有字形。在为Windows创建新字体时使用。无需支持SYMBOL_CHARSET。
VDMX组紧跟表头。每组记录(只需要一组)具有以下布局:
VDMXGroup表:
类型 名称 描述
UINT16 区域经济共同体 此组中的高度记录数
UINT8 startsz 启动yPelHeight
UINT8 endsz 结束yPelHeight
VTABLE 进入[区域经济共同体] VDMX记录
vTable记录:
类型 名称 描述
UINT16 yPelHeight 适用于哪些值的yPelHeight。
INT16 YMAX 此yPelHeight的最大值(以像素为单位)。
INT16 YMIN 此yPelHeight的最小值(以像素为单位)。
此表必须按排序顺序出现(按yPelHeight排序),但不必连续。它应该有一个每个像素高度的条目,其中yMax和yMin不能线性缩放,其中线性缩放高度定义为:
暗示的yMax和yMin与缩放/舍入的yMax和yMin相同。
假设一旦yPelHeight达到255,所有高度将是线性的,或者至少接近线性而不再重要。请注意,虽然Ratios结构只能支持最大255的ppem尺寸,但vTable结构可以支持更大的像素高度(最高65535)。对于vTable记录,int16和uint16的选择取决于yMax和yMin是有符号值(并且127到-128的范围太小)以及对vTable元素进行字对齐的要求。
7.47.vhea 垂直标题表
垂直标题表(标记名称:’vhea’)包含垂直字体所需的信息。垂直字体的字形从上到下或从下到上书写。此表包含整个字体的一般信息。有关特定字形的信息在垂直度量表(标记名称:’vmtx’)中单独描述。这些表的格式类似于水平指标(’hhea’和’hmtx’)的格式。
垂直标头表中的数据必须与垂直标准表中显示的数据一致。垂直度量表中的提前高度和顶部边缘值必须与垂直标题表中的最大提前高度和最小底部边标值相对应。
有关构造CJK(中文,日文和韩文)字体的详细信息,请参阅OpenType CJK字体指南一节。
7.47.1.Table Format
版本1.0和版本1.1之间的区别是以下字段的名称和定义:
ascender成为vertTypoAscender
descender成为vertTypoDescender
lineGap变为vertTypoLineGap
垂直头表格式的1.0版如下:
版本1.0
类型 名称 描述
固定 版 垂直标题表的版本号; 版本1.0的0x00010000
INT16 上升 FUnits从中心线到前一行下降的距离。
INT16 降落 从中心线到下一线的上升点的距离。
INT16 lineGap 保留; 设为0
INT16 advanceHeightMax 最大提前高度测量 - 在字体中找到的FUnits。此值必须与垂直度量标准表中的条目一致。
INT16 minTop
SideBearing 在FUnits中以字体找到的最小顶部侧边测量值。此值必须与垂直度量标准表中的条目一致。
INT16 minBottom
SideBearing 在FUnits中以字体找到的最小底部侧边测量值。此值必须与垂直度量标准表中的条目一致。
INT16 yMaxExtent 定义为yMaxExtent = max(tsb +(yMax - yMin))。
INT16 caretSlopeRise caretSlopeRise字段的值除以caretSlopeRun字段的值确定了插入符的斜率。上升值为0,运行值为1表示水平插入符号。上升值为1,运行值为0表示垂直插入符号。对于其字形为倾斜或斜体的字体,中间值是理想的。对于垂直字体,水平插入符号最佳。
INT16 caretSlopeRun 请参阅caretSlopeRise字段。非垂直字体的值= 1。
INT16 caretOffset 倾斜字形上的突出显示需要从字形移开以产生最佳外观的量。对于非植入字体,设置值等于0。
INT16 保留的 设为0。
INT16 保留的 设为0。
INT16 保留的 设为0。
INT16 保留的 设为0。
INT16 metricDataFormat 设为0。
UINT16 numOf
LongVerMetrics 垂直度量表中的提前高度数。
垂直头表格式的1.1版如下:
版本1.1
类型 名称 描述
固定 版 垂直标题表的版本号; 版本1.1的0x00011000
注意非固定小数部分的表示,以固定数字表示。
INT16 vertTypoAscender 这种字体的垂直排版上升器。它是FUnits中距垂直轴的表意em-box中心基线到表意em-box右边缘的距离。
它通常设置为(head.unitsPerEm)/ 2。例如,em为1000 fUnits的字体会将此字段设置为500.有关表意文字框的说明,请参阅OpenType布局标记注册表的“基准标记”部分。
INT16 vertTypoDescender 这种字体的垂直印刷下降器。它是FUnits中从垂直轴的表意em-box中心基线到表意符号em-box左边缘的距离。
它通常设置为(head.unitsPerEm)/ 2。例如,em为1000 fUnits的字体会将此字段设置为-500。
INT16 vertTypoLineGap 此字体的垂直印刷间隙。应用程序可以通过以下表达式确定OpenType字体的单个间隔垂直文本的建议行间距:ideo embox width + vhea.vertTypoLineGap
INT16 advanceHeightMax 最大提前高度测量 - 在字体中找到的FUnits。此值必须与垂直度量标准表中的条目一致。
INT16 minTop
SideBearing 在FUnits中以字体找到的最小顶部侧边测量值。此值必须与垂直度量标准表中的条目一致。
INT16 minBottom
SideBearing 在FUnits中以字体找到的最小底部侧边测量值。此值必须与垂直度量标准表中的条目一致。
INT16 yMaxExtent 定义为yMaxExtent = max(tsb +(yMax - yMin))。
INT16 caretSlopeRise caretSlopeRise字段的值除以caretSlopeRun字段的值确定了插入符的斜率。上升值为0,运行值为1表示水平插入符号。上升值为1,运行值为0表示垂直插入符号。对于其字形为倾斜或斜体的字体,中间值是理想的。对于垂直字体,水平插入符号最佳。
INT16 caretSlopeRun 请参阅caretSlopeRise字段。非垂直字体的值= 1。
INT16 caretOffset 倾斜字形上的突出显示需要从字形移开以产生最佳外观的量。对于非植入字体,设置值等于0。
INT16 保留的 设为0。
INT16 保留的 设为0。
INT16 保留的 设为0。
INT16 保留的 设为0。
INT16 metricDataFormat 设为0。
UINT16 numOf
LongVerMetrics 垂直度量表中的提前高度数。
7.47.2.’vhea’ Table and OpenType Font Variations
在可变字体中,可能需要针对不同的变体实例调整’vhea’表中的各种字体度量值。可以在度量变化(MVAR)表中提供“vhea”条目的变体数据。使用值标记将不同的“post”条目与MVAR表中的特定变体数据相关联,如下所示:
‘vhea’进入 标签
上升 VASC
caretOffset vcof
caretSlopeRun VCRN
caretSlopeRise 录像机
降落 VDSC
lineGap vlgp
有关OpenType字体变体的一般信息,请参阅OpenType字体变体概述一章。
7.47.3.Vertical Header Table Example
偏移/长度 值 名称 评论
0/4 0x00011000 版 以定点格式表示的垂直标题表的版本号为1.1
4/2 1024 vertTypoAscender em-square高度的一半。
6/2 -1024 vertTypoDescender 减去em-square高度的一半。
8/2 0 vertTypoLineGap 印刷线间隙为0 FUnits。
10/2 2079 advanceHeightMax 在字体中找到的最大提前高度测量值是2079 FUnits。
12/2 -342 minTopSideBearing 在字体中找到的最小顶部边承测量值为-342 FUnits。
14/2 -333 minBottomSideBearing 在字体中找到的最小底部边承测量值为-333 FUnits。
16/2 2036 yMaxExtent max(tsb +(yMax - yMin))= 2036。
18/2 0 caretSlopeRise 插入符斜率上升为0,插入符斜率为1表示垂直字体的水平插入符号。
20/2 1 caretSlopeRun 插入符斜率上升为0,插入符斜率为1表示垂直字体的水平插入符号。
22/2 0 caretOffset 对于非植入字体,值设置为0。
24/4 0 保留的 设为0。
26/2 0 保留的 设为0。
28/2 0 保留的 设为0。
30/2 0 保留的 设为0。
32/2 0 metricDataFormat 设为0。
34/2 258 numOfLongVerMetrics 垂直度量表中的提前高度数为258。
7.48.vmtx 垂直度量表
垂直度量表允许您以垂直字体指定每个字形的垂直间距。此表由一个或两个数组组成,这些数组包含字体中每个字形的垂直布局的度量信息(提前高度和顶部边框)。垂直度量坐标系统如下所示。
OpenType™垂直字体需要垂直标题表(’vhea’)和下面讨论的垂直度量表。垂直标题表包含整个字体的一般信息。垂直度量表包含与特定字形有关的信息。这些表的格式类似于水平指标(’hhea’和’hmtx’)的格式。
有关构造CJK(中文,日文和韩文)字体的详细信息,请参阅OpenType CJK字体指南一节。
7.48.1.Vertical Origin and Advance Height
字形垂直原点的y坐标指定为字形顶部方位(记录在“vmtx”表中)和字形边界框顶部(即最大y)之和。
TrueType OpenType字体在字形数据(’glyf’)表中包含字形边界框信息。CFF OpenType字体不包含字形边界框信息,因此对于这些字体,字形边界框的顶部必须根据紧凑字体格式(’CFF’)表中的字符串数据计算。
OpenType 1.3 为CFF OpenType字体引入了可选的垂直原点(VORG)表,它直接记录了字形垂直原点的y坐标,因此无需计算边界框作为中间步骤。这提高了CFF OpenType客户端的准确性和效率。
在’vmtx’表中未指定字形垂直原点的x坐标。垂直书写实现可以利用基线(BASE)表中的基线值(如果存在),以便将x方向上的字形与所需的垂直基线对齐。
字形的前进高度从字形垂直原点的y坐标开始向下前进。默认情况下,其端点位于运行中下一个字形的垂直原点的y坐标处。度量调整OpenType布局功能(例如垂直字距调整(’vkrn’))可以类似于水平模式下的字距调整方式修改垂直前进。
7.48.2.Vertical Metrics Table Format
垂直度量表的整体结构由两个如下所示的数组组成:vMetrics数组后跟一组顶部轴承。对于表意字形的垂直构图,顶侧轴承相对于字形原点的顶部进行测量。
此表没有标题,但确实要求两个数组中包含的字形数等于字体中的字形总数。
vMetrics数组中的条目数由垂直标头表的numOfLongVerMetrics字段的值确定。
vMetrics数组包含每个条目的两个值。这些是阵列中包含的每个字形的前进高度和顶部边。
在等宽字体中,例如Courier或Kanji,所有字形都具有相同的前进高度。如果字体是等宽字体,则第一个数组中只需要一个条目,但需要一个条目。
垂直度量数组中的条目格式如下所示。
类型 名称 描述
UINT16 advanceHeight 字形的前进高度。FUnits中的无符号整数
INT16 topSideBearing 字形的顶部边角。FUnits中的有符号整数。
第二个数组是可选的,通常用于字体中一系列等宽字形。每种字体只允许一次这样的运行,它必须位于字体的末尾。此数组包含未在第一个数组中表示的字形的顶部边框,此数组中的所有字形必须与vMetrics数组中的最后一个条目具有相同的提前高度。因此,此数组中的所有条目都是等宽的。
通过从字体中的字形数中减去numOfLongVerMetrics的值来计算此数组中的条目数。因此,第一个数组中表示的字形总和加上第二个数组中表示的字形等于字体中的字形数。顶部侧面阵列的格式如下。
类型 名称 描述
INT16 topSideBearing [] 字形的顶部边角。FUnits中的有符号整数。
7.49.VORG 垂直原点表
此可选表指定字体中每个字形的垂直原点的y坐标。
该表可以选择仅以CFF OpenType字体存在。如果存在于TrueType OpenType字体中,则字体客户端必须忽略它,就像任何其他无法识别的表一样。这是因为TrueType OpenType字体不需要此表:TrueType OpenType字体中的垂直度量标准(’vmtx’)和字形数据(’glyf’)表提供了准确计算字形垂直原点的y坐标所需的所有信息。有关详细信息,请参阅“vmtx”表规范中的“垂直原点和高度”部分。
此表已添加到OpenType规范的1.3版中。请注意,支持垂直书写的所有OpenType字体仍然需要’vmtx’和Vertical Header(’vhea’)表。必须继续从’vmtx’表中获得提前高度; 这是他们存储的唯一地方。
如果VFF表存在于CFF OpenType字体中,则字体客户端可以选择获取字形垂直原点的y坐标:
直接来自VORG,或:
首先从CFF字符串数据计算字形边界框的顶部,然后从’vmtx’表中添加字形的顶边。
前一种方法提供了提高准确性和效率的优点,因为如后一种方法中由CFF字符串计算的边界框结果可以根据边界框算法的舍入决策和数据类型而不同。后一种方法为不知道或不选择支持VORG的字体客户端提供兼容性。
因此,VORG本身不添加任何新的字体度量值; 它简单地提高了CFF OpenType字体客户端的准确性和效率,因为从CFF字符串计算边界框的中间步骤变得不必要了。
有关构造CJK(中文,日文和韩文)字体的详细信息,请参阅OpenType CJK字体指南一节。
7.49.1.Vertical Origin Table Format
类型 名称 描述
UINT16 majorVersion 主要版本(从1开始)。设为1。
UINT16 minorVersion 次要版本(从0开始)。设为0。
INT16 defaultVertOriginY 如果vertOriginYMetrics数组中的字形没有条目,则在字体的设计坐标系中使用字形垂直原点的y坐标。
UINT16 numVertOriginYMetrics vertOriginYMetrics数组中的元素数。
紧接着是vertOriginYMetrics数组(如果numVertOriginYMetrics非零),它具有以下格式的numVertOriginYMetrics元素:
类型 名称 描述
UINT16 glyphIndex 字形索引。
INT16 vertOriginY 在字体的设计坐标系中,Y坐标是符号glyphIndex的字形的垂直原点。
此数组必须通过增加glyphIndex进行排序,并且不得包含多个具有相同glyphIndex的元素。在大小优化的实现中,垂直原点的y坐标等于defaultVertOriginY的字形在此数组中不会有条目。
如果字体中的所有字形共享相同的defaultVertOriginY值,则在大小优化的实现中VORG表的长度将为8个字节,因为vertOriginYMetrics数组将不存在。
通常,只有东亚字体中的全宽拉丁字形才会在vertOriginYMetrics数组中包含条目。例如,如垂直交替和旋转(’vrt2’)功能中所使用的那样,为垂直书写旋转的字形可以在适当设计时利用默认值。
在以下1000-unit-em字体的完整VORG表的示例中,除了具有字形索引10,12和13的字形外,字体中的每个字形都被指定为具有880的vertOriginY:
majorVersion =1
minorVersion =0
defaultVertOriginY =880
numVertOriginYMetrics=3
— vertOriginYMetrics[index]=(glyphIndex,vertOriginY)
[0]=(10,889)
[1]=(12,861)
[2]=(13,849)
7.50.VVAR 垂直度量变化表
VVAR表用于可变字体,以提供垂直字形度量值的变体。这可用于为’vmtx’表中的提前高度提供变化数据。在具有TrueType轮廓的字体中,它还可用于为从“vmtx”表和字形边界框获得的顶部和底部轴承提供变化数据。此外,它还可以用于具有CFF 2轮廓的字体,以提供垂直原点变化数据。
有关OpenType字体变体和与变体相关的术语的一般概述,请参阅OpenType字体变体概述一章。
在具有TrueType轮廓的字体中,光栅化器将生成表示左,右,顶部和底部轴承的“幻像”点。(有关幻像点的更多背景,请参阅“ 指示TrueType字形 ”一章。)在TrueType变量字体中,字形变体(’gvar’)表格将包括每个字形的幻像点的变体数据,允许为不同的变体实例插入字形度量,作为导出插值字形轮廓的一部分。因此,在具有TrueType轮廓的可变字体中不需要VVAR表。但是,对于需要字形度量但不是实际字形轮廓的文本布局操作,能够获得实例的调整后的字形度量而不需要插入字形轮廓,可以获得显着的性能优势。因此,建议将VVAR表包含在具有TrueType轮廓且支持垂直布局的可变字体中。
CFF 2光栅化器不会像TrueType光栅化器那样生成幻像点。因此,需要VVAR表来处理具有CFF 2轮廓的可变字体中的垂直字形度量的任何变化。
VVAR表的格式和处理类似于水平度量变化(HVAR)表。
7.50.1.Related and Co-Requisite Tables
VVAR表仅用于支持垂直布局的可变字体。它必须与垂直度量(’vmtx’)表结合使用,还可以与字体变体(’fvar’)表以及可变字体中使用的其他必需或可选表结合使用。有关一般信息,请参阅OpenType字体变体概述一章中的变体数据表和其他要求。
对于具有TrueType轮廓且支持垂直布局的可变字体,VVAR表是可选的,但建议使用。对于具有CFF 2轮廓且支持垂直布局的可变字体,如果变体空间中的字形前移高度存在任何变化,则需要VVAR表。
注意: VDMX表不用于可变字体。
7.50.2.Table Formats
垂直度量变化表具有以下格式。
垂直指标变化表:
类型 名称 描述
UINT16 majorVersion 度量变量表的主要版本号 - 设置为1。
UINT16 minorVersion 度量变量表的次要版本号 - 设置为0。
OFFSET32 itemVariationStoreOffset 从此表的开头到项目变体存储表的偏移量(以字节为单位)。
OFFSET32 advanceHeightMappingOffset 从该表的开头到提前高度的增量集索引映射的偏移量(可以是NULL)。
OFFSET32 tsbMappingOffset 从该表的开头到顶侧轴承的delta-set索引映射的偏移量(可以是NULL)。
OFFSET32 bsbMappingOffset 从该表的开头到底侧轴承的delta-set索引映射的偏移量(可以是NULL)。
OFFSET32 vOrgMappingOffset 从该表的开头到垂直原点的Y坐标的delta集合索引映射的偏移量(可以是NULL)。
项目变体存储表记录在OpenType字体变体常用表格格式一章中。
映射表是可选的。如果未提供给定的映射表,则将偏移量设置为NULL。
需要提前高度的变化数据。可以提供用于提前高度的增量集索引映射表,但是是可选的。如果未提供映射表,则将字形索引用作隐式增量集索引,如在HVAR表中。
侧轴承的变化数据是可选的。如果包含,则需要映射表来为每个字形提供增量集索引。
垂直原点的映射和变体数据不用于具有TrueType轮廓的字体,但如果字形垂直原点的Y坐标存在可变性,则可以将其包含在具有CFF 2轮廓的可变字体中,其默认值记录在VORG中表。垂直原点变化数据需要映射表。
有关其余详细信息,请参阅水平度量变化(HVAR)表章节。
8.OpenType布局标记注册表
标记注册表定义Microsoft支持的OpenType布局标记。OpenType布局标记是4字节字符串,用于标识OpenType布局字体中的脚本,语言系统,功能和基线。注册表建立了命名和使用这些标记的约定。已注册的标签具有特定含义,并向OpenType布局的开发人员和文本处理客户端传达准确的信息。Microsoft鼓励字体开发人员使用已注册的标签来确保字体,应用程序和操作系统之间的兼容性和易用性。Microsoft将根据请求提供其他标签列表。
以下部分包含脚本,语言系统和基线的常用标记示例集。Microsoft将根据请求提供其他标签列表。此外,“功能标记”部分定义了Microsoft迄今为止开发和注册的所有功能标记,包括每个功能的功能说明。
Microsoft期望已注册的标记和功能列表随着时间的推移而扩展。最新版本的注册表将在Microsoft的网站上提供。
OpenType布局标记注册表:
脚本标签
语言标签
功能标签
基线标签
8.1.脚本标签
脚本标记通常对应于Unicode脚本。但是,它们之间的关联可能并不总是一对一,并且OpenType脚本标记不能保证与Unicode脚本属性值别名或ISO 15924脚本ID相同。由于OpenType脚本标记的开发早于ISO 15924或Unicode脚本属性,因此本文档中定义的脚本标记的规则可能并不总是与ISO 15924脚本标识的规则相同。OpenType脚本标记还可以与特定的OpenType布局实现相关联,结果是可以为给定的Unicode脚本注册多个脚本标记(例如,’deva’和’dev2’)。
所有标签都是由一组有限的ASCII字符组成的四字符字符串; 有关标记数据类型的详细信息,请参阅数据类型。按照惯例,注册的脚本标签使用四个小写字母。
“脚本记录”中脚本标记的使用和处理在“OpenType布局公用表格式”一章的“ 脚本列表表和脚本记录”部分中进行了描述。
Script Script Tag
Adlam ‘adlm’
Ahom ‘ahom’
Anatolian Hieroglyphs ‘hluw’
Arabic ‘arab’
Armenian ‘armn’
Avestan ‘avst’
Balinese ‘bali’
Bamum ‘bamu’
Bassa Vah ‘bass’
Batak ‘batk’
Bengali ‘beng’
Bengali v.2 ‘bng2’
Bhaiksuki ‘bhks’
Bopomofo ‘bopo’
Brahmi ‘brah’
Braille ‘brai’
Buginese ‘bugi’
Buhid ‘buhd’
Byzantine Music ‘byzm’
Canadian Syllabics ‘cans’
Carian ‘cari’
Caucasian Albanian ‘aghb’
Chakma ‘cakm’
Cham ‘cham’
Cherokee ‘cher’
CJK Ideographic ‘hani’
Coptic ‘copt’
Cypriot Syllabary ‘cprt’
Cyrillic ‘cyrl’
Default DFLT
Deseret ‘dsrt’
Devanagari ‘deva’
Devanagari v.2 ‘dev2’
Dogra ‘dogr’
Duployan ‘dupl’
Egyptian Hieroglyphs ‘egyp’
Elbasan ‘elba’
Ethiopic ‘ethi’
Georgian ‘geor’
Glagolitic ‘glag’
Gothic ‘goth’
Grantha ‘gran’
Greek ‘grek’
Gujarati ‘gujr’
Gujarati v.2 ‘gjr2’
Gunjala Gondi ‘gong’
Gurmukhi ‘guru’
Gurmukhi v.2 ‘gur2’
Hangul ‘hang’
Hangul Jamo ‘jamo’
Hanifi Rohingya ‘rohg’
Hanunoo ‘hano’
Hatran ‘hatr’
Hebrew ‘hebr’
Hiragana ‘kana’
Imperial Aramaic ‘armi’
Inscriptional Pahlavi ‘phli’
Inscriptional Parthian ‘prti’
Javanese ‘java’
Kaithi ‘kthi’
Kannada ‘knda’
Kannada v.2 ‘knd2’
Katakana ‘kana’
Kayah Li ‘kali’
Kharosthi ‘khar’
Khmer ‘khmr’
Khojki ‘khoj’
Khudawadi ‘sind’
Lao ‘lao ‘
Latin ‘latn’
Lepcha ‘lepc’
Limbu ‘limb’
Linear A ‘lina’
Linear B ‘linb’
Lisu (Fraser) ‘lisu’
Lycian ‘lyci’
Lydian ‘lydi’
Mahajani ‘mahj’
Makasar ‘maka’
Malayalam ‘mlym’
Malayalam v.2 ‘mlm2’
Mandaic, Mandaean ‘mand’
Manichaean ‘mani’
Marchen ‘marc’
Masaram Gondi ‘gonm’
Mathematical Alphanumeric Symbols ‘math’
Medefaidrin (Oberi Okaime, Oberi Ɔkaimɛ) ‘medf’
Meitei Mayek (Meithei, Meetei) ‘mtei’
Mende Kikakui ‘mend’
Meroitic Cursive ‘merc’
Meroitic Hieroglyphs ‘mero’
Miao ‘plrd’
Modi ‘modi’
Mongolian ‘mong’
Mro ‘mroo’
Multani ‘mult’
Musical Symbols ‘musc’
Myanmar ‘mymr’
Myanmar v.2 ‘mym2’
Nabataean ‘nbat’
Newa ‘newa’
New Tai Lue ‘talu’
N’Ko ‘nko ‘
Nüshu ‘nshu’
Odia (formerly Oriya) ‘orya’
Odia v.2 (formerly Oriya v.2) ‘ory2’
Ogham ‘ogam’
Ol Chiki ‘olck’
Old Italic ‘ital’
Old Hungarian ‘hung’
Old North Arabian ‘narb’
Old Permic ‘perm’
Old Persian Cuneiform ‘xpeo’
Old Sogdian ‘sogo’
Old South Arabian ‘sarb’
Old Turkic, Orkhon Runic ‘orkh’
Osage ‘osge’
Osmanya ‘osma’
Pahawh Hmong ‘hmng’
Palmyrene ‘palm’
Pau Cin Hau ‘pauc’
Phags-pa ‘phag’
Phoenician ‘phnx’
Psalter Pahlavi ‘phlp’
Rejang ‘rjng’
Runic ‘runr’
Samaritan ‘samr’
Saurashtra ‘saur’
Sharada ‘shrd’
Shavian ‘shaw’
Siddham ‘sidd’
Sign Writing ‘sgnw’
Sinhala ‘sinh’
Sogdian ‘sogd’
Sora Sompeng ‘sora’
Soyombo ‘soyo’
Sumero-Akkadian Cuneiform ‘xsux’
Sundanese ‘sund’
Syloti Nagri ‘sylo’
Syriac ‘syrc’
Tagalog ‘tglg’
Tagbanwa ‘tagb’
Tai Le ‘tale’
Tai Tham (Lanna) ‘lana’
Tai Viet ‘tavt’
Takri ‘takr’
Tamil ‘taml’
Tamil v.2 ‘tml2’
Tangut ‘tang’
Telugu ‘telu’
Telugu v.2 ‘tel2’
Thaana ‘thaa’
Thai ‘thai’
Tibetan ‘tibt’
Tifinagh ‘tfng’
Tirhuta ‘tirh’
Ugaritic Cuneiform ‘ugar’
Vai ‘vai ‘
Warang Citi ‘wara’
Yi ‘yi ‘
Zanabazar Square (Zanabazarin Dörböljin Useg, Xewtee Dörböljin Bicig, Horizontal Square Script) ‘zanb’
8.2.语言系统标签
语言系统标签标识OpenType布局字体支持的语言系统。在这种情况下,“语言系统”的含义是一组关于如何呈现给定脚本中的文本的印刷约定。这些约定可以与特定语言相关联,具有特定的使用类型,具有不同的出版物和其他这样的因素。例如,对于特定语言,或者对于语音转录或数学符号,可能需要特定字符的特定字形变体。
原则上,可以跨多个场景共享一组给定的约定。例如,两种不同的语言(可能不相关)可能会遵循相同的约定。然而,语言系统标签可以在感知需要的基础上注册; 因此,无法保证每个标记代表一组独特且独特的约定。但是,可以注册标签以表示适用于多种语言的约定。在这种情况下,标记的文档描述应反映该意图。
还应注意,可能存在多组适用于给定语言的印刷约定。
因此,在几个方面,语言系统标签不一致地与语言对应。即便如此,许多注册标签旨在表示特定语言的印刷约定。对于标签与一种或多种语言之间存在相关性的情况,这里通过参考ISO 639-2和ISO 639-3来记录语言标识。
注意: ISO 639-2提供了各种语言以及某些语言集合的标识符。ISO 639-3为更全面的单个语言集提供了标识符,但不适用于集合。此处引用的ISO 639中的实体可以包括ISO 639-2或ISO 639-3中涵盖的任何单个语言,或ISO 639-2中涵盖的任何集合。
如果信息可用于声明文本内容语言的应用程序,则应用程序可以利用该信息来选择在显示该文本时要应用的默认语言系统标签。但是,最好让用户控制要使用的语言系统标签的选择。(根据应用场景,可以向内容作者,内容读者或两者提供此类控制。)
所有标签都是由一组有限的ASCII字符组成的四字符字符串; 有关标记数据类型的详细信息,请参阅数据类型。按照惯例,注册语言系统标签使用三个或四个大写字母(0x41到0x5A)。
在下表中,标记为星号(“*”)的条目已添加到注册表中,因为当前的OpenType版本已发布。
Language System Language System Tag Corresponding ISO 639 ID (if applicable)
Abaza ‘ABA ‘ abq
Abkhazian ‘ABK ‘ abk
Acholi ‘ACH ‘ ach
Achi ‘ACR ‘ acr
Adyghe ‘ADY ‘ ady
Afrikaans ‘AFK ‘ afr
Afar ‘AFR ‘ aar
Agaw ‘AGW ‘ ahg
Aiton ‘AIO ‘ aio
Akan ‘AKA ‘ aka
Alsatian ‘ALS ‘ gsw
Altai ‘ALT ‘ atv, alt
Amharic ‘AMH ‘ amh
Anglo-Saxon ‘ANG ‘ ang
Phonetic transcription—Americanist conventions APPH
Arabic ‘ARA ‘ ara
Aragonese ‘ARG ‘ arg
Aari ‘ARI ‘ aiw
Rakhine ‘ARK ‘ mhv, rmz, rki
Assamese ‘ASM ‘ asm
Asturian ‘AST ‘ ast
Athapaskan ‘ATH ‘ apk, apj, apl, apm, apw, nav, bea, sek, bcr, caf, crx, clc, gwi, haa, chp, dgr, scs, xsl, srs, ing, hoi, koy, hup, ktw, mvb, wlk, coq, ctc, gce, tol, tuu, kkz, tgx, tht, aht, tfn, taa, tau, tcb, kuu, tce, ttm, txc
Avar ‘AVR ‘ ava
Awadhi ‘AWA ‘ awa
Aymara ‘AYM ‘ aym
Torki ‘AZB ‘ azb
Azerbaijani ‘AZE ‘ aze
Badaga ‘BAD ‘ bfq
Banda BAD0 bad
Baghelkhandi ‘BAG ‘ bfy
Balkar ‘BAL ‘ krc
Balinese ‘BAN ‘ ban
Bavarian ‘BAR ‘ bar
Baulé ‘BAU ‘ bci
Batak Toba ‘BBC ‘ bbc
Berber ‘BBR ‘
Bench ‘BCH ‘ bcq
Bible Cree ‘BCR ‘
Bandjalang ‘BDY ‘ bdy
Belarussian ‘BEL ‘ bel
Bemba ‘BEM ‘ bem
Bengali ‘BEN ‘ ben
Haryanvi ‘BGC ‘ bgc
Bagri ‘BGQ ‘ bgq
Bulgarian ‘BGR ‘ bul
Bhili ‘BHI ‘ bhi, bhb
Bhojpuri ‘BHO ‘ bho
Bikol ‘BIK ‘ bik, bhk, bcl, bto, cts, bln, fbl, lbl, rbl, ubl
Bilen ‘BIL ‘ byn
Bislama ‘BIS ‘ bis
Kanauji ‘BJJ ‘ bjj
Blackfoot ‘BKF ‘ bla
Baluchi ‘BLI ‘ bal
Pa’o Karen ‘BLK ‘ blk
Balante ‘BLN ‘ bjt, ble
Balti ‘BLT ‘ bft
Bambara (Bamanankan) ‘BMB ‘ bam
Bamileke ‘BML ‘
Bosnian ‘BOS ‘ bos
Bishnupriya Manipuri ‘BPY ‘ bpy
Breton ‘BRE ‘ bre
Brahui ‘BRH ‘ brh
Braj Bhasha ‘BRI ‘ bra
Burmese ‘BRM ‘ mya
Bodo ‘BRX ‘ brx
Bashkir ‘BSH ‘ bak
Burushaski ‘BSK ‘ bsk
Beti ‘BTI ‘ btb, beb, bum, bxp, eto, ewo, mct
Batak Simalungun ‘BTS ‘ bts
Bugis ‘BUG ‘ bug
Medumba ‘BYV ‘ byv
Kaqchikel ‘CAK ‘ cak
Catalan ‘CAT ‘ cat
Zamboanga Chavacano ‘CBK ‘ cbk
Chinantec CCHN cco, chj, chq, chz, cle, cnl, cnt, cpa, csa, cso, cte, ctl, cuc, cvn
Cebuano ‘CEB ‘ ceb
Chechen ‘CHE ‘ che
Chaha Gurage ‘CHG ‘ sgw
Chattisgarhi ‘CHH ‘ hne
Chichewa (Chewa, Nyanja) ‘CHI ‘ nya
Chukchi ‘CHK ‘ ckt
Chuukese CHK0 chk
Choctaw ‘CHO ‘ cho
Chipewyan ‘CHP ‘ chp
Cherokee ‘CHR ‘ chr
Chamorro ‘CHA ‘ cha
Chuvash ‘CHU ‘ chv
Cheyenne ‘CHY ‘ chy
Chiga ‘CGG ‘ cgg
Western Cham ‘CJA ‘ cja
Eastern Cham ‘CJM ‘ cjm
Comorian ‘CMR ‘ swb, wlc, wni, zdj
Coptic ‘COP ‘ cop
Cornish ‘COR ‘ cor
Corsican ‘COS ‘ cos
Creoles ‘CPP ‘ crp, cpe, cpf, cpp
Cree ‘CRE ‘ cre
Carrier ‘CRR ‘ crx, caf
Crimean Tatar ‘CRT ‘ crh
Kashubian ‘CSB ‘ csb
Church Slavonic ‘CSL ‘ chu
Czech ‘CSY ‘ ces
Chittagonian ‘CTG ‘ ctg
San Blas Kuna ‘CUK ‘ cuk
Danish ‘DAN ‘ dan
Dargwa ‘DAR ‘ dar
Dayi ‘DAX ‘ dax
Woods Cree ‘DCR ‘ cwd
German ‘DEU ‘ deu
Dogri ‘DGO ‘ dgo
Dogri ‘DGR ‘ doi
Dhangu ‘DHG ‘ dhg
Divehi (Dhivehi, Maldivian) ‘DHV ‘ (deprecated) div
Dimli ‘DIQ ‘ diq
Divehi (Dhivehi, Maldivian) ‘DIV ‘ div
Zarma ‘DJR ‘ dje
Djambarrpuyngu DJR0 djr
Dangme ‘DNG ‘ ada
Dan ‘DNJ ‘ dnj
Dinka ‘DNK ‘ din
Dari ‘DRI ‘ prs
Dhuwal ‘DUJ ‘ duj, dwu, dwy
Dungan ‘DUN ‘ dng
Dzongkha ‘DZN ‘ dzo
Ebira ‘EBI ‘ igb
Eastern Cree ‘ECR ‘ crj, crl
Edo ‘EDO ‘ bin
Efik ‘EFI ‘ efi
Greek ‘ELL ‘ ell
Eastern Maninkakan ‘EMK ‘ emk
English ‘ENG ‘ eng
Erzya ‘ERZ ‘ myv
Spanish ‘ESP ‘ spa
Central Yupik ‘ESU ‘ esu
Estonian ‘ETI ‘ est
Basque ‘EUQ ‘ eus
Evenki ‘EVK ‘ evn
Even ‘EVN ‘ eve
Ewe ‘EWE ‘ ewe
French Antillean ‘FAN ‘ acf
Fang FAN0 fan
Persian ‘FAR ‘ fas
Fanti ‘FAT ‘ fat
Finnish ‘FIN ‘ fin
Fijian ‘FJI ‘ fij
Dutch (Flemish) ‘FLE ‘ vls
Fe’fe’ ‘FMP ‘ fmp
Forest Nenets ‘FNE ‘ enf, yrk
Fon ‘FON ‘ fon
Faroese ‘FOS ‘ fao
French ‘FRA ‘ fra
Cajun French ‘FRC ‘ frc
Frisian ‘FRI ‘ fry
Friulian ‘FRL ‘ fur
Arpitan ‘FRP ‘ frp
Futa ‘FTA ‘ fuf
Fulah ‘FUL ‘ ful
Nigerian Fulfulde ‘FUV ‘ fuv
Ga ‘GAD ‘ gaa
Scottish Gaelic (Gaelic) ‘GAE ‘ gla
Gagauz ‘GAG ‘ gag
Galician ‘GAL ‘ glg
Garshuni ‘GAR ‘
Garhwali ‘GAW ‘ gbm
Geez ‘GEZ ‘ gez
Githabul ‘GIH ‘ gih
Gilyak ‘GIL ‘ niv
Kiribati (Gilbertese) GIL0 gil
Kpelle (Guinea) ‘GKP ‘ gkp
Gilaki ‘GLK ‘ glk
Gumuz ‘GMZ ‘ guk
Gumatj ‘GNN ‘ gnn
Gogo ‘GOG ‘ gog
Gondi ‘GON ‘ gon
Greenlandic ‘GRN ‘ kal
Garo ‘GRO ‘ grt
Guarani ‘GUA ‘ grn
Wayuu ‘GUC ‘ guc
Gupapuyngu ‘GUF ‘ guf
Gujarati ‘GUJ ‘ guj
Gusii ‘GUZ ‘ guz
Haitian (Haitian Creole) ‘HAI ‘ hat
Halam (Falam Chin) ‘HAL ‘ flm, cfm, rnl
Harauti ‘HAR ‘ hoj
Hausa ‘HAU ‘ hau
Hawaiian ‘HAW ‘ haw
Haya ‘HAY ‘ hay
Hazaragi ‘HAZ ‘ haz
Hammer-Banna ‘HBN ‘ amf
Herero ‘HER ‘ her
Hiligaynon ‘HIL ‘ hil
Hindi ‘HIN ‘ hin
High Mari ‘HMA ‘ mrj
Hmong ‘HMN ‘ hmn
Hiri Motu ‘HMO ‘ hmo
Hindko ‘HND ‘ hno, hnd
Ho HO hoc
Harari ‘HRI ‘ har
Croatian ‘HRV ‘ hrv
Hungarian ‘HUN ‘ hun
Armenian ‘HYE ‘ hye, hyw
Armenian East HYE0 hye
Iban ‘IBA ‘ iba
Ibibio ‘IBB ‘ ibb
Igbo ‘IBO ‘ ibo
Ijo languages ‘IJO ‘ ijc, ijo
Ido ‘IDO ‘ ido
Interlingue ‘ILE ‘ ile
Ilokano ‘ILO ‘ ilo
Interlingua ‘INA ‘ ina
Indonesian ‘IND ‘ ind
Ingush ‘ING ‘ inh
Inuktitut ‘INU ‘ iku
Inupiat ‘IPK ‘ ipk
Phonetic transcription—IPA conventions IPPH
Irish ‘IRI ‘ gle
Irish Traditional ‘IRT ‘ gle
Icelandic ‘ISL ‘ isl
Inari Sami ‘ISM ‘ smn
Italian ‘ITA ‘ ita
Hebrew ‘IWR ‘ heb
Jamaican Creole ‘JAM ‘ jam
Japanese ‘JAN ‘ jpn
Javanese ‘JAV ‘ jav
Lojban ‘JBO ‘ jbo
Krymchak ‘JCT ‘ jct
Yiddish ‘JII ‘ yid
Ladino ‘JUD ‘ lad
Jula ‘JUL ‘ dyu
Kabardian ‘KAB ‘ kbd
Kabyle KAB0 kab
Kachchi ‘KAC ‘ kfr
Kalenjin ‘KAL ‘ kln
Kannada ‘KAN ‘ kan
Karachay ‘KAR ‘ krc
Georgian ‘KAT ‘ kat
Kazakh ‘KAZ ‘ kaz
Makonde ‘KDE ‘ kde
Kabuverdianu (Crioulo) ‘KEA ‘ kea
Kebena ‘KEB ‘ ktb
Kekchi ‘KEK ‘ kek
Khutsuri Georgian ‘KGE ‘ kat
Khakass ‘KHA ‘ kjh
Khanty-Kazim ‘KHK ‘ kca
Khmer ‘KHM ‘ khm
Khanty-Shurishkar ‘KHS ‘ kca
Khamti Shan ‘KHT ‘ kht
Khanty-Vakhi ‘KHV ‘ kca
Khowar ‘KHW ‘ khw
Kikuyu (Gikuyu) ‘KIK ‘ kik
Kirghiz (Kyrgyz) ‘KIR ‘ kir
Kisii ‘KIS ‘ kqs, kss
Kirmanjki ‘KIU ‘ kiu
Southern Kiwai ‘KJD ‘ kjd
Eastern Pwo Karen ‘KJP ‘ kjp
Bumthangkha ‘KJZ ‘ kjz
Kokni ‘KKN ‘ kex
Kalmyk ‘KLM ‘ xal
Kamba ‘KMB ‘ kam
Kumaoni ‘KMN ‘ kfy
Komo ‘KMO ‘ kmw
Komso ‘KMS ‘ kxc
Khorasani Turkic ‘KMZ ‘ kmz
Kanuri ‘KNR ‘ kau
Kodagu ‘KOD ‘ kfa
Korean Old Hangul ‘KOH ‘ okm
Konkani ‘KOK ‘ kok
Kikongo ‘KON ‘ ktu
Komi ‘KOM ‘ kom
Kongo KON0 kon
Komi-Permyak ‘KOP ‘ koi
Korean ‘KOR ‘ kor
Kosraean ‘KOS ‘ kos
Komi-Zyrian ‘KOZ ‘ kpv
Kpelle ‘KPL ‘ kpe
Krio ‘KRI ‘ kri
Karakalpak ‘KRK ‘ kaa
Karelian ‘KRL ‘ krl
Karaim ‘KRM ‘ kdr
Karen ‘KRN ‘ kar
Koorete ‘KRT ‘ kqy
Kashmiri ‘KSH ‘ kas
Ripuarian KSH0 ksh
Khasi ‘KSI ‘ kha
Kildin Sami ‘KSM ‘ sjd
S’gaw Karen ‘KSW ‘ ksw
Kuanyama ‘KUA ‘ kua
Kui ‘KUI ‘ kxu
Kulvi ‘KUL ‘ kfx
Kumyk ‘KUM ‘ kum
Kurdish ‘KUR ‘ kur
Kurukh ‘KUU ‘ kru
Kuy ‘KUY ‘ kdt
Koryak ‘KYK ‘ kpy
Western Kayah ‘KYU ‘ kyu
Ladin ‘LAD ‘ lld
Lahuli ‘LAH ‘ bfu
Lak ‘LAK ‘ lbe
Lambani ‘LAM ‘ lmn
Lao ‘LAO ‘ lao
Latin ‘LAT ‘ lat
Laz ‘LAZ ‘ lzz
L-Cree ‘LCR ‘ crm
Ladakhi ‘LDK ‘ lbj
Lezgi ‘LEZ ‘ lez
Ligurian ‘LIJ ‘ lij
Limburgish ‘LIM ‘ lim
Lingala ‘LIN ‘ lin
Lisu ‘LIS ‘ lis
Lampung ‘LJP ‘ ljp
Laki ‘LKI ‘ lki
Low Mari ‘LMA ‘ mhr
Limbu ‘LMB ‘ lif
Lombard ‘LMO ‘ lmo
Lomwe ‘LMW ‘ ngl
Loma ‘LOM ‘ lom
Luri ‘LRC ‘ lrc, luz, bqi, zum
Lower Sorbian ‘LSB ‘ dsb
Lule Sami ‘LSM ‘ smj
Lithuanian ‘LTH ‘ lit
Luxembourgish ‘LTZ ‘ ltz
Luba-Lulua ‘LUA ‘ lua
Luba-Katanga ‘LUB ‘ lub
Ganda ‘LUG ‘ lug
Luyia ‘LUH ‘ luy
Luo ‘LUO ‘ luo
Latvian ‘LVI ‘ lav
Madura ‘MAD ‘ mad
Magahi ‘MAG ‘ mag
Marshallese ‘MAH ‘ mah
Majang ‘MAJ ‘ mpe
Makhuwa ‘MAK ‘ vmw
Malayalam ‘MAL ‘ mal
Mam ‘MAM ‘ mam
Mansi ‘MAN ‘ mns
Mapudungun ‘MAP ‘ arn
Marathi ‘MAR ‘ mar
Marwari ‘MAW ‘ mwr, dhd, rwr, mve, wry, mtr, swv
Mbundu ‘MBN ‘ kmb
Mbo ‘MBO ‘ mbo
Manchu ‘MCH ‘ mnc
Moose Cree ‘MCR ‘ crm
Mende ‘MDE ‘ men
Mandar ‘MDR ‘ mdr
Me’en ‘MEN ‘ mym
Meru ‘MER ‘ mer
Pattani Malay ‘MFA ‘ mfa
Morisyen ‘MFE ‘ mfe
Minangkabau ‘MIN ‘ min
Mizo ‘MIZ ‘ lus
Macedonian ‘MKD ‘ mkd
Makasar ‘MKR ‘ mak
Kituba ‘MKW ‘ mkw
Male ‘MLE ‘ mdy
Malagasy ‘MLG ‘ mlg
Malinke ‘MLN ‘ mlq
Malayalam Reformed ‘MLR ‘ mal
Malay ‘MLY ‘ msa
Mandinka ‘MND ‘ mnk
Mongolian ‘MNG ‘ mon
Manipuri ‘MNI ‘ mni
Maninka ‘MNK ‘ man, mnk, myq, mku, msc, emk, mwk, mlq
Manx ‘MNX ‘ glv
Mohawk ‘MOH ‘ moh
Moksha ‘MOK ‘ mdf
Moldavian ‘MOL ‘ mol
Mon ‘MON ‘ mnw
Moroccan ‘MOR ‘
Mossi ‘MOS ‘ mos
Maori ‘MRI ‘ mri
Maithili ‘MTH ‘ mai
Maltese ‘MTS ‘ mlt
Mundari ‘MUN ‘ unr
Muscogee ‘MUS ‘ mus
Mirandese ‘MWL ‘ mwl
Hmong Daw ‘MWW ‘ mww
Mayan ‘MYN ‘ myn
Mazanderani ‘MZN ‘ mzn
Naga-Assamese ‘NAG ‘ nag
Nahuatl ‘NAH ‘ nah
Nanai ‘NAN ‘ gld
Neapolitan ‘NAP ‘ nap
Naskapi ‘NAS ‘ nsk
Nauruan ‘NAU ‘ nau
Navajo ‘NAV ‘ nav
N-Cree ‘NCR ‘ csw
Ndebele ‘NDB ‘ nbl, nde
Ndau ‘NDC ‘ ndc
Ndonga ‘NDG ‘ ndo
Low Saxon ‘NDS ‘ nds
Nepali ‘NEP ‘ nep
Newari ‘NEW ‘ new
Ngbaka ‘NGA ‘ nga
Nagari ‘NGR ‘
Norway House Cree ‘NHC ‘ csw
Nisi ‘NIS ‘ dap, njz, tgj
Niuean ‘NIU ‘ niu
Nyankole ‘NKL ‘ nyn
N’Ko ‘NKO ‘ nqo
Dutch ‘NLD ‘ nld
Nimadi ‘NOE ‘ noe
Nogai ‘NOG ‘ nog
Norwegian ‘NOR ‘ nob
Novial ‘NOV ‘ nov
Northern Sami ‘NSM ‘ sme
Sotho, Northern ‘NSO ‘ nso
Northern Tai ‘NTA ‘ nod
Esperanto ‘NTO ‘ epo
Nyamwezi ‘NYM ‘ nym
Norwegian Nynorsk (Nynorsk, Norwegian) ‘NYN ‘ nno
Mbembe Tigon ‘NZA ‘ nza
Occitan ‘OCI ‘ oci
Oji-Cree ‘OCR ‘ ojs
Ojibway ‘OJB ‘ oji
Odia (formerly Oriya) ‘ORI ‘ ori
Oromo ‘ORO ‘ orm
Ossetian ‘OSS ‘ oss
Palestinian Aramaic ‘PAA ‘ sam
Pangasinan ‘PAG ‘ pag
Pali ‘PAL ‘ pli
Pampangan ‘PAM ‘ pam
Punjabi ‘PAN ‘ pan
Palpa ‘PAP ‘ plp
Papiamentu PAP0 pap
Pashto ‘PAS ‘ pus
Palauan ‘PAU ‘ pau
Bouyei ‘PCC ‘ pcc
Picard ‘PCD ‘ pcd
Pennsylvania German ‘PDC ‘ pdc
Polytonic Greek ‘PGR ‘ ell
Phake ‘PHK ‘ phk
Norfolk ‘PIH ‘ pih
Filipino ‘PIL ‘ fil
Palaung ‘PLG ‘ pce, rbb, pll
Polish ‘PLK ‘ pol
Piemontese ‘PMS ‘ pms
Western Panjabi ‘PNB ‘ pnb
Pocomchi ‘POH ‘ poh
Pohnpeian ‘PON ‘ pon
Provençal / Old Provençal ‘PRO ‘ pro
Portuguese ‘PTG ‘ por
Western Pwo Karen ‘PWO ‘ pwo
Chin ‘QIN ‘ bgr, cnh, cnw, czt, sez, tcp, csy, ctd, flm, pck, tcz, zom, cmr, dao, hlt, cka, cnk, mrh, cbl, cnb, csh
K’iche’ ‘QUC ‘ quc
Quechua (Bolivia) ‘QUH ‘ quh
Quechua ‘QUZ ‘ quz
Quechua (Ecuador) ‘QVI ‘ qvi
Quechua (Peru) ‘QWH ‘ qwh
Rajasthani ‘RAJ ‘ raj
Rarotongan ‘RAR ‘ rar
Russian Buriat ‘RBU ‘ bxr
R-Cree ‘RCR ‘ atj
Rejang ‘REJ ‘ rej
Riang ‘RIA ‘ ria
Tarifit ‘RIF ‘ rif
Ritarungo ‘RIT ‘ rit
Arakwal ‘RKW ‘ rkw
Romansh ‘RMS ‘ roh
Vlax Romani ‘RMY ‘ rmy
Romanian ‘ROM ‘ ron
Romany ‘ROY ‘ rom
Rusyn ‘RSY ‘ rue
Rotuman ‘RTM ‘ rtm
Kinyarwanda ‘RUA ‘ kin
Rundi ‘RUN ‘ run
Aromanian ‘RUP ‘ rup
Russian ‘RUS ‘ rus
Sadri ‘SAD ‘ sck
Sanskrit ‘SAN ‘ san
Sasak ‘SAS ‘ sas
Santali ‘SAT ‘ sat
Sayisi ‘SAY ‘ chp
Sicilian ‘SCN ‘ scn
Scots ‘SCO ‘ sco
Sekota ‘SEK ‘ xan
Selkup ‘SEL ‘ sel
Old Irish ‘SGA ‘ sga
Sango ‘SGO ‘ sag
Samogitian ‘SGS ‘ sgs
Tachelhit ‘SHI ‘ shi
Shan ‘SHN ‘ shn
Sibe ‘SIB ‘ sjo
Sidamo ‘SID ‘ sid
Silte Gurage ‘SIG ‘ xst, stv, wle
Skolt Sami ‘SKS ‘ sms
Slovak ‘SKY ‘ slk
North Slavey ‘SCS ‘ scs
Slavey ‘SLA ‘ scs, xsl
Slovenian ‘SLV ‘ slv
Somali ‘SML ‘ som
Samoan ‘SMO ‘ smo
Sena ‘SNA ‘ seh
Shona SNA0 sna
Sindhi ‘SND ‘ snd
Sinhala (Sinhalese) ‘SNH ‘ sin
Soninke ‘SNK ‘ snk
Sodo Gurage ‘SOG ‘ gru
Songe ‘SOP ‘ sop
Sotho, Southern ‘SOT ‘ sot
Albanian ‘SQI ‘ sqi
Serbian ‘SRB ‘ srp
Sardinian ‘SRD ‘ srd
Saraiki ‘SRK ‘ skr
Serer ‘SRR ‘ srr
South Slavey ‘SSL ‘ xsl
Southern Sami ‘SSM ‘ sma
Saterland Frisian ‘STQ ‘ stq
Sukuma ‘SUK ‘ suk
Sundanese ‘SUN ‘ sun
Suri ‘SUR ‘ suq
Svan ‘SVA ‘ sva
Swedish ‘SVE ‘ swe
Swadaya Aramaic ‘SWA ‘ aii
Swahili ‘SWK ‘ swa
Swati ‘SWZ ‘ ssw
Sutu ‘SXT ‘ ngo
Upper Saxon ‘SXU ‘ sxu
Sylheti ‘SYL ‘ syl
Syriac ‘SYR ‘ aii, amw, cld, syc, syr, tru
Syriac, Estrangela script-variant (equivalent to ISO 15924 ‘Syre’) SYRE syc, syr
Syriac, Western script-variant (equivalent to ISO 15924 ‘Syrj’) SYRJ syc, syr
Syriac, Eastern script-variant (equivalent to ISO 15924 ‘Syrn’) SYRN syc, syr
Silesian ‘SZL ‘ szl
Tabasaran ‘TAB ‘ tab
Tajiki ‘TAJ ‘ tgk
Tamil ‘TAM ‘ tam
Tatar ‘TAT ‘ tat
TH-Cree ‘TCR ‘ cwd
Dehong Dai ‘TDD ‘ tdd
Telugu ‘TEL ‘ tel
Tetum ‘TET ‘ tet
Tagalog ‘TGL ‘ tgl
Tongan ‘TGN ‘ ton
Tigre ‘TGR ‘ tig
Tigrinya ‘TGY ‘ tir
Thai ‘THA ‘ tha
Tahitian ‘THT ‘ tah
Tibetan ‘TIB ‘ bod
Tiv ‘TIV ‘ tiv
Turkmen ‘TKM ‘ tuk
Tamashek ‘TMH ‘ tmh
Temne ‘TMN ‘ tem
Tswana ‘TNA ‘ tsn
Tundra Nenets ‘TNE ‘ enh, yrk
Tonga ‘TNG ‘ toi
Todo ‘TOD ‘ xal
Toma TOD0 tod
Tok Pisin ‘TPI ‘ tpi
Turkish ‘TRK ‘ tur
Tsonga ‘TSG ‘ tso
Tshangla ‘TSJ ‘ tsj
Turoyo Aramaic ‘TUA ‘ tru
Tulu ‘TUM ‘ tum
Tumbuka ‘TUL ‘ tcy
Tuvin ‘TUV ‘ tyv
Tuvalu ‘TVL ‘ tvl
Twi ‘TWI ‘ aka
Tày ‘TYZ ‘ tyz
Tamazight ‘TZM ‘ tzm
Tzotzil ‘TZO ‘ tzo
Udmurt ‘UDM ‘ udm
Ukrainian ‘UKR ‘ ukr
Umbundu ‘UMB ‘ umb
Urdu ‘URD ‘ urd
Upper Sorbian ‘USB ‘ hsb
Uyghur ‘UYG ‘ uig
Uzbek ‘UZB ‘ uzb
Venetian ‘VEC ‘ vec
Venda ‘VEN ‘ ven
Vietnamese ‘VIT ‘ vie
Volapük ‘VOL ‘ vol
Võro ‘VRO ‘ vro
Wa WA wbm
Wagdi ‘WAG ‘ wbr
Waray-Waray ‘WAR ‘ war
West-Cree ‘WCR ‘ crk
Welsh ‘WEL ‘ cym
Walloon ‘WLN ‘ wln
Wolof ‘WLF ‘ wol
Mewati ‘WTM ‘ wtm
Lü ‘XBD ‘ khb
Khengkha ‘XKF ‘ xkf
Xhosa ‘XHS ‘ xho
Minjangbal ‘XJB ‘ xjb
Soga ‘XOG ‘ xog
Kpelle (Liberia) ‘XPE ‘ xpe
Sakha ‘YAK ‘ sah
Yao ‘YAO ‘ yao
Yapese ‘YAP ‘ yap
Yoruba ‘YBA ‘ yor
Y-Cree ‘YCR ‘ cre
Yi Classic ‘YIC ‘
Yi Modern ‘YIM ‘ iii
Zealandic ‘ZEA ‘ zea
Standard Moroccan Tamazight ‘ZGH ‘ zgh
Zhuang ‘ZHA ‘ zha
Chinese, Hong Kong SAR ‘ZHH ‘ zho
Chinese Phonetic ‘ZHP ‘ zho
Chinese Simplified ‘ZHS ‘ zho
Chinese Traditional ‘ZHT ‘ zho
Zande ‘ZND ‘ zne
Zulu ‘ZUL ‘ zul
Zazaki ‘ZZA ‘ zza
8.3.功能标签
功能提供有关如何使用字体中的字形来呈现脚本或语言的信息。例如,阿拉伯字体可能具有替换初始字形表单的功能,而汉字字体可能具有垂直定位字形的功能。所有OpenType布局功能都定义了字形替换,字形定位或两者的数据。
每个OpenType布局功能都有一个功能标记,用于标识其排版功能和效果。通过检查要素的标记,文本处理客户端可以确定要素的功能并决定是否实现它
所有标签都是由一组有限的ASCII字符组成的四字符字符串; 有关标记数据类型的详细信息,请参阅数据类型。按照惯例,注册的功能标签使用四个小写字母。例如,’mark’功能管理变音标记的位置,’swsh’功能渲染斜线字形。
标签的标签空间由四个大写字母(AZ)组成,没有标点符号,空格或数字,保留为供应商空间。字体供应商可以使用此类标签来标识私有功能。例如,特征标记PKRN可以指定可以用于克服标点符号的私有特征。私人功能的互操作性无法保证。
功能定义可能无法提供正确实现字形替换或定位操作所需的所有信息。在许多情况下,文本处理客户端可能需要提供其他数据。例如,’init’功能的功能是提供初始字形表单。功能查找表中没有任何内容表明在文本处理过程中何时或何处应用此功能。要在阿拉伯文本中正确使用“init”功能,其中初始字形表单出现在由字符连接属性确定的连接字母组的开头,文本处理客户端必须能够识别要应用该功能的字形,基于字符上下文和连接属性。在所有情况下,文本处理客户端负责应用,组合,
提供的功能描述包括有关可用于实现每个功能的查找类型的详细信息。查询信息仅供参考; 用于实现功能的查找集将因平台,应用程序,字体和字体开发人员而异。
注册功能
功能按字母顺序列出
功能描述和实现
下面列出的功能按标签名称的字母顺序排序。单击要素标签以查看要素说明和实施,或转到要素说明页面。
Feature Tag Friendly Name
‘aalt’ Access All Alternates
‘abvf’ Above-base Forms
‘abvm’ Above-base Mark Positioning
‘abvs’ Above-base Substitutions
‘afrc’ Alternative Fractions
‘akhn’ Akhands
‘blwf’ Below-base Forms
‘blwm’ Below-base Mark Positioning
‘blws’ Below-base Substitutions
‘calt’ Contextual Alternates
‘case’ Case-Sensitive Forms
‘ccmp’ Glyph Composition / Decomposition
‘cfar’ Conjunct Form After Ro
‘cjct’ Conjunct Forms
‘clig’ Contextual Ligatures
‘cpct’ Centered CJK Punctuation
‘cpsp’ Capital Spacing
‘cswh’ Contextual Swash
‘curs’ Cursive Positioning
‘cv01’ – ‘cv99’ Character Variants
‘c2pc’ Petite Capitals From Capitals
‘c2sc’ Small Capitals From Capitals
‘dist’ Distances
‘dlig’ Discretionary Ligatures
‘dnom’ Denominators
‘dtls’ Dotless Forms
‘expt’ Expert Forms
‘falt’ Final Glyph on Line Alternates
‘fin2’ Terminal Forms #2
‘fin3’ Terminal Forms #3
‘fina’ Terminal Forms
‘flac’ Flattened accent forms
‘frac’ Fractions
‘fwid’ Full Widths
‘half’ Half Forms
‘haln’ Halant Forms
‘halt’ Alternate Half Widths
‘hist’ Historical Forms
‘hkna’ Horizontal Kana Alternates
‘hlig’ Historical Ligatures
‘hngl’ Hangul
‘hojo’ Hojo Kanji Forms (JIS X 0212-1990 Kanji Forms)
‘hwid’ Half Widths
‘init’ Initial Forms
‘isol’ Isolated Forms
‘ital’ Italics
‘jalt’ Justification Alternates
‘jp78’ JIS78 Forms
‘jp83’ JIS83 Forms
‘jp90’ JIS90 Forms
‘jp04’ JIS2004 Forms
‘kern’ Kerning
‘lfbd’ Left Bounds
‘liga’ Standard Ligatures
‘ljmo’ Leading Jamo Forms
‘lnum’ Lining Figures
‘locl’ Localized Forms
‘ltra’ Left-to-right alternates
‘ltrm’ Left-to-right mirrored forms
‘mark’ Mark Positioning
‘med2’ Medial Forms #2
‘medi’ Medial Forms
‘mgrk’ Mathematical Greek
‘mkmk’ Mark to Mark Positioning
‘mset’ Mark Positioning via Substitution
‘nalt’ Alternate Annotation Forms
‘nlck’ NLC Kanji Forms
‘nukt’ Nukta Forms
‘numr’ Numerators
‘onum’ Oldstyle Figures
‘opbd’ Optical Bounds
‘ordn’ Ordinals
‘ornm’ Ornaments
‘palt’ Proportional Alternate Widths
‘pcap’ Petite Capitals
‘pkna’ Proportional Kana
‘pnum’ Proportional Figures
‘pref’ Pre-Base Forms
‘pres’ Pre-base Substitutions
‘pstf’ Post-base Forms
‘psts’ Post-base Substitutions
‘pwid’ Proportional Widths
‘qwid’ Quarter Widths
‘rand’ Randomize
‘rclt’ Required Contextual Alternates
‘rkrf’ Rakar Forms
‘rlig’ Required Ligatures
‘rphf’ Reph Forms
‘rtbd’ Right Bounds
‘rtla’ Right-to-left alternates
‘rtlm’ Right-to-left mirrored forms
‘ruby’ Ruby Notation Forms
‘rvrn’ Required Variation Alternates
‘salt’ Stylistic Alternates
‘sinf’ Scientific Inferiors
‘size’ Optical size
‘smcp’ Small Capitals
‘smpl’ Simplified Forms
‘ss01’ Stylistic Set 1
‘ss02’ Stylistic Set 2
‘ss03’ Stylistic Set 3
‘ss04’ Stylistic Set 4
‘ss05’ Stylistic Set 5
‘ss06’ Stylistic Set 6
‘ss07’ Stylistic Set 7
‘ss08’ Stylistic Set 8
‘ss09’ Stylistic Set 9
‘ss10’ Stylistic Set 10
‘ss11’ Stylistic Set 11
‘ss12’ Stylistic Set 12
‘ss13’ Stylistic Set 13
‘ss14’ Stylistic Set 14
‘ss15’ Stylistic Set 15
‘ss16’ Stylistic Set 16
‘ss17’ Stylistic Set 17
‘ss18’ Stylistic Set 18
‘ss19’ Stylistic Set 19
‘ss20’ Stylistic Set 20
‘ssty’ Math script style alternates
‘stch’ Stretching Glyph Decomposition
‘subs’ Subscript
‘sups’ Superscript
‘swsh’ Swash
‘titl’ Titling
‘tjmo’ Trailing Jamo Forms
‘tnam’ Traditional Name Forms
‘tnum’ Tabular Figures
‘trad’ Traditional Forms
‘twid’ Third Widths
‘unic’ Unicase
‘valt’ Alternate Vertical Metrics
‘vatu’ Vattu Variants
‘vert’ Vertical Writing
‘vhal’ Alternate Vertical Half Metrics
‘vjmo’ Vowel Jamo Forms
‘vkna’ Vertical Kana Alternates
‘vkrn’ Vertical Kerning
‘vpal’ Proportional Alternate Vertical Metrics
‘vrt2’ Vertical Alternates and Rotation
‘vrtr’ Vertical Alternates for Rotation
‘zero’ Slashed Zero
如何注册功能
Microsoft鼓励字体开发人员在实现注册功能时使用“已注册”功能标记。但是,字体开发人员也可以定义和注册自己的功能。
Microsoft欢迎提名注册新功能和功能标签。要获得注册资格,功能必须具有由其标记明确标识的单个功能。功能的功能应在最低有用级别定义,并且必须与当前注册功能的功能明显不同。当字体开发人员向Microsoft注册功能标记和功能时,他们不必提供实现细节。
Microsoft保留在Microsoft Tag Registry中正式分配功能标签的权利。虽然Microsoft已保留此注册表中列出的功能和功能标记定义,但Microsoft字体不一定包含所有功能。
8.3.1.a-e
标签:’aalt’
友好名称: Access All Alternates
注册人: Adobe
功能:此功能可使所选字符的所有变体都可访问。这有几个目的:应用程序可能不支持通常访问所需字形的功能; 用户可能需要在正常替换支持的上下文之外的字形,或者用户可能不知道哪个特征产生所需的字形。由于未涵盖多对一替换,因此该表中不会出现连字,除非它们是另一个连字的变体形式。
示例:用户在Poetica中输入P,并且可以选择四种标准资本形式,八种资本形式,初始资本形式和小资本形式。
推荐实现: ‘aalt’表将字形分组为语义单元。这些单位包括字形,表示应用程序存储的基础Unicode值的默认形式。虽然这些替换中的许多是一对一(GSUB查找类型1),但其他替换需要从集合中选择(GSUB查找类型3)。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。与任何一对多替换中一样,多个面中存在的替换应该在一个族中一致地排序,以便这些替换在家庭成员之间切换时可以正常工作。应首先在字体中订购此功能,以优先于其他功能。
应用程序界面:应用程序确定给定字符的默认形式的GID(未应用任何功能的Unicode值)。然后检查是否在’aalt’覆盖表中找到GID。如果是,则应用程序将此值传递给要素表,并返回关联组中的GID。
UI建议:虽然大多数一对多替换功能可以在全球范围内应用,并且结果合理,但“aalt”并非旨在支持此用途。应用程序应向用户指示用户文档中的哪些字形具有替代形式(即,在’aalt’的覆盖表中)。当用户选择其中一个字形并应用’aalt’特征时,应用程序可以在上下文中顺序显示表单,或者呈现一次显示所有表单的调色板,或者让用户在这些方法之间进行选择。应用程序可能会假设集合中的第一个字形是首选形式,因此字体开发人员应相应地对它们进行排序。如果只存在一个备用,则此功能可以直接在备用和默认表单之间切换。
脚本/语言敏感度:无。
功能交互:此功能可与其他功能结合使用。
标签:’abvf’
友好名称:基础表格
注册人:微软
功能:替代元音的上基形式。
示例:在像Khmer这样的复杂脚本中,元音OE必须分为前基础形式和基础形式。以上基础形式的OE将被替换以形成在基本辅音上方显示的正确字母。
推荐实现:此功能将GID替换为字形的上述部分(GSUB查找类型1)。
应用程序界面:在使用具有上述形式的拆分元音的序列中,应用程序必须将前基础字形插入正确的位置,然后应用基于上面的表单功能。应用程序返回GID以获取放置在基本字形上方的片段的正确形式。在调用此功能后,应用程序还可以根据需要选择放置此字形。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:高棉文字中必需。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’abvm’
友好名称:基础标记定位
注册人:微软
功能:在基本字形上方定位标记。
示例:在像Devanagari(印度语)这样的复杂脚本中,Anuswar需要位于基本字形上方。该基本字形可以是基本辅音或合取。基本字形和基本字形上方其他标记的存在/不存在决定了Anuswar的位置,因此它们不会相互重叠。
推荐实现: ‘abvm’表提供定位信息(x,y)以启用标记定位(GPOS查找类型4,5)。
应用程序界面:应用程序必须定义上面需要定位标记的基本字形的GID以及标记本身。如果它们位于coverage表中,则应用程序将序列传递给’abvm’表并获取标记的定位值(x,y)或定位调整作为回报。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:印度语脚本中必需。
特征交互:可用于定位默认标记; 或者使用像’abvs’这样的特征基于上下文要求从多个替代品中选择的那些。
标签:’abvs’
友情名称:基础替换
注册人:微软
功能:替换基本字形的连字并在其上方标记。
示例:在像Kannada(印度语)这样的复杂脚本中,元音的元音符号I标记位于基本辅音之上。该标记与辅音Ga结合形成结扎线。
推荐实现:此功能的查找将辅音和元音符号的每个序列映射到字体中的相应连字(GSUB查找类型4)。
应用程序界面:应用程序必须定义基本字形的GID以及与其组合的标记以形成连字。应用程序将序列传递给’abvs’表。如果它们位于coverage表中,则它将获取连字的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:印度语脚本中必需。
功能互动:无。
标签:’afrc’
友好名称:替代分数
注册人:微软
功能:用斜线替换用替代形式分隔的数字。
示例:用户在配方中输入3/4并获得三分之一坚果分数。
推荐实现: ‘afrc’表将由斜线(U + 002F)或分数(U + 2044)字符分隔的数字集映射到字体中相应的分数字形(GSUB查找类型4)。
应用程序界面:应用程序必须定义要替换的全部GID序列。当在’afrc’覆盖表中找到完整序列时,应用程序将序列传递给’afrc’表并获得新的GID作为回报。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:无。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’akhn’
友情名称: Akhand
注册人:微软
功能:优先用连字替换一系列字符。无论序列之前或之后的任何字符如何,都可以进行这种替换。
示例:在梵文脚本中,形式Kssa被认为是Akhand字符(意思是牢不可破),并且序列Ka,Halant,Ssa应始终产生连字Kssa,而不管在上述给定序列之前/之后的字符。
推荐实现:此功能将用于生成给定脚本中定义的Akhands的序列映射到它们形成的连字(GSUB查找类型4)。
应用程序界面:应用程序传递完整的GID序列。如果它们位于Akhand表的coverage表中,则应用程序将获取akhand连字的GID作为回报。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:大多数印度语脚本都需要。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的印度语脚本。应用程序应按适当的顺序处理此功能和某些其他功能,以获得正确的基本形式:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’ half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’blwf’
友好名称:基础表格以下
注册人:微软
功能:在辅音中替换辅音的以下形式。
示例:在像Oriya(印度语)这样的复杂脚本中,辅音Va具有用于生成合取的低于基础的形式。给定序列Gha,Virama(Halant),Va; 以下基本形式的Va将被替代以形成合取GhVa。
推荐实现:此功能替代了VID(halant)的GID序列,后跟辅音; 通过以下基本形式的辅音的GID(GSUB查找类型4)。
应用程序界面:在合并形成序列中,如果辅音被识别为具有以下基本形式,则应用程序返回GID。在调用此功能后,应用程序还可以根据需要选择放置此字形。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:在许多印度语脚本中都需要。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的印度语和印度语相关脚本。对于印度语脚本,应用程序应按适当的顺序处理此功能和某些其他功能,以获得正确的基本形式集:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’ blwf’,’half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。
标签:’blwm’
友好名称:基础标记定位
注册人:微软
功能:在基本字形下方放置标记。
示例:在像古吉拉特语(印度语)这样的复杂脚本中,元音符号U需要位于构成基本字形的基本辅音/合取之下。此位置可以根据基本字形以及基本字形下方其他标记的存在/不存在而变化。
推荐实现: ‘blwm’表提供定位信息(x,y)以启用标记定位(GPOS查找类型4,5)。
应用程序界面:应用程序必须定义下面需要定位标记的基本字形的GID以及标记本身。如果它们位于coverage表中,则应用程序将序列传递给’blwm’表并获取标记的定位值(x,y)或定位调整作为回报。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:印度语脚本中必需。
特征交互:可用于定位默认标记; 或者使用像’blws’这样的特征基于上下文要求从多个替代品中选择的那些。
标签:’blws’
友情名称:基础替换
注册人:微软
功能:生成包含基本字形和基础形式的连字。
示例:在Malayalam脚本(印度语)中,合取Kla需要使用基本字形Ka和基础形式的辅音La形成的结扎。此特征也可用于替换使用基本字形形成的连字。印度语脚本中的基础matras。
推荐实施: ‘blws’表映射已识别的合并形成序列; 或辅音元音符号序列; 到它们的连字(GSUB查找类型4)。
应用程序界面:对于’blws’覆盖表中找到的GID,应用程序将GID序列传递给表,并返回绑定的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:印度语脚本中必需。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’calt’
友好名称: Contextual Alternates
注册人: Adobe
功能:在指定的情况下,使用可提供更好连接行为的替代形式替换默认字形。用于脚本字体,旨在将其部分或全部字形连接起来。
示例:在Caflisch Script中,当o后面跟着一个升序字母时,o被o.alt2替换。
推荐实现: ‘calt’表指定每次替换发生的上下文,并将一个或多个默认字形映射到替换字形(GSUB查找类型6)。
应用程序界面:应用程序将GID序列传递给要素表,并获取新的GID。请注意,必须传递完整序列。
UI建议:默认情况下,此功能应处于活动状态。
脚本/语言敏感度:不适用于表意文字脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’case’
友好名称:区分大小写的表格
注册人: Adobe
功能:将各种标点符号移动到一个位置,该位置可以更好地处理所有大写序列或衬里数字; 也将旧式数字改为衬里数字。默认情况下,文本面中的字形设计为使用小写字符。某些角色应垂直移动以适应所有大写或衬里文本的较高视觉中心。衬里数字与大写字母的高度相同(或接近它),并且与全部大写文本相比更好。
示例:用户选择一个文本块并应用此功能。破折号,包围字符,guillemet引号等向上移动以匹配大写字母,旧式数字变为衬里数字。
推荐实现:字体可以通过替换不同的字形(GSUB查找类型1)或重新定位原始字形(GPOS查找类型1)来实现此更改。
应用程序界面:应用程序查询是否在“案例”功能的coverage表中找到特定GID。如果是这样,它会将这些ID传递给表并返回新的GID或位置调整(XPlacement和YPlacement)。
UI建议:当用户更改多个字符序列的大小写时,默认情况下应用此功能(或将其关闭)会很好。应用程序还可以检测仅由大写字母组成的单词,并根据用户首选项设置应用此功能。
脚本/语言敏感度:仅适用于欧洲脚本; 在西班牙语环境中尤为突出。
特征交互:此功能会覆盖影响数字的其他特征的结果(例如“onum”和“tnum”)。
标签:’ccmp’
友好名称:字形组成/分解
注册人:微软
功能:为了最小化字形交替的数量,有时需要将字符的默认字形分解为两个或多个字形。另外,为了更好的字形处理,最好将两个或多个字符的默认字形组合成单个字形。该特征允许这种组成/分解。该特征应作为处理的第一个特征进行处理,并且只应在调用时进行处理。
示例:在Syriac中,字符0x0732是一个组合标记,其上方有一个点,并且在基本字符下方有一个点。为了避免多个字形变体适合所有基本字形,字符被分解为两个字形……上方的点和下方的点。然后可以使用GPOS正确放置这两个字形。在阿拉伯语中,最好在处理形状之前将shadda与fatha(0x0651,0x064E)组合成一个连字。这允许字体供应商在进行进一步处理时对标记组合进行特殊处理,而不需要更大的上下文规则。
推荐实现: ‘ccmp’表将字符序列映射到其对应的连字(GSUB查找类型4)或字形字符串(GSUB查找类型2)。使用GSUB查找类型4时,必须将由大量字形组成的序列放在需要较少字形的序列之前。
应用程序界面:对于在’ccmp’覆盖表中找到的GID,应用程序将GID序列传递给表,并获取连字的GID或多次替换的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感度:无。
功能交互:此功能需要在任何其他功能之前实现。
标签:’cfar’
友情名称: Ro之后的Conjunct Form
注册人:微软
功能:在联合Ro(“Coeng Ra”)之后发生在高棉文字中替代以下基础或后基础形式。
在高棉语中,Ro的联合形式重新排列在基本辅音的左侧。然而,它包裹在基本辅音之下,因此可以与下基部或后基部连体辅音和元音形式进行印刷交互。在应用程序重新排序了联合Ro的字形之后,它不再是基于底部或后基础形式的字形的直接上下文。应用程序可以检测到这一点,并在以下基础和后基础联合形式的范围内应用此功能,触发查找以替换可能需要的替代基础或过去基础形式。
示例:在高棉语中,Coeng Ro用前基础连接形式表示,Coeng Yo用后基础连接形式表示,但在两种情况下,形式的一部分包裹在基础之下。辅音簇TRYo用另一种形式的Coeng Ya表示,它下降到较低的位置,因此它不会与Coeng Ro在基座下方碰撞。
推荐实现: ‘cfar’表将基础或后基础联合形式映射到替代形式(GSUB查找类型1)。
应用程序界面:对于’cfar’表中定义的替换,应用程序将GID传递给表并获取备用表单的GID。如果音节包含Coeng Ra,后跟其他连接辅音或元音,则应用程序应用此功能。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:高棉语言中必需。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的高棉文字。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’cjct’
友好名称: Conjunct Forms
注册人:微软
功能:在印度语脚本中生成辅音形式的辅音。这类似于Akhands特征,但是在形成印度音节的过程中应用于不同的连续点。
印度语脚本与连接 - 辅音行为相关联,例如使用“半”形式。一些辅音可能不具有半形式,并且当与某些辅音结合时不会表现出连接行为,但可能与其他辅音结合形式。一对给定的辅音是否会影响音节的其他形状行为,例如重新排序的元音标记或reph被放置的位置。Conjunct Forms特征可以在最终重新排序之前的整形过程中的某个点处使用,使得应用程序可以确定是否相对于辅音放置了重新排序的元音或reph。
更一般地,Akhands特征和Conjunct Forms特征可以在印度音节的形成中的两个点处使用,以及其间应用的诸如半形式和下形式之类的其他特征,从而为字体开发者提供形状的灵活性。印度音节是从字符序列的默认字形派生的。
示例:在印地语(梵文脚本)中,辅音簇DGa用合取结扎形式表示。
推荐实现: ‘cjct’表映射辅音序列(名义形式),然后是virama(halant),接着是第二个辅音(名义形式或半形式)到相应的合取形式(GSUB查找类型4) )。
应用程序接口:对于’cjct’表中定义的替换序列,应用程序将GID序列传递给表,并获取合并形式的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:与梵文相似的印度语脚本中需要。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的印度语脚本。应用程序应按适当的顺序处理此功能和某些其他功能,以获得正确的基本形式:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’ half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’clig’
友好名称:上下文连字
注册人: Adobe
功能:用一个字形替换一系列字形,这是印刷目的的首选。与其他连字特征不同,’clig’指定推荐连字的上下文。在某些脚本设计和swash连字中,此功能非常重要。
示例: ft的字形替换Bickham脚本中的序列ft,除非前面有升序字母。
推荐实现: ‘clig’表将字形序列映射到链接上下文中的相应连字(GSUB查找类型8)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。上下文连字集将根据设计和脚本而有所不同。
应用程序界面:对于在’clig’覆盖表中找到的GID集,应用程序将GID序列传递给表并返回一个新的GID。请注意,必须传递完整序列。注意:这可能包括更改字符代码。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下,此功能应处于活动状态。
脚本/语言敏感性:几乎适用于所有脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’dlig’。
标签:’cpct’
友好名称:中心CJK标点符号
注册人: Adobe
功能:为不包含居中和非居中表单的字体设置特定标点符号。
示例:用户可以使用中文字体调用此功能,以便在需要时获得居中的标点符号。例子包括U + 3001和U + 3002,包括它们的垂直变体,分别是U + FE11和U + FE12。
推荐实现:字体指定少量全角字形的X轴和Y轴调整(GPOS查找类型1)。
应用程序界面:对于在’cpct’覆盖表中找到的GID,应用程序将GID传递给表并返回位置调整(XPlacement,XAdvance,YPlacement和YAdvance)。
UI建议:此功能默认情况下处于关闭状态。
脚本/语言敏感度:主要用于中文字体。
特征交互:此特征与所有其他字形宽度特征(例如’tnum’,’fwid’,’hwid’,’halt’,’palt’,’twid’)互斥,当它是应用。
标签:’cpsp’
友情名称: Capital Spacing
注册人: Adobe
功能:全局调整所有大写文本的字形间距。大多数字体包含大写字母和小写字符,大写字母定位为使用小写字母。当大写字母用于单词时,它们之间需要更多空间以提高易读性和美观性。此功能不适用于等宽设计。当然,用户可能希望覆盖此行为,以便出于美观原因进行更明显的字母间距。
示例:用户在所有大写字母中设置标题,“大写间距”功能打开间距。
推荐实现: ‘cpsp’表存储所覆盖的大写字母的备用提前宽度,通常以均匀的百分比(GPOS查找类型1)增加它们。
应用程序界面:对于’cpsp’覆盖表中的GID,应用程序将一系列GID传递给’cpsp’表,并返回一组XPlacement和XAdvance调整。应用程序可以依赖于用户应用该特征(例如,通过选择用于改变全部大写的文本)或者应用其自己的启发法来识别由大写字母组成的单词。
UI建议:默认情况下,此功能应处于启用状态。应用程序可能希望允许用户重新指定百分比以适合个人品味和功能。
脚本/语言敏感性:不应用于连接脚本(例如大多数阿拉伯语)。
功能交互:除了任何其他功能外,还可以使用(请注意,此功能与其他GPOS功能(如“kern”)相加)。
标签:’cswh’
友好名称: Contextual Swash
注册人: Adobe
功能:此功能将默认字符字形替换为指定上下文中对应的斜线字形。请注意,给定字符可能有多个swash替换。
示例:用户在Poetica中设置单词“HOLIDAY”,此功能处于活动状态,并显示适用于初始H的三种替代形式和适用于内侧L的一种替代形式。
推荐实现: ‘cswh’表将默认表单的GID映射到链接上下文中的一个或多个相应的swash表单的GID,这可能需要从集合中选择(GSUB查找类型8)。如果字体中存在多种样式的swash,则应按顺序对每个字符的表单集进行排序。
应用程序界面:对于’cswh’覆盖表中的GID,应用程序将GID传递给’cswh’表并获取一个或多个新GID。如果返回多个GID,则应用程序必须为用户提供选择所需GID的方法。
UI建议:默认情况下,此功能应处于非活动状态。当返回多个GID时,应用程序可以在上下文中按顺序显示表单,或者提供一次显示所有表单的调色板,或者让用户在这些方法之间进行选择。应用程序可能会假设集合中的第一个字形是首选形式,因此字体开发人员应相应地对它们进行排序。
脚本/语言敏感度:不适用于表意文字脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’swsh’和’init’。
标签:’curs’
友好名称:草书定位
注册人:微软
功能:在阿拉伯语等草书脚本中,此功能可以粗略地定位相邻的字形。
示例:在阿拉伯语中,通过将Reem的入口点上的Meem的出口点重叠,将Meem后跟Reh。
推荐实现: ‘curs’表提供了要定位的字形的入口和出口点(x,y)(GPOS查找类型3)。
应用程序界面:对于位于coverage表中的GID,应用程序返回前后字形的定位点位置。
UI建议:默认情况下,可以根据用户的偏好使此功能处于活动状态或非活动状态。
脚本/语言敏感度:可以在任何草书中使用。
功能互动:无。
标签:’cv01’ - ‘cv99’
友好名称: Character Variant 1 - Character Variant 99
注册人:微软
功能:字体可能具有一个或多个字符的样式变体字形,其中一个字符的变体与其他字符的变体没有系统地相关。或者,字符及其套管对(或相关的预组合字符)可能存在变化,但不适用于其他不相关的字符。在某些使用场景中,可能需要为应用程序提供对不同Unicode字符的字形变体的单独控制。
这些功能的功能类似于Stylistic Alternates功能(’salt’)和Stylistic Set功能(参见’ss01’ - ‘ss20’)的功能。虽然文体集功能假设重复的风格变体适用于广泛的Unicode字符集,但这些功能适用于特定字符具有不适用于广泛字符集的变体的场景。Stylistic Alternates功能提供对字形变体的访问,但不允许应用程序逐个字符地控制它们; Character Variant功能提供更大的控制粒度。
这些特征的功能还与本地化形式(“locl”)特征的功能相关,因为对于特定语言,字符的特定变体可能是优选的。但是,在实践中,将特定的字形变体与所有相关语言的特定语言系统相关联可能是不可行的; 例如,在开发字体时可能不知道特定语言的要求。
这些特征与文体集特征之间的区别最容易理解为应用于单个字符的变体与应用于一系列字符的变体。实际上,如果变体适用于两院制脚本中的字符,则套管对字符可能具有相同的变体。此外,Unicode包括用于某些基本+标记组合的预先组合的字符,因此单个抽象字符可以合并到许多Unicode字符中。因此,特定抽象字符的变体可适用于若干相关的Unicode字符。在这些情况下,Character Variant功能可用于相关字符集。
推荐实现: ‘cv XX ‘表将字符的默认形式的GID映射到该字符的样式替代的GID。每个’cv XX ‘功能都使用备用(GSUB查找类型3)替换。(如果字符只有一个变体,也可以使用单替换查找,类型1)。在每个’cv XX ‘特征中,所有字形的变体数量应该相同。
这些GSUB功能的功能表的FeatureParams字段可以设置为0,或者设置为功能参数表的偏移量。此功能的“功能参数”表的结构如下:
类型 名称 描述
UINT16 格式 格式编号设置为0。
UINT16 featUiLabelNameId “name”表名称ID,用于为此功能的用户界面标签指定字符串(或多个语言的字符串)。(可能是NULL。)
UINT16 featUiTooltipTextNameId “name”表名称ID,指定应用程序可用于此功能的工具提示文本的字符串(或多个语言的字符串)。(可能是NULL。)
UINT16 sampleTextNameId “名称”表名称ID,用于指定说明此功能效果的示例文本。(可能是NULL。)
UINT16 numNamedParameters 命名参数的数量。(可能为零。)
UINT16 firstParamUiLabelNameId 第一个“名称”表名称ID,用于指定要素参数的用户界面标签的字符串。(如果numParameters为零,则必须为零。)
UINT16 charCount 此功能为其提供字形变体的字符数。(可能为零。)
uint24 字符[charCount] 此功能为其提供字形变体的字符的Unicode标量值。
featUiLabelNameId提供的名称ID旨在为该功能提供用户界面字符串; 例如,“Capital-eng variants”。如果设置为NULL,则不会将“name”表字符串用于功能名称。
featUiTooltipTextNameId提供的名称ID旨在提供用户界面字符串,该字符串提供应用程序可在弹出“工具提示”帮助窗口中使用的功能的简要说明(例如“为大写英文选择字形变体”)。如果设置为NULL,则“名称”表字符串不会用于功能“工具提示”帮助文本。
sampleTextNameId提供的名称ID旨在提供可在用户界面中使用的字符串,以说明该功能的效果。如果该特征影响多个字符或者该特征影响组合标记,则应用程序可能不明显使用什么字符串来呈现说明性样本; 可以为此目的提供“名称”表字符串。
如果numNamedParameters不为零,则firstParamUiLabelNameId和numNamedParameters在“name”表中指定一系列连续的名称ID。这些用于为各个变体提供用户界面字符串。名称ID的范围从firstParamUiLabelNameId开始并在firstParamUiLabelNameId + numNamedParameters-1结束。这些名称ID中的每一个对应于用于从类型3替换查找返回的GID数组中选择特定GID的特征参数值。参数值和名称ID之间的关系是:name ID = parameter + firstParamUiLabelNameId - 1. numNamedParameters的值不应超过与该功能关联的查找中的备用字形数; 但请注意 不应假定GSUB类型3查找的返回数组中的GID数量等于numNamedParameters:numNamedParameters不应超过数组中GID的数量,但可能更少。如果numNamedParameters为零,则没有’name’表字符串与要素参数关联。
featUiLabelNameId,featUiTooltipTextNameId和firstParamUiLabelNameId的值应位于特定于字体的名称ID范围(256-32767)中,但这不是此功能参数规范中的要求。firstParamUiLabelNameId + numNamedParameters - 1的值不应超过32767。
可以使用多种语言提供功能的用户界面标签,“工具提示”帮助文本或功能参数。每个英语字符串应作为后备包含在内。虽然可以使用不同UI语言的不同样本文本字符串,但可能不需要对示例文本字符串进行本地化。如果仅提供一个样本文本字符串,则应用程序可以将其与任何UI语言一起使用。
charCount字段和字符数组用于标识此功能为其提供字形变体的Unicode字符。应用程序可以在呈现用户界面或用于其他目的时使用此信息。字符列表的内容由字体开发人员决定 - 列表可能是详尽的,有代表性的或空的 - 并且不会影响该功能的操作。如果字体开发人员选择不包含此类信息,则charCount可以设置为零,在这种情况下,不能包含字符数组。
应用程序开发人员可自行决定是否或如何使用功能参数表中提供的数据或“名称”表中的相关字符串。
注意:由于使用此功能参数表提供的字符串将用于应用程序用户界面,因此长度是一个重要的考虑因素。字符串应尽可能短。建议要素或要素参数名称的长度为25个字符或更少,并且“工具提示”帮助文本的长度为250个字符或更少。
应用程序界面:应用程序负责计算和枚举字体中的功能数量,标签名称格式为“cv01”到“cv99”,并为用户提供适当的选择机制。该应用程序还负责解释任何功能参数表(如果应用程序开发人员希望使用该数据)并在用户界面中显示引用的字符串。对于在’cv XX ‘覆盖表中找到的GID,应用程序将GID传递到’cv XX ‘表并获取一个或多个新GID; 应用程序选择一个返回的GID进行显示。应用程序可以使用索引参数作为返回的GID数组的索引。
UI建议:默认情况下应关闭此功能。应用程序可以将给定字符的字形变体显示为用户界面中的字形调色板。如果提供了“功能参数”表,则可以在应用程序用户界面中显示功能UI标签或功能和参数UI标签(如果提供); 或者样本文本字符串(如果提供)可以在应用程序用户界面中显示。
脚本/语言敏感度:无。对于每个相应的[/ distinct]’cv XX ‘特征,FeatureList中的FeatureParams必须指向同一组值。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。请注意,在应用’cv XX ‘功能后,用户可能希望应用其他印刷功能,例如’smcp’; 字体开发人员负责订购替换查找以获得所需的用户体验。如果要与需要强制替换连字或上下文表单的复杂脚本一起使用,则应在强制脚本行为的功能之前应用此功能。
标签:’c2pc’
友情名称:来自首都的小资本
注册人: Tiro Typeworks / Emigre
功能:此功能可将大写字符转换为小写字母。它通常用于以其他方式设置在所有大写字母中的单词,例如首字母缩写词,但它们以小号形式表示,以避免破坏文本流。有关帽子,小帽子和小型帽子之间关系的说明,请参阅’pcap’功能说明。
示例:用户键入联合国儿童基金会或美国国家航空航天局,应用’c2pc’并获取娇小的上限文本。
推荐实现: ‘c2pc’表将大写字形映射到相应的小型上限形式(GSUB查找类型1)。
应用程序界面:对于’c2pc’覆盖表中的GID,应用程序将GID传递给’c2pc’表,并获取新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感性:仅适用于具有大写和小写形式的脚本(例如拉丁语,西里尔语,希腊语)。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’pcap’。
标签:’c2sc’
友情名称:来自首都的小资本
注册人: Adobe
功能:此功能可将大写字符转换为小写字母。它通常用于以其他方式设置在所有大写字母中的单词,例如首字母缩写词,但是小号形式需要这些单词以避免破坏文本流。
示例:用户键入UNICEF或SCUBA,应用“c2sc”并获取小型文本。
推荐实现: ‘c2sc’表将大写字母映射到相应的小型表单(GSUB查找类型1)。
应用程序界面:对于’c2sc’覆盖表中的GID,应用程序将GID传递给’c2sc’表,并获取新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅适用于两院制脚本(即具有案例差异的脚本),例如拉丁语,希腊语,西里尔语和亚美尼亚语。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’smcp’。
标签:’dist’
友好名称:距离
注册人:微软
功能:提供控制字形之间距离的方法。
示例:在Devanagari(印度语)脚本中,可以使用此来调整元音符号U和辅音之间的距离。
推荐实现: ‘dist’表提供了一个字形需要移向或远离另一个字形的距离(GPOS查找类型2)。
应用程序界面:对于’dist’覆盖表中的GID,应用程序将其GID传递给表并返回它们之间需要维护的距离。
UI建议:默认情况下,可以根据用户的偏好使此功能处于活动状态或非活动状态。
脚本/语言敏感性:印度语脚本中必需。
功能互动:无。
标签:’dlig’
友好名称:酌情连结
注册人: Adobe
功能:用一个字形替换一系列字形,这是印刷目的的首选。此功能涵盖了可根据用户的喜好使用特殊效果的连字。
示例: ct的字形替换字形序列ct,或U + 322E(“星期五”的汉字连字)替换序列U + 91D1 U + 66DC U + 65E5。
推荐实现: ‘dlig’表将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。酌情连结的集合将因设计和脚本而异。
应用程序界面:对于在’dlig’覆盖表中找到的GID集,应用程序将GID序列传递给表并返回一个新的GID。请注意,必须传递完整序列。这可能包括更改字符代码。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感性:几乎适用于所有脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’clig’。
标签:’dnom’
友好名称:分母
注册人: Adobe
功能:用分母数字替换斜线后面的选定数字。
示例:在用户选择的字符串11/17中,当用户应用分数特征(’frac’)时,应用程序将17转换为分母。
推荐实现: ‘dnom’表将数字和相关字符集映射到字体中相应的分子字形(GSUB查找类型1)。
应用程序界面:对于’dnom’覆盖表中的GID,应用程序将GID传递给表并获取新的GID。
UI建议:当用户应用“压裂”功能时,应用程序通常应调用此功能。
脚本/语言敏感度:无。
功能交互:此功能支持’压裂’。它可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’dtls’
友好名称:无点形式
注册人:微软
功能:此功能为数学字母数字字符提供无点形式,例如U + 1D422 MATHEMATICAL BOLD SMALL I,U + 1D423 MATHEMATICAL BOLD SMALL J,U + 1D456 U + MATHEMATICAL ITALIC SMALL I,U + 1D457 MATHEMATICAL ITALIC SMALL J等等上。
无点形式将用作基础形式,用于在它们上面放置数学重音。
示例:向i添加波形符时,在将波浪线重音添加到顶部之前替换无点形式。
推荐实现:单个替换,适用于所有虚线字符。
应用程序界面:数学布局处理程序根据基础公式框的高度自动调用要素。
UI建议:在推荐用法中,此功能会触发正确显示数学公式所需的替换。它应该在适当的上下文中应用,由数学布局处理程序确定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感度:应用于数学公式布局。
要素交互:此要素适用于数学公式布局期间的各个字形。
标签:’expt’
友好名称:专家表格
注册人: Adobe
功能:与JIS78表格功能一样,此功能将日语字体中的标准表格替换为印刷师喜欢的相应表格。尽管包括了大多数JIS78替换,但专家替换继续处理更多字符。
示例:用户将调用此功能以使用U + 555E替换汉字字符U + 5516。
推荐实现: ‘expt’表将许多默认(JIS90)GID映射到相应的替换(GSUB查找类型1)。
应用程序界面:对于’expt’覆盖表中的GID,应用程序将GID传递给表,并为每个GID返回一个新的GID。注意:这是字符代码的更改。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下,应用程序可以选择将此功能设置为活动或非活动状态,具体取决于其目标市场。
脚本/语言敏感度:仅适用于日语。
特征交互:此特征与所有其他特征互斥,应用时应关闭,除了’palt’,’vpal’,’vert’和’vrt2’特征,可以另外使用。
8.3.2.f-j
标签:’falt’
友好名称:最终字形在线替代
注册人:微软
功能:用专门为此目的设计的替代形式替换行最终字形(根据需要,它们将具有更少或更多的前进宽度),以帮助证明文本的正当性。
示例:在阿拉伯语脚本中,为行最终字形提供替代形式将导致更好的理由。例如。用尾巴稍长/短的尾巴替换长尾叶尾巴。
推荐实现: ‘falt’表将行最终字形(以隔离或最终形式)映射到相应的替代形式(GSUB查找类型3)。
应用程序界面:对于’falt’覆盖表中的GID,应用程序将GID传递给表并获取新的GID。
UI建议:默认情况下,可以根据用户的偏好使此功能处于活动状态或非活动状态。
脚本/语言敏感度:可以在任何草书中使用。
功能交互:只有在所有其他功能都应用于运行后才需要应用于最后。
标签:’fin2’
友好名称:终端表格#2
注册人:微软
功能:当前面的基本字符不能连接时,用适当的形式替换Syriac单词末尾的Alaph字形,并且前面的基本字符不是Dalath,Rish或无点的Dalath-Rish。
示例:当Alaph前面有一个He时,Alaph将被适当的形式替换。
此功能仅用于Syriac脚本alaph字符。
推荐实现: ‘fin2’表将默认的字母表格映射到相应的最终表单(GSUB查找类型5)。
应用程序界面:应用程序负责记录单词边界。对于在’fin2’覆盖表中找到的单词中间的GID,应用程序将GID传递给该功能并获取新的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感度:仅用于Syriac脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’init’和’fina’。
标签:’fin3’
友好名称:终端表格#3
注册人:微软
功能:当前面的基本字符是Dalath,Rish或无点Dalath-Rish时,在Syriac单词结尾处替换Alaph字形。
示例:当Alaph前面有Dalath时,Alaph将被适当的形式替换。
此功能仅用于Syriac脚本alaph字符。
推荐实现: ‘fin3’表将默认的字母表格映射到相应的最终表单(GSUB查找类型5)。
应用程序界面:应用程序负责记录单词边界。对于在’fin3’覆盖表中找到的单词中间的GID,应用程序将GID传递给该功能并获取新的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感度:仅用于Syriac脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’init’和’fina’。
标签:’fina’
注意:此功能描述在2016年进行了重大修订。
友好名称:终端表格
注册人: Microsoft / Adobe
功能:在最终上下文中使用替换形式替换具有适用连接属性的字符的字形。这适用于具有以下Unicode Joining_Type属性值之一的字符:
Right_Joining,如果字符来自从右到左的脚本。
Left_Joining,如果字符来自从左到右的脚本。
Dual_Joining。
Unicode Joining_Type属性值从Unicode字符数据库(UCD)获得。具体来说,Joining_Type属性值记录在UCD文件ArabicShaping.txt中,其当前版本可从http://www.unicode.org/Public/UCD/latest/ucd/ArabicShaping.txt获得。
示例:在阿拉伯语脚本字体中,应用程序将在字符ARABIC LETTER WAW(U + 0648“و”)上应用“fina”功能,当它跟随左连接字符时,从而将默认的“و”字形替换为它的右连接,最终形式。
推荐实现: ‘fina’功能用于将默认表单映射到相应的单连接,最终表单。这通常使用单个替换(类型1)GSUB查找来实现,尽管上下文替换GSUB查找(类型5,6或8)也可能是适当的。
应用程序界面:应用程序负责解析字符串并识别哪些加入相关的特征 - 初始形式(’init’),中间形式(’medi’),终端形式(’fina’)和孤立形式(’ isol’) - 根据字符Joining_Type属性应用于哪些GID。还可以考虑其他因素,例如控制字符的存在。对于应用了’fina’功能并且在’fina’覆盖表中找到的GID,应用程序将GID传递到与该功能关联的查找表并获取新的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应默认应用于适当的上下文中,具体取决于脚本特定的处理。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:可以在任何具有连接行为的脚本中使用 - 也就是说,在ArabicShaping.txt中明确给出Joining_Type属性的脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’init’,’isol’和’medi’。
标签:’flac’
友好名称:扁平的上升形式
注册人:微软
功能:此功能提供扁平形式的重音,可用于大写字母等高层基础。此功能应仅更改重音的形状,不应在垂直或水平方向上移动。重音的移动由数学处理客户端完成。如果数字引擎的基数高于MATH.MathConstants,则数学引擎会对其进行压平。FlattenedAccentBaseHeight。
示例:根据字体参数,可以在默认情况下使用带有波形符的小写字母a和使用波形符的大写字母A可以使用展平的表单
推荐实现:单个替换,用其展平形式替换上升字形。有关详细信息,请参阅MATH表规范。
应用程序界面:数学布局处理程序根据基础公式框的高度自动调用要素。
UI建议:在推荐用法中,此功能会触发正确显示数学公式所需的替换。它应该在适当的上下文中应用,由数学布局处理程序确定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感度:应用于数学公式布局。
要素交互:此要素适用于数学公式布局期间的各个字形。
标签:’frac’
友好名称:分数
注册人: Microsoft / Adobe
功能:用斜线替换用“普通”(对角线)分数代替的数字。
示例:用户在配方中输入3/4并获得四分之一分数。
推荐实现: ‘frac’表将由斜线或分数字符分隔的数字集映射到字体中对应的分数字形。这些可以是预合成的分数(GSUB查找类型4)或任意分数(GSUB查找类型1)。
应用程序界面:应用程序必须根据用户输入定义要替换的完整GID序列(即用户选择确定字符串的分隔)。当在’frac’覆盖表中找到完整序列时,应用程序将序列传递给’frac’表并获得新的GID作为回报。当’frac’表不包含完全匹配时,应用程序执行两个步骤。首先,它使用’numr’功能将斜杠前面的数字(在’numr’覆盖表中使用)替换为分子,并用分数斜杠字符(U + 2044)替换印刷斜杠字符(U + 002F) )。其次,它使用’dnom’功能来替换所有剩余的数字(如’dnom’中所列)
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:无。
功能交互:此功能可能要求应用程序调用’numr’和’dnom’功能。它可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’fwid’
友好名称:全宽
注册人: Adobe
功能:替换在其他宽度上设置的字形,并在完整(通常为em)宽度上设置字形。在CJKV字体中,这可能包括“低ASCII”拉丁字符和各种符号。在欧洲字体中,此功能使用等宽字形替换按比例间隔的字形,这些字形通常设置为0.6 em的宽度。
示例:用户可以使用日语字体调用此功能以获取完整的等宽拉丁字形,而不是相应的按比例分隔的版本。
推荐实现:字体可能包含设计为在全宽度上设置的备用字形(GSUB查找类型1),或者它可以为比例字形指定备用(全宽)度量标准(GPOS查找类型1)。
应用程序界面:对于’fwid’覆盖表中的GID,应用程序将GID传递给表并返回新的GID或位置调整(XPlacement和XAdvance)。
UI建议:默认情况下,此功能通常是关闭的。
脚本/语言敏感性:适用于任何可以使用等宽字体的脚本。
特征交互:此功能与所有其他字形宽度特征(例如’tnum’,’halt’,’hwid’,’palt’,’pwid’,’qwid’和’twid’)互斥,应该转为当它被应用时关闭。它会停用’kern’功能。
标签:’half’
友情名称: Half Forms
注册人:微软
功能:在印度语脚本中生成半形式的辅音。
示例:在印地语(梵文脚本)中,通过将Ka加倍而获得的合取KKa用半形式的Ka表示,然后是完整形式。
推荐实现: ‘half’表将辅音序列和virama(halant)映射到其半个形式(GSUB查找类型4)。
应用程序接口:对于“half”表中定义的替换序列,应用程序将GID序列传递给表,并返回半形式的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:与梵文相似的印度语脚本中需要。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的印度语脚本。应用程序应按适当的顺序处理此功能和某些其他功能,以获得正确的基本形式:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’ half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’haln’
友好名称: Halant Forms
注册人:微软
功能:在印度语脚本中产生干扰形式的辅音。
示例:在梵语(梵文脚本)中,经常需要以音乐形式使用音节最终辅音。
推荐实现: ‘haln’表将辅音的序列映射到其halant形式(GSUB查找类型4),然后是virama(halant)。
应用程序接口:对于’haln’表中定义的替换,应用程序将GID序列传递给特征(基本上是辅音和virama),并获取halant表单的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:印度语脚本中必需。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’halt’
友好名称:替代半宽
注册人: Adobe
功能:重新设置设计为全宽度宽度的字形,使其适合半宽宽度。这与’hwid’的不同之处在于它不能替代新的字形。
示例:用户可以使用CJKV字体调用此功能,以更好地适应标点符号或符号字形,而不会中断等宽对齐。
推荐实现:字体指定全角字形的备用度量标准(GPOS查找类型1)。
应用程序界面:对于在’halt’覆盖表中找到的GID,应用程序将GID传递给表并返回位置调整(XPlacement,XAdvance,YPlacement和YAdvance)。
UI建议:通常,默认情况下应禁用此功能。但是,在符合日语文本布局要求(JLREQ)或类似CJK文本布局规范的应用程序中应使用不同的行为,这些规范期望半角形式的字符的默认字形为全角。此类实现应默认启用此功能,或者应选择将此功能应用于需要对CJK文本布局目的进行特殊处理的特定字符,如括号,标点符号和引号。
脚本/语言敏感度:仅在CJKV字体中使用。
特征交互:此特征与所有其他字形高度特征(例如,’fwid’,’hwid’,’palt’,’tnum’,’twid’)互斥,应用此功能时应关闭此特征。它会停用’kern’功能。另见’vhal’。
标签:’hist’
友好名称:历史形式
注册人: Microsoft / Adobe
功能:有些字体在过去常用,但今天看起来不合时宜。最着名的例子是s的长形式; 其他人将包括旧的Fraktur k。某些字体包括作为替代的历史形式,因此它们可用于“周期”效果。此功能将默认(当前)表单替换为历史备用项。虽然一些连字也用于历史效果,但此功能仅处理单个字符。
示例:用户在Adobe Jenson中应用此功能以获取M,Q和Z的古老形式。
推荐实现: ‘hist’表将默认表单映射到相应的历史表单(GSUB查找类型1)。
应用程序界面:对于’hist’覆盖表中的GID,应用程序将GID传递给’hist’表并获取新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:无。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’hkna’
友情名称:水平假名替代
注册人: Adobe
功能:用专门为水平书写设计的表格替换标准假名。这是一种印刷优化,可以改善贴合度,使颜色更均匀。另见’vkna’。
示例:标准全宽假名(平假名和片假名)由专为水平使用而设计的表格替换。
推荐实现:字体包含一组特殊设计的字形,列在“hkna”覆盖表中。’hkna’功能将标准全宽形式映射到相应的特殊水平形式(GSUB查找类型1)。
应用程序界面:对于’hkna’覆盖表中的GID,应用程序将GID传递给该功能,并获取新的GID。
UI建议:此功能默认情况下处于关闭状态。
脚本/语言敏感度:仅适用于支持假名(平假名和片假名)的字体。
特征交互:此特征可与“kern”特征一起使用。由于它是用于水平使用,因此适用于垂直行为的特征(例如’vkna’,’vert’,’vrt2’或’vkrn’)不适用。
标签:’hlig’
友好名称:历史连字
注册人:微软
功能:有些连字在过去常用,但今天看起来不合时宜。某些字体包括作为替代的历史形式,因此它们可用于“周期”效果。此功能将默认(当前)表单替换为历史备用项。
示例:用户使用Palatino Linotype应用此功能,并为所有长形式形成历史连字,包括:长s + t,长s + b,长s + h,长s + k,以及其他几种形式。
推荐实现: ‘hlig’表将默认连字和字符组合映射到相应的历史连字(GSUB查找类型1)。
应用程序界面:对于’hlig’覆盖表中的GID,应用程序将GID传递给’hlig’表并获取新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:无。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’hngl’(2016年已弃用)
友好名称:韩文
注册人: Adobe
功能:用相应的hangul(音节)字符替换hanja(中国式)韩文字符。这有效地颠倒了标准输入法,其中输入了hangul并被hanja取代。这些替换中的许多是一对一的(GSUB查找类型1),但是hanja替换通常要求用户从几个可能的hangul字符(GSUB查找类型3)中进行选择。
示例:用户可以调用此功能从U + 4F3D获取U + AC00。
推荐实现:此表将字体中的每个hanja字符与一个或多个hangul字符相关联。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。与任何一对多替换一样,替代应该在一个系列中一致地排序,以便这些替换在家庭成员之间切换时可以正常工作。
应用程序界面:对于在’hngl’覆盖表中找到的GID,应用程序将GID传递给表并返回一个或多个新GID。如果返回多个GID,则应用程序必须为用户提供选择所需GID的方法。注意:这是语义值的变化。除了原始字符代码(当输入hanja时),应用程序应存储新字符的代码。
UI建议:默认情况下,此功能应处于非活动状态。应用程序可以在从多个hangul中选择时注意用户的选择,并在下次遇到源hanja字符时将其作为默认值提供。在没有这样的先验信息的情况下,应用程序可以假设集合中的第一个hangul是首选形式,因此字体开发者应该相应地对它们进行排序。
脚本/语言敏感度:仅限韩语。
特征交互:此特征与所有其他特征互斥,应用时应关闭,除了可以另外使用’palt’,’vert’和’vrt2’。
标签:’hojo’
友好名称: Hojo Kanji表格(JIS X 0212-1990汉字表格)
注册人: Adobe
功能: JIS X 0212-1990(又名“Hojo Kanji”)和JIS X 0213:2004字符集显着重叠。在某些情况下,他们的原型字形不同。在构建支持JIS X 0212-1990和JIS X 0213:2004的字体(例如支持Adobe-Japan 1-6字符集的字体)时,建议首选JIS X 0213:2004表格作为编码形式。’hojo’功能用于访问JIS X 0212-1990字形,用于编码JIS X 0213:2004表格时的情况。
示例:字形 由字形替换
由字形替换 。
。
推荐实施:通过相应的JIS X 0212-1990字形一对一替换JIS X 0213:2004字形。
应用程序界面:对于’hojo’覆盖表中的GID,应用程序将GID传递给表,并为每个GID获取一个新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅与汉字脚本一起使用。
特征交互:此功能与“jp78”,“jp83”,“jp90”,“nlck”以及类似功能相同。它可以与’palt’,’vpal’,’vert’和’vrt2’功能结合使用。
标签:’hwid’
友好名称:半宽
注册人: Adobe
功能:使用半em(en)宽度上的字形替换比例宽度上的字形或除半个em以外的固定宽度。许多CJKV字体都有多个宽度设置的字形; 此功能选择half-em版本。有各种上下文,这是首选行为,包括与旧桌面文档的兼容性。
示例:用户可以在半宽度上替换具有相同字符集的比例拉丁字形。
推荐实现:字体可能包含设计为在半宽度上设置的替代字形(GSUB查找类型1),或者它可以指定原始字形(GPOS查找类型1)的备用度量,这些字形调整它们的间距以适合一半 - em宽度。
应用程序界面:对于’hwid’覆盖表中的GID,应用程序将GID传递给表并返回新的GID或位置调整(XPlacement和XAdvance)。
UI建议:默认情况下,此功能通常是关闭的。
脚本/语言敏感度:通常仅用于CJKV字体。
特征交互:此特征与所有其他字形宽度特征(例如’tnum’,’fwid’,’halt’,’qwid’和’twid’)互斥,应用时应关闭。它会停用’kern’功能。
标签:’init’
注意:此功能描述在2016年进行了重大修订。
友好名称:初始表格
注册人: Microsoft / Adobe
功能:在初始上下文中发生时,替换具有适用的连接属性的字符的字形。这适用于具有以下Unicode Joining_Type属性值之一的字符:
Right_Joining,如果字符来自从左到右的脚本。
Left_Joining,如果字符来自从右到左的脚本。
Dual_Joining。
Unicode Joining_Type属性值从Unicode字符数据库(UCD)获得。具体来说,Joining_Type属性值记录在UCD文件ArabicShaping.txt中,其当前版本可从http://www.unicode.org/Public/UCD/latest/ucd/ArabicShaping.txt获得。
示例:在阿拉伯语脚本字体中,应用程序将“init”功能应用于字母ARABIC LETTER SEEN(U + 0633“س”),当它位于右连接字符之前时,从而将默认的“س”字形替换为它的左连接,初始形式。
推荐实现: ‘init’功能用于将默认表单映射到相应的单连接,初始形式。这通常使用单个替换(类型1)GSUB查找来实现,尽管上下文替换GSUB查找(类型5,6或8)也可能是适当的。
应用程序界面:应用程序负责解析字符串并识别哪些加入相关的特征 - 初始形式(’init’),中间形式(’medi’),终端形式(’fina’)和孤立形式(’ isol’) - 根据字符Joining_Type属性应用于哪些GID。还可以考虑其他因素,例如控制字符的存在。对于应用了’init’功能并且在’init’覆盖表中找到的GID,应用程序将GID传递给与该功能关联的查找表,并获取新的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应默认应用于适当的上下文中,具体取决于脚本特定的处理。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:可以在任何具有连接行为的脚本中使用 - 也就是说,在ArabicShaping.txt中明确给出Joining_Type属性的脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’fina’,’isol’和’medi’。
标签:’isol’
注意:此功能描述在2016年进行了重大修订。
友好名称:孤立的形式
注册人:微软
功能:在隔离(非连接)上下文中发生时,替换具有适用连接属性的字符的字形与替代形式。这适用于具有以下Unicode Joining_Type属性值之一的字符:
Right_Joining。
Left_Joining。
Dual_Joining。
Non_Joining,如果字符来自具有连接行为的脚本。
Unicode Joining_Type属性值从Unicode字符数据库(UCD)获得。具体来说,Joining_Type属性值记录在UCD文件ArabicShaping.txt中,其当前版本可从http://www.unicode.org/Public/UCD/latest/ucd/ArabicShaping.txt获得。具有连接行为的脚本是具有在ArabicShaping.txt中明确给出的字符属性的脚本。
请注意,在许多支持相关脚本的字体中,由于相关字符的默认形式是隔离的表单,因此可能无法实现此功能。在某些字体中,此功能可能涉及基于特定的隔离上下文的上下文替换。
示例:在阿拉伯语脚本字体中,应用程序在不与任何连接字符相邻时将“isol”功能应用于字母ARABIC LETTER HEH(U + 0647“ه”),从而可能将默认的“ه”字形替换为一种特殊的,孤立的形式(可能是一种语境和语言特定的替代,用一种孤立的形式代替另一种形式)。
推荐实现: ‘isol’功能用于将默认表单映射到备用非连接隔离表单。这通常使用单个替换(类型1)GSUB查找或通常是上下文替换GSUB查找(类型5,6或8)来实现。
应用程序界面:应用程序负责解析字符串并识别哪些加入相关的特征 - 初始形式(’init’),中间形式(’medi’),终端形式(’fina’)和孤立形式(’ isol’) - 根据字符Joining_Type属性应用于哪些GID。还可以考虑其他因素,例如控制字符的存在。对于应用了’isol’功能并且在’isol’覆盖表中找到的GID,应用程序将GID传递给与该功能关联的查找表并获取新的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应默认应用于适当的上下文中,具体取决于脚本特定的处理。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:可以在任何具有连接行为的脚本中使用 - 也就是说,在ArabicShaping.txt中明确给出Joining_Type属性的脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’fina’,’init’和’medi’。
标签:’ital’
友好名称:斜体
注册人: Adobe
功能:某些字体(例如Adobe的Pro日文字体)将在单个字体中包含某些字符的罗马字体和斜体字形。此功能将罗马字形替换为相应的斜体字形。
例如:用户将应用此功能,以取代乙乙。
推荐实现: ‘ital’表将罗马形式的字体映射到相应的斜体形式(GSUB查找类型1)。
应用程序界面:对于’ital’覆盖表中的GID,应用程序将GID传递给表,并为每个GID获取一个新的GID。
UI建议:当用户选择文本并应用斜体样式时,应用程序应检查此功能并使用它(如果存在)。
脚本/语言敏感度:主要适用于拉丁语; 请注意,许多非拉丁字体也包含拉丁文。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。在CJKV字体中,它应该激活’kern’特征(在其他脚本中无论如何都会这样)。
标签:’jalt’
友好名称: Justification Alternates
注册人:微软
功能:通过使用专门为此目的设计的替代形式替换字形来改进文本的对齐(根据需要,它们将具有更少或更多的前进宽度)。
示例:在阿拉伯语脚本中,为行最终字形提供替代形式将导致更好的理由并减少使用tatweels(Kashidas)。例如。用替代形式替换Swash Kaf。
推荐实现: ‘jalt’表将初始,中间,最终或隔离表单映射到相应的替代表单(GSUB查找类型3)。
应用程序界面:应用程序负责注意行结束/边界。对于在’jalt’覆盖表中找到的GID,应用程序将GID传递给该功能并获取新的GID。
UI建议:默认情况下,可以根据用户的偏好使此功能处于活动状态或非活动状态。
脚本/语言敏感度:可以在任何草书中使用。
功能交互:如果字体包含’init’,’medi’,’fina’,’isol’功能,则需要在调用此功能之前调用这些功能。
标签:’jp78’
友情名称: JIS78表格
注册人: Adobe
功能:此功能使用JIS C 6226-1978(JIS78)规范中的相应表格替换默认(JIS90)日语字形。
示例:用户将调用此功能以使用U + 555E替换汉字字符U + 5516。
推荐实现:当JIS90字形对应于JIS78表单时,’jp78’表将每个字形映射到它们的替换字符。虽然这些替换中的许多是一对一(GSUB查找类型1),但其他替换需要从集合中选择(GSUB查找类型3)。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。
应用程序界面:对于’jp78’覆盖表中的GID,应用程序将GID传递给表并获取一个或多个新GID。如果返回多个GID,则应用程序必须为用户提供选择所需GID的方法。应用程序可能会假设集合中的第一个字形是首选形式,因此字体开发人员应相应地对它们进行排序。注意:这是字符代码的更改。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅适用于日语。
特征交互:此特征与所有其他特征互斥,应用时应关闭,除了’palt’,’vpal’,’vert’和’vrt2’特征,可以另外使用。
标签:’jp83’
友情名称: JIS83表格
注册人: Adobe
功能:此功能使用JIS X 0208-1983(JIS83)规范中的相应表格替换默认(JIS90)日语字形。
示例:由于Unicode中的Han统一,因此没有具有不同Unicode值的JIS83字形,因此无法具体描述替换。
推荐实现:当JIS90字形对应于JIS83表单时,’jp83’表将每个字形映射到它们的替换字符(GSUB查找类型1)。
应用程序界面:对于’jp83’覆盖表中的GID,应用程序将GID传递给表并返回一个或多个新GID。如果返回多个GID,则应用程序必须为用户提供选择所需GID的方法。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅适用于日语。
特征交互:此特征与所有其他特征互斥,应用时应关闭,除了’palt’,’vpal’,’vert’和’vrt2’特征,可以另外使用。
标签:’jp90’
友情名称: JIS90表格
注册人: Adobe
功能:此功能使用JIS X 0208-1990(JIS90)规范中的相应表格替换JIS78或JIS83规范中的日语字形。
示例:用户将调用此功能以使用U + 5516替换汉字字符U + 555E。
推荐实现: ‘jp90’表将每个JIS78和JIS83表单以字体映射到JIS90表单(GSUB查找类型1)。该应用程序存储由替换产生的任何简化形式的记录(’jp78’或’jp83’特征); 对于这种形式,应用’jp90’功能撤消之前的替换。当没有替换记录时,应用程序使用’jp90’表返回默认表单。
应用程序界面:对于在’jp90’覆盖表中找到的GID,应用程序将GID传递给表,并为每个GID返回一个新的GID。注意:这是字符代码的更改。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅适用于日语。
特征交互:此特征与所有其他特征互斥,应用时应关闭,除了’palt’,’vpal’,’vert’和’vrt2’特征,可以另外使用。
标签:’jp04’
友情名称: JIS2004表格
注册人: Adobe
功能:日本国家语言委员会(NLC)为许多JIS字符定义了新的字形,并作为新的原型形式纳入JIS X 0213:2004。在“JP04”的特征是一个子集“nlck”特征,并且被用于在维持JIS X 0213的完整性的方式来访问这些原型字形:2004。
示例:字形 由字形替换
由字形替换 。
。
推荐实现:通过相应的JIS X 0213:2004字形一对一替换非JIS X 0213:2004字形。
应用程序界面:对于’jp04’覆盖表中的GID,应用程序将GID传递给表,并为每个GID返回一个新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅与汉字脚本一起使用。
特征交互:此功能与“jp78”,“jp83”,“jp90”,“nlck”以及类似功能相同。它可以与’palt’,’vpal’,’vert’和’vrt2’功能结合使用。
8.3.3.k-o
标签:’kern’
友好的名字:凯宁
注册人: Microsoft / Adobe
功能:调整字形之间的空间量,通常在字形之间提供光学一致的间距。虽然设计良好的字体总体上具有一致的字形间距,但是一些字形组合需要调整以提高易读性。除了在水平方向上的标准调整之外,该特征还可以通过设备表提供与尺寸相关的字距调整数据,在Y文本方向上提供“交叉流”字距调整,并且可以独立于提前调整来调整字形位置。请注意,此功能可能适用于两个以上字形的运行,并且不会用于等宽字体。另请注意,此功能不适用于垂直设置的文本。
示例: o在“To”组合中更靠近T.
推荐实现:字体存储一组字形对的调整(GPOS查找类型2或8)。这些可以存储为匹配左和右类的一个或多个表,和/或作为单独的对。可以为更大的字形组(例如,三元组,四元组等)提供额外的调整,以在特定组合中覆盖对密封的结果。
应用程序界面:应用程序将一系列GID传递给’kern’表,并获取这些GID的调整位置(XPlacement,XAdvance,YPlacement和YAdvance)。在一组字形上使用类型2查找时,记住不要使用最后一个字形,但要保持它在后续运行中作为第一个字形可用(这与正常查找行为不同)是至关重要的。
UI建议:默认情况下,此功能应处于水平文本设置的活动状态。应用程序可能希望允许用户进一步添加手动指定的调整以满足特定需求和品味。
脚本/语言敏感度:无。
特征交互:如果’kern’被激活,’palt’也必须被激活(如果它存在)。如果’palt’被激活,则不要求也必须激活’kern’。可以用于除了导致固定(均匀)前进宽度的任何其他功能之外的其他功能(例如’fwid’,’halt’,’hwid’,’qwid’和’twid’)。
标签:’lfbd’
友情名称:左边界
注册人: Adobe
功能:通过文本水平线左端的明显左侧范围对齐字形,替换对齐字形的默认行为。此功能由Optical Bounds(’opbd’)功能调用。
示例:当文本左对齐并应用此功能时,以T,D和W开头的后续行将通过变化量向左移动。
建议的实现:受影响的字形的值描述了应该更改放置和提前宽度的数量(GPOS查找类型1)。
应用程序界面:对于’lfbd’覆盖表中的GID,应用程序将GID传递给表并获取新的XPlacement和XAdvance值。
UI建议:当用户调用“opbd”功能时,应用程序会调用此功能。
脚本/语言敏感度:无。
特征交互:不应该应用于使用固定宽度特征的字形(例如’fwid’,’halt’,’hwid’,’qwid’和’twid’)或垂直特征(例如’vert’,’vrt2’,’vpal’,’valt’和’vhal’)。由’opbd’功能调用。
标签:’liga’
友好名称:标准连字
注册人: Microsoft / Adobe
功能:用一个字形替换一系列字形,这是印刷目的的首选。此功能涵盖了设计人员/制造商在正常条件下应该使用的连字。
示例: ffl的字形替换了字形序列ff l。
推荐实现: ‘liga’表将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。标准连字集将根据设计和脚本而有所不同。
应用程序界面:对于’liga’覆盖表中找到的GID集,应用程序将GID序列传递给表并返回一个新的GID。请注意,必须传递完整序列。
UI建议:此功能在某些上下文中提供关键功能,默认情况下应处于活动状态。
脚本/语言敏感性:几乎适用于所有脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’ljmo’
友好的名字:领先的Jamo Forms
注册人:微软
功能:替换群集的主要jamo形式。
示例:在Hangul脚本中,jamo集群由三个部分组成(前导辅音,元音和尾随辅音)。当找到一系列领先类别的jamos时,它们的组合前导jamo形式被替换。
推荐实现: ‘ljmo’表将将一系列jamos转换为其主要jamo形式所需的序列(GSUB查找类型4)。
应用程序界面:对于’ljmo’表中定义的替换,应用程序将GID序列传递给该功能,并获取前导jamo表单的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:支持Ancient Hangul书写系统时,汉语脚本必需。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’lnum’
友情名称:衬里数字
注册人: Adobe(由Adobe修改,这是更新的描述)
功能:此功能可将选定的无衬里数字更改为衬里数字。
示例:用户调用此功能以获取衬里数字,这更符合所有大写文本。设计用于图形的各种字符也可以由该特征覆盖。如果衬里数字是默认形式,则此功能将撤消先前的替换。
推荐实现: ‘lnum’表将每个旧样式图和任何相关字符映射到相应的衬里形式(GSUB查找类型1)。如果默认数字是非线性的,它们也会映射到相应的衬里形式。
应用程序界面:对于在’lnum’覆盖表中找到的GID,应用程序将GID传递给’lnum’表并获取新的GID。即使当前的数字来自早期的替换,由于与图形宽度特征的交互,简单地恢复到原始GID可能是不正确的,因此最好使用该表。
UI建议:默认情况下,此功能应处于非活动状态。用户可以通过打开或关闭此功能在衬里和旧式设置之间切换。请注意,此功能与图宽度功能(’pnum’和’tnum’)不同。当用户调用此功能时,应用程序可能希望询问是否还需要改变宽度。
脚本/语言敏感度:无。
要素交互:此功能会覆盖Oldstyle Figures要素(’onum’)的结果。
标签:’locl’
友好名称:本地化表格
注册人: Tiro Typeworks / Adobe
功能:许多用于在广泛的地理区域上编写多种语言的脚本已经开发出特定字母的本地化变体形式,这些形式由个别文学社区使用。例如,保加利亚语和塞尔维亚语字母表中的一些字母形式与俄罗斯同行和彼此不同。在某些情况下,本地化形式仅与脚本“规范”略有不同,在其他情况下,形式是完全不同的。此功能可以使本地化的字形替换为默认表单。
示例:用户将此功能应用于文本以启用本地化的保加利亚形式的西里尔字母; 或者,该功能可能会以保加利亚制造的字体启用本地化的俄语表格,其中保加利亚表格是默认字符。
推荐实现:对于给定的Unicode值,该字体包含两个或多个语言环境的字形。’locl’表将默认表单的GID映射到相应的本地化替代的GID。这些是一对一替换(GSUB查找类型1)。
应用程序界面:本地化表单与特定语言相关联,并由语言标记激活。哪个字形用作本地化表单应由用户指定的语言确定。用户可以通过选择新语言来切换本地化表单,也可以通过关闭“locl”功能来启用默认表单。
UI建议:默认情况下,此功能应处于活动状态。
脚本/语言敏感性:适用于所有脚本和语言; 但当然行为因脚本和语言而异。
功能交互:此功能可与任何其他功能结合使用。它取代并扩展了为CJKV脚本定义的早期特定于语言环境的标签’zhcn’,’zhtw’,’jajp’,’kokr’和’vivn’。
标签:’ltra’
友好名称:从左到右的字形交替显示
注册人: Adobe
功能:此功能应用适用于从左到右文本的字形变体(镜像形式除外)(对于镜像形式,请参阅’ltrm’)。
推荐实现:这些必须是字形替换,并且建议它们是一对一的(GSUB查找类型1)。
应用程序界面:请参阅Advanced Typographic Extensions页面上的“从左到右和从右到左文本” 部分。
UI建议:无
脚本/语言敏感性:从左到右的文本运行。
特征交互:此功能将与其他预先成形功能同时应用,例如“ccmp”和“locl”。
标签:’ltrm’
友好名称:从左到右的镜像形式
注册人: Adobe
功能:此功能应用适用于从左到右文本的镜像表单。(对于从左到右的字形交替,请参阅’ltra’)。
示例:旧南阿拉伯语脚本是一个强大的从右到左脚本的案例,可以从左到右排列行,在这种情况下,某些字形需要使用’ltrm’功能进行镜像。
推荐实现:这些必须是字形替换,并且建议它们是一对一的(GSUB查找类型1)。
应用程序界面:请参阅Advanced Typographic Extensions页面上的“从左到右和从右到左文本” 部分。
UI建议:无
脚本/语言敏感性:从左到右的文本运行; 另见上面的例子。
特征交互:此功能将与其他预先成形功能同时应用,例如“ccmp”和“locl”。
标签:’mark’
友情名称: Mark Positioning
注册人:微软
功能:位置标记相对于基本字形的字形。
示例:在阿拉伯语脚本中,将Hamza定位在Yeh上方。
推荐实现:此功能可以实现为MarkToBase附件查找(GPOS LookupType = 4)或MarkToLigature附件查找(GPOS LookupType = 5)。
应用程序界面:对于在“标记”覆盖表中找到的GID,应用程序返回标记字形的定位或位置调整值。脚本/语言敏感度:无。
功能互动:无。
标签:’med2’
友好名称: Medial Forms#2
注册人:微软
功能:当前面的基本字符可以连接时,在Syriac字样的中间替换Alaph字形。
示例:当Alaph前面有Heth时,Alaph将被适当的形式替换。
此功能仅用于Syriac脚本alaph字符。
推荐实现: ‘med2’表将默认的字母表单映射到相应的中间表单(GSUB查找类型5)。
应用程序界面:应用程序负责记录单词边界。对于在’med2’覆盖表中找到的单词中间的GID,应用程序将GID传递给该功能并获取新的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感度:仅用于Syriac脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’init’和’fina’。
标签:’medi’
注意:此功能描述在2016年进行了重大修订。
友好名称: Medial Forms
注册人: Microsoft / Adobe
功能:在内侧上下文中发生替换具有适用连接属性的字符的字形与替代形式。这适用于具有Unicode Joining_Type属性值Dual_Joining的字符。
Unicode Joining_Type属性值从Unicode字符数据库(UCD)获得。具体来说,Joining_Type属性值记录在UCD文件ArabicShaping.txt中,其当前版本可从http://www.unicode.org/Public/UCD/latest/ucd/ArabicShaping.txt获得。
示例:在阿拉伯语脚本字体中,应用程序将“medi”功能应用于字母ARABIC LETTER QAF(U + 0642“ق”),当它跟随左连接字符并位于右连接字符之前时,从而替换默认的“ق”字形及其双重连接,内侧形式。
推荐实现: ‘medi’功能用于将默认表单映射到相应的双连接,中间表单。这通常使用单个替换(类型1)GSUB查找来实现,尽管上下文替换GSUB查找(类型5,6或8)也可能是适当的。
应用程序界面:应用程序负责解析字符串并识别哪些加入相关的特征 - 初始形式(’init’),中间形式(’medi’),终端形式(’fina’)和孤立形式(’ isol’) - 根据字符Joining_Type属性应用于哪些GID。还可以考虑其他因素,例如控制字符的存在。对于应用了’medi’功能并且在’medi’覆盖表中找到的GID,应用程序将GID传递给与该功能关联的查找表并获取新的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应默认应用于适当的上下文中,具体取决于脚本特定的处理。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:可以在任何具有连接行为的脚本中使用 - 也就是说,在ArabicShaping.txt中明确给出Joining_Type属性的脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’fina’,’init’和’isol’。
标签:’mgrk’
友情名称:数学希腊语
注册人: Adobe
功能:用数学符号中常用的相应形式(希腊字母表的子集)替换希腊字形的标准印刷形式。
示例:用户将此功能应用于U + 03A3(Sigma),并获得U + 2211(求和)。
推荐实现: ‘mgrk’表将希腊字形映射到用于数学的相应表格(GSUB查找类型1)。
应用程序界面:对于’mgrk’覆盖表中的GID,应用程序将GID传递给要素表并获取新的GID。注意:这是语义值的变化。除原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下,此功能应在大多数应用程序中关闭。面向数学的应用程序可能希望默认激活此功能。
脚本/语言敏感度:可以应用于包含希腊语脚本覆盖范围的任何字体。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’mkmk’
友好名称:标记为马克定位
注册人:微软
功能:相对于其他标记定位标记。在阿拉伯语等各种非拉丁文字中都需要。
例如:在阿拉伯语中,上面有Hamza的连接标记Ha; 也可以通过将这些标记相对于彼此定位来获得。
推荐实现:此功能可以实现为MarkToMark附件查找(GPOS查找类型6)。
应用程序界面:应用程序获取标记的定位值或位置调整。
UI建议:默认情况下,此功能应处于活动状态。
脚本/语言敏感度:无。
功能互动:无。
标签:’mset’
注册人:微软
功能:使用字形替换为Windows 95的字体定位阿拉伯语组合标记
示例:在阿拉伯语中,与Alef相比,当放置在Yeh Barree上方时,Hamza的位置不同。
Windows 95实现:与’mark’功能相比,’mset’使用字形替换来组合标记和基本字形。它用正确定位的标记字形替换默认标记字形。字体设计器在字体文件中描述标记的轮廓时指定标记的位置。为Windows 95创建的Microsoft阿拉伯字体使用上下文替换查找(GSUB LookupType = 5)来实现’mset’功能。
标签:’nalt’
友好名称:备用注释表单
注册人: Adobe
功能:用各种符号形式替换默认字形(例如,放置在空心圆圈,实心圆圈,正方形,圆括号,菱形或圆形框中的字形)。在某些情况下,注释表单可能已经存在,但是用户可能想要不同的注释表单。
示例:用户调用此功能从U + 3131(hangul“ga”)获取U + 3200(带圆圈的“ga”形式)。
推荐实现: ‘nalt’表将各种标准表单的GID映射到一个或多个相应的注释表单。虽然这些替换中的许多是一对一(GSUB查找类型1),但其他替换需要从集合中选择(GSUB查找类型3)。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。如果存在多个表单,则应对每个字符的表单集进行一致排序 - 包括字体内和整个系列。
应用程序界面:对于’nalt’覆盖表中的GID,应用程序传递GID并获取一组新GID,然后存储用户选择的GID。
UI建议:默认情况下,此功能应处于非活动状态。应用程序必须为用户提供从表返回的集合中选择所需表单的方法。它可以在一组替换中记录所选表单的位置,并在下次调用此功能时将该位置的字形提供为默认选择。在没有这样的先验信息的情况下,应用程序可以假设集合中的第一个字形是首选形式,因此字体开发者应该相应地对它们进行排序。
脚本/语言敏感度:主要用于CJKV字体,但可以应用于欧洲脚本。
特征交互:此特征与所有其他特征互斥,应用时应关闭,除了’vert’和’vrt2’特征,可以另外使用。
标签:’nlck’
友情名称: NLC汉字表格
注册人: Adobe Systems Inc.
功能:日本国家语言委员会(NLC)在2000年为许多JIS字符定义了新的字形形状.’nlck’功能用于访问这些字形。
示例:字形 由字形替换
由字形替换 。
。
推荐实现:通过相应的NLC字形一对一替换非NLC字形。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅与汉字脚本一起使用。
特征交互:此功能与“jp78”,“jp83”,“jp90”和类似功能相同。它可以与’palt’,’vpal’,’vert’和’vrt2’功能结合使用。
标签:’nukt’
友好名称: Nukta Forms
注册人:微软
功能:在印度语脚本中生成Nukta表单。
例如:在印地语(梵文脚本)中,当与nukta结合时,辅音给出其nukta形式。
推荐实现: ‘nukt’表将辅音序列后跟nukta映射到辅音的nukta形式(GSUB查找类型4)。
应用程序界面:应用程序将GID(辅音和nukta)序列传递给表,然后返回nukta表单的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:印度语脚本中必需。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的印度语脚本。应用程序应按适当的顺序处理此功能和某些其他功能,以获得正确的基本形式:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’ half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’numr’
友好名称:分子
注册人: Adobe
功能:用斜线替换斜杠前面的选定数字,并用分数斜线替换印刷斜杠。
示例:在用户选择的字符串11/17中,应用程序将11转换为分子,并在用户应用分数特征(’frac’)时将斜杠转换为小数斜杠。
推荐实现: ‘numr’表将数字和相关字符集映射到字体中相应的分子字形。它还将印刷斜线(U + 002F)映射到分数斜线(U + 2044)。所有映射都是一对一的(GSUB查找类型1)。
应用程序界面:对于’numr’覆盖表中的GID,应用程序将GID传递给表并获取新的GID。
UI建议:当用户应用“压裂”功能时,应用程序通常应调用此功能。
脚本/语言敏感度:无。
功能交互:此功能支持’压裂’。它可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’onum’
友情名称: Oldstyle Figures
注册人: Microsoft / Adobe
功能:此功能将选定的图形从默认或衬里样式更改为旧样式。
示例:用户调用此功能以获取oldstyle数字,这更适合普通大写和小写文本的流程。设计用于数字的各种角色也可以具有旧式版本。
推荐实现: ‘onum’表将每个衬里图和任何相关字符映射到相应的旧样式(GSUB查找类型1)。如果默认数字是非衬里的,它们也会映射到相应的旧样式。
应用程序界面:对于’onum’覆盖表中的GID,应用程序将GID传递给’onum’表并获取新的GID。
UI建议:默认情况下,此功能应处于非活动状态。用户可以通过打开或关闭此功能来切换默认和旧式图形集。注意:此功能与图宽特征’pnum’和’tnum’分开。当用户改变图形样式时,应用程序可能想要查询是否还需要改变宽度。
脚本/语言敏感度:无。
要素交互:此功能会覆盖“衬里数字”功能(“lnum”)的结果。
标签:’opbd’
友情名称:光学界
注册人: Adobe(由Adobe修改,这是更新的描述)
功能:在水平设置中将字形按其明显的左或右范围对齐,或在垂直设置中对齐明显的顶部或底部范围,替换对齐字形按其原点对齐的默认行为。这种行为的另一个名称是视觉证明。给定字形的光学边缘仅与其前进宽度或边界框间接相关; 此功能提供了获得真正视觉对齐的方法。
示例:当文本左对齐并应用此功能时,以T,D和W开头的后续行将通过变化量向左移动。当文本右对齐并应用此特征时,以r,h和y结尾的后续行同样会以不同的度数向右移动。
建议的实现:受影响的字形的值是使用左,右,上和下的单独记录定义的。每条记录都描述了应该更改放置和提前宽度的数量(GPOS查找类型1)。
应用程序界面:对于’opbd’覆盖表中的GID,应用程序调用两个相关表中的一个,具体取决于字形的位置。对于水平线左端的字形,它调用’lfbd’表,对于水平线右端的字形,它调用’rtbd’表。
UI建议:默认情况下,此功能应处于活动状态。它有效地改变了线路长度,因此理由算法应该考虑到这种调整。
脚本/语言敏感度:无。
特征交互:不应该应用于使用固定宽度特征的字形(例如’fwid’,’halt’,’hwid’,’qwid’和’twid’)或垂直特征(例如’vert’,’vrt2’,’vpal’,’valt’和’vhal’)。使用’lfbd’和’rtbd’功能。
标签:’ordn’
好记的名称:序数
注册人: Adobe
功能:使用相应的序数形式替换默认的字母字形,以便在数字后使用。follow-a-figure规则的一个例外是数字字符(U + 2116),它实际上是一个连字替换,但最好通过此功能访问。
示例:用户应用此功能将2.o变为2. o(secundo的缩写)。
推荐实现: ‘ordn’表将各种小写字母映射到链接上下文中的相应序数形式(GSUB查找类型6),并将序列号映射到数字字符(GSUB查找类型4)。
应用程序界面:对于在’ordn’覆盖表中找到的GID集,应用程序将GID序列传递给表并获取新的GID。请注意,必须传递完整序列。注意:这可能是语义值的变化。除原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:主要适用于拉丁文脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’ornm’
友情名称:饰品
注册人: Adobe
功能:这是一个双功能功能,它使用两种输入方法让用户可以访问字体中的装饰字形(例如fleurons,dingbats和border元素)。一种方法用来自全套可用装饰品的选择替换子弹角色; 另一个用分配给它们的饰品替换特定的“低级ASCII”字符。第一种方法支持普通用户或浏览用户; 第二个支持高级用户。
示例:用户输入qwwwwwwwwwe以形成Adobe Caslon中繁荣框的顶部,或输入项目符号,然后选择蓟dingbat。
推荐实现: ‘ornm’表将字体中的所有饰品映射到项目符号字符(GSUB查找类型3),并将字体中的每个饰品映射到相应的字母数字字符(GUSB查找类型1)。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。与任何一对多替换中一样,多个面中存在的替换应该在一个族中一致地排序,以便这些替换在家庭成员之间切换时可以正常工作。
应用程序界面:调用此功能时,应用程序必须注意所选文本是项目符号字符(U + 2022)还是字母数字字符。在第一种情况下,它将子弹的GID传递给’ornm’表并获取一组GID,并为用户提供从中选择的方法。在第二种情况下,对于在’ornm’覆盖表中找到的GID,它将GID传递到’ornm’表并获取新的GID。
UI建议:默认情况下,此功能应处于非活动状态。当返回多个GID(子弹案例)时,应用程序可以在上下文中按顺序显示表单,或者提供一次显示所有表单的调色板,或者让用户在这些方法之间进行选择。一旦用户选择了特定装饰,则下次输入项目符号时,该装饰应该是默认选择。在没有这样的先验信息的情况下,应用程序可以假设集合中的第一个装饰是首选形式,因此字体开发者应该相应地对它们进行排序。
脚本/语言敏感度:无。
功能交互:此功能与所有其他替换(GSUB)功能互斥,应用时应关闭这些功能。
8.3.4.p-t
标签:’palt’
友好名称:比例替代宽度
注册人: Adobe
功能:重新设计设计为全宽度宽度的字形,使其适合单独(或多或少成比例)的水平宽度。这与’pwid’的不同之处在于它不能替代新的字形(GPOS,而不是GSUB特征)。用户可能更喜欢等宽字形,或者可能只是想确保字形适合并且不在垂直设置中旋转(设计用于比例间距的拉丁形式将被旋转)。
示例:用户可以使用日语字体调用此功能,以获得具有全宽设计但具有单个度量标准的Latin,Kanji,Kana或Symbol字形。
推荐实现:字体指定全角字形的备用度量标准(GPOS查找类型1)。
应用程序界面:对于’palt’覆盖表中的GID,应用程序将GID传递给表并返回位置调整(XPlacement,XAdvance,YPlacement和YAdvance)。
UI建议:此功能默认情况下处于关闭状态。
脚本/语言敏感度:主要用于CJKV字体。
特征交互:此特征与所有其他字形宽度特征(例如’fwid’,’halt’,’hwid’,’qwid’和’twid’)互斥,应用时应关闭。如果’palt’被激活,则不要求也必须激活’kern’。如果’kern’被激活,’palt’也必须被激活(如果它存在)。另见’vpal’。
标签:’pcap’
友情名称: Petite Capitals
注册人: Tiro Typeworks / Emigre
功能:某些字体包含大写字母的额外大小,比常规小键盘短,并且异想天开地称为小型大写字母。这种形式最有可能出现在小写x高度的设计中,与较高的小型背景相比,它们更好地与小写文本协调(例如小型帽子,参见Emigre类型的家庭Eaves和Filosofia夫人)。此功能可将小写字符转换为小写字母。可以包括与小型首都相关的表格,例如特别设计的数字。

示例:用户以小写或大小写形式输入文本,并获得带有常规大写和小写大写的小文本文本或文本。请注意,一些设计人员可能会扩展小型帽查找以包括大写到小型替换,从而创建大写形式的移位层次结构。
推荐实现: ‘pcap’表将小写字形映射到相应的petite cap表单(GSUB查找类型1)。
应用程序界面:对于’pcap’覆盖表中的GID,应用程序将GID传递给’pcap’表,并获取新的GID。小盖帽替换应遵循smallcap(’smcp’)替换的语言规则。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感性:仅适用于具有大写和小写形式的脚本(例如拉丁语,西里尔语,希腊语)。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’pkna’
友好名称:比例假名
注册人: Adobe
功能:替换字形,假名和假名相关,使用比例字形设置均匀宽度(半宽或全宽)。
示例:用户可以使用日语字体调用此功能以获取比例字形,而不是相应的半宽或全宽假名字形。
推荐实现:该字体包含设计为按比例宽度设置的备用假名和假名相关字形(GSUB查找类型1)。
应用程序界面:对于’pkna’覆盖表中的GID,应用程序将GID传递给表并获取新的GID。
UI建议:默认情况下,此功能通常是关闭的。
脚本/语言敏感度:通常仅用于日语字体。
特征交互:此特征与所有其他字形宽度特征互斥(例如’fwid’,’halt’,’hwid’,’palt’,’pwid’,’qwid’,’twid’和’vhal’) ,应用时应关闭。应用此功能应激活’kern’功能。
标签:’pnum’
友好名称:比例数字
注册人: Microsoft / Adobe
功能:将在均匀(表格)宽度上设置的图形字形替换为在字形特定(比例)宽度上设置的相应字形。表格宽度通常是默认值,但不能安全地假设。当然,这种特性在等宽设计中不会出现。
示例:用户可以应用此功能以获得用于全屏标题中的日期的衬里数字的均匀间距。
推荐实现:为了简化相关的字距调整并获得给定宽度的最佳字形设计,此功能应使用新的字形图,而不是仅调整表格字形的拟合(尽管有些可能是简单的副本); 即不是GPOS功能。’pnum’表将衬里和/或旧样式的表格版本映射到相应的比例字形(GSUB查找类型1)。
应用程序界面:对于在’pnum’覆盖表中找到的GID,应用程序将GID传递到’pnum’表并获取新的GID。
UI建议:默认情况下应关闭此功能。当用户更改图形样式(’onum’或’lnum’)时,应用程序可能希望向用户询问此功能。
脚本/语言敏感度:无。
要素交互:此功能会覆盖表格数字功能(’tnum’)的结果。
标签:’pref’
友好名称:预基础表格
注册人:微软
功能:替代辅音的前基础形式。
在南亚或东南亚的一些剧本中,例如高棉语,某些辅音的联合形式总是被称为前基础形式。在南印度的一些剧本的情况下,存在书写惯例的变化,使得联合的Ra辅音可以被写为前基础形式,或者基础或后基础形式。字体可以被设计为支持一种或另一种约定。如果字体被设计为支持其中联合Ra是预基础形式的书写约定,则将使用预基础表单功能。
示例:在高棉语中,辅音Ra具有称为Coeng Ra的前基下标形式。当Coeng序列随后发生Ra时,其前碱形式被取代。
推荐实现: ‘pref’表映射将辅音转换为其基本前形式所需的序列(GSUB查找类型4)。
应用程序接口:对于’pref’表中定义的替换,应用程序将GID序列传递给表,并获取辅音的预基础形式的GID。在对印度南部的脚本进行整形时,应用程序可以检查处理此功能的结果,以确定是否需要重新排序联合辅音形式。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:在高棉语和缅甸语(缅甸语)脚本中需要具有辅音的基础前形式。对于可能显示基本形式的Ra的南部印度语脚本也是必需的,例如马拉雅拉姆语或泰卢固语。
特征交互:此特征与某些其他特征结合使用,以获得某些印度语和东南亚文字的必要形式。期望应用程序以适当的顺序处理此功能和某些其他功能,以获取给定脚本的正确基本表单集。对于印度语脚本,应按顺序应用以下功能:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’pres’
友情名称:前基础替代
注册人:微软
功能:在印度语脚本中生成预基础形式的合取。它还可以用于替换适当的字形变体用于前基元音符号。
示例:在古吉拉特语(印度语)脚本中,辅音Ka的加倍需要将第一个Ka替换为其前基础形式。这反过来与第二个Ka连接。应用此功能将导致双倍Ka的连接版本。
推荐实现: ‘pres’表将由virama(halant)分隔的辅音序列映射到结合的合取形式(GSUB查找类型4)。在基础前matra替换的情况下,可以使用上下文替换(GSUB查找类型5)替换适当的matra。
应用程序接口:对于’pres’表中定义的替换,应用程序将GID序列传递给要素,并获取连字的GID(或视情况而定的matra)。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:印度语脚本中必需。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’pstf’
友好名称:后基础表格
注册人:微软
功能:替代辅音的后基础形式。
示例:在Gurmukhi(印度语)脚本中,辅音Ya具有基础形式。当Ya用作合取形成中的第二个辅音时,其后基础形式被替换。
推荐实现: ‘pstf’表将辅音转换为后基形式所需的序列(GSUB查找类型4)。
应用程序接口:对于’pstf’表中定义的替换,应用程序将GID序列传递给要素,并获取辅音的后基础形式的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:在南亚和东南亚的脚本中需要具有辅音的后基础形式,例如:Gurmukhi,Malayalam,Khmer。
功能交互:此功能与某些其他功能结合使用,以获得必需的印度语形式和其他相关脚本。期望应用程序以适当的顺序处理此功能和某些其他功能,以获取给定脚本的正确基本表单集。对于印度语脚本,应按顺序应用以下功能:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’psts’
友好名称:后基础替代
注册人:微软
功能:用其连接形式替换基本字形和后基字形的序列。
示例:在Malayalam(印度语)脚本中,辅音Va具有基础形式。当Va加倍形成一个混合体–VVa; 第一个Va [base]和跟随它的post base形式用连字取代。
推荐实现: ‘psts’表将已识别的合取形成序列映射到相应的连字(GSUB查找类型4)。
应用程序接口:对于’psts’表中定义的替换,应用程序将GID序列传递给要素,并获取连字的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感度:可用于任何字母脚本。印度语脚本中必需的。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’pwid’
友好名称:比例宽度
注册人: Adobe
功能:使用按比例间隔的字形替换在均匀宽度(通常为全或半)上设置的字形。比例变量通常用于CJKV字体中的拉丁字符,但也可用于日语字体中的假名。
示例:用户可以使用日语字体调用此功能,以获得按比例间隔的字形,而不是相应的半宽罗马字形或全角假名字形。
推荐实现:字体包含设计为按比例宽度设置的备用字形(GSUB查找类型1)。
应用程序界面:对于’pwid’覆盖表中的GID,应用程序将GID传递给表并获取新的GID。
UI建议:应用程序可能希望默认情况下此功能处于活动或非活动状态,具体取决于其市场。
脚本/语言敏感度:虽然主要用于CJKV字体,但此功能可应用于欧洲脚本。
特征交互:此特征与所有其他字形宽度特征互斥(例如’fwid’,’halt’,’hwid’,’palt’,’qwid’,’twid’,’valt’和’vhal’),在应用时应该关闭它。应用此功能应激活’kern’功能。
标签:’qwid’
友好名称: Quarter Widths
注册人: Adobe
功能:替换其他宽度上的字形,并在宽度为四分之一(半个en)的宽度上设置字形。涉及的字符通常是数字和某些形式的标点符号。
示例:用户可以应用“qwid”将四位数字放在垂直文本列的单个插槽中。
推荐实现:字体可能包含设计为在四分之一宽度上设置的替代字形(GSUB查找类型1),或者它可以指定原始字形(GPOS查找类型1)的备用度量,这些字形调整它们的间距以适合四分之一 - em宽度。
应用程序界面:对于在’qwid’覆盖表中找到的GID,应用程序将GID传递给表并返回新的GID或位置调整(XPlacement和XAdvance)。
UI建议:默认情况下,此功能通常是关闭的。
脚本/语言敏感度:通常仅用于CJKV字体。
特征交互:此特征与所有其他字形宽度特征(例如’fwid’,’halt’,’hwid’和’twid’)互斥,应用时应关闭。它会停用’kern’功能。
标签:’rand’
友好名称:随机化
注册人: Adobe
功能:为了模拟手写文本的不规则性和多样性,此功能允许使用多种替代形式。
示例:用户在FF Kosmic中应用此功能以在一个单词中获得三种形式的f。
推荐实现: rand表将默认字形的GID映射到相应替换的一个或多个GID(GSUB查找类型3)。
应用程序界面:对于在rand coverage表中找到的GID,应用程序将GID传递给rand表并返回一个或多个新GID。应用程序通过伪随机算法选择其中一个,或者通过注意返回的ID序列,存储该序列,并在调用相应的字符代码时单步执行该序列。
UI建议:应通过首选项设置启用/禁用此功能; “enabled”是推荐的默认值。
脚本/语言敏感度:无。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’rclt’
友好名称:必需的上下文替代
注册人:微软
功能:在指定的情况下,将替换形式替换为默认字形,以提供更好的连接行为或其他字形关系。在脚本字体中特别重要的是设计为具有部分或全部字形连接,但也适用于例如改进间距的变体。此功能类似于’calt’,但不同之处在于不应该关闭’rclt’替换:它们被认为是纠正字体布局所必需的。
示例:在阿拉伯语书法字体中,’rclt’功能用于在上下文中替换字母sin和yeh的变体形式,以提供这两个字母之间的正确连接,这两个字母与其他字母的默认连接不同。
推荐实现: ‘rclt’表指定每次替换发生的上下文,并将一个或多个默认字形映射到替换字形(GSUB查找类型6)。
应用程序界面:应用程序将GID序列传递给要素表,并获取新的GID。请注意,必须传递完整序列。
UI建议:默认情况下,此功能应处于活动状态。建议不要关闭此功能,以避免破坏强制性整形。
脚本/语言敏感度:可能适用于任何脚本,但对于许多阿拉伯风格尤为重要。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。对于复杂脚本,应在基本脚本和语言整形功能之后对此功能进行查找和处理。
标签:’rlig’
友好名称:必需的连字
注册人:微软
功能:用一个字形替换一系列字形,这是印刷目的的首选。此功能涵盖了那些连接,脚本根据需要在正常条件下使用这些连接。此功能对于某些脚本确保正确的字形形成非常重要。
示例:阿拉伯字符lam后跟alef将始终形成连接的lamalef形式。这个结合形式是脚本塑造的要求。Syriac脚本也是如此。
推荐实现: ‘rlig’表将默认字形的GID映射到相应替换的一个或多个GID(GSUB查找类型3)。
应用程序界面: ‘rlig’表将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。标准连字集通常会通过脚本保持不变。
UI建议:默认情况下,此功能应处于活动状态。建议不要关闭此功能以避免破坏强制性脚本整形。
脚本/语言敏感度:适用于阿拉伯语和叙利亚语。可能适用于其他一些脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’liga’。
标签:’rkrf’
友情名称: Rakar Forms
注册人:微软
功能:在梵文和古吉拉特语剧本中为rakar制作辅音形式。
在梵文和古吉拉特文字中,涉及Ra跟随另一个辅音的辅音簇通过将一个替代形式的Ra与前一个辅音相结合来表示。取决于特定音节,前面的辅音可以以其完整形式或以半形式表示。由于涉及这些脚本的其他行为的交互,字体实现可能需要处理特定序列中的rakar形式和半形式的替换查找,以便为各种序列导出适当的显示。在推荐用法中,Rakar Forms功能在Half Forms功能之前处理; 对于给定的辅音-Ra组合的半形式可以通过随后应用半形式特征来导出。这种顺序排序可以获得正确的显示结果。
示例:在印地语(梵文脚本)中,合取KRa用合取结扎形式表示。
推荐实现: ‘rkrf’表映射辅音的序列(仅名义形式),然后是virama(halant),接着是Ra(名义形式)到相应的联合形式(GSUB查找类型4)。
应用程序接口:对于’rkrf’表中定义的替换序列,应用程序将GID序列传递给表,并获取半格式的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:在Devanagari和Gujarati脚本中必需。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的印度语脚本。应用程序应按适当的顺序处理此功能和某些其他功能,以获得正确的基本形式:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’ half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’rphf’
友情名称: Reph表格
注册人:微软
功能:将Reph形式替换为辅音和halant序列。
示例:在梵文(印度)脚本中,辅音Ra拥有一个reph形式。当Ra是音节的初始辅音并且后面是virama时,它在音节内的后基元音符号后重新定位,并且还用位于基本字形上方的标记代替。
推荐实现: ‘rphf’表将Ra和virama的默认形式的序列映射到Reph(GSUB查找类型4)。
应用程序界面:应用程序将Ra和virama的GID传递给表,并获取reph标记的GID。应用程序可以检查处理其他特征的结果,以确定reph标记应该重新排序到序列中的哪个位置。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感性:印度语脚本中必需。例如:Devanagari,Kannada。
特征交互:此特征与某些其他特征结合使用,以获得所需形式的印度语脚本。应用程序应按适当的顺序处理此功能和某些其他功能,以获得正确的基本形式:’nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’ half’,’pstf’,’cjct’。也可以应用可选印刷效果的其他自由选择功能。在处理完该功能的查找后,应处理此类自由选择功能的查找。
标签:’rtbd’
友好名称:右边界
注册人: Adobe
功能:通过文本水平线右端的明显右侧范围对齐字形,替换对齐字形的默认行为。此功能由Optical Bounds (’opbd’)功能调用。
示例:当文本右对齐并应用此功能时,以r,h和y结尾的后续行将以不同的度数向右移动。
建议的实现:受影响的字形的值描述了应该更改放置和提前宽度的数量(GPOS查找类型1)。
应用程序界面:对于在’rtbd’覆盖表中找到的GID,应用程序将GID传递给表并获取新的XPlacement和XAdvance值。
UI建议:当用户调用“opbd”功能时,应用程序会调用此功能。
脚本/语言敏感度:无。
特征交互:不应该应用于使用固定宽度特征的字形(例如’fwid’,’halt’,’hwid’,’qwid’和’twid’)或垂直特征(例如’vert’,’vrt2’,’vpal’,’valt’和’vhal’)。由’opbd’功能调用。
标签:’rtla’
友好名称:从右到左的替代品
注册人: Adobe
功能:此功能适用于适合从右到左文本的字形变体(镜像形式除外)。(对于镜像表单,请参阅’rtlm’。)
推荐实现:这些必须是字形替换,并且建议它们是一对一的(GSUB查找类型1)。
应用程序界面:请参阅Advanced Typographic Extensions页面上的“从左到右和从右到左文本” 部分。
UI建议:无。
脚本/语言敏感性:从右到左的文本运行。
特征交互:此功能将与其他预先成形功能同时应用,例如“ccmp”和“locl”。
标签:’rtlm’
友好名称:从右到左的镜像形式
注册人: Adobe
功能:适合于该功能适用镜像形式从右到左的文本等,比那将由字符级镜像由OpenType布局引擎执行步骤来覆盖这些字符。(对于从右到左的字形交替,请参阅’rtla’。)
示例: ‘rtlm’功能将U + 2232(CLOCKWISE CONTOUR INTEGRAL)的字形替换为其中整数符号已镜像但圆形箭头保持其方向的字形。
实现:这些必须是字形替换,并且建议它们是一对一的(GSUB查找类型1)。
应用程序界面:请参阅Advanced Typographic Extensions页面上的“从左到右和从右到左文本” 部分。
UI建议:无。
脚本/语言敏感性:从右到左的文本运行。
特征交互:此功能将与其他预先成形功能同时应用,例如“ccmp”和“locl”。
标签:’ruby’
友好名称: Ruby Notation Forms
注册人: Adobe
功能:日本排版通常使用较小的假名字形,通常是上标形式,以澄清读者可能不熟悉的汉字的含义。这些被称为“ruby”,来自四点大小类型的旧排版术语。此功能可识别字体中为此用途设计的字形,并将其替换为默认设计。
示例:用户将此功能应用于假名字符U + 3042,以获取注释的ruby表单。
推荐实现:字体包含为ruby表示法启用的所有假名字符的替代字形。’ruby’表将默认表单的GID映射到相应的ruby替换的GID。这些是一对一替换(GSUB查找类型1)。
应用程序界面:对于’ruby’覆盖表中的GID,应用程序将默认表单的GID传递给表,并获取ruby表单的新GID。然后,应用程序根据其默认值对这些表单进行缩放和定位,这可能需要用户参数。
UI建议:默认情况下,此功能应处于非活动状态。应用程序可以为用户提供指定缩放程度和基线偏移的机会。
脚本/语言敏感度:仅适用于日语。
功能交互:此功能会覆盖受影响字符的任何其他功能的结果。
标签:’rvrn’
友好名称:必需的变化替代
注册人:微软
功能:此功能用于支持OpenType字体变体的字体,以便为特定变体实例选择替代字形。(有关OpenType字体变体的背景信息,请参阅OpenType字体变体概述。)
当使用可变字体时,给定字形ID的所有插值变体具有完全相同的轮廓和点。可以使用字形变化机制来进行显着的轮廓变化,例如减少重量或窄宽变体中的笔划,但是这种方法可能难以实现并且可能不会为所有变化实例产生期望的结果。相反,可以通过替换为不同的字形ID来实现这些场景的更好结果。应用的特定替换将由用户选择的特定变体实例来限制。使用所需的变体替换功能以及GSUB表中的FeatureVariations表来实现此条件行为。
示例:可变字体支持从细到黑的重量变化。美元符号的默认字形有两个垂直笔划贯穿字形的完整范围。在粗体变体实例中,默认字形将替换为只有一个垂直笔划的替代字形。在黑色变体实例中,默认字形替换为替代字形,在顶部和底部只有一个垂直条,两个计数器之间没有垂直条。
推荐实现:该功能用于激活单个替换(GSUB类型1)查找,并始终与FeatureVariations表一起使用。通常,FeatureRecord中使用’rvrn’标记引用的FeatureTable将LookupCount设置为0; 通过这种方式,默认变体实例没有应用任何字形替换,而是使用默认字形。通过将要素表的替换添加到FeatureVariations表中的备用要素表来获得特定变体实例的备用字形。可以使用指定特定变化轴值范围的条件集来选择不同的备用特征表。
一个或多个条件表用于确定为其选择备用要素表(和关联查找)的变化轴值范围。用于触发条件的轴值通常应位于用于命名实例的值之间。当使用由于处理数值时的小差异而可能出现的命名实例时,这将避免在不同应用程序中出现不一致行为的任何可能性。
DFLT脚本的默认语言系统可以引用此功能的功能记录,其中的功能表将替换特定的变体实例,以使用应用默认的,与语言无关的字形替换的查找; 此功能记录应该是此功能的第一个功能记录。某些应用程序可能会选择处理此功能而不处理其他功能或脚本/语言系统层次结构; 为此,他们应该选择此功能的第一个功能记录,以获得与语言无关的结果的最合适的替换。
应用程序界面:在使用可变字体时,在支持OpenType字体变体的实现中,必须应用’rvrn’功能。即使不支持其他OpenType布局处理,也应在支持使用变体的任何布局过程中处理该功能。
该特征仅在导出最终字形ID(GSUB)的过程中应用; 它不用于字形定位(GPOS)。它应该在GSUB处理的早期处理,然后应用本地化表单功能或与复杂脚本的形成或自由排版的排版效果相关的功能。
处理’rvrn’功能还需要处理FeatureVariations表。扫描ConditionSet表以查找与当前变体实例匹配的ConditionSet,然后使用相应的FeatureTableSubstitution表来定位备用要素表。有关处理FeatureVariations表的完整详细信息,请参阅OpenType布局公用表格式。
找到适用的要素表时,仅处理单个替换(GSUB类型1)查找; 任何其他查找类型都将被忽略。对于coverage表中的任何字形ID,应用程序将字形ID传递给查找,并获取新的字形ID。
UI建议: ‘rvrn’功能是强制性的:默认情况下它应该是活动的,而不是直接暴露给用户控制。
脚本/语言敏感度:用于所有语言和脚本。
特征交互:应在初始字符到字形映射之后,应用本地化表单(’locl’)功能之前,与复杂脚本的形成相关的任何特征或任何自由特征进行处理。
标签:’salt’
友情名称:文体交替
注册人: Adobe
功能:许多字体包含替代字形设计,以实现纯粹的美学效果; 这些并不总是适合像swash或历史这样的明确类别。与斜体字形的情况一样,可能存在多个替代形式。此功能使用样式替换替换默认表单。
示例:用户将此功能应用于Industria以获取g的替代形式。
推荐实现: ‘salt’表将默认表单的GID映射到一个或多个GID,以用于相应的样式替代。虽然这些替换中的许多是一对一(GSUB查找类型1),但其他替换需要从集合中选择(GSUB查找类型3)。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。与任何一对多替换中一样,多个面中存在的替换应该在一个族中一致地排序,以便这些替换在家庭成员之间切换时可以正常工作。
应用程序界面:对于’salt’覆盖表中的GID,应用程序将GID传递给’salt’表并返回一个或多个新GID。如果返回多个GID,则应用程序必须为用户提供选择所需GID的方法。
UI建议:默认情况下,此功能应处于非活动状态。当返回多个GID时,应用程序可以在上下文中按顺序显示表单,或者提供一次显示所有表单的调色板,或者让用户在这些方法之间进行选择。应用程序可能会假设集合中的第一个字形是首选形式,因此字体开发人员应相应地对它们进行排序。
脚本/语言敏感度:无。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’sinf’
友好的名字:科学的Inferiors
注册人: Microsoft / Adobe
功能:用较差的数字替换衬里或旧式数字(较小的字形,低于标准基线,主要用于化学或数学符号)。也可以用字母下部替换小写字符。
示例:应用程序可以使用此功能自动访问劣质数字(比缩放数字更清晰)。
推荐实现: ‘sinf’表将数字映射到相应的下层形式(GSUB查找类型1)。
应用程序界面:对于’sinf’覆盖表中的GID,应用程序将GID传递给该功能并获取新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感性:几乎适用于任何脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’size’
注意: STAT表已取代此功能的使用。有关详细信息,请参阅“ 建议”部分中的“具有光学尺寸变量的族” 。
友好名称:光学尺寸
注册人: Adobe
功能:此功能存储有关字体光学尺寸的两种信息:设计尺寸(优化字体的点尺寸)和尺寸范围(字体可以很好地服务的点尺寸范围),以及帮助应用程序使用大小范围的其他信息。设计大小对于确定正确的跟踪行为很有用。大小范围在包含多个范围的字体的家庭中很有用。其他值用于标识共享相关大小范围的字体集,并标识其共享名称。请注意,尺寸是指标称最终输出尺寸,与观察放大率或分辨率无关。
必要的实施:
此GPOS功能的功能表不包含查找; 其“功能参数”字段记录从Feature表开头到五个16位无符号整数值的数组的偏移量。必须在使用该功能的任何系列中的所有字体中实现大小功能。在此用法中,如果不存在“印刷族名称”,则族是一组共享印刷族名称(名称ID 16)或字体族名称(名称ID 1)的字体。
第一个值表示720 /英寸单位(decipoints)的设计尺寸。设计大小条目必须为非零。当存在设计大小但没有建议的大小范围时,阵列的其余部分将由零组成。
第二个值没有独立含义,但作为一个标识符,用于关联子系列中的字体。共享印刷或字体系列名称且仅按大小范围不同的所有字体应具有相同的子系列值,并且没有重量或样式不同的字体应具有相同的子系列值。如果此值为零,则将忽略数组中的其余字段。
第三个值使应用程序能够为由第二个值标识的子系列使用单个名称。如果前面的值不为零,则必须将该值设置在256 - 32767(含)范围内。它在“名称”表中记录字段的值,该表必须包含以Windows Unicode和Macintosh Roman编码的英语字符串,并且可能包含本地化为其他脚本和语言的其他字符串。这些字符串中的每一个都是应用程序应使用的名称,与姓氏一起用于表示菜单中的子系列。应用程序将根据其选择标准选择适当的版本。
第四个和第五个值表示推荐使用范围的小端(不包括)和推荐使用范围(包括)的大端,以720 /英寸单位(decipoints)存储。范围不得重叠,通常应该是连续的。
示例: Bell Centennial中的“大小”信息为[60 0 0 0 0]。这告诉应用程序字体的设计大小是六个点,因此较大的大小可能需要按比例缩小默认的字形间距。Minion Pro Semibold Condensed Subhead中的“尺寸”信息为[180 3 257 139 240]。这些值告诉应用程序:
字体的设计大小为18分;
该字体是字体子系列的一部分,这些字体仅由每个覆盖的大小范围不同,并且共享任意标识符号3;
‘name’表中的ID 257是该子系列的建议菜单名称。在这种情况下,名称为ID 257的字符串为Semibold Condensed;
从大于13.9点到24点的尺寸,建议使用此字体。
应用程序界面:当用户指定大小时,应用程序将检查活动字体中的“大小”功能。如果未找到,则应用程序将遵循其默认行为。如果找到一个,则应用程序遵循指定的偏移量以检索五个值。
设计尺寸:提供基于尺寸的跟踪的应用程序具有可以应用的预定义曲线。默认情况下,此曲线应设置为不对字体的设计大小进行调整(数组中的第一个值,在decipoints中)。
尺寸范围:如果’size’数组中的第二个值不为零,则该字体具有建议的大小范围。当用户选择任何此类字体时,应用程序将使用此子系列值和相同的印刷系列名称构建所有字体的列表,并记下当前字体的大小范围。应用程序可能希望此时缓存子系列列表。如果指定的大小落在当前字体的范围内,则应用程序将使用当前字体。如果没有,应用程序将检查子系列中的其他范围,如果指定的大小属于其中一个范围,则使用该字体。如果指定的大小不在任何范围内,则使用范围最接近指定值的字体。如果指定的大小恰好落在两个范围之间,则使用具有较大值的范围。
UI建议:默认情况下,此功能应处于活动状态。应用程序可能希望将跟踪曲线呈现给用户以通过GUI进行调整。在启动时,以及添加或删除字体时,应用程序可能希望构建具有此类范围的字体列表,并在其字体选择UI中显示已过滤的子系列名称,每个过滤的名称代表完整的相关大小集。应用程序还可以呈现允许用户选择非默认大小的设置(例如,在最终输出用于屏幕上观看的情况下,较小的光学尺寸将产生更好的结果)。在这种情况下,字体选择UI应显示未过滤的名称。应用程序应通知用户是否从具有大小范围的子系列中删除或添加字体,并查询所需行为。
脚本/语言敏感度:无。GPOS FeatureList中所有“大小”功能的FeatureParams必须指向同一组值。
功能互动:无。
标签:’smcp’
友情名称:小资本
注册人: Microsoft / Adobe
功能:此功能可将小写字符转换为小写字母。这对应于常见的SC字体布局。它通常用于以大型和小型大写字母设置的显示行,例如标题。可以包括与小型大写相关的表格,例如旧式数字。
示例:用户以混合大写和小写形式输入文本,并获取大小文本。
推荐实现: ‘smcp’表将小写字形映射到相应的小型表单(GSUB查找类型1)。
应用程序界面:对于’smcp’覆盖表中的GID,应用程序将GID传递给’smcp’表,并获取新的GID。请注意,应用程序应将ß(U + 00DF)视为一对s字符,而土耳其无点我将映射到正常的小字符I.
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅适用于两院制脚本(即具有案例差异的脚本),例如拉丁语,希腊语,西里尔语和亚美尼亚语。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。另见’c2sc’。
标签:’smpl’
友好名称:简化表格
注册人: Adobe
功能:用相应的“简化”形式替换“传统”中文或日文形式。
示例:当输入U + 6AAF,U + 81FA或U + 98B1时,用户获得U + 53F0。
推荐实现: ‘smpl’表将字体中的每个传统形式映射到相应的简化形式(GSUB查找类型1)。请注意,多个传统表单可能会映射到单个简化表单。
应用程序界面:对于’smpl’覆盖表中的GID,应用程序将GID传递给表,并为每个GID获取一个新的GID。注意:这是字符代码的更改。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:此功能默认情况下处于关闭状态,但可以通过首选项设置进行默认设置。
脚本/语言敏感度:仅适用于中文和日文。
特征交互:此特征与所有其他特征互斥,应用时应关闭,除了’palt’,’vert’和’vrt2’特征,可以另外使用; ‘trad’和’tnam’是互斥的,并覆盖’smpl’的结果。
标签:’ss01’ - ‘ss20’
友情名称:文体套装1 - 文体套装20
注册人: Tiro Typeworks
功能:除了或代替各个字形的样式选项(参见’salt’功能),某些字体可能包含与字符集部分对应的风格变体字形集,例如拉丁字体的小写字母的多个变体。风格集中的字形可以被设计为在视觉上协调,以特定方式交互,或以其他方式一起工作。包括风格集在内的字体示例包括Zapfino Linotype和Adobe的Poetica。使用标签名称约定’ss01’,’ss02’,’ss03’…’ss20’按顺序编号的各个功能提供了一种机制,使这些集合中的字形通过GSUB查找索引与默认表单相互关联,并为用户提供从可用的风格集中选择。
推荐实现: ‘ss XX ‘表将默认表单的GID映射到GID,以便在每个集合中使用相应的样式替代方案。每个’ss XX ‘功能使用一对一(GSUB查找类型1)替换。字体开发人员可以选择仅从默认表单映射到每个样式集的变体,或者可以选择在每个特征中的所有样式集之间映射,这取决于预期的用户体验。例如,除了从默认表单映射之外,功能’ss03’可能包含将’ss01’和’ss02’中的变体字形映射到’ss03’中相应变体的查找。
这些GSUB特征的特征表的FeatureParams字段可以设置为0,或者设置为包含两个连续uint16值的特征参数表的偏移量,如下所示:
版本(设置为0):这对应于“次要”版本号。将来可能会在此功能参数表的末尾添加其他数据。
UI名称ID:将“名称”,指定用于该功能的用户界面标签的字符串(或字符串,支持多国语言)表名ID。uiLabelNameId的值应该在特定于字体的名称ID范围(256-32767)中,但这不是此功能参数规范中的要求。该功能的用户界面标签可以以多种语言提供。应包含英文字符串作为后备。字符串应保持最小长度,以适应不同的应用程序界面。
应用程序界面:请注意,应用程序负责计算和枚举字体中的特征数量,其标记名称为’ss01’到’ss20’,并为用户提供适当的选择机制。对于在’ss XX ‘覆盖表中找到的GID,应用程序将GID传递到’ss XX ‘表并返回一个或多个新GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:无。对于每个相应的[/ distinct]’ss XX ‘特征,FeatureList中的FeatureParams必须指向同一组值。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。请注意,在应用“ss XX ”功能后,用户可能希望将特定于字形的功能(例如“salt”)应用于生成的布局中的各个字形; 字体开发人员负责订购替换查找以获得所需的用户体验。
标签:’ssty’
友好名称:数学脚本样式交替
注册人:微软
功能:此功能提供调整为更适合在下标和上标中使用的字形变体。脚本样式表单不应缩放或移动为字体; 缩放和移动它们是由数学处理客户端完成的。相反,’ssty’功能应该提供字形表单,这些形式在Math引擎缩放和定位时会产生看起来很好的形状作为上标和下标。在设计脚本表单时,字体开发人员可能会认为MATH.MathConstants.scriptPercentScaleDown和MATH.MathConstants.scriptScriptPercentScaleDown将是Math引擎使用的缩放因子。
此功能可以有一个指示脚本级别的参数:1表示简单下标和上标,2表示二级下标和上标(即脚本上的脚本),依此类推。(目前,仅使用前两个替代项)。对于此功能未涵盖的字形,原始字形用于下标和上标。
示例:取决于公式字母b将替换为脚本级别1变量和字母c
推荐实现:替换替换,参数1或2对应于子脚本或超级脚本级别的替代字形。如果字体中没有定义第二级替换,则也可以使用单个替换。可以从此表中省略没有脚本替换的字形。有关详细信息,请参阅MATH表规范。
应用程序界面:数学布局处理程序根据数学公式内的嵌套级别自动调用特征。
UI建议:在推荐用法中,此功能会触发正确显示数学公式所需的替换。它应该在适当的上下文中应用,由数学布局处理程序确定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感度:应用于数学公式布局。
要素交互:此要素适用于数学公式布局期间的各个字形。
标签:’stch’
友好名称:拉伸雕文分解
注册人:微软
功能:包含其他字符的Unicode字符(如Syriac缩写标记(U + 070F))需要能够拉伸才能动态适应所附文本的宽度。此功能定义了一个分解集,该分解集由描述拉伸字形的奇数个字形组成。分解中的奇数编号字形是固定参考点,它们从封闭文本的开头到结尾均匀分布。可以根据需要重复偶数编号的字形以填充固定字形之间的空间。第一个和最后一个字形可以是宽度在基线处的简单字形,也可以是标记字形。所有其他分解字形应具有宽度,但必须定义为标记字形。
示例:在Syriac中,字符0x070F是一个控制字符,在Syriac脚本中显示为缩写上方的一行。该线的两端和中点应该有一个圆圈。该字符的分解序列应包括一行开头的圆,连接线,中点线上的圆,第二个连接线和该行末尾的圆。连接线将重复以填充圆形字形之间的空间。
推荐实现: ‘stch’表将字符映射到包含奇数个对应字形的集合(GSUB查找类型2)。渲染引擎将替换集中的最后一个字形重新排序到所包含的字符集的末尾。来自替换集的剩余字形位于被包围的字符集的开头。分解集中的奇数编号字形被定位,使得它们在被封闭的文本的宽度上均匀分布。分解集中的偶数字形由渲染引擎重复,因此固定的奇数字形之间的空间宽度由间隔偶数字形填充。
应用程序接口:对于在’stch’覆盖表中找到的GID,应用程序将GID序列传递给表,并返回GID以进行多次替换。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感度:无
功能互动:无
标签:’subs’
友好名称:下标
注册人: Microsoft / Adobe
功能: ‘subs’功能可以用下标字形替换默认字形,或者它可以将字形替换与定位调整组合以正确放置。
推荐实现:首先,单个或上下文替换查找实现下标字形(GSUB查找类型1)。然后,如果字形需要重新定位,则应用程序可以应用单个调整,对调整或上下文调整定位查找来修改其位置。
应用程序界面:对于’subs’覆盖表中的GID,应用程序将GID传递给该功能并获取新的GID。注意:这是语义值的变化。除原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感性:几乎适用于任何脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’sups’
友情名称:上标
注册人: Microsoft / Adobe
功能:用优质数字替换衬里或旧式数字(主要用于脚注指示),并用优质字母替换小写字母(主要用于缩写法语标题)。
示例:应用程序可以使用此功能自动访问脚注中的上级数字(比缩放数字更清晰),或者用户可以将其应用于Mssr以获取经典表单。
推荐实现: ‘sups’表将数字和小写字母映射到相应的高级表单(GSUB查找类型1)。
应用程序界面:对于在’sups’覆盖表中找到的GID,应用程序将GID传递给该功能并获取新的GID。注意:这可以包括语义值的更改。除原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感性:几乎适用于任何脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’swsh’
友情名称: Swash
注册人: Microsoft / Adobe
功能:此功能用相应的斜体字形替换默认字符字形。请注意,给定字符可能有多个swash替换。
示例:当用Poetica设置文本并且此功能处于活动状态时,用户输入&符号,并在该面中选择63个&符号形式。
推荐实现: ‘swsh’表将默认表单的GID映射到一个或多个相应的swash表单的GID。虽然这些替换中的许多是一对一(GSUB查找类型1),但其他替换需要从集合中选择(GSUB查找类型3)。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。如果字体中存在多种样式的swash,则应按顺序对每个字符的表单集进行排序。
应用程序界面:对于在’swsh’覆盖表中找到的GID,应用程序将GID传递给’swsh’表并获取一个或多个新GID。如果返回多个GID,则应用程序必须为用户提供选择所需GID的方法。
UI建议:默认情况下,此功能应处于非活动状态。当返回多个GID时,应用程序可以在上下文中按顺序显示表单,或者提供一次显示所有表单的调色板,或者让用户在这些方法之间进行选择。应用程序可能会假设集合中的第一个字形是首选形式,因此字体开发人员应相应地对它们进行排序。
脚本/语言敏感度:不适用于表意文字脚本。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’titl’
友情名称:标题
注册人: Adobe
功能:此功能将默认字形替换为专门为标题设计的相应表单。这些可以是全身和/或更大的身体,并调整为更大尺寸的观看。
示例:用户在Adobe Garamond中应用此功能以获取标题上限。
推荐实现: ‘titl’表将默认表单映射到相应的标题表单(GSUB查找类型1)。
应用程序界面:对于’titl’覆盖表中的GID,应用程序将GID传递给’titl’表并获取新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:无。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’tjmo’
友好名称:追踪Jamo表格
注册人:微软
功能:替换群集的尾随jamo形式。
示例:在Hangul脚本中,jamo集群由三个部分组成(前导辅音,元音和尾随辅音)。当找到一系列尾随类别的jamos时,它们的组合尾随jamo形式被替换。
推荐实现: ‘tjmo’表将将一系列jamos转换为其尾随jamo形式所需的序列(GSUB查找类型4)。
应用程序界面:对于’tjmo’表中定义的替换,应用程序将GID序列传递给要素,并返回尾随的jamo表单的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:支持Ancient Hangul书写系统时,汉语脚本必需。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’tnam’
友好名称:传统名称表格
注册人: Adobe
功能:用相应的“传统”形式替换“简化”日语汉字形式。这相当于传统表单功能,但明确限于适用于个人名称的传统表单(某些字体中多达205个字形)。
示例:用户输入U + 4E9C并获得U + 4E9E。
推荐实现: ‘tnam’表将字体中的简化形式映射到可用于个人名称的相应传统形式(GSUB查找类型1)。应用程序存储由替换产生的任何简化形式的记录(’smpl’特征); 对于这样的形式,应用’tnam’功能撤消先前的替换。
应用程序界面:对于’tnam’覆盖表中的GID,应用程序将GID传递给表并获取新的GID。注意:这是字符代码的更改。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感度:仅适用于日语。
特征交互:可能包含受比例交替宽度特征(’palt’)影响的一些字符; ‘trad’和’tnam’是互斥的,并覆盖’smpl’的结果。
标签:’tnum’
友好名称:表格数字
注册人: Adobe
功能:替换在比例宽度上设置的图形字形,以及在均匀(表格)宽度上设置的相应字形。表格宽度通常是默认值,但不能安全地假设。当然,这种特性在等宽设计中不会出现。
示例:用户可以应用此功能以使旧样式数字在列中垂直对齐。
推荐实现:为了简化相关的字距调整并获得给定宽度的最佳字形设计,此功能应使用新的字形图,而不是仅调整比例字形的拟合(尽管有些可能是简单的副本); 即不是GPOS功能。’tnum’表将衬里和/或旧样式的比例版本映射到相应的表格字形(GSUB查找类型1)。
应用程序界面:对于’tnum’覆盖表中的GID,应用程序将GID传递给’tnum’表并获取新的GID。
UI建议:默认情况下应关闭此功能。当用户更改图形样式(’onum’或’lnum’)时,应用程序可能希望向用户询问此功能。
脚本/语言敏感度:无。
要素交互:此功能会覆盖比例数字功能(’pnum’)的结果。
标签:’trad’
友好名称:传统表格
注册人: Adobe
功能:用相应的“传统”形式替换“简体”中文汉字或日文汉字形式。
示例:用户输入U + 53F0,可选择U + 6AAF,U + 81FA或U + 98B1。
推荐实现: ‘trad’表将每个简化形式的字体映射到一个或多个传统形式。虽然这些替换中的许多是一对一(GSUB查找类型1),但其他替换需要从集合中选择(GSUB查找类型3)。制造商可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。与任何一对多替换中一样,多个面中存在的替换应该在一个族中一致地排序,以便这些替换在家庭成员之间切换时可以正常工作。
应用程序界面:对于’trad’覆盖表中的GID,应用程序将GID传递给表并返回一个或多个新GID。如果返回多个GID,则应用程序必须为用户提供选择所需GID的方法。应用程序存储由替换产生的任何简化形式的记录(’smpl’特征); 对于此类表单,应用“trad”功能会撤消之前的替换。注意:这是字符代码的更改。除了原始字符代码外,应用程序还应存储新字符的代码。
UI建议:默认情况下,此功能应处于非活动状态。如果没有从传统到简化的转换记录,则必须为用户提供一组可供选择的可能性。应用程序可能会记录用户的选择,并在下次遇到源简化字符时将其作为默认值提供。在没有这样的先验信息的情况下,应用程序可以假设集合中的第一个字形是首选形式,因此字体开发者应该相应地对它们进行排序。
脚本/语言敏感度:仅适用于中文和日文。
特征交互:可能包含受比例交替宽度特征(’palt’)影响的一些字符; ‘trad’和’tnam’是互斥的,并覆盖’smpl’的结果。
标签:’twid’
友好名称:第三宽度
注册人: Adobe
功能:使用在三分之一宽度上设置的字形替换其他宽度上的字形。涉及的字符通常是数字和某些形式的标点符号。
示例:用户可以应用“twid”将三位数字放在垂直文本列的单个插槽中。
推荐实现:字体可能包含设计为在第三个em宽度上设置的备用字形(GSUB查找类型1),或者它可以指定原始字形(GPOS查找类型1)的备用度量,这些字符调整它们的间距以适合第三个 - em宽度。
应用程序界面:对于’twid’覆盖表中的GID,应用程序将GID传递给表并返回新的GID或位置调整(XPlacement和XAdvance)。
UI建议:默认情况下,此功能通常是关闭的。
脚本/语言敏感度:通常仅用于CJKV字体。
特征交互:此特征与所有其他字形宽度特征(例如’fwid’,’halt’,’hwid’和’qwid’)互斥,应用时应关闭。它会停用’kern’功能。
8.3.5.u-z
标签:’unic’
友情名称: Unicase
注册人: Tiro Typeworks / Emigre
功能:此功能将大写和小写字母映射到一组混合的小写和小写形式,从而形成一个单独的字母表(对于unicase的示例,请参阅Emigre类型系列Filosofia)。取代的字母可能因字体而异,视设计而定。如果对齐x高度,可以替换smallcap字形,或者可以使用特殊设计的unicase形式。替换也可能包括特别设计的数字。
示例:用户以大写,小写或大小写形式输入文本,并获取unicase文本。
推荐实现: ‘unic’表将一些大写和小写字形映射到相应的unicase形式(GSUB查找类型1)。
应用程序界面:对于在’unic’覆盖表中找到的GID,应用程序将GID传递给’unic’表,并获取新的GID。
UI建议:默认情况下应关闭此功能。
脚本/语言敏感性:仅适用于具有大写和小写形式的脚本(例如拉丁语,西里尔语,希腊语)。
功能交互:此功能可以与其他替换(GSUB)功能结合使用,其结果可能会覆盖。
标签:’valt’
友好名称:备用垂直度量标准
注册人: Adobe(由Adobe修改,这是更新的描述)
功能:重新定位字形,使其在全高度指标内以视觉方式居中,以便在垂直设置中使用。通常适用于全角度拉丁字形,它们在公共水平基线上对齐,而在CJKV字体中垂直设置时不旋转。
示例:应用此功能会将罗马h从默认的全宽位置向下或向上移动。
推荐实现:字体指定原始字形的备用度量标准(GPOS查找类型1)。
应用程序界面:对于’valt’覆盖表中的GID,应用程序将GID传递给表并返回位置调整(YPlacement)。
UI建议:默认情况下,此功能应在垂直设置上下文中处于活动状态。
脚本/语言敏感度:仅适用于具有垂直书写模式的脚本。
特征交互:此特征与所有其他字形高度特征(例如“vhal”和“vpal”)互斥,应用时应关闭。它会停用’kern’功能。
标签:’vatu’
友好名称: Vattu Variants
注册人:微软
功能::在一个印度符号辅音合取中,用一个连字字形替换一个基本辅音和一个连接辅音的下一个vattu(低于基础)形式,或者一个辅音的一半形式和一个跟随的vattu形式。
示例:在Devanagari(印度语)脚本中,辅音Ra采用vattu形式,当它不是合音中的音节初始辅音时。这种vattu形式与基础辅音以及半辅音形式结合。
推荐实现: ‘vatu’表将辅音和vattu表单组合映射到它们各自的连字(GSUB查找类型4)。
与Vattu Variants特征相关联的查找适用于使用基础形式特征和(半形式加vattu连字)半形式特征导出的字形。应使用低于基础的表格特征来推导出辅音的名义vattu形式; Vattu Variants特征仅应用于替换名义vattu形式和基本辅音或半形式与连字字形。如果使用Rakar Forms功能,则不需要Vattu Variants功能。
应用程序接口:对于’vatu’表中定义的替换,应用程序将GID序列传递给表,并获取vattu变体连接的GID。
UI建议:在推荐用法中,此功能会触发正确显示给定脚本所需的替换。它应该在适当的上下文中应用,由脚本特定的处理决定。通常不应将该特征的控制暴露给用户。
脚本/语言敏感度:用于印度语脚本。例如:梵文。
特征交互:此功能可以与某些其他功能结合使用 - ‘nukt’,’akhn’,’rphf’,’rkrf’,’pref’,’blwf’,’half’,’pstf’,’cjct’ - 派生所需形式的印度语脚本。对于使用Vattu变量功能的印度语脚本实现,应用程序应按适当顺序处理此功能和其他功能以获取正确的基本表单。也可以应用可选印刷效果的其他自由选择功能。
标签:’vert’
友好名称:垂直交替
注册人: Microsoft / Adobe
功能:在垂直书写模式下将默认字形转换为适合直立呈现的字形。虽然在垂直书写模式下设置东亚书写系统中大多数字符的字形仍保持直立,但有些必须进行转换 - 通常是通过旋转,移位或不同的组件排序 - 用于垂直书写模式。
示例:在垂直书写模式下,左括号(U + FF08)被旋转的形式(U + FE35)替换。
在垂直书写模式中,HIRAGANA LETTER SMALL A(U + 3041“ぁ”)的字形被转换为向上和向右移动的字形,该字形在垂直书写模式下正确定位。
在垂直书写模式中,SQUARE MAIKURO(U + 3343“㍃”)的字形,其组件片假名字符从左到右,从上到下排序(如水平书写模式),将转换为字符,其组件片假名字符为从上到下然后从右到左排序(如垂直书写模式行进展)。
推荐实现:字体包括此功能所涵盖的字形版本,这些字形在某些可视方式上与默认字形不同,例如通过旋转,移位或不同的组件排序。’vert’功能使用类型1(单替换)GSUB查找将默认字形映射到垂直写入模式的相应交替字形。
应用程序界面:对于在’vert’覆盖表中找到的GID,应用程序将GID传递给与该功能关联的查找表,然后返回新的GID。
UI建议:默认情况下,此功能应在垂直书写模式下处于活动状态。
脚本/语言敏感度:仅适用于具有垂直书写功能的脚本。
特征交互: ‘vert’和’vrtr’特征旨在结合使用:’vert’用于在垂直书写中直立呈现的字形,以及用于侧向呈现的字形的’vrtr’。由于对于给定的字形,它们必须永远不能同时激活,因此两个特征之间不应存在相互作用。这些功能适用于在垂直书写模式下以图形方式旋转横向运行的字形的布局引擎,例如符合Unicode技术报告#50:Unicode垂直文本布局的那些。
请注意,相反依赖于字体为所有横向字形提供预旋转字形的布局引擎应使用’vrt2’功能代替’vert’和’vrtr’。因为’vrt2’提供预旋转的字形,所以’vert’特征不应该与’vrt2’一起使用,但除了任何其他特征之外,它还可以使用。
标签:’vhal’
友好名称:备用垂直半指标
注册人: Adobe
功能:重新设计设计为在全高度上设置的字形,使它们适应半高度。
示例:用户可以使用CJKV字体调用此功能,以更好地适应标点符号或符号字形,而不会中断等宽对齐。
推荐实现:字体指定全高字形的备用度量标准(GPOS查找类型1)。
应用程序界面:对于在’vhal’覆盖表中找到的GID,应用程序将GID传递给表并返回位置调整(XPlacement,XAdvance,YPlacement和YAdvance)。
UI建议:通常,默认情况下应禁用此功能。但是,在符合日语文本布局要求(JLREQ)或类似CJK文本布局规范的应用程序中应使用不同的行为,这些规范期望半角形式的字符的默认字形为全角。此类实现应默认启用此功能,或者应选择将此功能应用于需要对CJK文本布局目的进行特殊处理的特定字符,如括号,标点符号和引号。
脚本/语言敏感度:仅在CJKV字体中使用。
特征交互:此特征与所有其他字形高度特征(例如,“valt”和“vpal”)互斥,应用此特征时应关闭此特征。它会停用’kern’功能。另见’停止’。
标签:’vjmo’
友情名称: Vowel Jamo Forms
注册人:微软
功能:替代群集的元音jamo形式。
示例:在Hangul脚本中,jamo集群由三个部分组成(前导辅音,元音和尾随辅音)。当发现一系列元音类群时,它们的组合元音语音形式被替换。
推荐实现: ‘vjmo’表将将一系列jamos转换为元音jamo形式所需的序列(GSUB查找类型4)。
应用程序界面:对于’vjmo’表中定义的替换,应用程序将GID序列传递给该功能,并获取元音jamo表单的GID。
UI建议:默认情况下,此功能应处于启用状态。
脚本/语言敏感性:支持Ancient Hangul书写系统时,汉语脚本必需。
功能交互:此功能会覆盖所有其他功能的结果。
标签:’vkna’
友情名称: Vertical Kana Alternates
注册人: Adobe
功能:用专门为垂直书写设计的表格替换标准假名。这是一种印刷优化,可以改善贴合度,使颜色更均匀。另见’hkna’。
示例:标准全宽假名(平假名和片假名)由专为垂直使用而设计的表单替换。
推荐实现:字体包含一组专门设计的字形,列在“vkna”覆盖表中。’vkna’功能将标准全宽形式映射到相应的特殊垂直形式(GSUB查找类型1)。
应用程序界面:对于’vkna’覆盖表中的GID,应用程序将GID传递给该功能,并获取新的GID。
UI建议:此功能默认情况下处于关闭状态。
脚本/语言敏感度:仅适用于支持假名(平假名和片假名)的字体。
特征交互:由于此特征仅供垂直使用,因此适用于水平行为的特征(例如“kern”)不适用。
标签:’vkrn’
友好名称:垂直字距
注册人: Adobe
功能:调整字形之间的空间量,通常在字形之间提供光学一致的间距。虽然设计良好的字体总体上具有一致的字形间距,但是一些字形组合需要调整以提高易读性。除了垂直方向的标准调整之外,该功能还可以通过设备表提供与尺寸相关的字距调整数据,在X文本方向上提供“交叉流”字距调整,以及独立于提前调整的字形位置调整。请注意,此功能可能适用于两个以上字形的运行,并且不会用于等宽字体。另请注意,此功能仅适用于垂直设置的文本。
示例:当片假名字符U + 30B9或U + 30D8在垂直设置中跟随U + 30C8时,U + 30C8向上移动以更均匀地适合。
推荐实现:字体存储一组字形对的调整(GPOS查找类型2或8)。这些可以存储为匹配左和右类的一个或多个表,和/或作为单独的对。可以为更大的字形组(例如,三元组,四元组等)提供额外的调整,以在特定组合中覆盖对密封的结果。
应用程序界面:应用程序将一系列GID传递给’vkrn’表,并获取这些GID的调整位置(XPlacement,XAdvance,YPlacement和YAdvance)。在一组字形上使用类型2查找时,记住不要使用最后一个字形,但要保持它在后续运行中作为第一个字形可用(这与正常查找行为不同)是至关重要的。
UI建议:默认情况下,对于垂直文本设置,此功能应处于活动状态。应用程序可能希望允许用户进一步添加手动指定的调整以满足特定需求和品味。
脚本/语言敏感度:无
特征交互:如果’vkrn’被激活,’vpal’也必须被激活(如果它存在)。如果’vpal’被激活,则不要求’vkrn’也必须被激活。除了导致固定(均匀)前进高度的功能之外,可以使用除任何其他功能之外的任何功能。
标签:’vpal’
友好名称:比例替代垂直度量标准
注册人: Adobe
功能:重新设计设计为在全高度上设置的字形,使其适合单个(或多或少比例)垂直高度。这与’valt’的不同之处在于它不能替代新的字形(GPOS,而不是GSUB特征)。用户可能更喜欢等宽字形,或者可能只是想确保字形适合。
示例:用户可以使用日语字体调用此功能,以获得具有全高设计但具有单个指标的Latin,Kanji,Kana或Symbol字形。
推荐实现:字体指定全高字形的备用高度(GPOS查找类型1)。
应用程序界面:对于’vpal’覆盖表中的GID,应用程序将GID传递给表并返回位置调整(XPlacement,XAdvance,YPlacement和YAdvance)。
UI建议:此功能默认情况下处于关闭状态。
脚本/语言敏感度:主要用于CJKV字体。
特征交互:此特征与所有其他字形高度特征(例如“valt”和“vhal”)互斥,应用时应关闭。如果’vpal’被激活,则不要求’vkrn’也必须被激活。如果’vkrn’被激活,’vpal’也必须被激活(如果它存在)。另见’palt’。
标签:’vrt2’
友好名称:垂直交替和旋转
注册人: Adobe
功能:用适合垂直书写的形式(即顺时针旋转90度)替换一些固定宽度(半宽,三角或四分之一宽度)或比例宽度的字形(主要是拉丁文或片假名)。请注意,这些是’vert’表中覆盖的字形的超集。
ATM / NT 4.1和Windows 2000 OTF驱动程序对OpenType字体强加以下要求,其中CFF轮廓用于垂直书写:’vrt2’功能必须存在于GSUB表中,它必须包含LookupType 1的单个查找和LookupFlag 0,查找必须有一个子表。前一个特征’vert’被忽略。
旋转的字形必须被设计成使得它的顶侧轴承与记录在垂直提前垂直度量(“vmtx”)表分别是相同的左侧轴承和水平提前,相应的直立字形的作为记录在水平度量标准(’hmtx’)表。(旋转字形的水平前进可以设置为任何值,因为字形仅用于垂直书写使用。但是,供应商可以将其设置为head.unitsPerEm,以防止在字体校样测试期间重叠。)
因此,在’vrt2’特征中具有旋转形式的比例宽度字形在垂直和水平书写中将呈现相同的间隔。为了使字距调整也产生相同的结果,开发人员必须确保垂直字距(’vkrn’)特征记录旋转的字形之间的kern值,这些字符与Kerning中相应的直立字形之间的kern值相同(’kern’)功能。
示例:比例或半宽拉丁文和半角片假名字符顺时针旋转90度以进行垂直书写。
推荐实现:字体包括此功能所涵盖的字形的旋转版本。’vrt2’表将标准(水平)形式映射到相应的垂直(旋转)形式(GSUB查找类型1)。此功能应该是字体中的最后一个替换,并从其他功能中获取输入。
应用程序界面:对于’vrt2’覆盖表中的GID,应用程序将GID传递给该功能,并获取新的GID。
UI建议:当垂直书写模式打开时,默认情况下此功能应处于活动状态,尽管用户必须能够覆盖它。
脚本/语言敏感度:仅适用于具有垂直书写功能的脚本。
要素交互:覆盖’vert’(垂直书写)功能,该功能是此功能的子集。除了任何其他功能外,还可以使用。
标签:’vrtr’
友好名称:垂直交替旋转
注册人: Adobe / Microsoft / W3C
功能:将默认字形转换为适合垂直书写模式中侧向呈现的字形。虽然在垂直书写模式下设置东亚书写系统中大多数字符的字形仍保持直立,但其他字符的字形(例如其他字符或特定西式标点符号)的字形预计会在垂直书写中横向呈现。
示例:作为第一个示例,具有非方形em-box的字体中的FULLWIDTH LESS-THAN SIGN(U + FF1C“<”)和FULLWIDTH GREATER-THAN SIGN(U + FF1E“>”)的字形被转换到纵横比与默认字形不同的字形,这些字形在垂直书写模式下适合侧向呈现。作为第二个例子,在水平书写模式下,呈现略微上升的水平笔划的刷子脚本字体中的LEFT SQUARE BRACKET(U + 005B,“[”)的字形可能在其左上角使用钝角,但是为垂直书写模式提供具有该角的锐角的替代字形。
推荐实现:字体包括此功能所涵盖的字形版本,当布局引擎顺时针旋转90度以进行垂直书写时,可以通过某些视觉方式与默认字形的旋转版本不同,例如通过移位或形状。’vrtr’功能将默认字形映射到相应的待旋转字形(GSUB查找类型1)。
应用程序界面:对于’vrtr’覆盖表中的GID,应用程序将GID传递给与该功能关联的查找表,然后返回新的GID。
UI建议:默认情况下,对于垂直书写模式中的横向运行,此功能应始终处于活动状态。
脚本/语言敏感度:在垂直书写模式下设置时适用于任何脚本。
特征交互: ‘vrtr’和’vert’特征旨在结合使用:’vrtr’用于在垂直书写中侧向呈现的字形,’vert’用于呈现直立呈现的字形。由于对于给定的字形,它们必须永远不能同时激活,因此两个特征之间不应存在相互作用。这些功能适用于在垂直书写模式下以图形方式旋转横向运行的字形的布局引擎,例如符合Unicode技术报告#50:Unicode垂直文本布局的那些。
请注意,相反依赖于字体为所有横向字形提供预旋转字形的布局引擎应使用’vrt2’功能代替’vrtr’和’vert’。由于’vrt2’提供预先旋转的字形,’vrtr’功能不应与’vrt2’一起使用,但除了任何其他功能外,它还可以使用。
标签:’zero’
友好的名字: Slashed Zero
注册人: Adobe
功能:某些字体既包含默认形式零,也包含在计数器中使用斜线斜线的替代形式。特别是在精简设计中,在资本和衬里数字可以任意混合的任何情况下,很难区分0和O(零和大写字母O)。此功能允许用户从默认值0更改为斜线表单。
示例:设置标签时,用户应用此功能以获得斜线0。
推荐实现: ‘zero’表将衬里形式为零的GID映射到相应的斜线形式(GSUB查找类型1)。
应用程序界面:对于“零”覆盖表中的GID,应用程序将GID传递给“零”表并获取新的GID。
UI建议:最佳地,应用程序将其存储为首选项设置,并且用户可以使用该功能在两种表单之间来回切换。大多数应用程序都希望默认设置禁用此功能。
脚本/语言敏感性:不适用于使用0以外的表单作为零的脚本。
特征交互:仅适用于衬里图形,因此被旧式图形特征(例如“onum”)取消激活。
8.4.基线标签
BASE表中使用基线标记来提供可应用于特定脚本或使用上下文的其他字体度量值。
基线标签可以在BASE表的HorizAxis子表中用于水平布局,也可以在VertAxis子表中用于垂直布局。给定的基线标签对每个布局方向都有特定的含义。例如,’romn’基线标签用于指定水平布局中拉丁文本的水平基线,以及垂直布局中旋转拉丁文本的垂直基线; ‘icfb’基线标签用于指定水平布局中“表意字符面”区域(如下所述)的下边缘,以及垂直布局中的左边缘。
所有标签都是由一组有限的ASCII字符组成的四字符字符串; 有关标记数据类型的详细信息,请参阅数据类型。按照惯例,注册的基线标签使用四个小写字母。
在此部分中,符号<axis>。<baseline tag>用于表示在BASE表中指定的布局方向轴表中使用的给定基线标记。例如,HorizAxis.ideo表示BASE表的HorizAxis子表中使用的’ ideo ‘基线标记。
以下是注册的基线标签:
基线标签 HorizAxis的基准 VertAxis的基线
挂 悬挂基线。这是西藏和其他类似剧本中音节似乎悬挂的水平线。 对于垂直书写模式,藏文(或其他类似文字)字符的垂直基线(现在看起来是垂直的)顺时针旋转90度。
旋流流化床 表意字符面对底边。(有关用法,请参阅下面的表意字符面。) 表意字符面向左边缘。(有关用法,请参阅下面的表意字符面。)
ICFT 表意字符面对上边缘。(有关用法,请参阅下面的表意字符面。) 表意字符面对右边缘。(有关用法,请参阅下面的表意字符面。)
IDEO 表意文字框底边。(有关用法,请参阅下面的表意文字Em-Box。) 表意文字框左边缘。如果此标记存在于VertAxis中,则该值必须设置为0.(有关用法,请参阅下面的表意形式Em-Box。)
IDTP 表意符号em-box上边缘基线。(有关用法,请参阅下面的表意文字Em-Box。) 表意符号em-box右边缘基线。如果此标记存在于VertAxis中,则强烈建议将该值设置为head.unitsPerEm。(有关用法,请参阅下面的表意文字Em-Box。)
数学 关于哪些数学字符居中的基线。 关于垂直书写模式顺时针旋转90度的数学字符的基线是居中的。
romn 拉丁语,西里尔语和希腊语等字母脚本使用的基线。 对于垂直书写模式,字符的字母基线顺时针旋转90度。(这不适用于垂直书写模式中保持直立的字母字符,因为这些字符不会旋转。)
表意Em-Box
某些应用程序使用表意em-box指标来布局CJK文本。字体的表意符号框是矩形,它为水平和垂直书写方向定义围绕字体的全宽表意字形的标准擒纵机构。它通常是正方形,但可以是非正方形,如在日本报纸布局中使用的具有垂直浓缩设计的字体的情况。
表意符号框的左,右,上,下边缘确定如下:
ideoEmboxLeft = 0
如果定义了HorizAxis.ideo:
ideoEmboxBottom = HorizAxis.ideo
如果定义了HorizAxis.idtp:
ideoEmboxTop = HorizAxis.idtp
其他:
ideoEmboxTop = HorizAxis.ideo + head.unitsPerEm
如果定义了VertAxis.idtp:
ideoEmboxRight = VertAxis.idtp
其他:
ideoEmboxRight = head.unitsPerEm
如果定义了VertAxis.ideo且非零:
警告:错误的VertAxis.ideo值
否则如果这是CJK字体:
ideoEmboxBottom = OS / 2.sTypoDescender
ideoEmboxTop = OS / 2.sTypoAscender
ideoEmboxRight = head.unitsPerEm
其他:
无法确定此字体的ideoEmbox
确定字体是否是CJK(中文,日文或韩文),如上面第二个“Else”子句,可以通过检查’meta’表的’dlng’条目(如果存在)来完成,OS / 2.ulUnicodeRange字段的CJK相关位,或OS / 2.ulCodePageRange字段。
请注意,非CJK字体可以指定HorizAxis.ideo基线; 当使用基于表意文字框的对齐时,应用程序可以在将字体与同一行文本上使用的表意字体对齐时使用。
表意符号框中心基线定义为水平轴上表意em-box顶部和底部基线之间的中间位置,以及垂直轴中表意em-box左右基线之间的中间位置。这些中心基线以整个字体设计单位计算。如果需要,计算中使用的除法必须舍入到最接近0的单位。因此,为了获得中心基线放置的最大精度,供应商应确保表意符号框的相对边缘是偶数个设计单元。
例:
Kozuka Mincho字体系列(在1000个单位的em上设计)的表意基线标签的值为:
HorizAxis.ideo = -120; HorizAxis.idtp = 880.
由于这描述了一个方形表意文字框,仅记录以下内容就足够了:
HorizAxis.ideo = -120。
如果HorizAxis.ideo不存在,那么下面将用于表意em-box的底部和顶部,因为这是一个CJK字体:
OS / 2.sTypoDescender = -120; OS / 2.sTypoAscender = 880。
兼容性说明:
大多数应用程序希望CJK字体中全宽度表意文字的宽度恰好是一个em,因此强烈建议将VertAxis.idtp(如果存在)设置为head.unitsPerEm。
虽然OpenType规范允许CJK字体的OS / 2.sTypoDescender和OS / 2.sTypoAscender字段指定与BASE表中的HorizAxis.ideo和HorizAxis.idtp不同的度量,但CJK字体开发人员应该知道某些应用程序可能不会完全阅读BASE表,只需使用OS / 2.sTypoDescender和OS / 2.sTypoAscender字段来描述表意文字框的底部和顶部边缘。如果开发人员希望他们的字体能够与这些应用程序一起正常工作,他们应该确保其CJK字体的BASE表中的任何表意em-box值描述与OS / 2.sTypoDescender和OS / 2.sTypoAscender相同的底部和顶部边缘。领域。
某些传统平台或应用程序可能根本不使用OS / 2字段。因此,CJK字体通常应具有hhea.descender,OS / 2.sTypoDescender和HorizAxis.ideo(如果存在)字段中记录的相同下降值,以及hhea.ascender,OS / 2.sTypoAscender中记录的相同上升值,和HorizAxis.idtp(如果存在)字段。
有关构造CJK字体的更多信息,请参阅“OpenType CJK字体指南”部分。
表意文字人脸
除了表意文字框度量标准之外,一些应用程序还使用表意字符面部度量来布置CJK文档。表意字符面(ICF)指定CJK字体中表意字形的平均或近似边界框。(这与FontBBox不同,如PostScript编程语言中所述,它是叠加字体中所有字形的边界框。)它也可以用于不包含表意文字的字体(例如,假名 - 只有字体)表示与字体中其他现有字形平衡的表意文字的度量标准。
在日语中,ICF的术语是heikin jizura。
ICF指标通常不用作文本基线,但可以这种方式使用它们。相反,ICF指标允许应用程序提供页面元素与文本的改进的视觉对齐。
ICF度量通常在应用程序中表示为表示ICF盒边缘长度与表意em-box边缘长度之比的百分比,并且概念化为在表意em-box中居中的正方形。但是,OpenType允许更精细地指定ICF度量,ICF框的左,下,右和上边缘分别使用VertAxis.icfb,HorizAxis.icfb,VertAxis.icft和HorizAxis.icft值指定。这为字体设计者提供了指定非正方形和/或非居中ICF框的灵活性。
字体设计者应根据他们希望在没有跟踪或字距调整的情况下设置文本时字体出现的紧密程度或宽松程度来设置ICF框边缘的值(日语中的beta gumi)。因此,ICF框周围的表意符号框的左上边界是字体的默认擒纵机构。
应用程序可以使用ICF框作为对齐工具,以确保字形触摸文本框的边缘,并且页面对象在视觉上与文本边对齐。它对于在同一行上对齐不同大小的字形也很有用。在日本传统的纸质工作流程中,ICF盒子经常用于这些目的。它提供的光学对齐结果优于使用表意文字框。
HorizAxis.icfb是CJK字体中定义ICF指标所需的最小信息。首先,必须如上所述计算表意符号em-box尺寸。然后按以下顺序计算ICF边缘:
如果定义了HorizAxis.icfb:
icfBottom = HorizAxis.icfb
margin = HorizAxis.icfb - ideoEmboxBottom
如果定义了HorizAxis.icft:
icfTop = HorizAxis.icft
其他:
icfTop = ideoEmboxTop - 保证金
如果定义了VertAxis.icfb:
icfLeft = VertAxis.icfb
其他:
icfLeft =保证金
如果定义了VertAxis.icft:
icfRight = VertAxis.icft
其他:
icfRight = ideoEmBoxRight - icfLeft
其他:
无法确定此字体的ICF
对于上面的最后一种情况,即BASE表中没有ICF信息的字体,应用程序可以选择应用启发式算法,例如计算部分或全部表意字符和假名字形的边界框,然后对其边距求平均值使用表意符号框。
ICF中心基线定义为水平轴上ICF顶部和底部基线之间的中间位置,以及垂直轴上ICF左侧和右侧基线之间的中间位置。这些中心基线以整个字符单位定义。如果需要,计算中使用的除法必须舍入到最接近0的字符单元。因此,为了最大化中心基线放置的精度,供应商应确保ICF盒的相对边缘是偶数个字符单元。
例:
Kozuka Mincho字体系列的Extra Light和Heavy权重的ICF基线值(设计在1000个单位的em上,在上一节的例子中给出了表意em-box):
Kozuka Mincho Extra Light:
VertAxis.icfb = 41; HorizAxis.icfb = -79;
VertAxis.icft = 959; HorizAxis.icft = 839.
由于这描述了一个以方形表意文字框为中心的方形ICF,仅记录以下内容就足够了:
HorizAxis.icfb = -79。
Kozuka Mincho Heavy:
VertAxis.icfb = 26; HorizAxis.icfb = -94;
VertAxis.icft = 974; HorizAxis.icft = 854.
仅记录就足够了:
HorizAxis.icfb = -94。
强烈建议ICF框的每个边缘与表意文字框的相应边缘等距。在此之后,将在使用这些值的应用程序中产生更可预测的结果。也就是说,对于基于方形表意文字框的字体,ICF框应该是居中的正方形。
有关构造CJK字体的更多信息,请参阅“OpenType CJK字体指南”部分。
9.设计变体轴标记注册表
此注册表定义了用于OpenType字体的设计变化轴标记。通过为注册标签提供明确定义的语义和相关的变量数字标度,这提供了来自不同供应商的不同字体之间或字体与应用程序之间的某种程度的互操作性。
设计变量轴标签在变量字体的’fvar’表中使用,也在STAT表中使用。请注意,它们与非变量字体以及可变字体相关:即使字体可能不是可变字体,它仍然是其字体系列中的设计变体。STAT表允许应用程序理解给定系列中字体设计变体的关系,无论它们是作为非可变字体实现还是作为可变字体的变体实例实现。
设计变化轴标签的语法要求
设计变量轴标签是四个无符号字节(uint8 [4])的数组,可以等效地解释为由四个ASCII字符组成的字符串。轴标签必须以字母(0x41至0x5A,0x61至0x7A)开头,并且必须仅使用字母,数字(0x30至0x39)或空格(0x20)。空格字符只能作为少于四个字母或数字的标记中的尾随字符出现。
字体可以使用此注册表中定义的标记,也可以使用代工厂定义的标记。(代工厂定义的标签也可以称为“自定义”或“私有”标签。)代工厂定义的标签必须以大写字母(0x41至0x5A)开头,并且必须仅使用大写字母或数字。已注册的轴标签不得使用该模式,但可以使用任何其他有效模式。这可确保代工厂定义的标签和注册标签永远不会发生冲突。
已注册轴标签的文档
对于此注册表中定义的每个轴标记,需要或建议某些信息:
标签规范必须包含轴的美国英文名称,该名称可用作应用程序用户界面中的显示字符串以引用轴,或作为本地化显示字符串的基础。
标签规范必须包括轴的预期含义和设计变化行为的描述。
标签规范必须包含有关用于轴的数字刻度的信息。这必须包括对轴有效的值范围的规范。根据轴的性质,这可能是也可能不是有界范围。它还必须提供有关值的语义解释的信息,指定某个客观度量或可以解释值的某些约定。
在适当的时候,标签规范还应该以“常规”字体指示该轴的建议或要求的数值(通过定义比例)。
注意: 字体系列中的“常规”字体通常具有省略轴限定符的子系列名称。例如,一个代工厂可以创建一个适合12点大小的光学尺寸字体,名称中包含“文本”作为预期光学尺寸的指示器,但另一个代工厂可能会创建一个类似的字体而没有任何光学尺寸指示器。名称。建议的“常规”轴值的选择应考虑到这一点。
还可以提供附加信息,例如用于编程选择可能在应用中有用的轴值的建议。
需要对数值的语义解释的规范作为在不同字体之间,字体和软件实现之间以及OpenType字体变体与其他规范(例如CSS中的字体权重值)之间提供某种程度的互操作性的手段。
请注意,假设互操作性在不同程度上获得,具体取决于轴的性质和它使用的比例。例如,权重轴的比例提供有限程度的互操作性。当重量轴值为700(或“粗体”)时,两种不同的字体在应用于同一文本时可能不会产生相同的暗度或“颜色”; 但是在这两种情况下,用户都可以期望这些字体比每个相应字体系列中的“Regular”或“Semibold”字体更暗,并且应用程序开发人员可以产生如果用户将该轴值与特定值相关联则可预测的结果用户界面控件的状态或<strong>标记标记。
与此相反,光学尺寸轴的比例旨在提供更强的互操作性。例如,假设光学尺寸值为20的两种不同字体最适合于设置在20点的文本,因为比例是按照这种方式设计的。如果已使用不同的数字刻度定义此轴,则应用程序可能无法假设具有相同光学尺寸值的两个字体同样适用于给定的上下文。
并非所有轴都同样适合精确或客观的测量。例如,斜体量没有客观的比例。但斜体轴的定义范围为0.0到1.0,表示字体开发人员认为是非斜体设计和全斜体设计,这足以让应用程序将这些数值变化值与off /关联起来在用户界面中以斜体切换的状态,以提供有意义且熟悉的体验。它还为不同字体之间的比较提供了有用的基础,这可能很重要,例如,在字体回退实现中:如果请求的字体面的斜体轴设置为1,但在显示文本时必须使用字体后退字体,应用程序能够在后备字体中选择适当的斜体轴设置。
如果轴旨在与自动选择轴值以提供某些效果的编程机制相互作用,则可能需要更精确的数字刻度定义及其解释。应用程序和平台开发人员必须清楚哪些自变量应作为轴值选择的输入,以及如何从这些输入中导出轴刻度的数值。
对于支持给定轴的可变字体实现,“常规”值通常是“fvar”变异轴记录中该轴的默认值的良好选择。但是,“fvar”表中设置的默认值是特定于实现的,并且不需要字体将此“常规”值用作轴默认值。
已注册的轴标签
以下设计变化轴和标签已经注册; 链接页面提供轴标签描述。这些按标签的字母顺序列出。
轴标签 名称
‘ITAL’ 斜体
‘opsz’ 光学尺寸
‘slnt’ 倾斜
‘WDTH’ 宽度
‘wght’ 重量
如何注册设计变化轴标签
虽然字体开发人员总是可以使用代工厂定义的轴标签,但他们可能会选择,但Microsoft鼓励字体开发人员在实施注册轴适用的设计时使用注册的轴标签。Microsoft欢迎提名新的设计变异轴标签注册。
注册轴标签可用于两个关键目的。一个是培养一种设计变化的传统性和熟悉性。例如,通过定义光学尺寸变化的’opsz’标签,用于根据字体大小定制字形轮廓,不同的供应商可以将这种设计变体合并到字体中,并且可以呈现这些各种字体的变化将字体用户视为同一种变体。使用’opsz’轴实现的字体越多,设计师和内容作者就会越熟悉这种设计变体。当字体使用相同的概念时,如果不同的字体使用相似但不同的概念,它们将受益于更高的体验一致性。
注册轴标签的另一个关键目的是促进不同字体之间或字体与应用程序之间的互操作性。例如,通过为“opsz”轴指定与点中的文本大小相对应的数字刻度,这使应用程序可以实现自动选择光学尺寸变化的机制,该机制可以使用支持变体的任何字体。 ‘opsz’轴。
向注册表添加变异轴标签的优点主要取决于以下两个关键目的:设计变异轴在多个供应商的字体中实现并被发现对设计人员有用的可能性是多少; 应用程序实现利用对轴的可互操作理解的机制的可能性是多少。
要获得注册资格,必须提供轴的完整描述,包括上面列出的每种信息类别。如果轴旨在与以编程方式选择轴值的机制交互,则描述必须包括数字刻度的明确规范。必须合理地指示与上述注册的两个关键目的中的一个或两个对齐,并且合理地指示轴将以来自多个供应商的字体实现并且在软件平台和应用中得到支持。建议提出新注册的一方寻求来自多个字体和软件供应商的意见,并就所提出的轴的定义及其优点达成共识。
9.1.ital
轴定义
标签: ‘ital’
名称:斜体
描述:用于在非斜体和斜体之间变化。
有效数值范围:值必须在0到1的范围内。
比例解释:值0可以解释为“罗马”(非斜体); 值1可以解释为(完全)斜体。
推荐或必需的“常规”值: 0是必需的。
附加信息
Italic轴一直被视为字体系列中的一种设计变体。’ital’轴标签用于斜体字体的STAT表中,以提供与STAT表中其族相关的字体的完整表征。斜体轴可以用作可变字体内的变化轴,但预计这不常见。
斜体轴与斜轴(’slnt’)不同。字体可以使用其中一种,具体取决于设计的性质,但很少使用两者。虽然斜体设计通常在设计中包含一些倾斜,但使用斜体轴不需要使用倾斜轴。斜体字体不应在STAT表中表示为斜体并且还有一些倾斜,除非字体系列包括具有不同倾斜量的多个斜体设计。
9.2.opsz
轴定义
标签: ‘opsz’
名称:光学尺寸
描述:用于改变设计以适应不同的文字大小。
有效数值范围:值必须严格大于零。
比例解释:值可以解释为文本大小(以磅为单位)。
推荐或必需的“常规”值:建议使用9到13范围内的值。
建议的程序化交互:应用程序可以选择根据文本大小自动选择光学大小的变体。
附加信息
光学尺寸轴可用作可变字体内的变化轴。它也可以在具有光学尺寸变体的族中的非变量字体的STAT表中使用,以提供与STAT表中的族相关的字体的完整表征。在非可变字体的STAT表中,建议使用格式2轴值表来表征光学尺寸变体所针对的文本大小范围。
光学尺寸轴的比例是以磅为单位的文本大小。出于这些目的,文本大小由文档或应用程序确定用于其预期用途; 由于文档或应用程序缩放设置或预期的观看距离,显示器上的实际物理尺寸可能不同。
在自动选择光学尺寸变体的应用程序中,通常应基于具有默认或“100%”缩放级别的文本大小来完成,而不是基于文本大小和缩放级别的组合。
9.3.slnt
轴定义
标签: ‘slnt’
姓名: Slant
描述:用于在直立和倾斜文本之间变化。
有效数值范围:值必须大于-90且小于+90。
比例解释:值可以解释为从设计者认为对于该字体设计直立的倾斜倾斜角度(以逆时针方向)。
推荐或必需的“常规”值: 0是必需的。
附加信息
倾斜轴可用作可变字体内的变化轴。它也可以在STAT表中以非变量,倾斜字体使用,以提供与STAT表中其族相关的字体的完整表征。
倾斜轴与斜体轴(’ital’)不同。字体可以使用其中一种,具体取决于设计的性质,但很少使用两者。虽然斜体设计通常在设计中包含一些倾斜,但使用斜体轴不需要使用倾斜轴。斜体字体不应在STAT表中表示为斜体并且还有一些倾斜,除非字体系列包括具有不同倾斜量的多个斜体设计。
请注意,倾斜轴的刻度被解释为从直立起逆时针倾斜的倾斜角度。这意味着典型的右倾斜设计将具有负斜率值。这与’post’表中用于italicAngle字段的比例相匹配。
在实现’slnt’变体的变量字体中,’post’表的italicAngle字段中的值必须与’fvar’表中指定的默认’slnt’值匹配。对于可变字体的非默认实例,“slnt”轴值可用作实例的post.italicAngle值。
9.4.wdth
轴定义
标签: ‘wdth’
名称:宽度
描述:用于改变从较窄到较宽的文本宽度。
有效数值范围:值必须严格大于零。
比例解释:值可以解释为字体设计者认为该字体设计的“正常宽度”的百分比。
推荐或必需“常规”值:需要100。
建议的编程交互:应用程序可以选择自动选择变量字体的宽度变量,以便将文本范围适合目标宽度。
附加信息
宽度轴长期以来与面部名称一起使用,例如“Condensed”或“Extended”。字形宽度的变化通常是设计的主要方面,尽管其他次要细节(例如笔划粗细)也可能包含在此变体中。
宽度轴可用作可变字体内的变化轴。它也可以在具有宽度变体的族中的非变量字体的STAT表中使用,以提供与STAT表中的族相关的字体的完整表征。
宽度轴使用与OS / 2表的usWidthClass字段使用的比例相关但不同的比例。OS / 2表文档中usWeightClass的描述提供了一个从usWidthClass值到“%of normal”值的映射表。因为usWidthClass限制为九个整数值,所以粒度比Width轴小得多。
从’wdth’值映射到usWidthClass时,在映射值之间插入小数值然后舍入,并钳位到1到9的范围。
在实现’wdth’变体的变量字体中,OS / 2表的usWidthClass字段中的值必须对应于’fvar’表中指定的默认’wdth’值。对于可变字体的非默认实例,可以使用’wdth’轴值来派生该实例的OS / 2.usWidthClass值。
正常宽度的百分比是一个比较尺度,取决于所比较的具体项目。文本行的宽度很大程度上取决于文本的内容。这里没有指定特定的参考字符串作为比较的基础; 字体设计师可以选择他们认为是代表性的字符串,为设计变体赋予“wdth”值。理想情况下,’wdth’值应该为目标语言中的大多数字符串提供一个很好的估计,即使用’wdth’变体格式化的字符串宽度与使用“normal”变体格式化时相同字符串的宽度的比较。
当使用可变字体时,应用程序可以选择进行小的自动“wdth”调整,以便将文本范围适合某个目标大小。例如,可以在列中填充标题或改进段落布局。’wdth’值的相对变化(原始’wdth’与调整后的’wdth’的比率)可以用作所需调整的第一近似值。然而,由于宽度的相对变化可能取决于实际的文本内容,因此这可能无法提供获得所需宽度调整所需的精确调整。应用程序可能需要在多次尝试中优化调整。
9.5.wght
轴定义
标签: ‘wght’
名称:重量
描述:用于改变行程厚度或其他设计细节,以提供从较浅到较黑的变化。
有效数值范围:值必须介于1到1000之间。
比例解释:可以通过与OS / 2表中usWeightClass的值或CSS font-weight属性的直接比较来解释值。
推荐或必需的“常规”值:需要400。
附加信息
Weight轴长期以来与面部名称一起使用,例如“Regular”,“Light”或“Bold”。笔划厚度的变化通常是设计变化的主要方面,尽管其他次要细节(例如字形宽度或厚薄对比度)也可包含在此变体中。
权重轴可用作变量字体内的变化轴。它也可以在具有权重变体的族中的非变量字体的STAT表中使用,以提供与STAT表中的族相关的字体的完整表征。
在实现’wght’变体的可变字体中,OS / 2表的usWeightClass字段中的值必须与’fvar’表中指定的默认’wght’值匹配。对于可变字体的非默认实例,’wght’轴值可用作实例的OS / 2.usWeightClass值。
10.勘误表
此页面记录了OpenType规范中具有技术意义并可能导致不正确实现的错误。范围仅限于最初发布的OpenType 1.8.3规范暗示与预期设计相反的技术细节的问题。更正可以包括对与某些表字段相关的不正确值的校正,用于计算某些值的不正确的公式或类似的问题。更正不包括对数据结构的任何更改。如果校正所需的文本更改很小,则将在规范中进行更正,并在此处列出。如果需要更大的文本更改,则可能会在此处描述此问题,但实际更改可能会留给将来的版本。在任何一种情况下,状态将在下表中指出。
某些轻微的编辑错误,例如错误拼写没有技术影响的单词,有时可能会无声地更正,无需通知或版本更新。
日期 页 描述 状态
2018年8月26日 glyf - 字形数据 简单字形描述部分错误地指出简单字形描述适用于numberOfContours“大于零”。(numberOfContours字段的描述正确地指出“大于或等于零”。) 更正了1.8.3(2018-8-26)
2018年8月26日 TrueType指令集 从Microsoft Word移植内容时,不保留在OpenType 1.8.1中所做的更改,并且无意中删除了某些文本。 更正了1.8.3(2018-8-26)
2018年8月26日 TrueType指令集 在GET VARIATIONS的描述中,提供了两个使用IDEF进行GET VARIATIONS操作代码的示例。在OpenType 1.8中,示例错误地使用了NPUSHB而不是NPUSHW。在OpenType 1.8.1中,在一个示例中对此进行了更正,但错过了另一个示例中的错误。 更正了1.8.3(2018-8-26)
2018年8月26日 OpenType规范更改日志 未列出在OpenType 1.5中对ttinst1.doc所做的更改。 更正了1.8.3(2018-8-26)
11.附录
11.1.建议
本章概述了创建OpenType字体的建议。
字节顺序
所有OpenType字体都使用摩托罗拉式字节排序(Big Endian)。
混合大纲格式
Microsoft和Adobe都建议不要在单个字体中混合大纲格式。选择符合功能要求的格式。
文件名
OpenType字体可能具有.OTF,.TTF,.OTC或.TTC扩展名,具体取决于字体中的轮廓类型和所需的向后兼容性。
包含具有TrueType轮廓的单个字体资源的文件应具有.OTF或.TTF扩展名。在.OTF和.TTF之间的选择可能取决于对旧系统或以前版本的字体的向后兼容性的需求。
包含仅具有CFF轮廓数据(无TrueType轮廓)的单个字体资源的文件应具有.OTF扩展名。
字体集合文件(包含多个字体资源的文件)应该具有.OTC或.TTC作为扩展名,无论布局表是否存在于任何字体资源中,并且无论使用何种轮廓数据。.TTC扩展名可用于包含使用CFF大纲数据的字体资源的字体集合文件,以便与不知道.OTC扩展名的旧软件向后兼容。
使用OpenType字体变体机制和关联表的变量字体应遵循上述指南使用扩展名.OTF,.TTF,.OTC或.TTC。如果需要通过文件名提供文件包含可变字体的一些指示,建议的约定是在文件名末尾(扩展名之前)附加“VF”(带有前面的分隔符) - 例如,“Selawik-VF.ttf”。
在所有情况下,软件必须确定字体中存在的轮廓类型,而不是文件扩展名,而是文件内容。
表格对齐和长度
所有表应该对齐,以偏移量开始,偏移量是四个字节的倍数。虽然TrueType光栅化器不需要这样做,但它确实可以防止模糊的校验和计算,并大大加快某些处理器上的表访问速度。
所有表都应以实际长度记录在表目录中。为确保正确计算校验和,建议表以32位边界开始。在表之后(以及在下一个32位边界之前)的任何额外空格应该用零填充。
字形0:.notdef字形
必须将字形0指定为.notdef字形。.notdef字形对于向用户提供在字体中找不到字形的反馈非常重要。这个字形不应该没有轮廓,因为如果缺少字形并且不知道活动字体的限制,用户将只看到看起来像空格的内容。
建议.notdef字形的形状可以是空矩形,内部带有问号的矩形,也可以是带有“X”的矩形。用户可能无法识别创意形状(如漩涡或其他符号),表示字体中缺少字形且未在该位置显示。

基础表
BASE表允许字体中的不同脚本为同一基线标记指定不同的值。例如,当开发人员通过组合使用不同基线系统的多种字体的字形来制作多脚本字体时,可能会出现这种情况。
但是,当与不支持BASE表或支持BASE表的应用程序一起使用时,此字体中不同脚本的字形可能无法相对于彼此正确对齐,但假设特定基线不会因脚本而异。此外,并不总是能够确定字体中每个字形的脚本,一些“弱脚本”字符(如标点符号)可能会在多个脚本中使用,而某些字形(如饰品)可能根本没有脚本。
因此,强烈建议开发人员构造他们的字体,以便BASE表中的所有脚本记录特定基线的相同值,如果他们希望他们的字体在上述情况下按预期工作。
如果基线因脚本而异,强烈建议供应商将DFLT脚本条目添加到BASE表,如果客户端请求的脚本不匹配,或者客户端没有或无法确定脚本,则可以使用该表。
‘cmap’表
Windows’cmap’表
为Windows构建字体时,应包含平台ID 3的“cmap”子表。构建Unicode字体时,应为此子表使用编码ID 1。(此子表必须使用格式4.)为Windows构建符号字体时,应为此子表使用编码ID 0。
在构建支持Unicode增补字符(U + 10000到U + 10FFFF)的字体时,包括平台ID 3的’cmap’子表,编码ID 10.(此子表必须使用格式12.)以提供与旧软件的兼容性,还应包括编码ID 1的平台3的子表。根据应用程序支持和显示的文本内容,可以使用3/1/4或3/10/12子表。因此,U + 0000到U + FFFF范围内字符的字形映射在3/1/4和3/10/12子表之间必须相同。另请注意,3/10/12子表中映射的字符必须是3/1/4子表中映射的字符的超集。
请记住,编码记录必须按平台ID按排序顺序存储,然后按编码ID存储。
Macintosh’cmap’表
当构建包含将在Macintosh上使用的罗马字符的字体时,需要额外的子表,指定平台ID为1且编码ID为0(此子表可以使用’cmap’格式0,2,4或6)。
为了使Macintosh’cmap’表有用,Macintosh所需的字形必须具有小于256的字形索引(因为’cmap’子表格式0使用uint8索引,因此不能索引255以上的任何字形)。
Apple’cmap’子表格应根据Apple指南构建。
‘cvt’表
只有在字体说明需要时才应定义。
‘fpgm’表
只有在TrueType字体指令要求时才应定义。
‘glyf’表
‘glyf’表包含TrueType轮廓数据,可以通过Agfa MicroType Compression进行优化。建议开发人员在最终确定并向字体添加数字签名之前执行此优化。这对于创建者的签名在嵌入的OpenType字体中保持有效是必要的。
‘hdmx’表
此表改进了具有TrueType轮廓的OpenType字体的性能。除非使用指令来控制“幻像点”,否则根本不需要该表,如果’head’表中flags字段的第2位和第4位为零,则应省略该表。(请参阅第2章中的’head’表文档。)Microsoft建议将此表包含在具有一个或多个非线性缩放字形的字体中(即,设置’head’表标志字段的第2或4位)。
设备记录应定义为8到14点的所有尺寸,甚至是16到24点的点尺寸。但是,该表需要逐个像素的大小,这取决于输出设备的水平分辨率。’hdmx’中的记录应涵盖96 dpi设备(CGA,EGA,VGA)和300 dpi设备(激光和喷墨打印机)。
因此,’hdmx’应包含以下像素大小(PPEM)的条目:11,12,13,15,16,17,19,21,24,27,29,32,33,37,42,46,50 ,54,58,67,75,83,92,100。这些值已四舍五入到最近的像素。例如,300 dpi的12点将测量37.5像素,但这个列表的舍入值为37。
这将为字体文件添加大约9,600个字节。但是,当客户端请求这些设备记录覆盖的提前宽度时,速度将有显着提高。
如果字体包含LTSH表,则不需要高于线性阈值的’hdmx’值。
‘头’表
尽管fontRevision值的历史用法是变化的,但建议使用该字段将其设置为Fixed 16.16值,并将其舍入并零填充到三个小数位。示例:十进制1.5设置为0x00018000并报告为“1.500”; 十进制1.001设置为0x00010041并报告为“1.001”。所需的所有数据。如果字体已使用Agfa MicroType压缩进行压缩,则必须在“head”表的flags字段中指明。
‘hhea’表
所需的所有数据。建议等宽字体将numberOfHMetrics设置为3(参见’hmtx’)。
‘hmtx’表
所需的所有数据。建议等宽字体在numberOfHMetrics字段中有三个条目。包含CFF数据的OpenType字体必须将numberOfHMetrics设置为等于字体中的字形数,因此不能使用’hmtx’表中通常可用的“重复最后宽度”优化。
‘kern’表
应包含单个字距调整对子表(格式0)。Windows不支持格式2(类的二维kern值数组); 也不使用多个表(仅使用找到的第一个格式0表),也不使用覆盖位0到4(即假定水平数据,字距调整值,无交叉流和覆盖)。
OpenType规范允许带有CFF轮廓的字体在’kern’表中表达它们的字距。许多OpenType文本布局引擎都支持这一点。但是,Windows GDI的OpenType CFF驱动程序在准备字距调整对以通过其对字距调整API进行报告时,会忽略CFF OT字体中的“kern”表。
当’kern’表和GPOS表都存在于字体中时,请求OpenType布局引擎将字距应用于特定脚本和语言系统的文本运行:(a)如果’kern’特征的数量GPOS表中已解析语言系统中的查找为零,然后应应用“kern”表,然后应用所请求的任何剩余GPOS功能。(b)如果GPOS表中已解析语言系统中的“kern”特征查找次数不为零,那么所有GPOS查找(包括“kern”查找)都应以通常的方式应用,并且“kern”应用表数据被忽略了。
如果存在“kern”表但字体中不存在GPOS表,则OpenType布局引擎应将“kern”表应用于文本,而不管文本的已解析语言系统如何。
如果不考虑与旧环境的兼容性,则鼓励字体供应商在GPOS表的“kern”功能中记录字距,而不是在“kern”表中。
OpenType字体变体机制不包括任何表示’kern’表中数据变化的方法。因此,应使用GPOS表实现变量中的字距调整。
‘loca’表
具有TrueType轮廓的字体所需的所有数据。我们建议本地偏移量应该是16位对齐的,包括该表的短格式和长格式。
字体中字形的实际排序可以根据预期的利用率进行优化,最常用的字形出现在字体文件的开头。此外,经常一起使用的字形应该在文件中组合在一起。这将有助于最小化字体加载到内存时所需的交换量。
LTSH表
此表改进了具有TrueType轮廓的OpenType字体的性能。如果设置了’head’中的第2或第4位标志,则应使用该表。
‘maxp’表
具有TrueType轮廓的字体所需的所有数据。具有CFF或CFF2数据的字体必须仅填充numGlyphs字段。
‘名字’表
“名称”表中的平台和编码ID应与“cmap”表中的一致。如果不是,则不会在Windows中加载字体。为Windows构建Unicode字体时,平台ID应为3,编码ID应为1.为Windows构建符号字体时,平台ID应为3,编码ID应为0,并且引用的字符串数据必须为以UTF-16编码。
构建包含将在Macintosh上使用的罗马字符的字体时,需要一个额外的名称记录,指定平台ID为1,编码ID为0。
每组名称记录应显示为美国英语(Microsoft记录的语言ID = 0x0409,Macintosh记录的语言ID = 0); 可以由字体供应商自行添加Microsoft记录集(平台ID 3)的其他语言字符串。
请记住,尽管引用了“first”和“second”,但名称记录必须按排序顺序存储(按平台ID,编码ID,语言ID,名称ID)。’name’表平台/编码ID必须与’cmap’表平台/编码ID匹配,这就是Windows知道要使用哪个名称集的方式。
名称字符串
我们建议使用名称ID 8-12来标识制造商,设计者,描述符,供应商的URL以及设计者的URL。URL必须包含站点的协议,例如http //或mailto:或ftp://。OpenType字体属性扩展可以向用户枚举此信息。
‘name’表中的Subfamily字符串应该用于重量(超轻到超黑)和样式(倾斜/斜体或不是)的变体。因此,例如,“Helvetica Narrow Italic”的完整字体名称应定义为姓氏“Helvetica Narrow”和Subfamily“Italic”。这样,Windows可以以合理的方式对字体的标准四个权重进行分组,以用于仅支持“粗体”和“斜体”组合的非排版感知应用程序。
全字体名称字符串通常包含字符串1和2的串联。如果字符串是字符串2中指示的“常规”,则有时只有字符串1中包含的系列名称用于完整字体名称。在许多情况下,完整的字体名称将向用户公开。
在可变字体中,需要印刷系列和印刷子系列名称(名称ID 16和17)。支持OpenType字体变体的应用程序通常会向用户显示“排版系列名称”以及“排版子系列”名称或命名实例的备用子系列名称,如字体变体(’fvar’)中所指定表。在某些情况下,字体供应商可能希望提供可变字体以及与变量字体的命名实例相对应的一些非可变字体集。在这种情况下,供应商可能希望为作为可变字体实现的系列具有不同的系列名称,并且使用多个非可变字体实现该系列。在这种情况下,建议的约定是在变量字体系列名称的末尾附加“VF”。但请注意,这将导致不同的系列,并且如果只有另一个可用,则使用该系列格式化的内容可能无法在某些上下文中按预期显示。例如,
包含名称ID为6的名称的OpenType字体应包含名称为ID 6的这两个名称,其特征如下:
平台:1 [Macintosh]; 特定于平台的编码:0 [罗马]; 语言:0 [英文]。
平台:3 [Windows]; 特定于平台的编码:1 [Unicode]; 语言:0x409 [英语(美国)]。
如果存在,名称ID为6的名称(如果存在)可以忽略。
当转换为ASCII时,这两个名称字符串必须相同并且限制为可打印的ASCII子集,代码33到126,除了10个字符:’[‘,’]’,’(’,’)’,’{‘ ,’}’,’<’,’>’,’/‘,’%’。某些实现具有63个字符的长度限制; 但是,建议使用127个字符的长度限制。
这里的术语“PostScript名称”表示与上述两个相同的名称ID 6字符串相同的字符串。
根据PostScript语言字体使用的特定字体格式,PostScript字体的调用方法不同,并且生成的PostScript语言字体的语义不同。用于调用此字体的方法取决于Name ID 20的存在。
如果此字体中存在名称ID 20,则默认假设应该是名称ID 6定义的PostScript名称应与PostScript的“composefont”调用一起使用。此PostScript名称是PostScript语言CIDFont资源的名称,该资源对应于OpenType字体的字形。此名称可以通过适当的PostScript语言CMap引用和实例名称传递给PostScript语言“composefont”运算符。
如果此字体中不存在名称ID 20,则默认假设应该是由名称ID 6定义的PostScript名称应与PostScript的“findfont”调用一起使用,以便在PostScript解释器的上下文中定位字体。此PostScript名称是PostScript语言字体资源的名称,它对应于OpenType字体的字形。此名称有效传递给PostScript语言’findfont’运算符。这并不一定意味着生成的字体字典接受/ Encoding数组,例如当引用的字体是Type 0 PostScript字体时。
此规范仅适用于数据分叉OpenType字体。Macintosh资源分叉TrueType和其他Macintosh sfnt包装字体提供PostScript字体名称以与’findfont’调用一起使用,以便在FOND资源样式映射表中调用PostScript解释器中的字体。
开发人员可以选择在适当时忽略默认用法。例如,版本早于2015的PostScript打印机无法处理CID字体资源,而CJK OpenType / CFF-CID字体只能作为一组Type 1 PostScript字体下载。传统的CJK TrueType字体(没有名称ID 20)仍然可以作为CID字体资源最有效地下载。不应遵循默认值的全套情况的定义超出了本文档的范围。
名称ID 20字符串中保存的值被解释为PostScript字体名称,该名称旨在与“findfont”调用一起使用,以便在PostScript解释器中调用字体。
如果名称ID 20存在于字体中,则该字体中每个Macintosh平台的“cmap”子表必须有一个名称ID 20记录。特定名称ID 20记录与匹配的“cmap”子表指定的编码相关联。当名称ID 20记录具有相同的平台和平台特定的编码ID以及相应的语言/版本ID时,它与“cmap”子表匹配。名称ID 20条记录仅用于Macintosh的“cmap”子表。’cmap’子表的版本字段比对应的名称ID 20记录的语言ID值多一个,但’cmap’子表版本字段0除外。此版本字段,意思是“不是特定于语言的”,对应于语言ID值0xFFFF或十进制65535,
当转换为ASCII时,此名称字符串必须限制为可打印的ASCII子集,代码33到126,除了10个字符:’[‘,’]’,’(’,’)’,’{‘,’} ‘,’<’,’>’,’/‘,’%’。
此规范仅适用于数据分叉OpenType字体。Macintosh资源分叉TrueType和其他Macintosh sfnt包装字体提供PostScript字体名称以与’findfont’调用一起使用,以便在FOND资源样式映射表中调用PostScript解释器中的字体。
特定的Name ID 20字符串始终对应于特定的Macintosh’cmap’子表。但是,某些主机OpenType / TTF字体还包含一个’post’表格,格式4,它提供从字形ID到编码值的映射,并且还对应于特定的Macintosh’cmap’子表。不幸的是,’post’表格式4不包含用于识别它匹配的Macintosh’cmap’子表的规定,也不包含提供多个映射的规定。包含’post’表格式4的主机字体也应该只包含一个Macintosh’cmap’子表和一个Name ID 20字符串。如果有多个Macintosh’cmap’子表和多个Name ID 20字符串,则没有定义哪一个匹配’post’表格式4。
OS / 2表
所需的所有数据。
PANOSE值
PANOSE值可以改善用户在某些应用程序或字体管理实用程序中进行字体选择的体验。
如果字体是符号字体,则PANOSE值的第一个字节必须设置为“Latin Pictorial”(值= 5)。PANOSE评估文档在https://monotype.github.io/panose/上联机。
在使用OpenType字体变体机制的可变字体中,无法为字体支持的不同实例表示不同的PANOSE值。可以基于默认实例设置PANOSE值。
sTypoAscender,sTypoDescender和sTypoLineGap
sTypoAscender,sTypoDescender和sTypoLineGap字段用于指定单行间隔水平文本的建议默认行间距。基线到基线的距离计算如下:
OS / 2.sTypoAscender - OS / 2.sTypoDescender + OS / 2.sTypoLineGap
应使用sTypoAscender确定从文本框顶部到第一个基线的最佳默认偏移量。同样,应该使用sTypoDescender来确定从最后一个基线到文本框架底部的偏移量。
设置sTypoAscender和sTypoDescender值通常是合适的,使得距离(sTypoAscender - sTypoDescender)等于一个em。然而,这不是必需的,并且在某些情况下可能不适合。例如,如果字体是为脚本设计的(在水平布局中)需要相对于拉丁文脚本更大的垂直范围,但也需要支持拉丁文脚本,并且需要在设置时使拉丁字形的视觉大小与其他字体类似在相同的文本大小,那么该字体的(sTypoAscender - sTypoDescender)距离可能需要大于一个em。
通常设置sTypoLineGap值,使得默认的基线到基线距离约为em的120%。例如,在Minion Pro字体系列中,字体设计在每单位1000个网格上,(sTypoAscender - sTypoDescender)距离为1 em,sTypoLineGap值设置为200。
在CJK(中文,日文和韩文)字体中,允许sTypoDescender和sTypoAscender字段指定与BASE表中的HorizAxis.ideo和HorizAxis.idtp基线不同的度量。但是,某些应用程序可能根本不读取BASE表,而只是使用sTypoDescender和sTypoAscender字段来描述表意符号框的底部和顶部边缘。如果开发人员希望他们的字体能够与这些应用程序一起正常工作,他们应该确保BASE表中的任何表意符号em-box值都描述与sTypoDescender和sTypoAscender字段相同的底部和顶部边缘。有关详细信息,请参阅OpenType CJK字体指南和表意Em-Box。
usLowerOpticalPointSize和usUpperOpticalPointSize
在使用usLowerOpticalPointSize和usUpperOpticalPointSize领域已被STAT表取代。有关详细信息,请参阅下面的具有光学尺寸变体的系列。
‘post’表
尽管VM Usage字段可以设置为零,但所需的所有信息都是必需的。包含CFF轮廓的OpenType字体仅使用’post’表的格式3.0。必须按照Adobe字形列表规范中的描述分配字形名称,该规范指定所有Unicode字符的字形命名约定以及不具有标准Unicode值的字符命名约定,例如某些连字或字形变体。
请注意,必须提供所有字形的名称,因为不能假定所有Microsoft平台都支持Macintosh上提供的默认名称。
注意:PostScript字形名称不得超过31个字符,仅包括大写或小写英文字母,欧洲数字,句点或下划线,即来自集合[A-Za-z0-9_。]并且应以a开头字母,除了以句点开头的特殊字形名称“.notdef”。
‘准备’表
只有在TrueType字体指令要求时才应定义。
VDMX表
此表改进了具有TrueType轮廓的OpenType字体的性能。如果提示导致字体非线性缩放,则应该存在。如果不存在,则假定字体线性缩放。如果此表中的值不存在且字体超过线性高度,则可能发生剪切。
一般建议
TrueType集合
构建TTC文件的过程包括密切关注字体中的字形重新编号问题以及可能导致的“cmap”表和其他地方的副作用。要合并的字体还必须具有兼容的TrueType指令 - 即它们的预编程,函数定义和控制值不得冲突。
优化表排序
当按以下方式排序表时,具有TrueType轮廓的OpenType字体在Windows操作系统中更有效(从头到尾):
‘head’,’hhea’,’maxp’,OS / 2,’hmtx’,LTSH,VDMX,’hdmx’,’cmap’,’fpgm’,’prep’,’cvt’,’loca’,’glyf ‘,’kern’,’name’,’post’,’gasp’,PCLT,DSIG
如果在sfnt的主体(从头到尾列出)中使用以下sfnt表排序,则将更有效地处理包含CFF数据的OpenType字体的初始加载:
‘head’,’hhea’,’maxp’,OS / 2,’name’,’cmap’,’post’,’CFF’,(其他表格,方便)
非标准(符号)字体
Symbol或Wingdings(tm)等非标准字体对Microsoft平台有特殊要求。这些要求会影响’cmap’,’name’和OS / 2表; 所有其他表的要求和建议保持不变。
对于Macintosh,非标准字体可以继续使用平台ID 1(Macintosh)和编码ID 0(罗马字符集)。’cmap’子表应使用格式0并遵循标准的PostScript字符编码。
但是,对于Microsoft平台上的非标准字体,“cmap”和“name”表必须使用平台ID 3(Microsoft)和编码ID 0(Unicode,非标准字符集)。请记住,’name’表格编码应与’cmap’表一致。此外,OS / 2表中PANOSE值的第一个字节必须设置为“Latin Pictorial”(值= 5)。
‘cmap’子表(平台3,编码为0)必须使用格式4.字符代码应从0xF000开始,该字节位于Unicode的专用区。建议通过简单地将0xF000添加到格式0(Macintosh)编码来导出格式4编码。
在Windows下,只能访问非标准字体的前224个字符:空格和最多223个打印字符。这些用户空间在哪里开始并不重要,但建议使用0xF020。OS / 2表中的usFirstCharIndex和usLastCharIndex值将根据使用的实际最小和最大字符索引进行设置。
基线到基线距离
OS / 2表字段sTypoAscender,sTypoDescender和sTypoLineGap免费应用程序来自Macintosh或Windows特定的指标,这些指标受向后兼容性要求的约束。以下讨论仅适用于特定于平台的指标。
对于Windows和Macintosh,建议的基线到基线距离(BTBD)的计算方式不同,它基于不同的OpenType指标。但是,如果遵循以下建议,则Windows和Mac的BTBD将相同。
视窗
下表中的Windows度量标准由GDI CreateLogFont()API作为逻辑字体数据结构的一部分返回。
Windows指标 OpenType指标
上升 usWinAscent
降落 usWinDescent
内部领先 usWinAscent + usWinDescent - unitsPerEm
外部领导 MAX(0,LineGap - ((usWinAscent + usWinDescent) - (Ascender - Descender)))
建议的BTBD = 上升 + 下降 + 外部领先
应该清楚的是,“外部领导”永远不会小于零。高于或低于下降的像素将从角色中剪切掉; 这适用于所有输出设备。
usWinAscent和usWinDescent是OS / 2表中的值。unitsPerEm值来自’head’表。LineGap,Ascender和Descender值来自’hhea’表。
苹果
Ascender和Descender是Apple定义的度量标准,不要与Windows上升或下降混淆,也不应与AFM文件中的真正排版上升和下降混淆。下面的Macintosh指标由Apple Advanced Typography(AAT)GetFontInfo()API返回。
Macintosh Metric OpenType指标
伸 ASCENDER
伸 伸
领导 LineGap
建议的BTBD = 上升 + 下降 + 领先
如果像素在上升或下降之上延伸,则角色将在垂直方向上被压扁,以使所有像素都符合这些限制; 这仅适用于屏幕显示。
使他们匹配
如果你执行一些简单的代数,你会看到,当且仅当以下情况时,Macintosh和Windows上建议的BTBD将是相同的:
复制
LineGap >= (yMax - yMin) - (Ascender - Descender)
风格比特
为了向后兼容以前版本的Windows,“head”表中的macStyle位将用于确定字体是否是常规,粗体或斜体(在没有OS / 2表的情况下)。这完全独立于OS / 2表中的usWeightClass和PANOSE信息,“post”表中的ItalicAngle以及所有其他相关指标。如果存在OS / 2表,则使用fsSelection位来确定该信息。
辍学控制
如果位图与开启和关闭丢失控制存在差异,则需要进行丢失控制。需要丢失控制的两种情况是旋转字体或字体大小等于或小于8 ppem时。除非需要,否则不要使用SCANCTRL。对于罗马字体,当字体未旋转时,每个em(ppem)超过8个点,应避免使用SCANCTRL或掉线控制光栅化器。SCANCTRL不应用于“拉伸”字体(例如,以非方形宽高比显示的字体,如在EGA上找到的字体)。
嵌入式位图
三个表用于在OpenType字体中嵌入位图。它们是嵌入式位图定位器的EBLC表,嵌入式位图数据的EBDT表,以及嵌入式位图缩放信息的EBSC表。OpenType嵌入式位图也称为“sbits”。
OpenType字体中的sbits行为对客户端基本上是透明的。客户端无需知道光栅化器返回的位图是来自sbit还是来自扫描转换的轮廓。
“sbit”表中的度量标准覆盖了定义sbits的所有大小的大纲度量。带有’hdmx’表的字体应该用’sbit’值来纠正那些表。
允许使用“仅Sbit”字体,即具有嵌入式位图但没有轮廓数据的字体。必须注意确保除“glyf”和“loca”之外的所有必需的OpenType表都以这种字体存在。显然,这样的字体只能返回定义sbits的字形和大小。
这些度量标准由GDI CreateLogFont()API作为逻辑字体数据结构的一部分返回。
这些指标由Apple Advanced Typography(AAT)GetFontInfo()API返回。
OpenType CJK字体指南
本节提供了指向OpenType规范的各种CJK相关部分的链接清单。有些项目是要求; 其他人,建议:
将按照OpenType布局标记注册表的“基线标记”部分中的“ 表意形式Em-Box ”一节中的说明确定OpenType字体的表意框。另请参阅上面的OS / 2.sTypoAscender和OS / 2.sTypoDescender以及BASE表建议部分的说明。
CJK字体供应商可以选择提供表意字符面(ICF)指标,应用程序可以使用这些指标进行准确的文本对齐。这在OpenType布局标记注册表的“基线标记”部分的“ 表意字符面 ”一节中进行了描述。
用于垂直书写的所有OpenType字体必须包括Vertical Header(’vhea’)表和Vertical Metrics(’vmtx’)表。强烈建议用于垂直书写的CFF OpenType字体包括垂直原点(VORG)表。
如果将具有CFF轮廓的OpenType字体用于垂直布局,则某些传统平台可能要求在字形替换(GSUB)表中存在垂直旋转(’vrt2’)特征。有关此功能的说明和进一步要求,请参阅OpenType布局标记注册表的“功能标记”部分。
有关当前注册的OpenType布局功能的说明,请参阅OpenType布局标记注册表的功能标记部分,例如可以在字体中指定的备用半宽(’暂停’)和传统表单(’trad’)。
可变字体中的笔画减少
当设计字体系列以支持许多变化时,可能存在这样的情况:对于某些变化,期望对特定字形进行显着的结构改变。一个常见的例子是重量较重或宽度较窄的笔划减少,简化了字形的结构,使得计数器不会填充并在较小的文本大小时消失。在可变字体内,可以使用两种技术来实现笔画减少效果:
在变体数据中使用一对略微重叠的中间区域作为字形,以便为特定轮廓点引入增量,从而产生所需的结构变化,并且仅适用于一个或多个轴上的问题范围。
使用OpenType Layout Required Variation Alternates功能与GSUB表中的FeatureVariations表结合使用,以便在沿一个或多个轴的某个范围内选择变体实例时执行字形替换。
虽然这两种技术都是可能的,但应该注意的是,使用重叠的中间区域的第一种技术可能很难实现,并且如果使用转换范围内的任意轴值选择实例,则可能导致意外或不期望的结果。发生。建议使用第二种技术,因为它通常更容易实现和维护,并使字体设计者能够更好地控制转换点附近的行为。
有光学尺寸变体的家庭
在具有不同光学尺寸的字体或支持光学尺寸(’opsz’)设计轴的可变字体的系列中,应使用格式为2轴值表的STAT表来指示不同光学尺寸的文本尺寸范围建议使用变体或变量字体命名实例。这取代了OS / 2表中usLowerOpticalPointSize和usUpperOpticalPointSize字段以及OpenType布局“大小”功能的使用。
创建轴值表以对应于用于最大文本大小的字体或命名实例时,上限文本大小应有效地为无穷大。要在格式2轴值表中表示,请将rangeMaxValue设置为0x7FFFFFFF。
11.2.TrueType基础知识
OpenType字体是TrueType字体文件格式的扩展。
本章介绍了创建和指示TrueType字体所需的基本概念,或包含TrueType大纲数据的OpenType字体。首先概述了从纸张设计到创建可以发送到输出设备的位图所涉及的步骤,然后仔细查看流程中的每个步骤。
从设计到字体文件
TrueType字体可以源自在纸上绘制或在计算机屏幕上创建的新设计。也可以通过转换其他格式的字体来获取TrueType字体。无论如何,都需要创建一个TrueType字体文件,除其他外,它将字体中的每个字形描述为TrueType格式的轮廓。

从字体文件到纸张
本节介绍允许TrueType字体文件中的字形显示在栅格设备上的过程。
首先,存储在字体文件中的轮廓被标记为所请求的大小。缩放后,构成轮廓的点不再记录在用于描述原始轮廓的FUnits中,而是成为设备特定的像素坐标。
接下来,解释器执行与该字形相关联的指令。执行指令的结果是所请求的字形的网格拟合轮廓。然后扫描转换该轮廓以产生可以在目标设备上呈现的位图。
使用TrueType字体文件中的FUnit坐标数字化轮廓
缩放器将FUnits转换为像素坐标,并按应用程序请求缩放大小
概述“大小”到新网格
带像素坐标的缩放轮廓
解释器执行与字形“B”和gridfits相关的指令
网格轮廓
网格装配轮廓
扫描转换器决定打开哪些像素
位图在栅格设备上呈现
数字化设计
本节介绍用于确定定义字形轮廓的点的位置的坐标系。它还记录了相对于坐标轴的字形位置。
纲要
在TrueType字体中,字形形状由其轮廓描述。字形轮廓由一系列轮廓组成。简单的字形可能只有一个轮廓。更复杂的字形可以具有两个或更多个轮廓。可以通过组合两个或更多个更简单的字形来构造复合字形。某些没有可见表现形式的控制字符将映射到没有轮廓的字形。

轮廓由直线和曲线组成。曲线由描述二阶贝塞尔样条的一系列点定义。TrueType Bezierspline格式使用两种类型的点来定义曲线,曲线上的曲线和曲线外的曲线。定义曲线时,可以接受曲线点和曲线点的任意组合。直线由两个连续的曲线点定义。

构成曲线的点必须按连续顺序编号。在确定构成字形的形状的填充图案时,顺序是增加还是减少是有区别的。曲线的方向必须是这样的,如果在增加点数的方向上遵循曲线,则黑色空间(填充区域)将始终在右侧。
FUnits和em square
在TrueType字体文件中,点位置以字体单位或FUnits描述。FUnit是em square中最小的可测量单位,是用于调整和对齐字形的虚构。em方块的尺寸通常是字体的全身高度加上一些额外的间距,以防止文本行在没有额外前导的情况下排版时发生碰撞。

虽然在金属类型的时代,字形无法延伸到em方形之外,但数字字体并没有受到如此限制。em方块可以做得足够大,以完全包含所有字形,包括重音字形。或者,如果证明方便,则部分字形可以延伸到em方块之外。TrueType字体可以处理任何一种方法,因此可以选择字体制造商。图1-3一个延伸到em方块外的字符

em方形定义了一个二维坐标网格,其x轴描述了水平方向的运动,其y轴描述了垂直方向的运动。这将在下一节中更详细地讨论。
FUnits和网格
数字化字体的关键决定是确定构成字形轮廓的点的分辨率。这些点表示网格中的位置,其最小可寻址单位称为FUnit或字体单位。网格是二维坐标系,其x轴描述水平方向上的移动,其y轴描述垂直方向上的移动。网格原点具有坐标(0,0)。网格不是无限平面。每个点必须在-16384和+16383 FUnits范围内。根据所选的分辨率,可寻址网格位置的范围将更小。
坐标网格的粒度选择 - 即每个单位的单位数(upem) - 由字体制造商制作。如果将每个em的单位选择为2的幂,例如2048,则大纲缩放将是最快的。

em square的起源不需要与字形轮廓有任何一致的关系。然而,在实践中,应用程序依赖于给定字体的字形放置的某些约定的存在。对于旨在水平布局的罗马字体,通常假定y坐标值0对应于字体的基线。没有赋予x坐标为0的特定含义,但制造商可以通过为x原点选择标准含义来改善应用程序的性能。
例如,您可以放置一个字形,使其美学中心的x坐标值为0.也就是说,放置在列中时设计的一组字形使得它们的x坐标值为0是一致的很好地居中。此选项将用于汉字或任何垂直排版的字体。另一种方法是放置每个字形,使其最左边的极端轮廓点的x值等于字形的左侧轴承。以这种方式创建的字体可能允许某些应用程序更快地打印到PostScript打印机。
,左侧轴承是x -zero。在第二个(右),角色的美学中心是x -zero")
非罗马字体可能希望使用其他约定来表示x原点和y原点的含义。为了获得具有高光照和光照的最佳效果,角色的主体应该在前进宽度内大致居中。例如,对称字符将具有相等的左侧和右侧轴承。
em square的粒度由每个em的FUnits数量决定,或者更简单地由每个em的单位决定。分为FUnits的em square定义了一个坐标系,其中一个单位等于FUnit。此坐标系中定义的所有点必须具有整数位置。每个em的单元数越多,在em广场内寻址位置的可用精度就越高。
,每个em 16个单元(右)")
FUnits是相对单位,因为它们的大小随着em方块的大小而变化。无论点大小如何,每个em的单位数对于给定的字体保持不变。然而,每个em的点数将随着字形的点大小而变化。当字形显示在9点时,正方形正好是9点高,当字体以10点显示时正好是10点,依此类推。由于每个em的单位数不随着显示字体的点大小而变化,因此FUnit的绝对大小随点大小的变化而变化。

由于FUnits相对于em方形,因此无论字体呈现的点大小如何,字形上的给定位置都将在FUnits中具有相同的坐标位置。这很方便,因为它可以在仅考虑原始轮廓的情况下指示轮廓点,并将更改应用于最终呈现的任何大小和分辨率的字形。
缩放字形
本节介绍如何将字形轮廓从存储在字体文件中的主大小缩放到应用程序请求的大小。
设备空间
无论用于定义字形轮廓的em方块的分辨率如何,在可以显示该字形之前,必须缩放它以反映其显示的输出设备的大小,变换和特征。缩放的轮廓必须以反映绝对而非相对测量系统的单位描述字符轮廓。在这种情况下,构成字形轮廓的点以像素的形式描述。
直观地,像素是将出现在屏幕或打印机上的实际输出位。为了在管理轮廓时提供更高的精度,TrueType将像素坐标描述为最接近的像素的六十四分之一。
将FUnits转换为像素
通过将它们乘以比例,将em方形中的值转换为像素坐标系中的值。这个规模是:
pointSize 分辨率/(每英寸72点 units_per_em)
其中pointSize是字形显示的大小,分辨率是输出设备的分辨率。分母中的72表示每英寸的点数。
例如,假设在18点的72 dpi屏幕上,字形特征的长度为550个FUnits。每个人有2048个单位。以下计算显示该特征长度为4.83像素。
550 * 18 * 72 /(72 * 2048)= 4.83
显示设备特征
任何特定显示设备的分辨率由显示的点数或每英寸像素数(dpi)指定。例如,Windows下的VGA被视为96 dpi设备,大多数激光打印机的分辨率为300 dpi。某些设备(如EGA)在水平和垂直方向上具有不同的分辨率(即非方形像素); 在EGA的情况下,该分辨率为96×72。在这种情况下,每英寸的水平点必须与每英寸的垂直点区分开。
每个em的像素数取决于输出设备的分辨率。在72 dpi设备上,18点角色每个星期有18个像素。将分辨率更改为300 dpi,每个em有75个像素,或者更改为1200 dpi,每个em有300个像素。

在特定点大小的特定设备上显示类型会产生以每em(ppem)像素为单位测量的有效分辨率。计算每个像素的公式是:
ppem = pointSize * dpi / 72
=(每英寸像素数)(每个点的英寸数)(每个点的异食癖点数)
= dpi * 1/72 * pointSize
在300 dpi激光打印机上,12点字形将具有12 * 300/72或50 ppem。在2400 dpi的排字机上,它将具有12 * 2400/72或400 ppem。在VGA上,12点字形将具有12 * 96/72或16 ppem。类似地,72 dpi设备上12点字符的ppem将是12 * 72/72或12.这最后的计算指出了一个有用的经验法则:在任何72 dpi设备上,每个em的点和像素是相等的。但请注意,在传统印刷术中,英寸包含72.2752个点(而不是72个); 也就是说,一个点等于.013836英寸。
如果你知道ppem,在FUnits和像素空间坐标之间转换的公式是:
pixel_coordinate = em_coordinate * ppem / upem
em_coordinate位置(1024,0)将产生device_pixels坐标为(6,0),给定每em 2048个单位和每em 12个像素。
网格拟合字形轮廓
指示字形的基本任务是识别原始设计的关键特征并使用指令确保在不同设备上以不同大小呈现字形时保留这些特征。一致的干重,一致的颜色,均匀的间距以及消除像素丢失是常见的目标。
为了实现这些目标,有必要确保在对字形进行栅格化时打开正确的像素。正是打开的像素创建了字形的位图图像。由于字形轮廓的形状决定哪些像素将构成给定大小的该字符的位图图像,因此有时需要改变或扭曲原始轮廓描述以产生高质量图像。轮廓的这种扭曲称为网格拟合。
下图说明了角色的网格拟合如何扭曲原始设计中的轮廓。
和网格安装(右)")
如上图所示,TrueType中使用的网格拟合远远超出了将字形的左侧轴承与像素网格对齐。这种复杂的网格配件由指令指导。网格拟合的有益效果如下图所示。
和网格拟合(右)")
网格拟合是根据与其相关的指令拉伸字形轮廓的过程。一旦字形被网格拟合,点数将保持不变,但该点在坐标网格中的实际位置可能已经移位。也就是说,在字形拟合后,给定点数的坐标很可能已经改变。
什么是指示?
TrueType指令集提供了大量命令,旨在允许设计人员指定应如何呈现字符特征。指令是在缩放时保留字符设计的机制。换句话说,指令控制字形轮廓将针对特定大小或设备进行网格拟合的方式。
指示字体将在给定目标设备上以特定大小重新形成给定字形的轮廓,使得正确的像素包括在其轮廓内。重塑轮廓意味着移动轮廓点。据说被指令采取行动的点已被触及。注意,实际上不需要移动一个点来触摸。它必须简单地通过指令来执行。(参见MDAP,第3章。)
TrueType字体可以带或不带指令使用。未经过保护的字体通常可以在足够高的分辨率和点大小下产生高质量的结果。未构造字体将产生高质量结果的大小范围不仅取决于输出设备分辨率和字符的点大小,还取决于特定字体设计。字体的预期用途也可以是确定是否应该指示特定字体的因素。对于大多数字体,如果低分辨率设备上的小点尺寸的易读性很重要,则添加指令将至关重要。
指示字体是一个过程,涉及分析字形设计的关键元素,并使用TrueType指令集来确保它们被保留。说明书足够灵活,允许大致相同的特征在小尺寸下“均匀化”,同时允许原始设计的完整风味出现在具有足够多像素的尺寸。
TrueType解释器如何知道轮廓应该被扭曲以产生理想结果的方式?此信息包含在附加到字体中每个字符的说明中。说明指定字形设计的各个方面,这些方面在缩放时要保留。例如,使用指令可以控制单个字符或字体中所有字符的高度。您还可以保留角色内设计元素之间的关系,从而确保,例如,小尺寸m中三个垂直杆的宽度在小尺寸时不会显着不同。
下图说明了如何更改特定大小的字形轮廓将产生更好的结果。他们表明,由于茎与像素中心的关系中的偶然效应,未受保护的9点Arial小写m会遭受干的损失。在第二个字形中,指令已将字根与网格对齐,以使字形不会遭受类似的损失。
,指示(右)")
TrueType解释器
本节介绍TrueType解释器的操作。正如其名称所示,解释者“解释”或执行指示。
更具体地说,解释器处理流或指令序列。通常,这些指令从解释器堆栈中获取其参数,并将其结果放在该堆栈上。唯一的例外是少量用于将数据推送到解释器堆栈的指令。这些指令从指令流中获取它们的参数。
所有解释器的操作都在Graphics State的上下文中进行,这是一组变量,其值指导解释器的操作并确定特定指令的确切效果。
口译员的行动可归纳如下:
解释器从指令流中获取指令,指令操作码和数据的有序序列。操作码大小为1字节。数据可以由单个字节或两个字节(一个字)组成。如果一条指令从指令流中获取字,它将通过将两个字节放在一起来创建这些字。高字节首先出现在指令流中,低字节出现在第二个字节。
描述了以下指令流,因为它将在随后的示例中示出。注意,指针指示要执行的下一条指令。

执行指令
如果是推送指令,它将从指令流中获取其参数。
任何其他指令都会从堆栈中弹出所需的任何数据。流行音乐如下图所示。

指令产生的任何数据都被推送到解释器堆栈。推送如下所示。

如前面的讨论所示,解释器堆栈是LIFO或后进先出数据结构。指令从堆栈上放置的最后一项获取所需的任何数据。从堆栈中移除顶部项目的操作通常被称为pop。当一条指令产生一些结果时,它会将该结果推送到堆栈的顶部,在那里它可能是下一条指令的输入。
指令集包括用于操作堆栈的全范围操作符,包括用于将项目推入堆栈的操作符,从堆栈弹出项目,清除堆栈,复制堆栈元素等等。
执行的效果取决于构成图形状态的变量的值。
该指令可以修改一个或多个图形状态变量。在所示的图示中,使用从解释器堆栈获取的值更新Graphics State变量rp0。

重复该过程,直到没有进一步的指令要执行。
使用说明
指令可以出现在构成TrueType字体的字体文件表中的许多位置。它们可以作为字体程序,CVT程序或字形数据的一部分出现。出现在前两个中的说明适用于整个字体。在字形数据(’glyf’)中找到的那些适用于字体内的单个字形。
字体程序
字体程序由一组指令组成,这些指令在应用程序第一次访问字体时执行一次。它用于创建函数定义(FDEF)和指令定义(IDEF)。字体程序中定义的函数和指令可以在字体文件的其他地方使用。
CVT计划
CVT程序是每次点大小或变换发生变化时执行的一系列TrueType指令。它用于进行字体范围的更改,而不是管理单个字形。CVT程序用于在控制值表中建立值。
控制值表或CVT的目的是简化指令字体时保持一致性的任务。它是一个编号的值列表,可以通过两个间接指令(MIRP和MIAP)引用。CVT条目可用于存储字体中多个字形需要相同的值。例如,指令可能引用CVT条目,其目的是在字体上规范词干权重。
图1-12一些CVT样本条目
入门# 值 描述
0 0 上下平底座(底座线)
1 -39 大写圆底座
2 -35 小写圆底座
3 -33 图圆基
4 1082 x高度平坦
五 1114 x高度圆形重叠
6 1493 平顶帽
7 1522 圆帽
8 1463 数字平
9 1491 数字圆顶
10 1493 平坦的上升
11 1514 圆形上升器
12 157 x茎重量
13 127 y茎重
14 57 衬线
15 83 点和我之间的空间
引用CVT中的值的指令称为间接指令,而不是从字形轮廓中获取其值的直接指令。
作为TrueType字体文件的一部分,CVT中的值以FUnits表示。当轮廓从FUnits转换为像素单位时,CVT中的值也会被转换。
写入CVT时,您可以使用字形坐标系中的值(使用WCVTP),也可以使用原始FUnits中的值(使用WCVTF)。解释器将适当地缩放所有值。从CVT读取的值始终以像素为单位(F26Dot6)。
存储区
解释器还维护一个存储区,该存储区由一部分内存组成,可用于临时存储来自解释器堆栈的数据。存在使得可以读取存储数据的值并将新值写入存储的指令。存储位置的范围为0到n-1,其中n是在字体文件的maxProfile表中的maxStorage条目中建立的值。值为32位数
图1-13某些存储区域条目
地址 值
0 343
1 241
2 -27
3 4654
4 125
五 11
图形状态
图形状态由变量表及其值组成。所有指令都在图形状态的上下文中起作用。图形状态变量具有附录B“图形状态摘要”中指定的默认值。可以使用说明确定或更改其值。
图形状态建立了解释所有字形的上下文。所有图形状态变量都具有默认值。如果需要,可以在CVT程序中更改其中一些值。无论默认值是什么,它都将在任何字形的解释开始时重新建立。换句话说,图形状态没有字形间内存。处理单个字形时更改图形状态变量的值将导致仅对该字形保持有效的更改。
扫描转换器
TrueType扫描转换器采用字形的轮廓描述,并为该字形生成位图图像。
TrueType扫描转换器提供两种模式。在第一模式中,扫描转换器使用简单算法来确定哪些像素是该字形的一部分。规则可以陈述如下:
规则1
如果像素的中心位于字形轮廓内,则该像素将打开并成为该字形的一部分。
规则2
如果轮廓精确地落在像素的中心,则该像素将打开。
如果点具有非零的绕组数,则该点被认为是字形的内部点。绕组数本身通过从所讨论的点向无穷远绘制射线来确定。(光线指向不重要的方向。)从零计数开始,每当字形轮廓从右到左或从下到上穿过光线时,我们减去一。这种交叉被称为转换。每当字形的轮廓从左到右或从上到下穿过光线时,我们添加一个。这种交叉被称为过渡。如果最终计数不为零,则该点是内部点。
可以通过查看点数来确定轮廓的方向。方向始终从较低点数到较高点数。
下面的插图演示了在确定一个点是否在字形内时使用绕组数。点P1经过四个转换的序列(上过渡,关过渡,在过渡,关闭转换)。由于序列是偶数,因此绕组数为零,并且该点不在字形内。第二点,P2,经历了一个关断过渡后跟一个上由过渡随后关闭过渡产生的1的卷绕数。该点位于字形的内部。

什么是辍学?
只要字形内部的连接区域包含两个黑色像素无法通过仅穿过黑色像素的直线连接,就会发生丢失。

防止辍学
TrueType指令旨在允许您对字形进行网格拟合,以便通过简单的扫描转换器打开所需的像素,无论点大小或使用的变换如何。可能很难预见字形可能经历的所有可能的变换。因此,难以指示字形以确保对于每个期望的变换将发生轮廓的适当的网格拟合失真。对于每个em的非常少量的像素和复杂的字体,这个问题尤其困难。在这些情况下,字形的某些再现可能包含丢失。
通过查看连接两个相邻像素中心的假想线段,可以测试潜在的丢失。如果该线段与过渡时轮廓和非过渡轮廓相交,则存在潜在的压降条件。如果两个轮廓线在两个方向上继续以切割相邻像素中心之间的其他线段,则潜在的丢失仅变为实际的丢失。如果两个轮廓在穿过扫描线(形成短截线)之后立即连接在一起,则不会发生丢失,尽管字形的主干可能变得比期望的短。
为了防止丢失,类型制造商可以选择让扫描转换器使用另外两个规则:
规则3
如果两个相邻像素中心(垂直或水平)之间的扫描线与过渡轮廓和非过渡轮廓相交,并且规则1和2都没有打开任何像素,则打开左侧 - 大多数像素(水平扫描线)或最底部像素(垂直扫描线)
规则4
仅当两个轮廓在两个方向上继续与其他扫描线相交时才应用规则3。那就是不要打开“存根”的像素。检查与相交的扫描线段形成正方形的扫描线段以验证它们与两个轮廓相交。这些轮廓可能是与丢失扫描线段相交的轮廓不同的轮廓。这是非常不可能的,但可能必须通过网格拟合在一些奇异的字形中进行控制。
类型制造商可以选择仅使用规则1和2的简单扫描转换器,或者可以选择调用规则3或规则4.关于使用哪个扫描转换器的决定可以在字体宽度或不同的选择上进行。为每个字形指定。preProgram中的选择将是整个字体的默认选择。对单个字形的说明中的默认值所做的更改将仅适用于该字形。
11.3.TrueType指令集
当光栅化TrueType字形轮廓时,会使用字体文件中包含的指令暗示它们。TrueType指令集提供了一种强大的方法来控制所有或特定大小和分辨率的字形轮廓。对于屏幕分辨率的清晰字体,说明至关重要。以下部分详细讨论了提示和TrueType指令集。
指示TrueType字形
TrueType指令集
图形状态摘要
11.3.1.指示TrueType字形
指导雕文
本章概述了指示字形所涉及的基本任务。
选择扫描转换设置
在指示TrueType字体时要做出的关键决定之一是扫描转换模式的选择。字体设计者可以选择快速扫描转换模式和丢失控制扫描转换模式。通过设置Graphics State变量scan_control的值来进行此选择。解释器在确定是否将使用丢失控制模式时考虑以下三个条件中的每一个:
字形是否旋转?
字形是否拉伸?
ppem的当前设置是否小于指定的ppem值?
也可以完全关闭压差控制。
控制四舍五入
TrueType解释器使用round_state来确定值的舍入方式。指令用于设置round_state的值,即Graphics State变量。round_state的设置决定了解释器如何舍入值。
指令集可以轻松设置多个预定义的圆形状态,这些状态将值舍入到网格,像素中心(半网格)或网格或像素中心。也可以指定值应向下舍入或向上舍入。如果没有预定义的舍入选项就足够了,则SROUND指令可以非常精确地控制值的舍入,从而可以为舍入函数选择相位,阈值和周期。S45ROUND允许与SROUND相同的精细控制,但在沿x度平面的45度轴移动时使用。
在移动任何点之前,许多指令围绕它们获得的值。使用任何MDRP,MIRP,MIAP,MDAP或ROUND指令的效果取决于round_state图形状态变量的值以及control_value_cut_in的值。ROFF指令关闭舍入,但允许指令继续查看切入值。
点
轮廓点由它们在坐标网格中的位置以及它们是在曲线点上还是在曲线点之间指定。管理点意味着管理其在空间中的位置及其作为开启或关闭曲线点的状态。解释器使用区域和参考点来管理包含当前字形的点集,并引用该集合中的特定点。
区
字体缩放器解释器引用的任何点都在两个区域之一中,即可能构成字形描述的两组点之一。这些引用区域中的第一个是区域1(Z1),并且始终包含当前正在解释的字形。
第二个区域0(Z0)用于临时存储与区域1中字形中的任何实际点不对应的点坐标。当需要操作不存在的点时,区域0很有用。字形或者如果你需要记住中间点位置。(这是暮光之城。)
配置文件表确定了最大点数。这些是数字0到maxTwilightPoints -1并且都设置为原点。这些点可以与区域1中的任何点相同的方式移动。
通过使用MIAP和MIRP指令并将gep0设置为指向Z0,将区域0中的点移动到有用位置。通常,将Z0中的点设置为字体的关键度量位置很有用。
区域指针
三个区域指针gep0,gep1和gep2用于引用区域0或区域1.最初,所有三个区域指针都将指向区域1。
,gep2指向区域0(黄昏区域)")
参考点
区域指针提供对一组点的访问。参考点提供对组内特定点的访问。解释器使用三个编号的参考点:rp0,rp1和rp2。每个都可以设置为与区域1中的字形中的任何轮廓点或区域0中的任何点对应的数字。
如下图所示,两个不同的参考点可以指代相同的轮廓点。

区域指针和参考点共同属于图形状态。可以使用说明更改其值。许多TrueType指令依赖于图形区域指针和参考点来完全指定其操作。
幻影点
Microsoft光栅化器v.1.7或更高版本将始终在每个轮廓的末尾添加四个“幻像点”,以允许控制宽度或高度(早于v.1.7的MS光栅化器仅添加两个幻像点,仅允许宽度为受控)。
如果字形的整个轮廓集需要“n”个点(即,从0到n-1编号的轮廓点),则缩放器将添加点n,n + 1,n + 2和n + 3。点“n”将放置在字符原点,点“n + 1”将被放置在提前宽度点,点“n + 2”将被放置在顶部原点,点“n + 3”将被放置在放置在提前高度点。有关如何放置这些幻像点的说明,请参见图2-1(第17,18,19,20点)和图2-2(第27,28,29和30点)。
所有四个幻像点都可以由TrueType指令控制,对指示的字形的侧面,前进宽度和前进高度(在垂直定位的情况下)具有相应的效果。使用这些幻像点计算侧面轴承,前进宽度和前进高度,并将其称为设备特定的宽度和高度(因为它们反映了网格将宽度或高度与字形拟合到设备特征的结果) 。取决于应用于体模点的指令,特定于设备的宽度或高度可以与线性缩放的宽度或高度(通过简单的缩放操作获得)不同或相同。
在对与高度相关的幻像点(n + 2和n + 3)应用TrueType指令之前,请使用GETINFO []检查光栅化器是否为MS rasterizer v.1.7或更高版本。
确定距离
在最低级别,指示字形意味着管理点之间的距离。管理距离的第一步通常是确定其大小。例如,设置控制值表的第一步涉及测量字体中关键点之间的距离。测量字形轮廓中两点之间的距离虽然不难,但必须考虑某些因素。
所有距离测量都与投影矢量平行,投影矢量的方向将由圆的半径表示。将距离投影到该矢量上并沿其测量。距离具有反映向量方向的方向。测量可以指原始字符轮廓中的点之间或网格拟合轮廓中的点之间的距离。测量距离(MD)的指令采用布尔值,该布尔值确定是在原始轮廓上还是在网格拟合轮廓中测量距离。
此外,TrueType解释器区分三种不同类型的距离:黑色,白色和灰色。某些指令(MDRP,MIRP,ROUND)要求您指定距离类型。
黑色距离仅交叉黑色区域; 白色距离,白色区域; 灰色距离是两者的组合。在下图中,显示了黑色,白色和灰色距离的示例。距离[2,1]为黑色; [3,0]为灰色,[4,6]为白色。

距离类型用于确定使用round_state的ROUND和指令如何与不同的输出设备一起使用。对于灰色距离,舍入不受影响。但是,黑色或白色距离需要在进行舍入之前添加或减去补偿项。所需的补偿金额将由设备驱动程序设置。例如,如果打印引擎具有大像素,则解释器将通过缩小黑色距离和增加白色距离来进行补偿。灰色距离,因为它们结合了黑色和白色距离,不会改变。
当确定两点之间的距离时,始终在projection_vector指定的方向上测量距离。类似地,当移动一个点时,将沿着projection_vector测量它移动的距离。在考虑解释器如何投射距离时,您可能会发现将距离投影到与投影矢量平行的划线上会很方便。
在所示的示例中,沿着与projection_vector平行的线测量距离。在测量之前,必须将点1到点2的距离投影到projection_vector(即与projection_vector平行的线)上。由于从点1到点3的线与矢量平行,因此距离的投影可以简单地认为是从1到3的线。因为从点4到点1的线的投影垂直于矢量,尽管点不重合,但从点4到点1的距离为零。
矢量可以设置在任何所需的方向。在简单的情况下,可以将投影矢量设置为测量x方向上的距离。在这种情况下,矢量平行于x轴。与测量y方向上的距离类似,projection_vector必须与y轴平行。
为了确定projection_vector指向正x方向时两点之间的距离,只需要获取它们的x坐标之间的差值。例如,点(2,1)和(7,5)之间的距离将是5个单位。类似地,如果projection_vector指向正y方向,则点之间的距离将是4个单位。
请注意,因为projection_vector具有方向,所以距离具有符号。正距离是使用projection_vector测量的距离。负距离是针对projection_vector测量的距离。
在以下示例中,projection_vector指向东(在正x轴的方向上)。当从西向东(从点1到点2)测量时,点1和点2之间的距离是正的。从东到西(从第2点到第1点)进行测量时,它是负的。

在许多情况下,忽略与距离相关的符号是方便的。当auto_flip图形状态变量设置为TRUE时,CVT条目的符号将在需要时更改,以匹配实际测量的符号。这使得可以用单个CVT条目控制使用或反对projection_vector测量的距离。
控制运动
点可以移动的方向由图形状态变量freedom_vector建立。
移动一个点时,其移动被限制在与freedom_vector平行的方向上。假设freedom_vector指向正x轴的方向(指向东方),则正x方向(从西向东)的移动将具有正的幅度。负x方向(从东到西)的运动将具有负的幅度。
移动点
警告: 移动点时,freedom_vector和projection_vector是正交的是非法的。
有几条指令可以移动轮廓点。这些指令要么相对于参考点移动点(相对指令),要么将点移动到坐标系中的指定位置(绝对指令)。
下图说明了相对移动。移动点p使得它距参考点rp的距离为d。

下图说明了一个绝对的举动。这里,点p从其当前位置移动距离d到新位置。沿projection_vector测量距离。运动沿着freedom_vector。

在指定移动时,一些移动指令使用轮廓距离(直接指令)。其他指令仅通过引用CVT中的值或堆栈上的值(间接指令)间接指定d的值。
在尝试移动点时,您必须首先确定方向和距离。除此之外,决定是否要将该点移动到绝对距离或相对于另一个点。如果移动是相对的,请确保您知道指令将使用哪个参考点。在某些情况下,您可能需要将该参考点的值更改为您想要的值。最后决定是使用原始轮廓距离还是指CVT或堆栈中的距离。
通过选择使用原始轮廓距离,您可以保留两点之间的原始设计距离。相反,如果选择指定距离的间接方法,即使用CVT,则允许该距离与该字体或字形的某个重要值匹配。
除了MSIRP之外的所有移动指令都受round_state的影响。说明允许您选择是否应考虑round_state变量的设置。实际上,这意味着,如果打开舍入,实际移动点的距离将受到执行的舍入类型的影响。
在下面的示例中,点p将距离d移动到新位置p’,然后舍入到最近的网格边界。

管理距离的方向
auto_flip变量的存在归因于TrueType解释器区分在projection_vector方向上测量的距离(正距离)和在与projection_vector相反的方向上测量的距离(负距离)。
auto_flip布尔值的设置确定控制值表中值的符号是否重要。如果auto_flip设置为TRUE,则必要时将更改CVT条目的值以匹配实际测量的符号。这使得可以控制利用投影矢量或与投影矢量一起测量的距离。
例如,CVT可能包含大写主干宽度的条目。有时可以方便地从左到右控制宽度,而在其他时间从右到左控制它们可能是方便的。一个案例将产生正距离,另一个案例将产生负距离。如果没有auto_flip,则需要有两个CVT条目(+ UC_Stem和-UC_Stem)而不是一个。将auto_flip设置为TRUE使得从CVT读取的值的符号与我们在原始未修改域中控制的点之间的距离的符号相同。
通常,auto_flip设置为TRUE,但如果需要区分正距离或负距离,则必须将变量设置为FALSE。
插值点
当使用指令更改字符轮廓中的几个点的位置时,组成字符的曲线可能会扭曲或扭曲。可能需要平滑所得曲线。这种平滑过程实际上是对未移动的所有点的重新分布,使得它们相对于移动点的位置保持一致。
为了帮助管理轮廓的形状,解释器使用触摸点的概念。每当指令具有移动点的效果时,该点被标记为在x方向或y方向或两者上被触摸。IUP指令仅影响未触及的点。可以明确地取消一个点,使其受插值指令的影响。
维持minimum_distance
当字形特征的宽度减小到某个大小以下时,舍入值可能变为零。允许值舍入为零可能导致某些字形功能消失。例如,杆可能在小点尺寸处完全消失。通过设置一个像素的minimum_distance,您可以确保即使是小尺寸,这些功能也不会消失。
在下面显示的示例中,minimum_distance值用于确保r的主干不会以小尺寸消失。通过确保从点9到点10的距离总是至少一个像素,实现了该目标。
使用cut_in控制正则化
TrueType语言提供了几种协调字体中字形功能值的方法。这种协调导致称为正则化的外观均匀性。当可用于特征或字形的像素数量很少时,正则化很有用。它可以防止特征尺寸的微小差异因字形轮廓内像素中心位置的变化而变得极为夸大。当特征的大小或位置的微小差异可以通过可用像素的数量有效地表示时,正则化成为一种负担。
TrueType为您提供两个世界中最好的一个,使得可以在每个像素的少量像素处调整特征,同时允许轮廓在足够数量的像素可用时恢复到原始设计。有两种不同的方法可以实现这一目标。每个都使用cut_in值。第一种方法使用Control Value Table和control_value_cut_in,并允许您使用CVT中的条目来协调值。该方法允许协调各种值。第二种方法使正规化更进一步,并强制所有值恢复为单个值。它依赖于single_width_cut_in和single_width_value。
Control_value_cut_in
control_value_cut_in使得可以将CVT的正则化效果限制为表值与从原始轮廓取得的测量值之间的差足够小的情况。它允许解释器在某些尺寸下选择使用CVT值,而在其他尺寸下,可以恢复到原始轮廓。当表中的值与直接来自轮廓的测量值之间的绝对差值大于cut_in值时,使用轮廓测量值。control_value_cut_in的作用是允许在某个截止点以下进行正则化,同时允许设计的微妙处理以更大的尺寸接管。
cut_in值仅影响引用CVT中的值的指令,即所谓的间接指令,MIRP和MIAP,并且仅当第三个布尔值设置为TRUE时。
CVT值 原始大纲值 | DIFF | cut_in | DIFF | > cut_in使用大纲 | DIFF | _cut_in使用CVT
93 80 13 17/16 80 -
100 99 5/16 11/16 17/16 - 100
97 95 15/16 17/16 17/16 97
在所示的示例中,大写字母J在原始设计中低于基线。但是,当角色是网格拟合时,曲线通过间接指令保持在基线上。该指令引用CVT,但默认cut_in值为17/16。在该值处,曲线通过每个像素81个像素保持在基线上,但是如图所示,恢复到其原始设计,每个像素为82个像素。
和每个em 82个像素(右)")
cut_in的效果随其值而变化。减小cut_in的值将导致轮廓以较小的ppem值恢复到原始设计。增加cut_in的值将使轮廓以更高的ppem值恢复到原始设计。
single_width_cut_in
single_width_cut_in是解释器将忽略控制值表和轮廓中的值而忽略单宽度值的距离差。它允许功能恢复到每个em的少量像素的单个预定大小。
拥有所有受控字形功能假设相同的尺寸对于非常小的网格尺寸的某些字体可能是有利的。当single_width_value和原始值之间的绝对差小于此single_width_cut_in时,使用single_width_value。
single_width_cut_in的默认值为零。实际上,这意味着默认值是忽略此cut_in值。与control_value_cut_in一样,single_width_cut_in仅适用于间接指令。
single_width_value
当控制值表和single_width_value之间的差小于single_width_cut_in时,使用single_width_value。例如,如果single_width_value被设置为2个像素,则满足single_width_cut_in测试的特征将被规范化为2个像素宽。
按特定尺寸管理
大多数TrueType指令与大小无关。它们用于控制各种尺寸的特征。有时,有必要更改特定大小的字形轮廓以包含或排除某些像素。换句话说,偶尔希望对轮廓做出例外,否则将由其他指令产生。使用DELTA指令进行此类例外处理。
DELTA指令有两种类型。DELTAP指令通过移动点来工作。DELTAC指令通过更改CVT中的值来工作。
例如,在没有DELTA指令的情况下,回旋重音会缩小到9 ppem处的单个像素。使用DELTA,通过在9 ppem处将点5,2和1降低一个像素来改善外观。

delta_base
delta_base是用于计算delta指令将应用的点大小范围的基值。更改delta_base允许您更改受每条DELTA指令影响的ppem大小的范围。
三对DELTA指令根据它们可能影响的像素范围进行分组,每组以每个16个像素开始,大于前一个组。所有DELTAC1和DELTAP1指令都可能影响大小的字形,从每个delta_base像素开始到delta_base加上每个em 15个像素。DELTAP2和DELTAC2指令影响从delta_base开始加上每个em 16个像素的范围。DELTAP3和DELTAC3指令影响delta_base加上每个em 32个像素。
delta_shift
delta_shift值是引发异常的功率。通过改变delta_shift的值,可以权衡轮廓运动的精细控制,而不是总运动范围。低delta_shift有利于精细控制的移动范围。高delta_shift有利于精确控制运动范围。
点数可以移动一个称为步长的固定量的倍数。步长为1除以2为幂delta_shift。
管理抗锯齿
Windows为用户提供显示消除锯齿文本的选项。OpenType’gasp’表可用于控制灰度和网格拟合发生的大小范围。此外,TrueType指令可用于精确控制光栅化器1.7及更高版本中灰度像素的使用。
以下TrueType代码示例说明了TrueType指令如何确定安装的光栅化器是否支持消除锯齿,然后向光栅化器提供提示。
复制
PUSHB[2] 2 0 /* PUSH : storageID, FALSE */
WS /* FALSE by default */
PUSHB[3] 23 17 1 /* PUSH : jump1, jump2, rast. version flag */
GETINFO /* get the rasterizer version */
DUP
PUSHB[1] 34
LTEQ
ROLL
SWAP
JROT /* we are at MS rasterizer version 1.7 or higher (> 34) */
PUSHB[1] 64
GT
JROT /* we are in the MS version range (<= 64) */
PUSHB[2] 10 32 /* PUSH : jump3, HintForGray flag */
GETINFO /* we are on the new MS Rasterizer, ask for HintForGray */
PUSHW[1] 4096 /* PUSH : HintForGray flag */
NEQ
JROT
PUSHB[2] 2 1 /* PUSH : storageID, TRUE */
WS /* Storage #2 set to TRUE, grayscale */
PUSHB[1] 3 /* PUSH : jump4 */
JMPR
POP
POP
11.3.2.TrueType指令集
TrueType提供以下每个任务的说明和一组通用指令。本章介绍TrueType指令集。指令描述根据其功能按类别组织。
将数据推送到解释器堆栈
管理存储区域
管理控制值表
修改图形状态设置
管理大纲
通用说明
TrueType指令的剖析
TrueType指令由其操作码唯一指定。为方便起见,本书将参考其名称的说明。每个指令名称都是一个助记符,旨在帮助记住该指令的功能。例如,MDAP指令代表Move Direct Absolute Point。同样,RUTG是Round Up To Grid的缩写。澄清助记符的每条指令的简要描述标志着新指令的开始。
一个名称实际上可能指的是几个不同但密切相关的指令。每个名称后面都有一个括号内的布尔值列表,用于唯一地指定给定指令的特定变体。可以将布尔列表转换为二进制数,并将该数字添加到指令的基本操作码中,以获取任何指令变量的操作码。
要获取任何指令的操作码,请取代码范围中给出的两个操作码值中的较低者,并添加由二进制数字列表表示的无符号二进制数。最左边的位是最重要的。例如,给定具有操作码范围0xCO-0xDF和五个布尔标志(a到e)的指令,可以如下所示计算给定指令库的操作码:
操作码= 0xC0 + a·2 4 + b·2 3 + c·2 2 + d·2 1 + e·2 0
如果这些标志设置为11101,则代码将按如下方式计算:
0xC0 + 1·2 4 + 1·2 3 + 1·2 2 + 0·2 1 + 1·2 0
= 0xC0 + 0x10 + 0x8 + 0x4 + 0x1
= 0xC0 + 0x1D = 0xDD
指令操作码是指令流的一部分,是一系列操作码和数据。指令流不是堆栈。当指令流上的操作码和数据流逐渐用完时,通过执行另一条指令没有新的数据被添加到指令流(即,没有相当于将数据添加到指令流的推送指令)。可以使用后面部分中描述的跳转指令之一来改变通过指令流的控制流。
指令流显示为操作码和数据序列。由于指令流是1字节宽,因此字将被分解为高字节和低字节,其中高字节首先出现在流中。为了增加可读性,指令名称用于插图而不是操作码。箭头将指向等待执行的下一条指令。
和推送字指令(右)")
一些统称为推送指令的指令将数据从指令流移动到解释器堆栈。这些指令在从指令流中获取参数时是唯一的。所有其他TrueType指令在执行时从堆栈中获取所需的任何数据。由TrueType指令产生的任何结果都被推送到解释器堆栈。
需要两个参数并推送第三个参数的指令会期望两个参数位于堆栈的顶部。该指令推送的任何结果都显示在堆栈的顶部。

要轻松记住在算术或逻辑运算期间处理堆栈值的顺序,请想象从左到右写入堆栈值,从底部值开始。然后将操作员插入两个最右边的元件之间。例如,减去a,b将被解释为(ba):
cb - a
GT a,b将被解释为(b> a):
cb> a
语句push d,e表示按d然后按e将两个元素添加到堆栈中,如图所示。
为了表明要删除前两个堆栈元素,语句将弹出e,d。
已经注意到,在指令名之后的括号内的二进制数字列表唯一地标识指令变体。这是通过使位表示布尔标志列表来完成的,布尔标志可以设置为TRUE,值为1或FALSE,值为0.也可以将名称后面的二进制数字分组以形成更大的二进制数。在这种情况下,文档指定与每个可能的数字组合相关的含义。
指令规范由指令名称后跟其括号内的布尔标志组成。表格形式提供了描述标志和解释堆栈交互以及任何图形状态依赖关系的其他信息:
代码范围 识别该指令及其变体的十六进制代码范围
旗 括号二进制数的含义的解释
来自IS 通过推送指令从指令流中获取的任何参数
流行 从堆栈中弹出的任何参数
推 任何参数都被压入堆栈
用途 任何状态变量,该指令所依赖的值
集 此指令设置的任何状态变量
指令描述包括旨在阐明堆栈交互,图形状态效果和解释器表更改的插图。
在移动点的指令的情况下,将提供说明以阐明移动的方向和大小。在这些图示中,灰色阴影将用于指示点移动的顺序。填充越深,最近一点被移动。
数据类型
指令流
指令操作码总是字节。指令流中的值是字节。
堆栈
压入堆栈或从堆栈弹出的值始终为32位(int32或uint32)。当小于32位的值被压入堆栈时,通过用零填充高位并将字符号扩展为32位,将字节扩展为32位。在组合两个指令流字节以形成字的情况下,高阶位首先出现在指令流中。
注意:在16位系统(如Windows)上,所有堆栈操作都是16位值(int16或uint16)。必须小心避免溢出。同样重要的是要注意F26dot6值(用于内部标量数学)代替为10点6值(即不支持高16位)。
")
")
堆栈上的所有值都已签名。但是,指令以各种方式解释这些32位量。解释器将数量理解为整数和定点数。
诸如像素坐标之类的值表示为32位量,由26位整数和6位分数组成。这些是定点号,数据类型名称为F26Dot6。
freedom_vector和projection_vector的设置表示为2.14定点数。忽略32位数量的高16位。
给定的32位集将具有不同的值,具体取决于它的解释方式。以下32位值被解释为整数,其值为264。
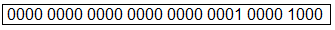
解释为F26Dot6定点数的相同32位数量值为4.125。
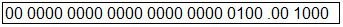
下图给出了将像素值表示为26.6个字的几个示例。
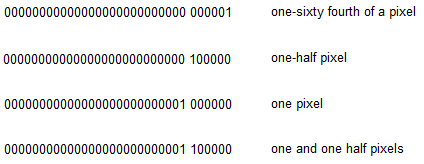
将数据推送到解释器堆栈
大多数TrueType指令从解释器堆栈中获取它们的参数。但是,一些指令从指令流中获取它们的参数。它们的目的是将数据从指令流移动到解释器堆栈。这些指令统称为推送指令。
推N字节
NPUSHB []
代码范围 0x40的
来自IS n:要推送的字节数(1个字节被解释为整数)b1,b2,… bn:n个字节的序列
推 b1,b2,bn:n个字节的序列,每个字节填充为32位(uint32)
从指令流中取n个无符号字节,其中n是范围(0..255)中的无符号整数,并将它们推入堆栈。n本身不会被推入堆栈。
推N字
NPUSHW []
代码范围 的0x41
来自IS n:要推送的字数(一个字节被解释为整数)w1,w2,… wn:由字节对形成的n个字的序列,高字节首先出现
推 w1,w2,… wn:n个字的序列,每个符号扩展为32位(int32)
从指令流中获取n个16位带符号的字,其中n是范围(0..255)中的无符号整数,并将它们推入堆栈。n本身不会被推入堆栈。
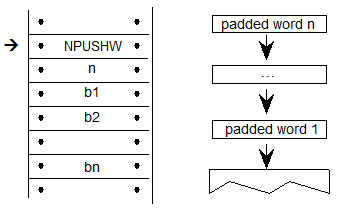
PUSH字节
PUSHB [ABC]
代码范围 0xB0 - 0xB7
ABC 要推送的字节数 - 1
来自IS b0,b1,.. bn:n + 1个字节的序列
推 b0,b1,…,bn:n + 1个字节的序列,每个字节填充到32位(uint32)
从指令流中获取指定的字节数,并将它们推送到解释器堆栈。
变量a,b和c是二进制数字,表示从000到111的数字(二进制为0-7)。因为实际的字节数(n)是1到8,所以1会自动添加到ABC图中以获得推送的实际字节数。
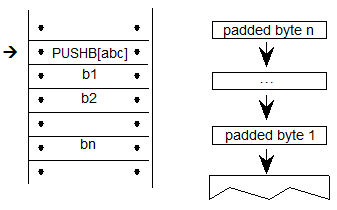
例:
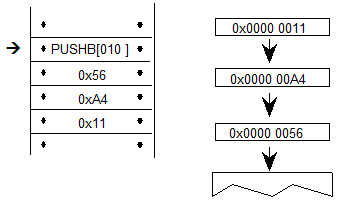
推词
PUSHW [ABC]
代码范围 0xB8 - 0xBF
ABC 要推的字数 - 1
来自IS w0,w1,… wn:由字节对组成的n + 1个字的序列,高字节首先出现
推 w0,w1,… wn:n + 1个字的序列,每个符号扩展为32位(int32)
从指令流中获取指定数量的单词并将它们推送到解释器堆栈。
变量a,b和c是二进制数字,表示从000到111(0-7二进制)的数字。因为实际的字节数(n)是1到8,所以会自动将1添加到abc图中以获得推送的实际字节数。
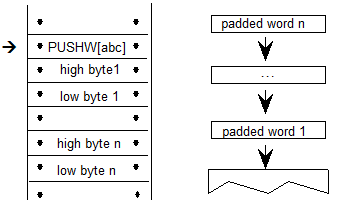
例:
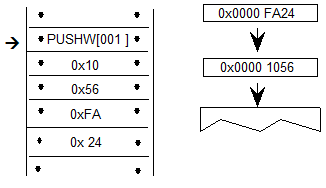
管理存储区域
解释器存储区是一个内存块,可用于存储和以后访问32位值。存在用于将值写入存储区域并从存储区域检索值的指令。尝试从之前没有写入值的存储位置读取值将产生不可预测的结果。
阅读商店
RS []
代码范围 0x43中
流行 location:存储区位置(uint32)
推 value:存储区域值(uint32)
获取 存储区域值
该指令从堆栈中弹出的存储区位置读取32位值,并将读取的值推入堆栈。它从堆栈中弹出一个地址,并将该存储区位置中的值推送到堆栈顶部。可用存储位置的数量在字体文件的maxProfile表中指定。
例:
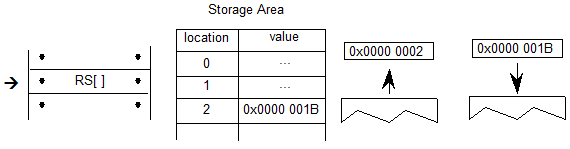
RS指令的作用是将存储区的值0x1B推送到堆栈。
写商店
WS []
代码范围 的0x42
流行 value:存储区域值(uint32)
location:存储区位置(uint32)
推 -
获取 存储区域值
该指令将32位值写入由位置索引的存储位置。它的工作原理是从堆栈中弹出一个值然后弹出一个位置。该值放在该地址指定的存储区位置。存储位置的数量在字体文件的maxProfile表中指定。
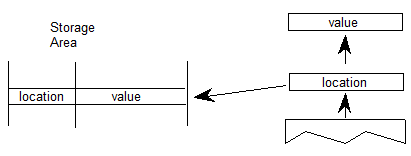
例:

将值0x0000 0118写入存储区中的位置3A。
管理控制值表
控制值表存储间接指令访问的信息。可以使用FUnits或像素单位将值写入CVT,这很方便。从CVT读取的值始终以像素为单位(F26Dot6)。与存储区域不同,此表由字体初始化并自动缩放。
以像素为单位写入控制值表
WCVTP []
代码范围 0×44
流行 value:以像素为单位的数字(F26Dot6定点数)
位置:控制值表位置(uint32)
推 -
集 控制值表条目
弹出堆栈中的位置和值,并将该值放入“控制值表”中的指定位置。该指令假定值以像素为单位而不是在FUnits中。
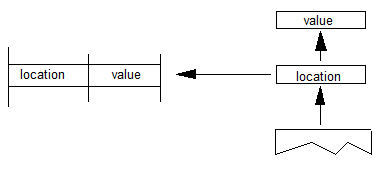
在FUnits中写入控制值表
WCVTF []
代码范围 0x70
流行 值:FUnits中的数字(uint32)
位置:控制值表位置(uint32)
推 -
集 控制值表条目
弹出堆栈中的位置和值,并将指定的值放入控制值表中的指定地址中。该指令假定值以FUnits而不是像素表示。在写入表之前缩放该值。
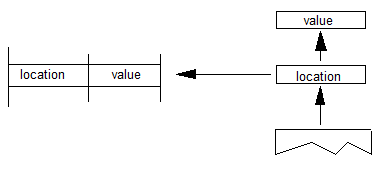
读取控制值表
RCVT []
代码范围 0×45
流行 位置:CVT条目号(uint32)
推 值:CVT值(F26Dot6)
获取 控制值表条目
弹出堆栈中的位置,并将控制值表中指定位置的值压入堆栈。
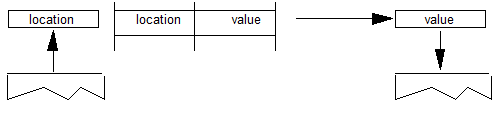
管理图形状态
指令可用于设置Graphics State变量的值,在某些情况下,还可以检索其当前值。
获得价值
检索状态变量值的指令的名称以单词get开头。获取指令将通过将该值放在堆栈顶部来返回有问题的状态变量的值。
该图显示了GPV或get projection_vector指令的效果。它从Graphics状态获取projection_vector的x和y分量,并将它们放在堆栈上。
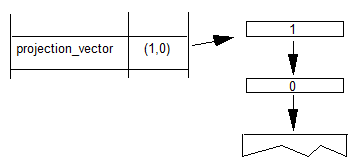
设置一个值
更改Graphics State变量值的说明具有以单词set开头的名称。设置指令期望它们的参数位于解释器堆栈的顶部

除了简单的集合和获取之外,还存在一些指令来简化状态变量值的管理。例如,存在许多指令来设置freedom_vector和projection_vector的方向。在设置矢量时,可以将其设置为坐标轴,线路指定的方向或从堆栈中取值的方向。存在一条指令,它直接将freedom_vector设置为与projection_vector相同的值。
设置自由度和投影向量以协调轴
SVTCA并[a]
代码范围 0x00 - 0x01
一个 0:将矢量设置为y轴
1:将矢量设置为x轴
流行 -
推 -
集 projection_vector
freedom_vector
将projection_vector和freedom_vector都设置为相同的坐标轴。
SVTCA是使用SFVTCA和SPVTCA指令的捷径。SVTCA [1]相当于SFVTCA [1],其次是SPVTCA [1]。该指令确保移动和测量都沿着相同的坐标轴。
例:
SVTCA [1]

SVTCA [0]
将测量和移动设置为y方向。
设置Projection_Vector以协调轴
SPVTCA并[a]
代码范围 0x02 - 0x03
一个 0:将projection_vector设置为y轴
1:将projection_vector设置为x轴
流行 -
推 -
集 projection_vector
根据标志a的值将projection_vector设置为其中一个坐标轴。
例:
SPVTCA [0]
将projection_vector设置为y轴,确保测量将在该方向上。
将Freedom_Vector设置为Coordinate Axis
SFVTCA并[a]
代码范围 0x04 - 0x05
一个 0:将freedom_vector设置为y轴
1:将freedom_vector设置为x轴
流行 -
推 -
集 freedom_vector
根据标志a的值将freedom_vector设置为其中一个坐标轴。
例:
SFVTCA [0]

将freedom_vector设置为y轴,确保沿该轴移动。
将Projection_Vector设置为Line
SPVTL并[a]
代码范围 0x06 - 0x07
一个 0:将projection_vector设置为与从p1到p2的线段平行
1:将projection_vector设置为垂直于从p1到p2的线段; 矢量逆时针旋转90度
流行 p1:点数(uint32)
p2:点数(uint32)
推 -
用途 zp2指向的区域中的p1点
zp1指向的区域中的点p2
集 projection_vector
将projection_vector设置为与点p1到点p2的线段平行或垂直的单位矢量。
例:
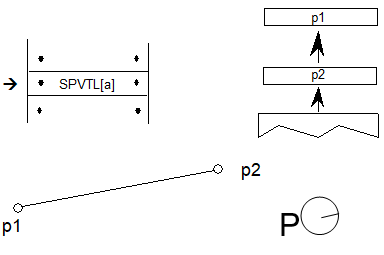
如果平行,则projection_vector从p1指向p2,如图所示。

如果垂直,则通过以所示的逆时针方式旋转平行矢量来获得projection_vector。
情况1:
SPVTL [1]
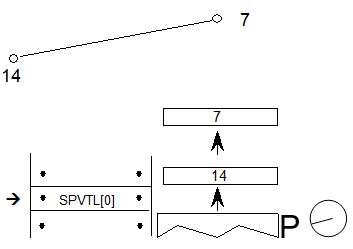
将projection_vector设置为与从点7到点14的直线平行。
案例2:
SPVTL [1]
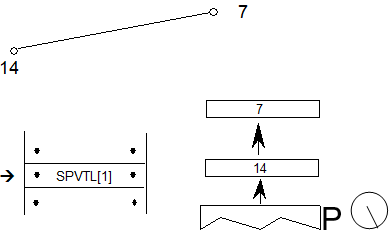
将projection_vector设置为垂直于从第7点到第14点的直线。
案例3:
SPVTL [1]
指定点的顺序很重要。该指令将projection_vector设置为垂直于从点14到点7的直线。
将Freedom_Vector设置为Line
SFVTL并[a]
代码范围 0x08 - 0x09
一个 0:将freedom_vector设置为与点p1和p2定义的线段平行
1:将freedom_vector设置为垂直于由点p1和p2定义的线段; 矢量逆时针旋转90度
流行 p1:点数(uint32)
p2:点数(uint32)
推 -
集 freedom_vector
用途 zp2指向的区域中的p1点
zp1指向的区域中的点p2
将freedom_vector设置为与点p1和p2定义的线段平行或垂直的单位矢量。

如果平行,则freedom_vector从p1指向p2,如图所示。

如果垂直,则通过以逆时针方式旋转平行矢量获得freedom_vector,如图所示。
将Freedom_Vector设置为投影矢量
SFVTPV []
码 为0x0E
流行 -
推 -
集 freedom_vector
将freedom_vector设置为与projection_vector相同。

之前

后
将Dual Projection_Vector设置为Line
SDPVTL并[a]
代码范围 0x86 - 0x87
一个 0:矢量与线平行
1:向量垂直于线
流行 p1:第一个点数(uint32)
p2:p2:第二个点数(uint32)
推 -
集 dual_projection_vector和projection_vector
用途 zp2指向的区域中的p1点
zp1指向的区域中的点p2
从堆栈中弹出两个点数,并使用它们来指定定义第二个double_projection_vector的行。在进行任何网格拟合之前,此dual_projection_vector使用来自缩放轮廓的坐标。它仅用于IP,GC,MD,MDRP和MIRP指令。当这些指令测量ungrid拟合点之间的距离时,它们将使用dual_projection_vector。当使用设置projection_vector的任何其他指令时,dual_projection_vector将消失。
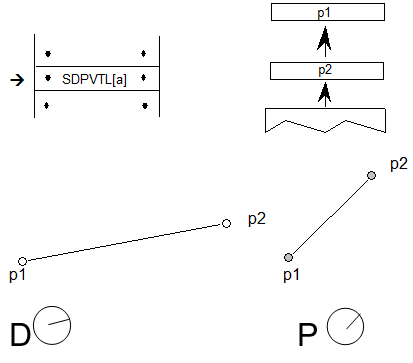
注意:在任何网格拟合发生之前,dual_projection_vector与原始轮廓中出现的点平行设置。
从Stack设置Projection_Vector
SPVFS []
代码范围 的0x0A
流行 y:projection_vector的y分量(用零填充的2.14定点数)
x:projection_vector的x分量(用零填充的2.14定点数)
推 -
集 projection_vector
使用从堆栈中获取的值x和y设置projection_vector的方向,以便它在x和y轴上的投影是x和y,它们被指定为带符号(二进制补码)定点(2.14)数字。(x2 + y2)的平方根必须等于0x4000(十六进制)。
如果要在不同分辨率下使用字形程序,字体程序或预编程保存和使用值,则必须特别小心。取自或放在堆栈上的值是所讨论的矢量的x和y分量的2.14个定点值。这些值基于标准化的矢量长度。更简单地,必须始终设置值使得(X ** 2 + Y ** 2)为1。
如果TrueType程序使用X和Y的特定值将矢量设置为特定角度,则这些值将不会在不同的宽高比上产生相同的结果。以1:1宽高比正确工作的值(例如VGA和8514)不一定会以1.33:1的比例(例如EGA)产生所需的结果。
出于同样的原因,如果TrueType程序正在使用GPV和GFV返回的值,则返回特定角度的值将随着当时使用的宽高比而变化。
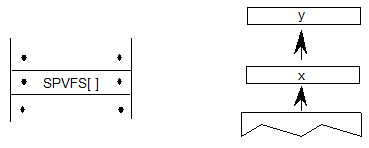
例:
SPVFS []
将projection_vector设置为指向x轴方向的单位矢量
从Stack中设置Freedom_Vector
SFVFS []
码 0x0B中
流行 y:freedom_vector的y分量(用零填充的2.14定点数)
x:x分量为freedom_vector(2.14定点数用零填充)
推 -
集 freedom_vector
使用从堆栈中获取的值x和y设置freedom_vector的方向。设置矢量使其在x和y轴上的投影为x和y,它们被指定为带符号(二进制补码)定点(2.14)数。(x2 + y2)的平方根必须等于0x4000(十六进制)。
如果要在不同分辨率下使用字形程序,字体程序或预编程保存和使用值,则必须特别小心。取自或放在堆栈上的值是所讨论的矢量的x和y分量的2.14个定点值。这些值基于标准化的矢量长度。更简单地,必须始终设置值使得(X ** 2 + Y ** 2)为1。
如果TrueType程序使用X和Y的特定值将矢量设置为特定角度,则这些值将不会在不同的宽高比上产生相同的结果。以1:1宽高比正确工作的值(例如VGA和8514)不一定会以1.33:1的比例(例如EGA)产生所需的结果。
出于同样的原因,如果TrueType程序正在使用GPV和GFV返回的值,则返回特定角度的值将随着当时使用的宽高比而变化。
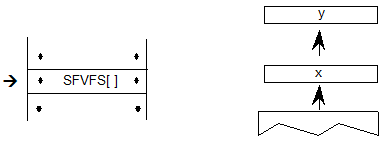
例:
将freedom_vector设置为指向y轴方向的单位矢量。
获取Projection_Vector
GPV []
代码范围 0x0C
流行 -
推 x:projection_vector的x分量(用零填充的2.14定点数)
y:projection_vector的y分量(用零填充的2.14定点数)
获取 projection_vector
将projection_vector的x和y分量作为两个2.14数字推送到堆栈上。
如果要在不同分辨率下使用字形程序,字体程序或预编程保存和使用值,则必须特别小心。取自或放在堆栈上的值是所讨论的矢量的x和y分量的2.14个定点值。这些值基于标准化的矢量长度。更简单地,必须始终设置值使得(X ** 2 + Y ** 2)为1。
如果TrueType程序使用X和Y的特定值将矢量设置为特定角度,则这些值将不会在不同的宽高比上产生相同的结果。以1:1宽高比正确工作的值(例如VGA和8514)不一定会以1.33:1的比例(例如EGA)产生所需的结果。
出于同样的原因,如果TrueType程序正在使用GPV和GFV返回的值,则返回特定角度的值将随着当时使用的宽高比而变化。
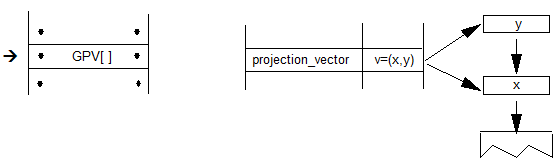
例:
情况1:
堆栈条目0x4000当被解释为2.14数字时仅为1.该命令显示,在这种情况下,projection_vector是指向x方向的单位向量。
案例2:
这里projection_vector是指向y轴方向的单位矢量。
案例3:
注意:0x2D41是sqrt(2)/ 2的十六进制等效值。作为该指令的结果,projection_vector被设置为相对于x轴成45度角。
获得Freedom_Vector
GFV []
代码范围 0X0D
流行 -
推 x:freedom_vector的x分量(用零填充的2.14数字)
y:freedom_vector的y分量(用零填充的2.14数字)
获取 freedom_vector
将freedom_vector的x和y组件放在堆栈上。freedom_vector作为两个2.14坐标放到堆栈上。
如果要在不同分辨率下使用字形程序,字体程序或预编程保存和使用值,则必须特别小心。取自或放在堆栈上的值是所讨论的矢量的x和y分量的2.14个定点值。这些值基于标准化的矢量长度。更简单地,必须始终设置值使得(X ** 2 + Y ** 2)为1。
如果TrueType程序使用X和Y的特定值将矢量设置为特定角度,则这些值将不会在不同的宽高比上产生相同的结果。以1:1宽高比正确工作的值(例如VGA和8514)不一定会以1.33:1的比例(例如EGA)产生所需的结果。
出于同样的原因,如果TrueType程序正在使用GPV和GFV返回的值,则返回特定角度的值将随着当时使用的宽高比而变化。
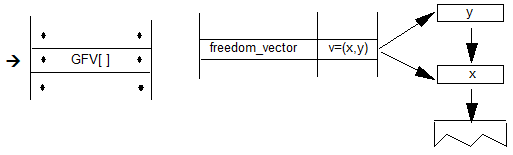
例:
GFV []
设置参考点0
SRP0 []
代码范围 为0x10
流行 p:点数(uint32)
推 -
集 RP0
影响 IP,MDAP,MIAP,MIRP,MSIRP,SHC,SHE,SHP
从堆栈中弹出一个点编号,并将rp0设置为该点编号。
设置参考点1
SRP1 []
代码范围 为0x11
流行 p:点数(uint32)
推 -
集 RP1
影响 IP,MDAP,MDRP,MIAP,MSIRP,SHC,SHE,SHP
从堆栈中弹出一个点编号,并将rp1设置为该点编号。
设置参考点2
SRP2 []
代码范围 0×12
流行 p:点数(uint32)
推 -
集 RP2
从堆栈中弹出一个点编号,并将rp2设置为该点编号。
设置区域指针0
SZP0 []
代码范围 0×13
流行 n:区号(uint32)
推 -
集 ZP0
影响 ALIGNPTS,ALIGNRP,DELTAP1,DELTAP2,DELTAP3,IP,ISECT,MD,MDAP,MIAP,MIRP,MSIRP,SHC,SHE,SHP,UTP
从堆栈中弹出区域编号n,并将zp0设置为具有该编号的区域。如果n为0,则zp0指向区域0.如果n为1,则zp0指向区域1.n的任何其他值都是错误。
例:
设置区域指针1
SZP1 []
代码范围 0×14
流行 n:区号(uint32)
推 -
集 ZP1
影响 ALIGNRPTS,ALIGNRP,IP,MD,MDRP,MSIRP,SHC,SHE,SHP,SFVTL,SPVTL
从堆栈中弹出区域编号n,并将zp1设置为具有该编号的区域。如果n为0,则zp1指向区域0.如果n为1,则zp1指向区域1.n的任何其他值都是错误。
例:
设置区域指针2
SZP2 []
代码范围 为0x15
流行 n:区号(uint32)
推 -
集 ZP2
影响 ISECT,IUP,GC,SHC,SHP,SFVTL,SHPIX,SPVTL,SC
从堆栈中弹出区域编号n,并将zp2设置为具有该编号的区域。如果n为0,则zp2指向区域0.如果n为1,则zp2指向区域1.n的任何其他值都是错误。
设置区域指针
SZPS []
代码范围 0x16
流行 n:区号(uint32)
推 -
集 zp0,zp1,zp2
影响 ALIGNPTS,ALIGNRP,DELTAP1,DELTAP2,DELTAP3,GC,IP,ISECT,IUP,MD,MDAP,MDRP,MIAP,MIRP,MSIRP,SC,SFVTL,SHPIX,SPVTL,SHC,SHE,SHP,SPVTL,UTP
从堆栈中弹出区域编号,并将所有区域指针设置为指向具有该编号的区域。如果n为0,则所有三个区域指针都将指向区域0.如果n为1,则所有三个区域指针将指向区域1.对于n,任何其他值都是错误。
圆形到半网格
RTHG []
代码范围 0x19
流行 -
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
用途 freedom_vector,projection_vector
从堆栈中弹出区域编号,并将所有区域指针设置为指向具有该编号的区域。如果n为0,则所有三个区域指针都将指向区域0.如果n为1,则所有三个区域指针将指向区域1.对于n,任何其他值都是错误。
将round_state变量设置为state 0 (hg)。在这种状态下,点的坐标四舍五入到最近的半网格线。
例
Round to Grid
RTG []
代码范围 为0x18
流行 -
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
用途 freedom_vector,projection_vector
将round_state变量设置为state 1 (g)。在此状态下,距离舍入到最近的网格线。
例
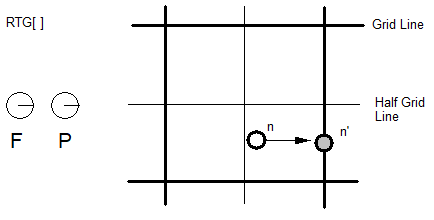
圆形到双网格
RTDG []
代码范围 0x3D之间
流行 -
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
用途 freedom_vector,projection_vector
将round_state变量设置为state 2 (dg)。在此状态下,距离舍入到最接近的半像素或整数像素。
例
向下舍入到网格
RDTG []
代码范围 0x7D
流行 -
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
用途 freedom_vector,projection_vector
将round_state变量设置为state 3 (dtg)。在此状态下,距离向下舍入到最接近的整数网格线。
例
向上舍入到网格
RUTG []
代码范围 0x7C
流行 -
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
用途 freedom_vector,projection_vector
将round_state变量设置为state 4 (utg)。在此状态下,距离向上舍入到最接近的整数像素边界
例
四舍五入
ROFF []
代码范围 0x7A
流行 -
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
用途 freedom_vector,projection_vector
将round_state变量设置为state 5 (off)。在这种状态下,舍入被关闭。
例
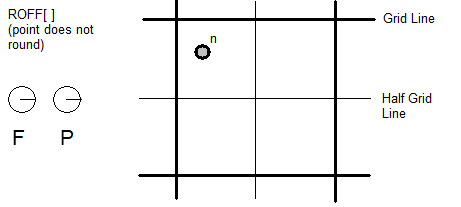
超级圆
环境[]
代码范围 0x76
流行 n:数字分解得到期间,阶段,门槛
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
SROUND允许您通过允许设置round_state的三个组件的值来精确控制round_state变量的效果:period,phase和threshold。
更正式地说,SROUND将26.6个固定点数的域映射到一组以相等距离分隔的离散值。SROUND从堆栈中获取一个参数n,它将其分解为句点,阶段和阈值。
该周期以网格间距的形式指定圆整值之间的间隔或间距的长度。
阶段指定值与周期的倍数的偏移量。
阈值指定映射到每个值的域的部分。更直观地说,阈值告诉值何时“向前”到下一个最大整数。
仅使用参数n的低8位。对于SROUND,gridPeriod等于1.0像素。该字节编码如下:位7和6编码周期,位5和4编码相位,位3,2,1和0编码阈值,如此处所示。
期
0 period = gridPeriod / 2
1 period = gridPeriod
2 period = gridPeriod * 2
3保留
相
0阶段= 0
1阶段=期间/ 4
2阶段=期间/ 2
3阶段= gridPeriod * 3/4
阈
0 threshold = period -1
1个阈值= -3/8 *期间
2阈值= -2/8 *期间
3阈值= -1/8 *期间
4阈值= 0/8 *周期
5阈值= 1/8 *周期
6阈值= 2/8 *期间
7阈值= 3/8 *期
8阈值= 4/8 *期间
9阈值= 5/8 *期间
10阈值= 6/8期
11阈值= 7/8 *期间
12阈值= 8/8 *期间
13阈值= 9/8 *期间
14阈值= 10/8 *期间
15阈值= 11/8 *期间
例如,SROUND(01:01:1000)将数字映射到值0.25,1.25,2.25,-0.25到0.75的数字映射到0.25。数字范围[0.75,1.75]映射到1.25。同样,[1.75,2.75]中的数字映射到数字2.25,依此类推。
在补偿发动机特性后发生舍入,因此舍入数字n的步骤为:
添加引擎补偿到n。
从n中减去相位。
将阈值添加到n。
将n截断为下一个最低周期值(忽略相位)。
将相位添加回n。
如果舍入导致正数变为负数,则将n设置为最接近0的正圆值。
如果舍入导致负数变为正数,则将n设置为最接近0的负圆值。
周期参数可以具有1/2像素,1像素或2像素的值。
相位参数可以具有0像素,1/4像素,1/2像素或3/4像素的值。
阈值参数可以具有-3/8周期,-2 / 8周期,11/8周期的值。它还可以具有特殊值max-number-small-than-period,这会导致舍入等效于CEILING。
超级45度
S45ROUND []
代码范围 0x77
流行 n:uint32分解得到期间,阶段,门槛(uint32)
推 -
集 round_state
影响 MDAP,MDRP,MIAP,MIRP,ROUND
S45ROUND类似于SROUND。gridPeriod是SQRT(2)/ 2像素而不是1像素。它对于与坐标轴成45度角进行测量非常有用。
设置LOOP变量
SLOOP []
代码范围 0×17
流行 n:循环图形状态变量的值(整数)
推 -
集 环
影响 ALIGNRP,FLIPPT,IP,SHP,SHPIX
从堆栈中弹出一个值n,并将循环变量count设置为该值。循环变量与SHP [a],SHPIX [a],IP [],FLIPPT []和ALIGNRP []一起使用。值n表示指令重复的次数。执行指令后,循环变量重置为1。
设置Minimum_ Distance
贴片[]
代码范围 0x1A的
流行 距离:minimum_distance的值(F26Dot6)
推 -
集 minimum_distance
弹出堆栈中的值并将minimum_distance变量设置为该值。假设距离以像素的六十四分之一表示。
INSTRuction执行ConTRoL
INSTCTRL []
代码范围 为0x8E
流行 s:选择器标志(int32)
value:uint16(填充为32位),用于设置instruction_control的值。
推 -
集 instruction_control
设置指令控制状态变量,可以打开或关闭指令的执行,并可以调节CVT程序中设置的参数的使用。INSTCTRL []只能在CVT程序中执行。
该指令清除并设置光栅化器中的各种控制标志。selector标志确定value参数的有效值。该值确定raterizer控制标志的新设置。在此版本中,有三个标志正在使用中:
选择器标志1用于禁止网格拟合。如果s = 1,则value参数的有效值为0(FALSE)和1(TRUE)。如果value参数设置为TRUE(v = 1),则不会执行与字形相关的任何指令。例如,要在旋转或拉伸字形时禁止网格拟合,请在预编程上使用以下序列:
推动[000] 6 / 要求GETINFO检查拉伸或旋转 /
获取信息[] 如果字形被拉伸或旋转,/ 将为TRUE *
如果[] / *测试堆栈顶部的值 /
PUSHB [000] 1 INSTCTRL的/ 值 /
PUSHB [000] 1 INSTCTRL的/ 选择器 /
INSTRCTRL [] / 基于选择器和值将关闭网格 /
EIF []
选择器标志2用于确定在执行与字形相关的指令时应忽略在CVT程序中设置的任何参数。这些包括,例如,scantype和CVT切入的值。如果s = 1,则value参数的有效值为0(FALSE)和2(TRUE)。如果value参数设置为TRUE(v = 2),则无论预编程可能对这些值进行任何更改,都将使用这些参数的默认值。如果value参数设置为FALSE(v = 0),则CVT程序更改的参数值将用于字形指令。
选择器标志3用于控制在使用ClearType TM时如何解释某些特定指令的某些方面。如果启用了选择器,则将以本机ClearType模式呈现字体,而不是向后兼容模式。如果value参数设置为TRUE(v = 4),则解释器将处于本机ClearType模式。如果value参数设置为FALSE(v = 0),则解释器将处于向后兼容模式。
SCAN转换ConTRoL
SCANCTRL []
代码范围 0x85
流行 n:指示何时开启压差控制模式的标志(16位字填充为32位)
推 -
集 scan_control
SCANCTRL用于设置图形状态变量scan_control的值,后者又决定扫描转换器是否将激活此字形的压降控制。使用丢失控制模式由三个条件决定:
字形是否旋转?
字形是否拉伸?
ppem的当前设置是否小于指定的阈值?
解释器从堆栈中弹出一个单词并查看低16位。
位0-7表示ppem的阈值。位0-7中的FF值表示调用所有大小的dropout_control。位0-7中的值0表示永远不会调用dropout_control。
位8-13用于在满足指定条件的情况下打开dropout_control。第8,9和10位用于打开dropout_control模式(假设其他条件不阻止它)。除非其他条件强制使用,否则比特11,12和13用于关闭丢失模式。第14和15位保留供将来使用。
位 意义如果设置
8 如果其他条件不阻塞且ppem小于或等于阈值,则将dropout_control设置为TRUE。
9 如果其他条件未阻止且旋转字形,则将dropout_control设置为TRUE
10 如果其他条件不阻塞且字形被拉伸,则将dropout_control设置为TRUE。
11 将dropout_control设置为FALSE,除非ppem小于或等于阈值。
12 除非旋转字形,否则将dropout_control设置为FALSE。
13 除非字形被拉伸,否则将dropout_control设置为FALSE。
14 保留供将来使用。
15 保留供将来使用。
例如:
为0x0000 没有调用dropout控件
0x01FF 总是做辍学控制
0x0A10 如果字形旋转并且每个小于16个像素,则执行丢失控制
扫描转换器可以在“正常”模式或“固定丢失”模式下操作,这取决于一组启用和禁用标志的值。
扫描类型
扫描类型[ ]
代码范围 0x8D
流行 n:16位整数
推 -
集 scan_control
弹出一个16位整数,其值用于确定扫描转换器将使用哪些规则。如果参数的值为0,则将使用快速扫描转换器。如果整数的值为1或2,则将使用简单的丢失控制。如果整数的值为4或5,则将使用智能丢失控制。进一步来说,
如果n = 0,则调用规则1,2和3(包括存根的简单丢失控制扫描转换)
如果n = 1,则调用规则1,2和4(不包括存根的简单丢失控制扫描转换)
如果n = 2,则仅调用规则1和2(快速扫描转换;关闭丢失控制)
如果n = 3,则n = 2
如果n = 4,则调用规则1,2和5(包括存根的智能丢失控制扫描转换)
如果n = 5,则调用规则1,2和6(智能丢失控制扫描转换,不包括存根)
如果n = 6,则n = 2
如果n = 7,则n = 2
扫描转换规则如下所示:
规则1 如果像素的中心位于字形轮廓内,则打开该像素。
规则2 如果轮廓精确地落在像素的中心,则该像素将打开。
规则3 如果两个相邻像素中心(垂直或水平)之间的扫描线与过渡轮廓和非过渡轮廓相交,并且规则1和2都没有打开任何像素,则打开左侧 - 大多数像素(水平扫描线)或最底部像素(垂直扫描线)。这是“简单”的丢失控制。
规则4 仅当两个轮廓在两个方向上继续与其他扫描线相交时才应用规则3。也就是说,不要打开“存根”的像素。检查与相交的扫描线段形成正方形的扫描线段以验证它们与两个轮廓相交。这些轮廓可能是与丢失扫描线段相交的轮廓不同的轮廓。这是非常不可能的,但可能必须通过网格拟合在一些奇异的字形中进行控制。
规则5 如果两个相邻像素中心(垂直或水平)之间的扫描线与过渡轮廓和非过渡轮廓相交,并且规则1和2都没有打开任何像素,请打开像素更接近过渡时轮廓和非过渡轮廓之间的中点。这是“智能”辍学控制。
规则6 仅当两个轮廓在两个方向上继续与其他扫描线相交时,才应用规则5。也就是说,不要打开“存根”的像素。
希望使用ScanType指令的新模式但仍希望在无法识别新模式的旧光栅化器上正常工作的新字体应该:
首先使用旧模式执行ScanType指令,这将给出所需新模式的最佳近似值(例如Smart Stubs的简单存根),然后
立即执行具有所需新模式的另一个ScanType指令。
设置控制值表切入
SCVTCI []
代码范围 0x1D
流行 n:cut_in的值(F26Dot6)
推 -
集 control_value_cut_in
影响 MIAP,MIRP
在Graphics State中设置control_value_cut_in。值n以像素的六十四分之四表示。
增加cut_in的值将增加将使用CVT值而不是原始轮廓值的大小范围。
设置Single_Width_Cut_In
SSWCI []
代码范围 0X1E
流行 n:single_width_cut_in的值(F26dot6)
推 -
集 single_width_cut_in
影响 MIAP,MIRP
在Graphics State中设置single_width_cut_in。值n以像素的六十四分之四表示。
设置单宽
SSW []
代码范围 为0x1F
流行 n:single_width_value的值(FUnits)
推 -
集 single_width_value
在Graphics State中设置single_width_value。single_width_value以FUnits表示。
将auto_flip布尔值设置为ON
FLIPON []
代码范围 送出0x4d
流行 -
推 -
集 auto_flip
影响 MIRP
将Graphics State中的auto_flip布尔值设置为TRUE,使MIRP指令忽略控制值表条目的符号。默认的auto_flip布尔值为TRUE。

将auto_flip布尔值设置为OFF
FLIPOFF []
代码范围 0x4E
流行 -
推 -
集 auto_flip
影响 MIRP
将Graphics State中的auto_flip布尔值设置为FALSE,使MIRP指令使用控制值表条目的符号。默认的auto_flip布尔值为TRUE。

设置角度_Weight
SANGW []
代码范围 的0x7E
流行 weight:angle_weight的值
推 -
集 angle_weight
由于支持AA(调整角度)指令,不再需要SANGW。AA是唯一在全局图形状态下使用angle_weight的指令。
从堆栈弹出权重值并相应地设置angle_weight状态变量的值
将Delta_Base设置为图形状态
SDB []
代码范围 0x5E
流行 -
推 -
集 delta_base
影响 DELTAP1,DELTAP2,DELTAP3,DELTAC1,DELTAC2,DELTAC3
弹出一个数字n,并将delta_base设置为值n。delta_base的默认值为9。
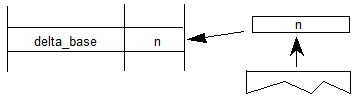
将Delta_Shift设置为图形状态
SDS []
代码范围 0x5F的
流行 n:delta_shift的值(uint32)
推 -
集 delta_shift
影响 DELTAP1,DELTAP2,DELTAP3,DELTAC1,DELTAC2,DELTAC3
将delta_shift设置为值n。delta_shift的默认值为3。
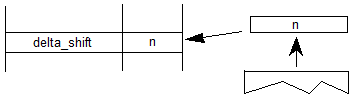
读写数据
以下说明可以获取和设置点坐标,测量两点之间的距离,以及确定每个像素和点大小的像素的当前设置。
将坐标投影到projection_vector上
GC [一]
代码范围 0x46 - 0x47
一个 0:使用点p的当前位置
1:使用原始轮廓中的点p的位置
流行 p:点数(uint32)
推 值:坐标位置(F26Dot6)
用途 zp2,projection_vector
测量当前projection_vector上的点p的坐标值,并将该值压入堆栈。
例
以下示例显示GC返回的值取决于projection_vector的当前位置。请注意,点p位于坐标网格中的位置(300,420)。
GC [1] 9
使用projection_vector和freedom_vector设置堆栈的坐标
SCFS []
代码范围 0x48
流行 值:从原点到移动点的距离(F26Dot6)
p:点数(uint32)
推 -
用途 zp2,freedom_vector,projection_vector
沿着freedom_vector将点p从其当前位置移动,以使其沿projection_vector的组件成为从堆栈弹出的值。
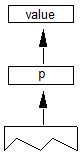
测量距离
MD [一]
代码范围 0x49 - 0x4A
一个 0:测量网格轮廓中的距离
1:测量原始轮廓的距离
流行 p1:点数(uint32)
p2:点数(uint32)
推 距离(F26Dot6)
用途 zp1与点p1,zp0与点p2,projection_vector
测量轮廓点p1和轮廓点p2之间的距离。返回的值以像素为单位(F26Dot6)如果距离为负,则根据投影矢量进行测量。反转列出的顺序将改变结果的符号。
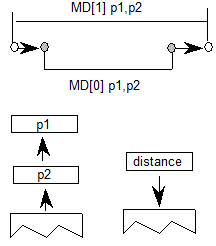
例:
在下图中,在25 dpi设备上,点25和31之间的MD [1]将返回比MD [0]更小的值,每个10像素。不同之处在于网格拟合的影响,在这个尺寸下,网格适合延伸到柜台。
每个EM测量像素数
MPPEM []
代码范围 0x4B
流行 -
推 ppem:每个像素(uint32)
该指令将每个em的像素数推入堆栈。每个像素的像素是渲染设备的分辨率和当前点大小以及当前变换矩阵的函数。该指令查看projection_vector并返回该方向上每个em的像素数。
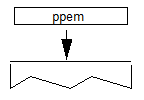
测量点大小
MPS []
代码范围 0x4C
流行 -
推 pointSize:当前字形的点大小(F26Dot6)
将当前点大小推入堆栈。
测量点大小可用于获得一个值,该值用作选择是否通过指令流分支到备用路径的基础。它可以不同地处理低于或高于某个阈值的点尺寸

管理大纲
以下指令集可以移动构成字形轮廓的点。它们是完成网格拟合实际工作的指令。它们包括移动点,移位点或点组,翻转点从曲线到曲线或反之亦然的指令,以及插值点
FLIP PoinT
FLIPPT []
代码范围 0x80的
流行 p:点数(uint32)
推 -
用途 循环,p在zp0中引用
翻转离开曲线的点,使它们位于曲线上,并使曲线上的点离开曲线。该点未标记为已触摸。FLIPPT指令的结果是重新定义了描述字形轮廓的一部分的轮廓
之前
后
FLIP RanGe ON
FLIPRGON []
代码范围 0×81
流行 highpoint:要翻转的点范围内的最高点数(uint32)
lowpoint:要翻转的点范围内的最低点数(uint32)
推 -
翻转以低点开始并以高点结束的一系列点,以便曲线点上的任何曲线点都变为曲线点。这些点未标记为已触摸
例:
之前
后
如图所示,将点0和点5之间的所有曲线点都设置在曲线点上
FLIP RanGe OFF
FLIPRGOFF []
代码范围 为0x82
流行 highpoint:要翻转的点范围内的最高点数(uint32)
lowpoint:要翻转的点范围内的最低点数(uint32)
推 -
翻转以低点开始并以高点结束的一系列点,以便曲线点上的任何曲线点都变为曲线点。这些点未标记为已触摸。
注意:此指令会更改曲线,但点的位置不受影响。因此,受此指令影响的点未标记为已触摸。
例:
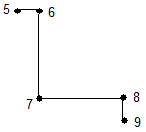
之前
后
SHift Point的最后一点
SHP并[a]
代码范围 0x32 - 0x33
一个 0:在zp1指向的区域中使用rp2
1:在zp0指向的区域中使用rp1
流行 p:要转移的点(uint32)
推 -
用途 zp0与rp1或zp1与rp2取决于标志
zp2与点p
loop,freedom_vector,projection_vector
将点p移动与参考点移位的量相同。点p沿freedom_vector移动,使得点p的新位置与点p的当前位置之间的距离与参考点的当前位置和参考点的原始位置之间的距离相同。
注意:点p从其当前位置移开,而不是从其原始位置移位。在其当前位置和原始位置之间测量参考点已经移动的距离。
在下图中,rp是参考点的原始位置,rp’是参考点的当前位置,p是点p的原始位置,p’是当前位置,p“是位移后的位置SHP指令。(白色表示原始位置,灰色表示当前位置,黑色表示该指令移动点的位置
SHift Contour的最后一点
SHC [α]
代码范围 0x34 - 0x35
一个 0:在zp1指向的区域中使用rp2
1:在zp0指向的区域中使用rp1
流行 c:要移动的轮廓(uint32)
推 -
用途 zp0与rp1或zp1与rp2取决于标志
zp2与轮廓c
freedom_vector,projection_vector
将轮廓c上的每个点移动与参考点移动的量相同。每个点沿freedom_vector移动,使得该点的新位置与该点的旧位置之间的距离与参考点的当前位置和参考点的原始位置之间的距离相同。沿projection_vector测量距离。如果参考点是定义轮廓的点之一,则该指令不会移动参考点。
该指令类似于SHP,但轮廓上的每个点都被移位。
最后一点是SHift Zone
SHZ并[a]
代码范围 0x36 - 0x37
一个 0:参考点rp2位于zp1指向的区域中
1:参考点rp1位于zp0指向的区域中
流行 e:要移动的区域(uint32)
推 -
用途 zp0与rp1或zp1与rp2取决于标志
freedom_vector,projection_vector
将指定区域(Z1或Z0)中的点移动与参考点移动的量相同。区域中的点沿freedom_vector移动,使得移位点的新位置与其旧位置之间的距离与参考点的当前位置与参考点的原始位置之间的距离相同。
SHZ [a]使用zp0和rp1或zp1和rp2。该指令类似于SHC,但区域中的所有点都被移位,而不仅仅是单个轮廓上的点。
通过PIXel量进行SHIFT点
SHPIX []
代码范围 0x38
流行 数量:班次的大小(F26Dot6)
p1,p2,… pn:要移位的点(uint32)
推 -
用途 zp2,loop,freedom_vector
移动指定金额指定的点数。当使用循环变量时,要移位的量仅被放入堆栈一次。也就是说,如果loop = 3,那么堆栈顶部的内容应该是点p1,点p2,点p3,数量。值量以像素的六十四分之四表示。
SHPIX独特地依赖于freedom_vector的方向。它没有使用projection_vector。在freedom_vector的方向上进行测量。
例
该指令在自由向量的方向上将点27,28和29移位80/64或1.25像素。距离是在freedom_vector的方向上测量的; 投影向量被忽略。
SHPIX []
移动堆栈间接相对点
MSIRP并[a]
代码范围 0x3A - 0x3B
一个 0:不要将rp0设置为p
1:将rp0设置为p
流行 d:距离(F26Dot6)
p:点数(uint32)
推 -
用途 zp1与点p和zp0与rp0,freedom_vector,projection_vector。
集 移动点后,该指令设置rp1 = rp0,rp2 =点p,如果a = 1,则rp0设置为p点。
使点p和rp0之间的距离等于堆栈上指定的值。堆栈上的距离是小数像素(F26Dot6)。MSIRP与MIRP指令具有相同的效果,除了它从堆栈而不是控制值表中获取其值。因此,cut_in不会影响MSIRP的结果。此外,MSIRP不受round_state的影响。
移动直接绝对点
MDAP并[a]
代码范围 0x2E - 0x2F
一个 0:不要舍入值
1:绕过值
流行 p:点数(uint32)
推 -
集 rp0 = rp1 =点p
用途 zp0,round_state,projection_vector,freedom_vector。
将参考点rp0和rp1设置为等于p。如果a = 1,则该指令将点p舍入到状态变量round_state指定的网格点。如果a = 0,它只是将点标记为当前freedom_vector指定的方向。此命令通常用于设置黄昏区域中的点。
例:
MDAP [0]
当a = 0时,该点被简单地标记为触摸,并且rp0和rp1的值设置为点p。
MDAP [1]假设round_state是圆形到网格并且libe_vector是显示的。
移动间接绝对点
MIAP并[a]
代码范围 0x3E - 0x3F
一个 0:不要绕距离,不要看control_value_cut_in
1:绕过距离并查看control_value_cut_in
流行 n:CVT条目号(uint32)
p:点数(uint32)
推 -
集 rp0 = rp1 =点p
用途 zp0,round_state,control_value_cut_in,freedom_vector,projection_vector
将点p移动到第n个控制值表条目指定的绝对坐标位置。沿当前projection_vector测量坐标。如果a = 1,则位置将按round_state指定的舍入。如果a = 1,并且如果CVT值与原始位置之间的设备空间差异大于control_value_cut_in,则原始位置将被舍入(而不是CVT值。)
完成舍入就好像整个坐标系已经旋转到与projection_vector一致。也就是说,如果round_state设置为1,并且projection_vector和freedom_vector与x轴成45°角,那么2.9像素点的MIAP [1]将沿projection_vector舍入到3.0像素。
上面的布尔值控制舍入和control_value_cut_in的使用。如果您希望此布尔值的含义仅指定MIAP []指令是否应该查看control_value_cut_in值,请使用ROFF []指令关闭舍入。
该指令可用于创建Twilight Zone点。
例:
MIAP [1] 4 7
情况1:
舍入为OFF

该点移动到CVT中指定的位置。
案例2:
cut_in测试成功,舍入为RTG。
CVT中的值受到舍入规则的影响,然后将点移动到圆角位置。

案例3:
cut_in测试失败,舍入为OFF。
这里没有移动点。
案例4:
cut_in测试失败,舍入为RTG。
在这种情况下,点移动到最近的网格位置。
移动直接相对点
MDRP [ABCDE]
代码范围 0xC0 - 0xDF
一个 0:移动后不要将rp0设置为p点
1:移动后将rp0设置为p点
b 0:不要保持距离大于或等于minimum_distance
1:保持距离大于或等于minimum_distance
C 0:不要绕距离
1:绕过距离
德 发动机特性补偿的距离类型
流行 p:点数(uint32)
推 -
集 在点p移动后,rp1设定为rp0,rp2设定为等于点p; 如果a标志设置为TRUE,则rp0设置为等于point
用途 zp0与rp0和zp1与点p,round_state,single_width_value,single_width_cut_in,freedom_vector,projection_vector。
MDRP沿freedom_vector移动点p,使得从新位置到当前位置rp0的距离与原始未构造轮廓中两点之间的距离相同,然后将其调整为与布尔设置一致。请注意,只有rp0和point p的原始位置以及rp0的当前位置才能确定沿freedom_vector的点p的新位置。
MDRP通常用于使用来自原始轮廓的值来控制字形要素的宽度或高度。由于MDRP使用直接测量并且未引用control_value_cut_in,因此它用于控制对所指示的字形唯一的测量。如果需要通过处理字体中其他字形中的点来协调点的控制,则需要MIRP指令。
尽管MDRP没有引用CVT,但其效果确实取决于单宽度切入值。如果从未构造轮廓获取的测量值与single_width_value之间的设备空间距离小于single_width_cut_in,则将优先使用single_width_value而不是轮廓距离。换句话说,如果两个距离足够接近(相差小于single_width_cut_in),则将使用single_width_value。
round_state Graphics State变量的设置将确定点p与点q的距离是否以及如何舍入。如果未设置圆位,则该值将保持不变。如果设置了圆形位,则效果将取决于舍入状态的选择。最小距离变量的值是两个点之间的距离可以舍入到的最小可能值。
使用MDRP指令测量的距离必须为黑色,白色或灰色。在Booleans de中指示该值允许解释器根据需要补偿发动机特性。值de指定距离类型,如章节“Instructing Glyphs”中所述。可能有三个值:Gray = 0,Black = 1,White = 2。
例1:
图形状态设置

RP0 7
RP1 ?
RP2 ?
情况1:

RP0 7
RP1 7
RP2 8
案例2:
RP0 8
RP1 7
RP2 8
例2:
移动点p使其与rp1的距离与原始轮廓中的距离相同。
移动间接相对点
MIRP [ABCDE]
代码范围 0xC0 - 0xDF
一个 0:不要将rp0设置为p
1:将rp0设置为p
b 0:不要保持距离大于或等于minimum_distance
1:保持距离大于或等于minimum_distance
C 0:不要绕距离,不要看control_value_cut_in
1:绕过距离并查看control_value_cut_in值
德 发动机特性补偿的距离类型
流行 n:CVT条目号(uint32)
p:点数(uint32)
推 -
用途 zp0与rp0和zp1与点p。round_state,control_value_cut_in,single_width_value,single_width_cut_in,freedom_vector,projection_vector
集 移动点后,该指令设置rp1 = rp0,rp2 =点p,如果a = 1,则rp0设置为p点。
MIRP指令可以保留两个点之间的距离,具有多种资格。根据布尔标志b的设置,距离可以保持大于或等于minimum_distance状态变量建立的值。类似地,可以根据round_state图形状态变量将指令设置为舍入距离。最小距离变量的值是两个点之间的距离可以舍入到的最小可能值。此外,如果设置了c布尔值,则MIRP指令将作用于control_value_cut_in。如果实际测量值与CVT中的值之间的差异足够小(小于cut_in_value),则将使用CVT值而不是实际值。
MIRP测量相对于点rp0的距离。更正式地说,MIRP沿着freedom_vector移动点p,使得从p到rp0的距离等于参考CVT条目中规定的距离(假设cut_in测试成功)
上面的c布尔值控制舍入和控制值表条目的使用。如果您希望此布尔值的含义仅指定MIRP []指令是否应该查看control_value_cut_in,请使用ROFF []指令关闭舍入。以这种方式,可以指定四舍五入并且不指定cut_in。
值de指定距离类型,如章节“指示字形”中所述。可能有三个值:灰色= 0,黑色= 1,白色= 2。
例1:
MIRP 3 17
情况1:
cut_in测试成功并且舍入已关闭。
移动该点使得RP0的距离等于CVT条目17中给出的距离。
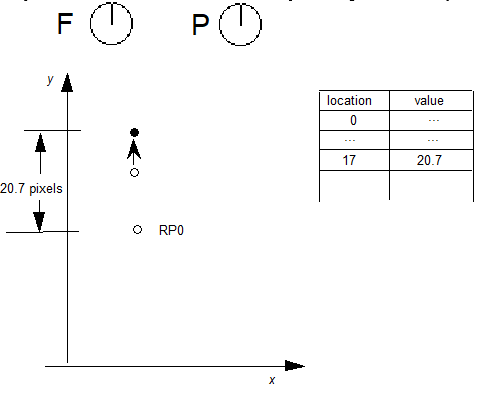
案例2:
cut_in测试成功,舍入设置为RTG。
CVT中的距离是圆形的,并且该点移动了圆形距离。
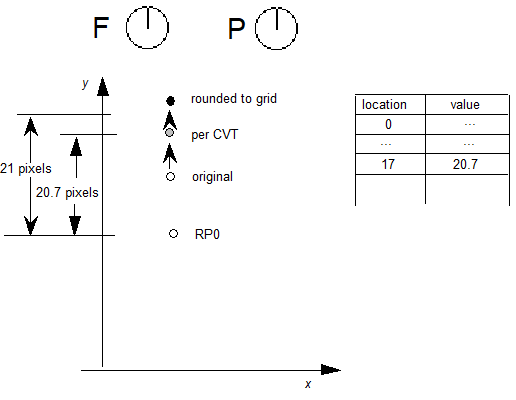
案例3:
cut_in测试失败,round_state为OFF。
这一点没有动摇。
案例4:
cut_in测试失败,round_state为RTG。
该点的当前位置四舍五入到网格。
ALIGN相对点
ALIGNRP []
代码范围 为0x3C
流行 p:点数(uint32
推 -
用途 zp1与点p,zp0与rp0,loop,freedom_vector,projection_vector。
将rp0和点p之间的距离减小到零。由于距离是沿projection_vector测量的,并且沿着freedom_vector移动,因此指令的效果是对齐点。
情况1:
案例2:
将点p移动到两行的InterSECTion
ISECT []
代码范围 为0x0F
流行 b1:第2行的终点(uint32)
b0:第2行的起点(uint32)
a1:第1行的终点(uint32)
a0:第1行的起点(uint32)
p:指向移动(uint32)
推 -
用途 zp2与点p,zp1与线A,zp0与线B
将点p放在线A和B的交点处。点a0和a1定义线A.类似地,b0和b1定义线B.ISECT忽略移动点p中的freedom_vector。
例:
ISECT [] 21 9 5 4 7
注意:如果线条彼此平行,则将点放在两条线的中间。
例:
ISECT [] 21 9 5 4 7
ALIGN积分
ALIGNPTS []
代码范围 0×27
流行 p1:点数(uint32)
p2:点数(uint32)
推 -
用途 zp1与点p1,zp0与点p2,freedom_vector,projection_vector。
通过沿freedom_vector移动它们沿projection_vector的两个投影的平均值,使点1和点2之间的距离为零。
例:
ALIGNPTS [] 3 7
通过最后一次相对伸展来插值点
IP []
代码范围 0x39
流行 p:点数(uint32)
推 -
用途 zp0与rp1,zp1与rp2,zp2与点p,循环,freedom_vector,projection_vector
移动点p,使其与rp1和rp2的关系与原始未构造轮廓中的相同。沿projection_vector进行测量,并且满足插值关系的移动被约束为沿freedom_vector。如果rp1和rp2在projection_vector上具有相同的位置,则该指令是非法的。
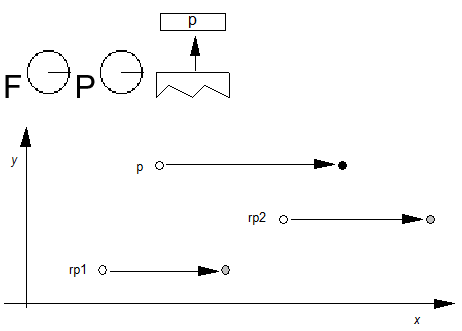
在所示的示例中,假设rp1和rp2引用的点如图所示移动。然后使用IP指令来保持它们与点p的相对关系。在IP之后,以下应该是真的
D(p,rp1)/ D(p’,rp1’)= D(p,rp2)/ D(p’,rp2’)
换句话说,保留了相对距离。
UnTouch Point
UTP []
代码范围 0x29
流行 p:点数(uint32)
推 -
用途 zp0与点p,freedom_vector
标记为p未触及。可以在x方向,y方向,两者或两者上触摸点。该指令使用当前的freedom_vector来确定是否触开x方向,y方向或两者的点。标记为未触摸的点将由IUP(插入未触摸的点)指令移动。使用UTP可以确保IUP即使之前触摸过一个点也会受到影响。
通过轮廓插入未触及的点
IUP并[a]
代码范围 0x30 - 0x31
一个 0:在y方向上插值
1:在x方向上插值
流行 -
推 -
用途 zp2,freedom_vector,projection_vector
通过轮廓考虑字形轮廓,移动每个轮廓中位于一对触摸点之间的任何未触摸点。如果未触摸点的坐标最初位于触摸对的坐标之间,则在新坐标之间线性插值,否则未触摸点移动最近触摸点移位的量。
该指令对zp2指向的字形区域中的点进行操作。该区域几乎总是区域1.将IUP应用于区域0是一个错误。
考虑所有在同一轮廓上的三个连续点。三个点中的两个,p1和p3已被触及。点p2未受影响。IUP在x方向上的作用是移动点p2,使得它们在移动之前与点p1和p3处于相同的相对位置。
IUP指令不会触及它移动的点。因此,受IUP指令影响的未受影响的点将受到后续IUP指令的影响,除非它们被中间指令触及。在这种情况下,忽略第一个插值,并根据其原始位置移动点。
管理例外
DELTA指令可用于改变特定大小的字形轮廓。它们通常用于打开或关闭特定像素。Delta指令通过移动点(DELTAP)或通过更改控制值表(DELTAC)中的值来工作。
更正式地说,DELTA指令从堆栈中获取可变数量的参数并允许使用形式的异常:在大小x处将运动d应用于点p(或在大小x处加上或减去小于或等于的量到控制值表条目c)。DELTA采用表单的例外列表:相对ppem值,异常的大小以及要应用异常的点号。
每个DELTA指令适用于下面指定的一系列大小。因此,大小以每em的相对像素(ppem)指定,即相对于delta_base。delta_base的默认值为9 ppem。要将delta_base设置为其他值,请使用SDB指令。
假设delta_base的默认值,DELTAP1和DELTAC1指令允许为9到24 ppem的字形更改值。降低delta_base的值允许您以较小的ppem数调用异常。
DELTAP2和DELTAC2在比DELTAP1和DELTAC1设置的值高16 ppem时触发,因此相对ppem的公式为
ppem - 16 - delta_base。
DELTAP3和DELTAC3的触发值比DELTAP2和DELTAC2设置的值高16 ppe,或者比DELTAP1和DELTAC1设置的值高32 ppem,因此相对ppem的公式为:
ppem - 32 - delta_base。
DELTA * 1 delta_base通过delta_base + 15 ppem
DELTA * 2 delta_base + 16 ppem到delta_base + 31 ppem
DELTA * 3 delta_base + 32 ppem到delta_base + 47 ppem
在指定DELTA指令时,arg 1的高4位描述将激活异常的相对ppem值。
arg 1的低4位描述了异常的大小。点移动的量是所述异常和图形状态变量delta_shift的函数。要设置delta_shift,请使用SDS指令

注意:始终注意DELTA指令期望参数列表根据ppem进行排序。堆栈中最低的ppem应该是最深的,并且堆栈中最高的ppem应该是最顶层的。
在以下指令的描述中,p i是点编号,c i是控制值表条目编号,arg i是由两部分组成的字节:相对ppem(ppem - delta_base)和异常的大小。
增加delta_shift将允许在牺牲总移动范围的情况下更精细地控制像素移动。步长是delta指令可以移动点的最小量。点可以以整数倍的步长移动。
步长为1除以2为幂delta_shift。给定delta_shift产生的移动范围可以通过获取允许的步数(16)并将其除以2来计算功率delta_shift来计算。例如,delta_shift等于2允许最小移动为±1/4像素(因为2 2等于4),最大移动为±2像素(16/4 = 4像素移动)。delta_shift为5允许最小移动为±1/ 32 像素(因为2 5等于32),但最大移动限制为±1/4像素。(16/32 =运动的1/2像素)。
在内部,为异常获得的值存储为4位二进制数。因此,在转换为二进制之前,必须将所需的输出范围转换为0到15之间的数字。这是DELTA指令的内部重映射表。
注意:输出范围内缺少零。
步数 →例外
-8 0
-7 1
-6 2
-5 3
-4 4
-3 五
-2 6
-1 7
1 8
2 9
3 10
4 11
五 12
6 13
7 14
8 15
DELTA例外P1
DELTAP1 []
代码范围 0x5D
流行 n:异常规范和点对的数量(uint32)
p1,arg 1,p2,arg 2,…,pn n arg n:n对异常规范和点(uint32s对)
推 -
用途 zp0,delta_base,delta_shift
DELTAP1按大小和配对参数中指定的数量移动指定的点。可以指定任意数量的点和参数。
分组[p i,arg i ]可以执行n次。argi的值可能在迭代之间变化。
DELTA例外P2
DELTAP2 []
代码范围 0x71
流行 n:异常规范和点对的数量(uint32)
p1,arg 1,p2,arg 2,…,pn n arg n:n对异常规范和点(uint32s对)
推 -
用途 zp0,delta_shift,delta_base
DELTAP2按大小和配对参数中指定的数量移动指定的点。可以指定任意数量的点和参数。
分组[p i,arg i ]可以执行n次。arg i的值可能在迭代之间变化。
DELTA例外P3
DELTAP3 []
代码范围 0x72
流行 n:异常规范和点对的数量(uint32)
p1,arg 1,p2,arg 2,…,pn n arg n:n对异常规范和点(uint32s对)
推 -
用途 zp0,delta_base,delta_shift
DELTAP3按大小和配对参数中指定的数量移动指定的点。可以指定任意数量的点和参数。
分组[p i,arg i ]可以执行n次。arg i的值可能在迭代之间变化。
DELTA例外C1
DELTAC1 []
代码范围 0x73
流行 n:异常规范对和CVT条目号对(uint32)
c 1,arg 1,c 2,arg 2,…,c n,arg n :(对uint32s对)
推 -
DELTAC1更改在大小中指定的每个CVT条目中的值以及在其配对参数中指定的量。
分组[c i,arg i ]可以执行n次。arg i的值可能在迭代之间变化。
DELTA例外C2
DELTAC2 []
代码范围 0x74
流行 n:异常规范对和CVT条目号对(uint32)
c 1,arg 1,c 2,arg 2,…,c n,arg n :(对uint32s对)
推 -
DELTAC2更改在大小中指定的每个CVT条目中的值以及在其配对参数中指定的量。
分组[c i,arg i ]可以执行n次。arg i的值可能在迭代之间变化。
DELTA例外C3
DELTAC3 []
代码范围 0x75
流行 n:异常规范对和CVT条目号对(uint32)
c 1,arg 1,c 2,arg 2,…,c n,arg n :(对uint32s对)
推 -
DELTAC3更改在大小中指定的每个CVT条目中的值以及在其配对参数中指定的量。
分组[c i,arg i ]可以执行n次。arg i的值可能在迭代之间变化。
DELTA异常的示例
假设你想沿着freedom_vector移动你的字形的1/8像素,每个像素12个像素。假设delta_base的默认值为9,delta_shift的默认值为3。
要指定异常应在12 ppem处进行,则从12中减去delta_base(即9),并将结果(即3)存储在arg i的高半字节中。
要指定要将点移动1/8像素,请将1/8乘以2加到幂delta_shift。换句话说,将1/8乘以2乘以第三个幂(或8),产生1.该值必须映射到一个内部值,使用所示的表为8。
将这两个结果放在一起产生高半字节中的3和低半字节中的8或56(00111000,二进制)。
要获得此单个异常,堆栈顶部为:56,15,1。
复制
(iteration)
(point number)
(arg1: ppem and magnitude)
现在,如果解释器执行
DELTAP1 []
那么这条指令将沿着freedom_vector移动字形的第15点(12 ppem)1/8像素。
管理堆栈
以下指令集可以管理堆栈中的元素。它们可以复制堆栈顶部的元素,从堆栈中删除顶部元素,清除堆栈,交换前两个堆栈元素,确定当前堆栈中元素的数量,将指定元素复制到堆栈堆栈顶部,将指定元素移动到堆栈顶部,并重新排列堆栈顶部三个元素的顺序。
复制顶部堆栈元素
DUP []
代码范围 为0x20
流行 e:stack元素(uint32)
推 e,e(两个uint32s)
复制堆栈顶部的元素。
POP顶级堆栈元素
POP []
代码范围 为0x21
流行 e:stack元素(uint32)
推 -
弹出堆栈的顶部元素。
清除整个堆栈
清除[]
代码范围 为0x22
流行 堆栈中的所有项目(uint32s)
推 -
清除堆栈中的所有元素。
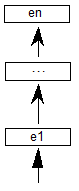
SWAP堆栈中的前两个元素
SWAP []
代码范围 0×23
流行 e2:堆栈元素(uint32)
e1:堆栈元素(uint32)
推 e1,e2(一对uint32s)
交换堆栈的前两个元素,使旧的top元素从顶部开始,第二个元素是top元素。
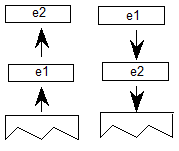
返回堆栈的DEPTH
深度[]
代码范围 0X24
流行 -
推 n:元素数量(uint32)
将n,当前堆栈中的元素数量推入堆栈。
例:
将INDEXed元素复制到堆栈顶部
CINDEX []
代码范围 0x25
流行 k:堆栈元素编号
推 e k:索引元素(uint32)
将第k个堆栈元素的副本放在堆栈顶部。
例:
将INDEXed元素移动到堆栈顶部
MINDEX []
代码范围 0×26
流行 k:堆栈元素编号
推 e k:索引元素
将索引元素移动到堆栈顶部。
MINDEX []
滚动前三个堆栈元素
ROLL []
代码范围 0x8a
流行 a,b,c(前三个堆栈元素)
推 b,a,c(元素重新排序)
执行堆栈顶部三个对象的循环移位,效果是将第三个元素移动到堆栈顶部并将前两个元素向下移动一个位置。ROLL相当于MINDEX [] 3。
管理控制流程
本节描述了那些可以改变指令流中项目执行顺序的指令。IF和JMP指令及其变体通过测试堆栈上元素的值并相应地更改指令指针的值来工作。
IF测试
IF []
代码范围 将0x58
流行 e:stack元素(uint32)
推 -
测试弹出堆栈的元素:如果它为零(FALSE),则指令指针跳转到指令流中的下一个ELSE或EIF指令。如果堆栈顶部的元素为非零(TRUE),则执行指令流中的下一条指令。执行继续,直到遇到ELSE指令或EIF指令结束IF。如果在EIF之前找到else语句,则指令指针将移动到EIF语句。
情况1:
堆栈顶部的元素为TRUE; 指令指针不受影响。IF终止于EIF。
案例2:
堆栈顶部的元素为TRUE。顺序执行指令流,直到遇到ELSE,然后指令指针跳转到终止IF的EIF语句。
案例3:
堆栈顶部的元素为FALSE; 指令指针移动到ELSE语句; 然后按顺序执行指令; EIF结束IF声明。
其他
ELSE []
代码范围 0x1B
流行 -
推 -
如果IF指令在堆栈上遇到FALSE值,则标记要执行的指令序列的开始。该指令序列用EIF指令终止。
万一
EIF []
代码范围 0×59
流行 -
推 -
标记IF []指令的结尾。
跳跃相对真实
JROT []
代码范围 0x78
流行 b:布尔值(uint32)
offset:移动指令指针的字节数(int32)
推 -
获得偏移量并测试布尔值。如果布尔值为TRUE,则有符号偏移量将被添加到指令指针,并且将在获得的地址处恢复执行。否则,不进行跳转。跳转是相对于指令本身的位置。也就是说,当添加偏移量以获得新地址时,指令指针仍然指向JROT []指令。

例:
情况1:
Boolean为FALSE。
案例2:
布尔值为TRUE。
跳
JMPR []
代码范围 为0x1C
流行 offset:移动指令指针的字节数(int32)
推 -
带符号的偏移量被添加到指令指针,并在指令流中的新位置恢复执行。跳转是相对于指令本身的位置。也就是说,当添加偏移量以获得新地址时,指令指针仍然指向JROT []指令。
跳转相对错误
JROF []
代码范围 0x79的
流行 e:stack元素(uint32)
offset:移动指令指针的字节数(int32)
推 -
在布尔值为FALSE的情况下,有符号偏移量将被添加到指令指针并在那里恢复执行; 否则,不采取跳跃。跳转是相对于指令本身的位置。也就是说,当添加偏移量以获得新地址时,指令指针仍然指向JROT []指令。
情况1:
元素是假的。
案例2:
element为TRUE。
逻辑功能
TrueType指令集包括一组逻辑函数,可用于测试堆栈元素的值或比较两个堆栈元素的值。逻辑函数比较32位值(uint32)并将布尔值返回到堆栈顶部。
要轻松记住逻辑运算期间处理堆栈值的顺序,请想象从左到右写入堆栈值,从底部值开始。然后将操作员插入两个最右边的元件之间。例如:
GT a,b将被解释为(b> a):
cb> a
少于
LT []
代码范围 为0x50
流行 e2:堆栈元素(uint32)
e1:堆栈元素(uint32)
推 布尔值(范围[0,1]中的uint32)
首先弹出e2,然后从堆栈中弹出e1并比较它们:如果e1小于e2,则表示为TRUE的1被推入堆栈。如果e1不小于e2,那么表示为FALSE的0被置于堆栈上。
例:
LT []
小于或等于
LTEQ []
代码范围 0x51
流行 e2:堆栈元素(uint32)
e1:堆栈元素(uint32)
推 布尔值(范围[0,1]中的uint32)
将e2和e1弹出堆栈并进行比较。如果e1小于或等于e2,则表示为TRUE的1被推入堆栈。如果e1不小于或等于e2,则表示为0,表示为FALSE。
例:
LTEQ []
比…更棒
GT []
代码范围 0×52
流行 e2:堆栈元素(uint32)
e1:堆栈元素(uint32)
推 布尔值(范围[0,1]中的uint32)
首先弹出e2然后从堆栈弹出e1并比较它们。如果e1大于e2,则表示为TRUE的1被推入堆栈。如果e1不大于e2,则表示为0,表示为FALSE。
例:
GT []
大于或等于
GTEQ []
代码范围 0x53
流行 e2:堆栈元素(uint32)
e1:堆栈元素(uint32)
推 布尔值(范围[0,1]中的uint32)
将e1和e2弹出堆栈并进行比较。如果e1大于或等于e2,则表示为TRUE的1被推入堆栈。如果e1不大于或等于e2,则表示为0,表示为FALSE。
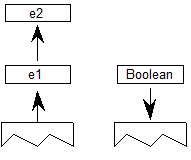
例:
GTEQ []
等于
情商[]
代码范围 0x54
流行 e2:堆栈元素(uint32)
e1:堆栈元素(uint32)
推 布尔值(范围[0,1]中的uint32)
将e1和e2弹出堆栈并进行比较。如果它们相等,则1表示TRUE被压入堆栈。如果它们不相等,则表示为0,表示为FALSE。
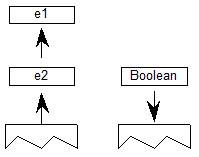
例:
情商[]
不是EQual
NEQ []
代码范围 0x55的
流行 e2:堆栈元素(uint32)
e1:堆栈元素(uint32)
推 布尔值(范围[0,1]中的uint32)
弹出堆栈中的e1和e2并进行比较。如果它们不相等,则表示为TRUE的1被推入堆栈。如果它们相等,则表示为0,表示为FALSE。
例:
NEQ []
奇
ODD []
代码范围 0x56储存
流行 e1:堆栈元素(F26Dot6)
布尔值
推 布尔值(范围[0,1]中的uint32)
用途 round_state
测试堆栈顶部的数字是否为奇数。从堆栈中弹出e1并在测试之前按照round_state的指定对其进行舍入。舍入值后,它将从固定点值移动到整数值(忽略任何小数值)。如果整数值是奇数,则表示TRUE的一个被推入堆栈。如果是偶数,则为零,表示FALSE被置于堆栈中。
例:
ODD []
此示例假定round_state是RTG。
甚至
甚至[]
代码范围 的0x57
流行 e1:堆栈元素(F26Dot6)
推 布尔值(范围[0,1]中的uint32)
用途 round_state
测试堆栈顶部的数字是否均匀。在测试之前,弹出e1离开堆栈并按照round_state的指定对其进行舍入。如果舍入的数字是偶数,则表示为TRUE的一个被推入堆栈(如果它是奇数,零,表示为FALSE)被放置到堆栈上。
例:
甚至[]
此示例假定round_state是RTG。
逻辑AND
和[]
代码范围 0x5A
流行 e1:堆栈元素(uint32)
e2:堆栈元素(uint32)
推 (e1和e2):逻辑和e1和e2(uint32)
弹出e1和e2离开堆栈并将逻辑和两个元素的结果推入堆栈。如果其中一个或两个元素都为FALSE(值为零),则返回零。如果两个元素都为TRUE(具有非零值),则返回一个。
例:
情况1:
和[]
案例2:
和[]
逻辑或
要么[ ]
代码范围 0x5B
流行 e1:堆栈元素(uint32)
e2:堆栈元素(uint32)
推 (e1和e2):逻辑和e1和e2(uint32)
将e1和e2弹出堆栈并将两个元素之间的逻辑或操作结果推入堆栈。如果两个元素都为FALSE,则返回零。如果两个元素都为TRUE,则返回一个。
例:
情况1:
要么[ ]
案例2:
要么[ ]
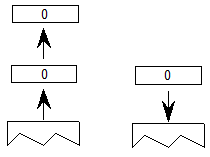
逻辑不
不是[]
代码范围 0x5C
流行 e:stack元素(uint32)
推 (不是e):e(uint32)的逻辑否定
弹出堆栈并返回在e上执行的逻辑NOT操作的结果。如果最初为零,则如果最初非零,则将其推入堆栈,零被推入堆栈。
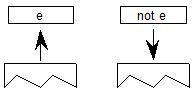
例:
情况1:
案例2:
算术和数学指令
这些指令对堆栈值执行算术运算。值被视为带符号(二进制补码)26.6定点数(F26Dot6),并以相同的形式给出结果。这些说明没有溢出或下溢保护。
要轻松记住算术运算期间处理堆栈值的顺序,请想象从左到右写入堆栈值,从底部值开始。然后将操作员插入两个最右边的元件之间。例如:
减去 a,b将被解释为(ba):cb - a
加
ADD []
代码范围 0X60
流行 n1,n2(F26Dot6)
推 (n2 + n1)
从堆栈中弹出n1和n2,并将两个元素的总和推入堆栈。
减去
SUB []
代码范围 0x61
流行 n1,n2(F26Dot6)
推 (n2 - n1):差异
从堆栈中弹出n1和n2,并将两个元素之间的差异推到堆栈上。
划分
DIV []
代码范围 0X62
流行 n1:除数(F26Dot6)
n2:股息(F26Dot6)
推 n2 / n1(F26Dot6)
从堆栈中弹出n1和n2,并将n2除以n1得到的商推到堆栈上。请注意,这会截断而不是舍入值。TrueType Rasterizer v.1.7及更高版本将捕获任何除零错误。
乘
MUL []
代码范围 0x63
流行 n1,n2:乘数和被乘数(F26Dot6)
推 n1 * n2(F26Dot6)
从堆栈中弹出n1和n2,并将两个元素的乘积推到堆栈上。
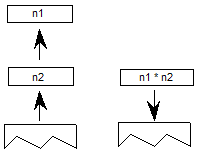
绝对值
ABS []
代码范围 0x64
流行 ñ
推 | n |:n的绝对值(F26Dot6)
从堆栈中弹出n并将n的绝对值推入堆栈。
例:
情况1:
案例2:
否定
NEG []
代码范围 0x65
流行 N1
推 -n1:否定n1(F26Dot6)
该指令从堆栈中弹出n1并将n1的否定值压入堆栈。
NEG []
地板
FLOOR []
代码范围 0x66
流行 n1:需要发言权的号码(F26Dot6)
推 n:n1楼(F26Dot6)
弹出n1并返回n,小于或等于n1的最大整数值。
例:
FLOOR []
情况1:
案例2:
案例3:
天花板
天花板[]
代码范围 0×67
流行 n1:需要上限的数字(F26Dot6)
推 n:n1的上限(F26Dot6)
弹出n1并返回n,最小整数值大于或等于n1。例如,15的上限为15,但15.3的上限为16. -0.8的上限为0.(n是大于或等于n1的最小整数值)
例:
天花板[]
情况1:
案例2:
前两个堆栈元素的最大值
MAX []
代码范围 0x8B
流行 e1:堆栈元素(uint32)
e2:堆栈元素(uint32)
推 最大值为e1和e2
从堆栈中弹出两个元素e1和e2,并将这两个元素中较大的一个推入堆栈。
顶部两个堆栈元素的最小值
MIN []
代码范围 0x8C
流行 e1:堆栈元素(uint32)
e2:堆栈元素(uint32)
推 最小的e1和e2
从堆栈中弹出两个元素e1和e2,并将这两个中较小的一个推入堆栈。
补偿发动机特性
以下两个功能可以补偿发动机特性。每个都取值并进行补偿。除了引擎补偿外,ROUND还根据round_state对值进行舍入。NROUND仅补偿发动机。
ROUND值
ROUND [AB]
旗 ab:发动机特性补偿的距离类型
流行 N1
推 N2
码 0x68 - 0x6B
在补偿引擎的同时根据状态变量round_state舍入值。n1从堆叠中弹出,并且根据发动机特性,增加或减少设定量。然后将获得的数字舍入并作为n2推回到堆栈上。
值ab指定距离类型,如章节“指示字形”中所述。可能有三个值:灰色= 0,黑色= 1,白色= 2。
没有价值的圆满
NROUND [AB]
旗 ab:发动机特性补偿的距离类型
流行 N1
推 N2
码 0x6C - 0x6F
NROUND [ab]执行与ROUND [ab](上面)相同的操作,除了它不会补偿在补偿发动机特性后获得的结果。n1从堆栈弹出,并根据发动机特性增加或减少设定量。然后将该图作为n2推回到堆栈上。
值ab指定距离类型,如章节“指示字形”中所述。可能有三个值:灰色= 0,黑色= 1,白色= 2。
定义和使用功能和说明
以下说明可以定义和使用功能和新指令。
除了一个简单的调用函数,还有一个循环和调用函数。
IDEF或指令定义调用可以修补旧的缩放器以添加新定义的指令。
功能DEFinition
FDEF []
代码范围 0x2c上
流行 f:函数标识符编号(0到n-1范围内的整数,其中n在’maxp’表中指定)
推 -
标记函数定义的开头。参数f是唯一标识此函数的数字。功能定义只能出现在字体程序或CVT程序中。功能不得超过64K
END函数定义
ENDF []
代码范围 0x2D
流行 -
推 -
标记函数定义或指令定义的结尾。
CALL功能
CALL []
代码范围 0x2B访问
流行 f:函数标识符编号(0到n-1范围内的整数,其中n在’maxp’表中指定)
推 -
调用由数字f标识的函数。
LOOP和CALL功能
LOOPCALL []
代码范围 0x2A
流行 f:0到n-1范围内的函数号整数,其中n在’maxp’表中指定
count:调用函数的次数(带符号的字)
推 -
调用函数f,计数次数。
例:
假设字体程序包含:
PUSHB(000),17 将17推入堆栈
FDEF [] 开始定义功能17
… 功能的内容
…
ENDF [] 结束定义
PUSHB(000),5 推数
PUSHB(000),17 推送功能号码
LOOPCALL [] 呼叫功能17次,5次
指令DEFinition
IDEF []
代码范围 0x89上
流行 操作码(8位代码用0填充到uint32)
推 -
开始指令的定义。指令定义在ENDF时终止,这在指令流中遇到。弹出的操作码的后续执行将指向该指令定义(IDEF)的内容。IDEF应该在字体程序或CVT程序中定义。IDEF仅影响未定义的操作码。如果已经定义了相关的操作码,则解释器将忽略IDEF。这将用作未来指令的修补机制。说明书的大小不得超过64K。
调试
TrueType指令集提供以下指令以帮助调试。
DEBUG电话
调试[]
代码范围 0x4F
流行 号码(uint32)
推 -
此指令仅用于调试目的,不应成为完成字体的一部分。某些实现可能不支持此指令。
杂项说明
以下指令获取有关当前字形和缩放器版本的信息。
获取信息
获取信息[ ]
代码范围 均为0x88
流行 选择器(整数)
推 结果(整数)
GETINFO用于获取有关字体缩放器版本和当前字形特征的数据。该指令弹出一个选择器,用于确定所需信息的类型,并将结果推送到堆栈上。
选择器位0表示缩放器版本号是所需信息。选择器位1表示对字形旋转状态的请求。选择器位2询问字形是否已被拉伸。选择器位3询问是否支持OpenType字体变体。选择器位4询问是否正在使用垂直幻像点。选择器位5询问字形是否被栅格化为灰度。
选择器位3指示关于是否支持OpenType字体变体的查询。结果在第10位返回:如果设置了第10位,则支持字体变体。
选择器位4指示是否支持垂直幻像点的查询。结果在第11位返回:如果设置了第11位,则支持垂直幻像点。注意:在MS Rasterizer上,直到MS Rasterizer 2.2 - 版本号41或更高版本才支持此方法。对于41版之前的版本,请参阅下面的注释。
以下选择器用于ClearType信息。选择器位6表示已启用ClearType。选择器位7指示启用“兼容宽度”ClearType。选择器位8表示启用了对称平滑ClearType。并且,选择器位9指示ClearType正在以BGR(蓝色,绿色,红色)顺序处理LCD条带。
推送到堆栈的结果包含所请求的信息。更确切地说,位0到7包括Scaler版本号。有关版本号的含义,请参阅下表。版本号0,4到32和43到255是保留的。
注意:在MS Rasterizer上,尽管在MS Rasterizer v.1.7中添加了对垂直幻像点的支持,但选择器位4无法可靠地用于查询MS Rasterizer v.2.2之前的垂直幻像点的支持。在提示垂直幻像点或询问灰度信息之前,请使用GETINFO检查正在使用的光栅化器是否为版本号35或更高版本。在检查是否启用ClearType之前,请确保光栅化器的版本号为36或更高。对于其他ClearType位,请确保光栅化器的版本号为37或更高版本。
如果当前字形已旋转,则位8设置为1。否则就是零。
如果当前字形已被拉伸,则位9设置为1。否则设置为0。
如果支持OpenType字体变化,则位10设置为1(对于MS Rasterizer v.2.2及更高版本)。否则设置为0。
如果使用垂直幻像点,则位11设置为1(对于MS Rasterizer v.2.2及更高版本)。否则将其设置为零。
如果光栅化是使用字体平滑技术(对于MS光栅化器v.1.7及更高版本)进行灰度化,则将位12设置为1。
如果启用了ClearType,则位13设置为1(对于MS rasterizer v.1.6 +或MS rasterizer v.1.8及更高版本)。否则设置为0。
如果ClearType宽度与双级和灰度宽度兼容(对于MS Rasterizer v.1.8及更高版本),则位14设置为1。如果宽度是自然的ClearType宽度,则设置为0。
如果正在使用ClearType对称平滑(对于MS Rasterizer v.1.8及更高版本),则位15设置为1。否则设置为0。
如果ClearType以BGR(蓝色,绿色,红色)顺序处理LCD条纹(对于MS Rasterizer v.1.8及更高版本),则位16设置为1。否则设置为0。
如果正在使用ClearType子像素文本(对于MS Rasterizer 2.0及更高版本),则位17设置为1。在这种情况下,右侧承载点上的任何提示都将被忽略。锐化茎的提示也可能具有最小的影响。否则设置为0。
如果正在使用ClearType对称渲染(对于MS Rasterizer v.2.0及更高版本),则位18设置为1。根据水平LCD条纹方向,这可能会影响水平特征的渲染。否则设置为0。
如果正在使用ClearType灰度渲染(对于MS Rasterizer v.2.1及更高版本),则位19设置为1。否则设置为0。
当选择器设置为请求多条信息时,该信息将被一起进行“或”运算并推送到堆栈中。例如,选择器值6请求有关旋转和拉伸的信息,并将导致位8和9的设置。
下表包含了上述信息。
查询选择器位 查询选择器位掩码 结果比特 结果位掩码 版本要求
版 0 00000001 0-7 0x000000FF 所有
雕文旋转 1 0x00000002 8 0x00000100 所有
雕文拉伸 2 0x00000004 9 0x00000200 所有
字体变体 3 0x00000008 10 0x00000400时 (> = 5 && <= 32)|| (> = 41 && <= 64)
垂直幻影点 4 0x00000010 11 0x00000800 (> = 5 && <= 32)|| (> = 41 && <= 64)
Windows字体平滑灰度 五 0x00000020 12 0x00001000 (> = 34 && <= 64)
ClearType已启用 6 0x00000040 13 0x00002000 (> = 36 && <= 64)
已启用ClearType兼容宽度 7 0x00000080 14 0x00004000 (> = 37 && <= 64)
ClearType水平LCD条纹方向 8 0x00000100 15 0x00008000 (> = 37 && <= 64)
ClearType BGR LCD条纹顺序 9 0x00000200 16 0x00010000在 (> = 37 && <= 64)
已启用ClearType子像素定位文本 10 0x00000400时 17 0x00020000 (> = 39 && <= 64)
启用ClearType对称渲染 11 0x00000800 18 0x00040000 (> = 40 && <= 64)
启用ClearType灰色渲染 12 0x00001000 19 0x00080000 (> = 40 && <= 64)
版本信息如下:
GETINFO版 Microsoft Rasterizer版本 笔记
1 Macintosh系统6 INIT
2 Macintosh系统7
3 1.0 16位Windows 3.1。
4 Macintosh系统6.2
五 麒麟打印机
6 Macintosh系统7.1
7 Macintosh QuickDraw GX
33 1.5 32位版本,新的扫描转换器
34 1.6 字体平滑,新SCANTYPE
35 1.7 复合缩放更改
36 1.6+ “Classic”ClearType(Windows CE)
37 1.8 的ClearType
38 1.9 子像素定位ClearType
39 2.0 Subpixel Positioned ClearType flag
40 2.1 Symmetric ClearType flag, ClearType Gray (and flag)
41 2.2 OpenType Font Variations
42 2.3 GETVARIATION support
获得变化
GETVARIATION []
代码范围 0x91
推 标准化轴坐标,字体中每个轴一个。(值为2.14定点数,在高16位用零填充。)
GETVARIATION用于获取每个轴的当前标准化变化坐标。第一个轴的坐标(在’fvar’表中定义)首先在堆栈上推送,然后是每个连续轴,直到最后一个轴的坐标在堆栈上。
由于在每个环境中都不支持此指令,因此需要在’fpgm’或’prep’表中为GETVARIATION OpCode 145(0x91)提供IDEF。这是一个例子:
PUSHB [000] 145 / * OpCode 0x91,GetVariation * /
IDEF []
NPUSHW [] 2 / 此字体中的轴数 /,0,0
ENDF []
该程序在堆栈上返回两个零,表示两个轴中每个轴的默认值。零将被解释为此字体的默认值。’maxp’表应正确反映IDEF的用法。
笔记:
为了正确处理从可变字体生成的实例字体,但仍然使指令在变量字体和实例字体之间提供相同的行为,建议在实例字体中进行以下设置。
识别并修改OpCode 0x91的现有活动IDEF,或者在“prep”表的末尾为OpCode 0x91添加新的IDEF。同一OpCode的多个IDEF有效,将使用最后执行的一个。通过在’prep’结束时放置一个新的IDEF,可以更容易地动态更新,并降低另一个IDEF覆盖此IDEF的可能性。
如上所述,OpCode 0x91的默认IDEF通常在堆栈上返回零,表示默认值。在从可变字体生成的实例字体的情况下,要返回的值必须与特定实例的标准化值匹配,第一个轴的坐标值首先在堆栈上推送,然后是按列出的顺序的每个连续轴在’fvar’表中。应该注意’maxp’表正确反映了此修改添加的maxInstructionDefs和maxStackElements。
以下是为实例添加的替换IDEF 145(0x91)的示例:
PUSHB [000] 145 / * OpCode 0x91,GetVariation * /
IDEF []
NPUSHW [] 2 / 此字体的轴数 /, - 16384,0
ENDF []
在这种情况下,它提供等效的GETVARIATION,第一个轴返回-1.0,第二个轴返回0.0。
11.3.3.图形状态摘要
下表总结了构成图形状态的变量。几乎所有的Graphics State变量都有一个默认值,如下所示。为字体中的每个字形重新建立该值。说明可用于重置所有图形状态变量的值。一些状态变量可以在CVT程序中重置。在这种情况下,值集将成为新的默认值,并将为每个字形重新建立。当状态变量的值由与特定字形相关联的指令更改时,它将仅保留该字形。
Graphics State变量的设置将影响某些指令的操作。列出了每个变量的受影响的指令。
图形状态变量 默认 设置为 影响
auto_flip 真正 FLIPOFF
FLIPON MIAP
MIRP
control_value_cut_in 17/16像素 SCVTCI MIAP
MIRP
delta_base 9 SDB DELTAP1
DELTAP2
DELTAP3
DELTAC1
DELTAC2
DELTAC3
delta_shift 3 SDS DELTAP1
DELTAP2
DELTAP3
DELTAC1
DELTAC2
DELTAC3
dual_projection_vectors - SDPVTL IP
GC
MD
MDRP
MIRP
freedom_vector x轴 SFVTCA
SFVTL
SFTPV
SVTCA
SFVFS GFV
gep0 1 SCE0
SCES AA
ALIGNPTS
ALIGNRP
DELTAP1
DELTAP2
DELTAP3
IP
ISECT
MD
MDAP
MIAP
MIRP
MSIRP
SHC
SHE
SHP
UTP
GEP1 1 SCE1
SCES AA
ALIGNPTS
ALIGNRP
IP
MD
MDRP
MIRP
MSIRP
SHC
SHE
SHP
SFVTL
SPVTL
GEP2 1 SCE3
SCES ISECT
IUP
GC
SHC
SHP
SFVTL
SHPIX
SPVTL
SC
instruct_Control 0 INSTCTRL 所有说明
环 1 SLOOP ALIGNRP
FLIPPT
IP
SHP
SHPIX
minimum_distance 1个像素 LMD MDRP
MIRP
projection_vector x轴 SPVTCA
SPVTL
SVTCA
SPVFS GPV
round_state 1 RDTG
ROFF
RTDG
RTG
RTHG
RUTG
再生技术用于
S45ROUND MDAP
MIAP
MDRP
MIRP
ROUND
RP0 0 SRP0 IP
MDAP
MIAP
MIRP
MSIRP
SHC
SHE
SHP
RP1 0 SRP1 IP
MDAP
MDRP
MIAP
MSIRP
SHC
SHE
SHP
RP2 0 SRP2 IP
MDRP
MIRP
MSIRP
SHC
SHE
SHP
scan_control 假 SCANCTRL
SCANTYPE
singe_width_cut_in 0像素 SSWCI MIAP
MIRP
single_width_value 0像素 SSW MIAP
MIRP
11.4.OpenType镜像对列表
1 | # |
11.5.压缩字体格式规范
Adobe技术说明#5176
此文件以.PDF格式提供。
11.6.Type 2 字符格式
Adobe技术说明#5177
此文件以.PDF格式提供。
11.7.CFF2字符格式
1简介
CFF2 CharString格式提供了一种在轮廓字体程序中对字形过程进行紧凑编码的方法。CFF2 CharStrings仅适用于OpenType字体文件中的CFF2字体表。
CFF2 CharString格式与Type 2 CharString格式紧密相关。类型2 CharStrings记录在Adobe Technical Note#5177,Type 2 CharString Format中,可在Adobe Font Technical Notes中找到。
开发CFF2 CharString格式的动机有两个:
通过删除OpenType字体中其他地方复制的所有数据来减小CFF2字体的大小,或者不在OpenType字体文件的上下文中使用。
添加对OpenType字体变体的支持。(有关一般概述和支持可变字体所需表格的完整列表,请参阅OpenType字体变体概述一章。)
因此,CFF2 CharString格式增加了一些新的运算符,并删除了更多的运算符。但是,类型2和CFF2 CharStrings之间的运算符和操作数的编码是相同的; 解释器将需要相对较少的变化来处理两种格式。有关Type 2和CFF2 CharString格式之间差异的完整列表,请参阅附录C对Type 2 CharStrings的更改。CFF2 CharStrings可以转换为Type 2 CharStrings,仅丢失变化数据。
本文档仅描述了CFF2 CharStrings的编码方式,并未尝试解释选择各种选项的原因。CFF2 CharStrings基于Type 1字体概念,本文档假定您熟悉Type 1字体格式规范。欲了解更多信息,请参阅下面的Adobe Type 1字体格式在Adobe字体技术说明。此外,假设熟悉CFF2表格式; 有关详细信息,请参阅Compact Font Format Version 2(CFF2)一章。
2 CFF2 CharStrings
以下部分描述了编码CFF2 CharString的一般概念。
2.1提示
CFF2 CharString格式支持六个提示运算符:hstem,vstem,hstemhm,vstemhm,hintmask和cntrmask。必须使用hstem,vstem,hstemhm和vstemhm运算符在CharString的开头声明提示信息(请参阅第3.1节),每个运算符都可以为多个词干提示获取参数。
CFF2提示操作符帮助光栅化器识别和控制字形内的词干和计数器区域。杆通常由两个位置(边缘)和相关的宽度组成。边缘提示有助于控制只有一条边的字符特征(参见第4.3节)。CFF2 CharString格式包括边缘提示,它等同于幽灵提示的Type 1概念(请参阅Adobe Type 1字体格式中关于ghost提示的部分)。它们用于定位边缘而不是具有两条边的杆。柱宽值-20保留用于顶边或右边,而值-21用于底边或左边。具有其他负宽度值的提示的操作未定义。
hintmask
该hintmask操作者具有同样的功能,在第8.1节“一个字符内改变的提示,”中描述的Adobe Type 1字体格式。它提供了一种激活或停用词干提示的方法,以便一次只激活一组非重叠提示。所述hintmask操作后面是指定干提示其是用于随后路径结构是活性的一个或多个数据字节。数据字节数必须完全是表示原始词干列表中词干数量所需的数量(由hstem,vstem,hstemhm和vstemhm指定的词干)命令),在原始词干列表中的每个词干的数据字节中使用一位。值为1的位表示活动的词干,值为零表示不活动的词干。
cntrmask
所述cntrmask(countermask)暗示导致以类似于干宽度如何由阀杆提示命令控制的方式来控制的字符计数器空间的任意但不重叠的集合。(有关详细信息,请参阅Adobe技术说明#5015,类型1字体格式补充,Adobe字体技术说明。)cntrmask运算符后跟一个或多个数据字节,指定两侧的词干提示的索引号。一个柜台空间。数据字节数必须完全是表示原始词干列表中的词干数量所需的数量(由hstem,vstem,hstemhm或vstemhm命令指定的词干),在每个词干的数据字节中使用一位原始的干名单。
对于图1中所示的示例,字形的词干列表将是:
H1 H2 H3 H4 H5 H6 H7 H8 V1 V2 V3 V4 V5并且以下cntrmask命令将用于控制这些词干之间的计数器空间:
cntrmask 0xB5 0xE8(H1 H3 H4 H6 H8 V1 V2 V3 V5)
cntrmask 0x4A 0x00(H2 H5 H7)数据字节中设置的位表示相应的词干提示界定了所需的计数器集。第一个命令中指定的提示优先级高于第二个命令中的提示。请注意,V4主干不会划分适当的计数器空间,因此在此示例中未引用。
请注意,提示只是提示,提示或建议。它们是智能光栅化器的附加指南。

如果字体的LanguageGroup不等于1(1一LanguageGroup值表示复杂的亚洲语言的字形),则cntrmask操作者,用三茎,来代替而使用hstem3和vstem3在类型1格式的提示,只要满足类型1规范中指定的相关条件。有关计数器控制提示的详细信息,请参阅Adobe技术说明#5015,类型1字体格式补充。
2.2灵活机制
的挠曲提供机制来提高浅曲线的绘制,其表示为在小的尺寸的字符形状的线段而不是作为小的峰或凹痕。它本质上是一种路径构造机制:参数描述了两条曲线的构造,另外一个参数用作当曲线应该以较小的尺寸和分辨率呈现为直线时的提示。
CFF2 flex机制是通用的; 使用flex运算符表示曲线的类型或方向没有限制。的挠曲操作者用于一般的情况下; 特殊情况可以使用flex1,hflex或hflex1运算符进行更有效的编码。图2显示了用于水平曲线的柔性机制的示例,图3显示了非标准角度的柔性曲线的示例。
flex操作符可用于任何方向或深度的任何弯曲角色特征,满足以下要求:
字符特征必须能够表示为两条rrcurveto运算符绘制的两条曲线。
曲线必须在称为连接点的公共点处相遇。
组合曲线的长度必须超过其深度。
2.3子程序
CFF2字体程序可以通过组合描述字体中字符的公共元素的程序语句来使用子例程来降低存储要求。
子例程通常是一系列CharString字节,表示在字体的CharString数据中出现在多个位置的子程序。可以在相同的字体DICT内调用本地子例程,并且可以在字体DICT之间共享全局子例程。
子例程可以包含CharStrings的部分,并且编码与CFF2 CharStrings相同。它们使用callsubr(用于本地子例程)或callgsubr(用于全局子例程)运算符调用,使用偏置索引作为参数的本地或全局Subrs数组。
CharString子程序可以调用其他子程序,达到实现限制允许的深度(见附录B)。当解释器到达其字节串的末尾时,子例程返回。
3 CharString编码
CFF2 CharString程序是一系列无符号8位字节,用于编码数字和运算符。字节值指定要以特定方式解释的运算符,数字或后续字节。
字节被解码为数字和运算符。需要CFF2 CharString解释器来计算参数堆栈上的参数数量。因此,它可以为单个运算符检测其他参数集。堆栈深度实现限制在附录B中规定。
从CharString解码的数字被推送到CFF2参数堆栈。运算符期望从这个参数堆栈按顺序使用它的参数,所有参数通常取自堆栈的底部(第一个参数最底部); 但是,某些操作员,尤其是子程序操作员,通常在堆栈顶部工作。如果运算符返回结果,则将它们推送到CFF2参数堆栈(最后一个结果最顶层)。
在下面的讨论中,除非另有说明,否则所有数字常量都是十进制数。
3.1 CFF2 CharString组织
CFF2 CharString程序的顺序和形式可表示为:
{hs * vs * cm * hm * mt subpath}?{mt subpath} *
哪里:
hs = hstem或hstemhm命令
vs = vstem或vstemhm命令
cm = cntrmask运算符
hm = hintmask运算符
mt = moveto(即任何moveto)运算符
subpath =指的是构造子路径(一个完整的闭合轮廓),其中可能包括适当的hintmask运算符。
以下符号表示具体用法:
*允许零次或多次发生
?允许零次或一次出现
- 允许一次或多次出现
{}表示分组
用文字表示,CharString中运算符序列的约束如下:
CFF2 CharStrings必须使用运算符或运算符类进行结构化,按以下特定顺序排序:
提示:以下每个提示运算符中的零个或多个,完全按以下顺序:hstem,hstemhm,vstem,vstemhm,cntrmask,hintmask。每个条目是可选的,并且每个条目可以由运算符的一次或多次出现来表示。如果CharString没有词干提示,则不得出现提示运算符cntrmask和/或hintmask。
路径构造:使用零个或多个路径构造运算符绘制角色的路径; 第二个和所有后续子路径也必须以其中一个moveto运算符开头。所述hintmask根据需要操作者都可以使用。
提示和路径构造运算符的任何操作数都可以由混合运算符及其操作数替换。如果使用vsindex运算符,则必须仅使用一次,并且在任何混合运算符之前。混合运算符可能不是嵌套的。提示掩码字节和子例程索引可能不会混合。
注意: CharStrings可以在完整标记之间的任何位置根据需要包含subr和gsubr调用。这意味着在多字节数字或运算符的字节之间,也不能在多字节命令的字节之间(例如,hintmask和cntrmask)之间发生subr(gsubr)调用。
3.2 CharString数字编码
包含32到254(含)的值的CharString字节表示整数。这些值在三个范围内解码(另见表1):
包含值(v在32和246之间)的CharString字节指定整数v - 139。因此,从-107到107的整数值可以在单个字节中编码。
含有值A charstring类型字节,v,247和250(含)之间,表示涉及下一个字节的整数,w根据下式,(v − 247) * 256 + w + 108。以这种方式可以以2字节编码108和1131之间的整数值。
包含值的CharString字节v,在251和254之间,表示w根据公式,涉及下一个字节的整数−[(v − 251) * 256] − w − 108。以-1131和-108之间的整数值可以以这种方式以2个字节编码。
如果CharString字节包含值255,则接下来的四个字节包含固定值(带有16个小数位的带符号定点数)。
注意:以五字节编码的数字(初始字节值为255的数字)的CFF2解释与在类型1格式中解释的数字不同。
除了上面列出的数字表示之外,-32768和+32767之间的数字可以使用运算符(28)后跟一个int16来表示。这允许在字体中偶尔出现的大数字的更紧凑的表示,但是更重要的是,这将允许更紧凑的数字编码,其可以用作callubr和callgsubr的参数。
表1. CFF2 CHARSTRING编码值
CharString字节值 解释 代表的数字范围 需要字节数
0到11 运营商 运营商0到11 1
12 escape:下一个字节被解释为附加运算符 操作员代码的附加0到255范围 2
13至18岁 运营商 运营商13至18 1
19,20 运算符(hintmask和cntrmask) 运营商19,20 2个或更多
21至27岁 运营商 运营商21至27 1
28 接下来的2个字节是一个int16 -32768到+32767 3
29至31岁 运营商 运营商29至31 1
32至246 结果= v - 139 -107到+107 1
247至250 下一个字节,w,结果=(v - 247)* 256 + w + 108 +108到+1131 2
251至254 下一个字节,w,结果= - [(v - 251)* 256] - w - 108 -108至-1131 2
255 接下来的4个字节是固定值 16位有符号整数,16位分数 五
3.3 CharString运算符编码
CharString运算符以一个或两个字节编码。并非所有可能的运算符编码值都已定义。有关运算符编码值的列表,请参阅附录A. 遇到无法识别的运算符时,将忽略该运算符并清除堆栈。
如果运算符字节包含值12,则下一个字节中的值指定运算符。这种转义机制允许对许多额外的运算符进行编码。
4个CharString运算符
CFF2 CharString运算符分为四组,按功能分类:
路径建设
提示
子程序
变异数据支持
以下定义使用与PostScript语言参考手册中使用的格式类似的格式。运算符名称后面的括号要么包含在CharString字节中表示此运算符的运算符值,要么包含表示双字节运算符的两个值(以12开头)。
许多运算符从CFF2参数堆栈中最底层的条目中获取参数; 此行为由出现在第一个参数左侧的堆栈底部符号“| - ”表示。清除参数堆栈的运算符由运算符定义的结果位置中的堆栈底部符号“| - ”表示。
由于这种堆栈清除行为,通常,参数不会在CFF2参数堆栈上累积,以便稍后由运算符序列删除,通常只能为下一个运算符提供参数。子程序调用和混合运算符会出现明显的异常。所有堆栈操作都必须遵守堆栈限制(参见附录B)。
4.1路径构造运算符
在CFF2 CharString中,通过顺序应用一个或多个路径构造运算符来构造路径。当前点最初是字符坐标系的(0,0)点。在本节中列出的运算导致当前点来改变,或者由通过MoveTo操作,或通过附加的一个或多个曲线或线段到当前点。完成操作后,当前点将更新到移动的位置,或更新到一个或多个段的最后一个点。
许多运算符可以采用多组参数,这些参数表示一系列路径构造操作。操作次数仅受堆栈大小限制(参见附录B)。
使用六个参数dxa,dya,dxb,dyb,dxc,dyc绘制所有Bézier曲线路径段; 其中dxa和dya是相对于当前点的,而所有后续参数都与前一点相关。许多曲线运算符利用了一些切点是水平或垂直(因此值为零)的情况,从而减少了所需的参数数量。
该柔性运营商正在考虑路径建构命令,因为他们指定两条曲线的绘制。还有一个额外的参数可以作为提示何时将曲线渲染为小尺寸和低分辨率的直线。
以下是三种类型的moveto运算符。对于CharString中的初始moveto运算符,参数相对于角色坐标系中的(0,0)点; 后续moveto运算符的参数与当前点相关。
每个字符路径和子路径必须以其中一个moveto运算符开头。如果遇到moveto运算符时当前路径打开,则在执行moveto操作之前,通过对前一个moveto坐标执行lineto操作来关闭路径。插入的lineto操作不会更改当前点。
rmoveto
| - dx1 dy1 rmoveto(21)| -
将当前点移动到相对坐标(dx1,dy1)处的位置。
hmoveto
| - dx1 hmoveto(22)| -
在水平方向上移动当前点dx1单位。
vmoveto
| - dy1 vmoveto(4)| -
在垂直方向上移动当前点dy1单位。
rlineto
| - {dxa dya} + rlineto(5)| -
从当前点到相对坐标dxa,dya的位置追加一条线。对所有后续参数对执行附加的rlineto操作。行数由堆栈中的参数数量确定。
hlineto
| - dx1 {dya dxb} * hlineto(6)| -
| - {dxa dyb} + hlineto(6)| -
将长度为dx1的水平线追加到当前点。使用奇数个参数,后续参数对被解释为dy和dx的交替值,其他线性运算符绘制交替的垂直和水平线。使用偶数个参数,参数被解释为交替的水平和垂直线。行数由堆栈中的参数数量确定。
vlineto
| - dy1 {dxa dyb} * vlineto(7)| -
| - {dya dxb} + vlineto(7)| -
将长度为dy1的垂直线追加到当前点。使用奇数个参数,后续参数对被解释为dx和dy的交替值,其他线性运算符绘制交替的水平和垂直线。使用偶数个参数,参数被解释为交替的垂直和水平线。行数由堆栈中的参数数量确定。
rrcurveto
| - {dxa dya dxb dyb dxc dyc} + rrcurveto(8)| -
将由dxa … dyc定义的Bézier曲线追加到当前点。对于每个后续的六个参数集,附加曲线将附加到当前点。曲线段的数量由数量堆栈上的参数数量确定,并且仅受数量堆栈的大小限制。
hhcurveto
| - dy1?{dxa dxb dyb dxc} + hhcurveto(27)| -
将dxa … dxc参数集描述的一条或多条Bézier曲线追加到当前点。对于每条曲线,如果有4个参数,则曲线的开始和结束都是水平的。第一条曲线不需要从水平开始(奇数参数情况)。请注意奇数参数情况的参数顺序。
hvcurveto
| - dx1 dx2 dy2 dy3 {dya dxb dyb dxc dxd dxe dye dyf} * dxf?hvcurveto(31)| -
| - {dxa dxb dyb dyc dyd dxe dye dxf} + dyf?hvcurveto(31)| -
将一条或多条贝塞尔曲线附加到当前点。第一个Bézier的切线必须是水平的,第二个必须是垂直的(除非如下所述)。
如果存在四个参数的倍数,则曲线从水平开始并以垂直结束。请注意,曲线在开始水平,结束垂直和开始垂直以及结束水平之间交替。最后一条曲线(奇数参数情况)不需要以水平/垂直结束。
rcurveline
| - {dxa dya dxb dyb dxc dyc} + dxd dyd rcurveline(24)| -
对于每组六个参数dxa … dyc,相当于一个rrcurveto,接着是使用dxd,dyd参数的一个rlineto。曲线的数量由参数堆栈上的计数确定。
rlinecurve
| - {dxa dya} + dxb dyb dxc dyc dxd dyd rlinecurve(25)| -
相当于一个rlineto每对的参数超出了六个参数DXB … DYD需要一个rrcurveto命令。行数由参数堆栈上的项目数确定。
vhcurveto
| - dy1 dx2 dy2 dx3 {dxa dxb dyb dyc dyd dxe dye dxf} * dyf?vhcurveto(30)| -
| - {dya dxb dyb dxc dxd dxe dyf dyf} + dxf?vhcurveto(30)| -
将一条或多条贝塞尔曲线追加到当前点,其中第一条切线为垂直,第二条切线为水平。这个命令是hvcurveto的补充; 有关更多信息,请参阅hvcurveto的说明。
vvcurveto
| - dx1?{dya dxb dyb dyc} + vvcurveto(26)| -
将一条或多条曲线追加到当前点。如果参数计数是四的倍数,则曲线开始和结束垂直。如果参数计数为奇数,则第一条曲线不以垂直切线开始。
柔性
| - dx1 dy1 dx2 dy2 dx3 dy3 dx4 dy4 dx5 dy5 dx6 dy6 fd flex(12 35)| -
导致两条贝塞尔曲线,如参数所述(如下图2所示),当弯曲深度小于fd/100设备像素时呈现为直线,当弯曲深度大于或等于时,呈现为曲线fd / 100设备像素。如图2所示,水平曲线的弯曲深度是从连接点到连接曲线上起点和终点的线的距离。如果曲线不是完全水平或垂直,则必须通过下面flex1描述中描述的方法确定曲线是更水平还是垂直,如图3所示。

注意:如果某些点与曲线中的其他点具有相同的x或y坐标,则可以使用以下形式的flex运算符省略参数:hflex,hflex1或flex1。
hflex
| - dx1 dx2 dy2 dx3 dx4 dx5 dx6 hflex(12 34)| -
当弯曲深度小于0.5(即fd为50)设备像素时,参数dx1 … dx6描述的两条曲线呈现为直线,当弯曲深度大于时,使曲线呈现为曲线或等于0.5个设备像素。
当满足以下条件时,使用hflex:
起点和终点,第一个和最后一个控制点具有相同的y值。
连接点和邻居控制点具有相同的y值。
弯曲深度为50。
hflex1
| - dx1 dy1 dx2 dy2 dx3 dx4 dx5 dy5 dx6 hflex1(12 36)| -
使得参数描述的两条曲线在柔性深度小于0.5个器件像素时呈现为直线,并且当柔性深度大于或等于0.5个器件像素时呈现为曲线。
如果不满足hflex的条件但是满足以下所有条件,则使用hflex1:
起点和终点具有相同的y值。
连接点和邻居控制点具有相同的y值。
弯曲深度为50。
flex1
| - dx1 dy1 dx2 dy2 dx3 dy3 dx4 dy4 dx5 dy5 d6 flex1(12 37)| -
使得参数描述的两条曲线在柔性深度小于0.5个器件像素时呈现为直线,并且当柔性深度大于或等于0.5个器件像素时呈现为曲线。
该D6参数将是或者是DX或DY值,取决于曲线上(参见图3)。要确定正确的值,通过对除d6之外的所有参数求和,计算从起点(x,y),第一条曲线的第一个点到最后一个弹性控制点(dx5,dy5)的距离; 叫这个(dx,dy)。如果abs(dx)> abs(dy),则最后一个点的x值由d6给出,其y值等于y。否则,最后一个点的x值等于x,其y值由d6给出。
flex1使用如果条件hflex和hflex1没有得到满足,但以下所有条件都为真:
起点和终点具有相同的x或y值。
弯曲深度为50。

4.2完成CharString轮廓定义
CFF2 CharStrings与Type 2 CharStrings的不同之处在于没有用于完成CharString轮廓定义的运算符.CharString字节字符串的末尾表示最后一个子路径的结尾,其作用与Type 2 endchar运算符相同。如果CharString中的最后一个运算符是call(g)subr,则CharString在该子例程结束时结束。
最小的合法CharString只是一个空字节字符串。
4.3提示操作符
必须在CharString程序程序的开头声明所有提示(有关详细信息,请参阅第3.1节)。
hstem
| - y dy {dya dyb} * hstem(1)| -
指定一个或多个水平词干提示(有关水平词干提示的详细信息,请参阅以下部分)。这允许多个数字对(受堆栈深度限制)用作单个hstem运算符的参数。
要求茎以升序编码(通过增加底边来定义)。编码值都是相对的; 在第一对中,y相对于0,而dy指定与y的距离。每个后续对的第一个值相对于前一对定义的最后一个边。
宽度为-20指定边缘提示的上边缘,-21指定边缘提示的下边缘。所有其他负宽度都有不明确的含义。
图4显示了使用顶部和底部边缘提示的字符柄的编码示例。边缘杆提示用于在控制杆宽度不是主要目的的情况下控制杆的边缘的位置。

图4中所示的边缘提示的编码将是:
121 -21 400 -20 hstem
vstem
| - x dx {dxa dxb} * vstem(3)| -
指定x坐标x和x + dx之间的一个或多个垂直主干提示,其中x相对于坐标轴的原点。
要求茎以升序编码(通过增加左边缘来定义)。编码值都是相对的; 在第一对中,x相对于0,dx指定距x的距离。每个后续对的第一个值相对于前一对定义的最后一个边。
宽度为-20指定边缘提示的右边缘,-21指定边缘提示的左边缘。所有其他负宽度都有不明确的含义。
重要的是要注意,系统提示不得与其他系统提示重叠,同样,vstem提示不得与其他vstem提示重叠。如果需要重叠提示,则必须使用hstemhm或vstemhm运算符而不是hstem或vstem运算符来定义重叠提示。此外,必须使用hintmask运算符选择性地应用提示,以便不会同时激活重叠的水平或垂直提示。有关hintmask运算符和图6中的示例的详细信息,请参见下文。
图5显示了字符轮廓的样本特征上重叠水平提示的示例。

图5中显示的两个提示的编码将是:
280 100 -70 40 hstemhm
同样,请注意,此处未显示的hintmask运算符也必须与这些提示一起使用。
hstemhm
| - y dy {dya dyb} * hstemhm(18)| -
具有相同的含义hstem(1),所不同的是它必须在适当位置的可使用hstem如果charstring类型包含一个或多个hintmask运算符。
vstemhm
| - x dx {dxa dxb} * vstemhm(23)| -
与vstem(3)具有相同的含义,但如果CharString包含一个或多个hintmask运算符,则必须使用它来代替vstem。
hintmask
| - hintmask(19)mask | -
指定哪些提示处于活动状态,哪些提示处于活动状态。如果任何提示重叠,则必须使用hintmask来建立非重叠的提示子集。hintmask可能在CharString中出现任意次数。在hintmask之后发生的路径运算符受新提示集的影响,但不移动当前点。如果词干提示区域重叠并且未使用hintmask运算符正确管理,则结果未定义。
所述掩模数据字节被定义如下:
数据字节的数量正是所需的数量,每个提示一位,以引用在CharString程序开头声明的词干提示的数量。
掩码的每个位,从第一个字节的最高有效位开始,按照在CharString的开头声明提示的顺序表示相应的提示区。
对于掩码中的每个位,值“1”指定相应的提示应处于活动状态。位值“0”指定提示应为非活动状态。
掩码中未使用的位(如果有)必须为零。
如果hstem和vstem提示都在CharString的开头声明,并且此序列直接由hintmask或cntrmask运算符跟随,则不需要包括vstem提示运算符(或者,如果适用,vstemhm运算符)。例如,图6显示了带有hstem和vstem提示的字符的一部分。

图6显示了两个重叠的hstem提示:hstem1,280到380; 和hstem2,从310到350.由于这些重叠,使用hintmask运算符将需要选择一个或另一个作为活动。它还显示了一个vstem提示:vstem1,从400到450.假设只定义了这三个提示,并且轮廓是以逆时针方向构造的,从水平线段开始,以(400,310)结束。在这种情况下,应该处于活动状态的第一个提示组是hstem2 plus vstem1。对于这种情况,提示和提示掩码将指定如下:
280 100 -70 40 hstemhm 400 50 hintmask 0x60
请注意,hstemhm用于指示将使用提示替换(使用hintmask)。提示按hstem1,hstem2和vstem1的顺序定义。的hintmask操作数,0x60的(01100000),指示哪些提示是在路径建设之初活性:为了在第二和第三的提示- hstem2和vstem1。
cntrmask
| - cntrmask(20)mask | -
指定要控制的计数器空间及其相对优先级。在运算符之后的字节中的掩码位引用词干提示声明; 第一个字节的最重要位是指声明的第一个词干提示,直到最后一个提示声明。要控制的计数器是由引用的词干提示分隔的计数器。第一个cntrmask命令中设置为1的位具有最高优先级; 后续的cntrmask命令指定较低优先级的计数器(参见图1和随附的示例)。
4.4子程序运算符
通过使用数字空间的负半部分,子程序的编号被更紧凑地编码,这有效地使紧凑可编码子程序数的数量加倍。应用的偏差取决于子数(gsubrs)的数量。如果subrs(gsubrs)的数量小于1240,则偏差为107.否则,如果小于33900,则为1131; 否则它是32768.此偏差被添加到编码的subr(gsubr)数字中,以在subr(gsubr)数组中找到适当的条目。
callsubr
subr#callsubr(10)
在Subrs数组中调用带索引subr#(实际上是subr编号加上子程序偏置编号,如2.3节所述)的CharString子程序。Subrs数组的每个元素都是一个CharString,编码方式与任何其他CharString一样。子程序调用仅从堆栈中删除subr#和operator,因此在子程序中的任何运算符都可以使用堆栈上的参数。类似地,在子例程返回到调用者之后,从子例程内部推送的值可用。调用未定义的subr(gsubr)具有未定义的结果。
这些子程序通常用于编码在整个字体程序中重复的路径操作符序列,例如,serif轮廓序列。子程序调用可以嵌套到附录B中的实现限制中指定的深度。
callgsubr
globalsubr#callgsubr(29)
经营范围相同的方式callsubr除了它调用全局子程序。
4.5变异数据运算符
为了支持CFF2 CharStrings中的变体数据,在CFF2 CharStrings中添加了两个新的运算符:vsindex和blend。
变量字体保存表示几个不同设计变体的等效数据,并使用算法在这些设计之间进行插值或混合,以获得连续的设计实例。这允许整个字体系列由单个可变字体表示。例如,变量字体可以包含等同于来自族的Light和Heavy设计的数据,然后可以对其进行插值以导出Light和Heavy之间的连续范围内的任何权重的实例。
有关OpenType字体变体的一般背景,有关用于支持可变字体的表格的详细信息,术语以及用于混合值以导出特定设计实例的插值算法的规范,请参阅OpenType字体变体概述一章。
CFF2格式的可变字体的轮廓数据的构建非常类似于将构建的非变量CFF2表,其结构和运算符与用于默认设计表示的结构和运算符完全相同。但是,在默认设计中出现值的任何地方,一个设计的单个值都会补充一组delta值,然后是混合运算符。(为了提高效率,单个混合运算符可以遵循一系列此类增量集,而不是在每个单独集之后。)与其他CharString运算符不同,混合在处理时不会清除堆栈。混合运算符的结果保留在堆栈中,由以下运算符处理。
在可变字体内,不同的字形可以使用不同的区域集合和相关的增量值来进行混合操作。处理给定的字形时,解释器必须确定要使用的集合。这些集存储在ItemVariationStore结构的CFF2表中。ItemVariationStore包含一个或多个ItemVariationData子表,每个子表包含一个变体区域列表。如果未指定其他子表,则默认使用第一个ItemVariationData子表(索引0)。当一组delta值需要一个非默认的ItemVariationData子表时,vsindex使用运算符。当在Private DICT中使用此运算符来设置非默认itemVariationData索引时,这将成为私有DICT的默认项变体数据索引,但也成为引用该私有DICT的所有CharStrings的默认项变体数据索引。当在CharString中使用vsindex运算符时,它将取代私有DICT中的任何vsindex。CFF2表中的所有私有DICT和CharStrings共享相同的ItemVariationStore。
Font Variations的语法支持运算符。
vsindex
| - ivs vsindex(15)| -
选择要用于在此CharString中进行混合的ItemVariationData子表; ivs参数是ItemVariationData索引。使用时,vsindex必须位于第一个混合运算符之前,并且可能只在CharString中出现一次。如果CharString中不存在vsindex运算符,则ItemVariationData索引将继承自Private DICT vsindex值。如果私有DICT中不存在vsindex运算符,则默认值为0。
混合
num(0)… num(n-1),delta(0,0)… delta(k-1,0),
delta(0,1)… delta(k-1,1)… delta(0,n-1)… delta(k-1,n-1)
n blend(16)val(0)… val(n-1)
对于k个区域,从n *(k + 1)个操作数产生n个内插结果值。
该共混物操作者在与其他运营商一起使用,以产生经内插的输入值用于其它操作者适用于当前选择的变化的实例。变量 - 实例设计向量在解释器中指定,在字体程序外部,并且解释器在处理混合运算符时应用设计向量以计算适当的插值。
仅对设计空间坐标值支持混合,例如提示和路径构造运算符的操作数。堆栈上的最后一个操作数n指定将在下一个运算符的堆栈中保留的操作数的数量。(例如,如果混合运算符与需要6个操作数的hflex运算符一起使用,则n将设置为6.)此操作数还通知处理程序混合运算符,运算符前面是n + 1几组操作数。
第一组操作数num(0)… num(n-1)包含适用于默认变体实例的以下CharsString运算符的n个操作数。
存在n个附加的操作数集合,delta(0,i)… delta(k-1,i),一个对应于第一组操作数中的每个值。每组包含给定操作数的变化调整增量,每个增量与设计变化空间的不同区域相关联。(见“变异空间,默认实例和调整增量”和“变化数据”部分中的OpenType字体变化概述章节用于与区域和相关联的调整增量的更多信息)。每个这些附加操作数套具有ķ操作数,其中ķ表示为其定义变化调整增量的区域数。此值由当前为CharString激活的ItemVariationData子表确定(请参阅vsindex)。
因此,第一组包含n个操作数,并且以下组包含n * k个操作数,在最后的n个操作数之前给出总共n *(k + 1)个操作数。
该共混物处理程序将比较的坐标当前选择的变化实例的设计向量为每个区域计算的内插因子的标量对于每个给定区域。然后将其应用于区域的调整增量,以计算要应用于默认值的净调整增量。有关插值算法的更多详细信息,请参阅OpenType字体变体概述一章中的实例值插值算法。
作为混合运算符的示例,请考虑使用混合来插入rmoveto运算符的输入。所述rmoveto运算符采用两个操作数,x和y,所以Ñ对于参数混合操作者将被设置为2。
另外,假设字体具有重量和宽度变化轴,并且字体的默认变体实例是常规。此外,假设此CharString使用三个区域的增量,其极值点对应于Light和Bold(权重轴的极值),还有Condensed(宽度轴极端,与Normal的正常宽度相反)。因此,k的值是3。
现在假设Regular,Light,Bold和Condensed变体实例需要的removeto运算符的x和y参数如下:
常规:100 200 rmoveto Light:100 150 rmoveto Bold:100 300 rmoveto Condensed:50 100 rmoveto
对于blend运算符,第一组参数将是默认实例所需的rmoveto参数:
100 200
以下几组混合参数是三个区域的增量集,每个rmoveto参数都有一组增量。作为delta的示例,Regular的默认实例的x参数为100,Condensed所需的x参数为50,因此第3个区域(索引2)的x参数delta为-50。因此,所有三个区域的第一个rmoveto操作数的增量集合为:
0 0 -50
并且所有三个区域的第二个rmoveto操作数的增量集合为:
-50 100 -100
将它们组合在一起,混合和rmoveto算子组合的CharString序列如下:添加括号以划分每个混合操作数集:
(100 200)(0 0 -50)( - 50 100 -100)2 混合 rmoveto
当针对特定变体实例处理混合运算符时,处理程序将计算每个区域的标量系数,然后将每个标量应用于相应区域的增量。例如,如果所选实例位于权重轴上的Regular和Light之间的中间位置以及宽度轴上的正常宽度之间,则区域0的标量将为0.5,而区域1和2的标量将各自为0.0。该混合操作将插值rmoveto如下参数:
x = 100 +(0 * 0.5)+(0 * 0.0)+( - 50 * 0.0)= 100 y = 200 +( - 50 * 0.5)+(100 * 0.0)+( - 100 * 0.0)= 175
这些混合结果被推到堆栈上。因此,将要执行的rmoveto操作是:
100 175 rmoveto
附录A. CFF2 CharString命令代码
单字节CFF2运算符
表2.单字节CFF2运算符
十二月 十六进制 操作者 注意
0 00 <保留>
1 01 hstem
2 02 <保留>
3 03 vstem
4 04 vmoveto
五 05 rlineto
6 06 hlineto
7 07 vlineto
8 08 rrcurveto
9 09 <保留>
10 0A callsubr
11 0B <保留>
12 0℃ 逃逸 2字节运算符的第一个字节。
13 0D <保留>
14 0E <保留>
15 0F vsindex
16 10 混合
17 11 <保留>
18 12 hstemhm
19 13 hintmask
20 14 cntrmask
21 15 rmoveto
22 16 hmoveto
23 17 vstemhm
24 18 rcurveline
25 19 rlinecurve
26 1A vvcurveto
27 1B hhcurveto
28 1C <数字> 指定无符号整数值的3字节序列的第一个字节(接下来的两个字节是uint16)。
29 1D callgsubr
三十 1E vhcurveto
31 1F hvcurveto
32至246 20到f6 <数字>
247至254 f7到fe <数字> 指定数字的2字节序列的第一个字节。
255 FF <数字> 指定固定值的5字节序列的第一个字节。
双字节CFF2运算符
表3.双字节CFF2运算符
十二月 十六进制 操作者
12 0到12 33 0c 00到0c 21 <保留>
12 34 0c 22 hflex
12 35 0c 23 柔性
12 36 0c 24 hflex1
12 37 0c 25 flex1
12 38至12 255 0c 26到0c ff <保留> 附录B. CFF2 CharString实施限制
以下是CFF2 CharString解释器的实现限制:
描述 限制
参数堆栈 513
阀杆提示数量(总H / V) 96
Subr嵌套,堆栈限制 10
CharString长度 65535
最大(g)子计数 65536 附录C从Type 2 CharStrings的变化
CFF2 CharStrings不包含宽度值。
CharString运算符集在CFF2中扩展,以包括blend和vsindex运算符。这些工作如上面第4.5节“ 变体数据操作符”中所述。对于CFF2 charstring类型运营商代码共混物是16,而对于vsindex是15。
将删除Type 2运算符endchar和return。
将删除Type 2逻辑,存储和数学运算符。
对于CFF2字体,CharStrings的填充规则必须始终是非零绕组数规则,而不是偶数奇数规则。允许重叠子路径。
堆栈深度从48增加到513。
附录D自早期版本以来的更改
自OpenType 1.8首次发布以来,已进行了以下更改和修订。
首次发布:OpenType 1.8(2016年9月)。请参阅附录C,类型2 CharStrings的更改。
OpenType 1。8。1(2017年1月):
对FontSets的所有引用都被删除或重写。
在1.0节简介中,添加了一个注释,即CFF2 CharStrings可以转换为Type2 CharStrings,只丢失变量数据。
在2.3和4.2节中,有关结束CharString和子例程的语句已得到纠正:这些语句在到达字节字符串结尾时结束。
在第3节“CharString编码”中,删除了对宽度的所有引用。
在第3.2节“CharString数字编码”表1中,从最后一行,第二列的文本开头删除了数字“255”。
在第3.3节“CharString运算符编码”中,添加了一个显式语句,当遇到无法识别的运算符时,应忽略它并清除堆栈。
在第4节中,删除了对算术和条件运算符的引用。
在4.3节,图6中,以下提示掩码示例中的十六进制和位掩码值已更正,从0xA0到0x60。
在4.4节子程序中,扩展了子程序的描述。
在4.5节中,“ vsindex(22)”被更正为“ vsindex(15)”。“ blend(23)”被校正为“ blend(16)”。该混合例如被更新为使用3个区域。
在4.5节中,添加了一个声明,如果存在,vsindex必须在第一次出现混合运算符之前,并且可能只在CharString中出现一次。混合运算符的描述已扩展。
在附录A表2中,“返回”被更正为“<保留>”。
在附录B,CFF2 CharString Implementation Limits中,删除了表行“TransientArray elements 32”。这不是必需的,因为删除了Type 2存储操作符。
将附录C“兼容性”的内容移至下一个附录中。
为了易读性和一致性,进行了许多小的格式化和措辞更改。所有出现的“CFF 2”都改为“CFF2”,并且“CharString”的大写一致。
OpenType 1。8。2(2017年7月):
在3.2节中,CharString Number Encoding,校正了为字节值251到254表示的所述值范围。
在附录B到513中修改了参数堆栈限制,并删除了对maxstack运算符的引用。
编辑修订。11.8.WGL4.0字符集
11.8.1.U+0020 U+00BB
统一 PostScript名称 描述性名称 MacChar MacIndex.notdef的 0
为0x0 1
0xd中 2
ü+ 0020 空间 空间 为0x20 3
U + 0021 exclam 感叹号 为0x21 4
U + 0022 quotedbl 引号 为0x22 五
U + 0023 numbersign 数字标志 0×23 6
U + 0024 美元 美元符号 0X24 7
U + 0025 百分 百分号 0x25 8
U + 0026 符号 符号 0×26 9
U + 0027 quotesingle 撇号 0×27 10
U + 0028 parenleft 左括号 0×28 11
U + 0029 parenright 右括号 0x29 12
U + 002A 星号 星号 0x2a 13
U + 002B 加 加号 0x2B访问 14
U + 002C 逗号 逗号 0x2c上 15
U + 002D 连字符号 连字符减号 0x2d 16
U + 002E 期 期 0x2E之间 17
U + 002F 削减 削减 值为0x2F 18
U + 0030 零 数字零 的0x30 19
U + 0031 一 数字一 0X31 20
U + 0032 二 数字二 0x32 21
U + 0033 三 数字三 0x33 22
U + 0034 四 数字四 0x34 23
U + 0035 五 数字五 0x35 24
U + 0036 六 数字六 0x36 25
U + 0037 七 数字七 0×37 26
U + 0038 八 数字八 0x38 27
ü+ 0039 九 数字九 0x39 28
U + 003A 结肠 结肠 0x3a 29
U + 003B 分号 分号 0x3b 三十
U + 003C 减 不到标志 为0x3C 31
U + 003D 等于 等于标志 0x3D之间 32
U + 003E 更大 大于号 0x3E的 33
U + 003F 题 问号 0x3F的 34
U + 0040 在 商业广告 0x40的 35
ü+ 0041 一个 拉丁文大写字母a 的0x41 36
U + 0042 乙 拉丁大写字母b 的0x42 37
U + 0043 C 拉丁文大写字母c 0x43中 38
U + 0044 d 拉丁文大写字母d 0×44 39
U + 0045 Ë 拉丁文大写字母e 0×45 40
U + 0046 F 拉丁大写字母f 0×46 41
U + 0047 G 拉丁大写字母g 0X47 42
U + 0048 H 拉丁文大写字母h 0x48 43
U + 0049 一世 拉丁文大写字母i ×49 44
U + 004A Ĵ 拉丁大写字母j 0x4a 45
U + 004B ķ 拉丁大写字母k 0x4b 46
U + 004C 大号 拉丁大写字母l 0x4c 47
U + 004D 中号 拉丁大写字母m 送出0x4d 48
U + 004E ñ 拉丁大写字母 0x4e 49
U + 004F Ø 拉丁大写字母o 0x4f 50
U + 0050 P 拉丁大写字母p 为0x50 51
U + 0051 Q 拉丁大写字母q 0x51 52
U + 0052 [R 拉丁大写字母r 0×52 53
U + 0053 小号 拉丁大写字母 0x53 54
U + 0054 Ť 拉丁文大写字母t 0x54 55
U + 0055 ü 拉丁文大写字母u 0x55的 56
U + 0056 V 拉丁文大写字母v 0x56储存 57
U + 0057 w ^ 拉丁文大写字母w 的0x57 58
U + 0058 X 拉丁大写字母x 将0x58 59
U + 0059 ÿ 拉丁大写字母y 0×59 60
U + 005A ž 拉丁大写字母z 0x5a 61
U + 005B bracketleft 左方括号 0x5b 62
U + 005C 反斜线 反斜线 0x5c 63
U + 005D bracketright 右方括号 0x5d 64
U + 005E asciicircum 抑扬的口音 0x5e 65
U + 005F 下划线 强调 0x5F的 66
U + 0060 坟墓 严肃的口音 0X60 67
U + 0061 一个 拉丁小写字母a 0x61 68
U + 0062 b 拉丁文小写字母b 0X62 69
U + 0063 C 拉丁文小写字母c 0x63 70
U + 0064 d 拉丁文小写字母d 0x64 71
U + 0065 Ë 拉丁文小写字母e 0x65 72
U + 0066 F 拉丁文小写字母f 0x66 73
U + 0067 G 拉丁小写字母g 0×67 74
U + 0068 H 拉丁文小写字母h 0x68 75
U + 0069 一世 拉丁小写字母i 0×69 76
U + 006A Ĵ 拉丁文小写字母j 的0x6A 77
U + 006B ķ 拉丁文小写字母k 0x6b 78
U + 006C 升 拉丁小写字母l 0x6c 79
U + 006D 米 拉丁小写字母m 0x6d 80
U + 006E ñ 拉丁小写字母 0x6e 81
U + 006F Ø 拉丁文小写字母o 0x6f 82
U + 0070 p 拉丁小写字母p 0x70 83
U + 0071 q 拉丁小写字母q 0x71 84
U + 0072 [R 拉丁小写字母r 0x72 85
U + 0073 小号 拉丁小写字母 0x73 86
U + 0074 Ť 拉丁文小写字母t 0x74 87
U + 0075 ü 拉丁文小写字母u 0x75 88
U + 0076 v 拉丁小写字母v 0x76 89
U + 0077 w ^ 拉丁小写字母w 0x77 90
U + 0078 X 拉丁文小写字母x 0x78 91
U + 0079 ÿ 拉丁小写字母y 0x79的 92
U + 007A ž 拉丁文小写字母z 0x7a 93
U + 007B braceleft 左括号 0x7b 94
U + 007C 酒吧 垂线 0x7c 95
U + 007D braceright 右大括号 0x7d 96
U + 007E asciitilde 波浪号 到0x7e 97
U + 00A0 空间* 不间断的空间 0xca 172
U + 00A1 exclamdown 倒置的感叹号 0xc1 163
U + 00A2 一分钱 分号 0xa2 132
U + 00A3 英镑 英镑符号 0xA3执行 133
U + 00A4 货币 货币符号 位于0xDB 189
U + 00a5 日元 日元符号 0xb4 150
U + 00a6 brokenbar 破吧 232
U + 00a7 部分 部分标志 0xa4 134
U + 00a8 分音符 二分法 0xac 142
U + 00A9 版权 版权标志 0xa9 139
U + 00AA ordfeminine 女性序数指标 为0xBB 157
U + 00ab guillemotleft 左guillemet 0xc7 169
U + 00AC logicalnot 没有签字 为0xC2 164
U + 00AD 连字符* 软连字符
U + 00AE 注册 注册商标标志 0xa8 138
U + 00AF 长音符号 macron,overline 0xF8的 218
U + 00B0 学位 学位标志 0xa1 131
U + 00B1 正负 加号 - 减号 0xb1 147
U + 00B2 twosuperior 上标二 242
U + 00B3 threesuperior 上标三 243
U + 00B4 急性 急性口音 是0xAB 141
U + 00b5 亩 微标志 0xB5执行 151
U + 00B6 段 段落标志 0xa6 136
U + 00B7 periodcentered 中间点,假名结合
U + 00b8开始 变音符号 变音符号 0xFC有 222
U + 00b9 onesuperior 上标一 241
U + 00BA ordmasculine 男性序数指标 0xbc 158
U + 00BB guillemotright 右guillemet 0xc8 170
*此字形名称也用于本文档中列出的另一个Unicode值。如果需要对此字形进行单独设计,则可以为其指定单<CODE>字形名称,其中<CODE>是一个4位大写十六进制数字,表示Unicode值。
例如,如果MICRO SIGN(U + 00B5)和GREEK SMALL LETTER MU(U + 03BC)需要不同的设计,则字形“mu”应设计为MICRO SIGN,字形“uni03BC”应设计为GREEK SMALL LETTER亩。
有关更多详细信息,请参阅Adobe字形列表规范。
11.8.2.U+00BC U+017E
统一 PostScript名称 描述性名称 MacChar MacIndexU + 00BC 四分之一 粗俗分数四分之一 245
U + 00BD 一半 粗俗的一半 244
U + 00BE 四分之三 粗俗分数四分之三 246
U + 00BF questiondown 倒置的问号 将0xC0 162
U + 00C0 Agrave 拉丁语大写字母带有严重口音 0xcb 173
U + 00C1 Aacute 拉丁语大写字母a带有尖锐的口音 0xe7 201
U + 00C2 Acircumflex 拉丁语大写字母a带有抑扬音 为0xE5 199
U + 00C3 Atilde 拉丁语大写字母a与代字号 的0xCC 174
U + 00C4 Adieresis 拉丁语大写字母a与分音符 0x80的 98
U + 00C5 戒指 拉丁语大写字母a上面有戒指 0×81 99
U + 00C6 AE 拉丁语大写字母a与e 0xae 144
U + 00C7 Ccedilla 拉丁语大写字母c与cedilla 为0x82 100
U + 00C8 Egrave 拉丁语大写字母e带有重音符号 0xe9 203
U + 00c9 Eacute 拉丁语大写字母e带有尖锐的口音 0×83 101
U + 00CA Ecircumflex 拉丁语大写字母e带有抑扬音 0xe6 200
U + 00CB Edieresis 拉丁语大写字母e与分音符 0xe8 202
U + 00cc Igrave 拉丁语大写字母带有严肃的口音 0xed 207
U + 00CD Iacute 拉丁语大写字母i带有尖锐的口音 0xea 204
U + 00CE Icircumflex 拉丁语大写字母i带有抑扬音 将0xEB 205
U + 00CF Idieresis 拉丁语大写字母i with diaeresis 0xec 206
U + 00D0 ETH 拉丁语大写字母eth 233
U + 00D1 Ntilde 拉丁语大写字母n与代字号 的0x84 102
U + 00d2 Ograve 拉丁语大写字母o带有重音符号 的0xf1 211
U + 00D3 Oacute 拉丁语大写字母o带有尖锐的口音 0xee 208
U + 00D4 Ocircumflex 拉丁语大写字母o带有抑扬音 0xef 209
U + 00d5 Otilde 拉丁语大写字母o与代字号 0XCD 175
U + 00D6 Odieresis 拉丁语大写字母o与分音符 0x85 103
U + 00d7 乘 乘法符号 240
U + 00d8 Oslash 拉丁语大写字母o斜中风 0XAF 145
U + 00d9 Ugrave 拉丁语大写字母u带有重音符号 0xF4中 214
U + 00da Uacute 拉丁语大写字母u带有尖锐的口音 0xf2 212
U +00分贝 Ucircumflex 拉丁语大写字母u带有抑扬音 0xf3 213
U + 00dc Udieresis 拉丁语大写字母u with diaeresis 0x86可以 104
U + 00dd Yacute 拉丁语大写字母y带有尖锐的口音 235
U + 00de 刺 拉丁大写字母刺 237
U + 00df germandbls 拉丁小写字母s 0xa7 137
U + 00E0 agrave 带有严重口音的拉丁文小写字母 均为0x88 106
U + 00e1 aacute 拉丁文小写字母带有尖锐的口音 87H的 105
U + 00E2 acircumflex 拉丁文小写字母a带有抑扬音 0x89上 107
U + 00e3 atilde 拉丁文小写字母与代字号 0x8b 109
U + 00e4 adieresis 拉丁语小写字母a与分音符 0x8a 108
U + 00e5 戒指 拉丁文小写字母a上面有戒指 0x8c 110
U + 00e6 AE 拉丁文小写字母a与e 0xbe 160
U + 00e7 ccedilla 拉丁小写字母c与cedilla 0x8d 111
U + 00E8 egrave 带有严重口音的拉丁文小写字母e 值为0x8F 113
U + 00e9 eacute 带有急性口音的拉丁文小写字母e 为0x8E 112
U + 00ea ecircumflex 带有抑扬音的拉丁文小写字母e 的0x90 114
U + 00eb edieresis 拉丁语小写字母e与分音符 0x91 115
U + 00ec igrave 拉丁文小写字母带有严肃的口音 0x93 117
U + 00ed iacute 带有尖锐口音的拉丁文小写字母 0x92 116
U + 00ee icircumflex 带有抑扬音的拉丁文小写字母 0x94的 118
U + 00ef idieresis 带有分音符的拉丁小写字母 位0x95 119
U + 00F0 ETH 拉丁小写字母 234
U + 00F1 ntilde 拉丁文小写字母n与代字号 0x96 120
U + 00F2 ograve 拉丁文小写字母o带有重音符号 0x98在全局 122
U + 00F3 oacute 带有急性口音的拉丁文小写字母o 0x97 121
U + 00f4 ocircumflex 拉丁文小写字母o带有抑扬音 0x99 123
U + 00f5 otilde 拉丁文小写字母o代字号 0x9b 125
U + 00f6 odieresis 拉丁语小写字母o与分音符 为0x9A 124
U + 00f7 划分 分裂标志 0xd6 184
U + 00f8 oslash 拉丁小写字母o斜中风 为0xBF 161
U + 00f9 ugrave 拉丁文小写字母带有重音符号 0x9d 127
U + 00FA uacute 带有急性口音的拉丁文小写字母u 为0x9c 126
U + 00FB ucircumflex 带有抑扬音的拉丁文小写字母 0x9e 128
U + 00FC udieresis 拉丁语小写字母u with diaeresis 0x9f 129
U + 00FD yacute 带有尖锐口音的拉丁文小写字母y 236
U + 00FE 刺 拉丁小写字刺 238
U + 00FF ydieresis 拉丁语小写字母y与分音符 0xd8 186
U + 0100 Amacron 拉丁大写字母a与macron
U + 0101 amacron 拉丁小写字母a与macron
U + 0102 Abreve 拉丁语大写字母a与breve
U + 0103 abreve 拉丁小写字母a与breve
U + 0104 Aogonek 拉丁语大写字母a与ogonek
U + 0105 aogonek 拉丁文小写字母与ogonek
U + 0106 Cacute 拉丁语大写字母c带有尖锐的口音 253
U + 0107 cacute 带有急性口音的拉丁文小写字母c 254
U + 0108 Ccircumflex 拉丁语大写字母c与抑扬
U + 0109 ccircumflex 带旋律的拉丁小写字母c
U + 010A Cdotaccent 拉丁大写字母c上面有一个点
U + 010B cdotaccent 拉丁小写字母c上面有一个点
U + 010C Ccaron 拉丁大写字母c与卡隆 255
U + 010d ccaron 拉丁小写字母c与卡隆 256
U + 010e Dcaron 拉丁语大写字母d与hacek
U + 010F dcaron 拉丁小写字母d与hacek
U + 0110 Dcroat 拉丁语大写字母d与中风
U + 0111 dcroat 拉丁小写字母d与中风 257
U + 0112 Emacron 拉丁语大写字母e与macron
U + 0113 emacron 带有macron的拉丁小写字母e
U + 0114 Ebreve 拉丁语大写字母e与breve
U + 0115 ebreve 拉丁小写字母e与breve
U + 0116 Edotaccent 拉丁大写字母e上面有一个点
U + 0117 edotaccent 带上面点的拉丁小写字母e
U + 0118 Eogonek 拉丁语大写字母e与ogenek
U + 0119 eogonek 与ogenek的拉丁小写字母e
U + 011A Ecaron 拉丁语大写字母e与hacek
U + 011B ecaron 拉丁小写字母e与hacek
U + 011C Gcircumflex 拉丁语大写字母g与抑扬
U + 011d gcircumflex 带旋律的拉丁小写字母g
U + 011E Gbreve 拉丁语大写字母g与breve 248
U + 011f gbreve 拉丁小写字母g与breve 249
U + 0120 Gdotaccent 拉丁大写字母g上面有一个点
U + 0121 gdotaccent 带上面点的拉丁小写字母g
U + 0122 Gcommaaccent 拉丁语大写字母g与cedilla
U + 0123 gcommaaccent 拉丁小写字母g与cedilla
U + 0124 Hcircumflex 拉丁语大写字母h与抑扬
U + 0125 hcircumflex 带旋律的拉丁文小写字母h
U + 0126 横条 拉丁语大写字母h中风
U + 0127 HBAR 拉丁小写字母h中风
U + 0128 Itilde 拉丁语大写字母我与代字号
U + 0129 itilde 拉丁文小写字母我与代字号
U + 012A Imacron 拉丁大写字母我与macron
U + 012B imacron 拉丁小写字母我与macron
U + 012C Ibreve 拉丁语大写字母i with breve
U + 012D ibreve 拉丁小写字母我和breve
U + 012E Iogonek 拉丁语大写字母i与ogonek
U + 012f iogonek 拉丁小写字母我跟ogonek
U + 0130 Idotaccent 拉丁大写字母我带点上面 250
U + 0131 dotlessi 拉丁小写字母我上面没有点 0xf5 215
U + 0132 IJ 拉丁语资本结合ij
U + 0133 IJ 拉丁小结扎ij
U + 0134 Jcircumflex 拉丁语大写字母j与抑扬
U + 0135 jcircumflex 带有抑扬符号的拉丁文小写字母j
U + 0136 Kcommaaccent 拉丁语大写字母k与cedilla
U + 0137 kcommaaccent 拉丁小写字母k与cedilla
U + 0138 kgreenlandic 拉丁小写字母kra
U + 0139 Lacute 拉丁语大写字母l带有尖锐的口音
U + 013A lacute 带有急性口音的拉丁文小写字母l
U + 013B Lcommaaccent 拉丁语大写字母l与cedilla
U + 013C室 lcommaaccent 拉丁小写字母l与cedilla
U + 013d Lcaron 拉丁语大写字母l与hacek
U + 013e lcaron 拉丁小写字母l与hacek
U + 013f Ldot 拉丁大写字母l与中间点
U + 0140 ldot 带有中间点的拉丁文小写字母l
U + 0141 Lslash 拉丁语大写字母l中风 226
U + 0142 lslash 拉丁小写字母l中风 227
U + 0143 Nacute 拉丁语大写字母n带有尖锐的口音
U + 0144 nacute 带有急性口音的拉丁文小写字母
U + 0145 Ncommaaccent 拉丁语大写字母n与cedilla
U + 0146 ncommaaccent 拉丁小写字母n与cedilla
U + 0147 Ncaron 拉丁语大写字母n与hacek
U + 0148 ncaron 拉丁小写字母n与hacek
U + 0149 napostrophe 拉丁文小写字母n前面有撇号
U + 014A 工程 拉丁大写字母eng
U + 014b 工程 拉丁小写字母
U + 014C Omacron 拉丁大写字母o与macron
U + 014d omacron 拉丁小写字母o与macron
U + 014e Obreve 拉丁语大写字母o与breve
U + 014F obreve 拉丁小写字母o与breve
U + 0150 Ohungarumlaut 拉丁语大写字母o具有双重口音
U + 0151 ohungarumlaut 带有双重口音的拉丁文小写字母o
U + 0152 OE 拉丁语资本结合与e 0xce 176
U + 0153 OE 拉丁语小结扎与e 0xcf 177
U + 0154 Racute 拉丁语大写字母r带有尖锐的口音
U + 0155 racute 带有急性口音的拉丁文小写字母r
U + 0156 Rcommaaccent 拉丁语大写字母r与cedilla
U + 0157 rcommaaccent 拉丁小写字母r与cedilla
U + 0158 Rcaron 拉丁语大写字母r与hacek
U + 0159 rcaron 拉丁小写字母r与hacek
U + 015A Sacute 拉丁语大写字母带有尖锐的口音
U + 015B sacute 带有尖锐口音的拉丁文小写字母
U + 015C Scircumflex 带有抑扬符号的拉丁语大写字母
U + 015D scircumflex 带旋律的拉丁小写字母
U + 015e Scedilla 拉丁语大写字母与cedilla 251
U + 015f上 scedilla 拉丁小写字母与cedilla 252
U + 0160 Scaron 拉丁语大写字母与hacek 228
U + 0161 scaron 拉丁小写字母与hacek 229
U + 0162 Tcommaaccent * 拉丁语大写字母与cedilla
U + 0163 tcommaaccent * 拉丁小写字母与cedilla
U + 0164 Tcaron 拉丁语大写字母与hacek
U + 0165 tcaron 拉丁小写字母与hacek
U + 0166 TBAR 拉丁语大写字母与中风
U + 0167 TBAR 拉丁小写字母与中风
U + 0168 Utilde 拉丁语大写字母u与代字号
U + 0169 utilde 拉丁文小写字母u与代字号
U + 016A Umacron 拉丁大写字母u与macron
U + 016B umacron 拉丁小写字母u与macron
U + 016C Ubreve 拉丁语大写字母u with breve
U + 016D ubreve 拉丁小写字母u with breve
U + 016E Uring 拉丁大写字母u上面有戒指
U + 016F uring 拉丁小写字母u上面有戒指
U + 0170 Uhungarumlaut 拉丁语大写字母u带双重口音
U + 0171 uhungarumlaut 带有双重口音的拉丁文小写字母u
U + 0172 Uogonek 拉丁大写字母u与ogonek
U + 0173 uogonek 拉丁小写字母u与ogonek
U + 0174 Wcircumflex 拉丁语大写字母w与抑扬
U + 0175 wcircumflex 带有抑扬符号的拉丁文小写字母
U + 0176 Ycircumflex 拉丁语大写字母y与抑扬
U + 0177 ycircumflex 拉丁语小写字母y与抑扬
U + 0178 Ydieresis 拉丁语大写字母y与分音符 0xd9 187
U + 0179 Zacute 拉丁语大写字母z带有尖锐的口音
U + 017A zacute 带有尖锐口音的拉丁文小写字母z
U + 017b Zdotaccent 拉丁大写字母z上面有一个点
U + 017c zdotaccent 带上面点的拉丁小写字母z
U + 017d Zcaron 拉丁语大写字母z与hacek 230
U + 017E zcaron 拉丁小写字母z与hacek 231
*此字形名称也用于本文档中列出的另一个Unicode值。如果需要对此字形进行单独设计,则可以为其指定单<CODE>字形名称,其中<CODE>是一个4位大写十六进制数字,表示Unicode值。
例如,如果MICRO SIGN(U + 00B5)和GREEK SMALL LETTER MU(U + 03BC)需要不同的设计,则字形“mu”应设计为MICRO SIGN,字形“uni03BC”应设计为GREEK SMALL LETTER亩。
有关更多详细信息,请参阅Adobe字形列表规范。
11.8.3.U+017F U+2013
统一 PostScript名称 描述性名称 MacChar MacIndex
U +拉丁文扩展-A 多头 拉丁小写字母s
U + 0192 弗洛林 拉丁文小写字母f,弗罗林标志 0xc4 166
U + 01fa Aringacute 拉丁语大写字母a上面有戒指和急性
U + 01fb aringacute 拉丁文小写字母带上面的戒指和急性
U + 01FC AEacute 拉丁语资本结扎与急性
U + 01fd aeacute 拉丁小结扎带急性
U + 01fe Oslashacute 拉丁大写字母o中风和急性
U + 01FF oslashacute 拉丁小写字母o中风和急性
U + 02c6 抑扬 非旋律的旋律 0xf6 216
U + 02c7 卡隆 修饰符字母hacek 为0xFF 225
U + 02c9 macron * 修饰符字母macron
U + 02d8 短音符 短音符 0xf9 219
U + 02d9 dotaccent 点在上面 0xFA回应 220
U + 02da 环 戒指上面 0xFB的才能 221
U +02分贝 反尾形符 反尾形符 0xFE的 224
U + 02dc 波浪号 没有间距
U + 02dd hungarumlaut 修饰符双重素数 0xfd 223
U + 0384 托诺斯 希腊tonos
U + 0385 dieresistonos 希腊dialytika tonos
U + 0386 Alphatonos 与tonos的希腊大写字母阿尔法
U + 0387 anoteleia 希腊ano teleia
U + 0388 Epsilontonos 希腊大写字母epsilon与tonos
U + 0389 Etatonos 希腊大写字母eta与tonos
U + 038A Iotatonos 希腊大写字母iota与tonos
U + 038c Omicrontonos 希腊大写字母omicron与tonos
U + 038e Upsilontonos 与tonos的希腊大写字母upilon
U + 038f Omegatonos 希腊大写字母欧米茄与tonos
U + 0390 iotadieresistonos 希腊小字母iota与dialytika和tonos
U + 0391 Α 希腊大写字母阿尔法
U + 0392 Beta版 希腊大写字母beta
U + 0393 伽玛 希腊大写字母伽玛
U + 0394 达美* 希腊大写字母三角洲
U + 0395 小量 希腊大写字母epsilon
U + 0396 泽塔 希腊大写字母zeta
U + 0397 埃塔 希腊大写字母eta
U + 0398 西塔 希腊大写字母theta
U + 0399 IOTA 希腊大写字母iota
U + 039A 卡帕 希腊大写字母kappa
U + 039b LAMBDA 希腊大写字母lamda
U + 039c 亩 希腊大写字母mu
U + 039d 怒江 希腊大写字母nu
U + 039e 习 希腊大写字母xi
U + 039f 奥米克 希腊大写字母omicron
U + 03a0 皮 希腊大写字母pi
U + 03a1 卢 希腊大写字母rho
U + 03a3 适马 希腊大写字母sigma
U + 03a4 牛头 希腊大写字母tau
U + 03a5 埃普西隆 希腊大写字母upilon
U + 03a6 披 希腊大写字母phi
U + 03a7 驰 希腊大写字母chi
U + 03a8 PSI 希腊大写字母psi
U + 03a9 欧米茄* 希腊大写字母欧米茄
U + 03aa Iotadieresis 希腊大写字母iota与dialytika
U + 03AB Upsilondieresis 希腊大写字母upilon与dialytika
U + 03ac alphatonos 与tonos的希腊小字母阿尔法
U + 03AD epsilontonos 与tonos的希腊小字母epsilon
U + 03ae etatonos 与tonos的希腊小字母eta
U + 03af iotatonos 与tonos的希腊小字母iota
U + 03b0 upsilondieresistonos 与dialytika和tonos的希腊小字母upilon
U + 03b1 α 希腊小写字母阿尔法
U + 03b2 公测 希腊小写字母
U + 03b3 伽马 希腊小写字母伽玛
U + 03b4 三角洲 希腊小写字母三角洲
U + 03b5 小量 希腊小字母epsilon
U + 03b6 泽塔 希腊小写字母zeta
U + 03b7 ETA 希腊小写字母eta
U + 03b8 THETA 希腊小写字母theta
U + 03b9 丝毫 希腊小写字母iota
U + 03ba 卡帕 希腊小写字母kappa
U + 03bb 拉姆达 希腊小写字母lamda
U + 03BC 亩* 希腊小写字母mu
U + 03bd NU 希腊小字母nu
U + 03be 喜 希腊小写字母xi
U + 03bf OMICRON 希腊小写字母omicron
U + 03c0 PI 希腊小写字母pi 0xb9 155
U + 03c1 RHO 希腊小写字母rho
U + 03C2 sigma1 希腊小写字母最后的西格玛
U + 03C3 西格玛 希腊小写字母sigma
U + 03c4 牛头 希腊小写字母tau
U + 03c5 埃普西隆 希腊小写字母upilon
U + 03c6 披 希腊小写字母
U + 03c7 志 希腊小写字母
U + 03c8 PSI 希腊小写字母psi
U + 03c9 欧米加 希腊小写字母欧米茄
U + 03ca iotadieresis 希腊小字母iota与dialytika
U + 03cb upsilondieresis 与dialytika的希腊小字母upilon
U + 03cc omicrontonos 希腊小字母omicron与tonos
U + 03cd upsilontonos 与tonos的希腊小字母upilon
U + 03ce omegatonos 希腊小字母欧米茄与tonos
U + 0400 uni0400 西里尔文大写字母即坟墓
U + 0401 afii10023 西里尔文大写字母io
U + 0402 afii10051 西里尔文大写字母dje
U + 0403 afii10052 西里尔文大写字母gje
U + 0404 afii10053 西里尔文大写字母乌克兰语即
U + 0405 afii10054 西里尔字母大写字母
U + 0406 afii10055 西里尔文大写字母byelorussian-ukrainian i
U + 0407 afii10056 西里尔字母大写字母yi
U + 0408 afii10057 西里尔文大写字母je
U + 0409 afii10058 西里尔文大写字母lje
U + 040A afii10059 西里尔字母大写字母
U + 040B afii10060 西里尔字母大写字母
U + 040C afii10061 西里尔文大写字母kje
U + 040D uni040D 西里尔文大写字母我与坟墓
U + 040E afii10062 西里尔字母大写简称
U + 040f afii10145 西里尔字母大写字母dzhe
U + 0410 afii10017 西里尔字母大写字母a
U + 0411 afii10018 西里尔文大写字母
U + 0412 afii10019 西里尔字母大写字母
U + 0413 afii10020 西里尔字母大写字母
U + 0414 afii10021 西里尔文大写字母德
U + 0415 afii10022 西里尔文大写字母即
U + 0416 afii10024 西里尔字母大写字母zhe
U + 0417 afii10025 西里尔字母大写字母
U + 0418 afii10026 西里尔文大写字母i
U + 0419 afii10027 西里尔字母大写字母i
U + 041A afii10028 西里尔文大写字母ka
U + 041B afii10029 西里尔文大写字母el
U + 041c afii10030 西里尔字母大写字母
U + 041D afii10031 西里尔字母大写字母
U + 041E afii10032 西里尔文大写字母o
U + 041f afii10033 西里尔字母大写字母
U + 0420 afii10034 西里尔字母大写字母
U + 0421 afii10035 西里尔字母大写字母
U + 0422 afii10036 西里尔文大写字母te
U + 0423 afii10037 西里尔字母大写字母u
U + 0424 afii10038 西里尔字母大写字母ef
U + 0425 afii10039 西里尔文大写字母哈
U + 0426 afii10040 西里尔字母大写字母谢谢
U + 0427 afii10041 西里尔文大写字母
U + 0428 afii10042 西里尔字母大写字母
U + 0429 afii10043 西里尔文大写字母shcha
U + 042A afii10044 西里尔文大写字母硬标志
U + 042b afii10045 西里尔文大写字母yeru
U + 042c afii10046 西里尔文大写字母软标志
U + 042D afii10047 西里尔文大写字母e
U + 042e afii10048 西里尔字母大写字母yu
U + 042f afii10049 西里尔文大写字母雅
U + 0430 afii10065 西里尔文小写字母a
U + 0431 afii10066 西里尔字母小写
U + 0432 afii10067 西里尔文小写字母
U + 0433 afii10068 西里尔小写字母
U + 0434 afii10069 西里尔文小写字母
U + 0435 afii10070 西里尔文小写即
U + 0436 afii10072 西里尔字母小字母
U + 0437 afii10073 西里尔文小写字母
U + 0438 afii10074 西里尔文小写字母i
U + 0439 afii10075 西里尔字母小字母我
U + 043A afii10076 西里尔文小写字母
U + 043b afii10077 西里尔文小写字母
U + 043c afii10078 西里尔文小写字母
U + 043d afii10079 西里尔文小写字母
U + 043E afii10080 西里尔文小写字母o
U + 043f afii10081 西里尔字母小写字母
U + 0440 afii10082 西里尔小写字母呃
U + 0441 afii10083 西里尔文小写字母
U + 0442 afii10084 西里尔文小写字母te
U + 0443 afii10085 西里尔文小写字母u
U + 0444 afii10086 西里尔文小写字母ef
U + 0445 afii10087 西里尔文小写字母哈
U + 0446 afii10088 西里尔小写字母谢谢
U + 0447 afii10089 西里尔文小写字母
U + 0448 afii10090 西里尔文小写字母
U + 0449 afii10091 西里尔文小写字母
U + 044A afii10092 西里尔文小写字母硬标志
U + 044B afii10093 西里尔文小写字母yeru
U + 044C afii10094 西里尔文小写字母软标志
U + 044d afii10095 西里尔文小写字母e
U + 044E afii10096 西里尔文小写字母yu
U + 044f afii10097 西里尔字母小雅
U + 0450 uni0450 西里尔文小写即坟墓
U + 0451 afii10071 西里尔文小写字母io
U + 0452 afii10099 西里尔文小写字母dje
U + 0453 afii10100 西里尔文小写字母gje
U + 0454 afii10101 西里尔字母小乌克兰语即
U + 0455 afii10102 西里尔小写字母
U + 0456 afii10103 西里尔文小写字母byelorussian-ukrainian i
U + 0457 afii10104 西里尔字母小字母
U + 0458 afii10105 西里尔文小写字母je
U + 0459 afii10106 西里尔文小写字母
U + 045A afii10107 西里尔字母小写字母
U + 045b afii10108 西里尔文小写字母
U + 045C afii10109 西里尔文小写字母kje
U + 045D uni045D 西里尔字母小写字母与坟墓
U + 045E afii10110 西里尔字母小字母
U + 045f afii10193 西里尔文小写字母dzhe
U + 0490 afii10050 西里尔字母大写与好转
U + 0491 afii10098 西里尔字母小写字母
U + 1e80 Wgrave 拉丁语大写字母w与坟墓
U + 1e81 wgrave 拉丁小写字母w与坟墓
U + 1e82 Wacute 拉丁语大写字母w与急性
U + 1e83 wacute 拉丁小写字母w与急性
U + 1e84 Wdieresis 拉丁语大写字母w与分音符
U + 1e85 wdieresis 拉丁文小写字母w与分音符
U + 1ef2 Ygrave 拉丁语大写字母y与坟墓
U + 1ef3 ygrave 拉丁小写字母y与坟墓
*此字形名称也用于本文档中列出的另一个Unicode值。如果需要对此字形进行单独设计,则可以为其指定单<CODE>字形名称,其中<CODE>是一个4位大写十六进制数字,表示Unicode值。
例如,如果MICRO SIGN(U + 00B5)和GREEK SMALL LETTER MU(U + 03BC)需要不同的设计,则字形“mu”应设计为MICRO SIGN,字形“uni03BC”应设计为GREEK SMALL LETTER亩。
有关更多详细信息,请参阅Adobe字形列表规范。
统一 PostScript名称 描述性名称 MacChar MacIndexU + 2013 endash 冲刺 0xd0 178
ü+ 2014 emdash 他们冲刺 0xd1 179
U + 2015年 afii00208 单杠
U + 2017年 underscoredbl 双低线
U + 2018 quoteleft 留下单引号 0xd4 182
U + 2019 quoteright 正确的单引号 0xd5 183
U + 201A quotesinglbase 单低-9引号 0xe2 196
U + 201B quotereversed 单高反转9引号
U + 201C quotedblleft 留下双引号 0xd2 180
U + 201D quotedblright 右双引号 0xd3 181
U + 201E quotedblbase 双低-9引号 0xe3 197
U + 2020 匕首 匕首 0XA0 130
U + 2021 daggerdbl 双匕首 0xe0的 194
U + 2022 子弹 子弹 的0xA5 135
U + 2026 省略 水平省略号 0xc9 171
U + 2030 个千 每千米标志 0xe4 198
U + 2032 分钟 主要
U + 2033 第二 双重素数
U + 2039 guilsinglleft 单个左指角度引号 的0xDC 190
U + 203A guilsinglright 单右指角引号 0xdd 191
U + 203C exclamdbl 双重感叹号
U + 203E uni203E 上划线
U + 2044 分数 分数斜线
U + 207F nsuperior 上标拉丁小写字母
U + 20A3 法郎 法国法郎标志 247
U + 20A4 里拉 里拉标志
U + 20A7 比塞塔 比塞塔标志
U + 20AC 欧元 欧元货币符号
U + 2105 afii61248 照顾
U + 2113 afii61289 脚本小l
U + 2116 afii61352 数字符号
U + 2122 商标 商标标志 和0xAA 140
U + 2126 欧米茄 欧姆标志 0xbd 159
U + 212E 预计 估计的符号
U + 215B oneeighth 粗俗分数八分之一
U + 215C threeeighths 粗俗分数三分之八
U + 215D fiveeighths 粗俗分数五分之八
U + 215E seveneighths 粗俗分数七分之八
U + 2190 arrowleft 向左箭头
U + 2191 arrowup 向上箭头
U + 2192 arrowright 向右箭头
U + 2193 arrowdown 向下箭头
U + 2194 arrowboth 左箭头
U + 2195 arrowupdn 向上箭头
U + 21a8 arrowupdnbse * 向上箭头与基地
U + 2202 partialdiff 偏微分 0xb6 152
U + 2206 三角洲 增量 0xc6 168
U + 220F 产品 n-ary产品 0xb8 154
U + 2211 合计 n-ary总和 0xb7 153
U + 2212 减去 减号 239
U + 2215 分数 划分斜线 0xda 188
U + 2219 以时间为中心* 子弹操作员 0xe1 195
U + 221A 基 平方根 0xc3 165
U + 221E 无穷 无穷 0XB0 146
U + 221F 正交 直角
U + 2229 路口 路口
U + 222B 积分 积分 0xba 156
U + 2248 approxequal 几乎等于 0xc5 167
U + 2260 notequal 不等于 0xAD,将 143
U + 2261 等价 相同
U + 2264 lessequal 小于或等于 0xb2 148
U + 2265 greaterequal 大于或等于 0xb3 149
U + 2302 房子** 屋
U + 2310 revlogicalnot ** 反转不签
U + 2320 积分** 上半部分
U + 2321 积分** 下半部积分
U + 2500 SF100000 框图纸光水平
U + 2502 SF110000 框图光垂直
U + 250C SF010000 箱子图纸向下和向右照亮
U + 2510 SF030000 箱子图纸向下和向左照亮
U + 2514 SF020000 框图亮起来
U + 2518 SF040000 框图亮起并左转
U + 251C SF080000 箱子图纸垂直和右
U + 2524 SF090000 箱子图纸垂直和左
U + 252C SF060000 箱子图纸灯光和水平
U + 2534 SF070000 框图亮起和水平
U + 253C SF050000 箱子图纸垂直和水平
U + 2550 SF430000 箱子图纸双水平
U + 2551 SF240000 箱子图纸双垂直
U + 2552 SF510000 箱子图纸单向和向右双向
U + 2553 SF520000 箱子图纸下来双,右单
U + 2554 SF390000 箱子图纸向下和向右翻倍
U + 2555 SF220000 箱子图纸向下单双左
U + 2556 SF210000 箱子图纸向下左右双单
U + 2557 SF250000 箱子图纸向下和向左翻转
U + 2558 SF500000 箱子图纸单向和向右双
U + 2559 SF490000 箱子图纸双向和右向单
U + 255A SF380000 箱子图纸加倍和向右
U + 255B SF280000 箱子图纸单双左
U + 255C SF270000 箱子图纸上下左右单
U + 255D SF260000 箱子图纸加倍左转
U + 255E SF360000 箱子图纸垂直单双和双
U + 255F SF370000 箱子图纸垂直双右单
U + 2560 SF420000 箱子图纸双垂直和右
U + 2561 SF190000 箱子图纸垂直单双左
U + 2562 SF200000 箱子图纸垂直双左单
U + 2563 SF230000 箱子图纸双垂直和左
U + 2564 SF470000 箱形图向下单向和横向双
U + 2565 SF480000 箱形图下来双层和水平单
U + 2566 SF410000 箱子图纸双下和水平
U + 2567 SF450000 箱子图纸单向和横向双
U + 2568 SF460000 箱形图画双向和横向单一
U + 2569 SF400000 箱子图纸加倍和水平
U + 256A SF540000 箱子图纸垂直单横双
U + 256B SF530000 箱子图纸垂直双层和水平单
U + 256C SF440000 箱子图纸双垂直和水平
U + 2580 upblock ** 上半区
U + 2584 dnblock 下半区
U + 2588 块 完整的块
U + 258C lfblock 左半块
U + 2590 rtblock ** 右半块
U + 2591 ltshade ** 浅色
U + 2592 阴凉处 中等色调
U + 2593 dkshade 阴暗的阴影
U + 25a0 filledbox 黑色方块
U + 25A1 H22073 白色方块
U + 25AA H18543 黑色小广场
U + 25AB H18551 白色的小广场
U + 25AC 填补** 黑色矩形
U + 25b2 triagup 黑色向上三角形
U + 25BA triagrt ** 黑色右指针
U + 25bc triagdn 黑色向下三角形
U + 25c4 triaglf ** 黑色左指针
U + 25ca 菱形 菱形 0xd7 185
U + 25cb 圈 白色圆圈
U + 25CF H18533 黑色圆圈
U + 25d8 invbullet ** 反向子弹
U + 25d9 invcircle ** 反白圈
U + 25e6 openbullet 白色子弹
U + 263A 笑脸** 白色的笑脸
U + 263B invsmileface ** 黑色的笑脸
U + 263C 太阳** 白色太阳与射线
U + 2640 女 女性的标志
U + 2642 男 男性的标志
U + 2660 铲 黑色锹西装
U + 2663 俱乐部 黑色俱乐部套装
U + 2665 心 黑心西装
U + 2666 钻石** 黑钻石套装
U + 266A 音符 八分音符
U + 266B musicnotedbl ** 发出八分音符
U + F001 科幻 结扎 写0xDE 192
U + F002 FL 结扎 0xdf 193
U + FB01 科幻 结扎 写0xDE 192
U + FB02 FL 结扎 0xdf 193
*此字形名称也用于本文档中列出的另一个Unicode值。如果需要对此字形进行单独设计,则可以为其指定单<CODE>字形名称,其中<CODE>是一个4位大写十六进制数字,表示Unicode值。
例如,如果MICRO SIGN(U + 00B5)和GREEK SMALL LETTER MU(U + 03BC)需要不同的设计,则字形“mu”应设计为MICRO SIGN,字形“uni03BC”应设计为GREEK SMALL LETTER亩。
有关更多详细信息,请参阅Adobe字形列表规范。
**这是一个可选的字形。
11.8.4.欧元货币符号
欧元是欧盟提议的单一货币的名称。根据欧洲委员会的说法,欧元将从1999年1月1日起作为货币存在,但随着2002年硬币和纸币的引入,它将逐渐进入普遍使用状态。
根据官方欧元网站上公布的信息,欧洲委员会在内部拟定了大约30个设计草案。在这些普通公众评估的十名成员中,将候选名单缩小为两种设计。欧盟委员会主席雅克桑特和负责欧元的欧洲委员Yves-Thibault de Silguy选择了最终设计。
欧洲象征出现在Courier New,Times New Roman和Arial中。
Microsoft和其他供应商已选择使用欧元符号字体和样式的实例 - 因此符号的设计具有其所在字体的特征。
对于任何给定的字体,传统上数字和货币符号的宽度相同。这有助于在电子表格等表格应用程序中正确排列值。为了使欧元符号成为Arial和Times New Roman的正确宽度,必须将其压缩。
要访问Microsoft Word 97中的符号,用户从“插入”菜单中选择“符号..”。Word还允许用户设置键盘快捷键以访问任何可用的符号。
欧元符号的Unicode分配是20AC。该符号将被添加到以下代码页的位置0x80:1250东欧,1252西方,1253希腊,1254土耳其和1257波罗的海。在1251西里尔文中,符号将被添加到位置0x88。

12.存档版本
OpenType规范是作为TrueType Open和TrueType规范的扩展而开发的。第一个版本于1997年4月发布。当前版本是OpenType 1.8.3。
以下列出了反向时间顺序的OpenType规范的所有已发布版本。为可用的存档版本提供链接。
OpenType 1.8.3(当前版本) - 2018年8月发布
OpenType 1.8.2 - 2017年7月发布
OpenType 1.8.1 - 2017年1月发布
OpenType 1.8 - 2016年9月发布
OpenType 1.7 - 2015年3月发布
OpenType 1.6 - 2009年4月发布; 2010年7月更新
OpenType 1.5 - 2008年5月发布
OpenType 1.4 - 2002年10月发布
OpenType 1.3 - 2001年4月发布
OpenType 1.25 - 2000年7月发布
OpenType 1.2 - 1998年11月发布
OpenType 1.1 - 1998年4月发布
OpenType 1.01 - 1997年10月发布
OpenType 1.0 - 1997年4月发布
有关详细的更改历史记录,请参阅当前版本的更改日志。
13.脚本开发规范
13.1.标准脚本(Latin, Cyrillic, Greek, etc)
本文档提供的信息将帮助字体开发人员为Unicode标准涵盖的所有“标准”脚本创建或支持OpenType字体,例如:拉丁语,西里尔语,希腊语和亚美尼亚语。
介绍
在本文档中,“标准”是指任何非复杂脚本,即任何不需要重新排序或上下文分析的脚本。
字体开发人员将学习如何在其字体中编写脚本功能,选择字符集,组织字体信息以及使用现有工具生成标准脚本字体。定义和说明了标准脚本的已注册功能,列出了编码,并包含了用于编译OpenType字体的布局表的模板。
本文档还介绍了Uniscribe的标准OpenType整形引擎的信息,Uniscribe是一个负责文本布局的操作系统组件。
除了作为标准脚本字体的创建和支持的入门和规范之外,本文档还旨在更广泛地说明OpenType布局体系结构,功能方案以及对文本整形和定位的操作系统支持。
词汇表
以下术语对于理解本文档中讨论的布局功能和脚本规则很有用。
基础字形 - 任何可以在其上方或下方具有变音符号的字形。布局操作是根据基本字形而不是基本字符定义的,因为连字可以作为基础。
字符 - 每个字符代表一个Unicode字符代码点。例如,’A’字符是U + 0041。角色可能有多种形式的字形。
变音符号 - 位于角色上方或下方的角色,用于提供发音指导(即重音符号,重音符号,波形符号等)
字形 - 字形表示一个或多个字符的形式。
Ligature - 连接形成单个字形的字形组合。字体设计者可以根据自己正在使用的字体来创建连字。
标准脚本 - 任何非复杂的脚本; 任何不需要在整形过程中重新排序或进行上下文分析的脚本。
塑造引擎
Uniscribe标准整形引擎分阶段处理文本。阶段是:
使用OTLS(OpenType库服务)整形(替换)字形
使用OTLS定位字形
下面的描述将帮助字体开发人员理解标准特征编码模型的基本原理,并帮助应用程序开发人员更好地理解布局客户端如何将职责划分为操作系统功能。
使用OTLS进行整形
Uniscribe的第一步是塑造字符串,将所有字符映射到它们的名义形式字形。
接下来,Uniscribe调用OTLS来应用这些功能。所有OTL处理都分为一组预定义的功能(在本文档的“功能”部分中进行了描述和说明)。每个特征一个接一个地应用于音节中的适当字形,OTLS处理它们。Uniscribe可以为OTL服务提供尽可能多的调用功能。这可确保以所需顺序执行功能。
塑造过程的步骤概述如下。并非所有列出的功能都适用于所有标准脚本语言,但默认情况下是“打开”的功能。但是,您可以选择基于脚本或语言系统实现更多功能。
塑造功能:
语言形式
应用特征’ ccmp ‘来预处理任何需要合成或分解的字形
印刷形式
应用特征’ liga ‘来组成任何可选的标准连字,如fi或fl
应用特征’clig’来组成任何可选的上下文连字
使用OTLS定位字形
Uniscribe接下来应用与定位相关的功能,调用OTLS函数来定位字形。
定位功能:
字距
应用特征“ kern ”以在需要调整的基本字形之间提供对字距调整,以获得更好的印刷质量
标记为基础
应用特征“ 标记 ”将变音符号字形定位到基本字形
马克
应用特征’ mkmk ‘将变音符号字形定位到其他变音符号字形
特征
已定义下面列出的功能,以创建标准脚本和语言的基本表单。无论应用程序选择支持标准脚本布局的模型,Uniscribe都需要一个固定的顺序来执行文本运行中的功能,以便始终获得正确的基本形式。这是通过按照下面列出的标准顺序逐个调用功能来实现的。
每个功能中的查找顺序也非常重要。有关在OpenType字体中查找和定义功能的详细信息,请参阅OpenType字体开发部分中的编码功能信息。
虽然OpenType字体中不需要下面列出的任何功能,但默认情况下它们处于“打开”或激活状态。注意; 还有更多功能(可以由用户自行决定激活),可以包含在字体中。您可以在OpenType规范中看到完整的功能列表。
应用OpenType字体编码的标准功能的顺序:
特征 功能功能 布局操作 需要
基于语言的表格:
CCMP 字符组成/分解替换 GSUB
印刷形式:
西甲 标准结扎替代 GSUB
clig 语境结扎替换 GSUB
定位功能:
DIST 距离 GPOS X
克恩 对字距调整 GPOS
标记 标记为基础定位 GPOS X
mkmk 标记以标记定位 GPOS X
[GSUB =字形替换,GPOS =字形定位]
上述特征的描述和示例
人物构成(和分解)
功能标记:“ccmp”
‘ccmp’功能用于将多个字形组合成一个字形,或将一个字形分解为多个字形。此功能在任何其他功能之前实现,因为有时候字体供应商想要控制字形的某些形状。使用此表的示例如下所示。’ccmp’表将默认的字母表格映射到组合形式(基本上是连字,GSUB查找类型4)和分解形式(GSUB查找类型2)。
。")
标准连字
功能标签:“liga”
‘liga’功能用于将字形映射到其可选的连接形式。字体开发人员应将此表用于他们希望用户能够按用户首选项控制的所有连字。Uniscribe有一个标志,允许停用此类功能。’liga’功能将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。请参阅“编码功能信息”部分中的订购连接。可选的连字集将根据字体设计和脚本而有所不同。

上下文连字
功能标签:“clig”
‘clig’特征用于将字形映射到它们的上下文连接形式,这可能是印刷目的的首选。与其他连字特征不同,’clig’指定推荐连字的上下文。在某些脚本设计和swash连字中,此功能非常重要。’clig’表将字形序列映射到链接上下文中的相应连字(GSUB查找类型8)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。请参阅“编码功能信息”部分中的订购连接。可选的上下文连字集将根据字体设计和脚本而有所不同。

字距
功能标签:“kern”
‘kern’特征用于调整字形之间的空间量,通常用于在字形之间提供光学一致的间隔。虽然设计良好的字体总体上具有一致的字形间距,但是一些字形组合需要调整以提高易读性。除了水平或垂直方向的标准调整之外,此功能还可以通过设备表提供与尺寸相关的字距调整数据,在Y文本方向上提供“交叉流”字距调整,并且可以调整字形位置,而与提前调整无关。请注意,此功能不会用于等宽字体。
字体存储一组字形对的调整(GPOS查找类型2或8)。这些可以存储为匹配左和右类的一个或多个表,和/或作为单独的对。如果使用两种形式,则应该列出最后的类,以便提供替换可能由类表产生的任何非理想值的方法。可以为更大的字形集(例如,三元组,四元组等)提供附加调整,以在特定组合中覆盖对字符串的结果。这些应该在成对之前。

标记为基础定位
功能标记:“标记”
“标记”功能将标记字形与基本字形或连字字形相关联。此功能可以实现为MarkToBase附件查找(GPOS LookupType = 4)或MarkToLigature附件查找(GPOS LookupType = 5)。

标记以标记定位
功能标签:“mkmk”
‘mkmk’功能将标记字形与另一个标记字形相关联。此功能可以实现为MarkToMark附件查找(GPOS LookupType = 6)。

附录
附录:编写系统标签
功能根据指定的脚本和语言系统进行编码。语言系统标签指定与语言或语言子组相关联的印刷约定。例如,为拉丁文脚本定义了不同的语言系统; 英语,德语,西班牙语等
目前,Uniscribe引擎仅支持每个脚本的“默认”语言。但是,字体开发人员可能希望构建其他应用程序支持的语言特定功能,并且将在未来的Microsoft OpenType实现中得到支持。
注意:强烈建议在所有OpenType字体中包含“dflt”语言标记,因为它定义了字体的基本脚本处理。如果未定义其他语言特定功能或应用程序不支持该特定语言,则使用“dflt”语言系统作为默认语言系统。如果正在使用的脚本不存在“dflt”标记,则该字体在某些应用程序中可能不起作用。
下表列出了脚本和语言系统的已注册标记名称。
标准脚本的已注册标记 标准语言系统的注册标签
脚本标记 脚本 语言系统标签 语言
“LATN” 拉丁 “DFLT” *默认脚本处理
Basic Latin和Latin-1语言:
“DAN” 丹麦
“全国民主联盟” 荷兰人
“ENG” 英语
“FOS” 法罗群岛
“FIN” 芬兰
“FLE” 佛兰芒语
“DEU” 德语
“ISL” 冰岛的
“IRI” 爱尔兰的
“ITA” 意大利
“NOR” 挪威
“PTG” 葡萄牙语
“ESP” 西班牙语
“SVE” 瑞典
Unicode扩展拉丁语言:
“AFK” 南非荷兰语
“EUQ” 巴斯克
“BRE” 布列塔尼
“猫 ” 加泰罗尼亚
“HRV” 克罗地亚
“CSY” 捷克
“NTO” 世界语
“ETI” 爱沙尼亚语
“FRA” 法国
“FRI” 弗里斯兰
“GRN” 格陵兰
“匈奴” 匈牙利
“拉特” 拉丁
“LVI” 拉脱维亚
“LTH” 立陶宛
“MTS” 马耳他语
“PLK” 抛光
“PRO” 普罗旺斯
“RMS” 罗曼什
“只读存储器 ” 罗马尼亚
“ROY” 吉普赛
“天空” 斯洛伐克
“SLV” 斯洛文尼亚
“LSB” 索布语(下)
“USB ” 索布语(上)
“TRK” 土耳其
“WEL” 威尔士语
“VIT” 越南
“cyrl” 西里尔 “DFLT” *默认脚本处理
“RUS” 俄语
“grek” 希腊语 “DFLT” *默认脚本处理
“警察 ” 科普特
“ELL” 希腊语
“armn” 亚美尼亚 “DFLT” *默认脚本处理
“HYE” 亚美尼亚
“geor” 格鲁吉亚 “DFLT” *默认脚本处理
“KAT” 格鲁吉亚
“RUNR” 符文 “DFLT” *默认脚本处理
“ogam” 欧甘文 “DFLT” *默认脚本处理
注意:脚本和语言标记都区分大小写(脚本标记应为小写,语言标记全部为大写)并且必须包含四个字符(即,必须为三个字符语言标记添加空格)。
13.2.复杂脚本(由通用整形引擎支持)
Microsoft排版
上次更新时间:2017年1月
本文档提供的信息将帮助字体开发人员为Unicode标准8.0中包含的复杂脚本创建OpenType字体,但不会被专用整形引擎支持。
介绍
本文档针对开发人员实现与Microsoft OpenType规范兼容的整形行为,以用于专用整形引擎不支持的复杂脚本。它包含有关通用整形引擎(USE)的术语,字体功能和行为的信息。虽然它不包含创建字体的说明,但它可以帮助字体开发人员了解Universal整形引擎如何处理复杂的脚本文本。
通用整形引擎的工作原理
通用整形引擎分阶段处理文本。阶段是:
人物分类
覆盖Unicode类别
拆分元音处理
群集验证
OpenType功能应用程序I.
基本集群形成,GSUB
字形重新排序
OpenType功能应用程序II
地形特征,GSUB
标准印刷功能,GSUB
应用程序GSUB请求的自定义替换功能
位置功能,GPOS
人物分类
为了整形,整形引擎接收的文本运行是一系列Unicode字符。项目化预处理可确保正在形成的文本的运行包含属于单个脚本的字符,但可能包含SCRIPT_COMMON字符。整形引擎将文本划分为音节群集并识别角色属性。字符属性用于解析音节并识别其部分以及确定是否需要任何特殊行为或上下文重新排序。通用整形引擎(USE)从Unicode数据生成字符属性。Unicode的类别与USE内部使用的类之间存在映射。本节定义了USE的类和子类是如何从Unicode数据派生的。
Unicode类别:
UISC = Unicode,印度音节类别
UGC = Unicode,通用类别
UIPC = Unicode,印度位置类别,在Unicode 8.0之前,此属性称为印度马特拉类别。
Sigla USE课程 求导
乙 基础 UISC =数量; UISC = Avagraha&UGC = Lo; UISC = Bindu&UGC = Lo; UISC =辅音; UISC = Consonant_Final&UGC = Lo; UISC = Consonant_Head_Letter; UISC = Consonant_Medial&UGC = Lo; UISC = Consonant_Subjoined&UGC = Lo; UISC = Tone_Letter; UISC = Vowel&UGC = Lo; UISC = Vowel_Independent; UISC = Vowel_Dependent&UGC = Lo
CGJ CGJ U + 034F
厘米 CONS_MOD UISC = Nukta; UISC = Gemination_Mark; UISC = Consonant_Killer
CS CONS_WITH_STACKER UISC = Consonant_With_Stacker
F CONS_FINAL UISC = Consonant_Final&UGC!= Lo; UISC = Consonant_Succeeding_Repha
调频 CONS_FINAL_MOD UISC = Syllable_Modifier
GB BASE_OTHER UISC = Consonant_Placeholder; U + 2015,U + 2022,U + 25FB-25FE
H HALANT UISC = Virama; UISC = Invisible_Stacker
HN HALANT_NUM UISC = Number_Joiner
IND BASE_IND UISC = Consonant_Dead; UISC = Modifying_Letter; UGC = Po(标点符号),U + 104E,U + 2022除外; U + 002D
中号 CONS_MED UISC = Consonant_Medial&UGC!= Lo
ñ BASE_NUM UISC = Brahmi_Joining_Number
Ø 其他 任何其他SCRIPT_COMMON字符; 空格字符,UGC = Zs
[R REPHA UISC = Consonant_Preceding_Repha; UISC = Consonant_Prefixed
RSV 保留字符 当前未分配或以Unicode保留的任何字符
小号 SYM UGC =除U + 25CC外; UGC = Sc
SM SYM_MOD U + 1B6B,U + 1B6C,U + 1B6D,U + 1B6E,U + 1B6F,U + 1B70,U + 1B71,U + 1B72,U + 1B73
SUB CONS_SUB UISC = Consonant_Subjoined和UGC!= Lo
V 元音 UISC = Vowel&UGC!= Lo; UISC = Vowel_Dependent&UGC!= Lo; UISC = Pure_Killer
VM VOWEL_MOD UISC = Bindu&UGC!= Lo; UISC = Tone_Mark; UISC = Cantillation_Mark; UISC = Register_Shifter; UISC = Visarga
VS VARIATION_SELECTOR U + FE00-FE0F
WJ Word木匠 U + 2060
ZWJ 零宽度木工 UISC = Joiner
ZWNJ 零宽度非连接器 UISC = Non_Joiner
可以根据位置变化的类在Unicode的Indic_Positional_Category(UIPC)中定义,定义了其他子类:
Sigla USE子类 求导
CMAbv CONS_MOD_ABOVE UIPC =最高
CMBlw CONS_MOD_BELOW UIPC =底部
FAbv CONS_FINAL_ABOVE UIPC =最高
FBlw CONS_FINAL_BELOW UIPC =底部
FPst CONS_FINAL_POST UIPC =对
MAbv CONS_MED_ABOVE UIPC =最高
MBlw CONS_MED_BELOW UIPC =底部
MPRE CONS_MED_PRE UIPC =左
MPST CONS_MED_POST UIPC =对
SMAbv SYM_MOD_ABOVE U + 1B6B,U + 1B6D,U + 1B6E,U + 1B6F,U + 1B70,U + 1B71,U + 1B72,U + 1B73
SMBlw SYM_MOD_BELOW U + 1B6C
VAbv VOWEL_ABOVE UIPC =最高
VOWEL_ABOVE_BELOW UIPC = Top_And_Bottom
VOWEL_ABOVE_BELOW_POST UIPC = Top_And_Bottom_And_Right
VOWEL_ABOVE_POST UIPC = Top_And_Right
VBlw VOWEL_BELOW UIPC =底部; UIPC =过度使用
VOWEL_BELOW_POST UIPC = Bottom_And_Right
VPRE VOWEL_PRE UIPC =左
VPst VOWEL_POST UIPC =对
VOWEL_PRE_ABOVE UIPC = Top_And_Left
VOWEL_PRE_ABOVE_POST UIPC = Top_And_Left_And_Right
VOWEL_PRE_POST UIPC = Left_And_Right
VMAbv VOWEL_MOD_ABOVE UIPC =最高
VMBlw VOWEL_MOD_BELOW UIPC =底部; UIPC =过度使用
VMPre VOWEL_MOD_PRE UIPC =左
VMPst VOWEL_MOD_POST UIPC =对
覆盖Unicode类别
USE对Unicode类别使用以下覆盖,以实现所需的整形行为。
覆盖到Indic_Syllabic_Category
复制
1 | # Indic_Syllabic_Category=Bindu |
覆盖到Indic_Positional_Category
复制
1 | # Indic_Matra_Category=Top |
拆分元音处理
USE根据UnicodeData.txt中定义的字符分解映射分解属于UISC = Vowel_Dependent的拆分元音字符:
复制
0DCF;SINHALA VOWEL SIGN AELA-PILLA;Mc;0;L;;;;;N;;;;;
0DD9;SINHALA VOWEL SIGN KOMBUVA;Mc;0;L;;;;;N;;;;;
0DDC;SINHALA VOWEL SIGN KOMBUVA HAA AELA-PILLA;Mc;0;L;0DD9 0DCF;;;;N;;;;;
如果未在UnicodeData.txt中定义分解,则由字体开发人员在GSUB处理期间处理任何所需的分解。
群集验证是基于分裂元音的分解状态完成的。因此,验证模式仅考虑基本位置(Pre,Above,Below,Post),因为完全分解仅占据一个位置。因此,群集验证取决于分解的顺序,这可能比普通元音更具限制性。
需要递归地应用分裂元音分解,以便在应用整形之前分裂元音被完全分解
注意,如果属于包含Pre的拆分元音类的字符没有规范分解,则由字体开发者指定分解。该分解中的逻辑第一个字形将被视为VPre。来自该分解的任何后续字形都不会重新排序。当前支持的脚本中没有此类别的字符
注意:字体开发人员必须包含所有必需分解的字形。
群集验证
群集验证允许根据字符序列(类和子类)将字符序列排列成称为“簇”的组。在Abugida书写系统中,群集是文本的正交单元,其结合了多个语音和拼写元素。期望控制形成簇的字符序列,使得单个视觉簇不具有多个不同的编码序列,因为在稳定性和安全性方面会产生数据交换的问题。
USE采用通用且允许的集群结构,以便足够灵活以适应各种脚本需求。集群逻辑的目标是启用与给定脚本规则图形一致的内容,而不是强制执行特定的正字法或语言规则。这些注意事项应该应用于另一层,例如拼写检查器。
USE使用的最大集群方案可以如下可视化:
通用整形引擎中标准簇的可视化形式
聚类分析和音节分析的模式和规则使用以下附加符号:
X* X的零次或多次出现的序列
X + 一次或多次出现X的序列
<X | Y> 元素的分离:X或Y.
[X] X的可选(零或一)出现
# 发生边界
× 在指定位置不允许边界
÷ 允许在指定位置的边界
^ 除了
格式良好的字符簇可以具有如下定义的组的组合。有四种选择:独立集群
复制
< IND | O | Rsv | WJ > [VS]
独立集群通常由单个成员组成。它可以与之结合的唯一其他字符类是VARIATION_SELECTOR。BASE_IND,OTHER,保留字符和单词joiner(WJ)每个集群只能有一个代码点。当VARIATION_SELECTOR出现在除紧接其中一个有效基数(IND,O,Rsv,WJ,B,GB,N,S)之外的任何上下文中时,它形成一个独立的簇。标准集群
复制
[< R | CS >] < B | GB > [VS] (CMAbv)* (CMBlw)* (< H B | SUB > [VS] (CMAbv)* (CMBlw)*)*
[MPre] [MAbv] [MBlw] [MPst]
(VPre)* (VAbv)* (VBlw)* (VPst)*
(VMPre)* (VMAbv)* (VMBlw)* (VMPst)*
(FAbv)* (FBlw)* (FPst)* [FM]标准集群中唯一需要的组件是BASE或BASE_OTHER。集群可以选择以REPH或CONS_WITH_STACKER开头。BASE或BASE_OTHER可以紧跟CONS_MOD_ABOVE CONS_MOD_BELOW顺序后面的VARIATION_SELECTOR和/或多个CONS_MOD字符。可以发生具有可选VARIATION_SELECTOR或可选CONS_MOD的HALANT BASE的多个序列。对于每个基本位置(Pre,Above,Below,Post),序列可以继续为零或一个CONS_MED; 每个基数位置的零到多个VOWEL字符; 每个基数位置的零到多个VOWEL_MOD; 在Above,Below和Post中分别为零到多个CONS_FINAL; 最后,一个可选的FINAL_MOD。
Virama终止了集群
复制
[< R | CS >] < B | GB > [VS] (CMAbv)* (CMBlw)* (< H B | SUB > [VS] (CMAbv)* (CMBlw)*)* H
这类似于标准群集,但终止于最终HALANT。当HALANT跟随BASE或BASE_OTHER时,它将形成一个簇。当Base之外的任何字符跟随Virama时,Virama和后续字符之间将有一个簇中断。可以发生具有可选VARIATION_SELECTOR或可选CONS_MOD的HALANT BASE的多个序列。CONS_SUBJ等同于序列BASE HALANT。Number-joiner终止集群
复制
N [VS] (HN N [VS])* HN
当HALANT_NUM跟随BASE_NUM时,它将形成一个集群。当BASE_NUM以外的任何字符跟随HALANT_NUM时,HALANT_NUM和后续字符之间将存在簇中断。BASE_NUM可以立即跟随VARIATION_SELECTOR。可以发生具有可选VARIATION_SELECTOR的HALANT_NUM BASE_NUM的多个序列。
数字集群
N [VS] (HN N [VS])*
当使用HALANT_NUM连接时,BASE_NUM可以与另一个BASE_NUM形成一个簇。可以重复加入。任何BASE_NUM后面都可以跟一个VARIATION_SELECTOR。符号集群
< S | GB > [VS] (SMAbv)* (SMBlw)*
SYM字符后面可以跟一个可选的VARIATION_SELECTOR,零到多个SYM_MOD_ABOVE,然后是SYM_MOD_BELOW。独立元音(IV)加上相依元音约束(DV)
Unicode标准的核心规范禁止从其他基础加上DV形成某些IV形式(例如,TUS表12-1)。由于这些组合适用于特定对,而不是全局跨类,因此USE维护禁止序列的列表。这个禁止序列列表是:
复制
0905 0946 ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN SHORT E
0905 093E ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN AA
0930 094D 0907 ; # DEVANAGARI LETTER RA, DEVANAGARI SIGN VIRAMA, DEVANAGARI LETTER I
0909 0941 ; # DEVANAGARI LETTER U, DEVANAGARI VOWEL SIGN U
090F 0945 ; # DEVANAGARI LETTER E, DEVANAGARI VOWEL SIGN CANDRA E
090F 0946 ; # DEVANAGARI LETTER E, DEVANAGARI VOWEL SIGN SHORT E
090F 0947 ; # DEVANAGARI LETTER E, DEVANAGARI VOWEL SIGN E
0905 0949 ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN CANDRA O
0906 0945 ; # DEVANAGARI LETTER AA, DEVANAGARI VOWEL SIGN CANDRA E
0905 094A ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN SHORT O
0906 0946 ; # DEVANAGARI LETTER AA, DEVANAGARI VOWEL SIGN SHORT E
0905 094B ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN O
0906 0947 ; # DEVANAGARI LETTER AA, DEVANAGARI VOWEL SIGN E
0905 094C ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN AU
0906 0948 ; # DEVANAGARI LETTER AA, DEVANAGARI VOWEL SIGN AI
0905 0945 ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN CANDRA E
0905 093A ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN OE
0905 093B ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN OOE
0906 093A ; # DEVANAGARI LETTER AA, DEVANAGARI VOWEL SIGN OE
0905 094F ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN AW
0905 0956 ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN UE
0905 0957 ; # DEVANAGARI LETTER A, DEVANAGARI VOWEL SIGN UUE
0985 09BE ; # BENGALI LETTER A, BENGALI VOWEL SIGN AA
098B 09C3 ; # BENGALI LETTER VOCALIC R, BENGALI VOWEL SIGN VOCALIC R
098C 09E2 ; # BENGALI LETTER VOCALIC L, BENGALI VOWEL SIGN VOCALIC L
0A05 0A3E ; # GURMUKHI LETTER A, GURMUKHI VOWEL SIGN AA
0A72 0A3F ; # GURMUKHI IRI, GURMUKHI VOWEL SIGN I
0A72 0A40 ; # GURMUKHI IRI, GURMUKHI VOWEL SIGN II
0A73 0A41 ; # GURMUKHI URA, GURMUKHI VOWEL SIGN U
0A73 0A42 ; # GURMUKHI URA, GURMUKHI VOWEL SIGN UU
0A72 0A47 ; # GURMUKHI IRI, GURMUKHI VOWEL SIGN EE
0A05 0A48 ; # GURMUKHI LETTER A, GURMUKHI VOWEL SIGN AI
0A73 0A4B ; # GURMUKHI URA, GURMUKHI VOWEL SIGN OO
0A05 0A4C ; # GURMUKHI LETTER A, GURMUKHI VOWEL SIGN AU
0A85 0ABE ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN AA
0A85 0AC5 ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN CANDRA E
0A85 0AC7 ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN E
0A85 0AC8 ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN AI
0A85 0AC9 ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN CANDRA O
0A85 0ACB ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN O
0A85 0ABE 0AC5 ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN AA, GUJARATI VOWEL SIGN CANDRA E
0A85 0ACC ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN AU
0A85 0ABE 0AC8 ; # GUJARATI LETTER A, GUJARATI VOWEL SIGN AA, GUJARATI VOWEL SIGN AI
0AC5 0ABE ; # GUJARATI VOWEL SIGN CANDRA E, GUJARATI VOWEL SIGN AA
0B05 0B3E ; # ORIYA LETTER A, ORIYA VOWEL SIGN AA
0B0F 0B57 ; # ORIYA LETTER E, ORIYA AU LENGTH MARK
0B13 0B57 ; # ORIYA LETTER O, ORIYA AU LENGTH MARK
0C12 0C55 ; # TELUGU LETTER O, TELUGU LENGTH MARK
0C12 0C4C ; # TELUGU LETTER O, TELUGU VOWEL SIGN AU
0C3F 0C55 ; # TELUGU VOWEL SIGN I, TELUGU LENGTH MARK
0C46 0C55 ; # TELUGU VOWEL SIGN E, TELUGU LENGTH MARK
0C4A 0C55 ; # TELUGU VOWEL SIGN O, TELUGU LENGTH MARK
0C89 0CBE ; # KANNADA LETTER U, KANNADA VOWEL SIGN AA
0C92 0CCC ; # KANNADA LETTER O, KANNADA VOWEL SIGN AU
0C8B 0CBE ; # KANNADA LETTER VOCALIC R, KANNADA VOWEL SIGN AA
0D07 0D57 ; # MALAYALAM LETTER I, MALAYALAM AU LENGTH MARK
0D09 0D57 ; # MALAYALAM LETTER U, MALAYALAM AU LENGTH MARK
0D0E 0D46 ; # MALAYALAM LETTER E, MALAYALAM VOWEL SIGN E
0D12 0D3E ; # MALAYALAM LETTER O, MALAYALAM VOWEL SIGN AA
0D12 0D57 ; # MALAYALAM LETTER O, MALAYALAM AU LENGTH MARK
0D85 0DCF ; # SINHALA LETTER AYANNA, SINHALA VOWEL SIGN AELA-PILLA
0D85 0DD0 ; # SINHALA LETTER AYANNA, SINHALA VOWEL SIGN KETTI AEDA-PILLA
0D85 0DD1 ; # SINHALA LETTER AYANNA, SINHALA VOWEL SIGN DIGA AEDA-PILLA
0D8B 0DDF ; # SINHALA LETTER UYANNA, SINHALA VOWEL SIGN GAYANUKITTA
0D8D 0DD8 ; # SINHALA LETTER IRUYANNA, SINHALA VOWEL SIGN GAETTA-PILLA
0D8F 0DDF ; # SINHALA LETTER ILUYANNA, SINHALA VOWEL SIGN GAYANUKITTA
0D91 0DCA ; # SINHALA LETTER EYANNA, SINHALA SIGN AL-LAKUNA
0D91 0DD9 ; # SINHALA LETTER EYANNA, SINHALA VOWEL SIGN KOMBUVA
0D91 0DDA ; # SINHALA LETTER EYANNA, SINHALA VOWEL SIGN DIGA KOMBUVA
0D91 0DDC ; # SINHALA LETTER EYANNA, SINHALA VOWEL SIGN KOMBUVA HAA AELA-PILLA
0D91 0DDD ; # SINHALA LETTER EYANNA, SINHALA VOWEL SIGN KOMBUVA HAA DIGA AELA-PILLA
0D91 0DDD ; # SINHALA LETTER EYANNA, SINHALA VOWEL SIGN KOMBUVA HAA DIGA AELA-PILLA
0D94 0DDF ; # SINHALA LETTER OYANNA, SINHALA VOWEL SIGN GAYANUKITTA
11005 11038 ; # BRAHMI LETTER A, BRAHMI VOWEL SIGN AA
1100B 1103E ; # BRAHMI LETTER VOCALIC R, BRAHMI VOWEL SIGN VOCALIC R
1100F 11042 ; # BRAHMI LETTER E, BRAHMI VOWEL SIGN E
11680 116AD ; # TAKRI LETTER A, TAKRI VOWEL SIGN AA
11686 116B2 ; # TAKRI LETTER E, TAKRI VOWEL SIGN E
11680 116B4 ; # TAKRI LETTER A, TAKRI VOWEL SIGN O
11680 116B5 ; # TAKRI LETTER A, TAKRI VOWEL SIGN AU
112B0 112E0 ; # KHUDAWADI LETTER A, KHUDAWADI VOWEL SIGN AA
112B0 112E5 ; # KHUDAWADI LETTER A, KHUDAWADI VOWEL SIGN E
112B0 112E6 ; # KHUDAWADI LETTER A, KHUDAWADI VOWEL SIGN AI
112B0 112E7 ; # KHUDAWADI LETTER A, KHUDAWADI VOWEL SIGN O
112B0 112E8 ; # KHUDAWADI LETTER A, KHUDAWADI VOWEL SIGN AU
11481 114B0 ; # TIRHUTA LETTER A, TIRHUTA VOWEL SIGN AA
114AA 114B5 ; # TIRHUTA LETTER LA, TIRHUTA VOWEL SIGN VOCALIC R
114AA 114B6 ; # TIRHUTA LETTER LA, TIRHUTA VOWEL SIGN VOCALIC RR
1148B 114BA ; # TIRHUTA LETTER E, TIRHUTA VOWEL SIGN SHORT E
1148D 114BA ; # TIRHUTA LETTER O, TIRHUTA VOWEL SIGN SHORT E
11600 11639 ; # MODI LETTER A, MODI VOWEL SIGN E
11600 1163A ; # MODI LETTER A, MODI VOWEL SIGN AI
11601 11639 ; # MODI LETTER AA, MODI VOWEL SIGN E
11601 1163A ; # MODI LETTER AA, MODI VOWEL SIGN AI
注意:以上是撰写本文时TUS中记录的禁止序列的完整列表。这包括来自USE当前未处理的脚本的序列(例如,Devanagari)。
结合Grapheme Joiner(CGJ)
为避免不必要的复杂性,已从上述模式中省略了CGJ。它可能出现在群集中的任何位置而不起作用。CGJ的目的是阻止规范化处理,这可能会改变序列中标记的顺序。如果修改USE以支持规范化,则需要更新CGJ处理。
零宽度非连接器(ZWNJ)
零宽度非连接器用于防止两个字符的融合。它继续前一个集群,但当后面的字符不是标记字符(gc = Mn或gc = Mc)时,会导致集群中断。ZWNJ不会重置群集模型。
零宽度木工(ZWJ)
零宽度连接器用于融合两个字符。它继续前面的集群并将其连接到后续字符,除非以下字符是另一个ZWJ。在这种情况下,两个ZWJ之间会有一个集群断点。ZWJ不会重置群集模型。
独立字符
BASE_IND类的字符作为独立字符出现,不形成具有以下字符的集群。当类VS或J的字符出现在集群外部时,即在运行开始时,或者跟随其中一个独立字符时,它们也应被视为独立字符。
有缺陷的集群
当一个簇以任何具有UGC = Mc或UGC = Mn的字符开始时,USE会插入一个虚线圆圈字形(U + 25CC)以指示一个损坏的簇。有缺陷的集群本身不会形成扩展集群。没有有效基数的标记序列为每个标记形成单独的簇。请注意,显式字符U + 25CC是有效的通用基础(GB,BASE_OTHER),因此可以形成扩展的集群。
最大簇长度
最大簇长度为31个字形。达到此限制后,将强制执行群集中断并启动新群集。
OpenType功能应用程序I.
基本簇形成GSUB
默认字形预处理组
这些功能一起应用,一次一个群集。与任何这些功能相关联的查找将在字体开发人员指定的查找顺序中触发。可以对不同特征的查找进行交错。建议使用此处给出的功能顺序。
locl - 本地化表单
这为形成任何特定于语言的表单提供了一个起点。USE利用编辑控件提供的任何语言系统标签来触发特定于语言的替换。
ccmp - 字形组成/分解
nukt - Nukta形式
此功能旨在实现组合nukta的替换。一般而言,nukta是辅音修饰符,可用于指示备用音素,通常用于向书写系统的本地语言指示外来声音。
akhn - Akhands
用于从序列中形成传统的连字
重新排序组
这些功能按此顺序单独应用,rphf,pref。每个功能的输出将按照下一节中的说明重新排序。
rphf - Reph form
此功能传统上用于调用preconsonantal r的组合形式,在以下基础之后重新排序。该特征可以一般用于识别具有reph的重新排序属性的任何组件。要素应用程序的范围限定为群集中的前三个字形。
pref - Pre-base forms
此特征可以一般用于标识具有pre-base medial consonant的重新排序属性的post-base组件。该功能适用于整个群集。
请注意,在应用所有基本功能之后才会重新排序。
正交单元整形组
与默认字形预处理组一样,这些功能一起应用,一次一个群集。因此,字体开发人员可以在字体的OTL中指定这些功能的查找顺序。这里给出的订单是推荐的,但不是必需的。
rkrf - Rakar形式
abvf - 基础形式
此功能应用于触发与基础组件相关的替换。
blwf - 低于基础的形式
此功能应用于触发与低于基础的组件相关的替换。
half - Half forms
此功能用于为使用它们的脚本调用半个表单。
pstf - 基础后形式
此功能应用于触发与基础后组件相关的替换。
vatu - Vattu变体
此功能用于触发具有低于基础形式的连字。
cjct - Conjunct forms
此功能用于完成其他功能尚未涵盖的基本联合形式。
字形重新排序
标记的所有重新排序和锚定都是相对于基本辅音完成的。USE在一个后期阶段进行重新排序。这是因为所有重新排序都取决于碱的形成,其可在基本簇形成期间被修改。USE不会对字体的要素表进行检查或预测。因此,在应用任何重新排序之前,必须为逻辑字形顺序设计基本特征的特征查找。有两种类型的字形需要重新排序:基于特征和基于属性。实际字形重新排序在基本簇形成(OpenType特征应用I)和拓扑替换(OpenType特征应用II的第一部分)之间完成。重新排序按逻辑顺序应用:rphf,pref,VPre,VMPre:
在重新排序之前

重新排序后

当基本群集被基本群集形成期间未被替换的显式virama破坏时,重新排序受到影响,因为重新排序组件不会重新排序超过显式的virama:
在重新排序之前

重新排序后

如果字体开发人员希望重定序行为不被显式virama阻止,则他们可以在基本集群形成期间将virama替换为备用字形,以便USE将集群视为没有显式virama的连续集群。
基于特征的重新排序
Sigla 名称 描述
rphf Reph表格 许多abugida脚本将一个preconsonantal r作为它前面的辅音上方的符号。这个标志叫做reph。出于OT布局的目的,reph通常使用标记字形进行渲染,因此必须遵循其应用的基础。产生reph字形的上下文必须使用’rphf’功能。此功能的输出在以下完整基础之后重新排序。Reph不会重新排序显式的Virama。rphf功能下的查找应该为每个群集输出不超过一个字形。
PREF 预基础形式 爪哇语和巴厘语等脚本根据上下文将内侧辅音重新排列到群集的开头。上下文逻辑以字体的OT逻辑编码。需要重新排序的案例应使用“perf”功能来识别要重新排序或将要重新排序的字形或字形。一个或多个字形可以替换单个特征字形,其将在集群中的第一间隔字形之前被重新排序,或者在显式变形之后的第一间隔字形(如果存在的话)中被重新排序。每个群集只重新排序一个这样的字形。
请注意,prebase内侧辅音(CONS_MED_PRE)不会被USE自动重新排序。相反,字体设计者应该使用’perf’特征来表示何时应该通过pref特征的应用重新排序属于该类的字形。每个群集只能使用’perf’重新排序一个字形。
基于财产的重新排序
Sigla 名称 描述
[R REPHA 在以下完整基础之后,USE对基础前REPHA进行重新排序,就好像已经应用了’rphf’功能一样。字体开发人员不需要显式使用’rphf’功能。
VPRE VOWEL_PRE 分裂元音的前基元音和前基元音分量在基本字形之前重新排序,如果存在,则在通过’perf’特征重新排序的基础前字形之前重新排序。
VMPre VOWEL_MOD_PRE 预基础元音修饰符在基本字形之前重新排序,并且如果存在,则在前基元音之前和/或在通过’perf’特征重新排序的基础前字形之前重新排序。
请注意,USE目前不支持类别REPHA。
请注意,拆分元音VOWEL_PRE_ABOVE,VOWEL_PRE_ABOVE_POST和VOWEL_PRE_POST具有多个包含pre-base元素的位置。由于拆分元音分解是在重新排序之前完成的,因此只有一个字形具有VOWEL_PRE类,因此在此阶段只需要这个元音类需要特殊处理。
OpenType功能应用程序II
地形特征,GSUB
USE应用像阿拉伯语这样的脚本所需的位置功能,这些脚本具有替代的字形形状,具体取决于单词中字形的位置。
isol - 孤立的形式
init - 初始表格
medi - 内侧表格
fina - 最终形式
USE将这些作为每个群集的必需功能应用,以便根据非连接或空白边界调用特定表单。当一个或两个字符具有适用于将在其上发生连接的连接侧的非连接属性时,属于加入脚本的字形之间出现非连接边界。控制字符ZWJ和ZWNJ可用于人工调用或阻止连接。连接属性由ArabicShaping.txt中的Unicode属性Joining Type定义。
注意: USE目前尚未实现对非加入脚本的地形特征的支持。需要额外的规范。
标准印刷报告,GSUB
剩余的必需功能一起应用于整个运行。字体开发人员可以指定这组功能的查找顺序:
abvs - 基础替换
blws - 低于碱基的替代品
calt - 上下文交替
clig - 上下文连字
haln - Virama形式
liga - 标准连字[仅限水平文本]
pres - 前碱基替换
psts - 基础后替换
rclt - 必需的上下文表单
rlig - 必需的连字[仅限水平文本]
vert - 垂直书写[由编辑控件实现]
vrt2 - 垂直交替和旋转[通过编辑控件实现]
垂直布局功能在文本布局垂直时应用,并由编辑控件作为自定义功能触发。应该只应用一个特征vert或vrt2,而不是两者。
应用程序GSUB请求的自定义替换功能
位置特征应用程序,GPOS
在GPOS处理期间,这些必需的功能同时应用于整个运行。建议使用此处指定的顺序,但是字体开发人员可以在OTL中为这组功能定义GPOS查找的顺序。
curs - 草书定位
此功能应用于相对于其他基础定位基础。
dist - distance
此功能应用于进行所需的宽度调整。
kern - Kerning
此功能应用于提供最佳字母间距。编辑控件可以禁用此功能。
mark - 标记定位
此功能应用于定位与基本标记相关的标记。
abvm - 基准标记定位
此功能在功能上等同于标记功能。它可以用作将上述标记处理与下面的标记处理分开的组织机制。
blwm - 低于基准的标记定位
此功能在功能上等同于标记功能。它可以用作组织机制,以将下面的标记处理与上面的标记处理分开。
mkmk - 标记到标记定位
此功能应用于定位与先前标记相关的标记。
从上下文查找中排除某些基本字形的重要OT技术是将基本字形分类为字体的GDEF表中的标记,因为OT处理中可以选择性地包括或省略标记。但是,无论何时使用此技术,必须使用以下方法添加基本字形的宽度特征。这是必要的,因为OT处理取消了与标记相关的宽度。有必要取消非间距标记的宽度,因为在OpenType处理期间不清楚应用非间距标记的宽度的位置。
典型的用例是具有预基元音的爪哇语。由于prebase元音直到基本簇形成之后才重新排序,因此它们存在于其逻辑位置。这可能会中断其他上下文替换。如果将元音视为标记,则可以将它们从OT上下文中排除,从而减少处理所需的上下文规则的数量。因此,可以使用dist特征恢复预基元音的预期宽度,例如(在VOLT OT语言中):
复制
DEF_LOOKUP “j.dist_preVowel” PROCESS_BASE PROCESS_MARKS ALL DIRECTION LTR
AS_POSITION
ADJUST_SINGLE
GLYPH “jSignE” BY POS ADV 1433 END_POS
GLYPH “jSignAi” BY POS ADV 1433 END_POS
END_ADJUST
END_POSITION
END
其他编码问题
处理无效的组合标记
组合不与有效基数一起出现的标记和符号被视为无效。USE将无效标记视为单独的群集,并显示位于虚线圆圈(U + 25CC)上的独立标记。如果需要多个标记来定位在虚线圆上,则可以将虚线圆显式地插入到文本流中,然后根据标准聚类规则插入任何标记。
为了允许对期望在虚线圆上定位无效标记的引擎实现进行整形,建议使用USE的字体包含虚线圆圈字符U + 25CC的字形。如果字体不支持此字符,则此类实现将在缺少的字形形状(白色框)上显示无效符号。
推荐的雕文
建议包含在使用USE的任何字体中的Unicode代码点是:
代码点 描述
U + 200B 零宽度空间
U + 200C 零宽度非连接器
U + 200D 零宽度连接器
U + 25CC 虚线圈
U + 00A0 不间断的空间
U + 00D7 乘法符号
U + 2012 图破折号
U + 2013 冲破
ü+ 2014 Em dash
U + 2015年 单杠
U + 2022 子弹
U + 25FB 白色中等方形
U + 25FC 黑色中等方形
U + 25FD 白色中等小方块
U + 25FE 黑色中等小方块
附录
编写系统和语言标签
OpenType功能根据指定的脚本和语言系统以字体启用。语言系统标签指定与语言或语言子组相关联的印刷约定。并非所有软件应用程序都支持在渲染文本时使用的特定语言标记。
注意:强烈建议在所有OpenType字体中包含“dflt”语言标记,因为它定义了字体的基本脚本处理。如果未定义其他语言特定功能或应用程序不支持该特定语言,则使用“dflt”语言系统作为默认语言系统。如果正在使用的脚本不存在“dflt”标记,则该字体在某些应用程序中可能不起作用。
下表列出了USE当前支持的脚本的已注册标记名称。随着Unicode启用新的复杂脚本并更新USE,此列表将会增长。此处未列出语言系统标记,应由字体开发人员根据相关脚本确定。
Universal Shaping Engine的注册标签
脚本 脚本标记
巴厘 巴厘岛
巴塔克 batk
婆罗米 布拉赫
布吉文 bugi
布迪文 buhd
查克马 cakm
湛 湛
Duployan DUPL
埃及象形文字 egyp
Grantha 奶奶
哈努诺文 哈诺
爪哇 java的
凯提 kthi
凯莉莉 卡利
卡罗须提文 哈尔
Khojki khoj
Khudawadi 信德
雷布查 LEPC
林布 肢
Mahajani mahj
曼达 普通话
摩尼教 摩尼
Meitei Mayek mtei
莫迪 MODI
蒙 旺
西非书面语 NKO
帕哈姆苗族 hmng
八思巴 phag
Psalter Pahlavi phlp
拉让 rjng
索拉什特拉 绍尔
沙拉达普拉 SHRD
悉昙 SIDD
僧伽罗语 双曲正弦
巽 SUND
Syloti Nagri sylo
他加禄语 tglg
塔格巴努亚文 TAGB
泰乐 故事
*泰坦 羊毛
大越 tavt
塔卡里文 takr
藏 tibt
提弗纳文 tfng
Tirhuta tirh
注意:脚本标记区分大小写(脚本标记应为小写),并且必须包含四个字符。
注意: Tai Tham支持仅限于单音节群。
13.3.阿拉伯语脚本
本文档提供的信息将帮助字体开发人员为Unicode标准涵盖的所有阿拉伯语脚本语言创建或支持OpenType字体。
介绍
字体开发人员将学习如何在其字体中编码复杂的脚本功能,选择字符集,组织字体信息以及使用现有工具生成阿拉伯字体。定义和说明了阿拉伯语脚本的注册功能,列出了编码,并包含了用于编译OpenType字体的阿拉伯语布局表的模板。
本文档还提供了有关Uniscribe的阿拉伯OpenType整形引擎的信息,Uniscribe是负责文本布局的Windows组件。
除了作为创建和支持阿拉伯字体的入门和规范之外,本文档还旨在更广泛地说明OpenType布局体系结构,功能方案以及对文本整形和定位的操作系统支持。
词汇表
以下术语对于理解本文档中讨论的布局功能和脚本规则很有用。
基础字形 - 任何可以在其上方或下方具有变音符号的字形。布局操作是根据基本字形而不是基本字符定义的,因为连字可以作为基础。
字符 - 每个字符代表一个Unicode字符代码点。例如’lam’字符是U + 0644。角色可能有多种形式的字形。
变音符号 - 位于角色上方或下方的角色,用于提供发音指导(即重音符号,重音符号,波形符号等)
字形 - 字形表示一个或多个字符的形式。例如,最终的,初始的和内侧的’lam’字形(U + FEDE,U + FEDF和U + FEE0)都是’lam’字符的形式(U + 0644)。
Kashida - 也称为’tatweel’字符(U + 0640)。该字符用于连接字符之间的伸长,用于调整。
Ligature - 连接形成单个字形的字形组合。例如,’lam alef’字形组合是阿拉伯语的强制连接。其他连字,如’lam meem initial’,是可选的。
塑造引擎
分析人物
使用OTLS进行整形
使用OTLS定位字形
处理无效的组合标记
Uniscribe阿拉伯语整形引擎分阶段处理文本。阶段是:
分析上下文形状的字符
使用OTLS(OpenType库服务)整形(替换)字形
使用OTLS定位字形
下面的描述将帮助字体开发人员理解阿拉伯特征编码模型的基本原理,并帮助应用程序开发人员更好地理解布局客户端如何将职责划分为操作系统功能。
分析人物
整形引擎为了整形而接收的单元是一串Unicode字符,按顺序排列。上下文分析引擎根据角色之前和之后的角色确定角色应采取的正确上下文形式。上下文形状映射到该表单的OTL功能(isol,init,medi,fina)。
此外,在分析过程中,引擎会验证有效的变音符号组合。有关其他信息,请参阅处理无效组合标记部分。
使用OTLS进行整形
Uniscribe的第一步是对字符串进行整形,将所有字符映射到它们的名义形式字形(例如U + 0627的字形)。然后,Uniscribe将上下文形状特征应用于字形字符串。
接下来,Uniscribe调用OTLS来应用这些功能。所有OTL处理都分为一组预定义的功能(在本文档的“功能”部分中进行了描述和说明)。每个特征一个接一个地应用于音节中的适当字形,OTLS处理它们。Uniscribe可以为OTL服务提供尽可能多的调用功能。这可确保以所需顺序执行功能。
塑造过程的步骤概述如下。并非所有列出的功能都适用于所有阿拉伯语脚本语言。
塑造功能:
语言形式
应用特征’ ccmp ‘来预处理任何需要合成或分解的字形(例如,’alef’后跟’hamza above’可以组成’alef with hamza above’)
应用特征’ isol ‘来获取孤立形式的字符
应用“ fina ” 功能以获取最终形式的字形
应用要素’ medi ‘来获取内侧形式的字形
应用特征’ init ‘以获取初始形式字形
应用功能’ rlig ‘来组成任何强制性连字,例如’lam alef’
应用特征’ calt ‘以应用任何所需的替代形式的连接; 这可以为类型设计者提供上下文交换字形的能力,以提供更好的书法表示
印刷形式
应用特征’ liga ‘来组成任何可选的连字,例如’lam meem’
应用特征’ dlig ‘来组成任何自由裁量的连字
应用特征’ cswh ‘以根据上下文替换任何斜盘字符; 例如,如果后面跟着不延伸到基线以下的n个字形,则可能会使用“中午”
应用特征’ mset ‘通过替换应用标记定位; 这不会产生最好的排版可能性,因为使用定位功能’ 标记 ‘
使用OTLS定位字形
Uniscribe接下来应用与定位相关的功能,调用OTLS函数来定位字形。
定位功能:
草书连接
应用特征’ curs ‘以根据需要连接草书字体字形
字距
应用特征“ kern ”以在需要调整的基本字形之间提供对字距调整,以获得更好的印刷质量
标记为基础
应用特征“ 标记 ”将变音符号字形定位到基本字形
马克
应用特征’ mkmk ‘将变音符号字形定位到其他变音符号字形
处理无效的组合标记
将文本中出现的标记和符号与有效的辅音基础组合在一起被认为是无效的。Uniscribe使用Unicode标准(第5.12节“Unicode标准3.1的’渲染非间距标记’)中定义的后备渲染机制显示这些标记,即位于虚线圆上。
请注意,要独立呈现标志(与任何基础明显隔离),应将其应用于空间(请参阅Unicode标准3.1的第2.5节“组合标记”)。Uniscribe要求在空间和标记之间放置ZWJ,以便它们组合成一个独立的标志。
为了使回退机制正常工作,阿拉伯语OTL字体应包含虚线圆(U + 25CC)的字形。如果字体中缺少此字形,则无效符号将显示在缺少的字形形状(白色框)上。
除了’虚线圆’之外,建议包含在任何阿拉伯字体中的其他Unicode代码点是:ZWNJ(零宽度非连接器; U + 200C),ZWJ(零宽度连接器U + 200D),LTR(左)右标记; U + 200E)和RTL(从右到左标记; U + 200F)。ZWNJ可以在两个字母之间使用,以防止它们形成草书连接。

如果找到无效组合,例如同一基本字符上的两个胖子,则导致无效状态的变音符号被放置在虚线圆圈上以向用户指示无效组合。非OpenType字体的整形引擎将导致无效的标记组合重击。这是插入无效基数的虚线圆所解决的问题。还应注意,虚线圆圈未插入应用程序的后备存储中。这是从ScriptShape函数返回的字形数组的运行时插入。
阿拉伯语的无效变音逻辑基于下面列出的类。有一个检查,以确保一个类的多个标记没有放在同一个基础上。此外,DIAC1和DIAC2类不应应用于相同的基本字符。
类 描述 代码点
DIAC1 阿拉伯语以上的变音符号 U + 064B,U + 064C,U + 064E,U + 064F,U + 0652,U + 0657,U + 0658,U + 06E1
DIAC2 阿拉伯语下面的变音符号 U + 064D,U + 0650,U + 0656
DIAC3 阿拉伯语座位shadda U + 0651
DIAC4 阿拉伯古兰经标志在上面 U + 0610 - U + 0614,U + 0659,U + 06D6 - U + 06DC,U + 06DF,U + 06E0,U + 06E2,U + 06E4,U + 06E7,U + 06E8,U + 06EB,U + 06EC
DIAC5 阿拉伯语古兰经标记如下 U + 06E3,U + 06EA,U + 06ED
DIAC6 阿拉伯语上标alef U + 0670
DIAC7 阿拉伯语madda U + 0653
DIAC8 阿拉伯语madda U + 0654,U + 0655
特征
已定义下面列出的功能,以便为阿拉伯语系统支持的语言创建基本表单。无论应用程序选择何种模型支持复杂脚本的布局,Uniscribe都需要一个固定的顺序来执行文本运行中的功能,以便始终获得正确的基本表单。这是通过按照下面列出的标准顺序逐个调用功能来实现的。
每个功能中的查找顺序也非常重要。有关在OpenType字体中查找和定义功能的详细信息,请参阅OpenType字体开发文档的“ 编码”部分。
应用以OpenType字体编码的阿拉伯语功能的标准顺序:
并非下面列出的所有功能都适用于所有阿拉伯语脚本语言。
特征 功能功能 布局操作 始终应用 默认开启 默认关闭
基于语言的表格:
CCMP 字符组成/分解替换 GSUB X
ISOL 孤立的字符形式替换 GSUB X
国际泳联 最终的字符形式替换 GSUB X
MEDI 内侧字符形式替换 GSUB X
在里面 初始字符形式替换 GSUB X
rlig 必需的结扎替换 GSUB X
rclt 必需的上下文替换替换 GSUB X
CALT 上下文交替替换 GSUB X
印刷形式:
西甲 标准结扎替代 GSUB X
dlig 酌情结扎替代 GSUB X
cswh 情境性的花花公子 GSUB X
MSET 通过替换标记定位 GSUB X
定位功能:
小人 草书定位 GPOS X
克恩 对字距调整 GPOS X
标记 标记为基础定位 GPOS X
mkmk 标记以标记定位 GPOS X
[GSUB =字形替换,GPOS =字形定位]
上述特征的描述和示例
本文档中描述和说明的许多注册功能都基于OpenType字体阿拉伯语排版。阿拉伯语排版包含布局信息和字形,以支持所支持的阿拉伯语脚本和语言系统的所有必需功能。在阿拉伯语排版字体将作为视觉OpenType布局工具(VOLT)的一部分,并根据VOLT补充文件的最终用户许可协议中的条款提供。在阿拉伯语排版字体可供下载该文件的附录
人物构成(和分解)
功能标记:“ccmp”
‘ccmp’功能用于将多个字形组合成一个字形,或将一个字形分解为多个字形。此功能在任何其他功能之前实现,因为有时候字体供应商想要控制字形的某些形状。使用此表的示例如下所示。’ccmp’表将默认的字母表格映射到组合形式(基本上是连字,GSUB查找类型4)和分解形式(GSUB查找类型2)。

上面说明的分解的基本原理是利用Word和Publisher等Microsoft应用程序中的颜色变音功能。
孤立的形式
功能标签:“isol”
‘isol’功能用于将Unicode字符值映射到其隔离的表单。这通常是相同的字形。但是,Unicode将阿拉伯语表示形式定义为与Unicode字符形式不同。如果供应商具有高质量的字体工具或可以编辑CMAP表的字体实用程序,则多个Unicode字符可以指向相同的字形ID。(GSUB查找类型1)。

最后的表格
功能标签:“fina”
‘fina’功能用于将Unicode字符值映射到其最终形式。(GSUB查找类型1)。

内侧表格
功能标签:“medi”
‘medi’功能用于将Unicode字符值映射到其中间形式。(GSUB查找类型1)。

初始表格
功能标记:“init”
‘init’功能用于将Unicode字符值映射到其初始形式。(GSUB查找类型1)。

必需的连字
功能标签:“rlig”
‘rlig’功能用于将字形值映射到正确的连接形式。字体开发人员应该将此表用于他们想要一直映射的所有连字。根据用户首选项应该是可选的连字不应包含在此表中。可选的连字在’liga’表中定义。
‘rlig’功能将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。请参阅OpenType字体开发文档的编码部分中的订购连字。所需的连字集将根据设计和脚本而有所不同。
注意:如果您希望字体与Windows9x / ME系统级支持具有某种程度的向后兼容性,您还需要在’liga’功能中包含’rlig’功能中的项目。这是因为较旧的操作系统不使用Uniscribe进行整形,也不了解’rlig’功能。

连接表格
功能标记:“rclt”或“calt”
在指定的情况下,使用提供更好的连接行为的替代形式替换默认字形。用于脚本字体,旨在将其部分或全部字形连接起来。’calt’功能指定每次替换发生的上下文,并将一个或多个默认字形映射到替换字形(GSUB查找类型6)。脚本正确性所需的替换应放在’rclt’下。“
注意:如果您希望字体与Windows7 / 8.1系统级支持具有某种程度的向后兼容性,您还需要在“calt”功能中包含“rclt”功能中的项目。这是因为较旧的操作系统不知道’rclt’功能。“calt”始终应用于阿拉伯语以使用旧字体保留文档。
‘calt’功能指定每次替换发生的上下文,并将一个或多个默认字形映射到替换字形(GSUB查找类型6)。脚本正确性所需的替换应放在’rclt’下。

标准连字
功能标签:“liga”
‘liga’功能用于将字形映射到其可选的连接形式。字体开发人员应该将此表用于默认情况下应该打开但可能由用户首选项关闭的所有连字。Uniscribe默认应用此功能,但允许停用此功能。可以通过传入自定义字体功能列表来禁用非必需功能,包括“liga”,该列表将整个运行中的功能指定为off。’liga’功能将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。请参阅OpenType字体开发文档的编码部分中的订购连字。可选的连字集将根据字体设计和脚本而有所不同。
注意:应始终形成的连字不应包含在此要素类型中。必需的连字在’rlig’表中定义。

酌情连结
功能标签:“dlig”
‘dlig’功能用于将字形映射到其可选的连接形式。字体开发人员应该将此表用于所有应该默认关闭的连字,但可以通过用户首选项打开。可以通过传入自定义字体功能列表来启用可选功能,包括“dlig”,该列表为整个运行指定可选功能。’dlig’功能将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。请参阅OpenType字体开发文档的编码部分中的订购连字。可选的连字集将根据字体设计和脚本而有所不同。

情境冲击
功能标签:“cswh”
‘cswh’功能根据字符周围的上下文将默认字符字形替换为相应的字符字形。请注意,给定字符可能有多个swash替换。’cswh’表将默认表单的字形ID映射到一个或多个相应的斜盘表单的字形ID。虽然这些替换中的许多是一对一(GSUB查找类型1),但其他替换需要从集合中选择(GSUB查找类型3)。字体开发人员可以选择构建两个表(每个查找类型一个)或仅使用查找类型3进行所有替换。如果字体中存在多种样式的swash,则应按顺序对每个字符的表单集进行排序
“cswh”功能默认处于关闭状态,但可以按用户首选项启用。可选功能(包括“cswh”)可以通过传入自定义字体功能列表来启用,该列表为整个运行指定可选功能。

通过替换标记定位
功能标记:“mset”
‘mset’功能用于使用字形替换为Windows 95的字体定位阿拉伯语组合标记。在阿拉伯语中,与Alef相比,当放置在Yeh Barree上方时,Hamza的位置不同。Windows 95实现:与“标记”功能相反,“mset”功能使用字形替换来组合标记和基本字形。它用正确定位的标记字形替换默认标记字形。字体设计器在字体文件中描述标记的轮廓时指定标记的位置。为Windows 95创建的Microsoft阿拉伯字体使用上下文替换查找(GSUB LookupType = 5)来实现’mset’功能。

示例:默认fatha位于高位,“mset”功能用于替换Beh上的低位形式。
草书定位
功能标记:“curs”
‘curs’功能定位草书字符,以便当前字符的出口点与后续字符的入口点匹配。’curs’表映射连接字形的连接点,并且可以实现为Cursive Attachment(GPOS查找类型3)。

字距
功能标签:“kern”
‘kern’特征用于调整字形之间的空间量,通常用于在字形之间提供光学一致的间隔。虽然设计良好的字体总体上具有一致的字形间距,但是一些字形组合需要调整以提高易读性。除了水平或垂直方向的标准调整之外,此功能还可以通过设备表提供与尺寸相关的字距调整数据,在Y文本方向上提供“交叉流”字距调整,并且可以调整字形位置,而与提前调整无关。请注意,此功能不会用于等宽字体。
字体存储一组字形对的调整(GPOS查找类型2或8)。这些可以存储为匹配左和右类的一个或多个表,和/或作为单独的对。如果使用两种形式,则应该列出最后的类,以便提供替换可能由类表产生的任何非理想值的方法。可以为更大的字形集(例如,三元组,四元组等)提供附加调整,以在特定组合中覆盖对字符串的结果。这些应该在成对之前。
使用Microsoft VOLT创建kern表

标记为基础定位
功能标记:“标记”
“标记”功能将标记字形与基本字形或连字字形相关联。此功能可以实现为MarkToBase附件查找(GPOS LookupType = 4)或MarkToLigature附件查找(GPOS LookupType = 5)。
使用Microsoft VOLT将标记定位到基础

使用Microsoft VOLT将标记定位到基础(连字)

标记以标记定位
功能标签:“mkmk”
‘mkmk’功能将标记字形与另一个标记字形相关联。此功能可以实现为MarkToMark附件查找(GPOS LookupType = 6)。
使用Microsoft VOLT定位标记以进行标记

附录
附录A:编写系统标签
附录B:ARABTYPE.TTF(样本字体)
附录A:编写系统标签
功能根据指定的脚本和语言系统进行编码。语言系统标签指定与语言或语言子组相关联的印刷约定。例如,为阿拉伯语脚本定义了不同的语言系统; 阿拉伯语,俾路支语,拉达克语,普什图语等。其他印刷系统可以定义为摩洛哥阿拉伯语或瓦哈比古兰经排版的传统。
目前,Uniscribe引擎仅支持每个脚本的“默认”语言。但是,字体开发人员可能希望构建其他应用程序支持的语言特定功能,并且将在未来的Microsoft OpenType实现中得到支持。
注意:强烈建议在所有OpenType字体中包含“dflt”语言标记,因为它定义了字体的基本脚本处理。如果未定义其他语言特定功能或应用程序不支持该特定语言,则使用“dflt”语言系统作为默认语言系统。如果正在使用的脚本不存在“dflt”标记,则该字体在某些应用程序中可能不起作用。
下表列出了脚本和语言系统的已注册标记名称。
阿拉伯文脚本的注册标签 阿拉伯语系统的注册标签
脚本标记 脚本 语言系统标签 语言
“阿拉伯” 阿拉伯 “DFLT” *默认脚本处理
“ARA” 阿拉伯
“BLI” 俾路支
“BLT” 巴尔蒂
“BBR” 柏柏尔
“BRH” Brahui
“FAR” 波斯语
“FUL” 富拉语
“HAU” 豪萨语
“HND” Hindko
“KNR” 卡努里
“KSH” 克什米尔
“KHW” Khowar
“KUR” 库尔德
“LDK” 拉达克
“MLY” 马来语
“MND” 曼丁哥
“PAS” 普什图语
“PAN” 旁遮普
“SRK” Saraiki
“SND” 信德
“SML” 索马里
“SWK” 斯瓦希里
“URD” 乌尔都语
“UYG” 维吾尔
注意:脚本和语言标记都区分大小写(脚本标记应为小写,语言标记全部为大写)并且必须包含四个字符(即必须为三个字符语言标记添加空格)。
附录B:ARABTYPE.TTF(样本字体)
在阿拉伯语排版字体将与Microsoft Visual OpenType布局工具(VOLT)分布并根据VOLT补充文件的最终用户许可协议中的条款提供。它仅供参考,不得更改或重新分发。
Arabic Typesetting支持Unicode阿拉伯语和阿拉伯语扩展块中的所有字符。因此,它可用于制作阿拉伯语,波斯语,乌尔都语,信德语,马来语和维吾尔语的文件。字体是阿拉伯语naskh书法风格。
阿拉伯语排版包含布局信息和字形,以支持所支持语言的所有必需功能。该字体包含1600多个阿拉伯字形。所有字体都不必支持这么多字形或连字。应将每种字体设计为字体创建者所需的字体。
许多形状的字形表单(例如连字)没有Unicode编码。这些字形在字体中具有id,应用程序可以通过“运行”依赖于这些字形的布局功能来访问这些字形。应用程序还可以通过遍历OpenType布局表或使用布局服务来识别字体中包含的非Unicode字形,仅用于提供信息。
阿拉伯语排版包含三个OpenType布局表:GSUB(字形替换),GPOS(字形定位)和GDEF(字形定义,区分基本字形,连字,标记字形类等)。
转到VOLT社区网站下载此示例字体。请务必阅读下载附带的最终用户许可协议。
13.4.布吉文脚本
介绍
本文档提供的信息将帮助字体开发人员为Unicode标准6.3所涵盖的Buginese脚本创建OpenType字体。Buginese脚本用于编写Buginese语言。它也被用来写Makasar和Mandar。
注意:从Windows 10开始,Buginese将由Universal Shaping Engine支持,而不是独立的整形引擎。展望未来,开发人员应该参考这个新规范。
介绍
本文档针对开发人员实现与Buginese脚本的Microsoft OpenType规范兼容的整形行为。它包含有关Buginese整形引擎的术语,字体特征和行为的信息。虽然它不包含创建Buginese字体的说明,但它可以帮助字体开发人员了解Buginese整形引擎如何处理Buginese文本。
条款
以下术语对于理解本文档中讨论的布局功能和脚本规则很有用。
基本字形 - 任何可以附加变音符号的字形。布局操作是根据基本字形而不是基本字符定义的,因为连字可以作为基础
字符 - 每个字符代表一个Unicode字符代码点。角色可能有多个字形
群集 - 在Brahmi派生的脚本中形成一个整体单元的一组字符,通常这对应于一个音节
辅音 - Buginese辅音有固有的元音(短元音/ a /)。例如,“Ka”和“Ta”,而不仅仅是“K”或“T”
格式控件 - Buginese脚本(U + 200c和U + 200D)的整形过程中使用的特殊格式字符。除非应用程序选择显示零宽度字形,否则这些字符没有可视外观
字形 - 字形表示一个或多个字符的形式
Halant - 在辅音之后用来“剥离”其固有元音的字符
Ligature - 连接形成单个字形的字形组合
马特拉 (从属元音) - 用于表示辅音不固有的元音。从属元音在梵语中被称为“matras”。它们总是与单个辅音或辅音簇组合描绘
OpenType布局引擎 - 负责以字体执行OpenType布局功能的库。在Microsoft文本格式堆栈中,它被命名为OTLS(OpenType布局服务)
OpenType标记 - 字体中脚本,语言系统或功能的4字节标识符
整形引擎 - 负责整形输入的代码,分类到特定脚本
Buginese塑形引擎如何工作
- [分析字符](#manalys)* [重新排序预基元音(VPre)](#reor1)* [为本地化表单和基本整形表单应用OpenType GSUB功能](#sub1)* [应用OpenType GSUB演示功能](#sub2)* [应用OpenType GPOS功能来定位字形或标记](#post)
Uniscribe Buginese整形引擎分阶段处理文本。阶段是:
分析人物
重新排序前基元音(VPre)
将OpenType GSUB功能应用于本地化表单和基本整形表单
应用OpenType GSUB演示功能
应用OpenType GPOS功能来定位字形或标记
下面的描述将帮助字体开发人员理解Buginese特征编码模型的基本原理,并帮助应用程序开发人员更好地理解布局客户端如何将职责划分为操作系统功能。
分析人物
为了整形,整形引擎接收的文本运行是一系列Unicode字符。整形引擎将文本划分为音节群集并识别角色属性。字符属性用于解析音节并识别其部分以及确定是否需要任何上下文重新排序。
在下图中,形成聚类的规则是根据字符流中的字符类给出的。符号的含义是:
C 辅音(1A00-1A16)
GB 通用基本字符(00A0,00D7,2012-2015,2022,25CC,25FB-25FE)
Ĵ 细木工(200C,200D)
Ø Buginese运行中的SCRIPT_COMMON字符
[R Buginese区块的保留字符(1A1C,1A1D)
小号 符号(1A1E,1A1F,A9CF)
VAbv 以上依赖于元音的元音(1A17,1A1B)
VBlw 低于碱依赖的元音(1A18)
VPRE 基础前依赖元音(1A19)
VPst 基于依赖后的元音(1A1A)
VS 变异选择器(FE00-FE0F)
WJ Word joiner(2060)
WS 空白区域(包括ZWSP在内的任何空格字符)
X* X的零次或多次出现的序列。由于这可以无限延长一个簇,因此序列中的任意限制为31个字符
X + 一次或多次出现x的序列
<X | Y> 元素的分离:X或Y.
[X] X的可选(零或一)出现
# 发生边界
× 在指定位置不允许边界
÷ 允许在指定位置的边界
^ 除了整形引擎插入一个占位符字形(U + 25CC),只要在没有有效基数的情况下出现组合标记。字符U + 25CC属于通用基类(GB)。格式良好的Buginese字符集定义如下:
简单的非复合集群
<S | Rsv | WS | O | J | WJ>符号(S),保留字符(Rsv),空格(WS),其他SCRIPT_COMMON字符(O),Joiners和word joiner(WJ)。
集群
<C | GB> [VS](VPre)*(VAbv)*(VBlv)*(VPst)* [J]辅音或通用基础和可选变体选择器。每个元音类型中的一个或多个可以按指定的顺序出现。零宽度连接器和零宽度非连接器将是它们出现的任何群集中的最后一个项目。
重新排序前基元音(VPre)
一旦Buginese整形引擎如上所述分析了集群运行,它就会执行任何所需的重新排序。预基元音(VPre)被重新排序到音节群的开头。允许一系列多个前基元音。这些序列作为块移动到簇的开头。在以下示例中,代码点的运行表示单个群集。
INPUT
1A00 1A19 034F 1A19 034F 1A17
基地 预基元音
重新排序
1A19 034F 1A19 034F 1A00 1A17
注意:必须编写Buginese字体中的OpenType查找以在重新排序后匹配字形序列。OpenType字体不应具有尝试执行重新排序的替换。如果字体开发人员试图用OpenType字体对这种重新排序信息进行编码,他们需要添加大量的多对多字形映射来覆盖整形引擎将使用的一般算法。
将OpenType GSUB功能应用于本地化表单和基本整形表单
Uniscribe调用OTLS来应用这些功能。OTL处理分为一组预定义的功能(在本文档的“功能”部分中进行了描述和说明)。GSUB功能的第一个应用程序按以下顺序应用于每个群集。
注意:在为Buginese脚本定义字体时,不需要使用此处列出的所有功能。
A.本地化表格
应用功能’locl’来预处理当前语言的任何本地化表单
为演示文稿表单应用OpenType GSUB功能
演示文稿表单功能在整个运行过程中同时应用。因此,几个特征在操作上等同于单个特征。因此,应用程序的顺序是字体中定义的功能的顺序。
C.表述形式
应用要素’ccmp’来替换字形组合/分解字形表单
应用要素’rlig’来替换所需的连字字形
应用特征’liga’替换标准连字字形
应用特征’clig’来替换上下文连字字形表单
•应用特征“calt”来替换上下文替换字形
应用OpenType GPOS功能
整形引擎接下来处理GPOS(字形定位)表,应用与定位有关的特征。所有功能同时应用于整个运行。
字体开发人员在创建GPOS功能和查找表时必须考虑重新排序的影响。
D. Kerning
应用’dist’功能进行任何所需的距离调整
应用特征’kern’以在字形之间提供对字距调整,以获得更好的印刷质量。请注意,某些应用程序可能会禁用此功能
E.标记放置
应用特征“标记”以相对于基本字形定位变音符号字形
应用特征’mkmk’将变音符号相对于彼此定位
Buginese脚本的功能
已定义下面列出的功能,以便为使用Buginese脚本的语言创建基本表单。无论应用程序选择支持复杂脚本布局的模型,Uniscribe都需要一个固定的顺序,以便在一行文本中执行本地化和基本的整形表单功能,以便始终获得正确的基本表单。这是通过按照下面列出的标准顺序逐个调用功能来实现的。
每个功能中的查找顺序也非常重要。有关在OpenType字体中查找和定义功能的详细信息,请参阅OpenType字体开发部分中的编码功能信息。
应用以OpenType字体编码的Buginese功能的标准顺序:
特征 功能功能 布局操作 需要
本地化表格
LOCL GSUB
演示表格
CCMP 字形组成/分解 GSUB X
rlig 必需的连字 GSUB X
西甲 标准连字 GSUB
clig 上下文连字 GSUB
CALT 上下文交替 GSUB
字距
克恩 对字距调整 GPOS
DIST 距离调整 GPOS X
标记位置
标记 标记定位 GPOS X
mkmk 标记以标记定位 GPOS X
[GSUB =字形替换,GPOS =字形定位]
功能示例
本文档中描述和说明的注册功能基于Microsoft OpenType字体Leelawadee UI(LeelawUI.ttf)。Leelawadee UI包含布局信息和字形,以支持Buginese脚本的所有必需功能。
以下示例中的插图显示了应用该特定功能的结果。在重新排序后,必须编写功能以匹配字形序列。请注意,要素的输入上下文可能是已应用先前要素的结果。
本地化表格
功能标签:“locl”
此功能与OpenType语言系统标记结合使用,以触发查找,这些查找将选择特定于语言的排版约定所需的替换字形。’locl’不应与默认语言系统一起使用,而只能与其他语言系统标签一起使用。有关与Buginese脚本相关的语言系统标签,请参阅本文档的附录。
演示表格
功能标记:“ccmp”
此功能可用于进行字形组合和分解。Leelawadee UI字体不使用此功能。
功能标签:“rlig”
此功能可用于形成所需的连字。Leelawadee UI字体使用此功能来形成iya连字。

功能标签:“liga”
此功能可用于形成标准连字。Leelawadee UI字体不使用此功能。
功能标签:“clig”
此功能可用于形成上下文连字。Leelawadee UI字体不使用此功能。
功能标签:“calt”
此功能可用于替换上下文替换。Leelawadee UI字体不使用此功能。
字距
功能标签:“kern”
此功能可用于调整字形对的位置。Leelawadee UI字体不使用此功能。
功能标签:“dist”
此功能可用于调整距离。Leelawadee UI字体不使用此功能。
请注意,标记字形的宽度由OTLS设置为零。如果标记字形必须具有宽度,则必须添加丢失的宽度以便正确显示。dist特征是必需的特征,应该用于此目的以及其他所需的距离调整。
标记位置
功能标记:“标记”
此功能用于相对于基本字形定位标记。Leelawadee UI字体使用此功能定位基座上方和下方的标记。

请注意,标记功能是必需的功能,并且始终由整形引擎触发。
功能标签:“mkmk”
此功能用于相对于彼此定位标记。Leelawadee UI字体使用此功能来定位一系列低于基础的标记。

请注意,mkmk功能是必需的功能,并且始终由整形引擎触发。
其他编码问题
处理无效的组合标记
组合不与有效基数一起出现的标记和符号被视为无效。形成引擎实现可以采用不同的策略来处理无效标记。例如,整形引擎实现可能将无效标记视为单独的集群,并显示位于某些默认基本字形上的独立标记,例如虚线圆(U + 25CC)。(请参阅Unicode标准4.0第5.13节中的后备渲染。)对于哪些序列被认为有效或不被认为有效,形成引擎实现可能会有所不同。例如,一些实现可以施加至多一个基于上的基元音标记的限制,而其他实现可以不限制。
为了允许对期望在虚线圆上定位无效标记的引擎实现进行整形,建议Buginese OT字体包含虚线圆圈字符U + 25CC的字形,并且将适当的标记定位查找写入位置标记相对于它。如果字体不支持此字符,则此类实现将在缺少的字形形状(白色框)上显示无效符号。
推荐的雕文
强烈建议包含在任何Buginese字体中的Unicode代码点是:
代码点 描述
U + 200B 零宽度空间
U + 200C 零宽度非连接器
U + 200D 零宽度连接器
U + 25CC 虚线圈
U + 00A0 不间断的空间
U + 00D7 乘法符号
U + 2012 图破折号
U + 2013 冲破
ü+ 2014 Em dash
U + 2015年 单杠
U + 2022 子弹
U + 25FB 白色中等方形
U + 25FC 黑色中等方形
U + 25FD 白色中等小方块
U + 25FE 黑色中等小方块
这些字形可以在文本中用作通用基础,因此应该在字体支持的标记定位查找中启用。
附录
编写系统和语言标签
功能根据指定的脚本和语言系统进行编码。语言系统标签指定与语言或语言子组相关联的印刷约定。例如,为Buginese脚本定义了不同的语言系统:Buginese,Makasar和Mandar。
并非所有软件应用程序都支持在渲染文本时使用的特定语言标记。
注意:强烈建议在所有OpenType字体中包含“dflt”语言标记,因为它定义了字体的基本脚本处理。如果未定义其他语言特定功能或应用程序不支持该特定语言,则使用“dflt”语言系统作为默认语言系统。如果正在使用的脚本不存在“dflt”标记,则该字体在某些应用程序中可能不起作用。
下表列出了脚本和语言系统的已注册标记名称。
Buginese脚本的注册标签 Buginese语言系统的注册标签
脚本标记 脚本 语言系统标签 语言
“bugi” 布吉文 “DFLT” *默认脚本处理
BUG 武吉士
MKR Makasar
MDR Mandar
注意:脚本和语言标记都区分大小写(脚本标记应为小写,语言标记全部为大写)并且必须包含四个字符(即,必须为三个字符语言标记添加空格)。
13.5.韩文脚本
本文档提供的信息将帮助字体开发人员为Unicode标准涵盖的韩语Hangul脚本创建或支持OpenType字体。
介绍
韩语Hangul脚本是一个“音节”脚本。通过组合元素,字母辅音和元音的序列来形成音节。组成音节的过程本质上是附加的,并遵循一组预定义的规则。每个组成音节的字形元素被整形并定位在方形显示单元中,通常称为“音节块”或“音节字形”。
Unicode标准为预先编写的Hangul音节提供编码,称为“现代韩文”,以及编码单个韩语字母元素的编码,称为“Jamo”,称为“旧韩语”。’Modern Hangul’在Unicode范围U + AC00到U + D7AF中有11,172个预先组成的字符。“旧韩语”音节可以由Unicode Hangul Jamo块(U + 1100到U + 11FF)中编码的Hangul Jamos组成。更具体地说,只有这些Jamo字符的某些序列可以组合形成旧的Hangul音节。这些序列在附录B中定义。只有附录B中定义的序列才会形成旧的韩语音节。Hangul Jamo Block中与附录B中的任何序列模式不匹配的字符代码序列将被视为一系列单独的非旧Hangul字符。

在本规范中,字体开发人员将学习如何解决Old Hangul音节形成,编码其字体中的复杂脚本功能,选择字符集,组织字体信息以及使用现有工具生成Old Hangul字体。定义并说明了韩语Hangul脚本的注册功能,列出了编码,并包含用于编译OpenType字体的韩语Hangul布局表的模板。
本文档还介绍了Uniscribe的韩国OpenType整形引擎的信息,Uniscribe是负责文本布局的Windows组件。
除了作为韩文字体的创建和支持的入门和规范之外,本文档还旨在更广泛地说明OpenType布局体系结构,功能方案以及对文本整形和定位的操作系统支持。
词汇表
以下术语对于理解本文档中讨论的布局功能和脚本规则很有用。
Jamo - 单个韩语字母元素或音节中的原子单位。辅音和元音都被称为Jamos。
辅音 - 表示单个辅音。辅音进一步分为主要辅音和尾随辅音。
领先的辅音(Leading Jamo)“Choseong” - 音节的首字母
尾随辅音(Trailing Jamo)“Jongseong” - 音节的最终角色
元音(Vowel Jamo)“Jungseong” - 音素; 音节中的独立单元。它不与任何辅音结合,导致任何辅音 - 元音组合的转换。
符号
本文档中使用以下表示法来说明布局操作:
L - 领导辅音
V - 元音
T - 尾随辅音
S - 音节
X - 非Jamo角色
{} - 表示0,1或多次出现
[] - 表示0或1次出现
() - 表示发生1次或多次
塑造引擎
撰写旧韩文版Jamo组合
分析音节
用OTLS形成字形
处理无效的组合标记
Uniscribe韩语整形引擎分阶段处理文本。阶段是:
撰写旧韩文版Jamo组合
使用OTLS识别音节边界
分析音节
使用OTLS形成字形(OpenType库服务)
下面的描述将帮助字体开发人员理解韩语Hangul特征编码模型的基本原理,并帮助应用程序开发人员更好地理解布局客户端如何将职责划分为操作系统功能。
撰写旧韩文版Jamo组合
整形引擎接收一系列字符(字符运行),它们已被识别为前导辅音(L),元音(V)和尾随辅音(T)Jamos的序列。在这些序列中的每一个中,整形引擎识别可以组合以形成注册的Jamos的最大字符长度。这是根据附录B中的标准字符组合列表完成的。
接下来,它用相应的旧Hangul Jamo替换它们。对序列中下一个最长的字符串重复此过程。对所有序列重复这种识别和替换过程。
这个过程的结果是一串注册的Old Hangul Jamos,如下例所示:
复制
V1L1L2L3V2V3T1T2T3L4L5V4T4V5V6L6V7
—> V1L1(L2L3)V2V3(T1T2T3)L4L5V4T4(V5V6)L6V7
—> V1L1(L23)V2V3(T123)L4L5V4T4(V56)L6V7
分析音节
整形引擎为了整形而接收的音节单元是一串Unicode字符,按顺序排列。由于每个韩文音节具有LVT的规范格式,因此在注册的Jamo序列中根据需要添加填充符Lf和Vf,以将它们中的每一个转换为规范形式。然后,整形引擎标记其中的每一个以进行适当的特征处理。然后将调用OTLS依次对每个音节执行OpenType布局处理。
重要的是要注意,如果正在分析的任何Jamo序列能够形成现代韩文音节,则整形引擎不应用OpenType特征来形成它们。现在韩语音节的组成预计将使用预先编写的部分(U + AC00 - U + D7AF)完成,如Unicode标准中所述。
使用OTLS进行整形
Uniscribe的第一步是塑造字符串,将所有字符映射到它们的名义形式字形。
接下来,Uniscribe调用OTL服务库来塑造旧韩语音节。所有OTL处理都分为一组预定义的功能(在本文档的“功能”部分中进行了描述和说明)。每个特征一个接一个地应用于音节中的适当字形,OTLS处理它们。Uniscribe可以为OTL服务提供尽可能多的调用功能。这可确保以所需顺序执行功能。
塑造过程的步骤概述如下。
塑造功能:
语言形式
应用要素’ ccmp ‘来预处理任何需要合成的字形
应用功能’ ljmo ‘获得领先的辅音Jamo
应用“ vjmo ” 功能获取元音Jamo
应用特征’ tjmo ‘来获得尾随辅音Jamo
处理无效的组合标记
将文本中出现的标记和符号与有效的辅音基础组合在一起被认为是无效的。遇到无效的字母组合时,Uniscribe只会启动一个新的音节/群集。
请注意,要独立呈现标志(与任何基础明显隔离),应将其应用于空间(请参阅Unicode标准3.1的第2.5节“组合标记”)。Uniscribe要求在空间和标记之间放置ZWJ,以便它们组合成一个独立的标志。

虽然不需要OpenType功能,但建议包含ZWJ(零宽度连接器; U + 200C),ZWNJ(零宽度非连接器; U + 200D)和ZWSP(零宽度空间; U + 200B)韩文韩文字体。
特征
已定义下面列出的功能,以便为韩语Hangul系统支持的语言创建基本表单。无论应用程序选择何种模型支持复杂脚本的布局,Uniscribe都需要一个固定的顺序来执行文本运行中的功能,以便始终获得正确的基本表单。这是通过按照下面列出的标准顺序逐个调用功能来实现的。
每个功能中的查找顺序也非常重要。有关在OpenType字体中查找和定义功能的更多信息,请参阅OpenType开发文档的“ 编码”部分。
应用以OpenType字体编码的韩语Hangul功能的标准顺序:
特征 功能功能 布局操作 需要
基于语言的表格:
CCMP 字符组成/分解替换 GSUB
ljmo 领先的辅音Jamo GSUB X
vjmo Vowel Jamo GSUB X
tjmo 尾随辅音Jamo GSUB X
[GSUB =字形替换,GPOS =字形定位]
上述特征的描述和示例
人物构成(和分解)
功能标记:“ccmp”
‘ccmp’功能用于将多个字形组合成一个字形(GSUB查找类型4)。此功能在任何其他功能之前实现,因为有时候字体供应商想要控制字形的某些形状。
此功能允许对应于附录B中描述的序列的Old Hangul Jamos的组合。要组成旧Hangul音节,然后使用’ljmo’,’vjmo’和’tjmo’功能将这些Jamo字形替换为适当的形式。应该在任何其他功能之前实现“ccmp”功能,以便将这些操作赋予最高优先级。它适用于以下各项:前导,元音和尾随Jamo序列。
例如:由’ccmp’功能组成的领先Jamos的以下序列(U1107 + U1109 + U1110)。

领先的辅音Jamo
功能标签:“ljmo”
‘ljmo’功能用于替换领导辅音Jamo的正确形状以用于Hangul音节。领先的辅音Jamos的形成是基于上下文的,取决于领先的Jamo是否单独跟随元音Jamo或一系列元音和尾随Jamo。
例如:当单独使用元音Jamo时,领先的Jamo(U1113)将被正确的前导形式替换。

Vowel Jamo
功能标签:“vjmo”
‘vjmo’功能用于替换元音Jamo的正确形状以用于Hangul音节。元音Jamos的形状是基于上下文的,取决于它是否仅在一个领先的Jamo之前,或者是领先的Jamo之后,后面跟着一个尾随的Jamo。
例如:Hangul元音Jungseong AE(U1162)在单独使用领先的Jamo之前被正确的形式取代。

尾随辅音Jamo
功能标记:“tjmo”
‘tjmo’功能用于替换尾部辅音Jamo的正确形状以用于Hangul音节。尾随辅音Jamos的形成是基于背景的,取决于尾随的Jamo是否先于Jamo填充和元音Jamo或者领先的Jamo和元音Jamo。
例如:当前面有一个领先的Jamo和元音Jamo时,U11C7被正确的尾随辅音取代。

更多例子
- Old Hangul Jamo包含领先的辅音,元音和尾随的Jamos。
输入顺序:该序列包括:Choseong Pieup,Choseong Sios,Choseong Thieuth,Jungseong O,Jungseong Ya,Jungseong I,Jongseong Rieul,Jongseong Mieum,Jongseong Hieuh。

应用’ccmp’功能:

应用’ljmo’,’vjmo’和’tjmo’功能:

2.领先的辅音Jamo + vowel Jamo +落后的Jamo。
输入顺序:该序列包括:Choseong Ssangkiyeok,Jungseong A,Jongseong Nieun-Sios。

应用’ljmo’,’vjmo’和’tjmo’功能:

3.领先的辅音Jamo + vowel Jamo
输入序列:该序列包括:Choseong Nieun-Kiyeok,Jungseong Ae。

应用’ljmo’和’vjmo’功能:

附录
附录A:编写系统标签
附录B:旧Hangul Jamos的标准组成
附录A:编写系统标签
功能根据指定的脚本和语言系统进行编码。语言系统标签指定与语言或语言子组相关联的印刷约定。
目前,Uniscribe引擎仅支持每个脚本的“默认”语言。但是,字体开发人员可能希望构建其他应用程序支持的语言特定功能,并且将在未来的Microsoft OpenType实现中得到支持。
注意:强烈建议在所有OpenType字体中包含“dflt”语言标记,因为它定义了字体的基本脚本处理。如果未定义其他语言特定功能或应用程序不支持该特定语言,则使用“dflt”语言系统作为默认语言系统。如果正在使用的脚本不存在“dflt”标记,则该字体在某些应用程序中可能不起作用。
下表列出了脚本和语言系统的已注册标记名称。
韩语Hangul脚本的注册标签 韩语韩语系统的注册标签
脚本标记 脚本 语言系统标签 语言
“挂” 韩语韩文 “DFLT” *默认脚本处理
“KOR” 朝鲜的
注意:脚本和语言标记都区分大小写(脚本标记应为小写,语言标记全部为大写)并且必须包含四个字符(即,必须为三个字符语言标记添加空格)。
附录B:旧Hangul Jamos的标准组成
领先的辅音
代码点 雕文 代码点 雕文 代码点 雕文
U + 115F
U + 1100 
U + 1101 IMG
U + 1102 IMG
U + 1113 IMG
U + 1114 IMG
U + 1115 IMG
U + 1116 IMG
U + 1102 IMG + U + 1109 IMG
U + 1102 IMG + U + 110C IMG
U + 1102 IMG + U + 1112 IMG
U + 1103 IMG
U + 1117 IMG
U + 1104 IMG
U + 1103 IMG + U + 1105 IMG
U + 1103 IMG + U + 1106 IMG
U + 1103 IMG + U + 1107 IMG
U + 1103 IMG + U + 1109 IMG
U + 1103 IMG + U + 110C IMG
U + 1105 IMG
U + 1105 IMG + U + 1100 IMG
U + 1105 IMG + U + 1100 IMG + U + 1100 IMG
U + 1118 IMG
U + 1105 IMG + U + 1103 IMG
U + 1105 IMG + U + 1103 IMG + U + 1103 IMG
U + 1119 IMG
U + 1105 IMG + U + 1106 IMG
U + 1105 IMG + U + 1107 IMG
U + 1105 IMG + U + 1107 IMG + U + 1107 IMG
U + 1105 IMG + U + 112B IMG
U + 1105 IMG + U + 1109 IMG
U + 1105 IMG + U + 110C IMG
U + 1105 IMG + U + 110F IMG
U + 111A IMG
U + 111B IMG
U + 1106 IMG
U + 1106 IMG + U + 1100 IMG
U + 1106 IMG + U + 1103 IMG
U + 111C IMG
U + 1106 IMG + U + 1109 IMG
U + 111D IMG
U + 1107 IMG
U + 111E IMG
U + 111F IMG
U + 1120 IMG
U + 1108 IMG
U + 1121 IMG
U + 1122 IMG
U + 1123 IMG
U + 1124 IMG
U + 1125 IMG
U + 1126 IMG
U + 1107 IMG + U + 1109 IMG + U + 1110 IMG
U + 1127 IMG
U + 1128 IMG
U + 1107 IMG + U + 110F IMG
U + 1129 IMG
U + 112A IMG
U + 1107 IMG + U + 1112 IMG
U + 112B IMG
U + 112C IMG
U + 1109 IMG
U + 112D IMG
U + 112E IMG
U + 112F IMG
U + 1130 IMG
U + 1131 IMG
U + 1132 IMG
U + 1133 IMG
U + 110A IMG
U + 1109 IMG + U + 1109 IMG + U + 1107 IMG
U + 1134 IMG
U + 1135 IMG
U + 1136 IMG
U + 1137 IMG
U + 1138 IMG
U + 1139 IMG
U + 113A IMG
U + 113B IMG
U + 113C IMG
U + 113D IMG
U + 113E IMG
U + 113F IMG
U + 1140 IMG
U + 110B IMG
U + 1141 IMG
U + 1142 IMG
U + 110B IMG + U + 1105 IMG
U + 1143 IMG
U + 1144 IMG
U + 1145 IMG
U + 1146 IMG
U + 1147 IMG
U + 1148 IMG
U + 1149 IMG
U + 114A IMG
U + 114B IMG
U + 110B IMG + U + 1112 IMG
U + 114C IMG
U + 110C IMG
U + 114D IMG
U + 110D IMG
U + 110C IMG + U + 110C IMG + U + 1112 IMG
U + 114E IMG
U + 114F IMG
U + 1150 IMG
U + 1151 IMG
U + 110E IMG
U + 1152 IMG
U + 1153 IMG
U + 1154 IMG
U + 1155 IMG
U + 110F IMG
U + 1110 IMG
U + 1110 IMG + U + 1110 IMG
U + 1111 IMG
U + 1156 IMG
U + 1111 IMG + U + 1112 IMG
U + 1157 IMG
U + 1112 IMG
U + 1112 IMG + U + 1109 IMG
U + 1158 IMG
U + 1159 IMG
U + 1159 IMG + U + 1159 IMG
** 元音
代码点 雕文 代码点 雕文 代码点 雕文
U + 1160
U + 1161 IMG
U + 1176 IMG
U + 1177 IMG
U + 1161 IMG + U + 1173 IMG
U + 1162 IMG
U + 1163 IMG
U + 1178 IMG
U + 1179 IMG
U + 1163 IMG + U + 116E IMG
U + 1164 IMG
U + 1165 IMG
U + 117A IMG
U + 117B IMG
U + 117C IMG
U + 1166 IMG
U + 1167 IMG
U + 1167 IMG + U + 1163 IMG
U + 117D IMG
U + 117E IMG
U + 1168 IMG
U + 1169 IMG
U + 116A IMG
U + 116B IMG
U + 1169 IMG + U + 1163 IMG
U + 1169 IMG + U + 1163 IMG + U + 1175 IMG
U + 117F IMG
U + 1180 IMG
U + 1169 IMG + U + 1167 IMG
U + 1181 IMG
U + 1182 IMG
U + 1169 IMG + U + 1169 IMG + U + 1175 IMG
U + 1183 IMG
U + 116C IMG
U + 116D IMG
U + 116D IMG + U + 1161 IMG
U + 116D IMG + U + 1161 IMG + U + 1175 IMG
U + 1184 IMG
U + 1185 IMG
U + 116D IMG + U + 1165 IMG
U + 1186 IMG
U + 1187 IMG
U + 1188 IMG
U + 116E IMG
U + 1189 IMG
U + 118A IMG
U + 116F IMG
U + 118B IMG
U + 1170 IMG
U + 116E IMG + U + 1167 IMG
U + 118C IMG
U + 118D IMG
U + 1171 IMG
U + 116E IMG + U + 1175 IMG + U + 1175 IMG
U + 1172 IMG
U + 118E IMG
U + 1172 IMG + U + 1161 IMG + U + 1175 IMG
U + 118F IMG
U + 1190 IMG
U + 1191 IMG
U + 1192 IMG
U + 1172 IMG + U + 1169 IMG
U + 1193 IMG
U + 1194 IMG
U + 1173 IMG
U + 1173 IMG + U + 1161 IMG
U + 1173 IMG + U + 1165 IMG
U + 1173 IMG + U + 1165 IMG + U + 1175 IMG
U + 1173 IMG + U + 1169 IMG
U + 1195 IMG
U + 1196 IMG
U + 1174 IMG
U + 1197 IMG
U + 1175 IMG
U + 1198 IMG
U + 1199 IMG
U + 1175 IMG + U + 1163 IMG + U + 1169 IMG
U + 1175 IMG + U + 1163 IMG + U + 1175 IMG
U + 1175 IMG + U + 1167 IMG
U + 1175 IMG + U + 1167 IMG + U + 1175 IMG
U + 119A IMG
U + 1175 IMG + U + 1169 IMG + U + 1175 IMG
U + 1175 IMG + U + 116D IMG
U + 119B IMG
U + 1175 IMG + U + 1172 IMG
U + 119C IMG
U + 1175 IMG + U + 1175 IMG
U + 119D IMG
U + 119E IMG
U + 119E IMG + U + 1161 IMG
U + 119F IMG
U + 119E IMG + U + 1165 IMG + U + 1175 IMG
U + 11A0 IMG
U + 11A1 IMG
U + 11A2 IMG
**尾随辅音
代码点 雕文 代码点 雕文 代码点 雕文
U + 11A8 IMG
U + 11A9 IMG
U + 11A8 IMG + U + 11AB IMG
U +器11c3 IMG
U + 11A8 IMG + U + 11B8 IMG
U + 11AA IMG
U + 11C4 IMG
U + 11A8 IMG + U + 11BE IMG
U + 11A8 IMG + U + 11BF IMG
U + 11A8 IMG + U + 11C2 IMG
U + 11AB IMG
U + 11C5 IMG
U + 11AB IMG + U + 11AB IMG
U + 11C6 IMG
U + 11AB IMG + U + 11AF IMG
U + 11C7 IMG
U + 11C8 IMG
U + 11AC IMG
U + 11AB IMG + U + 11BE IMG
U + 11C9 IMG
U + 11AD IMG
U +边11Ae IMG
U + 11CA IMG
U +边11Ae IMG + U +边11Ae IMG
U +边11Ae IMG + U +边11Ae IMG + U + 11B8 IMG
U + 11CB IMG
U +边11Ae IMG + U + 11B8 IMG
U +边11Ae IMG + U + 11BA IMG
U +边11Ae IMG + U + 11BA IMG + U + 11A8 IMG
U +边11Ae IMG + U + 11BD IMG
U +边11Ae IMG + U + 11BE IMG
U +边11Ae IMG + U + 11C0 IMG
U + 11AF IMG
U + 11B0 IMG
U + 11AF IMG + U + 11A8 IMG + U + 11A8 IMG
U + 11cc的 IMG
U + 11AF IMG + U + 11A8 IMG + U + 11C2 IMG
U + 11CD IMG
U + 11CE IMG
U + 11CF IMG
U + 11D0 IMG
U + 11AF IMG + U + 11AF IMG + U + 11BF IMG
U + 11B1 IMG
U + 11D1 IMG
U + 11D2 IMG
U + 11AF IMG + U + 11B7 IMG + U + 11C2 IMG
U + 11B2 IMG
U + 11AF IMG + U + 11B8 IMG + U +边11Ae IMG
U + 11D3 IMG
U + 11AF IMG + U + 11B8 IMG + U + 11C1 IMG
U + 11D4 IMG
U + 11D5 IMG
U + 11B3 IMG
U + 11D6 IMG
U + 11D7 IMG
U + 11AF IMG + U + 11F0 IMG
U + 11D8 IMG
U + 11B4 IMG
U + 11B5 IMG
U + 11B6 IMG
U + 11D9 IMG
U + 11AF IMG + U + 11F9 IMG + U + 11C2 IMG
U + 11AF IMG + U + 11BC IMG
U + 11B7 IMG
U + 11DA IMG
U + 11B7 IMG + U + 11AB IMG
U + 11B7 IMG + U + 11AB IMG + U + 11AB IMG
U + 11dB的 IMG
U + 11B7 IMG + U + 11B7 IMG
U + 11DC IMG
U + 11B7 IMG + U + 11B8 IMG + U + 11BA IMG
U + 11DD IMG
U + 11DE IMG
U + 11DF IMG
U + 11B7 IMG + U + 11BD IMG
U + 11E0 IMG
U + 11E1 IMG
U + 11E2 IMG
U + 11B8 IMG
U + 11B8 IMG + U +边11Ae IMG
U + 11E3 IMG
U + 11B8 IMG + U + 11AF IMG + U + 11C1 IMG
U + 11B8 IMG + U + 11B7 IMG
U + 11B8 IMG + U + 11B8 IMG
U + 11B9 IMG
U + 11B8 IMG + U + 11BA IMG + U +边11Ae IMG
U + 11B8 IMG + U + 11BD IMG
U + 11B8 IMG + U + 11BE IMG
U + 11E4 IMG
U + 11E5 IMG
U + 11E6 IMG
U + 11BA IMG
U + 11E7 IMG
U + 11E8 IMG
U + 11E9 IMG
U + 11BA IMG + U + 11B7 IMG
U + 11EA IMG
U + 11BA IMG + U + 11E6 IMG
U + 11BB IMG
U + 11BA IMG + U + 11BA IMG + U + 11A8 IMG
U + 11BA IMG + U + 11BA IMG + U +边11Ae IMG
U + 11BA IMG + U + 11EB IMG
U + 11BA IMG + U + 11BD IMG
U + 11BA IMG + U + 11BE IMG
U + 11BA IMG + U + 11C0 IMG
U + 11BA IMG + U + 11C2 IMG
U + 11EB IMG
U + 11EB IMG + U + 11B8 IMG
U + 11EB IMG + U + 11E6 IMG
U + 11BC IMG
U + 11EC IMG
U + 11ED IMG
U + 11BC IMG + U + 11B7 IMG
U + 11BC IMG + U + 11BA IMG
U + 11EE IMG
U + 11EF IMG
U + 11BC IMG + U + 11C2 IMG
U + 11F0 IMG
U + 11F0 IMG + U + 11A8 IMG
U + 11F1 IMG
U + 11F2 IMG
U + 11F0 IMG + U + 11BF IMG
U + 11F0 IMG + U + 11C2 IMG
U + 11BD IMG
U + 11BD IMG + U + 11B8 IMG
U + 11BD IMG + U + 11B8 IMG + U + 11B8 IMG
U + 11BD IMG + U + 11BD IMG
U + 11BE IMG
U + 11BF IMG
U + 11C0 IMG
U + 11C1 IMG
U + 11F3 IMG
U + 11C1 IMG + U + 11BA IMG
U + 11C1 IMG + U + 11C0 IMG
U + 11F4 IMG
U + 11C2 IMG
U + 11F5 IMG
U + 11F6 IMG
U + 11F7 IMG
U + 11F8 IMG
U + 11F9 IMG
13.6.希伯来语脚本
本文档提供的信息将帮助字体开发人员为Unicode标准涵盖的所有希伯来语脚本语言创建或支持OpenType字体。
介绍
在本规范中,字体开发人员将学习如何在其字体中编码复杂的脚本功能,选择字符集,组织字体信息以及使用现有工具生成希伯来字体。定义和说明了希伯来语脚本的注册功能,列出了编码,并包含了用于编译OpenType字体的希伯来语布局表的模板。
本文档还介绍了Uniscribe的希伯来OpenType整形引擎的信息,Uniscribe是负责文本布局的Windows组件。
除了作为创建和支持希伯来字体的入门和规范之外,本文档还旨在更广泛地说明OpenType布局体系结构,功能方案以及对文本整形和定位的操作系统支持。
词汇表
以下术语对于理解本文档中讨论的布局功能和脚本规则很有用。
基础字形 - 任何可以携带一个或多个组合标记的字形,通常在dagesh标记的上方,下方或基本字形内。布局操作是以base / glyph /而不是base / character /来定义的,因为连字可以作为基本字形。
Cantillation Mark(Teamin) - Masoretic Bible文本的一个特征,这些标记位于基本雕文的上方或下方,作为在礼拜仪式中正确吟唱文本的指南。旋转标记的正确位置经常受到其他变音标记的影响,并且应该由字体在上下文中处理。
字符 - 每个字符代表一个Unicode字符代码点。例如,’א’是Alef字符是U + 05D0。角色可能有多种形式的字形。
Diacritic Mark(Nikud) - 一种组合标记字符,应用于基本字符以提供发音指导。在希伯来语中,大多数变音符号在大多数情况下都是可选的,在大多数文本中都省略了。当它们发生时,它们需要相对于基本角色正确定位。圣经和现代希伯来语之间的印刷习惯可能略有不同。大多数变音符号是元音符号,除了一个之外的所有符号都位于基座下方。除了这些元音符号外,还有三个辅音标记:dagesh,shin和sin点。基本字符可以携带辅音标记和元音符号,并且在圣经文本中也可以携带标记。
字形 - 字形表示一个或多个字符的形式。
注意: Unicode希伯来语块包含Tiberian(巴勒斯坦)元音系统,这个系统已经成为许多世纪以来西方犹太教的标准。还有其他古代元音系统,其中最重要的是尚未编码的巴比伦系统。
塑造引擎
分析人物
使用OTLS进行整形
使用OTLS定位字形
处理无效的组合标记
Uniscribe希伯来语整形引擎分阶段处理文本。阶段是:
使用OTLS(OpenType库服务)整形(替换)字形
使用OTLS定位字形
以下描述将帮助字体开发人员理解希伯来特征编码模型的基本原理,并帮助应用程序开发人员更好地理解布局客户端如何将职责划分为操作系统功能。
分析人物
整形引擎为了整形而接收的单元是一串Unicode字符,按顺序排列。上下文分析引擎验证有效的变音符号组合。有关其他信息,请参阅本文档后面的处理无效组合标记。
使用OTLS进行整形
Uniscribe的第一步是塑造字符串,将所有字符映射到它们的名义形式字形。
接下来,Uniscribe调用OTLS来应用这些功能。所有OTL处理都分为一组预定义的功能(在本文档的“功能”部分中进行了描述和说明)。每个特征一个接一个地应用于音节中的适当字形,OTLS处理它们。Uniscribe可以为OTL服务提供尽可能多的调用功能。这可确保以所需顺序执行功能。
塑造过程的步骤概述如下。并非所有列出的功能都适用于所有希伯来语脚本语言。
塑造功能:
语言形式
应用特征’ ccmp ‘来预处理任何需要合成或分解的字形。例如,’sin dot’和’shin dot’仅与’SHIN’一起使用,因此如果基座不是’SHIN’,则会插入一个虚线圆圈,让’sin / shin dot’坐下。
印刷形式
应用特征’ dlig ‘来组成任何自由裁量的连字
使用OTLS定位字形
Uniscribe接下来应用与定位相关的功能,调用OTLS函数来定位字形。
定位功能:
字距
应用特征“ kern ”以在需要调整的基本字形之间提供对字距调整,以获得更好的印刷质量
标记为基础
应用特征“ 标记 ”将变音符号字形定位到基本字形
处理无效的组合标记
将文本中出现的标记和符号与有效的辅音基础组合在一起被认为是无效的。Uniscribe使用Unicode标准(第5.12节“Unicode标准3.1的’渲染非间距标记’)中定义的后备渲染机制显示这些标记,即位于虚线圆上。
为了使回退机制正常工作,希伯来语OTL字体应包含虚线圆(U + 25CC)的字形。如果字体中缺少此字形,则无效符号将显示在缺少的字形形状(白色框)上。
除了“虚线圆圈”之外,建议包含在任何希伯来语字体中的其他Unicode代码点包括:LTR(从左到右标记; U + 200E)和RTL(从右到左标记; U + 200F)。

如果找到无效组合,例如同一基本字符上的两个“nikuds”,则导致无效状态的变音符号被放置在虚线圆圈上以向用户指示无效组合。非OpenType字体的整形引擎将导致无效的标记组合重击。这是插入无效基数的虚线圆所解决的问题。还应注意,虚线圆圈未插入应用程序的后备存储中。这是从ScriptShape函数返回的字形数组的运行时插入。
希伯来语的无效变音符号逻辑基于下面列出的类。有一个检查,以确保一个类的多个标记没有放在同一个基础上。
类 描述 代码点
DIAC 希伯来语变音 U + 05B0 - U + 05B6,U + 05BB
CANT1 希伯来语的通风 - 左上方 U + 0599,U + 05A1,U + 05A9,U + 05AE
CANT2 希伯来语的通风 - 在中心左侧 U + 0597,U + 05A8,U + 05AC
CANT3 希伯来语的通风 - 高于中心 U + 0592-U + 0595,U + 05A7,U + 05AB
CANT4 希伯来语的中心 - 正确的中心 U + 0598,u + 059C,U + 059E,U + 059F
CANT5 希伯来语的通风 - 在右上方 U + 059D,U + 05A0
CANT6 希伯来语的通风 - 左下方 U + 059B,U + 05A5
CANT7 希伯来语的通风 - 低于中心左侧 U + 0591,U + 05A3,U + 05A6
CANT8 希伯来语的通风 - 低于中右翼 U + 0596,U + 05A4,U + 05AA
CANT9 希伯来语的通风 - 在右下方 U + 059A,U + 05AD
CANT10 希伯来语cantilation - Masora Circle U + 05AF
DAGESH 希伯来语dagesh / mapiq U + 05BC
DOTABV 希伯来语上方点 U + 05C4
HOLAM 希伯来语holam U + 05B9
METEG 希伯来语Meteg / sof pasuq U + 05BD
PATAH 希伯来语patah U + 05B7
QAMATS 希伯来胫/罪孽点 U + 05B8
RAFE 希伯来拉菲 U + 05BF
SHINSIN 希伯来胫/罪孽点 U + 05C1,U + 05C2
特征
已定义下面列出的功能,以便为希伯来语系统支持的语言创建基本表单。无论应用程序选择何种模型支持复杂脚本的布局,Uniscribe都需要一个固定的顺序来执行文本运行中的功能,以便始终获得正确的基本表单。这是通过按照下面列出的标准顺序逐个调用功能来实现的。
每个功能中的查找顺序也非常重要。有关在OpenType字体中查找和定义功能的详细信息,请参阅OpenType字体开发文档的“ 编码”部分。
应用以OpenType字体编码的希伯来语功能的标准顺序:
并非下面列出的所有功能都适用于所有希伯来语脚本语言。
特征 功能功能 布局操作 需要
基于语言的表格:
CCMP 字符组成/分解替换 GSUB
印刷形式:
dlig 酌情结扎替代 GSUB
定位功能:
克恩 对字距调整 GPOS
标记 标记为基础定位 GPOS X
[GSUB =字形替换,GPOS =字形定位]
上述特征的描述和示例
人物构成(和分解)
功能标记:“ccmp”
‘ccmp’功能用于将多个字形组合成一个字形,或将一个字形分解为多个字形。此功能在任何其他功能之前实现,因为有时候字体供应商想要控制字形的某些形状。使用此表的示例如下所示。’ccmp’表将默认的字母表格映射到组合形式(基本上是连字,GSUB查找类型4)和分解形式(GSUB查找类型2)。

例; ‘ccmp’功能用于预先组成Yiddish结扎’yod yod patah’。(uni05F2 + uni05B7 - > uniFB1F)
酌情连结
功能标签:“dlig”
‘dlig’功能还用于将字形映射到其可选的连接形式。字体开发人员应将此表用于他们希望用户能够按用户首选项控制的所有连字。Uniscribe有一个标志,允许停用此类功能。’dlig’功能将字形序列映射到相应的连字(GSUB查找类型4)。具有更多组件的连接必须存储在具有较少组件的组件之前,以便找到它们。请参阅OpenType字体开发文档的编码部分中的订购连字。可选的连字集将根据字体设计和脚本而有所不同。

例; ‘dlig’功能用于替代alef lamed ligature。
字距
功能标签:“kern”
‘kern’特征用于调整字形之间的空间量,通常用于在字形之间提供光学一致的间隔。虽然设计良好的字体总体上具有一致的字形间距,但是一些字形组合需要调整以提高易读性。除了水平或垂直方向的标准调整之外,此功能还可以通过设备表提供与尺寸相关的字距调整数据,在Y文本方向上提供“交叉流”字距调整,并且可以调整字形位置,而与提前调整无关。请注意,此功能不会用于等宽字体。
字体存储一组字形对的调整(GPOS查找类型2或8)。这些可以存储为匹配左和右类的一个或多个表,和/或作为单独的对。如果使用两种形式,则应该列出最后的类,以便提供替换可能由类表产生的任何非理想值的方法。可以为更大的字形集(例如,三元组,四元组等)提供附加调整,以在特定组合中覆盖对字符串的结果。这些应该在成对之前。
用希伯来语字体进行字距调整的可能性很小。一些例外情况可能是使用字距调整来为带有diactitics(Nikud或Teamin)的基础添加空间,或者在手写样式字体上使用更好的间距。但是,此功能可用于类型设计者可能希望利用字距调整的实例。
标记为基础定位
功能标记:“标记”
“标记”功能将标记字形与基本字形或连字字形相关联。此功能可以实现为MarkToBase附件查找(GPOS LookupType = 4)或MarkToLigature附件查找(GPOS LookupType = 5)。
使用Microsoft VOLT将标记定位到基础

附录
附录A:编写系统标签
附录B:VILNA.TTF(示例字体)
附录C:建议雕文
附录A:编写系统标签
功能根据指定的脚本和语言系统进行编码。语言系统标签指定与语言或语言子组相关联的印刷约定。例如,为希伯来语脚本定义了不同的语言系统; 希伯来语,Judezmo,意第绪语等
目前,Uniscribe引擎仅支持每个脚本的“默认”语言。但是,字体开发人员可能希望构建其他应用程序支持的语言特定功能,并且将在未来的Microsoft OpenType实现中得到支持。
注意:强烈建议在所有OpenType字体中包含“dflt”语言标记,因为它定义了字体的基本脚本处理。如果未定义其他语言特定功能或应用程序不支持该特定语言,则使用“dflt”语言系统作为默认语言系统。如果正在使用的脚本不存在“dflt”标记,则该字体在某些应用程序中可能不起作用。
下表列出了脚本和语言系统的已注册标记名称。
已注册的希伯来语脚本标签 希伯来语系统的注册标签
脚本标记 脚本 语言系统标签 语言
“黑布尔” 希伯来语 “DFLT” *默认脚本处理
“IWR” 希伯来语
“JUD” 拉迪诺
“JII” 意第绪语
注意:脚本和语言标记都区分大小写(脚本标记应为小写,语言标记全部为大写)并且必须包含四个字符(即,必须为三个字符语言标记添加空格)。
附录B:VILNA.TTF(示例字体)
该格特曼维尔纳字体将被分发的Microsoft Visual OpenType布局工具(VOLT)和下VOLT补充文件的最终用户许可协议中的条款提供。它仅供参考,不得更改或重新分发。
Guttman Vilna包含布局信息和字形,以支持希伯来语脚本支持的语言的所有必需功能。应将每种字体设计为字体创建者所需的字体。
某些形状的字形表单(例如连字)没有Unicode编码。这些字形在字体中具有id,应用程序可以通过“运行”依赖于这些字形的布局功能来访问这些字形。应用程序还可以通过遍历OpenType布局表或使用布局服务来识别字体中包含的非Unicode字形,仅用于提供信息。
Guttman Vilna包含三个OpenType布局表:GSUB(字形替换),GPOS(字形定位)和GDEF(字形定义,区分基本字形,连字,标记字形类等)。
转到VOLT社区网站下载此示例字体。请务必阅读下载附带的最终用户许可协议。
附录C:建议的字形
希伯来语有三种情况,其中METEG / SOF PASUQ放在一个nikud的部分之间。为了允许正确显示,建议在字体中添加以下三个字形。’ccmp’功能可与Lookup Type 4一起使用以形成连接形式。这些字形不需要分配Unicode字符值。
此外,Unicode还为meteg和hataf元音的组合提供了进一步的建议。

13.7.印度语
13.7.1.孟加拉
请注意:本文档反映了2005年针对印度语脚本OpenType字体和整形引擎实现的建议所做的更改。虽然根据之前的建议制作的印度语字体仍然可以在新版本的Uniscribe中正常运行,但字体开发人员可能会选择更新字体,特别是如果他们希望避免早期实现的某些限制。
本文档提供的信息将帮助字体开发人员为Unicode标准涵盖的所有孟加拉语脚本语言创建或支持OpenType字体。孟加拉语剧本与梵文剧本密切相关,用来写孟加拉语,阿萨姆语和马尼普里语。
介绍
本文档针对开发人员实现印度语整形行为与印度语脚本的Microsoft OpenType规范兼容。它包含有关孟加拉语脚本的印度形成引擎的术语,字体特征和行为的信息。虽然它不包含创建孟加拉字体的说明,但它将帮助字体开发人员了解印度形成引擎如何处理印度文字。此外,孟加拉语脚本的注册功能也通过示例进行了定义和说明。
新的印度形成引擎允许印刷惯例的变化,使字体开发人员可以通过选择字形指定到某些OpenType特征来控制整形。例如,reph和pre-pended matra在音节群内重新排序的位置受到半形式存在的影响。见下图。
在下面的例子中(Ra + halant + Da + halant + Ka + I-matra),Ra + halant将形成reph,但Da如何分类将决定reph的位置以及预先设置的位置MATRA。

选项1 =孟加拉塑造引擎的重新排序行为,其中’Da’具有半形式; 将reph放在第一个主要辅音上; 并且I-matra将立即定位在“半形式”D(a)的前面。
选项2 =如果Da没有半形并且未在半特征中列出,则将显示halant-form并且整形引擎将其视为第一个用于定位reph的主要辅音。并且I-matra将立即定位在其前面的基座(或半形式)的前面,在这种情况下是Ka。
词汇表
以下术语对于理解本文档中讨论的布局功能和脚本规则很有用。
基本形式的辅音 - 在基本字形上方出现的辅音的变体形式。在孟加拉语中,只有辅音Ra具有上基形式,称为“reph”。
Akhand连字 - 可能出现在音节中任何位置的必要辅音连字,可能涉及也可能不涉及基本字形。Akhand连字是最重要的,并且首先形成; 有些语言将它们包含在字母表中。Akhand连字可以半形式或全形式显示。
基本字形 - 以“完整”(名义)形式书写的音节中唯一的辅音或辅音合取。在孟加拉语中,音节的最后一个辅音(除了以字母“Ra”结尾的音节外)通常形成基本字形。在没有元音(一个单词的最后一个字母)的“简并”音节中,halant形式的最后一个辅音作为基本辅音并被映射为基本字形。布局操作是根据基本字形而不是基本字符定义的,因为基础通常可以是连字。
低于基本形式的辅音 - 在基本字形下方出现的辅音的变体形式。在孟加拉语中,辅音Ra和Ba具有低于基础的形式。在字形序列中,以下基础形式位于形成基本字形的辅音之后。低于基础的形式由非间距标记字形表示。
孟加拉语音节 - 孟加拉语书写系统的有效拼写“单元”。音节由辅音字母,独立元音和从属元音组成。在文本序列中,这些字符以语音顺序存储(尽管它们在显示时可能不以语音顺序表示)。一旦音节成形,它就是不可分割的。光标无法定位在音节中。本文档中讨论的转换不跨越音节边界。
群集 - 在印度语脚本中形成一个整体单元的一组字符,通常是一个音节。
辅音 - 每个都代表一个辅音。辅音可以以不同的语境形式存在并且具有固有的元音(通常是短元音“a”)。例如,“Ka”和“Ta”,而不仅仅是“K”或“T”。
辅音合奏(又名“合取”) - 两个或更多辅音的结构。辅音合奏可以有完整形式和半形式,也可以只有完整形式。
Halant(Virama) - 在辅音之后使用的字符“剥离”它固有的元音。在每个孟加拉语音节中,除了最后一个辅音之外,其他所有的音乐都是如此; 如果音节没有元音,那么halant也会跟随最后一个辅音。
注意:包含halant字符的音节可以通过使用不同的辅音形式或合取而形成没有可见的halant符号。
Halant形式的辅音 - 通过将halant(virama)添加到标称形状而产生的形式。Halant形式用于没有元音的音节或半形式的音节,当半形式没有明显的形状时。
辅音的一半形式(前基础形式) - 辅音的一种变体形式,如果它们不参与结扎,则出现在基本辅音的左侧。半形的辅音在形成基本字形的辅音之前。对于大多数辅音,孟加拉语有明显形状的半形式。如果辅音不具有半形的独特形状并且不形成任何结扎,则将显示具有明确的Virama(与halant形式相同的形状)。
Matra(Dependent Vowel) - 用于表示辅音不固有的元音。从属元音在梵语中被称为“matras”。它们总是与单个辅音或辅音簇组合描绘。不同印度语脚本之间的最大差异可以在将依赖元音附加到基本字符的规则中找到。
新的整形行为 - 在此版本的印度语OpenType字体规范中定义的整形行为。本文档中的信息主要涉及新的实施模型。关于兼容性的评论中可能会提到旧行为。
Nukta - 一种改变前面的辅音(或matra)发音方式的组合字符。
旧的整形行为 - 在先前版本的印度语OpenType字体规范中定义的整形行为。
OpenType布局引擎库负责以字体执行OpenType布局功能。在Microsoft文本格式堆栈中,它被命名为OTLS(OpenType布局服务)。
OpenType标记 - 字体中脚本,语言系统或功能的4字节标识符。
后基本形式的辅音 - 基本字形右侧出现的辅音的变体形式。采用后基础形式的辅音之前是形成基本字形的辅音加上halant(virama)。后基础形式通常是间距字形。
前基本形式的辅音 - 基本字形左侧出现的辅音的变体形式。请注意,大多数前基础辅音形式在基本辅音之前在逻辑上和视觉上都是如此。半形式是这种预基形式的例子。但是,在某些剧本中,前基础Ra可能在逻辑上遵循基本辅音(即,它在语音上和文本的字符序列中跟随它),即使它在基础之前在视觉上呈现。整形引擎使用动态检测这种情况 功能并根据需要重新排序预基础形式的字形。
Reph - 孟加拉语中使用的字母“Ra”的上述基本形式,当“Ra”是音节中的第一个辅音并且不是基本辅音时。
Shaping Engine - 处理知道语言规则的文本字符串的代码。
Split Matra - 一种分解为碎片以进行渲染的matra。通常,不同的部分出现在相对于基部的不同位置。例如,matra的一部分可以放置在集群的开头,另一部分放在集群的末尾。
音节 - 印度文字处理的单个单位。对每个音节独立地执行印度文本的整形。下面描述识别每个音节的边界的过程。
Vattu - 辅音的基础形式。

1.前基础形式
2.基础辅音
3.基础形式(reph)
4。基础后(matra)
5。基础形式(vattu)
塑造引擎
分析文字
重新排序字符
形状字形序列(GSUB处理)
位置字形序列(GPOS处理)
基本要素
无效的组合标记
使用ZWJ,ZWNJ和NBSP
印度形成引擎分阶段处理孟加拉语文本。阶段是:
分析文本序列; 把它分成音节群
根据需要重新排序字符
应用OpenType GSUB字体功能以获得正确的字形形状
应用OpenType GPOS功能来定位字形或标记
下面的描述将帮助字体开发人员理解孟加拉语特征编码模型的基本原理,并帮助应用程序开发人员更好地理解布局客户端如何将职责划分为操作系统功能。
分析音节
角色属性
整形引擎将文本划分为音节群集并识别角色属性。
在确定正确的字符或字形重新排序时以及在OpenType特征应用程序中,字符属性用于解析音节和识别其部分。每个字符的属性分为两种类型:静态属性和动态属性。
静态属性定义了不会从字体更改为字体的基本特征:字符类型(辅音,matra,vedic符号等)或matra重新排序的类型。它们在脚本之间有所不同,但不能由字体开发人员控制。
动态属性是字体相关的,并在加载字体时由整形引擎检索。这些属性会影响整形和重新排序行为。
*注意:在旧的整形引擎实现中,所有辅音属性都是静态的:假设辅音具有特定的连接形式。在新的实现模型中,辅音连接行为是动态属性。
从印度字体中检索动态角色属性
字体通过实现标准功能来定义辅音的动态属性。整形引擎从字体中读取的辅音类型(和相应的特征标签)是:
Reph
半形式
Ra / Rra的基础重排序形式
基础形式以下
后基础表格
上述每个功能都与之一起应用 输入由两个字符组成的序列的功能:for 和 ,功能适用于辅音+ Halant组合; 对于, 和 ,功能适用于Halant +辅音组合。这是为每个辅音完成的。如果这两个字形形成一个连字,在上下文中没有其他字形,这意味着辅音具有相应的形式。例如,如果替换发生在 和 将特征应用于序列Da + Halant,然后将Da分类为具有半形式。
注意,可以实现字体以仅在某些音节中将Ra重新排序到前基础位置,否则将其显示为基础或后基础形式。这意味着Pre-base-form分类与Below-base-form或post-base-form分类不相互排斥。然而,如上所述使用无上下文替换来确定所有分类。
字体相关的字符分类仅定义辅音类型。但是,对于每个字符类,重新排序的位置是固定的。
*注意:对于支持旧实现的字体,所有功能都应用于Consonant + Halant序列。
印度输入处理
当输入序列中还有字符时,应重复以下步骤。所有整形操作都是在一个音节的基础上完成的,与其他角色无关。
在输入中查找下一个音节
引擎应该找到与以下模式之一匹配的字符序列:
辅音音节
{C + [N] + <H + [<ZWNJ | ZWJ>] | <ZWNJ | ZWJ> + H>} +
C + [N] + [A] + [<H + [<ZWNJ | ZWJ>] | {M} + [N] + [H]>] + [SM] + [(VD)]基于元音的音节:
[RA + H] + V + [N] + [<[<ZWJ | ZWNJ>] + H + C | ZWJ + C>] + [{M} + [N] + [H]] + [SM] + [ (VD)]独立群集(仅在单词的开头):
#[RA + H] + NBSP + [N] + [<[<ZWJ | ZWNJ>] + H + C>] + [{M} + [N] + [H]] + [SM] + [(VD) ]哪里
{} 零次或多次出现
[] 可选的发生
<|> '之一'
() 一两次出现
C 辅音
V 独立元音
ñ nukta
H halant /比拉马
ZWNJ 零宽度非连接器
ZWJ 零宽度木匠
中号 matra(每种类型中最多一种:前,下,下或后基)
SM 音节修饰符号
VD 吠陀
一个 anudatta(U + 0952)
NBSP 没有休息的空间
识别音节内的关键位置
音节结构由以下部分组成:Reph + HalfConsonant(s)+ MainConsonant(s)+ BelowBaseConsonant(s)+ PostBaseConsonant(s)+ PreBaseReorderingRa + MatrasAndSigns
辅音部分包括所有相关的halants和nuktas。(例如,BelowBaseConsonant的一个实例由一系列Halant + Under-base-forming辅音组成。)除主辅音外,所有部分都是可选的。
所有部分都按照它们在音节中出现的顺序显示,具有一个限定条件:取决于字体实现,PreBaseReorderingRa可能出现在所有BelowBaseConsonants之前,AfterBaseConsonants之后和PostBaseConsonants之前,或PostBaseConsonants之后。此外,可以实现字体以仅在某些音节中将Ra重新排序到预基础位置,否则将其显示为基础或后基础形式。因此,最终确定特定音节中Ra的出现是否可以作为基础前重新排序Ra来处理,只能在 功能已应用于该音节。
在一个以上的辅音不具有半音,低音,后音或前音形的情况下,可能存在几个主要辅音。在第一个辅音不具有半形的群集的情况下,整形引擎将其识别为第一个“完整形式”并继续识别第二个完整形式辅音(如果有的话)。然后,该信息将用于确定reph或任何matras,元音修饰符或压力标记的重新排序行为。
所有其他元素按其相对于基础的位置进行分类:前基(半形式和重新排序前基础Ra形式),低于基础,高于基础和后基础。
印度群集受以下限制:
每个音节只允许一个reph。
每个音节只允许一个预基重新排序Ra。
nukta可以放在辅音,matra或独立的元音上。它不能放在预先组成的nukta字符上。
允许来自每个定位类的一个matra(Kannada脚本中的例外)。复合matra被视为属于其组件所属的所有类。
每个群集允许一个音节修饰符。
吠陀标志是组合标记(用于梵语),应该包含在所有印度语脚本中。
Danda和Double Danda是标点符号,应该包含在所有印度语脚本中。
重新排序字符
一旦印度形成引擎如上所述分析了集群,它就根据若干规则(如下所述)创建并管理表示集群的适当重新排序的元素(字形)的缓冲区。
在重新排序后,必须编写印度语字体中的OpenType查找以匹配字形序列。OpenType字体不应具有尝试执行重新排序的替换。如果字体开发人员试图用OpenType字体编码这样的重新排序信息,他们需要添加大量的多对多字形映射来覆盖整形引擎将使用的一般算法。
查找基本辅音:整形引擎使用以下算法找到音节的基本辅音:从音节的结尾开始,向后移动,直到找到没有基础或后基础形式的辅音(post - 基础形式必须遵循以下基础形式),或者不是基础前重新排序Ra,或者到达第一个辅音。辅音停在附近将成为基地。
如果音节以Ra + Halant(在具有Reph的脚本中)开头且具有多个辅音,则Ra被排除在基本辅音的候选者之外。
分解并重新排序Matras:群集中的每个matra和任何音节修饰符都会移动到相对于群集中辅音的适当位置。在任何重新定位之前,整形引擎将两部分或三部分的matra分解成它们的组成部分。马特拉字符被分类为它们具有亲和力的合取中的辅音,并被重新排序到以下位置:
在音节的前半部分形成之前
在辅助辅音之后
后形式辅音后
主辅音后(以上标记)
将标记重新排序为规范顺序:如果需要,相邻的nukta和halant或nukta和vedic标志总是重新定位,因此nukta是第一个。
最终重新排序:在应用了本地化表单和基本整形表单 GSUB功能之后(见下文),整形引擎在将所有剩余字体功能应用于整个集群之前执行一些最终字形重新排序。
重新排序matras:如果在应用基本特征之前已经重新排序了基础前matra字符,则可以根据是否已形成半形式将字形移近主辅音。matra的实际位置定义为“在最后的独立halant字形之后,在初始matra位置之后和在主辅音之前”。如果ZWJ或ZWNJ遵循这个习惯,那么位置就会被移动。
重新排序reph: Reph的原始位置始终位于音节的开头(即,它不会在字符重新排序阶段重新排序)。但是,它将根据基本形式的整形结果进行重新排序。reph的可能位置,取决于脚本,是; 主要之后,之后的基础辅音形式,以及后基辅音形式之后。
如果reph应位于基础后辅音形式之后,请继续执行步骤5。
如果reph重新定位类不在post-base之后:target position位于第一个post-reph辅音和last main辅音之间的第一个显式halant字形之后。如果ZWJ或ZWNJ正在跟随这个halant,那么位置会在它之后移动。如果找到这样的位置,则这是目标位置。否则,请继续执行下一步。
注意:在旧实现字体中,在整形引擎中修改了分类,在这一步中没有找到reph位置的情况。
如果reph应该在主辅音后重新定位:从第一个辅音不与主要结扎,或者找到第一个辅音,即不是潜在的前基础重新排序Ra。
如果reph应该放在post-base辅音之前,找到第一个post-base分类辅音不与main结扎。如果未找到辅音,则目标位置应位于第一个matra,音节修饰符或vedic符号之前。
如果在步骤3或4中没有找到辅音,则将reph移动到紧接在预定的reph位置之后具有重新排序类的第一个后基部matra,音节修饰符或vedic符号之前的位置。例如,如果reph的重新排序位置是post-main,它将跳过也具有post-main位置的基于matras的上方matras。
否则,将reph重新排序到音节的结尾。
重新排序预基础重排序辅音:如果找到预基础重排序辅音,请根据以下规则对其重新排序:
仅在应用期间重新排序由替换产生的字形 特征。(注意,字体可能会形成一个Ra辅音 一般情况下,但在某些情况下阻止它。)
尝试以与基础前matra相同的方式找到目标位置。如果找到,请重新排序前基础辅音字形。
如果未找到位置,请在主辅音之前立即重新排序。
孟加拉语的字符重新排序类:
人物 重新排序类
09B0,09F0(reph) AfterSubscript
09BF,09C7,09C8 BeforeHalf
09C1-09C4,09E2,09E3 AfterSubscript
09BE,09C0,09D7 AfterPostscript
0981 AfterPostscript
形状字形序列(GSUB处理)
首先使用cmap查找将字符串中的所有字符映射到其名义字形。然后,整形引擎使用GSUB查找继续对字形进行整形(替换)。
为特征的局部形式和基本整形形式在某时刻的群集或群集的相关部分施加一个。
基本整形形式特征之后的结果已经应用影响最终音节分析,最终指定Ra作为基础重新排序形式和reph和matras的最终重新排序位置。接下来,演示文稿表单的功能同时应用于整个集群。注意:由于演示文稿表单功能同时应用于整个群集,因此多个功能在操作上等同于单个功能。提供了多个功能,以帮助字体开发人员组织他们实现的查找。
注意:在应用基本整形表单的功能之后以及应用演示表单的功能之前,会发生最终重新排序。字体开发人员在创建GSUB特征和查找表时必须考虑初始重新排序(在应用任何特征之前)和最终重新排序(在应用基本整形表单特征之后)的影响。
这些预定义的功能在“ 功能”部分中进行了描述和说明,并按以下顺序应用。
塑造功能:
本地化表格
应用功能’locl’来选择特定于语言的表单。
基本塑造形式
应用特征’nukt’来代替nukta形式的辅音。
应用feature_’akhn’_替换所需的akhand连字,或替换优先于稍后应用的特征生成的表单的表单。
应用特征’rphf’来替换reph字形(’Ra’的基础形式)。
应用特征blwf’替换以下基础形式(ba + ra phala)。
应用“半”特征来替换半形式的前基础辅音。
应用特征pstf’来替换后基础形式的辅音。
应用特征’ vatu ‘来替换ligature consonant-vattu或conjunct-vattu形式,用于辅音或合取字形(全部或半形式)的序列,然后是以下基部标记。
应用功能’cjct’来替换合取形式。(当基底前辅音不具有半形时,尤其需要这种结合形式。)
演示表格
应用功能’init’替换初始表单
应用特征’pres’代替前基础辅音合取和前基础合作。(即,辅音和matra合并到基本字形的左侧)。
应用特征’abvs’来代替基于上方的matra合取,reph合取,基础上元音修饰符和基于上方的应力和音调标记。
应用特征“blws”来代替低于基础的辅音合取,低于基础的matra合取,低于基础的元音修饰形式和低于基础的应力和音调标记形式。
应用特征’psts’来替换后基辅音合取,后基matra合取和后基元音修饰符。
应用特征’haln’来代替halant形式的基础(或合取基础)字形在以halant结尾的音节中。
应用特征’calt’来替换辅音的上下文替换。
位置字形序列(GPOS处理)
整形引擎接下来处理GPOS(字形定位)表,应用与定位有关的特征。所有功能同时应用于整个群集。
字体开发人员在创建GPOS功能和查找表时必须考虑重新排序的影响(即,字形将按照应用GSUB 演示表单功能后的顺序排列)。
定位功能:
字距
应用特征’kern’来调整距离(例如,在后基础或前基础元素与基本字形之间提供字距调整)。
应用’dist’功能来调整距离。(注意 - ‘dist’功能的使用方法与’kern’功能相同。使用’dist’功能的优点是它不依赖于应用程序来启用字距调整。因此,如果你想要确保始终显示某些间距调整,您应该使用’dist’功能)。
高于基数的标记
应用特征’abvm’来定位基础字形或基础后的matra上方基础上的标记(基础上的辅音形式,matras,元音修饰符或重音/音调标记)。
低于基数的标记
应用特征’blwm’来定位基础字形或基础后的matra上的基础下方标记(低于基础的辅音形式,matras,元音修饰符或应力/色调标记)。
基本要素
通常,需要一个特征来处理基本字形以及后基础,前基础或基础上元素之一。由于无法对基本字形旁边的所有这些元素重新排序,因此我们需要跳过“中间”的元素(重新排序)。
解决方案是将不同的标记附加类分配给音节和位置形式的不同元素,并且在任何给定的查找工作中仅分配一种标记类型。例如,在基础上的替换中,我们大多数时候只需要考虑基础上的元素。
通常,最好将标记为“标记”的字形标记为Unicode标准中的标记以及辅音的低于基础/高于基础的形式。然后,根据它们相对于基部的位置,应将不同的附着类分配给不同的标记。
例如,在整形引擎对集群内的元素进行重新排序之后,matra将始终出现在音节修饰符之前,例如candrabindu。然而,在实际的序列中,可能在matra和candrabindu之间可能出现一些其他标记字形,例如nukta。因此,在处理matra和candrabindu时,您可能需要考虑在它们之间可能出现一些其他标记字形的可能性。使用查找标志,您可以指定查找应仅处理某类标记,例如“基础标记”,并忽略所有其他标记。以这种方式,无论是否存在来自另一个类的标记,都将发生匹配。否则,查找将无法应用。
使用Microsoft VOLT,您可以将字形分配给附件类。
在下面的示例中,此“abvm”功能设置为仅 处理TopMark,因此将忽略另一个标记类的存在。如果使用了Process ALL并且matra之后是另一个标记字形,则此定位查找将无法应用。这个例子来自Devanagari字体Mangal。

无效的组合标记
组合不与有效基数一起出现的标记和符号被视为无效。形成引擎实现可以采用不同的策略来处理无效标记。例如,整形引擎实现可能将无效标记视为单独的集群,并显示位于某些默认基本字形上的独立标记,例如虚线圆圈。(请参阅Unicode标准4.0第5.13节中的后备渲染。)对于哪些序列被认为有效或不被认为有效,形成引擎实现可能会有所不同。例如,一些实现可以施加至多一个基于上的基元音标记的限制,而其他实现可以不限制。
为了允许对期望在虚线圆上定位无效标记的引擎实现进行整形,建议孟加拉语OT字体包含虚线圆圈字符U + 25CC的字形。如果字体不支持此字符,则此类实现将在缺少的字形形状(白色框)上显示无效符号。

除了’虚线圆’之外,推荐包含在任何孟加拉语字体中的其他Unicode代码点是ZWJ(零宽度非连接器; U + 200C),ZWNJ(零宽度连接器; U + 200D)和ZWSP (零宽度空间; U + 200B)。有关更多信息,请参阅OpenType字体开发文档的“ 建议字形”部分。
ZWJ,ZWNJ和NBSP对辅音成形的影响
Unicode定义了与印度语脚本相关的zwj和zwnj的特定行为。特定于印度的行为保留了zwj请求文本元素之间连接的一般行为,而zwnj禁止文本元素之间的连接。
在这种情况下使用ZWJ的主要目的是防止形成结扎 - 结合(在梵文或Gujuarati,要求半形式,低于基础形式或后基础形式)。印度语引擎不需要采取任何措施来防止结扎 - 结合形成:ZWJ的存在将阻止GSUB替换查找与输入字形序列匹配。如果第一个辅音不具有半形式,则应该产生一种明显的形式,这也可能在发动机没有特别动作的情况下发生。
在此上下文中使用ZWJ的第二个意图是在第一个辅音是RA的情况下防止显示reph。如果群集以RA H(halant)ZWJ开头,则引擎必须确保未应用’rphf’功能,并且不会重新排序reph。请注意,在RA是第一个辅音的情况下,在这种情况下使用任何一个木匠都应该阻止reph的形成和重新排序。
使用ZWNJ的主要目的是防止结合连体或半形式,并显示明确的halant形式。整形引擎必须采取特定的动作来防止一系列Consonant + Halant + ZWNJ的半形式。
以下示例说明了这些行为:

正如zwj可用于隔离显示半形式一样,它也可用于隔离显示标记,子基础或基础形式。然而,与独立的半形式不同,显示它们的序列必须以不间断空间(NBSP)开始。这是因为标记,子基础和后基础形式具有“零宽度”,因此必须放在NBSP上。例如,要获得没有虚线圆的I-matra形状,应该键入NBSP + I-matra。
在下图中,使用NBSP显示没有虚线圆圈的I-matra。
NBSP和ZWJ的组合用于隔离地显示低于碱性的Ra形式。

特征
已定义下面列出的功能,以便为孟加拉语系统支持的语言创建基本表单。无论应用程序选择支持复杂脚本布局的模型,整形引擎都需要一个固定的顺序来执行文本运行中的功能,以便始终获得正确的基本形式。
基本整形形式的特征一次一个地应用于集群或集群的一部分。结果影响了连接行为和最终重新排序的分析。接下来将表示形式的特征应用于整个集群。必须始终应用强制性功能; 列出的自由选择的表示形式功能应默认应用,但可以由客户端抑制(通常由用户自行决定)。
每个功能中的查找顺序也非常重要。有关在OpenType字体中查找和定义功能的详细信息,请参阅OpenType字体开发文档的“ 编码”部分。
用于孟加拉语脚本的OpenType功能,按以下顺序应用:
特征 功能功能 布局操作
本地化表格:
LOCL 本地化形式替代 GSUB
基本形状形式:
nukt Nukta形式替代 GSUB
akhn Akhand结扎替代 GSUB
rphf Reph表格替换 GSUB
blwf 低于基础的形式替代 GSUB
半 半形式替代 GSUB
PSTF 基础后形式替代 GSUB
瓦图 Vattu变种 GSUB
cjct 联合形式替换 GSUB
强制性表述形式:
在里面 初始表格 GSUB
PRES 前碱替代 GSUB
ABVS 基础替代 GSUB
blws 低于碱的替代 GSUB
PST的 后基础替代 GSUB
haln Halant形式替代 GSUB
全权委托表格形式:
CALT 上下文交替 GSUB
定位功能:
克恩 字距 GPOS
DIST 距离 GPOS
abvm 高于基准的标记定位 GPOS
blwm 低于基准的标记定位 GPOS
[GSUB =字形替换,GPOS =字形定位]
功能示例
本文档中描述和说明的许多注册功能都基于Microsoft OpenType字体Vrinda。Vrinda包含布局信息和字形,以支持孟加拉语脚本和支持的语言系统所需的所有功能。
以下示例中的插图显示了应用该特定功能的结果。在重新排序后,必须编写功能以匹配字形序列。请注意,要素的输入上下文可能是已应用先前要素的结果。
本地化表格
功能标签:“locl”
此功能与OpenType语言系统标记结合使用,以触发查找,这些查找将选择特定于语言的排版约定所需的替换字形。’locl’不应与默认语言系统一起使用,而只能与其他语言系统标签一起使用。有关与孟加拉文脚本相关的语言系统标签,请参阅本文档的附录。
基本的塑造形式
Nukta
功能标签:“nukt”
所述nukta改变前面的辅音或元音,发音的方式。最常见的nukta表单已被定义为Unicode中具有各自代码点的单独字符。所有辅音以及akhand形式都应该有相关的nukta形式。
注 - 除了使用替换之外,还可以通过使用’blwm’定位功能将nukta定位为基本字形上的基础标记来创建nukta形式。
nukt特征的输入上下文总是由辅音的完整形式组成。将使用半特征替换半形式的nukta辅音。
Nukta功能用于替换Ya + Nukta的预先组成的字形(Yya):

Akhand
功能标签:“akhn”
akhand是必需的辅音连字,可能出现在音节的任何地方,并且可能涉及或可能不涉及基本字形。Akhand连字是最重要的,并且首先形成; 有些语言将它们包含在字母表中。
akhand特征的输入上下文总是由辅音的完整形式组成。Akhand连字的一半形式将在半特征中稍后调用。
因为akhand特征在特征序列的早期应用并且应用于整个集群,所以它还可以用于创建某些形式,这些形式必须在特定上下文中优先于在后续特征应用期间创建的形式。
Ka + halant + Ssa被KaSsa结扎取代:

Ja + halant + Nya被JaNya Ligature取代:

Reph
功能标记:“rphf”
应用此功能会替换Reph字形。如果群集的第一个辅音由Ra + Halant的完整形式组成,则此特征将替换Reph的组合标记形式。此外,使用’abvm’GPOS功能调整Reph字形的位置。
Reph功能的输入上下文总是由Ra + Halant的完整形式组成。
示例1- Reph功能替换Ra的标记字形。在最终重新排序之后,在’abvm’GPOS功能中调整定位:

示例2 - 应用了多个辅音的Reph功能。注意 - reph被重新命令定位在第一主辅音上,而不是半音:

下面是辅音的形式
功能标签:“blwf”
当孟加拉语中没有与前一个辅音结合时,这个特征代替了基本形式的辅音,如孟加拉语中的Ra + Ba。
Halant + Ra(前面是一个不形成结扎的辅音)代替低于基础的Ra:

Halant + Ba(前面是一个不形成结扎的辅音)代替了以下的Ba:

辅音的一半形式
功能标记:“half”
应用此特征可替代半形式 - 在基础前位置使用的辅音形式。具有半形式的辅音应列在“ 半”形状中。对于大多数辅音,孟加拉语有明显形状的半形式。如果辅音不具有半形的独特形状并且不形成任何结扎,则将显示具有明确的Virama(与halant形式相同的形状)。
注意 - 在半特征中列出辅音的结果(无论它是否具有真正的半形)将影响reph和预先设定的matra的重新排序(和定位)。请参阅本文档“ 简介”部分中的插图。
此功能适用于’main’辅音之前的所有辅音。
半特征替代Ka的一半形式:

适用于多个辅音的半功能:

后基本形式的辅音
功能标记:“pstf”
应用此功能可替换后基础表单,例如’Bengali Ya’。
当它是音节中的最后一个辅音时,Ya的后基础形式被替换:

Vattu变种
功能标签:“vatu”
‘ vatu’特征可用于替代完整(或半)形式辅音和低于基础的vattu(孟加拉语ra-phala)的结扎。’blws’也可用于这些结扎取代。
‘vatu’特征的输入上下文由辅音(全部或半形式)+ vattu字形组成。
‘vatu’功能用于替换Ka +低于基础Ra的结扎:

‘vatu’功能用于替换Tta +低于基础Ra的结扎:

联合形式
功能标记:“cjct”
应用特征’cjct’来替换合取形式,其中辅音 - 群集对中的第一个辅音不具有半形式。如果辅音不采用半形式但形成’conconctct连词与某些后续辅音相结合,则此功能允许控制重新排序’和reph和pre-pended matras。
‘cjct’功能用于替换Gha + Na的结扎:

演示表格
重新排序字形后,应用演示文稿查找以提供文本的最佳印刷渲染。表示形式的功能同时应用于整个群集,按照在字体中指定的顺序在每个功能中执行查找。
该PRES,ABVS,blws,PST文件和haln功能都必须用软件实现:他们都需要正确的脚本行为,并没有应该永远被视为自由支配。由于这一点,并且因为它们全部同时应用于整个集群,它们在功能上并不相同:一组查找可以在这些特征之间划分,或者在其中一个特征之下组合在一起,效果没有差别。然而,提供这些多个特征作为字体开发者的帮助,用于基于它们适用的字形组合来组织查找。对每种方法的使用方式没有具体要求; 但是,下面提供的示例说明了典型用法。
初始表格
功能标记:“init”
此功能用于替换孟加拉文脚本中元音E和Ai的初始形式。的初始形式是不具有关于该字形的前侧的连接条的字形变体。
所有初始形式必须基于由完整形式的辅音组成的输入上下文。
应用的初始功能:

前碱基取代
功能标记:“pres”
此功能用于替换用半形式制作的前基础辅音合奏,这种形式在孟加拉语中最常见。由此产生的混合物可以是全部或半形式。
此功能还用于选择I-Matra的印刷正确形式。例如,字体可以具有若干版本的I-Matra,以在具有不同辅音基础或聚类的上下文中使用。此外,’pres’特征可以包含具有某些碱基的I-matra的预先组成的连字。
实施例1-半Ka +全Ka被KaKa结合取代:

实施例2-半Ka +全Ma被KaMa结合取代:

实施例3-半La +全Ka被LaKa结合取代:

例4 - 半Ka +半Ssa +全Nna被KaSsaNna结扎取代:

示例5 - ‘pres’功能也用于用I-Matra替换连字:


高于碱基的取代
功能标记:“abvs”
此功能用于涉及基础上标记的替换。这些替换可用于选择标记的上下文形式,创建标记连接或创建标记基结扎。此查找也处理特定的上下文相关形式或基础辅音。
用于替换reph + matre I组合的结扎的’abvs’功能:

用于替换reph + candrabindu字形的连字的’abvs’功能:

低于碱基的取代
功能标记:“blws”
此功能用于涉及低于基础的标记或辅音的字形替换。这种取代可用于产生具有低于基础辅音的基础字形的结合,低于标记结扎或低于标记基础结扎。特定的上下文相关形式也由此查找处理。
示例1-‘blws’替换base + below-base conjuncts:

实施例2-在存在低于基础的辅音的情况下,以下基质的matra可以改变结扎形状:

示例3-当conjunct base + matra形成新的连字时,’blws’替换:

基础后替换
功能标记:“psts”
此功能用于替换后基辅音或matras。这种取代可用于产生具有基底后辅音或基底后matra结扎的基础字形的结合。它还可用于指定后基础表单的上下文替换。
实施例1-用于替代碱基和后基质matra的混合物的’psts’:

示例2-用于替换基础和后基础matra的合取的’psts’:

Halant形式的辅音
功能标签:“haln”
此功能用于替代的预组成halant碱(或碱的混合)的字形与结束音节形式halant。(而不是使用替换,也可以通过使用’blwm’定位功能将halant定位为基本字形上的基础标记来创建halant形式。)
如果音节以halant结尾,则此特征仅应用于基本字形,或者如果非最终辅音不采用半形式并且不与下一个辅音形成合取结合,则此特征仅应用于基本字形。
示例1 - 用于替换基本字形的halant形式的’haln’特征:

示例2 - ‘haln’功能用于替换halant形式的合取基本字形:

上下文替代
功能标签:“calt”
与之前的演示文稿查找不同,“ calt”功能是可选的,用于替换自由选择的上下文替换。重要的是要注意,应用程序可能允许用户关闭此功能,因此不应该用于任何强制孟加拉语排版。
定位功能
距离
功能标签:“dist”
此功能包括调整字形之间距离的定位查找,例如前后基本元素之间的字距调整和基本字形。注意; 特征’dist’可以与’kern’特征一样使用。使用’dist’功能的优点是它不依赖于应用程序来启用字距调整。
高于基数的标记
功能标签:“abvm”
此功能可将基本字形或后基质matra上的所有高于基准的标记定位。在OpenType字体中编码此功能的最佳方法是使用链接上下文定位查找,该查找触发基于上标记的标记到基础和标记到标记的附件。
MS Volt中的’abvm’查找使用’Anchor Attachment’来调整基线上方标记的位置:

使用“单一调整”在MS Volt中进行上下文“abvm”查找,以便在某些基础上定位candrabindu:

低于基数的标记
功能标签:“blwm”
此功能可在基本字形上定位所有低于基准的标记。在OpenType字体中编码此功能的最佳方法是使用链接上下文定位查找,该查找触发基于标记的标记到基础和标记到标记的附件。
MS Volt中的’blwm’查找使用’Anchor Attachment’来调整底部标记的位置:

孟加拉语音节的例子
使用OpenType中提供的各种功能,可以形成复杂的孟加拉语音节。以下示例显示了整形引擎如何将OpenType功能一次一个地应用于输入字符串。这些组合不一定代表实际的音节或单词,而是用于说明孟加拉语字体中的各种OpenType特征。
示例#1:

示例#2:

附录
附录A:编写系统标签
附录A:编写系统标签
功能根据指定的脚本和语言系统进行编码。为阿萨姆语,孟加拉语和马尼普里语定义了不同的语言系统,尽管它们都使用孟加拉文字。
目前,大多数整形引擎实现仅支持每个脚本的“默认”语言系统。但是,字体开发人员可能希望构建其他应用程序支持的语言特定功能,并且将在未来的Microsoft OpenType实现中得到支持。
注意:强烈建议在所有OpenType字体中包含“dflt”语言标记,因为它定义了字体的基本脚本处理。如果未定义其他语言特定功能,或者应用程序不支持该特定语言,则使用“dflt”语言系统作为默认语言。如果正在使用的脚本不存在“dflt”标记,则该字体在某些应用程序中可能不起作用。
下表列出了脚本和语言系统的已注册标记名称。注意新的印度形成实现’bng2’被使用(旧行为实现使用’beng’)。
孟加拉语脚本的注册标签 孟加拉语系统的注册标签
脚本标签 脚本 语言系统标签 语言
“bng2” 孟加拉 “DFLT” *默认脚本处理
“ASM” 阿萨姆
“BEN” 孟加拉
“MNI” 曼尼普尔
注意:脚本和语言标记都区分大小写(脚本标记应为小写,语言标记全部为大写)并且必须包含四个字符(即,必须为三个字符语言标记添加空格)。
13.7.2.梵文
请注意:本文档反映了2005年针对印度语脚本OpenType字体和整形引擎实现的建议所做的更改。虽然根据之前的建议制作的印度语字体仍然可以在新版本的Uniscribe中正常运行,但字体开发人员可能会选择更新字体,特别是如果他们希望避免早期实现的某些限制。
本文档提供的信息将帮助字体开发人员为Unicode标准涵盖的所有梵文脚本语言(包括经典梵语)创建或支持OpenType字体。其他使用梵文脚本编写的语言包括印地语,克什米尔语,康卡尼语,马拉地语,尼泊尔语,梵语和信德语。
介绍
本文档针对开发人员实现印度语整形行为与印度语脚本的Microsoft OpenType规范兼容。它包含有关Devanagari脚本的印度形成引擎的术语,字体特征和行为的信息。虽然它不包含创建梵文字体的说明,但它可以帮助字体开发人员了解印度形成引擎如何处理印度文字。此外,还通过示例定义和说明了梵文脚本的注册特征。
新的印度形成引擎允许印刷惯例的变化,使字体开发人员可以通过选择字形指定到某些OpenType特征来控制整形。例如,reph和pre-pended matra在音节群内重新排序的位置受到半形式存在的影响。见下图。
在下面的示例中(Ra + halant + Da + halant + Ma + I-matra),Ra + halant将形成reph,但Da如何分类将决定reph的位置以及预先设置的位置MATRA。

选项1:虽然Da在梵文中没有真正的半形式,但它可以在’half’特征查找中列出,代替Da的’halant form’。因此,整形引擎将其视为半形式,并且将reph定位在第一主辅音上; 并且I-matra将立即定位在“半形式”D(a)的前面。
选项2:通过不在“半”特征查找中列出Da,将显示halant表单,并且整形引擎将其视为第一个用于定位reph的主要辅音。并且I-matra将立即定位在其前面的基座(或半形式)的前面,在这种情况下是Ma。
词汇表
以下术语对于理解本文档中讨论的布局功能和脚本规则很有用。
基本形式的辅音 - 在基本字形上方出现的辅音的变体形式。在梵文中,只有辅音Ra具有上基形式,称为“reph”。
Akhand连字 - 必要的辅音连字,可能出现在音节的任何地方,可能或可能不涉及基本字形。Akhand连字是最重要的,并且首先形成; 有些语言将它们包含在字母表中。梵文中的Akhand连字可以半形式或全形式显示。
基本字形 - 正字体音节中唯一的辅音或辅音合奏,以“完整”(标称)形式书写。在梵文中,音节的最后一个辅音(除了以字母“Ra”结尾的音节外)通常形成基本字形。在没有元音(一个单词的最后一个字母)的“简并”音节中,halant形式的最后一个辅音作为基本辅音并被映射为基本字形。布局操作是根据基本字形而不是基本字符定义的,因为基础通常可以是连字。
低于基本形式的辅音 - 在基本字形下方出现的辅音的变体形式。在梵文中,只有辅音Ra具有低于基础的形式。在字形序列中,以下基础形式位于形成基本字形的辅音之后。低于基础的形式由非间距标记字形表示。
群集 - 在印度语脚本中形成一个整体单元的一组字符,通常是一个音节。
辅音 - 每个都代表一个辅音。辅音可以以不同的语境形式存在并且具有固有的元音(通常是短元音“a”)。例如,“Ka”和“Ta”,而不仅仅是“K”或“T”。
辅音合奏(又名“合取”) - 两个或更多辅音的结构。辅音合奏可以有完整形式和半形式,也可以只有完整形式。
梵文音节 - 梵文书写系统的有效拼写“单位”。音节由辅音字母,独立元音和从属元音组成。在文本序列中,这些字符以语音顺序存储(尽管它们在显示时可能不以语音顺序表示)。一旦音节成形,它就是不可分割的。光标无法定位在音节中。本文档中讨论的转换不跨越音节边界。
Halant(Virama) - 在辅音之后使用的字符“剥离”它固有的元音。在每个梵文音节中,除了最后一个辅音之外,其他所有的音乐都是如此; 如果音节没有元音,那么halant也会跟随最后一个辅音。
注意:包含halant字符的音节可以通过使用不同的辅音形式或合取而形成没有可见的halant符号。
Halant形式的辅音 - 通过将halant(virama)添加到标称形状而产生的形式。Halant形式用于没有元音的音节或半形式的音节,当半形式没有明显的形状时。
辅音的一半形式(前基础形式) - 辅音的一种变体形式,如果它们不参与结扎,则出现在基本辅音的左侧。半形的辅音在形成基本字形的辅音之前。对于大多数辅音,梵文有明显形状的半形。如果辅音不具有半形的独特形状并且不形成任何结扎,则将显示具有明确的Virama(与halant形式相同的形状)。
Matra(Dependent Vowel) - 用于表示辅音不固有的元音。从属元音在梵语中被称为“matras”。它们总是与单个辅音或辅音簇组合描绘。不同印度语脚本之间的最大差异可以在将依赖元音附加到基本字符的规则中找到。
新的整形行为 - 在此版本的印度语OpenType字体规范中定义的整形行为。本文档中的信息主要涉及新的实施模型。关于兼容性的评论中可能会提到旧行为。
Nukta - 一种改变前面的辅音(或matra)发音方式的组合字符。
旧的整形行为 - 在以前版本的印度语OpenType字体规范中定义的整形行为。
OpenType布局引擎 - 负责以字体执行OpenType布局功能的库。在Microsoft文本格式堆栈中,它被命名为OTLS(OpenType布局服务)。
OpenType标记 - 字体中脚本,语言系统或功能的4字节标识符。
后基本形式的辅音 - 基本字形右侧出现的辅音的变体形式。采用后基础形式的辅音之前是形成基本字形的辅音加上halant(virama)。后基础形式通常是间距字形。
前基本形式的辅音 - 基本字形左侧出现的辅音的变体形式。请注意,大多数前基础辅音形式在基本辅音之前在逻辑上和视觉上都是如此。半形式是这种预基形式的例子。但是,在某些剧本中,前基础Ra可能在逻辑上遵循基本辅音(即,它在语音上和文本的字符序列中跟随它),即使它在基础之前在视觉上呈现。整形引擎使用’pref’功能动态检测此类情况,并根据需要重新排序预基形式字形。
Rakaar - Devanagari中“Ra”的基础形式,与大多数前面的辅音形成一个结扎线。如果前面的辅音具有半形式,那么辅音 - 拉卡尔组合通常也具有半形式。
Reph - 在“梵语”中使用的字母“Ra”的上述基本形式,当“Ra”是音节中的第一个辅音并且不是基本辅音时。
Shaping Engine - 负责整形输入的代码,分类为特定脚本。
Split Matra - 一种分解为碎片以进行渲染的matra。通常,不同的部分出现在相对于基部的不同位置。例如,matra的一部分可以放置在集群的开头,另一部分放在集群的末尾。
音节 - 印度文字处理的单个单位。对每个音节独立地执行印度文本的整形。下面描述识别每个音节的边界的过程。
Vattu(Rakar) - 辅音的低音形式。在梵文中,“Ra”可以在群集中采用vattu形式; 这个“Vattu-Ra”也被称为Rakaar。

1.前基础形式
2.基础辅音
3.基础形式(reph)
4。基础后(matra)
5。基础形式(vattu / rakaar)
塑造引擎
分析文字
重新排序字符
形状字形序列(GSUB处理)
位置字形序列(GPOS处理)
基本要素
无效的组合标记
使用ZWJ,ZWNJ和NBSP
印度形成引擎分阶段处理梵文文本。阶段是:
分析文本序列; 把它分成音节群
根据需要重新排序字符
应用OpenType GSUB字体功能以获得正确的字形形状
应用OpenType GPOS功能来定位字形或标记
以下描述将帮助字体开发人员理解Devanagri特征编码模型的基本原理,并帮助应用程序开发人员更好地理解布局客户端如何将职责划分为操作系统功能。
分析文字
角色属性
整形引擎将文本划分为音节群集并识别角色属性。在确定正确的字符或字形重新排序时以及在OpenType特征应用程序中,字符属性用于解析音节和识别其部分。每个字符的属性分为两种类型:静态属性和动态属性。
静态属性定义了不会从字体更改为字体的基本特征:字符类型(辅音,matra,vedic符号等)或matra重新排序的类型。它们在脚本之间有所不同,但不能由字体开发人员控制。
动态属性是字体相关的,并在加载字体时由整形引擎检索。这些属性会影响整形和重新排序行为。
*注意:在旧的整形引擎实现中,所有辅音属性都是静态的:假设辅音具有特定的连接形式。在新的实现模型中,辅音连接行为是动态属性。
从印度字体中检索动态角色属性
字体通过实现标准功能来定义辅音的动态属性。整形引擎从字体中读取的辅音类型(和相应的特征标签)是:
Reph’rphf’
半形’半’
Ra / Rra’pref’的前碱基重排序形式
低于基础形成’blwf’
后基础形式’pstf’
上述每个特征与’locl’特征一起应用于输入由两个字符组成的序列:对于’rphf’和’half’,特征应用于辅音 + Halant组合; 对于’pref’,’blwf’和’pstf’,功能适用于Halant + 辅音组合。这是为每个辅音完成的。如果这两个字形形成一个连字,在上下文中没有其他字形,这意味着辅音具有相应的形式。例如,如果在将“half”和“locl”特征应用于序列Da + Halant时发生替换,则Da被分类为具有半形式。
注意,可以实现字体以仅在某些音节中将Ra重新排序到前基础位置,否则将其显示为基础或后基础形式。这意味着Pre-base-form分类与Below-base-form或post-base-form分类不相互排斥。然而,如上所述使用无上下文替换来确定所有分类。
字体相关的字符分类仅定义辅音类型。但是,对于每个字符类,重新排序的位置是固定的。
*注意:对于支持旧实现的字体,所有功能都应用于Consonant + Halant序列。
印度输入处理
当输入序列中还有字符时,应重复以下步骤。所有整形操作都是在一个音节的基础上完成的,与其他角色无关。
在输入中查找下一个音节
引擎应该找到与以下模式之一匹配的字符序列:
辅音音节:
{C + [N] + <H + [<ZWNJ | ZWJ>] | <ZWNJ | ZWJ> + H>} + C + [N] + [A] + [<H + [<ZWNJ | ZWJ>] | {M} + [N] + [H]>] + [SM] + [(VD)]基于元音的音节:
[RA + H] + V + [N] + [<[<ZWJ | ZWNJ>] + H + C | ZWJ + C>] + [{M} + [N] + [H]] + [SM] + [ (VD)]独立群集(仅在单词的开头):
#[RA + H] + NBSP + [N] + [<[<ZWJ | ZWNJ>] + H + C>] + [{M} + [N] + [H]] + [SM] + [(VD) ]哪里:
{} 零次或多次出现
[] 可选的发生
<|> “之一”
() 一两次出现
C 辅音
V 独立元音
ñ nukta
H halant /比拉马
ZWNJ 零宽度非连接器
ZWJ 零宽度木匠
中号 matra(每种类型中最多一种:前,下,下或后基)
SM 音节修饰符号
VD 吠陀
一个 anudatta(U + 0952)
NBSP 没有休息的空间
识别音节内的关键位置
音节结构由以下部分组成:Reph + HalfConsonant(s)+ MainConsonant(s)+ BelowBaseConsonant(s)+ PostBaseConsonant(s)+ PreBaseReorderingRa + MatrasAndSigns
辅音部分包括所有相关的halants和nuktas。(例如,BelowBaseConsonant的一个实例由一系列Halant + Under-base-forming辅音组成。)除主辅音外,所有部分都是可选的。
所有部分都按照它们在音节中出现的顺序显示,具有一个限定条件:取决于字体实现,PreBaseReorderingRa可能出现在所有BelowBaseConsonants之前,AfterBaseConsonants之后和PostBaseConsonants之前,或PostBaseConsonants之后。此外,可以实现字体以仅在某些音节中将Ra重新排序到预基础位置,否则将其显示为基础或后基础形式。因此,只有在将“pref”特征应用于该音节之后,才能最终确定特定音节中的Ra的出现是否可以被视为基础前重排序Ra。
在一个以上的辅音不具有半音,低音,后音或前音形的情况下,可能存在几个主要辅音。在第一个辅音不具有半形的群集的情况下,整形引擎将其识别为第一个“完整形式”并继续识别第二个完整形式辅音(如果有的话)。然后,该信息将用于确定reph或任何matras,元音修饰符或压力标记的重新排序行为。
所有其他元素按其相对于基础的位置进行分类:前基(半形式和重新排序前基础Ra形式),低于基础,高于基础和后基础。
印度群集受以下限制:
每个音节只允许一个reph。
每个音节只允许一个预基重新排序Ra。
nukta可以放在辅音,matra或独立的元音上。它不能放在预先组成的nukta字符上。
允许来自每个定位类的一个matra(Kannada脚本中的例外)。复合matra被视为属于其组件所属的所有类。
每个群集允许一个音节修饰符。
吠陀标志是组合标记(用于梵语),应该包含在所有印度语脚本中。
Danda和Double Danda是标点符号,应该包含在所有印度语脚本中。
重新排序字符
一旦印度形成引擎如上所述分析了集群,它就根据若干规则(如下所述)创建并管理表示集群的适当重新排序的元素(字形)的缓冲区。
在重新排序后,必须编写印度语字体中的OpenType查找以匹配字形序列。OpenType字体不应具有尝试执行重新排序的替换。如果字体开发人员试图用OpenType字体编码这样的重新排序信息,他们需要添加大量的多对多字形映射来覆盖整形引擎将使用的一般算法。
查找基本辅音:整形引擎使用以下算法找到音节的基本辅音:从音节的结尾开始,向后移动,直到找到没有基础或后基础形式的辅音(post - 基础形式必须遵循以下基础形式),或者不是基础前重新排序Ra,或者到达第一个辅音。辅音停在附近将成为基地。
如果音节以Ra + Halant(在具有Reph的脚本中)开头且具有多个辅音,则Ra被排除在基本辅音的候选者之外。
分解和重新排序Matras:群集中的每个matra和任何音节修饰符都将移动到相对于群集中辅音的适当位置。在任何重新定位之前,整形引擎将两部分或三部分的matra分解成它们的组成部分。马特拉字符被分类为它们具有亲和力的合取中的辅音,并被重新排序到以下位置:
在音节的前半部分形成之前
在辅助辅音之后
后形式辅音后
主辅音后(以上标记)
将标记重新排序为规范顺序:如果需要,相邻的nukta和halant或nukta和vedic标志总是重新定位,因此nukta是第一个。
最终重新排序:在应用了本地化表单和基本整形表单 GSUB功能之后(见下文),整形引擎在将所有剩余字体功能应用于整个集群之前执行一些最终字形重新排序。
重新排序matras:如果在应用基本特征之前已经重新排序了基础前matra字符,则可以根据是否已形成半形式将字形移近主辅音。matra的实际位置被定义为“在最后的独立halant字形之后,在初始matra位置之后和主辅音之前”。如果ZWJ或ZWNJ遵循这个习惯,那么位置就会被移动。
重新排序reph: Reph的原始位置始终位于音节的开头(即,它不会在字符重新排序阶段重新排序)。但是,它将根据基本形式的整形结果进行重新排序。reph的可能位置,取决于脚本,是; 主要之后,之后的基础辅音形式,以及后基辅音形式之后。
如果reph应位于基础后辅音形式之后,请继续执行步骤’e’。
如果reph重新定位类不在post-base之后:target position位于第一个post-reph辅音和last main辅音之间的第一个显式halant字形之后。如果ZWJ或ZWNJ正在跟随这个halant,那么位置会在它之后移动。如果找到这样的位置,则这是目标位置。否则,请继续执行下一步。
注意:在旧实现字体中,在整形引擎中修改了分类,在这一步中没有找到reph位置的情况。
如果reph应该在主辅音后重新定位:从第一个辅音不与主要结扎,或者找到第一个辅音,即不是潜在的前基础重新排序Ra。
如果reph应该放在post-base辅音之前,找到第一个post-base分类辅音不与main结扎。如果未找到辅音,则目标位置应位于第一个matra,音节修饰符或vedic符号之前。
如果在步骤’c’或’d’中没有找到辅音,则将reph移动到紧接在预定的reph位置之后具有重新排序类的第一个后基matra,音节修饰符或vedic符号之前的位置。例如,如果reph的重新排序位置是post-main,它将跳过也具有post-main位置的基于matras的上方matras。
否则,将reph重新排序到音节的结尾。
重新排序预基础重排序辅音:如果找到预基础重排序辅音,请根据以下规则对其重新排序:
仅在应用’pref’功能期间重新排序由替换产生的字形。(请注意,字体可能会形成与’pref’功能一致的Ra辅音,但在某些情况下会阻止它。)
尝试以与基础前matra相同的方式找到目标位置。如果找到,请重新排序前基础辅音字形。
如果未找到位置,请在主辅音之前立即重新排序。
梵文的字符重新排序类:
characters Reorder Class
0930(reph) BeforePostscript
093F BeforeHalf
0945-0948 AfterSubscript
0941-0944,0962,0963 AfterSubscript
093E,0940,0949-094C AfterSubscript
形状字形序列(GSUB处理)
首先使用cmap查找将字符串中的所有字符映射到其名义字形。然后,整形引擎使用GSUB查找继续对字形进行整形(替换)。
为特征的局部形式和基本整形形式在某时刻的群集或群集的相关部分施加一个。
基本整形形式特征之后的结果已经应用影响最终音节分析,最终指定Ra作为基础重新排序形式和reph和matras的最终重新排序位置。接下来,演示文稿表单的功能同时应用于整个集群。注意:由于演示文稿表单功能同时应用于整个群集,因此多个功能在操作上等同于单个功能。提供了多个功能,以帮助字体开发人员组织他们实现的查找。
注意:在应用基本整形表单的功能之后以及应用演示表单的功能之前,会发生最终重新排序。字体开发人员在创建GSUB特征和查找表时必须考虑初始重新排序(在应用任何特征之前)和最终重新排序(after_basic整形form_特征已应用)的影响。
这些预定义的功能在“功能”部分中进行了描述和说明,并按以下顺序应用。
塑造功能:
本地化表格
应用功能’locl’来选择特定于语言的表单。
基本塑造形式
应用特征’nukt’来代替nukta形式的辅音。
应用要素’akhn’来替换所需的akhand连字,或替换优先于稍后应用的要素所生成的表单的表单。
应用特征’rphf’替换reph字形(’Ra’的基础形式)。
应用特征’rkrf’替换任何rakaar连字。
应用特征’blwf’替换以下基础形式。
应用“半”特征来替换半形式的前基础辅音。
应用特征’ vatu ‘来替换ligature consonant-vattu或conjunct-vattu形式,用于辅音或合取字形(全部或半形式)的序列,然后是下面的基础rakaar标记。(如果使用rkrf功能,则不需要此功能,但可用于旧行为实现)。
应用功能’cjct’来替换合取形式。(当前基础辅音不具有半形式时,这尤其对于结扎结合形式是必需的)。
演示表格
应用特征’pres’代替前基础辅音合取和前基础合作。(即,辅音和matra合并到基本字形的左侧)。
应用特征’abvs’来代替基于上方的matra合取,reph合取,基础上元音修饰符和基于上方的应力和音调标记。
应用特征“blws”来代替低于基础的辅音合取,低于基础的matra合取,低于基础的元音修饰形式和低于基础的应力和音调标记形式。
应用特征’psts’来替换后基辅音合取,后基matra合取和后基元音修饰符。
应用特征’haln’来代替halant形式的基础(或合取基础)字形在以halant结尾的音节中。
应用特征’calt’来替换辅音的上下文替换。
位置字形序列(GPOS处理)
整形引擎接下来处理GPOS(字形定位)表,应用与定位有关的特征。所有功能同时应用于整个群集。
字体开发人员在创建GPOS功能和查找表时必须考虑重新排序的影响(即,字形将按照应用GSUB演示表单功能后的顺序排列)。
定位功能:
字距
应用特征’kern’来调整距离(例如,在后基础或前基础元素与基本字形之间提供字距调整)。
应用’dist’功能来调整距离。(注意 - ‘dist’功能的使用方法与’kern’功能相同。使用’dist’功能的优点是它不依赖于应用程序来启用字距调整。因此,如果你想要确保始终显示某些间距调整,您应该使用’dist’功能)。
高于基数的标记
应用特征’abvm’来定位基础字形或基础后的matra上方基础上的标记(基础上的辅音形式,matras,元音修饰符或重音/音调标记)。
低于基数的标记
应用特征’blwm’来定位基础字形或基础后的matra上的基础下方标记(低于基础的辅音形式,matras,元音修饰符或应力/色调标记)。
基本要素
通常,需要一个特征来处理基本字形以及后基,前基,上基或下基元素之一。由于无法对基本字形旁边的所有这些元素重新排序,因此我们需要跳过“中间”的元素(重新排序)。
解决方案是将不同的标记附加类分配给音节和位置形式的不同元素,并且在任何给定的查找工作中仅分配一种标记类型。例如,在基础上的替换中,我们大多数时候只需要考虑基础上的元素。
通常,最好将标记为“标记”的任何字形标记为Unicode标准中的组合标记以及辅音的低于基础/高于基础的形式。然后,根据它们相对于基部的位置,应将不同的附着类分配给不同的标记。
例如,在整形引擎对集群内的元素进行重新排序之后,matra将始终出现在音节修饰符之前,例如candrabindu。然而,在实际的序列中,可能在matra和candrabindu之间可能出现一些其他标记字形,例如nukta。因此,在处理matra和candrabindu时,您可能需要考虑在它们之间可能出现一些其他标记字形的可能性。使用查找标志,您可以指定查找应仅处理某类标记,例如“基础标记”,并忽略所有其他标记。以这种方式,无论是否存在来自另一个类的标记,都将发生匹配。否则,查找将无法应用。
使用Microsoft VOLT,您可以将字形分配给附件类。
在下面的示例中,此“abvm”功能设置为仅处理TopMark,因此将忽略另一个标记类的存在。如果使用了Process ALL并且matra之后是另一个标记字形,则此定位查找将无法应用。这个例子来自Devanagari字体Mangal

无效的组合标记
组合不与有效基数一起出现的标记和符号被视为无效。形成引擎实现可以采用不同的策略来处理无效标记。例如,整形引擎实现可能将无效标记视为单独的集群,并显示位于某些默认基本字形上的独立标记,例如虚线圆圈。(请参阅Unicode标准4.0第5.13节中的后备渲染。)对于哪些序列被认为有效或不被认为有效,形成引擎实现可能会有所不同。例如,一些实现可以施加至多一个基于上的基元音标记的限制,而其他实现可以不限制。
为了允许对期望在虚线圆上定位无效标记的引擎实现进行整形,建议Devanagari OT字体包含虚线圆圈字符U + 25CC的字形。如果字体不支持此字符,则此类实现将在缺少的字形形状(白色框)上显示无效符号。

除了’虚线圆’之外,推荐包含在任何梵文字体中的其他Unicode代码点是ZWJ(零宽度连接器; U + 200D),ZWNJ(零宽度非连接器; U + 200C)和ZWSP (零宽度空间; U + 200B)。有关更多信息,请参阅OpenType字体开发文档的“建议字形”部分。
ZWJ,ZWNJ和NBSP对辅音成形的影响
Unicode定义ZWJ和ZWNJ与印度语脚本相关的特定行为。特定于印度的行为保留了ZWJ请求文本元素之间连接的一般行为,而ZWNJ禁止文本元素之间的连接。
在这种情况下使用ZWJ的主要目的是防止形成结扎 - 结合(在梵文或Gujuarati,要求半形式,低于基础形式或后基础形式)。印度语引擎不需要采取任何措施来防止结扎 - 结合形成:ZWJ的存在将阻止GSUB替换查找与输入字形序列匹配。如果第一个辅音不具有半形式,则应该产生一种明显的形式,这也可能在发动机没有特别动作的情况下发生。
在此上下文中使用ZWJ的第二个意图是在第一个辅音是RA的情况下防止显示reph。如果群集以RA H(halant)ZWJ开头,则引擎必须确保未应用’rphf’功能,并且不会重新排序reph。请注意,在RA是第一个辅音的情况下,在这种情况下使用任何一个木匠都应该阻止reph的形成和重新排序。
ZWJ的第三种用途涉及RA,特别是在梵文脚本的情况下:序列RA H ZWJ 用于用于马拉地语的“睫毛RA”的编码表示。但是,除了要求不创建和重新订购reph之外,不需要在引擎中执行其他操作。
使用ZWNJ的主要目的是防止结合连体或半形式,并显示明确的halant形式。整形引擎必须采取特定的动作来防止一系列Consonant + Halant + ZWNJ的半形式。
以下示例说明了其中一些行为:

正如ZWJ可以用于单独显示半个形状一样,它也可以用于单独显示标记,子或后基础形式。然而,与独立的半形式不同,显示它们的序列必须以不间断空间(NBSP)开始。这是因为标记字形必须与基本字形组合:要单独出现,必须提供NBSP作为基础。例如,要获得没有虚线圆的I-matra形状,应该键入NBSP + I-matra。
在下图中,使用NBSP显示没有虚线圆圈的I-matra。NBSP和ZWJ的组合用于隔离地显示低于碱性形式的Ra(Rakaar)。

最后更新时间:2008年5月22日
特征
已定义下面列出的功能,以便为Devanagari系统支持的语言创建基本表单。无论应用程序选择支持复杂脚本布局的模型,整形引擎都需要一个固定的顺序来执行文本运行中的功能,以便始终获得正确的基本形式。
基本整形形式的特征一次一个地应用于集群或集群的一部分。结果影响了连接行为和最终重新排序的分析。接下来将表示形式的特征应用于整个集群。必须始终应用强制性功能; 列出的自由选择的表示形式功能应默认应用,但可以由客户端抑制(通常由用户自行决定)。
每个功能中的查找顺序也非常重要。有关在OpenType字体中查找和定义功能的详细信息,请参阅OpenType字体开发文档的“编码”部分。
用于梵文脚本的OpenType功能,按以下顺序应用:
特征 功能功能 布局操作
本地化表格:
LOCL 本地化的表格替换 GSUB
基本塑形形式:
nukt Nukta形式替代 GSUB
akhn Akhand结扎替代 GSUB
rphf Reph表格替换 GSUB
PREF Rakaar形式替代 GSUB
blwf 低于基础的形式替代 GSUB
半 半形式替代 GSUB
瓦图 Vattu变种 GSUB
cjct 联合形式替换 GSUB
强制性表格形式:
PRES 前碱替代 GSUB
ABVS 基础替代 GSUB
blws 低于碱的替代 GSUB
PST的 后基础替代 GSUB
haln Halant形式替代 GSUB
酌情呈报表格:
CALT 上下文交替 GSUB
定位功能:
克恩 字距 GPOS
DIST 距离 GPOS
abvm 高于基准的标记定位 GPOS
blwm 低于基准的标记定位 GPOS
[GSUB =字形替换,GPOS =字形定位]
功能示例
本文档中描述和说明的许多注册功能都基于Microsoft OpenType字体Mangal(Mangal.ttf)。Mangal包含布局信息和字形,以支持所有支持的梵文脚本和语言系统所需的功能。获取Mangal字体的说明在本文档的附录中给出。
以下示例中的插图显示了应用该特定功能的结果。在重新排序后,必须编写功能以匹配字形序列。请注意,要素的输入上下文可能是已应用先前要素的结果。
本地化表格
功能标签:“locl”
此功能与OpenType语言系统标记结合使用,以触发查找,这些查找将选择特定于语言的排版约定所需的替换字形。’locl’不应与默认语言系统一起使用,而只能与其他语言系统标签一起使用。有关与梵文脚本相关的语言系统标签,请参阅本文档的附录。
基本的塑造形式
Nukta
功能标签:“nukt”
所述nukta改变前面的辅音或元音,发音的方式。最常见的nukta表单已被定义为Unicode中具有各自代码点的单独字符。所有辅音以及akhand形式都应该有相关的nukta形式。
注 - 除了使用替换之外,还可以通过使用’blwm’定位功能将nukta定位为基本字形上的基础标记来创建nukta形式
nukt特征的输入上下文总是由辅音的完整形式组成。将使用半特征替换半形式的nukta辅音。
Nukta特征应用替代Ka-nukta预先组成的字形:

Akhand
功能标签:“akhn”
akhand是必需的辅音连字,可能出现在音节的任何地方,并且可能涉及或可能不涉及基本字形。Akhand连字是最重要的,并且首先形成; 有些语言将它们包含在字母表中。在梵文中有2个Akhand连字。
akhand特征的输入上下文总是由辅音的完整形式组成。Akhand连字的一半形式将在半特征中稍后调用。
因为akhand特征在特征序列的早期应用并且应用于整个集群,所以它还可以用于创建某些形式,这些形式必须在特定上下文中优先于在后续特征应用期间创建的形式。
使用’akhn’功能,Ka + halant + Ssa被KaSsa结扎取代:

Ja + halant + Nya被JaNya Ligature取代:

Reph
功能标记:“rphf”
应用此功能会替换Reph字形。如果群集的第一个辅音由RA + Halant的完整形式的,这一功能替代品的结合标记形式Reph。此外,使用’abvm’GPOS功能调整Reph字形的位置。
Reph功能的输入上下文总是由Ra + Halant的完整形式组成。
Reph特征代替Ra的标记字形。在最终重新排序之后,在’abvm’GPOS功能中调整定位:

Reph功能应用了多个辅音。注意:reph被重新命令在第一主辅音上定位:

Rakaar
功能标记:“rkrf”
应用此特征可替代辅音 - rakaar (基底Ra)结扎线或akhand-rakaar结扎线。对于不与rakaar形成连字的辅音,’rkrf’特征也可用于替换预先组成的字形为辅音加rakaar。
注意:rakaar形式特征是专门针对那些可能出现辅音 - rakaar结扎的半形式的脚本所必需的。这包括梵文和古吉拉特语剧本。它不用于其他印度语脚本。
rakaar特征的输入上下文总是由完整形式的辅音+ halant + Ra组成。应使用半特征替换半形式的rakaar连字。
‘rkrf’功能用于替代Ka的rakaar形式:

还应创建’nukta’字形以及’akhand’连字的Rakaar变体:


对于不与rakaar形成连字的辅音(如Cha),’rkrf’特征也可用于替换预组成的字形,用于辅音加rakaar组合:


辅音的基础形式
功能标签:“blwf”
当rakaar与前一个辅音不形成连字时,此功能可替代以下基本形式的辅音,如梵语中的Ra(又名’rakaar’)。如果rakaar和前面的辅音形成一个结扎线,它应该在前一个特征’rkrf’中被替换。
Halant plus Ra(前面是一个不形成’rkrf’连字的辅音)替代了rakaar形式:

辅音的一半形式
功能标记:“half”
应用此特征可替代半形式 - 在基础前位置使用的辅音形式。具有半形式的辅音应列在“半”形状中。梵文具有明显形状的大部分辅音以及nukta和Akhand字形的半形式。如果辅音不具有半形的独特形状并且不形成任何结扎,则将显示具有明确的Virama(与halant形式相同的形状)。
注意 - 在半特征中列出辅音的结果(无论它是否具有真正的半形)将影响reph和预先设定的matra的重新排序(和定位)。请参阅本文档“简介”部分中的插图。
此功能适用于’main’辅音之前的所有辅音。
示例1 - 半特征替代Ka的一半形式:
13.7.3.古吉拉特语
13.7.4.古尔穆基
13.7.5.卡纳达语
13.7.6.马拉雅拉姆语
13.7.7.奥里亚语
13.7.8.泰米尔
13.7.9.泰卢固语
13.8.爪哇
13.9.高棉
13.10.老挝
13.11.缅甸
13.12.僧伽罗语
13.13.叙利亚
13.14.塔纳文
13.15.泰国
13.16.藏
14.ClearType字体清晰度
14.1.概览
ClearType是Microsoft开发的一种软件技术,可提高现有LCD(液晶显示器)上文本的可读性,例如笔记本电脑屏幕,掌上电脑屏幕和平板显示器。使用ClearType字体技术,计算机屏幕上的文字看起来几乎与打印在纸张上的文字一样清晰。
ClearType的工作原理是访问LCD屏幕每个像素中的各个垂直颜色条纹元素。在ClearType之前,计算机可以显示的最小细节级别是单个像素,但是在LCD监视器上运行ClearType时,我们现在可以显示文本的特征,其宽度小到像素的一小部分。额外的分辨率增加了文本显示中细微细节的清晰度,使其在较长时间内更容易阅读。
微软是如何开发ClearType的?
ClearType建立在致力于Microsoft高品质字体技术的传统之上。自九十年代初以来,微软一直在不断改进其显示和字体功能,包括进一步开发最初由Apple授权的TrueType字体技术。为了进一步改进微软的字体渲染技术,微软研究人员花了两年多的时间筛选了大量与排版和阅读心理相关的研究。他们的结论是阅读是模式识别的一种形式。只有当词汇识别是潜意识的任务时,人们才会沉浸在阅读中,而有意识的思维可以自由地阅读文本的意义。
所发现的是,当字体形状的形状和重量等印刷元素以及字母之间的间距共同作为易于识别的图案呈现单词时,单词识别只是潜意识的。考虑到这些发现,微软开始仔细研究如何在屏幕上呈现类型。
ClearType显示技术如何工作?
要了解ClearType的工作原理,首先要了解LCD屏幕与其他类型显示器的不同之处。大多数屏幕创建的图像由像素组成,放大时看起来像单个方块。LCD屏幕上的一个像素的等效物实际上由三个子像素组成:一个红色,一个绿色和一个蓝色(RGB)。总之,这些子像素三元组组合在一起被人眼看作单个像素。
如果我们要看一个像素,我们的眼睛会看到它如上图所示。但是,如果我们要放大图像,我们会看到每个像素实际上由三个独立的子像素组成。所以,如果我们在液晶屏上看到白色,我们真的看着红色,绿色和蓝色条纹。

这有助于提高数字显示的质量?
传统的计算机字体渲染假设每个像素都是“开”或“关”,显示为微小的黑色方块。字母在计算机屏幕上出现锯齿状,因为它们是由许多这些小方块或像素组成的。传统的灰度级假定每个像素没有内部结构,因此它使锯齿状边缘平滑但牺牲了边缘清晰度。ClearType知道LCD由彩色子像素组成。ClearType使用人类视觉系统的模型来选择子像素的亮度值。使用ClearType,计算机屏幕上的字母显得平滑,没有锯齿状,但边缘仍然清晰。
ClearType字体渲染
- 这就是小写’m’在原始字体轮廓中的外观。
- 这是在没有ClearType的情况下在屏幕上呈现时’m’的特写。注意’m’是如何在’m’的茎或’腿’中有硬的,锯齿状的阶梯或“锯齿”。
- 这是使用ClearType在屏幕上呈现时“m”的特写。注意’锯齿’是如何更加微妙,字母更流畅。

关于ClearType的常见问题
ClearType如何工作?
ClearType是一种子像素字体渲染形式,它使用像素的红 - 绿 - 蓝(RGB)组件分别绘制文本,而不是使用整个像素。当像素以这种方式使用时,水平分辨率理论上会增加300%。
LCD屏幕上的图像元素实际上由单独的水平方向的红色,绿色和蓝色子像素组成。例如,具有800×600像素的显示分辨率的LCD屏幕实际上具有2400×600个单独的子像素。人眼不能在如此小的尺度上区分颜色,因此这三种基色的组合可以模仿任何中间颜色。子像素字体渲染通过在子像素级别而不是在像素级别的抗锯齿来利用这一点。
我为什么要调整显示器?
没有两个屏幕完全相同,每个人都以略微不同的方式感知颜色。
如何判断我的笔记本电脑或平板显示器是否设置为原始分辨率?
要查看您的屏幕是否设置为其原始分辨率,请尝试查看以下眼睛测试图像。图像由许多垂直黑线组成。如果您在此图像中看到交替的白色条带垂直运行,则可能是以非原始分辨率运行。

我是一名设计师。如何在不安装Windows的情况下查看我的字体在ClearType下的呈现方式?
类型设计者可以许可我们的Visual TrueType(VTT)字体提示工具。更新了VTT,让设计师在ClearType下证明他们的字体。有关更多信息,请参阅VTT。
14.2.向后兼容性
支持ClearType的Microsoft Windows XP版本与我们的第二代ClearType技术相吻合。第一代产品在Windows XP发布前一年发布了Microsoft Reader for Windows和Microsoft PocketPC。第二代ClearType带来了更丰富的过滤算法,以及对各种现有TrueType™字体的更好支持。
(这种过滤的一个很好的描述可以在BétriseyC,Blinn JF,Dresevic B,Hill B,Hitchcock G,Keely B,et al.dis署edFiltering for Patterned Displays。Society for Information Display International Symposium Digest of Technical Papers 2000: 1-4。可从research.microsoft.com/apps/pubs/?id=68631下载。)
尽管在Microsoft Windows实现中TrueType光栅化器和ClearType过滤之间存在明显的体系结构区别,但这些组件之间存在显着的交互,因为TrueType和传统的抗锯齿技术之间也存在明显的相互作用。大部分交互涉及来自TrueType光栅化器的信息的准确性,特别是因为它与ClearType的非对称性质有关。
将ClearType添加到Microsoft Windows的主要设计目标之一是保持对现有字体的支持,而无需对这些字体进行修改。我们的初步调查显示,有三个关键问题会影响此兼容性问题。首先,在相对较少的情况下,较小尺寸的暗示指令将导致我们称之为“点爆炸” - 其中一个点将移动到像素网格中的随机远程位置。第二个问题是使用ClearType提示的字体与使用双级或字体平滑的先前渲染技术暗示的字体之间的提前宽度的差异。最后,第三个问题涉及提示,主要是“超级暗示”的字体,试图清理无关的像素,
第二代ClearType解决了这些向后兼容性问题。第一期“爆炸字形”是通过一种称为非对称超级采样的技术解决的,本文稍后将对此进行简要讨论。使用称为兼容宽度的技术解决了第二个不兼容宽度问题,这与本文中讨论的问题无关。
第三个问题和本白皮书的目标是描述Microsoft Windows TrueType光栅化器解释器中使用的技术,这些技术可以在Microsoft ClearType光栅化时改善提示字形的显示。
本白皮书的目标受众是一位字体设计师,他将校对在ClearType中显示的现有字体,或者为新字体或现有字体添加或更新指令或提示的字体设计者。预计读者对TrueType指令集及其命名有一定的了解。本文不针对字体光栅化器的实现者。
本文档中使用的一些术语的快速说明。Microsoft倾向于将TrueType引擎称为光栅化器,而Apple®使用术语缩放器。我将在本文档中使用光栅化术语。Apple通常也会将TrueType指令集应用为“指示字体”,而Microsoft通常会使用术语“提示字体”。这两个术语在本文档中的含义相同。此外,由于AppleMacintosh®TrueType实现与Microsoft TrueType实现之间存在差异,除非另有说明,否则所有引用都将指向Microsoft Windows TrueType光栅化器。
TrueType字体和ClearType
ClearType的Microsoft Windows实现以超标位图的形式获取TrueType光栅化器的输出,并应用过滤来创建alpha值的图像。TrueType光栅化器将TrueType字体作为输入,TrueType字体由轮廓轮廓和一组指令组成,以及描述要显示的大小,显示分辨率以及字符代码和缩放变换等其他杂项输入的相关信息。
TrueType解释器提供的指令旨在允许设计人员指定应如何呈现字符功能。由于指令集的丰富性,字体中提供的原始轮廓与TrueType光栅化器输出的位图之间可能存在显着的交互。这种交互级联并影响ClearType等渲染方法。
双层渲染
TrueType的原始设计对应于最常见的渲染形式是双层,或者背景的一个像素颜色和前景的一个像素颜色的时代。这通常称为黑白渲染。有几种常用的技术可用于应用指令来改善字形,特别是在较小的尺寸下,字形特征的大小接近于像素的大小。但是,大多数这些技术通常会应用某种程度的“delta”提示来改善字形。
Delta提示
Delta提示是一类提示技术,它们的名称来自TrueType DELTAC或DELTAP指令。在DELTAP的情况下,Delta指令沿着自由向量移动一个有限的量,或者在DELTAC的情况下将Delta的值调整为有限的量。关于delta指令的关键是它们只能以一组给定的大小工作。因为增量的距离是有限的并且难以在简单的大小范围内执行增量,所以通常具有可以在附加条件下移动点的TrueType函数。
Delta提示通常在校对字体提示质量的同时实现。如果在给定尺寸或尺寸范围内,当特定像素被认为是不正确时打开或关闭时,一个或多个点将被移动任意量以便产生正确的像素图案。由于相对较大的像素存在大量松弛,因此用于增量的值的准确性不高。
ClearType与TrueType指令的交互

TrueType解释器与ClearType非常兼容。微软在原始设计上与Apple Computer合作,包括对非方形像素的支持,这在TrueType首次发布时仍然在Microsoft Windows平台上很常见。ClearType的实现也是不对称的,导致非方形虚拟像素。由于LCD面板上的子像素排列由垂直取向的彩色元素组成,因此沿x轴的分辨率至少高三倍,而沿y轴的分辨率与没有ClearType解决方案的分辨率相同。实际上,TrueType的实际水平分辨率比y轴大16倍。
然而,这种不对称性在使用用于抗锯齿的传统过度缩放技术实现时会导致问题。典型问题涉及提示指令使用的自由度和项目向量。


在上面的例子中,小写“k”的对角线杆在左图像中设置有自由矢量和投影矢量,以典型的方式控制对角线杆的重量。在右图中,当’k’被一个大因子(例如沿x轴的十六个)非对称地过度缩放时,自由矢量和投影矢量变得几乎垂直。这导致了先前描述的“点爆炸”。为了解决这个问题,我们从传统的过度缩放转变为ClearType非对称超级采样。
ClearType非对称超级采样

对于ClearType,您可以想象一个网格,在x方向上每个像素具有十六个紧密间隔的网格线,在y方向上每个像素一个网格线。舍入指令(RTDG [],RDTG [],RUTG [],RTG [],RTHG []和ROFF [])现在适用于此虚拟网格,MDAP [R],MIAP [R],MDRP [… R]也是如此……]和ROUND […]。不循环的指令,例如SHP [],IP [],IUP [X],ALIGNRP [],ISECT []与没有ClearType的情况相同。类似地,在x方向上使用ClearType,SCVTCI []将CVT切入减少到其实际值的十六分之一,与通过四舍五入到网格的十六分之一获得的额外虚拟分辨率相匹配。SMD []将最小距离减小到其实际值的½,大致匹配ClearType获得的额外视觉分辨率。(理论上说,视觉增益在1.7到3倍之间,因此我们使用2来提高效率。)
这种方法的其他好处是MPPEM []和MD []指令测量有意义的PPEms(每Em的像素数,一种用于测量类型尺寸的设备相关方式)和距离,纵横比基本保持正方形,消除了投影矢量和自由度的问题矢量变得接近垂直。
但是,某些TrueType指令的这种行为是不对称的,所以当向量设置为y方向时,行为正好是双层舍入在实际像素网格而不是虚拟像素网格上的情况。
在所有这些示例中,我们指的是沿x方向(沿着x轴)的额外分辨率,但是从Microsoft Windows TrueType光栅化器的角度来看,我们将其称为“ClearType Direction”。“ClearType Direction”可以是x方向或y方向。如果是额外的子像素分辨率在y方向上的情况,则虚拟网格将改变方向,并且额外的精度将仅沿y方向发生。
向后兼容ClearType
通常,这种非对称超级采样技术非常有效,但是一些暗示用于双级渲染的传统字体可能会产生一些问题。具体来说,对于具有许多类似delta的指令和高度约束提示的双层“超级暗示”的字体最有可能受到ClearType的影响。
问题区域的一个示例涉及传统增量指令。通过沿x轴的额外分辨率,当自由矢量设置为ClearType方向时执行的delta指令具有更高精度的潜力,但之前使用双层渲染的使用相对邋to导致delta的极度夸大喜欢说明。
为了解决这种情况,我们需要在使用ClearType方向处理自由向量的指令时为ClearType创建向后兼容模式。以下是我们如何处理ClearType的向后兼容模式中的各种指令。应该注意的是,这些是本文档中提到的兼容性技术,将来可能会添加其他兼容性技术。
DELTAP和SHPIX
许多字体使用DELTAP或SHPIX来修复不幸的像素模式。尽管类似三角形指令的问题已出现在字体平滑抗锯齿中,但它们对于ClearType来说甚至更成问题。因此,跳过所有DELTAP,除了在非ClearType方向上的先前触摸点上的DELTAP和DELTAC。如果复合字形处于ClearType方向,以便对变音符号进行适当的居中和垂直定位,则也会跳过复合字形。内联增量有时用于调整水平笔划的位置,而CVT增量并不总是正确设置矢量,因此保持它们以避免在y方向上不校正权重(x中的权重由收紧来处理) CVT插件。)
(内联增量是在先前触摸的点上的IUP指令之前发生的增量。在IUP指令之后发生后IUP增量,而在IUP指令之前发生前IUP增量。)
在TrueType光栅化器中,我们假设如果我们正在执行SHPIX指令,则我们处于为一系列PPEM大小实现增量指令的函数的上下文中。如果在未触及的点上发生这样的增量,无论它是否在ClearType方向上,它都会在轮廓中产生凹痕。虽然对于双层,这意味着翻转一个或多个像素,但它会扭曲ClearType中的笔划。如果在触摸点上发生这样的增量,则它沿着整个轮廓移动,例如以不同方式放置笔划。如果在ClearType方向上发生这种情况,则会扭曲笔划的自然间距。因此,我们仅保留非ClearType方向上的触摸点的增量。
如前所述,对于复合材料,触摸/未触摸的规则不会以相同的方式应用。在执行相应组件的代码时,可能先前已触摸标记为未触摸的点。然而,应用于该点的后续SHPIX或可能的DELTAP将不会在轮廓中产生另一个凹痕,而是移动整个轮廓。这在双层中用于重新定位变音符号以确保基本字符和变音符号之间的一个像素的最小距离。因此,我们也在复合材料中保持增量。
一些增量实现为各种字体中的函数,并且它们在字体之间并不总是具有相同的功能编号。为了检测这种情况,我们在函数的开头寻找签名代码。我们正在寻找两种常见的签名来表示内联增量。
复制
MPPEM[]
GTEQ[]
SWAP[]
MPPEM[]
LTEQ[]
AND[]
IF[]
SHPIX[]
ELSE[]
POP[]
POP[]
EIF[]
ENDF[]
复制
MPPEM[]
EQ[]
IF[]
SHPIX[]
ELSE[]
POP[]
POP[]
EIF[]
ENDF[]
TypeMan Talk DiagEndCtrl
某些字体使用旧的TypeMan Talk DiagEndCtrl(对角线结束控制)命令,该命令又调用支持函数,该函数计算x方向的内联增量以消除“交叉”笔划的副作用。因此,作为异常的例外,不会跳过ClearType方向中的这些内联增量。
(TypeMan Talk是为TypeMan工具设计的高级TrueType提示语言。该工具最初由Type Solutions,Inc。的Sampo Kaasila编写,现为Bitstream®Inc。的全资子公司.Microsoft已更新TypeMan Talk语言Visual TrueType产品。)
RDTG
在某些字体中,点使用MDRP与RDTG对齐,前面是SPVTL(不是SDPVTL)。为了正确对齐,RDTG在这些情况下向下舍入到物理网格。
从历史上看,如果要对齐的点距离要对齐的线偏离1.5°或更多,则TypeMan Talk Align已转换为SPVTL,然后是RDTG和MDRP。这有一个主要问题:MDRP指令使用设置的投影矢量来测量未构造轮廓上的原始距离。这给了我们一个或多或少错误的“原始”距离,这取决于参考点已经移动了多远。(请注意,在对齐线对齐之前,参考点很可能在x和y中稍微移动。)随后,当MDRP移动点时,它再次使用相同的投影向量,但这次是在指示的轮廓上,以确定最终必须移动点的距离。幸运的是,这与RDTG一起使用,
然而,在ClearType方向上,这些错误的“原始”距离将向下舍入到最接近的像素的十六分之一,并且随之变得高度可见(距离略低于一个像素,这在bi中被舍入为零) -level,在ClearType中被忽略的距离太大。因此,我们必须在这里做一个例外。
PreProgram中的ROUND
在一些东亚字体中,数字是在预编程中计算和ROUND的,没有正确设置向量,这垂直错位了水平笔划(离网,导致辍学)。因此,所有舍入都是对物理网格进行的,而在预先计划中。
未接地的MIRP和CVT切入
在某些字体中,计算了分数笔划权重并在MIRP [… r …]中使用。虽然这在字体平滑中提供了一些额外的粒度,但它不必要地量化ClearType中的笔画权重,因为非圆形MIRP现在尊重CVT切入。
我们的目标是避免使用分段字体平滑目标CVT和绕过CVT切入的未接地MIRP(小r)。在这里,我们可以尊重CVT切入,即使四舍五入标志不需要这样做。我们假设上下文是一个已经调整用于字体平滑的笔画粗细,并且强制MIRP使用特定距离的唯一方法是“手动”舍入CVT然后关闭舍入标记,这是我们不想在ClearType中做什么,即强制执行不自然的重量。
总而言之,在ClearType打开的情况下,始终执行CVT切入。
MSIRP和CVT切入
某些字体预先计算了笔画粗细,然后使用MSIRP [。],既不涉及舍入也不涉及CVT插件。因此,MSIRP [。]现在尊重CVT切入点。
类似于之前讨论过的未解决的MIRP问题,对于这个问题,我们尊重CVT切入,以防在所涉及的父(参考)和子(目标)点之间存在非平凡的轮廓距离,在这种情况下我们假设context是一个笔画粗细,否则我们假设上下文是一个重音放置函数,在这种情况下我们像以前一样使用实际距离。
TypeMan Talk DStroke和IStroke
一些传统字体使用旧的TypeMan Talk DStroke和IStroke命令,这显然不适用于非方形宽高比。因此,虽然在各自的支持功能中,光栅化器假装是非方形的宽高比,即使实际上它不是。
我们需要使用TypeMan Talk DStroke和IStroke命令避免在(部分)自动提示字体中折叠笔划。这里我们假设FDEF函数64到66是TypeMan Talk DStroke和IStroke命令的支持函数,这可能使笔画在ClearType中崩溃。为了确定我们是否真的遇到了这些函数的上下文,我们只查看前几个字节,因为这些函数的确切实现可能会随着时间的推移而改变,但希望是前导码(查看存储位置22)没有。该功能的签名是:
复制
#PUSH 22
RS[]
IF[]
绕过这些函数的最简单方法是将存储位置22标记为零,表示不使用DStroke或IStroke,否则我们将不得不清理堆栈。DStroke不起作用的原因如下。DStroke将成对的点带到相同的y(或x),MIRP [… r …]浮点,然后将它移回旧的y(或x。)现在我们在MIRP上重新解释没有回合, CVT切入实际上会切入,原始距离可以应用,只是在将点带到相同的y(或x)之前采用原始距离,这意味着它可能会偏离。结果,对角行程重量(以x为单位)开始在很大程度上取决于所涉及的控制点的距离(y),这不是我们想要的。对于非方形宽高比而言,DStroke不是NOP,
间距函数
类似于DStroke和IStroke,有一些间距函数也不适用于非方形纵横比。因此,在这些情况下,光栅化器假装为非方形纵横比。
为了避免膨胀的字符,我们避免使用一些特定的间距函数。我们假设函数0,1,2,4,7和8是这个间隔代码的支持函数,它可能会挤压字符或同时向左或向右或向两个方向拉动它们。这与使用暮光区域的其他事情有关。间距算法意味着要超过一定的大小,例如30 PPEm,因此我们可能会认为,在额外的视觉分辨率下,我们应该以相当小的PPEm大小或完全关闭它。存储位置24用于绕过该功能。该功能的签名是以下之一:
复制
SVTCA[X]
#PUSH 24
RS[]
IF[]
复制
SVTCA[X]
RTG[]
#PUSH 24
RS[]
IF[]
对角线笔划功能
某些字体使用斜线笔划方法,使一些斜体字体在ClearType下直立或后倾。因此,解释器识别相应的支持功能并假装替代的CVT切入值。
我们假设函数58处理对角线笔划。如果签名与以下代码匹配,我们将更改CVT切入值。
复制
DUP[]
DUP[]
#PUSH[], 1
ADD[]
GC[N]
#PUSH[], 64
SWAP[]
WS[]
TypeMan Talk VacuFormRound
有些字体使用了旧的TypeMan Talk VacuFormRound命令,该命令可能适用于某些双级像素模式,但总是在ClearType中创建菱形。因此,解释器试图跳过所有相关代码。
我们期望函数0包含签名:
复制
RCVT[]
SWAP[]
GC[N]
ADD[]
DUP[]
#PUSH, 38
通过此签名,我们确认IUP [X]和IUP [Y]已经执行。存储位置8将返回零以停止大多数VacuFormRounds。在类型2 VacuFormRound的情况下,MD指令在VacuFormRound中,将略微增加投影矢量的最小可能量(1),以抛出类型2 VacuForms,其被锁定距离恰好为1个像素。
使用带有ClearType的TrueType指令
如前所述,ClearType光栅化的精度可以很自然地与TrueType解释器集成。当使用ClearType暗示字体时,可以证明它们可以使用ClearType和其他光栅化技术验证提示是否正常工作。TrueType指令集中还有其他支持,可以帮助字体优化ClearType,并帮助防止其他类型的问题,正如我们讨论的向后兼容性。
获取信息
除其他外,GETINFO []指令可用于查询当前字形使用的光栅化类型。通过设置一个或多个选择器位来使用该指令,并且堆栈上的返回值是基于设置了哪个选择器位的位或位组。这些选择器位和返回值位完全记录在TrueType指令规范中,但值得描述ClearType相关值。
ClearType(选择器位6,返回位13)
通过设置选择器位6来请求该标志。如果设置了返回位13,则表示将使用ClearType渲染呈现此大小的字形。如果清除了返回位13,则只能假设它不是正在呈现的ClearType; 它并不意味着正在执行哪种类型的渲染。
兼容宽度ClearType(选择器位7,返回位14)
通过设置选择器位7来请求该标志。如果设置了返回位14,则表示将在提示后调整该字体大小的字形,以便返回与双级渲染完全相同的提前宽度。如果未设置返回位14,则高级宽度将作为整数返回到最近的像素或舍入到最接近的像素的十六分之一。前者称为自然宽度ClearType,后者称为子像素定位ClearType。
对称平滑ClearType(选择器位8,返回位15)
在较大尺寸下,ClearType通过对称渲染解决方案表现更好。标准ClearType由某些图形系统专用,在其他图形系统中使用较低尺寸,使用6×1滤波技术 - 沿x轴分辨率为6倍,沿y轴没有分辨率变化。使用对称平滑的ClearType,使用6×5滤波技术 - 沿x轴的分辨率为6倍,沿y轴的分辨率为5倍。此后一种解决方案往往会在较小的尺寸下产生更多模糊,但可防止较大尺寸的锯齿。
通过设置选择器位8来请求该标志。如果设置了返回位15,则表示对此字体大小启用了对称平滑的ClearType。如果未设置返回位15,则不启用对称平滑的ClearType,并且正在使用6×1滤波技术。
BGR ClearType(选择器位9,返回位16)
ClearType的主要环境是与液晶显示器(LCD)类似的显示器,这些显示器实现带有垂直条纹的颜色。在大多数情况下,这些显示器具有红色滤色器,然后是绿色,然后是从左到右的蓝色。在某些情况下,可以颠倒这种排序。这可能是由于显示过滤器的创建或显示文本在屏幕上反转。
可以通过设置选择器位9来请求BGR状态。如果设置了返回位16,则表示ClearType正在以BGR(蓝色,绿色,红色)顺序处理LCD条带。如果清楚,则ClearType正在以RGB(红色,蓝色,绿色)顺序处理LCD条纹。
使用ClearType的GETINFO用法
GETINFO指令返回的ClearType信息对于希望与ClearType兼容的现有字体和需要对ClearType和其他渲染方法使用不同提示技术的新字体都很有用。
在使用带有ClearType的GETINFO指令之前,应该查询光栅化器版本,也可以通过设置选择器位1并检查返回结果的位0到7(第一个字节)中的结果来完成GETINFO指令。如果版本号为35或更高,则可以使用ClearType选择器。如果版本号为37或更大,则可以使用上面讨论的其余ClearType选择器。
如果GETINFO中的信息经常在指令中使用,则将标志的状态保存在存储位置是很常见的。
对于现有双级提示需要兼容性的指令,对ClearType有影响的代码(例如delta类指令或函数)可以被条件IF包围,只有在未启用ClearType时才会执行。同样,可以改进ClearType呈现的附加指令也可以被条件IF包围,该条件IF仅在启用ClearType时执行。这些技术可用于CVT程序(预编程)和字形程序,如果某些提示技术在函数中实现,则条件代码可以在该函数中实现。
INSTCTRL
具有选择器标志3和值TRUE(4)的INSTCTRL指令应该用于已经验证在ClearType环境中正常工作的新字体和现有指令字体。通常,此指令将放置在CVT程序的开头,堆栈中的选择器为3,值为4。虽然与INSTCTRL相关的其他选择器标志仅限于CVT程序,但选择器3可用于CVT程序或字形程序。
(这与当前的OpenType规范相反,但设计在此选择器中。为了确保一个字形不会更改另一个字形的设置,如果指令选择器设置在字形的开头,则应清除它在字形的末尾。如果指令选择器专门用于CVT程序,则不需要这样做。)
如果在CVT程序中使用带有选择器标志2且值为TRUE(2)的INSTRCTRL,它将禁用选择器标志3的效果,并且每个字形必须独立地控制它。
正如本文档的大部分内容所述,已经做了大量工作以允许ClearType使用现有字体。在少数情况下,必须修改现有指令行为(如TrueType指令规范中所述)以保持向后兼容性。当使用INSTCTRL ClearType指令时,它返回对TrueType指令规范中描述的行为的指令。
结论已经采取了大量措施使ClearType在Microsoft Windows中实现最佳性能。字体铰链的持续支持是必要的,以便字体在许多类型的显示器和许多类型的渲染环境中将继续是最易读和易读的。本文描述了用于使现有的,未修改的字体与ClearType一起正常工作的技术,但更重要的是,它为开发人员提供了有关如何使用INSTCTRL指令确保TrueType解释器对字体的一致行为的新字体的信息。
Microsoft建议具有指示字形代码的新字体在CVT程序开头包含以下序列:
复制
#PUSH 4,3
INSTCTRL[]
使用此代码,一如既往,应使用ClearType,传统字体平滑和双层渲染来验证质量保证。
14.3.ClearType字体集合

ClearType字体集是设计师和工程师在尊重,灵活性和好奇心方面成功合作的结果。ClearType字体从一开始就被认为是技术与最佳设计专业技术的结合!这通过使用子像素渲染技术改善了某些类型的监视器上的文本外观。
下面列出的ClearType字体集合首次随Windows Vista和Office 2007一起提供,从此成为Windows的一部分。
康斯坦丁
枕梁
宋体
坎布里亚
Candara
索拉
现在阅读:

英语:现在阅读:Microsoft ClearType字体集 - .pdf - 15,896KB 下载
日语:现在阅读:Microsoft ClearType字体集 - .pdf - 4,716KB 下载
2003年,微软召集了雷德蒙德的一个团队进行头脑风暴,了解ClearType,并启动一个新项目; 创建一组专门设计用于ClearType的新字体。我们很高兴提供这本书的下载,讲述了这些字体是如何创建的。
坎布里亚数学:

Cambria Math - .pdf - 2,144KB 下载
本书侧重于数学排版的Cambria Math字体实现,而不是数学排版引擎软件,旨在作为字体用户的数学家和科学家的介绍,以及对理解一般原理感兴趣的设计师和字体开发人员Microsoft的数学排版方法和Cambria Math字体的功能。
类型样品:
类型样本 - .pdf - 3,507KB 下载
示例布局:
Constantia - .pdf - 216KB 下载
Corbel - .pdf - 108KB 下载
Calibri - .pdf - 242KB 下载
Cambria - .pdf - 225KB 下载
Candara - .pdf - 108KB 下载
Consolas - .pdf - 65KB 下载
15.传统的字体技术
15.1.TrueType字体
15.1.1.概览
TrueType是由Apple Computer设计的数字字体技术,现在Apple和Microsoft都在其操作系统中使用。微软已经以数百种不同的风格分发了数百万种高质量的TrueType字体,包括它们的产品系列和流行的TrueType字体包。
TrueType字体在计算机屏幕和打印机上提供最高质量,并包含一系列易于使用的功能。
我们的TrueType文档历史中简要讨论了TrueType开发的历史,它解释了该技术的各种形式,以及TrueType存在的一些原因。
我需要什么才能使用TrueType?
TrueType字体技术由两个部分组成:TrueType字体自身,有数千种不同的样式,可以单独购买,也可以从字体制造商那里购买; 和TrueType光栅化器,是Apple Macintosh系列计算机上System 7.x内置的软件,也是微软Windows系列操作系统的软件。
两种组件 - 字体和光栅化器,都是在计算机系统上显示和打印TrueType字体所必需的。它是TrueType字体,TrueType光栅化器和软件程序之间的交互,其中使用TrueType字体确定字体中字体的外观。
我在哪里可以获得TrueType?
如果您使用的是Mac或Windows机器,那么您可能已经使用了TrueType光栅化器以及Apple和Microsoft包含的基本操作系统的TrueType字体。
如果您使用的是Apple Macintosh或基于Windows的计算机,则只需购买要使用的字体即可。
TrueType光栅化器
TrueType字体技术由两部分组成:字体本身的描述(TrueType字体文件),以及读取字体描述并生成位图(TrueType光栅化器)的程序。
TrueType光栅化器是一种计算机程序,通常作为操作系统或打印机控制软件的一部分。考虑到这一点,它已经用一个定义良好的客户端界面和便携式C中的干净模块化结构编写。
TrueType Rasterizer的工作是为屏幕和打印机(也称为光栅设备)生成字符位图。它通过执行以下任务来完成此任务:
从TrueType字体文件中读取字符的轮廓描述(线条和样条线)。
将字符的大纲描述缩放到请求的大小和设备分辨率。
将轮廓描述调整为像素网格(基于提示信息)。
用像素填充调整后的轮廓(扫描转换)。
什么是TrueType字体?
数字字体不仅包含与给定字母或脚本相关联的字符。TrueType字体文件包含TrueType光栅化器和操作系统软件使用的许多不同类型的信息,以确保字符显示在计算机屏幕上或完全按照字体设计者的预期打印出来。TrueType字体中的所有信息都排列在一系列表格中。有关这些表的技术信息,您可以看到我们的TrueType规范。
除了每个字符的形状之外,TrueType字体还包括有关字符应如何在文本块中垂直和水平间隔的信息,字符映射细节(控制字体中包含的各种字符以及访问它们所需的击键) ),还有更多。字体还包括制造商的详细信息,例如版权,名称和许可权限。
字符描述
TrueType字体包含的一个更明显的事情是每个字符的形状。包含在TrueType字体中的每个字母形式都存储为轮廓,或者更准确地说,作为从一系列点构造的角色的数学描述。因此,TrueType被称为轮廓字体格式。
将字符存储为轮廓的最大优点可能是每个字符只需要一个轮廓来生成您需要的所有字符大小。单个轮廓可以扩展到大范围的不同尺寸,其中一些如下所示。这使得相同的角色能够在不同分辨率的监视器上显示,并且可以以大量不同的尺寸打印出来。缩放角色轮廓是一种简单的数学运算,实际上是其他变换,例如旋转和反射。

用户实际上从未看到存储在轮廓字体中的轮廓,因为在屏幕或打印机上显示字符之前,必须通过TrueType光栅化器生成位图。这是因为屏幕显示和打印机都使用点图案来表示图像(充分放大任何屏幕图像或打印输出,你会注意到像素图案)。TrueType字体中包含的字符轮廓按比例缩放到请求的大小,并通过打开轮廓所包含的像素转换为位图。此过程称为扫描转换或光栅化。
字符集和映射
TrueType字体还包含字符映射 - 有关字体中包含的字符的类型和数量的信息,以及有关如何从键盘访问这些字符的详细信息。
PC和Mac上的TrueType字体
尽管TrueType字体可以在Macintosh和Windows平台上使用,但每种操作系统处理字体的方式略有不同,这导致供应商为每个平台生成单独的字体版本。一些供应商将为您提供Mac和Windows格式的TrueType文件,而其他供应商可能会将它们视为不同的产品。有关具体细节请联系各个供应商
由于两个平台上使用的文件系统不同,因此出现了这种奇怪现象。信息可以包含在字体中,以确定字体是否可以在两种系统上使用,或者是否使用其中一种。
在Macintosh上,TrueType字体文件有时称为SFNT,在Windows下称为.TTF。字体中包含的信息是相同的,并且进行必要的调整以允许字体在两个平台上运行是一项相对简单的任务。
15.1.2.历史
TrueType数字字体格式最初由Apple Computer,Inc。设计。它是一种避免向其他字体技术的所有者支付每字体版税的方法,并且是Adobe的Type 1格式的一些技术限制的解决方案。
最初的代码名为“Bass”(因为这些是可缩放的字体,你可以缩放鱼),后来的“Royal”,TrueType格式被设计为高效的存储和处理,并且可扩展。它还可以使用已经在字体行业中使用的提示方法以及开发新的提示技术,从而可以轻松地将现有字体转换为TrueType格式。TrueType的提示实现的这种程度的灵活性使其在设计用于在屏幕上显示的字符时非常强大。微软也一直在寻找解决类似问题的大纲格式,并且Apple同意将TrueType许可给微软。
Apple于1991年5月在其Macintosh操作系统System 7中提供了完整的TrueType支持。其最近的开发工作包括TrueType GX,它将TrueType格式扩展为MacOS新图形架构QuickDraw GX的一部分。TrueType GX包含一些仅限Apple的字体格式扩展,支持样式变体和线条布局管理器。
Microsoft于1992年4月首次在Windows 3.1中包含TrueType。不久之后,Microsoft开始重写TrueType光栅化器以提高其效率和性能并消除一些错误(同时保持与早期版本的兼容性)。新的TrueType光栅化器1.5版首先在Windows NT 3.1中提供。此后进行了一些小修改,Windows 95和NT 3.51中的版本是1.66版本。新功能包括增强功能,如字体平滑(或更技术上,灰度光栅化)。
Microsoft正在进行的开发工作包括TrueType Open规范。TrueType Open适用于任何Microsoft平台和Apple Macintosh机器,并包含允许多语言排版和精细排版控制的功能。
TrueType Open格式的下一个扩展是TrueType Open版本2,与Adobe Systems合作生成一种能够包含TrueType(和Open)和PostScript数据的格式。
15.2.非标准字体编码
15.2.1.遗留阿拉伯字体编码
阿拉伯语有一类遗留字体,它们使用Windows中没有充分记录的机制和传统的整形实现。本主题提供有关此类字体的一些详细信息。
这些字体可追溯到20世纪90年代 这些是TrueType字体,因为它们是.ttf文件,通常遵循TrueType规范。但是,它们使用未在TrueType或OpenType规范中定义的未记录的详细信息,并且不符合如何为阿拉伯语实现Unicode字体的当前规范。
字体编码和字符集声明
这些字体使用Windows符号编码 - 也就是说,它们具有用于平台ID 3的cmap子表,编码ID为0.本身,Windows符号编码不包含可互操作的字符语义,而是隐含字体特定的语义。正如预期的那样,cmap子表中没有建立阿拉伯字符语义。相反,这是使用OS / 2表中的特殊值来完成的,这些值未在TrueType或OpenType规范中记录。
请注意,其中一些字体还可能包含其他平台和编码的cmap子表。但是,不应该使用它们。这些字体是在使用单字节编码的时代创建的,而这些替代的cmap子表很可能是对已声明编码的重新定义。例如,Royal Arabic字体包含Mac Roman cmap子表,但映射的字形与Mac Roman字符集不匹配。
这些字体包括版本0 OS / 2表。版本0包括fsSelection字段,该字段是uint16值,各种位定义为标志。仅定义了一组有限的位 - 位0到6 - ; 其余位记录为保留位并设置为0.但是,在此类字体中,值在fsSelection字段的保留的高位字中设置。这些非标准化值是声明字符语义的方式。
在fsSelection字段的高位字中设置的值不是位标志,否则用于fsSelection字段。相反,高位字节设置为以下常量值之一:
C
复制
#define ARABIC_CHARSET_SIMPLIFIED 178
#define ARABIC_CHARSET_TRADITIONAL 179
第一个对应于gdi32.h中定义的ARABIC_CHARSET常量,用于LOGFONT结构的lfCharset成员。第二种用于某些字体,但未在gdi32.h中定义。
注意:Windows GDI中的CHARSET值与代码页之间存在对应关系,代码页在OS / 2表(版本1及更高版本)的ulCodePageRange字段中引用。但是,ulCodePageRange字段用于指示字体中支持的逻辑字符集,但不说明字体中使用的实际字符编码。对于此类字体,ulCodePageRange字段不相关。
注意:已知类似地使用fsSelection字段的高位字也用于传统的希伯来语和泰语字体。
字体编码的性质
就Unicode字符而言,此类字体支持的阿拉伯字符是U + 0620到U + 065F范围内的子集。
这些传统字体编码中的每一种都是表示形式编码。也就是说,所有表示形式的字形都由cmap表中的某些字符代码直接映射。演示表格将包括阿拉伯字母的基本上下文形状:孤立,初始,中间,最终。此外,还有其他一些连字的表现形式; 这些没有在这里详细记录。
注意:字体本身没有任何内容可以确定可能使用这些字体显示的文本数据的编码顺序。当然,这些字体可能与一些支持以视觉而非逻辑顺序编码的阿拉伯语内容的遗留应用程序结合使用。
如上所述,字体使用Windows Symbol cmap子表。在大多数使用Windows符号编码的字体中,字符索引值的范围为0xF020到0xF0FF。(在传统的单字节应用程序中,这些应用程序将映射到代码点范围0x20到0xFF。)但是,在这类字体中,假设两个编码声明的范围不同:
ARABIC_CHARSET_SIMPLIFIED:0xF100到0xF1FF
ARABIC_CHARSET_TRADITIONAL:0xF200到0xF2FF
这些范围反映在字体的OS / 2表的usFirstCharIndex和usLastCharIndex字段中。
Unicode到传统字体映射
下面提供了代码片段,用于提供从Unicode字符到传统字体编码中的代码点的映射。如上所述,字体编码是表示形式编码。因此,这些是Unicode字符的上下文形式的映射。映射在逻辑上假设每个阿拉伯字母有四种不同的上下文形状,但在某些情况下,相同的表示形式代码点被映射到多个上下文 - 例如,隔离和初始上下文的一个遗留表示形式代码点。
在这些代码片段中假设以下常量:
C
复制
#define NUM_ARABIC_LETTER_TABLES 0x0004
#define U_ARABIC_SCRIPT_COUNT 0x40
旧版简化阿拉伯语映射
以下提供了ARABIC_CHARSET_SIMPLIFIED的映射:
C
复制
/****
S I M P L I F I E D A R A B I C
*****/
// index for invalid glyph is 0x00
// These are based on starting index 0xF100
const USHORT cpOldTTFSimpArabicShapes[NUM_ARABIC_LETTER_TABLES][U_ARABIC_SCRIPT_COUNT] =
{
// Isolate Shapes
{
0x00 , 0xad , 0x45 , 0x43 , 0xbb , 0x47 , 0xba , 0x41 , // 0x620
0x4a , 0xa9 , 0x4c , 0x4e , 0x51 , 0x54 , 0x57 , 0x58,
0x59 , 0x5a , 0x60 , 0x62 , 0x64 , 0x66 , 0x68 , 0x69 , // 0x630
0x6a , 0x6e , 0x72 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0x75 , 0x78 , 0x7a , 0x7c , 0x7e , 0xe1 , 0xa4 , // 0x640
0xa5 , 0xac , 0xa8 , 0xc7 , 0xc8 , 0xcb , 0xc4 , 0xc5,
0xca , 0xc9 , 0xc6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,},
// Initial shapes
{
0x00 , 0xad , 0x45 , 0x43 , 0xbb , 0x47 , 0xae , 0x41 , // 0x620
0x49 , 0xa9 , 0x4b , 0x4d , 0x4f , 0x52 , 0x55 , 0x58,
0x59 , 0x5a , 0x60 , 0x61 , 0x63 , 0x65 , 0x67 , 0x69 , // 0x630
0x6a , 0x6b , 0x6f , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0x73 , 0x76 , 0x79 , 0x7b , 0x7d , 0x7f , 0xa1 , // 0x640
0xa5 , 0xac , 0xa6 , 0xc7 , 0xc8 , 0xcb , 0xc4 , 0xc5,
0xca , 0xc9 , 0xc6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,},
// Medial shapes
{
0x00 , 0xad , 0x46 , 0x44 , 0xbb , 0x48 , 0xae , 0x42 , // 0x620
0x49 , 0xa9 , 0x4b , 0x4d , 0x4f , 0x52 , 0x55 , 0x58,
0x59 , 0x5a , 0x60 , 0x61 , 0x63 , 0x65 , 0x67 , 0x69 , // 0x630
0x6a , 0x6c , 0x70 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0x74 , 0x77 , 0x79 , 0x7b , 0x7d , 0x7f , 0xa2 , // 0x640
0xa5 , 0xac , 0xa6 , 0xc7 , 0xc8 , 0xcb , 0xc4 , 0xc5,
0xca , 0xc9 , 0xc6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,},
// Final shapes
{
0x00 , 0xad , 0x46 , 0x44 , 0xbb , 0x48 , 0xaf , 0x42 , // 0x620
0x4a , 0xaa , 0x4c , 0x4e , 0x50 , 0x53 , 0x56 , 0x58,
0x59 , 0x5a , 0x60 , 0x62 , 0x64 , 0x66 , 0x68 , 0x69 , // 0x630
0x6a , 0x6d , 0x71 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0x75 , 0x78 , 0x7a , 0x7c , 0x7e , 0xe1 , 0xa3 , // 0x640
0xa5 , 0xab , 0xa7 , 0xc7 , 0xc8 , 0xcb , 0xc4 , 0xc5,
0xca , 0xc9 , 0xc6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00, },
};
遗产传统阿拉伯语映射
以下提供了ARABIC_CHARSET_TRADITIONAL的映射:
CS
复制
/****
T R A D I T I O N A L A R A B I C
*****/
// index invalid glyph is 0x00
// These are based on starting index 0xF200
const USHORT cpOldTTFTradArabicShapes[NUM_ARABIC_LETTER_TABLES][U_ARABIC_SCRIPT_COUNT] =
{
// Isolate shapes
{
0x00 , 0xd5 , 0x45 , 0x43 , 0xda , 0x47 , 0xd9 , 0x41 , // 0x620
0x4c , 0xd1 , 0x50 , 0x54 , 0x58 , 0x60 , 0x64 , 0x65,
0x67 , 0x69 , 0x6b , 0x70 , 0x74 , 0x78 , 0x7e , 0xa2 , // 0x630
0xa3 , 0xaa , 0xae , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0xb2 , 0xb6 , 0xba , 0xbe , 0xc2 , 0xc6 , 0xca , // 0x640
0xcb , 0xd4 , 0xd0 , 0xe7 , 0xe8 , 0xeb , 0xe4 , 0xe5,
0xea , 0xe9 , 0xe6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,},
// Initial shapes
{
0x00 , 0xd5 , 0x45 , 0x43 , 0xda , 0x47 , 0xd6 , 0x41 , // 0x620
0x49 , 0xd1 , 0x4d , 0x51 , 0x55 , 0x59 , 0x61 , 0x65,
0x67 , 0x69 , 0x6b , 0x6d , 0x71 , 0x75 , 0x79 , 0x7f , // 0x630
0xa3 , 0xa7 , 0xab , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0xaf , 0xb3 , 0xb7 , 0xbb , 0xbf , 0xc3 , 0xc7 , // 0x640
0xcb , 0xd4 , 0xcd , 0xe7 , 0xe8 , 0xeb , 0xe4 , 0xe5,
0xea , 0xe9 , 0xe6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,},
// Medial shapes
{
0x00 , 0xd5 , 0x46 , 0x44 , 0xdb , 0x48 , 0xd7 , 0x42 , // 0x620
0x4a , 0xd1 , 0x4e , 0x52 , 0x56 , 0x5a , 0x62 , 0x66,
0x68 , 0x6a , 0x6c , 0x6e , 0x72 , 0x76 , 0x7a , 0xf1 , // 0x630
0xa4 , 0xa8 , 0xac , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0xb0 , 0xb4 , 0xb8 , 0xbc , 0xc0 , 0xc4 , 0xc8 , // 0x640
0xcc , 0xd4 , 0xce , 0xe7 , 0xe8 , 0xeb , 0xe4 , 0xe5,
0xea , 0xe9 , 0xe6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,},
// Final shapes
{
0x00 , 0xd5 , 0x46 , 0x44 , 0xdb , 0x48 , 0xd8 , 0x42 , // 0x620
0x4b , 0xd2 , 0x4f , 0x53 , 0x57 , 0x5c , 0x63 , 0x66,
0x68 , 0x6a , 0x6c , 0x6f , 0x73 , 0x77 , 0x7c , 0xa1 , // 0x630
0xa5 , 0xa9 , 0xad , 0x00 , 0x00 , 0x00 , 0x00 , 0x00,
0x5f , 0xb1 , 0xb5 , 0xb9 , 0xbd , 0xc1 , 0xc5 , 0xc9 , // 0x640
0xcc , 0xd3 , 0xcf , 0xe7 , 0xe8 , 0xeb , 0xe4 , 0xe5,
0xea , 0xe9 , 0xe6 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , // 0x650
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00, },
};
15.2.2.草书的建议
具有连接字符的字体(如阿拉伯语字体)的问题是需要最小尺寸的重叠。这种重叠是必要的,以避免舍入导致一列像素不呈现的问题,在连接中留下小的间隙。字符之间的这种中断可以在下面的图1中看到。

本文档的目的是为字体供应商推荐制定避免此问题的字体的指南。
雕文设计
在设计连接字形以避免由于舍入导致的像素丢失时,当将2048 em square(推荐值)用于TrueType轮廓时,必须提供至少70字体单位重叠。在所有PPEM尺寸的光栅化过程期间,70个单位的量将允许至少保持字符的宽度。
为了使重叠最有效,重叠应该完全在字形的左侧或字形的右侧。我的建议是重叠将在字形的尾端。因此,对于草书英文字体,重叠将在右侧(参见图2)。从右到左语言的重叠将位于左侧(参见图3)。


将重叠分割到字体的两侧并不能正确解决发生舍入的所有情况,因为每一侧可能向下舍入并导致一列像素无法呈现。
15.2.3.修复光栅化问题
从轮廓到像素
字形的轮廓是使用直线和曲线(Béziers)对字形形状的数学描述。
曲线的特定选择是无关紧要的。只要我们有控制点,二次和三次Bézier曲线都可以。需要控制点来将字形缩放到所需的类型大小和分辨率(或简称为ppem大小)。
屏幕是黑色和白色点(像素)的规则间隔网格。
栅格化字形本质上意味着打开缩放轮廓内的所有像素。
天真地这样做会导致上述光栅悲剧:分离的拱门,不平等的茎,缺少衬线等。
什么地方出了错?
控制点坐标是整数。没有小数位或小数。
在Truetype中,设计网格(em-square)通常为2048乘2048字体单位。
在类型1中,设计网格是1000×1000字体单位。类型1允许小数位。
但是:1000个单位中的253.7与10000中的2537相同。因此,为了参数,没有小数位。
像素网格也是整数,也没有分数像素。例如,在12 pt和96 dpi时,em-square是16 x 16像素。如果像素网格不是整数,我们只需将其舍入。在屏幕上,无论如何我们不能从12分12.2分。
缩放字体
缩放轮廓要做的就是将所有坐标乘以16/2048,即首先将它们乘以16,然后将它们除以2048。
唯一能够(并且会)出错的是分裂。大多数整数不分裂。因此,计算机将不得不舍入一些数字。这与决定像素相同。由于四舍五入,“事情不再累加。” 总是必须让路。有些东西(距离,比例)一定不能让路。
请注意,如果我们使用小数坐标和/或允许小数点大小,计算机仍然必须决定像素。最后,分数的问题是相同的,只是更难以理解。
暗示,网格拟合,指导:
必须告诉计算机,哪些事情一定不能让位。这就是俗称暗示。更确切地说,它被称为网格拟合或指示,因为我们给计算机提供了如何在打开像素之前将轮廓拟合到网格的精确指令。提示的目的是……
保持位置和距离的规律性
保持近乎规则的位置和距离
保留比例
控制数字化外观
不能吃蛋糕也吃它:
我们不能将茎的左右边缘都放在正确的位置并且具有正确的茎重(在像素方面是正确的)。我们必须做出权衡,选择以下其中一项:
leftEdge + stemWeight = rightEdge
rightEdge - stemWeight = leftEdge
rightEdge - leftEdge = stemWeight
权衡是右边的变量。他们将不得不让路。
控制点丰富多彩
在TrueType中,没有边和茎的概念。只有控制点。
有曲线上的点(![] [4])和曲线外点(![] [5])。曲线上和曲线外的点都称为控制点。
VTT的“显示更少的点”隐藏了曲线外点。
我们必须选择我们想要定义边缘的控制点(![] [7])。
x和y方向

一对控制点定义一对边缘,这些边缘又限定了一个杆。
这些控制点之间距离的“水平部分”(= x方向上的距离,或dx)定义了垂直干的重量
这些控制点之间距离的“垂直部分”(= y方向上的距离,或dy)定义了水平主干的重量
VTT的“测量工具”显示了x和y方向两种距离的测量值
垂直是x,水平是y?
这可能有点令人困惑:
对于垂直杆,相关距离为x(即水平)。我们沿x方向移动点以使其适合网格。
对于水平杆,相关距离为y(即垂直)。我们在y方向上移动点以使其适合网格。
“触动”点将“相应地”跟随

假设我们在y方向上对上述点进行网格拟合(“触摸”)以控制水平主干。那么其他(“未触动”)点呢?

它们遵循“相应地”,因为在x和y方向上的一对IUP指令(“插值 - 未触摸点”)VTT在其他指令的末尾添加。
始终触及“极端”:
如果我们不“触摸”所有极端,IUP不能插入“触摸”点对之间的所有“未触摸”点,只能将它们与“触摸”点一起移动。
这可能不是我们想要的。但是,当我们连接“网格拟合”时,我们仍然可以看到这个中间阶段。根据需要将其关闭。
保持常规距离的链接:
因此,杆的左右边缘只是一对控制点。如果我们移动这些点,其他点将“相应地”。现在,让我们优先考虑左边缘和茎重量。
这就是链接工具的用途。它定义了以下关系:
一个父点(在我们开始的边缘)和
一个孩子点(在权衡的边缘必须让路)。
跨越茎干的连接保留了茎的重量。
穿过衬线的连接保留了衬线的重量。
跨越黑色距离的链接保持一个像素的最小距离。
复制
bottomOfSerif + serifWeight = topOfSerif
链接拱门(以及更多):
防止拱门“辍学”。
大纲的麻烦:
注意左侧杆上x方向的两个链接。我们可以看到一个干,但计算机不能。它只是看到一堆无关的控制点。我们必须通过链接或移位来关联这些控制点,即使它们位于干的同一边缘。
但为什么有两个链接,而不是四个?如果它们之间没有间隙,IUP [X]会照顾其他人。
将其与类型1中的vstem或hstem提示进行比较。
真的没有干,只是控制点:
“克罗地亚人”有多少链接?

幸运的是,这种情况很少见。
此外,有不同的方法来做到这一点。
链接柜台:
定期隔开茎。链接可能需要另一个链接,这反过来可能需要第三个链接等。
一个完美的’米’?
链条链从左侧到右侧分7个步骤。每个步骤可以偏离1/2像素。因此,右侧轴承可能会偏离3½像素。
权衡:比例(宽度与高度),提前宽度,所见即所得。
在96dpi时,3½像素是x高度的50%(7像素)。相比之下,在600 dpi时,3½像素仅为x高度的8%。如何“排队”以便看到你得到了什么?
其他连接策略
我们可以连接杆的左边缘而不是计数器,将链条减少到4个步骤。
权衡:专柜,wysiwyg程度较低。
我们可以从外到内而不是从左到右连接到无条件的所见即所得。权衡:词干的间距为奇数个像素。
对于额外的粗体m,我们可能希望将中间干减少到1个像素。
等等
将其与类型1中的vstem3提示进行比较。我们不必知道它的作用,如果它不能达到我们想要的效果,我们也无法做任何事情。
其他“走得太远”的方法
链接太多会创建一个循环的链接链。这意味着没有任何东西可以让路。但是我们不能继续绕过一圈。总是必须让路。
保留比例的插值:
这在12 pt和96 dpi时看起来相当可以接受。
计数器的比例或中间横杆的位置:


它仍然很好,10,但不是8和6磅。在8和6磅时,顶盖高度必须向下舍入,而中间杆的位置似乎已经向上舍入。比例并不等于capheight。
放置横杆的插值:

插值不保留从父项到子项的距离。插值保留了从父#1到子节点的距离相对于从父#1到父#2的总距离的比例。它就像素而言。
横杆都设置好了:
横杆都设置好了:

我们可以插入中间横杆的底部边缘并链接到其顶部边缘。
权衡:这往往会推动横梁(但对B来说很好)。
我们可以插入横杆的顶部边缘并向下链接。
权衡:这往往会推动横梁下降(对A来说可能更好)。
将其与类型1中的hstem3提示进行比较。
我们正在插值:
将顶部碗与底部碗水平对齐的一种方法。
按比例放置笔画
这适用于插值。但我们也可以将它们联系起来。跨白色或灰色距离的链接不保持最小距离。最终,距离向下舍入到0像素,对于较小的尺寸(一致性)保持为0。
插值错误:
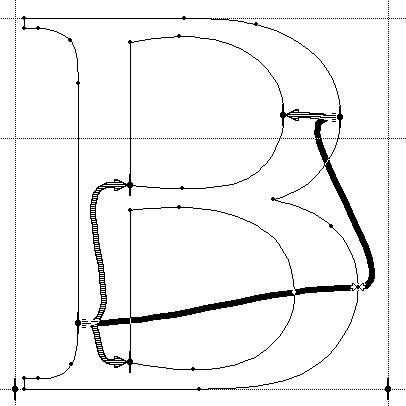
插值不相反。我们无法推断底碗相对于顶碗的位置。子点必须在父点之间。
将孩子安置在父母之间:
在8和6磅时,两个碗之间的裆部处的点大致位于中间横杆的中心,而在7点处则不是。
一个很好的插值:
极值点不知道去哪里。我们必须告诉他们。链接的父级和子级成为插值的父级。
将孩子留在里面的插值:
像素有什么不同。请注意,最后一次插值与许多点大小相关,尽管我们只是查看其中一个。6磅B有相当奇怪的碗的事实是另一个问题,非常特定于该点大小。
控制值表条目以控制接近规则:


B,12,11和10磅:根据设计,圆形垂直笔画比直笔画宽一点。我们不能在12和10点看到这个。相比之下,在11点我们可以看到有点太多了。
控制值表的作用
圆形笔划刚好超过1½像素,最多可达2个像素。直笔划不到1½像素,向下舍入到1像素。
我们需要两个笔划都可以参考的公共参考距离。控制值是一组特征的主要宽度或长度,例如杆宽或衬线长度。控制值在控制值表(cvt)中列表。你必须通过测量角色的特征来填充cvt。
将其与类型1中的蓝色值和字典进行比较。
控制值如何运作?
预编程(准备)缩放所需ppem大小的控制值。在准备中,我们可以调整,在ppem大小和其下方,直线和圆形笔划的缩放cvt值应该相同,并且相似。然后链接可以使用来自cvt的相应值,而不是使用两个控制点之间的实际距离。结果,我们有
复制
leftEdge + stemWeightFromCvtForRoundStrokes = rightEdge
leftEdge + stemWeightFromCvtForStraightStrokes = rightEdge
对于设定的ppem尺寸及以下产生相同的杆重量。
哪个cvts使用?
Cvts归因于:
角色组(UC,LC,……)
链接颜色(黑色,白色,灰色)
链接方向(x,y,对角线)
特征(距离,直线或圆形行程,左侧或右侧支撑,绝对或相对高度,……)
VTT将为给定属性和实际距离选择最佳匹配。我们可以覆盖这个选择。
使用cvts:



将其与类型1中的提示替换命令进行比较。
我们只是将正确的cvts放在正确的位置,但我们必须将它们放在那里。然后我们可以覆盖1像素干变为2像素的大小。我们还可以覆盖例如圆形笔划是否应该与直线笔划相关联,反之亦然,以便在较小尺寸下获得更大的对比度。
cvts的其他原因:
即使看起来具有相同重量的笔划有时也不会。
可能已从手绘图中扫描了轮廓。
轮廓可能已从其他大纲格式转换。例如,三次Bézier曲线(类型1)不会相同地转换为二次Bézier曲线(TrueType)。数学只能以控制点总数(和字体大小)为代价来近似它们。
直线仍然是个问题。例如,从类型1转换为TrueType,转换必须从1000乘1000网格扩展到2048乘2048网格。为此,必须将所有坐标乘以2048/1000。问题是分裂,再次。
我们将使用平均每搏输入重量作为实际的cvt值。
cvts的其他地方:

O看起来很容易做到。问号仅表示VTT未找到UC White X LSB的cvt。
高度指南的Cvts:


高度指南的Cvts有点棘手。我们必须存储方块的绝对值(基线,上限高度)(如H),以及圆形的相对值(过冲和下冲)(如O)。我们希望从顶盖高度到顶盖高度过冲以及从基线到底线下冲的连接,使用相同的cvt两次。但是O在盖子高度或基线上没有控制点。因此,我们必须模拟这种行为。
在高度指南上锚定控制点:
如果将VTT归为“灰色-Y-绝对(或相对)高度”,VTT将为高度选择一个cvt我们可以覆盖此选项。
带有锚点和cvt数字的’O’:

在日常字体制作中,您可以从高处开始,然后使用链接和插值从那里开始。但我们首先必须了解没有加起来的事情以及链接和cvts如何解决这个问题。
我们也使用cvts作为正方形。像这样我们可以调整上限以协调罗马与斜体或粗体。
将其与类型1中的蓝线进行比较。
Deltas用于数字化外观
网格拟合是
ppem大小独立
像素大小独立
将圆形笔划链接到任何ppem大小的最近像素数,并使用cvts使它们的宽度相同。链接不指定多个像素,也不指定特定像素。
但在连接后,我们可能会留下膝盖或肘部和其他不幸的像素模式。首先,我们应该确保没有与round-to-halfgrid等的链接可以控制这种模式。
最后的O:
例如,12 pt / 96 dpi(16 ppem)的增量可以将顶部1/8像素的偏离曲线点移动到左边,而另一个增量可以将底部1/8像素的点移动到右边。
这些增量适用于
特定的ppem大小
特定像素量
我们必须检查并修复可能在屏幕上显示的所有尺寸。我们可以在链接和插值之间插入增量,或者为特定大小添加位图,如果这可以节省许多增量。
提示暗示与自动提示:
提示需要大量的工作。虽然VTT使学习更容易,工作更快,但我们仍然需要学习所有各种提示策略并开展工作。
自动提示会很好,但是你会相信计算机有足够的“品味”来做出正确的权衡吗?
无论如何,什么是“正确”的权衡?
权衡取舍总是相同的吗?或者它们对于不同的字体,用法或客户有什么不同?
VTT的未来可能会在可以做出逻辑决策或数字紧缩的情况下寻求更多的计算机辅助。
Summa summarum
Type 1和TrueType之间的主要区别是:
类型1中您需要担心的很多情况
很多情况下你无法在Type 1中做任何事情
你应该把哪两个放入OpenType字体?这取决于你将用它做什么。
15.2.4.从字体到字体文件
为TrueType准备字体
在启动TrueType提示项目之前,需要准备所有字体和字体源。
今天,两种最常见的字体存储方式是Ikarus或PostScript格式。许多字体使用贝塞尔绘图程序或基于商业贝塞尔的字体程序绘制,并制作成PostScript字体文件。使用贝塞尔字体程序可以实现可接受的打印质量,而无需使用专业类型代工厂所需的标准化标记程序。通常,设计师会在不注意贝塞尔点标记的精确位置的情况下标记贝塞尔曲线。准备字体文件以进行提示以确保在最终字体文件中使用最少量的指令时,需要更高质量的过程。一个问题的一个例子是,如果一个字形假设在基线上并且它不是或者如果一个词干被认为是完全笔直的而不是,需要额外的提示才能使它们正确。请记住,如果您从错误的大纲开始,您将无法在以后改进它们。
为Trebuchet设计轮廓
当前的TrueType生产过程是分开的:在Macintosh上完成设计和提示过程,以及在Windows上测试字体文件。
Trebuchet是一个旨在成为干净的屏幕阅读字体的项目,以及可扩展的打印轮廓字体。
在完成绘图和单个图像之后,我使用Macromedia Fontographer 4.1为Macintosh开始了大纲。从我为之前的项目创建的轮廓开始,这是一个未发布的怪诞风格设计。
Trebuchet是一种具有现代几何特征的无衬线字体。我使用了一致的杆距,精确的组高度对齐和直线行程和点对齐的零容差。在所有字体的设计中并非总是这样,特别是现代设计较少。
我在Trebuchet的设计过程中使用的方法使我也很容易提示最终的字体文件。
在完成轮廓后,我使用了类似于下一节中描述的方法。唯一的区别是我还使用了两个额外的专业工具:一个是轮廓转换工具,另一个是TrueType表工具。您可以使用下面描述的方法获得类似的结果。
使用Fontographer 4.1准备字体
在本节中,我们将讨论使用Macromedia Fontographer 4.1 for the Macintosh来创建可与Visual TrueType一起使用的TrueType文件。
有关如何使用Fontographer和程序的更深入的方面进行绘制的信息,请参阅Fontographer用户手册或出自Stephen Moye的出色的书“Fontographer:Type by Design”,由MIS Press出版(1995)ISBN:1558284478。
使用Fontographer时,您应该了解一些设置和过程。
启动Fontographer 4.1。然后从“文件”菜单中选择“新字体…”将显示一个无标题-1字体的窗口。
注意:Fontographer的原始版本用于创建PostScript字体。初始默认设置适用于Macintosh PostScript字体。
选择“元素”菜单和“字体信息…”将显示“ 字体信息”对话框。在这里,您可以命名此字体,设置样式,编码,指标并插入版权声明。保存新的Fontographer文件时,该名称将用于创建Fontographer文件。当从Fontographer文件生成字体文件名和字体格式表信息的字体时,也使用此名称。创建族时使用该样式,而Fontographer使用此字段与名称字段类似。“字体度量”设置此字体文件的字体单位。字体度量标准(或每个Em的单位)默认为1000,是PostScript字体的标准设置。在TrueType中,为获得最佳性能,强烈建议TrueType字体文件为每个2048单位(UPEM)。
练习1:设置字体信息和字体指标。
如果您还没有这样做,请从“文件”菜单中选择“新字体…”。然后从“元素”菜单中选择“字体信息…”。您现在应该显示“字体信息”对话框。通过在Name:FamilyName字段中键入名称(例如:MyFont)来命名字体。为名称:样式名称字段设置默认的“普通”样式。该字段当前显示为空白,但通过选择“样式名称”弹出菜单,已选中“普通”菜单项。对于Encoding字段,我们将默认编码设置为Macintosh。接下来的字段是字体度量字段。我们将字体度量字段中的所有值缩放2.048。这会将字体的指标设置为每个2048个单位。设置字段如下:

Ascent = 1638,Descent = 410,Em Square = 2048,Leading = 0,Underline Position = -272,Underline Width = 41.单击“OK”按钮。
您现在在2048 UPEM中有一个字体。然后双击“A”字符(十进制#65)。在“A”字符窗口中,绘制图像。如果您熟悉Fontographer并以1000个单位工作,您会注意到为点坐标显示的单位大约是您预期的两倍。(实际上是2.048倍。)从1000单位字体复制到此文件的任何字形将自动缩放到2048个单位。
练习1-1a:使用现有字体进行操作
在下一个练习中,我们将打开现有的PostScript打印机字体,缩放字体指标,使用Fontographer创建TrueType字体并讨论其他一些TrueType工具。
重要提示:字体是受版权保护的软件。使用此类受版权保护的软件进行衍生作品违反了大多数用户许可协议。仅使用您绘制或创建的字体,这些字体是您或您公司的财产。
从“文件”菜单中选择“打开字体…”对话框将根据对话框底部选中的项目显示文件。选择一种PostScript打印机字体。您现在应该有一个窗口显示PostScript打印机字体中的所有字形。接下来,执行练习1中我们遵循的步骤以缩放字体度量。首先从Elements菜单中选择’Font Info …’。请注意,添加时Ascent和Descent的值等于Em Square。正如我们在练习1中所做的那样,通过将它们乘以2.048来缩放Font Metrics中的所有值。单击“确定”,字体文件现在为2048个单位。
Macintosh PostScript字体通常不包含一些符号字符作为轮廓。如果打印机字体属于这种情况,则应创建轮廓或使用库中的一组标准符号字符。从“文件”菜单中选择“保存”以创建Fontographer文件。
在我们输出TrueType字体之前,建议对从一个或多个已存在的字形构建的字形使用复合字形。’Aacute’是一个应该用大写字母A和急性变音符号制作的例子。
使用Fontographer构建“Aacute”复合字形:
在主字符窗口中选择大写字形。
从“编辑”菜单中选择“复制参考”(cmd-G)
在主窗口中选择“Aacute”字符。从“编辑”菜单中选择“粘贴”(cmd-V)。
在主窗口中选择“急性”变音符,然后从“编辑”菜单中选择“复制参考”(cmd-G)。
双击主窗口中的“Aacute”打开“Aacute”字形。
在’Aacute’窗口’Paste’(cmd-V)急性字形。
将变音符号放在基本字形上。
我发现在Fontographer中创建复合的最有效方法是首先获取/粘贴基本字形,然后获取/粘贴变音符号。这对于稍后在生产过程中使用TrueType进行操作非常重要。
您现在可以从Fontographer中的bézier轮廓生成TrueType字体。
从“文件”菜单中选择“生成字体文件…”。在“生成字体文件”对话框中,您可以选择“简单”对话框项或“高级”对话框项。在“简单”对话框项中,您可以生成Macintosh字体或PC字体。在此示例中,我使用并建议使用“简单”对话框项并生成Macintosh TrueType字体文件。
注意:Macintosh和PC字体有什么区别?Macintosh使用两种类型的文件格式:资源文件和数据文件。Macintosh上的字体需要是资源文件。Macintosh上的基本TrueType字体包含’FOND’资源和’sfnt’资源。“FOND”资源中的信息是Mac OS所需的附加信息。’sfnt’是TrueType字体。TrueType数据文件由Visual TrueType使用,并通过在Fontographer中创建PC字体或将“sfnt”资源转换为数据文件来生成。此外,Mac OS使用名为“Finder信息”的文件信息来识别文件类型。Fontographer输出具有Visual TrueType所需的不同“Finder信息”的PC TrueType字体。
“Finder信息”应该是:
Type = sfnt
Creator =’mdos’,’bass’或’Bass’很常见,但不是必需的。
创建者代码是必需的,必须是4个字符。
您可以使用包括ResEdit在内的多个应用程序更改“查找器信息”。

在生成字体文件之前,我们需要采取一些额外的步骤。第一步是:通过选择’计算机:Macintosh’,Fontographer将生成一个Macintosh自动提示的TrueType字体行李箱。由于这是一个资源文件,因此Visual TrueType无法打开该文件。Visual TrueType仅打开数据文件。您将需要使用可以将此Macintosh TrueType字体资源转换为数据或PC TrueType字体的应用程序。Apple Computer的TrueEdit就是这样一个程序。可以从fonts.apple.com获得Apple字体工具。
在“简单”模式下生成Macintosh字体的另一个步骤是不会生成“yacute”和“multiply”字形的错误。解决此问题的方法如下:
打开元素:’字体信息…’对话框,并将’字体:’中允许的字符数增加两个数字。
然后将’yacute’和’multiply’字形复制并粘贴到最后两个空格。
选择新的“yactue”(单击一下),然后选择“Element:Selection Info …”(cmd-I)。在“字符信息”对话框的“字符名称:”字段中输入“yacute”。然后单击“设置Unicode”按钮。这应该将’Unicode’字段设置为$ 00FD(注意:在Fontographer中,美元符号表示值以十六进制表示。另一种常见方法是使用前面的0x或x。)
单击“确定”按钮,您将看到一个警告对话框。’有多个具有该名称的字形。你想交换两个字形的名字吗?’ 单击确定。
现在,当您输出Macintosh字体时,将生成这些字形并将其放置在字形顺序的末尾。
此方法将字形置于合理的顺序。此订单类似于Apple Computer在原始TrueType规范中发布的原始推荐订单。1.0。
在上面的第3项中,通过设置’字符名称’和’Unicode’; 十六进制数我们完成两件事。在TrueType字体文件中编写两个表时,Fontographer使用此信息。’post’表包含一个字形索引,并与PostScript名称配对。’字符名称’在’post’表中设置字形的PostScript名称。编写Windows版本的“cmap”(字符映射表)时使用“Unicode”编号。在Windows“cmap”中,映射是Unicode编号的字形索引。
您可以使用此方法添加字形和字形信息,以创建覆盖多个Windows代码页的大字体(例如WGL4字符集)。
最后,一旦输出Macintosh TrueType字体行李箱,就可以使用TrueEdit工具。TrueEdit会将TrueType字体行李箱转换为可在Visual TrueType或运行Microsoft Windows的PC上使用的TrueType数据文件。
练习1-1b。为Visual TrueType创建数据文件
启动TrueEdit。从“文件”菜单中打开行李箱文件。选择“另存为…”,出现“另存为…”对话框。将“文件类型”更改为“低音文件”。我在生产周期的不同阶段使用不同的文件名和扩展名。保存’Myfont.suit’时,我更喜欢重命名文件’MyFont.fog.ttf’。
注意:Bassomatic和.bass是Apple计算机为某些早期TrueType软件提供的原始名称。RoyalT是第一个TrueType指令编辑器,仍可从Apple Computer获得。由于Visual TrueType和RoyalT最初只打开’sfnt’类型的数据文件。Bassomatic这个名字来自电视喜剧系列Saturday Night live。TrueType的原名是Apple Royal。RoyalT是’皇室’这个词的双关语。特许权使用费是当时常见的字体许可做法。
使用Visual TrueType
现在我们已经创建了一个TrueType数据文件,现在我们可以启动提示过程了。
在接下来的部分中,我将讨论提示准备。我建议先阅读文本,然后使用您在上一节中创建的.ttf文件,按照步骤测量并提示您的字体。
首先,由于其简单的设计,我使用了无衬线字体进行测量。然后在讨论提示时,我使用了一个更常见的衬线示例。通过不包括衬线的提示,衬线的提示结构和哲学可以很容易地转移到无衬线设计。
我们用于从Fontographer生成TrueType的方法创建了一个已经“暗示”的TrueType字体文件。这些提示是由Fontographer自动生成的,并且不是由训练有素的印刷工程师/设计师完成的良好提示字体的质量。人为干预对于在屏幕上以及激光打印机上实现干净的字体至关重要。
使用Visual TrueType,我们将删除这些自动提示,并使用专为当前字体设计的经过深思熟虑的手动提示替换它们。
练习2-1a:提示准备。
启动Visual TrueType。从“文件”菜单中选择“打开…”并打开您的字体。通过从菜单中选择“视图:字符集”(cmd-9)并将文件首选项设置为“基于字形索引”,您将看到字体中的所有字形。
接下来,从“文件”菜单中选择“准备字体…”。在“准备字体”对话框中,应选中所有框。通过单击“确定”,“准备字体”将删除自动生成的提示并导入三个模板以构建三个重要的表。VTT构建了一个模板’Cvt’表,我们可以在后面填写更多字体特定数据。创建的另外两个表是“预编程”和“字体程序”。有关’Cvt’,’prep’和’fpgm’的说明,请参阅本文档末尾的附录或参阅本文档。
创建控制值表条目
在我们开始暗示单个字形之前,我们需要组织一些关于整个字体和整个系列的数据。
在投石机家庭我有四种字体。经常,粗体,斜体和粗体斜体。在低分辨率下,我必须保持整个家庭的x高度,帽子,高度和所有其他高度不变。我需要保持常规和斜体的颜色相同,粗体和粗体斜体相同。我终于需要控制粗体重量和常规体重之间的关系,以显示各种尺寸的重量差异。为了控制所有这些条件,可以使用几种方法。一种方法是确保如果字体之间的原始轮廓相似,则它们的控制值是相同的。字体中的所有字体通常包含相同的主要组的高度Cvt值。在实际轮廓中,斜体字体的茎重通常比常规字体轻。
注意:在打印机分辨率和高屏幕分辨率下,将不使用Cvt值并使用原始距离。
在字体之间存在差异的情况下,可以使用更稳健的方法。一些TrueType提示使用VTT中提到的提示方法作为“继承”。继承使用函数将值从主Cvt复制到其他依赖的Cvts。该方法用于小的ppem尺寸,并且不在限定的ppem尺寸之上使用。稍后在讨论预编程时,我们将使用一种简单的继承方法。
一般程序是通过测量VTT中的轮廓来编译控制值信息。然后,当测量所有四种字体时,比较数据。您可能需要平均一些值以使家庭具有凝聚力。
测量轮廓特征
使用控件值时,Visual TrueType使用四个主要字符组。大写,小写,数字和其他。在印刷上,“其他”组由子组组成,例如数学或标点符号。
在Visual TrueType中,从“视图:控制值”(cmd-4)菜单项打开“Cvt”窗口。’Prepare Font’导入了Cvt,Font程序和Pre-program的模板。
Cvt中的前28个条目成对分组。这是一种提示方法,Visual TrueType用于修改高度,以便在低尺寸时保持两个值相同。在此提示方法中,第一个Cvt值通常是平坦值或基值,第二个值是过冲(距基值的距离)。
示例:在字体中我将调用’MyFont’,如果Cvt#2设置为1465.这是大写字形与基线的垂直距离。下一个值Cvt#3将是25.这是从基线到所有圆形大写字形顶部的距离减去平面字形的距离。UC圆距= 1490,UC平距= 1465.差值= 25.这是TrueType提示的高级方法,它保持圆形字形与平面字形单位一致,有足够的像素显示圆形过冲。
这是如何工作的……大写圆形字形使用Cvt#3作为其高度。通过从预编程(/ 修改双指定高度: /)进行的函数调用,函数读取来自Cvt#2的值。然后它将该值从字体单位舍入到像素。接下来它读取Cvt#3并舍入该值。然后它将两者加在一起,最后用该值写入Cvt#3。
在Visual TrueType中,我们使用一些高级提示概念。因此,一些Cvts已被保留用于特定用途。重要的是不要更改或更改这些Cvts,否则Visual TrueType将不会按预期运行。
Cvts 0..36用于高度,Cvts 40..64由程序编译器保留,Cvts 65..156可用于主要组功能。Cvts 157和158保留用于喇叭口和杯子,并由Pre-program的一部分使用,该部分将控制小尺寸的喇叭口。不应删除保留的Cvts。用户定义的Cvts可以从Cvt#159开始添加。
现在我们可以开始手动测量单个字形的过程。
测量高度
第一次测量是字形组的垂直(Y)高度。

以下准则可用于计算字体高度。
Cvt#0是ASCENDER_HEIGHT,通过测量小写字母b,d,h,k和l的高度来获得。
Cvt#1是上升者的超调量。如果高度实际上高于其他上升者,这可能是小写的’f’高度。
Cvt#2(CAP_HEIGHT)是从基线到大写“扁平”字形的视觉顶部测量的。例如:B,D,E,F,H,I,J,K,L,M,N,P,R,T,U,V,W,X,Y和Z.该值应为点暗示将来自何处。与基线相似。这可能不是字形最顶部的值。
Cvt#3是大写圆形字形的顶部超调。此值的计算方法是使用大写圆形字形中最常见或最平均的值(例如:C,G,O和Q.)从基线到字形顶部测量。通过Cvt#2减去该值。
Cvt#4(FIGURE_HEIGHT)是从基线到平面图形字形顶部的值。(例如:5,7)
Cvt#5是数字顶部超调值。
Cvt#6(X_HEIGHT)是小写的平顶值。与CAP_HEIGHT类似,它不一定是小写x的顶部,而是小写平面字形的视觉顶部。
Cvt#7是小写顶部超调值。
Cvt#8(UC_BASELINE)这个值通常为零。
Cvt#9这是底部大写超调。该值通常为负值,与Cvt#3的绝对值相同。
Cvt#10(LC_BASE_HEIGHT)此值通常为零。
Cvt#11是底部小写过冲。该值通常为负值,与Cvt#7的绝对值相同。
Cvt#12(图_BASE_HEIGHT)这个值通常为零。
Cvt#13是底部超调。该值通常为负值,与Cvt#5的绝对值相同。
Cvt#14(DESCENDER_HEIGHT)此值是通常从小写p和q测量的平坦下降值。小写的g和j可以相同或不同。
Cvt#15是下降器超调值。如果圆形下降器(g或j)低于扁平下降器,则使用。
Cvt#16(PARENTHESIS_TOP)是括号,括号和大括号的顶部。这些字形通常与小写上升值对齐。该值通常与Cvt#0相同。
Cvt#17可用于设计,其中一对支架或支架超过括号高度。通常这个值保留为零。
Cvt#18(PARENTHESIS_BOTTOM)这是括号的底部。该值为负值,通常与Cvt#14相同。
Cvt#19是括号的过冲。如果使用过冲,则该值为负。
Cvt#20(SUP_ao_BOTTOM)此值适用于’a’,’o’序号,通常与Cvt#24相同。
Cvt#21这是序数的超调量,通常与Cvt#25相同。
Cvt#22(SUP_ao_TOP)这个值是’a’,’o’序数,并且通常与Cvt#26相同。
Cvt#23这是序数的超调量,通常与Cvt#27相同
Cvt#24(SUP_12_BOTTOM)这是平底的上层(优于一两个。)
Cvt#25是上三级的圆形超调值。
Cvt#26(SUP_12_TOP)这是高级数字的平顶。(在一整套上级中,价值是上级5和7的顶部。)
Cvt#27是卓越的顶部超调值。
早期版本的Visual TrueType使用28..35的Cvts用于serif字体。这些早期版本仅使用一个Cvt条目来实现垂直serif距离。然后是用于暗示衬线的水平方向的功能。
我描述的用于暗示衬线的方法需要水平方向和垂直方向的Cvt条目。我已经为每个主要字形组中的X和Y serif距离预定义了Cvts。我通常通过从主干的右侧到右衬线的右端,从左衬线的左侧到左侧极端水平测量来测量衬线。垂直于字形基部到最顶端的衬线。

本节中的最后一个Cvt是36号。这个Cvt被高级函数用于斜体笔画。在直立字体中,此值为“0”。稍后当我们测量斜体字体时,我将解释如何测量它。
在斜体字体中,此值是从大写笔划的左极端到大写平面高度的水平距离。在数学中,这个距离是’run’,因此注释’/ ITALIC_RUN /‘。大写的平面高度在数学上称为“上升”。
规范实际距离以创建一致的Cvt表
当您测量了Cvt值的距离时,需要为整个字体协调实际的公共值或平均值。
在MyFont中,Cvt#3,5,7,9,11和13是过冲值。(圆形高度和平坦高度之间的差异。)MyFont生产的实际过冲距离的测量值:
Cvt#3 = 27,#5 = 21,#7 = 21,#9 = -25,#11 = -20,和#13 = -20。
关于你想要多大程度地规范自己的价值观,这是个人偏好的问题。我发现它更容易,更清洁,并且“暗示”的基本工作是尽可能地规范化。
如果我们将Cvt#7(小写顶部圆形)保留为21个单位而Cvt#11保留为20个单位(小写底部圆形),则小写字母的顶部将至少在一个尺寸上大于底部。
在MyFont中,组中过冲的最大值与最小值之间的差异非常小。比较三个最重要的字符组(大写,小写和数字),大写平均值为26个单位,小写字母为20.5个单位,数字为20个。
我用于大写过冲的值是25个单位,对于小写和我用过的数字是20个.5个单位的差异不是很大的区别,但是在中等分辨率下,这对于这个字体来说是一个很大的数量。
注意:在字符组之间,应将5个或更大单位的值视为足够大,以使其与其他值不同。在字符组和主要特征(如大写词干距离)内,应考虑较大的值(~10个单位)。
现在我们已经查看了高度值,我们可以编译MyFont的信息。
1509 / * ASCENDER_HEIGHT * /
0
1465 / * CAP_HEIGHT * /
25
1465 / * FIG_HEIGHT * /
25
1071 / * X_HEIGHT * /
20
/ * UC_BASE_HEIGHT * /
-25
/ * LC_BASE_HEIGHT * /
-20
/ * FIGURE_BASE_HEIGHT * /
-20
-420 / * DESCENDER_HEIGHT * /
0
1465 / * PARENTHESIS_TOP
0
-420 / * PARENTHESIS_BOTTOM * /
0
595 / * SUPERIOR_ao_BOTTOM * /
-10
1480 / * SUPERIOR_ao_TOP * /
10
595 / * SUPERIOR_12-BOTTOM * /
-10
1480 / * SUPERIOR_12_TOP
10
当测量大写字母的顶部和图形高度时,我发现圆形字形(如“O”和“零”)的高度值相同。但平面字形,’H’和’5’略有不同。’H’是1464单位,’5’是1470单位。这是原始设计中可能已经或可能未出现的差异。如果我将CAP_HEIGHT保留为1464并且将FIG_HEIGHT保留在1470,则数字将在某些尺寸上高一个像素,并且圆形数字将通过提示过于强大。我决定数字和大写应该是一样的。我将CAP_HEIGHT四舍五入到1465并将Drawing_HEIGHT降低了5到1465.然后,当25个单位超调时,这些组将以低尺寸对齐。这种类型的差异很常见,这是暗示大纲所涉及的决策类型的一个很好的例子。其他可能不太清楚的值是Cvt#22和26.在这种字体中,没有平坦的上级要测量。通过从上三的测量顶部减去Cvt#25中的优越过冲来计算该值。
测量茎和笔画
我们需要为Cvt采取的最后一个主要测量是群体的茎距离。这些距离通常是:
直线特征,圆形特征,对角线距离和衬线距离。这些可以进一步分为水平(X)和垂直(Y),大写,小写,数字,标点符号,高级数字,数学和其他许多其他。
由’Prepare Font’导入的Cvt模板包含一些拉丁字体的常见预定义Cvt值。在Cvt左侧的注释和十六进制Cvt属性编号中记录了每个预定义Cvt的使用说明。
我们将测量字符组中的字体距离,大写,小写,数字,其他,标点符号,上级,数学和变音符号。
从水平或’x’方向的大写开始,我们将测量大写的H左右茎。这是UC,X,直线或杆距离。继续测量其他大写的茎并记下它们的距离。接下来测量圆形大写字形(B,C,D,G,O,P,Q,R,S)。注意它们的值。测量对角线字形(K,M,N,R,V,W,X,Y,Z)。在水平方向垂直于基线测量对角线笔划(就像直线笔划一样)。
在衬线字体中,测量从大写词干到衬线上最极端点的水平衬线长度。两个Cvt是预定义的,一个用于较短距离,一个用于较长距离。如果所有衬线长度大致相同,则仅使用值。

下一组Cvts用于垂直或“y”距离。测量直杆距离。测量圆’y’距离,对角线和衬线。’y’衬线距离通常是从基线上的一个点到衬线的顶部以及从CAP_HEIGHT到衬线的底部测量的。
对小写和数字做同样的事情。在小写Cvt组中,Cvts是针对i,j点距离预定义的。X距离是水平点距离,第一Y距离是垂直点距离,第二Y距离是从i / j的顶部到点的底部的白色空间。
继续并测量模板注释定义的距离。对于直线或圆形特征,有一个替代的Cvt。如果有两个主要距离,将使用此选项。最初只需要一次测量。
现在我们已经测量了所有主要的字形距离,我们可以创建一些实际的Cvt值。使用的值应该是最常见的距离,类似于但不一定是数学平均值。创建此Cvt值时,组的特征的距离可能非常相似,或者可能包含两个主要距离。如果是这种情况,可能需要将距离分成两组或更多组。一个简单的例子是,如果字体具有两个基本长度的衬线,则使用两个Cvts,一个用于较短距离,一个用于较长距离。25个字体单位的距离足够大,需要新的Cvt,但在准备Cvt时没有“黄金法则”。需要在每个字体的基础上做出具体决定。
在MyFont中,大写主要字形的距离测量值为:
复制
X_straight X_round
B = 200/211/198
C = 211
D = 200/209
E = 200
F = 200
G = 201/211
H = 200
I = 201
J = 198
K = 200
L = 200
N = 190
O = 210/211
P = 200/207
Q = 210/211
R = 200/211
S = 201/200
T = 201
U = 200/199
如果我们使用大写x_straight距离的数学平均值,则值为199.但是查看值时,最常见的值是200.通常,使用最常见和舍入的值是最好和最简单的。查看x_rounds值,210将是一个很好的常见舍入值。你应该注意到大写的N和S偏离他们组的主要距离相当于10个单位。您可以根据自己的判断使用较大的公共值或其他更接近的字符,例如大写字母N.在此阶段,没有足够的功能偏离此字体以保证额外的Cvt。当提示诸如大写字母S的字形时,您可能决定最好使用较小的直线值而不是较大的圆值。在这个字体中我会使用常见的,
在从Cvt模板测量并确定每个预定义Cvt的值之后,请填写相应Cvt中的值。填写完值后,通过选择“编译:编译所选窗口…”来编译Cvt表。
当您知道如何使用这些Cvts进行提示时,通过测量距离来构建Cvt将会更加清晰。始终牢记,当您在字体中提示更多字形时,您可以添加本地字形距离。如果两个或多个要素需要保持相同的像素大小,请添加这些。如果某个要素仅在字形上出现一次,请将此视为唯一要素,并且不需要控制值。
在我们提示之前,我们需要填写另外三个以更全局的方式使用的Cvts。Cvts 65,66和67是字体宽继承Cvts。继承用于通过对许多Cvts使用一个主Cvt来全局控制阀杆厚度。Cvt 65是主要的Cvt,将用于将所有词干保持在一个像素。Cvt 66用于控制高于该一个像素尺寸的X方向。Cvt 67用于独立于一个像素尺寸之上的X方向控制Y方向。然后在更大的尺寸,大约30PPEM及以上我们使用更具体的组Cvts。
为这些控制值选择值的一般方法是:
使用距离Cvt 65最窄的杆距离。通常使用小写的“o”Y距离。这是一个像素的距离。这将迫使更大的距离保持在一个像素,直到我们想要摆脱这种类型的控制。在MyFont中,Cvt 65的值与Cvt 72相同,小写,Y,直。
对于Cvt 66,X方向,我使用主导的X距离。这通常是大写的词干。如果看起来像一个干的重量用作主导控制值另一个常见的Cvt可能是小写X词干Cvt。
Cvt 67用于Y方向,并且通常与Cvt 65和小写Y距离相同。
填写Cvts 65,66和67.编译Cvt窗口。

Cvt属性
大多数距离Cvts具有十六进制数字并且在Cvt编号和Cvt值的右侧进行注释。十六进制数称为’Cvt Attribute’。Cvt属性可帮助VTT编译器选择合适的Cvt。
您可以通过选择Cvt中的十六进制数来查看Cvt属性。然后从’编辑’菜单’选择编辑Cvt属性…’示例:数字0x1241属性是小写,黑色,X方向,笔画。
当使用小写字形进行链接时,使用设置,笔直并使用Cvt,编译器将使用带有此Cvt属性的Cvt。Cvt属性已在Cvt模板中设置,可以使用此“编辑Cvt属性…”对话框进行更改。
选择各种Cvt属性并注意设置以及它们与Cvt注释的关系。
提示和Cvt属性
在这里,我们将看到如何使用这些Cvt属性。在VTT的主窗口中,我们将输入一个应该选择合适的Cvt的提示。
在已经测量的文本字体和创建的Cvt中,显示大写的O.(对于本练习。如果没有完全填写的Cvt,您可以使用Prepare Font并为大写X直Cvt添加Cvt值# 68和X轮Cvt#70。)
从“Visual TrueType”菜单中,启用菜单项“显示X方向”。
应取消选择菜单项“显示Y方向”。
应取消选择“显示”菜单中的“网格设置”和“像素”项。
从“显示”菜单中选择“显示较少的点数”。
在提示工具图标栏中,应启用X方向工具。选择Xlink工具。
从大写O的最左侧曲线,将Xlink工具拖动到另一个最内点。
按住Shift键并单击箭头。从弹出菜单中选择圆形,Cvt,最小距离工具。
您应该看到Cvt#70显示在Cvt Xlink符号中。按住Shift键并单击符号,将出现一个Cvt弹出窗口,显示Cvt 70,其属性为(UpperCase Black X Round)。大写字母O右侧最外面的链接和圆形Xlink Cvt工具应保留为默认值, Cvt#70也应该自动选择。
VTT编译器使用该属性来选择Cvt 70.编译器还使用了UPPERCASE的字形组数据。当我们从字符组数据文件(CharGrp.txt。)运行’准备字体’时导入。此组数据显示在每个字形主窗口的顶部。
接下来按住Shift键并单击箭头,将其中一个Xlink更改为一个笔画/用Cvt。显示的Cvt应该已更改为68,箭头将更改为方形图标。这显示了编译器如何使用Xlink类型来选择适当的笔划类型。接下来再次将箭头更改为距离/使用Cvt箭头(尖头箭头).Cvt图标应包含一个问号,表示编译器无法为此链接找到合适的Cvt。如果我们定义了一个Cvt属性为大写,黑色,X,距离的Cvt,编译器就会选择那个Cvt。
使用完全填充的Cvt,在主窗口中显示小写字母o。再次,选择Xlink工具并链接o的左圆形笔划。按住Shift键并单击箭头,选择圆形箭头。将箭头更改为圆形/使用Cvt。应该选择Cvt 83。将箭头更改为笔划/笔直/使用Cvt和Cvt 81应该被选中。最后,选择距离箭头/与Cvt。与没有选择Cvt的大写字母不同,选择了Cvt 94。Cvt 94是小写字母i,j点上的距离,并且具有X小写黑色距离的属性。它被选中,因为这是我们使用的Xlink唯一具有正确属性的Cvt。如果有两个具有相同属性的Cvts,编译器将选择其值最接近链接中两点之间的实际距离的Cvt。
开始暗示
当暗示字体系列时,通常最好从正常或正常的直立重量开始。对于杆厚度,过冲和字体高度的决定对于正常的直立重量是最关键的。所有其他权重和样式应基于对普通字体的决定。常见的决定是,茎何时从一个像素转变为两个像素。如果茎对于正常重量来说太早了两个像素,则可能难以提示粗体字体,因此它看起来很粗体。如果正常重量字体在诸如12点的小尺寸下过于粗体,则对于用户来说也会令人困惑。
我们将从正常权重字体中最重要的字形开始提示,即控制字符。控制字符是用于间隔字体中的所有其他字符以及用于确定干厚度和断点的字符。在大写字母组中,最常用的控制字符是圆形控制字符的大写字母O和直线控制字符的大写字母H或大写字母I以及对角线字符串的大写字母V. 所有大写字形在圆形和直线控制字符之间间隔开。在小写字母中,’o’用于圆形,’n’用于直线,小写’v’用于对角线。数字在零之间间隔开。
我首先提示主要三组中的控制字符,大写,小写和数字。当这些完成后,我决定如何控制茎断裂的时间以及每个组如何与其他组一起工作。在确定权重之后,我开始暗示主要三组中的其余字形。当所有主要组的字形都有主要提示时。我继续前进。我将三个主要组的字形分隔为最终质量。
然后我转到字体的其余部分。所有其他字形在它们最常用的字形之间间隔开。例如,间距数学符号我们使用零。标点符号(如引号或括号)使用小写控制字符,其他小写上升字符和/或大写字符的组合。’T’用于间隔©,®和’商标’,因为它通常是间距期间右侧第一个字形。
开始提示时,首先为字形设置提示结构,以便尽可能地控制大多数大小。然后在您提示主要控制字符后,查看每个PPEM大小的每个PPEM大小像素形状和间距的更具体。特定大小的特定提示是通过更改主要提示或添加带有Delta提示的例外来完成的。
提示第一个字形
我将在提示示例中使用常规权重的serif文本字体。这是一个简单的通用设计,并显示了衬线的使用。提示无衬线字体是相似的,减去衬线的链接。我们将开始用大写字母暗示,从’O’开始。
首先要做的是控制垂直方向。我们首先要控制高度。在主窗口中使用大写O的VTT中,显示Y方向,从“Visual TrueType”菜单中关闭X方向。关闭gridfitting和像素,然后从“Display”菜单中选择Show Lesswer Points。从工具栏中选择Ylink工具。按住Shift键并单击O的最顶点,然后选择圆形到网格图标。您应该会在所选的点上看到一个带有锚符号的空Cvt图标。Shift-单击Cvt图标并选择Cvt#3(UC,top,overshoot)。接下来选择最底部的点和顶部相同,除了这次选择Cvt#9(UC,底部,下冲)。通过从“编译”菜单中选择“编译此窗口”(cmd-R)来编译这些提示。接下来,我们将使用链接和Cvt控制顶部和底部的圆形笔划。在仍然选择Ylink工具的情况下,单击并从最底部点拖动到定义圆形笔划的最内点。Shift-单击箭头并选择具有Cvt和最小距离的圆形笔划。应该已经自动选择了Cvt#74。使用相同的步骤控制顶部圆形行程,方法是从最顶部点到最顶部行程的最内部点进行链接。Cvt#74也应该已经自动选择。编译提示。应该已经自动选择了Cvt#74。使用相同的步骤控制顶部圆形行程,方法是从最顶部点到最顶部行程的最内部点进行链接。Cvt#74也应该已经自动选择。编译提示。应该已经自动选择了Cvt#74。使用相同的步骤控制顶部圆形行程,方法是从最顶部点到最顶部行程的最内部点进行链接。Cvt#74也应该已经自动选择。编译提示。
现在我们将添加水平方向的提示。关闭“显示Y方向”并启用“显示X方向”。在我们开始暗示X方向之前,我们必须决定我们将采取什么样的提示策略。该策略将影响间距和提示生成的位图的宽度。我们有几个选择。让我们试着用每一个来暗示它是如何改变图像的。
提示大写字母O的第一种方法
第一种方法是使用侧支点从两侧链接到主字形。这将使字形不会在前进宽度之外扩展并最有效地控制间距。这种方法的问题是,当前进宽度压缩或扩展时,字形将被压缩或扩展。任何舍入值都会影响位图的宽度。如果字体宽或样式扩展,此方法最有效。
首先从工具栏中选择Xlink工具。从左侧承载点到O的最左侧部分的链接。单击箭头并将其更改为距离,没有Cvt,并且不保持最小距离。当距离太小时,这不会强制像素为白色。现在链接左圆形笔划并将箭头更改为圆形,Cvt,并保持最小距离。应该选择Cvt#70。从右侧承载到最左侧的O.将箭头更改为距离,没有Cvt,并且不保持最小距离。从字形上最右边的点链接到定义右X圆形笔划的最右上点。将箭头更改为圆形,Cvt,并保持最小距离。应该选择Cvt#70。编译提示。
从“显示”菜单中启用“Gridfit”,“像素,显示大小运行”和“显示文本字符串”。注意关闭和打开gridfit时像素模式如何变化。现在从“尺寸”菜单中选择“9pt”。使用向上箭头键以点大小向上移动,并特别注意位图外部与右侧和左侧边缘点之间的关系。当侧支点和位图的外侧位于相同的X位置时,该侧与下一个字符的原点之间没有空白区域。将大小重置为9pt或更小的大小,以便在字形的两侧没有空白区域。请注意,在顶部的Text字符串中,重复的大写O是如何触摸的。这被认为是不好的间距。选择Xlink工具。Shift-单击右侧支撑链接的箭头并将其属性更改为距离,无Cvt并保持最小距离。位图应该压缩一个像素,并且当重复大写O时,文本字符串现在不应该崩溃。
提示大写O的第二种方法
第二种方法是从右边和字形连接到左边。如果任何舍入导致值增加,则此方法将所有位图推到左侧。如果可以选择向左或向右拉动,建议将位图拉到左侧。在大多数应用程序中,闪烁的光标将与键入的最后一个字符的末尾重叠。如果位图在其单元格中向右拉,则闪烁的光标将消除位图的右侧部分。用户在打字时会发现难以阅读这些字符。
提示大写O的第三种方法
第三种方法是从左侧支撑和跨越字形链接到右侧。与前一种方法一样,这将倾向于将位图推向右侧。
提示大写O的第四种方法
第四种方法是不使用sidebearings,而只是从字形的起始点开始提示。这是具有舍入起点的效果最小的方法,起点将控制位图的原点。当字体具有足够的侧面空间时,这是最有用的。该方法还需要对某些尺寸的间距进行一些手动例外处理。但这是保持字形原始位置的好方法。
我已经决定使用当前的字体,我将使用上面提到的第一种提示方法。从侧面提示,右侧的初始提示保持最小距离。
我将继续对所有其他字形使用此方法。这将在整个字体中保持某种类型的一致性。我可能需要为特定字形和特定大小制作例外。
将初始提示放在大写字母O上后,选择大写字母H.稍后我们将返回O.
正如我们对大写O所做的那样,在主窗口中设置Y方向,关闭X,然后关闭像素和gridfitting。
注意:在提示另一个方向之前,Visual TrueType中不要求首先提示一个方向。您可能会发现在X方向开始提示更直观。
从工具栏中选择Ylink工具。Shift在Y方向上单击H的底部,然后从浮动调色板中选择“round to grid”。下一班次点击Cvt标志,然后为UC_BASE_HEIGHT选择Cvt 8。对杆的另一侧重复这些步骤。接下来,在H的顶部单击并重复前面的步骤,但这次选择Cvt#2作为CAP_HEIGHT。
下一系列链接将从这些点开始,并将控制衬线。从基点(Cvt 8)链接并链接到左侧的衬线。从同一个基点开始,对右侧做同样的事情。
注意:提示时我们不需要触摸所有点。如果两个点位于同一位置并形成一条完整的直线,我们可以使用任一点进行提示,而另一个点将使用提示点。因为在编译提示时,称为“插入未使用点”的指令会使这两个点一起移动。
从顶部CAP_HEIGHT点连接到左侧衬线的另一侧。然后为右侧做同样的事情。在所有衬线链接中应该选择Cvt 80。如果没有,Shift点击Cvt标志并将Cvt更改为您为UC,Y serifs设置的Cvt。链接狭窄区域时,可能需要放大以选择或链接到点。
Y方向上的最后两个链接将控制H上的条形。从工具栏中选择YInterpolate工具。就像从serif链接的顶部到字形顶部的serif链接一样。接下来将插值拉伸到条形图的底部。现在从工具栏中选择Ylink工具,然后选择指向栏顶部的链接。按住Shift键并单击箭头并将箭头更改为笔划。应选择Cvt 72或适用于此栏的Cvt。
你现在可能有几个问题。
为什么我们从衬线的顶部链接到控制栏?
从衬线顶部连接将保持条形相对于衬线展开或收缩的位置。另一种方法可以是从基线点开始使用,并且顶点高度点的顶部可以作为条形图的父级。这两种方法都可以接受。您可以尝试任一方法,并根据您看到的像素模式选择最佳方法。更改链接时,请确保选择基点链接而不是未使用的点。如果这样,您将创建一个新的起点。
我们也可能根本没有内插条。另一种方法可能是按住键点击条形图底部的一个点,将该点环绕到网格,然后从那里链接到条形图的顶部。这将使条形与其他暗示点无关。条形将圆到靠近其原始轮廓坐标的位置。效果是杆有时会很高,有时会很低,通常它的位置会不一致。
为什么我们插入和舍入底点而不是栏上的顶点?
如果我们在插值中使用顶点作为子点,则条形将倾向于向下舍入并且可能导致条形低。在视觉上看起来更好,而不是低,所以我使用底部点,如果栏不能居中,它将被推高。
编译Y方向提示。
现在关闭Y方向并打开X方向。
我们将继续暗示X方向,就像我们暗示大写的O一样,从侧面暗示暗示。从工具栏中选择Xlink工具。从右侧承载点连接到杆的右侧外侧。按住Shift键并单击箭头并将其更改为距离,无Cvt并保持最小距离。从左侧轴承到左侧轴杆的外侧连接。此链接将具有与右侧负载链接相同的设置。(链接保留在最后一个设置。)现在Xlink从左侧杆的左侧到另一侧定义左侧杆底部。按住Shift键并单击箭头并选择笔划,Cvt,最小距离箭头。Cvt 68应该是自动选择的。现在对右侧击球做同样的事情。选择刚刚链接到的点,并链接到X方向上相同位置的点,并且位于H条的另一侧。按住Shift键并单击箭头并将设置更改为directon,不保持最小距离且不保持Cvt。这将使杆的顶部与杆的底部保持相等。这个链接是必要的,因为轮廓不会像大写的那样继续到词干。对于另一侧的笔划也是如此。现在我们将从左右茎控制衬线的长度。从左侧杆的左侧连接到顶部的衬线。应该选择Cvt 78或79。链接到底部衬线,你应该选择相同的Cvt。按住Shift键并单击箭头并将设置更改为directon,不保持最小距离且不保持Cvt。这将使杆的顶部与杆的底部保持相等。这个链接是必要的,因为轮廓不会像大写的那样继续到词干。对于另一侧的笔划也是如此。现在我们将从左右茎控制衬线的长度。从左侧杆的左侧连接到顶部的衬线。应该选择Cvt 78或79。链接到底部衬线,你应该选择相同的Cvt。按住Shift键并单击箭头并将设置更改为directon,不保持最小距离且不保持Cvt。这将使杆的顶部与杆的底部保持相等。这个链接是必要的,因为轮廓不会像大写的那样继续到词干。对于另一侧的笔划也是如此。现在我们将从左右茎控制衬线的长度。从左侧杆的左侧连接到顶部的衬线。应该选择Cvt 78或79。链接到底部衬线,你应该选择相同的Cvt。中风。现在我们将从左右茎控制衬线的长度。从左侧杆的左侧连接到顶部的衬线。应该选择Cvt 78或79。链接到底部衬线,你应该选择相同的Cvt。中风。现在我们将从左右茎控制衬线的长度。从左侧杆的左侧连接到顶部的衬线。应该选择Cvt 78或79。链接到底部衬线,你应该选择相同的Cvt。
如果在任何时候未选择Cvt(?),则选择您在Cvt表中定义的正确Cvt。当前链接的某个属性与Cvt表中定义的任何属性不匹配时,不会选择Cvt。内部顶部衬线链接的Xlink可以跨过定义H的条的轮廓。这种类型的链接将是灰色的,并且不会找到Cvt。衬线的Cvt具有颜色为白色的属性。可以为黑色,白色或灰色的衬线定义Cvts。我发现这个重复。我只需手动选择正确的Cvt。
从另一个Xlink链接,将此左侧茎干定义为顶部衬线长度。您可能必须手动选择Cvt。Xlink横跨底部衬线。对右茎上的衬线做同样的事情。编译提示。
接下来我们将提示主对角字形。选择大写的“V”。
提示对角线被认为是最难控制的图像之一。对于MyFont中的大写“V”,将使用名为“stroke”的Visual TrueType链接。笔划是一种高级提示指令,可以在水平和垂直方向上移动点。笔划提示的基本概念由构成对角线笔划的两对点组成。这些对是笔划底部的点,第二对是笔划的顶部。类似于直线笔划的Xlink,但有一个底部和顶部的链接。
用于暗示’V’启用X和Y方向。(您需要启用两个方向,因为对角线笔划在X和Y中都有效。)从左外侧点向左拖动到“V”裆部的内侧点。然后沿着轮廓的直线部分从最后一个曲线点向上拖动笔划的顶部,到另一侧拖动到一个曲线点,该曲线点是对角线轮廓的直线部分上的最后一个点。对角线行程链接应自动选择Cvt 76。如果没有,请选择Cvt作为大写对角线笔画。现在对于从内裆点开始的另一个对角线开始(将由第一个笔划控制)并且跨越对角线连接到下部外侧点。然后将笔划的顶部连接到另一边’ 沿着轮廓的对角线的最后一点。选择的Cvt应该是较大的大写X对角线Cvt的大写对角线Cvt或Cvt。
现在选择Xshift工具并从左对角点(由对角线笔划控制)连接到衬线到衬线末端。按住Shift键并单击已链接的serif点,然后选择round to grid。
我们使用Xshift而不是Xlink的原因是因为在这个对角线上我们从对角线笔划链接。所有对角线笔划的点都不会精确地放在网格边界上。如果我们使用其中一个点不在网格边界上的Xlink,我们链接到的点将舍入到类似于网格边界的位置。即使我们使用round to grid的链接设置也是如此。(我们称之为“圆形到网格”更真实地围绕距离设置。)当应用灰度时,这会在更高分辨率下导致不需要的结果。
对于笔划内部和另一个右对角线,Xshift和圆周距离相同。最后,X将这个点移动到括号内衬中心的极值处,并将其围绕到网格。现在关掉X方向。并开始暗示Y方向。

按住Shift键并单击底部点,然后选择圆形到网格,并选择Cvt作为大写基线或过冲。在我的情况下,我使用过冲Cvt 9.Ylink到定义胯部的点,距离,没有Cvt并保持最小距离链接。按住Shift键并单击右上角,选择round to grid and Cvt 2.对左侧执行相同操作。YLink到衬线的两侧并选择’Y’衬线Cvt 80.为双方做这个。
最后,我们需要插入Stroke命令中使用的Y方向上的点。这不是必需的,但强烈建议,因为它将创建更平滑的像素模式。在Y方向上,使用Y插值工具,选择我们用于将V的顶部锚定到Cvt 2的顶点和我们锚定到Cvt 9的底点。这些是Y插值的父项。对于要插值的点(或子点),选择在笔划命令中使用的两个笔划上的点,并且位于父点之间。我们不需要插入与插值的底部父点位于同一Y位置的点。
编译提示。

现在我们对大写的所有三个主要字形都有提示,我们将开始暗示小写字母和图形的主要字形。选择小写的“o”并使用与我们用于大写’o’相同的提示结构。此时应选择小写Cvt值。在编译’o’的提示后,移动到小写’n’。在X方向上向内链接,就像我们在其他字形上所做的那样,并且链接在左侧的干线上。链接到Xlink内部顶部过渡交叉点的点。这类似于我们在大写字母H上用来控制任一干的顶部的链接。从侧面连接到右侧杆的右侧连接。现在控制左侧和右侧杆的衬线。将Cvt用于小写X serif,Cvt 91和/或92。
选择Y方向并关闭X方向。按住Shift键并单击以围绕n的顶部和底部,就像我们对其他部分一样。选择底部点的小写基线Cvt 10和顶部圆点的Cvt 7,如果左侧杆的顶部位于x高度,则选择Cvt 6.(如果左侧杆的顶部未与圆形或你可以从圆顶部分链接到它的x高度。)使用带有serif Cvt(93)的Ylinks作为底部衬线,就像我们之前做的大写一样。Ylink从圆顶部分到定义顶部笔划的内部点。从圆形顶部开始,到与左杆相交的笔划顶部。这里将保持此点的最小距离,并且不使用Cvt。Ylink穿过茎到另一边。选择用于备用或辅助功能的Cvt。我已经将Cvt 85定义为一个薄的交替直线笔画。我将使用相同的Cvt作为小写的h,m,b,d,q和r。接下来我们将控制左上角的衬线。在这里,我在衬线内部有一个极值。在大多数情况下,我想将极值舍入到网格中。这些极值是在拱形或直线行程的峰值处的点。我们在X方向上为大写H选择的词干点是极值。这里在Y方向上,点15是极值。该点应该用作其他周围点的参考点。从我们之前使用的衬线点的顶部向下Ylink并向下舍入到x高度,到达极值点15.使用距离Cvt并保持最小距离链接。和r。接下来我们将控制左上角的衬线。在这里,我在衬线内部有一个极值。在大多数情况下,我想将极值舍入到网格中。这些极值是在拱形或直线行程的峰值处的点。我们在X方向上为大写H选择的词干点是极值。这里在Y方向上,点15是极值。该点应该用作其他周围点的参考点。从我们之前使用的衬线点的顶部向下Ylink并向下舍入到x高度,到达极值点15.使用距离Cvt并保持最小距离链接。和r。接下来我们将控制左上角的衬线。在这里,我在衬线内部有一个极值。在大多数情况下,我想将极值舍入到网格中。这些极值是在拱形或直线行程的峰值处的点。我们在X方向上为大写H选择的词干点是极值。这里在Y方向上,点15是极值。该点应该用作其他周围点的参考点。从我们之前使用的衬线点的顶部向下Ylink并向下舍入到x高度,到达极值点15.使用距离Cvt并保持最小距离链接。我们在X方向上为大写H选择的词干点是极值。这里在Y方向上,点15是极值。该点应该用作其他周围点的参考点。从我们之前使用的衬线点的顶部向下Ylink并向下舍入到x高度,到达极值点15.使用距离Cvt并保持最小距离链接。我们在X方向上为大写H选择的词干点是极值。这里在Y方向上,点15是极值。该点应该用作其他周围点的参考点。从我们之前使用的衬线点的顶部向下Ylink并向下舍入到x高度,到达极值点15.使用距离Cvt并保持最小距离链接。
这是我们没有为应该在其他字形中使用的特征定义Cvt的第一个实例。顶部衬线特征以几个字形重复,我们应该以完全相同的方式控制它们。

停在这里。我们应该使用Cvt作为从serif顶部到极值点15的链接。此特征在其他字形中重复(b,d,h,I,j,k,l,m,p和r。)由于我们在创建Cvt时没有看到这个,我们可以在157号添加这个新的Cvt。(157是下一个可用的Cvt。)测量从衬线顶部到所有字形中极值的Y的距离。找到一个好的平均值并为Cvt 157创建新的Cvt条目。
创建一个新的Cvt。打开Cvt窗口。键入新的Cvt编号(157),后跟冒号。添加一些空格,然后键入Cvt值。在值之后,您可以添加Cvt属性。通过键入“零”和“x”,Visual TrueType会将其解释为Cvt属性。突出显示“0x”然后从“编辑”菜单中选择“编辑Cvt属性…”菜单项。设置此Cvt的属性。
编译完Cvt窗口后,我们可以恢复提示。Shift - 单击Cvt符号并选择新的Cvt 157。
用距离连接到点17,没有Cvt并且不保持最小距离。链接到第18点并使用距离Cvt(93)并保持最小距离。编译小写n的提示。
现在提示小写’v’,因为我们使用小写Cvts做大写的’V’。
转到最后的主要字形组,数字。打开图零并以与我们对大写O和小写o相同的方式提示,使用图Cvt值。提示旁边的图1. 1的提示结构类似于小写字母n的左侧但没有从左过渡笔划中断。您也可以使用Cvt 157作为顶部衬线Y距离。一旦你完成了零和一个,我将继续下一部分,这将使这些组一起工作并控制阀杆厚度。
控制阀杆厚度,断点并使字体保持一致
我们只暗示了大写和小写的三个字形以及图组中的两个字形,因此我们可以在暗示其余字形之前比较所有主要特征。在这里,我们将关注断点和茎厚度。要查找的项目和要问的问题是:
大写,小写和数字是否从一个像素到两个像素均匀分布等等。例如,如果大写字母在其他像素之前断开,则这将是一个视觉问题。
在PPEM中,茎从一个像素到两个像素?如果太快(15PPEM),当字体实际上重量较轻时,字体将显示为粗体。20PPEM是大多数常规重量字体变成两个像素的好时机。
什么时候圆形比直杆更重?
什么时候出现过冲?一旦它们首次出现,它们总是比平面大吗?群体之间是否一致?他们应该或者是否可以使大写字母的行为与小写字母不同?
在启用gridfitting的情况下查看字体,并显示文本和大小运行。在“文件”菜单中,选择“首选项…”菜单项。在对话框中,使用O,H,V,o,v,n,0和1在“额外文本”对话框字段中键入示例文本。从9PPEM开始查看文本字符串中所有字形的粗细。不要关心奇数像素模式,这里我们只关注厚度和断点。
在MyFont中,茎在17PPEM处转向两个像素。这是由Pre-program的一部分控制的,使用Cvt继承设置低于17PPEM。
我们运行Prepare Font时导入了Pre-program。继承部分将使用主Cvt用于其他Cvts,使它们在指定大小之前具有相同的距离。这就是我们如何控制所有相同的直到17PPEM。我们可以通过更改此主Cvt值或使用称为Delta提示的异常来更改字体中所有词干的粗细,这些异常将扩展或减少特定大小的主Cvts值。要查找继承部分,请从“视图”菜单中选择“预编程”(cmd-3)。在预编程窗口中,从“编辑”菜单中选择“查找”(cmd-F)。搜索“继承的使用”。
你应该看到一个继承的描述,后面跟着一个注释,用于插入DeltaC指令(参见关于Delta提示指令的语法的TrueType规范)来改变主Cvt 65.在那个注释之后是’fpgm中对函数31的两个函数调用’表。
复制
CALL[], 66, 65, 8, 31
第一个函数调用将Cvt 65中的值复制到Cvt 66直到8PPEM。应将此“8”更改为您希望茎断裂为两个像素的PPEM大小。我建议从17PPEM开始。
在模板预编程中,这些函数调用中左起第三个值设置为8PPEM。应将此值更改为更高的值以进行继承调用。
复制
CALL[], 67, 65, 8, 31
第二个函数调用将Cvt 65复制到Cvt 66直到8PPEM。
这是预编程中第一次使用继承。在这里,我们开始的过程将使所有词干保持一个像素,直到我们希望它们变成两个像素。
我们使用每个组和Cvts组的下一个函数调用列表完成该过程。
第一组函数调用是大写的。大写组中的第一部分调用是将X主Cvt66复制到其他X大写Cvts,直到指定的大小
复制
CALL[], 68, 66, 8, 3
.
.
从0..16PPEM Cvt 66的值与Cvt 65相同。因此,将Cvt 66复制到Cvts 68,69,70,71,76和77将使它们与65相同。
高于16PPEM Cvt 66不再等于Cvt 65,但所有其他X UC Cvts保持等于66。
然后在31PPEM之上,所有X UC Cvts现在都恢复到它们的设定值。这样可以使17PPEM以下的所有组中的所有茎保持相同,并且所有组中的所有X距离在17和30PPEM之间保持相同。
下一部分控制Y Cvts并复制Cvt 67,Y主Cvt复制到全部大写Y Cvts。在16PPEM以上,所有Y茎都使用它们自己的设定值。应根据每种单独的字体定制这些阈值。
通过使用继承来概括权重控制:
我们首先提示主要组中的控制字符。
查看字体并确定茎将保持一个像素的PPEM。
将预编程中第一个函数调用中的继承PPEM值从默认值8设置为字体将变为两个像素的值。该值通常为17PPEM。
确定组可以使用哪些PPEM大小自己的Cvts而不是主方向X或Y Cvt。通常需要将X方向控制为比Y更高的PPEM尺寸。
使用增量和间距对提示进行例外处理
现在我们已经在预编程中设置了继承值来控制权重,现在我们可以最终确定字体的主要部分。
从大写控制字符O,H和V开始。对于大多数文本字体,清理提示可以从9PPEM开始。如果我们有一套很好的固定提示,我们的字形应该在28PPEM以上的大尺寸上完成。与更常见的文本设计相比,更华丽的设计可能需要在更大的尺寸上进行一些改进。
所有字体无论多么聪明,提示通常都需要某种类型的条件语句来控制一个大小的提示,而不是另一个大小。在TrueType中,Delta提示用于产生这些异常。
首先选择大写字母O.选择9PPEM。这是我们可能使屏幕位图清洁的最小尺寸。在我的衬线字体中,主要提示是在右侧保持一个像素。我的继承设置确保了茎都是一个像素,幸运的是位图模式是对称的。O在其细胞中向左拉。在这种低分辨率下,这是一个很好的位图。宽度忠实于缩放的原始宽度(不是手动更改),并且有一个白色像素,因此在重复时不会崩溃。
然后,我将选择大写的H来检查它是否也向左拉或者是否居中。如果一个控制字符拉出一个方向而另一个控制字符中心则存在间距问题。在大写字母H中,从衬线的末端开始没有零侧面。视觉上它居中。我需要决定是否要将H的右侧部分移动到一个像素上,或者将O的左侧移动到一个像素上。我可以使用Visual TrueType XDelta工具来移动这些部分。
要在视觉上更好地测试哪个外观,请在主窗口中选择O,然后从工具栏中选择XDelta工具。按住Shift键并单击左侧有一个Xlink的左侧点,然后会出现一个弹出对话框。将光标拖动到弹出Delta标尺上的+1值。字形和位图应压缩一个像素。通过窗口顶部显示的文本字符串,您可以比较UC H和UC O.现在,较低文本字符串中的间距应居中。如果您发现UC O看起来过于浓缩,则反转添加XDelta的过程。按住Shift键并单击该点并将Delta标尺返回到零值。这删除了XDelta并将字形的位图返回到原始位置。
接下来选择大写字母H.使用相同的XDelta过程。但是这一次从右侧支撑着Xlink的点,我们可以压缩大写的H并将它像大写的O一样。再次查看文本字符串,看看H是否现在对于字体来说太压缩了。决定你最满意的是哪个图像,O或H.在我们最终确定决定之前,我们应该看看其他像字形空间的方式。查看所有其他大写字形,看看是否更多中心或更多拉。如果比拉动更中心,最好压缩大写字母O.如果更多的字形向左拉,那么最好强制大写字母H向左拉。一旦你有一个决定验证小写空格如何。如果原始字体间隔正确,则小写字符的行为方式应与大写字母相同。目标是选择产生最少工作量的方法。有时有半拉和半中心。在这种情况下,你必须选择一个。
在我的情况下,我的小写向左拉。我对压缩的H的图像感到满意。此外,H在该尺寸上有点扩展,使其像素变窄,不会损害其可读性。
在H的右侧插入XDelta之后,我将向上移动到10PPEM。
我将以与9PPEM相同的方式继续10PPEM的过程。决定是将控制字符定位在左侧还是中间位置。在此过程中,我在移动字形或对其间距进行任何更改后查看位图模式。我发现最简单的方法是校正间隔的PPEM大小,同时校正视觉位图模式。
在我的字体中,15PPEM的大写字母O的位图模式是不可接受的。它是对称但不光滑的。在所有四个角落都有额外的像素,这些像素会造成沉重的,破旧的外观。我可以通过使用Delta Hints移动一些暗示点来纠正这个问题。
通过查看轮廓和位图图案,如果轮廓在内部轮廓的底部向上和向下移动,这可能足以移除额外的像素。通过从工具栏中选择Y方向和YDelta工具,按住Shift键并单击与控制O的顶部圆形部分相关联的顶部内部轮廓点。应显示弹出标尺。将光标滑动到+4/8。这将使Ylink点在Y方向上移动半个像素。现在轮廓应该清除一些像素,并给出一个不同的,更好的模式。+4/8的值应该足以完成这项工作。您可以通过增加或减少此移动量来测试不同的数量。
由于较低级别的TrueType指令,任何提示未触及的点也会向上移动。您可以在VTT Talk窗口(cmd-5)中看到此Visual TrueType Talk指令。在命令的末尾是’Smooth []’命令。然后将该命令编译成IUP [X]和IUP [Y] TrueType指令(cmd-2)。这些指令移动尚未暗示的点已被暗示的点。效果使轮廓平滑。Delta工具可以单独或相邻点移动点。通过移动点击,我们移动点和它的邻居,使轮廓平滑。这会使点与其他提示内联,而不是之后。单独移动点仅在杂散像素靠近某个点时有用,并且可以通过移动该点来移除它。
对下部内轮廓做同样的事情,我们现在有一个像素宽度的图像。在我的情况下,我有一个比没有Delta提示更好的图像,但我的图像现在不对称。我发现通过在X方向上移动单击并且右侧的外部左侧提示点+2/8和左侧的-2/8移动右侧内部和外部提示的轮廓点,我现在已经完成了对称图像。此字形现在已完成此大小。
继续移动尺寸,直到没有间距或图像问题。像我们对9PPEM大小所做的那样移动和引用其他控制字符。完成大写字母O后,移动到大写字母H,然后是大写字母V.完成大写字母后,对小写字母,数字和最终剩余字形使用相同的过程。
在所有控制字符间隔开后,完成开始完成从大写字母A到Z开始的大写字母的其余部分。参考字体MyFont.fog.ttf.source中的提示示例,以获取大写字母剩余部分上的样本提示模式,小写和图形字形。
复合字形
在所有字形间隔正确并且图像得到改进之后,我们可以最终确定复合字形。这些字形没有Visual TrueType工具。我们需要编辑TrueType(’glyf’程序)(cmd-2)指令。
如果字体文件在原始Fontographer文件中使用复合,Fontographer会构建复合指令。使用Fontographer中的Get Reference菜单项做了这个。
在字符/字形集(cmd-9)中选择“Aacute”。选择TrueType窗口(cmd-2)。窗口是空白的。(说明是二进制形式,不是可读形式)。要查看说明,请编译(cmd-R)窗口。可见指令是从指令的二进制文件创建的。在MyFont中,Fontographer编写的指令是:
复制
OVERLAP[]
OFFSET[R], 36, 0, 0
OVERLAP[]
OFFSET[R], 141, 399, 334
第一条指令是OVERLAP []。这是一个旨在提供信息并标记所有字形的指令,因为假设是一个重叠的复合(一个复合字形,其组件的轮廓重叠。)所有形式的Microsoft Windows都不支持此OVERLAP []指令。我们不建议在TrueType字体中重叠轮廓,因为在某些PostScript设备上,这些区域显示为白色而非黑色。如果你有一个具有加入基本字形的变音符号的字形,最好加入这些轮廓而不是制作复合字形。’Ccedilla’字形通常是带有cedilla的连接C. 这不应该是复合材料。
删除复合字形中的OVERLAP [R]指令。编译(cmd-R)TrueType窗口。你现在应该:
复制
OFFSET[R], 36, 0, 0
OFFSET[R], 141, 399, 334
在第一个OFFSET [R]指令之前插入以下命令:
复制
USEMYMETRICS[]
编译(cmd-R)TrueType窗口。你现在应该:
复制
USEMYMETRICS[]
OFFSET[R], 36, 0, 0
OFFSET[R], 141, 399, 334
USEMYMETRICS指令强制此字形从第一个OFFSET指令中指定的字形获取度量(提前宽度)。OFFSET指令由3个参数和一个布尔标志组成。设置布尔标志,以使复合的位图与原始位图形状匹配。这是使用’R’的语法设置的。第一个参数是组件的字形索引。下一个值是每个em的X偏移量。最终值是Y偏移量。基本字形应该始终是第一个,并且通常对于X和Y都具有零偏移量。第二个OFFSET是变音符号。X偏移用于使变音符居中,并且对于所有复合字形中的所有Y距离,Y通常始终相同。由于变音符号位于小写字母中,因此需要向上移位。
用于定位变音符号的值被设置为高分辨率,并且当正确设置时,在大多数尺寸下给出良好的结果。在小尺寸下,舍入可以影响位图的位置。我们使用高级TrueType函数,这将有助于保持diacritic在X中的基本字形上居中,第二个将确保变音符号不会向下舍入到基本字形的顶部。
从“视图”菜单中打开“字体程序”(cmd-7)窗口。找到(cmd-F)’功能79’。这是用于确保字形不触及基本字形顶部的函数。下一个功能#80用于在X方向上定位变音符号。
要使用这些函数,我们需要在每个复合字形的本地TrueType指令(cmd-2)中添加一条CALL指令。在每个函数中都有一个注释,显示CALL指令的语法示例。
首先添加X方向的调用。为了获得正确的结果,我们首先需要使用X方向的函数。函数80使用5个参数。第一个是可以应用于变音符号的偏移值。这通常是不必要的,并设置为零。接下来的两个值是变音符轮廓中的点数。四个和第五个值是变音符号上的两个点数。最终值是功能编号。
CALL 80的语法是:
复制
CALL[], 0 , A1, A2, B1, B2, 80
SHC[2], 2
A1和A2应该是变音符号的点。B1和B2应该是基本字形的点。如果在基本字形之间没有两个定义的点,则下一个指令移动轮廓号2(变音符号)。可以从一组或两组点值重复点数。要在变音符号上使用一个点,在基本字形上使用一个点,您可以将参数设置为A1,A1,B1,B1。(在MyFont中,实际值为33,33,17,17。)
MyFont的X方向说明如下:
复制
USEMYMETRICS[]
OFFSET[], 36, 0, 0
OFFSET[], 141, 399, 334
CALL[], 0 , 33, 36, 17, 18, 80
SHC[2], 2
现在我们可以添加Y功能。对于这个方向,我们需要知道基本字形顶部的点编号和变音符底部的点编号。在MyFont中,点18是A顶部的点之一。点33是锐角底部的点。
CALL 79的语法是:
复制
CALL[], 2, B1, A1, 79
第一个数字’2’是要移位的轮廓编号。第一和第二轮廓是基本字形’A’。轮廓编号从零开始。(在这个字形中有轮廓0,1和2)第三个轮廓是锐角,用数字2表示。下一个数字是基本字形顶部的点,第二个是底部的点。急性的。最后一个数字是要调用的函数。
“Aacute”的最终说明如下:
复制
USEMYMETRICS[]
OFFSET[], 36, 0, 0
OFFSET[], 141, 399, 334
CALL[], 0 , 33, 36, 17, 18, 80
SHC[2], 2
CALL[], 2 , 18, 33, 79
将两个调用添加到TrueType窗口后,编译它们(cmd-R)。
您需要在所有复合字形中重复这些词干。在具有低于基本字形的变音符号的字形中,不应使用Y函数。这个字形的一个例子是sans serif’Ccdeilla’。Y函数不会向下传播变音符号,只会向上运行。
可能出现的其他问题通常是由一些语法或手动改变变音符号位置引起的。一个问题的一个例子是,如果变音符号垂直定位不好而且复合材料垂直定位在大写字母中很差,那么你可能会错误地改变主变音符号的高度。当小写复合词变音符号垂直高而大写字母很好时,一些铰链手动添加了Delta提示以降低基本字形中的变音符号。然后,当大写复合材料使用相同的字形时,变音符号实际上现在位于此PPEM大小的基本字形顶部之下。当调用Y定位函数时,它不会改变该变音符号,因为距离不等于零,但它是小于零的全像素。
如果在X函数之前调用Y函数,则X定位可能无法预测。始终先调用X功能。
在具有变音符号的复合字形中,包含多个轮廓,(bollé和dieresis)调用是Y方向所必需的,并且X方向需要两个移位轮廓调用。
在Trebuchet Bold中,’Adieresis’的说明是:
复制
USEMYMETRICS[]
OFFSET[R], 36, 0, 0
OFFSET[R], 142, 44, 370
CALL[], 0, 14, 32, 5, 6, 80
SHC[2], 2
SHC[2], 3
CALL[], 2, 5, 17, 79
CALL[], 3, 5, 29, 79
第一行根据第一个OFFSET字形的指标设置指标。
第二行调用基本字形“A”,其字形索引为十进制36。
第三行称为变音符号’dieresis’字形索引142,并在X中将其移动超过44,在Y中移位370单位。
下一行是用于在’X’中定位的函数调用。它定位点14,即左点的内点和点32,即右点的左内点,在基本字形的两个顶点之间,点5和6。
接下来的两行移动轮廓号2(dieresis的左点)和轮廓3(dieresis的右点)。
最后两行是Y定位。第一次调用检查dieresis的左点是否接触基本字形,第二次调用检查dieresis的右点。CALL中的第一个设置参数是轮廓2,左点和轮廓3,右点。点5是基本字形顶部的一个点,用于两个调用。点17位于dieresis左侧点的底部。点号29位于dieresis右侧点的底部。
开始完成字体文件
在我们纠正了复合指令的任何问题并添加了更正任何间距错误的函数之后,我们可以整理任何剩余的字形。
在提示过程中,字体文件中的值可能已更改。提示后的第一个过程是更新存储在’maxp’表中的字体文件值。要更新此表,请从“文件”菜单中选择菜单项“Recalc’maxp’表…”。在警告对话框中,单击是按钮。
我们将设置的字体的下一个功能是控制灰度设备(如Windows光栅化器)何时显示灰度图像。在’gasp’表中设置值可以控制灰度。在“文件”菜单中,选择“编辑”gasp’表…’在喘气表对话框中,将值设置为默认值。在左侧是最大尺寸的条目,将使用右侧的设置。使用默认值时,字形显示在8 PPEM以下时,它们将不使用提示并将使用灰度图像。从9 PPEM到15 PPEM提示将使用(网格适合),灰度不会仅产生黑色或白色图像。高于15 PPEM将显示两个提示(网格拟合)和灰度图像。要以当前字体设置此表,我建议使用灰度,没有网格适合低于8 PPEM。我会使用从9 PPEM到“从一个像素转到两个像素”的“网格拟合,没有灰度”。然后从两个像素PPEM和向上“使用网格拟合和灰度”为所有其他大小。
在主窗口中选择大写字母O.注意PPEM大小,第一个图像是茎厚度的两个像素。在MyFont,这是17 PPEM。然后从’文件’菜单中选择’编辑’喘气’表…’将第二个默认设置从15 PPEM更改为16 PPEM。单击“设置”按钮。这样就可以在灰度设备上设置“喘气”表,灰度等级应该高于16 PPEM。
接下来,从“显示”菜单中启用“灰度”菜单项(将自动检查“MS光栅器1.7”。)打开像素和网格拟合后,查看字体中的几个小写和大写字形。在Visual TrueType中,不会读取’gasp’表。当在VTT中打开灰度时,它将在所有尺寸上打开。查看具有灰度的尺寸的字形,图像的厚度为一个像素。请注意,未完全覆盖像素的对角线和圆形图像现在是灰色的。在某些区域,例如小写字母v,细对角线笔画看起来模糊不清。这就是我们建议仅在您有足够的厚度来显示两个像素时才打开灰度的原因。如果您发现即使字体是两个像素,某些功能也会显得模糊或定义不清。尝试在VTT中打开灰度显示它们。如果您发现非灰色图像更清晰,请将’gasp’表中的值重置为高于建议值。
要以默认值查看图像(在VTT首选项中设置的比例超过4倍),您的显示器设置需要设置为16种颜色(或灰色)或更高。如果您的显示器设置少于16种颜色,您可能会看到意外的结果或看起来像素丢失的内容。这些丢失的像素实际上是灰度值,无法在黑白模式下显示。
设置’喘气’表后,我们现在可以在发送字体之前开始最后的步骤。最后一个主要步骤是验证您的工作,通常称为“校对”字体。
字体制作的校对阶段是创建良好TrueType字体的重要部分。字体制作校对部分的两个主要阶段是美学评估和技术字体文件验证。第一阶段应该是300 dpi打印输出和低分辨率屏幕打样的美学评估。完成美学评估后,应测试字体文件的技术稳定性。
在完成字体之前,应该多次进行美学评估阶段。更准确地说,该评估在提示生产周期期间分阶段完成,并且完全在提示周期结束时完成。美学校对的第一次应该开始是有足够的字形和提示。可以检查这些提示以查看它们是否以300dpi打印机分辨率正确控制字形。您应该检查提示是否过于强大或是否有在屏幕分辨率下不明显的错误,但现在在打印机分辨率下使轮廓变形。在出现字体之前,也应该对整个字体进行校对。
Microsoft的字体文件的校对和测试是通过在Windows 95及更高版本中安装Windows NT,Windows 3.1和Macintosh OS上的字体文件来完成的。
在我们将字体移动到Windows之前,我们需要从Visual TrueType源文件创建可用的二进制版本。由于我们在Visual TrueType中添加了提示,因此已在文件中添加了其他源信息。该文本信息允许我们以人类可读的方式查看提示和指令。编辑或修改Visual TrueType中的提示时,文本信息是必需的。此文件格式在概念上类似于软件工程师使用源代码编写应用程序然后将此源代码编译为机器语言的方式。
在我们在Windows中安装TrueType字体之前,我们将删除额外的源代码。在Visual TrueType中,从“文件”菜单中选择“发送字体…”。当您选择“发送字体…”时,将在对话框中警告您建议重命名字体文件,这样就不会覆盖源数据。如果您确实覆盖了您在Visual TrueType中处理的源文件,则无法在字体中编辑或附加提示信息。
运行“发送字体”时不要覆盖源文件
需要此附加源文本信息才能进行更正。在使用Visual TrueType进行提示时,通常会将源文件命名为“MyFile.ttf.source”。当您完成并准备剥离字体文件的副本时,将此文件重命名为“MyFile.ttf”或“MyFile.ttf.stripped”也很常见。
重命名字体并运行“发送字体…”后,需要将文件移动到可由Macintosh或Windows读取的服务器上。Windows NT Server支持两种操作系统。您还可以使用格式化为1.44Mb或720k PC驱动器的软盘和可以读取PC软盘的Macintosh。
字体测试工具
准备测试字体和运行几个工具有几个步骤。
第一步是根据新的提示信息计算一些新表。
使用Windows控制台工具’Cachet.exe’,我们可以计算’VDMX’,’LTSH’和’hdmx’表。这些表有助于提高字体中图像的性能和外观。
有关’VDMX’,’LTSH’和’hdmx’表的完整说明,请参阅OpenType规范。
将.ttf字体文件从软盘或服务器复制到具有cachet.exe工具的目录。双击c:win95目录中的“dosprmpt”。这将以全屏或平铺模式显示MS-DOS控制台窗口(提示:使用ALT +进入控制台窗口将在最大化和平铺之间切换。)
一些基本的MS-DOS命令。
CD
会将目录更改为指定的目录。
例如:’CD win95’将使当前目录为win95
CD ..
将目录更改为一级。
例如:如果在提示符下显示的当前目录是C:win95system,则CD ..将使当前目录为C:win95
DIR
显示当前目录的内容。
DIR 。
显示当前目录中的子目录。
。
表示所有文件。’ .ttf’表示扩展名为.ttf的所有文件
DEL
删除文件
DEL * .ttf
删除当前目录中扩展名为.ttf的所有文件。
提示和测试周期的结构如下:
源文件包含所有可编辑信息,并且是主文件。
所有提示完成后,从源文件的VTT’文件’菜单中运行’Recalc“maxp”table’。
通过从VTT“文件”菜单中选择“发送字体…”来删除源文件中的第二个剥离文件,以删除编辑器使用的额外信息。
将文件复制到Windows并运行CacheTT以生成一些新表。
将字体加载到Windows中并使用写字板打印和查看字体。
运行Flint以验证所有指令和表。
我们将使用的第一个工具是cachett.exe。CacheTT是NT控制台和Windows 95 DOS应用程序。它通过计算TrueType光栅化器的值来创建和/或修改VDMX,hdmx和LTSH表。
提示字体后,有必要计算特定大小的当前度量信息。如果提示通过移动侧支点来控制提前宽度,则缩放时高级宽度的值将与特定大小的实际提示版本不匹配。CacheTT使用光栅化器以像素为单位计算实际宽度并将其存储在“hdmx”表中。
垂直地,提示可能会导致字形位图比没有提示更少或更大的一个或多个像素,并且轮廓值只是缩放。在Windows中,如果未计算这些位图图像并且Windows使用原始度量标准信息,则会在超过已知单元格高度时对其进行裁剪。VDMX表在提示特定大小后存储实际高度(以像素为单位),因此不会剪切位图。
计算LTSH表是为了通过告诉光栅化器何时可以预期字体没有暗示宽度来帮助提高性能。
有关这些表的完整说明,请参阅Microsoft OpenType规范。
使用cachet.exe工具将当前目录更改为目录。在我的示例中,我当前的目录是C:win95。在提示我输入CD toolscachett。我的cachet.exe驻留在与win95目录相同级别的目录的子目录中。
键入以下命令运行cacheTT:
复制
cachett myfile.ttf myfile2.ttf
在DOS提示符下。Cachett将默认重新计算或创建VDMX,hdmx和LTSH表。有关默认设置以及如何自定义cacheTT的完整说明,请参阅随工具提供的CacheTT用户指南“cachettug.doc”。
使用cacheTT创建新文件后,您现在可以在Windows应用程序中使用此字体。将文件复制到Windows 95中的Fonts文件夹中。我使用Microsoft WordPad创建测试文档。写字板是一个简单的文字处理器,可用于校对字体。我使用这些文档来检查颜色,重新检查间距并在激光打印机上生成更高分辨率的打印输出。
如果发现要更正的问题,请对原始源文件进行更正。然后在此更正的文件上重新运行Ship Font和Cachett。
在您对提示的字体文件的内部外观完全满意后,您现在可以对TrueType字体文件信息进行最终测试。
工具Flint是一个Windows 95应用程序,它使用光栅化器并报告.ttf文件中的任何指令或表是否有任何警告或错误。警告或错误的示例是指令引用不存在的Cvt值。这将被视为应该纠正的错误。
劳奇弗林特。从文件菜单中选择’选择字体…’。选择.ttf文件。从“设置”菜单中选择“大小” 将分辨率保持在72x72。将大小设置为所需的磅值。我建议4-500点。要选择Flint报告错误的方式,请从“设置”菜单中选择“输出”菜单项。通过选中“将结果输出到文件”,您可以选择将结果保存在.txt文件中。您还可以设置Flint将用于测试提示的容差。如果提示移动轮廓点超过此设定值,则会发出警告。这是为了检查是否找到了任何非预期的提示。或者可能错误地移动错误的点或Cvt并导致轮廓失真。默认设置为5.000。该值以像素为单位。
选择输出方法后,您就可以处理字体了。从“测试”菜单中选择“运行”,将处理字体。
通过在源文件中修复它们来纠正字体中的任何错误后,重新运行所有步骤非常重要。
准备剩余的家庭成员
完成常规重量字体的测试和更正后。我们将处理的下一个字体是斜体字体。斜体字体的高度距离应与常规体重字体相同。斜体字体的茎宽通常小于直立的家庭成员。
在测量茎距时,我们不会尝试匹配常规距离,并错误地强制茎干相同。为每种字体使用正确的距离。然后在提示过程中,我们将确保通过继承和提示控件确定词干距离的断点在样式之间保持一致。
使用我们在处理常规字体时使用的相同步骤创建斜体字体的.ttf文件。创建.tff后,在Visual TrueType中打开文件。接下来运行’准备字体…’
像我们对常规字体所做的那样测量斜体组并创建一个Cvt表。
在创建Cvt表时,我们需要测量一个额外的值。该值称为“斜体运行”,由stroke命令使用。它出现在Cvt#36。
在Visual TrueType中,打开斜体字体。从工具栏中选择度量工具。测量斜体角度,最能代表字体的角度。通常这可以从UC I,UC H或LC l完成。
如果设计为衬线,并且很难找到从基线到顶盖高度的两个点,则将测量工具放在假想线上,该线与斜体杆的一侧平行并从斜面杆的一侧延伸到基线。从基线测量到大写字形的顶部和斜体的茎。VTT中显示为’dx’的值是x距离或斜体运行。在我的例子中,值为399.将此值添加到Cvt#36中的Cvt表。编译Cvt窗口。

在我们开始测量干距离之前,我们应该添加Cvt字体范围的继承值。我们希望茎与常规重量一致,因此我们将使用常规重量的继承值。我在正常重量中使用的值是最薄单像素控制的74,主要X控制的193从大写的茎干取得,而主要Y控制的74从小写的Y茎距离取得。在Cvts 65,66和67中输入您的值。
现在我们可以开始测量X和Y茎。从正常体重开始分组开始。当以斜体测量X茎时,我们将测量对角行程距离。测量是从主冲程的左侧到右侧,与基线平行。

对于Y行程测量,Y对角行程很少。唯一可能的Y对角线笔划可以是小写和大写K.Y测量是从对角线笔划的一侧到另一侧垂直于基线。
如果您选择的区域附近没有任何点,则测量工具将捕捉到轮廓。当光标平行于X测量的基线拖动或垂直拖动Y测量时,箭头线将是直线。X距离可能比相同重量的直立式字体的杆测量值略薄。在我的斜体字体中,我的距离平均为178个单位。常规重量为200个单位。
测量圆距时,选择将用于X链接的极值点。在我的斜体字体中,测量值始终为210个单位。(相比之下,常规重量为210个单位。)
在X直线距离中,斜体中没有直茎。直杆的Cvt值可以设置为与主要X对角线距离相同的值,或者用作替代的手动选择的Cvt,用于更大或更小的对角线。
对于serif X距离,我们不会使用Cvt。衬线从对角线笔划向X突出,并且与对角线的主笔划的距离不一致。在提示阶段,我们将使用X移位和舍入控制衬线的网格(锚)方法。
继续测量X和Y的剩余值。通过将平均组值添加到Cvt表并编译Cvt窗口来完成。
暗示斜体
现在我们已经设置了Cvt表,我们将开始使用控制字符和组进行提示。
从大写组开始。选择大写字母O.即使这是一个斜体字形,提示结构也会与常规直立字体相同。打开像素(cmd-B。)注意轮廓上的极值点是X方向或Y方向上与网格线平行的唯一点。在暗示这些点将移动到网格边界,就像移动常规字体的点一样。两者之间的点将在这些点之间进行平滑/插值。
我们再次需要确定一个用于间隔字形的提示策略。常规重量中使用的方法是以侧面形式连接并保持左侧的最小距离。
我将使用一种方法,从侧面提示,而不是保持最小距离或不使用控制值。当出现问题时,我将使用Delta提示来控制间距。您可以尝试使用第3节中描述的其他提示方法。“提示第一个字形”。
在我的斜体字体中,大写字母O的左侧几乎位于右侧。如果我们在右侧保持最小距离,我们会错误地将字形推向左侧。
从工具栏中选择X链接工具,并从右侧支撑链接到O. Shift-click的外部右侧极值,并将链接更改为距离,无Cvt,并且不保持最小距离。左侧的下一个链接具有相同的链接设置。X通过左侧阀杆连接一个圆形的Cvt,并保持最小距离链接。从右极值链接以控制正确的行程并完成X方向。

选择Y方向并转动X方向。与常规大写O一样,使用顶部和底部点上的Y链接工具进行shift键单击。选择,舍入到网格,然后按住Shift键单击高速公路标志,为顶部超调点添加Cvt#3,为底部超调点添加Cvt#9。Y链接带有Cvt的圆形链接,并保持顶部和底部圆形笔划的最小距离。编译大写O的提示。
现在我们可以开始暗示几个对角线笔画中的第一个。在主窗口中选择大写字母H. 在暗示具有主对角线笔划的斜体字形时,我们需要添加一个额外的步骤。我们需要为笔划设置斜体角度。同时启用X和Y方向。从工具栏中选择角度工具。从大写字母H的斜体笔触的底部,单击并向上并沿着对角线笔划的角度向上拖动。当您从光标的原点向上,向下,向左或向右移动光标时,您将看到一条将显示的黑线。释放鼠标时,线条将变为灰色,并且已设置此字形的斜体角度。要休息角度,请重新选择新原点并重复此过程。
同时启用X和Y方向。对于H的提示,我们将使用与常规字体中用于大写V对角线的类似类型的提示结构。H的主干用Stroke命令暗示。衬线将在X中暗示,从主对角线笔划X移位,然后四舍五入到网格。
与其他字形一样,我们需要决定如何启动字形原点或第一个提示。这可以影响字形的间距和居中。由于斜体字体的字形轮廓几乎总是在前进宽度的右侧,因此我倾向于从右侧承载和从左侧到左侧在X方向上的暗示进行链接。从左侧链接会导致字形通常比现在更多地向右推。
我还喜欢在使用笔画工具时首先在X方向上进行提示。笔划工具要求您同时显示X和Y方向。如果我先提示Y方向,屏幕上会有很多信息供我在添加笔画链接时清楚地看到字形。
从右侧承载点X链接到H的右对角行程顶部的点上的X和Y方向。该点应该是对角行程的最终曲线点。在带括号的衬线上,所选择的点将是过渡到衬线曲线的最后曲线点和对角线直线部分的最后一个点。
从工具栏中选择“笔触”工具。从对角线的顶部穿过茎杆连接第一个冲程对,并穿过底部连接到最终的冲程对。选择X移位工具,并使用距离衬线最近的笔划点,从笔划的每一侧链接到衬线上的最远点。与X转换工具链接后,将此点转换为网格。
现在添加Y提示,首先将H的两侧顶部锚定到Cvt 2.Y链接,以使用Cvt 80(衬线高度)控制杆两侧的衬线距离。在顶部提示完成后,执行H的底部锚定两个底部点并选择Cvt 8.Y与Cvt 80连接以控制所有衬线高度。
最后选择Y插值工具。首先选择父母,在底部锚定点和顶部锚定点之一。通过选择条形图上的底部点作为子点并将该点环绕到网格来控制条形。接下来我们需要控制我们在stroke命令中使用的点。选择两个笔划上使用的所有点作为插值的子点。选择Y链接工具并使用直线,Cvt和保持最小距离Y链接在栏上链接。应该选择的Cvt是薄Y直行程Cvt。在我的字体中它是Cvt 72.编译提示。
提示的下一个主要字形是大写字母V.它的提示结构与常规字体的V相同。
其他提示方法
当你看其他字形时,如何开始暗示更复杂的形状似乎并不明显。我们上面使用的方法可以应用于大多数其他形状。
看一个小写的衬线’a’,我们可以将它分成几个部分,看看它与我们已经暗示的字形有多相似。

上图可以帮助您查看主要功能和笔画。垂直线显示将使用X提示的区域。水平线为Y提示,对角线显示主对角线笔划。
在X方向的’a’的左侧,圆形笔划与大写或小写“o”的左侧相同。我们将使用带有Cvt的圆形X链接来实现该功能。正确的行程和尾部可以与我们在大写的“H”上遇到的其他对角线笔划相同。首先,我们将在对角线上做中风。查看对角线,看看沿着此笔划的对角线绘制的两条平行线是如何显示完整笔划特征的。内部计数和圆形笔划如何与对角线笔划相交。将此笔划与大写“H”的笔划进行比较。交叉条的点在H的两侧的内行程之间插值。在’a’上,我们有几个点中断a右侧的内行程。我们可以使用笔划在笔划转回的过渡处使用两个点并进入尾部。在图示中,这些点编号,左侧28个,右侧19个。用于此笔划的第二对点是笔划的两个顶点,即点15和16.然后在X中,我们将插入沿着内部对角笔划的点,这些点位于交点,点0,14和32.点32控制计数器,需要沿左侧的对角线保持一致的重量。如果我们不控制这一点,它将向左和向右移动并导致中心部分变薄或变胖。(注意:在这个轮廓中,两个点用于定义圆形和对角线笔划的交叉区域。这是一种标记常见但不总是必要的轮廓的方法。暗示这些使用的点是沿着要控制的区域。在这个例子中,它们是沿着对角线的点0和14。)

在控制主对角线后,尾部可以像我们对衬线那样处理,并使用X移位,将尾部的最远点四舍五入到网格。上一个插图中的点24是小写的一个特征。
‘a’的完整提示是,从左侧承载到a(#7)的最左侧点,带有X链接,使用距离,没有Cvt并且不保持最小距离。X连接圆形行程,带有Cvt(至#38。)Xlink,带有从碗内侧到右对角行程顶部内侧点的距离链接(#15。)使用Stroke工具选择前两个品脱作为第一对(15和16)和底部的两个点,它们是曲线开始前的最后两个点(28和19).X在第0,32和15点沿左对角线插入点.X将X中尾部的最远点移动到网格(#24)。
在Y中选择顶点(#11)并使用Cvt 7(小写顶部过冲)将其舍入到网格。使用Cvt 11(小写基线过冲)对底部(#3)执行相同操作.Y横跨底部的链接( #42)带有圆形Cvt链接。将右对角线的顶点(#16)四舍五入到网格并使用Cvt 6(x-height。)Y移动到该点,这将向下倾斜笔划的顶部(#15)并且不绕该点。将笔划的底部四舍五入到网格(#26)并使用Cvt 11.然后Y链接到尾部的圆形笔划(#21。)Y链接到尾部的顶部(#23),带有距离链接,保持最小距离,没有Cvt。(注意:如果此尾部是其他小写字形的重复特征,则应为此功能定义Cvt并在所有其他尾部使用它。)最后Y从圆形行程(#11)的顶部到圆形(#3)的点移动(不是圆形)到使用Y移位与对角线和圆形笔划(#0)相交的底点。编译提示。
提示喇叭形的茎和杯状衬线
当某些字体的条纹呈喇叭形时,它们在小屏幕尺寸下显示为平板衬线,因为没有足够多的像素来表示闪光。杯形衬线有时会有一个大的像素显示杯子,当杆小到两个像素时。在这两种情况下,当没有足够的分辨率将它们显示为轻微特征时,我们不希望显示这些耀斑。在Pre-program和Cvt程序中,我们设置了一个测试,当提示应用于耀斑时,将使杆保持笔直。它使用Cvt#157和#158预留用于火炬或杯子远离主干的距离。

当暗示一个展开的大写字母I时,我们想要用X链接和Cvt控制X中的干的中间。然后从X链路的两侧我们将X链接一个距离Cvt,并且不保持最小距离Cvt。我们将使用Cvt 157或158.预编程将测试距离是否足够大,以便显示两个像素。如果距离太小而不能显示两个像素Cvt 157和158将被设置为零字体单位并且不会出现闪光。
这些是喇叭形大写字母I的X提示。测量了耀斑距离,并且在Cvt 157中放置了50的值。在X方向上,X使用Cvt 68连接直线连杆并保持最小距离。从第一个连接点X链接到顶部扩口有一个距离,Cvt 157,并且不保持最小距离。对底部喇叭口做同样的事情。从杆的右侧,连接到顶部和右下部的扩口点,其设置与左侧扩口相同(使用Cvt 157)。编译提示。启用“显示:显示大小”运行菜单项后,您应该看到杆保持笔直,直到有两个像素为耀斑。要测试这个,你可以改变其中一个耀斑,这样它就不会使用Cvt。

附录
附录基于Microsoft Typography网站上的TrueType提示页面。
基本全局表
基本TrueType提示涉及三个对整个字体都是全局的表:控制值表,预编程表和字体程序表。
控制值表(’Cvt’)
TrueType允许通过使用存储在“Cvt”表中的值来控制要素的规则性。控制值是特征的测量值,例如小写的杆宽。这些茎虽然彼此相似,但可能具有略微不同的轮廓距离。使用Cvts可以控制距离,使得它们在低分辨率下具有相同的像素宽度。在更高的分辨率下,将不使用控制值,但是自然距离将显示在杆中。“控制值”表不要求这些值为字形要素距离。值是整数,可以从许多TrueType指令访问。该表也可以写入以及从其他表中读取。
可以存储在控制值表中的字形和字体特征的其他示例是:帽高度,x高度,过冲距离,上升高度,基线,图形高度,衬线长度和高度,斜体角度,组(大写,小写,干距离,群距离。其他功能可能是:较小的组距离,例如数学符号词干距离,大括号,括号或括号距离。

预编程(’准备’)
在每种字体中都有一些始终适用的条件。在TrueType中,我们通过放置在预编程中的代码来控制这些条件。每次更改字形大小或分辨率时以及执行字形的本地指令之前,都会执行’prep’表。这是控制所有字形的全局条件的好地方。在“准备”中放入什么的一些例子是……
使用提示指令时以及何时不使用提示指令时进行控制。在Microsoft字体中,我们关闭低于8ppem和高于2048ppem的提示。我们认为没有必要使用低于8ppem或高于2048ppem的提示。这也可以防止出现一些技术问题。
打开控制以检查连续笔划中的缺失像素。在某些情况下,轮廓可能会在像素中心之间传递,并会在位图中产生漏洞。此控件检查这些条件并添加出现这些“丢失”的像素。
改变’Cvt’中用于控制组特征的值,例如大写的茎和圆。在这里,您可以控制杆从一个像素到两个像素的大小等等。通常强制圆形和直线特征相等,直到达到所需的大小。
设置’Cvt’切入限制。这是一个阈值(或阈值),用于确定是否将使用’Cvt’值或将使用实际距离。我使用三个阈值设置:一个用于设置小ppem尺寸,因此最常使用’Cvt’; 一个用于中等ppem尺寸,其中设置了更合理的阈值; 并设置一个高ppem阈值以始终使用实际距离而不是’Cvt’值。您将在下面看到如何设置一些指令以查看此“Cvt”切入限制。
设置最小距离。有时需要在一个轮廓点和另一个轮廓点之间保持最少一个像素(例如,在字形的词干上提示)。我总是将最小距离设置为一个像素。如果我然后提示越过一个杆并且实际距离小于半个像素,则杆宽总是被强制为一个像素。
字体程序(’fpgm’)
此表存储可以从“准备”或字形指令调用的函数。函数用于消除重复代码在多个字形中的使用。一个常见的例子是控制变音符号在基本字形上的位置。TrueType支持复合字形(由其他字形组成的字形)。在复合字形中,这些已经暗示的字形的位图可能不会以与水平和垂直方向上的原始未打印轮廓位置相同的方式放置。函数通常用于确保变音中心超过基本字形,并且变音符号不接触基本字形的顶部。
II。专业术语
高度宽度 - 字形的水平距离,包括两侧的空白区域。
位图 - 由像素组成的图像。在本文档中,位图是指处理字形提示后显示的字符。这不应与’位图字体文件’混淆。
代码页 - 一组预定义的字符。硬件制造商,软件制造商和标准组织已经为特定用途和设备定义了一组字符。也称为“字符集”。美国英语版的Windows 95使用1252 Windows Latin 1(ANSI)代码页。有关Microsoft Windows使用的代码页列表,请参阅Microsoft Press出版的Nadine Kano所着的“开发国际软件”一书,ISBN 1-55615-840-8。
复合字形 - 由一个或多个其他字形组成的字形,并使用来自这些原始字形的所有数据。TrueType中的复合字形包含指向原始字形的指针以及一些其他定位信息。这种字形构造方法通过对具有相同部分的所有字形使用相同的图像来节省文件空间并保持质量。复合字形的示例是拉丁语1字符,例如’Aacute’和’Eacute’。
字符 - 计算机术语是指代码页或键盘布局中的位置。小写字母a是ASCII代码页中的字符。请参阅“字形”。
变音符号 - 通常与另一个符号一起使用的标记。在拉丁字体中,这些有时被称为“口音”。在希伯来语和阿拉伯语中,这些是表示元音的标记。
特征 - 这些可以是组的字母组,词干或轮的高度,以及衬线。
字体 - 字体的成员。传统上是特定样式的特定点大小。特定轮廓字体文件的现代解释。Times New Roman Italic是Times New Roman字体系列中的字体或字体文件。
功能 - 计算机编程中用于特定类型子程序的通用术语。
字形 - 字体文件中的图像。为了比较,小写的’a’是一个字符。在最新的字体文件技术(OpenType和TrueType GX)中,字体文件中可以有几个小写字母“a”。
字形索引 - 字形从0开始给出数字。访问字形的表和指令使用这些数字。
高级语言 - 语言来自二进制计算机语言的距离越远,人类可读性越高。Visual TrueType链接是一种高级提示语言。TrueType是一种较低级别的提示语言。
提示 - 一组用于可缩放字体的简单字体指令,可帮助计算机更一致地显示位图。该术语通常是用于所有字体技术的通用术语。TrueType字体信息更准确地称为指令,因为它们强烈控制位图图像。
插值 - 在两个移动的关键点之间移动点,并保持关系与所有点的原始位置相同。
拉丁语 - 基于拉丁字母的语言。例如英语,法语,德语,西班牙语和意大利语。
低级语言 - 语言越接近二进制计算机语言。TrueType被认为是一种低级提示语言。计算机汇编语言是一种较低级别的语言,而Pascal是一种更高级别的语言。
映射 - 将字形与字符匹配。在TrueType字体中,“字符映射表”将字形与Macintosh操作系统的字符代码和Microsoft Windows的Unicode编号进行匹配。
轮廓 - 一系列曲线和直线,用像素填充以制作图像。
过冲 - 组中圆形和平面字形高度与基线之间的差异。圆形字符需要更高和更低的投影,以提供相同高度的外观。
PPEM - 每个像素的首字母缩写词。每个像素的像素是非分辨率相关的度量单位。PPEM通过以下等式计算:PPEM = pt size * resolution / 72。
光栅化器 - 从可缩放字体获取信息并以特定大小和分辨率显示位图的软件。Microsoft Windows和Macintosh操作系统包含TrueType光栅化器,用于在屏幕和打印机上显示TrueType字体。PostScript字体由PostScript光栅化器显示为Adobe Type Manager和/或PostScript打印机的一部分。
圆角 - 转换为像素时的距离和值通常是像素的分数。这些像素部分被转换为整个,一半或指定的像素部分。示例:距离为1.4像素。当此距离舍入到网格时,它将等于1个像素。
可缩放字体 - 不一定包含特定于分辨率和大小的预定义图像的字体文件。这些字体文件使用一个源来显示所有可能的点大小和分辨率。
Sidebearing - 从字形的最左边部分到其原点或最右边部分的距离以及字形的前进宽度的结尾,这是字形本身及其两个侧边所占据的总空间。
表 - TrueType字体文件被分成称为表的类似数据的部分。
字体 - 一个系列中的字体集合。Times New Roman是一种字体,Times New Roman Italic是一种字体。
单位 - TrueType字体使用2048单位每EM测量系统。相比之下,PostScript使用1000单位系统。
III。有关TrueType和字体设计的更多信息
互联网资源
Adobe Systems Incorporated
Apple字体/工具组
TypeRight.Org中的字体版权和类型设计问题
图书
Fontographer:Type by Design,Stephen Moye,MIS Press(1995)ISBN:1558284478
开发国际软件(Microsoft Windows代码页),Nadine Kano,Microsoft Press,ISBN:1556158408
15.2.5.提示
提示是生成高质量字体的重要部分。对于在低分辨率输出设备上小尺寸上易读的每种字体,它都是必不可少的。精心设计的字体提供过去仅通过手动调整的位图提供的质量 - 但具有所有速度和减少的内存要求,这些都是轮廓字体格式的特征。此外,由于位图仍然由轮廓字体产生,因此可以以不同的尺寸旋转,缩放和查看文本,甚至在保持高图像质量的同时打印出文本。
与其他字体格式相比,TrueType字体格式在提示功能方面提供了更多的功能和灵活性。因此,当在屏幕上显示文本时,精心设计的TrueType字体是最好的字体。
本文详细解释了提示是什么,为什么有必要,以及提示的TrueType方法与其他字体格式采用的方法有何不同。作为演示TrueType格式功能的一种方法,此处显示了几个示例,它们将TrueType字体与ATM光栅化器呈现的等效PostScript Type 1字体并排比较。
什么是暗示?
在最基本的级别提示(或者更准确地说,指示)字体是一种精确定义哪些像素被打开以便在小尺寸和低分辨率下创建最佳可能字符位图形状的方法。由于字形轮廓确定哪些像素将构成给定大小的字符位图,因此通常需要修改轮廓以创建良好的位图图像; 实际上,修改轮廓直到打开所需的像素组合。一个暗示是一种添加到字体中的数学指令,用于扭曲特定大小的角色轮廓。从技术上讲,提示会导致操作在扫描转换轮廓之前修改轮廓的缩放控制点坐标。在TrueType中,这些提示的组合以及由此产生的失真提供了对产生的位图形状的非常精细的控制。
以这种方式修改轮廓导致所谓的 网格拟合。根据单个字体文件中包含的说明,TrueType光栅化器调整字形轮廓以适合适合于显示文本大小的位图网格。该轮廓调整是根据具体情况进行的, 如下图1所示。


网格拟合明确地确保了字形的某些特征是正规化的,并且允许我们克服传统上与以低分辨率显示文本相关联的许多问题。因为轮廓仅在指定数量的小尺寸处扭曲,所以较高分辨率的字母轮廓保持不变,并且不失真。
虽然许多字体格式和应用程序提供了一些提示功能,但这些提示通常由一些全局参数组成,这些参数只能指定应保持相同的距离。TrueType使设计人员能够准确地规定字形及其间距在低分辨率下以及文本设置中的显示方式。
为什么提示是必要的?
将未修改的轮廓的控制点缩放到小尺寸的计算机屏幕上会导致严重的质量控制问题。在低分辨率下,几乎没有可用于描述字符形状的像素,诸如干重,横杆宽度和衬线细节等特征可能变得不规则,不一致甚至完全错过。这些不规则性大大降低了文本设置的易读性和整体吸引力。
这些问题是像素的绝对和有限大小的结果。在引入输出设备的像素网格之前,数学缩放字符轮廓没有问题。在这一点上,轮廓的一部分可能只通过一小部分像素,而不是完全包含像素。如果在这种情况下打开像素,则曲线的该部分将比原始轮廓宽; 如果它被取消,它将会变得更加强大。
是否打开这样一个像素或将其关闭的决定是至关重要的。在利用灰度光栅化器功能的系统和显示器上,使用不同级别的灰色可能会减少一定程度的难度,但是当文本显示为单色位图时,光栅化器只能进行二元选择(打开或关闭), 黑色或白色,1或0)。在这种情况下,如果轮廓没有网格拟合通过提示,位图将通过数学上向上或向下舍入的点坐标的结果产生。引入向上和向下舍入的“机会”效应会严重影响低分辨率下的类型质量。正如图2中下方所示,舍入可以有一些不愉快的副作用。



如何提示帮助?
由于提示基本上是关于改善小尺寸和低分辨率的文本外观,因此在提示字体时我们的许多问题与绘制字体时相同。在微软,我们竭尽全力确保我们发布的所有字体都被暗示到非常高的水平。我们试图通过暗示解决的问题分为以下七个类别:颜色,可读性,间距,重量,对齐,对称性和“局部美学”(每个字符的实际位图形状)。
颜色
颜色可以说是文本设置中最引人注目的方面。在屏幕尺寸上比在高分辨率下或在打印页面上更是如此。单词或行的颜色的突然和不均匀变化可能会分散读者的注意力。如果文字要清晰,那么均匀的颜色是必不可少的。
在排版的背景下,“颜色”一词指的是页面或屏幕上黑白的平衡。页面的黑色字符形状和白色背景组合起来产生“颜色”。无论颜色有多大胆或多亮,它至少应该是均匀一致的。
单词的颜色由许多问题决定和复杂化 - 例如厚和细茎重量之间的对比,字符的内部空间的大小,字符间距和行间距的数量,对角线笔划的锯齿状,以及中风的总厚度。过度斑驳,黑暗或明亮的区域往往会吸引读者的注意力,使阅读过程变得流畅而有效。
保持均匀的文本颜色意味着该类型对于读者来说仍然是不显眼的。下面的图3演示了用于设置文本的不同字体中均匀和不均匀颜色之间的差异。


可读性
可读性是良好提示字体的第二个关键属性。每个字形都应该可以识别为特定字符。如果不是这种情况,则很难用字体达到所需的易读性标准。在非常低的分辨率下,很难充分表现一个角色。这是妥协的一个因素发挥作用的地方; 使’m’在9 ppem看起来像’m’可能需要一些玩位图。下面的图4显示了一些特别难以理解的字形。



间距
低分辨率下可读性差的另一个原因是字符间距不一致。这种不规则间距是由两件事造成的:位图宽度向上或向下舍入以适合字符轮廓,以及位图宽度(以像素为单位)与高分辨率打印机上字符的设置宽度之间的差异。实际上,人物之间和单词之间的空间应该作为眼睛的规则间隔出现。确保字形不会以小尺寸相互碰撞,这对于保持整个字体的均匀颜色至关重要。
低分辨率的间距字符可能非常困难。应该怎么做,例如,当小写的“i”占据四个像素的总宽度并且具有一个像素的茎宽度时?在任一侧放置一个空间像素会产生剩余像素的问题。将其添加到右侧或左侧将影响字符中字母“i”之前或之后的字符间距,而添加到字符串宽度通常会使字体中的其余字符过于繁重。这些是重要的考虑因素,因为如下图所示,字符间距可能会对字体的易读性产生深远的影响。使用控件TrueType提供调整字符周围的空间以及实际的字母形式本身,确保文本设置相对容易,如右下图所示。(我们将在本文后面提供有关TrueType如何使间距问题更容易处理的更多信息。)


。扩大")
。扩大。")
重量
在精心设计的字体中,控制字符笔划的重量。这不仅在给定字体内很重要,而且与同一字体系列中的其他字体有关。如果在相同尺寸下罗马或斜体的重量同样重或甚至更重,那么将重量视为粗体是没有意义的。以下是通过良好质量着色解决的具体考虑因素:
在ppem尺寸下,角色的茎宽是否扩展到两个,三个,四个和五个像素的茎?这是适合字体的重量和外观,还是太晚了,或者是toosoon?
常规字符的权重如何与同一字体系列的粗体和斜体相比较?应该可以充分控制杆加宽(更多像素)以在everysize处产生重量差异。
在下方的大写字母之前,大写字母是否会在茎中变宽?
数字的权重是否遵循大写或小写字符?或者都不是?
在直线和方形特征之前,圆形角色特征会变宽吗?或相反亦然?
超调是否一致?他们发生得太早还是太晚?他们是否在同一家庭中使用字体?
这些问题中的每一个对于帮助屏幕上的易读性都很重要。如果屏幕上的两个字体权重之间没有明显差异,则很难从文本中分辨出标题。如果大写字形看起来比小写字形更大胆,那么它们会过多地关注自己。如果圆形字符过早变宽,它们会影响文本设置的间距和颜色。


呈现的PostScript版本的Times和Times Bold。扩大。")
渲染。扩大。这里两种字体之间的权重关系更加明显。")
对准
提示字体时的另一个重要考虑因素是对字体内和各种字体系列中的各种对齐的控制 。通常,类似的元素应保持相同例如,在小尺寸下,其中一个或两个像素差异比在24个像素的高度上更明显。在实践中,这意味着强制大写字符对齐到相同的高度,并在下降级别,上升级别和x高度处使用小写字符执行相同操作。当单词设置为大写字符时,高度需要正确对齐。但更重要的是,这些相同的元素需要在同一字体系列的不同变体中正确对齐。通常重要的是确保x高度,例如,在整个句子设置为常规权重时精确对齐,除了一个用斜体或粗体设置的单词。 图7比较了与不正确对齐之一正确对齐的示例。


呈现的PostScript版本的Helvetica,Helvetica Italic,Helvetica Bold和Helvetica Bold Italic。扩大。")
渲染的Arial,Arial Italic,Arial Bold和Arial Bold Italic的TrueType版本。扩大。")
对称
尽管对称性可以很容易地归入以下类别(局部美学),但这里将单独讨论,因为它通常需要在整个字体中进行控制。尽管在具有对角线笔划的角色轮廓中经常出现细微之处,但处理对角线的最干净方法之一是以小尺寸对称地对待它们。这可确保“锯齿”正规化并最小化。下图显示了如何对称地处理对角线笔划可以改善局部形状的外观。
和小写'w'(15 ppem / 11 point),由Adobe Type Manager v3.01呈现。扩大。")
和小写的“w”(15 ppem / 11点)。")
对于几乎对称的字符,仅用几个像素非对称地处理几乎没有意义。在文本行中,如下所示,对称位图可以显着改善整体外观:


地方美学
上面讨论的类别是影响整个字体外观的类别。当然,考虑局部美学也很重要 - 各个位图的形状本身。例如,提示在帮助避免单个像素突刺和平坦运行方面特别有用。它还可以帮助确保特定位图不会变形,保持可读性,并且碗和计数器没有关闭。
提示与其他方法
形状修改
TrueType为设计人员或工程师提供了比任何其他人更多的灵活性和对最终位图外观的控制今天使用的字体格式。通过使用TrueType指令集中的各种命令,设计人员能够移动字形轮廓上的任何点,以便打开或关闭位图网格上的任何像素。这提供了与简单位图编辑器一样多的控制。命令不仅可以用于提高小尺寸字体的易读性,还可以从根本上改变任何尺寸的任何位图的外观 - 例如,可以生成不同尺寸将产生不同形状的字体。因为TrueType是一种编程语言(在汇编级别),所以该格式为字体设计师和工程师提供了惊人的多功能性。受提示命令影响的大小也可以通过设置低和高大小阈值来确定,或切入。
最近在微软字体中证明了这种灵活性的一个实际例子,该字体专门用于在NTSC信号下在电视上显示。在初步工作中,很明显,在小尺寸下,不可能令人满意地呈现某些角色特征 - 例如大写字母N的斜条。设计者意识到使每个字形尽可能个性化,建立了一个阈值,低于该阈值编程某些字符以改变形状。下面的插图是21和22ppem的轮廓和结果位图。

光学缩放
由于TrueType使设计人员或程序员能够在每个尺寸上改变字母形状,因此可以将光学缩放内置到TrueType字体中,允许对不同尺寸的字符进行微调,以确保其正确显示。
位图字体的设计总是涉及一定程度的光学缩放,每个尺寸都必须单独进行光栅化 - 并且通常是设计的。不幸的是,这些修改总是涉及甚至是妥协因素; 这个像素还是那个像素?在TrueType字体中,创建光学正确字母的能力扩展到非常大的尺寸(高达2048 ppem)和TrueType Open的功能,TrueType规范的新扩展(编辑:这最终演变为OpenType计划)。
非线性缩放
非线性缩放通常(可理解地)与光学缩放混淆。虽然光学缩放的概念涉及改变字符的形状以确保在特定尺寸下的正确外观,但TrueType中的非线性缩放只是使字形及其侧面轴承的宽度变宽或缩小,其尺寸为:如果宽度以线性方式缩放(例如,以规则模式从小尺寸增大到大尺寸),我们可能会遇到间距或重量问题。例如,在小写’i’通常会缩放以占据四个像素的前进宽度的情况下,我们可能会选择强制它适合三个像素,在一个像素的任一侧放置一个白色空间像素黑茎。在这种情况下,
实际上,非线性缩放意味着TrueType提示不仅仅限于控制每个字符的形状。类型设计者能够通过改变字母两边的空白量来调整字符间距。此工具对于帮助在文本行中保持均匀,一致的颜色至关重要,并且是TrueType提示的一个亮点,在其他字体格式中不可用。
对角线控制
对角线控件是TrueType提示的另一个特性,有助于提高字体的视觉质量。保持对角线尽可能对称有助于避免不必要的锯齿或“踩踏”。使用单独的矢量来测量字形轮廓上的距离和移动点,可以对对角线笔元素中的点定位进行非常精细的控制。在下面所示的示例中,可以看到必须移动点以确保在一个方向上测量正确的位图笔划的距离,而实际上它在稍微不同的方向上移动。此功能允许我们测量元素的真实宽度,例如对角线笔划,并保持它,而不是在直线水平测量上不准确地判断我们的判断。


以这种方式控制对角线使TrueType字体能够表示比其他字体格式更高保真度的斜体和斜字形。下图显示了TrueType对角线控件可以进行多少甚至更多的设置。
。")
。")
提示中的情报
使用TrueType,智能在提示中而不是在光栅化器中。也就是说,对原始轮廓描述的所有改变都是通过字体中包含的指令而不是由自己动作的光栅化器来执行的。这种方法有三个重要的含义。
首先,它意味着大部分计算在字体生成期间而不是在运行时进行。从这个意义上说,TrueType类似于编译语言,而在执行期间执行大部分工作的轮廓字体技术更像是解释器。
其次,提示中的智能意味着字体供应商可以精确控制字体的最终外观 - 因为它们应用了提示。相比之下,使用依赖于光栅化器来应用提示或执行其他轮廓调整的方法,字体供应商对字体的最终外观的控制较少。
最后,通过提示中的智能,工具供应商可以改进其提示技术,而无需用户购买新的光栅化器或其他打印机ROM。这意味着最终用户可以仅以字体本身的价格升级其字体,而不会产生任何其他硬件或软件成本。
15.2.6.提示教程
15.2.6.1.介绍
基本提示哲学和TrueType指令
在讨论TrueType提示时,最好将TrueType视为一种编程语言。生产TrueType的字体公司都使用不同的方法。字体公司中的个别印刷工程师也可以使用不同的提示哲学。单一类型的工程师可以使用从字体到字体的不同总体策略。
(字体是一个系列中的字体集合.Times New Roman是一种字体,Times New Roman Italic是一种字体。)
在本文档中,我首先以一般的高级方式讨论提示过程,然后将该高级描述转换为实际的TrueType代码。
关于提示工具的说明
用于生成专业字体的工具不一定是商业上可用的。软件和字体公司已经开发出满足其开发需求的特定软件。在本文档中,应将所有TrueType指令使用的语法视为特定于本文档和/或特定TrueType开发工具。有关TrueType指令及其语法的完整说明,请参阅Microsoft TrueType规范版本1.66(或更高版本)或特定TrueType编辑器的手册。除了专有工具之外,目前已知的TrueType编辑器还有:Apple Computer的RoyalT和TypeSolution的TypeMan和StingRay。
开始
如果您曾经绘过一幅图片,您就会知道从一个空白表面开始并勾勒出基本形状。然后你添加音调。在此之后,您会越来越具体,直到您决定绘画完成为止。一般来说,每幅画都是以同样的方式完成的。但细节总是不同的。边缘锐化不同。无论是否添加亮点。也许你会使用经典的红线,也许不会。这就是暗示的内容。决定。
您必须考虑的第一件事是您要提示的字体类型以及单独字体与整个字体的关系。当字体Times New Roman的核心字体被暗示时,类型工程师将所有字体都包含在家族中(常规,斜体,粗体和粗体斜体)。他们测量每种字体,并确定诸如高度或茎值之类的值是否应该通过族或者特定于字体是一致的。
15.2.6.2.基本全局表
基本TrueType提示涉及三个对整个字体都是全局的表:控制值表,预编程表和字体程序表。
控制值表(’cvt’)
TrueType允许通过使用存储在’cvt’表中的值来控制要素的规则性。控制值是特征的测量值,例如小写的茎宽度。这些茎虽然彼此相似,但可能具有略微不同的轮廓距离。使用cvts可以控制距离,使得它们在低分辨率下具有相同的像素宽度。在更高的分辨率下,将不使用控制值,但是自然距离将显示在杆中。“控制值”表不要求这些值为字形要素距离。值是整数,可以从许多TrueType指令访问。该表也可以写入以及从其他表中读取。
可以存储在控制值表中的字形和字体特征的其他示例是:帽高度,x高度,过冲距离,上升高度,基线,图形高度,衬线长度和高度,斜体角度,组(大写,小写,干距离,群距离。其他功能可能是:较小的组距离,例如数学符号词干距离,大括号,括号或括号距离。

预编程(’准备’)
在每种字体中都有一些始终适用的条件。在TrueType中,我们通过放置在预编程中的代码来控制这些条件。每次更改字形大小或分辨率时以及执行字形的本地指令之前,都会执行’prep’表。这是控制所有字形的全局条件的好地方。在“准备”中放入什么的一些例子是……
使用提示指令时以及何时不使用提示指令时进行控制。在Microsoft字体中,我们关闭低于8ppem和高于2048ppem的提示。我们认为没有必要使用低于8ppem或高于2048ppem的提示。这也可以防止出现一些技术问题。
打开控制以检查连续笔划中的缺失像素。在某些情况下,轮廓可能会在像素中心之间传递,并会在位图8中产生漏洞。此控件检查这些条件并添加出现这些“丢失”的像素。
改变用于控制组特征的’cvt’中的值,例如大写的茎和圆。在这里,您可以控制杆从一个像素到两个像素的大小等等。通常强制圆形和直线特征相等,直到达到所需的大小。
设置’cvt’切入限制。这是一个阈值(或阈值),用于确定是使用’cvt’值还是使用实际距离。我使用三个阈值设置:一个用于设置小ppem尺寸,因此最常使用’cvt’; 一个用于中等ppem尺寸,其中设置了更合理的阈值; 并设置一个高ppem阈值以始终使用实际距离而不是’cvt’值。您将在下面看到如何设置一些指令以查看此“cvt”切入限制。
设置最小距离。有时需要在一个轮廓点和另一个轮廓点之间保持最少一个像素(例如,在字形的词干上提示)。我总是将最小距离设置为一个像素。如果我然后提示越过一个杆并且实际距离小于半个像素,则杆宽总是被强制为一个像素。
字体程序(’fpgm’)
此表存储可以从“准备”或字形指令调用的函数。函数用于消除重复代码在多个字形中的使用。一个常见的例子是控制变音符号在基本字形上的位置。TrueType支持复合字形(由其他字形组成的字形)。在复合字形中,这些已经暗示的字形的位图可能不会以与水平和垂直方向上的原始未打印轮廓位置相同的方式放置。函数通常用于确保变音中心超过基本字形,并且变音符号不接触基本字形的顶部。
15.2.6.3.提示和TrueType指令
在本节中,我们将介绍提示的目标,使用TrueType提示和单独的字形提示。本节包含存储在TrueType字形表(’glyf’)中的一些内容。
提示的目标
提示的最终目标是最好地表示将在其显示的所有分辨率下的字体。PC使用几种不同的分辨率和宽高比。最常见的是每英寸96点的VGA,120 dpi的SVGA和72 dpi的Macintosh。所有这些设备的宽高比均为1:1。当提示字体时,类型工程师确定它们将提示的每个em大小的最低像素并保持令人满意的结果。通常最低的ppem大小为9.这相当于VGA屏幕上的7点,SVGA上的5.5点和Macintosh上的9点。某些PC屏幕和某些打印机具有非方形宽高比。Microsoft Core字体在预编程中包含代码以检查当前的宽高比。
我们的一些目标已经在控制全球问题的“准备”计划中得到了解决。在准备中,我们已经查看了所有字体是否可以在’cvt’中使用相同的高度值来表示大写,小写,高度,上升等的顶部,无论过冲是否相同以及何时打开。
字形的基本暗示
我们将看到的第一个例子是暗示大写字母“O”。

用于暗示图2中的大写字母O的高级提示策略
控制顶部和底部与其他大写字形一致。
控制顶部曲线和底部曲线与其他uc曲线相同且一致。
控制左曲线和右曲线与其他uc曲线相同且一致。
通过移动它们来平滑轮廓,修复未指示的所有点。
图2的低级提示策略
在编写提示代码时,在切换到另一个方向之前完全提示一个方向更有效。这不是TrueType中的要求。我首先控制Y(垂直)方向和高度。然后我处理X(水平)方向。
将提示方向设置为Y.
将pt 3移动到与“uc top round height”对应的控制值,并将其四舍五入为网格线。(转换为像素时的距离和值通常是像素的分数。这些像素分数被转换为整数,一半或指定的像素分数。例如:距离是1.4像素。当此距离舍入到网格时,它将等于1个像素。)
将pt 9移动到与“uc bottom round height”对应的控制值,并将其四舍五入为网格线。
将pt3和pt20之间的距离控制为“uc Y round”或其实际距离的控制值,并将pt 20舍入到网格边界。
将pt9和pt15之间的距离控制为“uc Y round”或其实际距离的控制值,并将圆pt 15控制到网格边界。
将方向设置为X.
将pt 0放在网格边界上。
将pt0和pt12之间的距离控制为“uc X round”或其实际距离的控制值,并将圆pt 12控制到网格边界。
将第6页放在网格边界上。
将pt6和pt18之间的距离控制为“uc X round”或其实际距离的控制值,并将pt 18舍入到网格边界。
插值在X和Y方向上触摸的点之间未触及的所有点。(在两个移动的关键点之间移动点,并保持关系与所有点的原始位置相同。)
图2的TrueType指令
提示指令移动字形上的关键点。移动这些关键点时,它们的X,Y坐标将转换为像素和像素的分数。当这些像素数量按指令舍入时,它们取决于’round_state’变量的设置。默认设置为“round to grid”。其他可能的设置是:舍入到半网格,舍入到最近的网格或半网格,向上舍入到网格,向下舍入到网格,舍入(不舍入)以及最终更精细地控制round_state。我们示例中的round_state设置是“round to grid”。
复制
SVTCA[Y] /* set the hint direction to Y /
MIAP[R], 3,3 / move pt 3 to the value of cvt 3 and rounding the value/
MIAP[R], 9,9 / move pt 9 to the value of cvt 9 and rounding the value/
SRP0[], 3 / set the current reference point to pt 3 /
MIRP[m>RBl], 20, 73 / control the top round feature /
SRP0[], 9 / set the current reference point to pt 9 /
MIRP[m>RBl], 15, 73 / control the bottom round feature /
SVTCA[X] /set the direction to X */
SRP0[], 23 /hinting from the left sidebearing point /
MDRP[MRBl], 12, 69 /controlling the left round distance /
SRP0[], 24 /hinting from the right sidebearing point */
MDRP[MRBl], 18, 69 / controlling the right round distance /
IUP[X] / interpolating all unused points in the X direction /
IUP[Y] / interpolating all unused points in the Y direction */
(Sidebearing:从字形的最左边部分到其原点或最右边部分的距离以及字形的前进宽度的结尾,这是字形本身及其两个侧边所占据的总空间。)
让我们更具体地看一下每一行:
SVTCA [Y]
将提示方向设置为垂直方向或Y方向。已翻译:将矢量设置为控制轴Y.矢量是直线段。“图形状态”中有三个矢量:一个称为“投影矢量”,一个称为“自由矢量”,另一个称为“双投影矢量”。投影矢量是测量距离的方式。自由矢量是点移动的方向(X,Y或对角线)。一些指令使用双投影矢量来测量来自其原始未编织位置的点之间的点。
MIAP [R],3,3
移动间接绝对点。将点3移动到CVT 3的值并舍入。间接是指使用CVT而不是直接使用实际坐标距离。舍入点的直接方法将编码为:MDAP [R],3
MIAP [R],9,9
与MIAP [R],3,3相同,但使用第9点和第9点。
SRP0 [],3
设置参考点零点到点3.将当前参考点设置为pt3。之后,当我们使用“相对”点编写指令时,它需要一个“引用”点。如果pt’b’是相对点,则它取决于pt’a’的位置,参考点或“参考”点。
MIRP [m> RBl],20,73
移动间接相对点。移动和回合pt20。轮廓点20是相对点,并且相对于在先前指令SRP0中设置的参考点3移动。这是间接点,因为我们使用cvt来控制它的距离。MIRP指令有四个参数。前三个参数是布尔值。这里我们使用与TrueType编辑器对应的符号。
第一个参数可以设置为使MIRP点成为下一个参考点,例如使用SRP0指令完成或无法设置。这种情况’m’表示未设置。
第二个参数可以设置为保持距离大于或等于最小距离,或者它不能保持距离。这里因为这是一个圆形笔划,我们想要保持距离,所以在这里设置一个“>”符号。
第三个布尔参数做了两件事:将距离舍入到网格边界并查看’prep’表中设置的’cvt’切入限制。或者不要绕过距离,也不要看“cvt”的限制。
最后一个参数用于定义此距离是跨越黑色要素,白色要素还是灰色要素。黑色特征的一个例子是在X方向上的大写“I”的主干上。白色特征的一个例子是“O”中的计数器(白色空间)或侧面。灰色特征是此提示穿过黑色特征和白色特征时。
SRP0 [],9将
轮廓点9 设置为当前参考点。
MIRP [m> RBl],
15,73将pt15移动到网格边界。控制底部圆形特征与控制顶部相同。使用与uc Y Round cvt相对应的相同’cvt’73。
SVTCA [X]
将方向设置为X.
SRP0 [],23将
pt23设置为当前参考点。点23和24不是轮廓上的点。它们被称为“幻影”点。这些点显示基线上的左侧承载和前进宽度。(字形的水平距离,包括两侧的空白区域。)幻影点可以通过指令控制。在这里,我们从这些幻影点向内暗示到字形。我们不需要使用指令来移动点,因为幻影点总是在网格边界上。
MDRP [M> RWh],0
移动直接相对点。移动和回合pt0。与MIRP类似,但该指令不使用控制值。设置参数1(’M’),使pt0成为当前参考点。第二个参数设置为不保持最小距离。我们正在完善这一点,这是一个白色的功能。移动pt0时,使用从pt23到pt0的实际距离。
MIRP [m> RBl],
12,69将pt12移动到网格边界。使用cvt 69 for uc X Round功能并控制字形的左轮。参数设置与Y轮特征相同。
SRP0 [],24将
pt24设置为当前参考点。我们开始暗示字形的右侧。从Phantom点进入24。
MDRP [M> RWh],6将
pt6移动到网格边界。与左侧相同的提示。我们将点6移动到距离点24的实际距离并且不使用cvt值。通过从侧面暗示,我们可以保持字形及其侧面的关系并保持间距。
MIRP [m> RBl],18,69将
pt18移动到网格边界。使用相同的cvt 69,用于控制正确的X Round功能。
IUP [X]
插入未使用的点。通过在X方向上相对于在X方向上暗示的点移动点来平滑轮廓。
IUP [Y]
平滑Y方向。
15.2.6.4.函数和增量提示
第3部分中描述的高级描述和大写“O”的TrueType提示不包括其他指令,如增量提示或特定大小的附加函数调用。要微调特定低分辨率尺寸的字体,我们可以使用特殊功能或增量提示。我不会详细讨论函数,因为它们是由软件或类型工程师为其特定需求编写的TrueType代码片段。所有字体公司都使用的函数非常少。
达美提示
Delta提示是特殊提示,可以在特定的ppem大小中生成异常。它们允许以像素的小部分移动点,以便可以改变位图。这对于删除和添加像素或移位全部或部分位图非常有用。
有两种类型的增量提示:移动轮廓点的增量(DeltaP); 和改变’cvt’值(DeltaC)的那些。两个增量都有三个参数:轮廓点或cvt#,ppem大小和移动量。
按DeltaP
让我们回到我们的示例大写’O’。
如果我们想在14ppem将pt0向右移动一个像素,我们可以使用DeltaP提示移动该点。智能放置增量提示允许整个部分或整个字形移动增量提示的数量。由于指令是从上到下处理的,因此移动参考点的DeltaP将影响使用此参考点的任何相对点。在下一个例子中,我想将uc O字形缩小到右边的一个像素。通过在pt0的指令之后放置DeltaP,该点移动指定的量。由于pt12使用pt0作为参考点,因此它也将被移位。如果DeltaP被放置在pt12的指令之后,则只会影响pt0。
复制
SVTCA[Y]
MIAP[R], 3,3
MIAP[R], 9,9
SRP0[], 3
MIRP[m>RWh], 20, 73
SRP0[], 9
MIRP[m>RBl], 15, 73
SVTCA[X]
SRP0[], 23
MDRP[MRBl], 12, 69
SRP0[], 24
MDRP[M>RWh], 6
MIRP[m>RBl], 18, 69
IUP[X]
IUP[Y]
DeltaC
微调字体时控制的一个重要情况是其茎宽从一个像素增加到两个或两个到三个的点。使用中等或常规重量字体和粗体字体时,粗体字必须至少为两个像素。它的自然重量通常小于两个像素,并且会向下舍入到一个像素。使用“准备”中的DeltaC,我们可以改变此cvt增加的大小,并且使用此cvt的所有字形都将受到一个命令的影响。这使类型工程师能够控制家庭的重量。
15.2.7.提示示例:斜体
就提示而言,斜体字形最难的特征是它的倾斜笔画。斜体“O”可以像罗马“O”一样暗示,同样也可以暗示为“V”。因此,以下示例使用UC“H”。
使用VTT中的“对角线”命令或工具暗示斜体笔划,其对于一般对角线笔划和斜体笔划同样有效。因此,为了暗示斜体,我们需要知道如何正确使用对角线笔划。
对角线描边命令采用两个父点和两个子点以及CVT。两个父点锚定到网格,然后通过对角线笔划命令相对于父点控制两个子点。这类似于链接命令或工具,其中子点是相对控制的到一个父点,除了我们有两个。具有两个基本几何的原因是:例如,垂直笔划上的“XLink”完全定义了控制笔画宽度的方向,仅仅因为它是“XLink”,而不是“YLink” 。对于对角线笔划,我们需要指定该对角线的方向,我们唯一可以这样做的方法是指定两个父点。在几何中,两个点定义直线。
为了正确使用对角线笔划,我们还必须记住,最后的“平滑”命令将调整x方向和y方向上的所有“未提示”或“未触摸”点。虽然平滑命令可以在仅存在x或y命令时完美地完成,但它可能无法通过对角线命令执行我们想要的操作,例如“对角线”或“DAlign”。例如,如果我们想使用对角线命令来提示斜体笔划,并且如果我们仅在x方向上暗示父点,则最终平滑命令可能会以我们可能不同意的方式调整y方向上的父点的。
因此,在使用对角线命令之前,我们需要在两个方向上提示两个父点。反过来,对角线命令将提示孩子指向垂直于两个父点定义的线的方向。这里的关键字是一个方向,而不是两个方向。与父母分数一样,儿童分数可能会以不愉快的方式通过最终顺利进行调整。因此,对于斜体笔划,我们应该在使用对角线笔划命令之前在y方向上提示子点。
最后但并非最不重要的是,VTT模板中内置了一种机制,允许对斜体笔划的“斜体”进行全局控制。对于黑白渲染,与ClearType渲染相反,斜体笔划将呈现为像素的“步进模式”,向上x像素,向上y像素。与许多其他光栅悲剧一样,这种踩踏模式可能是“过于斜体”(即对于给定数量的像素向上过多的像素)或“不足够斜体”(即没有足够的像素跨越)。更糟糕的是,它可能在一个角色上看起来过于斜体,而在另一个角色上看起来不够斜体,即使角色设计有相似或相同的斜体角度。
要使用此机制,我们必须为斜体运行和上升定义CVT,如“使用Visual TrueType提示斜体”中所述,并使用GlyphStrokeAngle命令或工具。然后我们将使用XDist命令或工具从底部父点链接到顶部父点,即x方向但没有CVT的链接。最后,我们为子点选择斜体角度舍入方法,这是键入命令时的“正斜杠”(即“XDist / [0,1]”),或者在使用时使用中间点的斜线链接工具(即右键单击控制点并选择中间带点的斜杠)。
示例:Arial UC“H”

此示例的VTTTalk如下所示(添加了行号以供下面的进一步评论):
复制
1: /* VTTTalk glyph 43, char 0x48 (H) /
2: / GUI generated Tue Aug 24 17:00:37 2004 /
3:
4: GlyphStrokeAngle(21,20)
5: SetItalicStrokePhase()
6: SetItalicStrokeAngle()
7:
8: / Y direction /
9: YAnchor(0,2)
10: YDist(0,7)
11: YDist(0,8)
12: YDist(0,11)
13: YAnchor(1,8)
14: YDist(1,2)
15: YDist(1,5)
16: YDist(1,6)
17: YIPAnchor(0,10,1)
18: YDist(10,9)
19: YLink(10,3,72,>=)
20: YDist(3,4)
21:
22: / X direction */
23: XIPAnchor(13,7,0,12)
24: XDist/(7,6)
25: Diagonal>>(6,5,7,8,76)
26: DAlign(8,9,4,5)
27: XDist/(0,1)
28: Diagonal>>(0,11,1,2,76)
29: DAlign(11,10,3,2)
30:
31: Smooth()
评论:
第4到第6行:使用’GlyphStrokeAngle’工具生成; 斜体运行是CVT#20,斜体上升是CVT#21
第9行:提示在y方向上左击的底点(左)父点#0
第13行:提示在y方向上左击的顶点(左)父点#1
第10到12行和第14到第16行:提示右笔画(#6和#7)的父点,以及所有笔画的子点(#2,#5,#8和#11),y -方向。使用’YDist’代替’YAnchor’只会创建更小的代码。
第17到20行:横向的提示点在y方向(#10,#9,#3和#4)。
第23行:在x方向上提示底部父点(#0和#7)。同时,这定义了字符的间距,因此这是必须改进间距时要设置的点。
第24行:提示相对于右下方父母(#7)的右笔画(#6)的右上方父母。注意“XDist”和“(”之间的“/”。这将使用先前由’GlyphStrokeAngle’命令建立的字形笔划角度。
第25行:此时,右侧笔划的父母都在x方向和y方向都被暗示,而且,两个孩子都在y方向上被暗示,因此可以正确地应用对角线命令。在这个例子中,它使用CVT#76来控制父母#6和#7以及孩子#5和#8的对角线笔画的重量。
第26行:此时,右斜体笔划的两个孩子都在x方向和y方向都被暗示,因此可以正确应用对角线对齐命令,将点#4和#9与先前提示的点对齐# 5和#8。
第27至29行:类似于左行程的第24至26行。
请注意,“对角线”和“DAlign”命令都可以有一个额外的(可选)参数,该参数指定在ppem大小及其上方,它们施加的几何严格的“抓地力”可以在某种程度上“松散”。在上面的示例中,这可能不是必需的,但是例如对于略微锥形的笔划,对于小的ppem尺寸完全“平行化”笔划的侧面可能是有用的,而如果ppem尺寸足够高以允许执行则尝试使其逐渐变细。所以。同样地,笔划可以是喇叭形的,在这种情况下,严格的“抓握”可能在小的ppem尺寸而不是大的尺寸上有用。要在键入命令时使用此功能,请在参数列表的末尾添加ppem大小,如下所示:
复制
Diagonal>>(6,5,7,8,76,@42)
DAlign(8,9,4,5,@42)
这将“松开”在ppem尺寸42处及其上方的严格“抓地力”。使用对角线和对齐工具时,请参阅“ 使用Visual TrueType提示斜体 ”中所述的“ppem limits”工具(“挂锁工具”)和“ Visual TrueType 4.2发行说明 “。
上面的例子假设CVT用于斜体运行并且上升到控制程序中,如下所示(参见下面的“ItalicRun”和“ItalicRise”):
复制
InstructionsOn @8..2047
DropOutCtrlOff @144
CvtCutIn = 4, 2.5@29, 0@128
/* Heights */
UpperCase
Grey
Y
SquareHeight
2: 1466
8: 0
/* Glyph Stroke Angle */
UpperCase
Grey
X
ItalicRun
20: 307
Y
ItalicRise
21: 1466
/* Strokes */
UpperCase
Black
Y
StraightStroke
72: 166
Diag
StraightStroke
76: 191
如果我们想要改变特定ppem大小的所有大写斜体笔画的“斜体”,我们所要做的就是向CVT#20添加“Delta”,如下所示:
复制
UpperCase
Grey
X
ItalicRun
20: 307 Delta(1@13)
这会使ppem size 13的斜体运行增加1个像素。同样,通过输入-1而不是1,我们可以将斜体运行减少1个像素。我们可能只想对黑白渲染这样做,在这种情况下我们使用“BDelta”而不是“Delta”。
上述方法通常在标准化斜体笔划的步进模式方面做得相当不错,以系统的方式呈现斜体字体,这有望使其更容易阅读。但由于技术原因超出了本例范围,可能存在“异常”像素。在这些情况下,最简单的补救措施是在适当的情况下,在单个ppem大小的单个字形上应用“XBDelta”或可能的“YBDelta”。
Serif字体带来了额外的难度,因为笔划的父节点和子节点可能不在底座或帽线上,这通常是sans-serif字体的情况。这个问题的一个实际解决方案是插入父点和子点,而不是锚定和链接它们。
示例:Times New Roman UC“H”

此示例的VTTTalk如下所示:
/* VTTTalk glyph 43, char 0x48 (H) /
/ GUI generated Tue Aug 24 21:19:21 2004 */
1: GlyphStrokeAngle(21,20)
2: SetItalicStrokePhase()
3: SetItalicStrokeAngle()
4:
5: /* Y direction /
6: YAnchor(42,8)
7: YDist(42,24)
8: YDist(24,23)
9: YDist(42,25)
10: YDist(25,26)
11: YDist(42,41)
12: YDist(41,40)
13: YDist(42,43)
14: YAnchor(57,2)
15: YDist(57,9)
16: YDist(9,8)
17: YDist(57,10)
18: YDist(10,11)
19: YInterpolate(11,17,18,23)
20: YIPAnchor(57,34,42)
21: YLink(34,0,72)
22: YDist(0,1)
23: YInterpolate(1,2,8)
24: YDist(34,33)
25: YInterpolate(33,32,26)
26: YInterpolate(34,35,40)
27: YDist(57,56)
28: YInterpolate(43,49,50,56)
29: YDist(57,58)
30: YDist(58,59)
31: YInterpolate(0,65,59)
32:
33: / X direction */
34: XInterpolate(67,18,49,66)
35: XNoRound(17)
36: XDist/(18,17)
37: Diagonal>>(17,2,18,32,76)
38: DAlign(32,33,1,2)
39: XNoRound(50)
40: XDist/(49,50)
41: Diagonal>>(49,35,50,65,76)
42: DAlign(35,34,0,65)
43:
44: Smooth()
乍一看,这看起来比sans-serif“H”复杂得多,甚至还没有完成(例如,衬线的长度没有在x方向上暗示)。但仔细观察后我们会发现它几乎是一样的。对于左对角线笔画,父节点为#49和#50,子节点为#35和#65,后者将在下面的注释中进一步说明:
评论:
第28行:通过在#43和#56点之间进行y插值,在y方向上提示父点#49和#50。
第13和27行:分别通过来自点#42和#57的y-dist在y方向上提示#43和#56。这个y-dist同时确定了衬线的“厚度”,因此我们可能希望使用CVT作为衬线厚度,并用“YLink”代替“YDist”。
第6和第14行:提示点#42和#57在y方向y-分别将它们锚定到基线和帽线,非常类似于无衬线情况。
第26和31行:在y方向上提示子点#35和#65,再次对它们进行y插值。
#35在#34和#40之间进行y插值
第12行:来自#41点的y-dist点#40
第11行:来自#42点的y-dist点#41,其又被y锚定到基线。
第20行:y-插入基线和capsline之间的#34
#65在#0和#59之间进行y插值,而#59和#59类似于点#34和#40的y-disted和y-linked。
第34行:在x方向上提示底部父点(#18和#49),类似于无衬线情况,但注意没有四舍五入; 通常最好不要在x方向上将这些点强制在最近的网格线上。
第39和40行:相对于左下方父母(#49)提示左上方父母(#50 )。再次注意“/”,并注意“XNoRound”关闭舍入,原因与上述相同。
第41行:此时,左笔画的两个父母都在x方向和y方向都被暗示,而且,两个孩子都在y方向上被暗示,因此可以正确地应用对角线命令。
因此,它的长短不一:用衬线,斜体笔划的父母和子点被“通过”衬线暗示。这导致相对平滑的轮廓,即使在小的ppem尺寸下,这对于ClearType渲染是有利的,同时通常它还导致用于黑白渲染的合理的像素图案。与sans-serif示例一样,可能存在“异常”像素,对于该像素,补救措施再次适用于应用“XBDelta”或“YBDelta”。
关于“ItalicRun”和“ItalicRise”存在的相同假设适用,并且与sans-serif示例一样,serif case的斜体运行也可以是“delta-ed”。
通常可以以类似的方式暗示小写字符和数字,记住它们使用单独的CVT集合用于“ItalicRun”和“ItalicRise”。由于斜体运行和上升是使用CVT定义的,因此“CVT继承”可用于均衡大写和小写之间或不同小写字符组之间的不同斜体角度。最后但并非最不重要的是,应该提到的是,这两个例子仅代表一种暗示斜体字符的方式,虽然这种方式已被证明相当有用,但可能还有其他方法可以实现相同的目标。
16.工具
Visual OpenType布局工具(VOLT) VOLT是一种用于将OpenType布局表添加到字体的工具。
Microsoft Visual TrueType(VTT) 一种专业级工具,用于以图形方式指示TrueType和OpenType TM字体。
OpenType字体签名工具 开发用于Microsoft签名字体文件的工具。
16.1.VOLT
Microsoft Visual OpenType布局工具(VOLT)提供了一个易于使用的图形用户界面,可将OpenType布局表添加到具有TrueType轮廓的字体中。它是免费许可的,可以从为其设置的在线社区下载。
VOLT支持多种替换和定位类型。它还包含一个用于查看布局表查找应用程序的校对工具。它允许导入和导出字形名称,查找,字形组和完整项目。
社区成员使用该工具将OpenType布局表添加到支持脚本的各种字体,包括阿拉伯语(Naskh和Nastaliq书写样式),孟加拉语,西里尔语,梵文,希腊语,古吉拉特语,Gurmukhi语,卡纳达语,拉丁语,僧伽罗语,叙利亚语,泰卢固语和Thaana。
得到VOLT
VOLT论坛和社区
VOLT培训视频
16.1.1.用户指南
16.1.1.1.教程
使用VOLT:Volt和InDesign教程
OpenType格式最重要的特性之一是它能够在单一字体内支持增加的排版复杂性。从多种风格的图形到复杂的特定于脚本的连字,OpenType允许以前很难实现的印刷丰富度。OpenType字体通过存储可由OpenType感知的操作系统和应用程序公开的额外数据来实现此目的。虽然OpenType字体向后兼容预OpenType程序(OpenType超集TrueType和Adobe Type 1格式),但新的布局功能不适用于旧程序。
第1步:入门
打开文件
在将任何布局功能添加到VOLT中的字体之前,必须注意一些事项。第一次打开字体时,可能会出现下面的对话框:
添加脚本和语言
下一步是添加包含OTL功能的脚本和语言对。本教程重点介绍基于拉丁语的字体,因此在单击窗口底部的“添加脚本”按钮后,请指定OpenType脚本名称<latn>。VOLT然后自动创建一个关联的“默认”语言(见上图) - 这是我们将添加OTL功能的语言。
‘编辑字形’窗口
现在我们已经创建了脚本和语言,熟悉VOLT的“编辑字形”窗口(单击“编辑字形”按钮)非常有用。在此窗口中,用户可以浏览和搜索字体的完整字形集。每个字形都有自己的框,其中列出了VOLT字形名称(可以更改)和由字体编码确定的代码点。正如您将看到的,当我们开始创建OTL功能时,此窗口将变得非常有用。
第2步:添加连字
虽然传统上大多数字体都包含某些基本连字,但在文档中使用它们很少容易。大多数程序都没有提供访问连字的简单方法,通常连字没有正确映射到字体中,或者提供支持的程序不会从字母中抽象字形(导致拼写检查器等工具出现问题)。但是,通过在InDesign中使用正确构造的OpenType字体,印刷工作者可以正确且轻松地实现连字 - 无论是基本的(如’fi’)还是更专业的(如’fj’)。
第一步是使用<liga>“默认”语言创建一个功能。单击选择“默认”语言,然后单击VOLT窗口底部的“添加功能”按钮。键入<liga>然后按ENTER键。然后VOLT将识别该命令并将其标记为“Standard Ligatures”(见下图)。
接下来,我们在我们一直在使用的窗格右侧的窗格中添加一个查找,该窗格将与<liga>我们创建的功能相关联。单击VOLT窗口底部的“添加下载”按钮将创建新的替代功能。您为这个新查找提供的名称并不重要,但提供描述性和简洁的标签总是有用的。由于我们将只创建一个连字查找(可以容纳多个连字,如您所见),我们将简单地命名查找’连字’。键入名称并按Enter后,我们必须将查找链接到<liga>我们创建的功能。这可以通过单击“连字”查找并将其拖动到。来完成<liga>标有“标准连字”的功能。完成此操作后,您应该会看到“标准连接”功能下面列出的“连字”查找(请参见下图)。
现在我们可以开始将实际替换添加到我们的’连字’查找中。双击’ligatures’查找,将弹出查找编辑窗口。这是我们在InDesign中打开连字时指定哪些字母组合应在其位置替换的连字符的位置。我们可以从添加最常见的连字开始,几乎所有字体都支持 - ‘fi’。为此,我们必须确定三个字形的名称:f,i和’fi’字形。正如您将看到的,VOLT通过关联的字形名称引用字形,可以在“编辑字形”窗口中找到,如前所示。请注意,字形名称通常因字体而异。
打开“编辑字形”窗口并滚动字体,直到找到所有三个字形(当您浏览时,请记下它们的名称 - 如果您愿意,您当然可以重命名它们)。以下是示例字体中的三个字形:

现在我们知道要使用哪些字形,我们返回到“连字”查找的编辑窗口。单击“From Glyphs - > To Glyphs”列下方的框,然后键入以下内容,用适当的字形名称替换为您的字体:
glyph_name_f glyph_name_i -> glyph_name_fi
然后按ENTER键。将添加’fi’结扎,您的窗口应如下所示:
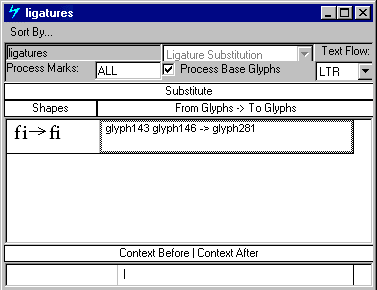
要向同一查找添加更多连字,可以通过在当前行之后按Enter来添加其他行。通过在一次查找中保留所有连字,在解释替换时,字体将更有效。您的字体可能支持的其他常见连字包括’ffi’,’fl’,’ffl’。有些字体支持额外的连字,例如’Qu’或’fj’或不合时宜的连字,如’st’或’ct’。以下是在我们添加更多连字
之后我们的“连字”查找的显示方式:
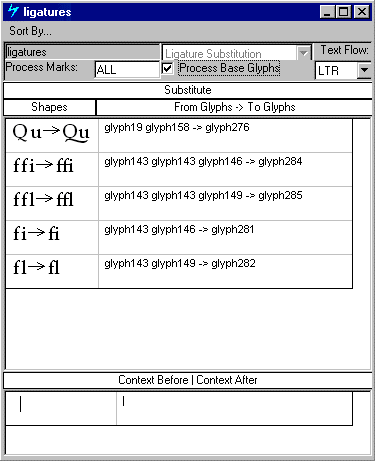
完成添加连字后,关闭“连字”查找编辑窗口并返回主VOLT窗口。
第3步:添加小型大写字母
对于处理多个字形集(例如小型字母)的功能,VOLT提供了创建“字形组”的功能。一旦构造了字形组,它们就允许VOLT用户更轻松,更快速地执行某些任务。如果字体设计者正在创建要添加到多种字体的功能,则可以将字形组从一种字体导出到另一种字体,从而可以更轻松地为类似字体添加布局支持。字体中的不同布局功能也可以使用相同的字形组 - 另一种节省时间。
创建字形组
对于小型大写字母替换,我们要创建两个组:一个包含小写字母(在打开小型大写时将替换)和一个包含小写大写字母(要替换)的组。要创建第一个组,请单击主VOLT窗口右下角的“添加字形组”按钮。虽然名称不一定特别重要,但为组提供描述性名称会有所帮助。我们将此组称为“latin_lower_case_group”。按ENTER键,然后双击您创建的新组。
我们现在可以在编辑窗口中指定我们要包含在组中的字形。单击“名称”列的第一行,然后键入要添加的第一个字形的名称 - 在本例中为小写“a”。点击ENTER应该使’a’出现在相邻的’Shapes’列中。按顺序继续,添加每个小写字母(给每个字形在组中自己的行),直到你达到’z’。滚动到底部,您的窗口应如下所示:
现在我们已经完成了小写,我们需要创建小型的大写字形组。重复上述步骤,但不是添加小写字母,而是按顺序添加字体的小型大写字母(从“A”到“Z”)。将此组称为“small_caps_group”。
添加’smcp’功能和相关查找使用我们的字形组,我们现在必须在VOLT中创建小型大写字母查找功能(smcp)。在脚本/语言窗格中,突出显示“默认”语言,然后单击VOLT窗口底部的“添加功能”按钮。键入<smcp>并按Enter键。然后VOLT应标记“小首都”特征。
接下来,在右侧的“查找”窗格中,我们通过单击窗口底部的“添加替换”按钮添加新的替换功能。为此查找命名为’small_caps’并按Enter键。双击新组将打开编辑窗口; 这是我们告诉VOLT用小型大写组代替小写组的地方。这与我们进行’fi’结扎替换的方式类似,但有一个重要区别:使用尖括号(<和>)命名字形组。所以,在’From Glyphs - > To Glyphs’列中,我们输入:
复制
<latin_lower_case_group> -> <small_caps_group>然后按ENTER键。您的窗口应如下所示:
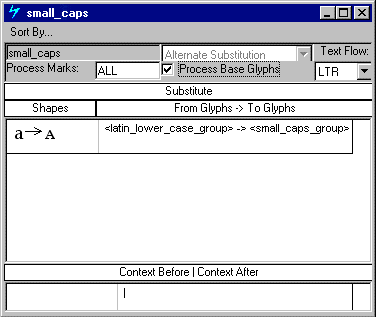
现在查找完成,返回主VOLT窗口。突出显示我们创建的’small_caps’查找,并将其拖到脚本/语言窗格中的’Small Capitals’功能。然后它应该显示为“小首都”功能下的分支(见下图)。小盘股替代现已到位。
https://docs.microsoft.com/en-us/typography/tools/volt/images/smcp_complete.gif
注意
VOLT的“查找”窗格中查找的垂直顺序确实会影响查找在InDesign等程序中的执行方式。如果给定的查找在列表中比另一个更高,则优先级更高(您可以通过单击查找并向上或向下拖动来更改顺序)。这在具有对相同字形执行布局操作的功能的字体中很重要。我们的字体中的一个例子是小帽功能和我们创建的'fi'结扎:两者都影响小写字母'f'和'i'。因此,重要的是我们创建的小型帽子特征高于结扎特征 - 这样,InDesign就会知道小型帽子应该取代结扎线并且'fi'结扎线不会出现在小帽子中。 f'和'i'第4步:添加旧式数字
旧式数字(或数字) - 更传统的数字有时被称为“小写” - 长期以来一直是数字排版中的一个问题。大多数字体根本没有提供旧式数字的选项,而那些通常带有衬里(全部资本高度)数字,旧式采用辅助(或“专家”)字体。虽然旧式数字在精美文字排版中是优选的,因为它们优雅和更和谐的外观,以及周围的字母,容易访问它们一直是个问题。
现在,通过正确完成的OpenType字体,印刷工人可以无缝访问衬里和旧式数字(只需在InDesign中切换“旧式”菜单选项)。要添加对此功能的支持,我们将使用OpenType布局功能<onum>。
创建字形组
与小型大写一样,为此功能创建字形组将非常有用:再次,我们只是将一组字形替换为另一组字形。但是,由于我们现在已经熟悉了字形组的概念,这次我们可以采取一些小的捷径。我们可以使用VOLT的方法来指定带方括号([和])的字形范围,而不是单独指定组中每个字形。
首先,我们将添加衬里数字组(当在InDesign中打开“旧样式数字”功能时,将替换为旧样式组)。像我们之前一样添加一个新组,并将其命名为“lining_numerals”。然后,在组编辑窗口中,我们将输入组的字形范围。在“编辑字形”窗口中,找到第一个衬里数字(’0’)的字形名称和最后一个字形(’9’)的字形名称。然后,在组编辑窗口的第一行中键入:
复制
[glyph_name_0 - glyph_name_9]
并使用字体中的相应名称替换两个字形名称。点击ENTER后,您的窗口应如下所示:
接下来,为旧样式数字创建另一个字形组(名称为’os_numerals’),再次指定0到9范围。创建“onum”功能和关联查找创建两个组后,我们可以添加该<onum>功能 - 突出显示“默认”语言并单击“添加功能”按钮。键入<onum>并按Enter键。VOLT将标注新功能“Old Style Numerals”。对于最后一步,我们必须创建将执行替换的查找,然后将其链接到<onum>我们创建的功能。单击“添加替换”按钮并将新查找命名为“old_style”。在编辑窗口中,键入:
复制
<lining_numerals> -> <os_numerals>然后按ENTER键。返回主VOLT窗口,单击我们创建的’old_style’查找并将其拖到脚本/语言窗格中的’旧样式数字’功能。旧式数字布局功能现已完成。
第5步:添加区分大小写的功能
精细排版的一个更常被忽视的细节是根据其背景调整某些字母位置。最常见的情况是在ALL CAPS中设置文本。当方括号和括号等字符与全部大写文本集一起使用时,它们通常显得太低(因为它们垂直对齐以使用小写字母)。
虽然桌面排版员通常可以在必要时手动调整字符基线,但是当遇到许多这样的情况时(在设置书籍文本时可能会发生),任务有点令人生畏。但是,结合使用OpenType布局功能<case>和InDesign的“全部大写”菜单选项,可以自动完成这些区分大小写的调整。在此示例中,我们将创建一个<case>查找,以便在打开“全部大写”时将垂直调整的方括号替换为普通方括号。
创建<case>功能和关联的查找
在主VOLT窗口中,突出显示“默认”语言,然后单击“添加功能”按钮,然后键入<case>并按Enter。VOLT将为新功能“Case-Sensitive Forms”贴上标签。接下来,转到右侧的“查找”窗格,然后单击“添加替换”。为新查找命名为’all_caps_brackets’。找到并注意要替换的括号的字形名称和调整后的括号(总共四个字形)后,在编辑窗口中输入两个替换行:
复制
glyph_name_left_bracket -> glyph_name_left_bracket_adjusted
和
复制
glyph_name_right_bracket -> glyph_name_right_bracket_adjusted
将这两行添加到查找后,返回主VOLT窗口并将’all_caps_brackets’查找拖到’区分大小写的表单’功能中。当然,您可以根据需要为<case>查找添加尽可能多的调整- 括号和某些标点符号通常可以在所有大写设置中进行垂直调整。
第6步:编译并测试您的字体
现在我们已经添加了所有OpenType布局功能,我们可以使用VOLT来测试或“校对”字体。但是测试可以开始,VOLT必须首先编译字体:单击工具栏上的“编译”按钮。如果您添加的功能有任何问题,VOLT会在此时通知您。成功编译字体后,我们可以继续使用校对工具。
要访问VOLT的内置测试工具,请单击VOLT工具栏中的“校对工具”按钮。首先在“脚本”下拉框中选择“拉丁文”,然后在“语言”下拉框中选择“默认”。我们将开始测试我们添加的第一个功能:’fi’连字。首先,键入字体’f’字形的名称,空格,然后输入’i’字形的名称。以下是您的校对工具窗口的外观:
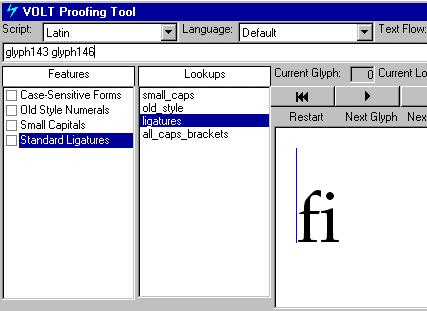
要测试“fi”连字,请突出显示您在校对工具中输入的字形名称,单击“标准连字”复选框,然后单击右侧窗格中的“完成”按钮。如果您已正确创建查找,则应该看到’f’和’i’变成’fi’结扎。

使用其他功能重复此过程,键入相关的字形名称,选中相应的“功能”复选框,然后点击“完成”。
编译和安装您的字体
一旦确认OpenType布局功能正常工作,请执行最终的“编译”和“保存”,然后退出VOLT。找到字体文件并将其安装在“控制面板”的Windows Fonts文件夹中。
第7步:在InDesign中测试您的字体
在系统上安装字体后,启动InDesign并使用空白文本框创建新文档。在字符调色板中,选择您的字体并键入一些文本。
输入’fi’并突出显示它(然后选择’Ligatures’):
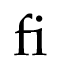
小帽(选择’小帽’):
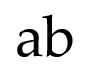
旧式数字(选择’旧式’):
全部大写调整括号(选择’全部大写’):
现在您的OpenType布局启用字体似乎已准备好,请在VOLT中将其打开并从“文件”菜单中选择“发送字体”。这将删除私有VOLT数据,使字体可供分发和使用(请务必保存预先发布的字体文件版本,以便将来修改布局功能)。
16.1.1.2.菜单和工具栏
文件菜单
打开字体 - 打开用于VOLT的字体。一次只能打开一个文件。
保存字体 - 保存对已打开文件的更改。
将字体另存为 - 以其他名称保存字体文件。
Ship Font - 编译OpenType表并从字体中删除VOLT工作表。这节省了发货字体的空间。
最近使用的文件列表 - 打开最近在VOLT中处理过的文件。
退出 - 关闭VOLT。
项目菜单
添加脚本 - 将脚本节点添加到书写系统树。
删除脚本 - 从写入系统树中删除当前选定的脚本及其子项。
添加语言 - 将语言节点添加到当前选定的脚本节点。
删除语言 - 从书写系统树中删除当前选定的语言及其子项。
添加功能 - 将功能节点添加到当前选定的语言节点。
删除功能 - 从写入系统树中删除当前选定的功能标记。不会从查找列表中删除分配给要删除的功能的查找(请改用“删除查找”)。
添加替换 - 将替换类型查找元素添加到查找列表。
添加定位 - 将定位类型查找元素添加到查找列表。
删除查找 - 从查找列表中删除当前选定的查找元素。
添加标志符号组 - 将标志符号组元素添加到组列表中。
删除标志符号组 - 从组列表中删除当前选定的标志符号组元素。
16.1.1.3.项目窗口
主项目窗口提供了您正在处理的字体的OpenType布局表结构的鸟瞰图。OTL表生成是一种定义明确的结构化活动,它利用了“构建块”概念。各个窗格包含不同级别的详细信息。
最右边的窗格显示称为“字形组”的单位。用于生成字形组的最小信息单位是字形。这些单位帮助将字形串起来。字形组是查找生成的构建块。查找窗格列出了功能使用的查找。这些查找将字形组和字形串在一起,以启用字形替换和定位。
最左侧的窗格包含来自查找和字形组窗格的信息,以及有关脚本,语言和功能的信息。它允许字体开发人员查看为该字体构造的OTL表的整体结构。
查看字形
选择“编辑字形”按钮将启动字形网格,您可以在其中查看字形,名称,CMAP条目和指定的类型。对于连字,您还可以设置它们具有的组件数(这会影响连字中的标记到结扎定位查找和插入符号放置)。

创建功能树
在主项目窗口中,您可以创建脚本/语言系统/功能/查找树。输入“name <tag>” 形式的每个项目(带有尖括号的标记)。您只能输入标签或仅输入名称,VOLT将推断所有已注册标签的其他部分。

已注册标记的列表存储在VOLT应用程序目录中的一个名为的文件中tags.txt。随着我们注册更多标签,将会有更多更新。在将来的VOLT版本中,该机制将更改为通过NLS +获取本地化名称。列出功能的顺序是为了便于查找应用的功能,并不意味着也不会影响查找处理顺序。
脚本,语言系统和功能始终按字母顺序排序。这些顺序不会影响字体中的处理顺序。
带标签的语言系统 被VOLT标记为默认语言系统。带标签的功能由VOLT标记为必需的功能。请注意这里与原始OTL格式的区别,其中任何功能或语言系统可以指定为必需或默认。
添加查找
要向要素添加查找,必须在“查找列表”中单独创建它们,然后将它们拖放到相应的要素中。
查找不按功能列表的字母顺序排列。查找在执行时显示,每次只调用一次。因此,重要的是由字体开发者预先确定订单。
要更改查找顺序,请将它们拖放到查找列表中。这也将改变它在特征树中的外观顺序。
添加字形组
您可以在主项目窗口中添加字形组。拥有字形组对字体功能没有任何影响,但在查找中使用预定义的组可能会加快速度。要在替换或定位查找中引用组,请在角括号中写下组的名称,例如。

组始终按字母顺序显示。
名称
任何带有标签(脚本,语言系统和功能)的东西都可能有一个名称,其中包含任何类型的字符。这些项目由其标签引用。所有名称都区分大小写。字形名称只能包含字母和数字。使用VOLT 1.1版,我们也允许’。’ 和字形名称中的’_’字符。
16.1.1.4.字形网格
字形网格列出字体中的所有字形及其名称,字形ID,相应的CMAP条目,分配的类型和组件编号。所有这些信息(字形ID本身除外)都可以通过工具的顶部进行更改。选择工具/选项以设置网格中显示的字形大小。

在处理字体之前,应该命名其中包含的所有字形。这可能是一个单调乏味且耗时的过程,尤其是对于大字体。VOLT包含几个选项来帮助加快此任务并帮助您重用其他字体中使用的字形名称。这些选项记录在文件选项部分中

要更改字形信息,请在网格中选择一个字形并更改其上面的数据。单击网格中的其他位置或以其他方式更改焦点会提交更改。

“查找”按钮(也可通过Ctrl-F访问)允许您按名称或Unicode值搜索字形(字形按ID顺序显示)。
字形名称
编辑字形名称时,按ENTER键提交名称更改并自动转到下一个字形。这对于输入字形名称组很方便。字形名称可能包含拉丁字母和数字。在VOLT 1.1版中,字符’。’ ‘_’对字形名称也有效。
字形类型
字形类型的有效选项是“简单”,“连字”,“标记”和“组件”。字形类型在OpenType规范的Glyph类定义表部分中定义。“简单”字形是单个字符,间距字形。“连字”字形是一个多字符,间距字形。“标记”字形是非间距组合字形,“组件”字形是单个字符的一部分,间距字形。
提示:全局将所有字形设置为“简单”,并根据需要更改为其他类型。为此,请定义包含所有字形的字形组(例如,[glyph1 - glyphxxxx]),然后在组工具中选择“全部标记为…”。
字形ID
此字段无法编辑。
统一
VOLT允许您编辑此字段,提供基本的“cmap”编辑功能。VOLT 1.0版不允许一个字形有多个’cmap’条目。使用VOLT 1.1版,此限制将被删除。您可以使用U + xxxx,0x或&H为每个字形输入一个或多个Unicode代码点。有效输入将显示为U + xxxx。要将多个Unicode代码点分配给单个字形,请使用以下格式:’U + xxxx,U + xxxx,…’。您可以用分号替换逗号。
使用VOLT 1.1,我们还增加了对替代字形的支持。要输入代理字符代码,请使用代理对,例如“U + D800DC00”。
组件
对于定义为连字的字形,这表示组件的数量,稍后用于定义插入符号放置。
16.1.1.5.雕文组
使用字形组工具,您可以通过双击主项目窗口中的组名称或选择“编辑组”按钮来打开组的定义。

组是一组字形或其他组合在一起。字形和组由名称引用,仅在编译时绑定。
如上所示,Glyph Group Tool显示两列表。在右侧,列出了成员字形/组/范围/枚举。它们使用字体中的实际字形在左栏中预览。
右栏中的有效条目是:
有效的字形名称,在字形网格中指定
在尖括号中引用其他字形组(嵌套限制为100级):
连续范围的字形,格式为[StartingGlyphName - EndGlyphName]
字形枚举,用大括号括起来:{GlyphName1,…,GlyphNameN}
可以在替换和定位工具中使用相同的条目语法,通常可以输入字形名称的任何位置(校对工具除外)。通过菜单选项“Mark All Glyphs As …”,可以为组中的所有字形指定相同的类型。选择菜单选项后,该组将立即绑定到字形。这种分配字形类型的方法有时比使用字形网格更方便。
字形名称和形状
字形名称列表包含可编辑字形名称列表,每行一个名称。VOLT维护与这些名称对应的实际字形形状的侧栏。

用户完成编辑线后,形状会出现在名称旁边(移动插入符号,按下输入或更改焦点)。如果该行不包含有效的字形名称,则会显示红色错误符号而不是形状。用户可以通过在字形定义工具中编辑名称或更改字形名称来更正问题。如果错误未得到纠正,将在编译期间报告。
添加和删除字形
要在组中添加或删除字形,用户可以编辑字形名称列表,就像它是文本窗口一样。在行尾按Enter键会启动一个新行,退格键和删除键会删除字符以及换行符。还可以进行切割,复制,粘贴和拖放。一旦用户离开一条线,与该行中的名称对应的字形形状将显示在字形形状列中。如果该行不包含有效名称,则会显示红色错误符号而不是字形。字形形状列表不可编辑。
还可以将字形定义工具中的字形拖动到字形名称列表中,以将其名称添加到组中。新的字形出现在拖动它们的地方的新行(插入回车符)上。
往返
没有必要保留组中字形的顺序。当字形组工具重新打开时,字形应按其字形ID的顺序出现。
汇编
字形组未编译,但用于编译使用它们的查找的coverage和类定义。对于编译,可以始终考虑按字形ID对字形组进行排序。
16.1.1.6.字形替换
可以使用Substitution Tool以下两种方式之一编辑替换查找:
在主项目窗口中双击它; 要么
选择它并按“编辑查找”按钮。
查找标题
查找标题占据工具的顶部。定位工具中使用相同类型的标头来描述定位查找。

替换工具
标头包含以下字段:
查找名称
查找类型,为替换自动设置(您必须手动指定查找类型以进行定位查找); 如果替换条目具有不一致的类型,则此字段将更改为“未知替换”以提醒您; 尝试编译此类查找将导致错误。
处理标记,用于定义查找对标记的行为。有效条目是:
ALL - 处理所有标记字形
NONE - 此查找跳过所有标记字形
组名称 - 仅处理此组中的标记,跳过其他标记。
注意
在查找头中以这种方式使用的所有标记组必须是互斥的。如果您需要使用此功能,建议您事先将标记分成几个单独的组,然后在查找标题中使用这些组。分组通常遵循标记的几何位置(上面的标记,下面的标记等),并且类似于组合由Unicode分配的标记类。处理基础字形 - 禁用时,查找会跳过所有非标记字形。
文本流 - 有效条目是从左到右(LTR)或从右到左(RTL); 影响替换/定位操作的显示(预览),以及放置字形以进行定位的方式; 使用阿拉伯语或希伯来语等语言时设置为RTL。
替换清单
替换列表由两列组成:右侧的描述和左侧的预览。描述使用字形名称和组来指定替换。预览列显示替换中涉及的字形。
所有替换都按以下格式定义:LeftHandSide - > RightHandSide。例如,’Ampersand - > AlternativeAmpersand’可以定义单个或替代替换,’LatinSmallLetterF LatinSmallLetterI - > LatinSmallLigatureFI’可以定义简单的连字。
单个菜单选项允许您订购替换,如果您正在处理大字形集,这将非常方便。请阅读警告:第一个字形的排序通常不会改变查找的处理方式。但是,如果您在定义替换时使用组(请参见下文),则无法完成排序(组不会被分解),新排序可能会影响查找的行为。
在替换中使用组
组可以在替换中用作简写符号,意味着应该用组中的每个元素执行替换。可以使用任何组表示法(对预定义组,范围或枚举的引用)(请参阅“组工具”部分)。最多可以在替换的每一侧使用一个字形组。如果在每个替换大小上使用组,则它们的基数必须匹配。这种替换被编译成一系列替换,其中组被随后的第一个,第二个等等替换为组的成员。例如,替换:
‘[LatinSmallLetterA - LatinSmallLetterZ] - > [LatinSmallCapZ - LatinSmallCapZ]’
将被编入系列:
‘LatinSmallLetterA - > LatinSmallCapA’,’LatinSmallLetterB - > LatinSmallCapB’
等等。
注意
组中的字形总是按其字形ID排序,而不是按组描述方式隐含的顺序排序。使用上下文
替换的底部是用于描述上下文。通过使用上下文,您声明上面的替换不会发生在应用查找的任何地方,但仅在被指定的上下文包围时才会发生。
16.1.1.7.雕文定位
通过双击主项目窗口或选择它并按“编辑查找”按钮,可以在定位工具中编辑定位查找。这是迄今为止最复杂的工具; 以下仅是一般性描述。

查找标题
请参阅替换工具部分。
查找类型
必须先选择查找类型,然后才能将任何数据输入定位工具。下面是每个查找类型的简要说明。
雕文定位器
您可以通过拖放字形和锚点图像来指定定位操作。您也可以在一个小表格中输入下面的调整或坐标,以便稍后在定位器上显示。
对于每个操作,定位器上会出现多个图像,对应于您可以定位的字形和锚点。无法定位的“非活动”形状以灰色显示。另外,三行表示字体上升,基线和下行。建议定位操作不要越过上升和下降边界。
在左下角是一个小的“预览”,定位在较小的尺寸的结果。选择预览下方的尺寸。
单一调整
“单一调整”操作用于定位单个字形,在以上下文方式使用时最有用。
字形: 输入要在右侧列表中定位的字形名称。可以使用字形组。组中的所有字形(在一行中)将接受相同的处理(对其位置的相同调整)。您不能在不同的行中重复相同的字形两次。
定位: 选择字形或字形组。在定位器中,拖动字形图像以获得所需的调整操作。拖动高’宽度锚’进入调整前进宽度。如果在字形列表中的简单行上输入了多个字形,则可以从下面的下拉列表中选择不同的形状,以查看定位操作如何影响列表中的每个字形。
配对调整

允许您定位字形对。类似于单个调整,除了现在有两个字形列表,第一个字形和第二个字形。
每对条目(每个字形列表中的一个)单独调整。与单个调整一样,如果使用字形组,则组中的所有字形都将获得相同的处理和定位。
锚附件
此选项允许您定义Mark-To-Base,Mark-To-Mark和Mark-To-Ligature查找。实际查找类型由使用的字形类型定义。您不能在一次查找中混合使用不同的字形类型。
在标记旁边,输入标识要定位到的锚点的锚点名称。一个字形可以具有任意数量的不同锚(具有不同的名称)。如果两个标记相对于基本字形共享相同的位置,则它们可以使用相同的锚名称。
要定义“标记到基础查找”,请在第一个字形列表中输入基础列表,并在第二个列表中输入标记列表。从每个列表中选择一个条目后,将标记和锚点定位在定位器中。在基础或标记列表中使用字形组时,从定位器上方的下拉框中选择要使用的字形。请注意,一个组中的字形不共享相同的定位值。但是,您可以通过选择“全部第一个相同”或“全部第二个相同”按钮将一个锚位置应用于组中的所有字形。
注意
移动锚点会影响基础锚点和标记锚点。要仅移动一个锚点,请先将另一个锚点向下锁定(参见下文)。
注意
标记值在查找之间全局共享。例如,如果两个不同的查找使用名为“TopCenter”的相同锚点将顶部标记定位在字母“A”上,则更改一个查找可能会影响另一个查找。您可以锁定基础锚点以防止其更改,然后使用标记锚点微调位置,反之亦然。锁定锚: 在定位器下方,提供一个选项来锁定其中一个或两个锚。在明确解锁之前,无法(无意)更改锁定的锚。如果另一个查找使用同一个锚(由字形ID和锚名称标识),它也将被锁定在该查找中。
定义Mark-To-Mark和Mark-to-Ligature Lookups: 这类似于定义mark-to-base查找。唯一的区别是为每个连字字形定义许多锚点的位置,而不是每个简单基本字形一个锚点(每个组件一个锚点)。当前“活动”组件由定位器上方的组件下拉框控制。“非活动”组件锚点和标记显示为灰色。
草书附件
草书附件类似于锚附件。锚名称固定为第二个字形的“entry”,第一个字形的“exit”。用于定义草书定位查找。
插入位置
插入符号定位不会在OTL查找中编译,也无法链接到某个功能。收集来自插入符号定位操作的所有数据以生成GDEF数据,然后由OpenType布局服务用于测量操作和插入符号放置。
字形列表: 定义描述连字符的插入位置。只能输入连字字形。将高的“插入符号”锚点拖到连字符内的插入符号的右侧位置。结扎线的插入符号比其组件数少一个。通过操纵定位器上方的组件字段来选择“活动”锚点。
添加设备更正
检查“调整模式”框以进入所有定位更改仅影响当前所选尺寸的模式。“按此尺寸调整”复选框将显示所选尺寸的调整。这些调整始终显示在小预览中。检查“调整模式”,将其显示在大型定位器上,以进行其他更改。
取消选中“按此尺寸调整”复选框以清除此尺寸的调整。选择“清除”按钮可清除所有尺寸。
定义上下文定位
请参阅“替换工具”部分中的“使用上下文”。
16.1.1.8.打样
校对工具通常用于测试具有少量文本的字体。 
为此,请执行以下操作:
- 打开校对工具,然后选择要测试的脚本和语言系统。选择语言系统将填充功能列表。
- 选择书写方向(文本流程)。
- 通过在要素列表上方的长文本框中输入字形名称,或通过单击其下方的图片并通过击键输入字形来创建字形。每个击键都将使用当前的Unicode条目转换为字形,并且生成的字形名称将添加到运行中的名称中。

- 通过突出显示部分或所有字形名称并选中相应的功能框来选择功能。右侧是这些功能启用的查找列表。您可以在字形名称列表中来回移动光标,并在从一个字形转到另一个字形时看到功能发生变化。如果您只需要将某些功能应用于整个运行,请突出显示字形名称列表中的所有内容,然后选择所需的功能。

- 使用“下一个字形”和“下一个查找”按钮应用您的选择,并查看OpenType引擎如何处理您的字符串。“重新启动”会将您带到处理的开始,“完成”会显示最终结果。

16.1.1.9.文件选项
要保存您的工作,请从“文件”菜单中选择“保存字体”,或单击工具栏上的“保存”按钮。

VOLT将其数据保存在TTF内的临时表中。VOLT保留更多数据(使其界面更加用户友好),因此转换到OT组件是不可逆的。只要其他工具保留此表,就可以安全地打开并在不同的工具中保存相同的字体。
完成字体工作后,从“文件”菜单中选择“发送字体”。当出现字体时,将从字体中删除临时VOLT源代码表。

注意
VOLT源代码表包含VOLT数据的序列化文本显示,非常容易理解。我们不想鼓励任何人破解这些数据,但如果你看看那里有什么,你就会立即想出格式。格式与用于导入和导出查找,字形组和字形定义的格式相同,如以下“示例”部分所述。导入和导出选项
VOLT支持下面显示的复合屏幕捕获中显示的导入和导出选项。

导出字形范围

字形信息保存为.VTD文件。代码段如下所示。
复制
DEF_GLYPH “halfSha” ID 230 END_GLYPH
DEF_GLYPH “halfSsa” ID 231 END_GLYPH
DEF_GLYPH “halfSa” ID 232 END_GLYPH
DEF_GLYPH “halfHa” ID 233 END_GLYPH
DEF_GLYPH “halfKaSsa” ID 234 END_GLYPH
DEF_GLYPH “halfJaNya” ID 235 END_GLYPH
DEF_GLYPH “halfKaNukta” ID 236 END_GLYPH
DEF_GLYPH “halfKhaNukta” ID 237 END_GLYPH
许多字体开发人员以标准化方式将字形映射到字形ID。如果这样做,请使用字形编辑工具为您的字形命名一次,然后在库中应用导出的.VTD文件。
导出查找

查找信息保存为.VTL文件。代码段如下所示。
复制
DEF_GROUP “FullJaForms”
ENUM GLYPH “fullJa”
GLYPH “fullJaNukta”
GLYPH “fullJaRa”
GLYPH “fullJaNuktaRa” END_ENUM
END_GROUP
出口项目
使用覆盖,删除或破坏OpenType布局表或VOLT专用表的工具将字形添加到字体时,此选项特别有用。
导入选项
导入选项用于重用字形,查找,组和项目信息。例如,“导入PostScript名称”选项会将存储在字体POST表中的名称分配给VOLT使用的字形名称。
16.1.1.10.样品
访问补充文件
要访问VOLT的补充文件,请从Windows“开始”菜单(“开始”/“所有程序”/“Microsoft VOLT”)中选择“VOLT补充文件设置”选项。
首先出现VOLT补充文件EULA(最终用户许可协议)。接受EULA后,系统会询问您在本地硬盘驱动器上安装补充文件的位置。
曼加勒
此Mangal副本包含OpenType布局表,并使用VOLT构建。我们希望您觉得它很有用。
Mangal是为Devanagari设计的,支持脚本的复杂印刷要求。这些要求的非详尽清单包括:
产生’akhands’
用适当的Ra vattu形式代替
替换半形式的辅音
选择合适的元音符号来代替辅音的默认元音符号,用于形成音节
定位关于基本字形和连字的标记和元音符号
此字体是“正在进行中的工作”,并且仅说明了使用VOLT构建OpenType字体表的众多方法之一。我们在此图中的主要目标之一是尽可能多地表示VOLT的功能。举几个例子:我们在很多组中对字形进行了分类,并使用配对定位表提供了标记到标记的定位。要获得类似的结果,您可以选择以不同的方式对字形进行分类,使用较少的组,或使用锚点进行标记到标记的定位。
这些表提供了一种查看和理解使用VOLT构建OpenType表的基本思维过程的方法。它们不是为梵文创建表格的“典型”方式。VOLT为OpenType类型设计器提供了一个“可视化”工具,具有很多灵活性和选项来创建OpenType布局表!
字体本身的轮廓设计简单,用作Sans Serif UI字体。它是OpenType Indic规范的附录C中提到的字体。
Mangal可以被视为旗舰印度字体,具有OpenType的完整实现,从字形库到表格。Mangal是根据VOLT补充文件EULA的条款提供的,不得重新分发。
阿拉伯语排版
根据VOLT补充文件最终用户许可协议(EULA)的条款,阿拉伯语排版字体随VOLT一起分发。它仅供参考,不得更改或重新分发。
Arabic Typesetting支持Unicode阿拉伯语和阿拉伯语扩展块中的所有字符。因此,它可用于制作阿拉伯语,波斯语,乌尔都语,信德语,马来语和维吾尔语的文件。字体是阿拉伯语naskh书法风格。
阿拉伯语排版包含布局信息和字形,以支持所支持的脚本和语言的所有必需功能,并包含超过1600个阿拉伯字形。所有字体都不必支持这么多字形或连字。应将每种字体设计为字体创建者所需的字体。
许多形状的字形表单(例如连字)没有Unicode编码。这些字形在字体中具有ID,应用程序可以通过“运行”依赖于这些字形的布局功能来访问这些字形。应用程序还可以通过遍历OpenType布局表或使用布局服务来识别字体中的非Unicode字形,仅用于提供信息。
阿拉伯语排版包含三个OpenType布局表:GSUB(字形替换),GPOS(字形定位)和GDEF(字形定义,区分基本字形,连字,标记字形类等)。
的Uniscribe
为了测试您的字体,我们已经包含了Microsoft的Unicribe(Unicode脚本处理器)的更新测试版本。.dll和安装说明包含在usp.zip文件中。
根据VOLT补充文件EULA的条款也提供Uniscribe,并且不得重新分发。
16.1.2.发行说明
1.4
自上次公开的Visual OpenType布局工具(VOLT)版本发布以来,我们在整个产品中添加了各种功能并进行了改进。以下是快速更改列表,后面是每个更改的详细说明:
编译器优化可以显着节省编译表的大小
编译器优化以支持包含大量锚点或草书附件查找的字体
支持编译器和用户界面中的标记过滤集
提高项目编译,加载和保存的速度
用户界面改进
VOLT的多个错误修复,包括编译器,项目导入和导出,以及整个UI
编译器改进
减少生成的布局表大小的新优化,包括上下文和对定位查找。特别是对于包含大量复杂上下文查找的字体,大小节省是很重要的。在某些情况下,节省的编译表大小减少了4倍。
编译器现在能够使用大量已定义的附件锚来编译GPOS查找。这是最严重的编译器限制之一,没有任何解决方法可供字体开发人员克服。
VOLT现在实现了OpenType规范1.6中引入的标记过滤器字形集。使用标记字形集几乎与标记附件类相同,除非用户需要在查找编辑窗口中将“*”放在标记组名称的前面。此语法是有意的,以防止用户意外创建重叠标记类。
除自动优化外,VOLT还增加了手动控制对定位查找格式的功能。用户可以通过在查找名称末尾添加_PPF1或_PPF2来明确指定格式。
用户界面
扩展校对工具,支持超过100次查找的字体。当内容被厚窗口边框阻挡时,修复了表单布局问题。固定定位查找窗口,以便在窗口大小调整期间保留网格内的位置。添加了用于导入项目忽略字形定义的菜单项。
各种修复
修复了使用EXCEPT上下文编辑查找时的项目损坏。修复了在某些情况下涉及插入符号附件查找的VOLT崩溃问题。修复了使用很长锚名称的项目的编译错误。VOLT编译器和用户界面中的其他修复。
1.3
自两年前上一次公开发布VOLT以来,我们在整个产品中添加了各种功能并进行了改进。以下是快速更改列表,后面是详细说明:
字体资源管理器,允许用户快速搜索查找内的字形引用。
可用性改进,包括查找注释,新的UI选项和详细的错误消息。
编译在质量,兼容性和性能方面的改进。
整体性能改进,包括导入,导出和字体大小。
更新了补充文件和标签列表。
VOLT中的多个错误修复,包括编译器,项目导入和导出以及整个UI。
字体浏览器
字体资源管理器允许字体设计器即时搜索项目查找以查找字形的任何外观,无论它直接引用还是作为字形组的一部分。用户还可以搜索一系列字形。可以通过Explorer窗口中的多个参数来控制搜索。
从搜索结果中,字体开发人员可以快速跳转到查找输入或上下文中的特定行。这可以通过按住Ctrl键单击搜索结果中的相应行来完成。通过按住Alt键单击查找或组名,用户可以打开相应的查找或字形组。当用户点击字形名称时,VOLT将跳转到字形编辑器内的字形定义。在查找窗口中也启用了相同的Alt-Click(在输入或上下文字段内)。
单击工具栏上的“浏览”按钮或从“工具”菜单中可以访问字体资源管理器。
查阅评论
字体设计者现在可以为字体项目中的每个查找添加注释。如果注释行之一以“TODO:”开头,则将其视为此查找的特殊待办事项。可以从查找窗口菜单添加查找注释。
主窗口
主窗口现在支持视图选项,允许在主项目窗口内显示有关查找和字形组的详细信息。查找列表还可以显示查找内容,注释或待办事项。字形组可以显示组内容。可以从重新设计的选项对话框中控制视图选项。
VOLT现在可以记住其他VOLT窗口中使用的主要表单大小和位置,视图选项以及字体大小。整体表单布局已更改,为查找和组列表提供了更多空间。功能树以紧凑状态打开,默认情况下折叠查找列表。
项目改进
项目编译,加载和保存的性能得到显着改善。现在复杂字体的速度提高了几倍甚至几十倍。通过避免保留中间编译表也可以改善字体文件大小。
添加了选项以避免从VOLT覆盖cmap表,允许通过FontLab等其他字体工具进行cmap编辑。
已在查找和校对工具中添加了对FontLab字形语法的支持。’/‘现在允许作为字形与空格和逗号之间的分隔符,从而实现FontLab的简单复制粘贴。
添加了项目导入和编辑的各种问题的详细错误消息。
汇编
为某些编译错误和无效的项目源添加了详细的错误消息。
每个结扎的最大组件数从6增加到16。
垂直形式替换特征’vert’和’vrt2’以与GDI兼容的方式编译。
其他变化
将usp10.dll和示例字体更新到Windows Vista SP1附带的版本。
Tags.txt文件已更新,包括最近添加的功能和新的Indic v.2标签。
更新了Kern2Volt以支持更长的字形名称(最多255个字符)。
多个错误修复。
1.2
上下文查找的上下文排除语法
这是在VOLT查找中使用上下文的新方法,允许字体开发人员执行以前不可能执行的操作并更有效地实现查找。查找用户内部可以使用“EXCEPT”上下文,只有当输入与排除的上下文不匹配时才会发生替换或定位。要执行此操作,只需在要排除的上下文的开头键入“EXCEPT”单词(区分大小写)。您可以在一次查找中同时使用普通和“EXCEPT”上下文。唯一的限制是将所有’EXCEPT’上下文置于普通上下文之前。
以下是一些如何使用上下文异常的简单示例:
首先,在这个例子中,我们将在单词的末尾替换带有特殊形式的字母。通常情况下,你不能这样做或者非常不直观。
字母 - > EndOfWordForms在上下文中:EXCEPT | 快报
第二个示例混合普通和上下文,使代码更具可读性。之前,您需要至少两次查找才能执行此操作,这会导致不必要的替换。
A - > A.1在上下文中:除了| xy | X
导出和导入多个查找和多个组
您现在可以选择多个查找并将它们导出到单个文件中。同组可以完成。
此更改需要在导出文件语法中稍作更改。如果您有从旧版本导出的查找或组并希望在新VOLT中使用它们,这一点很重要。
即使您在文件中有一个查找,也应该在最后添加’END’关键字。(您可以使用自己喜欢的文本编辑器)。请注意:如果您将新VOLT的查找导入旧版本,则只会导入第一个查找。
如果您有使用锚点的定位查找,则应在文件中的所有锚点之前移动“END_POSITION”关键字。当然,不要忘记’结束’。
主窗口改进
您现在可以选择查找列表中的多个查找并将其拖动到功能树中。您也可以删除多个查找。
每次更改后,功能树都不会刷新和扩展。此外,如果在树中选择要素节点,则查找列表将自动选择与此要素关联的所有查找 - 这是检查要素中是否缺少某些查找的便捷方法。
用户可以随时从字体重新导入cmap表。使用其他工具在VOLT外部修改字体时非常有用。在VOLT中打开字体后,您不应该忘记首先执行此操作 - 否则cmap将被存储在VOLT项目中的数据覆盖。
校对工具改善了经验
现在,当您关闭校对工具窗口并再次打开它时,它会恢复用于测试字体的所有参数 - 输入字形,脚本和语言系统,应用的功能。
此外,调试查找变得更容易。您可以在其上方使用组合框并直接跳转到您感兴趣的查找,而不是使用查找导航按钮。
字形属性窗口改进
代理的字符代码可以作为标量值而不是代理对输入。代理对格式仍然被识别,但立即转换为标量值。请注意,由于此更改,旧版本的VOLT将无法理解从此新版本保存的字体,但仅限于在项目中使用代理字符。
搜索框已添加到字形编辑器 - 位于顶部的上方字形属性文本框中,带有“查找”按钮。按钮与以前相同,但是当您键入框时,VOLT将动态搜索并选择具有指定前缀的第一个字形。此外,如果您键入U + xxxx,它将搜索具有此字符映射到它的字形,例如U + 61或U + 0061将选择小拉丁语’a’。
定位查找编辑
新的,方便的模型,以限制锚定运动添加到定位窗口。使用鼠标拖动锚点时,可以按Shift键以允许锚点仅水平移动,并按Control键进行垂直移动。如果在拖动过程中按下Control / Shift,它将具有与从头开始按下时相同的效果 - 锚点将跳转到原始垂直或水平位置。
编译选项
您现在可以通过指示VOLT使用扩展查找来控制编译,或者选择使用格式2进行对定位查找(默认情况下,使用格式1)。这些选项保存在项目中,并在每次编译项目时使用。仅在需要时使用此选项 - 当字体中的表格大小变得太大而无法满足您的查找时。
各种错误修复
在VOLT中修复了多个次要错误并且没有那么小的错误。
补充文件已更新
补充文件已更新。新Uniscribe取自最近的Windows Vista构建,将最新的更改集成到脚本整形引擎中。Mangal字体也是最新的Vista版本。它被重命名为“Mangal Sample”并且有一些提示被删除。
1.1
初始发行
16.2.VTT
Microsoft Visual TrueType(VTT)是一种专业级工具,用于以图形方式指示TrueType和OpenType TM字体。

下载Visual TrueType
(只需点击链接,然后点击下载按钮。)
Visual TrueType是适合您的工具吗?
虽然VTT的图形用户界面大大简化了字体提示的任务,但该工具并不适合新手。学习曲线相当陡峭,仅仅因为提示需要专业技能而不管工具。即使是已经使用字体编辑器多年来设计字体的有成就的类型设计师也对VTT进行了评估,并认为专业暗示不适合他们。
说明和教程
提示概述/修复光栅化问题
印度提示培训视频
版本4.2发行说明和快捷方式列表
斜体暗示例子
发行说明
版本6.31 [2018年10月发布]
以下是自6.30 [2018年8月发布]以来的变化
引入“跟随喘气”模式,其中VTT中显示的文本可以遵循喘气表设置。以前,VTT支持编辑喘气表,但VTT中显示的文本不会遵循喘息表设置。“跟随喘息”模式是一种可选模式,其中主窗口,示例文本视图,瀑布视图和字符集视图中显示的文本将根据适当的喘气表设置进行渲染。
各种错误修复。错误修复包括从“大”字体导入字形时的修复错误,在TSIC表中修复标记交换错误,这是cvar变体表的源表,修复autohinter错误。
版本6.30 [2018年8月发布]
以下是自VTT发布的6.20 [2017年3月发布]以来的变化:
支持开放式字体变体,包括中间体。以前,VTT仅支持设计空间中极端轴的不同CVT。VTT现在可以在设计空间的任何位置改变CVT,包括轴主控器之间的中间点和设计空间的角。
在Variation CVT Windows中更新了UI。变量CVT窗口现在清楚地显示CVT如何在设计空间中的选定点处更改:它告诉您在该点编辑了哪些CVT,哪些CVT由于附近的增量而变化,以及哪些CVT未更改。您还可以添加,编辑和删除cvar表中表示的实例。您可以创建没有增量的临时实例,这样您就可以在设计空间中的各点之间快速切换以证明您的工作。最后,任何人都可以命名您创建的任何实例,以便于跟踪它们。
Visual TrueType和FontTools。在计算cvar表的变体增量数据时,Visual TrueType使用FontTools varLib库的端口。
Visual TrueType包括命令行实用程序vttshell.exe。此实用程序可用于从包含Visual TrueType源数据的字体编译和/或剥离源。使用该命令可以使用使用选项vttshell.exe -?。
版本6.20 [2017年3月发布]
以下是自VTT发布6.10 [2016年2月发布]以来的变化:
支持开放式字体变体。您可以使用VTT使用新的Variation CVT和Variation Windows提示变量字体,如下所述。VTT将根据Variation CVT窗口中显示的CVT生成一个cvar表。目前,VTT仅支持在可变字体轴的极值处为主控器改变CVT。支持中间cvar变体(例如,对于命名实例)是未来版本的计划。文档即将发布,但有关工作流程和说明的博客文章可在http://aka.ms/vtt-variations上找到。
变异CVT窗口。您可以使用此窗口在瀑布,文本示例和变体窗口中选择要校对的变量字体实例(请参见下文)。选择主实例时,可以调整该实例的CVT; 只需键入更改并按Ctrl-R重新编译即可。Variation CVT窗口将显示哪些CVT在字体中有所不同,以及它们与默认实例的区别。如果选择中间实例,则可以检查该实例的插值CVT。VTT尚不支持编辑中间实例CVT。
变异窗口。“变体”窗口显示当前字形轮廓和提示,就像主窗口一样,用于实例选择的变量字体实例(参见上文)。在Main和Variation窗口中,您可以在Main窗口中编辑提示,并在Variation窗口中查看对变化的影响。由于变量字体中的提示与默认实例相关联,并且仅跟随其他实例的插值CVT,因此您只能在主窗口中编辑提示。
将控制程序导出为XML。VTT 6.01添加了将字体提示转储到XML文件以导入其他字体的功能。不幸的是,这不包括控制程序。VTT 6.20现在将包含XML导出和导入中的控制程序。
版本6.10 [2016年2月发布]
以下是自VTT发布的6.01 [2015年8月31日发布]以来的变化:
用于拉丁和东亚字体的Autohinter。新的自动提示模式使用了一种新的轻量级提示策略,最适合当今的渲染环境,如DirectWrite。大多数自动投影仪会生成低级别的提示指令,您无法轻松编辑或改进这些指令。这个新的Autohinter生成高级提示,您可以通过VTT的图形用户界面轻松编辑。
能够为拉丁字体自动生成“控制值表”,节省您的时间,以便您可以立即开始向您的字体添加“视觉提示”,而无需测量字体,并手动填写相关的CVT条目。
错误和警告限制。当您打开字体时,VTT将显示它以字体检测到的错误和警告列表。如果字体中有许多错误和警告,这可能会减慢打开字体文件的过程。要加快打开时间,您可以设置要显示的错误和警告的数量限制。
遗产编译。设置此选项可确保您的字体编译与VTT版本4及以下版本完全相同。
添加复选框以在打开没有源数据的字体时允许将来抑制导入二进制提示消息。
全新的VTT图标,以及图形提示界面的新图标。
与性能相关的各种错误修复。
版本6.01 [2015年8月31日发布]
现在可以通过下载中心获得!此下载和未来版本将在 Microsoft下载中心 免费提供。不再在许可协议中传真
彩色字体支持(COLR / CPAL表)。COLR和CPAL表中定义的颜色图层的字形在整个VTT中呈现颜色,因此您可以校对颜色字形。
更新了光栅化器。光栅化器已更新为更加准确,现在包括Windows 8和10中默认使用的ClearType灰色渲染模式。
从XML导出/导入提示。将VTTTalk和所有低级代码导出或导入XLM文件。方便在文本编辑器中进行全局查找和替换操作,或者将提示移动到另一个逐点兼容的字体。有关更多详细信息,请参阅VTT中的帮助文件。
导入二进制字体提示。打开没有VTT源数据的字体时,可以将二进制数据导入到可编辑的低级代码中。
Unicode示例文本。示例文本和测试字符串现在支持Unicode字符,包括代理项。您还可以通过在“转到角色”对话框中输入其Unicode值,或通过在主窗口中键入或粘贴来跳转到任何字符。
新的键盘快捷键。您可以按Ctrl +向上箭头和Ctrl +向下箭头快速更改分辨率。我们还添加了快捷方式来关闭许多光栅化选项(例如,Ctrl + Shift + G用于ClearType灰色,Ctrl + Shift + F用于子像素定位等)。有关详细信息,请参阅VTT中联机帮助的键盘快捷方式部分。
使用空格键进行平移。与许多其他字体设计应用程序一样,您现在可以按住空格键并拖动鼠标光标以平移主窗口。与过去版本的VTT一样,左移键继续用于平移。
单个测试字符串。主窗口现在只显示一个测试字符串。此测试字符串显示带有提示高度宽度的文本。第二个测试字符串显示了带有未提前宽度(即指标)的文本,已被删除。
PostScript名称现在可见。如果存在,则当前字形的PostScript名称将显示在主窗口顶部的状态区域中。
新的像素网格显示。“显示网格”显示选项现在显示所有像素周围的边框,而不仅仅是激活的像素
支持高dpi显示。VTT在没有任何操作系统显示缩放的情况下呈现所有内容,因此您看到的光栅化正是您所获得的。
16.2.1.发行说明v4.2
新功能
VTT将自己安装到注册表中,只要您使用VTT一次,就可以右键单击字体并在VTT中打开它。
UI元素和控制点大小分别在50%到200%的范围内可扩展。选择Tools => Options => Appearance => Scale Visual instructions。96 dpi W95的推荐设置:控制点为100%,所有其他符号为75%。符号越小,它们在小屏幕上占用的空间越少,但它们可能越难抓。
灰度缩放现在有第四个选项,NT兼容,执行伽玛校正的方式与Windows 2000大致相同。
VTT包含Windows 2000中使用的TT Secure Rasterizer 1.7。
与Monotype的Jelle Bosma和Thomas Rickner合作,实现了Align和Stroke命令的新变种。(对于TT精明的用户:命令的功能有点专有,但就自由向量的选择而言,它们的行为更加可预测和明智。)UI将自动生成新的对齐和笔划命令,因为我们认为他们优于旧的,但旧的将继续工作。
新的对齐和笔划命令有两种形式,一种是严格的,一种是稍微放松一种。这背后的原因是在小ppem尺寸下我们不能渲染墨水陷阱和类似的直线偏差,因此我们更倾向于严格对齐各个点以获得更规则的像素图案。在某些(用户定义的)ppem大小的情况下,我们宁愿为align命令解锁这个严格的夹点,以更真实地渲染墨迹。要确定应该发生哪种ppem大小,请选择Tools => Options => Glyph visuals => Ppem Limits。对齐和描边命令将在其上显示挂锁。转到您要解锁严格抓地力的ppem尺寸,右键单击挂锁,然后选择打开的挂锁。

挂锁当前设置为打开27 ppem,可选择以23 ppem打开它(恰好是主窗口的当前ppem大小)或关闭挂锁
如果挂锁已经打开,您可以选择再次将其锁定,或以不同的ppem尺寸打开它。注意:要使用此功能,您需要导入新的FpgmTmpl.txt,因为它会生成对最近添加的功能82的调用。
新笔划命令的UI将允许“划出”字符“在…之外”,如下面的“v”所示:

这种方法有时优于“由内而外”。无论哪种情况,都有权衡。“从外到内”会忠实地呈现“v”的“外部”并让你控制笔画的关节,而它可能会在不幸的尺寸下填充墨水陷阱。“由内而外”将忠实地呈现计数器,而不是填充墨水陷阱,但可能导致关节太宽或太窄。
对齐并且特别是笔划有点笨重,就其图形表示而言,已经添加了快捷方式以快速打开或关闭它们。选择Ctrl + Shift + A切换对齐,按Ctrl + Shift + S切换。请注意,对齐和笔画完全可见,必须打开x和y方向(分别为快捷键Ctrl + Shift + X和Ctrl + Shift + Y)。
delta命令已根据生成的代码大小进行了优化。注意:要使用此功能,您需要导入新的FpgmTmpl.txt,因为它会生成对最近添加的功能70到73的调用。
delta工具已得到增强,允许应用特定于黑白模式或灰度模式的增量。要使用黑白特定增量,请确保关闭灰度,并右键单击该点到增量。你会得到一个略有不同的面板,表明这个delta将适用于“仅限b / w”:

要仅使用灰度缩放增量,请确保打开灰度缩放,然后右键单击该点到增量。现在,面板指示此增量将适用于“仅灰色”:

代码的大小现在显示在glyf,prep和fpgm窗口中供您参考。可以说明尝试不同的链接策略,其与产生的像素图案等效,但尺寸不同。也可以说明,可能由太多的增量生成多少代码,以及如何与更智能的链接策略产生的代码量进行比较。
添加了一个选项,以便以当前大小显示当前字形的VDMX。要使用此选项,请选择工具=>选项=>字形视觉=> VDMX高度。如果存在且处于gridfit模式,相应的值将显示为一对绿线。
添加了一个选项,以当前大小显示当前字形的指示度量。选择Tools => Options => Glyph visuals =>指示的指标,如果处于gridfit模式,相应的值将显示为一对绿线。
添加了一个选项来修复轮廓的方向。TrueType要求外轮廓顺时针运行,内轮廓逆时针运行。导入Fontographer生成的文件时,有时可能会出错。选择Tools => Options => Glyph visuals => outline errors,VTT将检查主窗口中显示的每个字形,如果出现问题则发出警报,并要求获得修复方向的权限。如果被拒绝,违规轮廓将以红色显示。如果获得批准,VTT将确定方向。如果所有提示都是可视化生成的,VTT将保留该轮廓上可能存在的任何提示。如果手动将某些命令输入VTT通话窗口,并且这些命令没有可视化表示(例如ASM语句或函数CALL),
已添加CVT类别的绝对(方形,平坦)高度和相对(圆形,过冲)高度。这允许UI自动为在y方向上舍入的控制点选择CVT。注意:要使用此功能,您需要导入新的CvtTmpl.txt,因为它已使用适当的属性进行设置。如果您想手动将属性添加到您自己的旧模板中(参见下面有关新控制程序的信息),请选择编辑=>编辑CVT属性,将链接颜色设置为“灰色”,将链接方向设置为“Y”,以及对于cvt类别,选择“Square Height”或“Round Height”,具体取决于它是实际高度还是过冲。
有时,您可能希望在不使用CVT的情况下在y方向上对控制点进行舍入。为此,请右键单击锚符号,然后选择no cvt。

Cvt(右)与否(左)?
VTT现在支持IntelliMouseTM作为某些导航操作的捷径。要在Windows 95下使用此设备,必须安装相应的驱动程序。Windows NT默认支持它。有关快捷方式的说明,请参阅下面的“快速参考指南”。
最后但并非最不重要的是,主窗口现在具有16级撤消/重做功能。它以“通常的方式”激活,即Ctrl + Z取消之前的修改,按Ctrl + Z最多16次撤消16次修改,同样,Ctrl + Y重做它们。在新添加的链接或插值导致另一个链接被删除的情况下,这可能会派上用场。
控制程序
增加了高级语言集成控制值和准备程序表。它的主要目标是通过将VTT当前的私有“cvt”和“prep”表组合成一个私有表(称为“控制程序”,缩小)来简化控制值的定义和缩放(“继承”)下的行为规范。来自“控制值”和“准备程序”)并避免印刷师必须使用汇编语言编程。新的控制程序替换当前的私有“cvt”并编译到“准备”表中。控制程序本质上是声明性的,因此可以更容易地为非程序员学习,因为它避免了必须对命令进行排序。以前版本的“cvt”将继续工作,但不会从控制程序中自动生成“准备”中受益。因此强烈建议用户试一试,因为它具有以下功能:
它通过允许用户可定义的字符组和要素类别来增加cvt属性的范围,因为在今天的WGL-4字体(更不用说专家集)中,并非所有字形都属于4个硬连线类别“大写”,“小写”, “图”和“其他”。可以将其他字符组和要素类别添加到新控制程序中,以及可视化间距所需的字形序列。
它增加了可以声明和使用字形笔划角度的粒度级别。以前,这是在VTT Talk中以每个字形为基础声明的,并且在cvt中使用每个字体(硬连线的cvts 2和36)。现在,它基于每个字符组在控制程序中完成,或者基于共享相同笔划角度的字符组内的子组完成。此外,行程角度声明现在允许以足够小的ppem尺寸将变化的行程角度调整为单个行程角度,因为标准“继承”可以用于斜体行程的相应cvts。
随着字形笔划角度的粒度增加,图形用户界面已被调整。笔画角度工具现在生成一对箭头,如下图所示:

雕文中风角度用斜体运行cvt 38并且上升cvt 39
左键单击并拖动鼠标以绘制角度,右键单击cvts以更改它们。务必打开x和y方向,并关闭网格拟合和像素。
控制程序允许“相对”继承,如之前仅用于高度及其超调,也适用于所有其他cvts。这允许例如在给定的ppem尺寸和高于给定的ppem尺寸时容易迫使圆形行程比直行程厚至少1个像素。
它使用与用于VTT Talk中常规增量的cvt-delta相同的高级语法,使其更易于使用,并允许编译器执行与常规增量相同的优化。
它简化了全局设置的管理,例如cvt cut-ins,drop-out control cut-off ppem size,以及打开指令的ppem大小范围,因为它们现在在3个简单的高级别中完成语言陈述。
它消除了以前用于指定cvt属性的令人尴尬的十六进制数字的需要。
注意:要使用新的控制程序,您需要导入新的FpgmTmpl.txt,因为它会生成最近添加的函数83,84,85和88的调用。相应地更新了CvtTmpl.txt以及CharGrp.txt模板。CvtTmpl.txt使用实例和大量注释逐步解释控制程序的语法。仅通过扩展给出的示例将很容易学习。CharGrp.txt已略微调整以匹配所有其他文本表。
VTT快速参考指南针对高级用户的秘密快捷方式
主窗口
捷径 描述
左键单击+ Shift +拖动鼠标 平底锅主窗口
左键单击+ Alt键 在主窗口中缩放(按下鼠标按钮和Alt键时,缩放将以小增量继续)
单击左键+ Ctrl键 缩小主窗口(按下鼠标按钮和Alt键时,缩放将以小增量继续)
左击+按Ctrl + Alt 在缩放到fUnit之间切换(在主窗口中放大到足以使一个fUnit等于一个像素)和缩放到适合(缩小主窗口以使字体高度适合窗口)
左键单击+ Alt +拖动鼠标 放大并平移主窗口
左键单击+ Ctrl +拖动鼠标 缩小并平移主窗口
左键单击+ Ctrl + Alt +拖动鼠标 在zoom-to-fUnit和zoom-to-fit以及平移主窗口之间切换
单击滚轮+拖动鼠标 平底锅主窗口
向你转动轮子 放大主窗口
旋转轮离你而去 缩小主窗口
单击+向您旋转滚轮+拖动鼠标 放大并平移主窗口
单击+旋转滚轮+拖动鼠标 缩小并平移主窗口
向上箭头 将ppem大小增加1
向下箭头 将ppem大小减少1
Shift +向上箭头 将ppem大小增加10
Shift +向下箭头 将ppem大小减少10
右箭头 转到下一个字形/字符
左箭头 转到上一个字形/字符
任何角色 去那个角色
使用移动控制点工具时
捷径 描述
左键单击控制点 为后续移动选择控制点,取消选择任何先前选择的控制点
右键单击控制点 选择控制点而不取消选择任何先前选择的控制点
左键双击控制点 选择轮廓的所有控制点,取消选择以前选择的任何控制点
右键双击控制点 选择contour_的所有控制点,而不取消选择任何先前选择的控制点
左键单击并拖动选框 选择选取框中的所有控制点,取消选择以前选择的任何控制点
右键单击并拖动选框 选择选取框中的所有控制点,而不取消选择任何先前选择的控制点
向左,向上,向右或向下箭头 将选定的控制点移动1 fUnit。在从不同的轮廓格式转换后,它通常用于清理轮廓
Shift +向左,向上,向右或向下箭头 将所选控制点移动10 fUnits
使用插入控制点工具时
捷径 描述
左键单击 将控制点插入最近的轮廓; 如果“显示更少的点”打开,则插入曲线上的点,否则为曲线外点
右键点击 使用单个控制点启动新轮廓。这将始终创建一个曲线上的点,通常用于为复合字形添加附着点
使用链接工具时,在最小距离符号上按下鼠标右键
捷径 描述
Alt键 将最小距离分辨率从1/8像素增加到像素的1 / 16,1 / 32和1/64
按Ctrl 将最小距离分辨率从1/8像素减小到像素的1 / 4,1 / 2和1/1
向你转动轮子 将最小距离分辨率从1/8像素增加到像素的1 / 16,1 / 32和1/64
旋转轮离你而去 将最小距离分辨率从1/8像素减小到像素的1 / 4,1 / 2和1/1
在使用链接,移位,插值或描边工具时,在cvt符号上按下鼠标右键时
捷径 描述
转移 按数字顺序排序或按CVT属性排序的CVT数字之间切换
点击滚轮 按数字顺序排序或按CVT属性排序的CVT数字之间切换
使用增量或移动工具时按下鼠标左键或右键
捷径 描述
Alt键 增加增量或将分辨率从1/8像素移动到像素的1 / 16,1 / 32和1/64
按Ctrl 减小增量或将分辨率从1/8像素移动到像素的1 / 4,1 / 2和1/1
转移 改变delta或从IUP后移动到内联,pre-IUP和后IUP
向你转动轮子 增加增量或将分辨率从1/8像素移动到像素的1 / 16,1 / 32和1/64
旋转轮离你而去 减小增量或将分辨率从1/8像素移动到像素的1 / 4,1 / 2和1/1
点击滚轮 改变delta或从IUP后移动到内联,pre-IUP和后IUP
错误修复
在W95平台上,随着显示的像素放大会偶尔崩溃,这已经被追溯到W95 API中的限制并且实施了变通方法
VTT不会让你打开只读字体,现在它会
始终强制HEAD表中的整数ppem大小
正确更新HEAD表中的“修改”日期
正确处理更大格式的4 CMAP
正确处理格式6 CMAP
许多其他化妆品问题已得到修复,我不记得了
16.2.2.斜体提示
注意
对于斜体提示的这种解释,假定了Microsoft Visual TrueType图形提示的工作知识。有许多方法可以暗示斜体字符,以下是使用最新版VTT中提供的图形提示工具的快速简单指南。我假设你已经在VTT中设置了你的字体,现在有一个控制程序。确保填写斜体上升并运行cvts for caps(标准模板中的cvt 20和21)和小写(cvt 22和23),否则VTT将假定字体是直立的,并且不会让您选择设置’GlyphStrokeAngle’。(同样,对于数字和所有其他具有斜体的字符组。)

让我们从sanserif,斜体,大写字母’I’开始。确保网格适合和像素关闭,并且“x”和“y”链接打开。选择’GlyphStrokeAngle’工具(’x-link’工具上方的工具)。选择杆的左下角,然后将光标拖动到左上角。出现一对箭头,其中cvts 20(斜体运行)和21(斜体上升)。您可以右键单击州际标志以在必要时更改这些cvts。VTT将寻找:
复制
UpperCase Grey X ItalicRun absolute
UpperCase Grey Y ItalicRise absolute
对于没有斜体笔划的字符,例如“o”,将工具从原点向斜体笔划方向拖动。
对于具有不同斜体笔划角度的字体(例如Garamond),您可以为不同的斜体运行引入新的cvts。对于任何新的运行,上升(小写的x高度,大写的上限)应该相同。现在你有几个不同的运行cvts,你可能希望在较小的屏幕尺寸下使它们完全相同。要执行此操作,您可以使用另一个运行cvt覆盖运行cvt,直到指定的大小(例如,低于12 ppem)所有字形笔划角度变得相同。这是’继承’,可以像控制程序中的任何其他继承一样进行控制。当尝试将整个字体或字符范围的斜体角度增量时,用cvts控制斜体角度将变得特别有用。
接下来,您可以添加’y’提示(我建议首先提示’y’方向)。确保在“y”方向上以某种方式触摸您打算在笔划中使用的任何点。在盖子’I’的情况下,将左下角固定在’x’方向的网格上(如果没有,则笔划工具将为您完成)。选择对角线笔划工具并将其从点0拖动到3,然后将点1拖动到2.笔划中间会出现一个州际符号,您现在可以编辑它。如果您正在处理的字体具有逐渐变细的笔触,则可以强制它们保持笔直直到指定的大小。转到(最小)尺寸,您希望笔划逐渐变细,右键单击笔划中间的挂锁(如果您看不到挂锁,从Tools / Options / Glyph visuals菜单中选择ppem limits。选择打开的挂锁。

对于一个sanserif斜体字符,如帽’H’,提示两个茎和水平条在’y’方向,那么所有需要在’x’方向完成的是暗示两个斜体笔画,然后将水平条的点对角地对齐到笔划的相应侧。再一次,您将看到一个挂锁,它允许您在选定的位置关闭对齐命令的约束,就像使用笔划一样。请注意,使用挂锁功能可以安全地对齐属于“墨迹”的点,因为您始终可以以足够像素的大小打开挂锁来呈现“墨迹”(另请参阅 VTT 4.2发行说明) 。

对于一个斜体的服务资本’我’,程序大致相同。我会再次建议首先添加’y’提示,小心确保触摸要在笔划中使用的’y’中的点(’y’插值通常是最好的)。至于用于中风的点,这并不像人们想象的那么明显。我建议你使用行程直道两端的偏离曲线点(18到8,然后在带衬圈的帽子上为21到5),因为这样可以提供更好的形状。一旦提示了笔划,您就可以根据需要使用移位,移位和锚点,dists或链接来提示衬线的末尾。

要使斜体字符空间化,请使用与直立字体相同的方法。使用cvt从侧面链接到角色上的点,或者简单地锚点。所有其他提示与用于直立字体的提示相同。
16.3.OpenType字体签名工具
此工具是为在Microsoft使用而开发的,并且不受外部支持。Microsoft不对此工具的外部使用提出任何声明,也不承担任何责任。此工具受版权保护。重新分配受到限制。有关详细信息,请参阅该工具的 最终用户许可协议。
除了提供的工具,要签署字体文件,您还需要一个
.spc文件和
.pvk文件。
您可以使用字体签名工具中提供的工具创建test.spc和test.pvk以进行测试,但是当您想要“为真实”签署字体文件时,您需要从证书颁发机构(如Verisign)获取这些文件。联系证书颁发机构时,申请“3级Authenticode数字签名”。询问“字体签名证书”并不是一个好主意,因为您需要的证书并非特定于字体签名。
包含您的公钥和其他信息的.spc文件驻留在您的硬盘驱动器上,并且可以分发给其他人。
.pvk文件包含与.spc文件中的公钥对应的私钥。从证书颁发机构收到.pvk文件后,建议不要将该文件存储在硬盘驱动器上,并且应始终将其存储在软盘上并根据需要使用。
签署OpenType字体文件
最低系统要求:
Window 2000:Beta 3或更高版本,或
Windows NT 4 + SP 4,或
Windows 9x + IE 5
下载该工具
下载 - 选择下面列出的位置之一,然后将disg.exe下载到计算机中,例如 C:\FontSign
文件详细信息 - dsig.exe - 192KB自解压文件Windows 2000和Windows NT用户 - 您必须具有管理员权限才能使用此工具。
步骤1
Windows NT / 2000:将mssipotf.dll移动到winnt \ system32
Windows 9x:将mssipotf.dll移动到\ windows \ system
第2步
通过在命令提示符下键入以下命令,在Windows中注册mssipotf.dll,
regsvr32 mssipotf.dll
第3步
签名字体文件,例如。myfont.TTF,转到下载字体签名工具的文件夹,然后在命令提示符下键入,
signcode -spc my.spc -v my.pvk -j mssipotf.dll myfont.ttf
-j mssipotf.dll选项是成功签名字体文件所必需的,因此必须包含在命令提示符中。此选项告诉signcode mssipotf.dll包含将对字体执行一系列检查以确定字形完整性的代码。此过程可能需要几秒钟或几分钟,具体取决于字体文件中的字形数。如果字体未通过此验证测试,则签名将失败。Signcode还有许多其他命令行选项,您可以通过键入Signcode来了解它们?在命令提示符下。在命令行中包含的其他推荐选项是,
-n“我的字体名称”
-i http://www.mycompany.com
-t http://timestamp.verisign.com/scripts/timstamp.dll
上面的三个选项将添加字体名称,将其链接到您的站点并为数字签名证书添加时间戳。
第4步
可以使用chktrust.exe验证成功签名的字体文件:
chktrust myfont.otf
在Windows 2000和Windows 98上验证签名文件的另一种方法是“右键单击”字体文件并选择“属性”。将显示“数字签名”选项卡,其中提供有关签名的更多详细信息,包括时间戳(如果在签名时使用)。
请注意,在Windows 2000中,与签名字体文件关联的图标是OpenType徽标(O),而不是TrueType徽标(TT)。但是,已签名的TTC仍然具有TT徽标。
建议
一般情况下,您应该在签名之前始终对字体进行测试。您需要通过转到下载字体签名工具的目录来创建自己的.cer和.pvk文件的虚拟版本,并在命令行上键入以下内容
makecert -n CN = JoeBob -sv test.pvk test.cer
cert2spc test.cer test.spc
setreg 1是的
Makecert将创建.cer和.pvk文件,相关证书将被称为“JoeBob”。将出现一个对话框,要求您提供.pvk文件的密码,然后在每次使用.pvk文件时要求确认密码。
最后,要测试签名字体,请在命令提示符下键入以下内容
signcode -spc test.spc -v test.pvk -j mssipotf.dll myfont.ttf
注意:在上面的示例中,我们使用了最小的signcode选项,因为我们只测试签名字体文件。
您还可以根据您的字体和公司修改随字体签名工具提供的signdemo.bat,然后键入
Signdemo MyFont.ttf
如果您使用测试证书对文件进行签名,则不应将签名文件分发用于官方目的。
故障排除
以下是一些常见问题:
问:我已经下载了字体工具,但没有看到misipotf.dll。
答:您需要设置文件夹设置以查看所有文件。请参阅有关如何执行此操作的Windows文档。
问:在DOS提示符下我的空间不足了?
答:Windows 95和98默认情况下对命令提示符下可输入的字符数有限制。因此,根据您使用的选项和某些选项的长度(即您的字体名称,公司的URL和时间戳URL),您可能无法键入要用于对字体进行签名的所有选项。在这种情况下,您可以编辑“Signdemo.bat”批处理文件以包含要使用的所有选项。要打开文件,请右键单击“Signdemo.bat”并选择“编辑”选项,然后根据需要修改选项。关闭文件并在DOS提示符下键入“Signdemo MyFont.ttf”。
问:我无法对文件进行签名,因为该文件是只读的。
答:签名会改变文件,因此不能只读。更改文件属性并再次尝试签名。
问:签署需要很长时间。
答:由于-j选项调用执行字形完整性检查的代码,因此签名可能需要很长时间。耐心点。
问:系统上是否有其他mssipotf.dll副本会导致问题?
答:如果mssipotf.dll位于执行路径中,则可以调用旧版本的mssipotf.dll。最好确保整个系统中只有一个mssipotf.dll(位于\ winnt \ system32目录中)。
问:我在签名过程中收到错误消息
答:这可能是由于字体不符合下面列出的签名标准。
字体文件标准
由于字体文件以外的文件以不同方式签名。要将文件标识为字体文件,该文件必须符合某些条件。标准概述如下。
头表中的幻数是正确的。
给定offset表中的表数值,offset表中的其他值是一致的。
表目录中的标记(包含指向每个表开头的指针)必须按字母顺序显示,并且没有重复项。
每个表的偏移量是4的倍数。(也就是说,表是长字对齐的。)
文件中的第一个实际表紧跟在表的目录之后。
如果表按偏移量排序,那么对于所有表i(其中索引0表示具有最小偏移量的表),
偏移[i] +长度[i] <=偏移[i + 1]和
偏移[i] +长度[i]> =偏移[i + 1] - 3。
换句话说,表不重叠,表之间最多有3个字节的填充。
表之间的填充字节全为零。
文件中最后一个表的偏移量加上其长度不大于文件的大小。
所有表的校验和都是正确的。
头表中的文件校验和是正确的。
Signcode不会签名,chktrust不会验证字体文件是否不符合上述所有条件。
这些规则背后的理念是,对字体文件施加的结构越多,恶意实体就越不可能将坏的字体文件伪装成一个好的字体文件。随着其他类型的签名用于签署字体文件,这将变得更加重要。
卸载
您可以通过取消注册mssipotf.dll来禁用字体签名和验证:
regsvr32 / u mssipotf.dll
(可选)您可以删除mssipotf.dll。
MICROSOFT软件的最终用户许可协议
重要事项 - 请仔细阅读:本Microsoft最终用户许可协议(“EULA”)是您(个人或单个实体)与Microsoft Corporation之间就上述Microsoft软件产品达成的法律协议,其中包括计算机软件,可能包括相关媒体,印刷材料和“在线”或电子文档(“软件产品”)。软件产品还包括Microsoft向您提供的原始软件产品的任何更新和补充。随软件产品一起提供的与单独的最终用户许可协议相关的任何软件均根据该许可协议的条款许可给您。通过安装,复制,下载,访问或以其他方式使用本软件产品,即表示您同意遵守本EULA的条款。
软件产品许可证
本软件产品受版权法和国际版权条约以及其他知识产权法律和条约的保护。软件产品是许可的,不是出售的。
授予许可。本EULA授予您以下权利:
软件产品。您可以在无限数量的计算机上安装和使用本软件产品,包括工作站,终端或驻留在您工作场所的其他数字电子设备(“计算机”),其唯一目的是为您的TrueType或OpenType字体添加数字签名。
其他权利和限制的说明。
逆向工程,反编译和反汇编的限制。你可能不会逆向工程,反编译。或者反汇编软件产品,除非且仅在适用法律明确允许的情况下,尽管有此限制。
租赁。您不得出租,租赁或出借该软件产品
软件转移。您可以永久转让本EULA下的所有权利,前提是您不保留任何副本,转让所有软件产品(包括所有组件,媒体和印刷材料,任何升级,本EULA,以及证书,如果适用)真实性)并且收件人同意本EULA的条款。如果软件产品是升级版,则任何转让都必须包括软件产品的所有先前版本。您不得分发本软件产品。
终止。在不影响任何其他权利的情况下,如果您未能遵守本EULA的条款和条件,Microsoft可以终止本EULA。在这种情况下,您必须销毁软件产品及其所有组件的所有副本。
版权。软件产品中的所有产权和知识产权(包括但不限于软件产品中包含的任何图像,照片,动画,视频,音频,音乐,文本和“小程序”),随附的印刷材料和软件产品的任何副本均归Microsoft或其供应商所有。通过使用“软件产品”可以访问的内容的所有权和知识产权是相应内容所有者的财产,可能受适用的版权或其他知识产权法律和条约的保护。本EULA授予您使用此类内容的权利。Microsoft未保留未明确授予的所有权利。
美国政府限制权利。根据1995年12月1日或之后发出的请求向美国政府提供的所有软件产品均享有本文其他地方所述的商业许可权利和限制。根据1995年12月1日之前发出的请求向美国政府提供的所有软件产品均按照FAR,48 CFR 52。02 - 14(1987年6月)或DFAR,48 CFR 252.227-7013(OCT)的规定提供“限制权利”。 1988),如适用。
出口限制。您同意不会将软件产品,软件产品的任何部分或任何软件产品的直接产品(以上统称为“受限制的组件”)的过程或服务出口或再出口到任何国家/地区,受美国出口限制的个人或实体。您明确同意不出口或再出口任何受限制的组件:(i)美国禁止或限制出口货物或服务的任何国家,目前包括但不限于古巴,伊朗,伊拉克,利比亚,朝鲜,苏丹,叙利亚和南斯拉夫联邦共和国(包括塞尔维亚,但不包括黑山),或任何国家,无论在何处,有意将受限制的组件传输或运输回这样的国家; (ii)您知道或有理由知道的任何个人或实体将在设计,开发或生产核武器,化学武器或生物武器时使用限制性组件; 或(iii)任何被美国政府任何联邦机构禁止参与美国出口交易的个人或实体。您保证并声明BXA和任何其他美国联邦机构均未暂停,撤销或拒绝您的出口特权。
杂项
如果您在美国购买此产品,则本EULA受华盛顿州法律管辖。
如果您在加拿大购买此产品,则本EULA受加拿大安大略省法律管辖。本协议各方不可撤销地为安大略省法院的管辖权提供法律服务,并进一步同意在安大略省约克司法区的法院提起本协议可能产生的任何诉讼。
如果此产品是在美国境外获得的,则可能适用当地法律。
如果您对本EULA有任何疑问,或者您希望以任何理由联系Microsoft,请与Microsoft联系,或写信:Microsoft销售信息中心/ One Microsoft Way / Redmond,WA 98052-6399。
不保证。
免责声明。在适用法律允许的最大范围内,Microsoft及其供应商按原样提供软件产品和任何(如果有)支持服务以及所有缺陷,并特此声明不承担任何明示,暗示或法定的保证和条件,包括不限于任何(如果有)暗示的适销性,适用于特定目的,缺乏病毒,准确或完整的答复,结果,以及没有疏忽或缺乏工作努力的保证或条件,所有关于软件产品,以及提供或未提供支持服务。此外,对于软件产品,没有任何关于标题,安静的享受,安静的占有,描述的对应或不侵权的保证或条件。
排除偶然,间接和某些其他损害。在适用法律允许的最大范围内,在任何情况下,MICROSOFT或其供应商均不对任何特殊,偶然,间接,惩罚性或后果性损害负责(包括但不限于损失利润或机密或其他信息的损害) ,因商业中断,人身伤害,隐私遗失,未能履行任何责任,包括合理的信任,合理的疏忽,以及由于任何其他方式产生或以任何方式产生的任何其他特殊或其他损失使用或无法使用软件产品,提供或未能提供支持服务,或在本EULA的任何条款下或与之相关的其他条款,即使在故障,侵权(包括疏忽)的情况下,
责任限制和补救措施。尽管您可能因任何原因(包括但不限于上述所有损害赔偿以及所有直接或一般损害)而可能遭受任何损害,但Microsoft及其任何供应商根据本EULA的任何规定承担的全部责任以及您的专有补救措施所有上述内容均应限于您为软件产品实际支付的金额中的较大者或5.00美元。上述限制,排除和免责声明应在适用法律允许的最大范围内适用,即使任何补救措施未能达到其基本目的。
